【Linux】-- 进程间通讯
目录
进程间通讯概念的引入
意义(手段)
思维构建
进程间通信方式
管道
站在用户角度-浅度理解管道
匿名管道 pipe函数
站在文件描述符角度-深度理解管道
管道的特点总结
管道的拓展
单机版的负载均衡
匿名管道读写规则
命名管道
前言
原理
创建一个命名管道
用命名管道实现myServer&myClient通信
匿名管道与命名管道的区别
命名管道的打开规则
system V共享内存
共享内存数据结构
共享内存的创建
key概念引入
key概念解析
基于共享内存理解信号量
总结
进程间通讯概念的引入
意义(手段)
在没有进程间通讯之前,理论上都是单进程的,那么也就无法使用并发能力,更无法实现多进程协同(将一个事,分几个进程做)。而进程间通讯,就是对于实现多进程协同的手段。
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
思维构建
进程间通讯重点,就在与如何让不同的进程资源的传递。而进程是具有独立性的,也就是说进程相通讯会难度较大 -- 因为进程间通讯的本质是:先让不同的进程看见同一份资源。
融汇贯通的理解:
进程的设计天然就是为了保证独立性的(即,进程之间无瓜葛),所以深入的说:所谓的同一份资源不能所属于任何一个进程,更强调共享,不属于任何一个进程。
进程间通信方式
管道
- 匿名管道pipe
- 命名管道
System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
管道
我们把从一个进程连接到另一个进程的数据流称为一个“管道”。
当在两个命令之间设置管道 "|" 时,管道符 "|" 左边命令的输出就变成了右边命令的输入。只要第一个命令向标准输出写入,而第二个令是从标准输入读取,那么这两个命令就可以形成一个管道。大部分的 Linux 命令都可以用来形成管道。
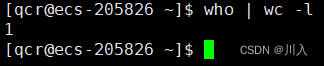
命令:who | wc -l
用于查看当前服务器下登陆的用户人数。
补充:
Linux who命令:用于显示系统中有哪些使用者正在上面,显示的资料包含了使用者 ID、使用的终端机、从哪边连上来的、上线时间、呆滞时间、CPU 使用量、动作等等。使用权限:所有使用者都可使用。
Linux wc命令:用于计算字数。在此处由于who中一个用户为一行,所以此处用 -l 显示行数,即登录用户个数。

