【Flink connector】文件系统 SQL 连接器:实时写文件系统以及(kafka到hive)实战举例
文章目录
- 一. 滚动策略:sink后文件切分(暂不关注)
- 1. 切分分区目录下的文件
- 2. 小文件合并
- 二. 分区提交
- 1. 分区提交触发器 (什么时候创建分区)
- 1.1. 逻辑说明
- 1.2. 举例说明
- 2. 分区时间提取器 (用于partition-time情况下partition commit策略)
- 2.1. 逻辑说明
- 2.2. 举例说明
- 3. 分区提交策略 (分区创建后怎么告知下游或系统)
- 3.1. 逻辑说明
- 3.2. 举例说明
- 4. Sink Parallelism
- 三. 完整示例
- 1. 官网(partition-time)
- 2. 实际测试(kafka->hive)
本文概述
flink支持动态写数据到文件系统,提供了分块写数据以及动态分区,接下来看flink是如何分块写数据,以及如何配置动态分区的建立。
文件系统连接器支持流写入,是基于 Flink 的 文件系统 写入文件的。
我们可以直接编写 SQL,将流数据插入到非分区表。 如果是分区表,可以配置分区操作相关的属性。具体参考分区提交。
一. 滚动策略:sink后文件切分(暂不关注)
1. 切分分区目录下的文件
分区目录下的数据被分割到 part 文件中。每个分区对应的 sink 的 subtask 都至少会为该分区生成一个 part 文件。
该策略基于大小,和指定的文件可被打开的最大 timeout 时长,来滚动 part 文件。
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| sink.rolling-policy.file-size | 128MB | MemorySize | 当part达到设定值时,文件开始滚动。 |
| sink.rolling-policy.rollover-interval | 30 min | Duration | 滚动前,part 文件处于打开状态的最大时长(默认值30分钟,以避免产生大量小文件)。 检查频率是由 sink.rolling-policy.check-interval 属性控制的。 |
| sink.rolling-policy.check-interval | 1 min | Duration | 周期检查文件打开时长。 |
根据描述默认情况下Flink采取了如上默认值的滚动策略。
todo:checkpoint 也会影响part文件的生成
对于 bulk formats 数据 (parquet、orc、avro):滚动策略与 checkpoint 间隔(pending 状态的文件会在下个 checkpoint 完成)控制了 part 文件的大小和个数。
2. 小文件合并
todo: checkpoint的间隔会影响文件产生的效率
file sink 支持文件合并,允许应用程序使用较小的 checkpoint 间隔但不产生大量小文件。
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| auto-compaction | false | Boolean | 在流式 sink 中自动合并功能。数据首先会被写入临时文件。当 checkpoint 完成后,该检查点产生的临时文件会被合并。这些临时文件在合并前不可见。 |
| compaction.file-size | (无) | MemorySize | 合并目标文件大小,默认值为滚动文件大小。 |
如果启用文件合并功能,会根据目标文件大小,将多个小文件合并成大文件。
在生产环境中使用文件合并功能时,需要注意:
- 只有 checkpoint 内部的文件才会被合并,至少生成的文件个数与 checkpoint 个数相同。
- 合并前文件是不可见的,那么文件的可见时间是:checkpoint 间隔时长 + 合并时长。
- 如果合并时间过长,将导致反压,延长 checkpoint 所需时间。
二. 分区提交
sink动态写分区包括如下两个操作:
- Trigger-提交分区的时机:通过什么来识别分区(watermark或处理时间),什么时候提交分区
- Policy-提交分区后通知下游:写_SUCCESS,hive metadata 中新增分区,或自定义:合并小文件等。
注意: 分区提交仅在(什么是?)动态分区插入模式下才有效。
1. 分区提交触发器 (什么时候创建分区)
1.1. 逻辑说明
Flink 提供了两种类型分区提交触发器:
- 第一种:根据分区的处理时间(没有根据字段吗)。基于
分区创建时间(这里指的是什么)和当前系统时间来触发分区。 这种触发器更具通用性,但不是很精确。例如,数据延迟或故障将导致过早提交分区。- 第二种:根据从分区字段提取的时间以及 watermark。 这需要 job 支持 watermark 生成,分区是根据时间来切割的,例如,按小时或按天分区。
感知分区的几种情况:
- 不管分区数据是否完整而只想让下游尽快感知到分区:(不推荐)
‘sink.partition-commit.trigger’=‘process-time’ (默认值)
‘sink.partition-commit.delay’=‘0s’ (默认值) 一旦数据进入分区,将立即提交分区。注意:这个分区可能会被提交多次(提交多次产生的影响ing:浪费多余的资源)。
- 如果想让下游只有在分区数据完整时才感知到分区,并且 job 中有 watermark 生成,
也能从分区字段的值中提取到时间:‘sink.partition-commit.trigger’=‘partition-time’
‘sink.partition-commit.delay’=‘1h’ (根据分区类型指定,如果是按小时分区可配置为 ‘1h’) 该方式是最精准地提交分区的方式,尽力确保提交分区的数据完整。
- 如果想让下游系统只有在数据完整时才感知到分区,但是没有 watermark,或者无法从分区字段的值中提取时间:
‘sink.partition-commit.trigger’=‘process-time’ (默认值)
‘sink.partition-commit.delay’=‘1h’ (根据分区类型指定,如果是按小时分区可配置为 ‘1h’) 该方式尽量精确地提交分区,但是数据延迟或者故障将导致过早提交分区。
延迟数据的处理:延迟的记录会被写入到已经提交的对应分区中,且会再次触发该分区的提交。
如下参数:
确定何时提交分区:这里只关注process-time trigger下的两个参数
sink.partition-commit.trigger:
默认值:process-time
描述:
- 基于机器时间: ‘process-time’:不需要分区时间提取器也不需要 watermark 生成器。
- 一旦 “当前系统时间” 超过了
"分区创建系统时间(比如flink消费到一条数据,触发了分区创建操作对应的时间)" 和 'sink.partition-commit.delay' 之和立即提交分区。- 基于提取的分区时间:‘partition-time’。需要 watermark 生成。一旦 watermark 超过了 “分区创建系统时间” 和 ‘sink.partition-commit.delay’ 之和立即提交分区。
sink.partition-commit.delay
默认值:0s
