Elasticsearch:使用 Logstash 构建从 Kafka 到 Elasticsearch 的管道 - Nodejs
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我构建了从 Beats => Kafka => Logstash => Elasticsearch 的管道。在今天的文章中,我将描述从 Nodejs => Kafka => Logstash => Elasticsearch 这样的一个数据流。在之前的文章 “Elastic:Data pipeline:使用 Kafka => Logstash => Elasticsearch” 中,我也展示了使用 Python 的方法。我的配置如下:

在上面的架构中,有几个重要的组件:
- Kafka Server:这就是数据首先发布的地方。
- Producer:扮演将数据发布到 Kafka topic 的角色。 在现实世界中,你可以具有任何可以为 kafka 主题生成数据的实体。 在我们的示例中,我们将生成伪造的用户注册数据。
- Elasticsearch:这将充当将用户注册数据存储到其自身的数据库,并提供搜索及分析。
- Logstash:Logstash 将扮演中间人的角色,在这里我们将从 Kafka topic 中读取数据,然后将其插入到 Elasticsearch 中。
- Kibana:Kibana 将扮演图形用户界面的角色,它将以可读或图形格式显示数据。
为了演示的方便,你可以在地址下载演示文件 GitHub - liu-xiao-guo/data-pipeline8。我的文件目录是这样的:
$ pwd
/Users/liuxg/data/data-pipeline8
$ tree -L 3
.
├── README.md
├── docker-elk
│ ├── docker-compose.yml
│ └── logstash_pipeline
│ └── kafka-elastic.conf
├── docker-kafka
│ └── kafka-docker-compose.yml
└── kafka_producer.js$ pwd
/Users/liuxg/data/data-pipeline8/docker-elk
$ ls -al
total 16
drwxr-xr-x 5 liuxg staff 160 May 14 2021 .
drwxr-xr-x 8 liuxg staff 256 Mar 5 07:36 ..
-rw-r--r-- 1 liuxg staff 29 May 7 2021 .env
-rw-r--r-- 1 liuxg staff 1064 May 13 2021 docker-compose.yml
drwxr-xr-x 3 liuxg staff 96 May 13 2021 logstash_pipeline
$ vi .env
$ cat .env
ELASTIC_STACK_VERSION=8.6.2上面的其它文件将在我下面的章节中介绍。如果你自己想通过手动的方式部署 Kafka 请参阅我的另外一篇文章 “使用 Kafka 部署 Elastic Stack”。
安装
Kafka,Zookeeper 及 Kafka Manager
我将使用 docker-compose 来进行安装。一旦安装好,我们可以看到:
- Kafka 在 PORT 9092 侦听
- Zookeeper 在 PORT 2181 侦听
- Kafka Manager 侦听 PORT 9000 侦听
kafka-docker-compose.yml
version: "3"
services:zookeeper:image: zookeeperrestart: alwayscontainer_name: zookeeperhostname: zookeeperports:- 2181:2181environment:ZOO_MY_ID: 1kafka:image: wurstmeister/kafkacontainer_name: kafkaports:- 9092:9092environment:KAFKA_ADVERTISED_HOST_NAME: 192.168.0.3 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181kafka_manager:image: hlebalbau/kafka-manager:stablecontainer_name: kakfa-managerrestart: alwaysports:- "9000:9000"environment:ZK_HOSTS: "zookeeper:2181"APPLICATION_SECRET: "random-secret"command: -Dpidfile.path=/dev/null我们可以使用如下的命令来进行启动(在 Docker 运行的前提下):
docker-compose -f kafka-docker-compose.yml up
一旦运行起来后,我们可以使用如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a4acc0730467 zookeeper "/docker-entrypoint.…" About a minute ago Up About a minute 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper
02ec8e8a1e30 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" About a minute ago Up About a minute 0.0.0.0:9000->9000/tcp kakfa-manager
a85c32c0c08e wurstmeister/kafka "start-kafka.sh" About a minute ago Up About a minute 0.0.0.0:9092->9092/tcp kafka我们发现 Kafka Manager 运行于 9000 端口。我们打开本地电脑的 9000 端口:


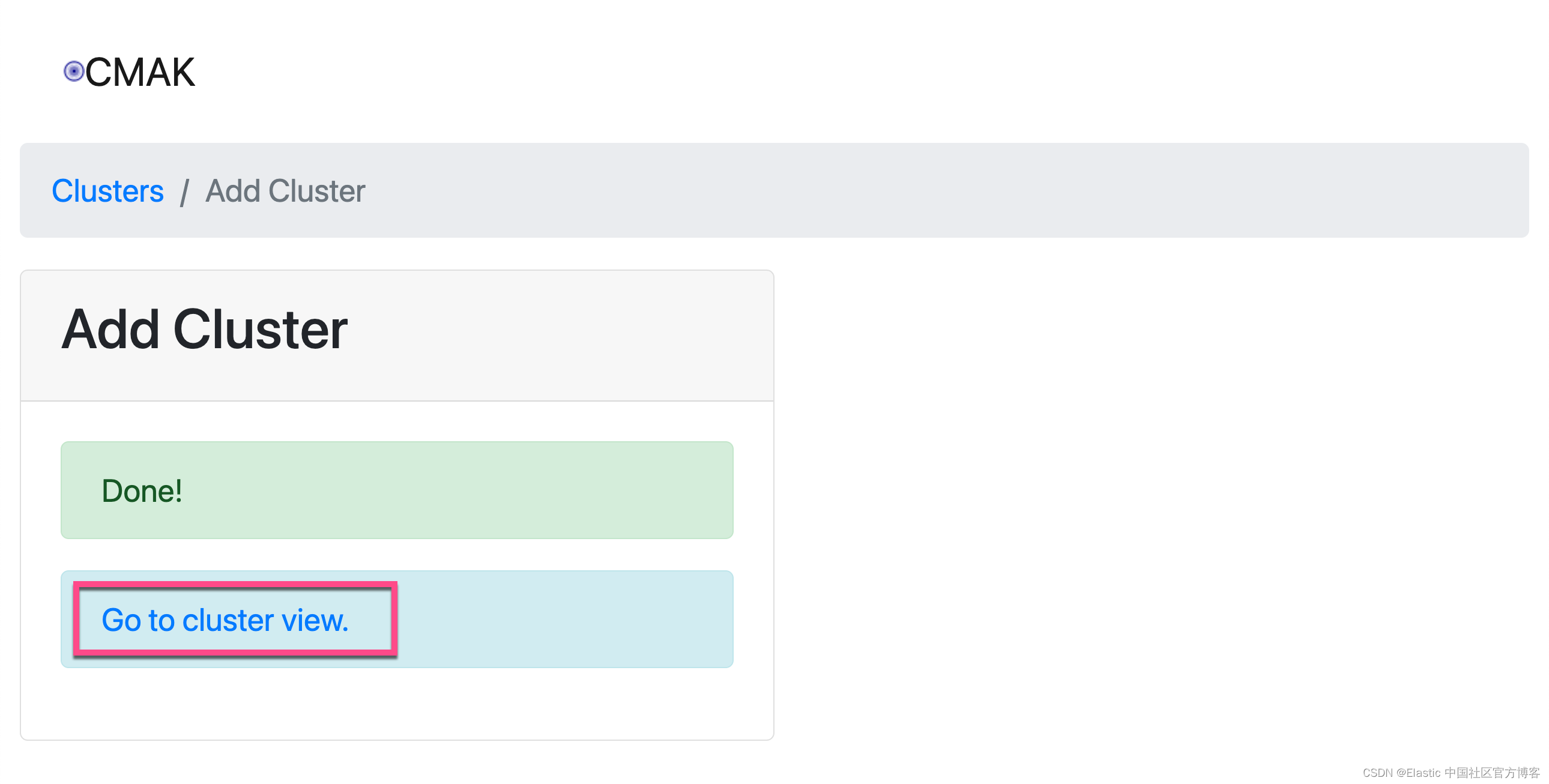 在上面它显示了一个默认的 topic,虽然不是我们想要的。
在上面它显示了一个默认的 topic,虽然不是我们想要的。
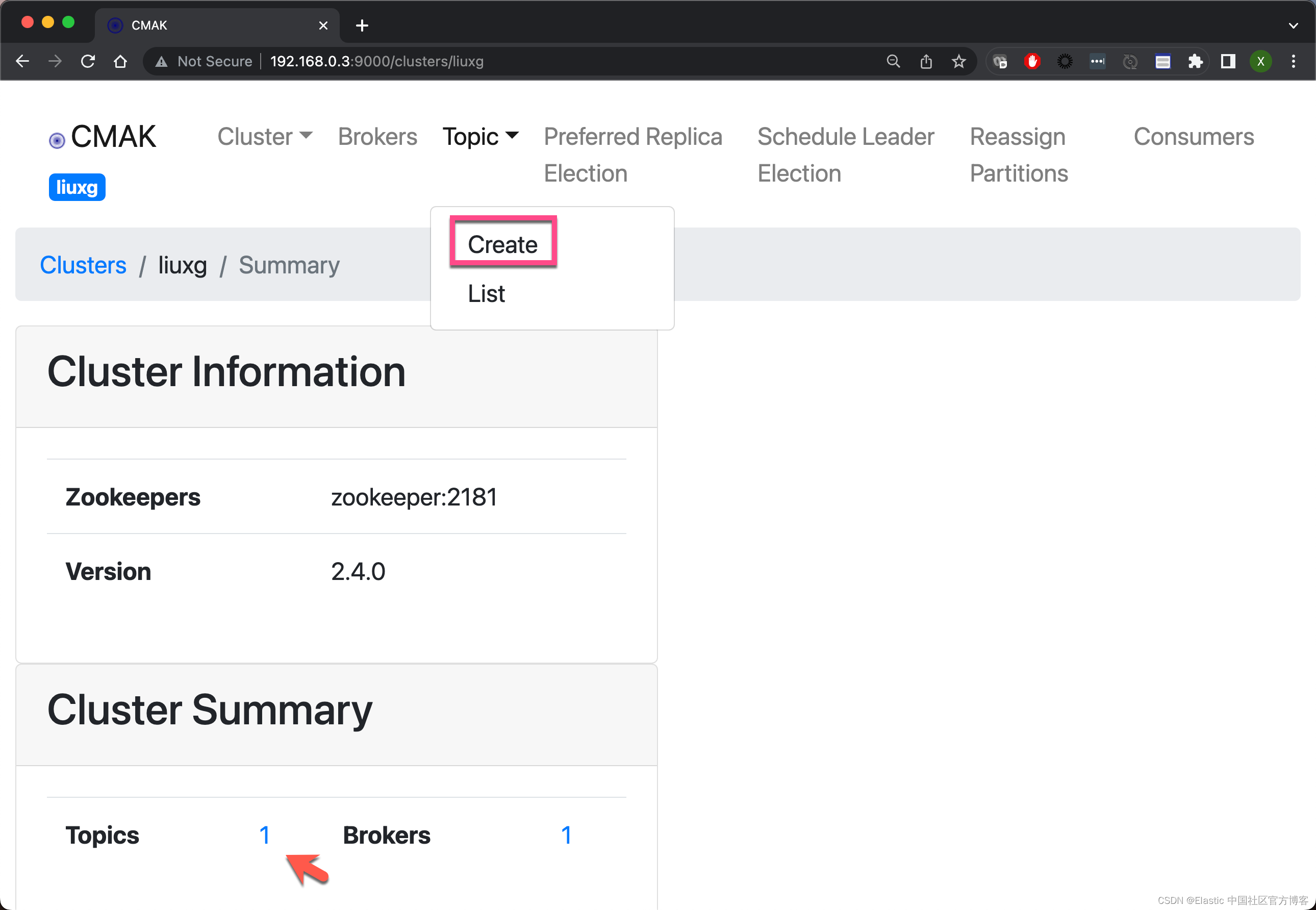



