C语言之数据在计算机内部的存储
文章目录
- 一、前言
- 二、类型的基本归类
- 1、整型家族
- 2、浮点数家族
- 3、构造类型
- 4、指针类型
- 三、整型在内存中的存储
- 1、原码、反码、补码
- 1.1 概念
- 1.2 原码与补码的转换形式
- 1.3 计算机内部的存储编码
- 2、大小端介绍~~
- 2.1 为什么要有大端和小端之分?
- 2.2 大(小)端字节序存储
- 2.3 一道百度系统工程师笔试题
- 3、数据范围的介绍
- 3.1 char与signed char数据范围
- 3.2 unsigned char数据范围
- 4、笔试题
- 四、浮点型在内存中的存储
- 1、引入
- 2、浮点数存储规则
- 2.1 概念
- 3、开局疑难解答
一、前言
- 前面我们已经学习了基本的内置类型:
- 以及他们所占存储空间的大小~~

类型的意义:
- 使用这个类型开辟内存空间的大小(大小决定了使用范围)
- 如何看待内存空间的视角
二、类型的基本归类
1、整型家族
- 下面是整形家族

-
char在字符存储的时候存的是一个ASCLL码值,而ASCLL码值是一个整数
-
数值有正数和负数之分
- 有些数值只有正数,没有负数(身高)—— unsigned
- 有些数值,有正数也有负数(温度)—— signed
2、浮点数家族
- 浮点数只分为两类,一个是【float】,一个是【double】
3、构造类型

4、指针类型

-下面我们来介绍一下这个空指针
void*叫做【空指针】- 对于int类型的指针可以用来接收int类型的数据的地址
- 对于char类型的指针可以用来接收char类型的数据的地址
- 对于float类型的指针可以用来接收float类型的数据的地址
- 对于
void类型的指针可以用来接收任何类型数据的地址【它就像一个垃圾桶一样,起到临时存放的作用】
void 表示空类型(无类型)
通常应用于函数的返回类型、函数的参数、指针类型
三、整型在内存中的存储
1、原码、反码、补码
1.1 概念
计算机中的整数有三种2进制表示方法,即原码、反码和补码。
- 三种表示方法均有符号位和数值位两部分,符号位都是用
0表示“正”,用1表示“负”,而数值位正数的原、反、补码都相同,负整数的三种表示方法各不相同
int a = 10;
- 对于正数说,因为原、反、补都是相同的~~
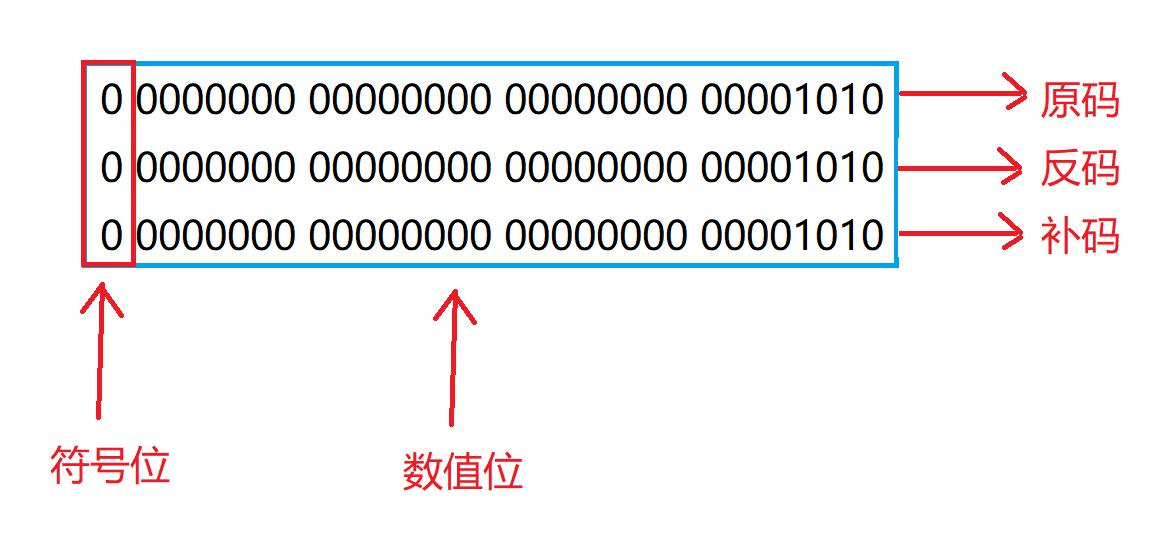
int a = -10;
- 对于负数来说就不太一样了,要得到反码就将原码除符号位外其余各位取反,要得到补码的话就在反码的基础上 + 1

1.2 原码与补码的转换形式
- 原码到补码 —— 1种方式
- 原码取反,+1得到补码
- 补码到原码 —— 2种方式
- 补码 - 1,取反得到原码
- 补码取反,+1得到原码

