Hive查询转换与Hadoop生态系统引擎与优势
目录
- 摘要
- 一、Hive是什么
- 二、HDFS是什么
- 三、Hive与HDFS的关系
- 四、什么是HiveQL
- 五、什么是mapreduce
- 六、Hive如何将查询转为mapreduce任务
- 七、Hadoop生态系统中的高性能引擎
- 八、使用Hadoop的优点
摘要
Hadoop生态系统中包含了多个关键组件,如Hive、HDFS、MapReduce等,它们相互配合实现了大规模数据的存储、查询和处理。Hive是建立在Hadoop之上的数据仓库工具,利用类SQL语言(HiveQL)对存储在HDFS中的数据进行查询和分析;而HDFS是Hadoop的分布式文件系统,提供高容错性的数据存储解决方案。Hive利用HDFS作为底层存储系统,通过HiveQL语言来查询和分析HDFS中的数据。Hive将查询转换为MapReduce任务的过程包括解析查询语句、优化执行计划、生成MapReduce任务、任务提交和执行以及结果输出和收集。此外,Hadoop生态系统中还有其他高性能引擎如Tez和Spark,它们能够进一步提高数据处理的效率和灵活性。使用Hadoop的优点包括能够处理大规模数据、具有高度容错性、成本效益高、灵活性强、可扩展性好以及能够实现并行处理等。
一、Hive是什么
Hive是一个建立在Hadoop之上的数据仓库工具,它提供了一种类似于SQL的查询语言(HiveQL),用于对存储在Hadoop集群中的数据进行查询和分析。Hive可以将结构化数据映射到Hadoop的分布式文件系统上,使得用户可以通过类似SQL的语法来查询和处理大数据。它通常用于数据仓库、数据分析和数据处理等场景。
二、HDFS是什么
HDFS(Hadoop Distributed File System)是Hadoop的核心组件之一,它是一个分布式文件系统,用于存储大规模数据,并提供高容错性、高可靠性的数据存储解决方案。HDFS将大文件分割成多个块(block),并将这些块分布存储在Hadoop集群的不同节点上,以实现数据的并行存储和处理。
三、Hive与HDFS的关系
Hive利用HDFS作为底层存储系统,将数据存储在HDFS的文件中。
Hive通过HiveQL语言来查询和分析HDFS中的数据,实现对大数据的处理和分析。
Hive的元数据(Metadata)通常存储在关系型数据库中(如MySQL),而HDFS则存储实际的数据文件。
四、什么是HiveQL
HiveQL(Hive Query Language)是Hive的查询语言,类似于SQL(Structured Query Language),用于在Hive中执行查询和分析操作。HiveQL使用户能够使用类似于SQL的语法来查询和操作存储在Hadoop分布式文件系统(HDFS)中的数据,而无需编写复杂的MapReduce程序。
HiveQL的特点包括:
类SQL语法:HiveQL的语法与SQL非常相似,这使得熟悉SQL的用户可以很快上手使用Hive进行数据查询和分析。支持复杂查询:HiveQL支持常见的SQL操作,如SELECT、JOIN、GROUP BY、ORDER BY等,同时还支持用户自定义函数(UDF)和用户自定义聚合函数(UDAF),使得用户可以执行复杂的查询和数据处理任务。转换为MapReduce任务:当用户提交HiveQL查询时,Hive会将查询转换为MapReduce任务在Hadoop集群上执行,从而实现对大规模数据集的并行处理。
五、什么是mapreduce
MapReduce任务是一种用于并行处理大规模数据的编程模型和计算框架,最初由Google提出,并在Apache Hadoop中得到实现和推广。MapReduce任务通常包括两个主要阶段:Map阶段和Reduce阶段。
Map阶段:
在Map阶段中,输入数据集被切分成若干个独立的数据块,并由多个Mapper任务并行处理。每个Mapper任务负责将输入数据块中的每条记录(键值对)映射为零个或多个中间键值对。Map函数是用户自定义的,它可以对输入数据进行过滤、提取、转换等操作,并生成中间键值对。Shuffle阶段:
在Map阶段结束后,所有Mapper任务的输出会被分区、排序和传输到Reducer任务所在的节点。这个过程称为Shuffle阶段。Shuffle阶段的主要任务是将Map任务的输出按照键进行排序,并将具有相同键的记录(键值对)分组到同一个Reducer任务中去。Reduce阶段:
在Reduce阶段中,每个Reducer任务会接收到一个或多个Mapper任务的输出,并对它们进行合并和处理。Reducer任务会依次处理每个中间键对应的值列表,并将它们按照用户定义的逻辑进行聚合、计算或其他处理,生成最终的输出结果。
MapReduce任务的特点包括:
分布式处理:MapReduce任务能够在大规模的计算集群上并行处理数据,充分利用集群中的计算资源,加速数据处理过程。
容错性:MapReduce任务具有高度的容错性,能够在节点故障或任务失败的情况下自动进行任务重启和数据恢复,保证任务的可靠执行。
