Spark基于DPU Snappy压缩算法的异构加速方案
一、总体介绍
1.1 背景介绍
Apache Spark是专为大规模数据计算而设计的快速通用的计算引擎,是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些不同之处使 Spark 在某些工作负载方面表现得更加优越。换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark SQL是Spark的计算模块之一,专门用于处理结构化的数据。Spark SQL允许用户使用标准的SQL语句来执行SQL的查询和读写,也可以使用Hive SQL来执行对Hive仓库的查询和读写。
在Spark作业中,数据通常在内存中进行计算和操作,并且通过网络进行节点间的数据传输。Snappy压缩算法已经被广泛应用于各种大数据处理框架中,并且通常是默认的压缩选项。在Spark系统中,用户无需额外的配置即可使用Snappy压缩算法,这使得它成为Spark处理数据的首选压缩方式之一。
Snappy压缩算法是一种同时具备非常高的压缩速度,和较为合理的压缩率的压缩算法。Snappy压缩具有速度快、占用内存小、通用性强的优点,被广泛应用于大规模数据处理、网络传输、数据库存储、机器学习、图像处理等多个领域。
目前使用Snappy算法进行压缩解压缩的场景全部基于CPU进行,CPU除了需要维持整个计算场景的数据调度,还需要额外的算力进行压缩解压缩计算。CPU作为通用处理芯片,在大数据高密集型的数据计算上并无明显优势,这使得大部分应用场景下基于CPU运算时计算算力成为性能的主要瓶颈。
中科驭数自研的基于KPU架构的DPU芯片作为专用的数据处理芯片,在处理复杂的数据计算时相比于CPU拥有极高的性能提升。因此将Snappy压缩解压缩算法由CPU卸载到DPU,可以极大的提升计算性能。在复杂场景下,CPU专注于数据传递和计算任务调度,DPU专注于压缩解压缩计算。
中科驭数HADOS是一款敏捷异构软件平台,能够为网络、存储、安全、大数据计算等场景进行提速。对于大数据计算场景,HADOS可以认为是一个异构执行库,提供了数据类型、向量数据结构、表达式计算、IO和资源管理等功能。为了发挥CPU与DPU各自的性能优势,我们开发了HADOS-RACE项目,结合HADOS平台,既能够发挥CPU高速稳定的计算调度能力,又可以发挥DPU的向量化执行能力。
我们通过实验发现,Spark读数据的解压和写数据的压缩过程,在耗时上占比比较高,将Snappy压缩解压缩的计算任务通过HADOS-RACE卸载到DPU上, 相比于纯CPU计算,性能可提升约2倍。
