flask-(数据连接池的使用,定制命令,信号的使用,表关系的建立和查询)
文章目录
- 连接池
- 实例
- flask定制命令
- flask 缓存的使用
- flask信号的使用
- sqlalchemy原生操作
- sqlalchemy操作表
- flask orm操作表
- 一对多的增加和跨表查询 (一对一只需要关联字段加上 ,unique=True)
- 多对多关系的增加和查询
- 多对多基本的增删改查
连接池
import pymysqlfrom dbutils.pooled_db import PooledDBPOOL = PooledDB(creator=pymysql, # 使用链接数据库的模块maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建maxcached=5, # 链接池中最多闲置的链接,0和None不限制maxshared=3, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制setsession=[], # 开始会话前执行的命令列表。ping=0,# ping MySQL服务端,检查是否服务可用。host='127.0.0.1',port=3306,user='root',password='123',database='luffy',charset='utf8')-第二步:使用from sql_pool import POOL # 做成单例conn = POOL.connection() # 从连接池种取一个链接(如果没有,阻塞在这)curser = conn.cursor()curser.execute('select * from luffy_order where id<2')res=curser.fetchall()print(res)
实例
from flask import Flask
app = Flask(__name__)@app.route('/')
def hello_world(): # put application's code hereconn = POOL.connection() # 从连接池种取一个链接(如果没有,阻塞在这)curser = conn.cursor()curser.execute('select * from luffy_course where id<2')res = curser.fetchall()return '数据查到了 %s' % resif __name__ == '__main__':app.run()
flask定制命令
使用 flask-script定制命令(老版本,不用了)
# flask 老版本中,没有命令运行项目,自定制命令
# flask-script 解决了这个问题:flask项目可以通过命令运行,可以定制命令
# 新版的flask--》官方支持定制命令 click 定制命令,这个模块就弃用了
# flask-migrate 老版本基于flask-script,新版本基于flask-click写的### 使用步骤-1 pip3 install Flask-Script==2.0.3-2 pip3 install flask==1.1.4-3 pip3 install markupsafe=1.1.1-4 使用from flask_script import Managermanager = Manager(app)if __name__ == '__main__':manager.run()-5 自定制命令@manager.commanddef custom(arg):"""自定义命令python manage.py custom 123"""print(arg)- 6 执行自定制命令python manage.py custom 123新版本定制命令
from flask import Flask
import click
app = Flask(__name__)@app.cli.command("create-user")
@click.argument("name")
def create_user(args):# from pool import POOL# conn=POOL.connection()# cursor=conn.cursor()# cursor.excute('insert into user (username,password) values (%s,%s)',args=[name,'123456'])# conn.commit()print(name)@app.route('/')
def index():return 'index'if __name__ == '__main__':app.run()# 运行项目的命令是:flask --app py文件名字:app run
# 命令行中执行
# flask --app 7-flask命令:app create-user lqz
# 简写成 前提条件是 app所在的py文件名字叫 app.py
# flask create-user lqz# django定制命令
# 1 app下新建文件夹management/commands/
# 2 在该文件夹下新建py文件,随便命名(命令名)# 3 在py文件中写代码
from django.core.management.base import BaseCommand
class Command(BaseCommand):help = '命令提示'def handle(self, *args, **kwargs):命令逻辑
# 4 使用命令
python manage.py py文件(命令名)
flask 缓存的使用
from flask import Flask
from flask_caching import Cacheconfig = {"DEBUG": True, # some Flask specific configs"CACHE_TYPE": "SimpleCache", # Flask-Caching related configs"CACHE_DEFAULT_TIMEOUT": 300
}app = Flask(__name__)
# tell Flask to use the above defined config
app.config.from_mapping(config)
cache = Cache(app)@app.route('/')
def index():cache.set('name', 'xxx')return 'index'@app.route('/get')
def get():res=cache.get('name')return resif __name__ == '__main__':app.run()
flask信号的使用
# 内置信号--》flask请求过程中--》源码中定义的---》不需要我们定义和触发---》只要写了函数跟它对应--》执行到这,就会触发函数执行
# Flask框架中的信号基于blinker,其主要就是让开发者可是在flask请求过程中定制一些用户行为request_started = _signals.signal('request-started') # 请求到来前执行
request_finished = _signals.signal('request-finished') # 请求结束后执行before_render_template = _signals.signal('before-render-template') # 模板渲染前执行
template_rendered = _signals.signal('template-rendered') # 模板渲染后执行got_request_exception = _signals.signal('got-request-exception') # 请求执行出现异常时执行request_tearing_down = _signals.signal('request-tearing-down') # 请求执行完毕后自动执行(无论成功与否)
appcontext_tearing_down = _signals.signal('appcontext-tearing-down')# 应用上下文执行完毕后自动执行(无论成功与否)appcontext_pushed = _signals.signal('appcontext-pushed') # 应用上下文push时执行
appcontext_popped = _signals.signal('appcontext-popped') # 应用上下文pop时执行
