【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例
【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例

🌈 个人主页:高斯小哥
🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅和支持~
💡 创作高质量博文(平均质量分92+),分享更多关于深度学习、PyTorch、Python领域的优质内容!(希望得到您的关注~)
🌵文章目录🌵
- 💾一、模型训练过程中的检查点保存
- 🚀二、模型部署与推理加速
- 📚三、模型迁移学习与微调
- 🔄四、模型版本控制与共享
- 🎨五、模型的可视化与调试
- 📚六、模型的序列化与反序列化
- 🌈七、总结与展望
- 🤝 期待与你共同进步
- 相关博客
本文旨在深入探讨PyTorch框架中
torch.save()的应用场景,并通过实战代码示例展示其具体应用。如果您对torch.save()的基础知识尚存疑问,博主强烈推荐您首先阅读博客文章《【PyTorch】基础学习:一文详细介绍 torch.save() 的用法和应用》,以全面理解其基本概念和用法。通过这篇文章,您将更好地掌握torch.save()在PyTorch框架中的实际运用,为您的深度学习之旅增添更多助力。期待您的阅读,一同探索PyTorch的无限魅力!
💾一、模型训练过程中的检查点保存
在深度学习模型的训练过程中,我们经常需要保存模型的中间状态,以便在训练中断时能够恢复训练进度,或者在模型性能达到某个要求时保存当前的最佳模型。torch.save() 在这个场景下发挥着至关重要的作用。
-
以下是一个简单的例子,展示了如何在训练循环中使用 torch.save() 保存模型的检查点:
import torch import torch.nn as nn import torch.optim as optim# 假设我们有一个简单的模型 class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)model = SimpleModel() optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.MSELoss()# 模拟一些训练数据 x_train = torch.randn(100, 10) y_train = torch.randn(100, 1)# 训练循环 for epoch in range(100):optimizer.zero_grad()outputs = model(x_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()# 每训练几个epoch保存一次模型检查点if (epoch + 1) % 10 == 0:torch.save({'epoch': epoch + 1,'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'loss': loss,...}, f'checkpoint_epoch_{epoch+1}.pth')在这个例子中,我们每10个epoch保存一次模型的检查点,包括当前的epoch数、模型的参数、优化器的状态以及当前的损失值。这样,即使训练过程中遇到中断,我们也可以从最近的检查点恢复训练。
🚀二、模型部署与推理加速
在模型部署阶段,我们通常需要将模型加载到特定的设备(如CPU或GPU)上进行推理。torch.save() 可以帮助我们保存已经优化过的模型,以便在部署时快速加载并运行。
-
通过保存和加载模型的参数,我们可以快速地在不同的环境中部署模型,而无需重新训练。此外,将模型加载到GPU上还可以加速推理过程,提高模型的响应速度。
# 训练完成后,保存最终模型 final_model_state_dict = model.state_dict() torch.save(final_model_state_dict, 'final_model.pth')# 在部署时加载模型 loaded_model_state_dict = torch.load('final_model.pth') model.load_state_dict(loaded_model_state_dict) model.eval() # 设置模型为评估模式# 将模型移动到指定设备 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model.to(device)# 进行推理...
📚三、模型迁移学习与微调
迁移学习是一种利用预训练模型在新任务上进行微调的技术。torch.save() 可以帮助我们保存预训练模型,以便在其他任务中进行迁移学习。
-
通过保存预训练模型和微调后的模型,我们可以方便地在新任务上利用已有的知识,加速模型的训练过程并提高性能。
# 假设我们有一个预训练的模型 pretrained_model = SomePretrainedModel() pretrained_model.load_state_dict(torch.load('pretrained_model.pth'))# 在新任务的数据集上进行微调 # ...(这里省略了数据加载和训练循环的代码)# 保存微调后的模型 finetuned_model_state_dict = pretrained_model.state_dict() torch.save(finetuned_model_state_dict, 'finetuned_model.pth')
🔄四、模型版本控制与共享
在模型开发和部署过程中,我们可能需要保存和管理不同版本的模型。torch.save() 结合文件名或路径的管理,可以帮助我们实现模型的版本控制。
-
通过保存不同版本的模型,并在文件名中明确标注版本号,我们可以轻松地管理和追踪模型的变更历史。同时,将模型文件上传到云存储或共享给团队成员,可以方便地实现模型的共享和协作:
# 保存不同版本的模型 torch.save(model1.state_dict(), 'model_v1.pth') torch.save(model2.state_dict(), 'model_v2.pth')# 加载特定版本的模型 def load_model_version(version):if version == 'v1':return torch.load('model_v1.pth')elif version == 'v2':return torch.load('model_v2.pth')else:raise ValueError("Invalid model version")# 使用特定版本的模型进行推理 model_state_dict = load_model_version('v2') loaded_model = SimpleModel() loaded_model.load_state_dict(model_state_dict) loaded_model.eval()# 模型共享 # 可以将保存的模型文件上传到云存储或共享给团队成员 # 其他人可以使用 torch.load() 加载模型进行推理或进一步训练
🎨五、模型的可视化与调试
