【项目设计】高并发内存池(六)[细节优化+测试]
🎇C++学习历程:入门
- 博客主页:一起去看日落吗
- 持续分享博主的C++学习历程
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记,树🌿成长之前也要扎根,也要在漫长的时光🌞中沉淀养分。静下来想一想,哪有这么多的天赋异禀,那些让你羡慕的优秀的人也都曾默默地翻山越岭🐾。

🍁 🍃 🍂 🌿
目录
- 1. 🌿 大于256KB的大块内存申请问题
- 2. 🌿 使用定长内存池配合脱离使用new
- 3. 🌿 释放对象时优化为不传对象大小
- 4. 🌿 多线程环境下对比malloc测试
- 5. 🌿 复杂问题的调试技巧
1. 🌿 大于256KB的大块内存申请问题
- 申请过程
每个线程的thread cache是用于申请小于等于256KB的内存的,而对于大于256KB的内存,我们可以考虑直接向page cache申请,但page cache中最大的页也就只有128页,因此如果是大于128页的内存申请,就只能直接向堆申请了。
| 申请内存的大小 | 申请方式 |
|---|---|
| x ≤ 256 K B ( 32 页 ) | 向thread cache申请 |
| 32 页 < x ≤ 128 页 | 向page cache申请 |
| x ≥ 128 页 | 向堆申请 |
当申请的内存大于256KB时,虽然不是从thread cache进行获取,但在分配内存时也是需要进行向上对齐的,对于大于256KB的内存我们可以直接按页进行对齐。
而我们之前实现RoundUp函数时,对传入字节数大于256KB的情况直接做了断言处理,因此这里需要对RoundUp函数稍作修改。
//获取向上对齐后的字节数
static inline size_t RoundUp(size_t bytes)
{if (bytes <= 128){return _RoundUp(bytes, 8);}else if (bytes <= 1024){return _RoundUp(bytes, 16);}else if (bytes <= 8 * 1024){return _RoundUp(bytes, 128);}else if (bytes <= 64 * 1024){return _RoundUp(bytes, 1024);}else if (bytes <= 256 * 1024){return _RoundUp(bytes, 8 * 1024);}else{//大于256KB的按页对齐return _RoundUp(bytes, 1 << PAGE_SHIFT);}
}现在对于之前的申请逻辑就需要进行修改了,当申请对象的大小大于256KB时,就不用向thread cache申请了,这时先计算出按页对齐后实际需要申请的页数,然后通过调用NewSpan申请指定页数的span即可。
static void* ConcurrentAlloc(size_t size)
{if (size > MAX_BYTES) //大于256KB的内存申请{//计算出对齐后需要申请的页数size_t alignSize = SizeClass::RoundUp(size);size_t kPage = alignSize >> PAGE_SHIFT;//向page cache申请kPage页的spanPageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(kPage);PageCache::GetInstance()->_pageMtx.unlock();void* ptr = (void*)(span->_pageId << PAGE_SHIFT);return ptr;}else{//通过TLS,每个线程无锁的获取自己专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);}
}
也就是说,申请大于256KB的内存时,会直接调用page cache当中的NewSpan函数进行申请,因此这里我们需要再对NewSpan函数进行改造,当需要申请的内存页数大于128页时,就直接向堆申请对应页数的内存块。而如果申请的内存页数是小于128页的,那就在page cache中进行申请,因此当申请大于256KB的内存调用NewSpan函数时也是需要加锁的,因为我们可能是在page cache中进行申请的。
//获取一个k页的span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0);if (k > NPAGES - 1) //大于128页直接找堆申请{void* ptr = SystemAlloc(k);Span* span = new Span;span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;span->_n = k;//建立页号与span之间的映射_idSpanMap[span->_pageId] = span;return span;}//先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){Span* kSpan = _spanLists[k].PopFront();//建立页号与span的映射,方便central cache回收小块内存时查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageId + i] = kSpan;}return kSpan;}//检查一下后面的桶里面有没有span,如果有可以将其进行切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;//在nSpan的头部切k页下来kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;//将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);//存储nSpan的首尾页号与nSpan之间的映射,方便page cache合并span时进行前后页的查找_idSpanMap[nSpan->_pageId] = nSpan;_idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;//建立页号与span的映射,方便central cache回收小块内存时查找对应的spanfor (PAGE_ID i = 0; i < kSpan->_n; i++){_idSpanMap[kSpan->_pageId + i] = kSpan;}return kSpan;}}//走到这里说明后面没有大页的span了,这时就向堆申请一个128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);//尽量避免代码重复,递归调用自己return NewSpan(k);
}
- 释放过程
| 释放内存的大小 | 释放方式 |
|---|---|
| x ≤ 256 K B ( 32 页 ) | 释放给thread cache |
| 32 页 < x ≤ 128 页 | 释放给page cache |
| x ≥ 128 页 | 释放给堆 |
因此当释放对象时,我们需要先找到该对象对应的span,但是在释放对象时我们只知道该对象的起始地址。这也就是我们在申请大于256KB的内存时,也要给申请到的内存建立span结构,并建立起始页号与该span之间的映射关系的原因。此时我们就可以通过释放对象的起始地址计算出起始页号,进而通过页号找到该对象对应的span。
static void ConcurrentFree(void* ptr, size_t size)
{if (size > MAX_BYTES) //大于256KB的内存释放{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}
因此page cache在回收span时也需要进行判断,如果该span的大小是小于等于128页的,那么直接还给page cache进行了,page cache会尝试对其进行合并。而如果该span的大小是大于128页的,那么说明该span是直接向堆申请的,我们直接将这块内存释放给堆,然后将这个span结构进行delete就行了。