message_flashed = _signals.signal('message-flashed') # 调用flask在其中添加数据时,自动触发# 内置信号的使用
# 案例 :
### 我们现在想在模板渲染之 : 记录日志 使用内置信号实现# 1 写一个函数
def before_render(*args, **kwargs):print(args)print(kwargs)# 谁(ip) 在什么时间 访问了哪个页面(template)print('记录日志,模板要渲染了')# 2 跟内置信号绑定
from flask.signals import before_render_template
before_render_template.connect(before_render) # 信号触发的函数# 3 源码中触发信号执行(我们不需要动)
# before_render_template.send() 源码再模板渲染之前,它写死了@app.route('/')
def index():return render_template('index.html')@app.route('/login')
def login():return render_template('login.html')if __name__ == '__main__':app.run()# 自定义信号
from flask import Flask, render_template
from flask.signals import _signals
import pymysqlapp = Flask(__name__)
app.debug = True# 1 定义信号
# 自定义信号
db_save = _signals.signal('db_save')# 2 写一个函数
def db_save_fun(*args, **kwargs):print(args)print(kwargs)print('表数据插入了')# 3 跟自定义置信号绑定
db_save.connect(db_save_fun)# 3 触发信号执行(需要我们做)
# before_render_template.send() 源码再模板渲染之前,它写死了@app.route('/')
def index():return render_template('index.html')@app.route('/create_article')
def create_article():conn = pymysql.connect(host='127.0.0.1', user='root', password='1234', database='cnblogs')cursor = conn.cursor()cursor.execute('insert into article (title,author) VALUES (%s,%s)', args=['测试测试标题', '测试作者测试'])conn.commit()# 手动触发信号db_save.send(table_name='article',info={'title':'测试测试标题','author':'测试作者测试'})return '插入成功'if __name__ == '__main__':app.run()# 步骤:
# 1 定义信号
db_save = _signals.signal('db_save')
# 2 写一个函数
def db_save_fun(*args, **kwargs):print(args)print(kwargs)print('表数据插入了')# 3 跟自定义置信号绑定
db_save.connect(db_save_fun)# 3 触发信号执行(需要我们做)
db_save.send() # 需要在代码中写,可以传参数,传入的参数--》db_save_fun 能拿到
sqlalchemy原生操作
# 操作原生sql ---》用得少
import pymysql
import threading
# 1 导入
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine
# 2 创建引擎
engine = create_engine("mysql+pymysql://root:1234@127.0.0.1:3306/cnblogs", max_overflow=0, # 超过连接池大小外最多创建的连接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)# 3 使用引擎,拿到链接
# conn = engine.raw_connection()
# # 4 剩下的一样了
# cursor=conn.cursor(pymysql.cursors.DictCursor)
# cursor.execute('select * from article limit 10')
# res=cursor.fetchall()
# print(res)## 多线程测试:
def task(arg):conn = engine.raw_connection()cursor = conn.cursor()cursor.execute("select * from article")result = cursor.fetchall()print(result)cursor.close()conn.close()for i in range(20):t = threading.Thread(target=task, args=(i,))t.start()
sqlalchemy操作表
# 1 建个 models.py 里面写 表模型
# 2 把表模型---》同步到数据库中
# 3 增删查改
# 1 导入
import datetime # 时间模块
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, IndexBase = declarative_base() # Base 当成 django的 models.Model# 2 创建表模型
class User(Base): # 模型层的名字__tablename__ = 'users' # 数据库表的名字id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(32), index=True, nullable=True)email = Column(String(32), unique=True)# datetime.datetime.now不能加括号,加了括号,以后永远是当前时间ctime = Column(DateTime, default=datetime.datetime.now)extra = Column(Text)# 3 没有迁移命令---》后期使用第三方模块,可以有命令
# 目前需要手动做
# sqlalchemy 不能创建数据库,能创建表,删除表,不能删除增加字段(第三方模块)
# 3.1 创建引擎
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/sqlalchemy01",max_overflow=0, # 超过连接池大小外最多创建的连接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
## 3.2 把表模型同步到数据库中
Base.metadata.create_all(engine) # 3.3 同步和删除表只能执行一条
# Base.metadata.drop_all(engine)flask orm操作表
基本操作
from models import User
from sqlalchemy import create_engine# 1 创建引擎
engine = create_engine("mysql+pymysql://root:1234@127.0.0.1:3306/sqlalchemy01",max_overflow=0, # 超过连接池大小外最多创建的连接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)# 2 orm操作--》借助于 engine 得到session(conn)对象
from sqlalchemy.orm import sessionmakerConnection = sessionmaker(bind=engine) # 绑定连接
session = Connection()# 3 使用conn---》进行orm操作
