高斯分布、高斯混合模型、EM算法详细介绍及其原理详解
相关文章
- K近邻算法和KD树详细介绍及其原理详解
- 朴素贝叶斯算法和拉普拉斯平滑详细介绍及其原理详解
- 决策树算法和CART决策树算法详细介绍及其原理详解
- 线性回归算法和逻辑斯谛回归算法详细介绍及其原理详解
- 硬间隔支持向量机算法、软间隔支持向量机算法、非线性支持向量机算法详细介绍及其原理详解
- 高斯分布、高斯混合模型、EM算法详细介绍及其原理详解
文章目录
- 相关文章
- 前言
- 一、高斯分布
- 二、高斯混合模型
- 三、EM算法
- 3.1 E步骤(Expectation)
- 3.2 M步骤(Maximization)
- 3.3 EM算法
- 总结
前言
今天给大家带来的主要内容包括:高斯分布,高斯混合模型,EM算法。废话不多说,下面就是本文的全部内容了!
一、高斯分布
小明是一所大学的老师,一次考试结束后,小明在统计两个班级同学的成绩:

其中,橙色的是一班的成绩,蓝色的是二班的成绩。但是,这次同学们非常调皮,都没有写上自己的名字和班级,这下给小明整不会了。他想:我能不能去猜一猜这些成绩里面,哪些是一班的,而哪些是二班的呢?

根据以往的经验,大多同学的成绩都分布在平均值左右,只有少数的同学考的非常好或者是非常不好,我们把这种概率分布叫做高斯分布:

描述高斯分布需要使用到两个参数:
- μ\muμ:描述数据的平均值,也被称为均值
- σ2\sigma^{2}σ2:描述数据的离散程度,也被称为方差

高斯分布的概率密度公式为:
P(x;μ,σ2)=12πσexp(−(x−μ)22σ2)P(x;\mu,\sigma^2)=\dfrac{1}{\sqrt{2\pi}\sigma}\exp(-\dfrac{(x-\mu)^2}{2\sigma^2}) P(x;μ,σ2)=2πσ1exp(−2σ2(x−μ)2)
二、高斯混合模型
现在我们已经清楚了什么是高斯分布,那让我们再回到小明的例子:

因为这是两个班级的成绩,所以小明尝试使用两个高斯分布来拟合:
P(x∣γ1)=12πσ1exp(−(x−μ1)22σ12)P(x∣γ2)=12πσ2exp(−(x−μ2)22σ22)\begin{array}{c}P(x|\gamma_{1})=\dfrac{1}{\sqrt{2\pi}\sigma_1}\exp(-\dfrac{(x-\mu_1)^2}{2\sigma_1^2})\\ P(x|\gamma_{2})=\dfrac{1}{\sqrt{2\pi}\sigma_2}\exp(-\dfrac{(x-\mu_2)^2}{2\sigma_2^2})\end{array} P(x∣γ1)=2πσ11exp(−2σ12(x−μ1)2)P(x∣γ2)=2πσ21exp(−2σ22(x−μ2)2)
这样的模型也被称为高斯混合模型。 在这个模型里面:
- 如果我们知道哪些点来自一班或者是来自二班,那么我们就可以计算出来各自班级成绩的平均值和方差
- 如果我们知道各自班级成绩的平均值和方差,我们也可以大概猜出来哪些点是来自一班的,哪些点是来自二班的
这其实是一个鸡生蛋,蛋生鸡的问题:

如果我们有数据就可以来拟合分布,如果我们有了概率分布,就可以来判断数据的类别。但是,问题是我们现在什么都没有,应该怎么办呢?
三、EM算法
根据以上分析,我们现在什么数据都没有,还想对成绩进行分类,显然是有难度的。我们应该怎么办呢?既然我们没有数据,不如先做一个合适的假设来确定一部分的值。现在我们假设两个分布是这样的:

而且两个类别的先验概率是相等的。需要注意的是,以上这些都是假设,但是由于这些假设的存在,所以下式的值就是已知的量:
P(γ1)=P(γ2)=0.5P(\gamma_{1})=P(\gamma_{2})=0.5 P(γ1)=P(γ2)=0.5
3.1 E步骤(Expectation)
现在我们来评估一下每个成绩点是属于哪个班级的,对于第iii个数据xix_{i}xi来说:

根据贝叶斯定理,xix_{i}xi属于一班的概率是这样求的:
γi1=P(γi∣xi)=P(xi∣γ1)P(γ1)P(xi∣γ1)P(γ1)+P(xi∣γ2)P(γ2)\gamma_{i1}=P(\gamma_i|x_i)=\dfrac{P(x_i|\gamma_1)P(\gamma_1)}{P(x_i|\gamma_1)P(\gamma_1)+P(x_i|\gamma_2)P(\gamma_2)} γi1=P(γi∣xi)=P(xi∣γ1)P(γ1)+P(xi∣γ2)P(γ2)P(xi∣γ1)P(γ1)
上面的式子看似复杂,但是其中的每一项现在都是已知的,直接计算就可以了。现在已经得到了xix_{i}xi属于一班的概率,那么xix_{i}xi属于二班的概率就是1减去xix_{i}xi属于一班的概率:
γi2=P(γ2∣xi)=1−γi1\gamma_{i2}=P(\gamma_{2}|x_{i})=1-\gamma_{i1} γi2=P(γ2∣xi)=1−γi1
这样我们就可以给每一个点涂上对应的颜色,来表示它们可能属于的班级:

这一步被称为E步骤(Expectation),可以理解为求每一个点属于每个类别的期望值。
3.2 M步骤(Maximization)
此时,我们已经得到了每一个点属于每个班级的可能性,我们就可以重新校准两个班级的高斯分布了,也就是重新计算两个班级的平均值和方差:
-
一班:
μ1=γ11x1+γ21x1+…+γN1xNγ11+γ21+…+γN1σ12=γ11(x1−μ1)2+…+γN1(xN−μ1)2γ11+…+γN1\begin{array}{l}\mu_1=\frac{\gamma_{11}x_1+\gamma_{21}x_1+\ldots+\gamma_{N1}x_N}{\gamma_{11}+\gamma_{21}+\ldots+\gamma_{N1}}\\ \sigma_1^2=\frac{\gamma_{11}(x_1-\mu_1)^2+\ldots+\gamma_{N1}(x_N-\mu_1)^2}{\gamma_{11}+\ldots+\gamma_{N1}}\end{array} μ1=γ11+γ21+…+γN1γ11x1+γ21x1+…+γN1xNσ12=γ11+…+γN1γ11(x1−μ1)2+…+γN1(xN−μ1)2 -
二班:
μ2=γ12x1+γ22x1+…+γN2xNγ12+γ22+…+γN2σ22=γ12(x1−μ2)2+…+γN2(xN−μ2)2γ12+…+γN2\begin{array}{l}\mu_2=\frac{\gamma_{12}x_1+\gamma_{22}x_1+\ldots+\gamma_{N2}x_N}{\gamma_{12}+\gamma_{22}+\ldots+\gamma_{N2}}\\ \sigma_2^2=\frac{\gamma_{12}(x_1-\mu_2)^2+\ldots+\gamma_{N2}(x_N-\mu_2)^2}{\gamma_{12}+\ldots+\gamma_{N2}}\end{array} μ2=γ12+γ22+…+γN2γ12x1+γ22x1+…+γN2xNσ22=γ12+…+γN2γ12(x1−μ2)2+…+γN2(xN−μ2)2
同时,也可以更新两个班级的先验概率:
-
一班:
P(γ1)=γ11+…+γN1NP(\gamma_1)=\frac{\gamma_{11}+\ldots+\gamma_{N1}}{N} P(γ1)=Nγ11+…+γN1 -
二班:
P(γ2)=γ12+…+γN2NP(\gamma_2)=\frac{\gamma_{12}+\ldots+\gamma_{N2}}{N} P(γ2)=Nγ12+…+γN2
这一步被称为M步骤(Maximization),可以理解为,通过当前的数据求出最可能的分布参数。
3.3 EM算法
以上两个步骤合起来就是EM算法。当然,算法还没有结束,我们现在只是通过E和M两个步骤求出了两个班级的成绩分布的新的平均值和方差:

后面的工作就是重复E和M两个步骤:
- E步骤:根据两个班级的成绩分布更新点属于两个班级的可能性
- M步骤:更新两个班级的成绩分布的平均值和方差
一直重复以上两个步骤,直到两个成绩分布收敛不再被更新:

这样我们就得到了一个还不错的分类效果:

虽然和真实数据相比仍然有误差,不过也可以猜的八九不离十了:

这样,通过EM算法,小明的问题就可以被解决了。
总结
以上就是本文的全部内容了,学习EM算法还需要一些概率论与数理统计和高等数学的相关知识,所以读者最好提前温习一下。学习机器学习避免不了学习高等数学、线性代数、概率论与数理统计和矩阵论,所以读者一定要好好学习这几门课程!
相关文章:
高斯分布、高斯混合模型、EM算法详细介绍及其原理详解
相关文章 K近邻算法和KD树详细介绍及其原理详解朴素贝叶斯算法和拉普拉斯平滑详细介绍及其原理详解决策树算法和CART决策树算法详细介绍及其原理详解线性回归算法和逻辑斯谛回归算法详细介绍及其原理详解硬间隔支持向量机算法、软间隔支持向量机算法、非线性支持向量机算法详细…...
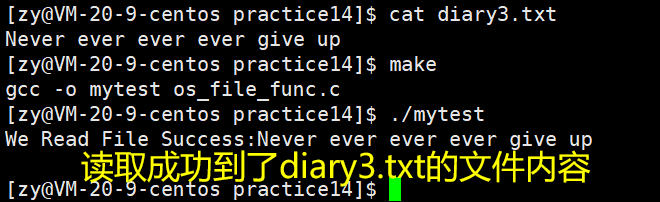
[Linux入门篇]一篇博客解决C/C++/Linux System Call文件操作接口的使用
目录 0.前言 1.C / C ->文件操作 1.1 C语言文件操作 1.1.1 C语言文件打开/关闭/写入 1.1.2 C语言文件的追加操作 1.1.3 C语言文件的读取 1.2 C语言文件操作 1.2.1 C文件打开 / 关闭 / 写入 1.2.2 C文件读取 1.2.3 文件追加 2.三个默认输入输出流 2.1 C语言中的三…...

数据结构和算法学习记录——删除有序数组中的重复项、合并两个有序数组
去重删除有序数组中的重复项题目来自:https://leetcode.cn/problems/remove-duplicates-from-sorted-array/description/题目描述给你一个 升序排列 的数组 nums ,请你原地删除重复出现的元素,使每个元素 只出现一次 ,返回删除后数…...

FPGA实现模拟视频BT656解码 TW2867四路PAL采集拼接显示 提供工程源码和技术支持
目录1、前言2、模拟视频概述3、模拟视频颜色空间4、逐行与隔行5、BT656数据与解码BT656数据格式BT656数据解码6、TW2867芯片解读与配置TW2867芯片解读TW2867芯片配置TW2867时序分析7、设计思路与框架8、vivado工程详解9、上板调试验证10、福利:工程代码的获取1、前言…...
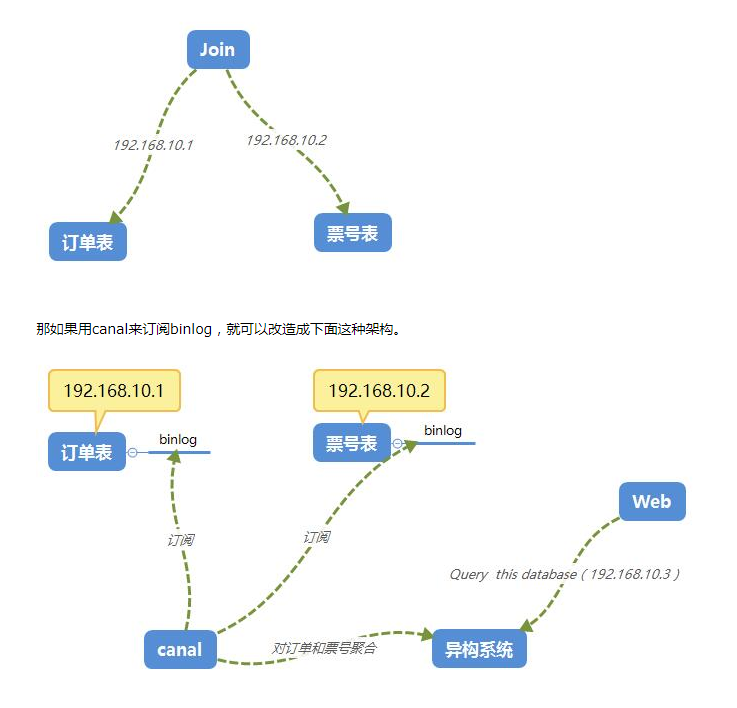
【建议收藏】超详细的Canal入门,看这篇就够了!!!
概述 canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。 背景 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部…...

