算法之美:堆排序原理剖析及应用案例分解实现
这段时间持续更新关于“二叉树”的专栏文章,关心的小伙伴们对于二叉树的基本原理已经有了初步的了解。接下来,我将会更深入地探究二叉树的原理,并且展示如何将这些原理应用到更广泛的场景中去。文章将延续前面文章的风格,尽量精炼明了,减少冗长的废话,旨在简洁清晰地阐述二叉树的原理及其应用。让我们一起深入了解,并探索其潜在的价值吧!
什么是堆排序
指利用堆这种数据结构所设计的一种排序算法,将二叉堆的数据进行排序,构建一个有序的序列。在这排序过程中,只需要个别【临时存储】空间,所以堆排序是原地排序算法,空间复杂度为O(1)。
本身大顶堆和小顶堆里面的元素是无序的,只是有一定的规则在里面:
1)大顶堆,每个父节点的值都大于或等于其子节点的值,即根节点的值最大;
2)小顶堆,每个父节点的值都小于或等于其子节点的值,即根节点的值最小;

堆排序流程
把无序数组构建成二叉堆,建堆结束后,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换(删除操作), 堆顶a[1]与最后一个元素a[n]交换,最大元素放到下标为n的位置, 末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆(堆化操作),这样会得到n个元素的次小值
反复执行上述步骤,得到一个有序的数组。
综上所述,这个堆排序的过程其实可以直接分为建堆和排序两大步骤:
1)【建堆】过程的时间复杂度为O(n),排序过程的时间复杂度为O(nlogn),所以 堆排序整体的时间复杂度为O(nlogn);
2)【堆排序】不是稳定的算法,在排序的过程中,将堆最后一个节点跟堆顶节点互换,可能改变值相同数据的原始相对顺序;
堆排序动画演示:Heap Sort Visualization (usfca.edu)
堆排序实现
public class HeapSort {/*** 从小到大进行堆排序* @param source*/public static void sort(int[] source) {//步骤一:构建堆,数组下标0不存储数据int[] heap = new int[source.length + 1];//根据待排序数组,构造一个无序的堆System.arraycopy(source, 0, heap, 1, source.length);//对堆中的元素做下沉调整,从长度的一半处开始,往堆顶索引1处扫描)//二叉堆特性:数组索引一半后的都是叶子节点,不需要做下沉,一半前都是非叶子节点,才需要做for (int i = (heap.length) / 2; i > 0; i--) {down(heap, i, heap.length - 1);}System.out.println("大顶堆:"+Arrays.toString(heap));// 步骤二:堆排序}/*** 比较大小,item[left] 元素是否小于 item[right]的元素*/private static boolean rightBig(int[] heap, int left, int right) {return heap[left] < heap[right];}/*** 交互堆中两个元素的位置*/private static void swap(int[] heap, int i, int j) {int temp = heap[i];heap[i] = heap[j];heap[j] = temp;}/*** 使用下沉操作,堆顶和最后一个元素交换后,重新堆化* 不断比较 节点 arr[k]和对应 左节点arr[2*k] 