探索数据库--------------mysql主从复制和读写分离
-
目录
前言
为什么要主从复制?
主从复制谁复制谁?
数据放在什么地方?
一、mysql支持的复制类型
1.1STATEMENT:基于语句的复制
1.2ROW:基于行的复制
1.3MIXED:混合类型的复制
二、主从复制的工作过程
三个重要线程
三、中继日志(relay log)
3.1中继日志介绍
3.2中继日志格式
3.3中继日志的作用
3.4相关参数解析
四、搭建mysql主从复制
①三台机器都关闭防火墙、核心防护
②Mysql主从服务器时间同步
主服务器 时间同步
从服务器 时间同步
slave1时间同步
slave2时间同步
③主服务器的mysql配置
④从服务器的mysql配置
slave1配置
slave2配置
⑤检测
去主服务器创建
去从服务器查看
五、MySQL主从复制延迟
六、MySQL读写分离
6.1什么是读写分离?
6.2为什么要读写分离呢?
6.3什么时候要读写分离?
6.4主从复制与读写分离
6.7MySQL 读写分离原理
6.8目前较为常见的 MySQL 读写分离分为以下两种:
6.8.1基于程序代码内部实现
6.8.2基于中间代理层实现
6.9读写分离原理
读写分离方案:
6.9搭建读写分离
①安装 Java 环境
②安装Amoeba软件
③ 配置 amoeba 读写分离
主服务器授权:
从服务器授权:
④修改Amoeba服务配置(读写分离(负载均衡))
amoeba.xml 配置文件的修改:
修改 dbServers.xml 数据库配置文件
⑤启动amoeba
⑥ 测试读写分离
主服务器:
从服务器:
七、温故而知新
7.1主从同步复制原理
7.2读写分离你们使用什么方式?
7.3如何查看主从同步状态是否成功
7.4如果I/O不是yes呢,你如何排查?
7.5show slave status能看到哪些信息(比较重要)
7.6主从复制慢(延迟)会有哪些可能?怎么解决?
7.7mysql主从复制版本
在企业应用中,成熟的业务通常数据量都比较大 - 单台Mysql在安全性、高可用性和高并发方面都无法满足实际的需求
- 配置多台主动数据库服务器以实现读写分离
主从复制和读写分离是为解决数据中的高并发
前言
为什么要主从复制?
保证数据的完整性
主从复制谁复制谁?
salve 复制 master的数据
数据放在什么地方?
二进制文件 mysql-bin-000001中记录完整的sql,slave复制二进制文件到本地节点,保存为中继日志文件方式最后基于这个中继日志 进行恢复 操作 ,将执行的sql同步到自己的数据库中,达到与master 数据一致
一、mysql支持的复制类型
1.1STATEMENT:基于语句的复制
在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制(5.7版本之前),执行效率高。高并发的情况可能会出现执行顺序的误差,事务的死锁。
1.2ROW:基于行的复制
把改变的内容复制过去,而不是把命令在从服务器上执行一 遍,精确,但效率低,保存的文件会更大。(5.7版本之后默认采用ROW模式)
1.3MIXED:混合类型的复制
默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。更智能,所以大部分情况下使用MIXED
二、主从复制的工作过程

两个日志(主:binlog二进制日志,从:relay-log中继日志)
三个线程(主:dump线程,从:IO线程和SQL线程)

1、主节点开启二进制日志,从节点开启中继日志。
2、Master 节点将数据的改变记录成二进制日志(bin log) ,当Master上的数据发生改变时(增删改),则将其改变写入二进制日志中。
3、从节点会在一定时间间隔内对Master的二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O线程请求主节点的二进制事件。(请求二进制数据)
4、同时主节点为每个I/O线程启动一个dump线程,用于通知和向其发送二进制日志,I/O线程接收到bin-log内容后,将内容保存至slave节点本地的中继日志(Relay log)中
5、从节点将启动SQL线程从中继日志中读取二进制日志,在本地重放,即解析成sql 语句逐一执行,使得其数据和主节点的保持一致。最后I/O线程和SQL线程将进入睡眠状态,等待下一次被唤醒。
●中继日志通常会位于 OS 缓存中,所以中继日志的开销很小。
●复制过程有一个很重要的限制,即复制在 Slave上是串行化的,也就是说 Master上的并行更新操作不能在 Slave上并行操作。
首先client端(tomcat)将数据写入到master节点的数据库中,master节点会通知存储引擎提交事务,同时会将数据以(基于行、基于sql、基于混合)的方式保存在二进制日志中
SLAVE节点会开启I/O线程,用于监听master的二进制日志的更新,一旦发生更新内容,则向master的dump线程发出同步请求
master的dump线程在接收到SLAVE的I/O请求后,会读取二进制文件中更新的数据,并发送给SLAVE的I/O线程
SLAVE的I/O线程接收到数据后,会保存在SLAVE节点的中继日志中
同时,SLAVE节点中的SQL线程,会读取中继日志中的数据,更新在本地的mysql数据库中
最终,完成slave——>复制master数据,达到主从同步的效果
①从数据库处理用户读操作,主数据库处理用户写操作。
②用户写入数据到主数据库时,主数据库更新并写入binlog二进制日志中。
③主数据库开启dump线程一边读取binlog日志一边通过网络将日志传输给从数据库。
④从数据库通过io线程接收binlog日志并保存为中继日志(即binlog日志只是换了名称)。
⑤从数据库开启sql线程将中继日志写入从数据库主从数据库复制完成。
主MySQL服务器做的增删改操作,都会写入自己的二进制日志(Binary log)
然后从MySQL从服务器打开自己的I/O线程连接主服务器,进行读取主服务器的二进制日志
I/O去监听二进制日志,一旦有新的数据,会发起请求连接
这时候会触发dump线程,dump thread响应请求,传送数据给I/O,通过tp的方式发送给I/O(dump线程要么处于等待,要么处于睡眠)
I/O接收到数据之后存放在中继日志
SQL thread线程会读取中继日志里的数据,存放到自己的服务器中。三个重要线程
dump线程:由主数据库开启,用于读取主的二进制日志并传输给从数据库 。
- 用于监听 I/O线程 请求
- 将二进制日志更新的数据发送给slave的I/O 线程
io线程:由从数据库开启,用于接收二进制日志并保存为中继日志。
sql线程:由从数据库开启,用于将中继日志写入备数据库中完成主从复制。
三、中继日志(relay log)
3.1中继日志介绍
中继日志
(relay log)只在主从服务器架构的从服务器上存在。从服务器(slave)为了与主服务器(Master)保持一致,要从主服务器读取二进制日志的内容,并且把读取到的信息写入本地的日志文件中,这个从服务器本地的日志文件就叫中继日志。然后,从服务器读取中继日志,并根据中继日志的内容对从服务器的数据进行更新,完成主从服务器的数据同步。搭建好主从服务器之后,中继日志默认会保存在从服务器的数据目录下。
3.2中继日志格式
文件名的格式是:
从服务器名 - relay-bin.序号。中继日志还有一个索引文件:从服务器名 - relay-bin.index,用来定位当前正在使用的中继日志。
3.3中继日志的作用
中继日志用于主从服务器架构中,从服务器用来存放主服务器二进制日志内容的一个中间文件。从服务器通过读取中继日志的内容,来同步主服务器上的操作。
中继日志是连接master(主服务器)和slave(从服务器)的信息,它是复制的核心,I/O线程将来自master的binlog存储到中继日志中,中继日志充当缓冲,这样master不必等待slave执行完成就可以发送下一个binlog。
3.4相关参数解析
mysql> show variables like '%relay%';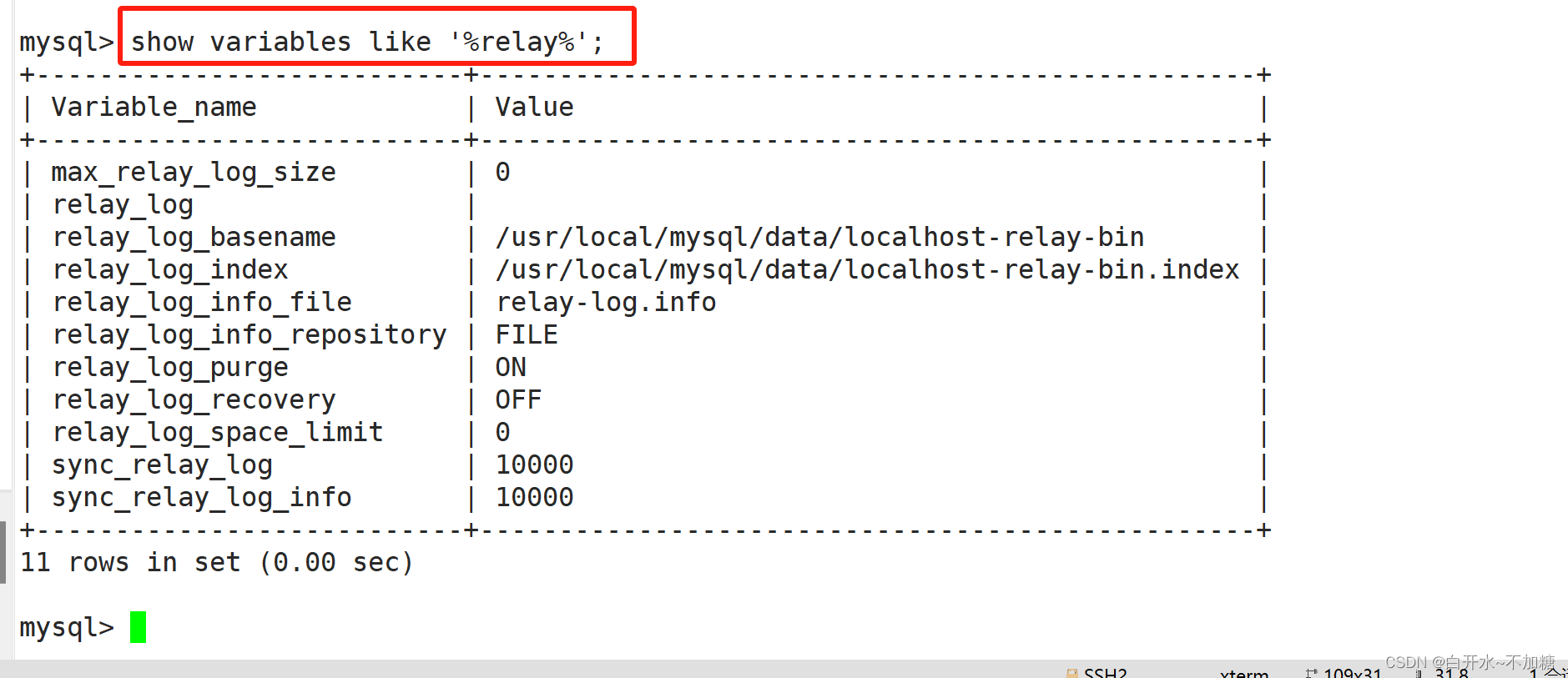
max_relay_log_size:标记relay log 允许的最大值,如果该值为0,则默认值为max_binlog_size(1G);如果不为0,则max_relay_log_size则为最大的relay_log文件大小;relay_log:定义relay_log的位置和名称,如果值为空,则默认位置在数据文件的目录(datadir),文件名默认为host_name-relay-bin.nnnnnnrelay_log_index:同relay_log,定义relay_log的位置和名称;一般和relay-log在同一目录relay_log_info_file:设置relay-log.info的位置和名称(relay-log.info记录MASTER的binary_log的恢复位置和relay_log的位置)relay_log_purge:是否自动清空不再需要中继日志时。默认值为1(启用)。relay_log_recovery:当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的relay-log,并且重新从master上获取日志,这样就保证了relay-log的完整性。默认情况下该功能是关闭的,将relay_log_recovery的值设置为 1时,可在slave从库上开启该功能,建议开启。relay_log_space_limit:防止中继日志写满磁盘,这里设置中继日志最大限额。注意!但此设置存在主库崩溃,从库中继日志不全的情况,不到万不得已,不推荐使用!
sync_relay_log:这个参数和sync_binlog是一样的,当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量I/O
当设置为0时,并不是马上就刷入中继日志里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘I/O操作。这个值默认是0,可动态修改,建议采用默认值。sync_relay_log_info:这个参数和sync_relay_log参数一样,当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay-log.info里,这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但会造成磁盘的大量I/O。当设置为0时,并不是马上就刷入relay-log.info里,而是由操作系统决定何时来写入,虽然安全性降低了,但减少了大量的磁盘I/O操作。这个值默认是0,可动态修改,建议采用默认值四、搭建mysql主从复制
master 服务器:192.168.246.7 ysql5.7slave1 服务器: 192.168.246.8 Mysql5.7slave2 服务器: 192.168.246.10 Mysql5.7
①三台机器都关闭防火墙、核心防护
#关闭防火墙、防护
systemctl stop firewalld
systemctl disable firewalld.service
setenforce 0
②Mysql主从服务器时间同步
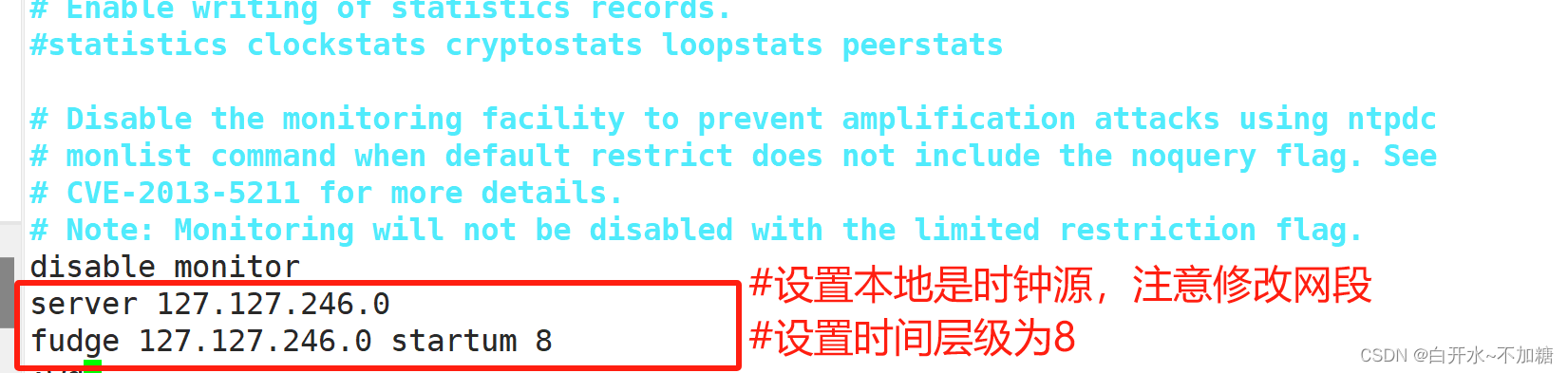
主服务器 时间同步
yum install ntp -y #安装ntp服务用来完成时间同步
vim /etc/ntp.conf #修改配置文件
#末行添加以下两行
server 127.127.246.0 #设置本地为时钟源,注意修改网段
fudge 127.127.246.0 stratum 8 #设置时间层级为8
service ntpd start #开启服务