其中,运行起来后who命令与wc命令就是两个不同的进程。who进程作为数据提供方,通过标准输入将数据写入管道,wc进程再通过标准输入将数据从管道中读取出,进而再将数据进行处理 "-l" ,后以标准输出的方式将结果给用户。
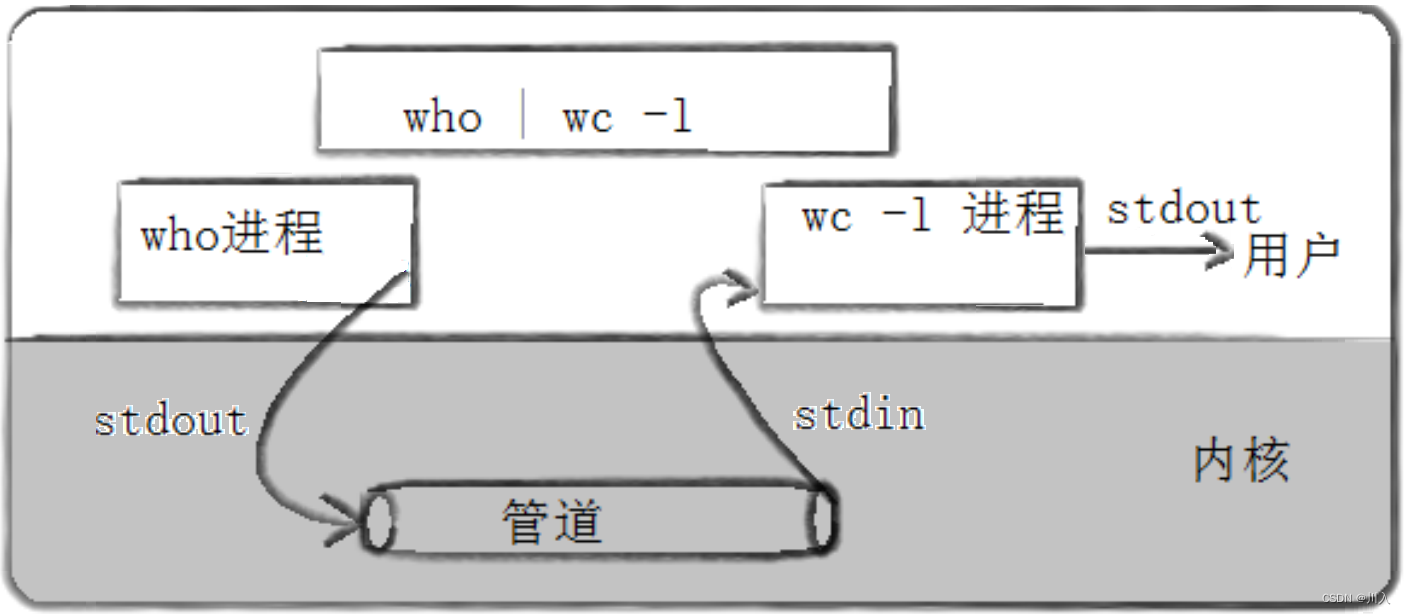
站在用户角度-浅度理解管道
匿名管道 pipe函数
#include <unistd.h>
功能:创建一无名管道。原型:int pipe(int pipefd[2]);参数:输出型参数,通过调用该参数,得到被打开的文件fd。
数组元素 含义 pipefd[0] 管道读端文件描述符 pipefd[1] 管道写端文件描述符 返回值:
成功时,返回0。出现错误时,返回-1。
1. 父进程创建管道
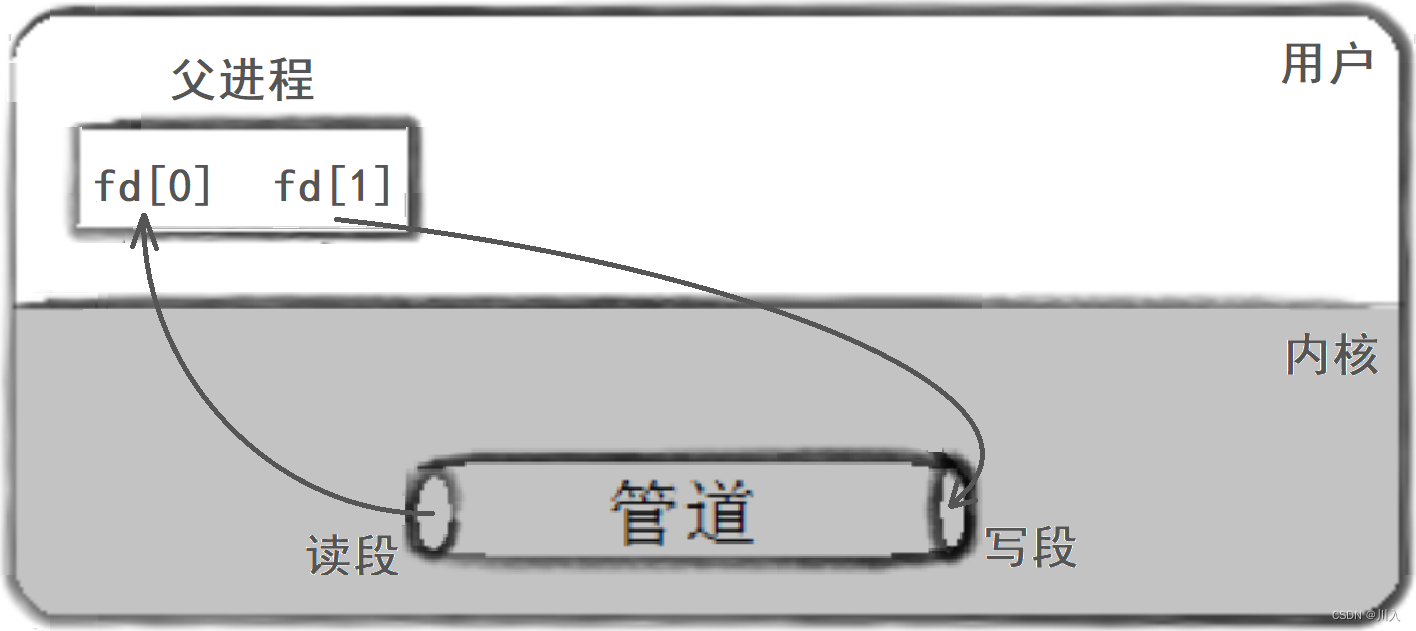
2. 父进程fork出子进程
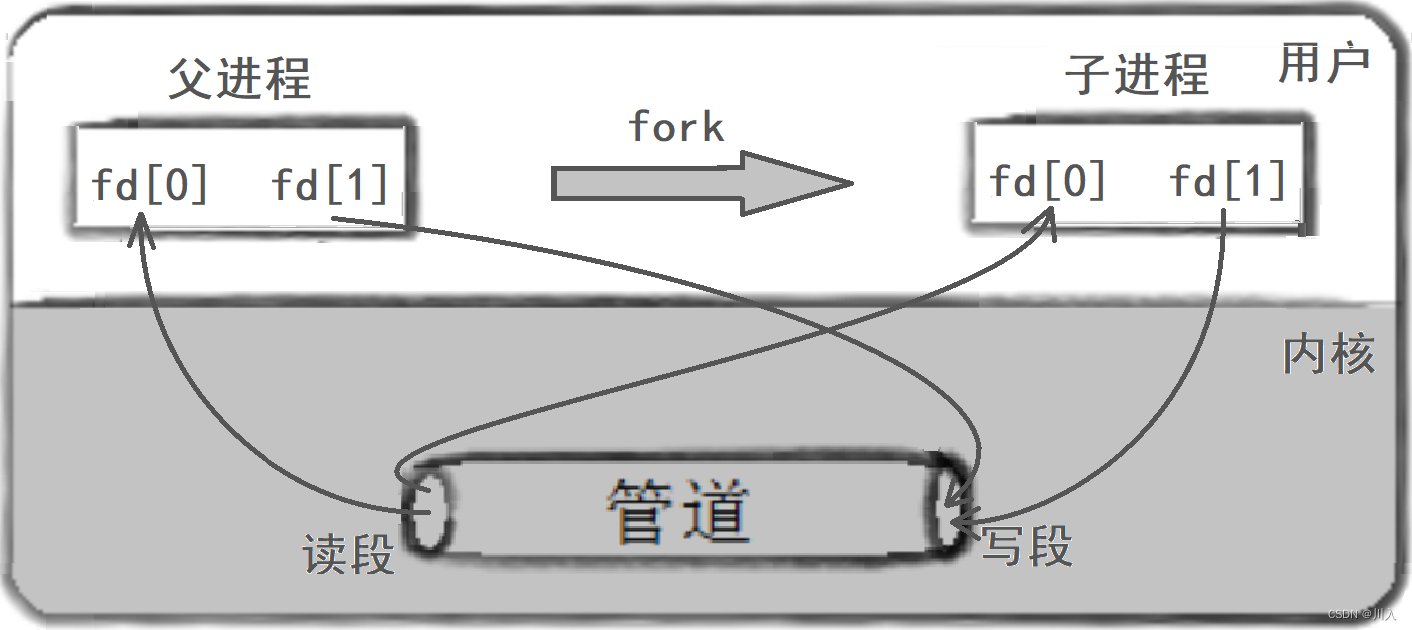
3. 父进程关闭读 / 写,子进程关闭写 / 读。(fork之后各自关掉不用的描述符)
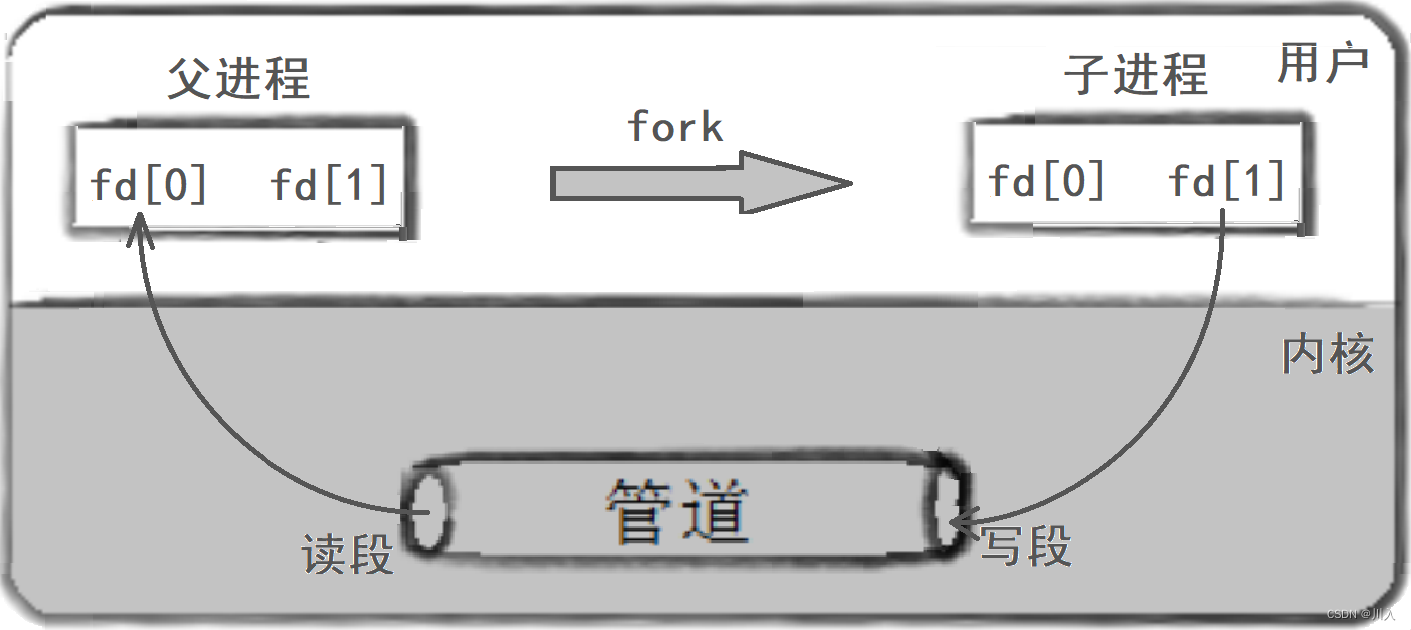
Note:对于pipe函数创建的管道,只能够进行单向通信。(反之,会导致读写导致管道中数据污染、混乱)。我们需要对于父或子进程中的fd参数中的,文件符号进行关闭。
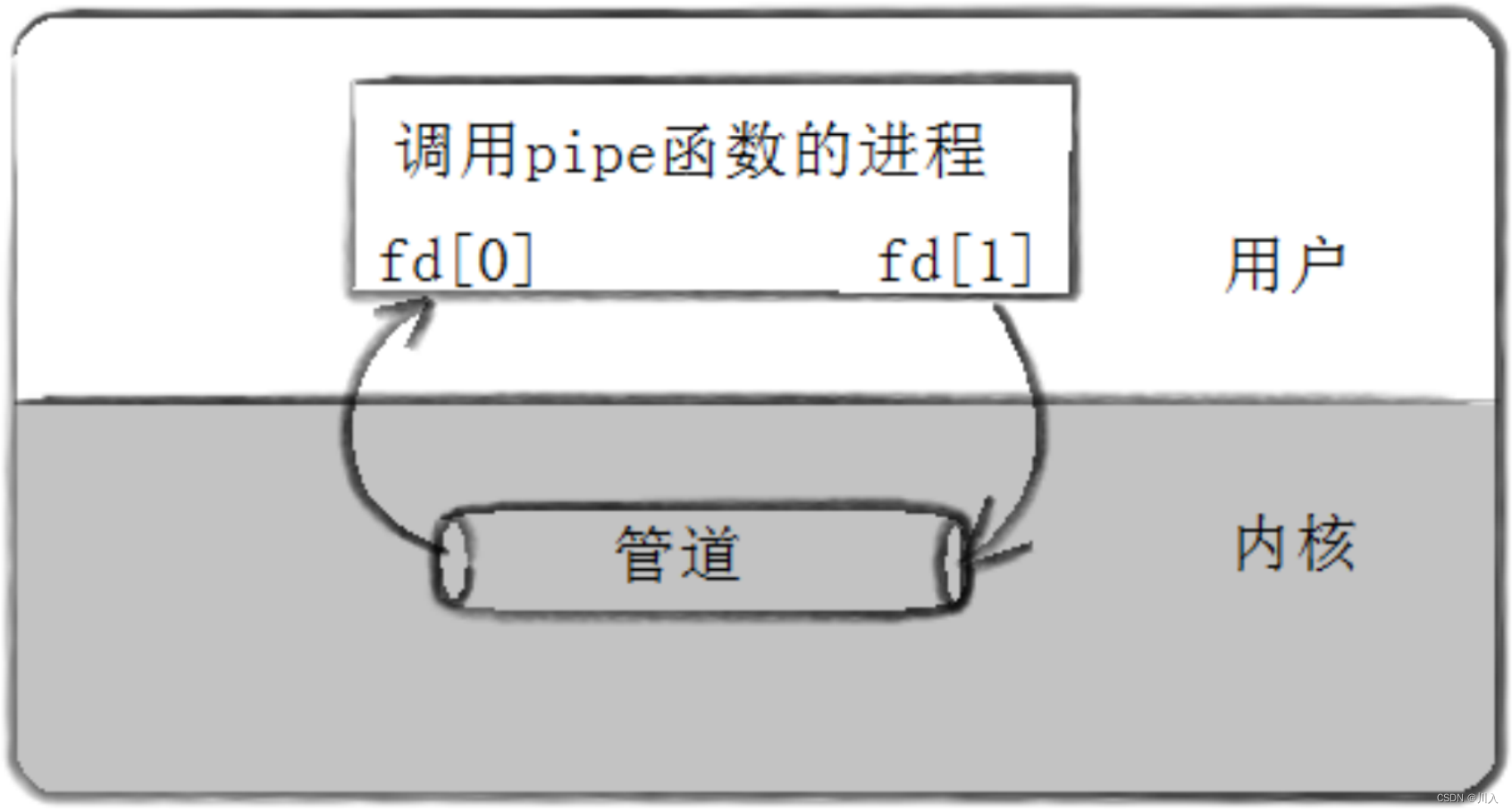 pipe函数的使用需要结合fork函数的父子进程。
pipe函数的使用需要结合fork函数的父子进程。
站在文件描述符角度-深度理解管道
#问:如何做到让不同的进程,看到同一份资源?
以fork让子进程继承,能够让具有“血缘关系”的进程进行进程间通讯。(管道:常用于父进程进程)
融汇贯通的理解:
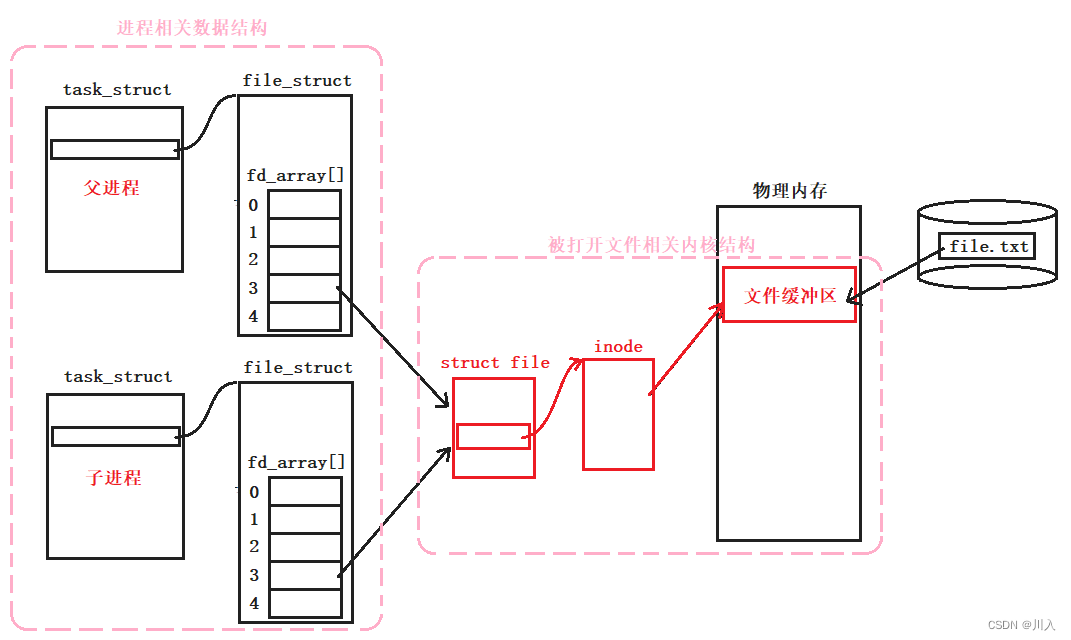
fork创建子进程,等于系统中多了一个子进程。而进程 = 内核数据结构 + 进程代码和数据。进程相关内核数据结构来源于操作系统,进程代码和数据一般来源于磁盘。
而由于为了进程具有独立性,所以创建子进程的同时,需要分配对应的进程相关内核结构。对于数据,被写入更改时操作系统采用写时拷贝技术,进行对父子进程数据的分离。
父进程与子进程拥有自身的fd_array[]存储文件描述符fd,但是其中存储的fd时相同的,而文件相关内核数据,并不属于进程数据结构,所以并不会单独为子进程创建。于是:父进程与子进程指向的是一个文件 -> 这就让不同的进程看到了同一份资源。
管道本质上就是一个文件。一个具有读写功能,并且无需放入磁盘的文件(通道是进程进行通讯的临时内存空间,无需将内容放入磁盘中保留)。
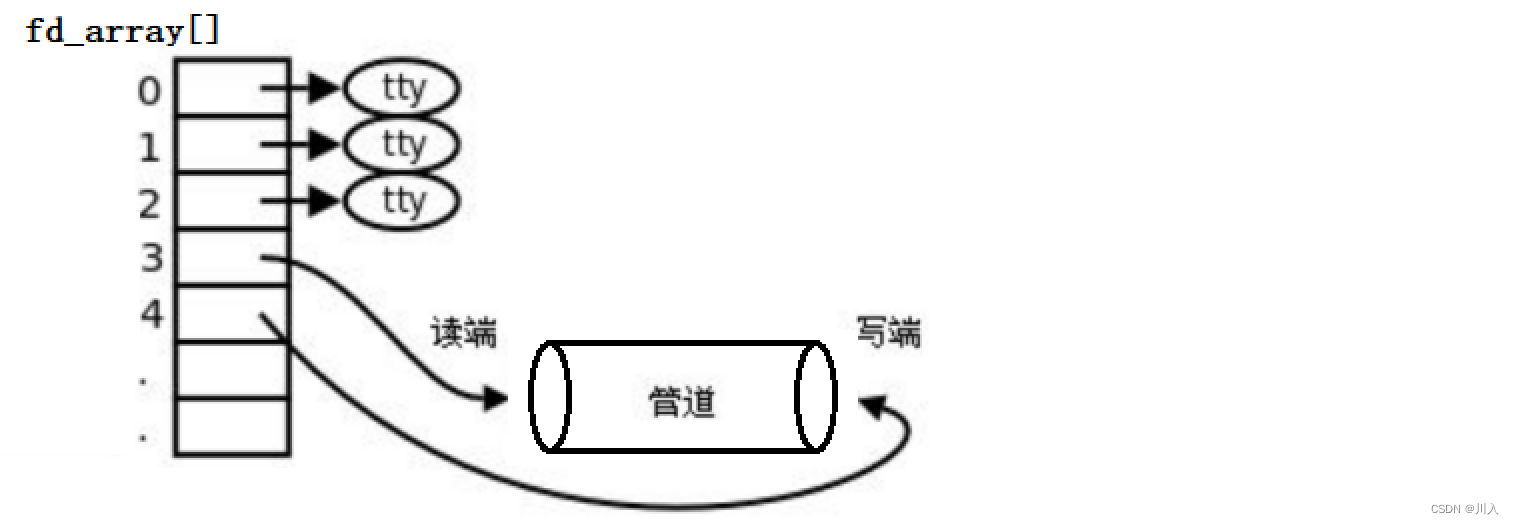
(tty:标准输入、标准输出、标准错误)
1. 父进程创建管道
2. 父进程fork出子进程
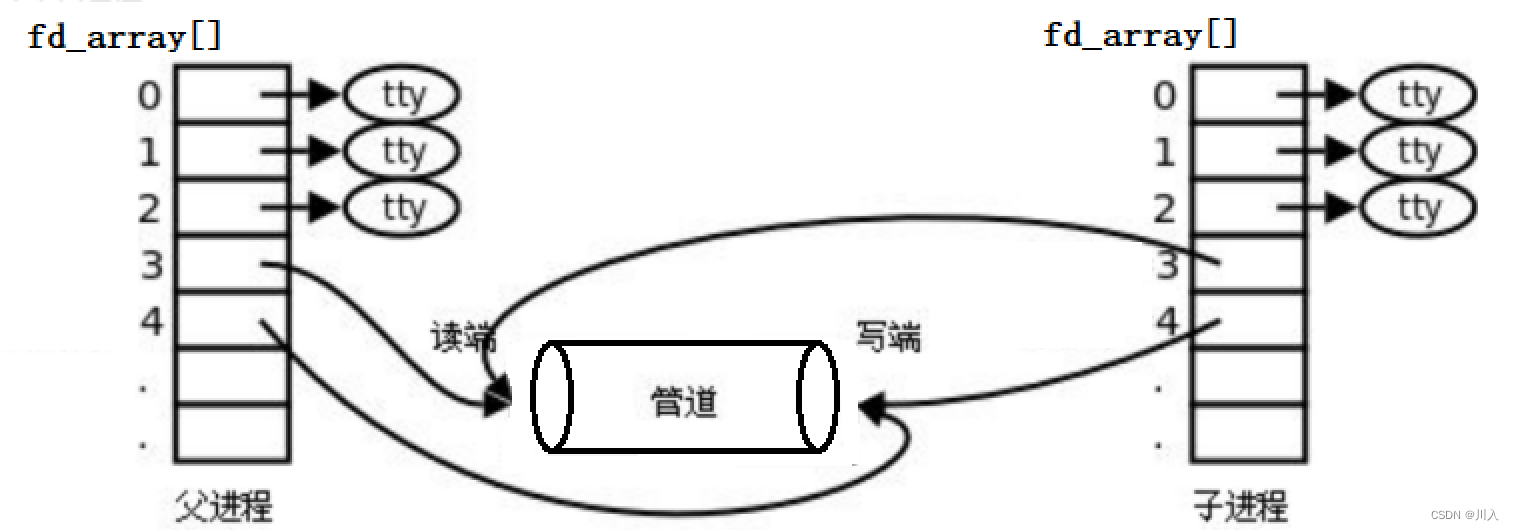
3. 父进程关闭读 / 写,子进程关闭写 / 读。(fork之后各自关掉不用的描述符)
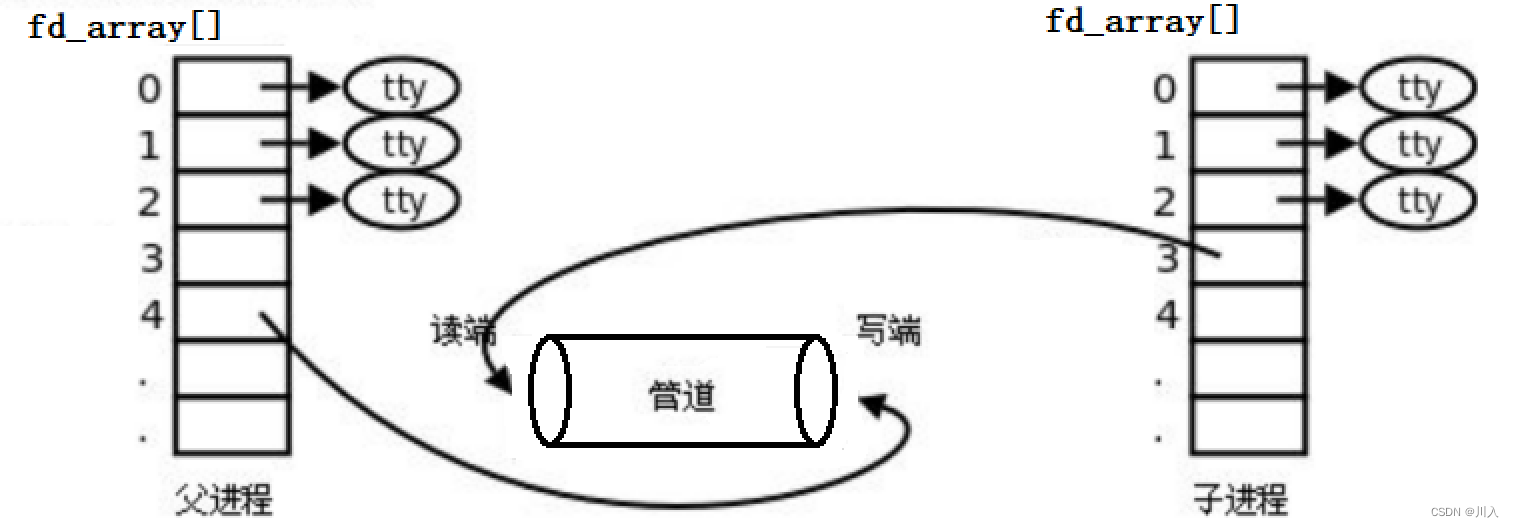
代码实现的关键:
- 创建管道 -- 分别以读写方式打开同一个问题
- 创建子进程 -- 以fork函数创建子进程
- 构造单向通讯的通道 -- 双方进程各自关闭自己不需要的文件描述符
#include <iostream>
#include <unistd.h>
#include <assert.h>
#include <string>
#include <string.h>
#include <sys/wait.h>
#include <sys/types.h>using namespace std;int main()
{//1.创建管道int pipefd[2] = {0};int n = pipe(pipefd);assert(n != -1);(void)n; // 只被定义没有被使用,Release下就会出现代码大量告警 -- 证明使用过// 用于调试验证fd申请
#ifdef DEBUGcout << "pipefd[0]: " << pipefd[0] << endl;cout << "pipefd[1]: " << pipefd[1] << endl;
#endif//2.创建子进程pid_t id = fork();assert(id != -1);if(id > 1){// 子进程 -- 只读// 3.构造单向通讯的通道, 父进程写入,子进程读取// 3.1 关闭子进程不需要的fdclose(pipefd[1]);char child_buffer[1024*4];while(true){ssize_t s = read(pipefd[0], child_buffer, sizeof(child_buffer) - 1);//3.2 访问控制:// a、写入的一方,fd没有关闭,如果有数据,就读,没有数据就等// b、写入的一方,fd关闭, 读取的一方,read会返回0,表示读到了文件的结尾!if(s > 0){child_buffer[s] = 0;cout << "child get a message[" << getpid() << "] Father# " << child_buffer << endl;}else if(s == 0){cout << "-----------writer quit(father), me quit!-----------" << endl;break;}}exit(0);}// 父进程 -- 只写// 3.构造单向通讯的通道, 父进程写入,子进程读取// 3.1 关闭父进程不需要的fdclose(pipefd[0]);string message = "我是父进程,发送有效信息。";int count = 0; // 传递的次数char father_buffer[1024*4];while(true){//3.2 构建一个变化的字符串snprintf(father_buffer, sizeof(father_buffer), "%s[%d] : %d",message.c_str(), getpid(), count++);//3.3 写入write(pipefd[1], father_buffer, strlen(father_buffer));//3.4 故意sleep凸显访问控制sleep(1);if(count == 3){cout << "----------------father wirte quit!----------------" <<endl;break;} }close(pipefd[1]);pid_t ret = waitpid(id, nullptr, 0);assert(ret > 0);(void)ret;return 0;
}
管道的特点总结
1. 管道是用来进程具有血缘关系的进程进行进程间通讯。
2. 管道具有通过让进程间通讯,提供访问控制。
a、写端快,读端慢,写满了不能再写了。
b、写端慢,读端快,管道没有数据的时候,读需要等待。
补充:
c、写端关闭,读端为0,标识读到了文件结尾。
d、读端关闭,写端继续写,操作系统终止写端进程。
3. 管道提供的是面向流式的通信服务 -- 面向字节流。
4. 管道是基于文件的,文件的生命周期是随进程的,所以管道的生命周期是随进程的。
5. 管道是单向通行的,就是半双工通信的一种特殊情况。
数据的传送方式可以分为三种:
单工通信(Half Duplex):是通讯传输的一个术语。一方固定为发送端,另一方固定为接收端。即:一方只能写一方只能读。
半双工通信(Half Duplex):是通讯传输的一个术语。指数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。即:一段时间内,只能一方写一方读。
全双工通信(Full Duplex):是通讯传输的一个术语。指通信允许数据在两个方向上同时传输,它在能力上相当于两个单工通信方式的结合。即:一段时间内,每方能写且读。
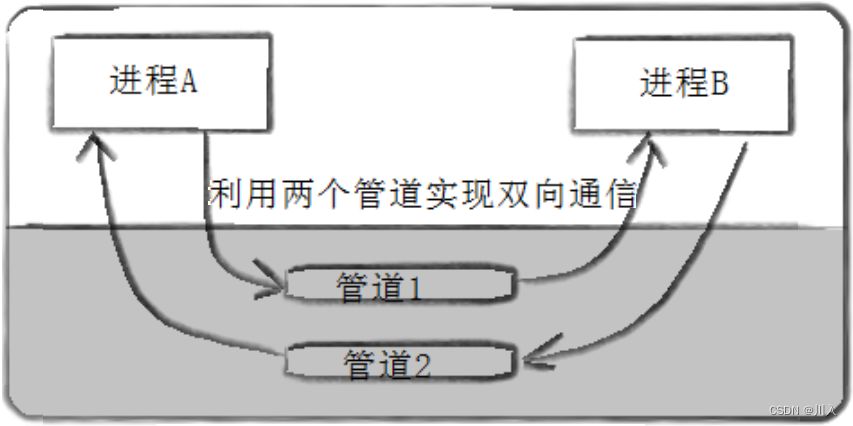
管道的拓展
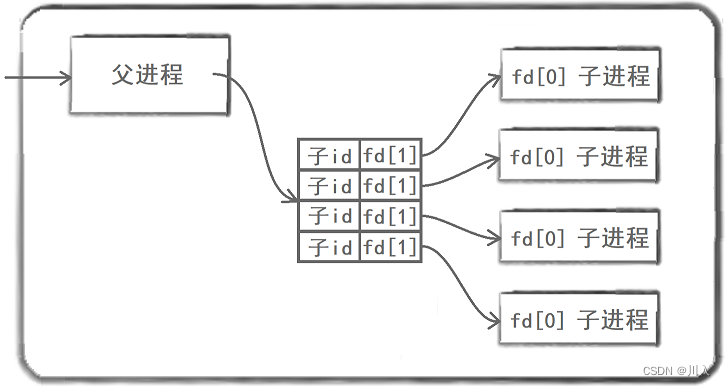
单机版的负载均衡
以循环fork函数开辟多个子进程,并利用pipe函数。针对于每一个子进程开辟一个管道,父进程通过管道安排其中一个子进程做某任务。
#pragma once#include <iostream>
#include <unordered_map>
#include <string>
#include <functional>typedef std::function<void()> func;std::vector<func> callbacks;
std::unordered_map<int, std::string> desc;void readMySQL()
{std::cout << "sub process[" << getpid() << "]执行访问数据库的任务" << std::endl;