和 右节点arr[2*k+1]的大小,如果当前结点小,则需要交换位置* 直到找到 最后一个索引节点比较完成 则结束* <p>* 数组中下标为 k 的节点* 左子节点下标为 2*k 的节点* 右子节点就是下标 为 2*k+1 的节点* 父节点就是下标为 k/2 取整的节点*/private static void down(int[] heap, int k, int range) {// 最后一个节点的下标是range,即元素总个数while (2 * k <= range) {//记录当前节点的左右子节点,较大的节点int maxIndex;if (2 * k + 1 <= range) {if (rightBig(heap, 2 * k, 2 * k + 1)) {maxIndex = 2 * k + 1;} else {maxIndex = 2 * k;}} else {maxIndex = 2 * k;}//比较当前节点和较大接的值,如果当前节点大则结束if (heap[k] > heap[maxIndex]) {break;} else {//否则往下一层比较,当前节点的k变为子节点中较大的值swap(heap, k, maxIndex);k = maxIndex;}}}/*** 从小到大进行堆排序* @param source*/public static void sort(int[] source) {//步骤一:构建堆,数组下标0不存储数据int[] heap = new int[source.length + 1];//根据待排序数组,构造一个无序的堆System.arraycopy(source, 0, heap, 1, source.length);//对堆中的元素做下沉调整,从长度的一半处开始,往堆顶索引1处扫描)//二叉堆特性:数组索引一半后的都是叶子节点,不需要做下沉,一半前都是非叶子节点,才需要做for (int i = (heap.length) / 2; i > 0; i--) {down(heap, i, heap.length - 1);}System.out.println("大顶堆:"+Arrays.toString(heap));// 步骤二:堆排序,把堆顶元素和数组最后一个索引元素交换;然后再堆化,然后堆顶又是最大元素,再和数组倒数第二索引处交换;持续进行直到最后// 类似删除操作,只需要下沉操作重新堆化即可//记录未排序的元素中最大的索引int maxUnSortIndex = heap.length - 1;//通过循环,交换堆顶元素和最大未排序元素的下标while (maxUnSortIndex != 1) {//交换元素swap(heap, 1, maxUnSortIndex);//排序后最大元素所在的索引,不要参与堆的下沉,所以 递减1maxUnSortIndex--;//继续对堆顶处的元素进行下沉调整down(heap, 1, maxUnSortIndex);}//把heap中的数据复制到原数组source中System.arraycopy(heap, 1, source, 0, source.length);}//Main入口public static void main(String[] args) {//待排序数组int[] arr = {923,23,12,4,9932,11,34,49,123,222,880};//堆排序HeapSort.sort(arr);//输出排序后数组中的元素System.out.println("堆排序:"+Arrays.toString(arr));}}海量数据之堆应用TopK思想
