【PyTorch】基础学习:一文详细介绍 torch.load() 的用法和应用
【PyTorch】基础学习:一文详细介绍 torch.load() 的用法和应用

🌈 个人主页:高斯小哥
🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支持~
💡 创作高质量博文(平均质量分92+),分享更多关于深度学习、PyTorch、Python领域的优质内容!(希望得到您的关注~)
🌵文章目录🌵
- 🔍一、torch.load()的基本概念
- 📚二、torch.load()的基本用法
- 💡三、torch.load()的高级用法
- 🔄四、torch.load()与torch.save()的配合使用
- 🔍五、常见问题及解决方案
- 🎯六、torch.load()在实际项目中的应用
- 🚀七、总结与展望
- 🤝 期待与你共同进步
- 相关博客
🔍一、torch.load()的基本概念
在PyTorch中,torch.load()是一个非常有用的函数,它用于加载由torch.save()保存的模型或张量。通过这个函数,我们可以轻松地将训练好的模型或中间结果加载到程序中,以便进行进一步的推理或继续训练。
简单来说,torch.load()的主要作用就是读取保存在文件中的数据,并将其转化为PyTorch能够处理的对象。这些对象可以是模型参数、优化器状态、数据集等等。
📚二、torch.load()的基本用法
-
下面是一个简单的示例,展示了如何使用
torch.load()加载一个保存的模型:import torch# 假设我们有一个已经训练好的模型,它被保存为'model.pth'文件 model = torch.load('model.pth')# 现在我们可以使用加载的模型进行推理或继续训练 output = model(input_data)
在上面的代码中,我们首先导入了PyTorch库。然后,我们使用torch.load()函数加载了名为’model.pth’的文件,并将其内容赋值给model变量。最后,我们可以像使用普通PyTorch模型一样使用这个加载的模型。
需要注意的是,torch.load()函数会默认将模型恢复到与保存时相同的设备(CPU或GPU)。然而,如果您希望将模型加载到不同的设备上,那么可以通过巧妙地设置map_location参数来实现这一需求。为了更好地掌握map_location参数的使用方法和技巧,博主强烈推荐您阅读博客文章《深入解析torch.load中的【map_location】参数》。
💡三、torch.load()的高级用法
除了基本用法外,torch.load()还有一些高级功能可以帮助我们更灵活地处理加载的数据。
-
加载部分数据:有时我们可能只需要加载模型的一部分数据,而不是整个模型。这可以通过使用
torch.load()的filter参数来实现。例如,如果我们只想加载模型的参数而不加载优化器的状态,可以这样操作:def filter_func(state_dict, prefix, local_metadata):# 只保留以'model.'为前缀的键值对return {k: v for k, v in state_dict.items() if k.startswith('model.')}model = torch.load('model.pth', filter=filter_func)在上面的代码中,我们定义了一个
filter_func函数,它根据键的前缀来筛选需要加载的数据。然后,我们将这个函数作为filter参数传递给torch.load(),从而只加载以’model.'为前缀的键值对。 -
加载到不同设备:如前所述,
torch.load()默认会加载模型到与保存时相同的设备上。如果需要加载到不同的设备上,可以通过设置map_location参数来实现。例如,如果我们将模型保存在GPU上,但现在想在CPU上加载它,可以这样操作:model = torch.load('model.pth', map_location=torch.device('cpu'))通过设置
map_location为torch.device('cpu'),我们告诉torch.load()将模型加载到CPU上。
🔄四、torch.load()与torch.save()的配合使用
torch.load()和torch.save()是PyTorch中用于序列化和反序列化模型或张量的两个重要函数。它们通常配合使用,以实现模型的保存和加载功能。
当我们训练好一个模型后,可以使用torch.save()将其保存到文件中。然后,在需要的时候,我们可以使用torch.load()将这个文件加载回来,以便进行进一步的推理或继续训练。
这种机制使得我们可以轻松地在不同的程序、不同的设备甚至不同的时间点上共享和使用模型。同时,通过结合使用torch.save()和torch.load()的高级功能,我们还可以实现更灵活的数据处理和设备迁移操作。
想要深入了解torch.save()的使用方法和技巧吗?博主特地为您准备了博客文章《【PyTorch】基础学习:torch.save()使用详解》。在这篇文章中,我们将全面解析torch.save()的使用方法和实用技巧,助您更自如地处理PyTorch模型的保存问题。期待您的阅读,一同探索PyTorch的更多精彩!
🔍五、常见问题及解决方案
在使用torch.load()时,可能会遇到一些常见问题。下面是一些常见的问题及相应的解决方案:
- 加载模型时报错:如果加载模型时报错,可能是由于保存的模型与当前环境的PyTorch版本不兼容。这时可以尝试升级或降级PyTorch版本,或者检查保存的模型是否完整无损。
- 设备不匹配:如果尝试将模型加载到与保存时不同的设备上,并且没有正确设置
map_location参数,可能会导致设备不匹配的问题。这时需要根据目标设备的类型(CPU或GPU)设置map_location参数。 - 部分数据加载失败:如果只想加载模型的部分数据但操作不当,可能会导致部分数据加载失败。这时可以使用
filter参数来筛选需要加载的数据,并确保筛选条件正确无误。
🎯六、torch.load()在实际项目中的应用
在实际项目中,torch.load()扮演着举足轻重的角色。它不仅能够帮助我们轻松加载预训练的模型进行推理,还可以让我们在分布式训练、迁移学习等复杂场景中实现模型的共享和重用。
- 推理应用:在部署模型进行推理时,我们通常需要将训练好的模型加载到服务器或移动设备上。这时,我们可以使用
torch.load()将模型文件加载到程序中,并利用加载的模型对输入数据进行预测。 - 迁移学习:迁移学习是一种将在一个任务上学到的知识迁移到另一个相关任务上的方法。通过
torch.load()加载预训练的模型,我们可以将其作为新任务的起点,并在此基础上进行微调或扩展。这样不仅可以节省训练时间,还可以提高模型在新任务上的性能。 - 分布式训练:在分布式训练场景中,多个节点需要共享模型的参数和状态。通过
torch.load()和torch.save(),我们可以将模型的状态信息在节点之间进行传递和同步,从而实现高效的分布式训练。
🚀七、总结与展望
通过本文的介绍,相信大家对torch.load()有了更深入的了解。它作为PyTorch中用于加载模型或张量的重要函数,具有广泛的应用场景和灵活的使用方法。通过掌握torch.load()的基本用法和高级功能,我们可以更加高效地进行模型的保存、加载和迁移操作,为深度学习项目的开发提供有力支持。
展望未来,随着深度学习技术的不断发展,模型的规模和复杂度也在不断增加。因此,如何更加高效地保存和加载模型将成为一个重要的研究方向。相信在PyTorch等开源框架的持续努力下,我们将拥有更加完善和强大的模型序列化工具,为深度学习领域的发展注入新的动力。
最后,希望本文能够为大家在PyTorch的学习和使用中提供一些帮助和启示。让我们携手共进,共同探索深度学习的无限可能!
🤝 期待与你共同进步
🌱 亲爱的读者,非常感谢你每一次的停留和阅读!你的支持是我们前行的最大动力!🙏
🌐 在这茫茫网海中,有你的关注,我们深感荣幸。你的每一次点赞👍、收藏🌟、评论💬和关注💖,都像是明灯一样照亮我们前行的道路,给予我们无比的鼓舞和力量。🌟
📚 我们会继续努力,为你呈现更多精彩和有深度的内容。同时,我们非常欢迎你在评论区留下你的宝贵意见和建议,让我们共同进步,共同成长!💬
💪 无论你在编程的道路上遇到什么困难,都希望你能坚持下去,因为每一次的挫折都是通往成功的必经之路。我们期待与你一起书写编程的精彩篇章! 🎉
🌈 最后,再次感谢你的厚爱与支持!愿你在编程的道路上越走越远,收获满满的成就和喜悦!祝你编程愉快!🎉
相关博客
| 博客文章标 | 链接地址 |
|---|---|
| 【PyTorch】基础学习:一文详细介绍 torch.save() 的用法和应用 | https://blog.csdn.net/qq_41813454/article/details/136777957?spm=1001.2014.3001.5501 |
| 【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例 | https://blog.csdn.net/qq_41813454/article/details/136778437?spm=1001.2014.3001.5501 |
| 【PyTorch】基础学习:一文详细介绍 torch.load() 的用法和应用 | https://blog.csdn.net/qq_41813454/article/details/136776883?spm=1001.2014.3001.5501 |
| 【PyTorch】进阶学习:一文详细介绍 torch.load() 的应用场景、实战代码示例 | https://blog.csdn.net/qq_41813454/article/details/136779327?spm=1001.2014.3001.5501 |
| 【PyTorch】基础学习:一文详细介绍 load_state_dict() 的用法和应用 | https://blog.csdn.net/qq_41813454/article/details/136778868?spm=1001.2014.3001.5501 |
| 【PyTorch】进阶学习:一文详细介绍 load_state_dict() 的应用场景、实战代码示例 | https://blog.csdn.net/qq_41813454/article/details/136779495?spm=1001.2014.3001.5501 |
相关文章:
【PyTorch】基础学习:一文详细介绍 torch.load() 的用法和应用
【PyTorch】基础学习:一文详细介绍 torch.load() 的用法和应用 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程ὄ…...

