数据库索引及优化
数据库索引及优化
什么是索引?
MySQL官方对索引的定义为:索引(INDEX)是帮助MySQL高效获取数据的数据结构。
索引的本质: 数据结构
为什么要引入索引?
引入索引的目的在于提高查询效率,就好像是字典一样,如果要查”mysql“这个单词,我们肯定要定位到m字母,然后从上往下找y字母,再找到剩下的sql。
如果没有索引,那么你可能需要a-z进行全表扫描,会非常慢,当数据量少的时候适用,数据量大的时候不适用,因此很多情况下我们要避免全表扫描的发生。
所以我们需要映入更高效的机制—索引。
我们可以简单理解为:排好序的快速查找结构。
图书馆借书就是索引很好的例子,先去图书馆电脑上查找书的位置可以理解为索引,就可以直接去找到对应位置的图书。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
索引的优缺点:
优点:
1.类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的IO成本(不需要全表扫描)
2.通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗
缺点:
1.实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引也是要占空间的。
2.虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
3.每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息
4.索引只提高效率的一个因素,如果你的MySQL有大量数据的表,就需要花时间研究建立最优秀的索引,或优化查询语句,索引都是不停的根据业务场景不停试验修改调整。 如:index(name) index(name,age,gender)在搜索的时候不是根据name来搜索
MySQL索引
MySQL目前主要有以下几种索引类型:
1.普通索引 key
2.唯一索引 unique key
3.主键索引 primary key
4.组合索引 index(name,age,gender)
5.全文索引
MySQL的索引结构包含有:
BTree索引
Hash索引
full-text全文索引
R-Tree索引
我们平常说的索引,如果没有特别指明,都是指B+树结构组织的索引
InnoDB存储引擎中的B+树索引。要介绍B+树索引,就不得不提二叉搜索树,平衡查找树和B树这三种数据结构。B+树就是从他们仨演化来的。
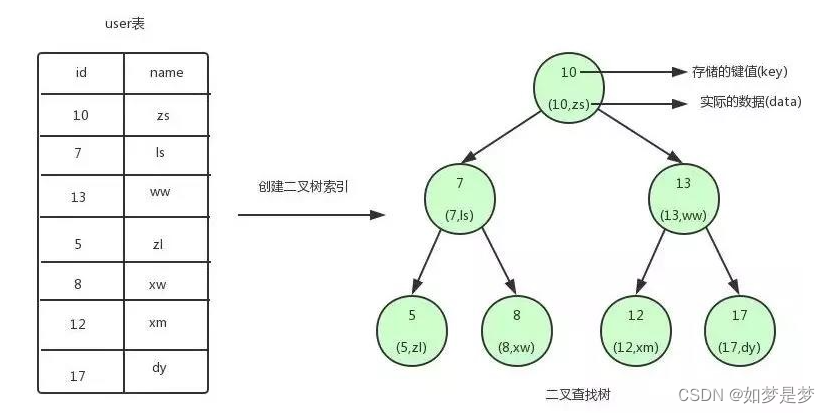
二叉查找树:
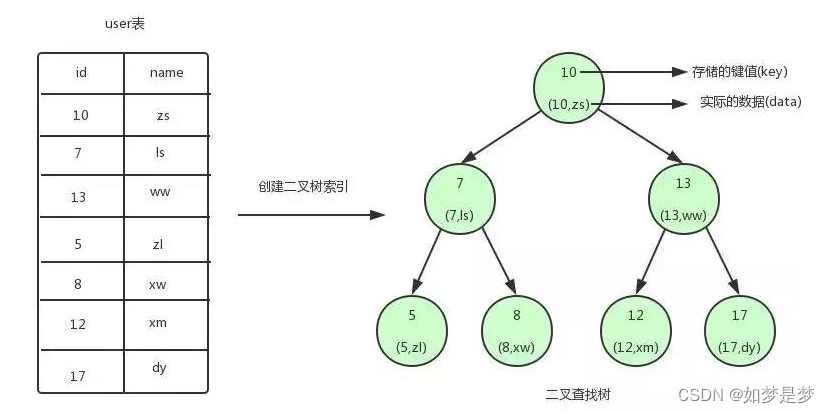
我们为user表(用户信息表)建立了一个二叉查找树的索引
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。顶端节点我们称为根节点,没有子节点的节点我们称之为叶节点。
如果我们需要查找id=12的用户信息,利用我们创建的二叉查找树索引,查找流程如下:
1.将根节点作为当前节点,把12与当前节点的键值10比较,12大于10,接下来我们把节点>10的右子节点作为当前节点。
2.继续把12和当前节点的键值13比较,发现12小于13,把当前节点的左子节点作为当前节点。
3.把12和当前节点的键值12对比,12等于12,满足条件,我们从当前节点中取出data,即id=12,name=xm。
平衡二叉树:

这个时候可以看到我们的二叉查找树变成了一个链表。如果我们需要查找id=17的用户信息,我们需要查找7次,也就相当于全表扫描了。导致这个现象的原因其实是二叉查找树变得不平衡了,就是高度太高了,从而导致查找效率的不稳定。
为了解决这个问题,我们需要保证二叉查找树一直保持平衡,就需要用到平衡二叉树了。平衡二叉树又称AVL树,在满足二叉查找树的特性的基础上,要求每个节点的左右子树的高度差不能超过1.