本文将简单介绍基于DPU的Snappy压缩解压缩计算原理,并介绍如何基于DPU和HADOS-RACE来加速Snappy压缩解压缩计算,为大规模数据分析和处理提供更可靠的解决方案。
1.2 挑战和困难
在数据处理和传输的领域,快速且高效的压缩算法对于提高系统性能至关重要。然而,尽管Snappy压缩解压缩算法以其快速的压缩和解压缩速度而闻名,但其却存在一个不容忽视的挑战,即对CPU和内存资源的大量占用,从而导致性能下降的问题。
Snappy算法在压缩和解压缩数据时需要进行复杂的计算和处理。虽然它以其高效的算法设计和优化而著称,但在处理大量数据时,仍会对CPU提出较高的要求。特别是在需要快速压缩或解压缩大文件时,Snappy算法的CPU消耗可能会变得更为显著,从而导致系统整体性能的下降。对于CPU性能较低的系统而言,这一挑战尤为严峻,可能导致系统响应变慢,甚至造成任务阻塞和性能瓶颈。
综上所述,Snappy压缩解压缩算法的高效性和速度带来了性能优势,但其对CPU的大量占用也成为其性能低下的一个主要挑战。
二、整体方案
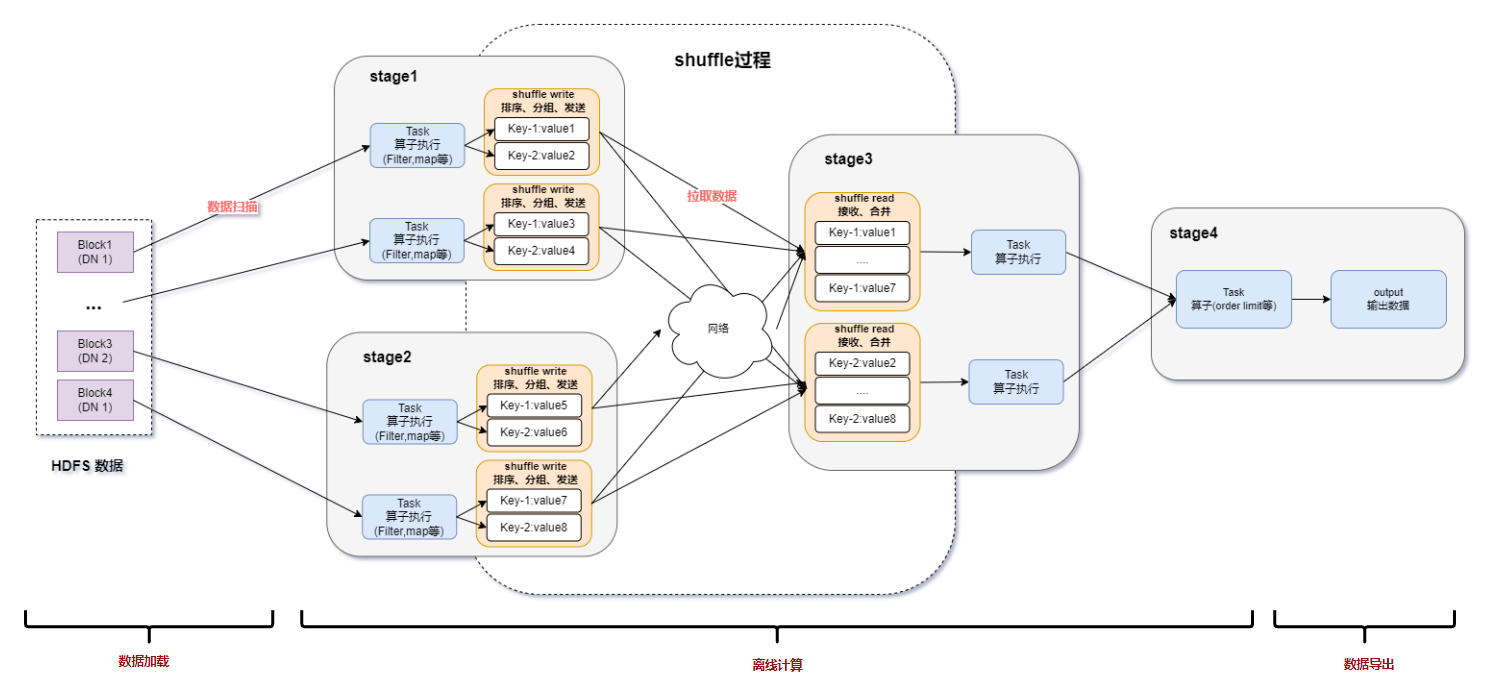
图一:Spark基于DPU Snappy压缩算法的异构加速整体方案
上图所示为Spark SQL的一个涉及FileScan、Shuffle、Aggregate、OrderBy计算的完整数据流转过程,Spark SQL的数据处理首先需要读取HDFS分布式文件存储系统中的Snappy压缩文件,然后会对Snappy压缩文件进行解压缩处理,从而得到计算所需的数据。拿到数据后根据SQL的逻辑进行相应的计算,常见的计算比如Filter、Aggregate、Join、Order By等,经过数据计算拿到想要输出的结果数据。最后会将结果数据写出并按Snappy格式进行压缩,得到的压缩文件会写回到HDFS中存储。
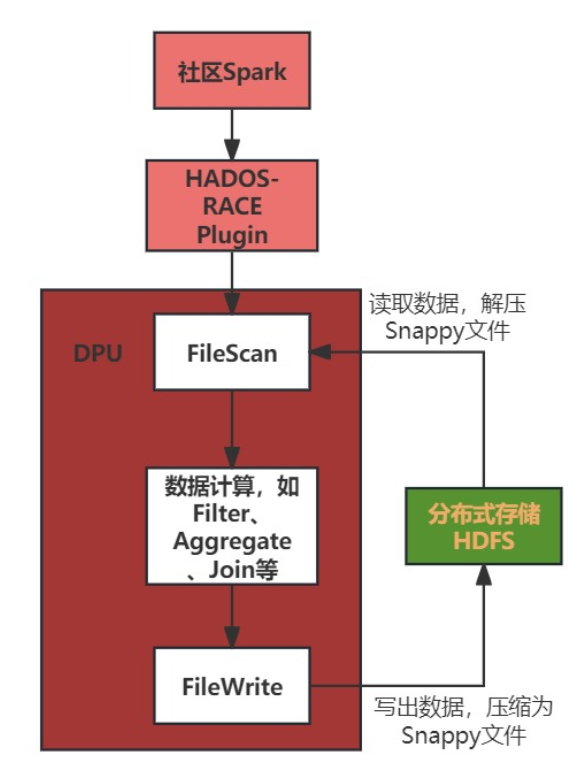
图二:基于DPU的算子卸载加速流程
上图所示为Spark将算子卸载到DPU进行计算的一个通用流程。首先Spark将SQL进行解析并得到最终的物理执行计划,然后将物理执行计划转化为具体的算子操作,Spark会通过HADOS-RACE Plugin将具体算子卸载到DPU进行处理。在DPU处理过程中,首先需要执行FileScan算子,将数据从HDFS文件系统中读取出来并对Snappy压缩文件执行解压缩操作。中间过程是对解压缩的数据进行计算,得到最终的结果数据。最后会将结果数据按Snappy格式压缩并导出到HDFS中存储。
在对整个Spark计算过程进行性能分析后,发现Snappy压缩和解压缩是两个耗时非常高的过程,占整个计算过程的比重较高。因此我们需要对Snappy的压缩和解压缩过程进行加速。