}void executeUlt()
{std::cout << "sub process[" << getpid() << "]执行url解析\n" << std::endl;
}void cal()
{std::cout << "sub process[" << getpid() << "] 执行加密任务\n" << std::endl;
}void save()
{std::cout << "sub process[" << getpid() << "] 执行数据持久化任务\n" << std::endl;
}void load()
{callbacks.push_back(readMySQL);desc.insert({callbacks.size(), "readMySQL: 执行访问数据库的任务"});callbacks.push_back(executeUlt);desc.insert({callbacks.size(), "executeUlt: 进行url解析"});callbacks.push_back(cal);desc.insert({callbacks.size(), "cal: 进行加密计算"});callbacks.push_back(save);desc.insert({callbacks.size(), "save: 执行数据持久化任务"});
}// 功能展示
void showHandler()
{for(const auto &iter : desc)std::cout << iter.first << " -> " << iter.second << std::endl;
}// 具有的功能数
int handlerSize()
{return callbacks.size();
}#include <iostream>
#include <vector>
#include <unistd.h>
#include <cassert>
#include <sys/wait.h>
#include <sys/types.h>
#include "Task.hpp"using namespace std;#define PROCESS_NUM 4int waitCommand(int waitfd, bool& quit)
{//此处由于是父进程写入一个整数 -- 用以子进程执行相关内容//规定:子进程读取的数据必须是4字节uint32_t command = 0;ssize_t s = read(waitfd, &command, sizeof(command));if(s == 0){quit = 1;return -1;}assert(s == sizeof(uint32_t));return command;
}void wakeUp(pid_t who, int fd, uint32_t command)
{write(fd, &command, sizeof(command));cout << "main process call: " << who << "process," << " execute: " << desc[command] << ", through write fd: " << fd << endl;
}int main()
{load();// 存储:<子进程id,父进程对应写端符fd>vector<pair<pid_t, int>> slots;//1. 创建多个进程for(int i = 0; i < PROCESS_NUM; ++i){//1.1 创建管道int pipefd[2] = {0};int n = pipe(pipefd);assert(n == 0);(void)n;//1.2 fork创建子进程pid_t id = fork();assert(id != -1);(void)id;if(id == 0){// 子进程 -- 关闭写端close(pipefd[1]);while(true){// 用于判断是否bool quit = 0;int command = waitCommand(pipefd[0], quit);if(quit){break;}if(command >= 1 && command <= handlerSize())callbacks[command - 1]();elsecout << "error, 非法操作" << endl;}exit(1);}//将父进程读端关闭close(pipefd[0]);slots.push_back(make_pair(id, pipefd[1]));}while(true){int select;int command;cout << "############################################" << endl;cout << "## 1. show funcitons 2.command ##" << endl;cout << "############################################" << endl;cout << "Please Select> ";cin >> select;if(select == 1)showHandler();else if(select == 2){cout << "Enter command" << endl;cin >> command;// 随机挑选进程int choice = rand() % PROCESS_NUM;//将任务指派给指定的进程wakeUp(slots[choice].first, slots[choice].second, command);}elsecout << "输入错误,请重新输入" << endl;}// 关闭父进程写端fd,所有的子进程都会退出for(const auto &slot : slots)close(slot.second);// 回收所有的子进程信息for(const auto &slot : slots)waitpid(slot.first, nullptr, 0);return 0;
}匿名管道读写规则
- 当没有数据可读时
- O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来到为止
- O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
- 当管道满的时候
- O_NONBLOCK disable: write调用阻塞,直到有进程读走数据
- O_NONBLOCK enable:调用返回-1,errno值为EAGAIN
- 如果所有管道写端对应的文件描述符被关闭,则read返回0
- 如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
- 当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
- 当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
原子性:要么做,要么不做,没有所谓的中间状态。
POSIX.1-2001要求PIPE_BUF至少为512字节。(在Linux上,PIPE_BUF为4096字节。)
拓展:
讨论原子性,需要在多执行流下,数据出现并发访问的时候,讨论原子性才有意义。(此处不深入)
融会贯通的理解:
匿名管道就是一个文件,一个内存级别的文件,并不会在磁盘上存储,并不会有自身的文件名。作为基础间通讯的方式是:看见同一个文件 -- 通过父子进程父子继承的方式看见。
是一个,只有通过具有 “血缘关系” 的进程进行使用,可以称做:父子进程通讯。
命名管道
前言
匿名管道只能使用于具有“亲缘关系”的进程之间通信,而对于毫无关系的两个进程无法使用匿名管道通讯,如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。命名管道是一种特殊类型的文件。
原理
当两个进程需要同时带开一个文件的时候,由于为了保证进程的独立性,所以两个进程会有各自的files_struct,而对于文件数据,并不会为每一个进程都备一份(是内存的浪费),此时A进程的files_struct与B进程的files_struct是不同的,但是其中的文件符fd指向的是由磁盘文件加载到内存中的同一份数据空间。
命名管道就是如此,其原理与匿名管道很相识。命名管道在磁盘中,所以其有自己的文件名、属性信息、路径位置……,但是其没有文件内容。即,命名管道是内存文件,其在磁盘中的本质是命名管道在磁盘中的映像,且映像的大小永远为0。意义就是为了让毫无关系的基进程,皆能够调用到命名管道。而管道中的数据是进程通讯时的临时数据,无存储的意义,所以命名管道在磁盘中为空。
创建一个命名管道
- 命名管道可以从命令行上创建:
命令:mkfifo fifo
创建一个名为fifo命名管道
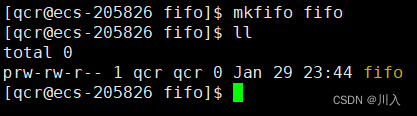
此时文件类型不是常用 - 与 d ,而是 p ,此文件的类型为管道:

此时会发现处于等待状态。因为由于我们写了,但是对方还没有打开,于是处于阻塞状态。

此时 echo "hello name_pipe"(进程A)就是写入的进程, cat(进程B)就是读取的进程。这就是所谓的一个进程向另一个进程写入消息的过程(通过管道写入的方式)。
我们可以在命令行上使用循环的方式,往管道内每隔1s写入数据。即,进程A原来应向显示器文件写入的数据,通过输入重定向的方式,将数据写入管道中,再将管道中数据通过输出重定向,通过进程B将数据写入到显示器文件中。如此,以毫无相关的进程A与进程B通过命名管道进行数据传输 - 进程间通信。
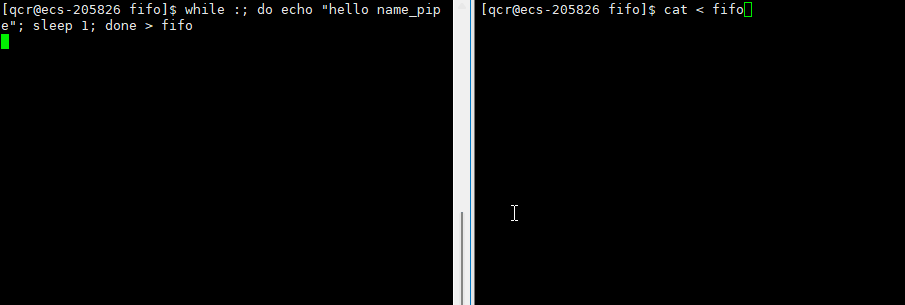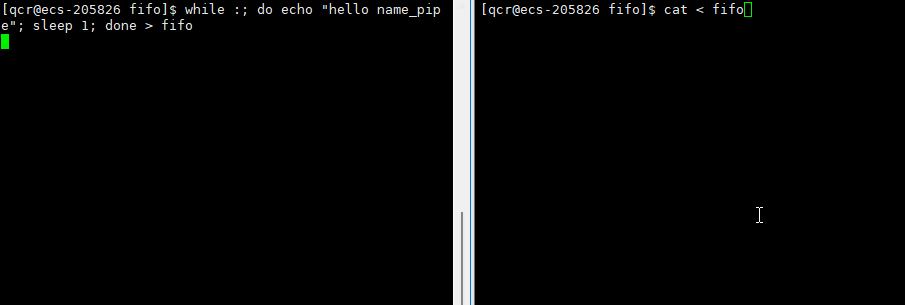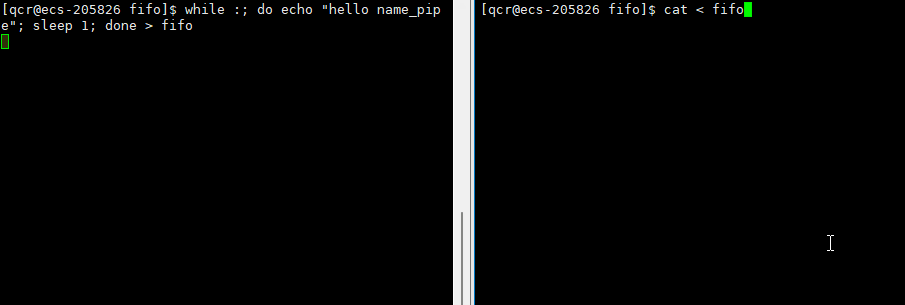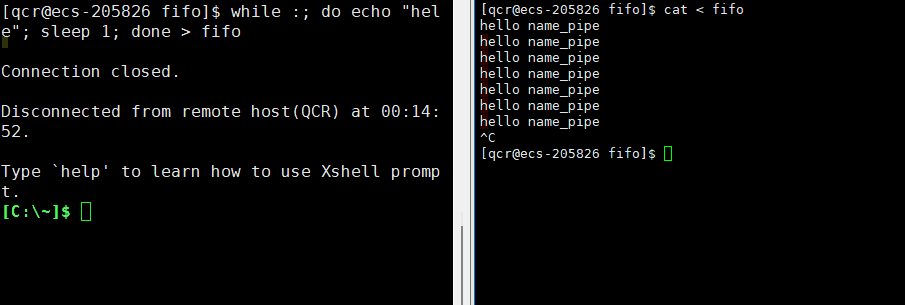
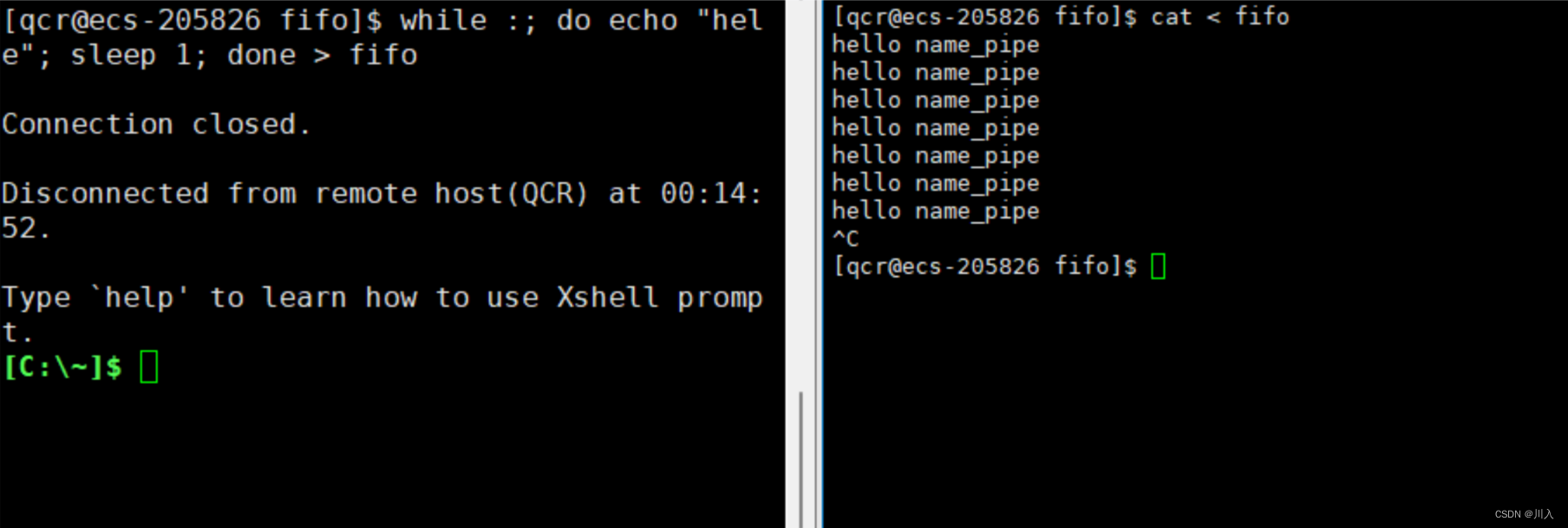
此时我们通过终止读取进程方,导致写入端向管道写入的数据无意义了(无读取端),此时作为写入端的进程就应该被操作系统杀掉。此时需要注意,echo是内置命令,所以是bush本身自行执行的命令,所以此时杀掉写入端的进程无疑就是杀掉bush。于是bush被操作系统杀死,云服务器即退出。
内置命令:让父进程(myshell)自己执行的命令,叫做内置命令,内建命令。
- 命名管道可以从程序里创建:
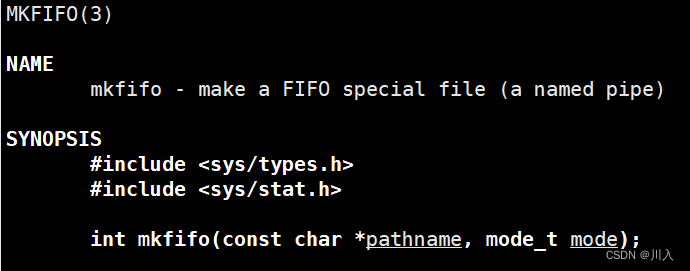
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
参数:
pathname:创建的命名管道文件。
- 路径的方式给出。(会在对应路径下创建)
- 文件名的方式给出。(默认当前路径下创建)
mode:创建命名管道文件的默认权限。
- 我们创建的文件权限会被umask(文件默认掩码)进行影响,umask的默认值:0002,而实际创建出来文件的权限为:mode&(~umask)。于是导致我们创建的权限未随我们的想法,如:0666 -> 0664。需要我们利用umask函数更改默认。
- umask(0); //将默认值设为 0000
返回值:
命名管道创建成功,返回0。
命名管道创建失败,返回-1。
用命名管道实现myServer&myClient通信
利用命名管道,实现服务端myServer与客户端myClient之间进行通讯。将服务端myServer运行起来并用mkfifo函数开辟一个命名管道。而客户端myClient中利用open打开命名管道(命名管道本质为文件),以write向管道中输入数据。以此服务端myServer利用open打开命名管道,以read从管道中读取数据。
comm.hpp
所展开的头文件集合。
#ifndef _COMM_H_
#define _COMM_H_#include <iostream>
#include <string>
#include <cstring>
#include <cstdlib>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/wait.h>std::string ipcPath = "./fifo.ipc";#endifLog.hpp
编程的日志:就是当前程序运行的状态。
#ifndef _LOG_H_
#define _LOG_H_#include <iostream>
#include <ctime>#define Debug 0
#define Notice 1
#define Warning 2
#define Error 3std::string msg[] = {"Debug","Notice","Warning","Error"
}std::ostream &Log(std::string message, int level)
{std::cout << " | " << (unsigned)time(nullptr) << " | " << msg[level] << " | " << message;
}#endifmyServer.cc
细节:
mkfifo的第二个参数传入权限0666之前需要以umask(0),对于服务端因为只需要在命名管道中读取数据,所以以只读的方式(O_RDONLY)open管道文件,后序以fork开辟子进程,让子进程read读取即可,同时也需要注意,C语言的字符串结尾必须是 '\0'(读取大小:sizeof(buffer) - 1)。
由于我们让子进程执行读取工作,所以需要以waitpid等在子进程(此处我们让nums个子进程进行,所以waitpid的第一个参数为 -1 ,等待任意一个子进程)。
由于open打开了管道类型的文件,所以需要以close(fd)关闭文件,由于mkfifo开辟了管道,所以需要以unlink删除管道文件。
#include "comm.hpp"// 管道文件创建权限(umask == 0)
#define MODE 0x0666// 读取数据大小
#define READ_SIZE 64// 从管道文件读取数据
static void getMessage(int fd)
{char buffer[READ_SIZE];while(true){memset(buffer, '\0', sizeof(buffer));ssize_t s = read(fd, buffer, sizeof(buffer) - 1); // C语言字符串需要保证结尾为'\0'if(s > 0){std::cout <<"[" << getpid() << "] "<< "myClient say> " << buffer << std::endl;}else if(s == 0){// 写端关闭 - 读到文件结尾std::cerr <<"[" << getpid() << "] " << "read end of file, clien quit, server quit too!" << std::endl;}else{// 读取错误perror("read");exit(3);}}
}int main()
{//1. 创建管道文件umask(0);if(mkfifo(ipcPath.c_str(), MODE) < 0){perror("mkfifo");exit(1);}#ifdef DEBUGLog("创建管道文件成功", Debug) << " step 1 " << std::endl;#endif//2. 正常的文件操作int fd = open(ipcPath.c_str(), O_RDONLY);if(fd < 0){perror("open");exit(2);}#ifdef DEBUGLog("打开管道文件成功", Debug) << " step 2 " << std::endl;#endifint nums = 3;// 创建3个子进程for(int i = 0; i < nums; ++i){pid_t id = fork();if(fd == 0){// 子进程 - 读取管道数据getMessage(fd);exit(1);}}// 父进程 - 等待子进程for(int i = 0; i < nums; i++){waitpid(-1, nullptr, 0);}// 4. 关闭管道文件close(fd);#ifdef DEBUGLog("关闭管道文件成功", Debug) << " step 3 " << std::endl;#endifunlink(ipcPath.c_str()); // 通信完毕,就删除管道文件#ifdef DEBUGLog("删除管道文件成功", Debug) << " step 4 " << std::endl;#endifreturn 0;
}myClient.cc
细节:
对于客户端因为只需要在命名管道中写入数据,所以以只写的方式(O_WRONLY)open管道文件,后序write即可。
#include "comm.hpp"int main()
{//1. 获取管道文件 - 以写的方式打开命名管道文件int fd = open(ipcPath.c_str(), O_WRONLY);if(fd < 0){perror("open");exit(1);}//2. ipc过程std::string buffer; //用户级缓冲区while(true){std::cout << "Please Enter Message Line :> ";std::getline(std::cin, buffer);write(fd, buffer.c_str(), buffer.size());}//3. 通信完毕,关闭命名管道文件close(fd);return 0;
}由于命名管道的创建是在服务端myServer中,所以需要先运行myServer。