# 3.1 增加数据# user = User(name='lqz', email='3@qq.com')
# # 插入到数据库
# conn.add(user) # 放个对象# # 提交
# conn.commit()
# # 关闭链接
# conn.close()# 3.2 查询数据
# 查询User表中id为1的所有记录--》放到列表中
# res=conn.query(User).filter_by(id=1).all()
# print(res)## 3.3 删除
# res = conn.query(User).filter_by(name='lqz').delete()
# print(res)
# conn.commit()## 3.4 修改
# res=conn.query(User).filter_by(name='9999').update({'extra':'xxsss'})
# conn.commit()
一对多的增加和跨表查询 (一对一只需要关联字段加上 ,unique=True)
modles.py文件
import datetime
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base, relationship
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, IndexBase = declarative_base() # Base 当成 models.Model# 一对多 :一个兴趣被多个人喜欢 一个人只喜欢一个兴趣
class Hobby(Base):__tablename__ = 'hobby'id = Column(Integer, primary_key=True)caption = Column(String(50), default='篮球')def __str__(self):return self.captiondef __repr__(self):return self.captionclass Person(Base):__tablename__ = 'person'id = Column(Integer, primary_key=True)name = Column(String(32), index=True, nullable=True)# hobby指的是tablename而不是类名,uselist=False# 外键关联--》强外键--》物理外键hobby_id = Column(Integer, ForeignKey("hobby.id")) # 如果是一对一加上unique=True# 跟数据库无关,不会新增字段,只用于快速连表操作# 类名,backref用于反向查询hobby = relationship('Hobby', backref='pers') # 重点!!!!!!!! 正反向查询要通过这个字段def __str__(self):return self.namedef __repr__(self):return self.name# views.py中
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from models import Hobby, Person, Userengine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/sqlalchemy01",max_overflow=0, # 超过连接池大小外最多创建的连接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)Session = sessionmaker(bind=engine)
session = Session()# 1 增加 Hobby
# hobby = Hobby(caption='足球')
# hobby1 = Hobby(caption='篮球')
# session.add_all([hobby, hobby1]) # 列表套对象
# session.commit() # 一定要记得提交# 2 增加Person
# p1 = Person(name='彭于晏', hobby_id=1) # 可以是查询出来的对象 也可以是id 但是id写死了
# p2 = Person(name='刘亦菲', hobby_id=2)
# session.add_all([p1, p2])
# session.commit()# 3 简便方式增加person---》增加Person,直接新增Hobby
# hobby1 = Hobby(caption='乒乓球')
# # 同时把数据插入两张表
# p1 = Person(name='彭于晏', hobby=hobby1) # 前提是表模型 必须有 relationship
# session.add(p1)
# session.commit()# # 4 基于对象的跨表查询---正向
# per = session.query(Person).filter_by(name='彭于晏').first()
# print(per)
# # 正向 Person的对象通过 hobby 查询到 Hobby的caption字段
# print(per.hobby.caption)# 5 基于对象的跨表查询---正向
# hobby=session.query(Hobby).filter_by(caption='乒乓球').first()
# print(hobby)# 反向--->拿到多条 可以通过索引取值
hobby=session.query(Hobby).filter_by(caption='乒乓球').first()
print(hobby.pers)
print(hobby.pers[0].name) # 列表套对象多对多关系的增加和查询
# 多对多 models.py
class Boy2Girl(Base):__tablename__ = 'boy2girl'id = Column(Integer, primary_key=True, autoincrement=True)girl_id = Column(Integer, ForeignKey('girl.id'))boy_id = Column(Integer, ForeignKey('boy.id'))# boy = relationship('Boy', backref='boy'def __str__(self):return self.namedef __repr__(self):return self.nameclass Girl(Base):__tablename__ = 'girl'id = Column(Integer, primary_key=True)name = Column(String(64), unique=True, nullable=False)class Boy(Base):__tablename__ = 'boy'id = Column(Integer, primary_key=True, autoincrement=True)name = Column(String(64), unique=True, nullable=False)# 与生成表结构无关,仅用于查询方便,放在哪个单表中都可以--等同于manytomanygirls = relationship('Girl', secondary='boy2girl', backref='boys')def __str__(self):return self.namedef __repr__(self):return self.nameif __name__ == '__main__':# 3.1 创建引擎engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/sqlalchemy01",max_overflow=0, # 超过连接池大小外最多创建的连接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置))## 3.2 把表模型同步到数据库中Base.metadata.create_all(engine)# 3.3 删除表# Base.metadata.drop_all(engine)# 视图类中
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from models import Hobby, Person, User, Girl, Boy2Girl, Boyengine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/sqlalchemy01",max_overflow=0, # 超过连接池大小外最多创建的连接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)Session = sessionmaker(bind=engine)
