消息队列面试题
目录
1. 为什么使用消息队列
2. 消息队列的缺点
3. 消息队列如何选型?
4. 如何保证消息队列是高可用的
5. 如何保证消息不被重复消费(见第二条)
6. 如何保证消息的可靠性传输?
7. 如何保证消息的顺序性(即消息幂等性)
8. 如何快速处理积压消息
9. MQ的架构和重要组件RocketMQ
10. RabbitMQ运转流程
1. 为什么使用消息队列
-
解耦:
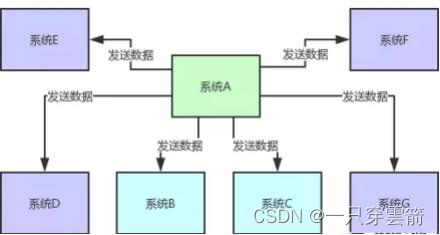
一旦A挂了,就会导致下游所有系统都没有数据,使用消息中间件来解耦,A只需要把数据发给中间 件,下游系统自行调用
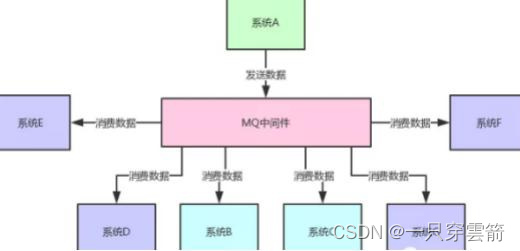
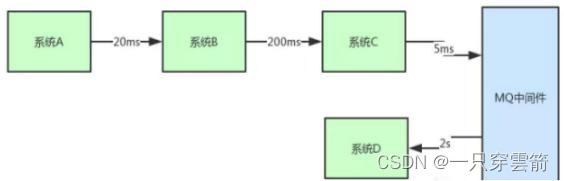
- 异步:系统C发送个消息到MQ中间件里,由系统D消费到消息之后慢慢的异步来执行这个耗 时2s的业务处理。这种方式直接将核心链路的执行性能提升了10倍。
- 削峰:某套系统低峰期并发也就100多个,高峰期并发量会增到5000以上,而这个数据库只 支撑每秒1000左右的并发写入,一旦高峰期出现并发量很大,就容易宕机。使用MQ后,消息 被MQ保存起来,然后系统按照自己的消费能力来消费,比如每秒消费1000个,这样慢慢写入 数据库,就不会轻易宕机。
2. 消息队列的缺点
- 可用性低:本来其他系统只要运行好好的,那你的系统就是正常的。现在你非要加入个消息队 列进去,那消息队列挂了,你的系统不是挂了。因此,系统可用性会降低 。解决方法:使用MQ集群,防止一个挂了还能继续使用
- 复杂性高:需要考虑消息有没有重复消费(即消息幂等性)、消息丢失、保证消息传递性等问 题 ,为什么会出现这种情况? 正常情况下,消费者在消费完消息后,会发送一个确认的消息给消息队列,消息队列知道该消息被消费了,就会把该消息从队列删除。RabbitMQ是发送一个ACK确认消息,RocketMQ是返回一个CONSUME_SUCESS。 解决方法: 如果消息是数据库插入操作,给消息一个唯一主键,如果出现重复消费的情况,会导致主键冲突,数据库避免有脏数据。如果消息是set入redis的话,是不会存在重复的,因set操作是幂等操作。 如果上面两种情况还不行,上大招。准备一个第三方介质,来做消费记录。以redis为例,给消息分配一个全局id,只要消费过该消息,将<id,message>以K-V形式写入redis. 那消费者开始消费前,先去redis中查询有没有消费记录即可。
- 数据一致性问题:MQ带来系统响应提高,但是如果消息没消费,就会导致数据不统一 解决:即防止生产者弄丢数据、消息队列弄丢数据、消费者弄丢数据。消息队列一般会 持久化到磁盘,生产者数据丢失MQ事务会回滚,可以尝试重新发送。消费者丢失数据一 般都是采用了自动确认消息模式导致消费信息被删,只要改为手动即可,即消费者消费 完之后,调用一个MQ的确认方法就行了。 缺点:rabbitMQ事务开启,就会变为同步阻塞操作,生产者会阻塞等待是否发送成功, 太耗性能会造成吞吐量的下降。
- 消息队列的延时与过期失效问题: 解决:消息队列的延迟和过期失效是消息队列的自我保护机制,目的是为了防止本身被 挤爆,当然也可以关闭这个机制。但是不推荐关闭,可以改为某个消息消费失败5次后, 可以把这个消息丢弃等,但是丢弃的数据最好写个临时程序又重新放入MQ队列或记录下 来重新处理。
3. 消息队列如何选型?

