文生图大模型三部曲:DDPM、LDM、SD 详细讲解!
1、引言
跨模态大模型是指能够在不同感官模态(如视觉、语言、音频等)之间进行信息转换的大规模语言模型。当前图文跨模态大模型主要有:
-
文生图大模型:如 Stable Diffusion系列、DALL-E系列、Imagen等
-
图文匹配大模型:如CLIP、Chinese CLIP、BridgeTower等
今天主要讨论Stable Diffusion,首先让我们看一下,Stable Diffusion能做什么呢?
-
最简单的形式:给它一个文本提示(Text Prompt) ,它将返回与文本匹配的图像。
-
除此之外,Stable Diffusion还可以用于图像超分、图像修复、样本生成等领域。

Stable Diffusion的发展历程,主要经过如下三个阶段:
-
DDPM:无条件图片生成(不支持文本提示)
-
LDM:有条件图片生成(支持文本等其他形式提示)
-
Stable Diffusion:基于LDM发展而成的强大的文生图大模型
接下来,本文将按照Stable Diffusion的发展历程展开讲解!
2、DDPM
2.1 概要
Denoising Diffusion Probabilistic Models(去噪概率扩散模型,DDPM)在图像生成领域具有里程碑的意义,当前一些主流的文本转图像模型如DALL·E 2、stable-diffusion 和 Imagen 均采用了扩散模型(Diffusion Model)作为图像生成模型,这也引发了对扩散模型的研究热潮。相比传统的GAN来说,扩散模型训练更稳定,而且能够生成更多样的样本。
2.2 基本原理
任务:从随机“向量”到真实图像的生成。和GAN不同的是,DDPM的输入和输出形状是一样的。
动机:DDPM的核心动机,如果我们一点一点地往图像中加噪声,直到把它变成高斯噪声;然后我们把所有加噪的过程逆过来,就可以把高斯分布映射成真实图像的分布。
做法:基于以上动机,作者就设置了如图的加噪声过程(diffusion)和去噪过程(denoising),作者假设加噪过程是个马尔可夫过程,即当前状态只跟上一个状态相关。
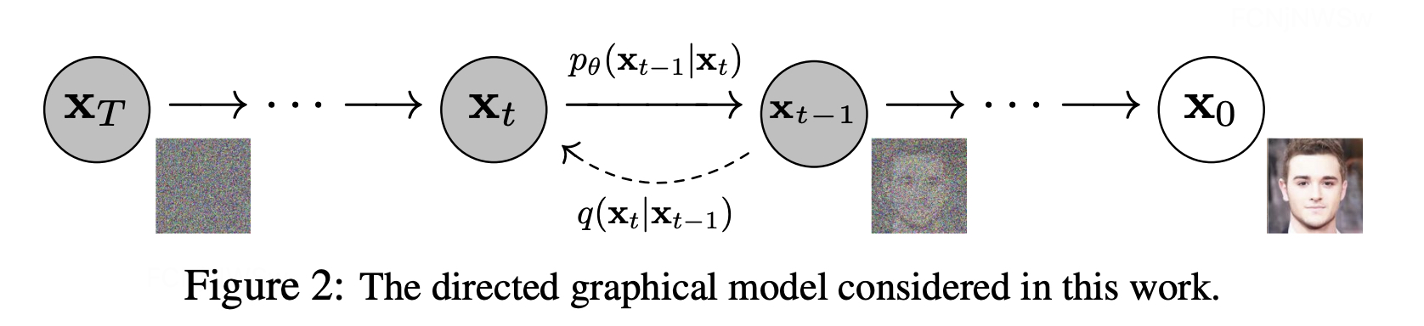
扩散模型包括两个过程:
-
前向过程(扩散,加噪):对原图x0逐渐增加高斯噪音直至数据变成随机噪音的过程。
-
反向过程(去噪):是一个去噪的过程,如果知道反向过程的每一步噪声的真实分布,那么从一个随机噪音N(0, 1)开始,逐渐去噪就能生成一个真实的样本。
简单来讲,图像生成的过程,就是一个去噪的过程;因此扩散模型的关键在于学习图像在前向过程中加入的噪声。
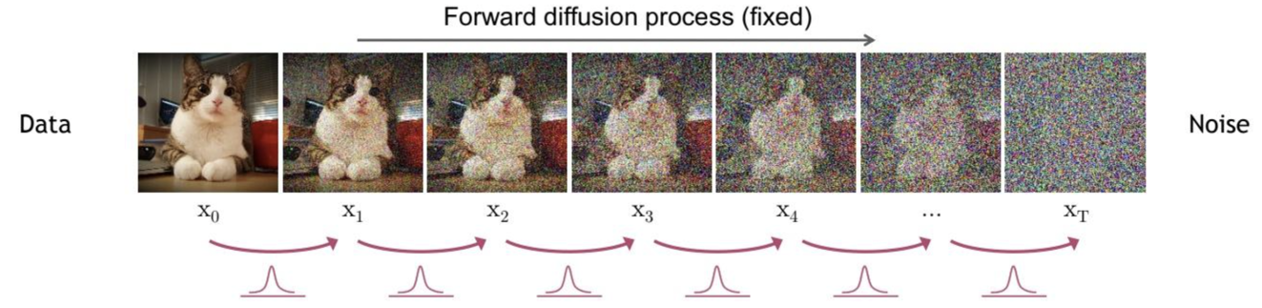
前向过程中,从原图x0到x1,x1到x2,最后到的过程,可以用如下公式表示:
![]()
式中,xt-1表示第t-1步的噪声图,xt表示第t步的噪声图。理论上,已知x0和 t,可以通过一步步推导获得xt,但是实际上,这种方式比较耗费计算资源。因此作者通过一种方式(重参数化技巧),能实现x0到xt的直接计算,这样就能节省大量资源,如下如所示:如果能从x0直接到x4,就不需要从x1到x2到x3再到x4。

