万字详解PHP+Sphinx中文亿级数据全文检索实战(实测亿级数据0.1秒搜索耗时)
Sphinx查询性能非常厉害,亿级数据下输入关键字,大部分能在0.01~0.1秒,少部分再5秒之内查出数据。
Sphinx
- 官方文档:http://sphinxsearch.com/docs/sphinx3.html
- 极简概括:
由C++编写的高性能全文搜索引擎的开源组件,C/S架构,跨平台(支持Linux、Windows、MacOS),支持分布式部署,并可直接适配MySQL。 - 解决问题:
因为MySQL的 like %keyword% 不走索引,且全文索引不支持中文,所以需要借助其它组件。适用于不经常更新的数据的全文搜索。 - 同类产品:
ElasticSearch、Solr、Lucene、Algolia、XunSearch。 - 使用思路:
发送给Sphinx关键字,然后Sphinx返回id给PHP,PHP再调用MySQL根据id查询。也就是帮着MySQL找id的,MySQL走主键索引,查询性能很高。 - API支持:
Sphinx附带了三种不同的API,SphinxAPI、SphinxSE和SphinxQL。SphinxAPI是一个可用于Java、PHP、Python、Perl、C和其他语言的原生库。SphinxSE是MySQL的一个可插拔存储引擎,支持将大量结果集直接发送到MySQL服务器进行后期处理。SphinxQL允许应用程序使用标准MySQL客户端库和查询语法查询Sphinx。 - SQL扩展
Sphinx不仅限于关键字搜索。在全文搜索结果集之上,您可以计算任意算术表达式、添加WHERE条件、排序依据、分组依据、使用最小值/最大值/AVG值/总和、聚合等。本质上,支持成熟的SQL SELECT。
建表
CREATE TABLE `articles` (`id` int unsigned NOT NULL AUTO_INCREMENT,`content` varchar(16000) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL,PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=320974 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
亿级大数据源准备
- 决策分析:
亿级的数据量,还都得是中文,如果是52个大小写字母和10个数字可以随机,中文随机效果差,最好是有能阅读通畅的数据源,而不是随机汉字数据源。 - 尝试寻找:
尝试看了txt版的《三国演义》,发现行数太少,所以转变思维,更大的数据量,只能是长篇小说,翻看了最长的小说,也才22万行,1行小说对应1条MySQL数据,数据量还是太少,虽然循环小说内容插入也行,但还是差点意思。 - 资源整合:
程序员天天玩的就是数据,这点小事难不倒我,去网盘找txt小说资源合集https://www.aliyundrive.com/s/LBBg4ZvWip2/folder/63a138e95845afd3baa947db96342937033c254f
找到了如下35000本txt的小说。 - 数据合并:
下载了几千个txt小说,需要用命令把这些合并成一个文件,使用cat * > all.txt方便PHP程序逐行读取。整合后的单个txt文件9.57个G。 - 数据入库:
大数据文件一次加载会把内存撑爆,所以需要使用yield 生成(迭代)器去逐行读取文件。
set_time_limit(0);$file = 'C:/Users/Administrator/Desktop/all.txt';/*** @function 逐行读取大文件* @param $file_name string 文件名* @return Generator|object*/function readLargeFile($file_name) {$file = fopen($file_name, 'rb');if (! $file) {return false;}while (! feof($file)) {$line = fgets($file);if ($line !== false) {yield $line;}}fclose($file);}// 使用生成器逐行读取大文件$file_resource = readLargeFile($file);if(! $file_resource) {echo '文件读取错误';die;}$db = \Illuminate\Support\Facades\DB::table('articles');$arr = [];foreach ($file_resource as $line) {//获取单行编码$from_charset = mb_detect_encoding($line, 'UTF-8, GBK, GB2312, BIG5, CP936, ASCII');//转码操作,因为有些是ANSI,GBK的编码,最好转换成UTF-8$utf8_str = @iconv($from_charset, 'UTF-8', $line);//遇见空行,直接过滤if(in_array($utf8_str, ["\n", "\r", "\n\r", "\r\n"])) {continue;}$arr[] = ['content' => $utf8_str];if(count($arr) >= 10000) {$db->insert($arr);$arr = [];}}
-
性能调优:
MyISAM引擎:
insert 发现1秒才1400行的插入速度,不行得调整。
改为批量插入,一次性插入10000行数据,并修改/etc/my.cnf 里面的max_allowed_packet,将1M改为512M。
优化后,每秒2万的插入速度。如果是InnoDB引擎
可以调整redo log 刷盘策略,set global innodb_flush_log_at_trx_commit=0。
并添加缓冲池innodb_buffer_pool_size大小为系统总内存的70%。
把max_allowed_packet,将1M改为512M,就行了。 -
数量检查:
两万年后,用SELECT count(*) FROM articles一看,数据量109 450 000,搞定。 -
性能测试:
SELECT count(*) FROM articles where content like ‘%晴空万里%’,找出来了1931个,花了242秒。
编译安装并配置Sphinx Server
虚拟机里的CentOS,记得要足够的空间,用来存储数据
一个亿的数据占了系统很大空间,系统存储空间所剩无几了,/usr/local地方没地方存,所以把Sphinx放到了/home下,因为/dev/mapper/centos-home挂载到了/home下。可以事先安装mmsge
wget https://files.cnblogs.com/files/JesseLucky/coreseek-4.1-beta.tar.gz
tar zxf coreseek-4.1-beta.tar.gz
cd /home/coreseek-4.1-beta/mmseg-3.2.14
./bootstrap
./configure --prefix=/home/mmseg
make && make install然后安装Sphinx
cd /home/coreseek-4.1-beta/csft-4.1
./buildconf.sh发现报错,不着急
automake: warnings are treated as errors
/usr/share/automake-1.13/am/library.am: warning: 'libstemmer.a': linking libraries using a non-POSIX
/usr/share/automake-1.13/am/library.am: archiver requires 'AM_PROG_AR' in 'configure.ac'
