HBase常用的Filter过滤器操作
HBase过滤器种类很多,我们选择8种常用的过滤器进行介绍。为了获得更好的示例效果,先利用HBase Shell新建students表格,并往表格中进行写入多行数据。
一、数据准备工作
(1)在默认命名空间中新建表格students,设置列族info、score。
hbase:002:0> create 'students','info','score'
2024-03-26 00:22:15,810 INFO [main] client.HBaseAdmin (HBaseAdmin.java:postOperationResult(3591)) - Operation: CREATE, Table Name: default:students, procId: 290 completed
Created table students
Took 3.1425 seconds
=> Hbase::Table - students(2)往students表格中写入5行数据,并用scan 'students'命令查看写入结果。
hbase:005:0> put 'students','s001','info:name','Jack'
Took 30.6978 seconds
hbase:017:0> put 'students','s001','info:age','18'
Took 0.0419 seconds
hbase:019:0> put 'students','s001','score:English','95'
Took 0.0472 seconds
hbase:021:0> put 'students','s002','info:name','Tom'
Took 0.0255 seconds
hbase:022:0> put 'students','s002','info:age','20'
Took 0.0160 seconds
hbase:023:0> put 'students','s002','score:Chinese','85'
Took 0.0296 seconds
hbase:024:0> put 'students','s002','score:Math','90'
Took 0.0155 seconds
hbase:025:0> put 'students','s003','info:name','Mike'
Took 0.0188 seconds
hbase:026:0> put 'students','s003','info:age','19'
Took 0.0183 seconds
hbase:027:0> put 'students','s003','score:Chinese','90'
Took 0.0178 seconds
hbase:028:0> put 'students','s003','score:Math','95'
Took 0.0445 seconds
hbase:029:0> put 'students','s004','info:name','Lucy'
Took 0.0104 seconds
hbase:030:0> put 'students','s004','score:English','100'
Took 0.0170 seconds
hbase:031:0> put 'students','s005','info:name','Lily'
Took 0.0249 seconds
hbase:032:0> put 'students','s005','score:Chinese','99'
Took 0.0228 seconds
hbase:033:0> scan 'students'
ROW COLUMN+CELL s001 column=info:age, timestamp=2024-03-26T00:25:17.982, value=18 s001 column=info:name, timestamp=2024-03-26T00:24:39.510, value=Jack s001 column=score:English, timestamp=2024-03-26T00:25:52.207, value=95 s002 column=info:age, timestamp=2024-03-26T00:26:46.922, value=20 s002 column=info:name, timestamp=2024-03-26T00:26:26.924, value=Tom s002 column=score:Chinese, timestamp=2024-03-26T00:27:13.181, value=85 s002 column=score:Math, timestamp=2024-03-26T00:27:28.787, value=90 s003 column=info:age, timestamp=2024-03-26T00:28:08.402, value=19 s003 column=info:name, timestamp=2024-03-26T00:27:48.629, value=Mike s003 column=score:Chinese, timestamp=2024-03-26T00:28:46.714, value=90 s003 column=score:Math, timestamp=2024-03-26T00:29:01.881, value=95 s004 column=info:name, timestamp=2024-03-26T00:29:19.868, value=Lucy s004 column=score:English, timestamp=2024-03-26T00:29:44.831, value=100 s005 column=info:name, timestamp=2024-03-26T00:30:04.231, value=Lily s005 column=score:Chinese, timestamp=2024-03-26T00:30:25.477, value=99
5 row(s)
Took 0.3369 seconds 二、过滤器的使用介绍
1.ValueFilter过滤器
根据数据列单元格的值进行过滤。值过滤器的比较方式有二进制位比较(binary)和子字符串匹配比较(substring)。
(1)按二进制位进行值比较
使用get命令,查询students表格中,行键为s001,单元格值为Jack的数据结果。
#ValueFilter(=,'binary:Jack')是值过滤器,比较方式是binary二进制
hbase:034:0> get 'students','s001',{FILTER=>"ValueFilter(=,'binary:Jack')"}
COLUMN CELL info:name timestamp=2024-03-26T00:24:39.510, value=Jack
1 row(s)
Took 0.6506 seconds使用scan命令,扫描出students表格中,单元格值为90的数据结果。
#查询结果是多条,需要用scan命令全表扫描,不能使用get命令
hbase:036:0> scan 'students',{FILTER=>"ValueFilter(=,'binary:90')"}
ROW COLUMN+CELL s002 column=score:Math, timestamp=2024-03-26T00:27:28.787, value=90 s003 column=score:Chinese, timestamp=2024-03-26T00:28:46.714, value=90
