Paper Digest|基于在线聚类的自监督自蒸馏序列推荐模型
论文标题: Leave No One Behind: Online Self-Supervised Self-Distillation for Sequential Recommendation
作者姓名: 韦绍玮、吴郑伟、李欣、吴沁桐、张志强、周俊、顾立宏、顾进杰
组织单位: 蚂蚁集团
录用会议: WWW 2024 Research Track
本文作者:韦绍玮|蚂蚁集团高级算法工程师。 主要研究方向是图算法,推荐算法与语言大模型。研究成果曾多次收录于主流机器学习相关会议(WWW/AAAI/ECML)。过去一年团队的主要工作聚焦于通用推荐算法的研究和应用,在WWW’24发表了基于在线聚类的自监督自蒸馏序列推荐模型“S4Rec”一篇论文。
背景
序列推荐作为一种重要的推荐模式,在诸多网络平台,如亚马逊、阿里巴巴等上发挥着至关重要的作用。一般来说,序列推荐以用户的物品交互历史序列作为输入,预测近期可能发生的用户-物品交互。
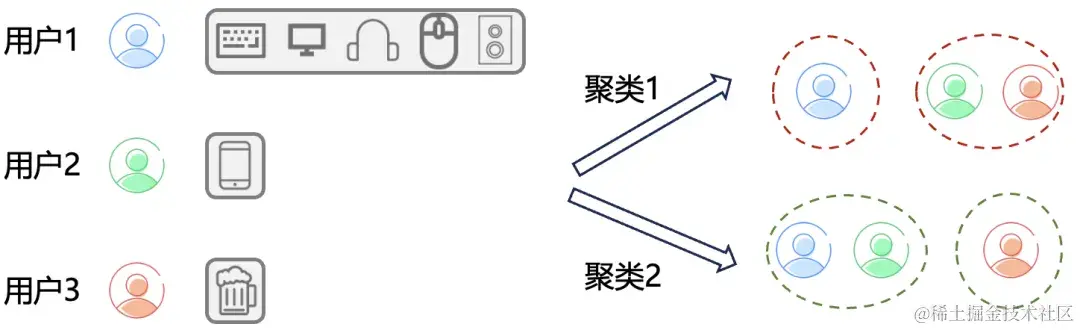
早期的序列推荐方法主要建模简单的低阶序列依赖,之后由于神经网络强大的非线性表达能力,多层感知机、递归神经网络以及Transformers等框架相继被引入至序列推荐。为了解决行为稀疏的用户信息缺失,训练得不够充分的问题,受计算机视觉(CV)和自然语言处理(NLP)使用的自监督学习启发,一些工作试图引入对比学习技术,通过最大化用户行为序列的增强视图的互信息来获取额外的监督信息,优化用户表征,进而改进序列推荐模型。为了进一步引入更多的信息,一些工作开始探索跨用户间共享的意图,如ICLRec。ICLRec通过K-means对用户进行聚类,它假设每一个簇代表着一个潜在意图,然后使用意图信息指导用户表征学习。然而,由于聚类算法属于无监督学习,聚类所得的簇的含义难以控制。下图展示了三位用户的行为历史序列,用户1比较活跃,历史行为丰富,因此序列长度较长;反之,用户1和用户2属于不活跃用户,历史交互只有1次。当我们尝试对三个用户聚类成两个簇的时候,可能会出现两种聚类模式(极端情况可能出现三种):
- 聚类1表示将用户按照是否活跃划分为两个簇;
- 聚类2表示将用户按照是否为电子产品爱好者划分为两簇;
我们不希望产生聚类1,因为只有聚类2是真正按照不同意图将用户区分开来。然而如果不加以设计的话,实际很有可能得到聚类1的结果。此外,K-means等传统聚类算法通常涉及对整个数据集的操作,这是相当耗时且耗费资源的。
综上分析,为了给用户,特别是行为稀疏用户提供更多可利用的信息,解决训练不充分的问题,蚂蚁集团提出了一种以在线聚类为基础的序列推荐模型,称为基于在线聚类的自监督自蒸馏模型 S 4 R e c S^4Rec S4Rec具体来说,我们首先对用户进行在线聚类, 识别用户不同的潜在意图。在这个过程中,我们利用对抗学习策略来确保聚类过程不受用户行为稀疏性因素的影响。随后,我们提出了一种自蒸馏方法来促进信息从行为丰富的用户(教师)传导到行为稀疏的用户(学生)。
方案设计
接下来我们详细介绍围绕用户聚类串联的整体方案 S 4 R e c S^4Rec S4Rec
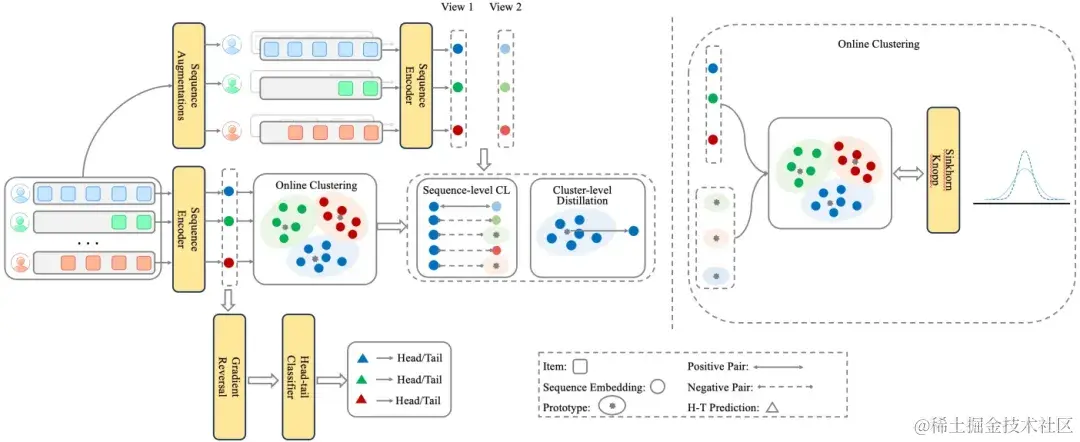
S 4 R e c S^4Rec S4Rec模型结构图
模块拆解
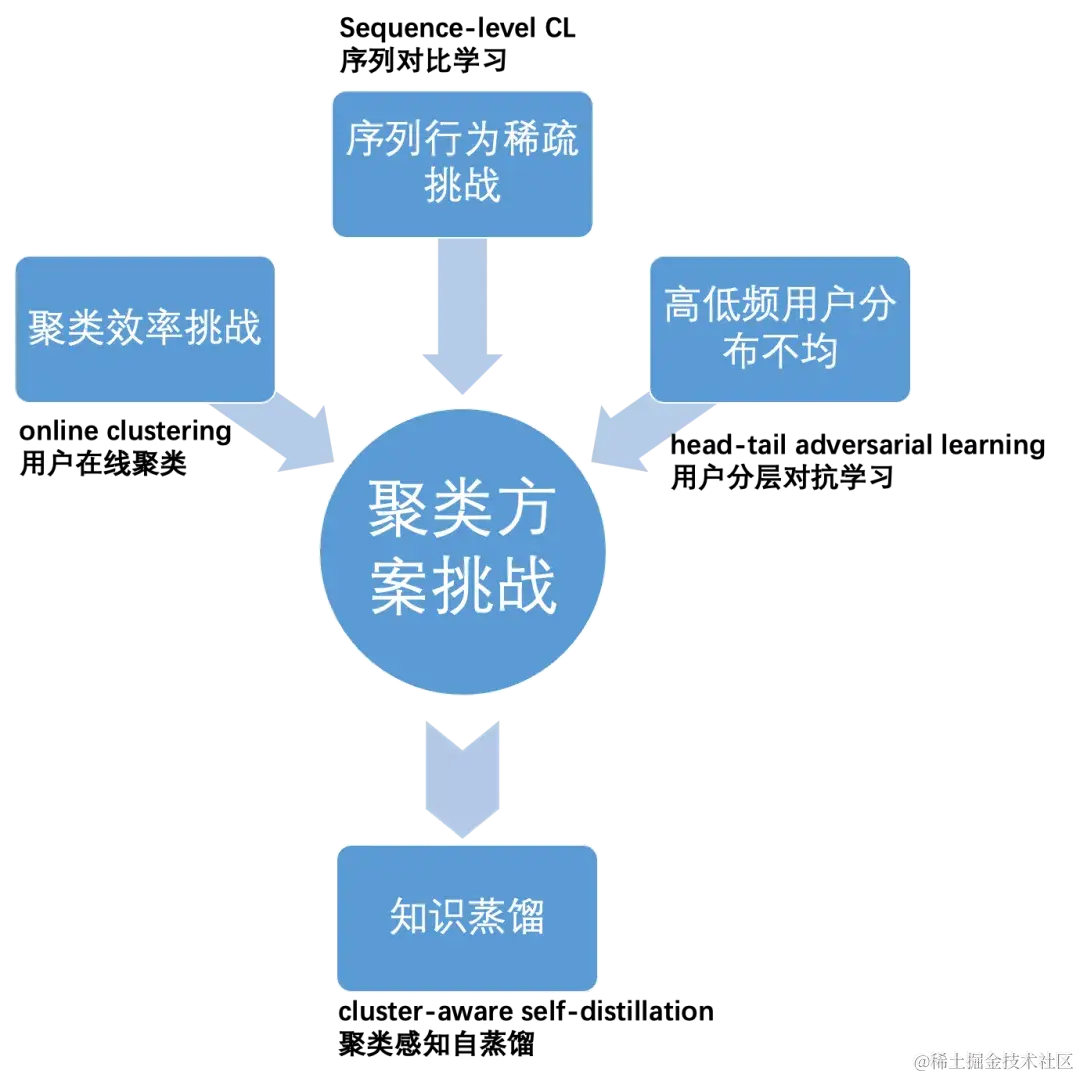
- 【主线】 兴趣聚类->知识蒸馏
根据用户的序列行为兴趣聚类,用所属聚类簇中心表征对用户表征进行知识蒸馏,将知识从行为丰富的用户传递给行为稀疏的用户。
- 挑战与解决方案
【问题1】 聚类效率挑战
-
- 问题分析:传统K-Means等离线聚类方案需要用全量数据迭代计算,计算成本高,并且与推荐主模型的两阶段计算模式会损失端到端的优化效率。
- 解决方案:在batch内实现基于原型的聚类,约束每个batch内的样本应该尽可能均匀地分配至不同的簇中,采用Sinkhorn-Knopp算法求解。
【问题2】序列行为稀疏的挑战
-
- 问题分析:兴趣聚类的主要输入是用户的历史行为序列,自然的难点就是低频用户的行为稀疏。
- 解决方案:将低频用户可被观测的行为视为其完整兴趣点的局部采样;对比学习的思路是通过mask/dropout等数据增强的方式对齐同一主体不同的局部view。在序列对比学习中,通过对用户序列输入随机mask生成两个view,基于InfoNCE Loss拉近两个view的序列表征,强化模型对稀疏行为序列表征的强健性。
【问题3】知识蒸馏的方案
-
- 问题分析:在原型聚类基础上,如何实现高频用户向低频用户的知识传递
- 解决方案:采用自蒸馏的方案实现U2C2U (user 2 cluster 2 user)的知识传递。具体实现为最大化用户表征(学生)和用户意图(教师)的分布相似度,聚类感知的自蒸馏损失定义为KL散度。
【问题4】高低频用户聚类分布不均衡的挑战
-
- 问题分析:基于行为序列的聚类结果与用户的行为频率高度耦合,导致高活用户与低活用户往往分布在不同的簇,进而阻断了高活到低活用户的知识传递。
- 解决方案:增加高低活用户的分类任务作为聚类的对抗学习任务,使得聚类任务避免受到用户行为稀疏度的影响,达到高活用户在各个簇中分布更加均匀的效果。具体方法是在编码器和分类器之间插入一个梯度反转层(GRL)。在反向传播过程中,用于最小化分类损失的梯度反向传播至分类器,并且在GRL之后,梯度将被反转,其进一步反传至编码器。也就是说,对于分类损失,我们对分类器的参数执行梯度下降,同时对编码器的参数执行梯度上升,从而实现对抗学习。
模型组件
Online Clustering: 用户在线聚类
基于用户行为序列和属性特征得到的表征的进行在线聚类,形成用户聚类簇分配和聚类质心。
首先,对用户原始特征 S u \mathcal{S}_{u} Su进行编码, f θ f_{\theta} fθ为编码器:
z u = f θ ( S u ) , \mathbf{z}_{u}=f_{\theta}(\mathcal{S}_{u}), zu=fθ(Su),
获取聚类簇隶属度向量,
μ k \bm{\mu}_k μk为参数化聚类原型:
p u k = exp ( z u μ k ⊤ / τ 1 ) ∑ k ′ exp ( z u μ k ′ ⊤ / τ 1 ) , \mathbf{p}_{u}^{k}=\frac{\exp(\mathbf{z}_{u}\bm{\mu}_k^{\top}/\tau_1)}{\sum_{k'}\exp(\mathbf{z}_{u}\bm{\mu}_{k'}^{\top}/\tau_1)}, puk=∑k′exp(zuμk′⊤/τ1)exp(zuμk⊤/τ1),