server 127.127.246.0
fudge 127.127.246.0 startum 8
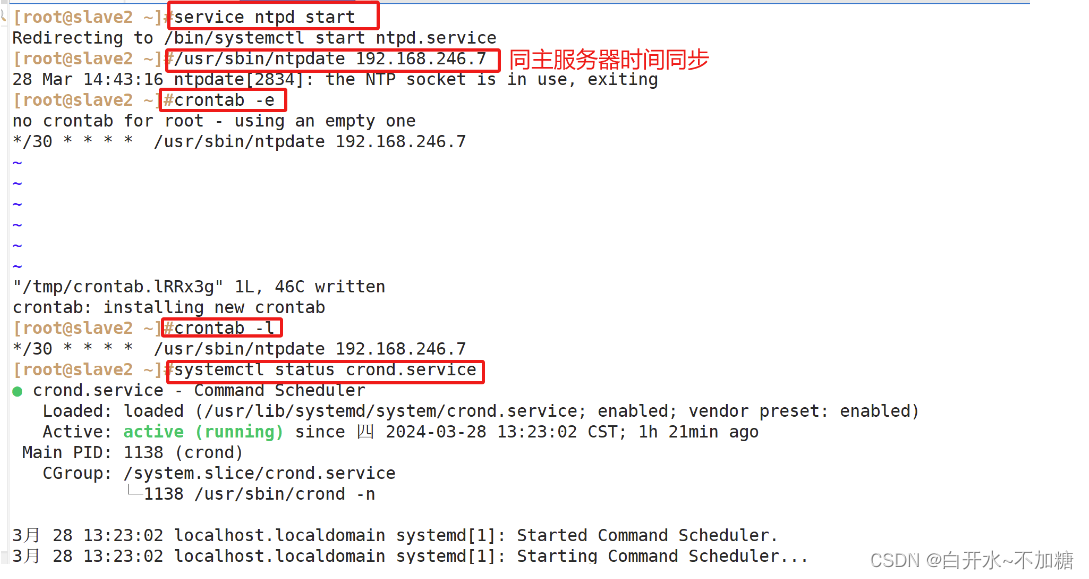
从服务器 时间同步
yum install ntp ntpdate -y #安装ntpdate同步
service ntpd start #开启服务
/usr/sbin/ntpdate 192.168.246.7 #使用 ntpdate同步本地时钟源
crontab -e #编辑定时任务
*/30 * * * * /usr/sbin/ntpdate 192.168.246.7 #三十分钟同步一次时间
crontab -l #查看定时任务
systemctl status crond.service #查看定时服务状态slave1时间同步


slave2时间同步

③主服务器的mysql配置
vim /etc/my.cnf
server-id = 1 #master和两台slave的id都要不同
log-bin = master-bin #添加,主服务器开启二进制日志
binlog_format = MIXED
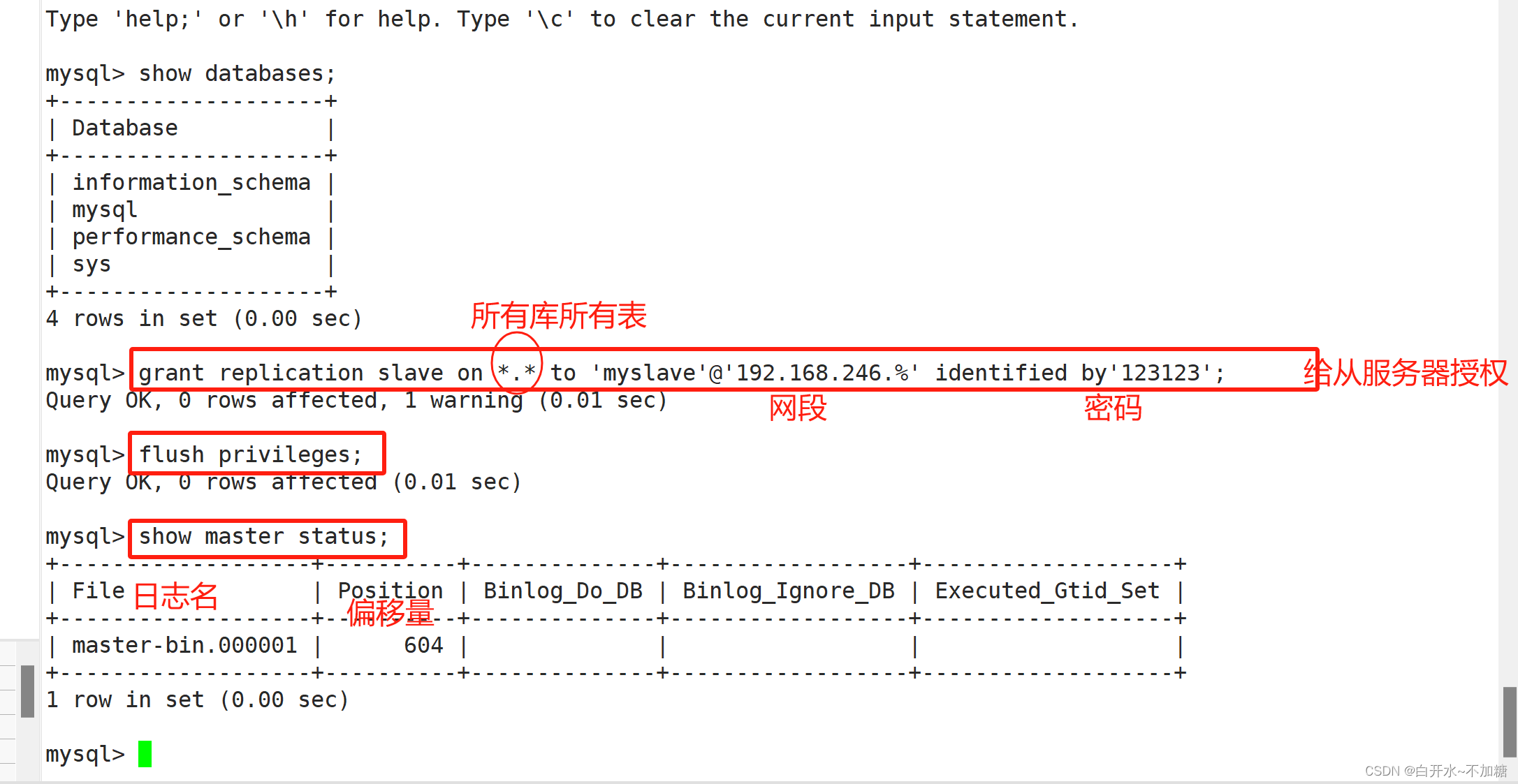
log-slave-updates = true #添加,允许slave从master复制数据时可以写入到自己的二进制日志systemctl restart mysqld #重启mysql服务mysql -uroot -p123123
grant replication slave on *.* to 'myslave'@'192.168.246.%' identified by '123123'; #同步权限所有用户所有表指定登录地址网段设置密码为123123
flush privileges; #刷新权限
show master status; #查看主服务器状态#File 列显示日志名,Position 列显示偏移量