session = Session()# 第一种简便方式增加# obj2 = Girl(name='张亦菲')
# obj3 = Girl(name='李娜扎')
# obj1 = Boy(name='张小勇', girls=[obj2, obj3]) # 在Boy 添加一个 通过girls关键字往 Girl 加上两个并建立关系
#
# session.add(obj1)
# session.commit()# # 4 基于对象的跨表查询---正向
boy = session.query(Boy).filter_by(name='张小勇').first()
print(boy.girls[0].name)# 5 基于对象的跨表查询---反向
# girl=session.query(Girl).filter_by(name='张亦菲').first()
# print(girl.boys)# 第二中添加方式 一张一张表的添加
# 1 增加 Boy
# boy = Boy(name='王小刚')
# boy2 = Boy(name='王小明')
# boy3 = Boy(name='王小勇')
# session.add_all([boy,boy2,boy3])
# session.commit()# 2 增加Girl
# girl = Girl(name='张小华')
# girl2 = Girl(name='刘小红')
# girl3 = Girl(name='李小丽')
# session.add_all([girl3, girl2, girl])
# session.commit()# 3 增加Boy2Girl
# obj1=Boy2Girl(boy_id=1,girl_id=1)
# obj2=Boy2Girl(boy_id=1,girl_id=2)
# obj3=Boy2Girl(boy_id=1,girl_id=3)
# session.add_all([obj2, obj3, obj1])
# session.commit()
多对多基本的增删改查
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session
from models import User, Person, Hobby, Boy, Girl, Boy2Girl
from sqlalchemy.sql import text# 添加
# obj1 = Boy(name='张小勇', girls=[obj2, obj3]) # 在Boy 添加一个 通过girls关键字往 Girl 加上两个并建立关系
# session.add(obj1)# 2 删除
# 2.1 session.query(Users).filter_by(id=1).delete()
# 2.1 session.delete(对象)
# user = session.query(User).filter_by(id=1).first()
# session.delete(user)
# session.commit()# 修改
# 1 方式一:
# session.query(Boy).filter_by(id=1).update({'name':'lqz'})
# session.commit()# # 2 方式二 类名.属性名,作为要修改的key
# session.query(Boy).filter_by(id=4).update({Boy.name:'lqz1'})
# session.commit()# id为4的人的名字后+ _nb 类似于django的 F 查询
# session.query(User).filter_by(id=2).update({'name':User.name+'_nb'},synchronize_session=False) # 字符串拼接
# session.query(User).filter_by(id=2).update({'id':User.id+6}, synchronize_session="evaluate") # 数字之间加
# session.commit()# # 3 方式三:
# 对象.name='xxx'
#session.add(对象)
# boy=session.query(Boy).filter_by(id=1).first()
# boy.name='xxzzyy'
# session.add(boy) # 有id就是修改,没有就是新增
# session.commit()
相关文章:
)
flask-(数据连接池的使用,定制命令,信号的使用,表关系的建立和查询)
文章目录 连接池实例flask定制命令flask 缓存的使用flask信号的使用sqlalchemy原生操作sqlalchemy操作表flask orm操作表一对多的增加和跨表查询 (一对一只需要关联字段加上 ,uniqueTrue)多对多关系的增加和查询多对多基本的增删改查 连接池 import pymy…...
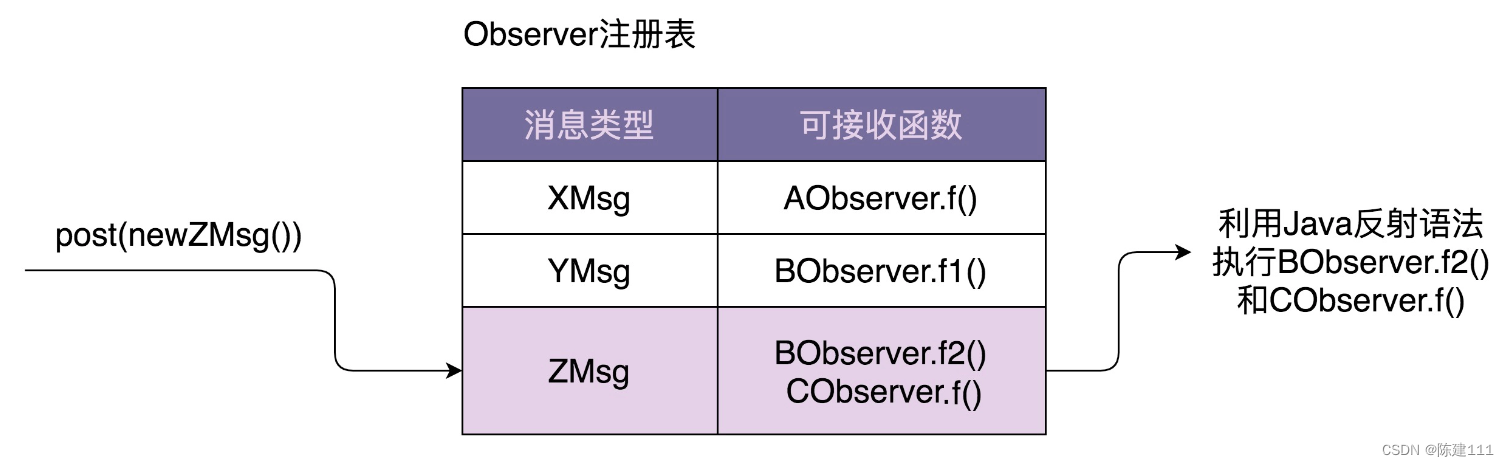
设计模式学习笔记 - 设计模式与范式 -行为型:2.观察者模式(下):实现一个异步非阻塞的EventBus框架
概述 《1.观察者模式(上)》我们学习了观察者模式的原理、实现、应用场景,重点节介绍了不同应用场景下,几种不同的实现方式,包括:同步阻塞、异步非阻塞、进程内、进程间的实现方式。 同步阻塞最经典的实现…...
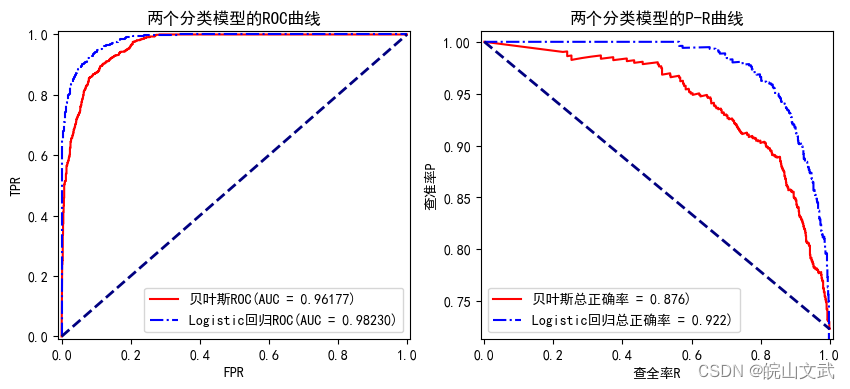
数据挖掘|贝叶斯分类器及其Python实现
分类分析|贝叶斯分类器及其Python实现 0. 分类分析概述1. Logistics回归模型2. 贝叶斯分类器2.1 贝叶斯定理2.2 朴素贝叶斯分类器2.2.1 高斯朴素贝叶斯分类器2.2.2 多项式朴素贝叶斯分类器 2.3 朴素贝叶斯分类的主要优点2.4 朴素贝叶斯分类的主要缺点 3. 贝叶斯分类器在生产中的…...
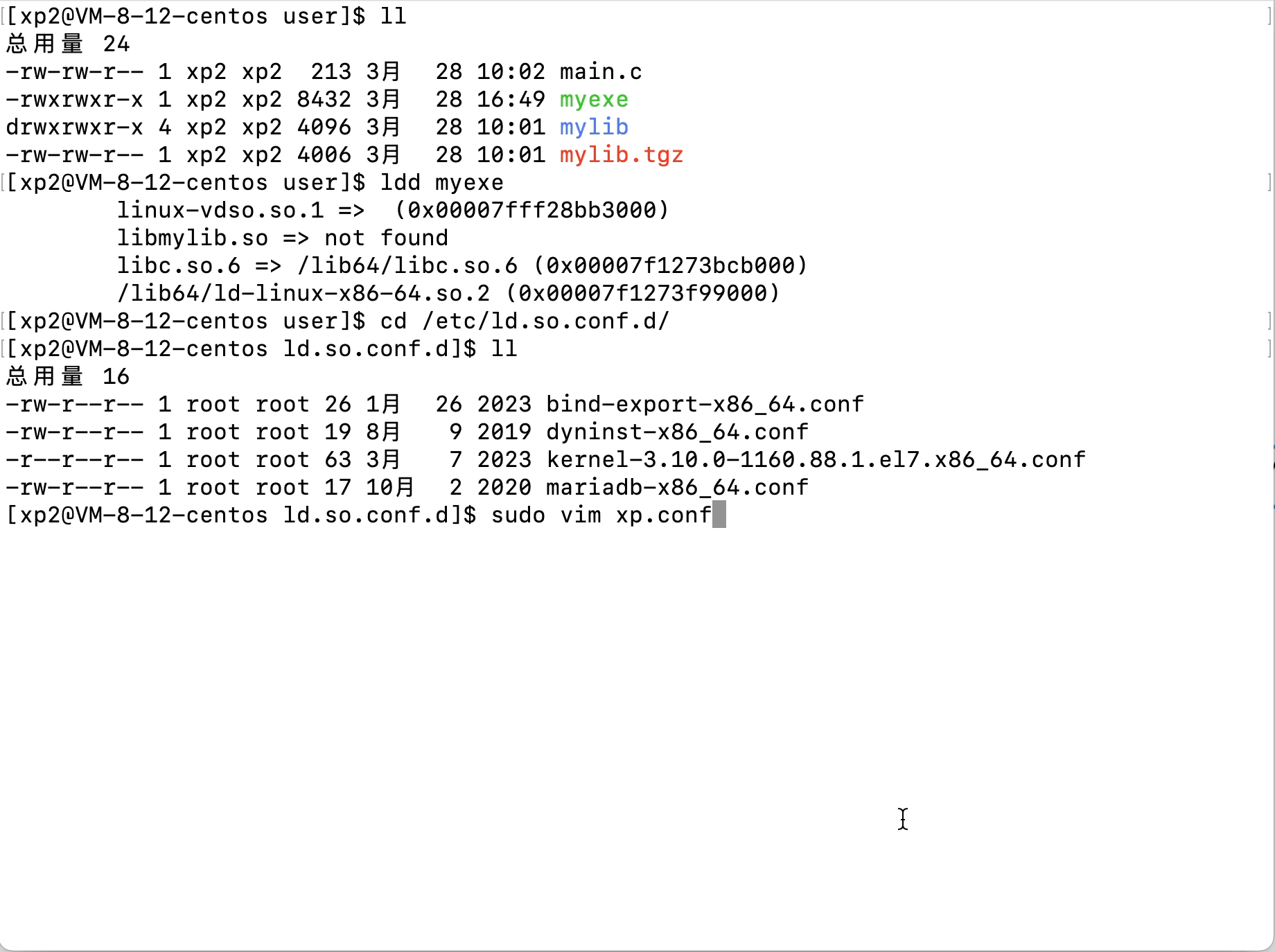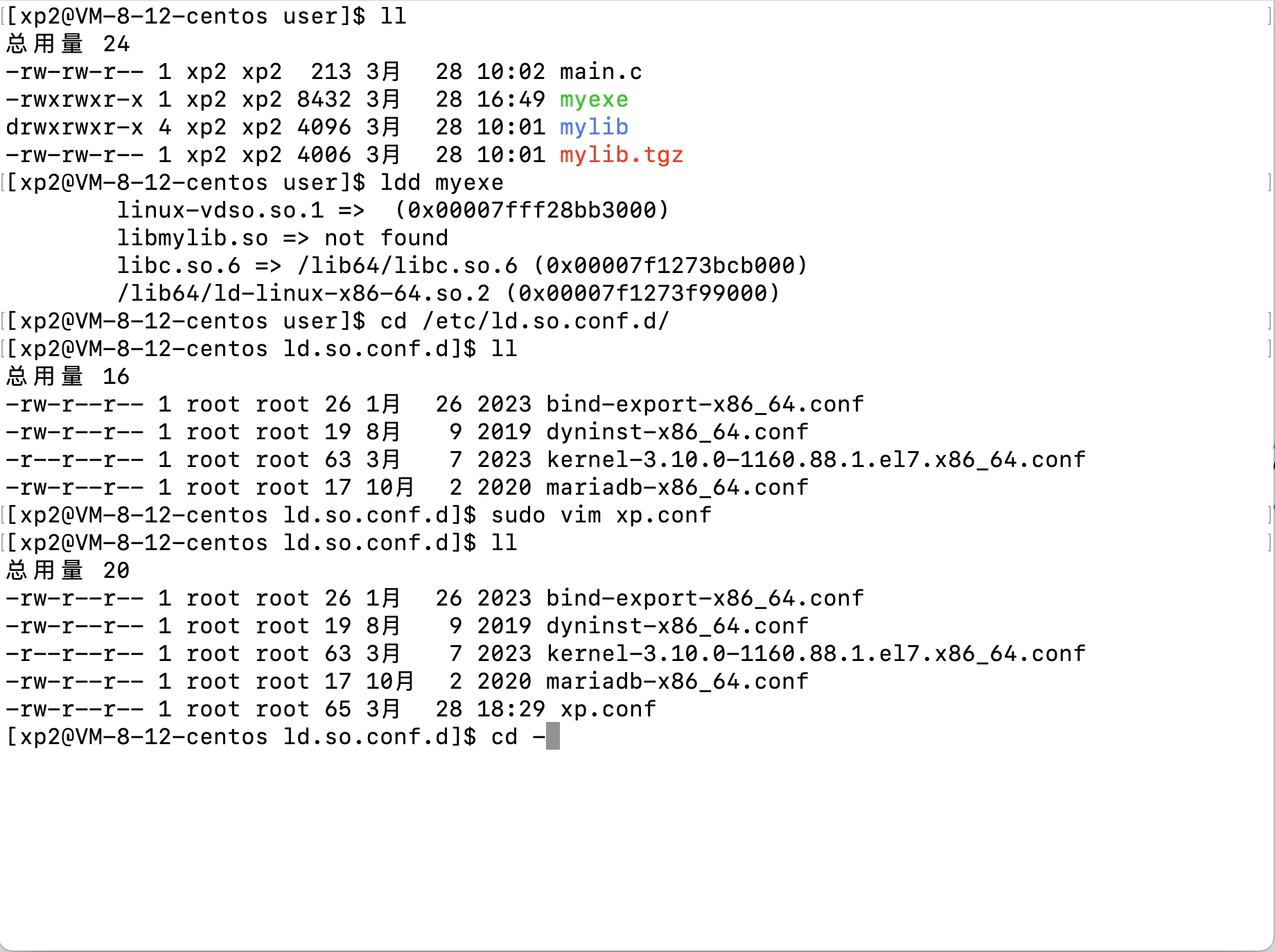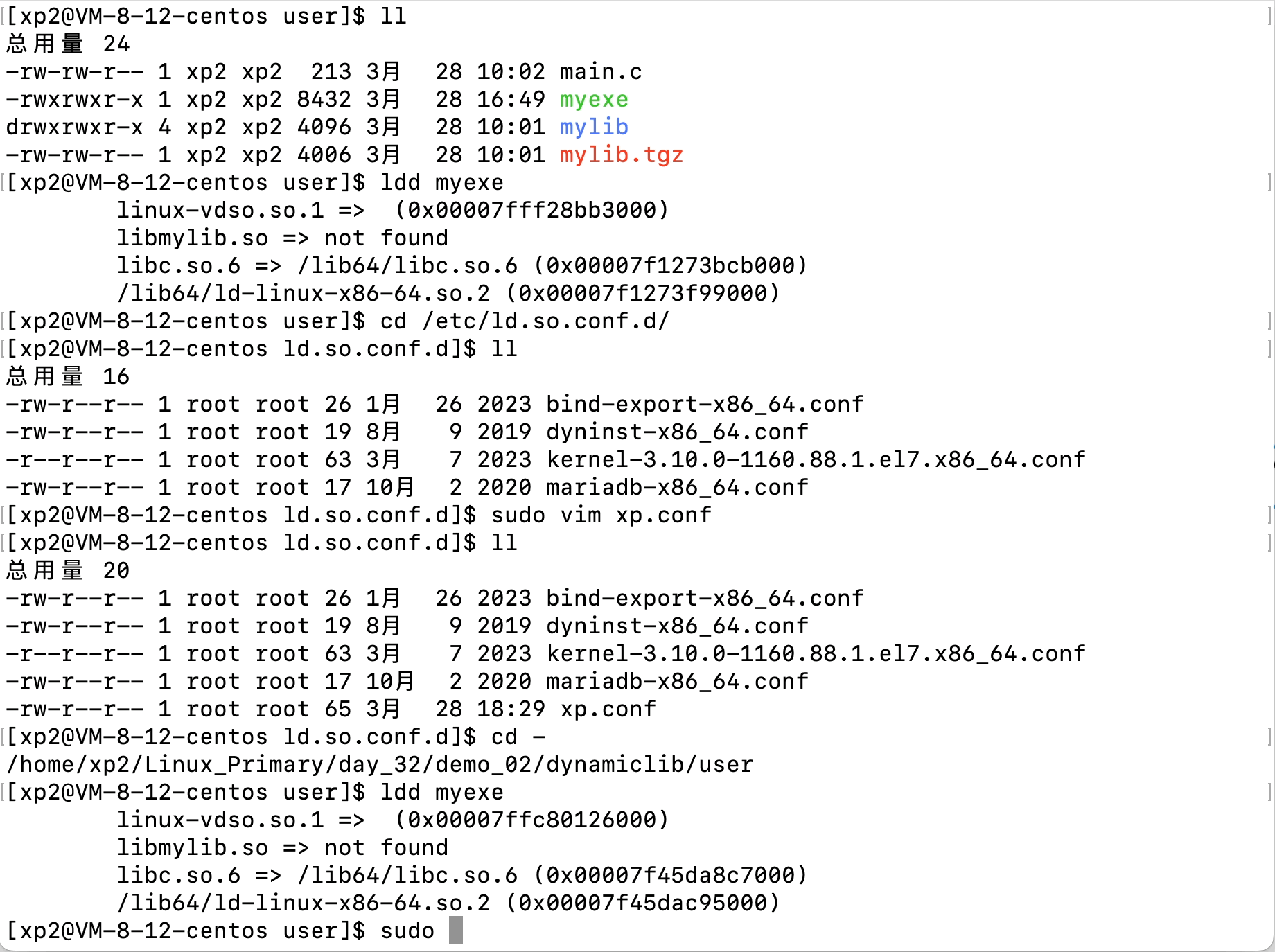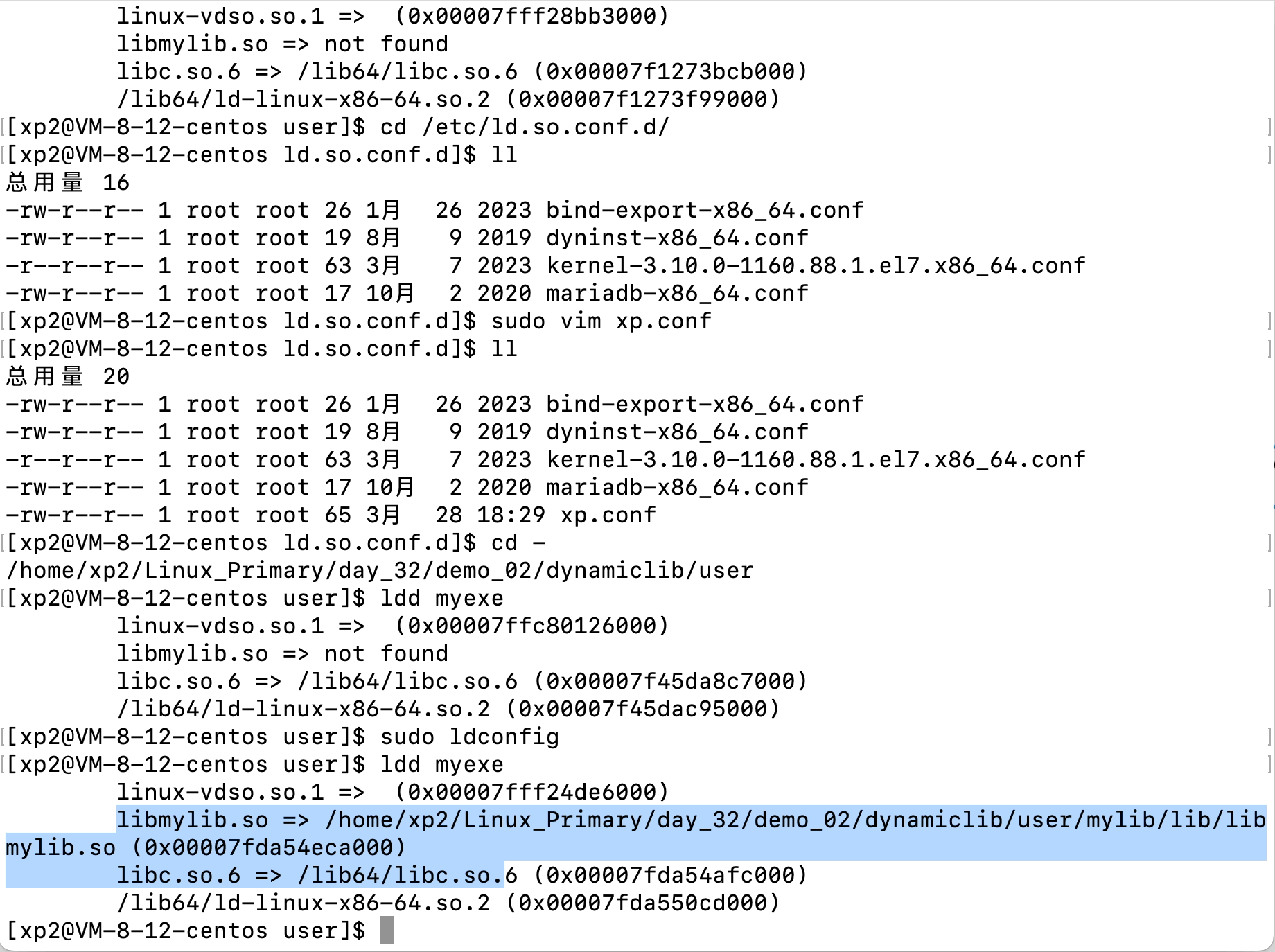
Linux文件(系统)IO(含动静态库的链接操作)
文章目录 Linux文件(系统)IO(含动静态库的链接操作)1、C语言文件IO操作2、三个数据流stdin、stdout、stderr3、系统文件IO3.1、相关系统调用接口的使用3.2、文件描述符fd3.3、文件描述符的分配规则3.3、重定向3.4、自制shell加入重…...
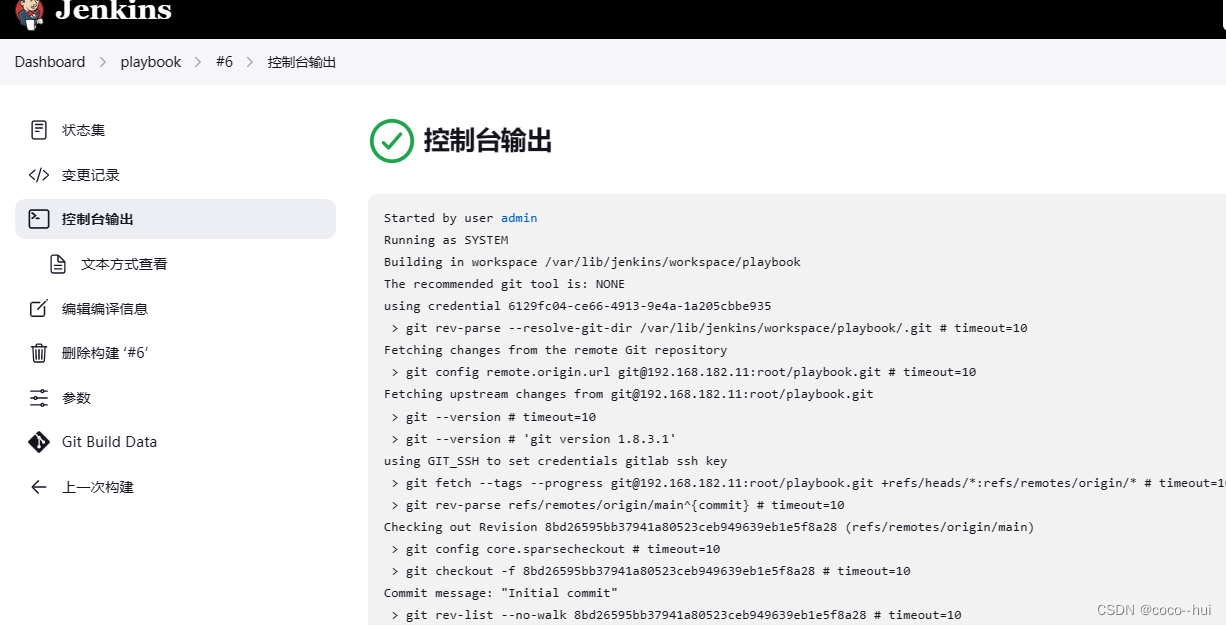
CI/CD实战-jenkins结合ansible 7
配置主机环境 在jenkins上断开并删除docker1节点 重新给master添加构建任务 将server3,server4作为测试主机,停掉其上后面的docker 在server2(jenkins)主机上安装ansible 设置jenkins用户到目标主机的免密 给测试主机创建用户并…...
内网渗透-(黄金票据和白银票据)详解(一)
目录 一、Kerberos协议 二、下面我们来具体分析Kerberos认证流程的每个步骤: 1、KRB_AS-REQ请求包分析 PA-ENC-TIMESTAMP PA_PAC_REQUEST 2、 KRB_AS_REP回复包分析: TGT认购权证 Logon Session Key ticket 3、然后继续来讲相关的TGS的认证过程…...
学习transformer模型-Dropout的简明介绍
Dropout的定义和目的: Dropout 是一种神经网络正则化技术,它在训练时以指定的概率丢弃一个单元(以及连接)p。 这个想法是为了防止神经网络变得过于依赖特定连接的共同适应,因为这可能是过度拟合的症状。直观上&#…...
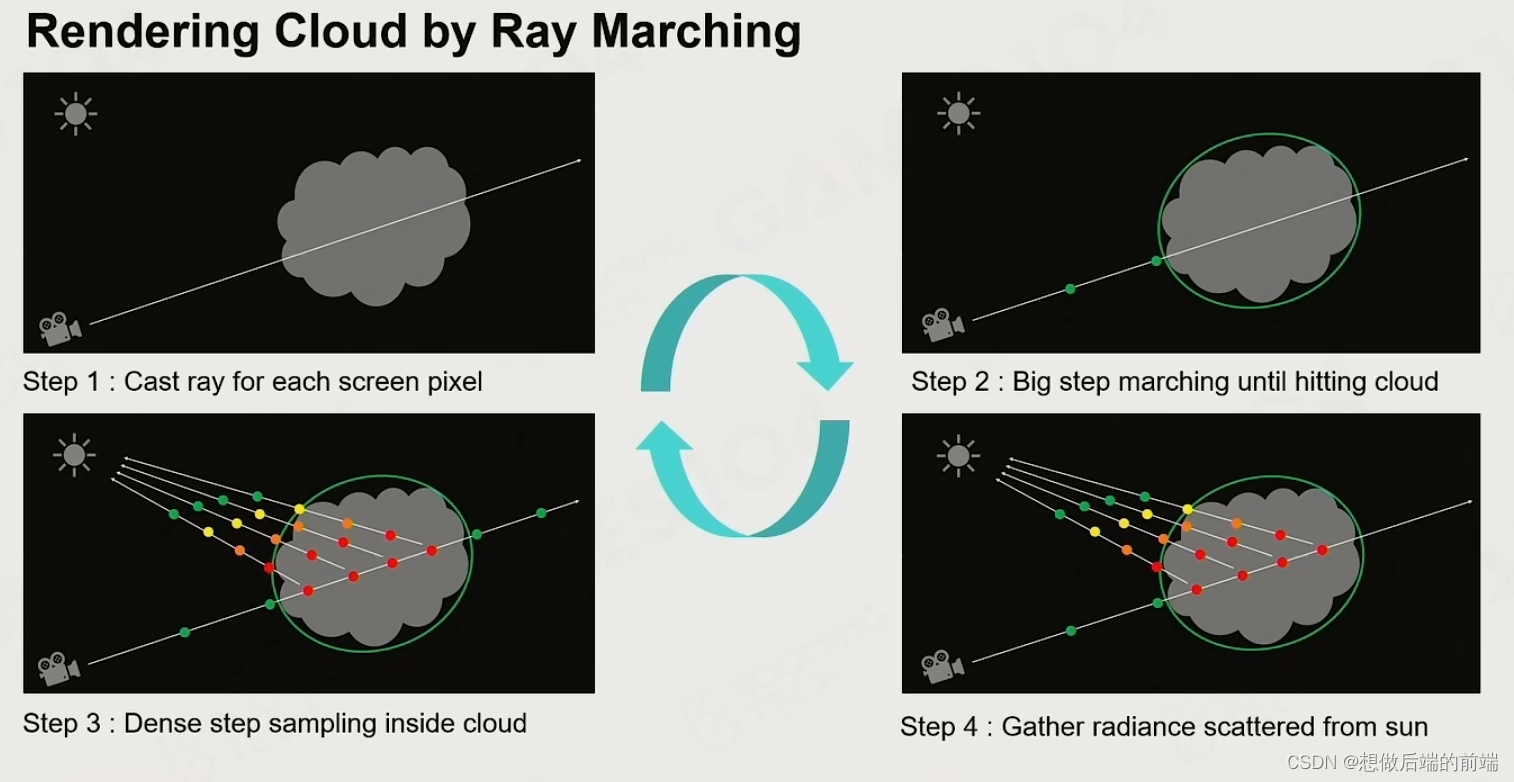
游戏引擎中的大气和云的渲染
一、大气 首先和光线追踪类似,大气渲染也有类似的渲染公式,在实际处理中也有类似 Blinn-Phong的拟合模型。关键参数是当前点到天顶的角度和到太阳的角度 二、大气散射理论 光和介质的接触: Absorption 吸收Out-scattering 散射Emission …...