//释放空闲的span回到PageCache,并合并相邻的span
void PageCache::ReleaseSpanToPageCache(Span* span)
{if (span->_n > NPAGES - 1) //大于128页直接释放给堆{void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);delete span;return;}//对span的前后页,尝试进行合并,缓解内存碎片问题//1、向前合并while (1){PAGE_ID prevId = span->_pageId - 1;auto ret = _idSpanMap.find(prevId);//前面的页号没有(还未向系统申请),停止向前合并if (ret == _idSpanMap.end()){break;}//前面的页号对应的span正在被使用,停止向前合并Span* prevSpan = ret->second;if (prevSpan->_isUse == true){break;}//合并出超过128页的span无法进行管理,停止向前合并if (prevSpan->_n + span->_n > NPAGES - 1){break;}//进行向前合并span->_pageId = prevSpan->_pageId;span->_n += prevSpan->_n;//将prevSpan从对应的双链表中移除_spanLists[prevSpan->_n].Erase(prevSpan);delete prevSpan;}//2、向后合并while (1){PAGE_ID nextId = span->_pageId + span->_n;auto ret = _idSpanMap.find(nextId);//后面的页号没有(还未向系统申请),停止向后合并if (ret == _idSpanMap.end()){break;}//后面的页号对应的span正在被使用,停止向后合并Span* nextSpan = ret->second;if (nextSpan->_isUse == true){break;}//合并出超过128页的span无法进行管理,停止向后合并if (nextSpan->_n + span->_n > NPAGES - 1){break;}//进行向后合并span->_n += nextSpan->_n;//将nextSpan从对应的双链表中移除_spanLists[nextSpan->_n].Erase(nextSpan);delete nextSpan;}//将合并后的span挂到对应的双链表当中_spanLists[span->_n].PushFront(span);//建立该span与其首尾页的映射_idSpanMap[span->_pageId] = span;_idSpanMap[span->_pageId + span->_n - 1] = span;//将该span设置为未被使用的状态span->_isUse = false;
}
说明一下,直接向堆申请内存时我们调用的接口是VirtualAlloc,与之对应的将内存释放给堆的接口叫做VirtualFree,而Linux下的brk和mmap对应的释放接口叫做sbrk和unmmap。此时我们也可以将这些释放接口封装成一个叫做SystemFree的接口,当我们需要将内存释放给堆时直接调用SystemFree即可。
//直接将内存还给堆
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#else//linux下sbrk unmmap等
#endif
}
- 简单测试
//找page cache申请
void* p1 = ConcurrentAlloc(257 * 1024); //257KB
ConcurrentFree(p1, 257 * 1024);//找堆申请
void* p2 = ConcurrentAlloc(129 * 8 * 1024); //129页
ConcurrentFree(p2, 129 * 8 * 1024);
当申请257KB的内存时,由于257KB的内存按页向上对齐后是33页,并没有大于128页,因此不会直接向堆进行申请,会向page cache申请内存,但此时page cache当中实际是没有内存的,最终page cache就会向堆申请一个128页的span,将其切分成33页的span和95页的span,并将33页的span进行返回。
而在释放内存时,由于该对象的大小大于了256KB,因此不会将其还给thread cache,而是直接调用的page cache当中的释放接口。
由于该对象的大小是33页,不大于128页,因此page cache也不会直接将该对象还给堆,而是尝试对其进行合并,最终就会把这个33页的span和之前剩下的95页的span进行合并,最终将合并后的128页的span挂到第128号桶中。
当申请129页的内存时,由于是大于256KB的,于是还是调用的page cache对应的申请接口,但此时申请的内存同时也大于128页,因此会直接向堆申请。在申请后还会建立该span与其起始页号之间的映射,便于释放时可以通过页号找到该span。
在释放内存时,通过对象的地址找到其对应的span,从span结构中得知释放内存的大小大于128页,于是会将该内存直接还给堆。
2. 🌿 使用定长内存池配合脱离使用new
tcmalloc是要在高并发场景下替代malloc进行内存申请的,因此tcmalloc在实现的时,其内部是不能调用malloc函数的,我们当前的代码中存在通过new获取到的内存,而new在底层实际上就是封装了malloc。
为了完全脱离掉malloc函数,此时我们之前实现的定长内存池就起作用了,代码中使用new时基本都是为Span结构的对象申请空间,而span对象基本都是在page cache层创建的,因此我们可以在PageCache类当中定义一个_spanPool,用于span对象的申请和释放。
//单例模式
class PageCache
{
public://...
private:ObjectPool<Span> _spanPool;
};然后将代码中使用new的地方替换为调用定长内存池当中的New函数,将代码中使用delete的地方替换为调用定长内存池当中的Delete函数。
//申请span对象
Span* span = _spanPool.New();
//释放span对象
_spanPool.Delete(span);注意,当使用定长内存池当中的New函数申请Span对象时,New函数通过定位new也是对Span对象进行了初始化的。
此外,每个线程第一次申请内存时都会创建其专属的thread cache,而这个thread cache目前也是new出来的,我们也需要对其进行替换。
//通过TLS,每个线程无锁的获取自己专属的ThreadCache对象
if (pTLSThreadCache == nullptr)
{static std::mutex tcMtx;static ObjectPool<ThreadCache> tcPool;tcMtx.lock();pTLSThreadCache = tcPool.New();tcMtx.unlock();
}
这里我们将用于申请ThreadCache类对象的定长内存池定义为静态的,保持全局只有一个,让所有线程创建自己的thread cache时,都在个定长内存池中申请内存就行了。
但注意在从该定长内存池中申请内存时需要加锁,防止多个线程同时申请自己的ThreadCache对象而导致线程安全问题。
3. 🌿 释放对象时优化为不传对象大小
当我们使用malloc函数申请内存时,需要指明申请内存的大小;而当我们使用free函数释放内存时,只需要传入指向这块内存的指针即可。
而我们目前实现的内存池,在释放对象时除了需要传入指向该对象的指针,还需要传入该对象的大小。
-
如果释放的是大于256KB的对象,需要根据对象的大小来判断这块内存到底应该还给page cache,还是应该直接还给堆。
-
如果释放的是小于等于256KB的对象,需要根据对象的大小计算出应该还给thread cache的哪一个哈希桶。
如果我们也想做到,在释放对象时不用传入对象的大小,那么我们就需要建立对象地址与对象大小之间的映射。由于现在可以通过对象的地址找到其对应的span,而span的自由链表中挂的都是相同大小的对象。