2 row(s)
Took 0.2162 seconds(2)按子字符串匹配比较
使用get命令,查询students表格中,行键为s001,单元格值包含子字符串ac的数据结果。
hbase:037:0> get 'students','s001',{FILTER=>"ValueFilter(=,'substring:ac')"}
COLUMN CELL info:name timestamp=2024-03-26T00:24:39.510, value=Jack
1 row(s)
Took 0.1578 seconds 使用scan命令,扫描出表格students中单元格值包含子字符串0的数据结果。
#查询结果是多条,需要用scan命令全表扫描,不能使用get命令
hbase:038:0> scan 'students',{FILTER=>"ValueFilter(=,'substring:0')"}
ROW COLUMN+CELL s002 column=info:age, timestamp=2024-03-26T00:26:46.922, value=20 s002 column=score:Math, timestamp=2024-03-26T00:27:28.787, value=90 s003 column=score:Chinese, timestamp=2024-03-26T00:28:46.714, value=90 s004 column=score:English, timestamp=2024-03-26T00:29:44.831, value=100
3 row(s)
Took 0.0868 seconds2.QualifierFilter过滤器
列限定符过滤器QualifierFilter是只根据数据列的列限定符进行过滤,并不关注列族名称。列限定符过滤器的常用比较方式为二进制位(binary)比较。
使用get命令,查询students表格中,行键为s001,列限定符为name的数据结果。
hbase:039:0> get 'students','s001',{FILTER=>"QualifierFilter(=,'binary:name')"}
COLUMN CELL info:name timestamp=2024-03-26T00:24:39.510, value=Jack
1 row(s)
Took 0.3310 seconds使用scan命令,扫描students表格中,列限定符为name的数据结果。
hbase:041:0> scan 'students',{FILTER=>"QualifierFilter(=,'binary:name')"}
ROW COLUMN+CELL s001 column=info:name, timestamp=2024-03-26T00:24:39.510, value=Jack s002 column=info:name, timestamp=2024-03-26T00:26:26.924, value=Tom s003 column=info:name, timestamp=2024-03-26T00:27:48.629, value=Mike s004 column=info:name, timestamp=2024-03-26T00:29:19.868, value=Lucy s005 column=info:name, timestamp=2024-03-26T00:30:04.231, value=Lily
5 row(s)
Took 0.0845 seconds3.ColumnPrefixFilter过滤器
列前缀符过滤器ColumnPrefixFilter是根据数据列的列限定符的前缀进行过滤。前缀过滤必须从第一个字符开始匹配,而子字符串过滤可以从任何位置开始进行子串匹配。前缀过滤器严格区分字母大小写。
使用get命令,查询出students表格中,行键为s002,列限定符的前缀字符串为Chi的数据结果。
hbase:042:0> get 'students','s002',{FILTER=>"ColumnPrefixFilter('Chi')"}
COLUMN CELL score:Chinese timestamp=2024-03-26T00:27:13.181, value=85
1 row(s)
Took 0.1693 seconds 使用scan命令,扫描students表格,列限定符的前缀字符串为Chi的数据结果。
hbase:044:0> scan 'students',{FILTER=>"ColumnPrefixFilter('Chi')"}
ROW COLUMN+CELL s002 column=score:Chinese, timestamp=2024-03-26T00:27:13.181, value=85 s003 column=score:Chinese, timestamp=2024-03-26T00:28:46.714, value=90 s005 column=score:Chinese, timestamp=2024-03-26T00:30:25.477, value=99
3 row(s)
Took 0.0397 seconds 4.RowFilter过滤器
行键过滤器RowFilter是根据行键对数据列进行过滤。
注意:一般不在get命令中使用行键过滤器,get命令必须指定唯一确定完整的行键,没有必要再对行键进行过滤。
(1)按二进制位比较。
使用scan命令,扫描students表格,筛选出行键值为s001的所有数据结果。
hbase:045:0> scan 'students',{FILTER=>"RowFilter(=,'binary:s001')"}
ROW COLUMN+CELL s001 column=info:age, timestamp=2024-03-26T00:25:17.982, value=18 s001 column=info:name, timestamp=2024-03-26T00:24:39.510, value=Jack s001 column=score:English, timestamp=2024-03-26T00:25:52.207, value=95
1 row(s)
Took 0.1297 seconds(2)按子字符串匹配比较。
使用scan命令,扫描students表格,筛选出行键值包含子字符串01的所有数据结果。
hbase:046:0> scan 'students',{FILTER=>"RowFilter(=,'substring:01')"}
ROW COLUMN+CELL s001 column=info:age, timestamp=2024-03-26T00:25:17.982, value=18 s001 column=info:name, timestamp=2024-03-26T00:24:39.510, value=Jack s001 column=score:English, timestamp=2024-03-26T00:25:52.207, value=95
1 row(s)
Took 0.3426 seconds5.PrefixFilter过滤器
行键前缀过滤器PrefixFilter是根据行键的前缀进行过滤。前缀过滤必须从行键的第一个字符开始匹配,严格区分字母大小写。
使用scan命令,扫描students表格,筛选出行键值以s00为前缀开头的数据结果。
hbase:047:0> scan 'students',{FILTER=>"PrefixFilter('s00')"}