2.3 重参数化
扩散过程的一个重要特性是可以直接基于原始数据x0来对任意t步的xt进行采样。在扩散阶段,根据重参数化,可以推导出x0到xt的直接公式:


扩散过程的这个特性很重要。首先,我们可以看到xt其实可以看成是原始数据x0和随机噪音ϵ的线性组合,其中和
为组合系数,它们的平方和等于1,我们也可以称两者分别为
signal_rate和noise_rate。
更近一步地,我们可以基于而不是来定义noise schedule,比如我们直接将设定为一个接近0的值,那么就可以保证最终得到的近似为一个随机噪音。其次,后面的建模和分析过程将使用这个特性。
2.4 网络结构
扩散模型的核心就在于训练噪音预测模型,由于噪音和原始数据是同维度的,所以我们可以选择采用AutoEncoder架构来作为噪音预测模型。DDPM所采用的模型是一个基于residual block和attention block的U-Net模型。如下所示:
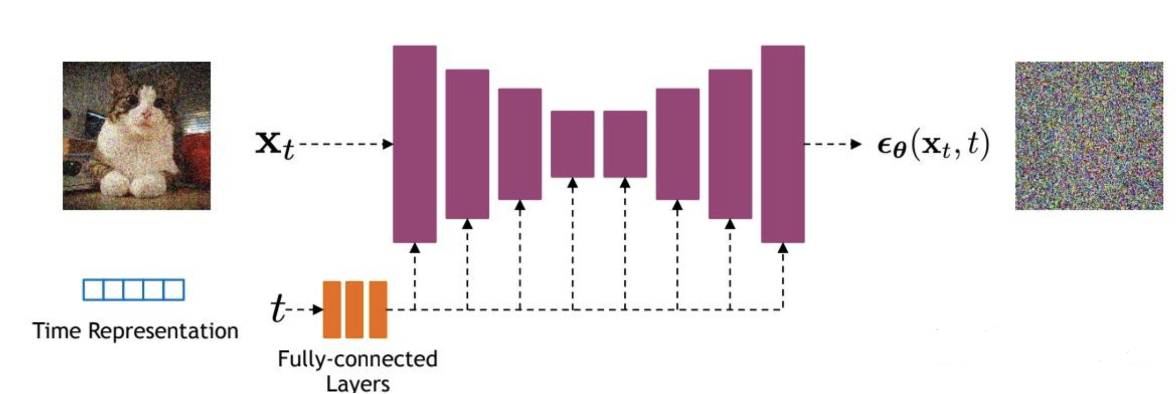
经U-Net改进过后的整体网络结构如下:
-
U-Net属于encoder-decoder架构,其中encoder分成不同的stages,每个stage都包含下采样模块来降低特征的空间大小(H和W),然后decoder和encoder相反,是将encoder压缩的特征逐渐恢复。
-
U-Net在decoder模块中还引入了skip connection,即concat了encoder中间得到的同维度特征,这有利于网络优化。
-
DDPM所采用的U-Net每个stage包含2个residual block,而且部分stage还加入了self-attention模块增加网络的全局建模能力。
-
扩散模型其实需要的是T个噪音预测模型,实际处理时,我们可以增加一个time embedding(类似transformer中的position embedding)来将timestep编码到网络中,从而只需要训练一个共享的U-Net模型。具体地,DDPM在各个residual block都引入了time embedding。
2.5 模型训练
虽然扩散模型背后的推导比较复杂,但是我们最终得到的优化目标非常简单,就是让网络预测的噪音和真实的噪音一致。DDPM的训练过程也非常简单,如下图所示,训练过程具体步骤为:
-
随机选择一个训练样本
-
从1~T随机抽样一个t
-
随机产生高斯噪音,并计算当前所产生的带噪音数据xt
-
输入网络预测噪音
-
计算产生的噪音和预测的噪音的L2损失
-
计算梯度并更新网络