我们采用软硬件结合的方式,在数据压缩解压缩链路的软硬件两大方面都进行了全面提升和加速。
在软件方面,基于硬件对不同场景、数据量的压缩解压缩表现,HADOS-RACE可以灵活选择合适的压缩、解压缩的硬件平台。
在硬件方面,自研的DPU计算引擎拥有强大的Snappy压缩、解压缩能力,满足日益复杂的计算场景。
三、核心加速阶段
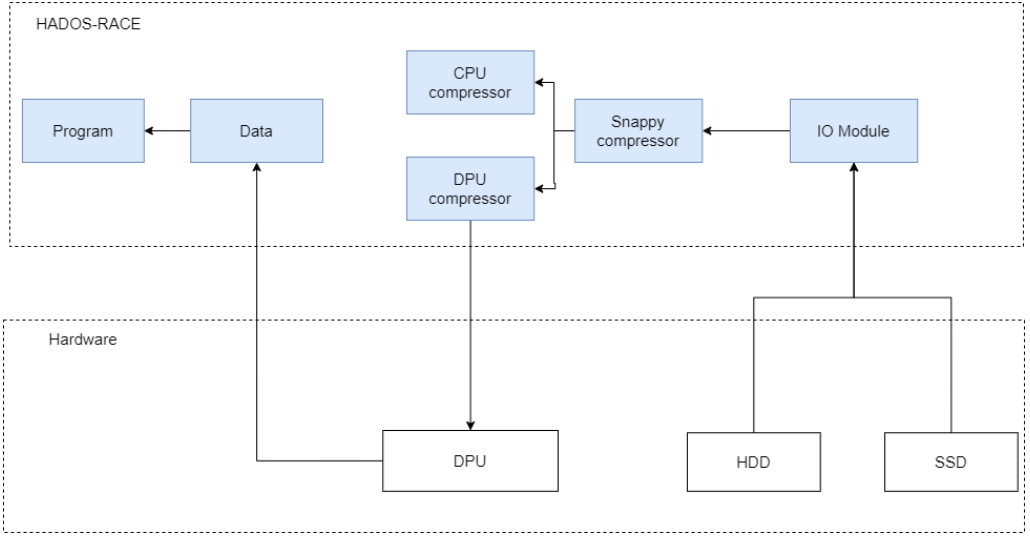
图三:基于DPU的整体加速流程图
加速阶段如上图所示,核心数据加速方案分为两个阶段,分别为 1.智能压缩解压缩策略选择阶段;2.对数据压缩解压缩阶段。
3.1 策略选择阶段
3.1.1 面临挑战
在数据压缩解压缩过程中,压缩解压缩策略选择阶段是整个过程的开始。传统的硬件体系结构中,数据的压缩和解压缩过程通常只能依赖CPU完成,没有其他策略可以选择,从而无法利用GPU、DPU等其他处理器资源。这种局限性导致数据压缩解压缩过程会大量占用CPU资源,从而降低系统的性能。
3.1.2 解决方案与原理
近年来,随着数据处理领域的不断发展和硬件技术的进步,DPU、GPU等计算资源的加入为数据压缩解压缩带来了新的可能性。这些不同的硬件平台具有各自独特的特点和优势,可以根据不同的场景和需求来选择合适的硬件平台进行数据压缩解压缩。
HADOS-RACE的IO模块负责将数据从硬盘读入内存中,并将其交由Compressor模块进行卸载策略判断。通过IO模块的数据加载过程,系统能够根据数据的特点和硬件平台的性能选择合适的压缩解压缩策略,从而实现数据处理的优化和提升。
在HADOS-RACE中,基于硬件对不同场景、数据量的性能表现,可以灵活配置压缩解压缩策略。例如,当数据量比较小的时候,可以直接通过CPU进行压缩解压缩,减少了内存和DPU硬件之间的数据传输,从而提高了系统的性能和效率。而对于大规模数据处理的场景,可以利用DPU等硬件资源进行并行计算,加速数据的处理速度。
3.1.3 优势与效果
HADOS-RACE的智能策略选择模块在数据加载过程中发挥了重要作用,通过分析数据的特征和硬件平台的性能,实现了对压缩解压缩策略的选择。这种灵活配置的策略不仅提高了数据处理的效率,也降低了系统的资源消耗,为数据处理和应用提供了更好的支持。
我们可以根据一定的策略选择合适的硬件平台来进行数据压缩解压缩,从而实现数据压缩解压缩的优化和提升。这为未来的数据压缩解压缩领域的发展带来了新的机遇和挑战,也为用户提供了更加灵活和高效的数据压缩解压缩方案。
3.2 压缩解压缩阶段
3.2.1 面临挑战