事务、并发、锁机制的实现
配置全局事务 DATABASES {default: {ENGINE: django.db.backends.mysql,NAME: mydb,USER:root,PASSWORD:pass,HOST:127.0.0.1,PORT:3306,ATOMIC_REQUESTS: True, # 全局开启事务,绑定的是http请求响应整个过程# (non_atomic_requests可局部实现不让事务控制)} } …...

PC-DARTS: PARTIAL CHANNEL CONNECTIONS FOR MEMORY-EFFICIENT ARCHITECTURE SEARCH
PC-DARTS:用于内存高效架构搜索的部分通道连接 论文链接:https://arxiv.org/abs/1907.05737 项目链接:https://github.com/yuhuixu1993/PC-DARTS ABSTRACT 可微分体系结构搜索(DARTS)在寻找有效的网络体系结构方面提供了一种快速的解决方案…...
git的下载与安装
下载 首先,打开您的浏览器,并输入Git的官方网站地址 点击图标进行下载 下载页面会列出不同操作系统和平台的Git安装包。根据您的操作系统(Windows、macOS、Linux等)和位数(32位或64位),选择适…...

windows文档格式转换的实用工具
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

四级缓存实现
CommandLineRunner接口的run方法 什么是多级缓存? 多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Server端的压力,提升服务性能。 一级缓存:1.CDN:内容分发网络 二级缓存:2.NGINX+Lua脚本+OpenResty服务器 负载均衡反向代理【静态和转发】 三级缓存:J…...

程序员如何规划职业赛道?
在快速发展的信息技术时代,程序员作为数字世界的构建者,面临着前所未有的职业选择和发展机会。选择合适的职业赛道,不仅关乎个人职业发展的高度和速度,更影响着个人职业生涯的满意度和幸福感。本文将从自我评估与兴趣探索、市场需…...

蓝桥杯day3刷题日记--P9240 冶炼金属
P9240 [蓝桥杯 2023 省 B] 冶炼金属 经典二分,先在第一组中找到最小值,在利用最小值限制范围寻找最大值 #include <iostream> #include <algorithm> using namespace std; int n,kk; int m[10001],num[10001]; int maxs,mins;bool check1…...