除了直接用于模型的保存和加载,torch.save() 还可以与一些可视化工具结合使用,帮助我们对模型进行调试和分析。例如,我们可以保存模型的中间层输出或梯度信息,然后使用可视化工具进行展示。
-
通过保存中间层输出或梯度信息,并结合可视化工具进行分析,我们可以更好地理解模型的内部工作机制,发现潜在的问题并进行调试:
# 在训练循环中保存中间层输出 def forward(self, x):intermediate_output = self.some_layer(x)# 保存中间层输出到文件或内存(这里以保存到文件为例)torch.save(intermediate_output, 'intermediate_output.pth')return self.fc(intermediate_output)# ...(训练循环代码)# 在训练完成后,加载中间层输出进行可视化分析 intermediate_data = torch.load('intermediate_output.pth') # 使用可视化工具(如TensorBoard、Matplotlib等)展示中间层输出
📚六、模型的序列化与反序列化
torch.save() 和 torch.load() 的底层机制实际上是 Python 的序列化和反序列化过程。这意味着除了保存和加载模型参数外,我们还可以利用这些函数保存和加载任何可序列化的 Python 对象。
-
通过序列化和反序列化,我们可以将模型的参数、优化器的状态、超参数以及训练过程中的其他信息保存到一个文件中,并在需要时完整地恢复这些信息。这使得我们能够轻松地重现实验结果、分享训练数据以及进行模型的迁移和复用:
# 保存一个字典对象 data_dict = {'model_state_dict': model.state_dict(),'optimizer_state_dict': optimizer.state_dict(),'hyperparameters': {'lr': 0.01, 'batch_size': 64},'training_loss_history': loss_history, # 假设这是训练过程中的损失记录 } torch.save(data_dict, 'training_data.pth')# 加载字典对象 loaded_data_dict = torch.load('training_data.pth') model.load_state_dict(loaded_data_dict['model_state_dict']) optimizer.load_state_dict(loaded_data_dict['optimizer_state_dict']) hyperparams = loaded_data_dict['hyperparameters'] loss_history = loaded_data_dict['training_loss_history']
🌈七、总结与展望
torch.save() 作为 PyTorch 中一个重要的函数,为模型的保存和加载提供了强大的支持。从模型训练过程中的检查点保存到模型部署与推理加速,再到模型迁移学习与微调,torch.save() 在深度学习项目的各个阶段都发挥着不可或缺的作用。此外,通过结合版本控制、模型可视化与调试以及高级序列化技术,我们可以进一步拓展 torch.save() 的应用场景,提高模型开发和部署的效率。
展望未来,随着深度学习技术的不断发展和应用领域的拓宽,对模型保存和加载的需求也将更加多样化和复杂化。相信 PyTorch 社区会不断完善和优化 torch.save() 及相关功能,为我们提供更加高效、灵活和安全的模型序列化工具,推动深度学习领域的持续进步。
🤝 期待与你共同进步
🌱 亲爱的读者,非常感谢你每一次的停留和阅读!你的支持是我们前行的最大动力!🙏
🌐 在这茫茫网海中,有你的关注,我们深感荣幸。你的每一次点赞👍、收藏🌟、评论💬和关注💖,都像是明灯一样照亮我们前行的道路,给予我们无比的鼓舞和力量。🌟
📚 我们会继续努力,为你呈现更多精彩和有深度的内容。同时,我们非常欢迎你在评论区留下你的宝贵意见和建议,让我们共同进步,共同成长!💬
💪 无论你在编程的道路上遇到什么困难,都希望你能坚持下去,因为每一次的挫折都是通往成功的必经之路。我们期待与你一起书写编程的精彩篇章! 🎉
🌈 最后,再次感谢你的厚爱与支持!愿你在编程的道路上越走越远,收获满满的成就和喜悦!祝你编程愉快!🎉
相关博客
| 博客文章标 | 链接地址 |
|---|---|
| 【PyTorch】基础学习:一文详细介绍 torch.save() 的用法和应用 | https://blog.csdn.net/qq_41813454/article/details/136777957?spm=1001.2014.3001.5501 |
| 【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例 | https://blog.csdn.net/qq_41813454/article/details/136778437?spm=1001.2014.3001.5501 |
| 【PyTorch】基础学习:一文详细介绍 torch.load() 的用法和应用 | https://blog.csdn.net/qq_41813454/article/details/136776883?spm=1001.2014.3001.5501 |
| 【PyTorch】进阶学习:一文详细介绍 torch.load() 的应用场景、实战代码示例 | https://blog.csdn.net/qq_41813454/article/details/136779327?spm=1001.2014.3001.5501 |
| 【PyTorch】基础学习:一文详细介绍 load_state_dict() 的用法和应用 | https://blog.csdn.net/qq_41813454/article/details/136778868?spm=1001.2014.3001.5501 |
| 【PyTorch】进阶学习:一文详细介绍 load_state_dict() 的应用场景、实战代码示例 | https://blog.csdn.net/qq_41813454/article/details/136779495?spm=1001.2014.3001.5501 |
相关文章:
【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例
【PyTorch】进阶学习:一文详细介绍 torch.save() 的应用场景、实战代码示例 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程…...