4. 如何保证消息队列是高可用的
- 普通集群模式:默认的集群模式,对于Queue来说,消息实体只存在于其中一个节点,A、B两个 节点仅有相同的元数据,即队列结构,但队列的元数据仅保存有一份,即创建该队列的rabbitmq 节点(A节点),当A节点宕机,你可以去其B节点查看,发现该队列已经丢失。 当消息进入A节点的Queue中后,consumer从B节点拉取时,RabbitMQ会临时在A、B间进行消息 传输,把A中的消息实体取出并经过B发送给consumer,所以consumer应平均连接每一个节点, 从中取消息。该模式存在一个问题就是当A节点故障后,B节点无法取到A节点中还未消费的消息实 体。如果做了队列持久化或消息持久化,那么得等A节点恢复,然后才可被消费,并且在A节点恢复 之前其它节点不能再创建A节点已经创建过的持久队列;如果没有持久化的话,消息就会失丢。这 种模式更适合非持久化队列,只有该队列是非持久的,客户端才能重新连接到集群里的其他节点, 并重新创建队列。假如该队列是持久化的,那么唯一办法是将故障节点恢复起来。
- 镜像模式:把需要的队列做成镜像队列,存在于多个节点。其实质和普通模式不同之处在于,消息 实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。该模式带来的副作用也很 明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽 将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用
- 主备模式:主节点提供读写,备用节点不提供读写。如果主节点挂了,就切换到备用节点,原来的 备用节点升级为主节点提供读写服务,当原来的主节点恢复运行后,原来的主节点就变成备用节点

- 多Master模式:一个集群无Slave,全是Master,例如2个Master或者3个Master,这种模式的优 缺点如下:
- 优点:配置简单,单个Master宕机或重启维护对应用无影响,在磁盘配置为RAID10时,即使 机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘丢失少量消 息,同步刷盘一条不丢),性能最高;
- 缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性 会受到影响。
- 多Master多Slave模式(异步复制):每个 Master 配置一个 Slave,有多对Master-Slave, HA, 采用异步复制方式,主备有短暂消息延迟,毫秒级。
- 优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为Master 宕机后, 消费者仍然可以从 Slave消费,此过程对应用透明。不需要人工干预。性能同多 Master 模式 几乎一样。
- 缺点: Master 宕机,磁盘损坏情况,会丢失少量消息。
- 多Master多Slave模式(同步双写)线上使用的话,推荐使用此模式集群:每个 Master 配置一个 Slave,有多对Master-Slave, HA采用同步双写方式,主备都写成功,向应用返回成功。
- 优点:数据与服务都无单点, Master宕机情况下,消息无延迟,服务可用性与数据可用性都 非常高
- 缺点:性能比异步复制模式略低,大约低 10%左右,发送单个消息的 RT会略高。目前主宕机后,备机不能自动切换为主机。
- Dledger部署:RocketMQ 4.5以后出现,每个Master配置二个 Slave 组成 Group,可以有多个 Dledger Group,一但 Master 宕机,Dledger 就可以从剩下的两个 Broker 中选举一个 Master 继 续对外提供服务。使用raft算法进行选举。
5. 如何保证消息不被重复消费(见第二条)
6. 如何保证消息的可靠性传输?
- 生产者弄丢数据:对RocketMQ来说,设计之初就避免了生产者丢失消息,即事务消息: 事务消息是在分布式系统中保证最终一致性的2PC(两阶段提交)的消息实现。他可以保证本地 事务执行与消息发送两个操作的原子性,也就是这两个操作一起成功或者一起失败。 事务消息只保证消息发送者的本地事务与发消息这两个操作的原子性,因此,事务消息的示例 只涉及到消息发送者,对于消息消费者来说,并没有什么特别的。