server-id = 1
log-bin=master-bin
binlog_format= MIXED
log-slave-updates= true
④从服务器的mysql配置
#修改配置文件
vim /etc/my.cnf
[mysqld]
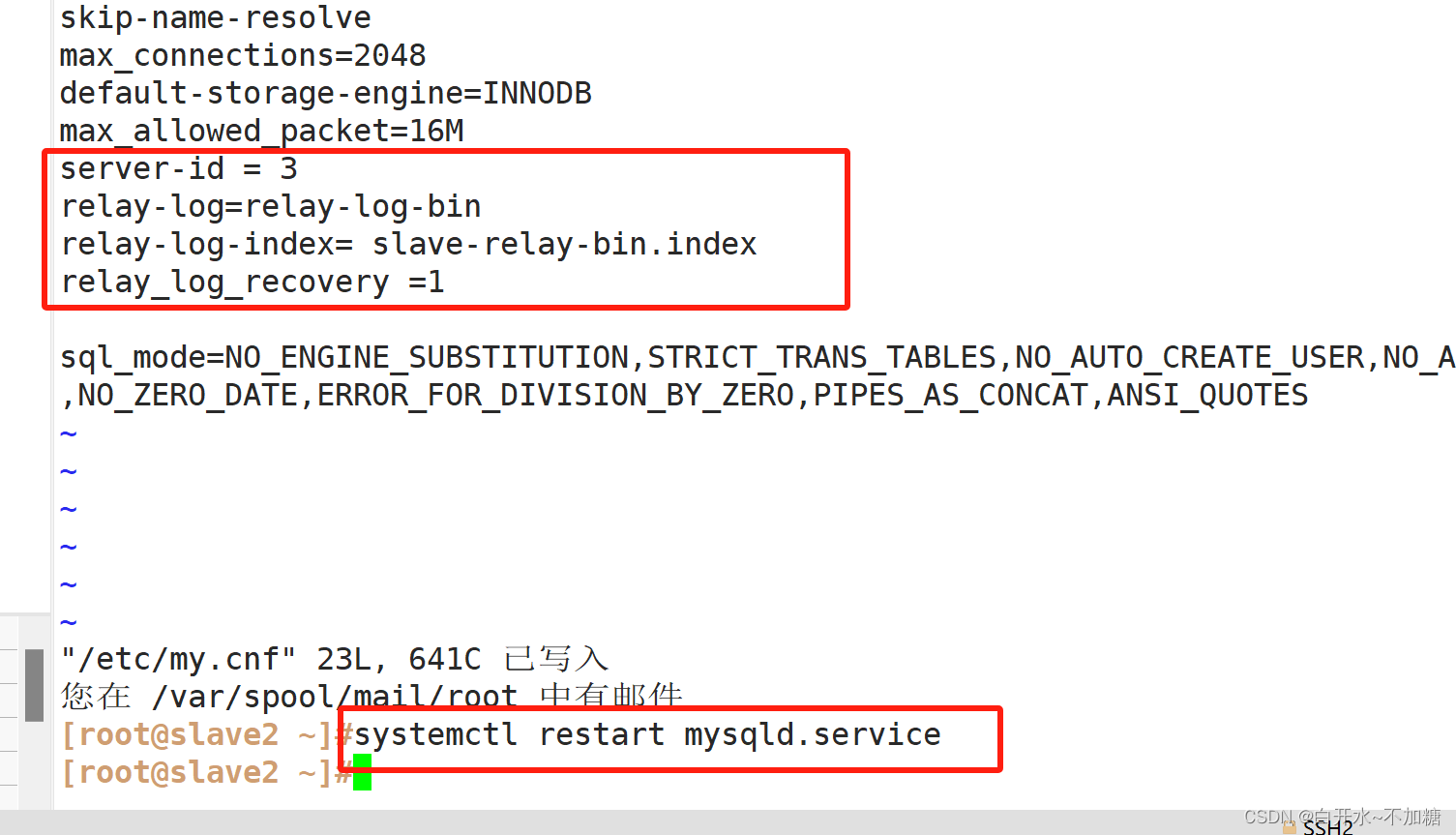
server-id = 2 #修改,注意id与Master的不同,两个Slave的id也要不同
relay-log=relay-log-bin #添加,开启中继日志,从主服务器上同步日志文件记录到本地
relay-log-index=slave-relay-bin.index #添加,定义中继日志索引文件的位置和名称,一般和relay-log在同一目录
relay_log_recovery = 1
#当 slave 从库宕机后,假如 relay-log 损坏了,导致一部分中继日志没有处理,则自动放弃所有未执行的 relay-log,并且重新从 master 上获取日志,这样就保证了relay-log 的完整性。默认情况下该功能是关闭的,将 relay_log_recovery 的值设置为 1 时, 可在 slave 从库上开启该功能,建议开启。
#重启服务
systemctl restart mysqld
#登录数据库,进行同步设置
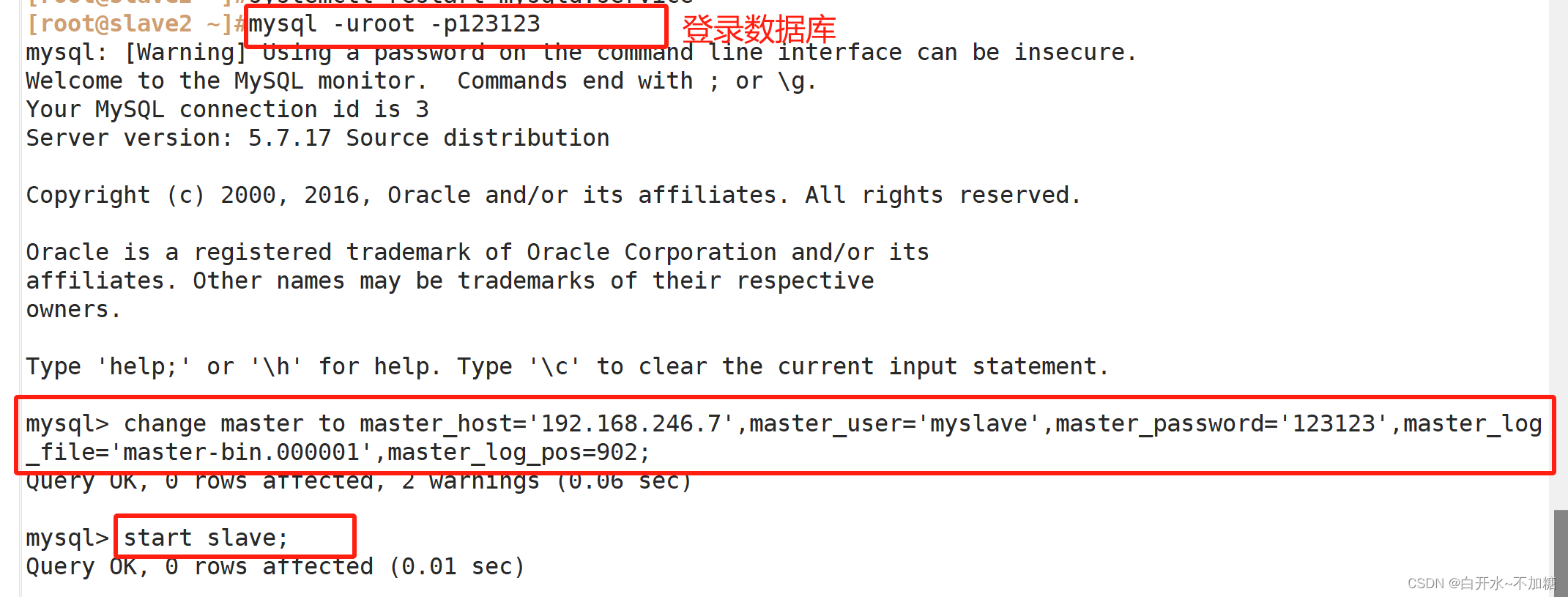
mysql -u root -p123123
change master to-> master_host='192.168.246.7', -> master_user='myslave', -> master_password='123123',-> master_log_file='mysql-bin.000001',-> master_log_pos=604;
#配置同步,注意master_log_file和master_log_pos的值要与master查询值一致start slave; #启动同步,如果有报错执行reset alsve;
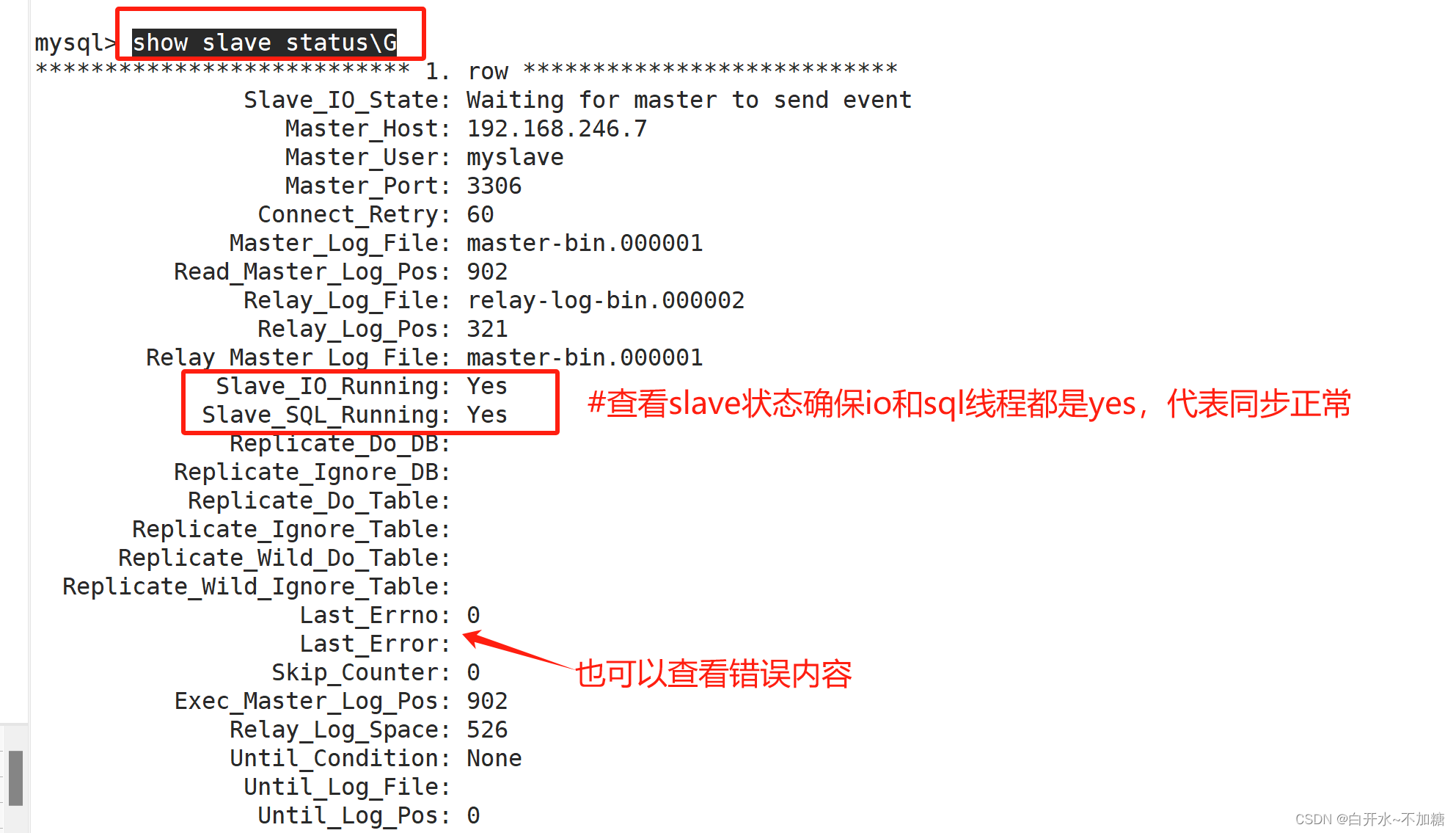
show slave status\G; #查看slave状态确保io和sql线程都是yes,代表同步正常Slave_IO_Running: Yes #负责与主机 io通信Slave_SQL_Running: Yes #负责自己的slave mysql进程##一般 "Slave_IO_Running: No" 的可能原因:1. 网络不通 2. my.cnf配置有问题(server-id重复)3. 密码、file文件名、pos偏移量不对 4. 防火墙没有关闭 slave1配置




server-id = 2
relay-log=relay-log-bin
relay-log-index= slave-relay-bin.index
relay_log_recovery =1slave2配置

