深度学习pytorch——Tensor维度变换(持续更新)
view()打平函数
需要注意的是打平之后的tensor是需要有物理意义的,根据需要进行打平,并且打平后总体的大小是不发生改变的。
并且一定要谨记打平会导致维度的丢失,造成数据污染,如果想要恢复到原来的数据形式,是需要靠人为记忆的。
现在给出一个tensor——a.shape=torch.Size([4, 1, 28, 28]),打平a.view(4,1*28*28),此时a.view(4,1*28*28).shape=torch.Size([4, 784])。
当然也可以向高维度:b.shape=torch.Size([4, 784]),打平b.view(4,28,28,1),此时b.view(4,28,28,1).shape=torch.Size([4, 28, 28, 1])
unsqueeze()维度增加
当使用unsqueeze()方法时,此时概念会发生改变,会为数据增加一个组别,这个组别的含义由自己定义。
语法:unsqueeze(index) 如果index为正,则在索引之前加入;如果index为负,则在索引之后加入
代码演示:
# a.shape : torch.Size([4, 1, 28, 28])# index 为正
print(a.unsqueeze(0).shape)
# torch.Size([1, 4, 1, 28, 28])
print(a.unsqueeze(3).shape)
# torch.Size([4, 1, 28, 1, 28])# index 为负
print(a.unsqueeze(-1).shape)
# torch.Size([4, 1, 28, 28, 1])
print(a.unsqueeze(-2).shape)
# torch.Size([4, 1, 28, 1, 28])# 注意不要超出索引范围,否则会报错
# 增加组别具体在数据上的表现
b = torch.tensor([1.2,2.3]) # 此时是一个dim为1,size为2的tensor
print(b.unsqueeze(-1)) # 是在最里层添加了一个维度
# tensor([[1.2000],
# [2.3000]])
print(b.unsqueeze(0)) # 是在最外层添加了一个维度
# tensor([[1.2000, 2.3000]])来个小例子:
# for example
# bias相当于给每个channel上的像素增加了一个偏置
b = torch.rand(32)
f = torch.rand(4,32,14,14)
# 现在我们要实现b+f,由于二者维度不同,不能操作(每个维度对应的size也要相同)
b = b.unsqueeze(1) # torch.Size([32, 1])
print(b.shape)
b = b.unsqueeze(2) # torch.Size([32, 1, 1])
print(b.shape)
b = b.unsqueeze(0) # torch.Size([1, 32, 1, 1])
print(b.shape)squeeze()维度减少
语法:squeeze(index) 如果index不填写,就是将所有size都为1的都去除;index就是去除对应的维度,但是只有size=1的才能被去除。
代码演示:
# b.shape = torch.Size([1, 32, 1, 1])
print(b.squeeze().shape) # torch.Size([32]) 如果不添加任何参数,就是将所有size=1的都去除
print(b.squeeze(0).shape) # torch.Size([32, 1, 1])
print(b.squeeze(1).shape) # torch.Size([1, 32, 1, 1]) 只有size=1的才能被去除expand()
条件:维度一致,并且只有size=1的才能扩张。