ROW COLUMN+CELL s001 column=info:age, timestamp=2024-03-26T00:25:17.982, value=18 s001 column=info:name, timestamp=2024-03-26T00:24:39.510, value=Jack s001 column=score:English, timestamp=2024-03-26T00:25:52.207, value=95 s002 column=info:age, timestamp=2024-03-26T00:26:46.922, value=20 s002 column=info:name, timestamp=2024-03-26T00:26:26.924, value=Tom s002 column=score:Chinese, timestamp=2024-03-26T00:27:13.181, value=85 s002 column=score:Math, timestamp=2024-03-26T00:27:28.787, value=90 s003 column=info:age, timestamp=2024-03-26T00:28:08.402, value=19 s003 column=info:name, timestamp=2024-03-26T00:27:48.629, value=Mike s003 column=score:Chinese, timestamp=2024-03-26T00:28:46.714, value=90 s003 column=score:Math, timestamp=2024-03-26T00:29:01.881, value=95 s004 column=info:name, timestamp=2024-03-26T00:29:19.868, value=Lucy s004 column=score:English, timestamp=2024-03-26T00:29:44.831, value=100 s005 column=info:name, timestamp=2024-03-26T00:30:04.231, value=Lily s005 column=score:Chinese, timestamp=2024-03-26T00:30:25.477, value=99
5 row(s)
Took 0.4404 seconds6.FamilyFilter过滤器
列族过滤器FamilyFilter是根据列族名称进行过滤。列族过滤器的比较方式有二进制位比较(binary)、子字符串匹配比较(substring)等。
(1)按二进制位比较。
使用scan命令,扫描表格students,筛选出列族名称值为info的数据结果。
hbase:005:0> scan 'students',FILTER=>"FamilyFilter(=,'binary:info')"
ROW COLUMN+CELL s001 column=info:age, timestamp=2024-03-26T00:25:17.982, value=18 s001 column=info:name, timestamp=2024-03-26T00:24:39.510, value=Jack s002 column=info:age, timestamp=2024-03-26T00:26:46.922, value=20 s002 column=info:name, timestamp=2024-03-26T00:26:26.924, value=Tom s003 column=info:age, timestamp=2024-03-26T00:28:08.402, value=19 s003 column=info:name, timestamp=2024-03-26T00:27:48.629, value=Mike s004 column=info:name, timestamp=2024-03-26T00:29:19.868, value=Lucy s005 column=info:name, timestamp=2024-03-26T00:30:04.231, value=Lily
5 row(s)
Took 0.0399 seconds (2)按子字符串匹配比较。
使用scan命令,扫描表格students,筛选出列族名称包含子字符串s的数据结果。
hbase:008:0> scan 'students',FILTER=>"FamilyFilter(=,'substring:s')"
ROW COLUMN+CELL s001 column=score:English, timestamp=2024-03-26T00:25:52.207, value=95 s002 column=score:Chinese, timestamp=2024-03-26T00:27:13.181, value=85 s002 column=score:Math, timestamp=2024-03-26T00:27:28.787, value=90 s003 column=score:Chinese, timestamp=2024-03-26T00:28:46.714, value=90 s003 column=score:Math, timestamp=2024-03-26T00:29:01.881, value=95 s004 column=score:English, timestamp=2024-03-26T00:29:44.831, value=100 s005 column=score:Chinese, timestamp=2024-03-26T00:30:25.477, value=99
5 row(s)
Took 0.0915 seconds7.SingleColumnValueFilter过滤器
单列值过滤器SingleColumnValueFilters是根据指定列族和列限定符的单个数据列的单元格值进行过滤,类似SQL中的”select列名from表名where列名=值”语句。
(1)按二进制位比较。
使用scan命令,扫描表格students,筛选出列族info,列限定符age的单元格值为19的数据列。
hbase:006:0> scan 'students',{COLUMN=>'info:age',FILTER=>"SingleColumnValueFilter('info','age',=,'binary:19')"}
ROW COLUMN+CELL s003 column=info:age, timestamp=2024-03-26T00:28:08.402, value=19
1 row(s)
Took 0.4166 seconds(2)按子字符串匹配比较。
使用scan命令,扫描表格students,筛选出列族info,列限定符name的值包括子字符串y的数据。
hbase:008:0> scan 'students',{COLUMN=>'info:name',FILTER=>"SingleColumnValueFilter('info','name',=,'substring:y')"}
ROW COLUMN+CELL s004 column=info:name, timestamp=2024-03-26T00:29:19.868, value=Lucy s005 column=info:name, timestamp=2024-03-26T00:30:04.231, value=Lily
2 row(s)
Took 0.0658 seconds
相关文章:

HBase常用的Filter过滤器操作
HBase过滤器种类很多,我们选择8种常用的过滤器进行介绍。为了获得更好的示例效果,先利用HBase Shell新建students表格,并往表格中进行写入多行数据。 一、数据准备工作 (1)在默认命名空间中新建表格students…...

容器安全与防御(德迅蜂巢)
通过容器可以快速的运行应用、迁移应用、快速集成、快速部署、也提高了系统的资源利用率,因此现在越来越多的企业把应用上云,来达到快速上线应用、方便运维的目的。容器安全也逐渐地被重视起来,了解容器如何检测当前企业环境内容器环境是否安…...

【面经八股】搜广推方向:面试记录(十一)
【面经&八股】搜广推方向:面试记录(十一) 文章目录 【面经&八股】搜广推方向:面试记录(十一)1. 自我介绍2. 实习经历问答4. 编程题5. 反问1. 自我介绍 。。。。。。 2. 实习经历问答 就是对自己实习事情要足够的清晰,不熟的不要写在简历上!!! 其中,有个 …...

第十四章 MySQL
一、MySQL 1.1 MySql 体系结构 MySQL 架构总共四层,在上图中以虚线作为划分。 1. 最上层的服务并不是 MySQL 独有的,大多数给予网络的客户端/服务器的工具或者服务都有类似的架构。比如:连接处理、授权认证、安全等。 2. 第二层的架构包括…...

C++项目——集群聊天服务器项目(七)Model层设计、注册业务实现
在前几节的研究中,我们已经实现网络层与业务层分离,本节实现数据层与业务层分离,降低各层之间的耦合性,同时实现用户注册业务。 网络层专注于处理网络通信与读写事件 业务层专注于处理读写事件到来时所需求的各项业务 数据层专…...