服务端myServer进程运行起来,我们就能看到创建的命名管道文件。此时服务端myServer处于阻塞状态也是管道文件的特性(写入端未开辟,读取端需要等待写入端开辟)。
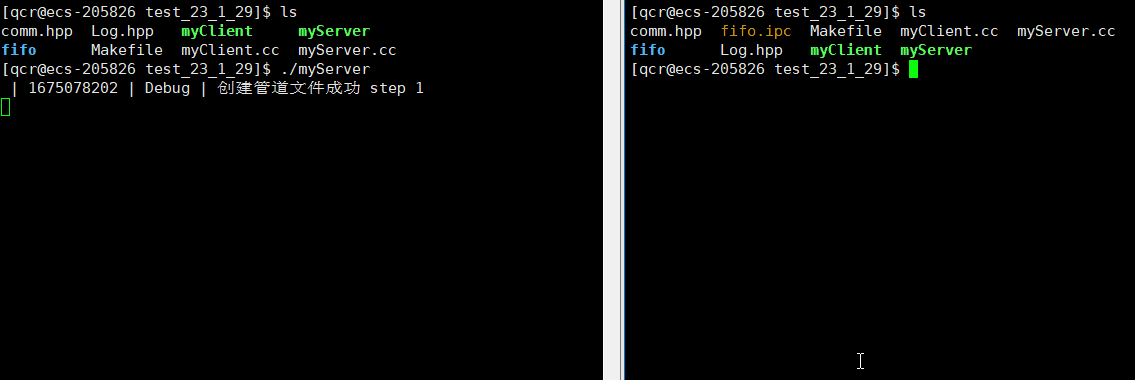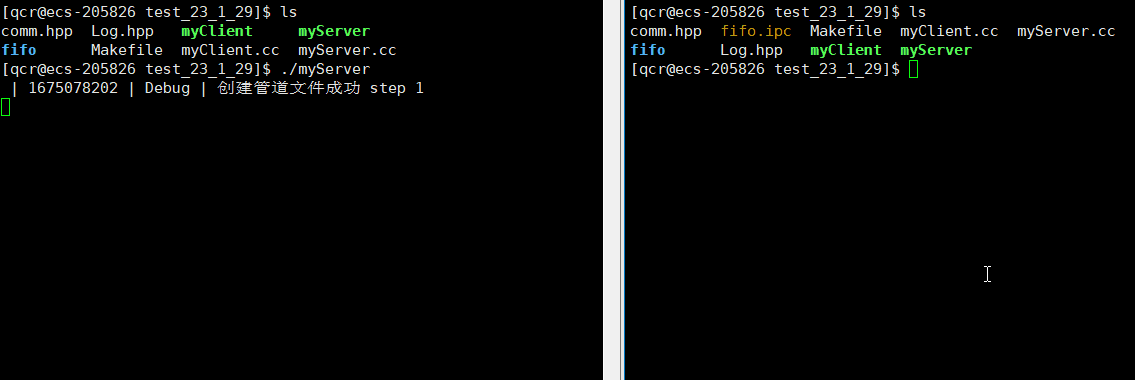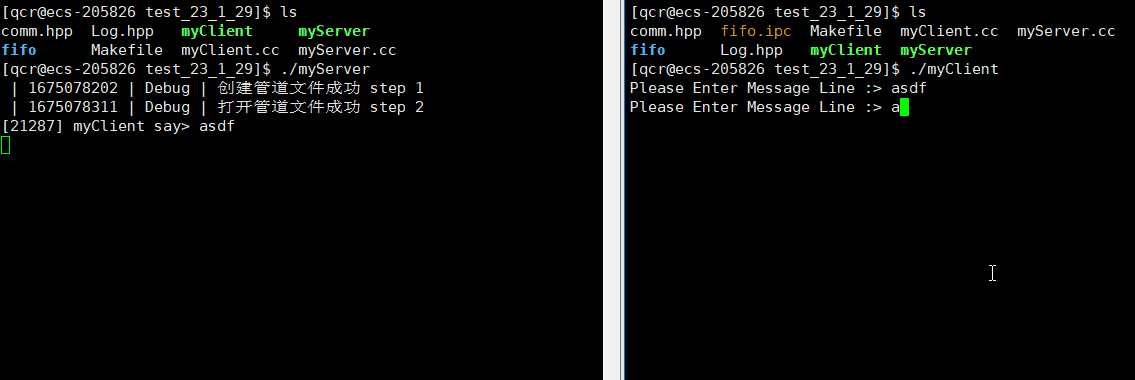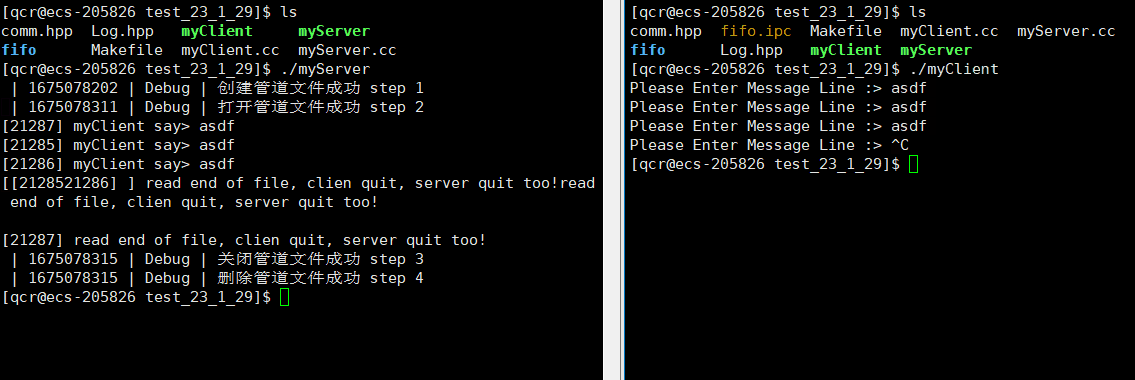
可以通过 ps 命令查看进程是否相关:
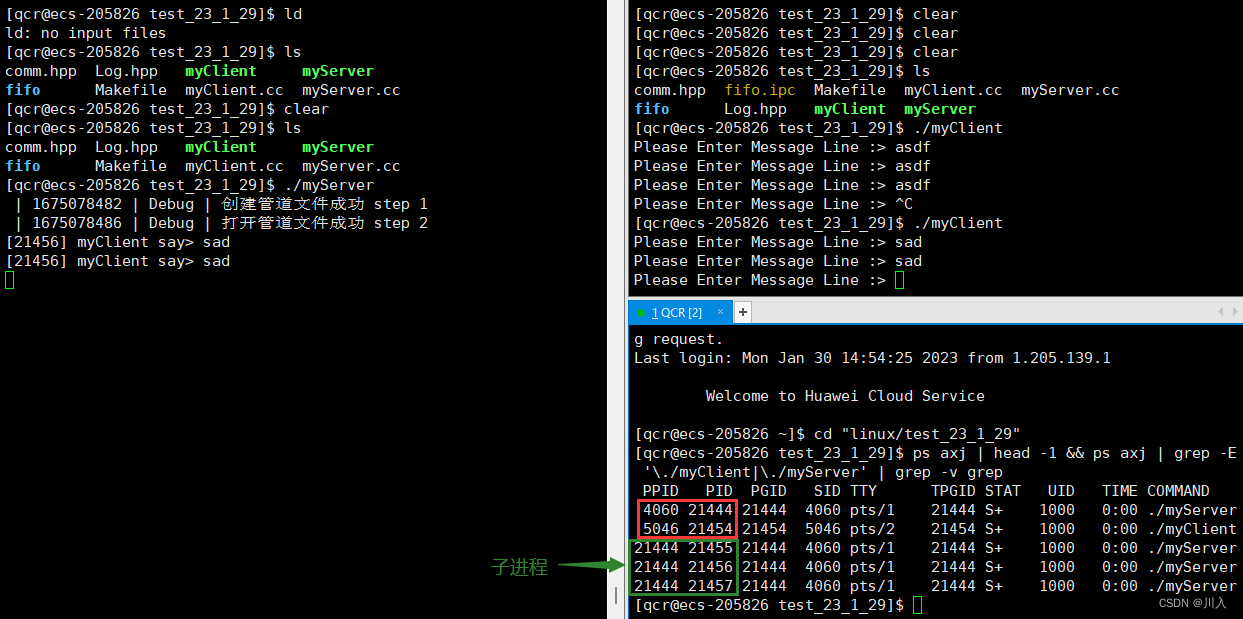
从此可以看出myServer与myClient是毫无相关的进程,即myServer的三个子进程与myClient也是毫无相关的进程。
匿名管道与命名管道的区别
- 匿名管道由pipe函数创建并打开。
- 命名管道由mkfififo函数创建,打开用open
- FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的语义。
命名管道的打开规则
- 如果当前打开操作是为读而打开FIFO时
- O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO
- O_NONBLOCK enable:立刻返回成功
- 如果当前打开操作是为写而打开FIFO时
- O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO
- O_NONBLOCK enable:立刻返回失败,错误码为ENXIO
system V共享内存
system V共享内存是与管道不同的,管道基于操作系统已有的文件操作。文件部分,无论有没有通讯的需求,这个文件都需要维护,有没有通讯都需要和指定进程建立关联,通不通讯都会有。
而共享内存是,不用来通讯,操作系统就不用进行管理,只有需要使用时,操作系统才提供 - 有通讯才会有,共享内存。共享内存是操作系统单独设立的内核模块,专门为进程间通讯设计 -- 这个内核模块就是system V。
即:前面的匿名管道、命名管道通讯是恰好使用文件方案可以实现。而共享内存是操作系统专门为了通讯设计。
共享内存的建立:
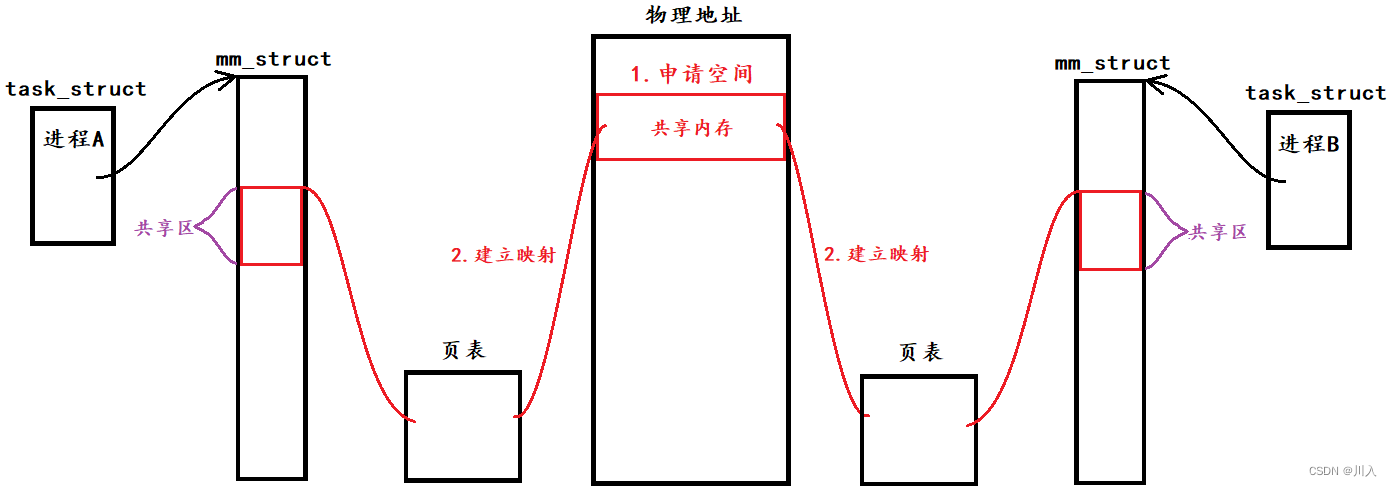
- 共享区:共享内存、内存映射和共享库保存位置。
共享内存数据结构
共享内存的提供者,是操作系统。
大量的进程进行通讯 -> 共享内存是大量的。所以,操作系统对于共享内存需要进行管理,需要管理 -> 先描述,再组织 -> 重新理解:共享内存 = 共享内存块 + 对应的共享内存的内核数据结构。
共享内存的数据结构 shmid_ds 在 /usr/include/linux/shm.h 中定义:
(cat命令即可)
struct shmid_ds
{
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
此处首先提一下key值(后面共享内存的建立引入),其是在上面的共享内存的第一个参数struct ipc_perm类型的shm_perm变量中的一个变量。
在 /usr/include/linux/ipc.h 中定义:
struct ipc_perm
{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
共享内存的创建
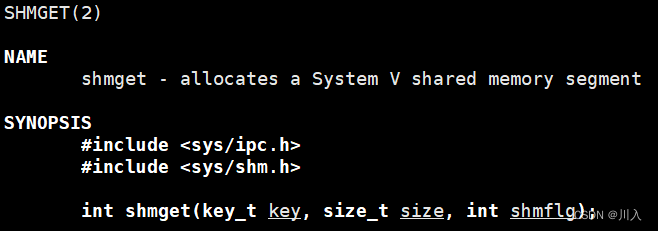
#include <sys/ipc.h> #include <sys/shm.h> // 用来创建共享内存 int shmget(key_t key, size_t size, int shmflg);参数:
key:这个共享内存段名字。
size:共享内存大小。
- 大小建议为4096的整数倍。(原因使用时讲解)
shmflg:由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的。
组合方式 作用 IPC_CREAT 创建共享内存,如果底层已经存在,获取之,并且返回。如果底层不存在,创建之,并且返回。 IPC_EXCL 没有意义 IPC_CREAT | IPC_EXCL 创建共享内存,如果底层不存在,创建之,并且返回。如果底层存在,出错返回。 IPC_CREAT | IPC_EXCL意义:可以保证,放回成功一定是一个全新的共享内存(shm)。
此外创建需要权限的初始化:
如:IPC_CREAT | IPC_EXCL | 0666
返回值:
成功返回一个非负整数,即该共享内存段的标识码(用户层标识符);失败返回-1。
key概念引入
进程间通讯,首先需要保证的看见同一份资源。
融会贯通的理解:
- 匿名管道:通过pipe函数开辟内存级管道 -- 本质是文件 -- 通过pipe函数的参数(文件符fd)-- 看见同一份资源。
- 命名管道:通过mkfifo函数根据路径开辟管道文件(可以从权限p看出)-- 本质是开辟一个文件(可以从第二个参数需要初始化权限看出)-- 利用open、write、read、close文件级操作 -- 看见同一份资源。
管道 -- 内存级文件 -- 恰巧利用文件操作。前面已有所提system V共享内存,是操作系统为进程间通讯专门设计 ,并无法利用类似于管道利用文件实现。于是便有了key。
key概念解析
key其实就是一个整数,是一个利用算法实现的整数。我们可以将key想象为一把钥匙,而共享内存为一把锁。