下面是平衡二叉树和非平衡二叉树的对比:
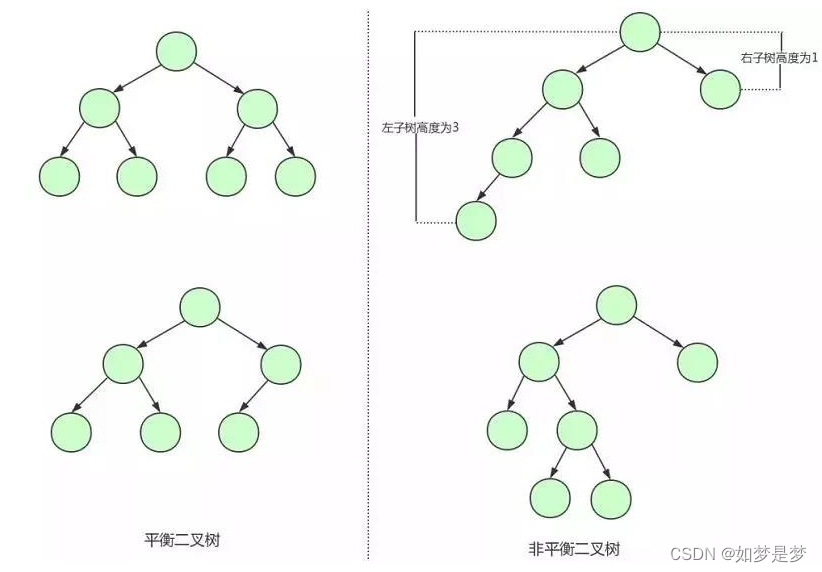
平衡二叉树保证了树的构造是平衡的,当我们插入或删除数据导致不满足平衡二叉树不平衡时,平衡二叉树会进行调整书上的节点来保持平衡。
B树:
因为内存的易失性。一般情况下,我们都会选择将user表中的数据和索引存储在磁盘这种外围设备中。但是和内存相比,从磁盘中读取数据的速度会慢上上百倍千倍甚至万倍,所以我们应当尽量减少从磁盘中读取数据的次数。
如果我们用树这种数据结构作为索引的数据结构,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块。我么都知道平衡二叉树可是每个节点只存储一个键值和数据的。那说明什么?说明每个磁盘块仅仅存储一个键值和数据!那如果我们要存储海量的数据呢?
可以想象到二叉树的节点会非常多,高度也会及其高,我们查找数据时也会进行很多次磁盘IO,我们查找数据的效率将会极低!
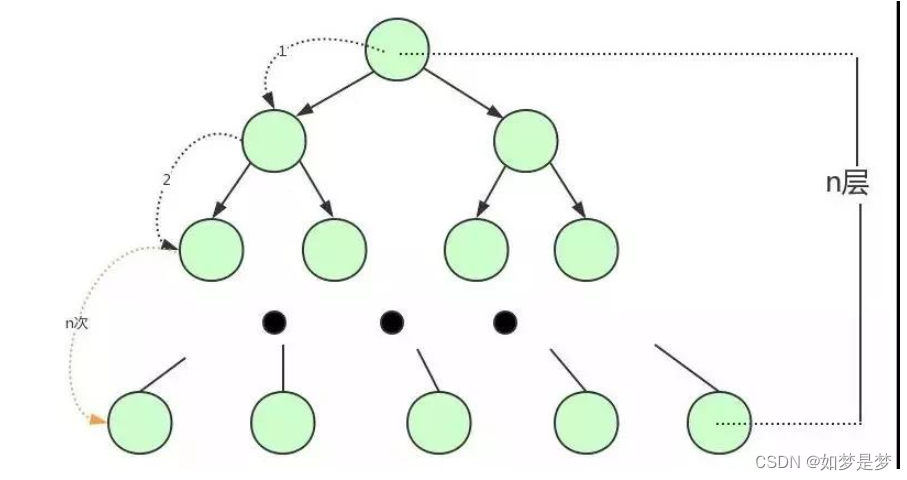
为了解决平衡二叉树这个弊端,我们因该寻找一种单个节点可以存储多个键值和数据的平衡树。也就是我们接下来要说的B树。B树(Balance Tree)即为平衡树的意思,下图即为一棵B树:
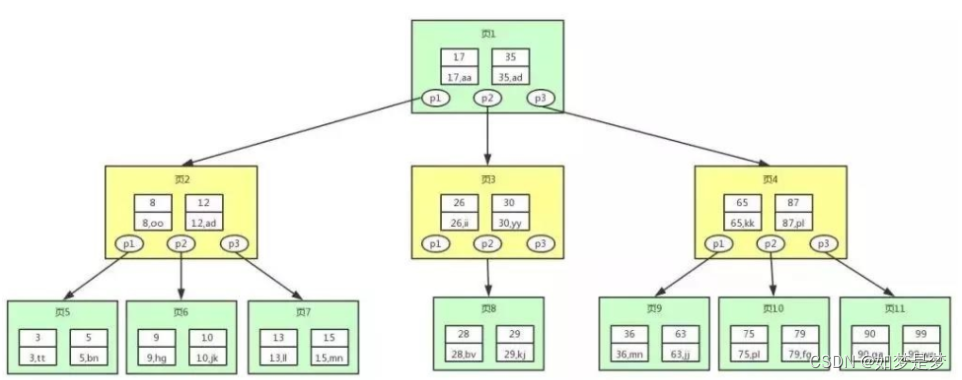
根节点的p1只想<17的节点,p2指向<17 <35节点,p3指向>35节点。
从上图可以看出,B树相对于平衡二叉树每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会很低。基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找也会比平衡二叉树高很多。
假如我们要查找 id=28 的用户信息,那么我们在上图 B 树中查找的流程如下:
1、先找到根节点也就是页1(磁盘加载到内存,此时发生一次IO),判断 28 在键值 17 和 35 之间,那么我们根据页1中的指针 p2 找到页3了