华为鲲鹏云认证考试内容有哪些?华为鲲鹏云认证考试报名条件
华为鲲鹏云认证考试是华为公司为了验证IT专业人士在鲲鹏计算及云计算领域的专业能力而设立的一项认证考试。以下是关于华为鲲鹏云认证考试的一些详细信息: 考试内容:华为鲲鹏云认证考试的内容主要包括理论考核和实践考核两大部分。理论考核涉及云计算、…...
v3-admin-vite 改造自动路由,view页面自解释Meta
需求 v3-admin-vite是一款不错的后端管理模板,主要是pany一直都在维护,最近将后台管理也进行了升级,顺便完成一直没时间解决的小痛痒: 在不使用后端动态管理的情况下。我不希望单独维护一份路由定义,我希望页面是自解…...

FIFO存储器选型参数,结构原理,工艺与注意问题总结
🏡《总目录》 目录 1,概述2.1,写入操作2.2,读取操作2.3,指针移动与循环2.4,状态检测3,结构特点3.1,双口RAM结构3.2,无外部读写地址线3.3,内部读写指针自动递增3.4,固定深度的缓冲区4,工艺流程4.1,硅晶圆准备...

jvm高级面试题-2024
说下对JVM内存模型的理解 JVM内存模型主要是指Java虚拟机在运行时所使用的内存结构。它主要包括堆、栈、方法区和程序计数器等部分。 堆是JVM中最大的一块内存区域,用于存储对象实例。一般通过new关键字创建的对象都存放在堆中,堆的大小可以通过启动参数…...