使用蓝色线画的数据必须保持一致;如果参数为-1,则意味着size保持不变。
repeat()
repeat()复制内存数据,括号内参数是copy次数。
代码演示:
print(b.repeat(4,32,1,1).shape) # torch.Size([4, 1024, 1, 1])转置
1、.t 矩阵转置,只适用于矩阵
2、transpose(dim1,dim2)转置
语法:交换dim1,dim2两个维度。注意transpose()方法会将数据变得不连续,所以通常需要借助于
contiguous()方法,用于将数据变得连续。
数据维度顺序必须和存储顺序一致。(说实话这一句我不太懂,然后我就去问了一下chatgpt)答案:
"数据维度顺序必须和存储顺序一致"是指在使用PyTorch进行数据处理和存储时,数据的维度顺序必须与存储的顺序一致。如果数据的维度顺序与存储的顺序不一致,可能会导致数据处理错误或结果不准确。
例如,如果使用PyTorch创建一个张量(tensor)并在存储时按默认的规则进行存储,即按行优先顺序存储,那么在对该张量进行操作时,需要按照相同的维度顺序进行操作,否则可能会导致错误。
总之,这句话的意思是在PyTorch中,需要保证数据的维度顺序和存储顺序一致,以确保数据处理和存储的正确性。
代码演示:
# a.shape=torch.Size([2, 3, 5, 5])
a1 = a.transpose(1,3).contiguous().view(2,3*5*5).view(2,3,5,5)
a2 = a.transpose(1,3).contiguous().view(2,3*5*5).view(2,5,5,3).transpose(1,3)
print(a1.shape,a2.shape) # torch.Size([2, 3, 5, 5]) torch.Size([2, 3, 5, 5])
print(torch.all(torch.eq(a,a1))) # tensor(False)
print(torch.all(torch.eq(a,a2))) # tensor(True)补充:其中all()方法是用来确定所有内容一致,eq()方法是用来比较数据一致。
说实话这个我也不是很懂,但是我去做了一下实验,将torch.eq(a,a2)和torch.eq(a,a1)都打印了出来,发现这是一个shape为torch.Size([2, 3, 5, 5])的张量,并且里面的数据都是ture或者false,然后我就明白了,原来eq()是用来比较对应的每个数据是否相同,all()是用来比较一个张量里面的所有值是否在相同。
permute()
个人认为这个方法非常强大,可以完成任意维度的交换。我们先来看一个使用transpose()方法进行维度交换:
# b.shape=torch.Size([4, 3, 28, 32])
print(b.transpose(1,3).shape) # torch.Size([4, 32, 28, 3])
print(b.transpose(1,3).transpose(1,2).shape) # torch.Size([4, 28, 32, 3])再来看一下permute()方法:
# b.shape=torch.Size([4, 3, 28, 32])
print(b.permute(0,2,3,1).shape) # torch.Size([4, 28, 32, 3])有没有感觉很强大。
相关文章:
深度学习pytorch——Tensor维度变换(持续更新)
view()打平函数 需要注意的是打平之后的tensor是需要有物理意义的,根据需要进行打平,并且打平后总体的大小是不发生改变的。 并且一定要谨记打平会导致维度的丢失,造成数据污染,如果想要恢复到原来的数据形式,是需要…...

Selenium-webdriver_manager判断是否已经下载过驱动(复用缓存驱动)
1,谷歌浏览器默认位置 2,ChromeDriverManager 下载的驱动位置 其中admin为机器的用户名 def installDriver(self):"""判断是否需要下载driver""""""找到本机谷歌浏览器版本""""""C:\P…...
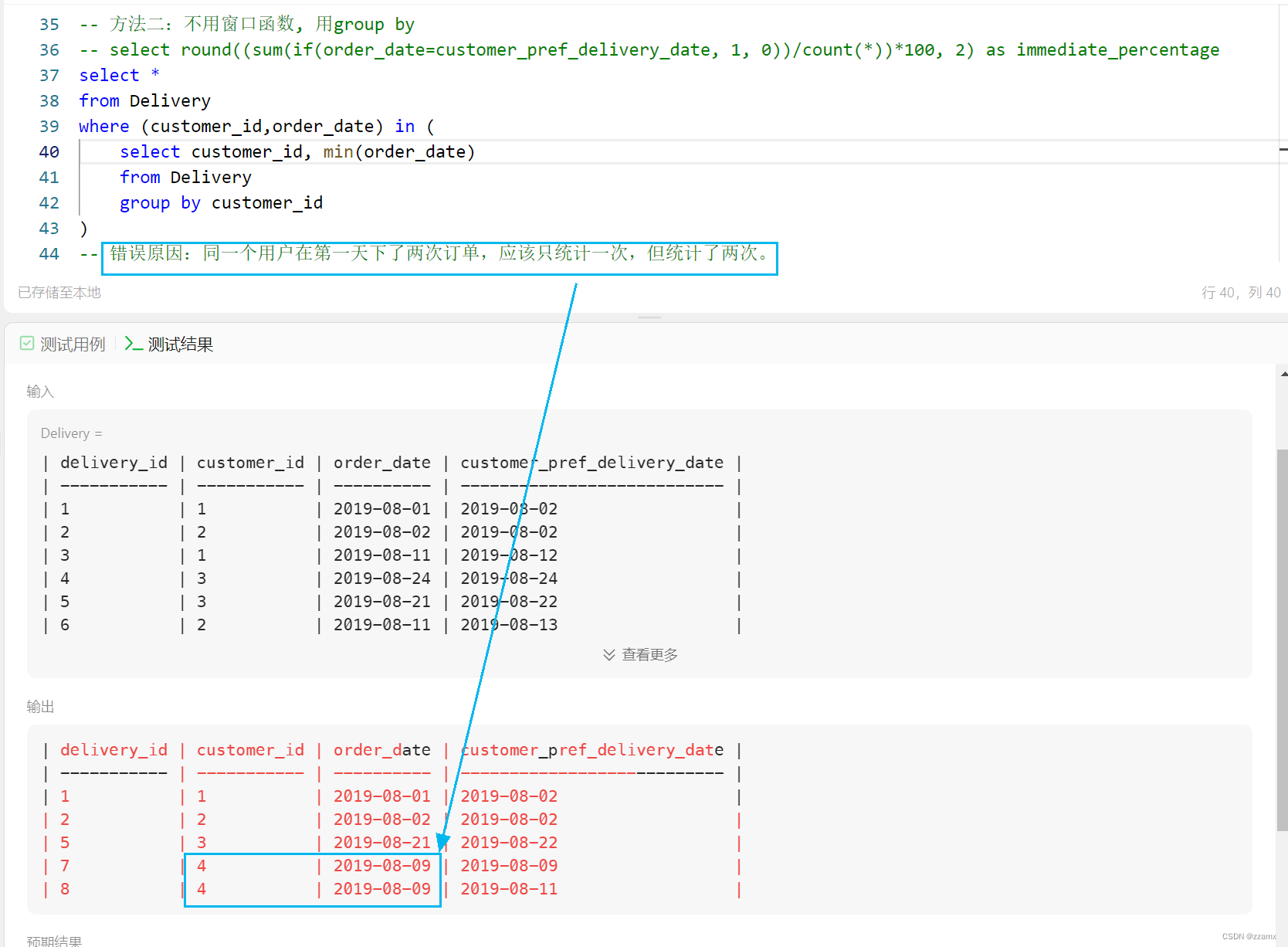
【SQL】1174. 即时食物配送 II (窗口函数row_number; group by写法;对比;定位错因)
前述 推荐学习: 通俗易懂的学会:SQL窗口函数 题目描述 leetcode题目:1174. 即时食物配送 II 写法一:窗口函数 分组排序(以customer_id 分组,按照order_date 排序),窗口函数应用。…...

