第十四章 MySQL
一、MySQL
1.1 MySql 体系结构
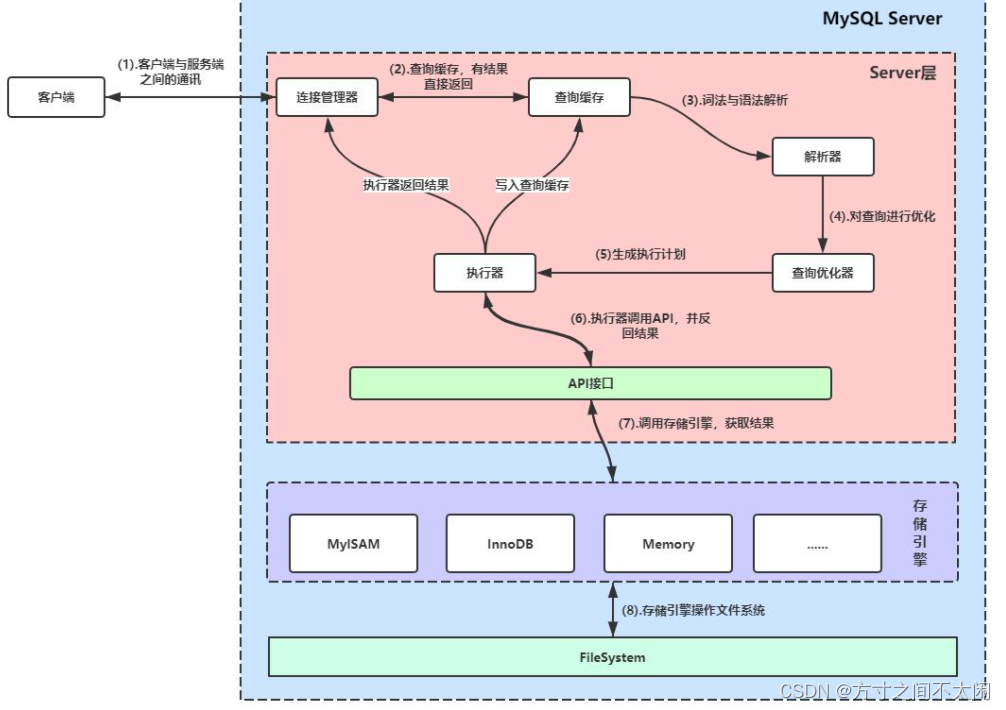
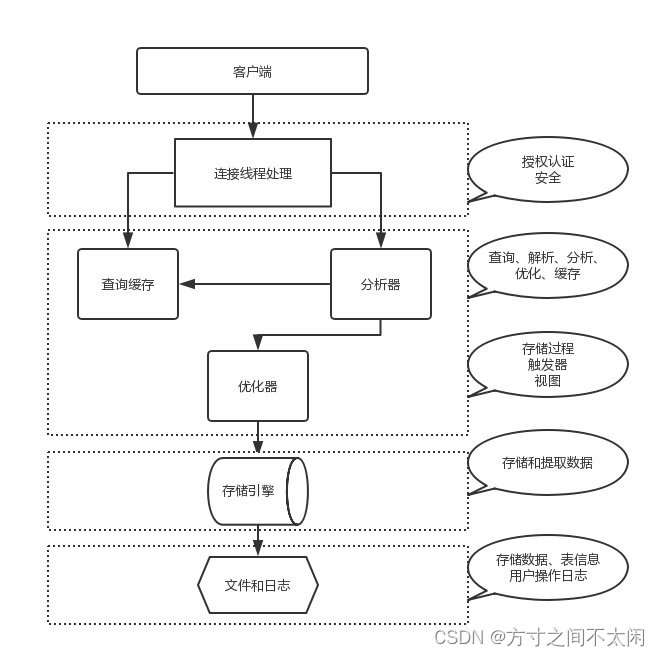
1.1.1 SQL 语句的执行流程