从一堆数据中选出前多少个最大或最小数
堆典型问题,思路方案:取大用小,取小用大
取最大的K个数用小顶堆,取最小的K个数用大顶堆;
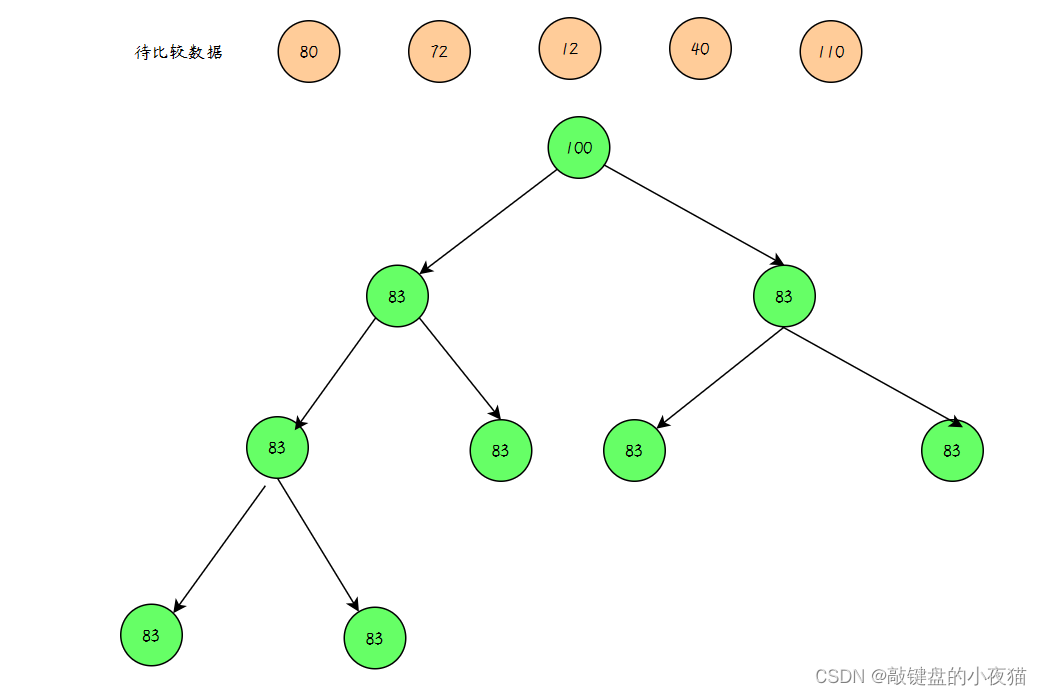
取海量数据里面最小的K个数
要找出数组中最小的k个数,就要【构造一个有k个元素的大顶堆】,大顶堆的堆顶元素值最大,比较堆顶的元素和扫描的元素,如果堆顶元素 < 扫描元素,继续扫描其他元素。如果堆顶元素 > 扫描元素 ,将堆顶元素出队,扫描元素插入大顶堆,将更小的元素换到堆中,反复根据上述步骤操作,直到比较完最后一个元素,此时堆里面的就是最小的k个数。
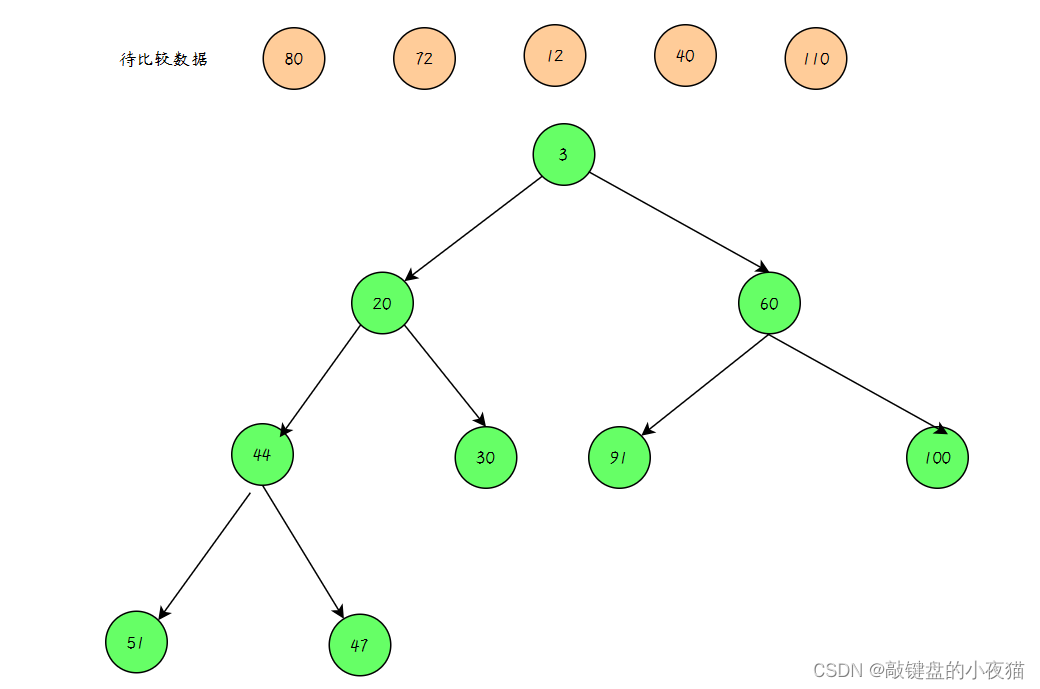
取海量数据里面最大的K个数
要找出数组中最大的k个数,就要【构造一个有k个元素的小顶堆】,小顶堆的堆顶元素值最小,比较堆顶的元素和扫描的元素,如果堆顶元。
素 > 扫描元素,继续扫描其他元素。如果堆顶元素 < 扫描元素 ,将堆顶元素出队,扫描元素插入小顶堆,将更大的元素换到堆中,反复根据上述步骤操作,直到比较完最后一个元素,此时堆里面的就是最大的k个数。
实际应用及实现
问题
如何100亿个数中找出最小的前k个数
问题分析
100亿个数,一个数占四个字节,那么100亿个数就需要40G的存储空间:1G = 10亿字节, 100亿个int = 400亿字节 = 40G。使用普通的电脑和服务器肯定不可能把全部数据,不能创建一个具有100亿个数据的堆,而且使用常规加载进去,存储空间不够大,时间复杂度也是很大。
解决方案
要找出数组中最小的k个数,就要【构造一个有k个元素的大顶堆】,大顶堆的堆顶元素值最大,比较堆顶的元素和扫描的元素,如果堆顶元素 < 扫描元素,继续扫描其他元素。如果堆顶元素 > 扫描元素 ,将堆顶元素出队,扫描元素插入大顶堆,将更小的元素换到堆中,反复根据上述步骤操作,直到比较完最后一个元素,此时堆里面的就是最小的k个数。
代码实现
public class MinTopKHeapSort {/*** 从小到大进行堆排序* @param source*/public static void sort(int[] source,int temp) {//步骤一:构建堆,数组下标0不存储数据int[] heap = new int[source.length + 1];//根据待排序数组,构造一个无序的堆System.arraycopy(source, 0, heap, 1, source.length);//对堆中的元素做下沉调整,从长度的一半处开始,往堆顶索引1处扫描)//二叉堆特性:数组索引一半后的都是叶子节点,不需要做下沉,一半前都是非叶子节点,才需要做for (int i = (heap.length) / 2; i > 0; i--) {down(heap, i, heap.length - 1);}System.out.println("大顶堆:"+Arrays.toString(heap)+", 新元素="+temp);// 循环将数组中剩余的数放入heap数组中,并进行堆排序,如果当前数小于Heap数组中的第一个数,则将当前数替换为第一个数if (temp < heap[1]) {heap[1] = temp;//重新堆化down(heap, 1, source.length-1);}System.arraycopy(heap, 1, source, 0, source.length);}/*** 比较大小,item[left] 元素是否小于 item[right]的元素*/private static boolean