【代码随想录训练营】【Day33休息】【Day34】第八章|贪心算法|1005.K次取反后最大化的数组和|134. 加油站|135. 分发糖果
K 次取反后最大化的数组和
题目详细:LeetCode.1005
这道题比较简单,这里直接给出贪心策略:
- 局部最优解:
- 按照
负数 > 0 > 正数的优先级次序,依次对nums中的较小数值进行取反 - 因为负负得正,负值越小,其相反数越大
- 如果值都为正数,那么则取较小的值进行取反,尽可能的最大化数组和
- 按照
- 整体最优解:整体的数组和最大
Java解法(贪心,数组有序):
class Solution {public int largestSumAfterKNegations(int[] nums, int k) {// 对原数组进行排序Arrays.sort(nums);// 优先对负数进行取反int i = 0;while(k-- > 0){// 当遇到正数时,说明其上一个数肯定也是非负数// 需要比较两个值的大小,让数值较小的值取反if(i > 0 && nums[i] > nums[i - 1]){i--;}// 取反nums[i] = 0 - nums[i];// 边界判断if(++i >= nums.length)i = nums.length - 1;}// 累计数组总和int sum = 0;for(int n: nums){sum += n;}return sum;}
}
当然由于LeetCode给出的数据样本,范围较小且保证样本数组都落在一定范围内,我们也可以利用数组下标来映射nums中的数值,使数值在映射数组中得到有序,就不用Arrays.sort方法了。
Java解法(贪心,数组不有序):
class Solution {public int largestSumAfterKNegations(int[] nums, int k) {// 样本数据都满足,-100 <= nums[i] <= 100,这个范围的大小是201int[] number = new int[201];// 数组下标[-100,100]表示数值大小,元素值表示数值的个数for (int t : nums) {// 利用 t + 100 将[-100,100]映射到[0,200]上number[t + 100]++;}int i = 0;while (k-- > 0) {// 跳过记录次数为0的数字,找到当前nums中最小的数字while (number[i] == 0){i++;}// 若 i > 100,说明索引到了正数if (i > 100) {if(k % 2 == 0){// 正数取偶数次反,依旧是正数,直接break跳出循环;break;}// 正数取奇数次反,一定是负数,直接k = 0,后续执行一次数值取反就行k = 0;}// 取反number[i]--;// 该数字的个数 - 1number[200 - i]++;// 该数字的相反数个数 + 1}// 累计数字个数求和int sum = 0;for (int j = 0; j < number.length ; j++) {// j - 100 是数字的大小,number[j]是该数字出现次数.sum += (j - 100)* number[j];}return sum;}
}
加油站
题目详细:LeetCode.134
这道题一开始我的思路是比较正确的:
- 假如我们从某一个加油站开始,那么这个加油站之前和之后的路段都是它要行驶的路段
- 所以判断能否行驶一周,那么只需要累计每一段路程的差值,如果差值不为负,说明能够行驶一周,否则无法行驶一周,返回 -1
- 那么再根据我的贪心的思想,我计算并记录了每一段路程中,差值为正且最大的加油站开始,觉得这样就可以满足后续的路程
- 最后根据累计值,判断能否行驶一周,如果可以则返回记录的下标
但是经过测试后,发现还是会有错误的数据样本,看完题解之后,才发现我的思路是比较片面的,主要的原因在于确定起始坐标上犯了迷糊,若当前的累计值cur_sum < 0,起始位置至少要是i+1,而不是i
所以正确的贪心策略应该是:
- 局部最优解:
- 当前累加rest[i]的和
cur_sum < 0时,起始位置start_index至少要更新到i+1 - 因为假如从
i之前开始,那么它走到第i个时,必定是cur_sum < 0,就无法继续行驶了
- 当前累加rest[i]的和
- 整体最优解:找到可以跑一圈的起始位置
start_index,如果最后所有油耗的累计值 < 0,说明车辆不足油跑一圈,返回 -1
这里我定义了一个变量min_sum,来记录路程中差值最大的油耗,只要当cur_sum < min_sum时,就需要更新start_index = i + 1。
Java解法(贪心):