描述: 该延迟时间之前分区不会被提交。如果是按天分区,可以设置为 ‘1 d’,如果是按小时分区,应设置为 ‘1 h’,当然也可以设置分钟,例如30min。
1.2. 举例说明
--默认值可以不配置
'sink.partition-commit.trigger'='process-time'
--当来第一条数据时(记录为时刻1),先创建hive分区文件夹,当时间超过 时刻1+1h 时,分区提交
--分区未提交时文件为.data开头的临时文件,分区提交时,会从cp中同步数据到临时文件中,并命名为正式文件。
'sink.partition-commit.delay'='1h'
2. 分区时间提取器 (用于partition-time情况下partition commit策略)
2.1. 逻辑说明
时间提取器从分区字段值中提取时间。
partition.time-extractor.kind
默认值:default
描述:从分区字段中提取时间的时间提取器。
支持default 和 custom。在默认情况下,可以配置 timestamp-pattern/formatter。对于custom,应指定提取器类。
partition.time-extractor.timestamp-pattern
默认值:无
描述:分区格式的数据拼接。
默认支持第一个字段按 ‘yyyy-MM-dd hh:mm:ss’ 这种模式提取。
- 如果需要从一个分区字段 ‘dt’ 提取 timestamp,可以配置成:‘$dt’。
- 如果需要从多个分区字段中提取分区,比如 ‘year’、‘month’、‘day’ 和 ‘hour’ 提取 timestamp,可以配置成:
$year-$month-$day $hour:00:00。如果需要从两个分区字段 'dt' 和 'hour' 提取 timestamp,可以配置成:'$dt$hour:00:00'。
partition.time-extractor.timestamp-formatter
默认值:yyyy-MM-dd HH:mm:ss
描述:分区格式的规定。具体数值由partition.time-extractor.timestamp-pattern设置。默认yyyy-MM-dd HH:mm:ss。
2.2. 举例说明
-- 'year'、'month' 和 'day'三个字段组成分区
-- 可不填,'default'为默认值,即从分区字段中获取
'partition.time-extractor.kind' = 'default'
--具体动态分区名怎么由字段拼接
'partition.time-extractor.timestamp-pattern' = '$year$month$day'
--分区名格式
'partition.time-extractor.timestamp-formatter' = 'yyyyMMdd'
3. 分区提交策略 (分区创建后怎么告知下游或系统)
3.1. 逻辑说明
分区提交策略定义了提交分区时的具体操作。
- metadata 存储(metastore),仅 hive 表支持该策略,
该策略下文件系统通过目录层次结构来管理分区。(todo:通过hive更新表元数据?)- success 文件,该策略下会在分区对应的目录下生成一个名为
_SUCCESS的空文件。
sink.partition-commit.policy.kind
默认值:无
描述:分区提交策略通知下游某个分区已经写完毕可以被读取了。
- metastore:向 metadata 增加分区。仅 hive 支持 metastore 策略,文件系统通过目录结构管理分区;
- success-file:在目录中增加 ‘_success’ 文件; 上述两个策略可以同时定:‘metastore,success-file’。
- custom:通过指定的类来创建提交策略。 支持同时指定多个提交略:‘metastore,success-file’。
sink.partition-commit.success-file.name
默认值:_SUCCESS
描述:使用success-file 分区提交策略时的文件名,默认值是 ‘_SUCCESS’。
sink.partition-commit.policy.class
默认值:无
描述: custom下才用: 实现PartitionCommitPolicy 接口的分区提交策略类。只有在 custom 提交策略下才使用该类。 可以自定义提交策略,如下
public class AnalysisCommitPolicy implements PartitionCommitPolicy {private HiveShell hiveShell;@Overridepublic void commit(Context context) throws Exception {if (hiveShell == null) {hiveShell = createHiveShell(context.catalogName());}hiveShell.execute(String.format("ALTER TABLE %s ADD IF NOT EXISTS PARTITION (%s = '%s') location '%s'",context.tableName(),context.partitionKeys().get(0),context.partitionValues().get(0),context.partitionPath()));hiveShell.execute(String.format("ANALYZE TABLE %s PARTITION (%s = '%s') COMPUTE STATISTICS FOR COLUMNS",context.tableName(),context.partitionKeys().get(0),context.partitionValues().get(0)));}
}
todo:如上通过hive语句来添加分区
3.2. 举例说明
'sink.partition-commit.policy.kind'='success-file'
'sink.partition-commit.success-file.name'='_SUCCESS_gao'
4. Sink Parallelism
在流模式和批模式下,向外部文件系统(包括 hive)写文件时的 parallelism 可以通过相应的 table 配置项指定。
默认情况下,该 sink parallelism 与上游 chained operator 的 parallelism 一样。
比如kafka作为source源(分区为5,设置并行度为5),(在同一个chained中)写分区时,hive sink的并行度自动设为5。
当配置了跟上游的 chained operator 不一样的 parallelism 时,写文件和合并文件的算子(如果开启的话)会使用指定的 sink parallelism。
| 键 | 默认值 | 类型 | 描述 |
|---|---|---|---|
| sink.parallelism | (无) | Integer | 将文件写入外部文件系统的 parallelism。这个值应该大于0否则抛异常。 |
注意: 目前,当且仅当上游的 changelog 模式为 INSERT-ONLY 时,才支持配置 sink parallelism。否则,程序将会抛出异常。
三. 完整示例