- 流程先发送一个half消息(可以理解为半个消息,这个消息作用在事务生效前检查一rocketMQ是否活着,对下游消费者不可见,上图步骤1,判断rocketMQ的状态,然后rocketMQ回复给生产者(步骤2),生产者再去操作自己的事务(步骤3),如果操作事务失败,给rocketMQ返回一个本地事务的状态rollback,然后rocketMQ丢弃掉。如果操作成功,给rocketMQ返回一个commit给下游服务(步骤4,这返回有三个状态,分别是commit、rollback、unknow)。
- 如果生产者在处理本地事务过于太久,先给rocketMQ返回一个unkown(步骤4),那 rocketMQ就不会跟消费者任何接触,而rocketMQ过会给生产者一个回查状态(步骤5)来确定 你到底执行完没(步骤6),返回给rocketMQ(步骤7,这里返回的状态还是commit、rollback、 unknow)。返回过来的commit就给消费者,返回是rollback就丢弃,返回的unknow的话,就会等待下一次去回查,以此类推循环查(默认是15次)。
- 缺点 因为要发个half消息,就会比普通消息慢,而这只是保证消息发送端的正常发送 使用限制事务消息不支持延迟消息和批量消息 为了避免单个消息被检查确认多次而导致消息堆积,我们默认单个消息检查次数为 15次。这个次数可以该broker配置文件的transactionCheckMax属性 在broker配置文件的transactionMsgTimeout来设置特定时间长度之后被检查 事务消息只保证了发送者的本地事务和发送消息这两个操作的原子性,但是并不保 证消费者本地事务的原子性
- RocketMQ内部保证消息不丢失:使用同步刷盘+Dledger(rocketMQ 4.7版本才有)来避免类似问题 刷盘机制:
- 同步刷盘:节点收到消息后,将数据持久化到硬盘后,再返回成功
- 异步刷盘:节点收到消息后,将消息存储在内存中,先返回成功,再持久化到硬盘 中。 Dledger,它是通过两段式提交的方式保证文件在主从之间成功同步
- Dledger的两段式(uncommitted阶段和commited阶段)内容如下: Leader Broker上的Dledger收到一条数据后,会标记为uncommitted状态,然后 他通过自己的DledgerServer组件把这个uncommitted数据发给Follower Broker的 DledgerServer组件。 接着Follower Broker的DledgerServer收到uncommitted消息之后,必须返回一个 ack给Leader Broker的Dledger。然后如果Leader Broker收到超过半数的 Follower Broker返回的ack之后,就会把消息标记为committed状态。 再接下来,Leader Broker上的DledgerServer就会发送committed消息给Follower Broker上的DledgerServer,让他们把消息也标记为committed状态。这样,就基 于Raft协议完成了两阶段的数据同步。
- 消费者保证消息不丢失: 要保证消息不丢失,消费端就不要使用异步消费机制。因为异步消费可能存在消费者本地出现 问题,而无法再去告知RocketMQ,应该消费端进行消费结束后在返回给RocketMQ一个ack 确认消息正常消费
- NameServer集群全部挂了保证消息不丢失:NameServer集群挂了,生产者无法往新的Topic发送消息,只能设计一个降级方案来处理(可 以先把消息存在数据库或redis,等RocketMQ恢复后再发送出去等方案)