这样,我们就把 Kafka 上的 kafka_logstash topic 创建好了。
我们可以登录 kafka 容器来验证我们已经创建的 topic。我们使用如下的命令来找到 kafka 容器的名称:
docker ps -s$ docker ps -s
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE
de7453250529 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" 9 minutes ago Up 9 minutes 0.0.0.0:9000->9000/tcp kakfa-manager 117kB (virtual 427MB)
65eba68350f1 zookeeper "/docker-entrypoint.…" 9 minutes ago Up 9 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper 33kB (virtual 288MB)
3394868b23e9 wurstmeister/kafka "start-kafka.sh" 9 minutes ago Up 9 minutes 0.0.0.0:9092->9092/tcp kafka 210kB (virtual 457MB)上面显示 kafka 的容器名称为 wurstmeister/kafka。我们使用如下的命令来进行登录:
docker exec -it wurstmeister/kafka /bin/bash然后我们在容器里 打入如下的命令:
$ docker exec -it kafka /bin/bash
root@3394868b23e9:/# kafka-topics.sh --list -zookeeper zookeeper:2181
__consumer_offsets
kafka_logstash上面的命令显示已经存在的被创建的 kafka_logstash topic。我们可以使用如下的命令来向这个被创建的 topic 来发送数据:
kafka-console-consumer.sh --bootstrap-server 192.168.0.3:9092 --topic kafka_logstash --from-beginningroot@3394868b23e9:/# kafka-console-consumer.sh --bootstrap-server 192.168.0.3:9092 --topic kafka_logstash --from-beginningElastic Stack 安装
我们接下来安装 Elastic Stack。同样地,我使用 docker-compose 来部署 Elasticsearch, Logstash 及 Kibana。你们可以参考我之前的文章 “Logstash:在 Docker 中部署 Logstash”。为了能够把数据传入到 Elasticsearch 中,我们需要在 Logstash 中配置一个叫做 kafka-elastic.conf 的配置文件:
kafka-elastic.conf
input {kafka {bootstrap_servers => "192.168.0.3:9092"topics => ["kafka_logstash"]}
}output {elasticsearch {hosts => ["elasticsearch:9200"]index => "kafka_logstash"workers => 1}
}请注意:在上面的 192.168.0.3 为我自己电脑的本地 IP 地址。为了说明问题的方便,我们没有对来自 kafka 里的 registered_user 这个 topic 做任何的数据处理,而直接发送到 Elasticsearch 中。
我们的 docker-compose.yml 配置文件如下:
docker-compose.yml
version: "3.9"
services:elasticsearch:image: elasticsearch:${ELASTIC_STACK_VERSION}container_name: elasticsearchenvironment:- discovery.type=single-node- ES_JAVA_OPTS=-Xms1g -Xmx1g- xpack.security.enabled=falsevolumes:- type: volumesource: es_datatarget: /usr/share/elasticsearch/dataports:- target: 9200published: 9200networks:- elastickibana:image: kibana:${ELASTIC_STACK_VERSION}container_name: kibanaports:- target: 5601published: 5601depends_on:- elasticsearchnetworks:- elastic logstash:image: logstash:${ELASTIC_STACK_VERSION}container_name: logstashports:- 5200:5200volumes: - type: bindsource: ./logstash_pipeline/target: /usr/share/logstash/pipelineread_only: truenetworks:- elastic volumes:es_data:driver: localnetworks:elastic:name: elasticdriver: bridge为方便起见,在我的安装中,我没有配置安全。如果你需要为 Elasticsearch 设置安全的话,请参考我之前的文章 “Elasticsearch:使用 Docker compose 来一键部署 Elastic Stack 8.x”。
我们使用如下的命令来启动 Elastic Stack。在 docker-compose.yml 所在的目录中打入如下的命令:
$ pwd
/Users/liuxg/data/data-pipeline8/docker-elk
$ ls
docker-compose.yml logstash_pipeline
$ docker-compose up
等所有的 Elastic Stack 运行起来后,我们再次通过如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3db5e4e6e23e kibana:8.6.2 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:5601->5601/tcp kibana
210b673dd89a logstash:8.6.2 "/usr/local/bin/dock…" About a minute ago Up About a minute 5044/tcp, 9600/tcp, 0.0.0.0:5200->5200/tcp logstash
05c434edd823 elasticsearch:8.6.2 "/bin/tini -- /usr/l…" About a minute ago Up About a minute 0.0.0.0:9200->9200/tcp, 9300/tcp elasticsearch
de7453250529 hlebalbau/kafka-manager:stable "/kafka-manager/bin/…" 51 minutes ago Up 51 minutes 0.0.0.0:9000->9000/tcp kakfa-manager
65eba68350f1 zookeeper "/docker-entrypoint.…" 51 minutes ago Up 51 minutes 2888/tcp, 3888/tcp, 0.0.0.0:2181->2181/tcp, 8080/tcp zookeeper
3394868b23e9 wurstmeister/kafka "start-kafka.sh" 51 minutes ago Up 51 minutes 0.0.0.0:9092->9092/tcp kafka我们可以看到 Elasticsearch 运用于 9000 端口,Kibana 运行于 5601 端口,而 Logstash 运行 5000 端口。 我们可以访问 Kibana 的端口地址 5601:

运行 Nodejs 应用导入模拟数据
我们接下来建立一个 Nodejs 的应用来模拟一些数据。首先,我们需要安装如下的包:
npm install kafkajs uuid randomstring random-mobile
我们在根目录下打入如下的命令:
npm init -y$ npm init -y
Wrote to /Users/liuxg/data/data-pipeline8/package.json:{"dependencies": {"kafkajs": "^2.2.4"},"name": "data-pipeline8","description": "This is a sample code showing how to realize the following data pipeline:","version": "1.0.0","main": "kafka_producer.js","devDependencies": {},"scripts": {"test": "echo \"Error: no test specified\" && exit 1"},"repository": {"type": "git","url": "git+https://github.com/liu-xiao-guo/data-pipeline8.git"},"keywords": [],"author": "","license": "ISC","bugs": {"url": "https://github.com/liu-xiao-guo/data-pipeline8/issues"},"homepage": "https://github.com/liu-xiao-guo/data-pipeline8#readme"
}
上述命令生成一个叫做 package.json 的文件。在以后安装的 packages,它也会自动添加到这个文件中。默认的设置显然不是我们想要的。我们需要对它做一些修改。
kafka_producer.js
// import { Kafka, logLevel } from "kafkajs";
const { Kafka } = require('kafkajs');
const logLevel = require("kafkajs");// import { v4 as uuidv4 } from "uuid";
const { v4: uuidv4 } = require('uuid');console.log(uuidv4());const kafka = new Kafka({clientId: "random-producer",brokers: ["localhost:9092"],connectionTimeout: 3000,
});var randomstring = require("randomstring");
var randomMobile = require("random-mobile");
const producer = kafka.producer({});
const topic = "kafka_logstash";const produce = async () => {await producer.connect();let i = 0;setInterval(async () => {var event = {};try {event = {globalId: uuidv4(),event: "USER-CREATED",data: {id: uuidv4(),firstName: randomstring.generate(8),lastName: randomstring.generate(6),country: "China",email: randomstring.generate(10) + "@gmail.com",phoneNumber: randomMobile(),city: "Hyderabad",createdAt: new Date(),},};await producer.send({topic,acks: 1,messages: [{value: JSON.stringify(event),},],});// if the message is written successfully, log it and increment `i`console.log("writes: ", event);i++;} catch (err) {console.error("could not write message " + err);}}, 5000);
};produce().catch(console.log)我们运行上面的 Nodejs 代码:
npm start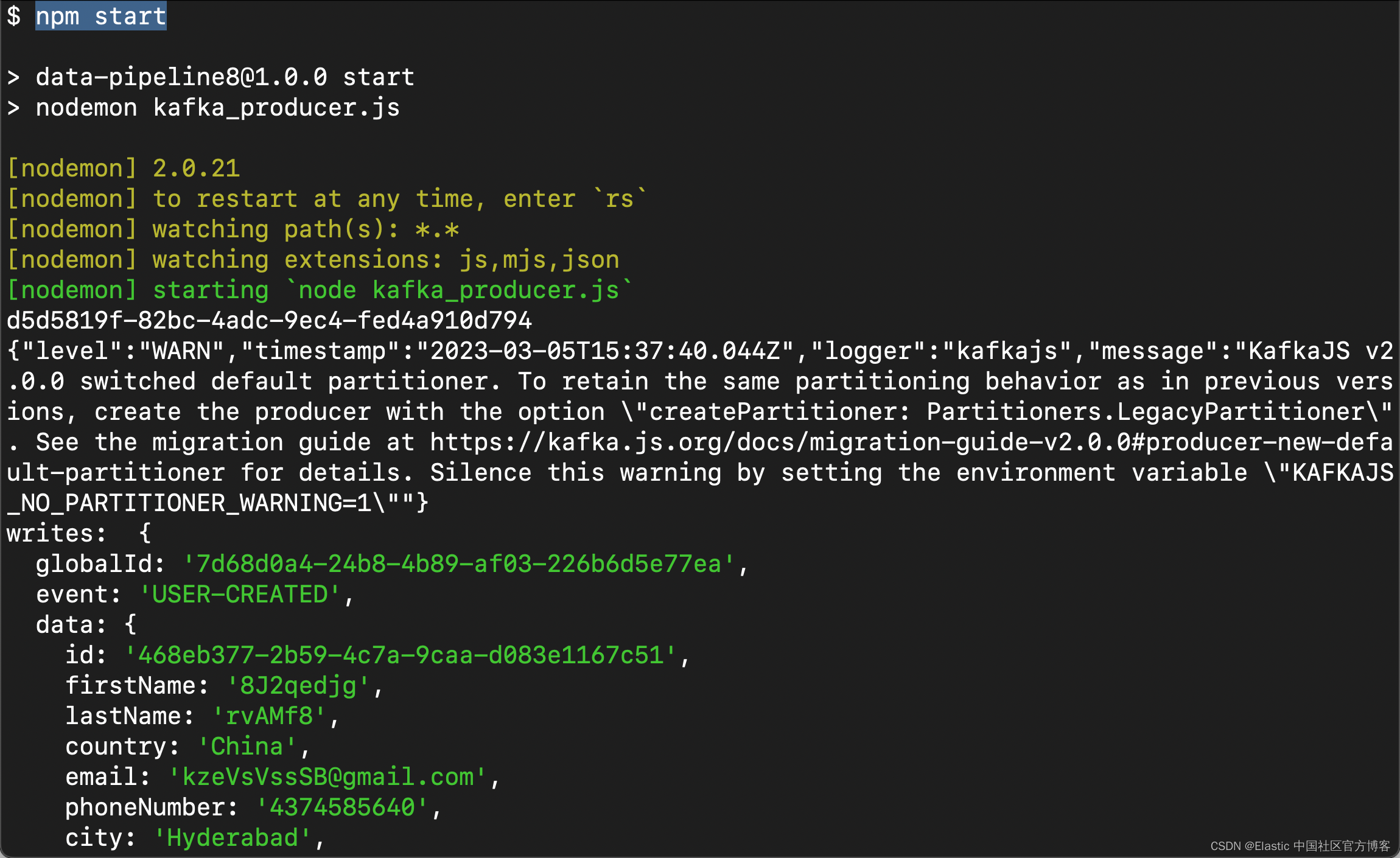
我们接下来在 Kibana 中来查看索引 kafka_logstash:
GET kafka_logstash/_count{"count": 103,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0}
}我们可以看到文档的数值在不断地增加。我们可以查看文档:
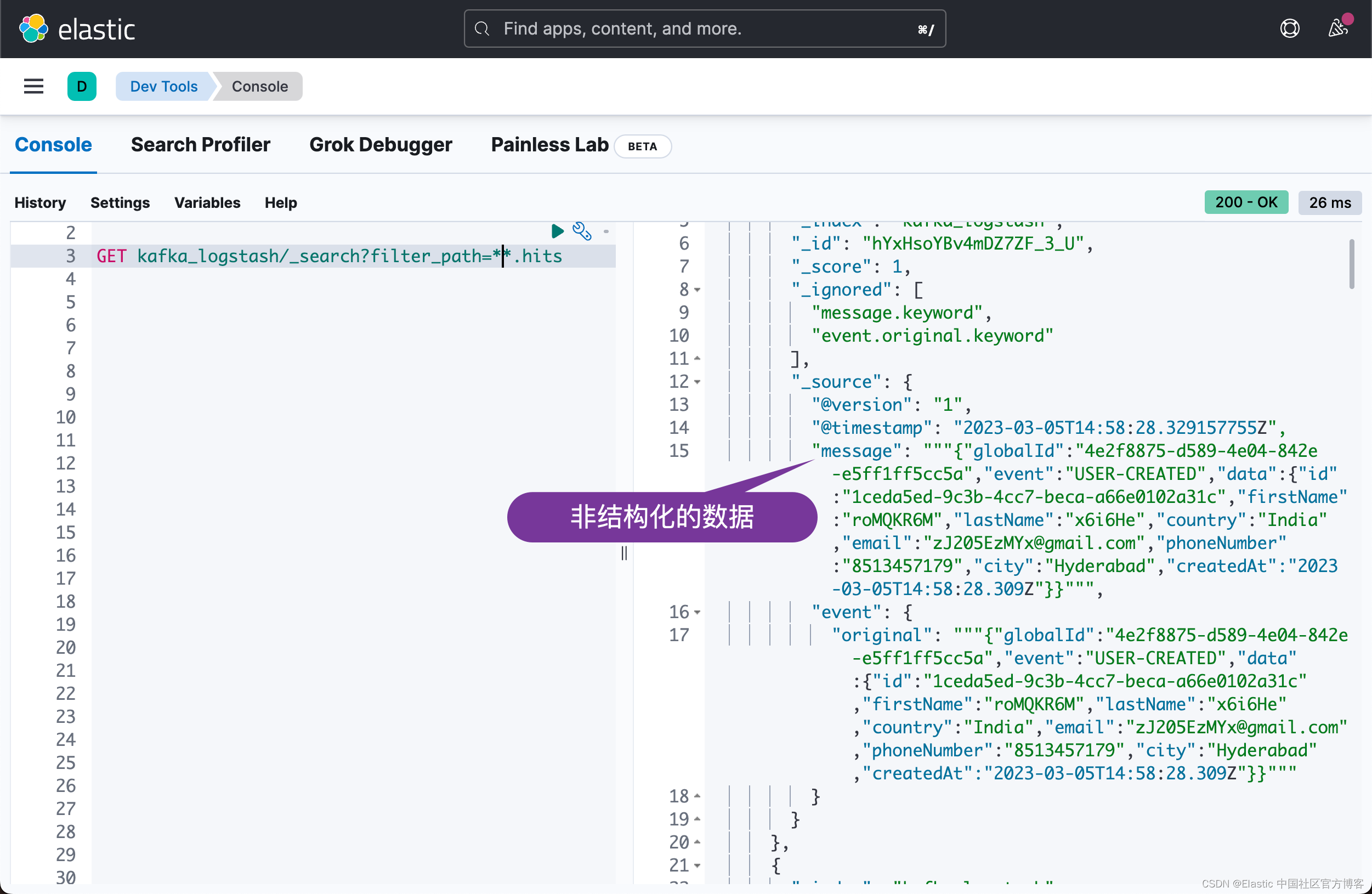
很显然我们收到了数据。从上面的结果中,我们可以看出来是一些非结构化的数据。我们可以针对 Logstash 的 pipeline 进行修改:
kafka-elastic.conf
input {kafka {bootstrap_servers => "192.168.0.3:9092"topics => ["kafka_logstash"]}
}filter {json {source => "message"}mutate {add_field => {"id" => "%{[data][id]}"}add_field => {"firstName" => "%{[data][firstName]}"}add_field => {"lastName" => "%{[data][lastName]}"}add_field => {"city" => "%{[data][city]}"}add_field => {"country" => "%{[data][country]}"}add_field => {"email" => "%{[data][email]}"}add_field => {"phoneNumber" => "%{[data][phoneNumber]}"}add_field => {"createdAt" => "%{[data][createdAt]}"}remove_field => ["data", "@version", "@timestamp", "message", "event", "globalId"]}
}output {elasticsearch {hosts => ["elasticsearch:9200"]index => "kafka_logstash"workers => 1}
}我们在 Kibana 中删除 kafka_logstash:
DELETE kafka_logstash我们停止运行 Nodejs 应用。我们把运行 Elastic Stack 的 docker-compose 关掉,并再次重新启动它:
docker-compose down
docker-compose up
我们再次运行 Nodejs 应用:

我们再次到 Kibana 中进行查看:
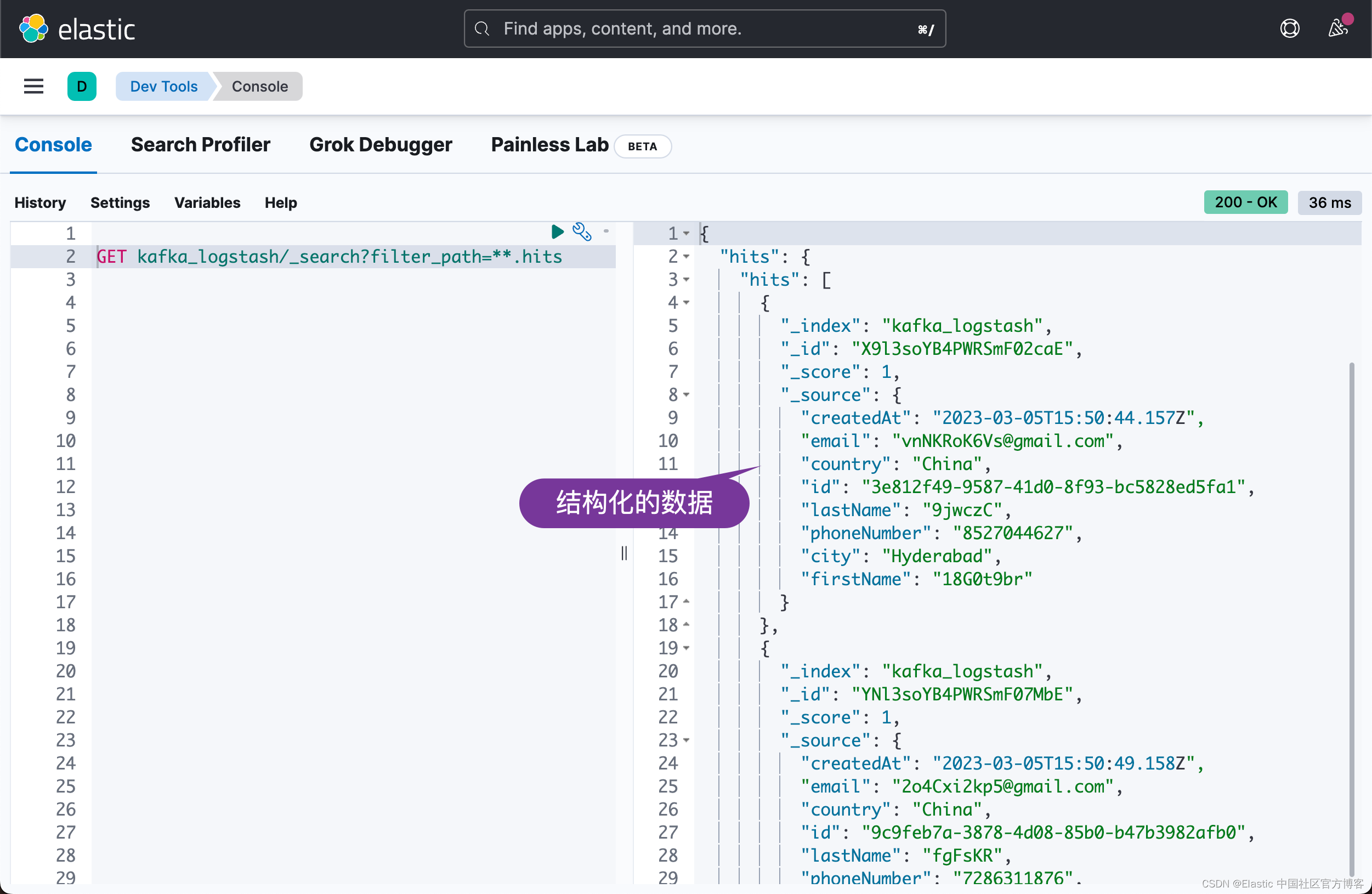
很显然,这次,我们看到结构化的输出文件。
相关文章:
Elasticsearch:使用 Logstash 构建从 Kafka 到 Elasticsearch 的管道 - Nodejs
在我之前的文章 “Elastic:使用 Kafka 部署 Elastic Stack”,我构建了从 Beats > Kafka > Logstash > Elasticsearch 的管道。在今天的文章中,我将描述从 Nodejs > Kafka > Logstash > Elasticsearch 这样的一个数据流。在…...