私域流量运营的关键要素和基本步骤
解锁增长的四大关键: 关键要素一:精准营销 精准营销是私域流量运营的核心所在。通过精细化运营和个性化服务,企业可以将普通用户转化为忠实粉丝,提高用户的粘性和转化率。采用数据驱动的精准营销策略,深度挖掘用户需求…...

k8s部署hadoop
(作者:陈玓玏) 配置和模板参考helm仓库:https://artifacthub.io/packages/helm/apache-hadoop-helm/hadoop 先通过以下命令生成yaml文件: helm template hadoop pfisterer-hadoop/hadoop > hadoop.yaml用kube…...
卡住)
deepspeed分布式训练在pytorch 扩展(PyTorch extensions)卡住
错误展示: Using /root/.cache/torch_extensions/py310_cu121 as PyTorch extensions root... Using /root/.cache/torch_extensions/py310_cu121 as PyTorch extensions root... 错误表现: 出现在多卡训练过程的pytorch 扩展,deepspee…...

Rust 的 HashMap
在 Rust 中,HashMap 是一个从键(key)映射到值(value)的数据结构。它允许你以 O(1) 的平均时间复杂度存储、检索和删除键值对。HashMap 实现了 std::collections::HashMap 结构体,通常通过 use std::collect…...
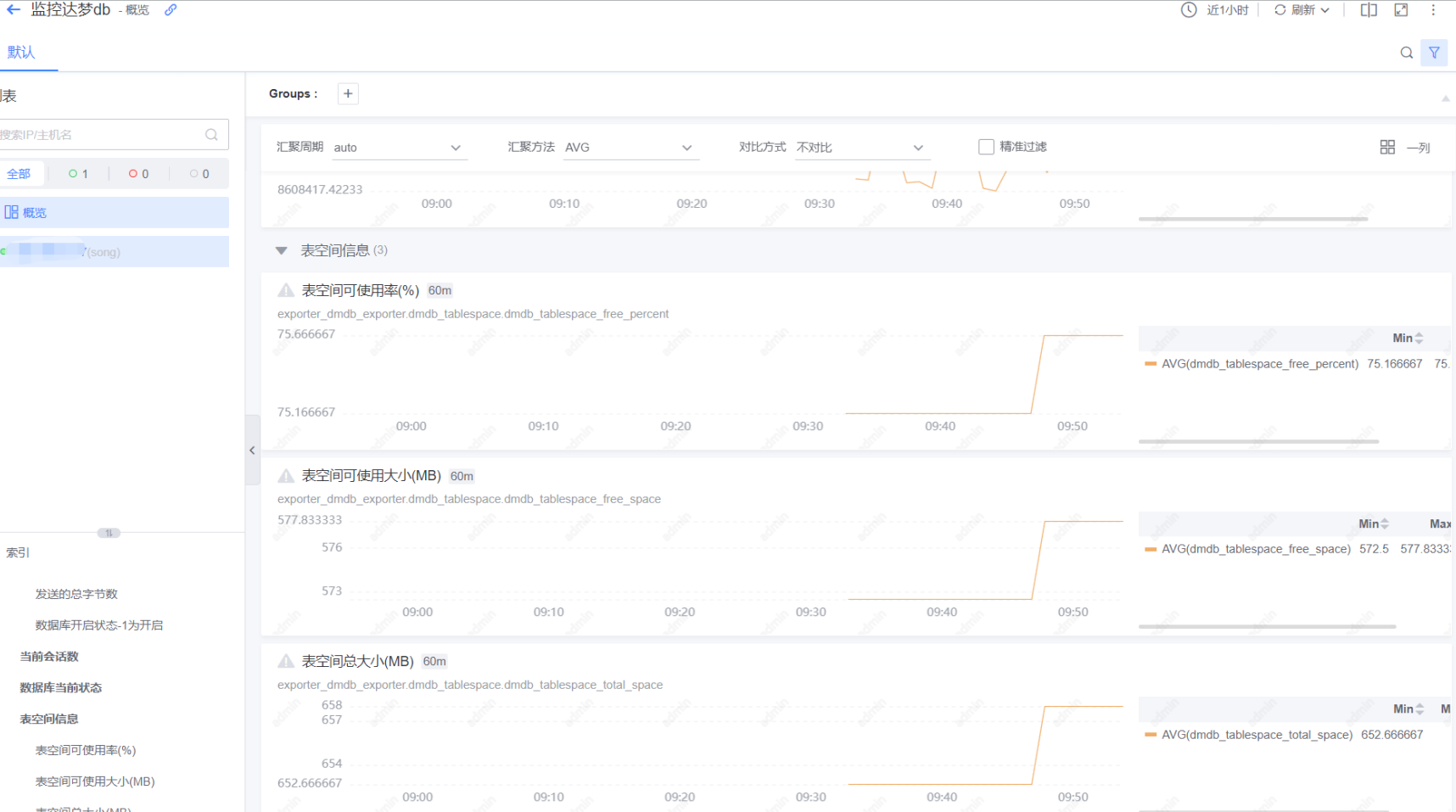
exporter方式监控达梦数据库
蓝鲸监控 随着国产化和信创的深入,开始普遍使用国产化数据库–如达梦数据库,蓝鲸平台默认没有对其进行监控,但是平台了提供监控告警的能力。比如脚本采集,脚本的是一种灵活和快速的监控采集方式,不同层的监控对象都可…...
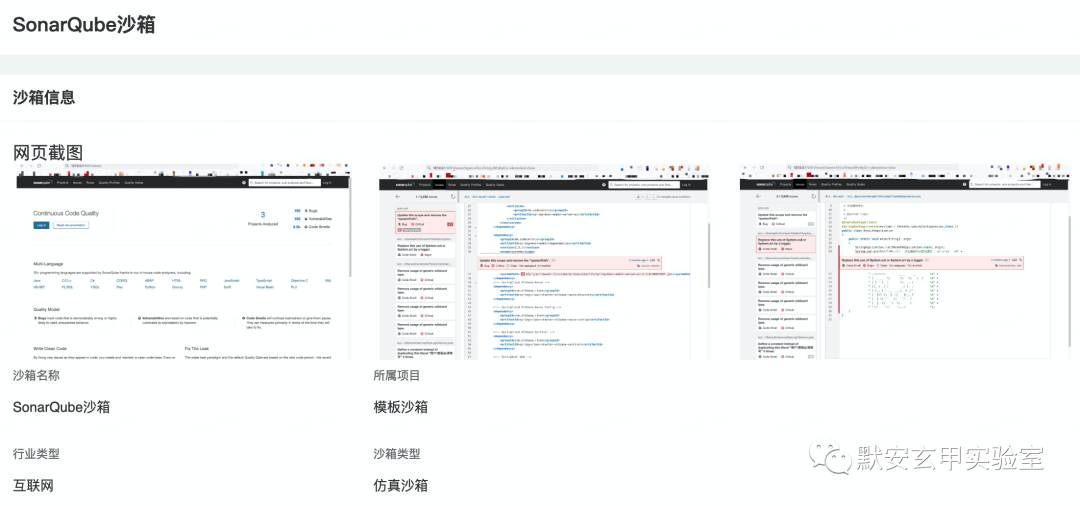
供应链安全之被忽略的软件质量管理平台安全
背景 随着我国信息化进程加速,网络安全问题更加凸显。关键信息基础设施和企业单位在满足等保合规的基础上,如何提升网络安全防御能力,降低安全事件发生概率?默安玄甲实验室针对SonarQube供应链安全事件进行分析,强调供…...

