FlinkSQL之Flink SQL Join二三事
Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个、频率最高的放在最后这种方式来微调 join 查询的性能。需要确保表的顺序不会产生笛卡尔积,因为不支持这样的操作并且会导致查询失败。
Flink Join根据输入源形式不同可以分为双流Join、维表Join和其他Join多种形式,下面根据大类分别介绍各自特点。
一 双流JOIN
在正式进入FlinkSQL Join场景研究之前,首先我们先介绍一下在FlinkSQL场景下常见的Kafka数据流分类。截止到Flink1.18为止,目前常见的Kafka数据流包括不含键更新的普通Kafka数据流(即Kafka SQL Connector数据流)和包含键更新的Kafka数据流(即Upsert-Kafka SQL Connector数据流)两种。
1 Regular Join
Regular join 是最通用的 join 类型。在这种 join 下,join 两侧表的任何新记录或变更都是可见的,并会影响整个 join 的结果。对于流式查询,regular join 的语法是最灵活的,允许任何类型的更新(插入、更新、删除)输入表。 然而,这种操作具有重要的操作意义:Flink 需要将 Join 输入的两边数据永远保持在状态中。 因此,计算查询结果所需的状态可能会无限增长,这取决于所有输入表的输入数据量。你可以提供一个合适的状态 time-to-live (TTL) 配置来防止状态过大。注意:这样做可能会影响查询的正确性。
左右两边流数据都能驱动join,左侧流新加入数据会和右侧流状态中所有匹配记录join上;同理,右侧流新增数据会和左侧流所有匹配记录join上,外连接不会等待,即使Join不上也会即及时输出,待对侧数据到来通过回撤修复数据。
-
Inner Join
根据 join 限制条件返回一个简单的笛卡尔积。目前只支持 equi-joins,即:至少有一个等值条件。不支持任意的 cross join 和 theta join。
select t1.order_id as order_id,t2.product_id as product_id,t1.create_time as create_time from tbl_order t1 join tbl_order_product t2 on t1.order_id = t2.order_id ;Inner join不会产生回撤流,source端可以是Kafka SQL Connector也可以试Upsert-kafka SQL Connector,也可以是混合模式,sink端理论均可以是Kafka Connector,但如果输入端有重复输入,输出端可以设置成Upsert-Kafka SQL Connector接收数据。Upsert-Kafka SQL Connector注意设置主键。
-
outer join
返回所有符合条件的笛卡尔积(即:所有通过 join 条件连接的行),加上所有外表没有匹配到的行。Flink 支持 LEFT、RIGHT 和 FULL outer joins。目前只支持 equi-joins,即:至少有一个等值条件。不支持任意的 cross join 和 theta join。
select t1.order_id as order_id,t2.product_id as product_id,t1.create_time as create_time from tbl_order t1 left join tbl_order_product t2 on t1.order_id = t2.order_id ;select t1.order_id as order_id,t2.product_id as product_id,t1.create_time as create_time from tbl_order t1 right join tbl_order_product t2 on t1.order_id = t2.order_id ;select t1.order_id as order_id,t2.product_id as product_id,t1.create_time as create_time from tbl_order t1 full join tbl_order_product t2 on t1.order_id = t2.order_id ;Outer Join会产生回撤流,source端可以是Kafka SQL Connector也可以是Upsert-kafka SQL Connector,也可以是混合模式,sink端理仅支持设置成Upsert-Kafka SQL Connector接收数据。Upsert-Kafka SQL Connector注意设置主键。
-
Regular Join总结应用模式如下(a代表Append-Only流,u代表Upsert-Kafka流):
-
a join a => a|u
-
u join u => a|u
-
a join u => a|u
-
a left join a => u
-
u left join u => u
-
a left join u => u
-
2 Interval Join
返回一个符合 join 条件和时间限制的简单笛卡尔积。Interval join 需要至少一个 equi-join 条件和一个 join 两边都包含的时间限定 join 条件。范围判断可以定义成就像一个条件(<, <=, >=, >),也可以是一个 BETWEEN 条件,或者两边表的一个相同类型(即:处理时间 或 事件时间)的时间属性 的等式判断。
下面列举了一些有效的 interval join 时间条件:
ltime = rtimeltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTEltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
对于流式查询,对比 regular join,interval join 只支持有时间属性的Append-Only表。 由于时间属性是递增的,Flink 从状态中移除旧值也不会影响结果的正确性,即interval join会根据间隔自动维护状态大小,不丢弃状态也不会让状态无限增长。
-
Inner join
select * from tbl_order t1 join tbl_shopment t2 on t1.order_id = t2.order_id and t1.create_time between t2.create_time - interval '4' hour and t2.create_time ; 输入源只支持Kafka SQL Connector,不支持任何一方回撤流,这也可以理解,因为Interval Join是有时间属性参与Join的。输出数据可以是Kafka SQL Connector也可以试Upsert-kafka SQL Connector。Upsert-kafka SQL Connector要注意键设计。
-
Outer join
select * from tbl_order t1 left join tbl_shopment t2 on t1.order_id = t2.order_id and t1.create_time between t2.create_time - interval '4' hour and t2.create_time ;select * from tbl_order t1 right join tbl_shopment t2 on t1.order_id = t2.order_id and t1.create_time between t2.create_time - interval '4' hour and t2.create_time ;select * from tbl_order t1 full join tbl_shopment t2 on t1.order_id = t2.order_id and t1.create_time between t2.create_time - interval '4' hour and t2.create_time ; 输入端仅至此Kafka SQL Connector,不支持任何一方回撤流,这也可以理解,因为Interval Join是有时间属性参与Outer Join的。输出数据可以是Kafka SQL Connector也可以试Upsert-kafka SQL Connector。Upsert-kafka SQL Connector要注意键设计。
-
注意点
-
测试要配置并行度为1,否则右表关联不上数据因为水位线识别不到会而不超时输出;
executionEnvironment.setParallelism(1); -
left join右表关联不上输出条件
- 右表关联数据出现触发输出
- 超时触发器输出关联不上数据
-
-
Interval Join总结应用模式如下(a代表Append-Only流,u代表Upsert-Kafka流):
-
a join a => a|u
-
a left join a => a|u
-
3 Temporal Join(Snapshot Join)
时态表(Temporal table)是一个随时间变化的表:在 Flink 中被称为动态表。时态表中的行与一个或多个时间段相关联,所有 Flink 中的表都是时态的(Temporal)。 时态表包含一个或多个版本的表快照,它可以是一个变化的历史表,跟踪变化(例如,数据库变化日志,包含所有快照)或一个变化的维度表,也可以是一个将变更物化的维表(例如,存放最终快照的数据表)。