- 保证消息不丢失主要的总结:
- 生产者使用事务消息机制。
- Broker配置同步刷盘+Dledger主从架构,
- 消费者不要使用异步消费。
- 整个MQ挂了之后准备降级方案
- 缺点:以上消息零丢失方案,在各个环节都大量的降低了系统的处理性能以及吞吐量。在很多场景下,这套方案带来的性能损失的代价可能远远大于部分消息丢失的代价。 所以,我们在设计RocketMQ使用方案时,要根据实际的业务情况来考虑。 例如,如果针对所有服务器都在同一个机房的场景,完全可以把Broker配置成异步刷盘来提 升吞吐量。而在有些对消息可靠性要求没有那么高的场景,在生产者端就可以采用其他一些更 简单的方案来提升吞吐,而采用定时对账、补偿的机制来提高消息的可靠性。而如果消费者不 需要进行消息存盘,那使用异步消费的机制带来的性能提升也是非常显著的。 RabbitMQ 生产者丢数据:从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式 来确保生产者不丢消息 transaction机制就是说,发送消息前,开启事务(channel.txSelect()),然后发送消息,如果 发送过程中出现什么异常,事务就会回滚(channel.txRollback()),如果发送成功则提交事务 channel.txCommit。这种方式有个缺点:吞吐量下降。 生产上用confirm模式的居多。一旦channel进入confirm模式,所有在该信道上发布的消息都 将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后,rabbitMQ 就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目 的队列了。如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。但是批量发送多少确定一次是关键,数量太少,效率太低。数量多,如果出问题,是不是所有的都要重发。
- 消息队列丢数据 消息从Exchange路由到Queue出现问题: 有两种方式处理无法路由的消息,一种是让服务端重发给生产者,另外一种是让交换机 路由到另外一个备份的交换机。
- 消息持久化到磁盘: 处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。这个持久化配置可以和 confirm机制配合使用,你可以在消息持久化磁盘后,再给生产者发送一个Ack信号。这 样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者 会自动重发。
- 使用集群:保证消息一定会被写入磁盘
- 消费者丢数据 消费者丢数据一般是因为采用了自动确认消息模式。这种模式下,消费者会自动确认收到信息 (即自动发ACK给消息队列)。这时rabbitMQ会立即将消息删除,这种情况下,如果消费者 出现异常而未能处理消息,就会丢失该消息。至于解决方案,采用手动确认消息即可
7. 如何保证消息的顺序性(即消息幂等性)
- 全局有序:整个MQ系统的所有消息严格按照队列先入先出顺序进行消费。
- 局部有序:只保证一部分关键消息的消费顺序
- 在RocketMQ的通常情况下,发送者发送消息时,会通过MessageQueue轮询的方式保证消息尽量均匀的分布到所有的MessageQueue上,而消费者也就同样需要从多个MessageQueue上消费消息。而 MessageQueue是RocketMQ存储消息的最小单元,他们之间的消息都是互相隔离的,在这种情况下, 是无法保证消息全局有序的。
- 而对于局部有序的要求,只需要将有序的一组消息都存入同一个MessageQueue里,这样 MessageQueue的FIFO设计天生就可以保证这一组消息的有序。RocketMQ中,可以在发送者发送消息 时指定一个MessageSelector对象,让这个对象来决定消息发入哪一个MessageQueue。这样就可以保 证一组有序的消息能够发到同一个MessageQueue里。 另外通常所谓的保证Topic全局消息有序的方式,就是将Topic配置成只有一个MessageQueue队列(默 认是4个)。这样天生就能保证消息全局有序了。
8. 如何快速处理积压消息
- 场景:例如某一天一个数据库突然挂了,大家大概率就会集中处理数据库的问题。等好不容易把数 据库恢复过来了,这时基于这个数据库服务的消费者程序就会积累大量的消息。 查看消息堆积,去web控制台处理消息堆积

- 如果Topic下的MessageQueue配置得是足够多的,那每个Consumer实际上会分配多个 MessageQueue来进行消费。这个时候,就可以简单的通过增加Consumer的服务节点数量 来加快消息的消费,等积压消息消费完了,再恢复成正常情况。最极限的情况是把Consumer 的节点个数设置成跟MessageQueue的个数相同。但是如果此时再继续增加Consumer的服 务节点就没有用了。
- 而如果Topic下的MessageQueue配置得不够多的话,那就不能用上面这种增加Consumer节 点个数的方法了。这时怎么办呢? 这时如果要快速处理积压的消息,可以创建一个新的 Topic,配置足够多的MessageQueue。然后把所有消费者节点的目标Topic转向新的Topic, 并紧急上线一组新的消费者,只负责消费旧Topic中的消息,并转储到新的Topic中,这个速度 是可以很快的。然后在新的Topic上,就可以通过增加消费者个数来提高消费速度了。之后再 根据情况恢复成正常情况。
- 消息设置了过期时间,过期就丢了 RabbitMQ可以设置过期时间(TTL),如果消息在queue中积压超过一定的时间就会被rabbitmq 给清理掉,这个数据就没了。 解决方法:夜深人静,写个程序,手动查询丢失的部分数据,重新补吧 积压消息长时间没处理,MQ放不下了 先把积压的消息读到redis或者es,快速消费掉积压的消息,降低MQ的压力,然后晚上重新导数据
9. MQ的架构和重要组件RocketMQ