1.3 计算机内部的存储编码
- 对于整形来说:数据存放内存中存放的是补码。
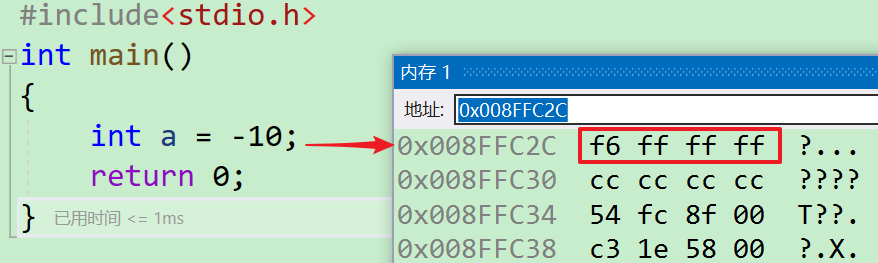
- 这里存储的是16进制类型的补码~~
- 在【进制转换】中,4位二进制表示1位16进制。通过将补码4位4位进行一个划分就可以得出8个16进制的数字为
ff ff ff f6,这里发现是倒着存的,那么就要涉及到大小端存储的~~
2、大小端介绍~~
2.1 为什么要有大端和小端之分?
在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit
- 但是在C语言中除了8 bit的char之外,还有16 bit的short 型,32 bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32 位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因 此就导致了大端存储模式和小端存储模式。
- 例如:一个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为 高字节, 0x22 为低字节。对于大端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在高 地址中,即 0x0011 中。小端模式,刚好相反。我们常用的 X86 结构是小端模式,而 KEIL C51 则 为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式 还是小端模式。大端】和【小端】的由来,接下去呢就正式地来给读者介绍一下这种倒着存放的方式
2.2 大(小)端字节序存储
- 【大端(存储)模式】:是指数据的
低位保存在内存的高地址中,而数据的高位,保存在内存的低地址中; - 【小端(存储)模式】:是指数据的
低位保存在内存的低地址中,而数据的高位,,保存在内存的高地址中;
- 对于下面这一个十六进制数
0x11223344,以进制的权重来看的话右边的权重低【0】,左边的权重高【3】,所以11为高位,44为低位。若是对其进行小端字节存储的话就要将44存放到低位,11存放到高位
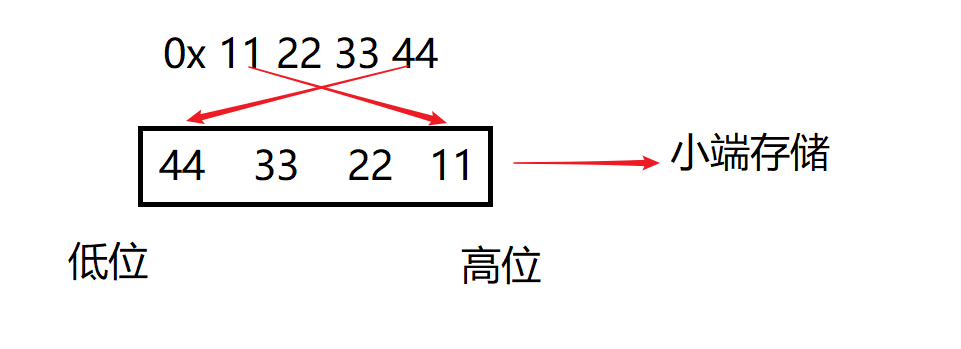
- 【大端字节序存储】是要将高位存放到低地址,低位存放到高地址,因此11要放在左边,44要放在右边
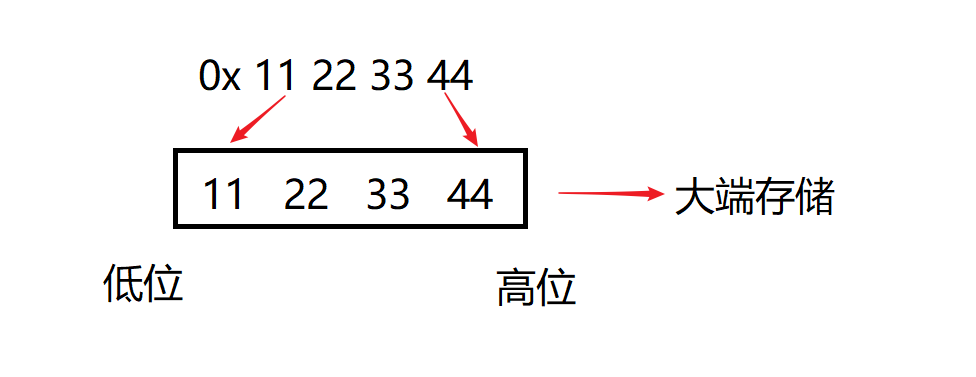
2.3 一道百度系统工程师笔试题
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(10分)
- 下面我通过一个简单的数作为案例来进行一个分析
int a = 1;
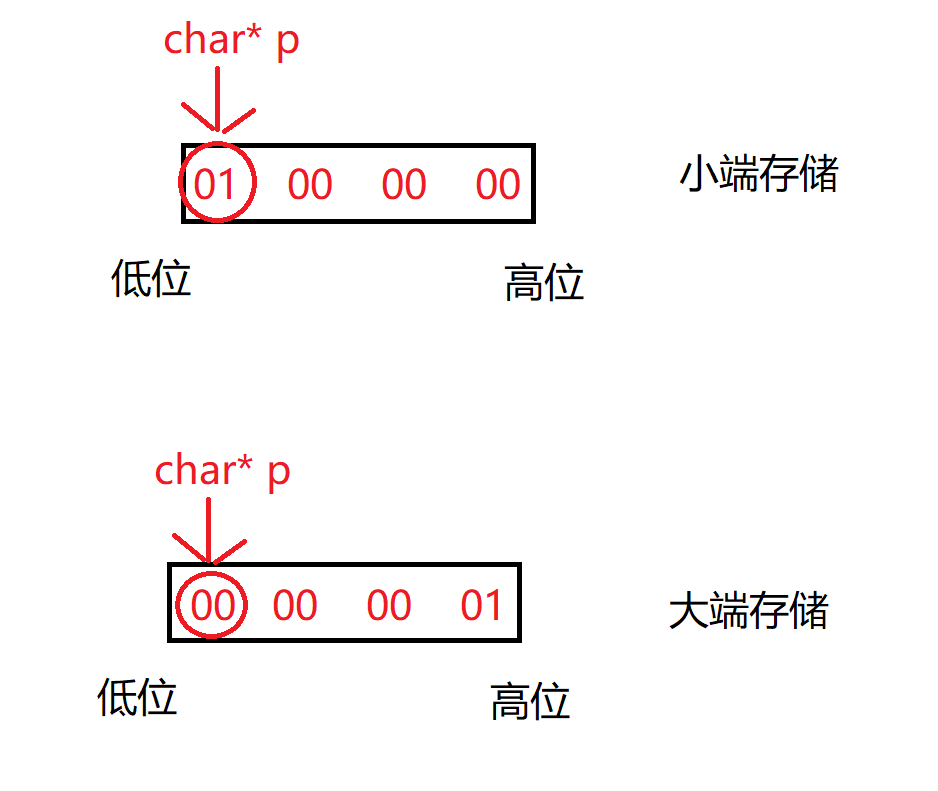
- 对于a以【小端字节序存储】会将
01放在低位;而以【大端字节序存储】会将01放在高位,那么此时我们只需要获取到内存中规定最低位即可 - 因为
01在内存中表示一个字节,而一个【char】类型的数据就为1个字节,所以此时我们可以使用到一个字符型指针接受要存放到内存中的这个数,然后对其进行一个解引用,就可以获取到低位的第一个字节了
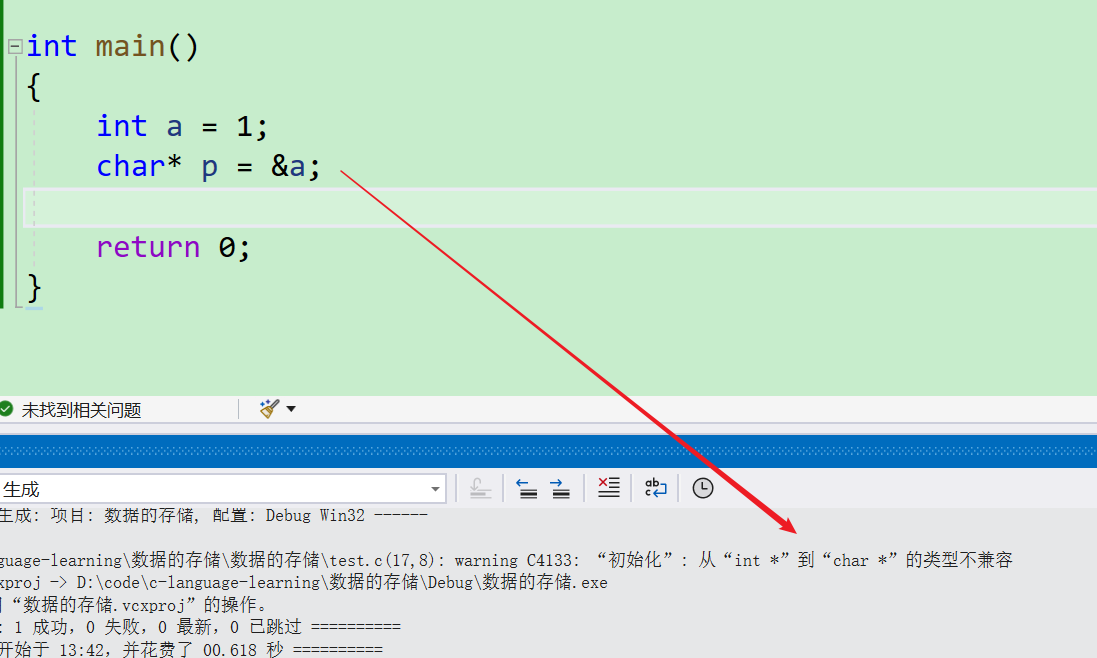
char* p = &a;
- 若直接使用一个字符型指针去接收一个整型数值的地址,就会出现问题,因为一个字符型的指针只能放得下一个字节的数据,所以我们要对这个整型的数值去进行一个强制类型转换为字符型的地址
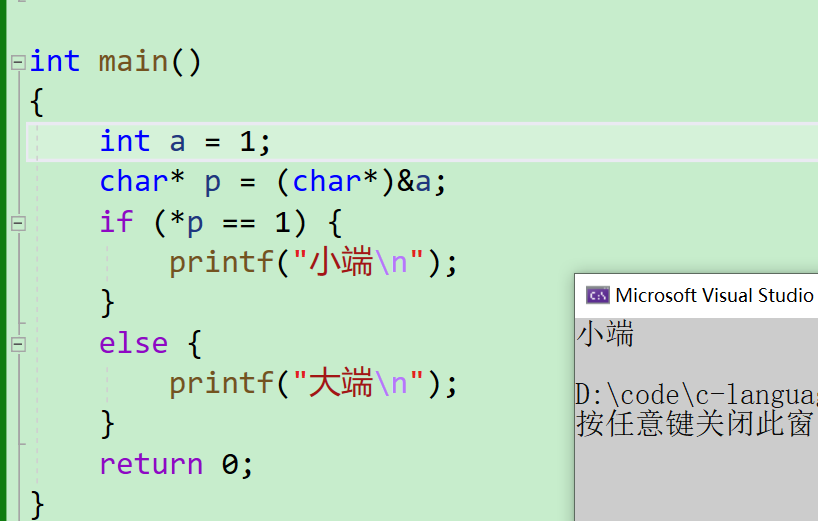
- 通过强制类型转换后,再对这个字符型指针进行解引用,就可以取到一个字节的数据,继而对其进行一个判断,如果为
1的话那就是【小端】,反之则是【大端】
char* p = (char *)&a;
if (*p == 1){printf("小端\n");
}
else {printf("大端\n");
}
- 通过学习了函数章节,我们可以对其进行一个分装~~
int check_sys(int num)
{char* p = (char*)#if (*p == 1) {return 1;}else {return 0;}
}
int ret = check_sys(1);
- 或者,对于这个if判断我们可以就直接写成解引用的形式,然后对其去进行一个判断
if (*(char*)&num == 1)
- 那既然是我们要return 1或者0的时候,其实在解引用获取到低地址的第一个字节时直接return即可~~
int check_sys(int num){return *(char*)#
}
3、数据范围的介绍
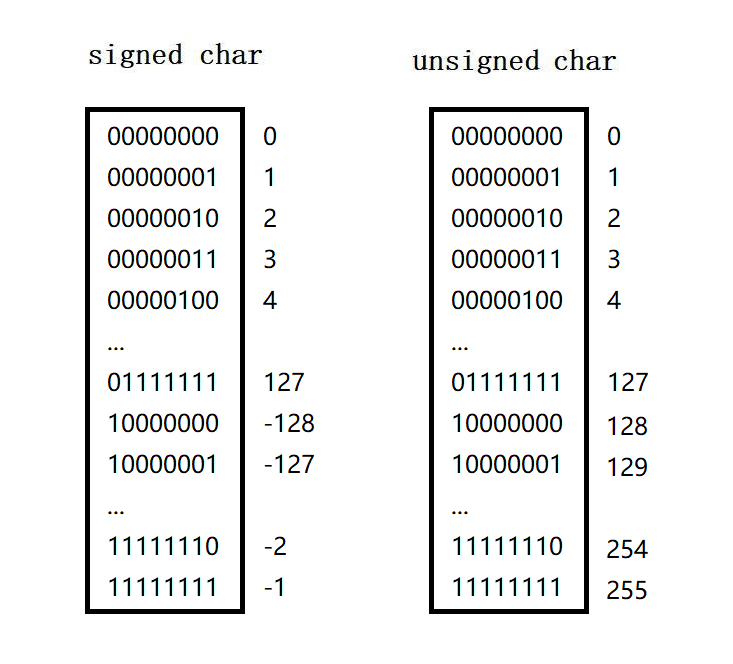
3.1 char与signed char数据范围
-
首先我们通过下面这幅图来看一看对于有符号的
char和无符号的char在内存中所能表示的范围各自是多少:
- 【signed char】:
-128 ~ 127 - 【unsigned char】:
0 ~ 255
- 【signed char】:
-
char数据类型在内存中占1个字节,也就是8个比特位。若是从
00000000开始存放,每次+1上去然后逢二进一,之后你就可以得出最大能表示的正整数为【127】,可是在继续+1后又会进行进位然后变为10000000,符号位为1,这是-128这是为什么呢?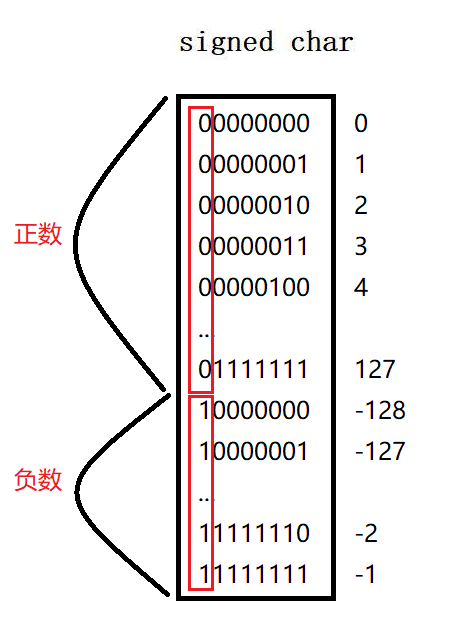
-
在内存中都是以【补码】的形式进行存放,所以我们看到的
1 1111111只不过是补码的形式 -
但是对于
10000000我们直接将其记作【-128】,它就对应的【-128】在内存中的补码,通过去写出【-128】的原、反、补码可以发现是需要9个比特位来进行存放,对于char类型的数值而言只能存放8个比特位,因此在转换为补码之后会进行一个截断 -
最后剩下的就是
10000000,即为有符号char的最小负数为【-128】
3.2 unsigned char数据范围
- 因为是无符号char,所以第一位不作为符号位,就是从
0 ~ 255
4、笔试题
- 有符号的数在整型提升的时候补符号位,无符号的数在整型提升的时候补0
%u是打印无符号整型,认为内存中存放的补码对应的是一个无符号数%d是打印有符号整型,认为内存中存放的补码对应的是一个有符号数
第一道
#include <stdio.h>
int main()
{char a = -1;signed char b = -1;unsigned char c = -1;printf("a = %d, b = %d, c = %d", a, b, c);return 0;