libstemmer_c/Makefile.am:2: while processing library 'libstemmer.a'
/usr/share/automake-1.13/am/library.am: warning: 'libsphinx.a': linking libraries using a non-POSIX
/usr/share/automake-1.13/am/library.am: archiver requires 'AM_PROG_AR' in 'configure.ac'
src/Makefile.am:14: while processing library 'libsphinx.a'vim ./configure.ac +62
再AC_PROG_RANLIB的下方添加AM_PROG_AR再次执行./buildconf.sh
发现有如下报错:
configure.ac:231: the top level
configure.ac:62: error: required file 'config/ar-lib' not found
configure.ac:62: 'automake --add-missing' can install 'ar-lib'vim buildconf.sh +5
把--foreign改成--add-missing再次执行./buildconf.sh
直到configure文件出现。./configure --prefix=/home/coreseek --with-mysql=/usr/local/mysql --with-mmseg=/home/mmseg --with-mmseg-includes=/home/mmseg/include/mmseg/ --with-mmseg-libs=/home/mmseg/lib/make && make install
若发现报错:有ExprEval字样
vim /home/coreseek-4.1-beta/csft-4.1/src/sphinxexpr.cpp
将所有的
T val = ExprEval ( this->m_pArg, tMatch );
替换为
T val = this->ExprEval ( this->m_pArg, tMatch ); 再次执行make,发现还报错
/home/coreseek-4.1-beta/csft-4.1/src/sphinx.cpp:22292:对‘libiconv_open’未定义的引用
/home/coreseek-4.1-beta/csft-4.1/src/sphinx.cpp:22310:对‘libiconv’未定义的引用
/home/coreseek-4.1-beta/csft-4.1/src/sphinx.cpp:22316:对‘libiconv_close’未定义的引用vim /home/coreseek-4.1-beta/csft-4.1/src/Makefile +249
把
LIBS = -ldl -lm -lz -lexpat -L/usr/local/lib -lrt -lpthread
改成
LIBS = -ldl -lm -lz -lexpat -liconv -L/usr/local/lib -lrt -lpthreadmake && make install
成功安装
装好之后配置它,汉字是提示,记得运行环境要删掉
cd /home/coreseek/etc
记得这个名字一定得是csft.conf,换成其它的也行,但是到后期增量索引合并时会报错
cp sphinx-min.conf.dist csft.conf
配置内容就是有汉字的地方
vim csft.conf
source articles 起个名,叫articles
{type = mysqlsql_host = 数据库IPsql_user = 数据库用户名sql_pass = 数据库密码sql_db = 数据库sql_port = 3306 端口sql_query_pre = select names utf8mb4 加上这行sql_query = select id,content from articles Sphinx建索引的数据源sql_attr_uint = group_id 这行用不上可以去掉sql_attr_timestamp = date_added 这行用不上可以去掉sql_query_info_pre = select names utf8mb4 加上这行sql_query_info = select id,content from articles where id=$id 用Sphinx做什么SQL的查询逻辑#sql_query_post = update sphinx_index_record set max_id = (select max(id) from articles) where table_name = 'articles'; 这个是增量索引要用的东西,这里暂时用不上,后文会讲。
}index articles 起个名,叫articles
{source = articles 名字与source一致path = /home/coreseek/var/data/articles 索引路径docinfo = extern 这行用不上可以去掉charset_dictpath = /home/mmseg/etc 新增这行,表示分词读取词典文件的位置charset_type = zh_cn.utf-8 设置字符集编码
}保存并退出,注意数据源要与索引是一对一的。然后留意两个文件
/home/coreseek/bin/indexer 是用来创建索引的
/home/coreseek/bin/searchd 是启动服务端进程的。
开启服务
开启服务
/home/coreseek/bin/searchd -c /home/coreseek/etc/csft.conf
> ps aux | grep search
root 83205 0.0 0.0 47732 1048 ? S 02:01 0:00 /home/coreseek/bin/searchd -c /home/coreseek/etc/csft.conf
root 83206 0.5 0.0 116968 3728 ? Sl 02:01 0:00 /home/coreseek/bin/searchd -c /home/coreseek/etc/csft.conf9312端口
> netstat -nlp | grep 9312
tcp 0 0 0.0.0.0:9312 0.0.0.0:* LISTEN 83206/searchd
配置文件参数说明
https://sphinxsearch.com/docs/current.html#conf-mem-limit
indexer段-----------------------------
mem_limit这是创建索引时所需内存,默认32M,可以适当调大,格式如下
mem_limit = 256M
mem_limit = 262144K # same, but in KB
mem_limit = 268435456 # same, but in byteshttps://sphinxsearch.com/docs/current.html#conf-query-log
在searchd段-----------------------------
listen 9312
表示sphinx默认端口
listen=9306
mysql41,表示Sphinx服务器将监听在 9306 端口,并使用 MySQL 4.1 协议与客户端进行通信。可以注释掉以下两行,使其不记录日志
#log = /home/coreseek/var/log/searchd.log
#query_log = /home/coreseek/var/log/query.logread_timeout
网络客户端请求读取超时,以秒为单位。可选,默认为5秒。Searchd将强制关闭未能在此超时时间内发送查询的客户端连接。
max_children