⑤检测
去主服务器创建

去从服务器查看
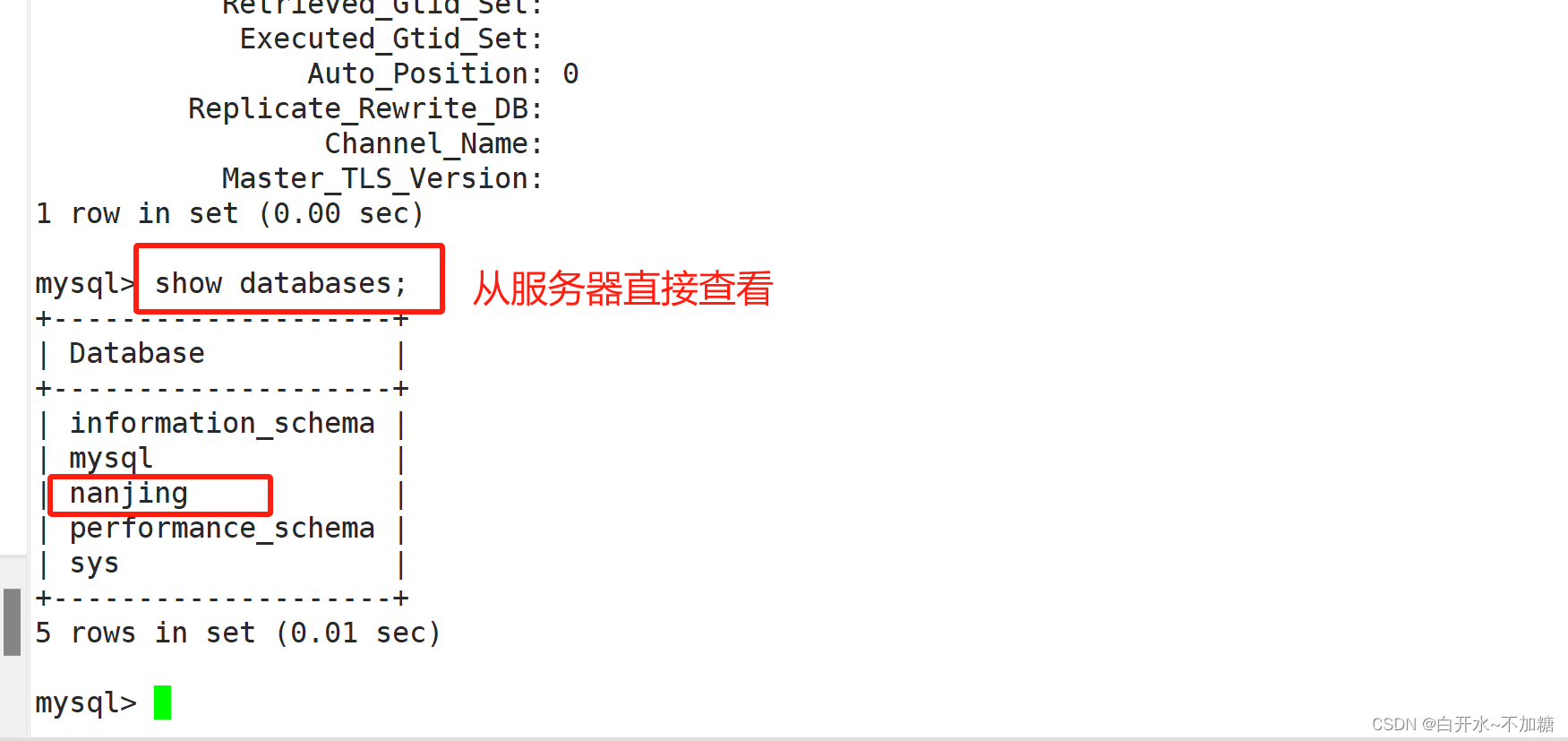

注:如数据中途加入主从复制的库 需要导出主服务器库 的库文件并且导入到从服务器中
五、MySQL主从复制延迟
1、master服务器高并发,形成大量事务
2、网络延迟
3、主从硬件设备导致
cpu主频、内存io、硬盘io
4、本来就不是同步复制、而是异步复制
从库优化Mysql参数。比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。
从库使用高性能主机。包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样提升了i/o方面性。
从库使用SSD磁盘
网络优化,避免跨机房实现同步
六、MySQL读写分离
6.1什么是读写分离?
- 读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE)
- 而从数据库处理SELECT查询操作
- 数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
6.2为什么要读写分离呢?
- 因为数据库的“写”(写10000条数据可能要3分钟)操作是比较耗时的。
- 但是数据库的“读”(读10000条数据可能只要5秒钟)。
- 所以读写分离,解决的是,数据库的写入,影响了查询的效率
6.3什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能。
6.4主从复制与读写分离
- 在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的
- 无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的
- 因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力
- 有点类似于rsync,但是不同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份
6.7MySQL 读写分离原理
- 读写分离就是只在主服务器上写,只在从服务器上读
- 基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询
- 数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
6.8目前较为常见的 MySQL 读写分离分为以下两种:
6.8.1基于程序代码内部实现
- 在代码中根据 select、insert 进行路由分类,这类方法也是目前生产环境应用最广泛的。
- 优点是性能较好,因为在程序代码中实现,不需要增加额外的设备为硬件开支;
- 缺点是需要开发人员来实现,运维人员无从下手。
- 但是并不是所有的应用都适合在程序代码中实现读写分离,像一些大型复杂的Java应用,如果在程序代码中实现读写分离对代码改动就较大。
6.8.2基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库
有以下代表性程序。
(1)MySQL-Proxy。MySQL-Proxy 为 MySQL 开源项目,通过其自带的 lua 脚本进行SQL 判断。
(2)Atlas。是由奇虎360的Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程。
(3)Amoeba。由陈思儒开发,作者曾就职于阿里巴巴。该程序由Java语言进行开发,阿里巴巴将其用于生产环境。但是它不支持事务和存储过程。
由于使用MySQL Proxy 需要写大量的Lua脚本,这些Lua并不是现成的,而是需要自己去写。这对于并不熟悉MySQL Proxy 内置变量和MySQL Protocol 的人来说是非常困难的。
Amoeba是一个非常容易使用、可移植性非常强的软件。因此它在生产环境中被广泛应用于数据库的代理层
6.9读写分离原理
- 只在主服务器上写,只在从服务器上读
- 主数据库处理事务性查询,从数据库处理SELECT查询
- 数据库复制用于将事务性查询的变更同步到集群中的从数据库
读写分离方案:
- 基于程序代码内部实现
- 基于中间代理层实现
MySQL-Proxy
Amoeba
mycat
搭建读写分离必须先搭建主从复制
6.9搭建读写分离
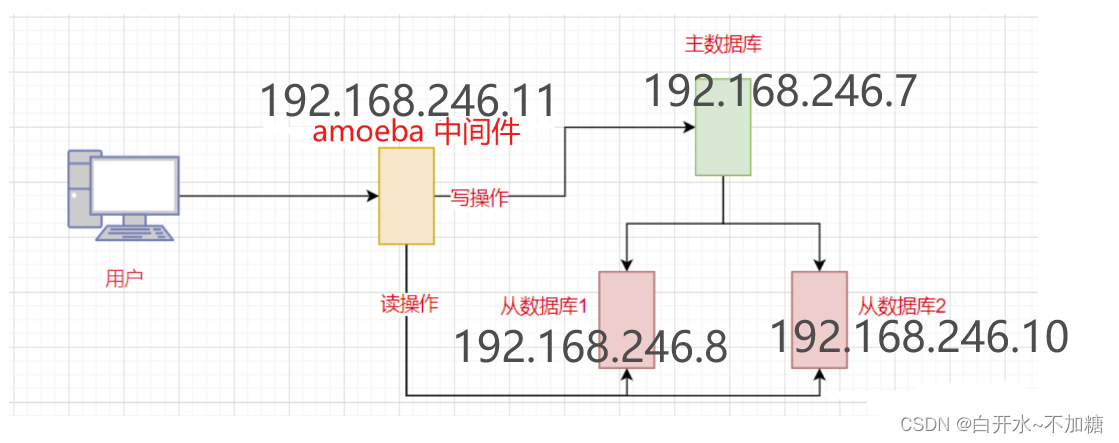
主mysql 服务器192.168.246.7
从mysql 服务器192.168.246.8
从mysql 服务器192.168.246.10
Amoeba 192.168.246.11
客户机 192.168.246.11
因为 Amoeba 基于是 jdk1.5 开发的,所以官方推荐使用 jdk1.5 或 1.6 版本,高版本不建议使用。
将jdk-6u14-linux-x64.bin 和 amoeba-mysql-binary-2.2.0.tar.gz.0 上传到/opt目录下。Amoeba服务器配置
安装 Java 环境
因为 Amoeba 基于是 jdk1.5 开发的,所以官方推荐使用 jdk1.5 或 1.6 版本,高版本不建议使用
①安装 Java 环境
[root@amoeba ~]# systemctl stop firewalld
[root@amoeba ~]# setenforce 0
[root@amoeba ~]# cd /opt/
[root@amoeba opt]# ls
[root@amoeba opt]#rz -E
[root@amoeba opt]#rz -E
[root@amoeba opt]#ls
amoeba-mysql-binary-2.2.0.tar.gz jdk-6u14-linux-x64.bin rh
[root@amoeba opt]#cp jdk-6u14-linux-x64.bin /usr/local/
[root@amoeba opt]# cd /usr/local/
[root@amoeba local]#chmod +x jdk-6u14-linux-x64.bin
[root@amoeba local]# ./jdk-6u14-linux-x64.bin
[root@amoeba local]#ls
bin etc games include jdk1.6.0_14 jdk-6u14-linux-x64.bin lib lib64 libexec sbin share src
[root@amoeba local]#mv jdk1.6.0_14/ /usr/local/jdk1.6
[root@amoeba local]#ls
bin etc games include jdk1.6 jdk-6u14-linux-x64.bin lib lib64 libexec sbin share src
[root@amoeba local]#vim /etc/profile

export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
[root@amoeba local]#source /etc/profile
[root@amoeba local]#java -version
java version "1.6.0_14"
Java(TM) SE Runtime Environment (build 1.6.0_14-b08)
Java HotSpot(TM) 64-Bit Server VM (build 14.0-b16, mixed mode)
[root@amoeba local]#②安装Amoeba软件
[root@amoeba local]#mkdir /usr/local/amoeba
[root@amoeba local]#ls
amoeba bin etc games include jdk1.6 jdk-6u14-linux-x64.bin lib lib64 libexec sbin share src
[root@amoeba local]#
[root@amoeba local]#tar zxvf /opt/amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
[root@amoeba local]#chmod -R 755 /usr/local/amoeba/
[root@amoeba local]#
[root@amoeba local]#/usr/local/amoeba/bin/amoeba
amoeba start|stop
[root@amoeba local]#