2、将 28 和页 3(磁盘加载到内存,此时发生一次IO) 中的键值相比较,28 在 26 和 30 之间,我们根据页3中的指针 p2 找到页 8(磁盘加载到内存,此时发生一次IO)。
3、将 28 和页 8 中的键值相比较,发现有匹配的键值 28,键值 28 对应的用户信息为(28,bv)
共只要进行三次IO就行。
B+树:
B+ 树是对 B 树的进一步优化。让我们先来看下 B+ 树的结构图:
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接
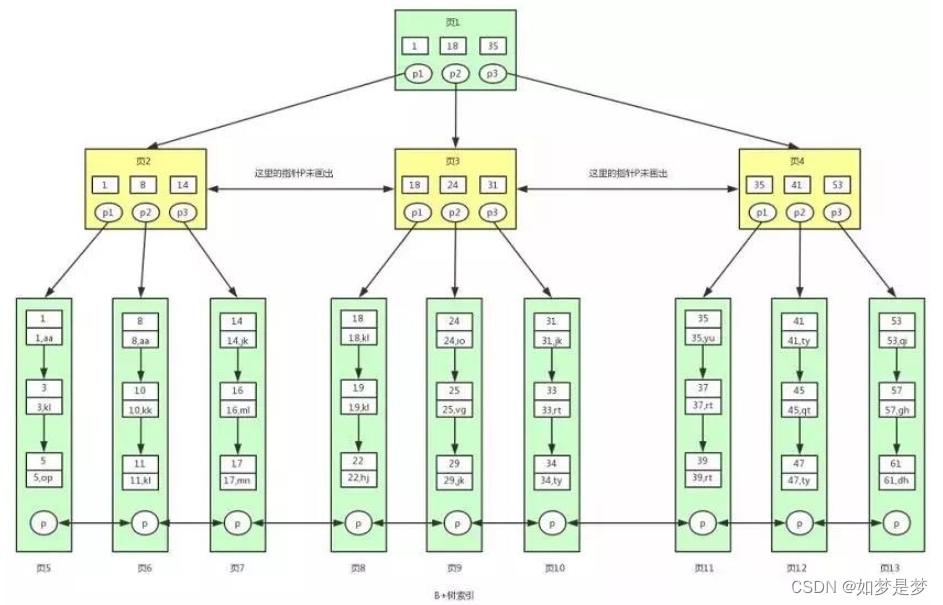
真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的IO,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
根据上图我们来看下 B+ 树和 B 树有什么不同:
①B+ 树非叶子节点上是不存储数据的,仅存储键值,而 B 树节点中不仅存储键值,也会存储数据。
之所以这么做是因为在数据库中页的大小是固定的,InnoDB 中页的默认大小是 16KB。
如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们査找数据进行磁盘的IO 次数又会再次减少,数据查询的效率也会更快。
假设每一页存数据可以存储100条,非叶子节点可以存储1000键值
如果B+树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放100条记录。
如果B+树有2层,最多能存放 1000 x100 =100000 条记录:
如果B+树有3层,最多能存放 1000 x1000x100 =100000000 条记录。
如果B+树有4层,最多能存放 1000 x1000x1000x100 =1000,0000.0000 条记录。相当多的记录!!!