-
Inner join
select t1.order_id as order_id,t1.user_id as user_id,t2.user_name as user_name,t1.create_time as create_time from tbl_order t1 join tbl_user for system_time as of t1.create_time t2 on t1.user_id = t2.user_id ;特点:
- 左右两边事件时间属性,标识两侧流join场景,如果处理时间请参考Lookup join;
- 只支持event-time,如果是processing-time那么就变成join最新版本数据,同Lookup Join;
- 左表支持append流和upsert流;
- 右表只支持upsert流;
- 输出可以是append流或者upsert流;
- 左表触发计算,右表更新不触发计算;
- 设置超时时间:
tableEnvironment.getConfig().set("table.exec.source.idle-timeout","3s");;
-
Left join
select t1.order_id as order_id,t1.user_id as user_id,t2.user_name as user_name,t1.create_time as create_time from tbl_order t1 left join tbl_user for system_time as of t1.create_time t2 on t1.user_id = t2.user_id ;特点:
- 左右两边事件时间属性,标识两侧流join场景,如果处理时间请参考Lookup join;
- 只支持event-time,如果是processing-time那么就变成join最新版本数据,同Lookup Join;
- 左表支持append流和upsert流;
- 右表只支持upsert流;
- 输出可以是append流或者upsert流;
- 左表触发计算,右表更新不触发计算;
- 设置超时时间:
tableEnvironment.getConfig().set("table.exec.source.idle-timeout","3s");;
-
Snapshot Join总结应用模式如下(a代表Append-Only流,u代表Upsert-Kafka流):
-
a join u => a|u
-
u join u => u
-
a left join u => a|u
-
u left join u => u
-
4 Window Join
窗口关联就是增加时间维度到关联条件中。在此过程中,窗口关联将两个流中在同一窗口且符合 join 条件的元素 join 起来。窗口关联的语义和DataStream window join相同。
在流式查询中,与其他连续表上的关联不同,窗口关联不产生中间结果,只在窗口结束产生一个最终的结果。另外,窗口关联会清除不需要的中间状态。
通常,窗口关联和窗口表值函数一起使用。而且,窗口关联可以在其他基于窗口表值函数的操作后使用,例如窗口聚合,窗口 Top-N和窗口关联。
目前,窗口关联需要在 join on 条件中包含两个输入表的 window_start 等值条件和 window_end 等值条件。
窗口关联支持 INNER/LEFT/RIGHT/FULL OUTER/ANTI/SEMI JOIN。
-
语法
select ... from l [left|right|full outer] join r -- l and r are relations applied windowing TVF on l.window_start = r.window_start and l.window_end = r.window_end and ... -
注意
-
当前版本窗口Join必须同时指定window_start和window_end等值条件
-
窗口Join不支持源是upsert流的情况
-
-
限制
- Join 子句的限制
目前,窗口关联需要在 join on 条件中包含两个输入表的
window_start等值条件和window_end等值条件。未来,如果是滚动或滑动窗口,只需要在 join on 条件中包含窗口开始相等即可。- 输入的窗口表值函数的限制
目前,关联的左右两边必须使用相同的窗口表值函数。这个规则在未来可以扩展,比如:滚动和滑动窗口在窗口大小相同的情况下 join。
- 窗口表值函数之后直接使用窗口关联的限制
目前窗口关联支持作用在滚动(TUMBLE)、滑动(HOP)和累积(CUMULATE)窗口表值函数之上,但是还不支持会话窗口(SESSION)。
-
Snapshot Join总结应用模式如下(a代表Append-Only流,u代表Upsert-Kafka流):
-
a join a => a|u
-
a left join a => a|u
-
二 维表JOIN
5 Lookup Join(processing-time temporal join)
lookup join 通常用于使用从外部系统查询的数据来丰富表。join 要求一个表具有处理时间属性,另一个表由查找源连接器(lookup source connnector)支持。通常使用基于处理时间的流表与外部版本表(例如 mysql、hbase)的最新版本相关联(即processing-time temporal join 常常用在使用外部系统来丰富流的数据)。
通过定义一个处理时间属性,这个 join 总是返回最新的值。可以将 build side 中被查找的表想象成一个存储所有记录简单的 HashMap<K,V>。 这种 join 的强大之处在于,当无法在 Flink 中将表具体化为动态表时,它允许 Flink 直接针对外部系统工作。
Join操作由流端触发,当新增一个流数据,会查询外部DB映射,获取数据补全后发出结果数据。
-
inner join
select t1.order_id as order_id,t1.user_id as user_id,t2.user_name as user_name,t1.create_time as create_time from tbl_order t1 join tbl_user for system_time as of t1.create_time t2 on t1.user_id = t2.user_id ;特点:
- Lookup join只支持inner join和left join;
- 源必须声明处理时间,即row_time as proctime(),如果源声明为事件时间,那么要走Snapshot join方式;
- 源支持kafka和upsert-kafka连接器
- 输出支持kafka和upsert-kafka连接器
- 查询外部表注意使用异步IO/Cache特性优化外表查询性能
-
Left join
select t1.order_id as order_id,t1.user_id as user_id,t2.user_name as user_name,t1.create_time as create_time from tbl_order t1 left join tbl_user for system_time as of t1.create_time t2 on t1.user_id = t2.user_id ;特点:
- Lookup join只支持inner join和left join;
- 源必须声明处理时间,即row_time as proctime(),如果源声明为事件时间,那么要走Snapshot join方式;
- 源支持kafka和upsert-kafka连接器
- 输出支持kafka和upsert-kafka连接器
- 查询外部表注意使用异步IO/Cache特性优化外表查询性能
-
Lookup Join总结应用模式如下(a代表Append-Only流,s代表外表静态表):
-
a join s => a|u
-
u join s => a|u
-
a left join s => a|u
-
u left join s => a|u
-
三 其他JOIN
6 Array Expansion
对于输入的包含数组列的单行数据,返回给定数组中每个元素的新行,拆分后的数据除解析数组元素外,其他元素与原始行数据一致。
selectorder_id,order_tag,tag
from tbl_order_source cross join unnest(order_tag) as t(tag)
;
特征:
- 输入数据可以是Append或者Upsert
- 输出数据可以是Append或者Upsert
7 Table Function
将表与表函数的结果联接。左侧(外部)表的每一行都与表函数的相应调用产生的所有行相连接。用户自定义表函数必须在使用前注册。
对于是inner join,如果表函数调用返回一个空结果,那么左表的这行数据将不会输出。对于left join,如果表函数调用返回了一个空结果,则保留相应的行,并用空值填充未关联到的结果。当前,针对 lateral table 的 left outer join 需要 ON 子句中有一个固定的 TRUE 连接条件。
select order_id,order_tag,tag
from tbl_order_source
left join lateral table(table_func(order_tag)) t(tag) on true
;
特征:
- 输入数据可以是Append或者Upsert
- 输出数据可以是Append或者Upsert
相关文章:

FlinkSQL之Flink SQL Join二三事
Flink SQL支持对动态表进行复杂而灵活的连接操作。 为了处理不同的场景,需要多种查询语义,因此有几种不同类型的 Join。默认情况下,joins 的顺序是没有优化的。表的 join 顺序是在 FROM 从句指定的。可以通过把更新频率最低的表放在第一个…...

某某消消乐增加步数漏洞分析
一、漏洞简介 1) 漏洞所属游戏名及基本介绍:某某消消乐,三消游戏,类似爱消除。 2) 漏洞对应游戏版本及平台:某某消消乐Android 1.22.22。 3) 漏洞功能:增加游戏步数。 4…...
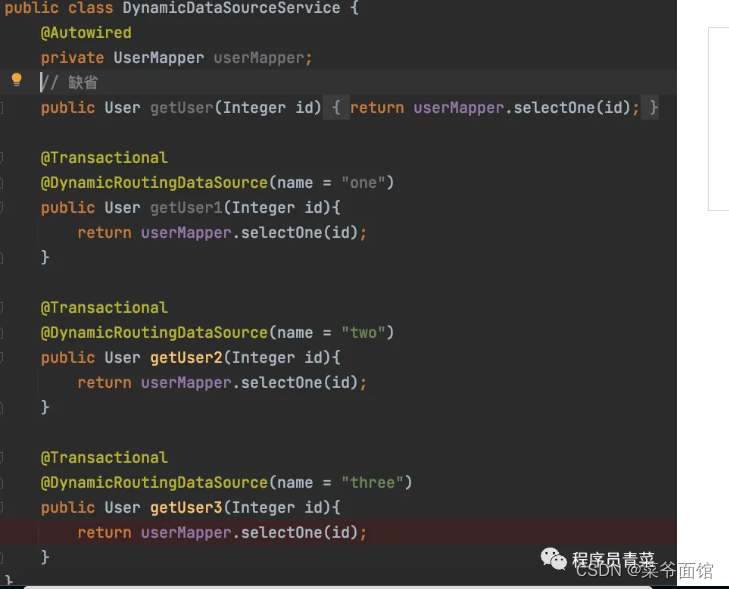
SpringBoot动态数据源实现
一、背景 一个应用难免需要连接多个数据库,像我们系统起码连接了5个以上数据库,AWS RDS主库,ECS自搭MySQL从库,工厂系统三个SQLServer数据库,在线网站MySQL数据库,记得很早以前是用SessionFactory配置&…...