rightBig(int[] heap, int left, int right) {return heap[left] < heap[right];}/*** 交互堆中两个元素的位置*/private static void swap(int[] heap, int i, int j) {int temp = heap[i];heap[i] = heap[j];heap[j] = temp;}/*** 使用下沉操作,堆顶和最后一个元素交换后,重新堆化* 不断比较 节点 arr[k]和对应 左节点arr[2*k] 和 右节点arr[2*k+1]的大小,如果当前结点小,则需要交换位置* 直到找到 最后一个索引节点比较完成 则结束*/private static void down(int[] heap, int k, int range) {//当前节点存在左子树while (2 * i < length) {//此时j为左子树节点int j = 2 * i;//如果当前节点存在右子树,并且右子树的值大于左子树的值if (j < length && arr[j + 1] > arr[j]) {//此时j为右子树节点j = j + 1;}//比较当前节点值与其左右子树值的大小if (arr[i] > arr[j]) {break;} else {swap(arr, i, j);i = j;}}}public static void main(String[] args) {//随机数据int[] arr = {923,982,23,1000,1990,12,4,9932,11,34,49,123,1,222,880};// 定义一个长度为k的数组int top = 3;int[] heap = new int[top];// 循环将数组中的前k个数放入Heap数组中; for (int i = 0; i < top; i++) {heap[i] = arr[i];}//循环将数组中剩余的数放入heap数组中,并进行堆排序for(int i = top; i < arr.length; i++){MinTopKHeapSort.sort(heap,arr[i]);}//输出排序后数组中的元素System.out.println("最小的 top k 数据:"+Arrays.toString(heap));}}延申方案
如果是百亿数据,只需要从文本中读取前k个出来,然后构建大顶堆,然后在从剩余的元素逐个读取比较即可
相关文章:
算法之美:堆排序原理剖析及应用案例分解实现
这段时间持续更新关于“二叉树”的专栏文章,关心的小伙伴们对于二叉树的基本原理已经有了初步的了解。接下来,我将会更深入地探究二叉树的原理,并且展示如何将这些原理应用到更广泛的场景中去。文章将延续前面文章的风格,尽量精炼…...
Net8 ABP VNext完美集成FreeSql、SqlSugar,实现聚合根增删改查,完全去掉EFCore
没有基础的,请参考上一篇 彩蛋到最后一张图里找 参考链接 结果直接上图,没有任何业务代码 启动后,已经有了基本的CRUD功能,还扩展了批量删除,与动态查询 动态查询截图,支持分页,排序 实现原理…...
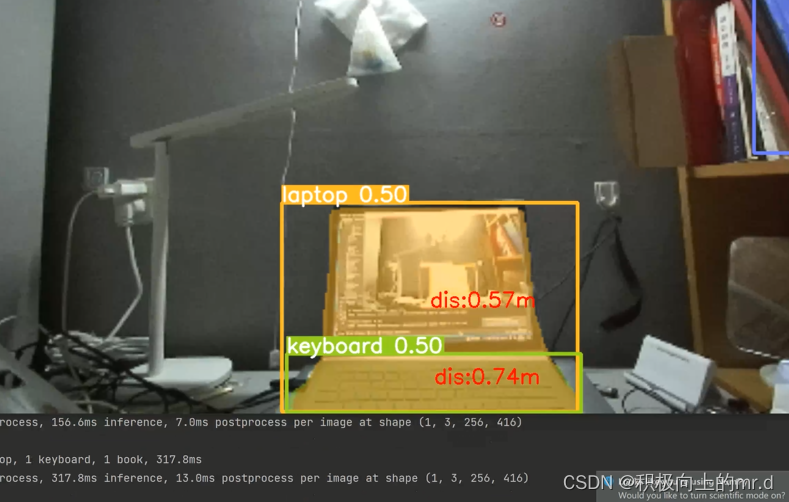
yolov8直接调用zed相机实现三维测距(python)
yolov8直接调用zed相机实现三维测距(python) 1. 相关配置2. 版本一2.1 相关代码2.2 实验结果 3. 版本二3.1 相关代码3.2 实验结果 相关链接 此项目直接调用zed相机实现三维测距,无需标定,相关内容如下: 1.yolov5直接调…...