一般根节点是常驻内存的,所以一般我们查找1亿数据,只需要2次磁盘IO。
②因为 B+ 树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的,
通过上图可以看到,在 lnnoD8 中,我们通过数据页之间通过双向链表连接以及叶子节点中数据之间通过单向链表连接的方式可以找到表中所有的数据。
二又树
二分查找->二插排序树(斜树)->平衡二叉树->红黑树->B树(多插平衡树)->B+树
最终让这个树:更矮更胖,减少查找的次数(减少10次数),
因为查找的次数和树的高度是相关的,数据库表的索引是放到硬盘上的,如果树的高度太高那么IO次数就会变多。
哈希索引(Hash索引):
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级査找,只需一次哈希算法即可立刻定位
到相应的位置,速度非常快。
散列表(Hash table,也叫哈希表)它通过把关键码值映射到表中一个位置来访问记录,以加快査找的速度,这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数
f(key)为哈希(Hash)函数
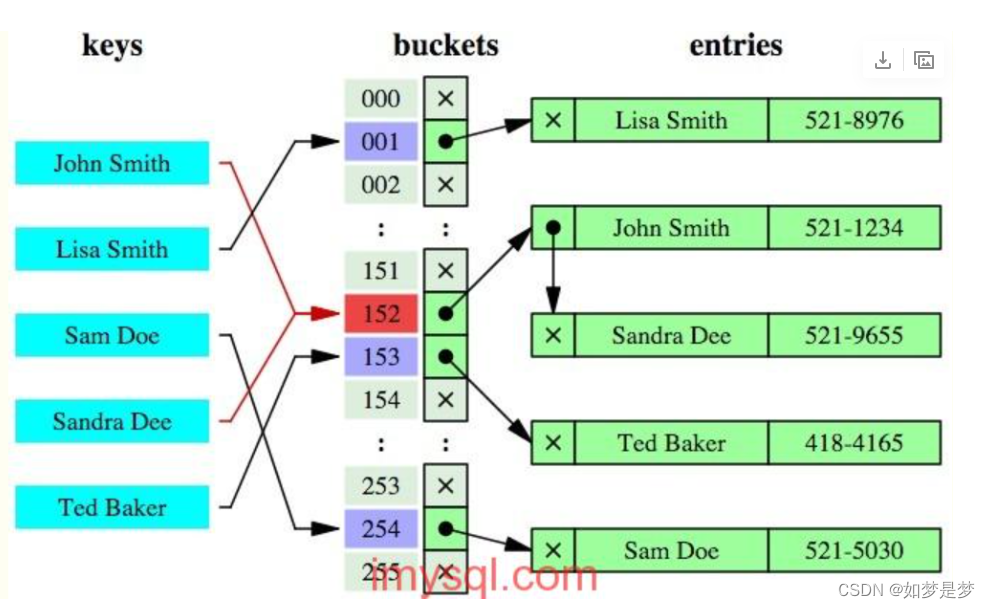
通常用的处理冲突的方法:
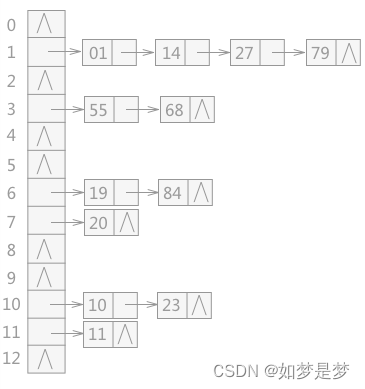
链地址法:
将所有产生冲突的关键字所对应的数据全部存储在同一个线性链表中。
例如有一组关键字为{19,14,23,01,68,20,84,27,55,11,10,79},其哈希函数为:H(KeV)=Key MOD13(取余操作可以实现分组,将数据分成了13组),使
用链地址法所构建的哈希表如图 3 所示:
聚集索引 VS 非聚集索引:
在 MySQL中,B+ 树索引按照存储方式的不同分为聚集索引和非聚集索引。
**1.聚集索引(聚簇索引):以 InnoDB 作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。*这是因为 InnoDB 是把数据存放在 B+ 树中的,而 B+ 树的键值就是主键,在 B+ 树的叶子节点中,存储了表中所有的教据。
这种以主键作为 B+ 树索引的键值而构建的 B+ 树索引,我们称之为聚集索引。
②非聚集索引(非聚簇索引):以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚集索引。
覆盖索引(Covering Index),也可以称为索引覆盖:
就是select的数据列只需要从索引中就能够取得,不必从数据表中读取。换句话说查询列要被所建的索引覆盖。
建立了索引index(col1,col2,clo3),查询时候没有使用select,也没有用select col1,col2,clo3,col4,col5,而是使用select col1,col2,co3,查询列要被所建的索引覆盖。
当一条查询语句符合覆盖索引条件时,sql只需要通过索引就可以返回査询所需要的数据,这样避免了査到索引后再返回数据表操作(回表),减少I/O提高效率。
在执行CREATE TABLE语句时可以创建索引,也可以单独用CREATE INDEX或ALTER TABLE来为表增加索引。
1.ALTER TABLE
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
ALTER TABLE table_name ADD INDEX index_name (column_list)
ALTER TABLE table_name ADD UNIQUE (column_list)
ALTER TABLE table_name ADD PRIMARY KEY(column_list)
说明:其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。索引名index_name可选,缺省时,MySQL将根据第一个索引列赋一个名称,另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
2.CREATE INDEX
CREATE INDEX可对表增加普通索引或UNIQUE索引
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
说明:table_name、inadex_name和column_list具有ALTER TABLE语句中相同的含义。另外,不能用CREATE INDEX语句创建PRIMARY KEY索引
3.删除索引
可利用ALTER TABLE或DROP INDEX语句来删除索引。类似于CREATE INDEX语句来删除索引。类似于CREATE INDEX语句,DROP INDEX可以在ALTER TABLE内部作为一条语句处理,语法如下。
DROP INDEX index_name ON table_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
其中,前两条语句是等价的,删除table_name中的索引index_name.