适用性广泛:MapReduce任务适用于各种类型的数据处理和分析任务,包括数据清洗、日志分析、文本处理、机器学习等领域。
六、Hive如何将查询转为mapreduce任务
Hive将查询转换为MapReduce任务的过程主要包括以下几个步骤:
解析查询语句:首先,Hive会解析用户提交的HiveQL查询语句,包括语法解析和语义解析,确定查询的逻辑执行计划。优化执行计划:Hive会对查询的逻辑执行计划进行优化,包括选择合适的物理执行计划、确定数据读取的方式、计算数据的分区和排序等。生成MapReduce任务:根据优化后的执行计划,Hive将查询转换为一系列的MapReduce任务。通常情况下,每个MapReduce任务对应查询中的一个阶段或操作,例如Map任务用于数据的扫描、过滤和转换,Reduce任务用于数据的聚合和计算。任务提交和执行:生成的MapReduce任务会被提交到Hadoop集群上的资源管理器(如YARN)进行调度和执行。在集群中,MapReduce任务将会并行处理HDFS中的数据,根据任务之间的依赖关系和数据流,逐步完成查询的各个阶段。结果输出和收集:一旦所有的MapReduce任务执行完成,Hive将会收集和合并各个任务的输出结果,并将最终的查询结果返回给用户或写入到目标存储中,如HDFS或数据库表。
以下是一个简单的示例,展示如何将一个Hive查询转换为MapReduce任务:
假设有一个Hive表 student_scores,包含学生的成绩信息,表结构如下:
CREATE TABLE student_scores (student_id INT,subject STRING,score INT
) STORED AS ORC;
现在要查询每个学生的平均成绩,并按照学生ID升序排列。查询语句如下:
SELECT student_id, AVG(score) AS avg_score
FROM student_scores
GROUP BY student_id
ORDER BY student_id;
这个查询会被转换为以下的MapReduce任务过程:
首先,Hive会将查询解析为逻辑执行计划,确定要执行的操作是分组聚合(GROUP BY)和排序(ORDER BY)操作。接着,Hive会将逻辑执行计划优化为物理执行计划,确定使用MapReduce任务来执行这些操作。Hive会生成两个MapReduce任务:Map任务:读取表数据,对每条记录进行映射,将学生ID作为键,成绩作为值。Reduce任务:对Map任务输出的键值对按照学生ID进行分组,并计算每个学生的平均成绩。生成的MapReduce任务会被提交到Hadoop集群中的资源管理器进行调度和执行。Map任务会并行处理表数据的各个分片,Reduce任务会处理各个Map任务输出的中间结果,最终得到每个学生的平均成绩。最后,MapReduce任务执行完成后,Hive会收集并合并Reduce任务的输出结果,并按照学生ID排序后返回给用户或写入到目标存储中。
七、Hadoop生态系统中的高性能引擎
Tez:Tez是一个基于Hadoop YARN的执行引擎,它可以更高效地执行复杂的数据处理工作流。与传统的MapReduce相比,Tez能够更好地处理数据流,并通过优化任务的执行顺序和资源利用率来提高性能。Tez通常与Hive等框架一起使用,作为执行引擎之一。在一些较新的Hive版本中,Tez可能已经作为默认的执行引擎。Spark:Spark是一个通用的集群计算框架,它提供了丰富的API,可以用于处理各种类型的数据处理任务,包括批处理、实时流处理、机器学习等。Spark通常与Hadoop一起使用,可以直接在Hadoop集群上运行,并利用Hadoop的存储系统(如HDFS)来存储数据。
八、使用Hadoop的优点
处理大规模数据:Hadoop是一个分布式计算框架,能够有效地处理大规模数据集。它能够轻松地处理成千上万台服务器上的数据,并将计算任务分发到各个节点上并行处理。容错性:Hadoop具有高度的容错性,能够在节点故障时自动恢复。它通过在集群中复制数据来实现容错性,并且能够在计算任务失败时重新启动任务。成本效益:Hadoop是开源软件,可以在普通的硬件上运行,并且具有很强的横向扩展性。这意味着你可以使用廉价的硬件构建一个强大的数据处理平台,从而降低了数据处理的成本。灵活性:Hadoop生态系统包含了许多不同的工具和项目,可以满足各种不同的数据处理需求。无论是批处理、实时处理、数据挖掘还是机器学习,Hadoop都有相应的工具和框架来支持。可扩展性:Hadoop的分布式架构使得它能够轻松地扩展到成百上千台服务器,并处理PB级别甚至EB级别的数据。通过增加节点,你可以很容易地扩展Hadoop集群的处理能力。并行处理:Hadoop采用分布式并行处理的方式,能够高效地处理大规模数据集。它将数据分割成小块,并将计算任务分发到集群中的多个节点上并行执行,从而加速数据处理过程。
相关文章:

Hive查询转换与Hadoop生态系统引擎与优势
目录 摘要一、Hive是什么二、HDFS是什么三、Hive与HDFS的关系四、什么是HiveQL五、什么是mapreduce六、Hive如何将查询转为mapreduce任务七、Hadoop生态系统中的高性能引擎八、使用Hadoop的优点 摘要 Hadoop生态系统中包含了多个关键组件,如Hive、HDFS、MapReduce等…...
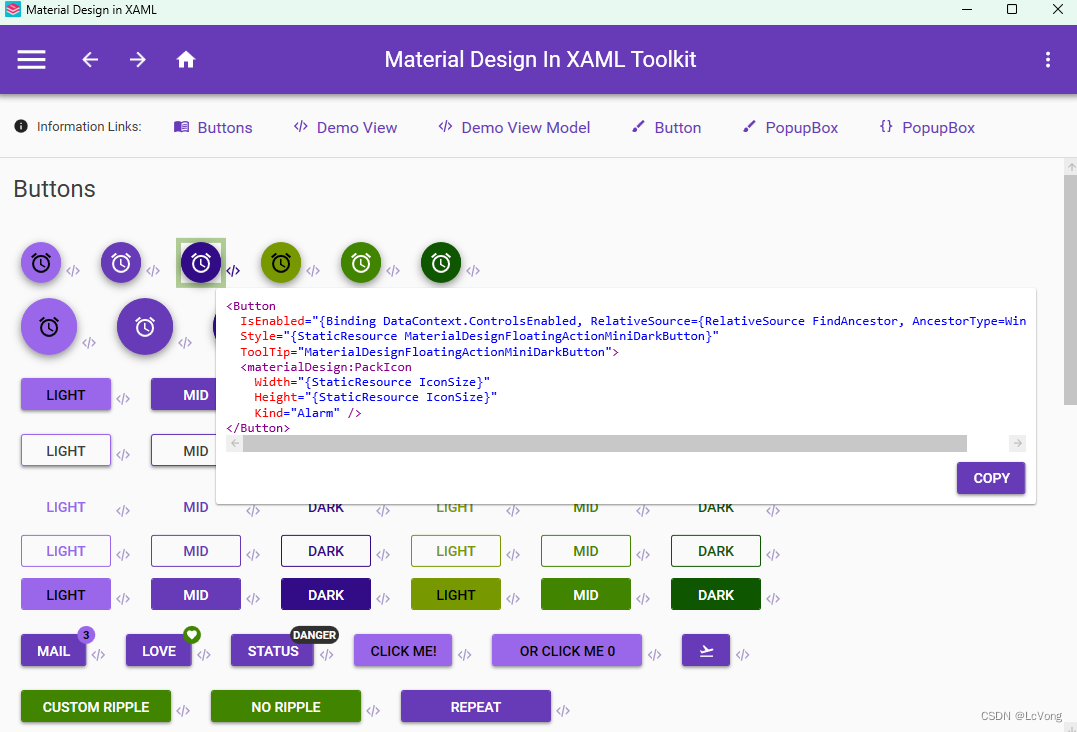
WPF上使用MaterialDesign框架---下载与配置
一、介绍: Material Design语言的一些重要功能包括 系统字体Roboto的升级版本 ,同时颜色更鲜艳,动画效果更突出。杜拉特还简要谈到了新框架的一些变化。谷歌的想法是让谷歌平台上的开发者掌握这个新框架,从而让所有应用就有统一的…...