mvcc介绍
前提:在介绍mvcc之前,先简单介绍一下mysql事务的相关问题,mvcc归根结底是用来解决事务并发问题的,当然这个解决不是全部解决,只是解决了其中的一部分问题! mysql事务 一、事务的基本要素(ACID&a…...

强化PaaS平台应用安全:关键策略与措施
PaaS(平台即服务,Platform-as-a-Service)是一种云计算服务模式,可以为客户提供一个完整的云平台(硬件、软件和基础架构)以用于快捷开发、运行和管理项目,从而降低了企业云计算应用的高成本和复杂…...

K8s 集群高可用master节点ETCD挂掉如何恢复?
写在前面 很常见的集群运维场景,整理分享博文内容为 K8s 集群高可用 master 节点故障如何恢复的过程理解不足小伙伴帮忙指正 不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前的风景已经和从前不一样了。——村上…...

【Godot 4.2】常见几何图形、网格、刻度线点求取函数及原理总结
概述 本篇为ShapePoints静态函数库的补充和辅助文档。ShapePoints函数库是一个用于生成常见几何图形顶点数据(PackedVector2Array)的静态函数库。生成的数据可用于_draw和Line2D、Polygon2D等进行绘制和显示。因为不断地持续扩展,ShapePoint…...
如何利用POI导出报表
一、报表格式 二、依赖坐标 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.16</version> </dependency> <dependency><groupId>org.apache.poi</groupId><art…...

自动部署SSL证书到阿里云腾讯云CDN
项目地址:https://github.com/yxzlwz/ssl_update 项目简介 目前,自动申请和管理免费SSL证书的项目有很多,如个人正在使用的 acme.sh。然而在申请后,如果我们的需求不仅限于服务器本地的使用,证书的部署也是一件麻烦事…...

【系统性】 循序渐进学C++
循序渐进学C 第一阶段:基础 一、环境配置 1.1.第一个程序(基本格式) #include <iosteam> using namespace std;int main(){cout<<"hello world"<<endl;system("pause"); } 模板 #include &…...

rust - 一个日志缓存记录的通用实现
本文给出了一个通用的设计模式,通过建造者模式实例化记录对象,可自定义格式化器将实例化后的记录对象写入到指定的缓存对象中。 定义记录对象 use chrono::prelude::*; use std::{cell::RefCell, ffi::OsStr, fmt, io, io::Write, path::Path, rc::Rc,…...
(黑马))
elasticsearch(RestHighLevelClient API操作)(黑马)
操作全是换汤不换药,创建一个request,然后使用client发送就可以了 一、增加索引库数据 Testvoid testAddDocument() throws IOException {//从数据库查出数据Writer writer writerService.getById(199);//将查出来的数据处理成json字符串String json …...