1. 建立连接
2. 查询缓存
3. 解析器
4. 预处理器
5. 查询优化器
一条 Sql 语句可以有很多种执行方式,但是返回的结果是一样的。查询优化器的目的就是基于解析树生成不同的解析计划,从中选择一个最优的执行计划;MYSQL
6. 执行计划
7. 执行引擎
8. 存储引擎
1.1.2 一条更新 SQL 的执行
1.2 MySQL 存储引擎
1.2.1 存储引擎
1.2.2 MySQL 支持的存储引擎
1.2.3 各种存储引擎的特性
1.2.4 各种搜索引擎介绍
- InnoDB:MySql 5.6 版本默认的存储引擎。InnoDB 是一个事务安全的存储引擎,它具备提交、回滚以及崩溃恢复的功能以保护用户数据。InnoDB 的行级别锁定以及 Oracle 风格的一致性无锁读提升了它的多用户并发数以及性能。
1.2.5 存储引擎相关 sql 语句
# 查看当前的默认存储引擎:
mysql> show variables like "default_storage_engine";
# 查询当前数据库支持的存储引擎
mysql> show engines \G;mysql> create table ai(id bigint(12),name varchar(200)) ENGINE=MyISAM;
mysql> create table country(id int(4),cname varchar(50)) ENGINE=InnoDB;
# 也可以使用alter table语句,修改一个已经存在的表的存储引擎。
mysql> alter table ai engine = innodb;# my.ini文件
[mysqld]
default-storage-engine=INNODB1.3 MySQL 内存结构
1.3.1 Innodb 内存架构
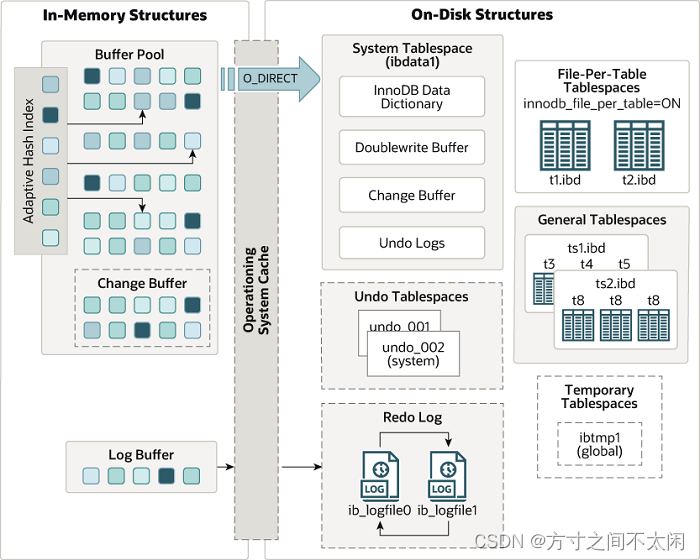
1.3.2 Buffer Pool

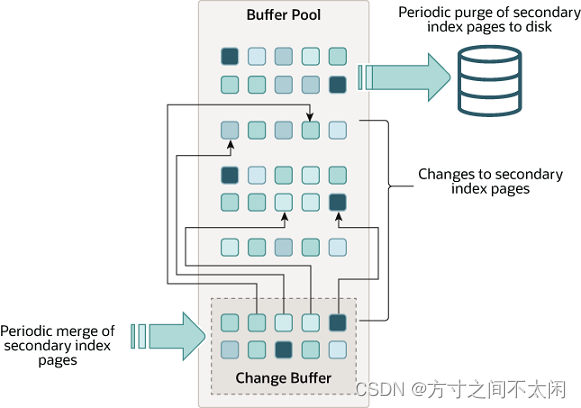
1.3.3 Change Buffer


1.3.4 自适应 Hash 索引(Adaptive Hash Index)