鸿蒙ARKTS--简易的购物网站
目录 一、media 二、string.json文件 三、pages 3.1 登录页面:gouwuPage.ets 3.2 PageResource.ets 3.3 商品页面:shangpinPage.ets 3.4 我的页面:wodePage.ets 3.5 注册页面:zhucePage.ets 3. 购物网站主页面ÿ…...
LabVIEW转动设备故障诊断系统
LabVIEW转动设备故障诊断系统 随着工业自动化技术的不断进步,转动设备在电力、化工、船舶等多个行业中扮演着越来越重要的角色。然而,这些设备在长期运行过程中难免会出现故障,如果不能及时诊断和处理,将会导致生产效率下降&…...
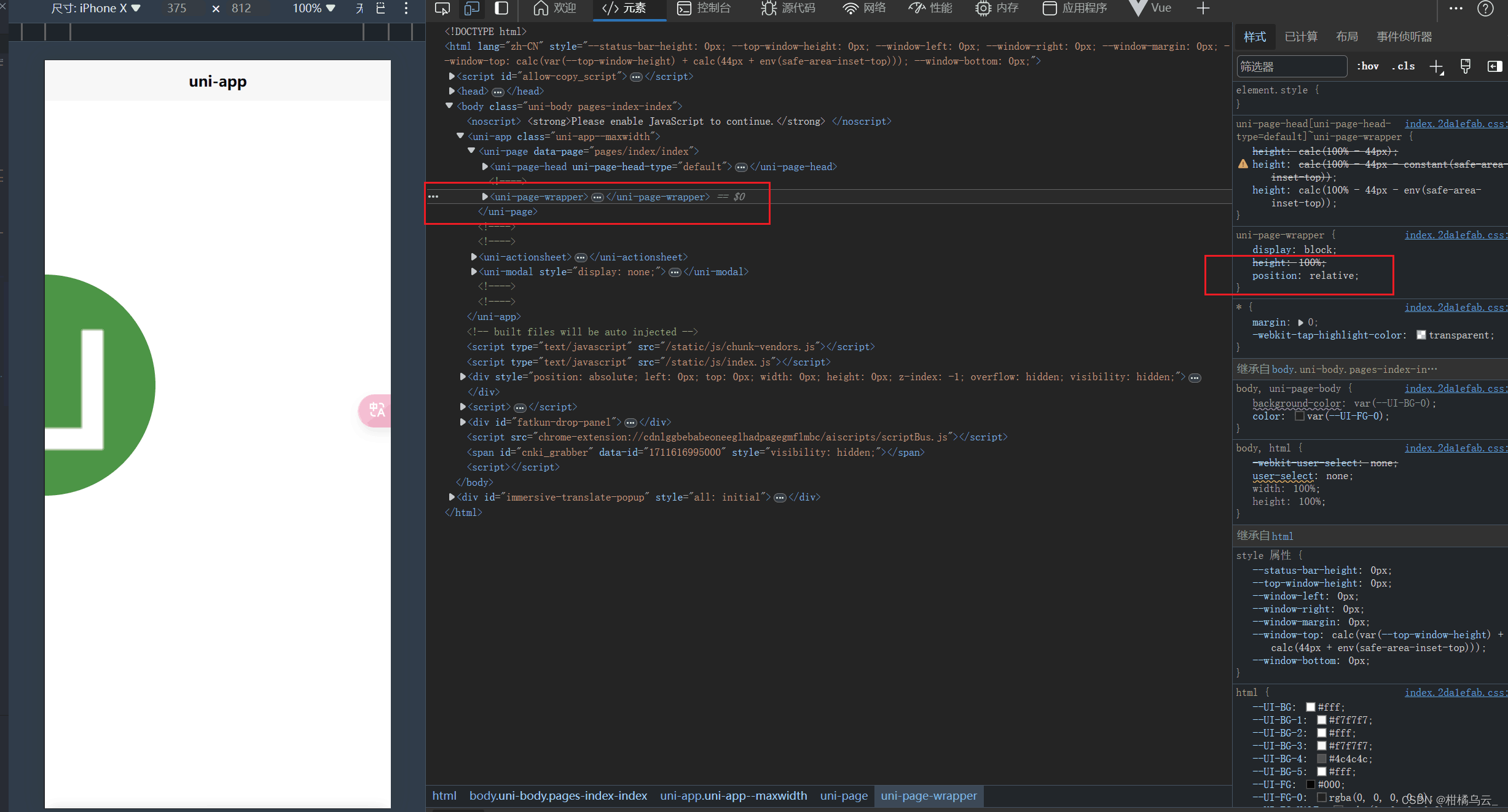
uniapp h5 touch事件踩坑记录
场景:悬浮球功能 当我给悬浮球设置了 position: fixed; 然后监听悬浮球的touch事件,从事件对象中拿到clientY和clientX赋值给悬浮球的left和top属性。当直接赋值后效果应该是这样子: 注意鼠标相对悬浮球的位置,应该就是左上角&a…...
)
webpack.prod.js(webpack生产环境配置文件)
生产环境:只打包不运行本地服务器 对于在config目录下的webpack.prod.js 1.在根目录下运行 npx webpack --config ./config/webpack.prod.js 2.在package.json文件中配置 "build":"npx webpack --config ./config/webpack.prod.js" const …...
,连接数据库和服务器接口,涉及雪花id服务)
利用python做模拟数据(测试数据),连接数据库和服务器接口,涉及雪花id服务
import datetime import jsonimport pymysql import requests import snowflake.client from faker import Faker#cmd启动snowflake服务: #snowflake_start_server --addresslocalhost --port8910 --dc1 --worker1 def create_testers():# 创建一个中文Faker实例fak…...