- NameServer(元数据管理):NameServer是RocketMQ的寻址服务,存储Broker的路由信息以及配置 信息,用户端(生成者消费者)依靠NameServer去选择对于的Broker服务,即每个Broker在启动的时 候会到NameServer注册,Producer在发送消息前会根据Topic到NameServer获取到Broker的路由信 息,Consumer也会定时获取Topic的路由信息,类似注册中心。主要负责对于源数据的管理,包括了对 于Topic和路由信息的管理。
- Broker:消息中转角色,负责存储消息,转发消息,处理Producer发送消息请求,Consumer消费消息的请求,并且进行消息的持久化,以及服务端过滤,就是集群中很重的工作都是交给了Broker进行处理。
- Producer(生产者)
- Producer Group:一类Producer的集合名称,这类Producer通常发送一类消息,且发送逻辑一致(设计组是防止rockertmq独有的事务消息回传的时候,防止生产者挂了机制)。
- Topic(主题,区分消息):一条消息必须有一个Topic,可以看做是你的信件邮寄地址。与生产者和消费者的关系非常松散,一个Topic可以有0个、1个、多个生产者向其发送消息,一个生产者也可以同时向不同的Topic发送消息。比如一个电商系统的消息可以分为:交易消息、物流消息。 Tag:表示消息的第二级类型,可以没有
- Message Queue:(消息队列,最小单位),一个topic下,我们可以设置多个queue(消息队列)。当我们发送消息时,需要要指定该消息的topic。RocketMQ会轮询该topic下的所有队列,将消息发送出去。Queue的引入使得消息的存储可以分布式集群化,具有了水平扩展能力。每个Queue内部是有序的,在RocketMQ中分为读和写两种队列,一般来说读写队列数量一致,如果不一致就会出现很多问题。至少要保证读队列数>=写队列数,否则会发现一些队列中的数据读取不到。
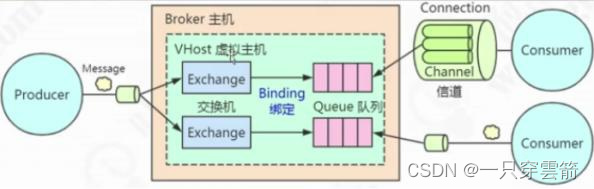
- RabbitMQ Server:也叫broker server,它是一种传输服务。他的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输。
- Exchange(交换器):生产者将消息发送到Exchange,由Exchange将消息路由到一个或多个Queue中(或者丢弃)。Exchange与Queue关系是多对多。Exchange并不存储消息。RabbitMQ中的Exchange有direct、fanout、topic常见三种类型,每种类型对应不同的路由规则。(用于接受、分发消息)
- Queue(队列):RabbitMQ的内部对象,用于存储消息。消息消费者就是通过订阅队列来获取消息,RabbitMQ中的消息都只能存储在Queue中,生产者生产消息并最终投递到Queue中,消费者可以从Queue中获取消息并消费。多个消费者可以订阅同一个Queue,这时Queue中的消息会被平均分摊给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理。(存储生产者的消息,本质是一个Erlang数据库,Queue与消费者是多对多的关系)
- Banding:用于把交换器的消息绑定到队列上。是Exchange和Queue之间的虚拟连接,binding里包含routing key
- Routing Key:用于把生成者的数据分配到交换器上。可以理解为队列唯一标识(或理解为路由规则),生产者在将消息发送给Exchange的时候,一般会指定一个routing key,来指定这个消息的路由规则,而这个routing key需要与Exchange Type及binding key联合使用才能最终生效。
- Channels信道:它建立在TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。(消息推送使用的通道)。几乎所有操作都在信道中进行,是消息读写的通道。
- VirtualHost虚拟主机:权限控制的基本单位,一个Virtual Host里面有若干Exchange和 MessageQueue,以及指定被哪些user使用,不同virtualHost相互隔离。不同的应用可以跑在不同的 vhost 中 补充: ①怎么实现消息到达队列后,消费者能在第一时间获取? 利用事件机制实时监听 ②生产者如何把消息发给多个队列? 生产者把消息发送给交换机,交换机利用绑定规则,绑定多个队列,队列里的消息只能消费一次,如果 多个系统消费,我们就需要有多个队列 ③消息是存到交换机还是队列呢?本质是什么? 消息是存到队列,队列本质是Erlang语言写的数据库,而交换机不会存储消息,只是消息有个特殊的标 识,消息到达交换机的时候,标识就会根据绑定规则的情况,把消息发到对应的一个或多个队列里。 ④交换机和队列是一对一的关系吗?消费者和队列呢? 交换机和队列是多对多,消费者和队列也是多对多,生产者和交换机也是多对多,但是一般生产环境尽 量配置一对一的,方便排查消息来源哪里,特殊业务除外。
10. RabbitMQ运转流程
- 生产者连接到RabbitMQ Broker , 建立一个连接( Connection) ,开启一个信道(Channel)
- 生产者声明一个交换器,并设置相关属性,比如交换机类型、是否持久化等
- 生产者声明一个队列井设置相关属性,比如是否排他、是否持久化、是否自动删除等
- 生产者通过路由键将交换器和队列绑定起来
- 生产者发送消息至RabbitMQ Broker,其中包含路由键、交换器等信息
- 相应的交换器根据接收到的路由键查找相匹配的队列。
- 如果找到,则将从生产者发送过来的消息存入相应的队列中。
- 如果没有找到,则根据生产者配置的属性选择丢弃还是回退给生产者
- 关闭信道。
- 关闭连接。消费者接收消息的过程:
- 消费者连接到RabbitMQ Broker ,建立一个连接(Connection ) ,开启一个信道(Channel) 。
- 消费者向RabbitMQ Broker 请求消费相应队列中的消息,可能会设置相应的回调函数, 以及做一些准备工作
- 等待RabbitMQ Broker 回应并投递相应队列中的消息, 消费者接收消息。
- 消费者确认( ack) 接收到的消息。
- RabbitMQ 从队列中删除相应己经被确认的消息。
- 关闭信道。
- 关闭连接
相关文章:
消息队列面试题
目录 1. 为什么使用消息队列 2. 消息队列的缺点 3. 消息队列如何选型? 4. 如何保证消息队列是高可用的 5. 如何保证消息不被重复消费(见第二条) 6. 如何保证消息的可靠性传输? 7. 如何保证消息的顺序性(即消息幂…...