由于CPU在数据处理方面具有较强的通用性和灵活性,因此压缩解压缩算法通常被设计为在CPU上执行。然而,与DPU相比,CPU的并行处理能力相对较弱,无法充分发挥硬件资源的潜力。在大规模数据处理的场景下,数据压缩解压缩过程可能成为CPU的瓶颈,导致系统性能下降。此外,由于数据压缩解压缩是一个计算密集型任务,当系统中同时存在其他需要CPU资源的任务时,压缩解压缩过程可能会与其他任务产生竞争,进一步加剧了CPU资源的紧张程度,导致系统整体的响应速度变慢。
3.2.2 解决方案与原理
在传统的硬件体系结构中,数据的压缩和解压缩过程通常只能依赖CPU完成。然而,随着芯片技术的不断发展和创新,现代计算机系统已经实现了DPU等计算资源的利用,从而在数据处理领域带来了革命性的变化。DPU的并行计算能力远远超过CPU,使得它成为处理大规模数据的理想选择。近年来,随着DPU技术的日益成熟和运用,数据压缩解压缩过程已经可以借助DPU来执行,从而大大减少了对CPU资源的占用,提升了系统的性能和效率。
随着DPU芯片技术的不断发展和成熟,DPU已经成为了处理大规模数据的强大工具。DPU的并行计算能力远远超过CPU,能够同时处理大量数据,极大地加快了数据处理的速度。因此,现在可以利用DPU来执行数据的压缩和解压缩过程,从而减少了对CPU资源的占用,提升了系统的性能和效率。
3.2.3 优势与效果
DPU在数据压缩解压缩中的应用,主要体现在以下几个方面:
首先,DPU能够同时处理多个数据块,实现真正的并行计算。在数据压缩解压缩过程中,可以将大规模数据划分成多个小块,然后通过DPU同时对这些数据块进行压缩或解压缩,极大地提高了处理速度。
此外,DPU的计算能力可以轻松处理大规模数据,从而满足了现代大数据处理的需求。可以利用DPU来执行数据的压缩和解压缩过程,从而提高系统的性能和效率。
综上所述,利用DPU进行数据压缩解压缩等算力的卸载,已经成为了计算机系统的重要趋势。通过充分利用DPU的并行计算能力和卡上内存,可以大大减少对CPU资源的占用,提升系统的性能和效率。相信在未来的snappy数据压缩解压缩领域,DPU将会发挥越来越重要的作用。
四、加速效果
基于目前HADOS-RACE已经实现的Snappy压缩解压缩方案,制定了对应的性能测试计划。首先生成snappy测试数据,使用基于CPU和DPU的Spark分别对数据进行处理,记录各自的Snappy压缩解压缩阶段和Spark整体端到端的耗时和吞吐。执行的测试语句为:select * from table where a1 is not null and a2 is not null(尽量减少中间的计算过程,突出Snappy压缩解压缩的过程)。
4.1 压缩解压缩加速效果