③ 配置 amoeba 读写分离
配置 Amoeba读写分离,两个 Slave 读负载均衡
#先在Master、Slave1、Slave2 的mysql上开放权限给 Amoeba 访问
主服务器授权:
grant all on *.* to test@'192.168.246.%' identified by '123123';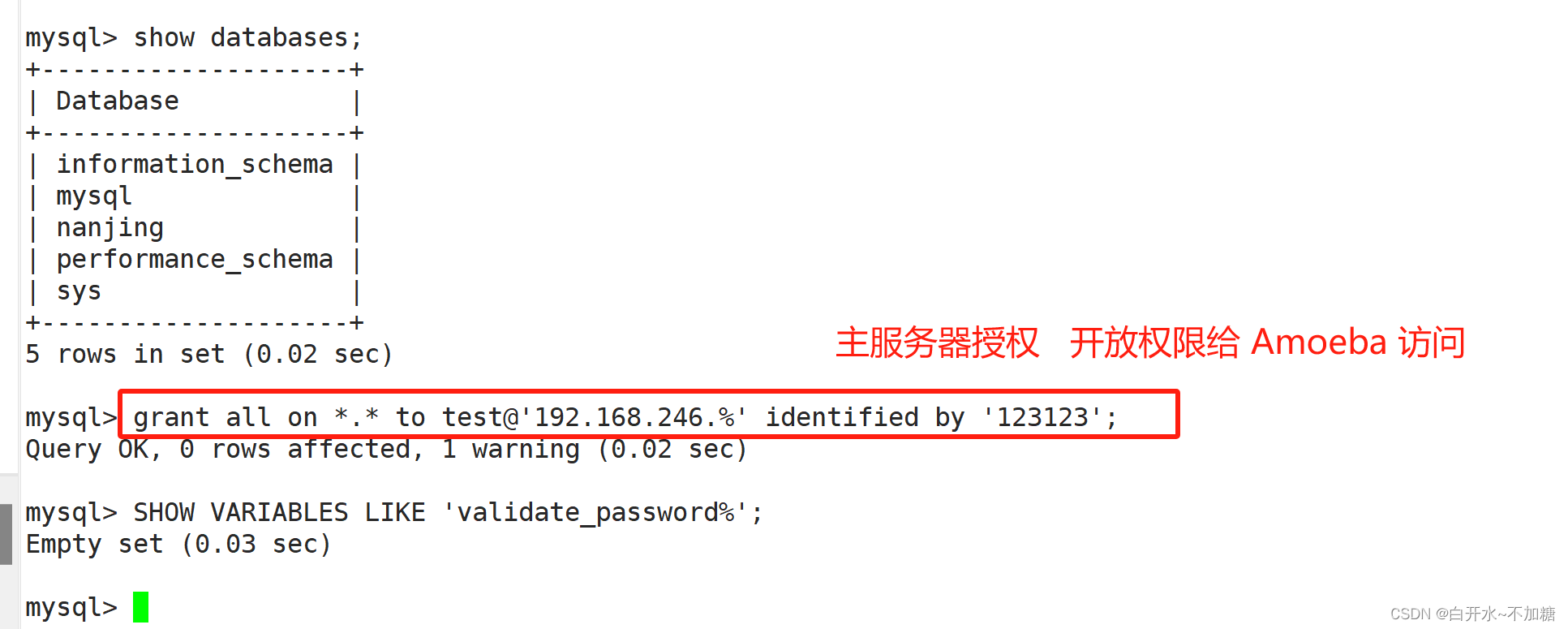
从服务器授权:

set global validate_password_policy=0;
set global validate_password_length=1;
#修改密码策略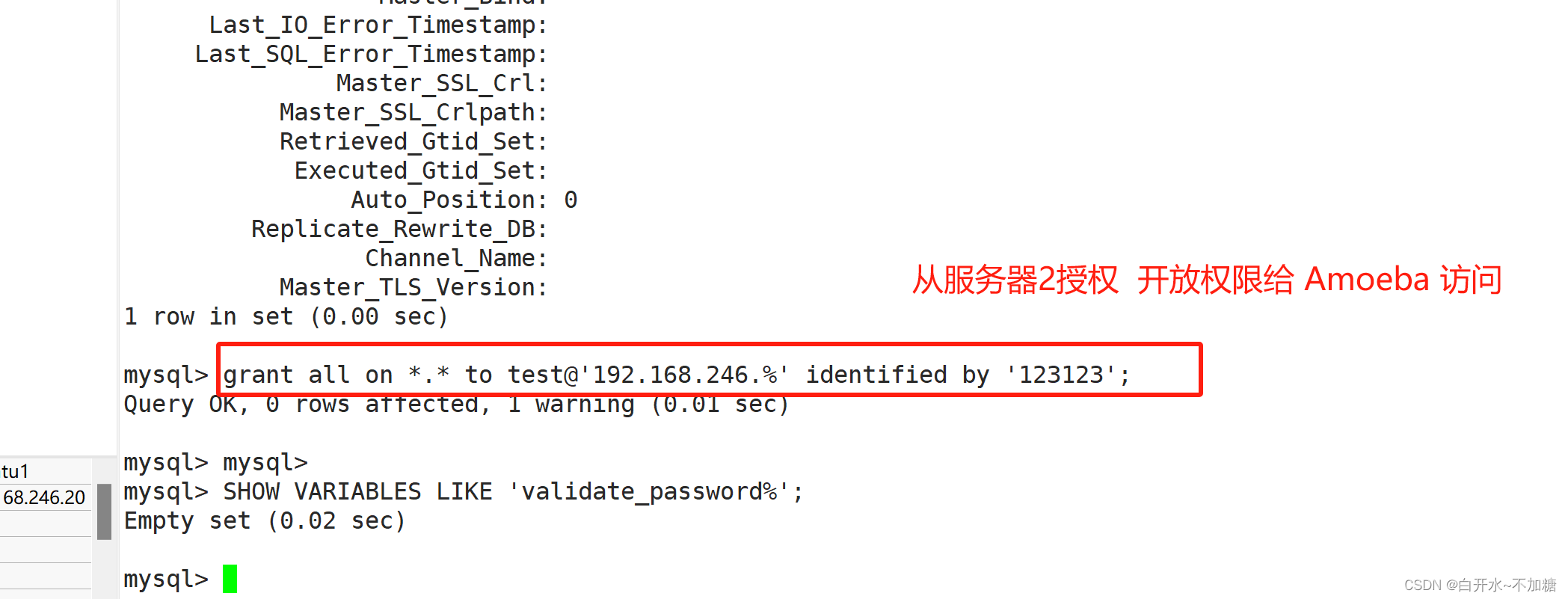
④修改Amoeba服务配置(读写分离(负载均衡))
amoeba.xml 配置文件的修改:
[root@amoeba ~]#cd /usr/local/amoeba/
[root@amoeba amoeba]#ls
benchmark bin changelogs.txt conf lib LICENSE.txt README.html
[root@amoeba amoeba]#cd /usr/local/amoeba/conf/
[root@amoeba conf]#ls
access_list.conf amoeba.xml dbServers.xml functionMap.xml log4j.xml ruleFunctionMap.xml
amoeba.dtd dbserver.dtd function.dtd log4j.dtd rule.dtd rule.xml
[root@amoeba conf]#cp amoeba.xml amoeba.xml.bak
[root@amoeba conf]#ls
access_list.conf amoeba.xml dbserver.dtd function.dtd log4j.dtd rule.dtd rule.xml
amoeba.dtd amoeba.xml.bak dbServers.xml functionMap.xml log4j.xml ruleFunctionMap.xml
[root@amoeba conf]#vim amoeba.xml
cd /usr/local/amoeba/conf/cp amoeba.xml amoeba.xml.bak
vim amoeba.xml #修改amoeba配置文件30修改
<property name="user">amoeba</property>
32修改
<property name="password">123123</property>
115修改
<property name="defaultPool">master</property>
117去掉注释–
<property name="writePool">master</property>
<property name="readPool">slaves</property>
115G跳转到115行
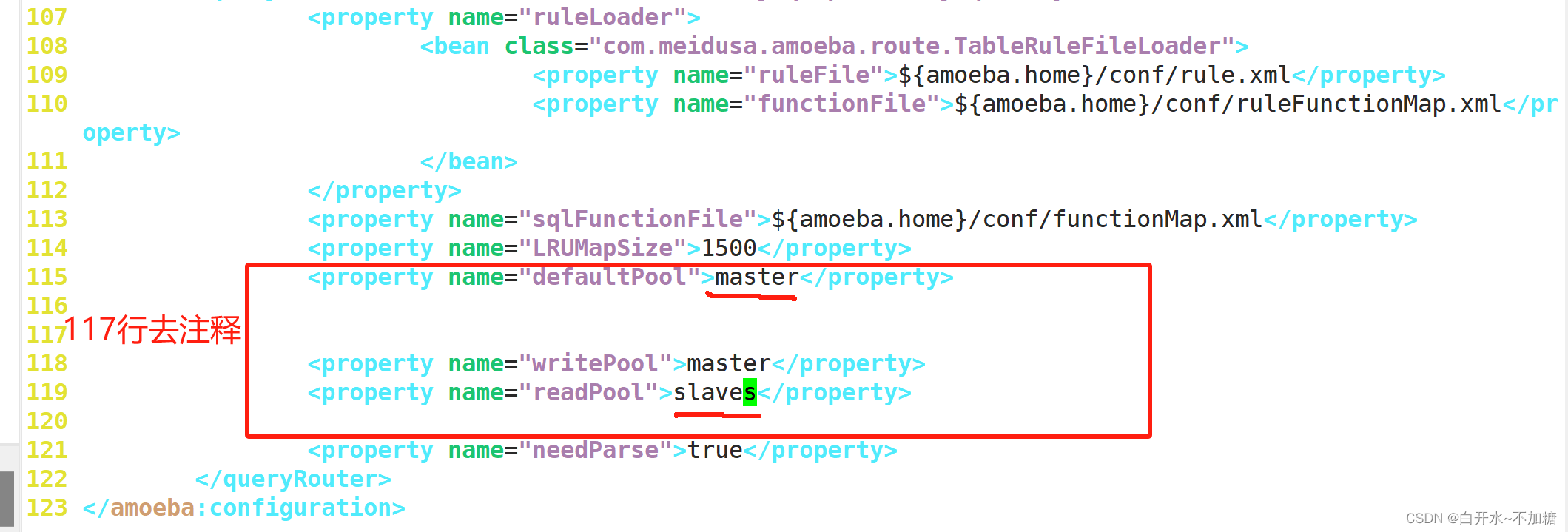
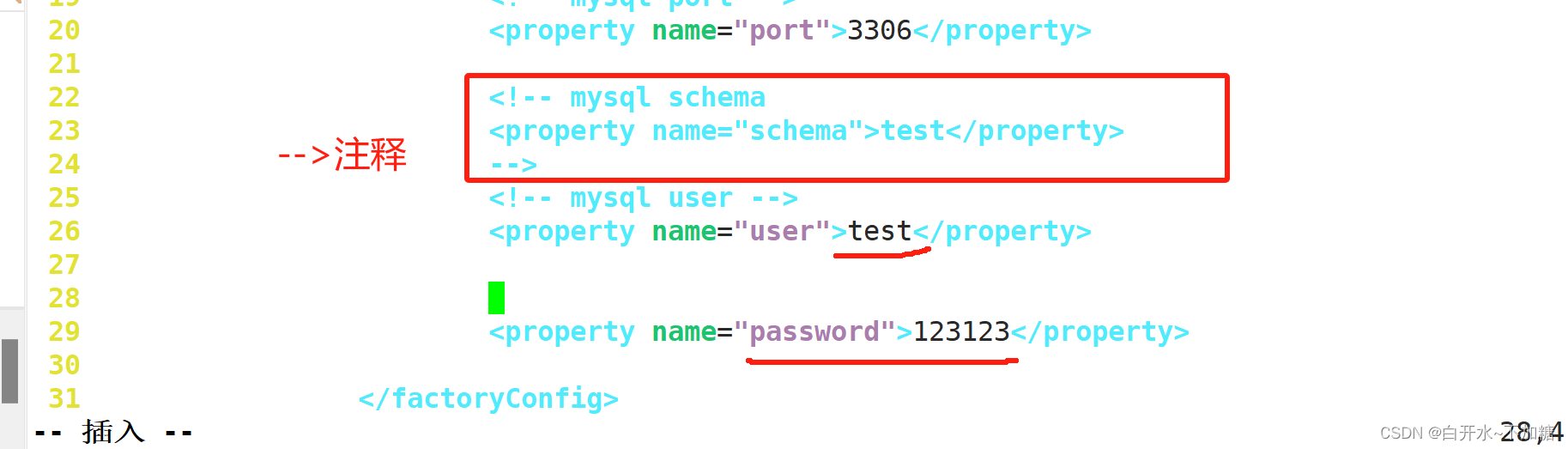
修改 dbServers.xml 数据库配置文件
cp dbServers.xml dbServers.xml.bakvim dbServers.xml #修改数据库配置文件23注释掉
作用:默认进入test库 以防mysql中没有test库时,会报错
<!-- mysql schema
<property name="schema">test</property>
-->
26修改
<!-- mysql user -->
<property name="user">test</property>
28-30去掉注释
<property name="password">123123</property>
45修改,设置主服务器的名Master
<dbServer name="master" parent="abstractServer">
48修改,设置主服务器的地址
<property name="ipAddress">192.168.246.7</property>
52修改,设置从服务器的名slave1
<dbServer name="slave1" parent="abstractServer">
55修改,设置从服务器1的地址
<property name="ipAddress">192.168.246.8</property>
58复制上面6行粘贴,设置从服务器2的名slave2和地址
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.246.10</property>
65修改
<dbServer name="slaves" virtual="true">
71修改
<property name="poolNames">slave1,slave2</property>/usr/local/amoeba/bin/amoeba start& #启动Amoeba软件,按ctrl+c 返回
netstat -anpt | grep java #查看8066端口是否开启,默认端口为TCP 8066