python入门(二)
python的安装很方便,我们这里就不再进行讲解,大家可以自己去搜索视频。下面分享一下Python的入门知识点。 执行命令的方式 在安装好python后,有两种方式可以执行命令: 命令行程序文件,后缀名为.py 对于命令行&…...

Mysql,MongoDB,Redis的横纵向对比
一,什么是Mysql Mysql是一款安全,可以跨平台,高效率的数据库系统,运行速度高,安全性能高,支持面向对象,安全性高,并且成本比较低,支持各种开发语言,数据库的存储容量大,有许多的内置函数。 二,什么是MongoDB MongoDB是基于分布式文件存储的数据库,是一个介于关…...

css3 实现html样式蛇形布局
文章目录 1. 实现效果2. 实现代码 1. 实现效果 2. 实现代码 <template><div class"body"><div class"title">CSS3实现蛇形布局</div><div class"list"><div class"item" v-for"(item, index) …...
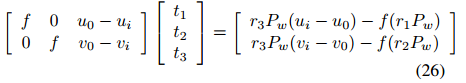
基于消失点的相机自标定
基于消失点的相机自标定 附赠最强自动驾驶学习资料:直达链接 相机是通过透视投影变换来将3D场景转换为2D图像。在射影变换中,平行线相交于一点称之为消失点。本文详细介绍了两种利用消失点特性的标定方法。目的是为根据实际应用和初始条件选择合适的标…...

Python:filter过滤器
filter() 是 Python 中的一个内置函数,用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。该函数接收两个参数,一个是函数,一个是序列,序列的每个元素作为参数传递给函数进行判定&…...

Python函数学习
Python函数学习 1.函数定义 在函数定义阶段只检查函数的语法问题 2.实参形参 总结: (1)位置参数就是经常用的按照位置顺序给出实参的值; (2)关键字实参形式:key123;放在…...

IDEA中的Project工程、Module模块的概念及创建导入
1、IDEA中的层级关系: project(工程) - module(模块) - package(包) - class(类)/接口具体的: 一个project中可以创建多个module一个module中可以创建多个package一个package中可以创建多个class/接口2、Project和Module的概念: 在 IntelliJ …...