}
- 我们来分析一下,可以看到【a】和【b】都是有符号位的char类型,那它们就是一样的,现在将
-1存放到这两个数据中去,首先你应该要考虑到的是一个数据放到内存中去是以补码的形式 - 所以我们首先将
-1转换为补码的形式
1 0000000 00000000 00000000 00000001
1 1111111 11111111 11111111 11111110
1 1111111 11111111 11111111 11111111
- 可是呢,需要存放的地方又是char类型的变量,只能存放8个字节,无法放得下这32个字节,因此便需要进行一个截断的操作,放到变量a和变量b中都只剩下
11111111这8个字节。 - 对于变量c来说,它是一个无符号的char类型变量,不过
-1存放到它里面还是11111111这8个字节不会改变,只不过在内存中的变化与有符号char不太一样~~
printf("a = %d, b = %d, c = %d", a, b, c);
- 以
%d的形式进行一个打印,但是呢三个变量所存放的都是char类型的变量,因此会进行一个整型提升,只是有符号数的整型提升和无符号数不太一样
//a b - 有符号数
11111111111111111111111111111111 - 补符号位//c - 无符号数
00000000000000000000000011111111 - 补0
- 在进行整型提升之后,这些二进制数据还是存放在内存中的,可是要输出打印在屏幕上的话还要转换为【原码】的形式
11111111111111111111111111111111
10000000000000000000000000000000
10000000000000000000000000000001 ——> 【-1】00000000000000000000000011111111 ——> 【255】
第二道
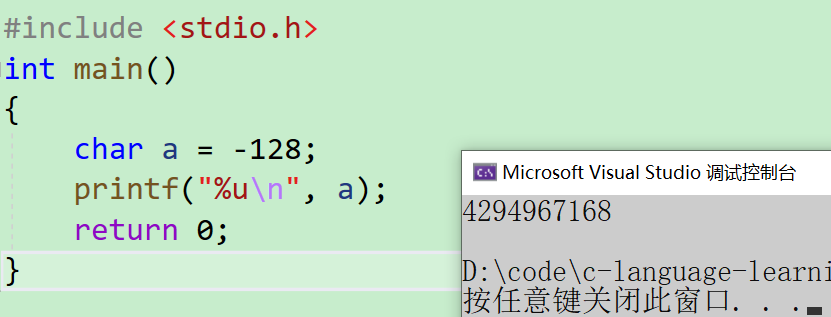
#include <stdio.h>
int main()
{char a = -128;printf("%u\n",a);return 0;
}
- 同理,一个整数存放到内存中,首先要将其转换为【补码】的方式
10000000 00000000 00000000 10000000
11111111 11111111 11111111 01111111
11111111 11111111 11111111 10000000
- 接着因为这32个二进制位要存放到一个
char类型的变量中,因为进行截断为10000000 - 然后在内存中需要进行一个整型提升,
char类型的变量将会填充符号位11111111111111111111111110000000 - 执行打印语句,可以看到这里是以
%u的形式进行打印,认为在内存中存放的是一个无符号整数。我们知道,对于无符号整数来说,不存在负数,所以其原、反、补码都是一样的,因此在打印的时候就直接将其转换为十进制进行输出
printf("%u\n",a);
输出:
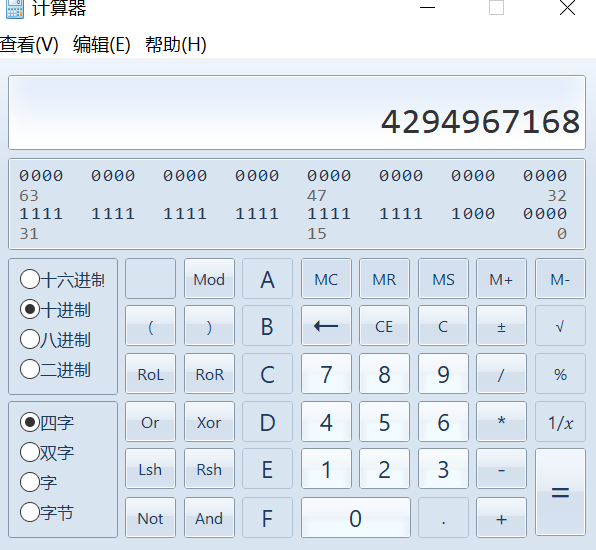
- 不信的话还可以使用计算器来算一下
第三道
#include <stdio.h>
int main()
{char a = 128;printf("%u\n",a);return 0;
}
- 接下去我们来看第三道题,可以看出和上面那题基本基本一样,只是把
-128变成了128而已 - 如果是【128】的话放到内存中就不需要像负数那样还要进行很多的转化了,因为正数的原、反、补码都一致,当我们内存中真正存的是
10000000又因为是%u的形式打印,然后需要整形提升
00000000 00000000 00000000 10000000
- 然后我们可以看到时
10000000符号位是1,所以整形提升的时候补1
11111111 11111111 11111111 10000000
- 所以还是和上题一样,这里就不多赘述~~
第四道
int main()
{int i = -20;unsigned int j = 10;printf("%d\n", i + j);return 0;
}
下面是解法:
int main()
{int i = -20;//1 0000000 00000000 00000000 00010100//1 1111111 11111111 11111111 11101011//1 1111111 11111111 11111111 11101100unsigned int j = 10;//0 0000000 00000000 00000000 00001010printf("%d\n", i + j);//1 1111111 11111111 11111111 11101100//0 0000000 00000000 00000000 00001010//------------------------------------------//1 1111111 11111111 11111111 11110110//1 1111111 11111111 11111111 11110110//1 0000000 00000000 00000000 00001001//1 0000000 00000000 00000000 00001010 —— 【-10】//按照补码的形式进行运算,最后格式化成为有符号整数return 0;
}
- 本次我们用到的是两个
int类型的数据,一个是有符号的,一个是无符号的。但无论是有符号还是无符号,放到内存中都是要转换为补码的形式 - 就是对算出来的两个补码一个二进制数的相加运算,注意这里是将整数存放到
int类型的变量中去,所以不需要进行【截断】和【整型提升】
1 1111111 11111111 11111111 111011000 0000000 00000000 00000000 00001010
------------------------------------------1 1111111 11111111 11111111 11110110
- 在运算之后要以
%d的形式进行打印输出,那就会将内部中存放的补码看做是一个有符号数,既然是有符号数的话就存正负,可以很明显地看到最前面的一个数字是1,所以是负数,要转换为原码的形式进行输出
1 1111111 11111111 11111111 11110110
1 0000000 00000000 00000000 00001001
1 0000000 00000000 00000000 00001010 —— 【-10】