DeepL Pro3.1 下载地址及安装教程
DeepL Pro是DeepL公司推出的专业翻译服务。DeepL是一家专注于机器翻译和自然语言处理技术的公司,其翻译引擎被认为在质量和准确性方面表现优秀.DeepL Pro提供了一系列高级功能和服务,以满足专业用户的翻译需求。其中包括: 高质量翻译…...

第十一届 “MathorCup“- B题:基于机器学习的团簇能量预测及结构全局寻优方法
目录 摘 要 第 1 章 问题重述 1.1 问题背景 1.2 问题描述 第 2 章 思路分析...
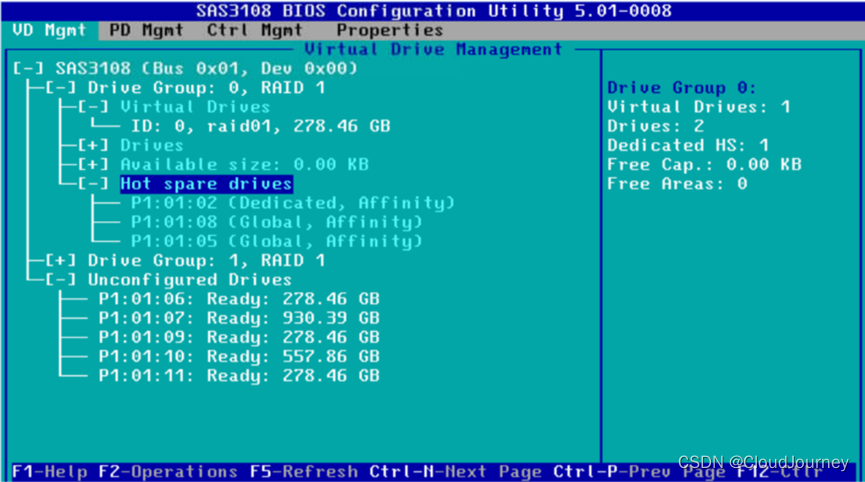
云计算探索-如何在服务器上配置RAID(附模拟器)
一,引言 RAID(Redundant Array of Independent Disks)是一种将多个物理硬盘组合成一个逻辑单元的技术,旨在提升数据存取速度、增大存储容量以及提高数据可靠性。在服务器环境中配置RAID尤其重要,它不仅能够应对高并发访…...
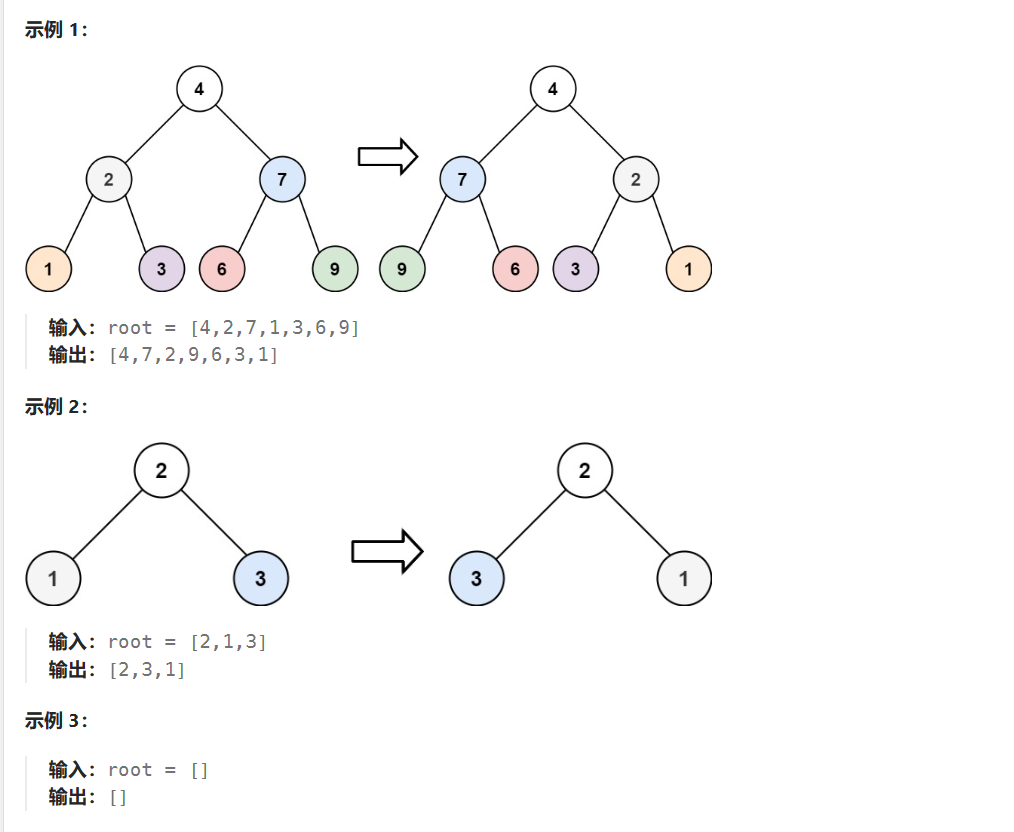
LeetCode226:反转二叉树
题目描述 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 解题思想 使用前序遍历和后序遍历比较方便 代码 class Solution { public:TreeNode* invertTree(TreeNode* root) {if (root nullptr) return root;swap(root->left, root…...