VBA语言専攻介绍(20240331更新)
VBA语言専攻简介 “VBA语言専攻”是大家汲取知识的源泉,是提高自己能力的净土,正如我对平台的介绍:社会的进步,源于对知识的尊重和敬仰。希望每一位学员,每一位关注平台的朋友,都能很好的利用这个平台来学…...

Golang- 邮件服务,发送邮件
依赖 go get -u github.com/jordan-wright/email文档 文档 示例代码 邮箱的相关配置 # email configuration email:port: 25 # 端口要配置25 否则可能出现EOF错误from: xxx1qq.comhost: smtp.qq.comis-ssl: truesecret: xxxxxnickname: 大锦余发送邮件代码 package utili…...

C语言:编译和链接
前言 在ANSI C的任何一种实现中,存在两个不同的环境。 第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令(二进制指令)。第2种是执行环境,它用于实际执行代码。 目录 1.翻译环境1.1 预处理(预编…...
JavaEE 初阶篇-深入了解多线程安全问题(出现线程不安全的原因与解决线程不安全的方法)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 多线程安全问题概述 1.1 线程不安全的实际例子 2.0 出现线程不安全的原因 2.1 线程在系统中是随机调度且抢占式执行的模式 2.2 多个线程同时修改同一个变量 2.3 线…...
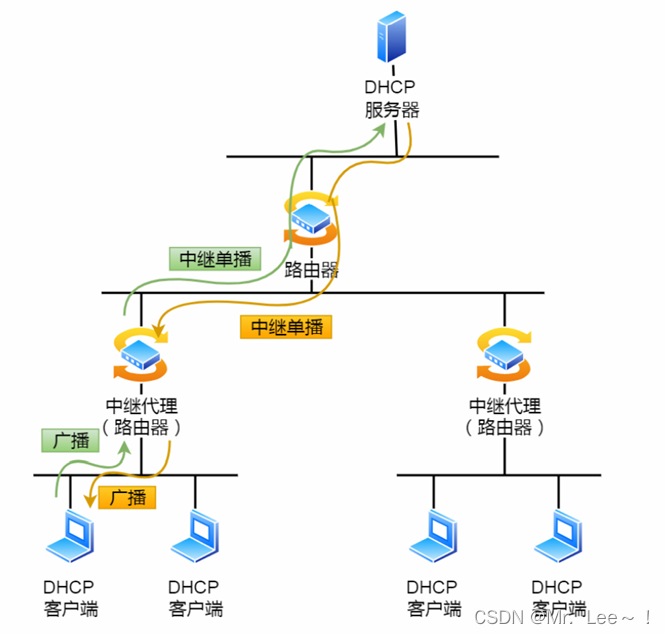
计算机网络⑦ —— 网络层协议
1. ARP协议 在传输⼀个 IP 数据报的时候,确定了源 IP 地址和⽬标 IP 地址后,就会通过主机路由表确定 IP 数据包下⼀跳。然⽽,⽹络层的下⼀层是数据链路层,所以我们还要知道下⼀跳的 MAC 地址。由于主机的路由表中可以找到下⼀跳的…...
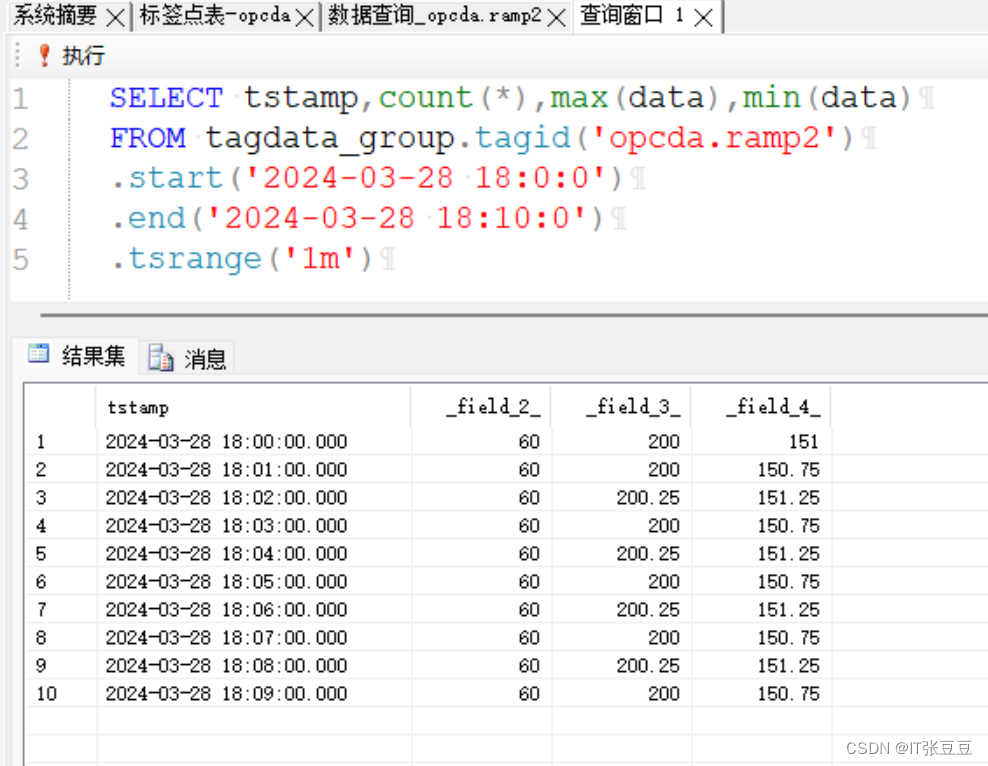
正弦实时数据库(SinRTDB)的使用(7)-历史统计查询
前文已经将正弦实时数据库的使用进行了介绍,需要了解的可以先看下面的博客: 正弦实时数据库(SinRTDB)的安装 正弦实时数据库(SinRTDB)的使用(1)-使用数据发生器写入数据 正弦实时数据库(SinRTDB)的使用(2)-接入OPC DA的数据 正弦实时数据库(SinRTDB)…...