假设存在聚类标签 q u \mathbf{q}_{u} qu,则可以用交叉熵损失对聚类以batch的形式进行优化:
L C l u s t ( z u , q u ) = − ∑ k q u k log p u k . \mathcal{L}_{Clust}(\mathbf{z}_{u},\mathbf{q}_{u})=-\sum_{k}\mathbf{q}_{u}^{k}\log\mathbf{p}_{u}^{k}. LClust(zu,qu)=−∑kquklogpuk.
问题关键在于如何构建聚类标签。
由于聚类属于无监督学习,我们在此仅对聚类结果施加一项弱约束,即希望每个batch内的样本应该尽可能均匀地分配至不同的簇中,从而避免陷入平凡解。我们通过将聚类标签 Q \mathbf{Q} Q建模为运输多面体(transportation polytope)来实现均匀划分,其形式化为:
Q = { Q ∈ R + B × K ∣ Q 1 K = 1 B 1 B , Q ⊤ 1 B = 1 K 1 K } , \mathbf{Q}=\{\mathbf{Q}\in\mathbb{R}_{+}^{B\times K}|\mathbf{Q}\mathbf{1}_{K}=\frac{1}{B}\mathbf{1}_{B},\mathbf{Q}^{\top}\mathbf{1}_{B}=\frac{1}{K}\mathbf{1}_{K}\}, Q={Q∈R+B×K∣Q1K=B11B,Q⊤1B=K11K},
上式的一种解的形式为归一化指数矩阵:
Q ∗ = d i a g ( m ) exp ( Z μ ⊤ ϵ ) d i a g ( v ) . \mathbf{Q}^*=diag(\mathbf{m})\exp(\frac{\mathbf{Z}\bm{\mu}^{\top}}{\epsilon})diag(\mathbf{v}). Q∗=diag(m)exp(ϵZμ⊤)diag(v).
其中, m \mathbf{m} m和 v \mathbf{v} v是待求解向量。我们将聚类看作一个最优传输问题,即需要将B个样本以最小代价分配到K个cluster中,进而可以使用解决最优传输问题的各种方法和工具,本文中使用Sinkhorn-Knopp算法求解上式。
由此,我们可以在训练过程中迭代优化聚类原型 μ k \bm{\mu}_k μk,以及获取用户的簇分配 p u k \mathbf{p}_{u}^{k} puk。
Sequence-level CL:序列对比学习
通过对序列进行随机增强,将两组不同增强序列的表征作为正样本对进行对比学习。通过序列对比学习的自监督模块强化模型对稀疏行为序列表征的强健性。
用户的行为序列自然地可用于获取自监督信号。给定数据增强算子的函数集 G \mathcal{G} G,包含如mask、reorder和insert等算子,以及用户序列 S u \mathcal{S}_{u} Su,我们可以创建两个增强视图:
S ~ u 1 = g u 1 ( S u ) , S ~ u 2 = g u 2 ( S u ) , g u 1 , g u 2 ∈ G , \tilde{\mathcal{S}}_{u}^{1}=g_{u}^{1}(\mathcal{S}_{u}),\tilde{\mathcal{S}}_{u}^{2}=g_{u}^{2}(\mathcal{S}_{u}), g_{u}^{1},g_{u}^{2}\in \mathcal{G}, S~u1=gu1(Su),S~u2=gu2(Su),gu1,gu2∈G,
经典的InfoNCE损失只利用了样本本身的监督信息。我们经过在线聚类后,获得了用户的簇分配,可以进一步考虑用负原型构建负样本对,丰富对比学习监督信息。因此InfoNCE Loss可重写为:
L S C L = L S C L ( z u 1 , z u 2 ) + L S C L ( z u 2 , z u 1 ) , \mathcal{L}_{SCL}=\mathcal{L}_{SCL}(\mathbf{z}_{u}^{1},\mathbf{z}_{u}^{2})+\mathcal{L}_{SCL}(\mathbf{z}_{u}^{2},\mathbf{z}_{u}^{1}), LSCL=LSCL(zu1,zu2)+LSCL(zu2,zu1),
L S C L ( z u 1 , z u 2 ) = − log exp ( z u 1 z u 2 ⊤ / τ 2 ) ∑ n ≠ u exp ( z u 1 z n ⊤ / τ 2 ) + ∑ k ′ ≠ h ( u ) exp ( z u 1 μ k ′ ⊤ / τ 2 ) , \mathcal{L}_{SCL}(\mathbf{z}^{1}_{u},\mathbf{z}^{2}_{u})= -\log\frac{\exp(\mathbf{z}^{1}_{u}\mathbf{z}^{2\top}_{u}/\tau_2)}{\sum_{n\neq u}\exp(\mathbf{z}^{1}_{u}\mathbf{z}^{\top}_{n}/\tau_2)+\sum_{k'\neq h(u)}\exp(\mathbf{z}^{1}_{u}\bm{\mu}^{\top}_{k'}/\tau_2)}, LSCL(zu1,zu2)=−log∑n=uexp(zu1zn⊤/τ2)+∑k′=h(u)exp(zu1μk′⊤/τ2)exp(zu1zu2⊤/τ2),
其中 h ( u ) h(u) h(u)是将 u u u映射到所属原型向量的下标的函数。
Cluster-aware Self-distillation: 聚类感知的自蒸馏
用所属聚类簇中心表征对用户表征进行知识蒸馏,通过聚类感知的自蒸馏模块将知识从行为丰富的用户传递给行为稀疏的用户。
考虑到大多数用户特征的稀疏性,样本级别的自监督信号是有限的。我们希望通过知识蒸馏(KD)连接原型粒度信息和样本粒度信息。然而,大多数KD方法都需要一个经过预训练的、相对复杂的教师模型。
针对链路较长的KD方法,自蒸馏方法通过利用同一骨干网络同时充当教师和学生来简化蒸馏流程。然而,相关工作需要通过不同的子网络配置来区分教师和学生。
我们则使用同一网络,不同输出来区分教师和学生,即用户意图和用户表征。首先计算用户表征和对应意图的归一化分布:

e u , s i = exp ( z u i / τ 3 ) ∑ i ′ exp ( z u i ′ / τ 3 ) , \mathbf{e}_{u,s}^{i}=\frac{\exp(\mathbf{z}_{u}^{i}/\tau_3)}{\sum_{i'}\exp(\mathbf{z}_{u}^{i'}/\tau_3)}, eu,si=∑i′exp(zui′/τ3)exp(zui/τ3),
聚类感知的自蒸馏损失可以直接定义为KL散度,最大化用户表征(学生)和用户意图(教师)的分布相似度:

L C K D ( μ h ( u ) , z u 1 ) = ∑ i e u , t i log e u , t i e u , s i , \mathcal{L}_{CKD}(\bm{\mu}_{h(u)},\mathbf{z}^{1}_{u})=\sum_{i}\mathbf{e}_{u,t}^{i}\log\frac{\mathbf{e}_{u,t}^{i}}{\mathbf{e}_{u,s}^{i}}, LCKD(μh(u),zu1)=∑ieu,tilogeu,sieu,ti,
这项损失为用户,特别是低活用户表征优化提供了额外的监督信号。
Head-tail Adversarial Learning: 用户分层对抗学习
利用梯度反转,减少聚类簇的头/尾语义。
聚类任务容易受到用户行为稀疏度的影响而将高低频用户分别独立成簇。低频用户所在的簇信息将变得稀疏,从而降低知识蒸馏的效果。因此引入用户分层标签的分类任务作为对抗学习,使得聚类任务避免受到用户行为稀疏度的影响,达到各分层用户在各个簇中分布更加均匀的效果。
具体来说,我们将学习到的用户表征作为输入,训练一个分类器,用以预测用户所属类别(如头/尾,高频/低频)。同时,编码器的目标则是生成能够有效欺骗分类器的用户表征。通过联合训练分类器和编码器,可以降低用户表征的类别信息,从而实现更均匀的聚类分布。
我们使用简单的全连接层作为用户类别分类器,并利用交叉熵损失来优化分类器。公式为:
c ^ = W z u , \hat{\mathbf{c}}=\mathbf{W}\mathbf{z}_{u}, c^=Wzu,
L A d v = − c ^ [ c ] + log ( ∑ i exp ( c ^ [ i ] ) ) , \mathcal{L}_{Adv}=-\hat{\mathbf{c}}[c]+\log(\sum_{i}\exp(\hat{\mathbf{c}}[i])), LAdv=−c^[c]+log(∑iexp(c^[i])),
其中, c ^ \hat{\mathbf{c}} c^是分类器的预测结果, c \mathbf{c} c是类别标签。在对抗性学习的设置下,分类器的目标是最小化分类损失失,编码器则反之。我们的具体方法是在编码器和分类器之间插入一个梯度反转层(GRL)。在反向传播过程中,用于最小化分类损失的梯度反向传播至分类器,并且在GRL之后,梯度将被反转,其进一步反传至编码器。也就是说,对于分类损失,我们对分类器的参数执行梯度下降,同时对编码器的参数执行梯度上升。我们以这种方式实现了对抗学习。
联合损失函数
最后,我们以多任务的形式联合优化主任务,用户在线聚类任务,序列粒度对比学习任务,聚类感知的自蒸馏任务以及用户分层对抗任务,其联合损失函数为:
L = L S R + α L C l u s t + β 1 L S C L + β 2 L C K D + λ L A d v . \mathcal{L}=\mathcal{L}_{SR}+\alpha\mathcal{L}_{Clust}+\beta_{1}\mathcal{L}_{SCL}+\beta_{2}\mathcal{L}_{CKD}+\lambda\mathcal{L}_{Adv}. L=LSR+αLClust+β1LSCL+β2LCKD+λLAdv.