1. 官网(partition-time)
以下示例展示了如何使用文件系统连接器编写流式查询语句,将数据从 Kafka 写入文件系统,然后运行批式查询语句读取数据。
CREATE TABLE kafka_table (user_id STRING,order_amount DOUBLE,log_ts TIMESTAMP(3),WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND
) WITH (...);CREATE TABLE fs_table (user_id STRING,order_amount DOUBLE,dt STRING,`hour` STRING
) PARTITIONED BY (dt, `hour`) WITH ('connector'='filesystem','path'='...','format'='parquet','sink.partition-commit.delay'='1 h','sink.partition-commit.policy.kind'='success-file'
);-- 流式 sql,插入文件系统表
INSERT INTO fs_table
SELECT user_id, order_amount, DATE_FORMAT(log_ts, 'yyyy-MM-dd'),DATE_FORMAT(log_ts, 'HH')
FROM kafka_table;-- 批式 sql,使用分区修剪进行选择
SELECT * FROM fs_table WHERE dt='2020-05-20' and `hour`='12';
如果 watermark 被定义在 TIMESTAMP_LTZ 类型的列上并且使用 partition-time 模式进行提交,sink.partition-commit.watermark-time-zone 这个属性需要设置成会话时区,否则分区提交可能会延迟若干个小时。
CREATE TABLE kafka_table (user_id STRING,order_amount DOUBLE,ts BIGINT, -- 以毫秒为单位的时间ts_ltz AS TO_TIMESTAMP_LTZ(ts, 3),WATERMARK FOR ts_ltz AS ts_ltz - INTERVAL '5' SECOND -- 在 TIMESTAMP_LTZ 列上定义 watermark
) WITH (...);CREATE TABLE fs_table (user_id STRING,order_amount DOUBLE,dt STRING,`hour` STRING
) PARTITIONED BY (dt, `hour`) WITH ('connector'='filesystem','path'='...','format'='parquet','partition.time-extractor.timestamp-pattern'='$dt $hour:00:00','sink.partition-commit.delay'='1 h','sink.partition-commit.trigger'='partition-time','sink.partition-commit.watermark-time-zone'='Asia/Shanghai', -- 假设用户配置的时区为 'Asia/Shanghai''sink.partition-commit.policy.kind'='success-file'
);-- 流式 sql,插入文件系统表
INSERT INTO fs_table
SELECT user_id, order_amount, DATE_FORMAT(ts_ltz, 'yyyy-MM-dd'),DATE_FORMAT(ts_ltz, 'HH')
FROM kafka_table;-- 批式 sql,使用分区修剪进行选择
SELECT * FROM fs_table WHERE dt='2020-05-20' and `hour`='12';
2. 实际测试(kafka->hive)
-- SET 'table.sql-dialect'='hive';
CREATE CATALOG myhive WITH ('type' = 'hive','default-database' = 'data_base','hive-conf-dir' = '/usr/bin/hadoop/software/hive/conf'
);CREATE TABLE source_kafka (`pv` string,`uv` string,`p_day_id` string
) WITH ('connector' = 'kafka-x','topic' = 'hive_kafka','properties.bootstrap.servers' = 'xxx:9092','properties.group.id' = 'luna_g','scan.startup.mode' = 'earliest-offset','json.timestamp-format.standard' = 'SQL','json.ignore-parse-errors' = 'true','format' = 'json','scan.parallelism' = '1');-- 通过sql hint来指定表的行为
-- 1. 分区名称策略
-- partition.time-extractor.timestamp-pattern'='$p_day_id' :分区数据组成
-- partition.time-extractor.timestamp-formatter' = 'yyyyMMdd' :分区格式-- 2. 分区提交策略
-- 'sink.partition-commit.delay'='5min':分区提交延迟:分区时间 + 延迟 与 process_time做对比--3. 通知下游策略
-- 'sink.partition-commit.policy.kind'='metastore,success-file':通知下游策略
-- 'sink.partition-commit.success-file.name'='_SUCCESS_gao' :成功文件名称insert into myhive.logsget.dws_thjl_pv_uv_d_xky_bak /*+ OPTIONS('partition.time-extractor.timestamp-pattern'='$p_day_id:00:00','sink.partition-commit.policy.kind'='metastore,success-file','sink.partition-commit.success-file.name'='_SUCCESS_gao111') */select * from source_kafka; 相关文章:
实战举例)
【Flink connector】文件系统 SQL 连接器:实时写文件系统以及(kafka到hive)实战举例
文章目录 一. 滚动策略:sink后文件切分(暂不关注)1. 切分分区目录下的文件2. 小文件合并 二. 分区提交1. 分区提交触发器 (什么时候创建分区)1.1. 逻辑说明1.2. 举例说明 2. 分区时间提取器 (用于partition-time情况下partition commit策略)2…...