单独分析Snappy压缩解压缩阶段,基于CPU的Snappy解压缩,吞吐量为300MB/s。而将解压缩任务卸载到DPU后,DPU核内计算的吞吐量可达到1585MB/s。可以看到,基于DPU进行Snappy解压缩,相比基于CPU进行Snappy解压缩,性能可提升约5倍。
对于系统整体而言,压缩解压缩计算的输入数据和输出数据,如果需要传输到CPU继续做计算,则有额外的PCIe数据传输的时间损耗,由于不同的数据量及压缩比带来的整体效果差别较大,所以以下测试数据仅供参考。表格中的DPU数据均为结合PCIe传输消耗的结果。压缩前的数据量均为128MB,但是由于数据内容不同导致压缩比不同,进而导致吞吐的不同,从以下测试结果中可以看出,压缩率越大,计算占比越高,DPU表现的越好。
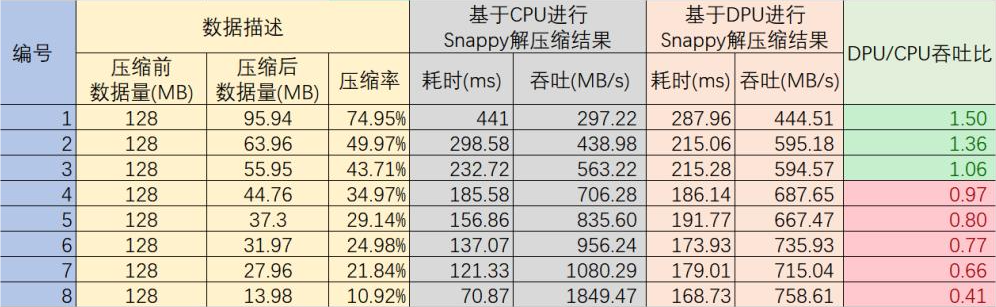
图四:基于DPU的Snappy压缩解压缩方案测试结果
4.2 端到端整体加速效果
基于CPU的Spark计算过程总体比基于DPU的Spark计算过程耗时减少了约50%。相当于基于DPU的端到端执行性能是基于CPU端到端性能的两倍。详细测试结果如下所示:
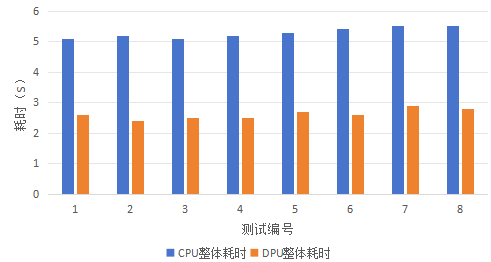
图五:基于DPU加速的端到端方案测试结果
4.3 结果分析
从测试结果中可以看到,在压缩率约为50%至70%时,基于DPU进行Snappy解压缩相比基于CPU进行Snappy解压缩,性能有1.1至1.5倍提升,其他情况下解压缩性能均有下降。造成这一现象的原因是,此次测试没有对DPU进行流程优化,从主机向DPU板卡传输数据时,DPU并没有并发执行计算任务。DPU的计算流程还有着极大的优化空间,优化后,DPU中的计算任务可以以流水线的形式进行调度,则数据传输过程将不会占用整体计算时间。
从Spark整个执行过程来看,基于DPU的Spark计算过程总体比基于CPU的Spark计算过程有2倍的性能提升。单独从Snappy压缩解压缩阶段看,在压缩率20%至100%之间,基于DPU的Snappy解压缩,相比于基于CPU的Snappy解压缩,性能上可以有1.5至5倍的性能提升。
五、未来规划
5.1 现有优势
性能方面,得益于DPU做算力卸载的高效性和智能策略选择算法,相对于传统压缩解压缩方式,基于DPU进行snappy压缩解压缩具备较为明显的性能优势。
资源占用方面,得益于将CPU的计算卸载到DPU上执行,服务器的CPU、内存、IO和网络资源占用等方面都有明显降低。特别是CPU资源,可以将压缩解压缩卸载到DPU的同时完成其他数据计算处理任务。
5.2 未来规划
优化和完善现有功能,继续增加其他算力的卸载。
未来计划在存算分离场景下适配snappy压缩解压缩功能。从远端读取数据后,首先数据会直接经过压缩或解压缩计算,从DPU卡出来的数据已经是经过压缩解压缩的,无需多余的数据传输和计算。