实验效果
实验设置
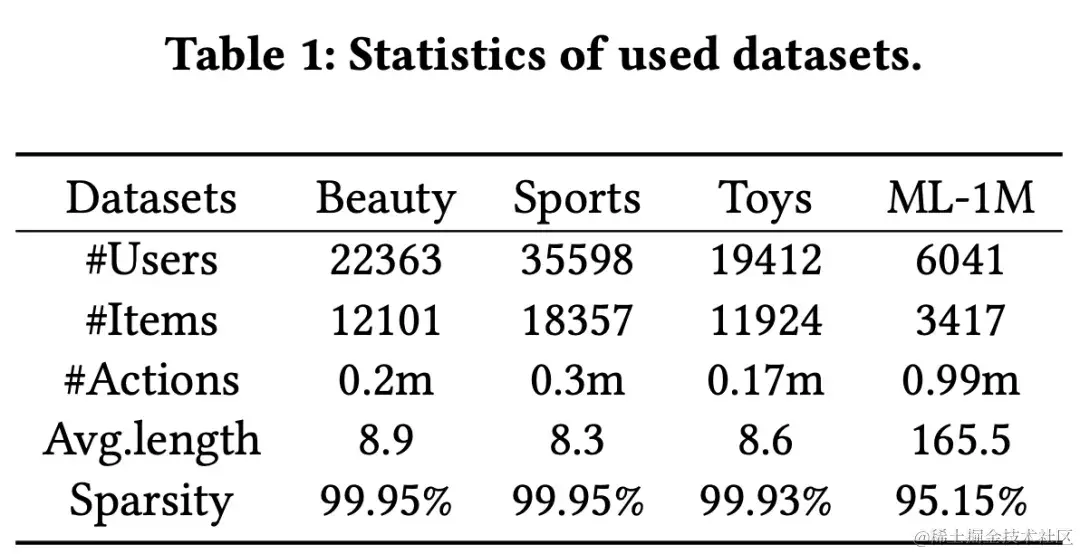
数据集
我们使用了四个常用的序列推荐基准数据集:Beauty、 Sports、 Toys 以及 ML-1M。
对比方法
标准序列模型:Caser、GRU4Rec、SASRec
序列模型+对比学习:BERT4Rec、S3-Rec、CL4SRec
序列模型+对比学习+意图因子:DSSRec、ICLRec
对比实验
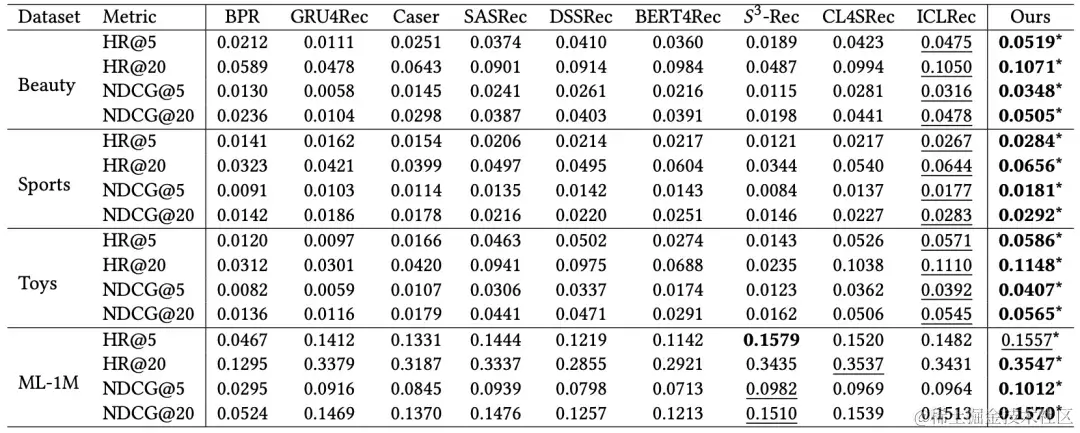
如上图所示, S 4 R e c S^4Rec S4Rec基本在所有指标取得最优性能。
与标准序列模型相比, S 4 R e c S^4Rec S4Rec无疑优于所有基准。尽管基于Transformer的编码器在标准序列模型中实现了最佳性能,但与 S 4 R e c S^4Rec S4Rec相比,它的性能仍然相对较差。因此,利用自监督信号来充分优化模型参数至关重要。
与使用自监督学习的序列模型相比, S 4 R e c S^4Rec S4Rec引入了用户意图原型,这些原型包含了用户行为序列的语义信息。这些对比方法专注于行为序列粒度的自监督学习,但未能利用意图级别信息。因此, S 4 R e c S^4Rec S4Rec能够取得较大的性能提升。
与ICLRec相比, S 4 R e c S^4Rec S4Rec总是在每个指标中的表现领先。ICLRec的性能是有限的,因为在ICLRec中两次连续的聚类分配之间没有对应关系。因此,从聚类簇中学习到的最终预测可能与下一轮的预测无关,可能会扰乱模型训练。此外,ICLRec的聚类还存在头尾用户分布不均衡问题,这导致了次优聚类。结果验证了在线聚类和对抗策略的有效性。
消融实验
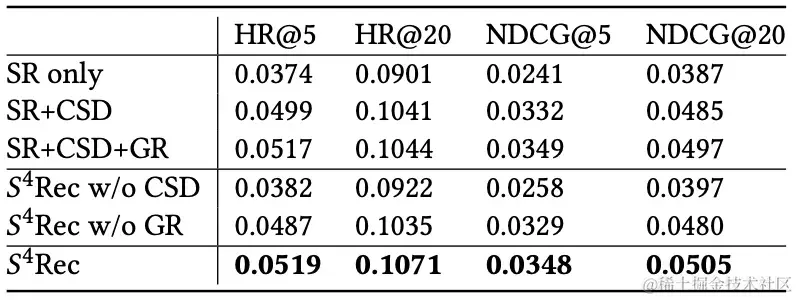
如上表所示,标准序列推荐模型(SR)和 S 4 R e c S^4Rec S4Rec都从能从设计的自监督模块(CSD)和用户分层对抗学习模块(GR)中获得性能提升。完整配置的 S 4 R e c S^4Rec S4Rec基本在所有指标都优于SR+CSD+GR,二者的主要区别在于所采用的聚类算法SR+CSD+GR使用的聚类是传统的k-means算法,需要在完整的数据集上执行,而 S 4 R e c S^4Rec S4Rec使用在线聚类。也就是说,尽管k-means算法利用了所有数据点,但在小批量内执行聚类不会影响推荐结果。
基于上述结果的结果,我们验证了所提出的设计的有效性。
用户分层对抗学习分析
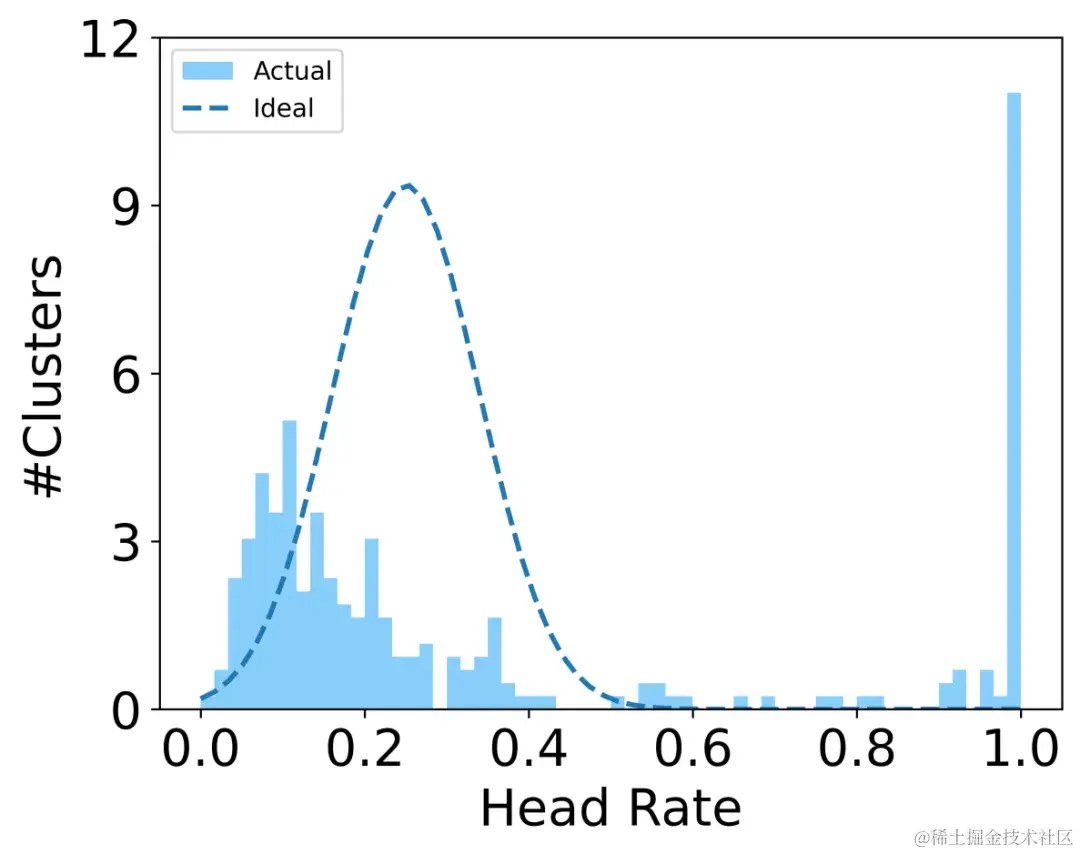
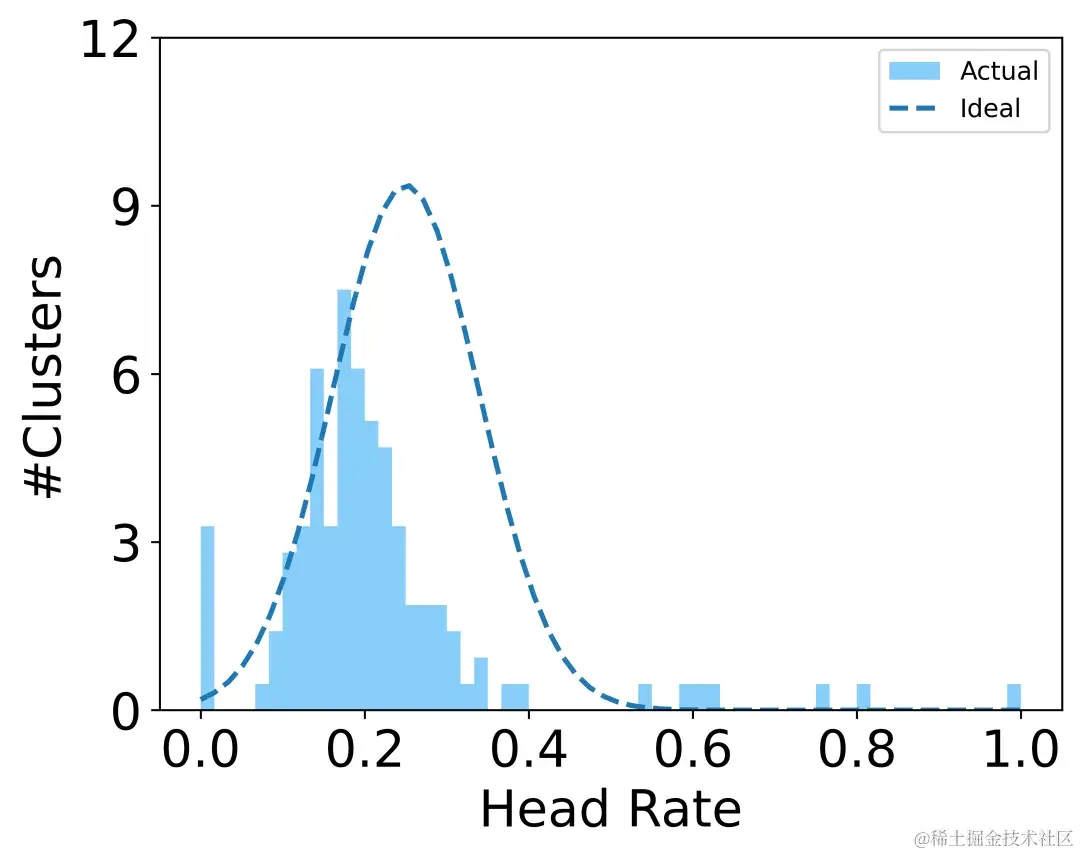
我们在真实数据集上对用户进行不施加约束的聚类,结果如上图(左)所示,直方图表现出明显的双峰特征,这表示丰富行为(长序列)的用户的学习表示往往聚成一簇,且与行为稀疏(短序列)的用户相互分离,直方图的双峰越明显,这符合我们在第一节中的分析。但是,理想情况下,学习到的用户表示应该受到用户潜在意图的影响,而不应当受行为稀疏性的影响,因此我们进一步引入用户对抗学习,使得不管是行为丰富用户还是行为稀疏用户在各个簇中分布都比较均匀均匀的效果。实验效果如上图(右)所示,实际聚类分布更加接近于理想的单峰分布。