更像是同心锁和一对对情侣,情侣拿着同样的钥匙只可解一堆锁中的一把锁。
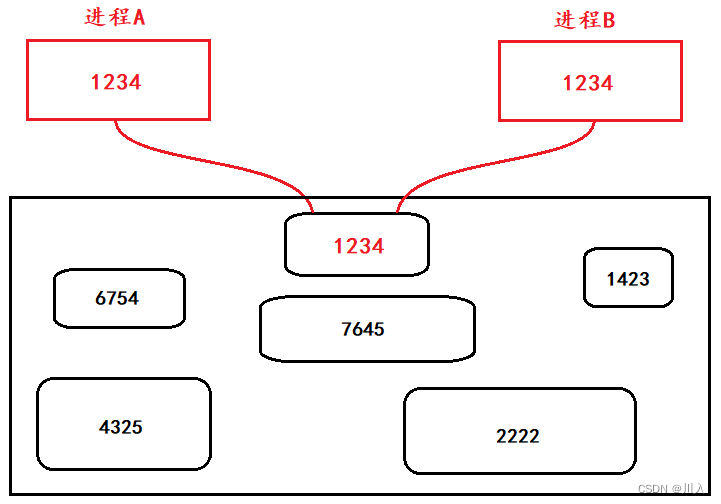
如同一把钥匙会按照固定的形状制造。其会使用同样的算法规则形成一个唯一值key,同时再创建共享内存时,会将key值设置进其中,此时两个毫无关系的进程,就可以通过key值用共享内存进行通讯(一方创建共享内存,一方获取共享内存)。
制造唯一值key的算法:
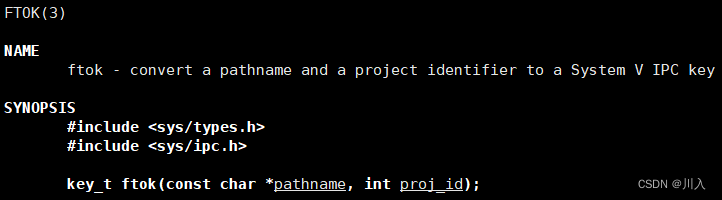
#include <sys/types.h> #include <sys/ipc.h>key_t ftok(const char *pathname, int proj_id);其不进行任何系统调用,其内部是一套算法,该算法就是将两个参数合起来,形成一个唯一值就可以,数值是几不重要。(对于第一个参数,ftok是拿带文件的inode标号,所以路径可以随意写,但必须保证具体访问权限),proj_id(项目id),随意写即可,一般是0~255之间,可以随便写,因为超了其也会直接截断。
返回值:
成功后,返回生成的key_t值。失败时返回-1。
note:
- 终究就是个简易的算法,所以key值可能会产生冲突,于是可以对传入ftok函数的参数进行修改。
- 需要保证需要通讯的进程使用的 pathname 与 proj_id 相同,如此才能保证生成的是同一个key值。
简易的使用shmget函数结合ftok函数:
其不进行任何系统调用,其内部是一套算法,该算法就是将两个参数合起来,形成一个唯一值就可以,数值是几不重要。(对于第一个参数,ftok是拿带文件的inode标号,路径可以随意写,但必须保证具体访问权限)
两个进程要通讯,就要保证两个看见统一个共享内存,本质上:保证两个看到同一个key。
与文件不同,文件是打开了,最后进程退出,文件没有进程与其关联,文件就会自动释放。
操作系统为了维护共享内存,就需要先描述,再组织。所以,共享内存在内核里,处理共享内存的存储内存空间,也需要存储对其描述信息的数据结构。所以,为了设置或获取其的属性,就通过第三个参数。(当只需要删除的时候,第三个参数设为nullptr即可)
操作系统管理物理内存的时候,页得大小是以4KB为单位。也就是4096byte,如果我们用4097byte,就多这1byte,操作系统就会在底层,直接创建4096 * 2byte的空间,此时多余的4095byte并不会使用,就浪费了。
此处,我们以4097byte申请,操作系统开辟了4096 * 2byte,但是查询下是4097byte,因为,操作系统分配了空间,但是并不代表对所有都有权利访问,我们要的是4097byte,那操作系统只会给对应的权限。所以建议配4096byte的整数倍。
prems:权限。此处为0 ,代表任何一个人,包括我们,都没有权力读写共享内存,此时创建共性内存也就没了意义。于是我们需要再加一个选项,设置权限。
nattch:n标识个数,attch表示关联。表示有多少个进程与该共享内存关联。
需要将指定的共享内存,挂接到自己的进程的地址空间。
参数:
- 要挂接的共享内存的用户管理的对应的id。(获取共享内存时的id)
- 我们需要指定的虚拟地址。共享内存挂接时,可将其挂接到指定的虚拟地址。(一般不推荐,因为虚拟地址的使用情况我们并不是十分的清楚。即使,我们能获取到),设置为nullptr让操作系统自行挂接即可。
- 挂接方式。设置为0即可,默认会以读写的方式挂好。
· 范围值,共享内存的起始地址。
文件描述符,文件有其对应的文件指针,可用户从来不会用文件指针,用的全是文件描述符,它们都可以用来标定一个文件。同样的道理shmid与key,它们都可以用来标定共享内存的唯一性。(key:标定共享内存在系统级别上的唯一性。shmid:标定共享内存的用户级别上的唯一性。)所以我们在用的时候全部都是shmid。只要是指令编写的时候,就是在用户层次的,所以ipcs等用的是shmid。
system V IPC资源,生命周期随内核,与之相对的是生命周期随进程。即,操作系统会一直保存这个资源,除非用户用手动命令删除,否则用代码删除。
共享内存由操作系统提供,并对其进行管理(先描述,再组织) -> 共享内存 = 共享内存块 + 对应的共享内存的内核数据结构。
融会贯通的理解:
一个内存为4G的地址空间,0~3G属于用户,3~4G属于内核。所谓的操作系统在进行调度的时候,执行系统调用接口、库函数。本质上都是要将代码映射到地址空间当中,所以我们的代码无论是执行动态库,还是执行操作系统的代码。都是在其地址空间中完成的。所以对于任何进程,3~4G都是操作系统的代码和数据,所以无论进程如何千变万化,操作系统永远都能被找到。
堆栈之间的共享区:是用户空间,该空间拿到了,无需经过系统调用便可直接访问。 -- 共享内存,是不用经过系统调用,直接可以进行访问!双方进程如果要通讯,直接进行内存级的读和写即。
融会贯通的理解:
前面所说的匿名管道(pipe)、命名管道(fifo)。都需要通过read、write(IO系统调用)来进行通讯。因为这两个属于文件,而文件是在内核当中的特定数据结构,所以其是操作系统维护的 -- 其是在3~4G的操作系统空间范围中。(无权访问,必须使用系统接口)
共享内存在被创建号之后,默认被清成全0,所以打印字符是空串。
共享内存就是天然的为了让我们可以快速访问的机制,所以其内部没有提供任何的控制策略。(共享内存中有数据读端读,没数据读端也读。甚至客户端(写入端)不在了,其也读。)更直接的说:写入端和读取端根本不知道对方的存在。
缺乏控制策略 -- 会带来并发的问题。
拓展:
并发的问题,如:
客户端想让一个进程处理一个完整的数据内容,然而客户端在未完全写入共享内存时,读取方就将不完整的数据读取并处理,此时处理结果为未定义。 -- 数据不一致问题
基于共享内存理解信号量
根据前面的学习:
- 匿名管道通过派生子进程的方式看见同一份资源。
- 命名管道通过路径的方式看见同一份资源。
- 共享内存通过key值得方式看见同一份资源。
所以,为了让进程间通讯 -> 让不同的进程之间,看见同一份资源 -> 本质:让不同的进程看见同一份资源。
通过前面得到学习我们会发现,如共享进程,其并没有访问控制,即:独断读取的时机是不确定的,这也就带来了一些时序问题 —— 照成数据的不一致问题。
引入两个概念:
- 临界资源:我们把多个进程(执行流)看到的公共的一份志愿,称作临界资源。
- 临界区:我们把自己的进程,访问的临界资源的代码,称作临界区。
所以,多个进程(执行流),互相运行的时候互相干扰,主要是我们不加以保护的访问了相同的资源(临界资源),在非临界区多个进程(执行流)互相是不干扰的。
而为了更好的进行临界资源的保护,可以让多个进程(执行流)在任何时刻,都只能有一个进程进入临界区 —— 互斥 。
互斥的理解:
我们可以将,一个执行流:人,临界区:电影院(一个位置的电影院)。

看电影一定要有位置(电影院中的唯一位子)。当前一个人在其中看电影,那么其他人必须等待他看完才可进入观看。并且电影院中,此唯一的位置是并不属于观影人的,而是买票,只要买了票,即在你进去看完电影之前,就拥有了这个位置。买票:就是对座位的 预定 机制。
同样的道理,进程想进入临界资源,访问临界资源,不能让进程直接去使用临界资源(不能让用户直接去电影院内部占资源),需要先申请票 —— 信号量 。
信号量 的存在是等于一张票。"票"的意义是互斥,而互斥的本质是串形化,互斥就是一个在跑另一个就不能跑,需要等待跑完才能跑。其必须串形的去执行。但是一旦串形的去执行,多并发的效率就差了。所以:
当有一份公共资源,只要有多个执行流访问的是这个公共资源的不同区域,这个时候可以允许多个执行流同时进入临界区。这个时候可以根据区域的数量(如同电影院座位的个数 -> 允许观影的人数),可以让对应的进程个数并发的执行自己临界区的代码(看电影的自行观影)。
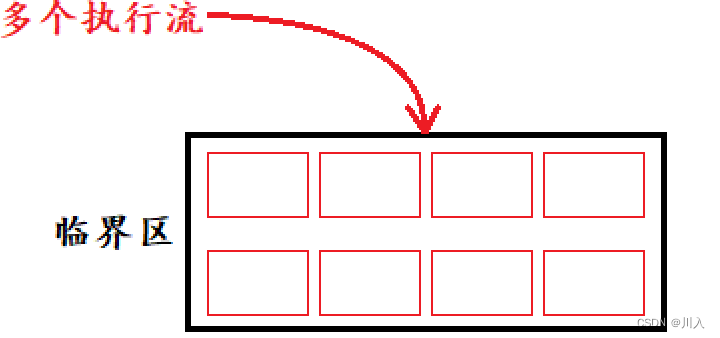