Android和IOS应用开发-Flutter 应用中实现记录和使用全局状态的几种方法
文章目录 在Flutter中记录和使用全局状态使用 Provider步骤1步骤2步骤3 使用 BLoC步骤1步骤2步骤3 使用 GetX:步骤1步骤2步骤3 在Flutter中记录和使用全局状态 在 Flutter 应用中,您可以使用以下几种方法来实现记录和使用全局状态,并在整个应…...

若依 ruoyi-cloud [网关异常处理]请求路径:/system/user/getInfo,异常信息:404
这里遇到的情况是因为nacos中的配置文件与项目启动时的编码不一样,若配置文件中有中文注释,那么用idea启动项目的时候,在参数中加上 -Dfile.encodingutf-8 ,保持编码一致,(用中文注释的配置文件,…...
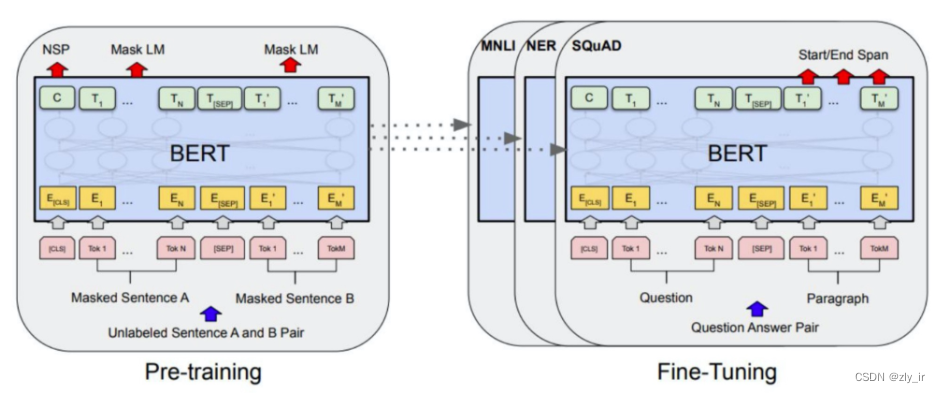
自然语言处理里预训练模型——BERT
BERT,全称Bidirectional Encoder Representation from Transformers,是google在2018年提出的一个预训练语言模型,它的推出,一举刷新了当年多项NLP任务值的新高。前期我在零、自然语言处理开篇-CSDN博客 的符号向量化一文中简单介绍…...

2024年信息技术与计算机工程国际学术会议(ICITCEI 2024)
2024年信息技术与计算机工程国际学术会议(ICITCEI 2024) 2024 International Conference on Information Technology and Computer Engineering ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 大会主题: 信息系统和技术…...