大模型日报2024-03-30
大模型资讯 提升大型语言模型推理速度:高效部署技术 摘要: 随着GPT-4、LLaMA和PaLM等大型语言模型(LLMs)不断拓展自然语言处理的边界,研究人员正在探索加速这些模型推理过程的技术。这些技术旨在提高模型部署的效率,以…...

【ARM 嵌入式 C 入门及渐进 14 -- C 代码中取余与取模的使用介绍】
请阅读【嵌入式开发学习必备专栏 】 文章目录 背景示例 背景 有些文件每行是固定的字符个数,那么如果任意给个字符的序号,怎么通过C 代码获取该字符所在的行呢? 处理这个问题就要用到 C 语言中的取余和取模运算了。 示例 在 C 语言中&…...
C++入门知识详细讲解
C入门知识详细讲解 1. C简介1.1 什么是C1.2 C的发展史1.3. C的重要性1.3.1 语言的使用广泛度1.3.2 在工作领域 2. C基本语法知识2.1. C关键字(C98)2.2. 命名空间2.2 命名空间使用2.2 命名空间使用 2.3. C输入&输出2.4. 缺省参数2.4.1 缺省参数概念2.4.2 缺省参数分类 2.5. …...
:以vggish为例)
pytorch中的torch.hub.load():以vggish为例
pytorch提供了torch.hub.load()函数加载模型,该方法可以从网上直接下载模型或是从本地加载模型。官方文档 torch.hub.load(repo_or_dir, model, *args, sourcegithub, trust_repoNone, force_reloadFalse, verboseTrue, skip_validationFalse, **kwargs)参数说明&a…...
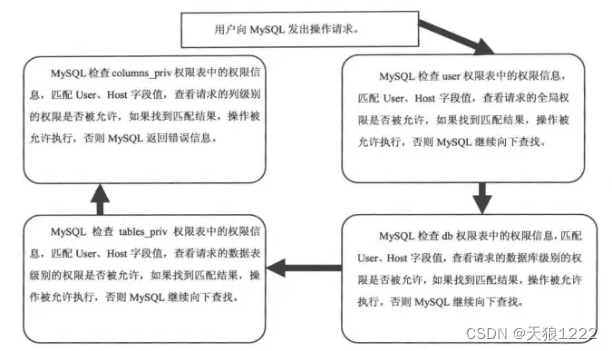
mysql 用户管理-权限管理