并发搜索数量,设置为0,表示不限制。
max_matches
参数用于设置每次搜索操作返回的最大匹配项数seamless_rotate
在 Sphinx 服务器配置文件中,seamless_rotate 参数用于控制索引旋转操作的行为,确保索引更新过程中的查询不会被中断。“旋转”(rotate)是指在更新索引数据时,将旧的索引文件替换为新生成的索引文件的过程。
当设置为 1 或 true(默认值),seamless_rotate 使得 Sphinx 能够在后台加载新的索引数据,同时继续使用旧的索引数据处理查询请求,直到新的索引完全加载并准备好被使用。这个过程完成后,新的索引将无缝地接管,替换旧的索引,而不会干扰或中断正在进行的搜索操作。
如果将 seamless_rotate 设置为 0 或 false,则在索引旋转时,Sphinx 会暂停处理新的查询请求,直到新的索引文件完全加载并准备就绪。这可能会导致短暂的服务中断,因此,除非有特殊需求,一般建议保持 seamless_rotate 的默认设置(即启用无缝旋转),以确保索引更新过程中搜索服务的连续性和稳定性。preopen_indexes
是否在启动时强制预打开所有索引。可选,默认为1unlink_old
用于控制在索引旋转时是否删除旧的索引文件。当设置为 1 或 true 时(默认值),旧的索引文件将被删除,保持默认值就好。
客户端配置
PHP SphinxClient手册:http://docs.php.net/manual/tw/class.sphinxclient.php
cp /home/coreseek-4.1-beta/testpack/api/*.php /test
vim /test/sphinxapi.php
把sphinxapi里面的SphinxClient()方法改为__construct(),防止稍高版本的PHP,产生类名和方法名一致的通知。可以先测试,只要返回数组,就Server和Client都能正常工作。
vim /test/test_coreseek.php
把里面的网络搜索改成晴空万里,把SPH_MATCH_ANY改成SPH_MATCH_PHRASE。
sphinx文件有个limit选项,这个默认是20,所以最多显示出20个,可以去修改它。
/usr/local/php5.6/bin/php /test/test_coreseek.php
这是二次改过的test_coreseek.php,对于新手有很友好的提示。
require ( "./sphinxapi.php" );
$search = new SphinxClient ();
//连接Sphinx服务器
$search->SetServer ( '127.0.0.1', 9312);
//设置超时秒数
$search->SetConnectTimeout ( 3 );
//查询出来的数据库ID存放位置
$search->SetArrayResult ( true );
//配置搜索模式
$search->SetMatchMode (SPH_MATCH_PHRASE);
//分页,参数1偏移量,从0开始,参数2限制条目
$search->SetLimits(0, 200);
//执行查询,参数1关键字
$res = $search->Query ("黑色衣服", "索引名称");if($res === false) {echo '查询失败';return;
}//获取主键
$primary_keys = [];
if(! empty($res['matches'])) {foreach($res['matches'] as $v) {$primary_keys[] = $v['id'];}
}//获取总数
$all_count = $res['total_found'];//获取耗时
$time = $res['time'];$ids = implode(',', $primary_keys);
echo <<<RESULT
主键id: $ids
查询总数:$all_count
耗时: $time
RESULT;
匹配模式
- 官方文档:https://sphinxsearch.com/docs/current.html#matching-modes
- 调用方法:
(new SphinxClient())->SetMatchMode (SPH_MATCH_ALL); - 分词举例:假设关键字“白色衣服”,词语被分成了“白色”和“衣服”。
| 匹配模式 | 一句话概括 | 会被匹配 | 不会被匹配 |
|---|---|---|---|
| SPH_MATCH_ALL | 同时包含这些分词时会被匹配 | 白色的绳子晾着他的衣服 | 他的衣服 |
| SPH_MATCH_ANY | 匹配任意一个分词就行 | 白色的纸 | 白云 |
| SPH_MATCH_PHRASE | 相当于like ‘%关键词%’ | 白色衣服 | 白色的衣服 |
| SPH_MATCH_EXTENDED | 支持Sphinx的表达式 | 下方有详解 | 白色的衣服 |
| SPH_MATCH_EXTENDED2 | SPH_MATCH_EXTENDED的别名 | 下方有详解 | 白色的衣服 |
| SPH_MATCH_BOOLEAN | 支持布尔方式搜索 | 下方有详解 | 白色的衣服 |
| SPH_MATCH_FULLSCAN | 强制使用全扫描模式 | 下方有详解 | 白色的衣服 |
详解:SPH_MATCH_FULLSCAN
SPH_MATCH_FULLSCAN,强制使用全扫描模式。注意,任何查询项都将被忽略,这样过滤器、过滤器范围和分组仍然会被应用,但不会进行文本匹配。
当满足以下条件时,将自动激活SPH_MATCH_FULLSCAN模式来代替指定的匹配模式:
查询字符串为空(即:它的长度是0)。
Docinfo存储设置为extern。
在完全扫描模式下,所有索引的文档都被认为是匹配的。这样的查询仍然会应用过滤器、排序和分组,但不会执行任何全文搜索。这对于统一全文和非全文搜索代码或卸载SQL服务器很有用(在某些情况下,Sphinx扫描比类似的MySQL查询执行得更好)。
详解:SPH_MATCH_BOOLEAN
https://sphinxsearch.com/docs/current.html#boolean-syntax
- kw1|kw2|kw3:或的关系,满足任意1项即可。
- kw1 -kw2,或者kw1 !kw2:表示!=kw2
详解:SPH_MATCH_EXTENDED
https://sphinxsearch.com/docs/current.html#extended-syntax
- kw1|kw2|kw3:或的关系,满足任意1项即可,
- kw1 -kw2,或者kw1 !kw2:表示!=kw2。
- @mysql字段名 字段全部内容:匹配某个字段的内容。
- @* 字段全部内容:匹配所有字段的内容。
- ^kw:表示以关键字开头。
- kw$:表示以什么关键字结尾。
实测索引创建性能
- 创建索引
/home/coreseek/bin/indexer -c /home/coreseek/etc/csft.conf articles,这里的article就是source段的名称。 - 服务器配置:CentOS7.6 16核4G内存 固态硬盘。
- Sphinx索引创建速度:36262.76/sec,每条语句大小约10~150个汉字。
- Sphinx索引文件创建速度:4441931 bytes/sec。
- 一共耗时:1亿条数据,创建索引花了50.5分钟,索引文件约10个G。
- 原文如下:
Coreseek Fulltext 4.1 [ Sphinx 2.0.2-dev (r2922)]
Copyright (c) 2007-2011,
Beijing Choice Software Technologies Inc (http://www.coreseek.com)using config file '/home/coreseek/etc/csft.conf'...
indexing index 'articles'...