Mybatis-xml映射文件与动态SQL
xml映射文件 动态SQL <where><if test"name!null">name like concat(%,#{name},%)</if><if test"username!null">and username#{username}</if></where> <!-- collection:遍历的集合--> <!-- …...
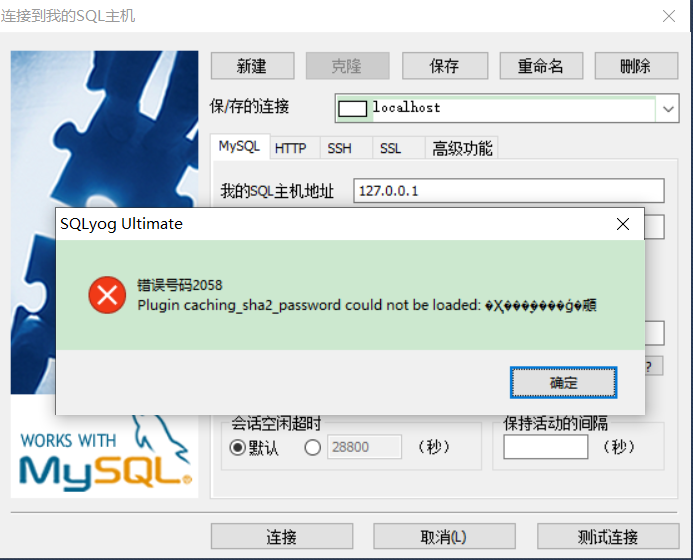
MySQL_数据库图形化界面软件_00000_00001
目录 NavicatSQLyogDBeaverMySQL Workbench可能出现的问题 Navicat 官网地址: 英文:https://www.navicat.com 中文:https://www.navicat.com.cn SQLyog 官网地址: 英文:https://webyog.com DBeaver 官网地址&…...
——FEC逻辑分析(6))
流媒体学习之路(WebRTC)——FEC逻辑分析(6)
流媒体学习之路(WebRTC)——FEC逻辑分析(6) —— 我正在的github给大家开发一个用于做实验的项目 —— github.com/qw225967/Bifrost目标:可以让大家熟悉各类Qos能力、带宽估计能力,提供每个环节关键参数调节接口并实现一个json全…...

command failed: npm install --loglevel error --legacy-peer-deps
在使用vue create xxx创建vue3项目的时候报错。 解决方法,之前使用的https://registry.npm.taobao.org 证书过期更换镜像地址即可 操作如下: 1.cd ~2.执行rm .npmrc3. sudo npm install -g cnpm --registryhttp://registry.npmmirror.com…...
KubeSphere集群安装-nfs分布式文件共享-对接Harbor-对接阿里云镜像仓库-遇到踩坑记录
KubeSphere安装和使用集群版 官网:https://www.kubesphere.io/zh/ 使用 KubeKey 内置 HAproxy 创建高可用集群:https://www.kubesphere.io/zh/docs/v3.3/installing-on-linux/high-availability-configurations/internal-ha-configuration/ 特别注意 安装前注意必须把当前使…...

Epuck2机器人固件更新及IP查询
文章目录 前言一、下载固件更新软件包:二、查询机器人在局域网下的IP 前言 前面进行了多机器人编队仿真包括集中式和分布式,最近打算在实物机器人上跑一跑之前的编队算法。但由于Epuck2机器人长时间没使用,故对其进行固件的更新,…...
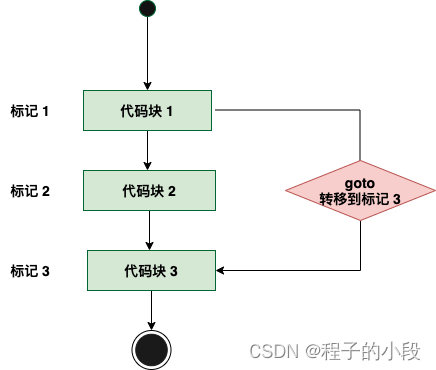
C goto 语句
C 语言中的 goto 语句允许把控制无条件转移到同一函数内的被标记的语句。 注意:在任何编程语言中,都不建议使用 goto 语句。因为它使得程序的控制流难以跟踪,使程序难以理解和难以修改。任何使用 goto 语句的程序可以改写成不需要使用 goto 语…...