信号量本质上:就是一个计数器,类似于int count = n(n张票)。
申请信号量:
- 申请信号量的本质:让信号量计数器 -- 。
- 释放信号量的本质:让信号量计数器++。
- 信号量申请成功,临界资源内部就一定会预留所需要的资源 —— 申请信号量本质其实是对临界资源的一种“ 预定 ”机制。
只要申请信号量成功 ……只要申请成功,一定在临界区中有一个资源对应提供的。
换句话说:首先,我们要进行访问信号量计数器,要每一个线程访问计数器,必须保证信号量本身的 --操作 以及 ++操作 是原子的。否者很难保护临界资源。其次,信号量需要是公共的,能被所有进程能看到的资源,叫做临界资源 —— 而信号量计数器存在的意义就是保护临界资源,但是其有又成了临界资源,所以其必须保证自己是安全的,才能保证临界资源的安全。
#:如果用一个整数,表示信号量。假设让多个进程(整数n在共享内存里),看见同一个全局变量,都可以进行申请信号量 —— 不可以的。
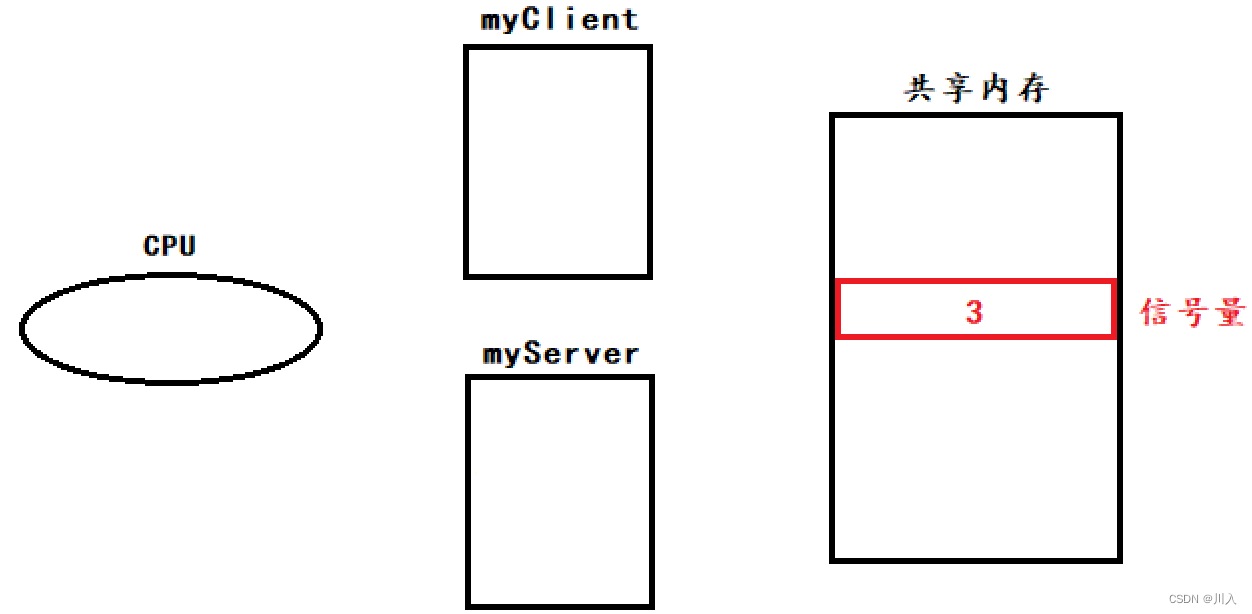
CPU执行指令的时候:
- 将内存中的数据加载到CPU内的寄存器中(读指令)。
- n--(分析 && 执行指令)。
- 将CPU修改完的数据n写回到内存(写回结果)。
复习:
执行流在执行的时候,在任何时刻都可能被切换。
切换的本质:CPU内的寄存器是只有一份的,但是寄存器需要存储的临时数据(上下文)是多份的,分别对应不同的进程!
我们知道,每一个进程的上下文是不一样的,寄存器只有一份,那么根据并发,为下一个进程让出位置。并且由于,上下文数据绝而对不可以被抛弃!
当进程A暂时被切下来的时候,需要进程A顺便带走直接的上下文数据!带走暂时保存数据的是为了下一次回来的时候,能够恢复上去,以此继续按照之前的逻辑继续向后运行,就如同没有中断过一样。
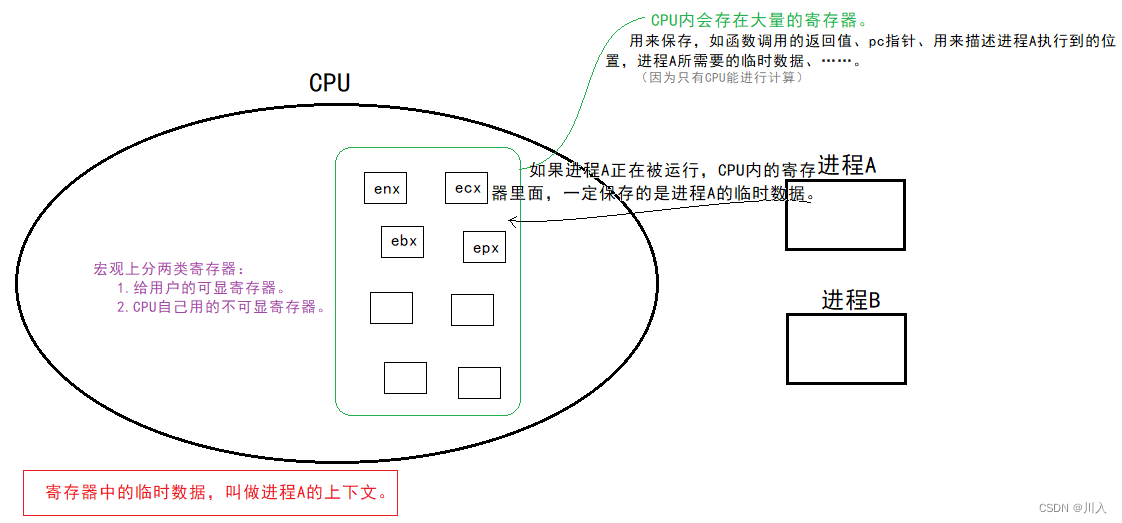
由于寄存器只有一套,被所有的执行流共享,但是寄存器里面的数据,属于一个执行流(属于该执行流的上下文数据)。所以对应的执行流需要将上下文数据进行保护,方便与上下文数据恢复(重新回到CPU,更具上下文数据继续执行)。
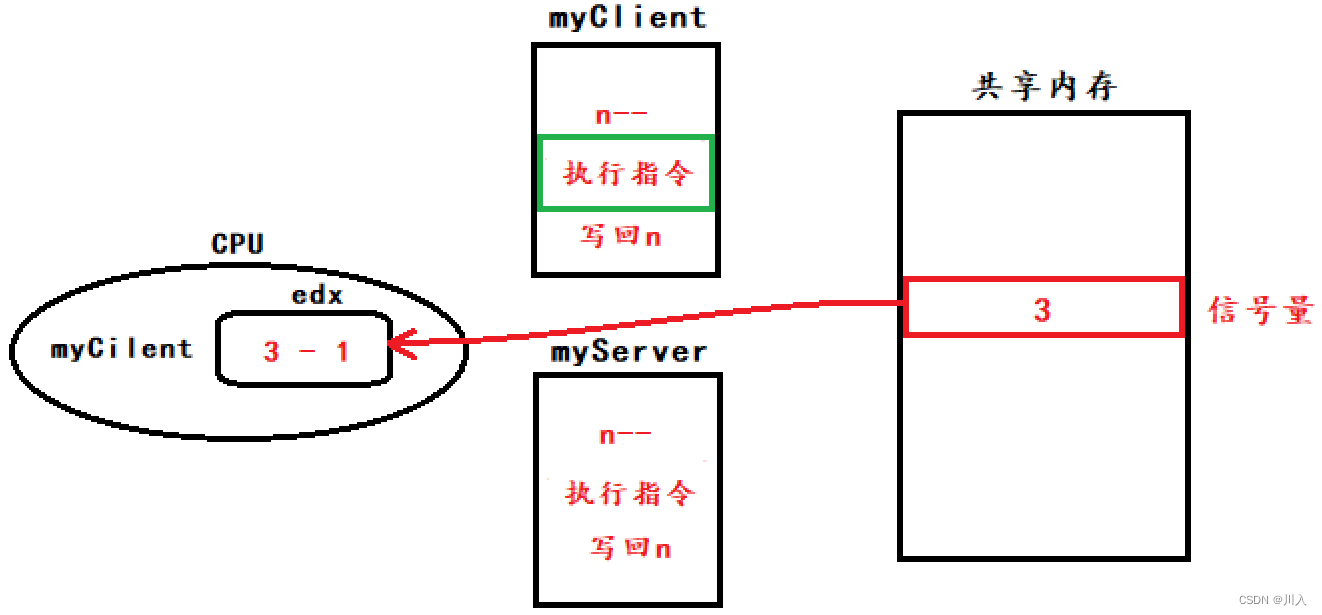
当myClient执行的时候,重点在于n--,到n++,因为时序的问题,会导致n有中间状态。切换为myServer执行的时候,中间状态会导致数据不一致。
即,CPU执行myClient中的写入数据到共享内存时,就被替换了:
(CUP执行到n的中间状态)
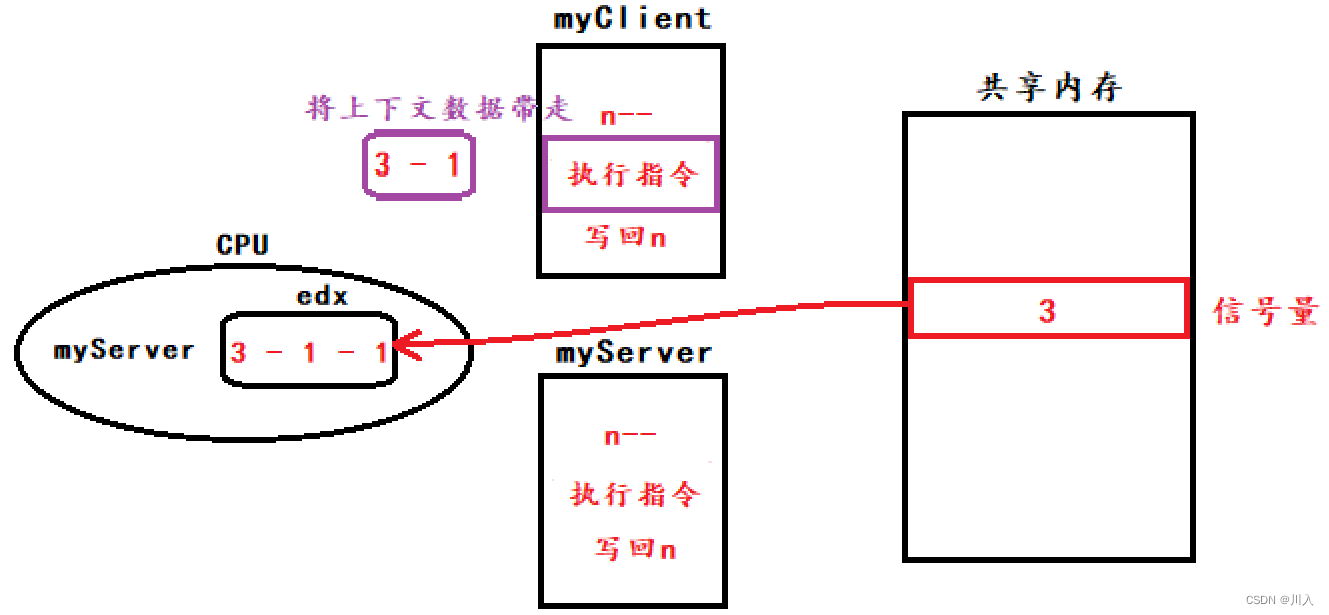
(myClient被切换为myServer)
(myServer信号量执行完了,并将n写回)
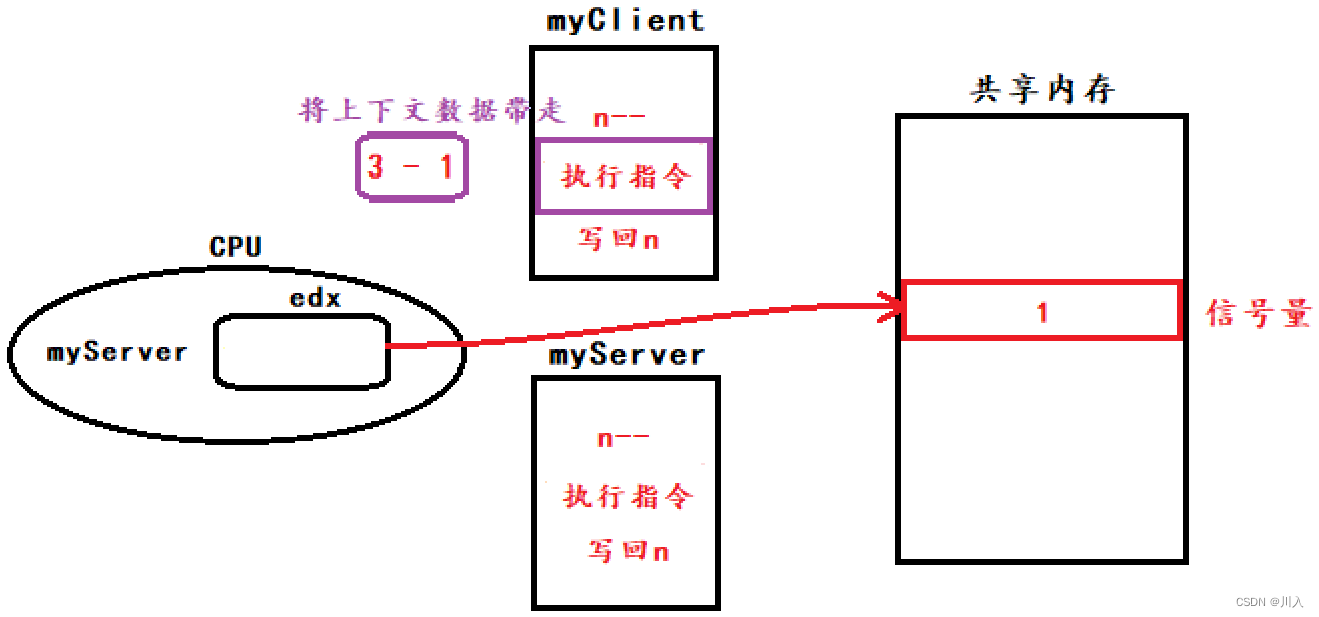
(myCilent带着自己的上下文数据,并将n写回)
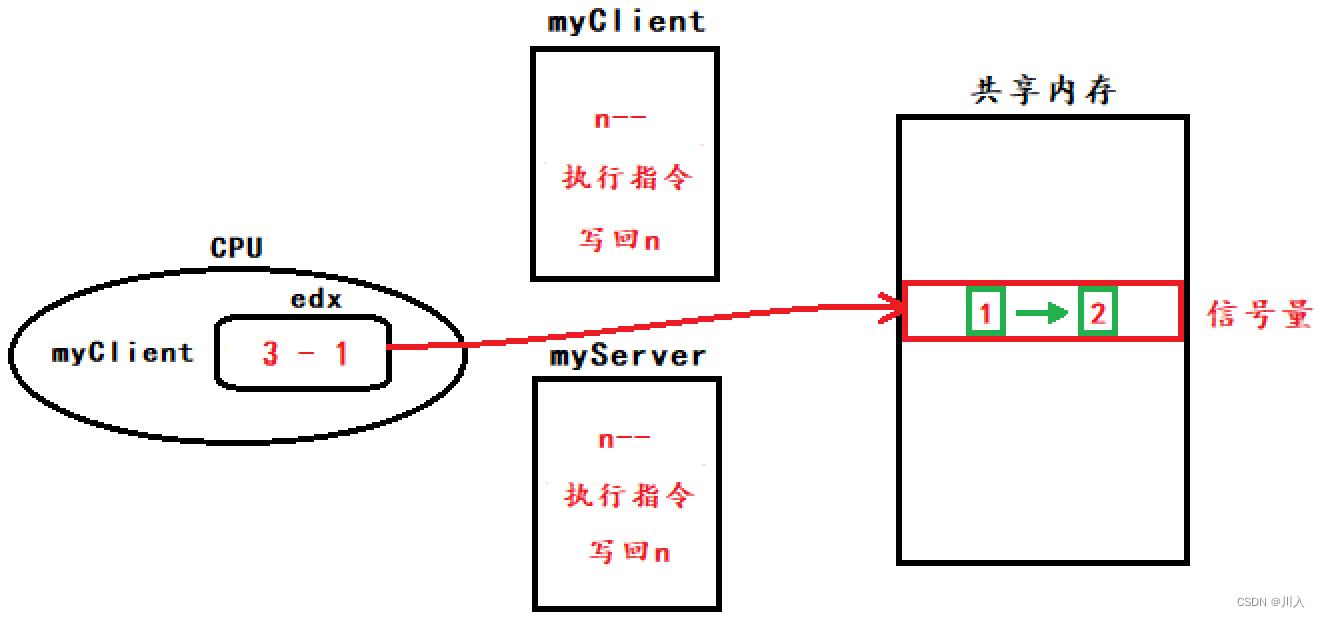
此时1 -> 2,凸显了信号量操作必须是原子性的,只有原子性才不会怕因时序,导致的数据不一致问题。
总结:
- 申请信号量 -> 计数器-- -> P操作 -> 必须是原子的
- 申请信号量 -> 计数器++ -> V操作 -> 必须是原子的
总结
所以,由于信号量的思想,也是让我们看见同一份资源,所以其本质与上面的管道、共享内存没有太大的区别。所以,信号量被纳入进程间通讯的范畴。
信号量是为了保证特定的临界资源不被受侵害,保证临界资源数据一致性。前面所讲:信号量也是一个临界资源,所以首先其需要保证自己的安全性 —— 提出信号量操作需是原子性的。
而信号量理论的提出是由于:临界区、临界资源的 互斥 ,当多个执行流(进程)才会真正的凸显出来,所以此处由于是进程间通讯 —— 需要提出信号量,但作用凸显在多线程 —— 多线程再深入讲解信号量。
相关文章:
【Linux】-- 进程间通讯
目录 进程间通讯概念的引入 意义(手段) 思维构建 进程间通信方式 管道 站在用户角度-浅度理解管道 匿名管道 pipe函数 站在文件描述符角度-深度理解管道 管道的特点总结 管道的拓展 单机版的负载均衡 匿名管道读写规则 命名管道 前言 原理…...
STM32模拟SPI时序控制双路16位数模转换(16bit DAC)芯片DAC8552电压输出
STM32模拟SPI时序控制双路16位数模转换(16bit DAC)芯片DAC8552电压输出 STM32部分芯片具有12位DAC输出能力,要实现16位及以上DAC输出需要外挂DAC转换ASIC。 DAC8552是双路16位DAC输出芯片,通过SPI三线总线进行配置控制输出。这里…...
基于intel x86+fpga智能驾驶舱和高级驾驶辅助系统硬件设计(二)
系统功能架构及各模块功能介绍 智能驾驶舱和高级驾驶辅助系统是一个车载智能终端嵌入式平台,系统是一个能够运行 虚拟化操作系统的软件和硬件的综合体。本文的车载主机包括硬件主控处理器、电源管理芯 片、存储设备、输入输出控制器、数字仪表系统系统、后座娱乐系统…...

oneblog_justauth_三方登录配置【Github】
文章目录oneblog添加第三方平台github中创建三方应用完善信息登录oneblog添加第三方平台 1.oneblog管理端,点击左侧菜单 网站管理——>社会化登录配置管理 ,添加一个社会化登录 2.编辑信息如下,选择github平台后复制redirectUri,然后去github获取cl…...