KubeSphere 社区双周报 | OpenFunction v1.0.0-rc.0 发布
KubeSphere 社区双周报主要整理展示新增的贡献者名单和证书、新增的讲师证书以及两周内提交过 commit 的贡献者,并对近期重要的 PR 进行解析,同时还包含了线上/线下活动和布道推广等一系列社区动态。 本次双周报涵盖时间为:2023.02.17-2023.…...

查漏补缺3月
SPI扩展序列化方式 分布式ID的相关问题 TCP的流量控制,避免浪费网络资源的滑动平均法也可以用在其他可能会出现资源浪费的情况等 讲一讲对自己这个 RPC 项目的想法,你是怎么设计这个项目的,想要实现那些功能? 你认为一个好的 RPC…...

如何使用Java实现类似Windows域登录
什么是域登录? 域登录是一种集中式身份验证和授权方法,用于访问企业内部网络和资源。在Windows环境中,域是一组计算机和用户帐户的集合,受到单个安全管理的控制。域登录允许用户在访问域资源时使用单个帐户名和密码进行身份验证&…...

生成模型与判别模型
生成模型与判别模型 一、决策函数Yf(X)或者条件概率分布P(Y|X) 监督学习的任务就是从数据中学习一个模型(也叫分类器),应用这一模型,对给定的输入X预测相应的输出Y。这个模型的一般形式为决策函数Yf(X)或者条件概率分布P(Y|X)。 …...

Kotlin lateinit 和 lazy 之间的区别 (翻译)
Kotlin 中的属性是使用var或val关键字声明的。Late init 和 lazy 都是用来初始化以后要用到的属性。 由于这两个关键字都用于声明稍后将要使用的属性,因此让我们看一下它们以及它们的区别。 Late Init 在下面的示例中,我们有一个变量 myClass࿰…...

Golang alpine Dockerfile 最小打包
最近在ubantu 上进行了 iris项目的alpine 版本打包,过程遇到了一些问题,记录一下。 golang版本 :1.18 系统:ubantu 代码结构 Dockfile内容 FROM alpine:latest MAINTAINER Si Wei<3320376695qq.com> ENV VERSION 1.1 ENV G…...
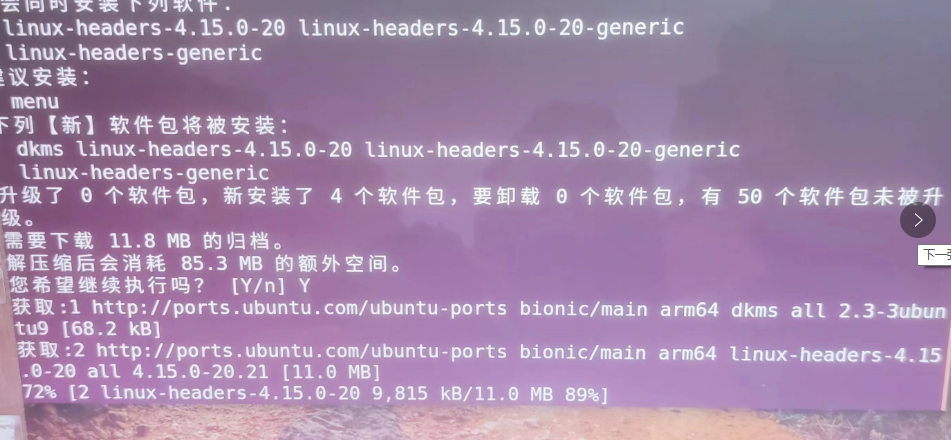
在NVIDIA JetBot Nano小车上更新WIFI驱动
前言:树莓派上的WIFI驱动类型比较多,经常有更好驱动的需求本文给出RealTek的无线WIFI模组,8821CU的驱动更新办法步骤第一 通过其他方式连接网络小车通过网线或者老的WIFI连接到网络上第二 构建驱动模块并下载驱动首先,我们需要打开一个ubuntu…...

2023年网络安全最应该看的书籍,弯道超车,拒绝看烂书
学习的方法有很多种,看书就是一种不错的方法,但为什么总有人说:“看书是学不会技术的”。 其实就是书籍没选对,看的书不好,你学不下去是很正常的。 一本好书其实不亚于一套好的视频教程,尤其是经典的好书…...