RpcContext :提供了在 RPC 调用过程中访问当前调用信息的方法
在 Dubbo 中,RpcContext 是一个上下文对象,它提供了在 RPC 调用过程中访问当前调用信息的方法。RpcContext.getClientAttachment() 方法用于获取客户端设置的附件(Attachment)信息。这些附件信息通常是在 RPC 调用发起方ÿ…...
)
机器学习 - 提高模型 (代码)
如果模型出现了 underfitting 问题,就得提高模型了。 Model improvement techniqueWhat does it do?Add more layersEach layer potentially increases the learning capabilities of the model with each layer being able to learn some kind of new pattern in…...

数值代数及方程数值解:预备知识——二进制及浮点数
文章目录 二进制IEEE浮点数 本篇文章的前置知识:数学分析 二进制 命题:二进制转化为十进制 二进制的数字表示为 ⋯ b 2 b 1 b 0 . b − 1 b − 2 ⋯ \cdots b_2b_1b_0.b_{-1}b_{-2}\cdots ⋯b2b1b0.b−1b−2⋯这等价于十进制下的 ⋯ b 2 2 …...

新数字时代的启示:揭开Web3的秘密之路
在当今数字时代,随着区块链技术的不断发展,Web3作为下一代互联网的概念正逐渐引起人们的关注和探索。本文将深入探讨新数字时代的启示,揭开Web3的神秘之路,并探讨其在未来的发展前景。 1. Web3的定义与特点 Web3是对互联网未来发…...