如何快速下载并剪辑B站视频
1、B站手机端右上角缓存视频; 2、在手机文件管理助手中找到android/data/80找到两个文件,video.m4s和audio.m4s,将它们发送到电脑,系统会默认保存在你的个人文件夹里,C:\users\用户名 3、下载ffmepg https://blog.cs…...
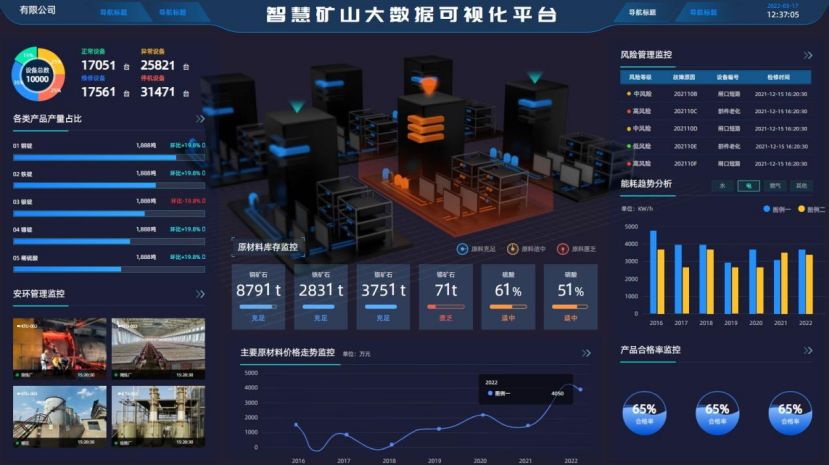
智慧矿山新趋势:大数据解决方案一览
1. 背景 随着信息技术的快速发展和矿山管理需求的日益迫切,智慧矿山作为一种创新的矿山管理方式应运而生。智慧矿山借助先进的信息技术,实现对矿山生产、管理、安全等各方面的智能化、高效化、协同化,是矿山行业转型升级的必然趋势。 欢迎关…...
Ubuntu使用Docker部署Nginx容器并结合内网穿透实现公网访问本地服务
目录 ⛳️推荐 1. 安装Docker 2. 使用Docker拉取Nginx镜像 3. 创建并启动Nginx容器 4. 本地连接测试 5. 公网远程访问本地Nginx 5.1 内网穿透工具安装 5.2 创建远程连接公网地址 5.3 使用固定公网地址远程访问 ⛳️推荐 前些天发现了一个巨牛的人工智能学习网站&#…...
面试笔记——Redis(使用场景、面临问题、缓存穿透)
Redis的使用场景 Redis(Remote Dictionary Server)是一个内存数据结构存储系统,它以快速、高效的特性闻名,并且它支持多种数据结构,包括字符串、哈希表、列表、集合、有序集合等。它主要用于以下场景: 缓…...

电机学(笔记一)
磁极对数p: 直流电机的磁极对数是指电机定子的磁极对数,也等于电机电刷的对数。它与电机的转速和扭矩有直接关系。一般来说,极对数越多,电机转速越低,扭矩越大,适用于低速、高扭矩的场合;相反&…...

数值分析复习:Newton插值
文章目录 牛顿(Newton)插值引入背景插值条件基函数插值多项式差商差商的基本性质差商估计差商的Leibniz公式 余项估计 本篇文章适合个人复习翻阅,不建议新手入门使用 牛顿(Newton)插值 引入背景 Lagrange插值每引入一…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...
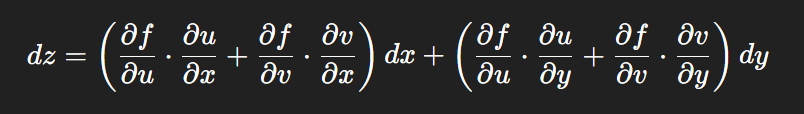
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...
 ----- Python的类与对象)
Python学习(8) ----- Python的类与对象
Python 中的类(Class)与对象(Object)是面向对象编程(OOP)的核心。我们可以通过“类是模板,对象是实例”来理解它们的关系。 🧱 一句话理解: 类就像“图纸”,对…...