因此我们可以在Span结构中再增加一个_objSize成员,该成员代表着这个span管理的内存块被切成的一个个对象的大小。
//管理以页为单位的大块内存
struct Span
{PAGE_ID _pageId = 0; //大块内存起始页的页号size_t _n = 0; //页的数量Span* _next = nullptr; //双链表结构Span* _prev = nullptr;size_t _objSize = 0; //切好的小对象的大小size_t _useCount = 0; //切好的小块内存,被分配给thread cache的计数void* _freeList = nullptr; //切好的小块内存的自由链表bool _isUse = false; //是否在被使用
};
而所有的span都是从page cache中拿出来的,因此每当我们调用NewSpan获取到一个k页的span时,就应该将这个span的_objSize保存下来。
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
span->_objSize = size;
此时当我们释放对象时,就可以直接从对象的span中获取到该对象的大小,准确来说获取到的是对齐以后的大小。
static void ConcurrentFree(void* ptr)
{Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr);size_t size = span->_objSize;if (size > MAX_BYTES) //大于256KB的内存释放{PageCache::GetInstance()->_pageMtx.lock();PageCache::GetInstance()->ReleaseSpanToPageCache(span);PageCache::GetInstance()->_pageMtx.unlock();}else{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);}
}
- 读取映射关系时的加锁问题
我们将页号与span之间的映射关系是存储在PageCache类当中的,当我们访问这个映射关系时是需要加锁的,因为STL容器是不保证线程安全的。
对于当前代码来说,如果我们此时正在page cache进行相关操作,那么访问这个映射关系是安全的,因为当进入page cache之前是需要加锁的,因此可以保证此时只有一个线程在进行访问。
但如果我们是在central cache访问这个映射关系,或是在调用ConcurrentFree函数释放内存时访问这个映射关系,那么就存在线程安全的问题。因为此时可能其他线程正在page cache当中进行某些操作,并且该线程此时可能也在访问这个映射关系,因此当我们在page cache外部访问这个映射关系时是需要加锁的。
实际就是在调用page cache对外提供访问映射关系的函数时需要加锁,这里我们可以考虑使用C++当中的unique_lock,当然你也可以用普通的锁。
//获取从对象到span的映射
Span* PageCache::MapObjectToSpan(void* obj)
{PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT; //页号std::unique_lock<std::mutex> lock(_pageMtx); //构造时加锁,析构时自动解锁auto ret = _idSpanMap.find(id);if (ret != _idSpanMap.end()){return ret->second;}else{assert(false);return nullptr;}
}4. 🌿 多线程环境下对比malloc测试
之前我们只是对代码进行了一些基础的单元测试,下面我们在多线程场景下对比malloc进行测试。
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(malloc(16));//v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){free(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次malloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次free %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime);printf("%u个线程并发malloc&free %u次,总计花费:%u ms\n",nworks, nworks*rounds*ntimes, malloc_costtime + free_costtime);
}void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{std::vector<std::thread> vthread(nworks);std::atomic<size_t> malloc_costtime = 0;std::atomic<size_t> free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector<void*> v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(ConcurrentAlloc(16));//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf("%u个线程并发执行%u轮次,每轮次concurrent alloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, malloc_costtime);printf("%u个线程并发执行%u轮次,每轮次concurrent dealloc %u次: 花费:%u ms\n",nworks, rounds, ntimes, free_costtime);printf("%u个线程并发concurrent alloc&dealloc %u次,总计花费:%u ms\n",nworks, nworks*rounds*ntimes, malloc_costtime + free_costtime);
}int main()
{size_t n = 10000;cout << "==========================================================" <<endl;BenchmarkConcurrentMalloc(n, 4, 10);cout << endl << endl;BenchmarkMalloc(n, 4, 10);cout << "==========================================================" <<endl;return 0;
}
其中测试函数各个参数的含义如下:
- ntimes:单轮次申请和释放内存的次数。
- nworks:线程数。
- rounds:轮次。
在测试函数中,我们通过clock函数分别获取到每轮次申请和释放所花费的时间,然后将其对应累加到malloc_costtime和free_costtime上。最后我们就得到了,nworks个线程跑rounds轮,每轮申请和释放ntimes次,这个过程申请所消耗的时间、释放所消耗的时间、申请和释放总共消耗的时间。
注意,我们创建线程时让线程执行的是lambda表达式,而我们这里在使用lambda表达式时,以值传递的方式捕捉了变量k,以引用传递的方式捕捉了其他父作用域中的变量,因此我们可以将各个线程消耗的时间累加到一起。
我们将所有线程申请内存消耗的时间都累加到malloc_costtime上, 将释放内存消耗的时间都累加到free_costtime上,此时malloc_costtime和free_costtime可能被多个线程同时进行累加操作的,所以存在线程安全的问题。鉴于此,我们在定义这两个变量时使用了atomic类模板,这时对它们的操作就是原子操作。
- 固定大小内存的申请和释放
此时4个线程执行10轮操作,每轮申请释放10000次,总共申请释放了40万次,运行后可以看到,malloc的效率还是更高的。