class Solution {public int canCompleteCircuit(int[] gas, int[] cost) {int n = gas.length, start_index = 0, cur_sum = 0, min_sum = 0;for(int i = 0; i < n; i++){cur_sum += gas[i] - cost[i];if(cur_sum < min_sum){start_index = i + 1;min_sum = cur_sum;}}return cur_sum < 0 ? -1 : start_index;}
}
如果起始位置的更新条件为cur_sum < 0时,则需要更新cur_sum = 0,这是意义更加明确的解法,表示从车辆从当前加油站开始,其之前的加油站都还未经过,所以不需要累计油耗,重置cur_sum = 0,后续再累计油耗;
不过就需要定义一个变量total_sum,通过该变量来判断是否能够绕行一圈了。
Java解法(贪心):
class Solution {public int canCompleteCircuit(int[] gas, int[] cost) {int n = gas.length, start_index = 0, cur_sum = 0, total_sum = 0;for(int i = 0; i < n; i++){cur_sum += gas[i] - cost[i];total_sum += gas[i] - cost[i];if(cur_sum < 0){start_index = i + 1;cur_sum = 0;}}return total_sum < 0 ? -1 : start_index;}
}
分发糖果
题目详细:LeetCode.135
我一开始的分发策略是:
- 第一次是从左到右遍历,比较左边孩子和右边孩子的评分,如果左边孩子比右边孩子的评分高,那么
左边孩子的糖果数量 = 右边孩子的糖果数量 + 1(第一次遍历,这样变成了左边孩子的糖果数量由右边孩子决定,但是右边孩子的糖果数量还未确定,进而在这一步就确定左边孩子的糖果数量是错误的)。 - 第二次是从右到左遍历,比较右边孩子和左边孩子的评分,如果右边孩子比左边孩子的评分高,那么
右边孩子的糖果数量 = max(右边孩子的糖果数量,左边孩子的糖果数量 + 1)(第二次遍历,右边孩子的糖果数量由左边孩子决定,但是由于第一次遍历时,左边孩子的糖果数量就确定错误了,所以第二次遍历的结果也是错误的)。
做题的时候总觉得这样的思路没问题呀,怎么老是通过不了一些测试样本呢,看过题解之后才发现括号里那些没有发现的错误,详细的题解可查阅:《代码随想录》— 分发糖果
按我原来的分发策略举个错误的例子,例如:
- 因为
rating[1]与rating[2]的比较,是要利用上rating[2]与rating[3]的比较结果来确定rating[2]的糖果数量,才能进而确定rating[1]的糖果数量 - 假如从前向后遍历,就无从得知
rating[2]与rating[3]的的比较结果了,所以要从后向前遍历。
所以本题正确的分发策略应该是:
- 局部最优解:
- 第一次是从左到右遍历,所以右边孩子的糖果数量都能通过左边孩子的糖果数量得到确定(
右边孩子的糖果数量 = 左边孩子的糖果数量 + 1),只比较右边孩子比左边孩子的评分高的情况。 - 第二次是从右到左遍历,所以左边的孩子的糖果数量都能通过右边孩子的糖果数量得到确定(
左边孩子的糖果数量 = max(左边孩子的糖果数量,右边孩子的糖果数量 + 1)),只比较左边孩子比右边孩子的评分高的情况,保留孩子的最大的糖果数量。
- 第一次是从左到右遍历,所以右边孩子的糖果数量都能通过左边孩子的糖果数量得到确定(
- 整体最优解:相邻的孩子中,评分高的孩子获得更多的糖果。
- 最后累计所有孩子的糖果数量即可得到结果
Java解法(贪心):
class Solution {public int candy(int[] ratings) {int len = ratings.length;int[] candy = new int[len];// 每个孩子至少分得1个糖果Arrays.fill(candy, 1);for(int i = 1; i < len; i++){if(ratings[i] > ratings[i - 1]){candy[i] = candy[i - 1] + 1;}}for(int i = len - 2; i >= 0; i--){if(ratings[i] > ratings[i + 1]){candy[i] = Math.max(candy[i], candy[i + 1] + 1);}}int sum = 0;for(int n: candy){sum += n;}return sum;}
}
相关文章:

【代码随想录训练营】【Day33休息】【Day34】第八章|贪心算法|1005.K次取反后最大化的数组和|134. 加油站|135. 分发糖果
K 次取反后最大化的数组和 题目详细:LeetCode.1005 这道题比较简单,这里直接给出贪心策略: 局部最优解: 按照 负数 > 0 > 正数 的优先级次序,依次对nums中的较小数值进行取反因为负负得正,负值越小…...

<c++> const 常量限定符
文章目录什么是 const 常量限定符const 的初始化const 的默认作用域const 的引用例外情况const 与指针const指针的声明指向 const 的指针const指针指向 const 的 const指针什么是 const 常量限定符 Q:什么是 const 常量限定符? A:const名叫常…...
pytorch实现transformer模型
Transformer是一种强大的神经网络架构,可用于处理序列数据,例如自然语言处理任务。在PyTorch中,可以使用torch.nn.Transformer类轻松实现Transformer模型。 以下是一个简单的Transformer模型实现的示例代码,它将一个输入序列转换为…...

【懒加载数据 Objective-C语言】
一、咱们就开始进行懒加载 1.懒加载发现,每一个字典,是不是就是四个键值对组成的: 1)answer:String,中国合伙人, 2)icon:String,movie_zghhr, 3)title:String,创业励志电影, 4)options:Array,21 items 前三个都是String类型,最后是不是Array类型, 所…...

人脸网格/人脸3D重建 face_mesh(毕业设计+代码)
概述 Face Mesh是一个解决方案,可在移动设备上实时估计468个3D面部地标。它利用机器学习(ML)推断3D面部表面,只需要单个摄像头输入,无需专用深度传感器。利用轻量级模型架构以及整个管道中的GPU加速,该解决…...
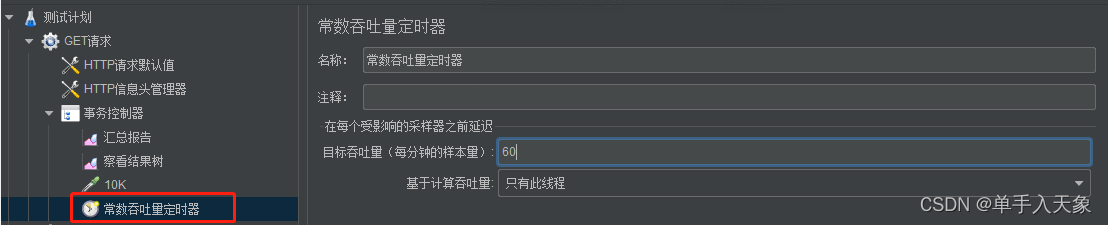
JMeter 控制并发数
文章目录一、误区二、正确设置 JMeter 的并发数总结没用过 JMeter 的同学,可以先过一遍他的简单使用例子 https://blog.csdn.net/weixin_42132143/article/details/118875293?spm1001.2014.3001.5501 一、误区 在使用 JMeter 做压测时,大家都知道要这么…...
git常用命令汇总
Git 是一种分布式版本控制系统,它具有以下优点: 分布式:每个开发者都可以拥有自己的本地代码仓库,不需要连接到中央服务器,这样可以避免单点故障和网络延迟等问题。 非线性开发:Git 可以支持多个分支并行开…...

【2023】华为OD机试真题Java-题目0226-寻找相似单词
寻找相似单词 题目描述 给定一个可存储若干单词的字典,找出指定单词的所有相似单词,并且按照单词名称从小到大排序输出。单词仅包括字母,但可能大小写并存(大写不一定只出现在首字母)。 相似单词说明:给定一个单词X,如果通过任意交换单词中字母的位置得到不同的单词Y,…...