记录一次es的性能调优
文章目录es性能调优启用g1垃圾回收器es性能调优 成都的es集群经常出现告警,查看日志发现 [gc][11534155] overhead, spent [38.3s] collecting in the last [38.6s]这是 JVM 垃圾回收过程中的一条日志,表示在最近 38.6 秒内,JVM 进行了一次…...
内核性能评估测试及具体修改操作步骤记录
步骤记录前言一、查看环境配置二、LRU缓存空间调整三、进程扫描时间间隔四、与其他内核对比的工作负载测试(另一个内核的编译)总结前言 记录的相关操作有:查看服务器硬件环境、LRU缓存大小修改、内核命名、内核编译以及进程执行周期的设置。…...

S7-200smart远程无线模拟量信号采集案例
本参考方案使用西门子PLCS7-200SMART 结合无线通讯终端DTD434MC和DTD433F实现 PLC对远端设备模拟量的远程无线输入输出查询控制。所使用到的设备:西门子S7-200smartPLC无线数据终端DTD434MC无线模拟量信号测控终端DTD433F所使用的协议:ModbusRTU协议方案…...

Blender Python材质处理入门
本文介绍在 Blender 中如何使用 Python API 获取材质及其属性。 推荐:用 NSDT场景设计器 快速搭建3D场景。 1、如何获取材质 方法1、 获取当前激活的材质 激活材质是当前在材质槽中选择的材料。 如果你选择一个面,则活动材料将更改为分配给选定面的材质…...
ChatGPT后劲很大,问题也是
ChatGPT亮相即封神,最初的访客是程序员、工程师、AI从业者、投资人,最后是无数懵懂又好奇的普通人:ChatGPT是什么?自己会被ChatGPT取代吗?看待ChatGPT的立场也是两个极端: 快乐,是因为ChatGPT太…...

世界那么大,你哪都别去了,来我带你了解CSS3 (二)
文章目录❤️🔥CSS文档流❤️🔥CSS浮动❤️🔥CSS定位❤️🔥CSS媒体查询❤️🔥CSS文档流 文档流是文档中可显示对象在排列时所占用的位置/空间。 例如:块元素自上而下摆放,内…...

2023年再不会Redis,就要被淘汰了
目录专栏导读一、同样是缓存,用map不行吗?二、Redis为什么是单线程的?三、Redis真的是单线程的吗?四、Redis优缺点1、优点2、缺点五、Redis常见业务场景六、Redis常见数据类型1、String2、List3、Hash4、Set5、Zset6、BitMap7、Bi…...

Java SPI机制了解与应用
1. 了解SPI机制 我们在平时学习和工作中总是会听到Java SPI机制,特别是使用第三方框架的时候,那么什么是SP机制呢?SPI 全称 Service Provider Interface,是 Java 提供的一套用来被第三方实现或者扩展的接口,它可以用来…...

vue实现输入框中输完后光标自动跳到下一个输入框中
前言 最近接到这么一个需求,做一个安全码的输入框,限制为6位数,但是每一个写入的值都是一个输入框,共计6个输入框,当前输入框写入值后,光标自动跳到下一个输入框中,删除当前输入框写入的值后再自…...

如何构建 C 语言编译环境?
C语言是一种通用的编程语言,它是由Dennis Ritchie于20世纪70年代初在贝尔实验室开发的。C语言的设计目标是提供一种结构化、高效、可移植的编程语言,以支持系统编程和应用程序开发。C语言广泛用于开发操作系统、网络设备、游戏、嵌入式系统、桌面应用程序…...
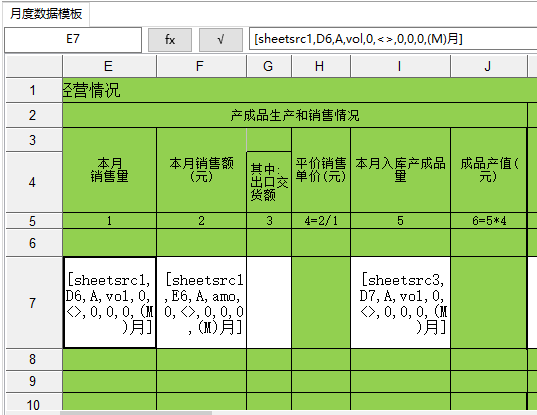
电子台账:模板制作之一——列过滤(水平过滤)
1 简介列过滤即水平过滤。一般情况下,企业数据源文件中有很多数据列,其中大部分数据列中的数据对电子台账来说是没有用的。列过滤就是确定企业数据文件的哪几列有用,以及有用的列分别对应到台账(模板)的哪一列。列过滤…...

【java】Java连接mysql数据库及mysql驱动jar包下载和使用
文章目录JDBCJDBC本质:JDBC作用:跟数据库建立连接发送 SQL 语句返回处理结果操作流程和具体的连接步骤如下:操作步骤:需要导入驱动jar包 mysql-connector-java-8.0.22.jar注册驱动获取数据库连接对象 Connection定义sql获取执行sq…...