一旦训练完成,其采样过程也非常简单:我们从一个随机高斯噪音开始,并用训练好的的网络预测每一步的(从T到1)噪音,并根据该噪声去噪,就能逐步获得精细的生成图像。
2.6 实现效果
衡量模型生成图像质量的指标:
-
Inception Score(IS):图像质量的期望值(Exp)和图像质量分布的分歧度(KL),越大越好。
-
Fréchet Inception Distance(FID):生成图像和真实图像在特征空间中的分布距离;衡量它们之间的差异,越小越好。
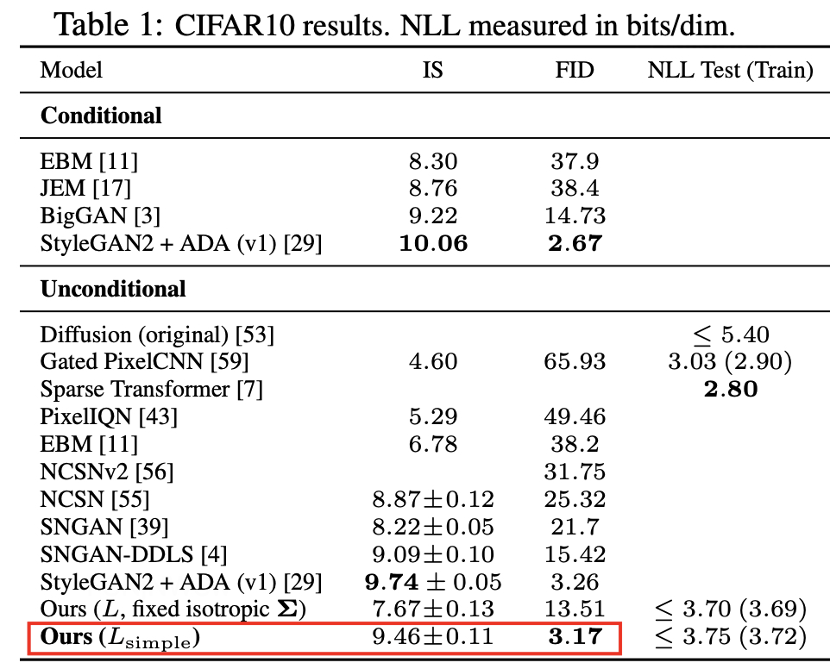
1、在CIFAR10数据集上,DDPM获得了9.46的Inception分数和3.17的最先进的FID分数。

2、在分辨率为256x256 LSUN数据集上,DDPM能生成与ProgressiveGAN同样高质量的图像。

2.7 不足点
虽然DDPM能够生成高质量的图片,但是还存在一些不足:
-
计算量大:由于DDPM整个扩散过程是在像素空间上进行的,所以计算量很高
-
不支持条件控制:DDPM是一个单纯的图像生成模型,不支持文本等提示信息,从而限制了其的发展。
3、LDM
3.1 概要
Latent Diffusion Models(潜在扩散模型,LDM)通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火。除此之外,LDM在无条件图片生成、图片修复、图片超分任务上也进行了实验,都取得了不错的效果。

3.2 主要创新点
-
LDM提出了cross-attention的方法来实现多模态训练,使得条件图片生成任务也可以实现。论文中提到的条件图片生成任务包括:类别条件图片生成(class-condition), 文图生成(text-to-image), 布局条件图片生成(layout-to-image)。这也为日后Stable Diffusion的开发奠定了基础。
-
DDPM在像素空间上训练模型,需要反复迭代计算,因此训练和推理代价都很高。DLM提出一种在潜在表示空间上进行扩散过程的方法,能够显著减少计算复杂度,同时也能达到十分不错的图片生成效果。
-
相比于其它空间压缩方法,论文提出的方法可以生成更细致的图像,并且在高分辨率图片生成任务(如风景图生成,百万像素图像)上表现得也很好。
3.3 网络结构
Latent Diffusion Models整体框架如图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E 和一个解码器D。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。