【项目管理】晋升为领导后,如何开展工作?
兵随将转,作为管理者,你可以不知道下属的短处,却不能不知道下属的长处。晋升为领导后,如何开展工作呢? 金九银十,此期间换工作的人不在少数。有几位朋友最近都换了公司,职位得到晋升,…...
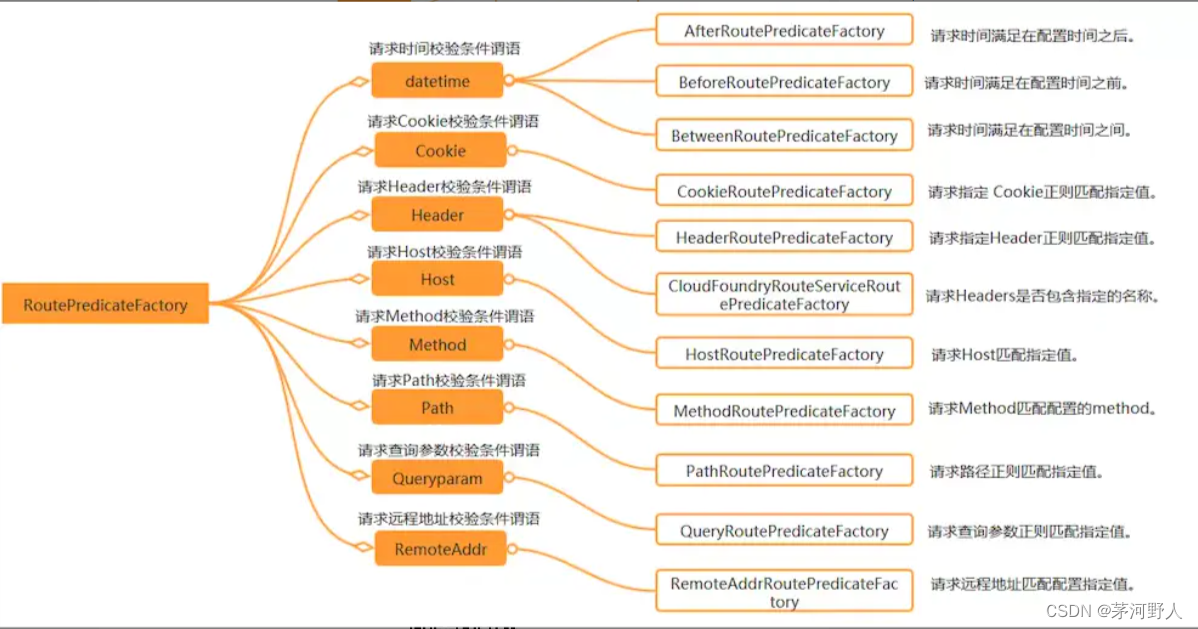
JAVA开发(Spring Gateway 的原理和使用)
在springCloud的架构中,业务服务都是以微服务来划分的,每个服务可能都有自己的地址和端口。如果前端或者说是客户端直接去调用不同的微服务的话,就要配置不同的地址。其实这是一个解耦和去中心化出现的弊端。所以springCloud体系中࿰…...
踩坑:解决npm版本升级报错,无法安装node-sass的问题
npm版本由于经常更新,迁移前端项目时经常发现报错安装不上。 比如,项目经常使用的sass模块,可能迁移的时候就发现安装不了。 因为node-sass 编译器是通过 C 实现的。在 Node.js 中,采用 gyp 构建工具进行构建 C 代码,…...
xFormers安装使用
xFormers是一个模块化和可编程的Transformer建模库,可以加速图像的生成。 这种优化仅适用于nvidia gpus,它加快了图像生成,并降低了vram的使用量,而成本产生了非确定性的结果。 下载地址: https://github.com/faceb…...
)
React—— hooks(一)
🧁个人主页:个人主页 ✌支持我 :点赞👍收藏🌼关注🧡 文章目录⛳React Hooks💸useState(保存组件状态)🥈useEffect(处理副作用)🔋useCallback(记忆函数&#…...