渗透测试修复笔记 - 02 Docker Remote API漏洞
需要保持 Docker 服务运行并且不希望影响其他使用 Docker 部署的服务,同时需要禁止外网访问特定的 Docker API 端口(2375):通过一下命令来看漏洞 docker -H tcp://ip地址:2375 images修改Docker配置以限制访问 修改daemon.json配…...
)
Spring(创建对象的方式3个)
3、Spring IOC创建对象方式一: 01、使用无参构造方法 //id:唯一标识 class:当前创建的对象的全局限定名 <bean id"us1" class"com.msb.pojo.User"/> 02、使用有参构造 <bean id"us2&…...
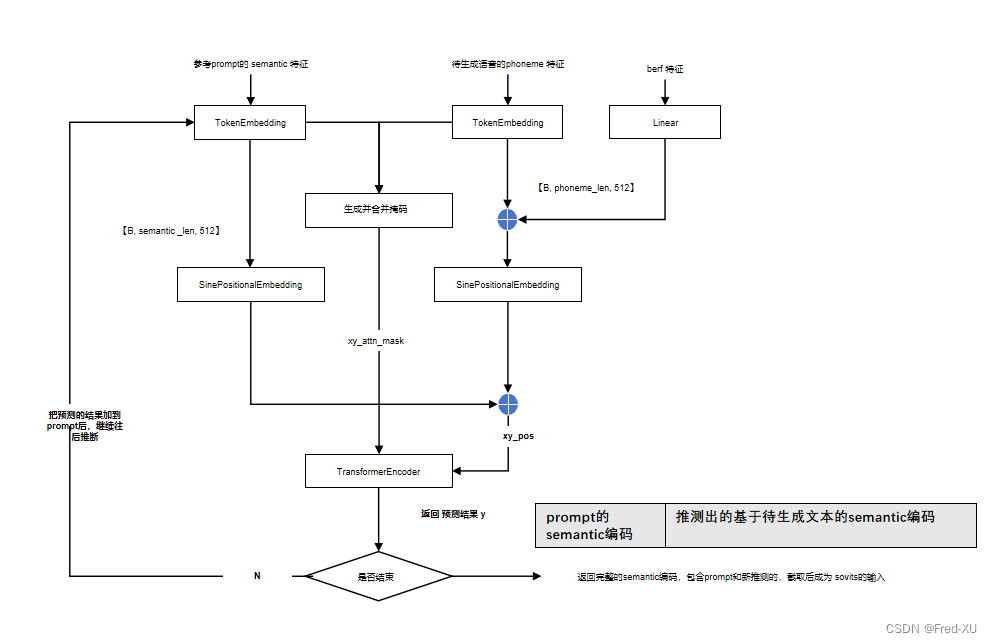
【GPT-SOVITS-02】GPT模块解析
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。 知乎专栏地址: 语音生成专栏 系列文章地址: 【GPT-SOVITS-01】源码梳理 【GPT-SOVITS-02】GPT模块解析 【GPT-SOVITS-03】SOVITS 模块-生成模型解析 【G…...
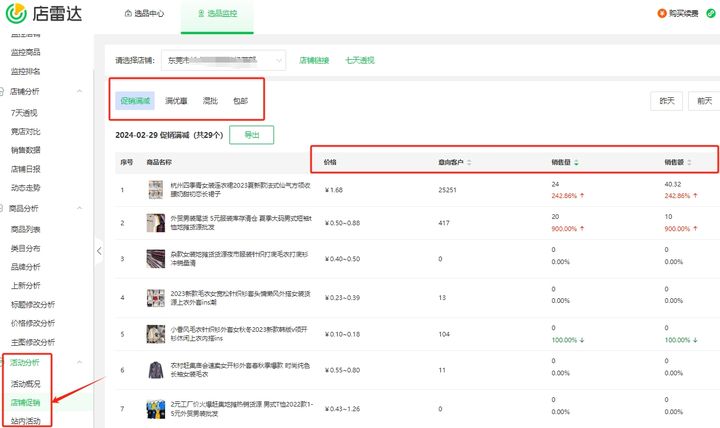
6个选品建议,改善你的亚马逊现状。
一、市场热点与需求调研 深入研究当前市场趋势,了解消费者需求的变化。使用亚马逊的销售数据、评价、问答等功能,以及第三方市场研究工具,比如店雷达,分析潜在热销产品的特点。注意季节性需求,提前布局相关选品&#…...

SQL中的SYSDATE函数
前言 在SQL语言中,SYSDATE 是一个非常实用且常见的系统内置函数,尤其在Oracle和MySQL数据库中广泛使用。它主要用来获取服务器当前的日期和时间,这对于进行实时数据记录、审计跟踪、有效期计算等场景特别有用。本文将详细解析SYSDATE函数的使…...

Rust的async和await支持多线程运行吗?
Rust的async和await的异步机制并不是仅在单线程下实现的,它们可以在多线程环境中工作,从而利用多核CPU的并行计算优势。然而,异步编程的主要目标之一是避免不必要的线程切换开销,因此,在单线程上下文中,asy…...