3.4 图片感知压缩
定义:利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后再用解码器恢复到原始像素空间。
原理:通过VAE这类自编码模型对原图片进行处理,忽略掉图片中的高频信息,只保留重要、基础的一些特征;这种方法能够大幅降低训练和采样阶段的计算复杂度。
感知压缩主要利用一个预训练的自编码模型,该模型能够学习到一个在感知上等同于图像空间的潜在表示空间。在感知压缩的过程中,设置下采样因子的大小为: f=H/h=W/w,通过对原图进行f倍的下采样,让扩散模型在潜在空间中进行,从而减小计算量。
论文对比了 f 在分别 {1, 2, 4, 8, 16, 32}下的效果,发现 f 在 {4−16}之间可以比较好的平衡压缩效率与视觉感知效果。作者重点推荐了LDM-4 和 LDM-8。
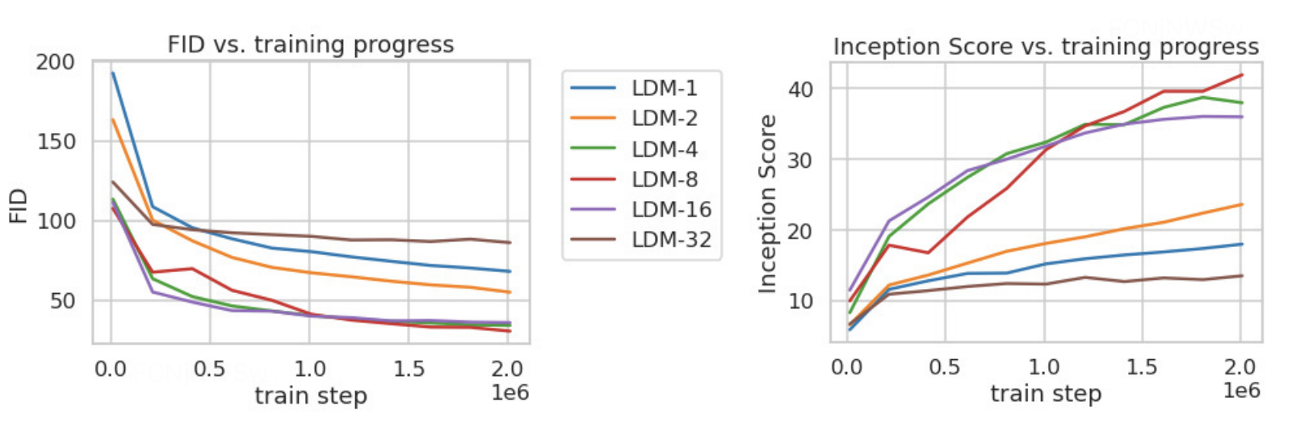

3.5 潜在扩散模型
扩散模型可以解释为一个时序去噪自编码器ϵ_θ (x_t,t),其目标是根据输入x_t和t,取预测噪声。相应的目标函数可以写成如下形式:

其中 t 从 {1,…,T} 中均匀采样获得。
而在潜在扩散模型中,引入了预训练的感知压缩模型,它包括一个编码器ε和一个解码器D。这样在训练时就可以利用编码器得到z_t,从而让模型在潜在表示空间中学习,相应的目标函数可以写成如下形式:
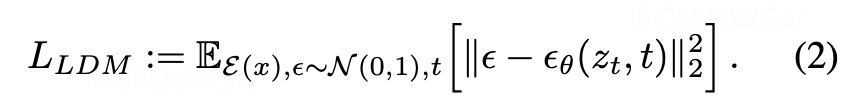
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。但是有一个重要的地方是论文为diffusion操作引入了Conditioning Mechanisms,通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
3.6 交叉注意力
本文在扩散过程中引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务得以实现。具体做法是通过训练一个条件时序去噪自编码器ϵ_θ (z_t,t,y),来通过 y来控制图片合成的过程。
为了能够从多个不同的模态预处理 y ,论文引入了一个领域专用编码器τ_θ,它用来将 y 映射为一个中间表示τ_θ (y) ,这样我们就可以很方便的引入各种形态的条件(文本、类别等等)。最终模型就可以通过一个cross-attention层映射将控制信息融入到UNet的中间层,cross-attention层的实现如下:

3.7 实现效果
无条件图像生成:
-
论文从FID和Precision-and-Recall两方面对比LDM的样本生成能力,实验数据集为CelebA-HQ、FFHQ和LSUN-Churches/Bedrooms;其效果超过了GANs和LSGM,并且超过同为扩散模型的DDPM。