VSYNC研究
Vsync信号是SurfaceFlinger进程中核心的一块逻辑,我们主要从以下几个方面着手讲解。软件Vsync是怎么实现的,它是如何保持有效性的?systrace中看到的VSYNC信号如何解读,这些脉冲信号是在哪里打印的?为什么VSYNC-sf / VS…...

python gRPC:根据.protobuf文件生成py代码、grpc转换为http协议对外提供服务
文章目录python GRPC:根据.protobuf文件生成py代码grpcio-tools安装和使用python GRPC的官网示例grpc转换为http协议对外提供服务工作问题总结grpc-ecosystem/grpc-gateway/third_party/googleapis: warning: directory does not exist.python GRPC:根据…...
Allegro如何输出ODB文件操作指导
Allegro如何输出ODB文件操作指导 在PCB设计完成之后,需要输出生产文件用于生产加工,除了gerber文件可以用生产制造,ODB文件同样也可以用于生产,如下图 用Allegro如何输出ODB文件,具体操作如下 首先确保电脑上已经安装了ODB这个插件,版本不受限制点击File...
koa-vue的分页实现
1.引言 最近确实体会到了前端找工作的难处,不过大家还是要稳住心态,毕竟有一些前端大神说的有道理,前端发展了近20年,诞生了很多leader级别的大神,这些大神可能都没有合适的坑位,我们新手入坑自然难一些&am…...