编译和链接知识点
为什么我们在vs等编译器上写出的代码通过运行就会实现相关功能呢? 解决这个问题的关键就是关于编译与链接的知识。 首先从大的分类里有两部分:编译和链接 而编译这一大的部分又分为预处理(也叫预编译),编译…...

大话设计模式之工厂模式
工厂模式(Factory Pattern)是一种创建型设计模式,它提供了一种创建对象的最佳方式,而无需指定将要创建的对象的确切类。通过使用工厂模式,我们可以将对象的创建和使用分离,从而使代码更具灵活性和可维护性。…...

Windows MySQL通过data 文件夹恢复数据
前言 在MySql数据库中,为了备份和恢复数据,通常会使用mysqldump工具来导出和导入数据。但是,如果数据库非常大,name导出和导入数据可能会需要很长时间。这时,一种更快速的备份和恢复数据的方式就是直接复制mysql的data文件夹。 什么是mysql的…...
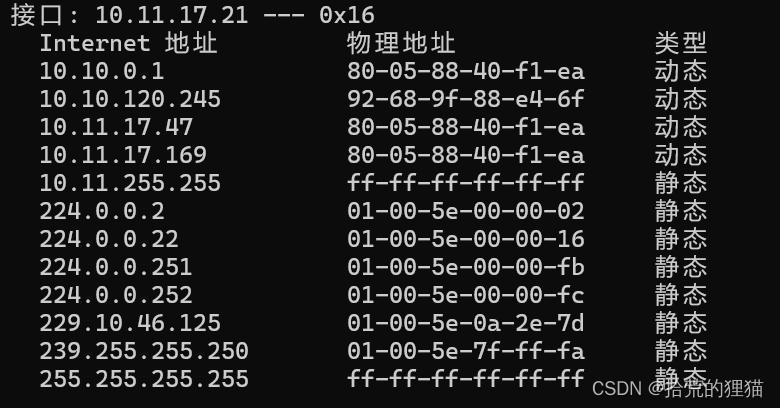
ARP协议定义及工作原理
ARP的定义 地址解析协议(Address Resolution Protocol,ARP):ARP协议可以将IPv4地址(一种逻辑地址)转换为各种网络所需的硬件地址(一种物理地址)。换句话说,所谓的地址解析的目标就是发现逻辑地址与物理地址的映射关系。 ARP仅用于IPv4协议&a…...
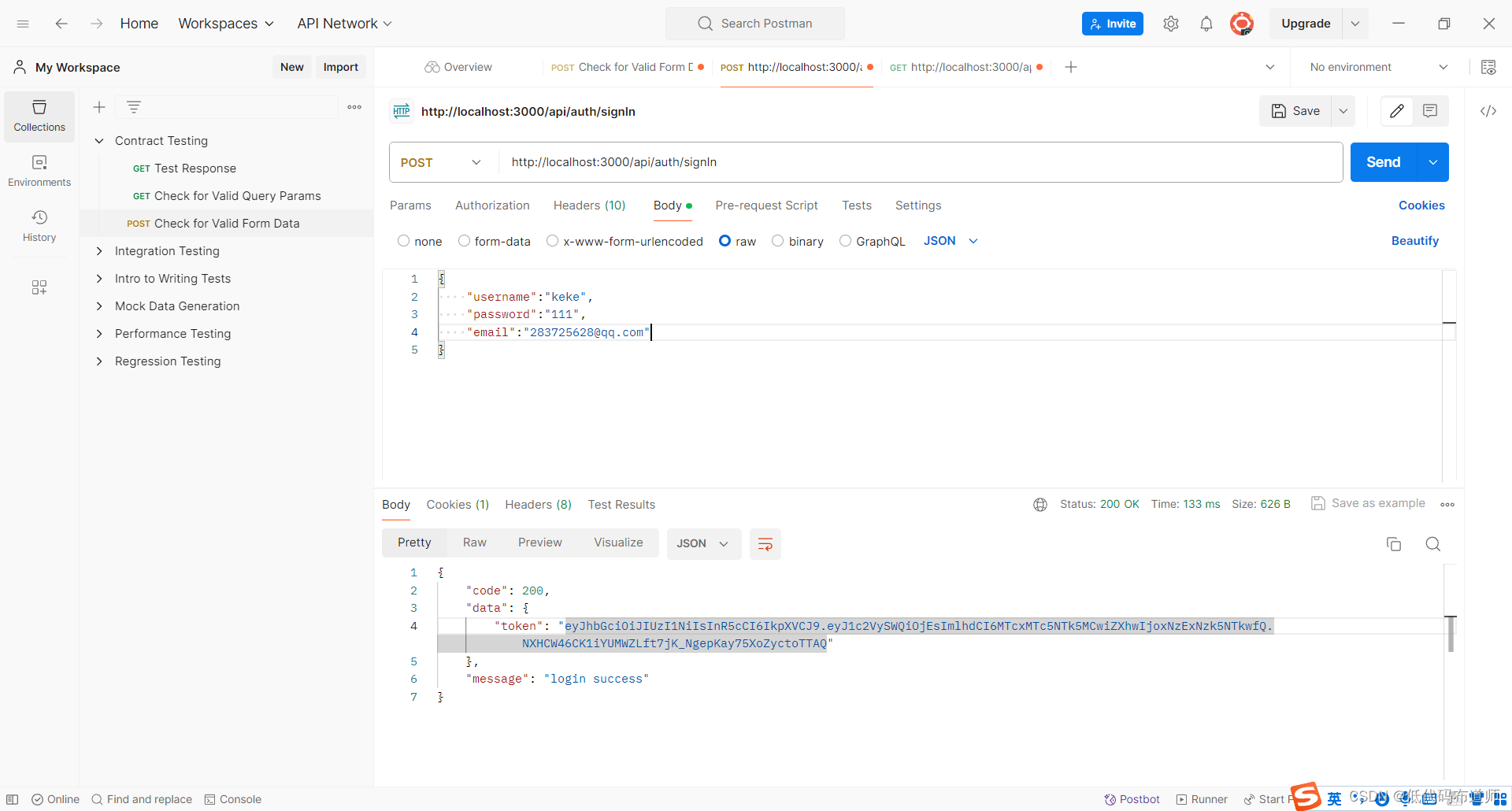
express实现用户登录和注册接口
目录 1 创建数据库2 连接数据库3 集成ORM库4 创建业务逻辑5 创建路由7 测试接口总结 我们在编写后端接口的时候操作数据库是一种常见的功能需求,express本身并不提供直接操作数据库的能力,需要借助第三方库来操作数据库,本篇讲解一下软件开发…...