有条件图像生成:
-
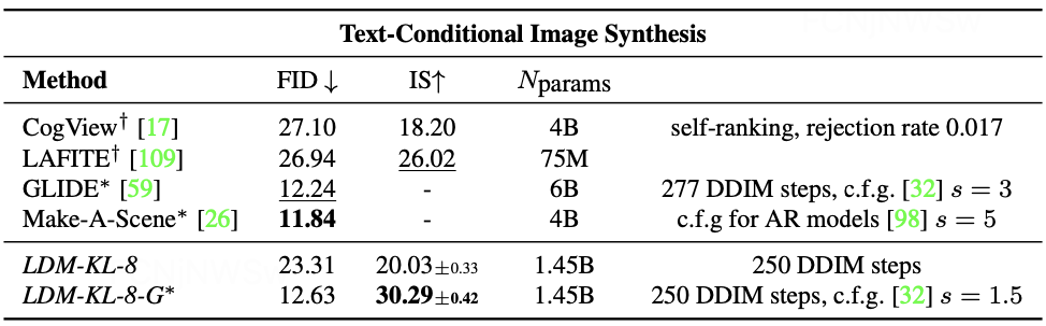
采用FID和IS作为衡量图像质量指标,LDM-KL-8-G*在FID和IS两项指标上均获得不错的结果;且在FID相同的情况下,网络参数量显著下降。
4、Stable Diffusion
4.1 概要
Stable diffusion是一种潜在的文本到图像的扩散模型。基于之前的大量工作(如DDPM、LDM的提出),并且在Stability AI的算力支持和LAION的海量数据支持下,Stable diffusion才得以成功。
Stable diffusion在来自LAION- 5B数据库子集的512x512图像上训练潜在扩散模型。与谷歌的Imagen类似,这个模型使用一个冻结的CLIP vitl /14文本编码器来根据文本提示调整模型。
Stable diffusion拥有860M的UNet和123M的文本编码器,该模型相对轻量级,可以运行在具有至少10GB VRAM的GPU上。
4.2 主要改进点
Stable diffusion是在LDM的基础上建立的,同时在LDM的基础上进行了一些改进:
-
数据集:在更大的数据集LAION- 5B上进行训练
-
条件机制:使用更强大的CLIP模型,代替原始的交叉注意力调节机制
除此之外,随着各种图形界面的出现、 微调方法的发布、控制模型的公开,SD进入全新架构SDXL时代,功能更加强大。
4.3 模型训练
SD的训练是采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs),单卡的训练batch size为2,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x2=2048。训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间约150,000小时(A100卡时),如果按照256卡A100来算的话,那么大约需要训练25天左右。
SD提供了不同版本的模型权重可供选择:
-
SD v1.1:在laion2B-en数据集上以256x256大小训练237,000步,上面我们已经说了,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512x512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024x1024以上,共170M样本。
-
SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512x512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512x512以下的样本。
-
SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512x512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
-
SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练225,000步数。
-
SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512x512尺寸训练595,000步数。
其实可以看到SD v1.3、SD v1.4和SD v1.5其实是以SD v1.2为起点在improved_aesthetics_5plus数据集上采用CFG训练过程中的不同checkpoints,目前最常用的版本是SD v1.4和SD v1.5。
4.4 条件控制
-
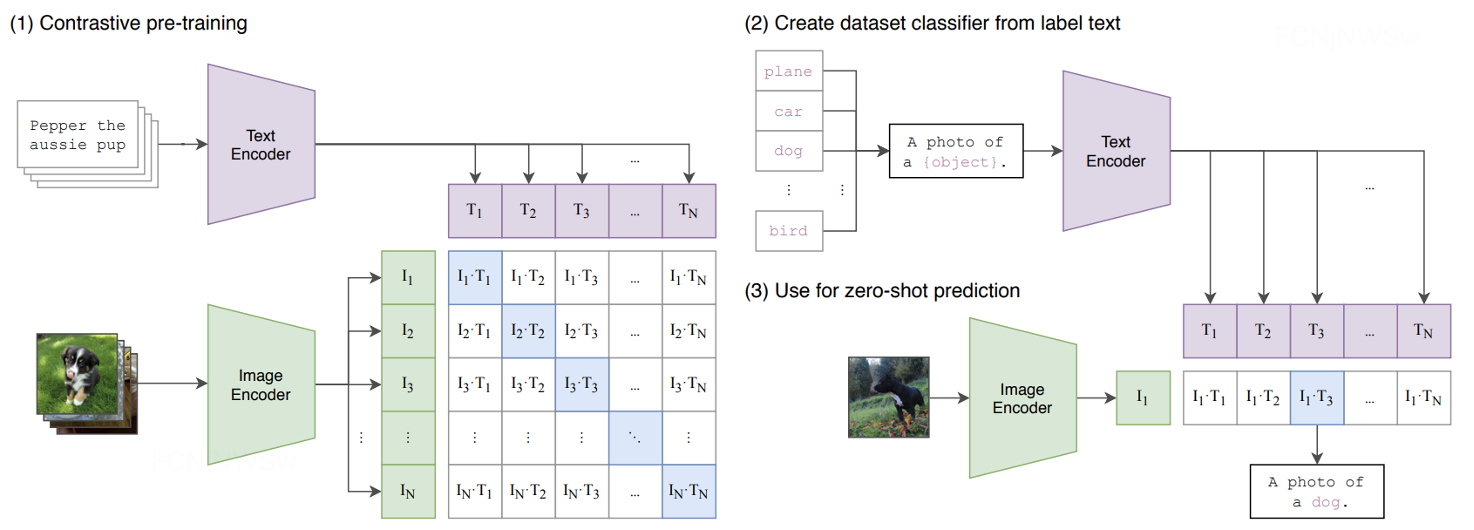