WARNING: Attribute count is 0: switching to none docinfo
collected 109450000 docs, 13406.8 MB
WARNING: sort_hits: merge_block_size=28 kb too low, increasing mem_limit may improve performance
sorted 3133.8 Mhits, 100.0% done
total 109450000 docs, 13406849231 bytes
total 3018.247 sec, 4441931 bytes/sec, 36262.76 docs/sec
total 322950 reads, 202.304 sec, 27.9 kb/call avg, 0.6 msec/call avg
total 20920 writes, 25.975 sec, 997.1 kb/call avg, 1.2 msec/call avg
实测查询性能
-
开启searchd服务
/home/coreseek/bin/searchd -c /home/coreseek/etc/csft.conf -
服务器配置:CentOS7.6 16核4G内存
-
实测亿级数据下搜索晴空万里只花费0.011秒,上文提到MySQL则需要242秒,性能差了22000倍。或许是受或分词器影响,Sphinx查询出来1898条,MySQL查询数据为1931条
-
多次测试:在109450000条数据中,从不同角度测试Sphinx SPH_MATCH_PHRASE匹配模式,相当于mysql where field like ‘%关键字%’:
| 类型 | 搜索关键字 | Sphinx搜索耗时(秒) | MySQL搜索耗时(秒) | Sphinx搜索数量 | MySQL搜索数量 |
|---|---|---|---|---|---|
| 数字 | 123 | 0.005 | 305.142 | 3121 | 8143 |
| 中文单字 | 虹 | 0.013 | 223.184 | 67802 | 103272 |
| 英文单字母 | A | 0.031 | 339.576 | 136428 | 1017983 |
| 单中文标点 | 。 | 4.471 | 125.106 | 67088012 | 67096182 |
| 单英文标点 | . | 0 | 251.171 | 0 | 6697242 |
| 可打印特殊字符 | ☺ | 0 | 355.469 | 0 | 0 |
| 中文词语(易分词) | 黑色衣服 | 0.066 | 346.442 | 1039 | 1062 |
| 中文词语(不易分词) | 夏威夷 | 0.011 | 127.054 | 3636 | 3664 |
| 中文词语(热门) | 你好 | 0.022 | 126.979 | 102826 | 137717 |
| 中文词语(冷门) | 旖旎 | 0.010 | 345.493 | 4452 | 4528 |
| 英文单词 | good | 0.010 | 137.562 | 553 | 1036 |
| 中文短语 | 他不禁一脸茫然 | 1.742 | 218.272 | 0 | 0 |
| 英文短语 | I am very happy | 0.015 | 355.235 | 1 | 0 |
| 长文本 | 陈大人不急着回答,他先从柜台下面又抽出了一份文案,翻了好一阵之后才回答道:“瞧,果然如此,如今广州这边官职该放得都放出去了,只剩下消防营山字营的一个哨官之职。不出所料的话,督抚大人准会委你这个职务。 | 0.131 | 129.204 | 1 | 1 |
实测Sphinx并发性能
压测方式 :ab -c 1 -n 10~1000 192.168.3.180/test_coreseek.php
中文定值关键字为华盛顿,英文定值关键字为XYZ,30位随机中文或英文字符,由代码生成。
生成任意正整数个中文字符
function generateRandomChinese($length) {$result = '';for ($i = 0; $i < $length; $i++) {$result .= mb_convert_encoding('&#' . mt_rand(0x3e00, 0x9fa5) . ';', 'UTF-8', 'HTML-ENTITIES');}return $result;
}生成任意正整数个英文字符
function generateRandomEnglish($length) {$result = '';for ($i = 0; $i < $length; $i++) {$result .= chr(mt_rand(97, 122)); // 小写字母ASCII码范围: 97~122;大写字母:65~90}return $result;
}
| 类型 | 请求量 (搜索次数) | 耗时(秒) |
|---|---|---|
| 固定中文多次搜索 | 10 | 0.256 |
| 固定中文多次搜索 | 100 | 1.435 |
| 固定中文多次搜索 | 1000 | 11.604 |
| 随机30位中文字符多次搜索 | 10 | 0.517 |
| 随机30位中文字符多次搜索 | 100 | 2.305 |
| 随机30位中文字符多次搜索 | 1000 | 17.197 |
| 固定英文多次搜索 | 10 | 0.327 |
| 固定英文多次搜索 | 100 | 0.747 |
| 固定英文多次搜索 | 1000 | 8.510 |
| 随机30位英文字符多次搜索 | 10 | 0.077 |
| 随机30位英文字符多次搜索 | 100 | 0.766 |
| 随机30位英文字符多次搜索 | 1000 | 9.428 |
创建增量索引前的数据查询问题
对于update很多数据,sphinx不会自动更新索引,所以可以选择在公司业务空闲时间重建索引。
对于insert,可以使用增量索引,创建一个表用于存储已经新增sphinx索引记录的最大值。
CREATE TABLE `sphinx_index_record` (`id` int unsigned NOT NULL AUTO_INCREMENT COMMENT 'Sphinx索引创建进度表id',`table_name` varchar(100) COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '表名',`max_id` int unsigned NOT NULL COMMENT '最大id',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;并insert一条数据:
INSERT INTO `test`.`sphinx_index_record` (`id`, `table_name`, `max_id`) VALUES (1, 'articles', 109450000);
- 对于Sphinx:当需要新增增量索引时,读取这个表中的数据,获取到这个值,使其创建索引的起始点,为max_id字段的值。
- 对于max_id字段的业务作用:可以封装一个方法,可以让这个值载入Redis,redis有值就读取,无值就查询然后载入Redis。
- 对于业务代码:例如100万行数据创建了Sphinx索引,然后又新增了1000条,这1000条数据没有sphinx索引,可以在业务代码中使用mysql union或者其它方式,让这1000条数据,做查询。
伪代码如下:
$max_id = 从缓存中获取获取的索引位置,假设是100万;
$kw = 搜索关键字;$id_s = sphinx($kw);sql1是根据sphinx的
$sql1 = select * from table where id in $id_s;
sql2是对未添加sphinx索引的剩余表数据的操作
$sql2 = select * from table where id > $max_id like "%$kw%";使用PHP的方式,或者mysql union的方式都行,让两个数据集合并,查询出的结果,通过接口返回。
这样兼顾新增的1000条数据也能被查询的到。
创建增量索引
这块需要承接上文。
第一步:自动维护索引最大值,这一步可以在首次创建索引时,就可以完成。
vim /home/coreseek/etc/csft.conf
在source段最后,添加一行代码,这是让sphinx创建增量索引后,自动维护sphinx_index_record表数据。
source articles {
...