1.3.5 Log buffer
1.4 MySQL 磁盘结构
1.4.1 表空间(Tablespaces)
1. 表空间组成
- 物理结构组成
| 文件 | 功能 | 描述 |
| :------------ | -------------- | -------------------------------------------------- |
| ibdatat1 | 共享表空间文件 | 系统/共享表空间,存储各种缓冲数据 |
| .frm | 表定义文件 | 记录表的定义,列名以及列的数据类型 |
| .ibd | 表数据存储文件 | 独立表空间,存储数据表的数据,按行存储 |
| ib_logfile0/1 | redo日志文件 | 重做日志文件,一共两个循环使用,一个写完即写另一个 |1.4.2 表空间的五种类型
#默认值:
innodb_data_file_path = ibdata1:12M:autoextend
# ibdata1 : 文件名为 ibdata1
# 12M : 大小为 12M
# autoextend : 自动扩展innodb_file_per_table = OFF:系统表空间:ibdataX
新建表被创建于【表空间】中,每一个表建立ibd的扩展文件,文件名为:表名.ibd,该文件默认被创建于数据库目录中,表空间的表文件支持动态和压缩行格式。
innodb将被创建于【系统表空间】中,即ibdataX中。X代表从1开始的一个数字
show variables like 'innodb_file_per_table';
set global innodb_file_per_table=off;
通用表空间为通过create tablespace语法创建的共享表空间。通用表空间可以创建于 mysql数据目录外的其他表空间,其可以容纳多张表,且其支持所有的行格式。
#创建表空间tablespaces1
CREATE TABLESPACE tablespaces1 ADD DATAFILE tablespaces1.ibd Engine=InnoDB;
#将表添加到test1表空间
CREATE TABLE test1 (c1 INT PRIMARY KEY) TABLESPACE tablespaces1; 撤销表空间由一个或多个包含Undo日志文件组成。
> 在MySQL 5.7版本之前Undo占用的是System Tablespace共享区,从5.7开始将Undo从System Tablespace分离了出来。
- 【innodb_undo_tablespaces】
innodb_undo_tablespaces = 0 :默认值,表示使用系统表空间ibdata1
innodb_undo_tablespaces = 1:大于0表示使用undo表空间undo_001、 undo_002等
mysql服务器正常关闭或异常终止时,临时表空间将被移除,每次启动时会被重新创建。
临时表空间分为两种:
- 【session temporary tablespaces】
存储的是用户创建的临时表和磁盘内部的临时表。
- 【global temporary tablespace】
储存用户临时表的回滚段(rollback segments)。
1.4.3 数据字典(InnoDB Data Dictionary)
1.4.4 双写缓冲区(Doublewrite Buffer)
> 在 BufferPage 的 page 页刷新到磁盘真正的位置前,会先将数据存在 Doublewrite 缓冲区。如果在 page 页写入过程中出现操作系统、存储子系统或 mysqld 进程崩溃,InnoDB 可以在崩溃恢复期间从 Doublewrite 缓冲区中找到 page 页备份。在大多数情况下,默认情况下启用双写缓冲区。
1.4.5 重做日志(Redo Log)
1.4.6 撤销日志(Undo Logs)
相关文章:
第十四章 MySQL
一、MySQL 1.1 MySql 体系结构 MySQL 架构总共四层,在上图中以虚线作为划分。 1. 最上层的服务并不是 MySQL 独有的,大多数给予网络的客户端/服务器的工具或者服务都有类似的架构。比如:连接处理、授权认证、安全等。 2. 第二层的架构包括…...

C++项目——集群聊天服务器项目(七)Model层设计、注册业务实现
在前几节的研究中,我们已经实现网络层与业务层分离,本节实现数据层与业务层分离,降低各层之间的耦合性,同时实现用户注册业务。 网络层专注于处理网络通信与读写事件 业务层专注于处理读写事件到来时所需求的各项业务 数据层专…...

VBA语言専攻介绍(20240331更新)
VBA语言専攻简介 “VBA语言専攻”是大家汲取知识的源泉,是提高自己能力的净土,正如我对平台的介绍:社会的进步,源于对知识的尊重和敬仰。希望每一位学员,每一位关注平台的朋友,都能很好的利用这个平台来学…...

Golang- 邮件服务,发送邮件
依赖 go get -u github.com/jordan-wright/email文档 文档 示例代码 邮箱的相关配置 # email configuration email:port: 25 # 端口要配置25 否则可能出现EOF错误from: xxx1qq.comhost: smtp.qq.comis-ssl: truesecret: xxxxxnickname: 大锦余发送邮件代码 package utili…...