SD采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77x768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中。
-
值得注意的是,这里的tokenizer最大长度为77(CLIP训练时所采用的设置),当输入text的tokens数量超过77后,将进行截断,如果不足则进行paddings,这样将保证无论输入任何长度的文本(甚至是空文本)都得到77x768大小的特征。 在训练SD的过程中,CLIP text encoder模型是冻结的。在早期的工作中,比如OpenAI的GLIDE和latent diffusion中的LDM均采用一个随机初始化的tranformer模型来提取text的特征,但是最新的工作都是采用预训练好的text model。比如谷歌的Imagen采用纯文本模型T5 encoder来提出文本特征,而SD则采用CLIP text encoder,预训练好的模型往往已经在大规模数据集上进行了训练,它们要比直接采用一个从零训练好的模型要好。
-
下面是SD中使用的条件控制模型CLIP的结构示意图
4.5 与其他模型对比
DALL-E2 :出自OpenAI,其基本原理和SD一样,都是源于最初的扩散概率模型(DDPM),与之不同发是,SD继承了LDM的思想,在潜在空间中进行扩散学习;而DALL-E2是在像素空间中进行扩散学习,所以其计算复杂度较高。
Imagen:由谷歌发布,采用预训练好的文本编码器T5,通过扩散模型,实现文本到低分辨率图像的生成,最后将低分辨率图像进行两次超分,得到高分辨率图像。
5、Conference
- 【扩散模型之LDM】Latent Diffusion Models 论文解读_ldm的损失函数-CSDN博客
- 【扩撒模型之DDPM】Denoising Diffusion Probabilistic Models论文解读
- 最强文生图跨模态大模型:Stable Diffusion_文生图数据集形式-CSDN博客
-
Denoising Diffusion Probabilistic Models
-
High-Resolution Image Synthesis with Latent Diffusion Models
-
https://huggingface.co/CompVis/stable-diffusion
-
GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
-
GitHub - hojonathanho/diffusion: Denoising Diffusion Probabilistic Models
-
DDPM - 搜索结果 - 知乎
-
Latent Diffusion Model - 搜索结果 - 知乎
相关文章:
文生图大模型三部曲:DDPM、LDM、SD 详细讲解!
1、引言 跨模态大模型是指能够在不同感官模态(如视觉、语言、音频等)之间进行信息转换的大规模语言模型。当前图文跨模态大模型主要有: 文生图大模型:如 Stable Diffusion系列、DALL-E系列、Imagen等 图文匹配大模型:如CLIP、Chinese CLIP、…...
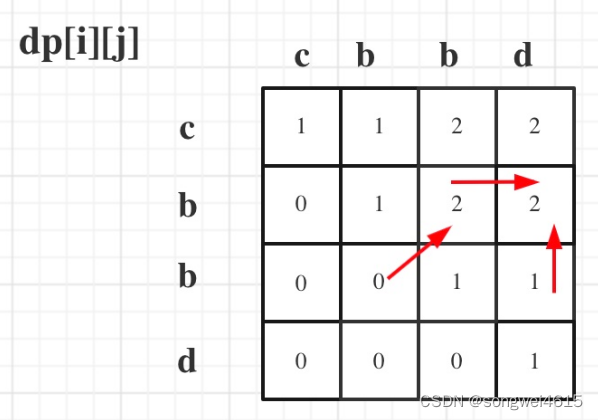
算法学习——LeetCode力扣动态规划篇10(583. 两个字符串的删除操作、72. 编辑距离、647. 回文子串、516. 最长回文子序列)
算法学习——LeetCode力扣动态规划篇10 583. 两个字符串的删除操作 583. 两个字符串的删除操作 - 力扣(LeetCode) 描述 给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个…...
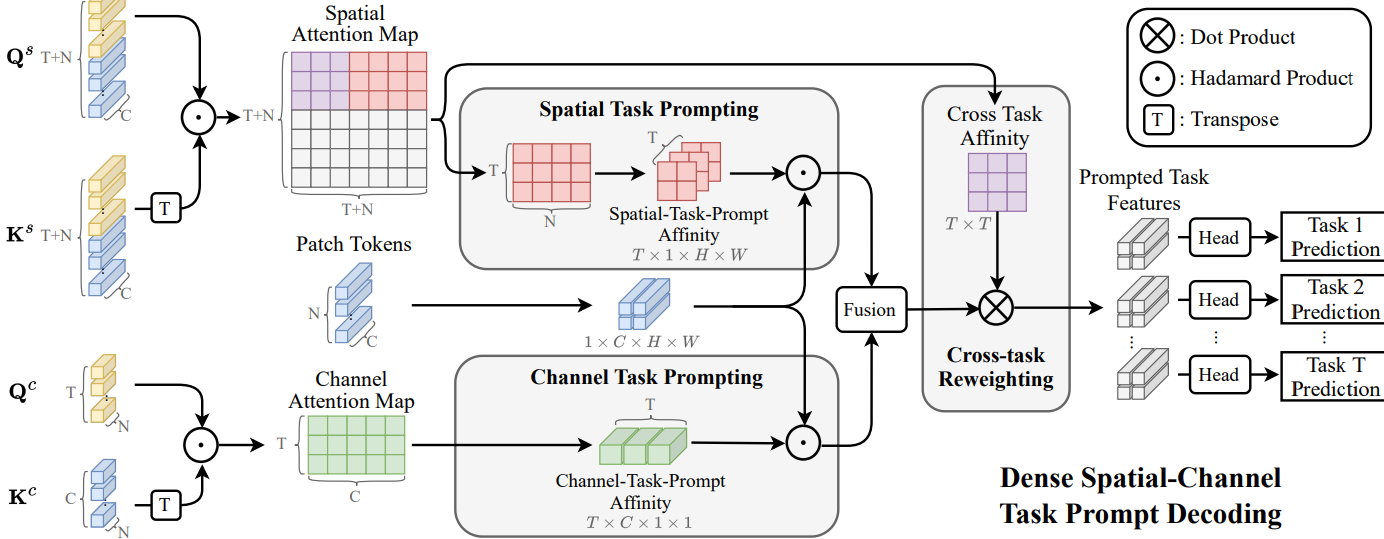
TASKPROMPTER
baseline模型的预训练权重就有1.6G! 多吓人呐,当时我就暂停下载了,不建议复现...