...
sql_query_post = update sphinx_index_record set max_id = (select max(id) from articles) where table_name = 'articles';
}第二步:新增增量索引配置
把source段复制出来,然后粘贴到下方,注意括号范围,不要嵌套,例如:
source articles_add
{type = mysqlsql_host = 数据库IPsql_user = 数据库用户名sql_pass = 数据库密码sql_db = 数据库sql_port = 3306 端口sql_query_pre = select names utf8mb4 加上这行-------------------------------修改这里start-------------------------------------------sql_query = select id,content from articles where id > (select max_id from sphinx_index_record where table_name = 'articles') Sphinx创建增量索引的数据源-------------------------------修改这里end-------------------------------------------sql_attr_uint = group_id 这行用不上可以去掉sql_attr_timestamp = date_added 这行用不上可以去掉sql_query_info_pre = select names utf8mb4 加上这行sql_query_info = select id,content from articles where id=$id 用Sphinx做什么SQL的查询逻辑
}这里记得index段也新增一个配置。永远记住,source段与index段一对一的。index articles_add 这里需要改
{source = articles_add 这里需要改path = /home/coreseek/var/data/articles_add 这里需要改#docinfo = externcharset_dictpath = /home/mmseg/etccharset_type = zh_cn.utf-8
}执行创建索引功能。
/home/coreseek/bin/indexer -c /home/coreseek/etc/csft.conf articles_add
合并索引:语法indexer --merge 主索引名 增量索引名
/home/coreseek/bin/indexer --merge articles articles_add
如果不关闭searchd,可以添加 --rotate参数强制合并索引。需要留意一下:如果主索引10个G,增量索引0.1G,则需要20.2G的临时空间去进行和合并。
多配置
这个也好办,直接在csft.conf配置文件内source段和index段复制粘贴,根据上文的两段文章,该创建索引的创建索引,该重启的重启。
不需要引入多个文件,就和MySQL一样,只需要一个/etc/my.cnf就行了,相加配置,接着往下续就行了。
新创建索引后不会生效,需要关闭searchd进程后重新启动。
集成到框架思路
方案1:
使用composer安装新的包,PHP8.0及以上不会报错。
记得要搜索sphinx client或sphinxapi,不要搜素sphinx,这会把SphinxQL的解决方案也给搜出来。
用这个包就行,composer require nilportugues/sphinx-search
用法与自带的完全一致,而且遇到PHP8不报错。
$sphinx = new \NilPortugues\Sphinx\SphinxClient();
$sphinx->setServer('192.168.3.180',9312);
$sphinx->SetConnectTimeout (3);
$sphinx->SetArrayResult (true);
$sphinx->SetMatchMode (SPH_MATCH_PHRASE);
$sphinx->SetLimits(0, 200);
$res = $sphinx->query ("黑色衣服", "articles");
print_r($res);
方案2:
使用原生自带的包,PHP8.0及以上会报错。
sphinxapi.php放置到app/Libs/Others目录下,并添加自己的命名空间App\Libs\Others\SphinxApi。
app/Libs/helper.php存放了自定义封装的方法,并使用composer dump-autoload配置,跟随框架自动加载。
封装成一个方法,方便调用,并放入helper.php下
function sphinx() {$sphinx = new App\Libs\Others\SphinxApi();$sphinx->SetServer (config('services.sphinx.ip'), config('services.sphinx.port'));$sphinx->SetConnectTimeout (config('services.sphinx.timeout');$sphinx->SetArrayResult (true);return $sphinx;
}//控制器随处调用
$sphinx = sphinx();
$sphinx->SetMatchMode (SPH_MATCH_PHRASE);
$sphinx->SetLimits(0, 200);
$res = $sphinx->Query ("黑色衣服", "索引名称");
...