学习了用户管理,再学习下权限管理。 3,权限管理 权限管理主要是对登录到MySQL的用户进行权限验证。所有用户的权限都存储在MySQL的权限表中,不合理的权限规划会给MySQL服务器带来安全隐患。数据库管理员要对所有用户的权限进行合理规…...
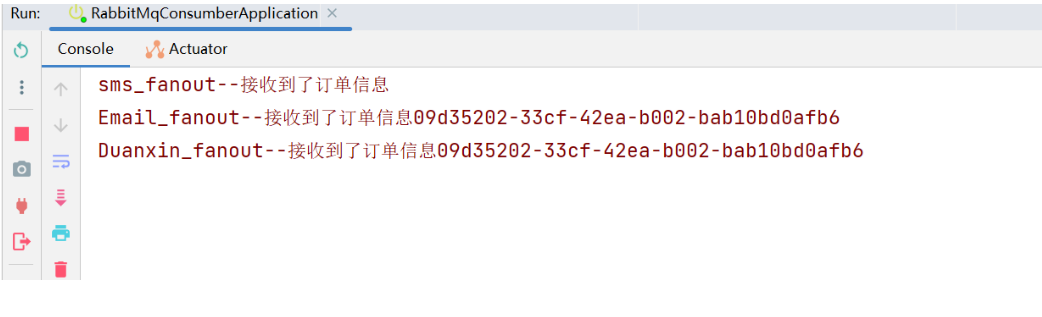
RabbitMQ--04--发布订阅模式 (fanout)-案例
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 发布订阅模式 (fanout)---案例前言RabbitListener和RabbitHandler的使用 1.通过Spring官网快速创建一个RabbitMQ的生产者项目2.导入项目后在application.yml文件中配…...
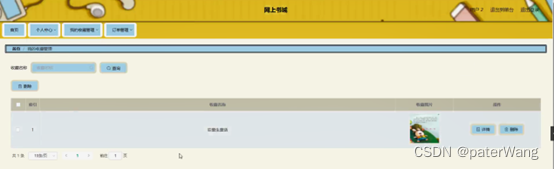
基于java+SpringBoot+Vue的网上书城管理系统设计与实现
基于javaSpringBootVue的网上书城管理系统设计与实现 开发语言: Java 数据库: MySQL技术: SpringBoot MyBatis工具: IDEA/Eclipse、Navicat、Maven 系统展示 前台展示 后台展示 系统简介 整体功能包含: 网上书城管理系统是一个基于互联网的在线购书平台&#…...
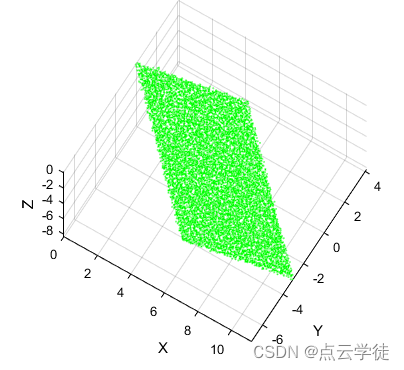
PCL点云处理之M估计样本一致性(MSAC)平面拟合(二百三十六)
PCL点云处理之M估计样本一致性(MSAC)平面拟合(二百三十五六) 一、算法介绍二、使用步骤1.代码2.效果一、算法介绍 写论文当然用RANSAC的优化变种算法MSAC啊,RANSAC太土太LOW了哈哈 MSAC算法(M-estimator Sample Consensus)是RANSAC(Random Sample Consensus)的一种…...