第五道
- 接下去第五道,是一个for循环的打印
int main()
{unsigned int i;for (i = 9; i >= 0; i--){printf("%u\n", i);}return 0;
}
运行结果:>死循环
-
有同学就很诧异为什么会陷入死循环呢?这不是就是一个正常的打印过程吗?
-
其实,问题就出在这个
unsigned,把它去掉之后就可以正常打印了 -
回忆一下我们在将无符号整数的时它的数据范围是多少呢
- 对于
char类型来说是0 ~ 255; - 对于
short来说是0 ~ 65536; - 对于
int类型来说是0 ~ 16,777,215;
- 对于
-
对比进行观察其实可以发现它们的数值范围都是 > 0的,所以对于无符号整数来说就不会存在负数的情况。因此这个for循环的条件【i >= 0】其实是恒成立的,若是当
i == 0再去--,此时就会变成【-1】 -
对于【-1】我们有看过它在内存中的补码形式为
11...11是全部都是1,而此时这这个变量i又是个无符号的整型,所以不存在符号位这一说,那么在计算机看来它就是一个很大的无符号整数。此时当i以这个数值再次进入循环的时候,继续进行打印,然后执行--i,最后知道其为0的时候又变成了-1,然后继续进入循环。。。
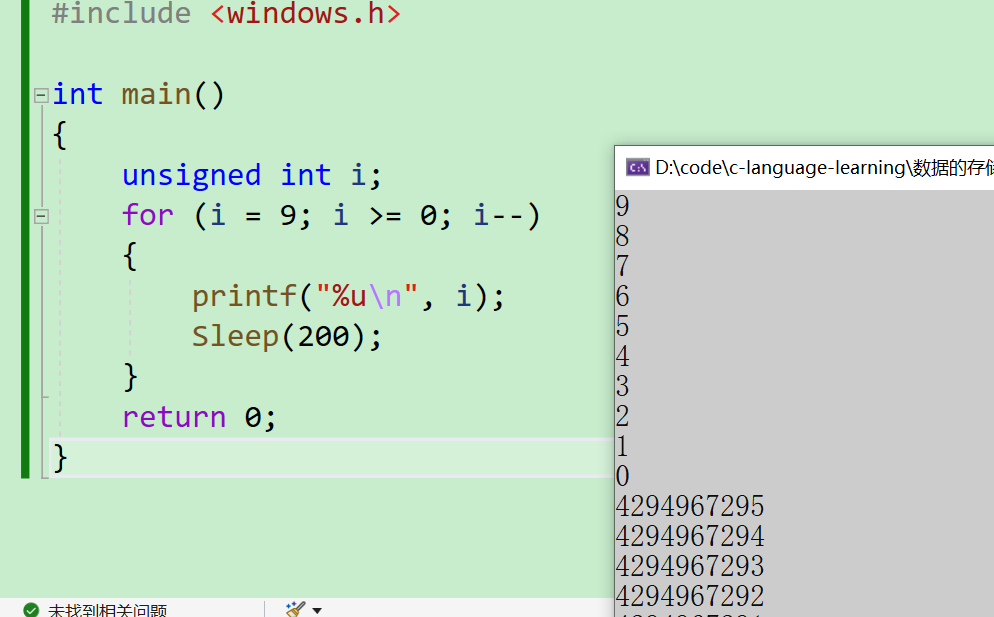
光是这么说说太抽象了,我们可以通过Sleep()函数在打印完每个数之后停一会,来观察一下
#include <windows.h>int main()
{unsigned int i;for (i = 9; i >= 0; i--){printf("%u\n", i);Sleep(200);}return 0;
}
- 接着你便可以发现,当
i循环到0的时候,突然就变成了一个很大的数字,这也就是印证了我上面的说法
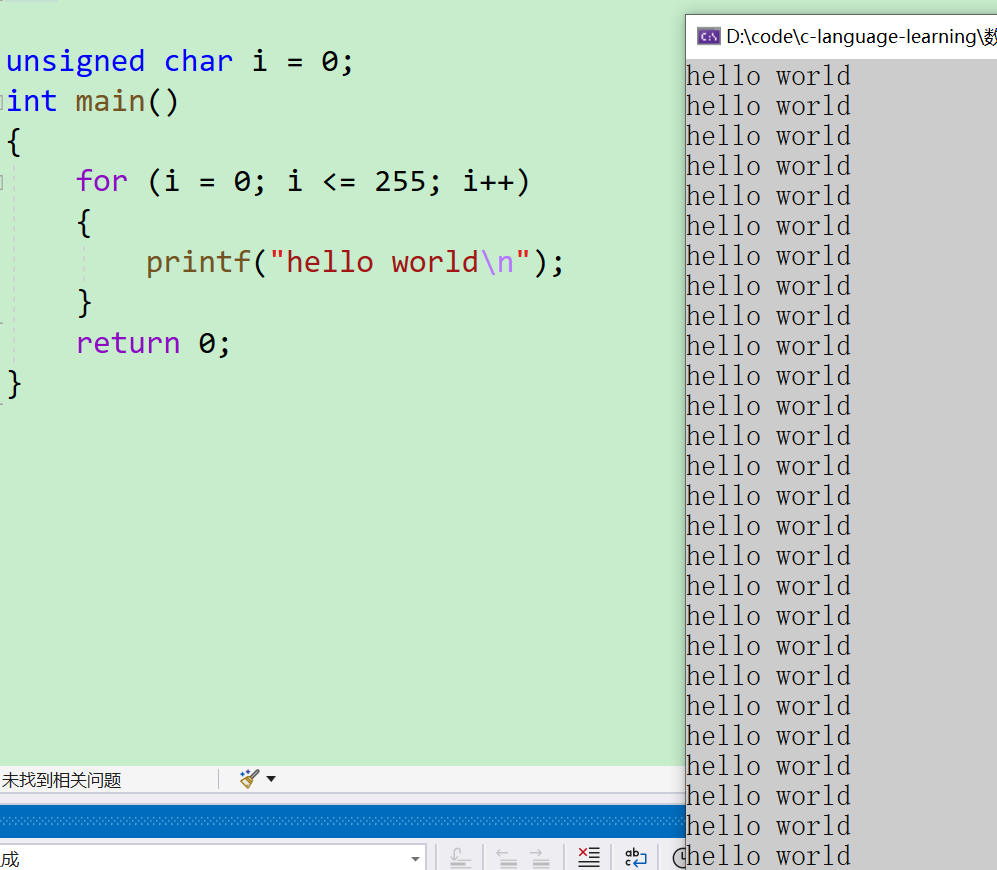
第六道
- 本题和四五道的原理是一样的,对于
unsigned char来说,最大的整数范围不能超过255,所以当这里的【i】加到255之后又会再+1就会变成00000000,此时又会进入循环从0开始,也就造成了死循环的结果
unsigned char i = 0;
int main()
{for (i = 0; i <= 255; i++){printf("hello world\n");}return 0;
}
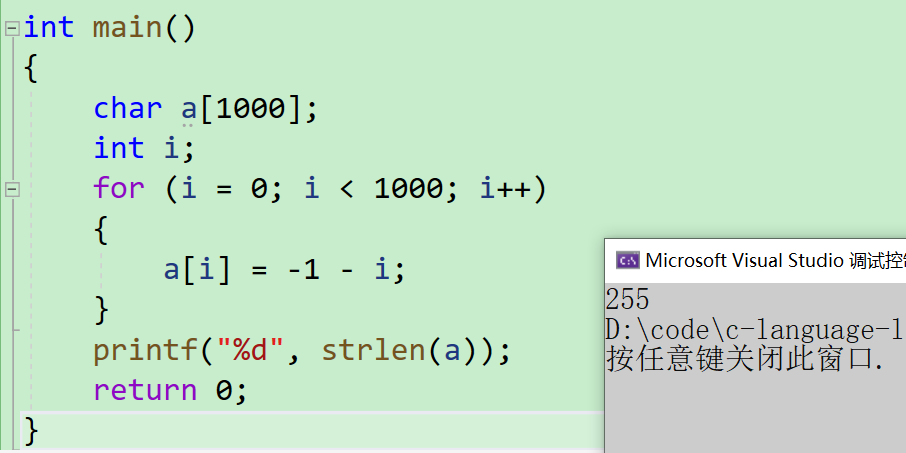
第七道
- 最后一道,我们来做做综合一些的,涉及到字符串函数strlen
int main()
{char a[1000];int i;for (i = 0; i < 1000; i++){a[i] = -1 - i;}printf("%d", strlen(a));return 0;
}
- 首先来看函数主体,也是一个for循环,在开头定义了一个char类型的数组,大小为1000,。在循环内部呢对它们进行一个初始化,那最后里面的数字一定是
-1 -2 -3 -4 -5 -6 -7 ...
-
但是呢,我们在上面学习过的有符号
signed char,它和char是一样的,数据的范围在【-128 ~ 127】,所以当i加到128的时候,这个位置上的值变为【-129】,此时在计算机内部会将它识别成【127】,同理【-130】会被识别成为【126】。。。依次类推,最后当这个值为【0】的时候若再去减就会变成【-1】,然后又变成【-2】【-3】【-4】。。。一直当这个i累加到1001的时候截止 -
我们要通过
strlen()去求这个数字的长度,对于strlen()来说,求的长度是到\0截止,那也就是上面的【0】,不需要去关心后面的第二、三轮回 -
那其实这也就转变成了让我们去求有符号char在内存中可以存储多少个。这很简单,范围是
-128 ~ +127,二者的绝对值一加便知为255
//-1 -2 -3 -4 -5 -6 -7 ...-128 127 126 ... 0 -1 -2 -3....
printf("%d", strlen(a));
- 来看一下运行结果~~
四、浮点型在内存中的存储
-
在第二模块,我有提到过一个叫做【浮点数家族】,里面包含了
[float]和[double]类型,对于浮点数其实我们不陌生,在上小学的时候就有接触到的3.14圆周率,还有以科学计数法表示的1E10 -
在计算机中整型类型的取值范围限定在:
limits.h;浮点型类型的取值范围限定在:float.h -
我们可以在【everything】中找找有关
float.h这个头文件
1、引入
- 首先要了解浮点数在内存中的存储规则,我们要通过一个案例来进行引入。请问下面四个输出语句分别会打印什么内容?
int main()
{int n = 9;float* pFloat = (float*)&n;printf("n的值为:%d\n", n); //1printf("*pFloat的值为:%f\n", *pFloat); //2*pFloat = 9.0;printf("num的值为:%d\n", n); //3printf("*pFloat的值为:%f\n", *pFloat); //4return 0;
}
- 来简单分析一下,整型变量n里面存放了9,然后通过强制类型转换为浮点型的指针,存放到pFloat中。
- 首先第一个去打印n的值毫无疑问就是
9 - 第二个对pFloat进行解引用访问,对于
float类型的指针与int一样都可以访问四个字节的地址,所以解引用便访问到了n中的内容,又因为浮点数小数点后仅6位有效,因此打印出来应该是9.000000 - 接下去通过pFloat的解引用修改了n的值,不过第三个以
%d的形式进行打印,应该也还是9 - 第四个的话也是以浮点数的形式进行打印,那应该也是
9.000000
- 首先第一个去打印n的值毫无疑问就是
- 可结果真的和我们想象的一样吗?让我们来看一下~~