Sphinx的不足之处
- 查询结果遗漏:受分词器影响,实测查询结果比实际的存储要少一些,这会造成信息的损失。
- 客户端代码陈旧:自带的的PHP Sphinx Api的代码,使用PHP8.0及以上会报错。
- 不会自动添加增量索引:MySQL新增的数据,Sphinx并不会自动创建索引。
- 不会自动改变索引:MySQL update的数据,Sphinx不会自动改变索引。
- 不支持Canal监听bin log实时同步Sphinx索引。
鸣谢
感谢3位博主在C++编译安装报错时提供的解决方案:
夜里小郎君的博文:https://blog.csdn.net/b876143268/article/details/53771310
mingaixin的博文:https://www.cnblogs.com/mingaixin/p/5013356.html
晚晚的博文:https://www.cnblogs.com/caochengli/articles/3028630.html
相关文章:
)
万字详解PHP+Sphinx中文亿级数据全文检索实战(实测亿级数据0.1秒搜索耗时)
Sphinx查询性能非常厉害,亿级数据下输入关键字,大部分能在0.01~0.1秒,少部分再5秒之内查出数据。 Sphinx 官方文档:http://sphinxsearch.com/docs/sphinx3.html极简概括: 由C编写的高性能全文搜索引擎的开源组件&…...
数据库索引及优化
数据库索引及优化 什么是索引? MySQL官方对索引的定义为:索引(INDEX)是帮助MySQL高效获取数据的数据结构。 索引的本质: 数据结构 为什么要引入索引? 引入索引的目的在于提高查询效率,就好像是…...
flink: 将接收到的tcp文本流写入HBase
一、依赖: <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.o…...
SpringBoot集成knife4j
SpringBoot集成knife4j 1、什么是Knife4j2、SpringBoor整合Knife4j2.1、Knife4j配置方式12.2 配置方式二2.3、写注解2.4、效果 1、什么是Knife4j 在日常开发中,写接口文档是我们必不可少的,而Knife4j就是一个接口文档工具,可以看作是Swagger…...

Vue3之setup方法
Vue 3 的 setup 方法是 Vue Composition API 的一部分,用于组织和复用 Vue 组件的逻辑代码。Vue Composition API 允许您以更具响应性和函数式的方式来组织和复用 Vue 组件中的代码,特别是在处理复杂逻辑或跨组件共享逻辑时非常有用。 以下是关于 setup…...

MySQL常见索引及其创建
MySQL索引 在 MySQL 数据库中,常见的索引类型包括以下几种: 普通索引(Normal Index):最基本的索引类型,没有任何限制。唯一索引(Unique Index):要求索引列的值是唯一的…...
高效测量“芯”搭档 | ACM32激光测距仪应用方案
激光测距仪概述 激光测距仪是利用激光对目标的距离进行准确测定的仪器。激光测距仪在工作时向目标射出一束很细的激光,由光电元件接收目标反射的激光束,计时器测定激光束从发射到接收的时间,计算出从观测者到目标的距离。激光测距仪分为手持激…...

基于Hive大数据分析springboot为后端以及vue为前端的的民宿系