数字化转型,效率增长才是王道
在当今商业世界,数字化已经成为推动企业增长的强大引擎。然而,值得注意的是,数字化并非只是简单地追求规模扩张,更重要的是实现降本增效。没有效率的增长,就像是在加速自我毁灭。在数字化转型的道路上,企业…...

RHCE-2-chrony服务器
简介 重要性 由于IT系统中,准确的计时非常重要,有很多种原因需要准确计时: 在网络传输中,数据包括和日志需要准确的时间戳 各种应用程序中,如订单信息,交易信息等 都需要准确的时间戳 Linux的两个时钟 硬…...

音频RK809
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、目的二、知识准备2.1Audio框架2.1.1 DAI2.1.2 CODEC2.1.3 machine三、原理图3.1 整体原理图3.2 喇叭部分3.3 麦克风部分四、设备树4.1 sound 部分4.2 codec 部分五、驱动讲...
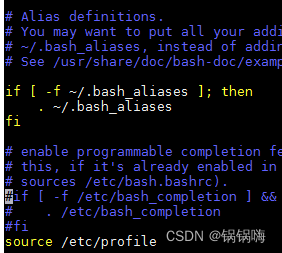
解决 linux 服务器 java 命令不生效问题
在Linux系统中,当你安装Java并设置了JAVA_HOME环境变量后,你可能需要使用source /etc/profile命令来使Java命令生效。这是因为/etc/profile是一个系统级的配置文件,它包含了系统的全局环境变量设置。 但是需要注意的是,source /e…...

对称与负电源测试:动态直流电子负载的设计、原理与应用
1. 项目概述:对称与负电源的静态与动态直流负载在电子实验室里,测试一个电源的性能,尤其是它的动态响应能力,是件既基础又关键的事。我们常说的“直流电子负载”就是这个领域的核心工具。我之前设计并分享过一个用于正电源测试的静…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

Keil µVision链接器错误204解决方案
1. 问题现象与背景解析最近在使用Keil Vision进行嵌入式开发时,不少工程师遇到了一个令人头疼的链接器错误。具体表现为编译时出现"FATAL ERROR 204: INVALID KEYWORD"的致命错误,错误位置指向链接器控制文件中的特定行。这个问题在C166和C51两…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...
)
YOLOv8道路交通信号标志识别检测系统(项目源码+YOLO数据集+模型权重+UI界面+python+深度学习+环境配置)
摘要 道路交通信号标志的自动检测是智能驾驶与交通管理系统中的核心环节。本文基于YOLOv8目标检测算法,构建了一个涵盖21类常见交通信号标志的检测系统,包括禁令标志、指示标志、警告标志及信号灯等。模型在包含1376张训练图像、488张验证图像和229张测…...

终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式
终极指南:用AlwaysOnTop免费开源工具彻底改变你的Windows工作方式 【免费下载链接】AlwaysOnTop Make a Windows application always run on top 项目地址: https://gitcode.com/gh_mirrors/al/AlwaysOnTop 你是否经常在多个窗口间来回切换,浪费宝…...

将deepseek v4 pro集成到codex桌面APP中使用
📕我是廖志伟,一名Java开发工程师、《Java项目实战——深入理解大型互联网企业通用技术》(基础篇)、(进阶篇)、《解密程序员的思维密码——沟通、演讲、思考的实践》作者、清华大学出版社签约作家、Java领域…...

还在古法编程?OpenAI Codex 全自动编程!稳定中转 Token 保姆级教程
OpenAI Codex 从安装到进阶实战|终端 AI 编程完全指南(2026 最新) 摘要:OpenAI Codex 是目前最强大的终端 AI 编程工具,支持代码生成、项目重构、Bug 修复、脚本自动化、批量代码优化等全场景能力。本文从零起步&…...