通过WSL在阿里云上部署Vue项目
参考: 阿里云上搭建网站-CSDN博客 云服务器重装 关闭当前运行实例 更换操作系统,还有其他的进入方式。 选择ubuntu系统(和WSL使用相同的系统)。 设置用户和密码。发送短信验证码。 新系统更新。秒速干净的新系统设置完成。 这…...
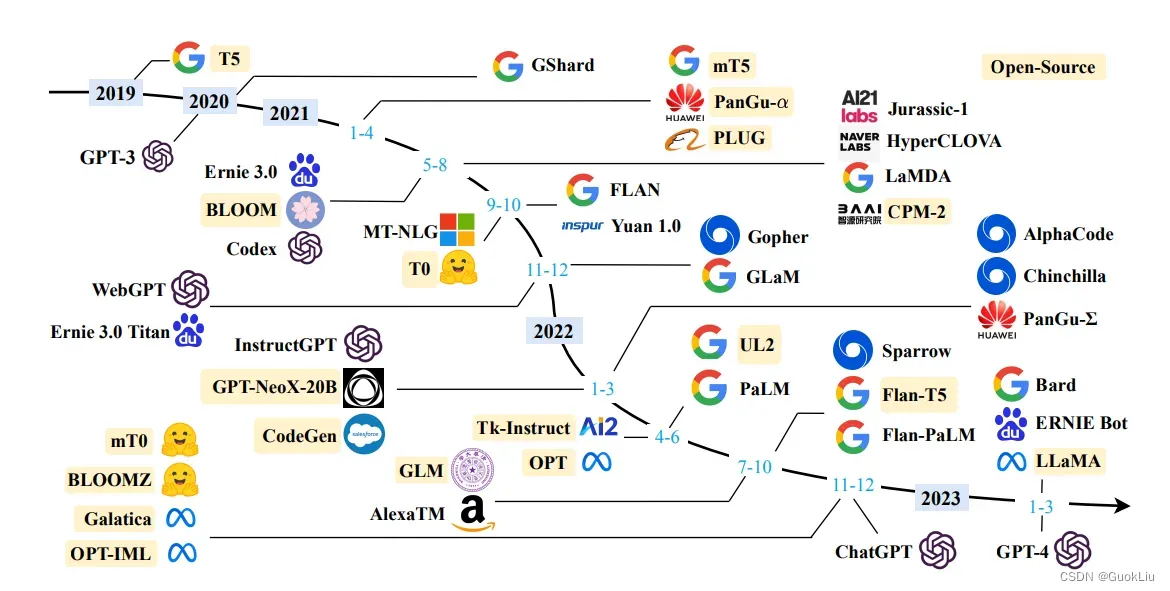
240330-大模型资源-使用教程-部署方式-部分笔记
A. 大模型资源 Models - Hugging FaceHF-Mirror - Huggingface 镜像站模型库首页 魔搭社区 B. 使用教程 HuggingFace HuggingFace 10分钟快速入门(一),利用Transformers,Pipeline探索AI。_哔哩哔哩_bilibiliHuggingFace快速入…...