element跑马灯/轮播图,第一页隐藏左边按钮,最后一页隐藏右边按钮(vue 开箱即用)
图示: 第一步: <el-carousel :class"changeIndex0?leftBtnNone:changeIndeximgDataList.length-1? rightBtnNone:" height"546px" :autoplay"false" change"changeNext"><el-carousel-item v-for…...

下载及安装PHP,composer,phpstudy,thinkPHP6.0框架
文章目录 目录 文章目录 前言 一、下载PHP 二、下载composer 三、下载PHPstudy 四、下载think PHP 1.下载 2.多应用开发 前言 thinkPHP是一款开源的PHP框架,它是基于MVC(Model-View-Controller)设计模式构建的。thinkPHP提供了丰富的…...

volatile使用场景总结
volatile关键字在Java中用于确保变量的可见性以及防止指令重排序,特别是在没有使用锁定机制时对变量进行读写的多线程环境中。以下是需要使用volatile修饰的一些场景: 确保变量的可见性 当一个变量被多个线程访问,且至少有一个线程在写&…...

AcWing 1413. 矩形牛棚(每日一题)
原题链接:1413. 矩形牛棚 - AcWing题库 作为一个资本家,农夫约翰希望通过购买更多的奶牛来扩大他的牛奶业务。 因此,他需要找地方建立一个新的牛棚。 约翰购买了一大块土地,这个土地可以看作是一个 R 行(编号 1∼R&…...