- 可以看到,我们猜测推理的4个里面对了两个,中间的两个出了问题,而且还是两个很古怪的数字,对于
n和*pFloat在内存中明明是同一个数,为什么浮点数和整数的解读结果会差别这么大?
这要涉及到浮点数在内存中【存】与【取】规则,接下去我们首先来了解一下这个规则~~
2、浮点数存储规则
2.1 概念
- 根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式:
V = (-1)^S * M * 2^E
(-1)^S表示符号位,占一位。当S = 0,V为正数;当S = 1,V为负数- M【尾数】表示有效数字,放在最低部分,占用23位(1 <= M < 2)
- 2^E表示指数位。
E为指数,占用8位【阶符采用隐含方式,即采用移码方法来表示正负指数】
- v = 5.5
- 整数部分的5可以写成
101,这毋庸置疑,但是这个小数部分的5要如何去进行转换呢?对于0.5来说我们刚才看了小数部分的权重之后知道是2-1,所以直接使这一位为1即可 - 接着我们就要去求出S、M和E,对于M来说是>= 1并且< 2的,不过这里的
101.1却远远大于1,所以我们可以通过在操作符中学习的【移位】操作将这个数进行左移两位,但是左移之后又要保持与原来的数相同,所以可以再乘上22*使得与原来的二进制相同。接着根据公式就可以写出*(-1)0 * 1.011 * 22这个式子,然后可以得出S、M、E为多少了
- 整数部分的5可以写成
- v = -5.5
- 这个和上面的一样,就是前面加了一个负号,那只是符号位进行了修改的话我们只需要变动S就可以了,即
S == 1
- 这个和上面的一样,就是前面加了一个负号,那只是符号位进行了修改的话我们只需要变动S就可以了,即
- v = 9.5
- 如果知道了第一题如何计算的话这题也是同样的道理,只是整数部分发生了一个变化而已
- 可并不是所有数的小数位都是
0.5,如果是0.25的话你可以将【2-2】置为1,依次类推。。。可以对于下面这个3.3里面的0.3你会如何去凑数呢,首先0.5肯定不能,那只能有0.25,但若是再加上0.125的话那就多出来了,那应该配几呢? - 其实你将后面的数一个个地去列出来就可以发现是没有数字可以配成
0.3的。所以我们可以得出这个数字其实是无法在内存中进行保存。这也是为什么浮点数在内存中容易发生精度丢失的原因
进一步探索指数E与尾数M的特性:
IEEE 754标准规定:
- 对于
32位的浮点数【float】,最高的1位是符号位S,接着的8位是指数E,剩下的23位为有效数字M