特征融合篇 | 利用RT-DETR的AIFI去替换YOLOv8中的SPPF(附2种改进方法)
前言:Hello大家好,我是小哥谈。RT-DETR模型是一种用于目标检测的深度学习模型,它基于transformer架构,特别适用于实时处理序列数据。在RT-DETR模型中,AIFI(基于注意力的内部尺度特征交互)模块是一个关键组件,它通过引入注意力机制来增强模型对局部和全局信息的处理能力…...
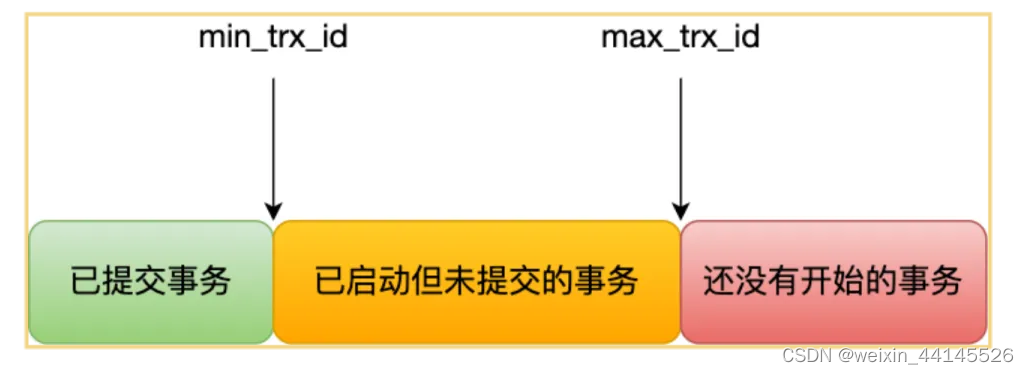
MVCC多版本并发控制
1.什么是MVCC MVCC (Multiversion Concurrency Control),多版本并发控制。MySQL通过MVCC来实现隔离性。隔离性本质上是因为同时存在多个并发事务可能会导致脏读、幻读等情况。要解决并发问题只有一种方案就是加锁。当然,锁不可避免…...