C语言:编译和链接
前言 在ANSI C的任何一种实现中,存在两个不同的环境。 第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令(二进制指令)。第2种是执行环境,它用于实际执行代码。 目录 1.翻译环境1.1 预处理(预编…...
JavaEE 初阶篇-深入了解多线程安全问题(出现线程不安全的原因与解决线程不安全的方法)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 多线程安全问题概述 1.1 线程不安全的实际例子 2.0 出现线程不安全的原因 2.1 线程在系统中是随机调度且抢占式执行的模式 2.2 多个线程同时修改同一个变量 2.3 线…...
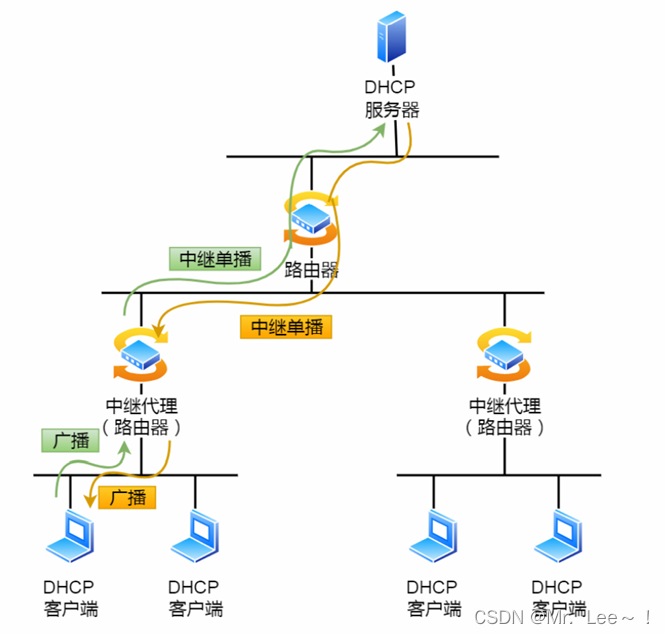
计算机网络⑦ —— 网络层协议
1. ARP协议 在传输⼀个 IP 数据报的时候,确定了源 IP 地址和⽬标 IP 地址后,就会通过主机路由表确定 IP 数据包下⼀跳。然⽽,⽹络层的下⼀层是数据链路层,所以我们还要知道下⼀跳的 MAC 地址。由于主机的路由表中可以找到下⼀跳的…...
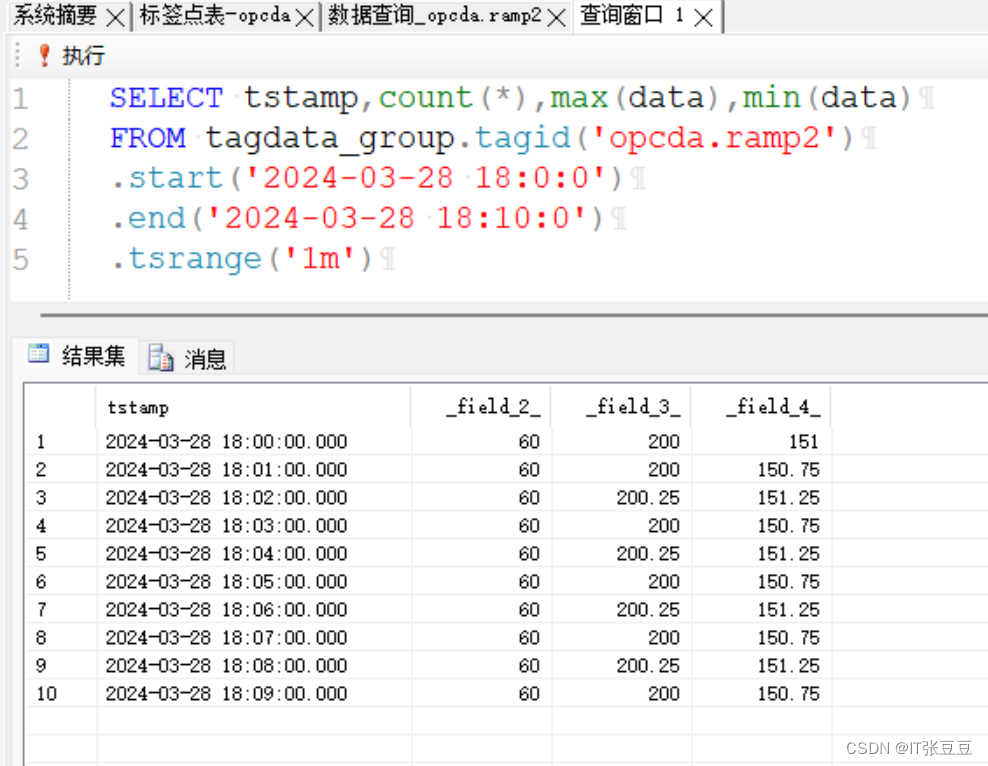
正弦实时数据库(SinRTDB)的使用(7)-历史统计查询
前文已经将正弦实时数据库的使用进行了介绍,需要了解的可以先看下面的博客: 正弦实时数据库(SinRTDB)的安装 正弦实时数据库(SinRTDB)的使用(1)-使用数据发生器写入数据 正弦实时数据库(SinRTDB)的使用(2)-接入OPC DA的数据 正弦实时数据库(SinRTDB)…...