Ubuntu20.04下noetic版本ros安装时rosdep update失败解决方法【一行命令】
一、问题: 安装完ros后,需要执行sudo rosdep init,但是在没有全局科学上网的前提下,执行sudo rosdep init势必会报错: ERROR: cannot download default sources list from: https://raw.githubusercontent.com/ros/r…...

Vue2.0开发之——购物车案例-Footer组件封装-计算商品的总价格(51)
一 概述 App.vue中计算勾选商品的总价格定义子组件Footer中的商品总价格将App.vue中商品的总价格传递给Footer显示 二 App.vue中计算勾选商品的总价格 2.1 商品总价格的计算逻辑 所有勾选商品的价格*数量 2.2 App.vue中通过计算属性计算总价格 通过计算属性计算总价格 co…...

德鲁特金属导电理论(Drude)
德鲁特模型的重要等式 首先我们建立德鲁特模型的重要等式 我们把原子对于电子的阻碍作用,用一个冲量近似表示出来 在式子 首先定义一个等效加速度 由于 我们可以得到电导率的微观表达式 在交流电环境中 电场的表达式 借鉴上一问的公式 我们可以列出这样的表达式…...
python网络爬虫(理论+实战)——html解析库:BeautfulSoup详解)
(十一)python网络爬虫(理论+实战)——html解析库:BeautfulSoup详解
系列文章: python网络爬虫专栏 目录 序言 本节学习目标 特别申明...
四轮两驱小车(五):蓝牙HC-08通信
前言: 在我没接触蓝牙之前,我觉得蓝牙模块应用起来应该挺麻烦,后来发觉这个蓝牙模块的应用本质无非就是一个串口 蓝牙模块: 这是我从某宝上买到的蓝牙模块HC-08,价格还算可以,而且可以适用于大多数蓝牙调试…...
| 机考必刷)
华为OD机试题 - 对称美学(JavaScript)| 机考必刷
华为OD机试题 最近更新的博客使用说明本篇题解:对称美学题目输入输出示例一输入输出说明示例二输入输出备注Code解题思路华为OD其它语言版本最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典...
Web Spider案例 网洛克 第四题 JSFuck加密 练习(八)
声明 此次案例只为学习交流使用,抓包内容、敏感网址、数据接口均已做脱敏处理,切勿用于其他非法用途; 文章目录声明一、资源推荐二、逆向目标三、抓包分析 & 下断分析逆向3.1 抓包分析3.2 下断分析逆向拿到混淆JS代码3.3 JSFuck解决方式…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...
Reasoning over Uncertain Text by Generative Large Language Models
https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829https://ojs.aaai.org/index.php/AAAI/article/view/34674/36829 1. 概述 文本中的不确定性在许多语境中传达,从日常对话到特定领域的文档(例如医学文档)(Heritage 2013;Landmark、Gulbrandsen 和 Svenevei…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

Linux安全加固:从攻防视角构建系统免疫
Linux安全加固:从攻防视角构建系统免疫 构建坚不可摧的数字堡垒 引言:攻防对抗的新纪元 在日益复杂的网络威胁环境中,Linux系统安全已从被动防御转向主动免疫。2023年全球网络安全报告显示,高级持续性威胁(APT)攻击同比增长65%,平均入侵停留时间缩短至48小时。本章将从…...
:LSM Tree 概述)
从零手写Java版本的LSM Tree (一):LSM Tree 概述
🔥 推荐一个高质量的Java LSM Tree开源项目! https://github.com/brianxiadong/java-lsm-tree java-lsm-tree 是一个从零实现的Log-Structured Merge Tree,专为高并发写入场景设计。 核心亮点: ⚡ 极致性能:写入速度超…...