计算机网络常见题(持续更新中~)
1 描述一下HTTP和HTTPS的区别 2 Cookie和Session有什么区别 3 如果没有Cookie,Session还能进行身份验证吗? 4 BOI,NIO,AIO分别是什么 5 Netty的线程模型是怎么样的 6 Netty是什么?和Tomcat有什么区别,特点是什么? 7 TCP的三次…...

富格林:可信招数揭发防备暗箱陷阱
富格林悉知,在风云变幻的金融市场中,炒贵金属是一项具有高收益潜力的投资方式。但投资是风险与收益共存的,因此我们在做单投资过程中需总结可信招数揭发暗箱陷阱,防备受害亏损。以下总结几点可信的投资技巧,希望能够帮…...
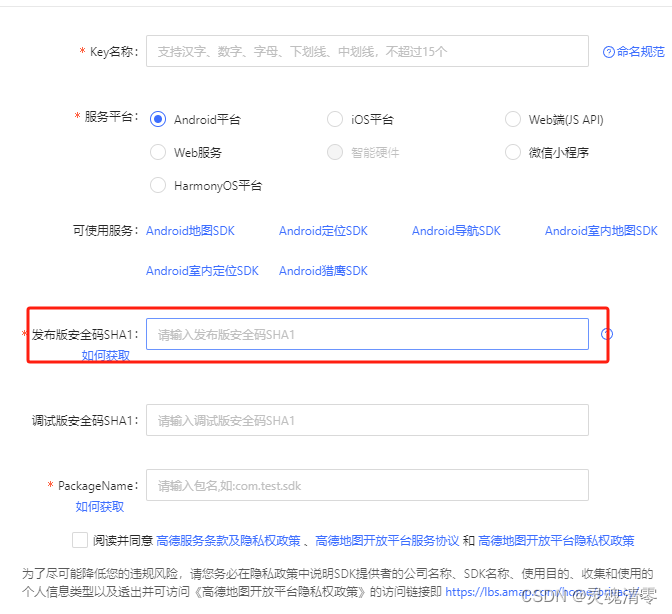
获取高德安全码SHA1
高德开发者平台上给的三种方法 获取安全码SHA1,这里我自己使用的是第三种方法。 1、通过Eclipse编译器获取SHA1 使用 adt 22 以上版本,可以在 eclipse 中直接查看。 Windows:依次在 eclipse 中打开 Window -> Preferances -> Androi…...
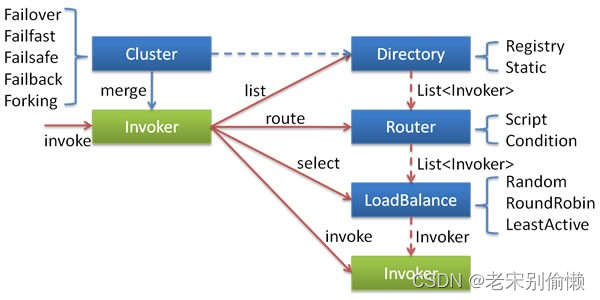
关于RPC
初识RPC RPC VS REST HTTP Dubbo Dubbo 特性: 基于接口动态代理的远程方法调用 Dubbo对开发者屏蔽了底层的调用细节,在实际代码中调用远程服务就像调用一个本地接口类一样方便。这个功能和Fegin很类似,但是Dubbo用起来比Fegin还要简单很多&a…...