- 对于
64位的浮点数【double】,最高的1位是符号位S,接着的11位是指数E,剩下的52位为有效数字M
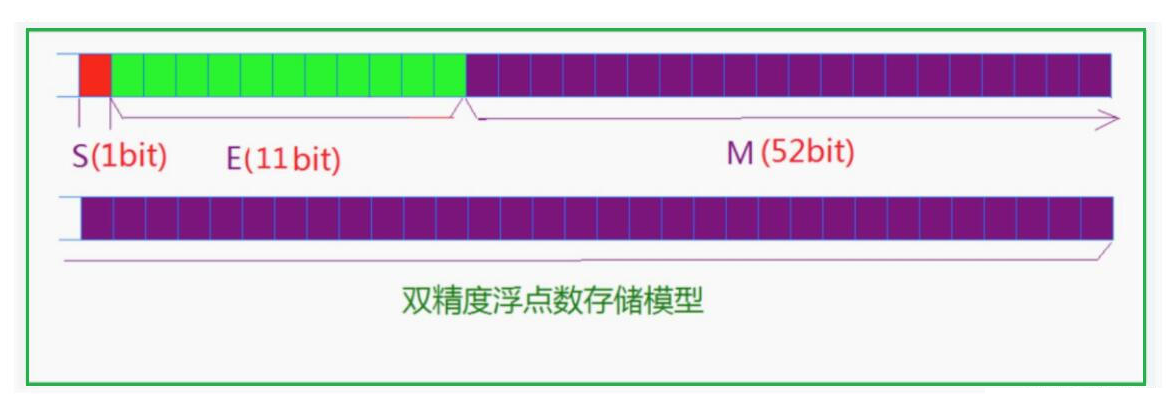
IEEE 754对有效数字M和指数E,还有一些特别规定:
首先是对于有效数字(尾数)M
- 前面说过
1 ≤ M < 2,也就是说,M可以写成1.xxxxxx的形式,其中xxxxxx表示小数部分 - IEEE 754规定,在计算机内部保存M时,默认这个数的第一位总是
1,因此可以被舍去,只保存后面的xxxxxx部分。比如保存1.01的时候,只保存01,等到读取的时候,再把第一位的1加上去。这样做的目的,是节省1位有效数字。 - 以32位浮点数为例,留给M只有
22位,但若是将第一位的1舍去以后,等于可以保存23位有效数字,精度相当于又高了一位
至于指数E,情况就比较复杂
-
首先,E为一个无符号整数(
unsigned int) -
那对于无符号整数来说,我们在上面有介绍过,如果E为8位,它的取值范围为
[0 - 255];如果E为11位,它的取值范围为[0 - 2047] -
但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存入内存时E的真实值必须再加上一个中间数,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023
-
简单一点,还是上面讲到过的
5.5,注意如果定义成【float】类型的变量的话要在后面加上一个f作为和【double】类型的区分
float f = 5.5f;
- 然后我们对
5.5这个数字去进行分析它存入到内存中的样子。通过上面算出来的
S = 0, M = 1.011, E = 2
去写出这32位浮点数存放到内存中是一个怎样的形式
-
对于符号数S来说就是把0存进去,占一位
-
对于指数E来说为2,32位浮点数要加上一个中间值127,所以要存入的十进制数为129,再将其转换为8位二进制即为
10000001 -
对于尾数M来说,需要舍去整数位1,然后将【小数部分】的
011这三位放到内存中,但是规定了M为23位,此时我们只需要在后面补上20个0即可 -
然后便可以对这个32个比特位进行划分,8位一个字节,得出
40 b0 00 00 -
还有一点莫要忘了!还记得我们上面讲到的【大小端】存放吗?要存放到内存中的最后一步就是将其进行小端存放【这是我的机器】,即为
00 00 b0 40
如何将浮点数从内存中【读取】出来呢?
指数E从内存中取出还可以再分成三种情况:
1. E不全为0或不全为1
- 对于这种情况就是最普通的,若是E存放在内存中的8位二进制数不全为0或者不全为1的话,那么直接按照上面说到过多一些M与E【写入内存】的规则进行一个逆推即可
- 以32位浮点数为例,因为我们在计算指数E的时候加上了一个
127,那么此时减去127即可;在计算尾数M的时候舍去了整数部分的1,那次此时再补上这个1即可
2. E全为0
- 对于E全0的这种情况很特殊,也就是意味着8位二进制全为0即
00000000,这个情况是在指数E加上127之后的结果,那么原先最初的指数是多少呢?那也只能是-127了。那如果这个指数是-127的话也就相当于是【1.xxxx * 2-127】,是一个非常小的数字,几乎是和0没有什么差别 - 这时,浮点数的指数E等于1-127(或者1-1023)即为真实值;对于尾数M不再加上第一位的1,而是还原为0.xxxxxx的小数。这样做是为了表示
±0,以及接近于0的很小的数字
3. E全为1
- 最后一种就是当E全为1的时候即
11111111,这个情况也是在指数E加上127之后的结果,那么原先最初的指数是多少呢?那便能是128了,那也只能是-127了。那如果这个指数是-127的话也就相当于是【1.xxxx * 2128】,是一个非常大的数字 - 这时,如果尾数M全为0,表示±无穷大(正负取决于符号位s);
以上就是有关浮点数如何【写入】内存和从内存中【读取】的所有相关知识
3、开局疑难解答
int main()
{int n = 9;float* pFloat = (float*)&n;printf("n的值为:%d\n", n); //1printf("*pFloat的值为:%f\n", *pFloat); //2*pFloat = 9.0;printf("num的值为:%d\n", n); //3printf("*pFloat的值为:%f\n", *pFloat); //4return 0;
}
- 首先写出【n = 9】在内存中的补码
0 0000000 00000000 00000000 00001001。然后是将这个n的地址存放到了一个浮点型的指针中去
int n = 9;
float* pFloat = (float*)&n;
- 那么此时进行一个打印,以
%d的形式打印n不用考虑就是9;但是后一个就不一样了,对浮点型的指针进行解引用,那也就是要将存放在内存中的浮点数进行读取出来
printf("n的值为:%d\n", n);
printf("*pFloat的值为:%f\n", *pFloat);
- 那编译器此时就会站在浮点数的角度去看待这个
00000000000000000000000000001001,将第一位看做是符号位0,即S == 0,然后接下去就是8个比特位E,不过可以发现这个E是全0呀00000000,就是我们上面所讲到的这种特殊情况 - 那此时后面的尾数M就不可以添上前面的整数部分1了,而是应该写成
0.xxxxxx的形式即0.000000000000000000001001。那对于指数E应该等于1-127为【-126】。所以最后写出来v的形式为
(-1)^0 * 0.000000000000000000001001 * 2^ (-126)
- 此时我们再去计算这个值打印的结果是多少,其实完全不需要计算,仔细观察就可以发现S为1,M为一个很小的数,若E再去乘上这个很小的数那只会更小,然后无限接近0,。那最后根据这个浮点数小数点后6位有效,便可以看出最终的结果为
0.000000
- 然后我们再来看下面的。此时pFloat进行解引用,然后将
9.0存放到n这块地址中去,那也就相当于是我们最先学习了如何将一个浮点数存放到内存中去
*pFloat = 9.0;
- 那我们可以很快将其转换为二进制的形式
1001.0,然后通过v的公式得出(-1)^0 * 1.001 * 2^3 - 此时再去将其转换为IEEE 754标准规定的32位浮点数。首先看到指数E为3,加上127之后为130,那么二进制形式即为
10000010,尾数M也是同理,舍去1后看到001,后面添上20个0补齐23个尾数位。最后的结果即为
——> 0 10000010 00100000000000000000000
- 然后去执行打印语句,那我们以浮点数的形式放进去,但是以
%d的形式打印n,那么这一串二进制就会被编译器看做是补码,既然是打印就得是原码的形式,不过看到这个符号位为0,那我们也不需要去做一个转换,它就是原码
printf("num的值为:%d\n", n);
- 那么最后机器就会将二进制形式的原码转换为十进制的形式然后打印。一样,我们可以将它放到【程序员】计计算器进行运行,然后找到十进制的形式,便是最后打印输出在屏幕上的结果
01000001000100000000000000000000 —— 1,091,567,616
好了,本文到这里就结束了,感谢大家的收看🌹🌹🌹
相关文章:
C语言之数据在计算机内部的存储
文章目录 一、前言二、类型的基本归类1、整型家族2、浮点数家族3、构造类型4、指针类型 三、整型在内存中的存储1、原码、反码、补码1.1 概念1.2 原码与补码的转换形式1.3 计算机内部的存储编码 2、大小端介绍~~2.1 为什么要有大端和小端之分?2.2 大(小&…...
程序人生——Java中基本类型使用建议
目录 引出Java中基本类型使用建议建议21:用偶判断,不用奇判断建议22:用整数类型处理货币建议23:不要让类型默默转换建议24:边界、边界、还是边界建议25:不要让四舍五入亏了一方 建议26:提防包装…...