uni-app 富文本编辑器
<template><view class"container"><view>标题:<u-input placeholder"请输入标题"></u-input></view><view class"page-body"><view classwrapper><view classtoolbar tap"…...

3D汽车模型线上三维互动展示提供视觉盛宴
VR全景虚拟看车软件正在引领汽车展览行业迈向一个全新的时代,它不仅颠覆了传统展览的局限,还为参展者提供了前所未有的高效、便捷和互动体验。借助于尖端的vr虚拟现实技术、逼真的web3d开发、先进的云计算能力以及强大的大数据处理,这一在线展…...

如何在Flutter中进行网络请求?
Hello!大家好,我是咕噜铁蛋,你们的好朋友!今天,我想和大家分享一下在Flutter中如何进行网络请求。Flutter作为一个跨平台的开发框架,网络请求是其实现数据交互的重要一环。下面,我将详细介绍几种…...

Sketch Measure: 设计标注自动化的创新实践
Sketch Measure: 设计标注自动化的创新实践 【免费下载链接】sketch-measure Make it a fun to create spec for developers and teammates 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-measure 在数字化产品开发流程中,设计稿到代码实现的转化始终…...

NSSCTF做题记录九 | [HUBUCTF 2022 新生赛]checkin
[HUBUCTF 2022 新生赛]checkin <?php show_source(__FILE__); //高亮显示当前代码 $username "this_is_secret"; //给$username赋值 $password "this_is_not_known_to_you"; //给$password赋值 include("flag.php");//here I chan…...

一站式屏幕神器eSearch:如何5分钟打造你的智能工作流?
一站式屏幕神器eSearch:如何5分钟打造你的智能工作流? 【免费下载链接】eSearch 截屏 离线OCR 搜索翻译 以图搜图 贴图 录屏 万向滚动截屏 屏幕翻译 Screenshot Offline OCR Search Translate Search for picture Paste the picture on the screen Scree…...

YOLOv8与SenseVoice-Small的多模态安防监控系统设计
YOLOv8与SenseVoice-Small的多模态安防监控系统设计 1. 系统设计背景与价值 在现代安防监控领域,单纯依靠视频分析已经无法满足复杂场景下的安全需求。传统的监控系统往往需要人工实时监控,不仅效率低下,而且容易遗漏关键信息。特别是在夜间…...

mitmproxy实战:从环境搭建到HTTPS抓包全攻略
1. 认识mitmproxy:你的网络调试瑞士军刀 第一次听说mitmproxy时,你可能觉得这是个复杂的安全工具。但实际用过后就会发现,它就像网络调试领域的瑞士军刀,能解决各种数据抓包难题。简单来说,mitmproxy是个开源的交互式中…...

Wan2.2-I2V-A14B镜像免配置:SSH直连后cd /workspace即可执行全部命令
Wan2.2-I2V-A14B镜像免配置:SSH直连后cd /workspace即可执行全部命令 1. 镜像概述与核心优势 Wan2.2-I2V-A14B私有部署镜像是一款专为文生视频模型定制的开箱即用解决方案。这个镜像最大的特点就是"免配置"——通过SSH连接后,只需进入/works…...

基于cv_unet_image-colorization的Python爬虫实战:自动化图像数据集着色
基于cv_unet_image-colorization的Python爬虫实战:自动化图像数据集着色 为计算机视觉项目快速构建高质量的彩色图像数据集 在计算机视觉项目中,获取高质量的标注数据集往往是最耗时耗力的环节。特别是当我们需要大量彩色图像数据时,手动收集…...

Guohua Diffusion 创意编程:用Processing可视化交互控制图像生成
Guohua Diffusion 创意编程:用Processing可视化交互控制图像生成 你有没有想过,自己随手画的一条线、选择的一个颜色,能立刻变成一幅由AI生成的完整画作?这听起来像是科幻电影里的场景,但现在,通过一点创意…...

Kafka消费者组避坑指南:从位移提交到重平衡的实战经验
Kafka消费者组实战避坑指南:从位移管理到重平衡优化 在分布式消息系统中,Kafka消费者组的稳定性直接决定了数据处理的可靠性。我曾亲眼见证过一个电商大促场景下,由于消费者组配置不当导致百万级订单积压的故障。本文将分享七个关键场景的深度…...

YOLO12入门必看:从上传图片到JSON结果输出完整操作流程
YOLO12入门必看:从上传图片到JSON结果输出完整操作流程 1. 引言:为什么你需要了解YOLO12? 如果你正在寻找一个既快又准的目标检测工具,那么YOLO12的出现,可能就是你一直在等的那个答案。 想象一下这样的场景&#x…...