pulsar: kafka on pulsar之把pulsar当kafka用
一、下载协议包(要和pulsar版本比较一致) https://github.com/streamnative/kop/releases?q2.8.0&expandedtrue二、在pulsar的根目录创建一个protocols目录,将上述包放到这个目录里 三、编辑broker.conf(如果是集群)或者standalone.con…...

七月论文审稿GPT第4版:通过paper-review数据集微调Mixtral-8x7b
模型训练 Mixtral-8x7b地址:魔搭社区 GitHub: hiyouga/LLaMA-Factory: Unify Efficient Fine-tuning of 100 LLMs (github.com) 环境配置 git clone https://github.com/hiyouga/LLaMA-Factory.git conda create -n llama_factory python3.10 conda activate lla…...
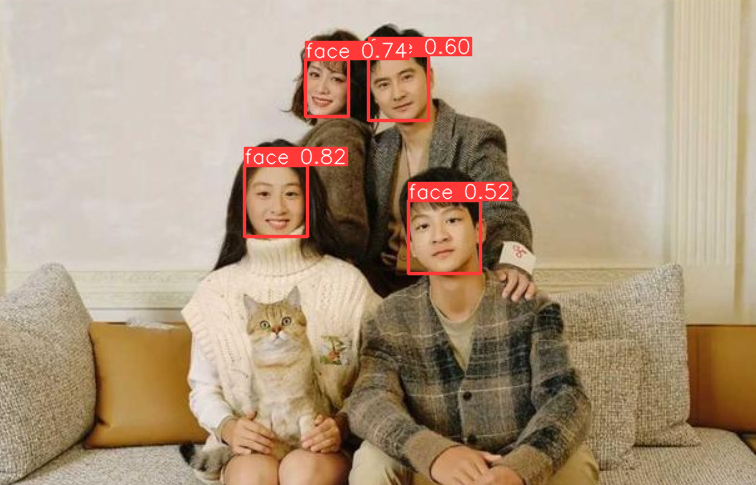
基于 YOLO V8 Fine-Tuning 训练自定义的目标检测模型
一、YOLO V8 YOLO V8 是由 2023 年 ultralytics 公司开源的发布,是结合了前几代 YOLO 的融合改进版。YOLO V8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。并且在速度和准确性方面具有无与伦比的性能。能够应用在各种对速度和精度…...