【排序算法】-- 深入理解桶排序算法
概述 在计算机科学中,排序算法是一种对数据进行有序排列的重要技术。桶排序(Bucket Sort)是一种常见的排序算法,它通过将数据分到有限数量的桶中,并对每个桶中的数据分别排序,最后按照顺序将所有桶中的数据…...
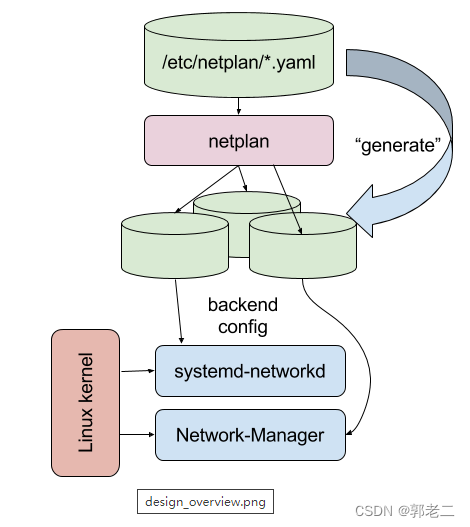
【Linux】Ubuntu使用Netplan配置静态/动态IP
1、说明 Ubuntu 18.04开始,Ubuntu和Debian移除了以前的ifup/ifdown命令和/etc/network/interfaces配置文件,转而使用ip link set或者/etc/netplan/01-netcfg.yaml模板和sudo netplan apply命令实现网络管理。 Netplan 是抽象网络配置描述器,用于配置Linux网络。 通过netpla…...
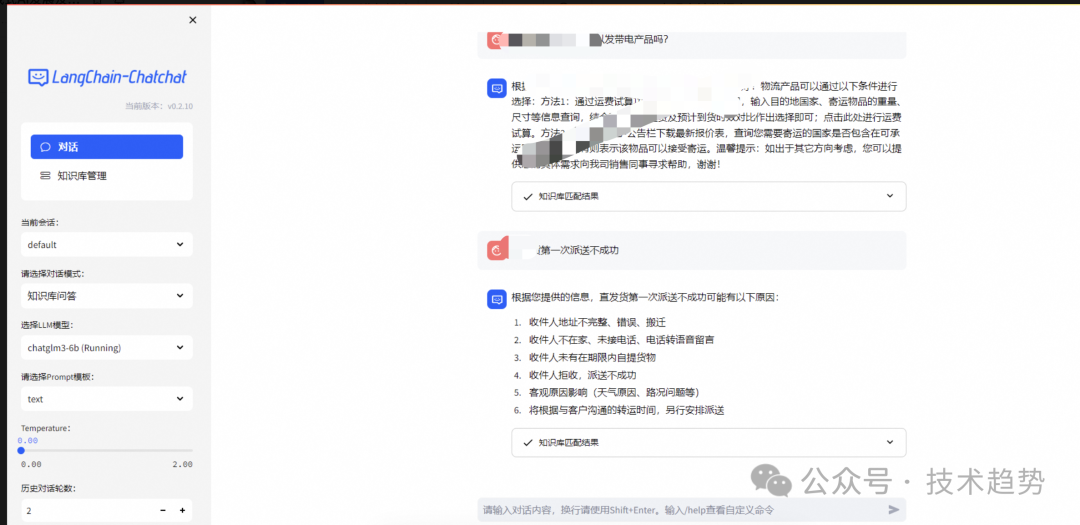
chatGLM3+chatchat实现本地知识库
背景 由于客服存在大量的问题为FAQ问题,需要精准回复客户,所以针对此类精准问题,通过自建同量数量库进行回复。 落地方案 通过chatGLM3-6Blangchain-chatchatbge-large-zh实现本地知识库库。 注意:相关介绍和说明请看官网~ 配置要…...
webpack5零基础入门-11处理html资源
1.目的 主要是为了自动引入打包后的js与css资源,避免手动引入 2.安装相关包 npm install --save-dev html-webpack-plugin 3.引入插件 const HtmlWebpackPlugin require(html-webpack-plugin); 4.添加插件(通过new方法调用) /**插件 *…...
el-input设置max、min无效的解决方案
目录 一、方式1:type“number” 二、方式2:oninput(推荐) 三、计算属性 如下表所示,下面为官方关于max,min的介绍: el-input: max原生属性,设置最大值min原生属性&a…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

边缘计算医疗风险自查APP开发方案
核心目标:在便携设备(智能手表/家用检测仪)部署轻量化疾病预测模型,实现低延迟、隐私安全的实时健康风险评估。 一、技术架构设计 #mermaid-svg-iuNaeeLK2YoFKfao {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...