macOS Sonoma 14.4.1 (23E224) 正式版发布,ISO、IPSW、PKG 下载
macOS Sonoma 14.4.1 (23E224) 正式版发布,ISO、IPSW、PKG 下载 2024 年 3 月 26 日凌晨,macOS Sonoma 14.4.1 更新修复了一个可能导致连接到外部显示器的 USB 集线器无法被识别的问题。它还解决了可能导致 Java 应用程序意外退出的问题,并修…...
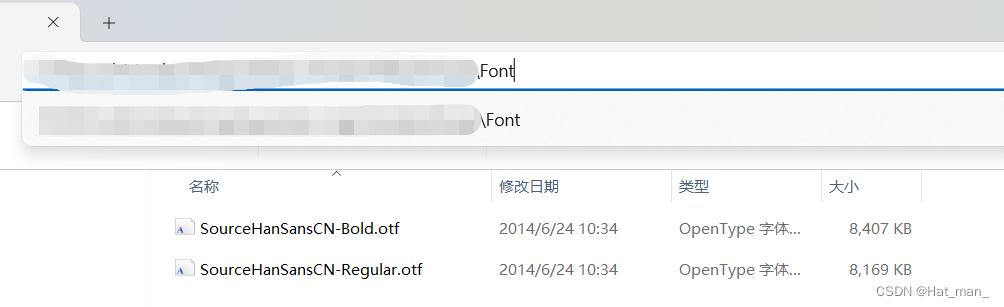
WPF使用外部字体,思源黑体,为例子
1.在工程中新建文件夹,命名为“Font"。 2.将下载好的字体文件复制到Font文件夹。 3.在工程中,加入静态资源 <Window.Resources><FontFamily x:Key"SYBold">/AnalyzeImage;Component/Font/#思源黑体 CN Bold</FontFamily…...
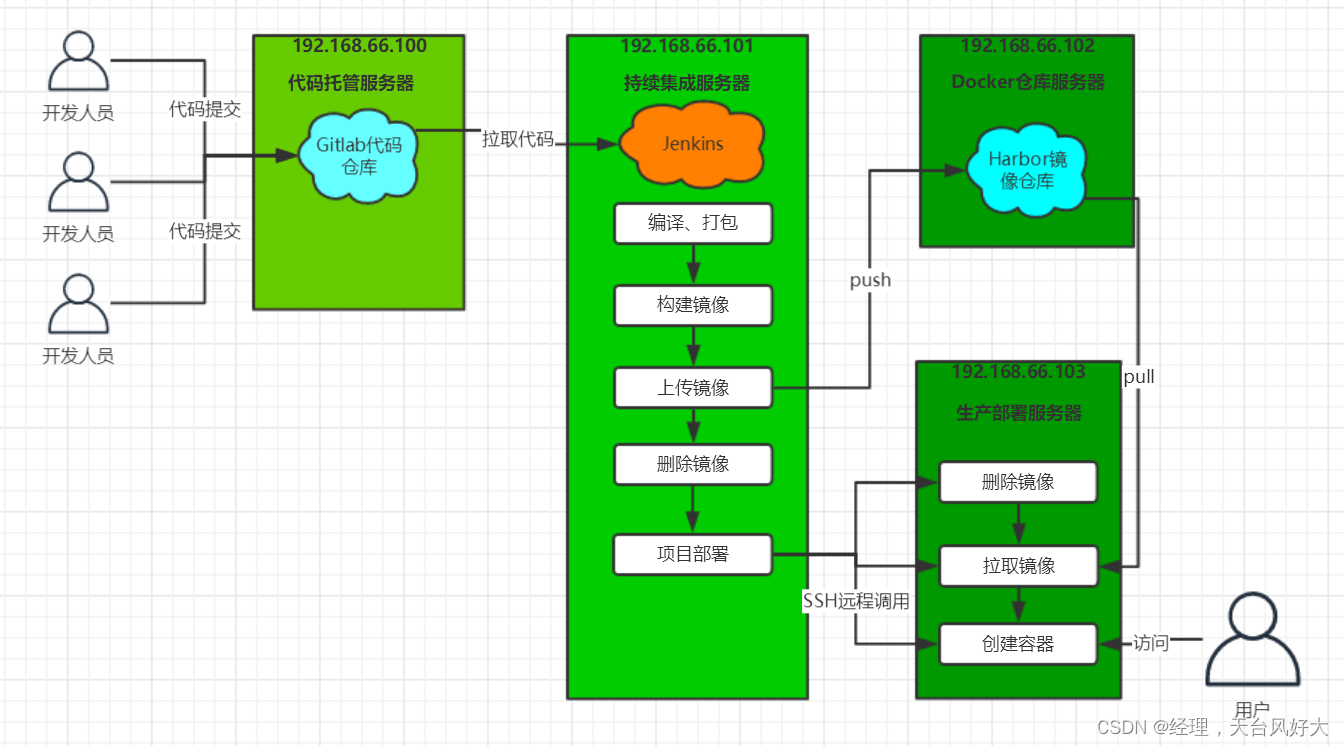
9、jenkins微服务持续集成(一)
文章目录 一、流程说明二、源码概述三、本地部署3.1 SpringCloud微服务部署本地运行微服务本地部署微服务3.2 静态Web前端部署四、Docker快速入门一、流程说明 Jenkins+Docker+SpringCloud持续集成流程说明 大致流程说明: 开发人员每天把代码提交到Gitlab代码仓库Jenkins从G…...