第三条语句只在删除PRIMARY KEY索引时使用,因为一个表只可能有一个PRIMARY KEY索引,因此不需要指定索引名。如果没有创建PRIMARY KEY索引,但表有一个或多个UNIQUE索引,则MySQL将删除第一个UNIQUE索引。
如果从表中删除了某列,则索引会受影响。对于多列组合的索引,如果删除其中的某列,则该列也会从索引中删除。如果删除组成索引的所有列,则整个列将被删除。
4.查看索引
mysql>show index from tblname
mysql>show keys from tblname
索引的使用场景 索引优化、sql优化
需要创建索引的情况
1、主键自动建立唯一索引 Primary Key = Unigue Key + Not Null
2、频繁作为査询条件的字段应该创建索引(银行系统的银行账号、电信系统的手机号、电商系統商品名字)
3、查询中与其它表关联的字段,外键关系建立索引
4、查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
5、直询中统计或者分组字段
6、单值/组合索引的选择问题:在高并发下倾向创建组合索 index(name,age,gender)
不需要创建索引的情况
1、表记录太少
经常增删改的表:提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
3、频繁更新的字段不适合创建索引,因为每次更新不单单是更新了记录还会更新索引,加重了IO负担
4、Where条件里用不到的字段不创建索引,如果根据银行卡号查找就要建立索引
5、数据重复且分布平均的表字段(如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果)
举例:
大家的国籍都是中国,固定且唯一的值,建立索引就没有任何效果。
性别不是男就是女,数据的差异率不高,建立索引也没有太多意义
假如一个表有10万行记录,字段A只有T和F两种值,且每个值的分布概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99。
个索引的选择性越接近于1,这个索引的效率就越高。
SQL中的逻辑刚除和物理删除
在实际开发中基本都会有删除数据的需求,删除又分为逻辑删除和物理删除。下面说下二者的区别:
一、所谓的逻辑删除其实并不是真正的删除,而是在表中将对应的是否删除标识(deleted)或者说是状态字段(status)做修改操作。比如0是删除,1是未删除。在逻辑上数据是被删除的,但数据本身依然存在库中。
对应的sql语句一般是这样的:update… set status/deleted=…
这样在做查询操作的时候,就可根据此字段进行查询,有删除标识的即可不显示
物理删除就是真正的从数据库中做删除操作了,对应的sql语句为 delete…where…做物理删除操作的数据将会不在库中了。
二、逻辑删除的目的:1、为了大数据分析,直接删除就没有数据了 2、删除后索引维护成本高
避免索引失效
1、尽量全值匹配
index(name,age,gender)组合索引, where name=‘zhansgan’ and age=23 and gender='男”,全值匹配,使用索引效率高,当建立了索引列后,能在where条件中使用索引的尽量使用
2、遵循最佳左前缀法则:如果组合索引,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中间列。
带头大哥不能死,中间兄弟不能断。
Index(name,aqe,gender)组合索引,where后面是name才会使用索引,否则都是全表扫猫,可以理解为有name这个火车头索引就不会失效,有了这个火车头火车就可以跑,没有火车头只有车厢就是全表扫描。
where name=‘zhangsan’ and age=23, where name=‘zhangsan’,name作为开头上面的索引是有效的
where age=23,gender=‘男’ name不作为开头索引无效,全表扫描
where name=‘zhansgan’ and gender=‘男’,中间兄弟不能断,只用了索引的一部分name
3、不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
4、尽量使用覆盖索引(只访问索引的査询(索引列和査询列一致)),减少使用 select*,使用select name,age,gender
5、mysql 在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
6、is null,is not null 也无法使用索引
7、like 如果以通配符开头(’%abc…’),会导致mysql索引失效,而变成全表扫描的操作
8、少用or,用它来连接时会索引失效
相关文章:
数据库索引及优化
数据库索引及优化 什么是索引? MySQL官方对索引的定义为:索引(INDEX)是帮助MySQL高效获取数据的数据结构。 索引的本质: 数据结构 为什么要引入索引? 引入索引的目的在于提高查询效率,就好像是…...
flink: 将接收到的tcp文本流写入HBase
一、依赖: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.o…...