⑤启动amoeba
/usr/local/amoeba/bin/amoeba start &
#后台启动Amoeba软件,按ctrl+c 返回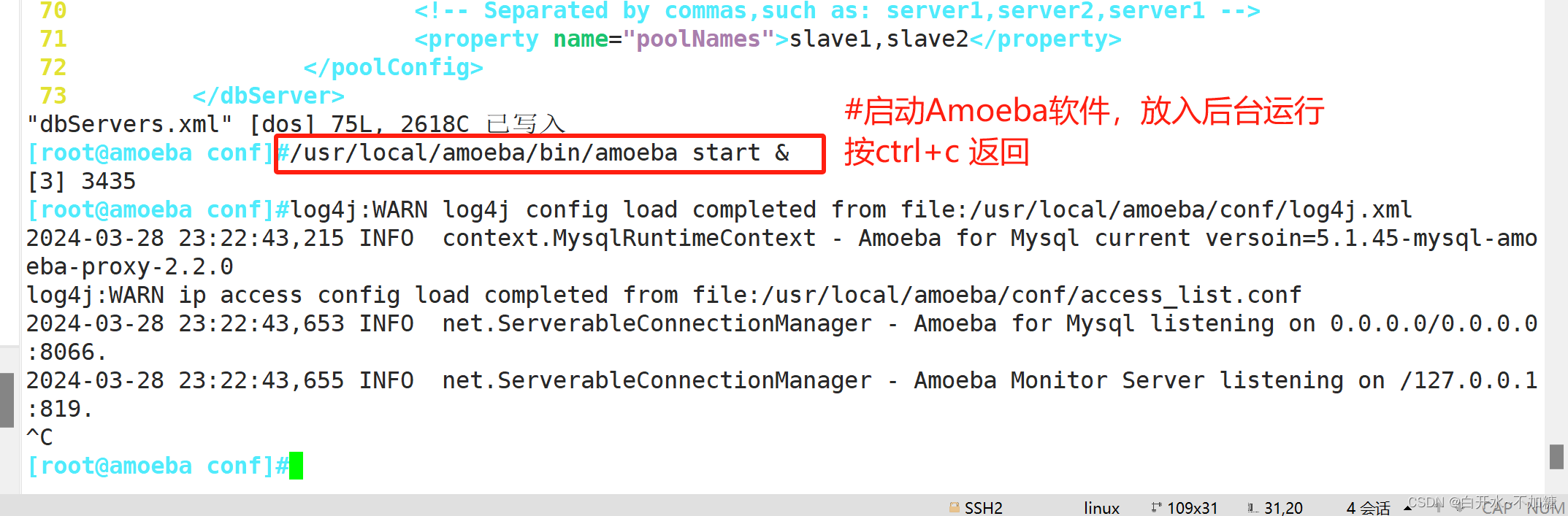
[root@amoeba conf]#netstat -anpt | grep java
tcp6 0 0 127.0.0.1:819 :::* LISTEN 3435/java
tcp6 0 0 :::8066 :::* LISTEN 3435/java
[root@amoeba conf]#netstat -anpt | grep 8066
tcp6 0 0 :::8066 :::* LISTEN 3435/java
[root@amoeba conf]#
⑥ 测试读写分离
在客户端服务器上进行测试:
使用yum快速安装MySQL虚拟客户端 安装mariadb
可换一台新机器,此处就不换了
[root@amoeba conf]#yum install -y mariadb-server mariadb
[root@amoeba conf]#systemctl start mariadb.service
[root@amoeba conf]#


在客户端服务器上测试:
mysql -u amoeba -p123456 -h 192.168.246,11 -P8066
//通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器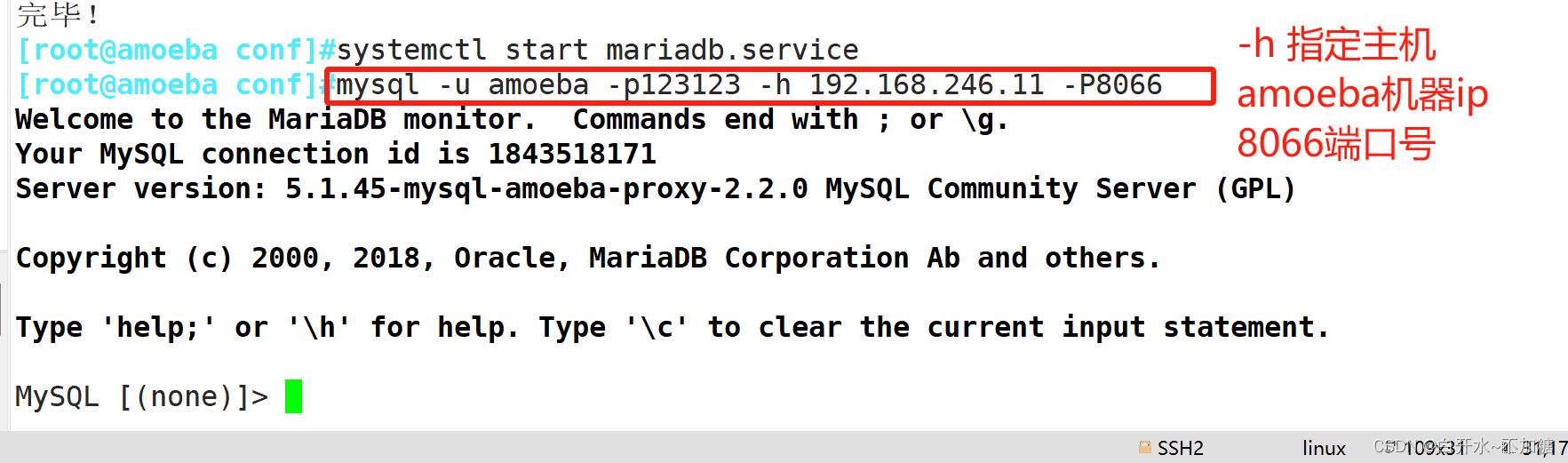
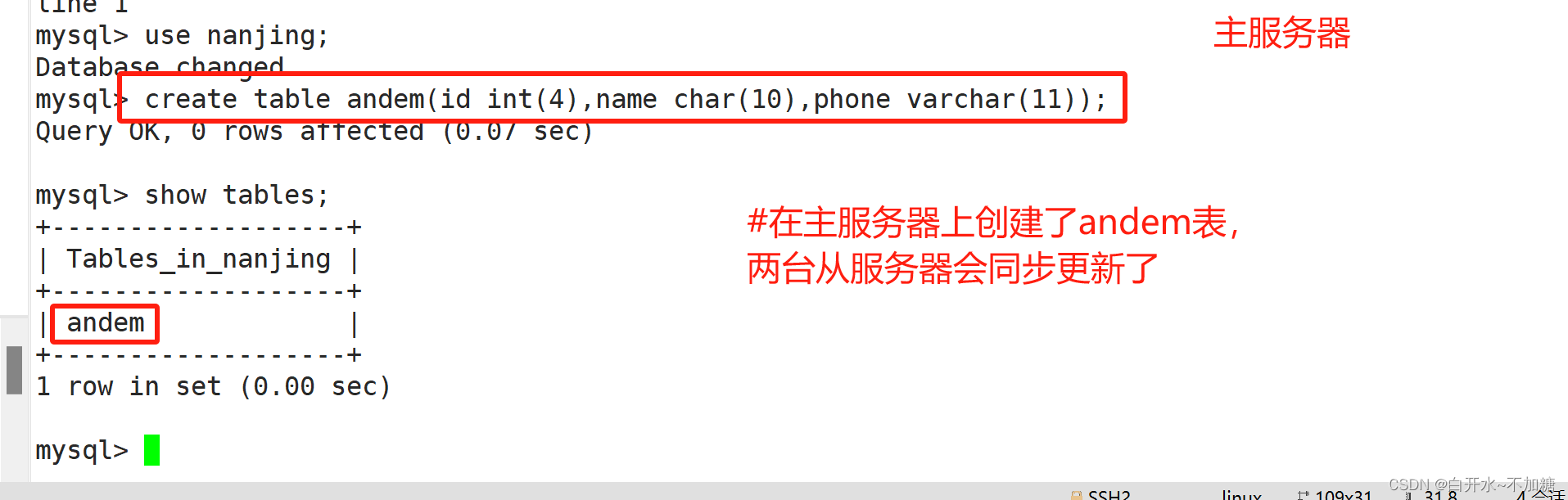
通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器
主服务器:
从服务器:


然后,我们停掉两台从服务器
主服务器:

从服务器1

从服务器2

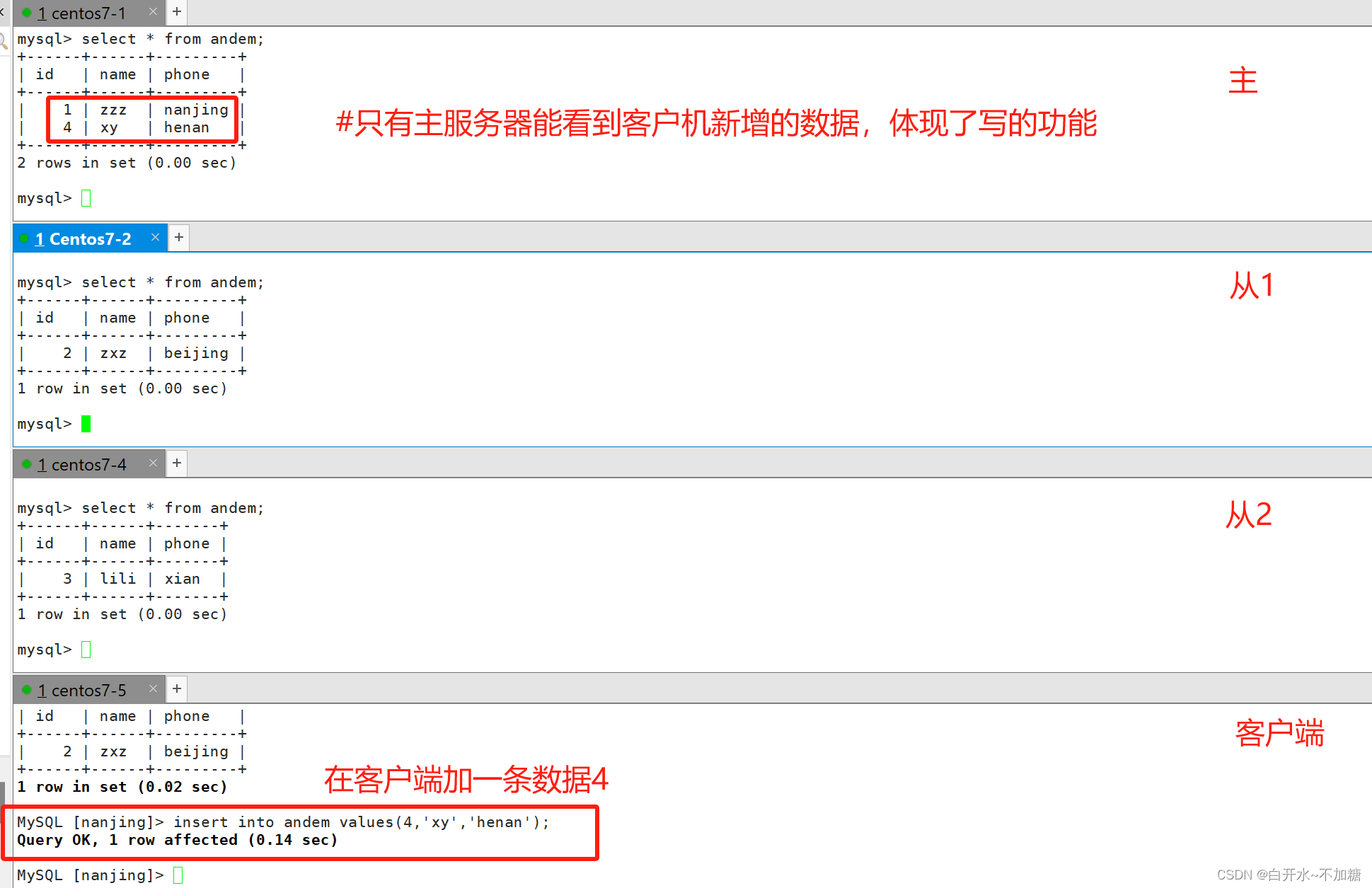
去客户端检测:
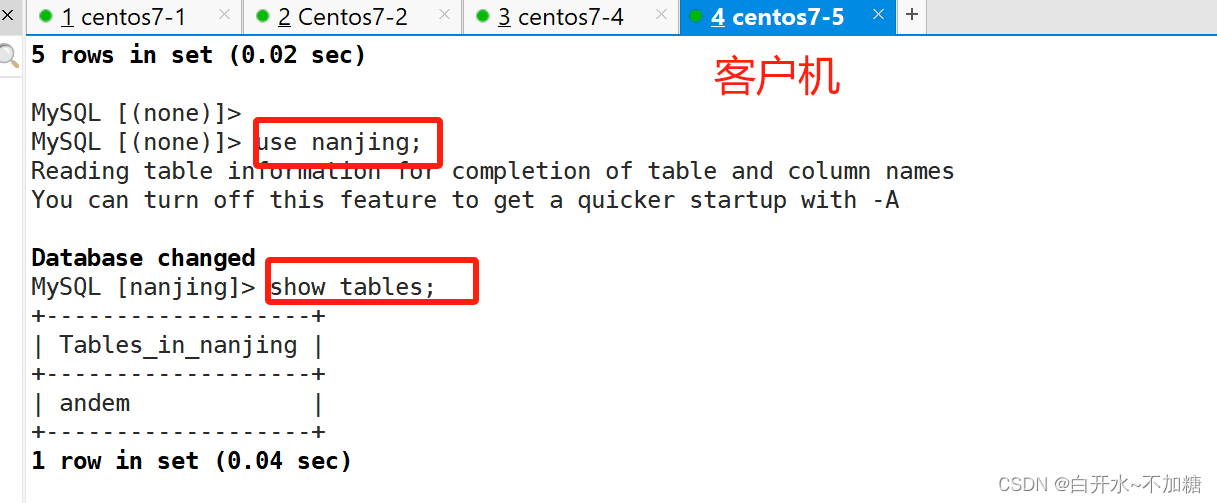
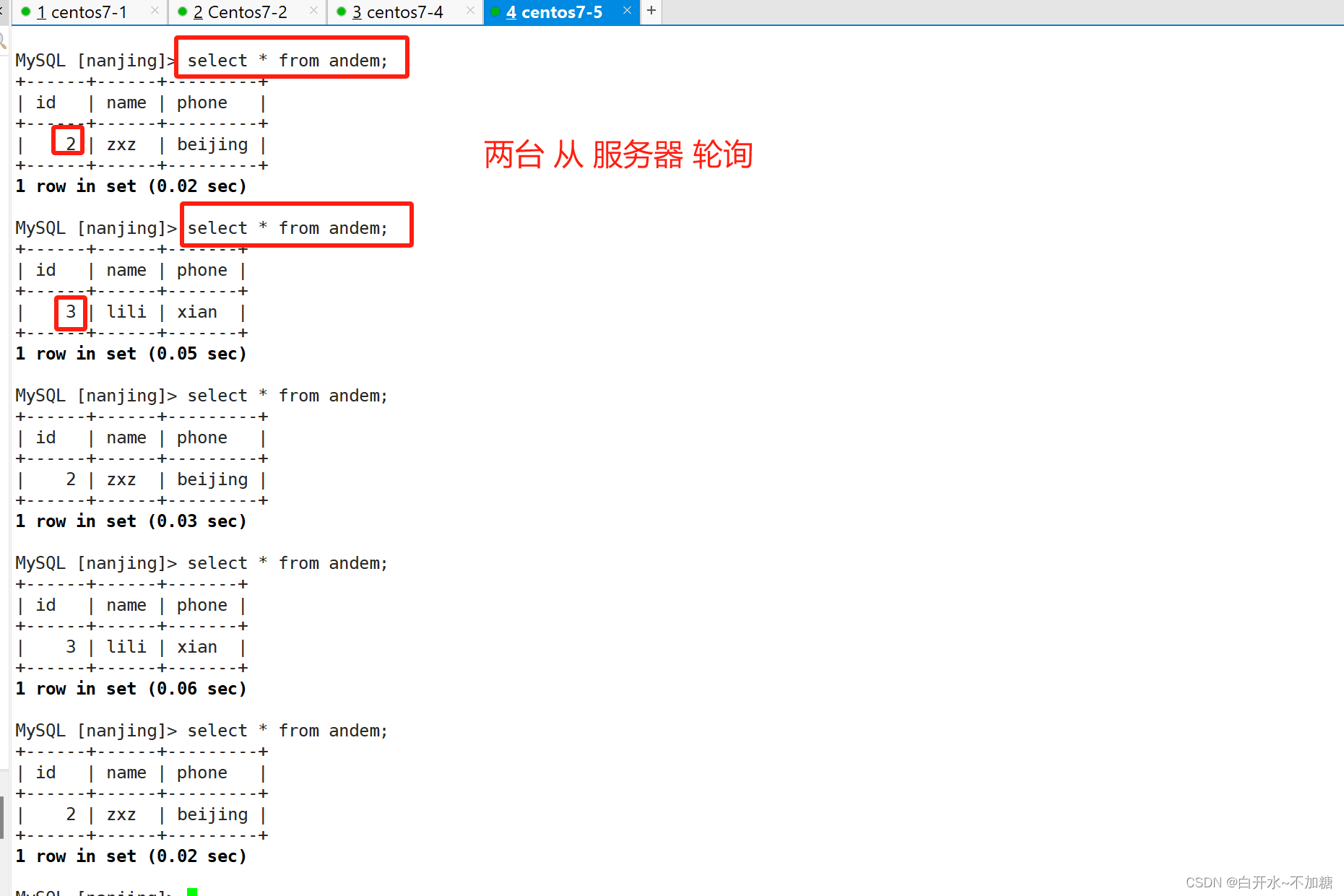
客户端会分别向slave1和slave2读取数据,显示的只有在两个从服务器上添加的数据,没有在主服务器上添加的数据
在客户端加数据看看