由于此时我们申请释放的都是固定大小的对象,每个线程申请释放时访问的都是各自thread cache的同一个桶,当thread cache的这个桶中没有对象或对象太多要归还时,也都会访问central cache的同一个桶。此时central cache中的桶锁就不起作用了,因为我们让central cache使用桶锁的目的就是为了,让多个thread cache可以同时访问central cache的不同桶,而此时每个thread cache访问的却都是central cache中的同一个桶。
- 不同大小内存的申请和释放
运行后可以看到,由于申请和释放内存的大小是不同的,此时central cache当中的桶锁就起作用了,ConcurrentAlloc的效率也有了较大增长,但相比malloc来说还是差一点点。

5. 🌿 复杂问题的调试技巧
多线程调试比单线程调试要复杂得多,调试时各个线程之间会相互切换,并且每次调试切换的时机也是不固定的,这就使得调试过程变得非常难以控制。
下面给出三个调试时的小技巧:
- 条件断点
一般情况下我们可以直接运行程序,通过报错来查找问题。如果此时报的是断言错误,那么我们可以直接定位到报错的位置,然后将此处的断言改为与断言条件相反的if判断,在if语句里面打上一个断点,但注意空语句是无法打断点的,这时我们随便在if里面加上一句代码就可以打断点了。
if(pos == _head)
{int x = 0;//随意写
}
- 查看函数栈帧
当程序运行到断点处时,我们需要对当前位置进行分析,如果检查后发现当前函数是没有问题的,这时可能需要回到调用该函数的地方进行进一步分析,此时我们可以依次点击“调试→窗口→调用堆栈”。
- 疑似死循环时中断程序
当你在某个地方设置断点后,如果迟迟没有运行到断点处,而程序也没有崩溃,这时有可能是程序进入到某个死循环了。
这时我们可以依次点击“调试→全部中断”。
这时程序就会在当前运行的地方停下来。
相关文章:
【项目设计】高并发内存池(六)[细节优化+测试]
🎇C学习历程:入门 博客主页:一起去看日落吗持续分享博主的C学习历程博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记&…...