自行车轮胎充气泵PCBA方案
轮胎充气泵PCBA方案由多种元器件设计组合而成,PCBA是英文Printed Circuit Board Assembly 的简称,也就是说PCB空板经过SMT上件,或经过DIP插件的整个制程,简称PCBA。PCBA是一个电子产品功能实现的最原始的状态,未经过任…...

200 22222
101. blob.png 新到组织的项目经理被分配管理一个具有多名干系人的项目。项目经理希望确定哪些干系人是内部的,哪些干系人是外部的。若要了解干系人的角色,项目经理应该查阅哪一份文件? A. 干系人登记册 B. 干系人分析 C. 干系人管理计划 D.…...
<JVM上篇:内存与垃圾回收篇>13 - 垃圾回收器
笔记来源:尚硅谷 JVM 全套教程,百万播放,全网巅峰(宋红康详解 java 虚拟机) 文章目录13.1. GC 分类与性能指标13.1.1. 垃圾回收器概述13.1.2. 垃圾收集器分类13.1.3. 评估 GC 的性能指标13.2. 不同的垃圾回收器概述13.…...

广义状态平均法功率变换器建模分析
两种状态平均法在功率变换器建模的应用比较 [!info] Bibliography [1] 高朝晖, 林辉张晓斌 & 吴小华, “两种状态平均法在功率变换器建模的应用比较,” 计算机仿真, no. 241-244248, 2008. [!note] 状态空间平均法采用直流量近似(线性系统模型)&…...

基于Spring Boot的快递管理系统
文章目录 项目介绍主要功能截图:登录我要收件我要寄件个人信息我收到的我寄出的物流管理用户管理部分代码展示设计总结项目获取方式🍅 作者主页:Java韩立 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项…...
)
nerdctl不完全使用指南(开发者)
目录 背景 环境配置 1.编译golang可执行文件 2.快速构建镜像 背景 k8s在1.22版本放弃docker作为runtime后采用了containerd,以containerd作为runtime的k8s安装方法已经出现了很多开源集成工具或者解决方案,在此不做赘述。本篇只要是描述在docker被取…...
)
【独家】华为OD机试 - 分糖果(C 语言解题)
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明本期…...
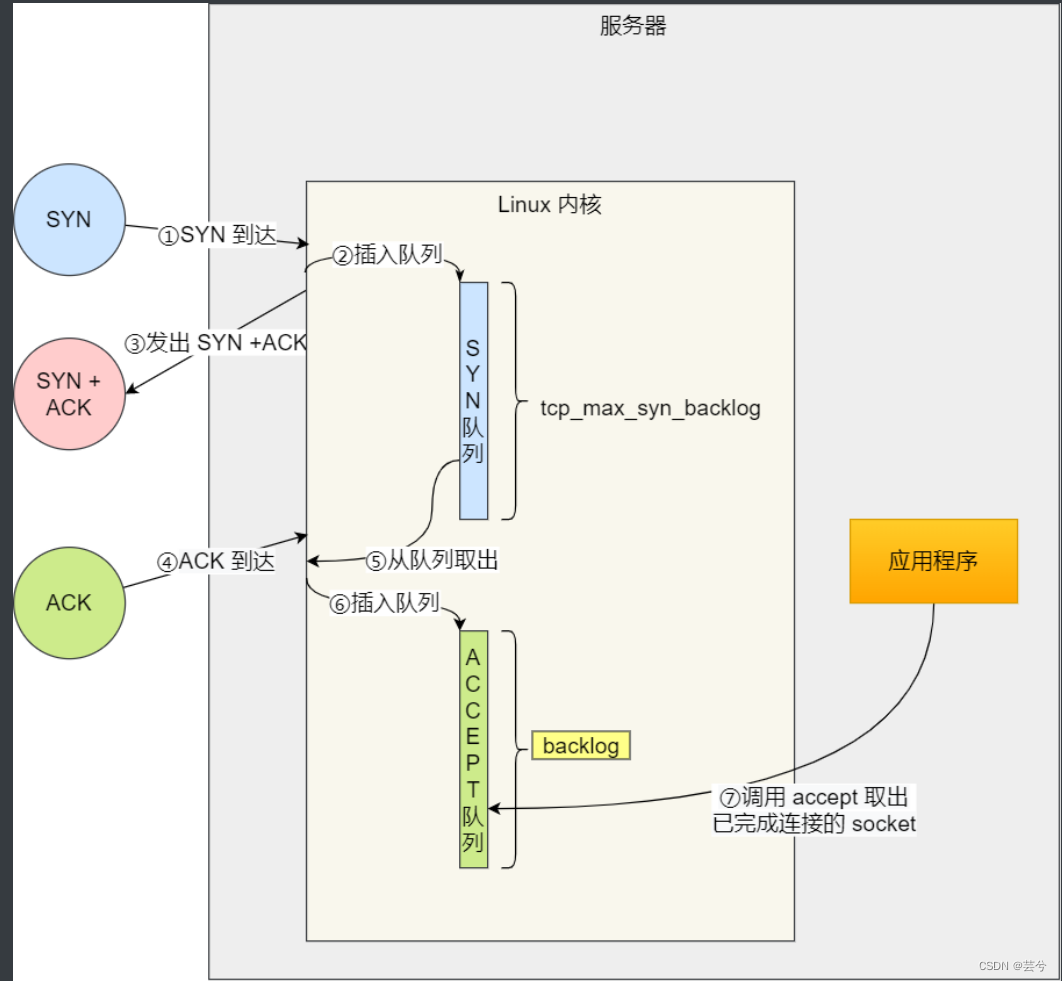
八股总结(二)计算机网络与网络编程
layout: post title: 八股总结(二)计算机网络与网络编程 description: 八股总结(二)计算机网络与网络编程 tag: 八股总结 文章目录计算机网络网络模型网络体系结构在浏览器输入一个网址后回车,背后都发生了什么&#x…...

ChatGPT 一本正经的胡说八道 那也看看原理吧
最近,ChatGPT横空出世。这款被马斯克形容为“强大到危险”的AI,不但能够与人聊天互动,还能写文章、改代码。于是,人们纷纷想让AI替自己做些什么,有人通过两分钟的提问便得到了一篇完美的论文,有人希望它能帮…...

ChatGPT:一个人机环境系统交互的初级产品
从人机环境系统智能的角度看,Chatgpt就是一个还没有开始上道的系统。“一阴一阳之谓道”,Chatgpt的“阴”(默会隐性的部分)尚无体现,就是“阳”(显性描述的部分)还停留在人类与大数据交互的浅层…...
PaddlePaddle本地环境安装(windows11系统)
写在前面: 这里是关于win11安装PaddlePaddle的步骤和方法,建议参考官方的方法。截止2023年3月份,PaddlePaddle的版本是2.4.2。 官方参考:飞桨PaddlePaddle快速安装使用方法 建议使用Anaconda安装 ,关于Anaconda创建环境的可以借鉴:深度学习Anaconda环境搭建(比较全面)…...
DBeaver 超级详细的安装与使用
一、下载DBeaver DBeaver是一种通用数据库管理工具,适用于需要以专业方式使用数据的每个人;适用于开发人员,数据库管理员,分析师和所有需要使用数据库的人员的免费(DBeaver Community) 的多平台数据库工具。 DBeaver支持80多个数据…...

计算机网络的166个概念 你知道几个第七部分
计算机网络传输层 可靠数据传输:确保数据能够从程序的一端准确无误的传递给应用程序的另一端。 容忍丢失的应用:应用程序在发送数据的过程中可能会存在数据丢失的情况。 非持续连接:每个请求/响应会对经过不同的连接,每一个连接…...

海尔三翼鸟:生态聚拢的密度,决定场景落地速度
最近学到一个新词,叫做涌现能力。 怎么理解呢?我们以当下最火的ChatGPT为例,GPT1模型是1.17亿参数,GPT2有15亿参数,GPT3有1750亿个参数。研究人员在放大模型规模的进程中发现一个惊人的现象,模型参数达到一…...

前端基础知识
文章目录前端基础知识HTML1. html基本结构2.常见的html标签注释标签标题标签(h1~h6)段落标签p换行标签 br格式化标签图片标签:img超链接标签表格标签列表标签表单标签input标签label标签select标签textarea 标签盒子标签div&span3. html特殊字符CSS1. 基本语法2…...

LiveData 面试题库、解答、源码分析
引子LiveData 是能感知生命周期的,可观察的,粘性的,数据持有者。LiveData 用于以“数据驱动”方式更新界面。换一种描述方式:LiveData 缓存了最新的数据并将其传递给正活跃的组件。关于数据驱动的详解可以点击我是怎么把业务代码越…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...
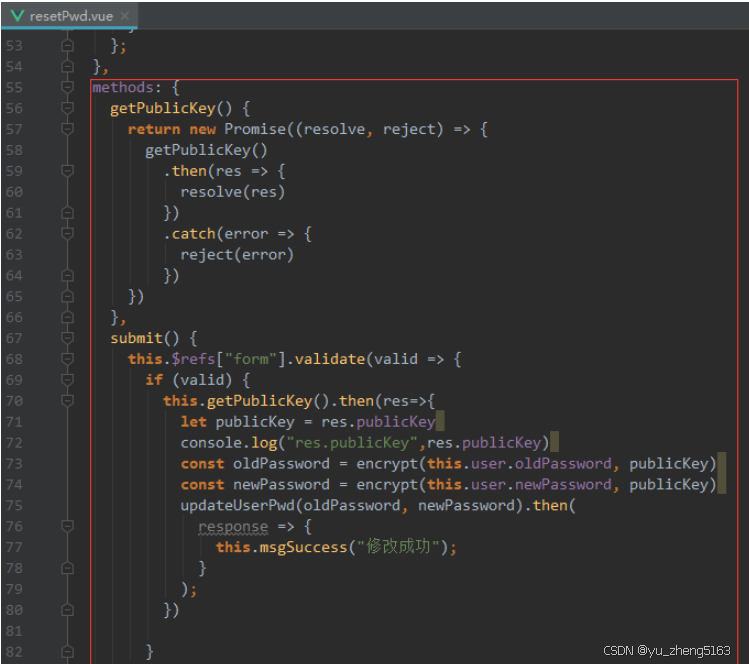
若依登录用户名和密码加密
/*** 获取公钥:前端用来密码加密* return*/GetMapping("/getPublicKey")public RSAUtil.RSAKeyPair getPublicKey() {return RSAUtil.rsaKeyPair();}新建RSAUti.Java package com.ruoyi.common.utils;import org.apache.commons.codec.binary.Base64; im…...
热门Chrome扩展程序存在明文传输风险,用户隐私安全受威胁
赛门铁克威胁猎手团队最新报告披露,数款拥有数百万活跃用户的Chrome扩展程序正在通过未加密的HTTP连接静默泄露用户敏感数据,严重威胁用户隐私安全。 知名扩展程序存在明文传输风险 尽管宣称提供安全浏览、数据分析或便捷界面等功能,但SEMR…...

Canal环境搭建并实现和ES数据同步
作者:田超凡 日期:2025年6月7日 Canal安装,启动端口11111、8082: 安装canal-deployer服务端: https://github.com/alibaba/canal/releases/1.1.7/canal.deployer-1.1.7.tar.gz cd /opt/homebrew/etc mkdir canal…...
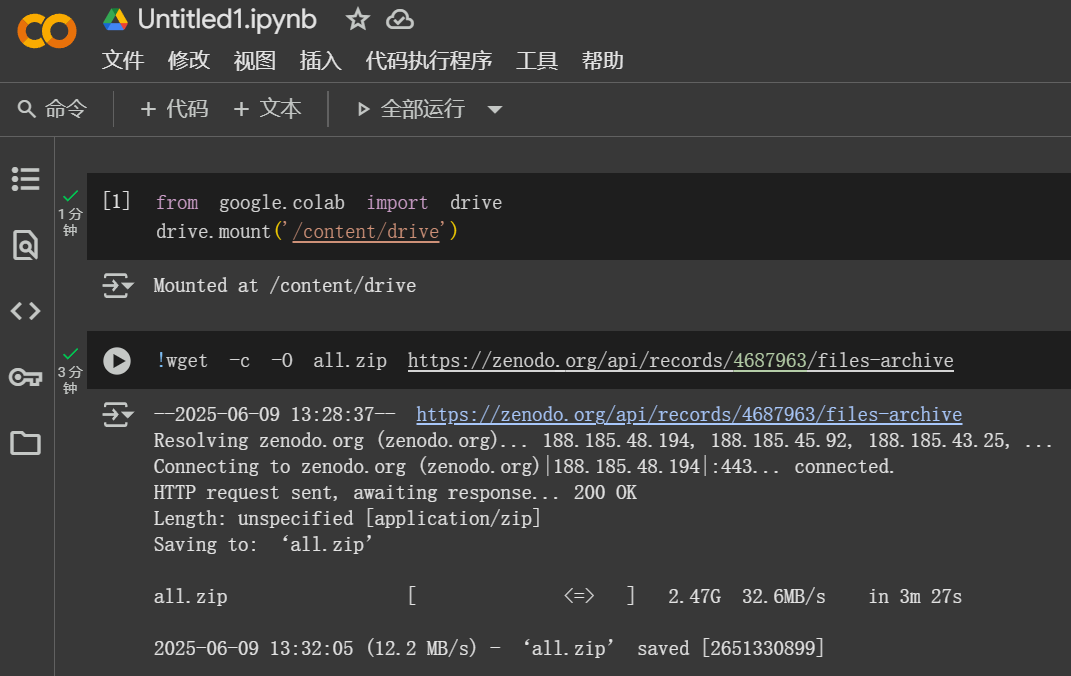
在Zenodo下载文件 用到googlecolab googledrive
方法:Figshare/Zenodo上的数据/文件下载不下来?尝试利用Google Colab :https://zhuanlan.zhihu.com/p/1898503078782674027 参考: 通过Colab&谷歌云下载Figshare数据,超级实用!!࿰…...

Docker、Wsl 打包迁移环境
电脑需要开启wsl2 可以使用wsl -v 查看当前的版本 wsl -v WSL 版本: 2.2.4.0 内核版本: 5.15.153.1-2 WSLg 版本: 1.0.61 MSRDC 版本: 1.2.5326 Direct3D 版本: 1.611.1-81528511 DXCore 版本: 10.0.2609…...