SpringBoot集成knife4j
SpringBoot集成knife4j 1、什么是Knife4j2、SpringBoor整合Knife4j2.1、Knife4j配置方式12.2 配置方式二2.3、写注解2.4、效果 1、什么是Knife4j 在日常开发中,写接口文档是我们必不可少的,而Knife4j就是一个接口文档工具,可以看作是Swagger…...

Vue3之setup方法
Vue 3 的 setup 方法是 Vue Composition API 的一部分,用于组织和复用 Vue 组件的逻辑代码。Vue Composition API 允许您以更具响应性和函数式的方式来组织和复用 Vue 组件中的代码,特别是在处理复杂逻辑或跨组件共享逻辑时非常有用。 以下是关于 setup…...

MySQL常见索引及其创建
MySQL索引 在 MySQL 数据库中,常见的索引类型包括以下几种: 普通索引(Normal Index):最基本的索引类型,没有任何限制。唯一索引(Unique Index):要求索引列的值是唯一的…...
高效测量“芯”搭档 | ACM32激光测距仪应用方案
激光测距仪概述 激光测距仪是利用激光对目标的距离进行准确测定的仪器。激光测距仪在工作时向目标射出一束很细的激光,由光电元件接收目标反射的激光束,计时器测定激光束从发射到接收的时间,计算出从观测者到目标的距离。激光测距仪分为手持激…...

基于Hive大数据分析springboot为后端以及vue为前端的的民宿系
标题基于Hive大数据分析springboot为后端以及vue为前端的的民宿系 本文介绍了如何利用Hive进行大数据分析,并结合Spring Boot和Vue构建了一个民宿管理系统。该民民宿管理系统包含用户和管理员登陆注册的功能,发布下架酒店信息,模糊搜索,酒店详情信息展示,收藏以及对收藏的…...
pnpm、monorepo分包管理、多包管理、npm、vite、前端工程化、保姆级教程
浅尝pnpm monorepo 多包管理方案 💡tips: 创建pnpm monorope多包管理框架流程 初始化 mkdir taurus & cd taurus pnpm init创建基础文件 创建文件pnpm-workspace.yaml packages:- packages/**创建文件夹packages/ -packages/ -package.json -pnpm-workspace…...