相关文章:
Spark基于DPU Snappy压缩算法的异构加速方案
一、总体介绍 1.1 背景介绍 Apache Spark是专为大规模数据计算而设计的快速通用的计算引擎,是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些不同之处使 Spark 在某些工作负载方面表现得更加优越。换句话说&am…...

如何使用python链表
在Python中,可以使用类来实现链表的数据结构。链表是一种数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的引用。 下面是一个简单的链表类的示例: class Node:def __init__(self, data):self.data …...

ADB的主要操作命令及详解
ADB,全称Android Debug Bridge,即安卓调试桥,是一个通用的命令行工具,其允许你与模拟器实例或连接的安卓设备进行通信。它可为各种设备操作提供便利,如安装和调试应用,并提供对Unix shell(可用来…...
傻瓜式启动关闭重启docker容器的脚本
运行脚本后,界面如下: 选择对应的编号后,会列举所有关闭的容器或者所有开启的容器列表,当我要启动一个容器 时输入1,就会出现下面的页面。 然后输入指定的编号后,就会启动对应的容器。 脚本代码如下&#…...
R语言使用dietaryindex包计算NHANES数据多种营养指数(2)
健康饮食指数 (HEI) 是评估一组食物是否符合美国人膳食指南 (DGA) 的指标。Dietindex包提供用户友好的简化方法,将饮食摄入数据标准化为基于指数的饮食模式,从而能够评估流行病学和临床研究中对这些模式的遵守情况,从而促进精准营养。 该软件…...
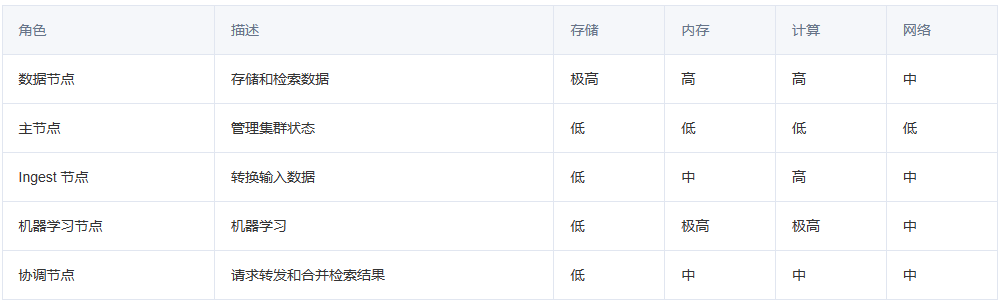
Elasticsearch 索引模板、生命周期策略、节点角色
简介 索引模板可以帮助简化创建和二次配置索引的过程,让我们更高效地管理索引的配置和映射。 索引生命周期策略是一项有意义的功能。它通常用于管理索引和分片的热(hot)、温(warm)和冷(cold)数…...
buy me a btc 使用数字货币进行打赏赞助
最近在调研使用加密货币打赏的平台,发现idatariver平台 https://idatariver.com 推出的buymeabtc功能刚好符合使用场景,下图为平台的演示项目, 演示项目入口 https://buymeabtc.com/idatariver 特点 不少人都听说过buymeacoffee,可以在上面发…...