Pikachu 靶场搭建
文章目录 环境说明1 Pikachu 简介2 Pikachu 安装 环境说明 操作系统:Windows 10PHPStudy 版本: 8.1.1.3Apache 版本:2.4.39MySQL 版本 5.7.26 1 Pikachu 简介 Pikachu是一个使用“PHP MySQL” 开发、包含常见的Web安全漏洞、适合Web渗透测试学习人员练…...

机器学习-绪论
机器学习致力于研究如何通过计算的手段、利用经验来改善系统自身的性能。在计算机系统中,“经验”通常以“数据”的形式存在,因此,机器学习所研究的主要内容,是关于在计算机上从数据中产生“模型”的算法,即“学习算法…...
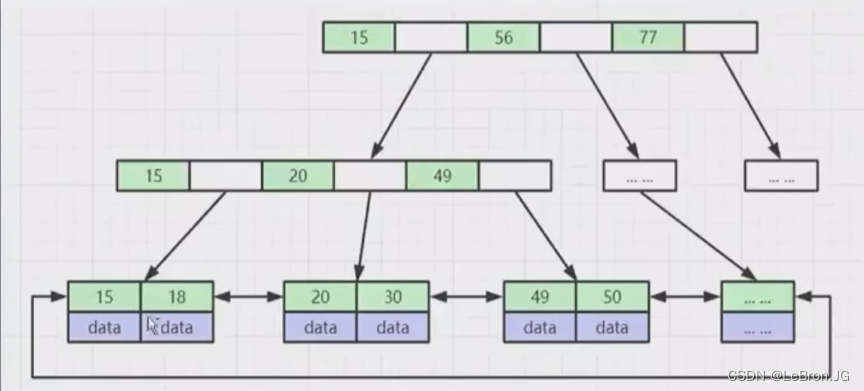
mysql 索引(为什么选择B+ Tree?)
索引实现原理 索引:排好序的数据结构 优点:降低I/O成本,CPU的资源消耗(数据持久化在磁盘中,每次查询都得与磁盘交互) 缺点:更新表效率变慢,(更新表数据,还要…...

蓝桥杯-带分数
法一 /* 再每一个a里去找c,他们共用一个st数组,可以解决重复出现数字 通过ac确定b,b不能出现<0 b出现的数不能和ac重复*/import java.util.Scanner;public class Main {static int n,res;static boolean[] st new boolean[15];static boolean[] backup new boolean[15];…...
消息队列面试题
目录 1. 为什么使用消息队列 2. 消息队列的缺点 3. 消息队列如何选型? 4. 如何保证消息队列是高可用的 5. 如何保证消息不被重复消费(见第二条) 6. 如何保证消息的可靠性传输? 7. 如何保证消息的顺序性(即消息幂…...

Android和IOS应用开发-Flutter 应用中实现记录和使用全局状态的几种方法
文章目录 在Flutter中记录和使用全局状态使用 Provider步骤1步骤2步骤3 使用 BLoC步骤1步骤2步骤3 使用 GetX:步骤1步骤2步骤3 在Flutter中记录和使用全局状态 在 Flutter 应用中,您可以使用以下几种方法来实现记录和使用全局状态,并在整个应…...