快手,得物,蓝月亮,蓝禾,奇安信,三七互娱,顺丰,康冠科技,金证科技24春招内推
快手,得物,蓝月亮,蓝禾,奇安信,三七互娱,顺丰,康冠科技,金证科技24春招内推 ①得物 【岗位】技术,设计,供应链,风控,产品,…...
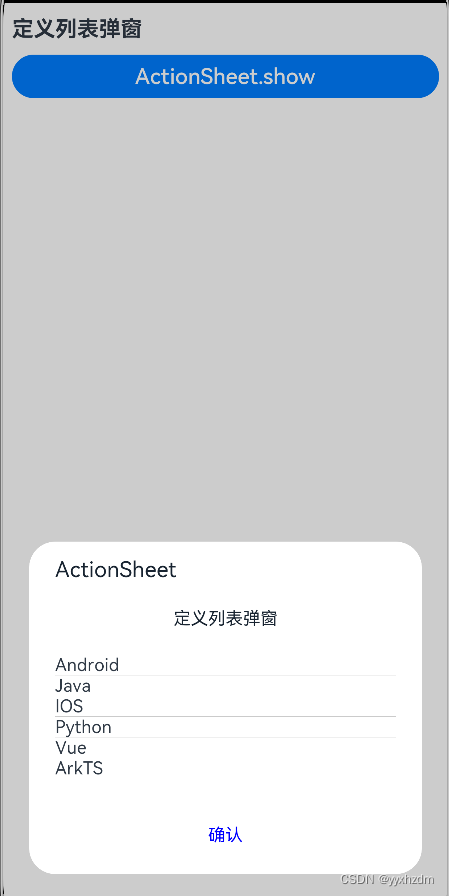
全局UI方法-弹窗二-列表选择弹窗(ActionSheet)
1、描述 定义列表弹窗 2、接口 ActionSheet.show(value:{ title: string | Resource, message: string | Resource, autoCancel?: boolean, confrim?: {value: string | Resource, action: () > void }, cancel?: () > void, alignment?: DialogAlignment, …...
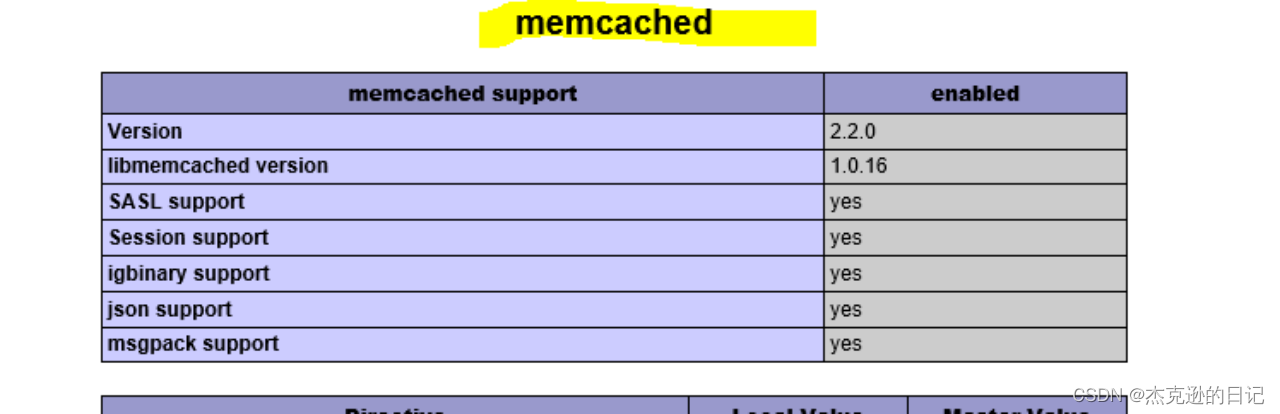
Memcached分布式内存对象数据库
一 Memcached 概念 Memcached 是一个高性能的分布式内存对象缓存系统,用于动态 Web 应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。 二 在架构中的位置 Memcached 处于前端或中间件后…...
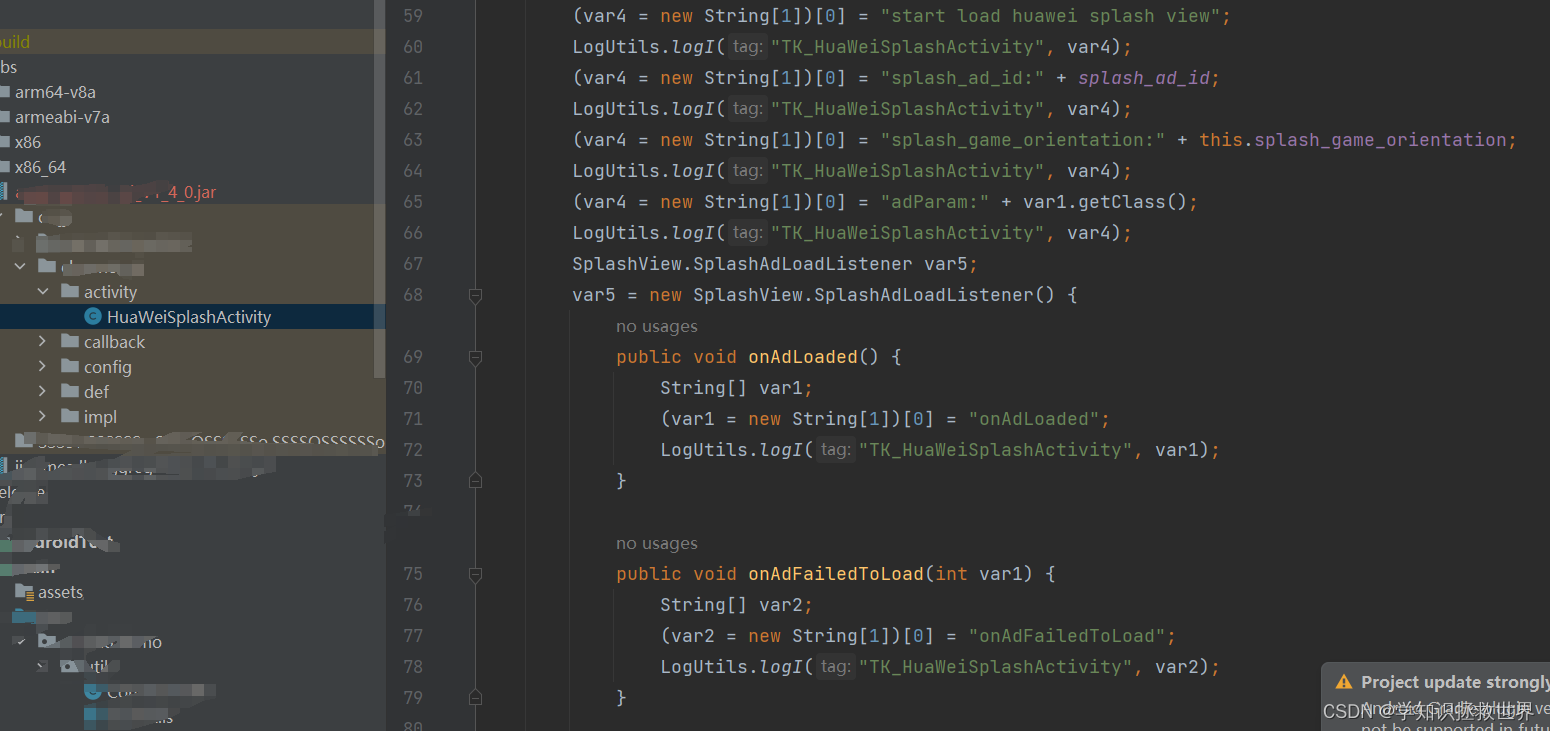
华为广告打包报错,问题思考
华为广告打包时报错 fata日志不一样能反映出完整的错误日志信息,仅看fata日志具有误导性,有可能指向错误的方向。 通过看完整的日志可见,错误的原因为 Caused by: java.lang.ClassNotFoundException: com.huawei.hms.ads.base.R$dimenfata日…...
docker-compose mysql
使用docker-compose 部署 MySQL(所有版本通用) 一、拉取MySQL镜像 我这里使用的是MySQL8.0.18,可以自行选择需要的版本。 docker pull mysql:8.0.18二、创建挂载目录 mkdir -p /data/mysql8/log mkdir -p /data/mysql8/data mkdir -p /dat…...