Solidity Uniswap V2 Router swapTokensForExactTokens
最初的router合约实现了许多不同的交换方式。我们不会实现所有的方式,但我想向大家展示如何实现倒置交换:用未知量的输入Token交换精确量的输出代币。这是一个有趣的用例,可能并不常用,但仍有可能实现。 GitHub - XuHugo/solidit…...

网络安全渗透测试工具
网络安全渗透测试常用的开发工具包括但不限于以下几种: Nmap:一款网络扫描工具,用于探测目标主机的开放端口和正在运行的服务,是网络发现和攻击界面测绘的首选工具。Wireshark:一个流量分析工具,用于监测网…...
springcloud+nacos服务注册与发现
快速开始 | Spring Cloud Alibaba 参考官方快速开始教程写的,主要注意引用的包是否正确。 这里是用的2022.0.0.0-RC2版本的springCloud,所以需要安装jdk21,参考上一个文章自行安装。 nacos-config实现配置中心功能-CSDN博客 将nacos-conf…...

【C++程序员的自我修炼】基础语法篇(一)
心中若有桃花源 何处不是水云间 目录 命名空间 💞命名空间的定义 💞 命名空间的使用 输入输出流 缺省参数 函数的引用 引用的定义💞 引用的表示💞 引用的特性💞 常量引用💞 引用的使用场景 做参数 做返回值…...
小狐狸JSON-RPC:钱包连接,断开连接,监听地址改变
detect-metamask 创建连接,并监听钱包切换 一、连接钱包,切换地址(监听地址切换),断开连接 使用npm安装 metamask/detect-provider在您的项目目录中: npm i metamask/detect-providerimport detectEthereu…...

union在c语言中什么用途
在C语言中,union是一种特殊的数据类型,可以在同一块内存中存储不同类型的数据。它的主要用途有以下几个: 1. 节省内存:由于union只占用其成员中最大的数据类型所占用的内存空间,可以在不同的情况下使用同一块内存来存…...
)
2024年华为OD机试真题- 寻找最优的路测线路-Java-OD统一考试(C卷)
题目描述: 评估一个网络的信号质量,其中一个做法是将网络划分为栅格,然后对每个栅格的信号质量计算。路测的时候,希望选择一条信号最好的路线(彼此相连的栅格集合)进行演示。现给出R行C列的整数数组Cov,每个单元格的数值S即为该栅格的信号质量(已归一化,无单位,值越大…...

WPF 多路绑定、值转换器ValueConvert、数据校验
值转换器 valueconvert 使用ValueConverter需要实现IValueConverter接口,其内部有两个方法,Convert和ConvertBack。我们在使用Binding绑定数据的时候,当遇到源属性和目标控件需要的类型不一致的,就可以使用ValueConverter…...
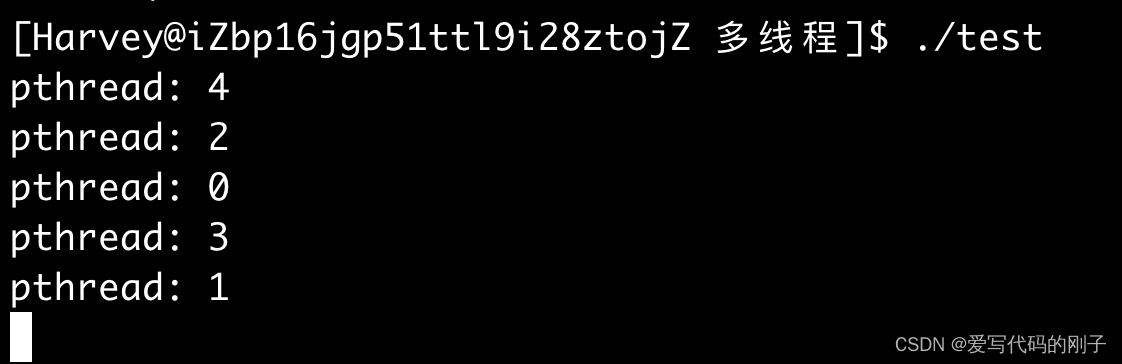
【Linux多线程】线程的同步与互斥
【Linux多线程】线程的同步与互斥 目录 【Linux多线程】线程的同步与互斥分离线程Linux线程互斥进程线程间的互斥相关背景概念问题产生的原因: 互斥量mutex互斥量的接口互斥量实现原理探究对锁进行封装(C11lockguard锁) 可重入VS线程安全概念常见的线程不安全的情况…...