编译和链接知识点
为什么我们在vs等编译器上写出的代码通过运行就会实现相关功能呢? 解决这个问题的关键就是关于编译与链接的知识。 首先从大的分类里有两部分:编译和链接 而编译这一大的部分又分为预处理(也叫预编译),编译…...

大话设计模式之工厂模式
工厂模式(Factory Pattern)是一种创建型设计模式,它提供了一种创建对象的最佳方式,而无需指定将要创建的对象的确切类。通过使用工厂模式,我们可以将对象的创建和使用分离,从而使代码更具灵活性和可维护性。…...

Windows MySQL通过data 文件夹恢复数据
前言 在MySql数据库中,为了备份和恢复数据,通常会使用mysqldump工具来导出和导入数据。但是,如果数据库非常大,name导出和导入数据可能会需要很长时间。这时,一种更快速的备份和恢复数据的方式就是直接复制mysql的data文件夹。 什么是mysql的…...
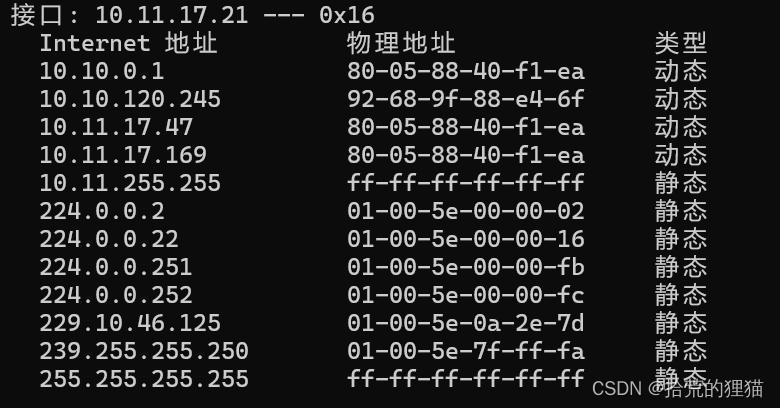
ARP协议定义及工作原理
ARP的定义 地址解析协议(Address Resolution Protocol,ARP):ARP协议可以将IPv4地址(一种逻辑地址)转换为各种网络所需的硬件地址(一种物理地址)。换句话说,所谓的地址解析的目标就是发现逻辑地址与物理地址的映射关系。 ARP仅用于IPv4协议&a…...
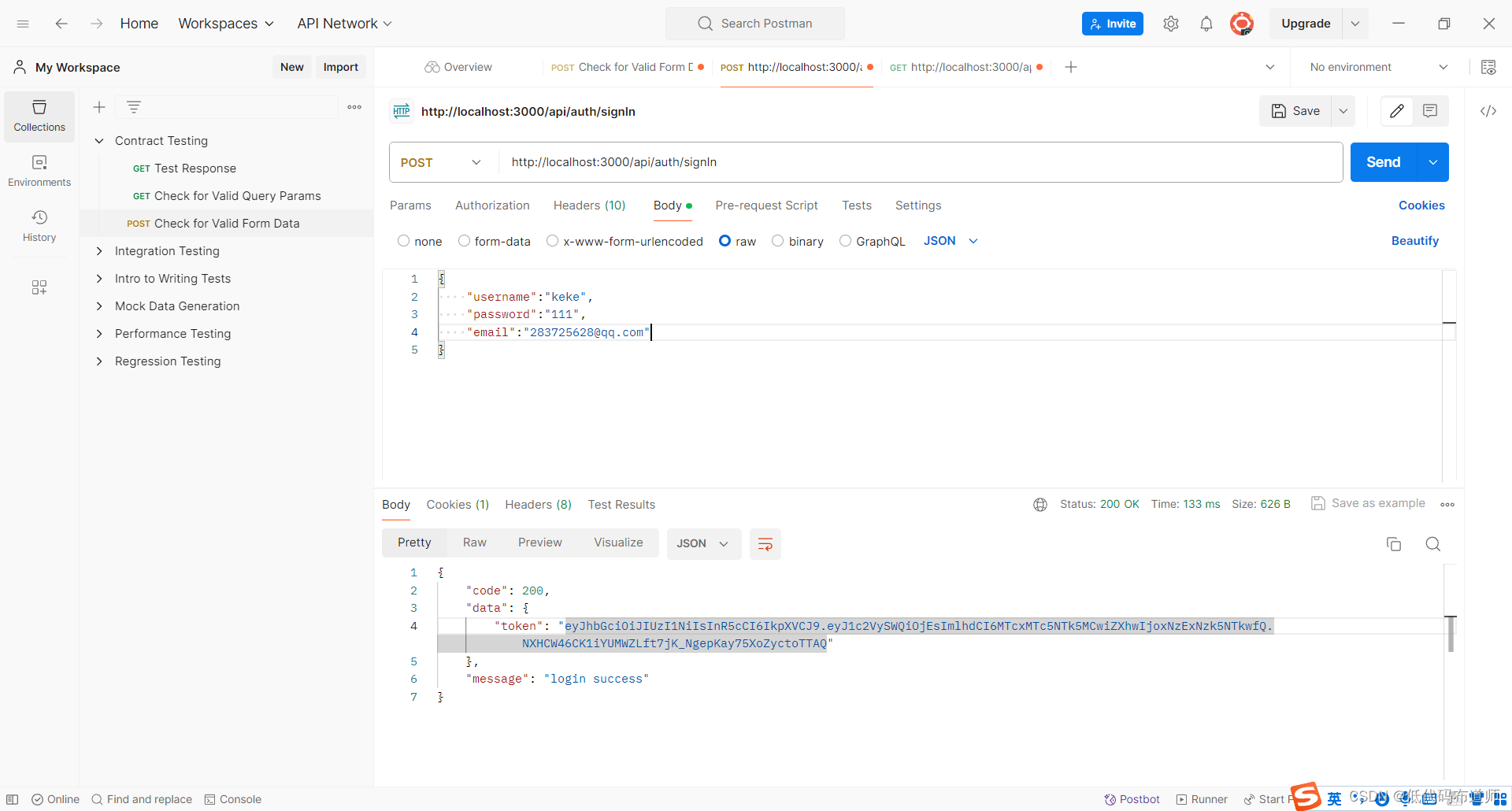
express实现用户登录和注册接口
目录 1 创建数据库2 连接数据库3 集成ORM库4 创建业务逻辑5 创建路由7 测试接口总结 我们在编写后端接口的时候操作数据库是一种常见的功能需求,express本身并不提供直接操作数据库的能力,需要借助第三方库来操作数据库,本篇讲解一下软件开发…...