然后再开启主从复制
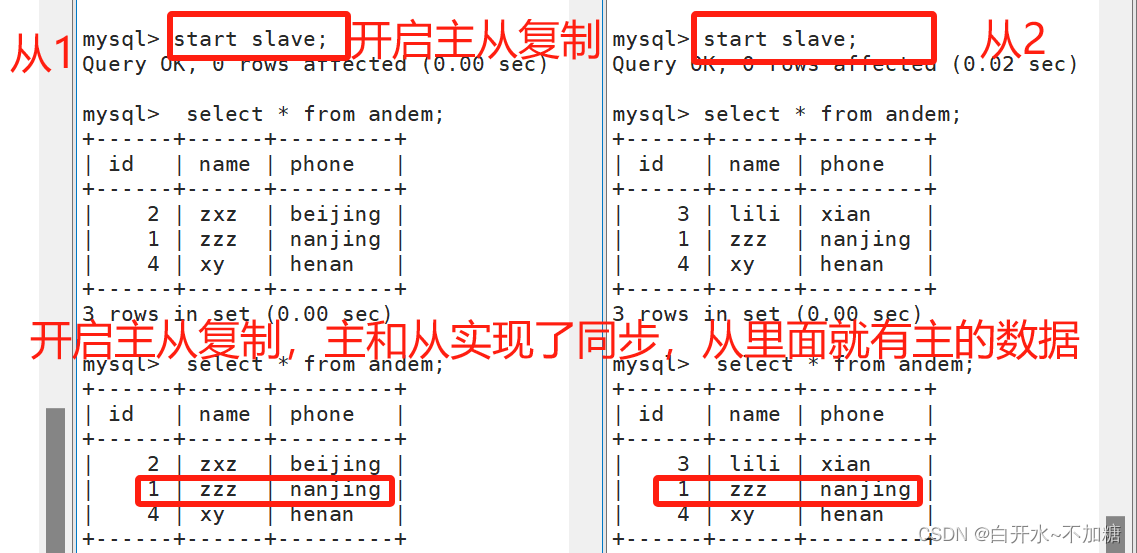
开启主从复制后,从服务器会和主服务器进行同步,因此两个从服务器都拥有了主服务器的数据
七、温故而知新
7.1主从同步复制原理
首先client端(tomcat)将数据写入到master节点的数据库中,master节点会通知存储引擎提交事务,同时会将数据以(基于行、基于sql、基于混合)的方式保存在二进制日志中
SLAVE节点会开启I/O线程,用于监听master的二进制日志的更新,一旦发生更新内容,则向master的dump线程发出同步请求
master的dump线程在接收到SLAVE的I/O请求后,会读取二进制文件中更新的数据,并发送给SLAVE的I/O线程
SLAVE的I/O线程接收到数据后,会保存在SLAVE节点的中继日志中
同时,SLAVE节点钟的SQL线程,会读取中继日志钟的熟,更新在本地的mysql数据库中
最终,完成slave——>复制master数据,达到主从同步的效果
7.2读写分离你们使用什么方式?
amoeba 代理 mycat 代码 sql_proxy
通过amoeba代理服务器,实现只在主服务器上写,只在从服务器上读;
主数据库处理事务性查询,从数据库处理select 查询;
数据库复制被用来把事务查询导致的变更同步的集群中的从数据库
7.3如何查看主从同步状态是否成功
在从服务器上内输入 show slave status\G 查看主从信息查看里面有IO线程的状态信息,还有master服务器的IP地址、端口事务开始号。
当 Slave_IO_Running和Slave_SQL_Running都是YES时 ,表示主从同步状态成功
7.4如果I/O不是yes呢,你如何排查?
首先排查网络问题,使用ping 命令查看从服务器是否能与主服务器通信
再查看防火墙和核心防护是否关闭(增强功能)
接着查看从服务slave是否开启
两个从服务器的server-id 是否相同导致只能连接一台
master_log_file master_log_pos的值跟master值是否一致
7.5show slave status能看到哪些信息(比较重要)
IO线程的状态信息
master服务器的IP地址、端口、事务开始的位置
最近一次的错误信息和错误位置
最近一次的I/O报错信息和ID
最近一次的SQL报错信息和id
7.6主从复制慢(延迟)会有哪些可能?怎么解决?
主服务器的负载过大,被多个睡眠或 僵尸线程占用 导致系统负载过大,从库硬件比主库差,导致复制延迟
主从复制单线程,如果主库写作并发太大,来不及传送到从库,就会到导致延迟
慢sql语句过多
网络延迟
7.7mysql主从复制版本
若主从版本不一致,从的版本一定要高于主,保证可以向下兼容
因为若主的版本更新,低版本的从无法兼容的。
相关文章:
探索数据库--------------mysql主从复制和读写分离
目录 前言 为什么要主从复制? 主从复制谁复制谁? 数据放在什么地方? 一、mysql支持的复制类型 1.1STATEMENT:基于语句的复制 1.2ROW:基于行的复制 1.3MIXED:混合类型的复制 二、主从复制的工作过程 三个重…...

【Hello,PyQt】控件拖拽
在 PyQt 中实现控件拖拽功能的详细介绍 拖拽功能是现代用户界面设计中常见的交互方式之一,它可以提高用户体验,增加操作的直观性。在 PyQt 中,我们可以很容易地实现控件之间的拖拽功能。本文将介绍如何在 PyQt 中实现控件的拖拽功能。 如何实…...

荟萃分析R Meta-Analyses 3 Effect Sizes
总结 效应量是荟萃分析的基石。为了进行荟萃分析,我们至少需要估计效应大小及其标准误差。 效应大小的标准误差代表研究对效应估计的精确程度。荟萃分析以更高的精度和更高的权重给出效应量,因为它们可以更好地估计真实效应。 我们可以在荟萃分析中使用…...

常用的8个应用和中间件的Docker运行示例
文章目录 1、Docker Web 管理工具 portainer2、在线代码编辑器 Code Server3、MySQL4、Redis5、Nginx6、PostgreSQL7、媒体管理工具 Dim8、Gitlab 1、Docker Web 管理工具 portainer Portainer 是一个轻量级的管理 UI ,可让你轻松管理不同的 Docker 环境࿰…...

UnoCSS实现背景图片样式加载
UnoCSS是一个好东西,可以把任何style样式通过css去描述。但是默认使用的tailwindcss有一个不完美,就是当使用图片时,背景图片无法通过原子化css直接描述。例如有一个背景图片,则必须为该图片单独出一个css样式,然后再加…...
vue前端工程化
前言 本文介绍的是有关于vue方面的前端工程化实践,主要通过实践操作让开发人员更好的理解整个前端工程化的流程。 本文通过开发准备阶段、开发阶段和开发完成三个阶段开介绍vue前端工程化的整体过程。 准备阶段 准备阶段我将其分为:框架选择、规范制…...

面向对象:继承
文章目录 一、什么叫继承?二、单继承三、多继承3.1多继承的各种情况3.1.1一般情况3.1.1特殊情况(菱形继承) 四、菱形继承引发的问题4.1 问题1:数据冗余4.2 问题2:二义性(无法确定到底是访问哪个) 五、虚拟继承解决菱形…...
ES学习日记(一)-------单节点安装启动
基于ES7.4.1编写,其实一开始用的最新的8.1,但是问题太多了!!!!不稳定,降到7.4 下载好的安装包上传到服务器或虚拟机,创建ES目录,命令mkdir -p /路径xxxx 复制安装包到指定路径并解压: tar zxvf elasticsearch-8.1.0-linux-x86_64.tar.gz -C /usr/local/es/ 进入bin目录安装,命…...
【管理咨询宝藏59】某大型汽车物流战略咨询报告
本报告首发于公号“管理咨询宝藏”,如需阅读完整版报告内容,请查阅公号“管理咨询宝藏”。 【管理咨询宝藏59】某大型汽车物流战略咨询报告 【格式】PDF 【关键词】HR调研、商业分析、管理咨询 【核心观点】 - 重新评估和调整商业模式,开拓…...
ArcGIS Pro横向水平图例
终于知道ArcGIS Pro怎么调横向图例了! 简单的像0一样 旋转,左转右转随便转 然后调整图例项间距就可以了,参数太多就随便试,总有一款适合你! 要调整长度,就调整图例块的大小。完美! 好不容易…...

线程创建的几种方式
1.继承Thread类 class MyThread extends Thread {public void run() {// 线程执行的任务for (int i 0; i < 5; i) {System.out.println("Thread: " i);try {Thread.sleep(1000); // 使线程休眠 1 秒} catch (InterruptedException e) {e.printStackTrace();}}}…...
)
Python教程:一文掌握Python多线程(很详细)
目录 1.什么是多线程? 1.1多线程与单线程的区别 1.2 Python 中的多线程实现方式 2.使用 threading 模块创建和管理线程 2.1创建线程:Thread 类的基本用法 2.2线程的启动和执行:start() 方法 2.3线程的同步和阻塞:join() 方…...

华为防火墙配置指引超详细(包含安全配置部分)以USG6320为例
华为防火墙USG6320 华为防火墙USG6320是一款高性能、高可靠的下一代防火墙,适用于中小型企业、分支机构等场景。该防火墙支持多种安全功能,可以有效抵御网络攻击,保护网络安全。 目录 华为防火墙USG6320 1. 初始配置 2. 安全策略配置 3. 防火墙功能配置 4. 高可用性配…...
固定在左上方某盒子内(如按钮)添加可拖动功能,使用react hook语法实现)
(含react-draggable库以及相关BUG如何解决)固定在左上方某盒子内(如按钮)添加可拖动功能,使用react hook语法实现
原生写法 // 封装组件 import React, { useState, useRef } from react;const DraggableModal ({ children }) > {const [position, setPosition] useState({ x: 0, y: 0 });const modalRef useRef(null);const handleMouseDown (e) > {const modal modalRef.curre…...

选择最佳图像处理工具OpenCV、JAI、ImageJ、Thumbnailator和Graphics2D
文章目录 1、前言2、 图像处理工具效果对比2.1 Graphics2D实现2.2 Thumbnailator实现2.3 ImageJ实现2.4 JAI(Java Advanced Imaging)实现2.5 OpenCV实现 3、图像处理工具结果 1、前言 SVD(stable video diffusion)开放了图生视频的API,但是限…...

微信小程序版本更新检测
app.vue文件 <script>export default {onLaunch: function() {console.log(App Launch)// #ifdef MP-WEIXINthis.getUpdateManager();// #endif},methods: {// 检测小程序更新getUpdateManager() {const updateManager wx.getUpdateManager();updateManager.onCheckFor…...

【每日力扣】343. 整数拆分与63. 不同路径 II
🔥 个人主页: 黑洞晓威 😀你不必等到非常厉害,才敢开始,你需要开始,才会变的非常厉害 343. 整数拆分 给定一个正整数 n ,将其拆分为 k 个 正整数 的和( k > 2 ),并使…...

洛谷 Cut Ribbon
思路:我们可以看出,这是一道完全背包问题,但是呢,有一点需要注意:那就是我们在装背包的时候并不能保证一定能装满背包,但是这里的背包要求是让我们装满的,所以我们需要判断这个背包装满才行&…...

#AS,idea,maven,gradle
Jdk,sdk。提前都是需要下好的。 Maven与gradle的思考: 用AS开发app时,gradle本就有,自己也可以指定,AGP同样。要注意gradle,AGP,jdk版本的事情。还有依赖库。 用idea开发网络程序时,也有内置的maven&…...
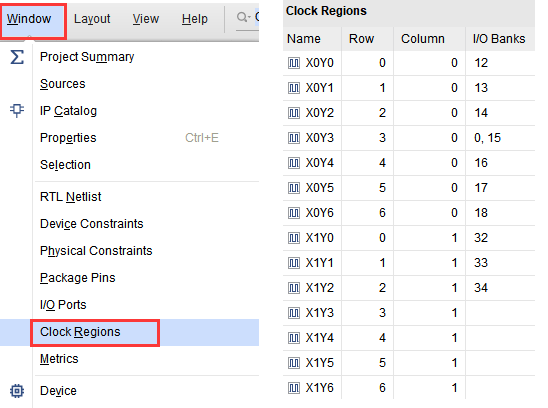
FPGA结构与片上资源
文章目录 0.总览1.可配置逻辑块CLB1.1 6输入查找表(LUT6)1.2 选择器(MUX)1.3 进位链(Carry Chain)1.4 触发器(Flip-Flop) 2.可编程I/O单元2.1 I/O物理级2.2 I/O逻辑级 3.布线资源4.其…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...

tomcat入门
1 tomcat 是什么 apache开发的web服务器可以为java web程序提供运行环境tomcat是一款高效,稳定,易于使用的web服务器tomcathttp服务器Servlet服务器 2 tomcat 目录介绍 -bin #存放tomcat的脚本 -conf #存放tomcat的配置文件 ---catalina.policy #to…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...

ThreadLocal 源码
ThreadLocal 源码 此类提供线程局部变量。这些变量不同于它们的普通对应物,因为每个访问一个线程局部变量的线程(通过其 get 或 set 方法)都有自己独立初始化的变量副本。ThreadLocal 实例通常是类中的私有静态字段,这些类希望将…...