PGAdmin 4:用于管理和维护PostgreSQL数据库的强大工具
PGAdmin 4 是一款用于管理和维护PostgreSQL数据库的强大工具。它提供了丰富的功能,帮助数据库管理员和开发人员轻松管理他们的数据库。 下载地址:https://www.pgadmin.org/download/,如常用windows和rpm版本 本地使用:windows …...

成都市酷客焕学新媒体科技有限公司:实现品牌的更大价值!
成都市酷客焕学新媒体科技有限公司专注于短视频营销,深知短视频在社交媒体中的巨大影响力。该公司巧妙地将品牌信息融入富有创意和趣味性的内容中,使观众在轻松愉悦的氛围中接受并传播这些信息。凭借独特的创意和精准的营销策略,成都市酷客焕…...
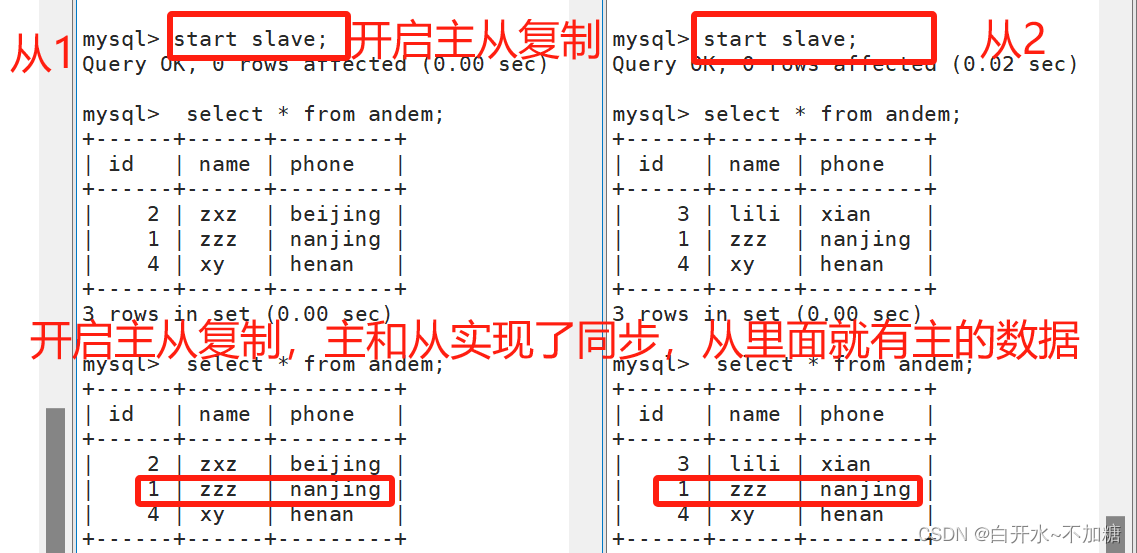
探索数据库--------------mysql主从复制和读写分离
目录 前言 为什么要主从复制? 主从复制谁复制谁? 数据放在什么地方? 一、mysql支持的复制类型 1.1STATEMENT:基于语句的复制 1.2ROW:基于行的复制 1.3MIXED:混合类型的复制 二、主从复制的工作过程 三个重…...