安全开发基础 -- DAST,SAST,IAST简单介绍
安全开发基础-- DAST,SAST,IAST 简介 DAST 动态应用程序安全测试(Dynamic Application Security Testing)技术在测试或运行阶段分析应用程序的动态运行状态。它模拟黑客行为对应用程序进行动态攻击,分析应用程序的反…...
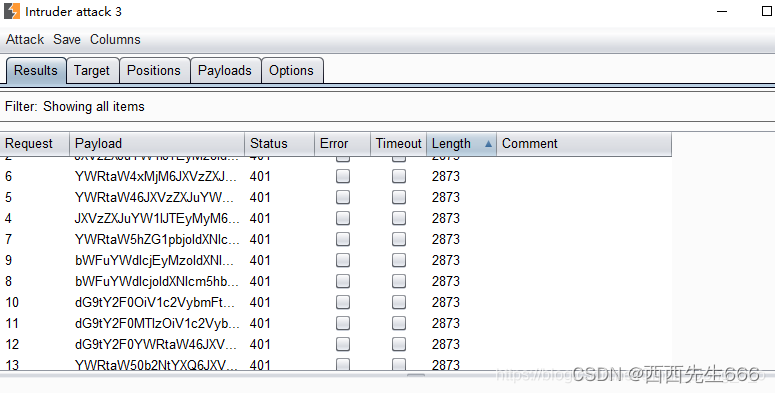
网络安全之暴力破解介绍及暴力破解Tomcat
网络安全之暴力破解介绍及应用场景一、暴力破解介绍1.1 暴力破解介绍1.2 暴力破解应用场景一、暴力破解Tomcat一、暴力破解介绍 1.1 暴力破解介绍 暴力破解字典:https://github.com/k8gege/PasswordDic 1.2 暴力破解应用场景 一、暴力破解Tomcat 登录Tomcat后台&a…...
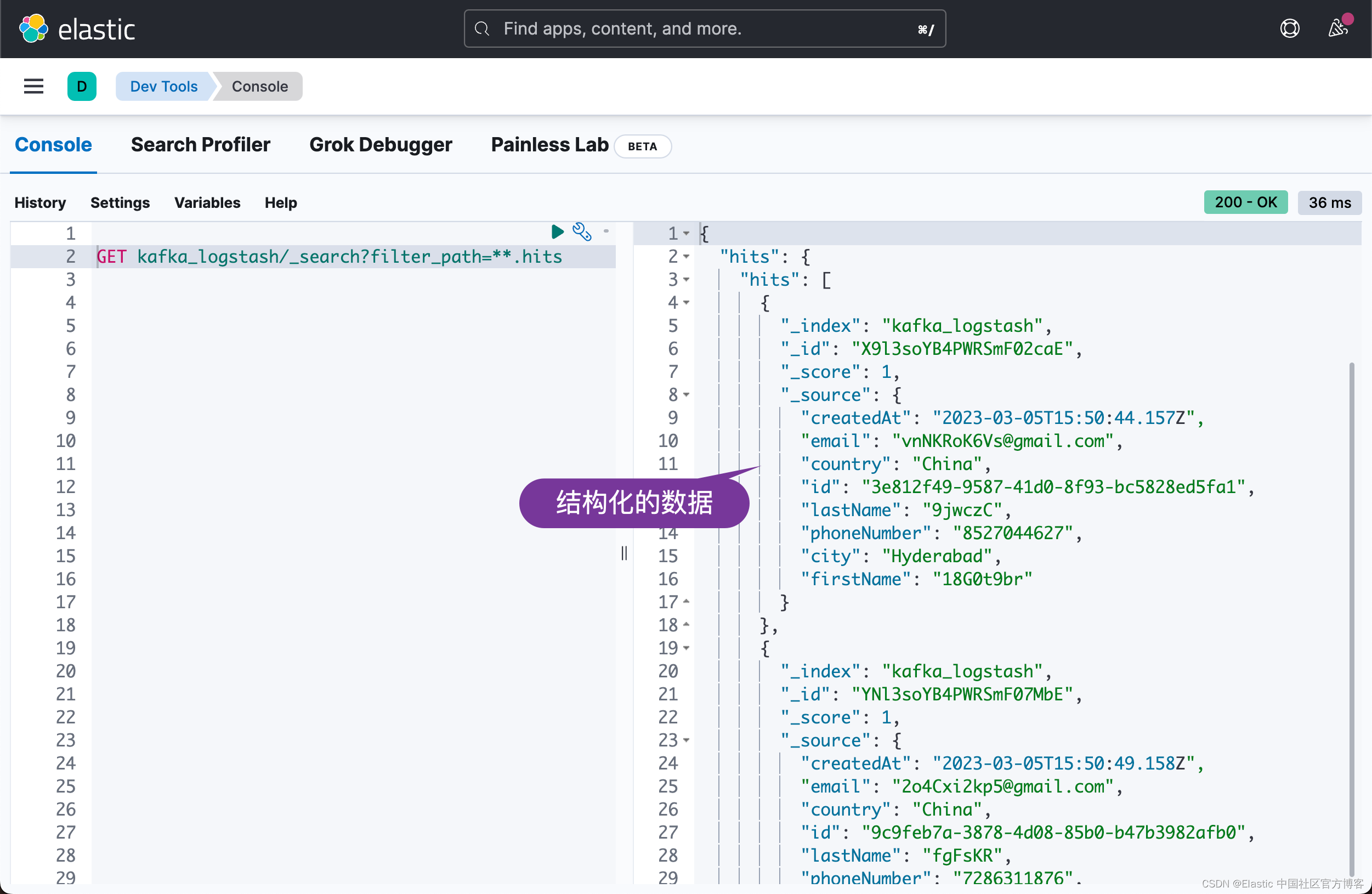
Elasticsearch:使用 Logstash 构建从 Kafka 到 Elasticsearch 的管道 - Nodejs
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我构建了从 Beats > Kafka > Logstash > Elasticsearch 的管道。在今天的文章中,我将描述从 Nodejs > Kafka > Logstash > Elasticsearch 这样的一个数据流。在…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

LINUX 69 FTP 客服管理系统 man 5 /etc/vsftpd/vsftpd.conf
FTP 客服管理系统 实现kefu123登录,不允许匿名访问,kefu只能访问/data/kefu目录,不能查看其他目录 创建账号密码 useradd kefu echo 123|passwd -stdin kefu [rootcode caozx26420]# echo 123|passwd --stdin kefu 更改用户 kefu 的密码…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

C# 表达式和运算符(求值顺序)
求值顺序 表达式可以由许多嵌套的子表达式构成。子表达式的求值顺序可以使表达式的最终值发生 变化。 例如,已知表达式3*52,依照子表达式的求值顺序,有两种可能的结果,如图9-3所示。 如果乘法先执行,结果是17。如果5…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

MinIO Docker 部署:仅开放一个端口
MinIO Docker 部署:仅开放一个端口 在实际的服务器部署中,出于安全和管理的考虑,我们可能只能开放一个端口。MinIO 是一个高性能的对象存储服务,支持 Docker 部署,但默认情况下它需要两个端口:一个是 API 端口(用于存储和访问数据),另一个是控制台端口(用于管理界面…...