标题基于Hive大数据分析springboot为后端以及vue为前端的的民宿系 本文介绍了如何利用Hive进行大数据分析,并结合Spring Boot和Vue构建了一个民宿管理系统。该民民宿管理系统包含用户和管理员登陆注册的功能,发布下架酒店信息,模糊搜索,酒店详情信息展示,收藏以及对收藏的…...
pnpm、monorepo分包管理、多包管理、npm、vite、前端工程化、保姆级教程
浅尝pnpm monorepo 多包管理方案 💡tips: 创建pnpm monorope多包管理框架流程 初始化 mkdir taurus & cd taurus pnpm init创建基础文件 创建文件pnpm-workspace.yaml packages:- packages/**创建文件夹packages/ -packages/ -package.json -pnpm-workspace…...
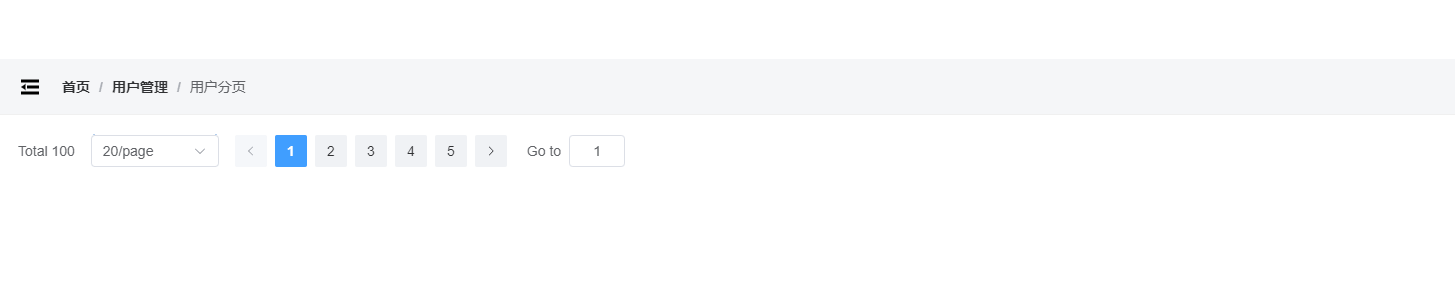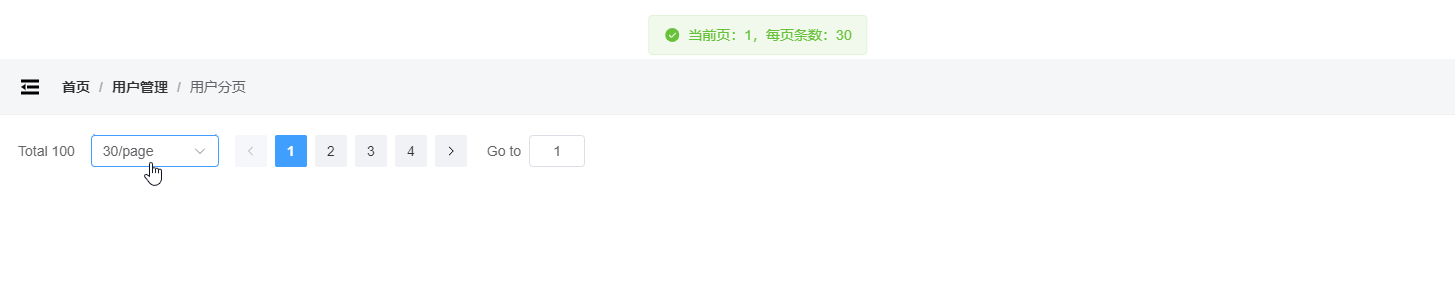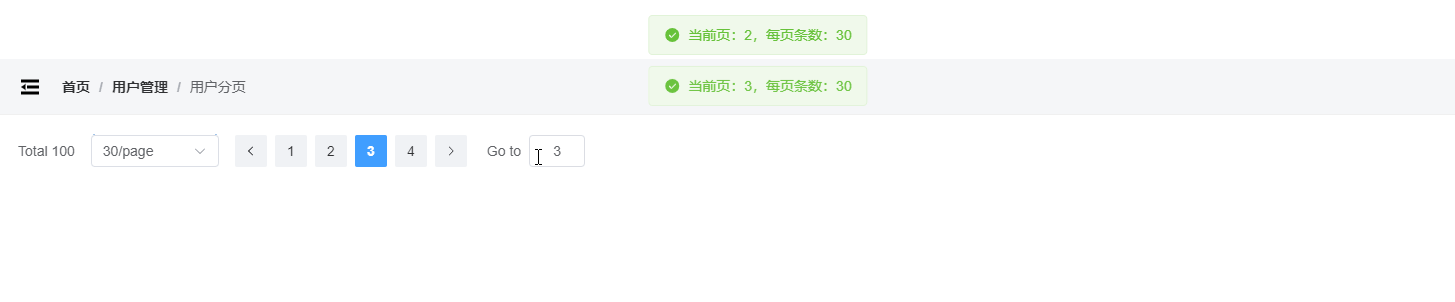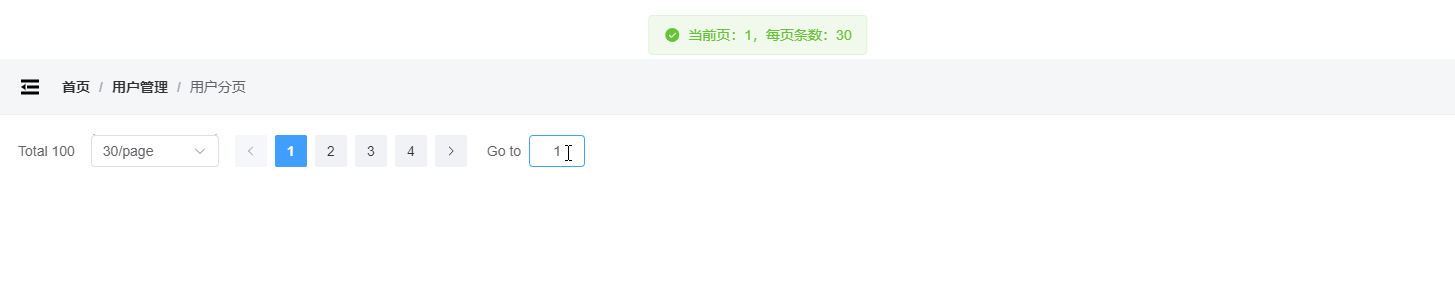
vue3封装Element分页
配置当前页 配置每页条数 页面改变、每页条数改变都触发回调 封装分页 Pagination.vue <template><el-paginationbackgroundv-bind"$attrs":page-sizes"pageSizes"v-model:current-page"page"v-model:page-size"pageSize":t…...

真机 ARM64 架构转模拟器 ARM64 架构
本文字数:2051字 预计阅读时间:15分钟 01 需要转换架构的原因 老版 Mac 使用 Intel 芯片,是x86_64架构,相应地在老版 Mac 上运行的模拟器使用的也就是 x86_64架构。 由于模拟器的 x86_64 架构与真机的 arm64、armv7 等架构不冲突&…...

敏捷教练CSM认证考了有没有用,谁说了算?
敏捷教练CSM证书是近年来备受关注的一项证书,它被认为可以提升敏捷开发团队的管理能力和项目执行效率。然而,对于这个证书的价值和含金量,人们的观点却不尽相同。那么,CSM证书到底有没有用,谁来说了算呢? 首…...

Docker-Container
Docker ①什么是容器②为什么需要容器③容器的生命周期容器 OOM容器异常退出容器暂停 ④容器命令清单总览docker createdocker rundocker psdocker logsdocker attachdocker execdocker startdocker stopdocker restartdocker killdocker topdocker statsdocker container insp…...

下载安装anaconda和pytorch的详细方法,以及遇到的问题和解决办法
下载安装Anaconda 首先需要下载Anaconda,可以到官网Anaconda官网或者这里提供一个镜像网站去下载anaconda镜像网站 安装步骤可参考该文章:Anaconda安装步骤,本篇不再赘述 注意环境变量的配置,安装好Anaconda之后一定要在环境变量…...

2020年天津市二级分类土地利用数据(矢量)
天津市,位于华北平原海河五大支流汇流处,东临渤海,北依燕山。地势以平原和洼地为主,北部有低山丘陵,海拔由北向南逐渐下降,地貌总轮廓为西北高而东南低。天津有山地、丘陵和平原三种地形,平原约…...