算法——动态规划:01背包
原始01背包见下面这篇文章:http://t.csdnimg.cn/a1kCL 01背包的变种:. - 力扣(LeetCode) 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。 简化一…...

写作类AI推荐(二)
本章要介绍的写作AI如下: 火山写作 主要功能: AI智能创作:告诉 AI 你想写什么,立即生成你理想中的文章AI智能改写:选中段落句子,可提升表达、修改语气、扩写、总结、缩写等文章内容优化:根据全文…...
(JAVA))
分寝室(20分)(JAVA)
目录 题目描述 输入格式: 输出格式: 输入样例 1: 输出样例 1: 输入样例 2: 输出样例 2: 题解: 题目描述 学校新建了宿舍楼,共有 n 间寝室。等待分配的学生中,有女…...

Spring 源码调试问题 ( List.of(“bin“, “build“, “out“); )
Spring 源码调试问题 文章目录 Spring 源码调试问题一、问题描述二、解决方案 一、问题描述 错误:springframework\buildSrc\src\main\java\org\springframework\build\CheckstyleConventions.java:68: 错误: 找不到符号 List<String> buildFolders List.of…...
Centos7安装RTL8111网卡驱动
方法一: // 安装pciutils # yum install -y pciutils // 查看pci设备信息 # lspci | grep -i Ethernet 09:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller (rev 03) // 上面看到是Re…...

吉时利KEITHLEY2460数字源表
181/2461/8938产品概述: Keithley 2460 高电流源表源测量单元 (SMU) 将先进的触摸、测试和发明技术带到您的指尖。Keithley 2460 将创新的图形用户界面 (GUI) 与电容式触摸屏技术相结合,使测试变得直观并最大限度地缩短学习曲线,从而帮助工程…...
)
数据库原理(含思维导图)
数据库原理笔记,html与md笔记已上传 1.绪论 发展历程 记住数据怎么保存,谁保存数据,共享性如何,独立性如何 人工管理阶段 数据不保存应用程序管理数据数据不共享数据不具有独立性 文件系统阶段 数据可以长期保存文件系统管…...

数据结构(六)——图
六、图 6.1 图的基本概念 图的定义 图:图G由顶点集V和边集E组成,记为G (V, E),其中V(G)表示图G中顶点的有限非空集;E(G) 表示图G中顶点之间的关系(边)集合。若V {v1, v2, … , vn},则用|V|…...

Android-AR眼镜屏幕显示
Android-AR眼镜 前提:Android手持设备 需要具备DP高清口 1、创建Presentation(双屏异显) public class MyPresentation extends Presentation {private PreviewSingleBinding binding;private ScanActivity activity;public MyPresentatio…...