数字化转型,效率增长才是王道
在当今商业世界,数字化已经成为推动企业增长的强大引擎。然而,值得注意的是,数字化并非只是简单地追求规模扩张,更重要的是实现降本增效。没有效率的增长,就像是在加速自我毁灭。在数字化转型的道路上,企业…...

RHCE-2-chrony服务器
简介 重要性 由于IT系统中,准确的计时非常重要,有很多种原因需要准确计时: 在网络传输中,数据包括和日志需要准确的时间戳 各种应用程序中,如订单信息,交易信息等 都需要准确的时间戳 Linux的两个时钟 硬…...

音频RK809
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、目的二、知识准备2.1Audio框架2.1.1 DAI2.1.2 CODEC2.1.3 machine三、原理图3.1 整体原理图3.2 喇叭部分3.3 麦克风部分四、设备树4.1 sound 部分4.2 codec 部分五、驱动讲...
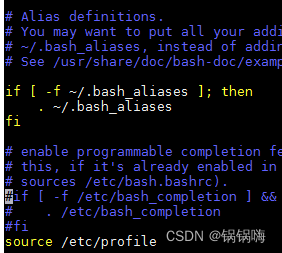
解决 linux 服务器 java 命令不生效问题
在Linux系统中,当你安装Java并设置了JAVA_HOME环境变量后,你可能需要使用source /etc/profile命令来使Java命令生效。这是因为/etc/profile是一个系统级的配置文件,它包含了系统的全局环境变量设置。 但是需要注意的是,source /e…...

22 多态
目录 多态的概念多态的定义及实现抽象类多态的原理单继承和多继承关系中的虚函数表继承和多态常见的面试问题 前言 需要声明的,下面的代码和解释的哦朴实vs2013x86环境,涉及指针是4bytes,如果要其他平台下,部分代码需要改动。比…...