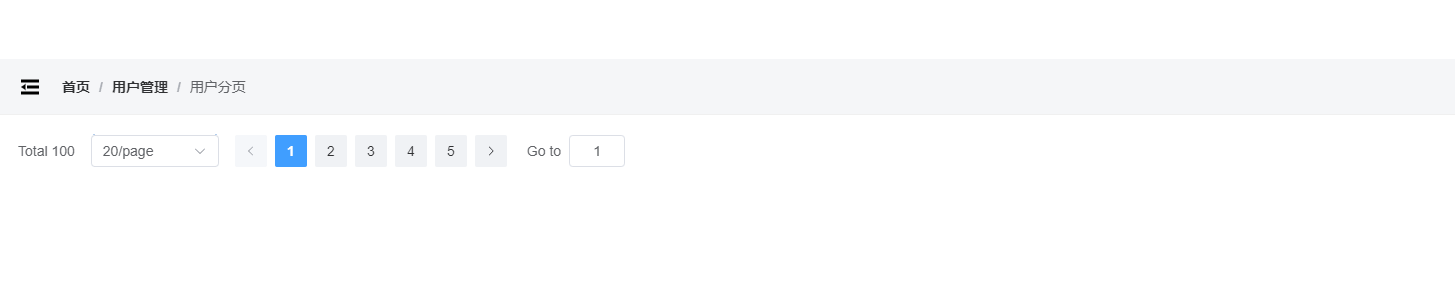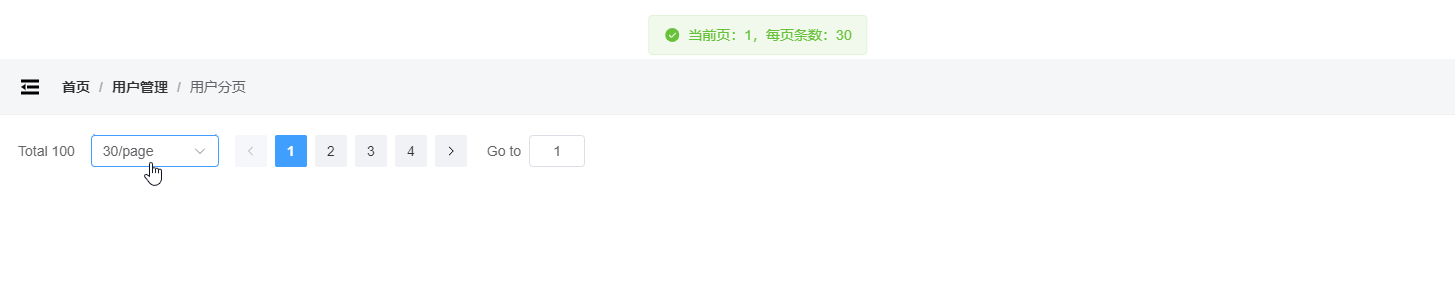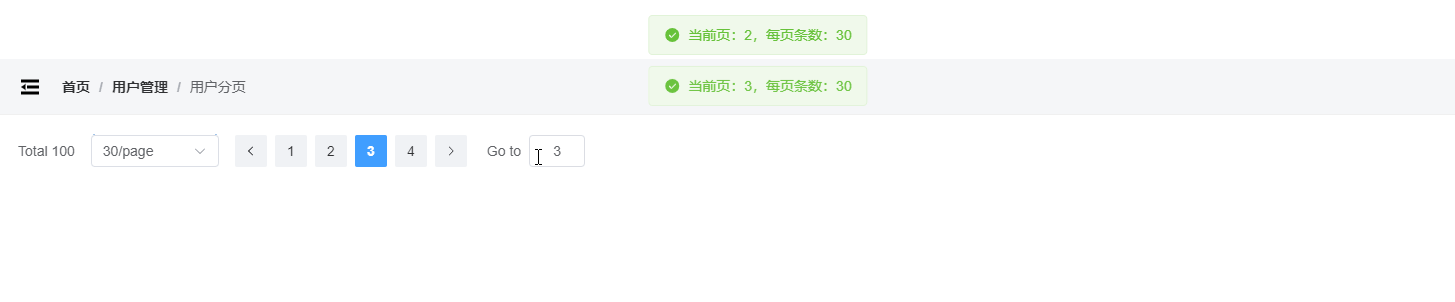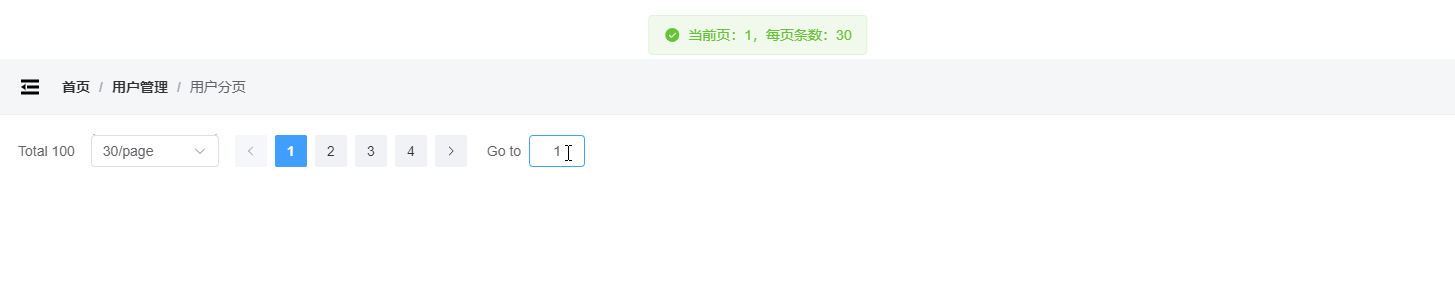
vue3封装Element分页
配置当前页 配置每页条数 页面改变、每页条数改变都触发回调 封装分页 Pagination.vue <template><el-paginationbackgroundv-bind"$attrs":page-sizes"pageSizes"v-model:current-page"page"v-model:page-size"pageSize":t…...

真机 ARM64 架构转模拟器 ARM64 架构
本文字数:2051字 预计阅读时间:15分钟 01 需要转换架构的原因 老版 Mac 使用 Intel 芯片,是x86_64架构,相应地在老版 Mac 上运行的模拟器使用的也就是 x86_64架构。 由于模拟器的 x86_64 架构与真机的 arm64、armv7 等架构不冲突&…...

敏捷教练CSM认证考了有没有用,谁说了算?
敏捷教练CSM证书是近年来备受关注的一项证书,它被认为可以提升敏捷开发团队的管理能力和项目执行效率。然而,对于这个证书的价值和含金量,人们的观点却不尽相同。那么,CSM证书到底有没有用,谁来说了算呢? 首…...

Docker-Container
Docker ①什么是容器②为什么需要容器③容器的生命周期容器 OOM容器异常退出容器暂停 ④容器命令清单总览docker createdocker rundocker psdocker logsdocker attachdocker execdocker startdocker stopdocker restartdocker killdocker topdocker statsdocker container insp…...