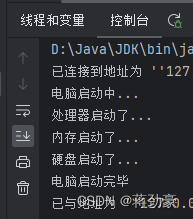
设计模式——结构型——外观模式Facade
处理器类 public class Cpu {public void start() {System.out.println("处理器启动了...");} } 内存类 public class Memory {public void start() {System.out.println("内存启动了...");} } 硬盘类 public class Disk {public void start() {Syste…...

OpenGL的MVP矩阵理解
OpenGL的MVP矩阵理解 右手坐标系 右手坐标系与左手坐标系都是三维笛卡尔坐标系,他们唯一的不同在于z轴的方向,如下图,左边是左手坐标系,右边是右手坐标系 OpenGL中一般用的是右手坐标系 1.模型坐标系(Local Space&…...
前端超分辨率技术应用:图像质量提升与场景实践探索-设计篇
超分辨率! 引言 在数字化时代,图像质量对于用户体验的重要性不言而喻。随着显示技术的飞速发展,尤其是移动终端视网膜屏幕的广泛应用,用户对高分辨率、高质量图像的需求日益增长。然而,受限于网络流量、存储空间和图像…...

C++11入门手册第一节,学完直接上手Qt(共两节)
入门 hello.cpp #include <iostream>int main() { std::cout << "Hello Quick Reference\n"<<endl; return 0;} 编译运行 $ g hello.cpp -o hello$ ./helloHello Quick Reference 变量 int number 5; // 整数float f 0.95; //…...
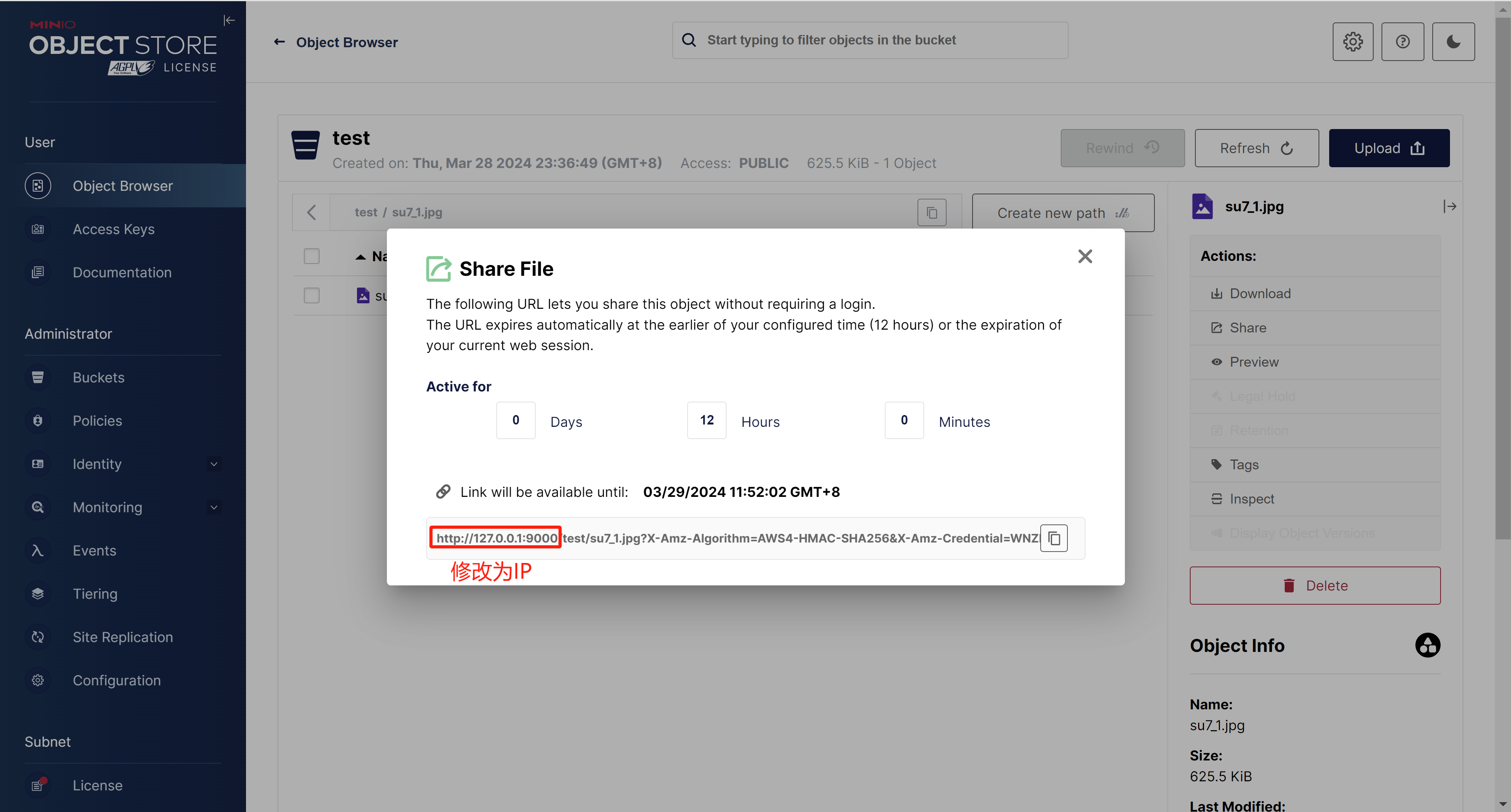
Docker部署MinIO对象存储服务
1. 拉取MinIO镜像 # 下载镜像 docker pull minio/minio#查看镜像 docker images2. 创建目录 # 文件存储目录 mkdir -p /opt/minio/data# 配置文件 mkdir -p /opt/minio/config# 日志文件 mkdir -p /opt/minio/logs3. 创建Minio容器并运行 docker run \ -p 9000:9000 \ -p 90…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...