我们进一步分析用户分层对抗权重对结果的影响。如上图所示,随着对抗分类损失权重的增大,聚类簇中的用户类别分布更加均匀,模型性能随之提升;当权重进一步增大,推荐性能开始下降。辅助任务影响到主任务的学习,可能也说明了用户类别与用户兴趣存在一定程度关联。
线上实验
S 4 R e c S^4Rec S4Rec已在支付宝多个营销推荐场景取得显著效果。
总结与展望
我们通过在线聚类以及用户类别对抗学习的约束,能够将用户进行分群,进一步利用分群信息指导用户表征学习,从而提升各分群用户的推荐效果。 在公开数据集的效果以及在支付宝营销推荐多个场景的推全,说明了方法的有效性和通用性。后续我们将对模型各模块做进一步优化,如更好地设计聚类目标,更好地使用意图信息以及与因果推断相结合等。
分布式全链路因果学习系统 OpenASCE:
https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
大模型驱动的知识图谱 OpenSPG:
https://github.com/OpenSPG/openspg
大规模图学习系统 OpenAGL:
https://github.com/TuGraph-family/TuGraph-AntGraphLearning
相关文章:
Paper Digest|基于在线聚类的自监督自蒸馏序列推荐模型
论文标题: Leave No One Behind: Online Self-Supervised Self-Distillation for Sequential Recommendation 作者姓名: 韦绍玮、吴郑伟、李欣、吴沁桐、张志强、周俊、顾立宏、顾进杰 组织单位: 蚂蚁集团 录用会议: WWW 2024 …...
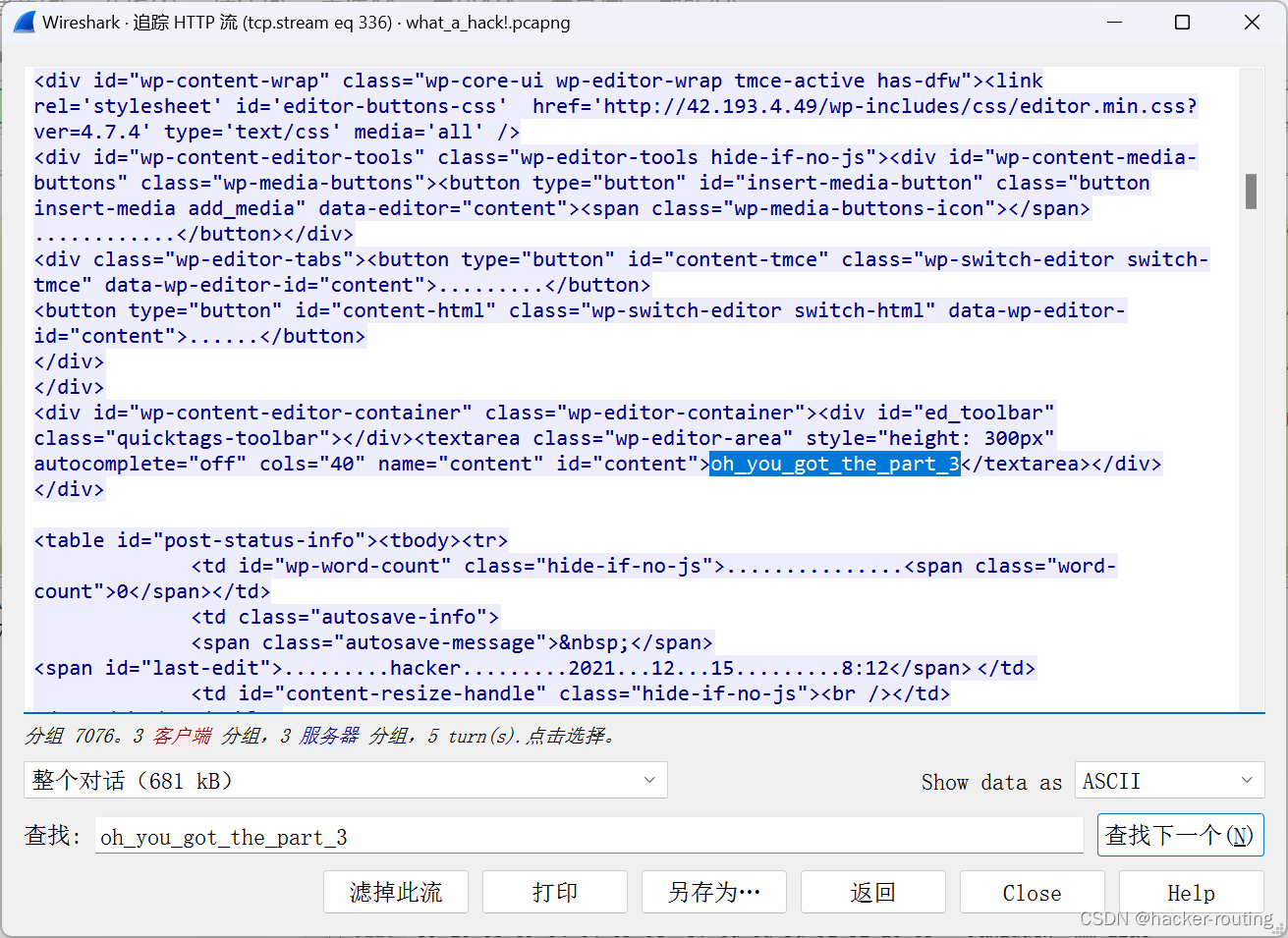
【CTFshow 电子取证】套的签到题
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~ ✨主攻领域:【渗透领域】【应急响应】 【Java、PHP】 【VulnHub靶场复现】【面试分析】 🎉点赞➕评论➕收…...
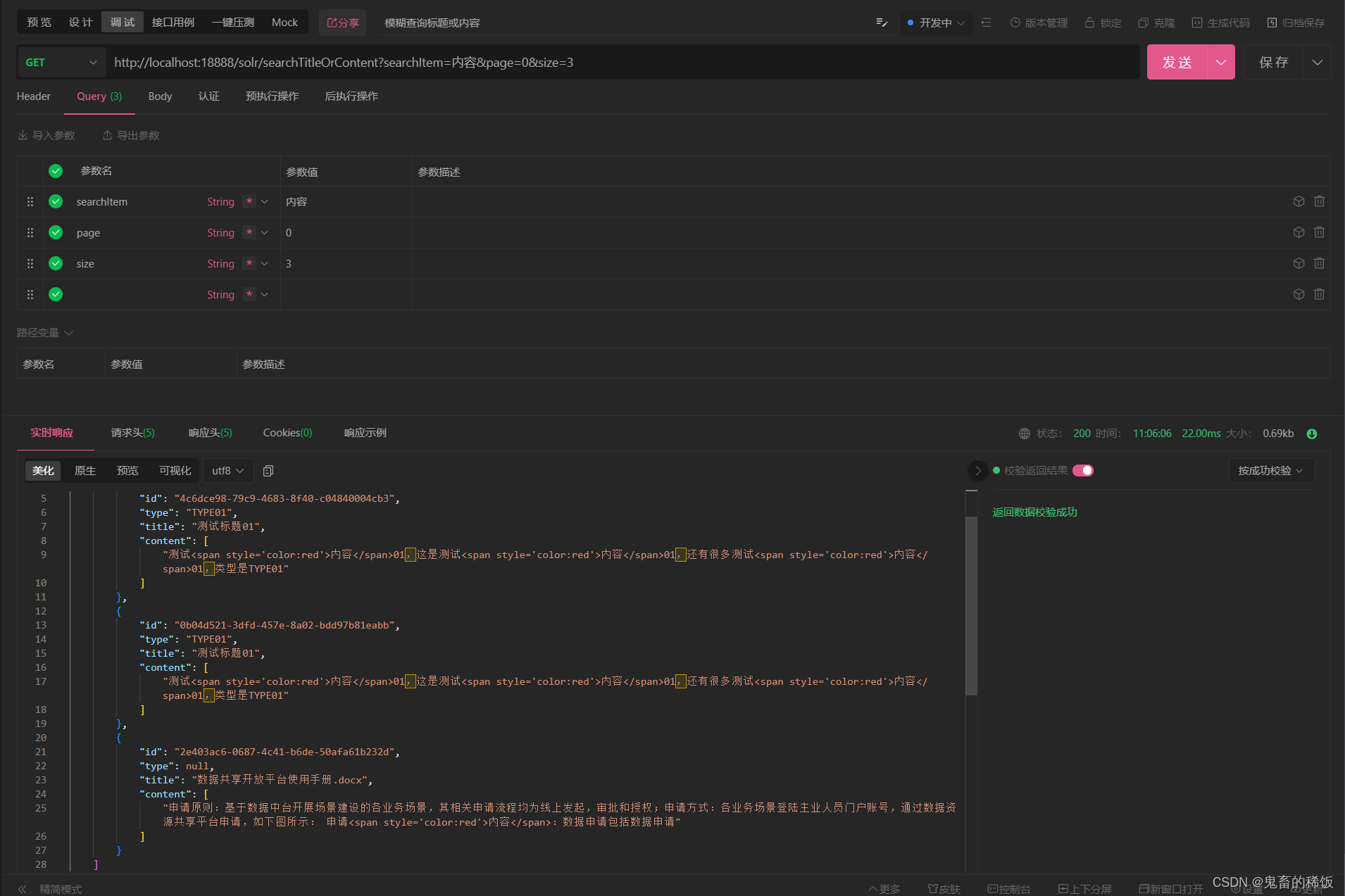
SpringBoot集成Solr全文检索
SrpingBoot 集成 Solr 实现全文检索 一、核心路线 使用 Docker 镜像部署 Solr 8.11.3 版本服务使用 ik 分词器用于处理中文分词使用 spring-boot-starter-data-solr 实现增删改查配置用户名密码认证使用 poi 和 pdfbox 组件进行文本内容读取文章最上方有源码和 ik 分词器资源…...