VOC(客户之声)赋能智能家居:打造个性化、交互式的未来生活体验
随着科技的飞速发展,智能家居已成为现代家庭不可或缺的一部分。然而,如何让智能家居更好地满足用户需求,提供更贴心、更智能的服务,一直是行业关注的焦点。在这个背景下,VOC(客户之声)作为一种用…...

时序预测 | Matlab实现GWO-BP灰狼算法优化BP神经网络时间序列预测
时序预测 | Matlab实现GWO-BP灰狼算法优化BP神经网络时间序列预测 目录 时序预测 | Matlab实现GWO-BP灰狼算法优化BP神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现GWO-BP灰狼算法优化BP神经网络时间序列预测(完整源码和数据…...

node.js学习(2)
版权声明 以下文章为尚硅谷PDF资料,B站视频链接:【尚硅谷Node.js零基础视频教程,nodejs新手到高手】仅供个人学习交流使用。如涉及侵权问题,请立即与本人联系,本人将积极配合删除相关内容。感谢理解和支持,…...

【pytest】测试数据存储在 Excel 或 TXT 文件中,如何参数化
如果测试数据存储在 Excel 或 TXT 文件中,你可以使用外部库来读取这些数据,并将其转化为参数化测试所需的格式。下面我将分别展示如何从这两种文件中读取数据,并用于参数化测试。 从 Excel 文件中读取测试数据 你可以使用 pandas 库来读取 …...
ubuntu22.04@Jetson Orin Nano安装配置VNC服务端
ubuntu22.04Jetson Orin Nano安装&配置VNC服务端 1. 源由2. 环境3. VNC安装Step 1: update and install xserver-xorg-video-dummyStep 2: Create config for dummy virtual displayStep3: Add the following contents in xorg.conf.dummyStep 4: Update /etc/X11/xorg.con…...

面向对象特征二:继承
继承的概述 生活中的继承 财产继承: 绿化:前人栽树,后人乘凉 “绿水青山,就是金山银山” 样貌: 继承之外,是不是还可以"进化": 继承有延续(下一代延续上一代的基因、财…...

宝塔面板CentOS Stream 8 x86 下如何安装openlitespeed
宝塔自带的软件商店里如果没办法安装,那么我们可以通过指令来手动安装: 第一步: yum install epel-release Package epel-release-8-19.el8.noarch is already installed. Dependencies resolved. Nothing to do. Complete! 第二步&#…...
)
LeetCode 2952.需要添加的硬币的最小数量:贪心(排序)
【LetMeFly】2952.需要添加的硬币的最小数量:贪心(排序) 力扣题目链接:https://leetcode.cn/problems/minimum-number-of-coins-to-be-added/ 给你一个下标从 0 开始的整数数组 coins,表示可用的硬币的面值ÿ…...
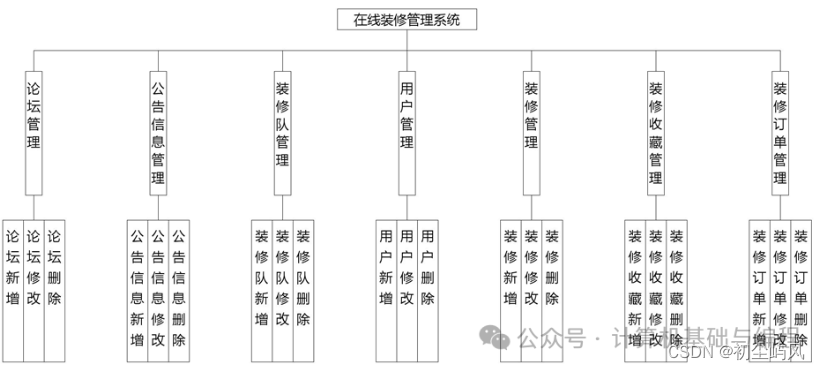
基于SpringBoot + Vue实现的在线装修管理系统设计与实现+毕业论文
介绍 系统包含用户、装修队、管理员三个角色 管理员: 管理员管理:管理其他管理员的账号和权限,确保系统管理的层次化和安全性。 装修队管理:审核装修队的资质,管理装修队的人员信息,监控工程进度ÿ…...
阿里云安全产品简介,Web应用防火墙与云防火墙产品各自作用介绍
在阿里云的安全类云产品中,Web应用防火墙与云防火墙是用户比较关注的安全类云产品,二则在作用上并不是完全一样的,Web应用防火墙是一款网站Web应用安全的防护产品,云防火墙是一款公共云环境下的SaaS化防火墙,本文为大家…...
)
STM32串口升级实战:从Bootloader到APP跳转的完整流程(附Ymodem协议详解)
STM32串口升级实战:从Bootloader到APP跳转的完整流程(附Ymodem协议详解) 在嵌入式设备开发中,固件升级功能几乎是每个产品的标配需求。想象一下这样的场景:你的STM32设备已经部署在客户现场,突然发现了一个…...