同模块设置不同应用主题方案
有时候公司内部会有不同应用但是有部分模块功能一样,只根据应用角色有些细节逻辑区分的场景。这时候往往采用模块化采用以应用至不同的APP。如果APP主题不一致,该如果解决。 方案: 在不同应用的config.gradle 下面根据不同应用定义不同的a…...
centos7 安装 hyperf
PHP > 7.4 Swoole PHP 扩展 > 4.5,并关闭了 Short Name OpenSSL PHP 扩展 JSON PHP 扩展 PDO PHP 扩展 Redis PHP 扩展 Protobuf PHP 扩展 composer create-project hyperf/hyperf-skeleton 推荐安装项 全部选n php.ini [swoole] extens…...
RZ/G2UL核心板-40℃低温启动测试
1. 测试对象HD-G2UL-EVM基于HD-G2UL-CORE工业级核心板设计,一路千兆网口、一路CAN-bus、 3路TTL UART、LCD、WiFi、CSI 摄像头接口等,接口丰富,适用于工业现场应用需求,亦方便用户评估核心板及CPU的性能。HD-G2UL-CORE系列工业级核…...
PyQt5可视化 7 饼图和柱状图实操案例 ①Qt项目的创建
目录 一、新建Qt项目 二、添加组件和布局 三、添加资源 1. 新建资源文件 2. 添加图标资源 四、frameHead 1. toolBtnGenData 2. toolBtnCounting 3. comboTheme 4. comboAnimation 5. Horizontal Spacer 6. toolBtnQuit 7. 设置toolBtnQuit的功能 8. frameHead的…...

0104路径搜索和单点路径-无向图-数据结构和算法(Java)
文章目录2 单点路径2.1 API2.2 算法实现后记2 单点路径 单点路径。给定一幅图和一个起点s,回答“从s到给定的目的顶点v是否存在一条路径?如果有,找出这条路径。”等类似问题。 2.1 API 单点路径问题在图的处理邻域中十分重要。根据标准设计…...

Maxscale读写分离实施文档
Maxscale介绍 MaxScale是maridb开发的一个mysql数据中间件,其配置简单,能够实现读写分离,并且可以根据主从状态实现写库的自动切换。 使用Maxscale无需对业务代码进行修改,其自带的读写分离模块,能够解析SQL语句&…...

websocket实现一个简单聊天框
websoket在客户端的使用 事件:open/message/error/close 方法:send/close var socket new WebSocket(url)// 服务连接成功时触发 socket.addEventListener(open, function() {console.log("连接成功了") })// 主动给websocket发消息 socket…...

Docker-安装应用
一、安装Tomcat 注意:新版Tomcat安装之后启动访问会出现404 修改:删除原有的webapps目录,修改webapps.dist为webapps 免修改版本:billygoo/tomcat8-jdk8 二、安装Mysql 1、安装 拉取镜像 docker pull mysql:5.7 运行镜像…...
Web3中的营销:如何在2023年获得优势
Mar. 2022, Daniel在过去的一年里,让人们对你的Web3项目或协议感兴趣已经变得越来越有挑战性。许多曾经充满希望的项目因为各种不同的原因,都在熊市中倒下了。然而,那些迄今为止幸存下来的项目都有一个共同点:强大的社区。Web3营销…...

Java中==和equals区别
文章目录Java中和equals区别1. Integer中和equals的问题1.1 Integer类型且不是通过new创建的比较1.2 手动new Integer()创建的比较1.3 Integer和int比较2. String中和equals的问题3. DemoJava中和equals区别 equals是方法,是运算符: 如果比较的对象是基…...

计算机科学导论笔记(三)
五、计算机组成 计算机组成部件可以分为三大类(子系统):中央处理单元(CPU)、主存储器和输入/输出子系统。 5.1 中央处理单元(CPU) 中央处理单元用于数据的运算,分为算术逻辑单元&a…...
Stream——数字类型的字符串排序
文章目录前言什么是数字类型的字符串一个简单的坑demo拯救坑代码对象集合中的数字类型排序(有坑)对象集合中的数字类型排序 解决扩展将数字类型字符串数组转换为Integer集合总结前言 想到给数据进行排序,一开始头脑中想到的就是sorted(),本篇文章重点说…...

.NET 8 预览版 1 发布!
.NET 8 是一个长期支持(LTS) 版本。这篇文章涵盖了推动增强功能优先级排序和选择开发的主要主题和目标。.NET 8 预览版和发布候选版本将每月交付一次。像往常一样,最终版本将在 11 月的某个时候在 .NET Conf 上发布。 .NET 版本包括产品、库、运行时和工具…...