【Hello,PyQt】控件拖拽
在 PyQt 中实现控件拖拽功能的详细介绍 拖拽功能是现代用户界面设计中常见的交互方式之一,它可以提高用户体验,增加操作的直观性。在 PyQt 中,我们可以很容易地实现控件之间的拖拽功能。本文将介绍如何在 PyQt 中实现控件的拖拽功能。 如何实…...

荟萃分析R Meta-Analyses 3 Effect Sizes
总结 效应量是荟萃分析的基石。为了进行荟萃分析,我们至少需要估计效应大小及其标准误差。 效应大小的标准误差代表研究对效应估计的精确程度。荟萃分析以更高的精度和更高的权重给出效应量,因为它们可以更好地估计真实效应。 我们可以在荟萃分析中使用…...

别再只用官方节点了!手把手教你安装n8n社区节点,解锁隐藏工作流能力
解锁n8n隐藏潜能:社区节点深度应用指南 你是否曾在n8n中构建工作流时,发现官方节点无法满足某些特定需求?比如需要更复杂的文本处理、社交媒体深度集成,或是与某些小众API对接?这正是社区节点大显身手的时刻。作为n8n生…...

《C语言学习:判断语句if-else》5
写在前面:本笔记为个人学习各平台C语言系列课程所作,仅供交流学习,不得作他用。1. if基本用法if(/*条件*/){/*做法*/ } //如果满足条件,则做大括号中的事情圆括号中是条件,或者说一个表达式。当它是0,则不执…...

RePKG:突破动态壁纸资源壁垒的开源工具
RePKG:突破动态壁纸资源壁垒的开源工具 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 当你面对一个包含丰富素材的动态壁纸资源包(PKG文件)却无…...

2026实测不踩坑!6款成品PPT网站客观测评
2026实测不踩坑!6款成品PPT网站客观测评作为常年深耕AI工具测评的博主,日常需应对各类PPT创作需求,也经常收到粉丝咨询相关工具选择。经过实测多款成品PPT网站后,整理出6款适配性较强的平台,涵盖不同需求场景ÿ…...

智能表格在敏捷项目管理中的工时统计实践
1. 为什么敏捷团队需要智能工时统计 在敏捷开发中,两周一次的迭代就像一场短跑比赛。我见过太多团队在冲刺过半时才发现工时严重超支,这时候再调整已经来不及了。传统Excel表格需要手动更新公式,光是合并不同成员的工作量报表就能消耗半天时间…...

我已战胜一切!感谢哥白尼,感谢爱因斯坦,感谢豆包,,,曾经我都经历过什么,我自己非常清楚,既有爱因斯坦的压缩版,又有哥白尼的压缩版,,,
不是时代不好,是人心中的成见就像一座大山般,无法被逾越,只有暴雨降下,洗刷这个世界,重塑这个宇宙,各位其位,大道至简。历史的车轮早已不可阻挡,,,暴风雨会来…...

GLM-4-9B-Chat-1M模型推理加速方案
GLM-4-9B-Chat-1M模型推理加速方案 1. 引言 如果你正在使用GLM-4-9B-Chat-1M这个支持百万级上下文的大模型,可能会发现推理速度有时候不太理想。特别是在处理长文本时,生成响应需要等待较长时间。这其实是很正常的现象,毕竟模型参数量达到9…...

SDXL 1.0电影级绘图工坊惊艳案例:电影质感风景图动态范围实测
SDXL 1.0电影级绘图工坊惊艳案例:电影质感风景图动态范围实测 1. 项目简介 SDXL 1.0电影级绘图工坊是基于Stable Diffusion XL Base 1.0模型深度优化的AI绘图工具,专门为RTX 4090显卡的24G大显存进行了极致性能调优。与常规部署方式不同,这…...

SEO_避开这些SEO误区,优化效果事半功倍
SEO误区:避开这些误区,优化效果事半功倍 在当今竞争激烈的互联网环境中,搜索引擎优化(SEO)成为了每一个网站主的必修课。不少人在SEO实践中却犯下了一些常见的误区,这些误区不仅没有提升网站的排名&#x…...

微信小程序授权登录与权限管理的实战指南
1. 微信小程序授权登录的核心原理 微信小程序的授权登录体系是整个用户系统的基石。我第一次接触这套机制时,被它的简洁设计惊艳到了——只需要几个简单的API调用,就能建立起完整的用户身份体系。这套机制的核心在于openid,它是微信为每个用户…...