用尾插的思想实现移除链表中的元素
目录 一、介绍尾插 1.链表为空 2.链表不为空 二、题目介绍 三、思路 四、代码 五、代码解析 1. 2. 3. 4. 5. 6. 六、注意点 1. 2. 一、介绍尾插 整体思路为 1.链表为空 void SLPushBack(SLTNode** pphead, SLTDataType x) {SLTNode* newnode BuyLTNode(x); …...

【Kubernetes】k8s删除master节点后重新加入集群
目录 前言一、思路二、实战1.安装etcdctl指令2.重置旧节点的k8s3.旧节点的的 etcd 从 etcd 集群删除4.在 master03 上,创建存放证书目录5.把其他控制节点的证书拷贝到 master01 上6.把 master03 加入到集群7.验证 master03 是否加入到 k8s 集群,检查业务…...
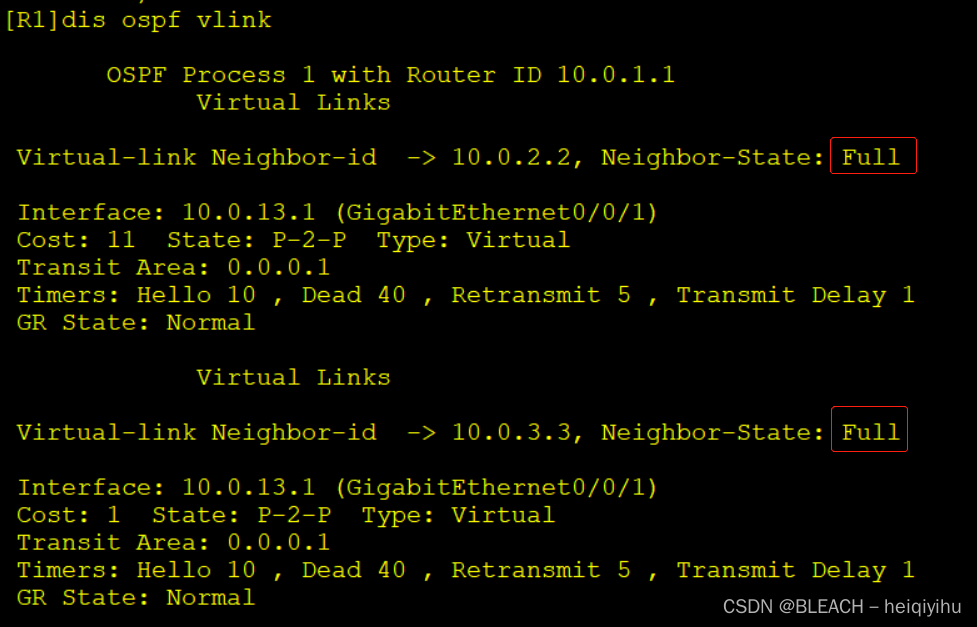
HCIP—OSPF虚链路实验
OSPF虚链路—Vlink 作用:专门解决OSPF不规则区域所诞生的技术,是一种虚拟的,逻辑的链路。实现非骨干区域和骨干区域在逻辑上直接连接。注意虚链路条件:只能穿越一个区域,通常对虚链路进行认证功能的配置。虚链路认证也…...
)
RAxML-NG安装与使用-raxml-ng-v1.2.0(bioinfomatics tools-013)
01 背景 1.1 ML树 ML树,或最大似然树,是一种在进化生物学中用来推断物种之间进化关系的方法。最大似然(Maximum Likelihood, ML)是一种统计框架,用于估计模型参数,使得观察到的数据在该模型参数下的概率最…...

Tomcat内存马
Tomcat内存马 前言 描述Servlet3.0后允许动态注册组件 这一技术的实现有赖于官方对Servlet3.0的升级,Servlet在3.0版本之后能够支持动态注册组件。 而Tomcat直到7.x才支持Servlet3.0,因此通过动态添加恶意组件注入内存马的方式适合Tomcat7.x及以上。…...

pytorch之诗词生成3--utils
先上代码: import numpy as np import settingsdef generate_random_poetry(tokenizer, model, s):"""随机生成一首诗:param tokenizer: 分词器:param model: 用于生成古诗的模型:param s: 用于生成古诗的起始字符串,默认为空串:return: …...

OpenAI的ChatGPT企业版专注于安全性、可扩展性和定制化。
OpenAI的ChatGPT企业版:安全、可扩展性和定制化的重点 OpenAI的ChatGPT在商业世界引起了巨大反响,而最近推出的ChatGPT企业版更是证明了其在企业界的日益重要地位。企业版ChatGPT拥有企业级安全、无限GPT-4访问、更长的上下文窗口以及一系列定制选项等增…...

JS06-class对象
class对象 className 修改样式 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content&quo…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...