WebGIS学习路线
7年经验的webgis码农在此文跟大家分享一些一路走来的所见所闻。希望能帮助刚刚跨入这个门槛的你。 入门之前我相信你已经搞清楚了以下几个问题: 1.什么是webgis? 2.webgis能够解决什么样的问题? 3.为什么你要学习webgis? 如果还没考虑清楚也没关系,可能你看完这篇文章…...
)
【独家】华为OD机试 - 停车场最大距离(C 语言解题)
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明本期…...

12.typedef的使用与结构体定义
欢迎访问个人网络日志🌹🌹知行空间🌹🌹 文章目录1.基础介绍2.typedef 的常用的几种情况3.使用typedef可能出现的问题参考资料1.基础介绍 typedef是C/C语言中保留的关键字,用来定义一种数据类型的别名。 typedef并没有…...

宝塔+docker+jenkins部署vue项目(保姆级教程)
1.使用宝塔安装docker 在软件商城安装Docker管理器 2.使用docker下载jenkins镜像 使用命令行 docker pull jenkins/jenkins:lts //lts表示支持版本较长3.创建并且挂载jenkins目录并赋值 jenkins_home为我创建的目录 可以修改任意目录 mkdir -p /jenkins_home cho…...

JVM面试总结
1.java内存模型JMM是java的内存模型,JMM-也叫Java Memory Model,这里反应翻译成存储更好,因为工作内存指的不是内存.而是CPU寄存器,主内存才是内存.屏蔽了各种硬件和操作系统的内存访问差异-把硬件的细节封装起来,实现让java程序在各平台下都能达到一致的内存访问效果,它定义了…...
C语言——文件操作
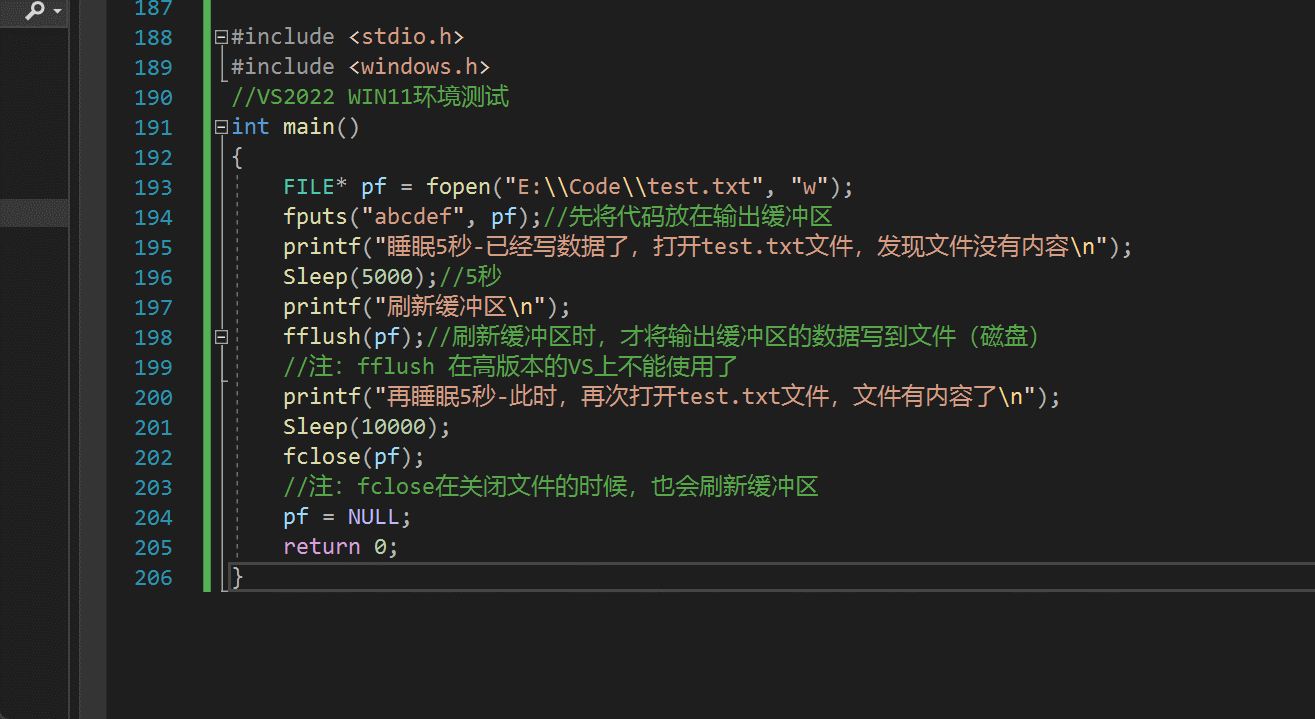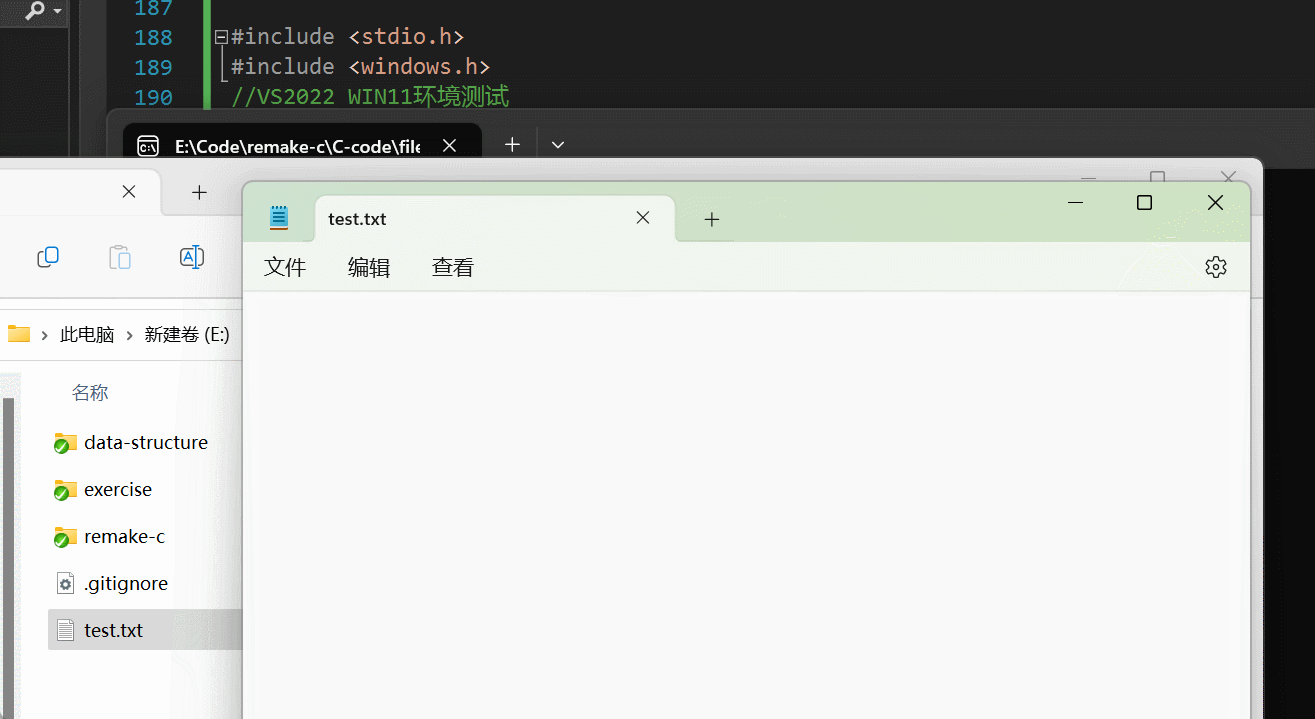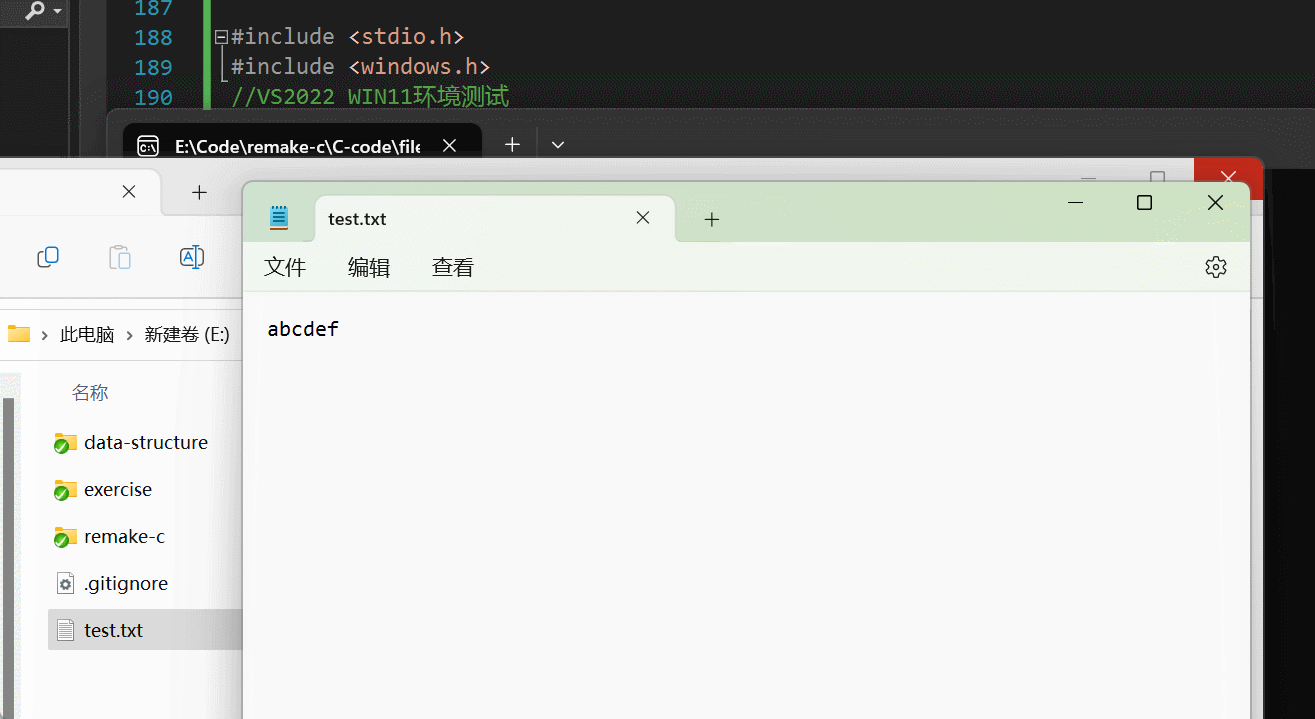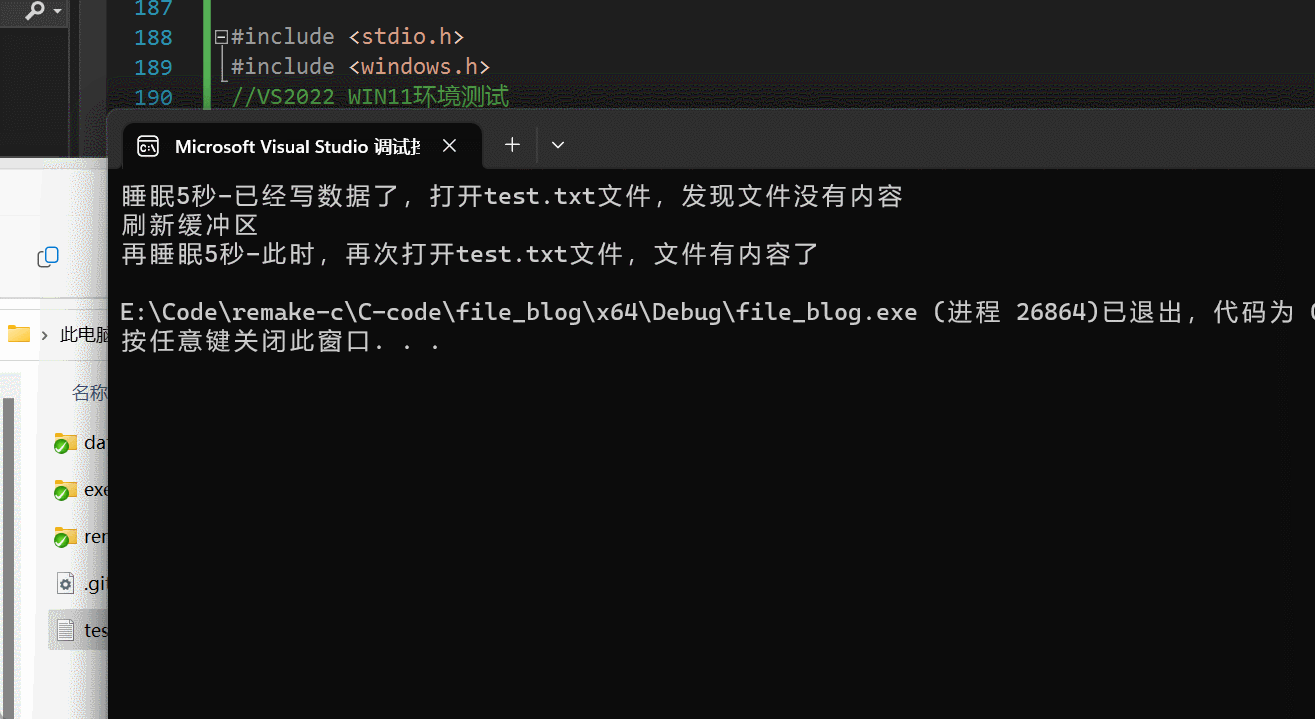
文章目录0. 思维导图1. 为什么使用文件2. 什么是文件2.1 程序文件2.2 数据文件2.3 文件名3. 文件的打开和关闭3.1 文件指针3.2 文件的打开和关闭4. 文件的顺序读写4.1 字符/字符串写入(出)4.2 格式化写入(出)4.3 二进制输入&#…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

MFC 抛体运动模拟:常见问题解决与界面美化
在 MFC 中开发抛体运动模拟程序时,我们常遇到 轨迹残留、无效刷新、视觉单调、物理逻辑瑕疵 等问题。本文将针对这些痛点,详细解析原因并提供解决方案,同时兼顾界面美化,让模拟效果更专业、更高效。 问题一:历史轨迹与小球残影残留 现象 小球运动后,历史位置的 “残影”…...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...