厨余垃圾处理设备工业监控PLC连接APP小程序智能软硬件开发之功能原理篇
接着上一篇《厨余垃圾处理设备工业监控PLC连接APP小程序智能软硬件开发之功能结构篇》继续总结一下厨余垃圾处理设备智能软硬件统的原理。所有的软硬件系统全是自己一人独自开发,看法和角度难免有局限性。希望抛砖引玉,将该智能软硬件系统分享给更多有类…...
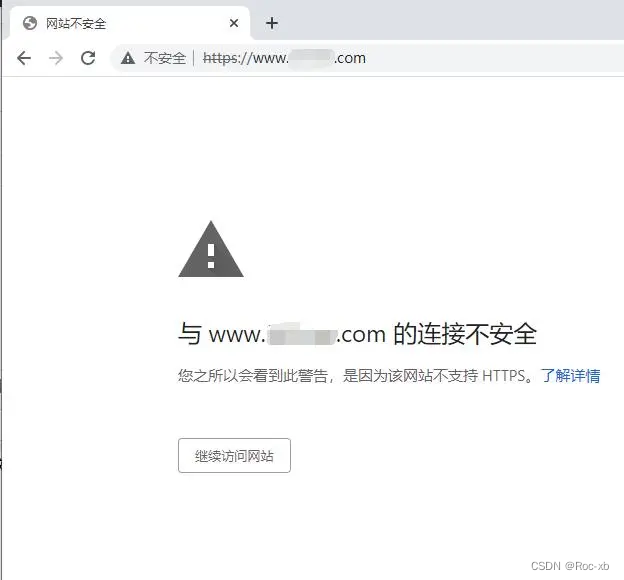
google浏览器网站不安全与网站的连接不安全怎么办?
使用google谷歌浏览器访问某些网站打开时google谷歌浏览器提示网站不安全,与网站的连接不安全,您之所以会看到此警告,是因为该网站不支持https造成的怎么办? 目录 1、打开谷歌google浏览器点击右上角【┇】找到设置...