下载安装anaconda和pytorch的详细方法,以及遇到的问题和解决办法
下载安装Anaconda 首先需要下载Anaconda,可以到官网Anaconda官网或者这里提供一个镜像网站去下载anaconda镜像网站 安装步骤可参考该文章:Anaconda安装步骤,本篇不再赘述 注意环境变量的配置,安装好Anaconda之后一定要在环境变量…...

2020年天津市二级分类土地利用数据(矢量)
天津市,位于华北平原海河五大支流汇流处,东临渤海,北依燕山。地势以平原和洼地为主,北部有低山丘陵,海拔由北向南逐渐下降,地貌总轮廓为西北高而东南低。天津有山地、丘陵和平原三种地形,平原约…...
设计模式——结构型——外观模式Facade
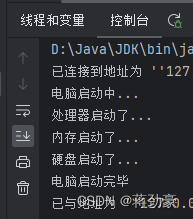
处理器类 public class Cpu {public void start() {System.out.println("处理器启动了...");} } 内存类 public class Memory {public void start() {System.out.println("内存启动了...");} } 硬盘类 public class Disk {public void start() {Syste…...

OpenGL的MVP矩阵理解
OpenGL的MVP矩阵理解 右手坐标系 右手坐标系与左手坐标系都是三维笛卡尔坐标系,他们唯一的不同在于z轴的方向,如下图,左边是左手坐标系,右边是右手坐标系 OpenGL中一般用的是右手坐标系 1.模型坐标系(Local Space&…...
前端超分辨率技术应用:图像质量提升与场景实践探索-设计篇
超分辨率! 引言 在数字化时代,图像质量对于用户体验的重要性不言而喻。随着显示技术的飞速发展,尤其是移动终端视网膜屏幕的广泛应用,用户对高分辨率、高质量图像的需求日益增长。然而,受限于网络流量、存储空间和图像…...

C++11入门手册第一节,学完直接上手Qt(共两节)
入门 hello.cpp #include <iostream>int main() { std::cout << "Hello Quick Reference\n"<<endl; return 0;} 编译运行 $ g hello.cpp -o hello$ ./helloHello Quick Reference 变量 int number 5; // 整数float f 0.95; //…...
Docker部署MinIO对象存储服务
1. 拉取MinIO镜像 # 下载镜像 docker pull minio/minio#查看镜像 docker images2. 创建目录 # 文件存储目录 mkdir -p /opt/minio/data# 配置文件 mkdir -p /opt/minio/config# 日志文件 mkdir -p /opt/minio/logs3. 创建Minio容器并运行 docker run \ -p 9000:9000 \ -p 90…...

基于Echarts的超市销售可视化分析系统(数据+程序+论文)
本论文旨在研究Python技术和ECharts可视化技术在超市销售数据分析系统中的应用。本系统通过对超市销售数据进行分析和可视化展示,帮助决策层更好地了解销售情况和趋势,进而做出更有针对性的决策。本系统主要包括数据处理、数据可视化和系统测试三个模块。…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

【Elasticsearch】Elasticsearch 在大数据生态圈的地位 实践经验
Elasticsearch 在大数据生态圈的地位 & 实践经验 1.Elasticsearch 的优势1.1 Elasticsearch 解决的核心问题1.1.1 传统方案的短板1.1.2 Elasticsearch 的解决方案 1.2 与大数据组件的对比优势1.3 关键优势技术支撑1.4 Elasticsearch 的竞品1.4.1 全文搜索领域1.4.2 日志分析…...
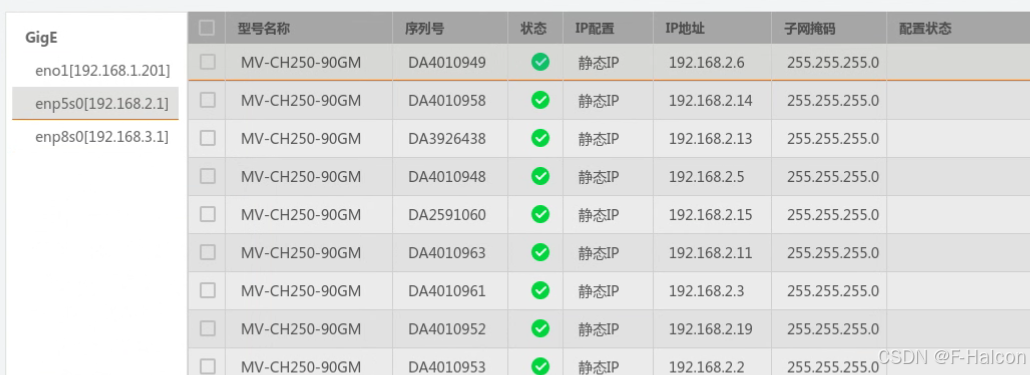
Ubuntu系统多网卡多相机IP设置方法
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...