Mysql八股文
Mysql八股文 数据库的三范式是什么 第一范式:列不可再分第二范式:行可以唯一区分,主键约束第三范式:表的非主属性不能依赖与 其他表的非主属性 外键约束且三大范式是一级一级依赖的,第二范式建立在第一范式上&#x…...

解析Android ANR问题
一、ANR介绍 ANR 由消息处理机制保证,Android 在系统层实现了一套精密的机制来发现 ANR,核心原理是消息调度和超时处理。ANR 机制主体实现在系统层,所有与 ANR 相关的消息,都会经过系统进程system_server调度,具体是ActivityManagerService服务,然后派发到应用进程完成对…...

ESP32设备驱动-MicroSD Card驱动
MicroSD Card驱动 1、SDCard介绍 SD卡是Secure Digital Card卡的简称,直译成汉语就是“安全数字卡”,是由日本松下公司、东芝公司和美国SANDISK公司共同开发研制的全新的存储卡产品。SD存储卡是一个完全开放的标准(系统),多用于MP3、数码摄像机、数码相机、电子图书、AV器…...

XC7K160T-1FBG484I、XC7A100T-2CSG324I FPGA可编程门阵列 PDF规格书
1、XC7K160T-1FBG484I说明:Kintex-7 FPGA有-3、-2、-1、-1L和-2L速度等级,其中-3具有最高的性能。-2L器件被筛选为较低的最大静态功率,并且可以在较低的核心电压下运行,以获得比-2器件更低的动态功率。-2L工业(I)温度器件仅在VCCI…...
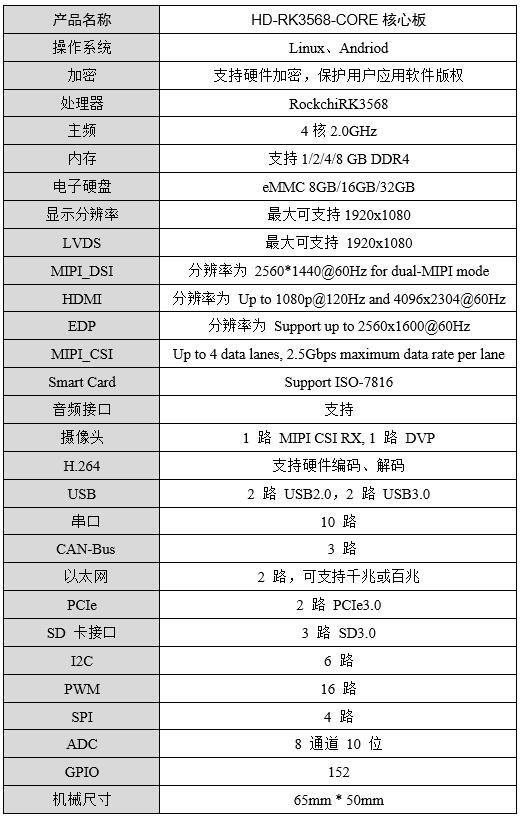
基于HD-RK3568-IO评估板的读写速度测试报告
1. 测试对象HD-RK3568-IOT 底板基于HD-RK3568-CORE工业级核心板设计(双网口、双CAN、5路串口),接口丰富,适用于工业现场应用需求,亦方便用户评估核心板及CPU的性能。适用于工业自动化控制、人机界面、中小型医疗分析器…...

jconsole远程linux下的tomcat
修改Tomcat的配置 进去 Tomcat 安装目录下的 bin 目录,编辑 catalina.sh vi catalina.sh定位到 ----- Execute The Requested Command ----------------------------------------- vi 编辑模式下,点击 Esc,输入 / ,然后粘贴 -…...
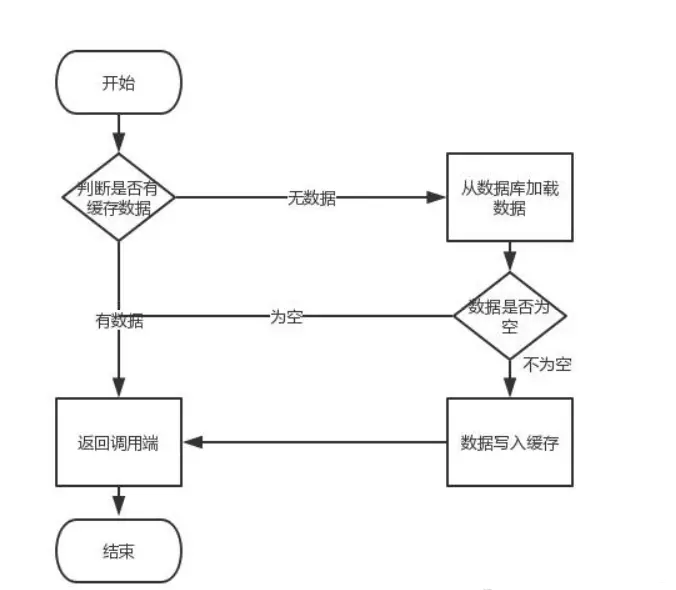
Redis和MySQL如何保持数据一致性?
在高并发的场景下,大量的请求直接访问MySQL很容易造成性能问题。所以,我们都会用Redis来做数据的缓存,削减对数据库的请求。但是,MySQL和Redis是两种不同的数据库,如何保证不同数据库之间数据的一致性就非常关键了。1.…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...