基于Axios封装请求---防止接口重复请求解决方案
一、引言 前端接口防止重复请求的实现方案主要基于以下几个原因: 用户体验:重复发送请求可能导致页面长时间无响应或加载缓慢,从而影响用户的体验。特别是在网络不稳定或请求处理时间较长的情况下,这个问题尤为突出。 服务器压力…...
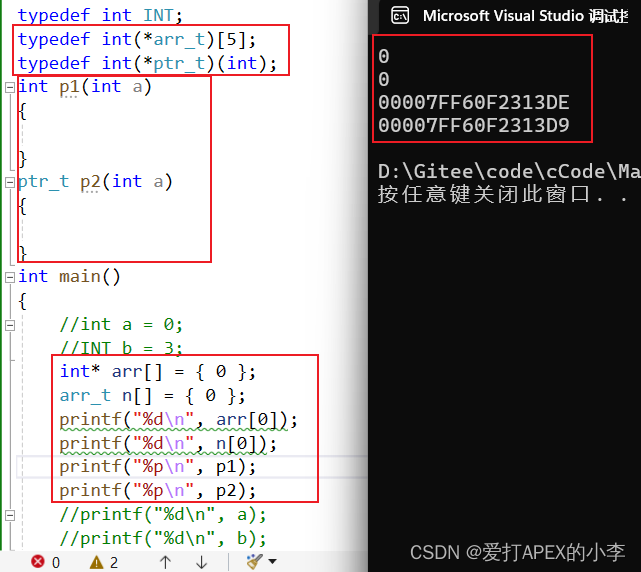
深入理解指针(7)函数指针变量及函数数组(文章最后放置本文所有原码)
一、函数指针变量 什么是函数指针变量呢? 既然是指针变量,那么它指向的一定是地址,而且我们可以通过地址来调用函数的。 函数是否有地址呢?地址是什么? 经过上面的测试可以看到函数也是有地址的,而且其地…...
office办公技能|word中的常见使用问题解决方案2.0
一、设置多级列表将表注从0开始,设置为从1开始 问题描述:word中插入题注,出来的是表0-1,不是1-1,怎么办? 写论文时,虽然我设置了“第一章”为一级标题,但是这三个字并不是自动插入的…...