图片转换成base64如何在html文件中使用呢
在HTML文件中使用Base64编码的图片非常简单。Base64编码是一种将二进制数据转换为ASCII字符串的方法,这使得可以直接在网页上嵌入图片数据,而无需引用外部图片文件。以下是如何在HTML中使用Base64编码的图片的步骤: 步骤 1: 将图片转换为Bas…...
【MATLAB源码-第24期】基于matlab的水声通信中海洋噪声的建模仿真,对比不同风速的影响。
操作环境: MATLAB 2022a 1、算法描述 水声通信: 水声通信是一种利用水中传播声波的方式进行信息传递的技术。它在水下环境中被广泛应用,特别是在海洋科学研究、海洋资源勘探、水下军事通信等领域。 1. **传输媒介**:水声通信利…...

公交客流统计摄像机系统,能替代监控摄像头吗?
公交车内乘客流量大,安全隐患较多,多年来监控摄像头已经成为车内的标配。随着科技技术的进步,如今公交客流统计摄像机系统,也逐渐部署到了各地公交上。那么公交客流统计摄像机系统,能替代监控摄像头吗?如今…...

告别手动操作!Open-AutoGLM部署教程,让AI接管你的手机
告别手动操作!Open-AutoGLM部署教程,让AI接管你的手机 1. 引言:AI手机助手的革命性突破 想象一下这样的场景:早上醒来,你只需要对手机说"帮我点一杯星巴克燕麦拿铁,加双份浓缩,送到公司&…...

Phi-3-mini-4k-instruct-gguf实操手册:中文短文本生成场景下的温度调优策略
Phi-3-mini-4k-instruct-gguf实操手册:中文短文本生成场景下的温度调优策略 1. 模型概述与使用场景 Phi-3-mini-4k-instruct-gguf 是微软推出的轻量级文本生成模型,特别适合处理中文短文本任务。这个经过优化的GGUF版本模型,在问答、文本改…...

独立站页面结构优化的注意事项是什么_独立站 SEO 与品牌建设的关系是什么
独立站页面结构优化的注意事项是什么 在当今的数字化时代,独立站(独立网站)已经成为个人品牌和企业展示自我、推广产品和服务的重要平台。单凭一个美观的独立站,难以在竞争激烈的网络环境中脱颖而出。因此,独立站页面…...
)
【MySQL】第五节 - 事务实战详解:从基础到并发控制(附 Navicat 可运行实验脚本)
《MySQL 事务实战详解:从基础到并发控制(附 Navicat 可运行实验脚本)》 为什么你必须掌握 MySQL 事务? 在现代应用系统中,数据一致性是核心诉求。事务(Transaction) 是保证数据完整性的“黄金…...

3个技巧让Blender对齐效率提升10倍:QuickSnap插件全攻略
3个技巧让Blender对齐效率提升10倍:QuickSnap插件全攻略 【免费下载链接】quicksnap Blender addon to quickly snap objects/vertices/points to object origins/vertices/points 项目地址: https://gitcode.com/gh_mirrors/qu/quicksnap 在三维建模的日常工…...

3分钟掌握哔哩下载姬:零安装B站视频下载神器使用指南
3分钟掌握哔哩下载姬:零安装B站视频下载神器使用指南 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#x…...

别再混淆了!一文搞懂目标检测中的AP、mAP和mAP@0.5:0.95区别
目标检测评估指标全解析:从AP到mAP0.5:0.95的实战指南 在计算机视觉领域,目标检测模型的性能评估一直是研究者关注的焦点。面对AP、mAP、mAP0.5:0.95等专业术语,不少开发者容易混淆它们的计算方式和适用场景。本文将深入剖析这些关键指标的技…...

Unpaywall终极指南:一键解锁全球学术论文的免费获取方案
Unpaywall终极指南:一键解锁全球学术论文的免费获取方案 【免费下载链接】unpaywall-extension Firefox/Chrome extension that gives you a link to a free PDF when you view scholarly articles 项目地址: https://gitcode.com/gh_mirrors/un/unpaywall-extens…...

Ansible Playbook在JumpServer中的高级用法:自动化运维效率提升技巧
Ansible Playbook在JumpServer中的高阶实战:效率倍增的自动化运维策略 开篇:当堡垒机遇上自动化运维 想象一下这样的场景:凌晨三点,服务器突然告警,传统运维需要手动登录每台机器检查状态,而熟练使用Ansibl…...