C之易错注意点转义字符,sizeof,scanf,printf
目录 前言 一:转义字符 1.转义字符顾名思义就是转换原来意思的字符 2.常见的转义字符 1.特殊\b 2. 特殊\ddd和\xdd 3.转义字符常错点----计算字符串长度 注意 : 如果出现\890,\921这些的不是属于\ddd类型的,,不是一个字符…...
)
等级保护测评无补偿因素的高风险安全问题判例(共23项需整改)
层面 控制点 要求项 安全问题 适用范围 充分条件 整改建议简要 安全物理环境 基础设施位置 应保证云计算基础设施位于中国境内 1.云计算基础设施物理位置不当 二级及以上 相关基础设施不在中国境内 云平台相关基础设施在中国境内部署 安全通信网络 网络架构 应…...

JavaScript笔记 09
目录 01 DOM操作事件的体验 02 获取元素对象的五种方式 03 事件中this指向问题 04循环绑定事件 05 DOM节点对象的常用操作 06 点亮盒子的案例 07 节点访问关系 08 设置和获取节点内容的属性 09 以上内容的小总结 01 DOM操作事件的体验 js本身是受事件驱动的脚本语言 什…...

操作教程|在MeterSphere中通过SSH登录服务器的两种方法
MeterSphere开源持续测试平台拥有非常强大的插件集成机制,用户可以通过插件实现平台能力的拓展,借助插件或脚本实现多种功能。在测试过程中,测试人员有时需要通过SSH协议登录至服务器,以获取某些配置文件和日志文件,或…...

Swashbuckle.AspNetCore介绍
使用 ASP.NET Core 构建的 API 的 Swagger 工具。直接从您的路由、控制器和模型生成精美的 API 文档,包括用于探索和测试操作的 UI。 除了 Swagger 2.0 和 OpenAPI 3.0 生成器外,Swashbuckle 还提供了由生成的 Swagger JSON 提供支持的令人敬畏的 swagg…...

【Spring】通过Spring收集自定义注解标识的方法
文章目录 前言1. 声明注解2. 使用 Spring 的工厂拓展3. 收集策略4. 完整的代码后记 前言 需求: 用key找到对应的方法实现。使用注解的形式增量开发。 MyComponent public class Sample1 {MyMethod(key "key1")public String test2() {return "She…...

基于深度学习的图书管理推荐系统(python版)
基于深度学习的图书管理推荐系统 1、效果图 1/1 [] - 0s 270ms/step [13 11 4 19 16 18 8 6 9 0] [0.1780757 0.17474999 0.17390694 0.17207369 0.17157653 0.168248440.1668652 0.16665359 0.16656876 0.16519257] keras_recommended_book_ids深度学习推荐列表 [9137…...