华为2023年年度报告启示:大学生如何把握未来科技趋势,规划个人发展路径
华为2023年年度报告展现了公司在技术创新、生态构建、社会责任等方面的卓越成就与前瞻布局。对于身处数字化时代的大学生而言,这份报告不仅是洞察科技行业发展趋势的窗口,更是规划个人学业与职业道路的重要参考。本文将从报告中提炼关键信息,…...

刚刚,璞华科技、璞华易研PLM产品荣获智能制造领域两大奖项!
刚刚,在e-works数字化企业网于北京举办的“第十三届中国智能制造高峰论坛暨第二十一届中国智能制造岁末盘点颁奖典礼”上,璞华科技凭借在智能制造领域的雄厚实力和产品口碑,荣获两大奖项。 璞华科技被评为e-works【2023年度智能制造优秀供应…...

乐维更改IP地址
1.1 系统IP调整 vim /etc/sysconfig/network-scripts/ifcfg-ens1921.2 Web相关服务IP变更 1.2.1 编辑/itops/nginx/html/lwjkapp/.env文件,更改ZABBIXSERVER、ZABBIXRPCURL、DB_HOST中的IP 1.2.2 进入/itops/nginx/html/lwjk_app/目录下,执行php bin/manager process-conso…...

大话设计模式之简单工厂模式
简单工厂模式(Simple Factory Pattern)是一种创建型设计模式,属于工厂模式的一种。在简单工厂模式中,有一个工厂类负责根据输入参数的不同来创建不同类的实例。 简单工厂模式包含以下几个要素: 1. **工厂类࿰…...
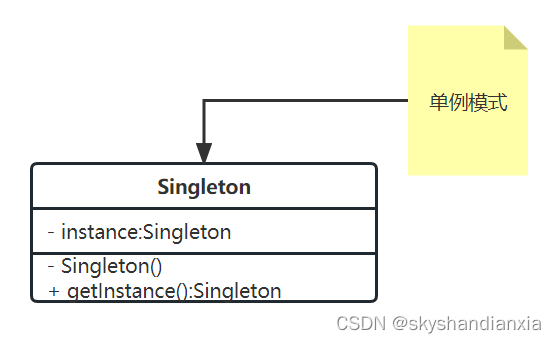
设计模式之单例模式精讲
UML图: 静态私有变量(即常量)保存单例对象,防止使用过程中重新赋值,破坏单例。私有化构造方法,防止外部创建新的对象,破坏单例。静态公共getInstance方法,作为唯一获取单例对象的入口…...

论文复现3:Stable Diffusion v1
abstract: 通过将图像形成过程分解为去噪自动编码器的顺序应用,扩散模型 (DM) 在图像数据及其他方面实现了最先进的合成结果。此外,他们的公式允许一种指导机制来控制图像生成过程,而无需重新训练。然而,由于这些模型通常直接在像素空间中运行,因此强大的 DM 的优化通常会…...

Halcon与VisionMaster对比
作为一个经验丰富的机器视觉算法工程师,我对于机器视觉软件的评价会基于多年的实践经验和对不同软件功能的深入了解。在评价VisionMaster和Halcon软件时,我会从使用场景、工作效率、使用便捷性等方面进行全面分析,并结合软件的优缺点进行讨论…...
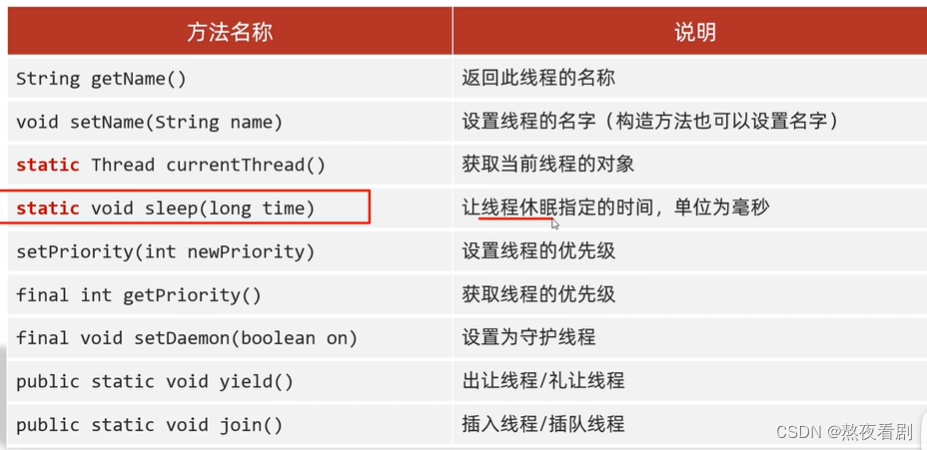
多线程的学习1
多线程 线程是操作系统能够进入运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。 进程:是程序的基本执行实体。 并发:在同一个时刻,有多个指令在单个CPU上交替执行。 并行:在同一时刻,…...

警务数据仓库的实现
目录 一、SQL Server 2008 R2(一)SQL Server 的服务功能(二)SQL Server Management Studio(三)Microsoft Visual Studio 二、创建集成服务项目三、配置“旅馆_ETL”数据流任务四、配置“人员_ETL”数据流任…...

Excel·VBA数组分组问题
看到一个帖子《excel吧-数据分组问题》,对一组数据分成4组,使每组的和值相近 目录 代码思路1,分组形式、可分组数代码1代码2代码2举例 2,数组所有分组形式举例 这个问题可以转化为2步:第1步,获取一组数据…...

【笔记】Hbase基础笔记
启动hbase:进入hbase安装目录 输入bin/start-hbase.sh 打开shell命令行模式:进入hbase安装目录 输入bin/hbase shell 退出shell命令行模式:exit 停止hbase:进入hbase安装目录 输入bin/stop-hbase.sh 启动关闭Hadoop和HBase的顺序一…...

创建vue3项目并集成cesium插件运行
创建vue3项目并集成cesium插件 一、vue项目创建 1、前期准备 node.js&npm或yarn 本地开发环境已经安装好。 参考安装 2、安装vue-cli,要求3以上版本 #先查看是否已经安装 vue -V#安装 npm install -g vue/cli4.5.17 示例:Idea工具 页面 Termin…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...

【2025年】解决Burpsuite抓不到https包的问题
环境:windows11 burpsuite:2025.5 在抓取https网站时,burpsuite抓取不到https数据包,只显示: 解决该问题只需如下三个步骤: 1、浏览器中访问 http://burp 2、下载 CA certificate 证书 3、在设置--隐私与安全--…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

【堆垛策略】设计方法
堆垛策略的设计是积木堆叠系统的核心,直接影响堆叠的稳定性、效率和容错能力。以下是分层次的堆垛策略设计方法,涵盖基础规则、优化算法和容错机制: 1. 基础堆垛规则 (1) 物理稳定性优先 重心原则: 大尺寸/重量积木在下…...