杰理之立体声利用数字音量节点实现左右声道平衡【篇】
利用数字音量通过dB转换,去设置LR声道的数据大小,实现LR声道数据幅值不同达到声道平衡的目的,适配用户人耳情况...

电源篇2——降压BUCK芯片的实战选型与设计考量
1. BUCK芯片选型的核心参数解析 第一次选BUCK芯片时,我看着密密麻麻的规格书参数直接懵了——效率95%、开关频率2MHz、最大电流3A...这些数字到底哪个最关键?后来踩过几次坑才明白,选型就像相亲,不能只看表面数据,得看…...

ofa_image-caption效果展示:同一张图不同光照/角度下的描述一致性验证
ofa_image-caption效果展示:同一张图不同光照/角度下的描述一致性验证 1. 引言:为什么关注描述一致性? 当你给同一张图片拍出不同角度、不同光线的照片时,AI模型能否给出一致的描述?这个问题看似简单,却直…...

JBL Live 780NC 耳机:开启 iPhone 用户 Auracast 新体验
JBL Live 780NC 耳机:Auracast 技术新突破 JBL 最新发布的 Live 780NC 耳机,最大亮点在于配备了 Auracast 技术。用户能够直接通过 JBL 耳机应用程序访问广播内容,这一功能的实现,让原本因苹果 iPhone 不支持 Auracast 而无缘该功…...

根据ai创建校园管理系统——MySQL数据库设计与建立
native效果展示一.DDL语句-- -- 校园二手交易系统 - DDL数据定义语句 -- -- 1. 初始化设置 SET FOREIGN_KEY_CHECKS 0; -- 临时关闭外键检查,避免删表报错 SET NAMES utf8mb4;-- 2. 创建并使用数据库 CREATE DATABASE IF NOT EXISTS campus_second_hand_trade D…...

毕业季干货|让论文效率翻倍的实用神器
我梳理了毕业之家和PaperRed的核心功能,并补充了两款专注于英文论文写作的高效工具。这些工具覆盖了从初稿生成、查重降重到英文学术润色的全流程,希望能帮你更高效地完成论文。 🎓 毕业之家:一站式毕业全流程专家 官网ÿ…...

NUKE构建系统扩展开发:如何自定义构建插件和工具集成
NUKE构建系统扩展开发:如何自定义构建插件和工具集成 【免费下载链接】nuke 🏗 The AKEless Build System for C#/.NET 项目地址: https://gitcode.com/gh_mirrors/nuk/nuke NUKE构建系统为C#/.NET开发者提供了强大的构建自动化框架,但…...

Phi-3-mini-128k-instruct实战:使用Qt开发跨平台AI桌面应用
Phi-3-mini-128k-instruct实战:使用Qt开发跨平台AI桌面应用 最近在捣鼓一些本地AI应用,发现很多开发者朋友对如何把大模型塞进自己的桌面程序里很感兴趣。特别是用C和Qt的,总觉得这块门槛有点高。其实没那么复杂,我今天就用微软开…...

Synopsys AXI VIP 从环境搭建到首个验证场景运行
1. 环境准备与VIP安装 第一次接触Synopsys AXI VIP时,我也被那一堆.run文件和环境变量搞得晕头转向。不过别担心,跟着我的步骤走,保证你能在半小时内搞定基础环境搭建。VIP(Verification IP)就像是验证工程师的瑞士军刀…...