若依 ruoyi-cloud [网关异常处理]请求路径:/system/user/getInfo,异常信息:404
这里遇到的情况是因为nacos中的配置文件与项目启动时的编码不一样,若配置文件中有中文注释,那么用idea启动项目的时候,在参数中加上 -Dfile.encodingutf-8 ,保持编码一致,(用中文注释的配置文件,…...
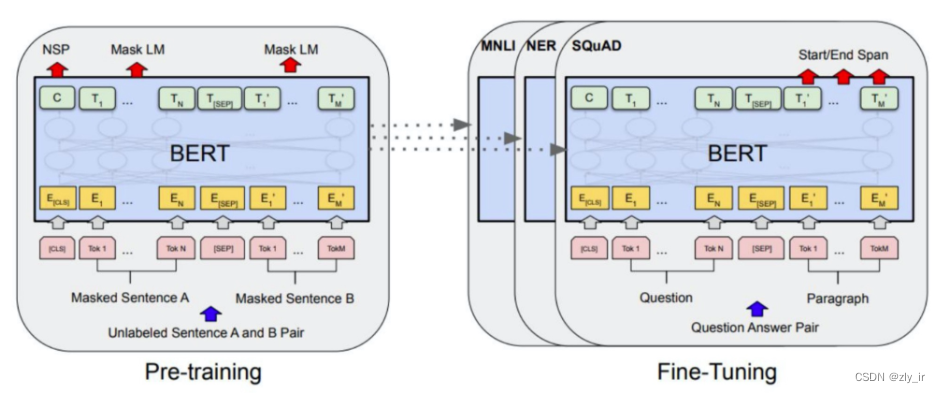
自然语言处理里预训练模型——BERT
BERT,全称Bidirectional Encoder Representation from Transformers,是google在2018年提出的一个预训练语言模型,它的推出,一举刷新了当年多项NLP任务值的新高。前期我在零、自然语言处理开篇-CSDN博客 的符号向量化一文中简单介绍…...

2024年信息技术与计算机工程国际学术会议(ICITCEI 2024)
2024年信息技术与计算机工程国际学术会议(ICITCEI 2024) 2024 International Conference on Information Technology and Computer Engineering ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 大会主题: 信息系统和技术…...

渗透测试修复笔记 - 02 Docker Remote API漏洞
需要保持 Docker 服务运行并且不希望影响其他使用 Docker 部署的服务,同时需要禁止外网访问特定的 Docker API 端口(2375):通过一下命令来看漏洞 docker -H tcp://ip地址:2375 images修改Docker配置以限制访问 修改daemon.json配…...
)
Spring(创建对象的方式3个)
3、Spring IOC创建对象方式一: 01、使用无参构造方法 //id:唯一标识 class:当前创建的对象的全局限定名 <bean id"us1" class"com.msb.pojo.User"/> 02、使用有参构造 <bean id"us2&…...
【GPT-SOVITS-02】GPT模块解析
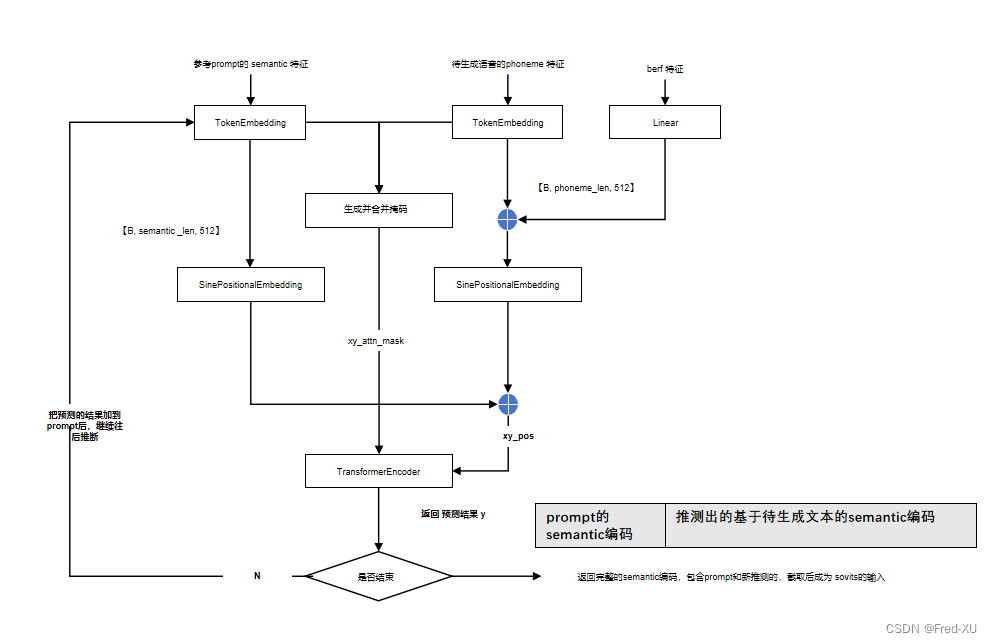
说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。 知乎专栏地址: 语音生成专栏 系列文章地址: 【GPT-SOVITS-01】源码梳理 【GPT-SOVITS-02】GPT模块解析 【GPT-SOVITS-03】SOVITS 模块-生成模型解析 【G…...
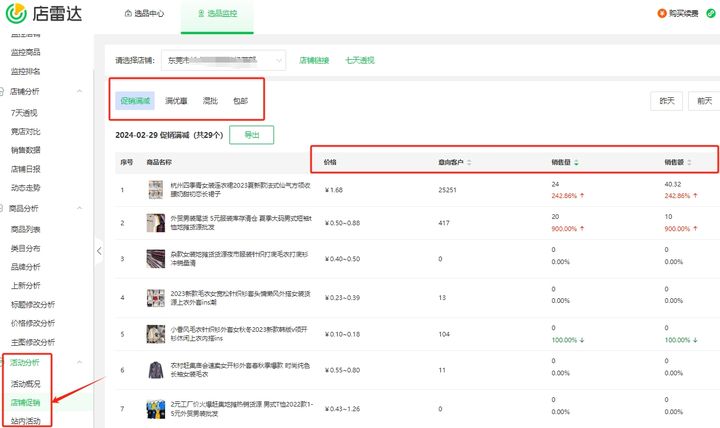
6个选品建议,改善你的亚马逊现状。
一、市场热点与需求调研 深入研究当前市场趋势,了解消费者需求的变化。使用亚马逊的销售数据、评价、问答等功能,以及第三方市场研究工具,比如店雷达,分析潜在热销产品的特点。注意季节性需求,提前布局相关选品&#…...

SQL中的SYSDATE函数
前言 在SQL语言中,SYSDATE 是一个非常实用且常见的系统内置函数,尤其在Oracle和MySQL数据库中广泛使用。它主要用来获取服务器当前的日期和时间,这对于进行实时数据记录、审计跟踪、有效期计算等场景特别有用。本文将详细解析SYSDATE函数的使…...

Rust的async和await支持多线程运行吗?
Rust的async和await的异步机制并不是仅在单线程下实现的,它们可以在多线程环境中工作,从而利用多核CPU的并行计算优势。然而,异步编程的主要目标之一是避免不必要的线程切换开销,因此,在单线程上下文中,asy…...

P2676 [USACO07DEC] Bookshelf B
[USACO07DEC] Bookshelf B 题目描述 Farmer John 最近为奶牛们的图书馆添置了一个巨大的书架,尽管它是如此的大,但它还是几乎瞬间就被各种各样的书塞满了。现在,只有书架的顶上还留有一点空间。 所有 N ( 1 ≤ N ≤ 20 , 000 ) N(1 \le N…...
)
【数学】第十三届蓝桥杯省赛C++ A组/研究生组《爬树的甲壳虫》(C++)
【题目描述】 有一只甲壳虫想要爬上一棵高度为 n 的树,它一开始位于树根,高度为 0,当它尝试从高度 i−1 爬到高度为 i 的位置时有 Pi 的概率会掉回树根,求它从树根爬到树顶时,经过的时间的期望值是多少。 【输入格式…...

Java毕业设计 基于springboot vue招聘网站 招聘系统
Java毕业设计 基于springboot vue招聘网站 招聘系统 springboot vue招聘网站 招聘系统 功能介绍 用户:登录 个人信息 简历信息 查看招聘信息 企业:登录 企业信息管理 发布招聘信息 职位招聘信息管理 简历信息管理 管理员:注册 登录 管理员…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...