P2676 [USACO07DEC] Bookshelf B
[USACO07DEC] Bookshelf B 题目描述 Farmer John 最近为奶牛们的图书馆添置了一个巨大的书架,尽管它是如此的大,但它还是几乎瞬间就被各种各样的书塞满了。现在,只有书架的顶上还留有一点空间。 所有 N ( 1 ≤ N ≤ 20 , 000 ) N(1 \le N…...
)
【数学】第十三届蓝桥杯省赛C++ A组/研究生组《爬树的甲壳虫》(C++)
【题目描述】 有一只甲壳虫想要爬上一棵高度为 n 的树,它一开始位于树根,高度为 0,当它尝试从高度 i−1 爬到高度为 i 的位置时有 Pi 的概率会掉回树根,求它从树根爬到树顶时,经过的时间的期望值是多少。 【输入格式…...

Java毕业设计 基于springboot vue招聘网站 招聘系统
Java毕业设计 基于springboot vue招聘网站 招聘系统 springboot vue招聘网站 招聘系统 功能介绍 用户:登录 个人信息 简历信息 查看招聘信息 企业:登录 企业信息管理 发布招聘信息 职位招聘信息管理 简历信息管理 管理员:注册 登录 管理员…...

Leetcode 1. 两数之和
心路历程: 很简单的题,双层暴力就可以,用双指针的话快一点。暴力时间复杂度O( n 2 n^2 n2),双指针时间复杂度O(nlogn) O(n) O(n) O(nlogn)。 注意的点: 1、题目需要返回原数组的索引,所以排序后还需要…...
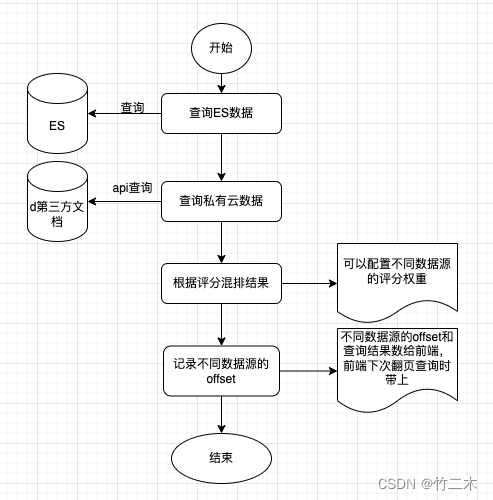
【elasticsearch实战】从零开始设计全站搜索引擎
业务需求 最近需要一个全站搜索的功能,我们的站点的特点是数据多源,即有我们本地数据库,也包含了第三方数据源,我们的数据类型除了网页,还包括了各种类型的文档,例如:doc、pdf、excel、ppt等格…...

基于tcp协议的网络通信(基础echo版.多进程版,多线程版,线程池版),telnet命令
目录 基础版 思路 辅助函数 服务端 代码 运行情况 -- telnet ip 端口号 传输的数据为什么没有转换格式 客户端 思路 代码 多进程版 引入 问题 解决 注意点 服务端 代码 运行情况 进程池版(简单介绍) 多线程版 引入 问题解决 注意点 服务端 代码 …...

Ubuntu20系统安装完后没有WIFI
Ubuntu20系统安装完后没有WIFI 查看后发现是缺少网卡,经过查询之后,发现是HRex39/rtl8852be 然后查询了Kernel版本 Check the Kernel Version in Linux $ uname -srm Linux 5.15.0-67-generic x86_64然后进行下载安装 Build(for kernel < 5.18) …...

计算机视觉——目标检测(R-CNN、Fast R-CNN、Faster R-CNN )
前言、相关知识 1.闭集和开集 开集:识别训练集不存在的样本类别。闭集:识别训练集已知的样本类别。 2.多模态信息融合 文本和图像,文本的语义信息映射成词向量,形成词典,嵌入到n维空间。 图片内容信息提取特征&…...

log4j2.xml配置文件不生效
问题 使用springboot配置log4j2,添加了依赖并排除默认的logging依赖,配置了log4j2.xml文件,放在scr目录下,运行可以在控制台输出日志,但不受配置文件影响 解决 配置文件log4j2.xml放在resources目录下生效...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...
淘宝扭蛋机小程序系统开发:打造互动性强的购物平台
淘宝扭蛋机小程序系统的开发,旨在打造一个互动性强的购物平台,让用户在购物的同时,能够享受到更多的乐趣和惊喜。 淘宝扭蛋机小程序系统拥有丰富的互动功能。用户可以通过虚拟摇杆操作扭蛋机,实现旋转、抽拉等动作,增…...