MATLAB 点云随机渲染赋色(51)
MATLAB 点云随机渲染赋色(51) 一、算法介绍二、算法实现1.代码2.效果总结一、算法介绍 为点云中的每个点随机赋予一种颜色,步骤和效果如图: 1、读取点云 (ply格式) 2、随机为每个点的RGB颜色字段赋值 3、保存结果 (ply格式) 二、算法实现 1.代码 代码如下(示例):…...

通过一篇文章让你完全掌握VS和电脑常用快捷键的使用方法
VS常用快捷键 前言一、 VS常用快捷键常用VS运行调试程序快捷键常用VS编辑程序快捷键 二、常用windows系统操作快捷键 前言 VS(Visual Studio)是一款强大的开发工具,提供了许多常用快捷键,以提高开发效率。这些快捷键包括文件操作…...

ChatGPT指引:借助ChatGPT撰写学术论文的技巧
ChatGPT无限次数:点击直达 ChatGPT指引:借助ChatGPT撰写学术论文的技巧 在当今信息技术高度发达的时代,人工智能技术的不断发展为学术研究者提供了更多的便利和可能。其中,自然语言处理技术中的ChatGPT无疑是一种强大的工具,它能…...
魔改一个过游戏保护的CE
csdn审核不通过 网易云课堂有配套的免费视频 int0x3 - 主页 文章都传到github了 Notes/外挂/魔改CE at master MrXiao7/Notes GitHub 为什么要编译自己的CE 在游戏逆向的过程中,很多游戏有保护,我们运行原版CE的时候会被检测到 比如我们开着CE运…...

rust嵌入式开发之await
嵌入式经常有类似通过串口发送指令然后等待响应再做出进一步反应的需求。比如,通过串口以AT命令来操作蓝牙模块执行扫描、连接,需要根据实际情况进行操作,复杂的可能需要执行7、8条指令才能完成连接。 对于这样的需求,如果用异步…...

UE4_碰撞_碰撞蓝图节点——Line Trace For Objects(对象的线条检测)
一、Line Trace For Objects(对象的线条检测):沿给定线条执行碰撞检测并返回遭遇的首个命中,这只会找到由Object types指定类型的对象。注意他与Line Trace By Channel(由通道检测线条)的区别,一个通过Obje…...
抽象类和接口的简单认识
目录 一、抽象类 1.什么是抽象类 2.抽象类的注意事项 3.抽象类与普通类的对比 二、接口 1.接口的简单使用 2.接口的特性 3.接口的使用案例 4.接口和抽象类的异同 一、抽象类 所谓抽象类,就是更加抽象的类,也就是说,这个类不能具体描…...
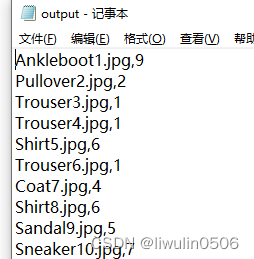
python-pytorch获取FashionMNIST实际图片标签数据集
在查看pytorch官方文档的时候,在这里链接中https://pytorch.org/tutorials/beginner/basics/data_tutorial.html的Creating a Custom Dataset for your files章节,有提到要自定义数据集,需要用到实际的图片和标签。 在网上找了半天没找到&a…...

深入探秘Python生成器:揭开神秘的面纱
一、问题起源: 想象一下,您掌握了一种魔法,在代码世界里,您可以轻松呼唤出一个整数。然而,事情并不总是看起来那样简单。在Python的奇妙王国中,我遇到了一个有趣的谜题: def tst():try:print(…...

红队攻防渗透技术实战流程:红队目标信息收集之批量信息收集
红队资产信息收集 1. 自动化信息收集1.1 自动化信息收集工具1.2 自动域名转换IP工具1.3 自动企业信息查询工具1.4 APP敏感信息扫描工具1.5 自动化信息工具的使用1.5.1 资产灯塔系统(ARL)1.5.1.1 docker环境安装1.2.2.9.1 水泽-信息收集自动化工具1. 自动化信息收集 1.1 自动化…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

2.Vue编写一个app
1.src中重要的组成 1.1main.ts // 引入createApp用于创建应用 import { createApp } from "vue"; // 引用App根组件 import App from ./App.vue;createApp(App).mount(#app)1.2 App.vue 其中要写三种标签 <template> <!--html--> </template>…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

LOOI机器人的技术实现解析:从手势识别到边缘检测
LOOI机器人作为一款创新的AI硬件产品,通过将智能手机转变为具有情感交互能力的桌面机器人,展示了前沿AI技术与传统硬件设计的完美结合。作为AI与玩具领域的专家,我将全面解析LOOI的技术实现架构,特别是其手势识别、物体识别和环境…...