Linux网卡bond的七种模式详解
像Samba、Nfs这种共享文件系统,网络的吞吐量非常大,就造成网卡的压力很大,网卡bond是通过把多个物理网卡绑定为一个逻辑网卡,实现本地网卡的冗余,带宽扩容和负载均衡,具体的功能取决于采用的哪种模式。 Lin…...
【学习笔记】java项目—苍穹外卖day01
文章目录 苍穹外卖-day01课程内容1. 软件开发整体介绍1.1 软件开发流程1.2 角色分工1.3 软件环境 2. 苍穹外卖项目介绍2.1 项目介绍2.2 产品原型2.3 技术选型 3. 开发环境搭建3.1 前端环境搭建3.2 后端环境搭建3.2.1 熟悉项目结构3.2.2 Git版本控制3.2.3 数据库环境搭建3.2.4 前…...
之vector超详用法整理)
C++之STL整理(2)之vector超详用法整理
C之STL整理(2)之vector用法(创建、赋值、方法)整理 注:整理一些突然学到的C知识,随时mark一下 例如:忘记的关键字用法,新关键字,新数据结构 C 的vector用法整理 C之STL整…...
机器学习作业二之KNN算法
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似&…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

Java线上CPU飙高问题排查全指南
一、引言 在Java应用的线上运行环境中,CPU飙高是一个常见且棘手的性能问题。当系统出现CPU飙高时,通常会导致应用响应缓慢,甚至服务不可用,严重影响用户体验和业务运行。因此,掌握一套科学有效的CPU飙高问题排查方法&…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...
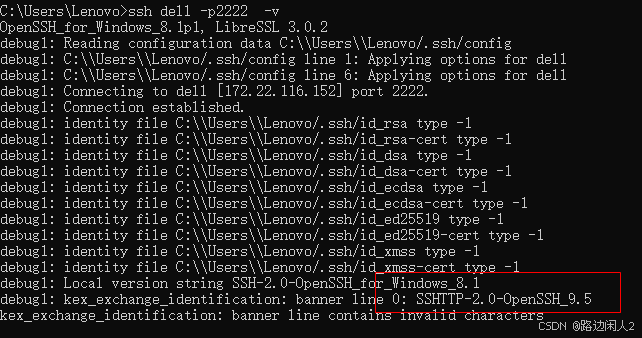
sshd代码修改banner
sshd服务连接之后会收到字符串: SSH-2.0-OpenSSH_9.5 容易被hacker识别此服务为sshd服务。 是否可以通过修改此banner达到让人无法识别此服务的目的呢? 不能。因为这是写的SSH的协议中的。 也就是协议规定了banner必须这么写。 SSH- 开头,…...

React核心概念:State是什么?如何用useState管理组件自己的数据?
系列回顾: 在上一篇《React入门第一步》中,我们已经成功创建并运行了第一个React项目。我们学会了用Vite初始化项目,并修改了App.jsx组件,让页面显示出我们想要的文字。但是,那个页面是“死”的,它只是静态…...

CTF show 数学不及格
拿到题目先查一下壳,看一下信息 发现是一个ELF文件,64位的 用IDA Pro 64 打开这个文件 然后点击F5进行伪代码转换 可以看到有五个if判断,第一个argc ! 5这个判断并没有起太大作用,主要是下面四个if判断 根据题目…...
大模型——基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程
基于Docker+DeepSeek+Dify :搭建企业级本地私有化知识库超详细教程 下载安装Docker Docker官网:https://www.docker.com/ 自定义Docker安装路径 Docker默认安装在C盘,大小大概2.9G,做这行最忌讳的就是安装软件全装C盘,所以我调整了下安装路径。 新建安装目录:E:\MyS…...