蓝桥集训之货币系统
蓝桥集训之货币系统 核心思想:背包 #include <iostream>#include <cstring>#include <algorithm>using namespace std;const int N 30,M 10010;typedef long long LL;LL f[M];int w[N];int n,m;int main(){cin>>n>>m;for(int i1;i&…...

基于微信小程序的校园服务平台设计与实现(程序+论文)
本文以校园服务平台为研究对象,首先分析了当前校园服务平台的研究现状,阐述了本系统设计的意义和背景,运用微信小程序开发工具和云开发技术,研究和设计了一个校园服务平台,以满足学生在校园生活中的多样化需求。通过引…...
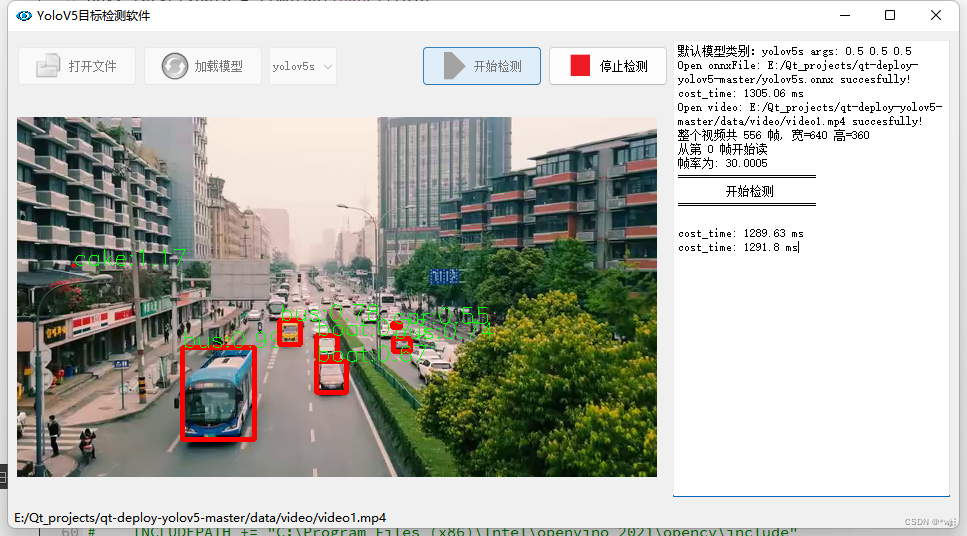
QT+Opencv+yolov5实现监测
功能说明:使用QTOpencvyolov5实现监测 仓库链接:https://gitee.com/wangyoujie11/qt_yolov5.git git本仓库到本地 一、环境配置 1.opencv配置 将OpenCV-MinGW-Build-OpenCV-4.5.2-x64文件夹放在自己的一个目录下,如我的路径: …...

【Python-Docx库】Word与Python的完美结合
【Python-Docx库】Word与Python的完美结合 今天给大家分享Python处理Word的第三方库:Python-Docx。 什么是Python-Docx? Python-Docx是用于创建和更新Microsoft Word(.docx)文件的Python库。 日常需要经常处理Word文档…...
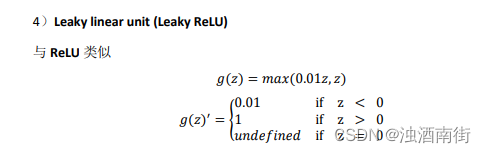
吴恩达深度学习笔记:浅层神经网络(Shallow neural networks)3.6-3.8
目录 第一门课:神经网络和深度学习 (Neural Networks and Deep Learning)第三周:浅层神经网络(Shallow neural networks)3.6 激活函数(Activation functions)3.7 为什么需要非线性激活函数?(why need a non…...

盘点最适合做剧场版的国漫,最后一部有望成为巅峰
最近《完美世界》动画官宣首部剧场版,主要讲述石昊和火灵儿的故事。这个消息一出,引发了很多漫迷的讨论,其实现在已经有好几部国漫做过剧场版,还有是观众一致希望未来会出剧场版的。那么究竟是哪些国漫呢,下面就一起来…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...