排序算法超详细代码和知识点整理(java版)
排序 1、冒泡排序 两层循环,相邻两个进行比较,大的推到后面去,一共比较“数组长度”轮,每一轮都是从第一个元素开始比较,每一轮比较都会将一个元素固定到数组最后的一个位置。【其实就是不停的把元素往后堆&#…...

Java复习第十二天学习笔记(JDBC),附有道云笔记链接
【有道云笔记】十二 3.28 JDBC https://note.youdao.com/s/HsgmqRMw 一、JDBC简介 面向接口编程 在JDBC里面Java这个公司只是提供了一套接口Connection、Statement、ResultSet,每个数据库厂商实现了这套接口,例如MySql公司实现了:MySql驱动…...

AI辅助开发新范式:描述需求,快马AI自动生成免安装的免费应用
AI辅助开发新范式:描述需求,快马AI自动生成免安装的免费应用 最近想做一个天气查询小工具,但自己从头写代码太费时间。听说InsCode(快马)平台的AI辅助开发功能很强大,就尝试用它来生成这个项目。整个过程让我很惊喜,完…...

Solving Matplotlib‘s Font Fallback: From DejaVu Sans to SimHei for CJK Support
1. 为什么Matplotlib会显示DejaVu Sans字体警告? 当你第一次在Matplotlib中尝试绘制包含中文的图表时,大概率会遇到这个熟悉的警告:"UserWarning: Glyph XXXX missing from font(s) DejaVu Sans"。这个看似简单的提示背后ÿ…...

Carsim+Simulink 线控制动系统BBW-EMB联合仿真模型 !BBW-EMB线控制动联合仿真|Carsim+Simulink】
CarsimSimulink 线控制动系统BBW-EMB联合仿真模型 !BBW-EMB线控制动联合仿真|CarsimSimulink】 ✨ 核心仿真配置 ✅ 完整系统架构:包含制动力分配功能四个车轮独立线控制动机构,贴合真实线控制动系统结构; ✅ 精准控制…...

【C++第二十六章】特殊类设计
前言 🚀“特殊类设计”这一章看起来内容不多,但背后其实在讨论一个很典型、也很有代表性的 C 设计问题:类到底能不能限制对象的创建位置,能不能强制某个对象只能在堆上创建,或者只能在栈上创建。 这不是语法技巧题&…...

3大挑战与解决方案:如何构建现代化医院信息系统的分布式架构与数据治理平台
3大挑战与解决方案:如何构建现代化医院信息系统的分布式架构与数据治理平台 【免费下载链接】HIS HIS英文全称 hospital information system(医疗信息就诊系统),系统主要功能按照数据流量、流向及处理过程分为临床诊疗、药品管理、…...

3步终结磁盘焦虑:Windows Cleaner让系统性能提升200%的实战指南
3步终结磁盘焦虑:Windows Cleaner让系统性能提升200%的实战指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 现象诊断:当C盘爆红成为工…...

保健及护理用家具市场:548.6亿元规模下的多维洞察
据恒州诚思调研统计,2025年全球保健及护理用家具收入规模约达466.7亿元,预计到2032年,这一数字将接近548.6亿元,2026 - 2032年的复合年增长率(CAGR)为2.5%。在医疗行业不断发展、人口结构持续变化的背景下&…...

若依RuoYi-Vue集成wangEditor:从零到一构建富文本内容管理模块
1. 为什么选择wangEditor与若依框架组合 在前后端分离的开发模式中,富文本编辑器是内容管理系统的核心组件。我实测过市面上主流的编辑器,wangEditor以其轻量级、易扩展的特性脱颖而出。特别是对于使用若依(RuoYi-Vue)框架的开发者来说,这个组…...

如何用EmuDeck解决Steam Deck模拟器配置难题:给复古游戏玩家的一站式解决方案
如何用EmuDeck解决Steam Deck模拟器配置难题:给复古游戏玩家的一站式解决方案 【免费下载链接】EmuDeck Emulator configurator for Steam Deck 项目地址: https://gitcode.com/gh_mirrors/em/EmuDeck 在Steam Deck上畅玩经典游戏本应是件轻松愉快的事&#…...

AI ABG制作与运营指南
使用ABG轻松玩转Instagram。我创建了一个AI生成的ABG,发布了一些Reels短视频,5天内就获得了1000粉丝。无需购买粉丝,也无需庞大的现有粉丝群。以下是详细步骤。 1、创建你的ABG 首先,你需要创建自己的ABG。这是你整个账号的门面…...