深度学习训练过程中,常见的关键参数和概念讲解
深度学习训练过程中的关键参数和概念对于构建、理解和优化模型至关重要。以下是一些最常见的参数和概念,以及它们的简要解释:
1. 学习率(Learning Rate)
- 学习率是优化算法中最重要的参数之一,它控制着权重调整的幅度。合适的学习率可以使模型快速收敛,而过高或过低的学习率都可能导致模型训练不成功。
2. 批次大小(Batch Size)
- 批次大小指的是在训练过程中一次前向和反向传播中用于更新网络权重的样本数量。它直接影响模型训练的内存消耗、速度和稳定性。
3. 迭代次数(Iterations)
- 迭代次数是指完成一个批次训练的总次数。一个迭代等于使用批次大小数量的样本进行一次前向传播和一次反向传播。
4. 循环次数(Epochs)
- 循环次数是指整个训练数据集被遍历的次数。一个Epoch意味着每个训练样本在训练过程中被使用了一次。
5. 损失函数(Loss Function)
- 损失函数计算模型的预测值和真实值之间的差异。它是训练过程中需要最小化的关键函数,不同的任务选择不同的损失函数。
6. 优化器(Optimizer)
- 优化器决定了模型参数的更新策略。常见的优化器包括SGD、Adam、RMSprop等,它们有助于快速有效地训练模型。
7. 正则化(Regularization)
- 正则化是一种减少模型过拟合的技术,它通过在损失函数中添加一个额外的项(例如L1或L2惩罚项)来限制模型的复杂度。
8. Dropout
- Dropout是一种特殊的正则化技术,它在训练过程中随机“丢弃”一部分神经网络的节点,从而防止模型过于依赖训练数据集中的特定样本。
9. 激活函数(Activation Function)
- 激活函数用于非线性变换输入,使得神经网络可以学习和表示复杂的数据。常见的激活函数包括ReLU、Sigmoid和Tanh等。
10. 学习率调度(Learning Rate Scheduling)
- 学习率调度指的是在训练过程中调整学习率的策略,例如,随着训练的进行逐渐减小学习率,以更细致地调整模型参数。
通过一个例子讲解批次大小、循环次数、迭代次数的区别
假设我们有一个数据集,总共包含1200个样本。我们想用这个数据集来训练一个深度学习模型。
样本数量
- 样本数量:数据集中的总样本数为1200个。
为了训练模型,我们决定使用小批量梯度下降法,这需要我们设定一个批次大小(Batch Size)。
批次大小(Batch Size)
- 批次大小(Batch Size):设定为100,意味着在每次训练(每次迭代)中,我们将使用100个样本。
接下来,我们需要确定循环次数(Epoch),即我们希望模型遍历整个数据集训练多少次。
循环次数(Epoch)
- 循环次数(Epoch):假设我们设置为5,这意味着我们希望模型遍历整个数据集5次来进行训练。
现在,我们来计算完成所有Epoch所需的迭代次数(Iteration)。
迭代次数(Iteration)
由于每次迭代我们使用100个样本,而整个数据集有1200个样本,所以完成一次Epoch(即遍历一次整个数据集)需要的迭代次数为:
- 迭代次数(每个Epoch)=样本数量批次大小=1200100=12迭代次数(每个Epoch)=批次大小样本数量=1001200=12
这意味着在每个Epoch中,我们需要12次迭代来遍历整个数据集。
既然我们计划进行5个Epoch的训练,那么总的迭代次数将会是:
- 总迭代次数 = 迭代次数(每个Epoch) × 循环次数(Epoch) = 12 × 5 = 60
结合起来
所以,在这个例子中:
- 我们有一个包含1200个样本的数据集。
- 我们设置批次大小(Batch Size)为100。
- 我们计划让模型遍历整个数据集5次(即5个Epoch)。
- 为了完成这5个Epoch的训练,我们将需要进行60次迭代。
这意味着在整个训练过程中,模型的权重将会根据训练数据更新60次,以逐步减少预测误差并提高模型的性能。
这些参数和概念是构建和优化深度学习模型过程中不可或缺的一部分。合理地选择和调整这些参数可以显著提高模型的性能和训练效率。
相关文章:

深度学习训练过程中,常见的关键参数和概念讲解
深度学习训练过程中的关键参数和概念对于构建、理解和优化模型至关重要。以下是一些最常见的参数和概念,以及它们的简要解释: 1. 学习率(Learning Rate) 学习率是优化算法中最重要的参数之一,它控制着权重调整的幅度…...

如何提高小红书笔记的收录率?
在小红书平台上,笔记的收录率是衡量一篇笔记是否受欢迎和有价值的重要因素。为了提高笔记的收录率,有几个关键点需要注意: 1.内容不涉及广告 在发布笔记前要先确保笔记内容不包含任何形式的广告或推广信息。小红书平台对于广告性质的内容有…...
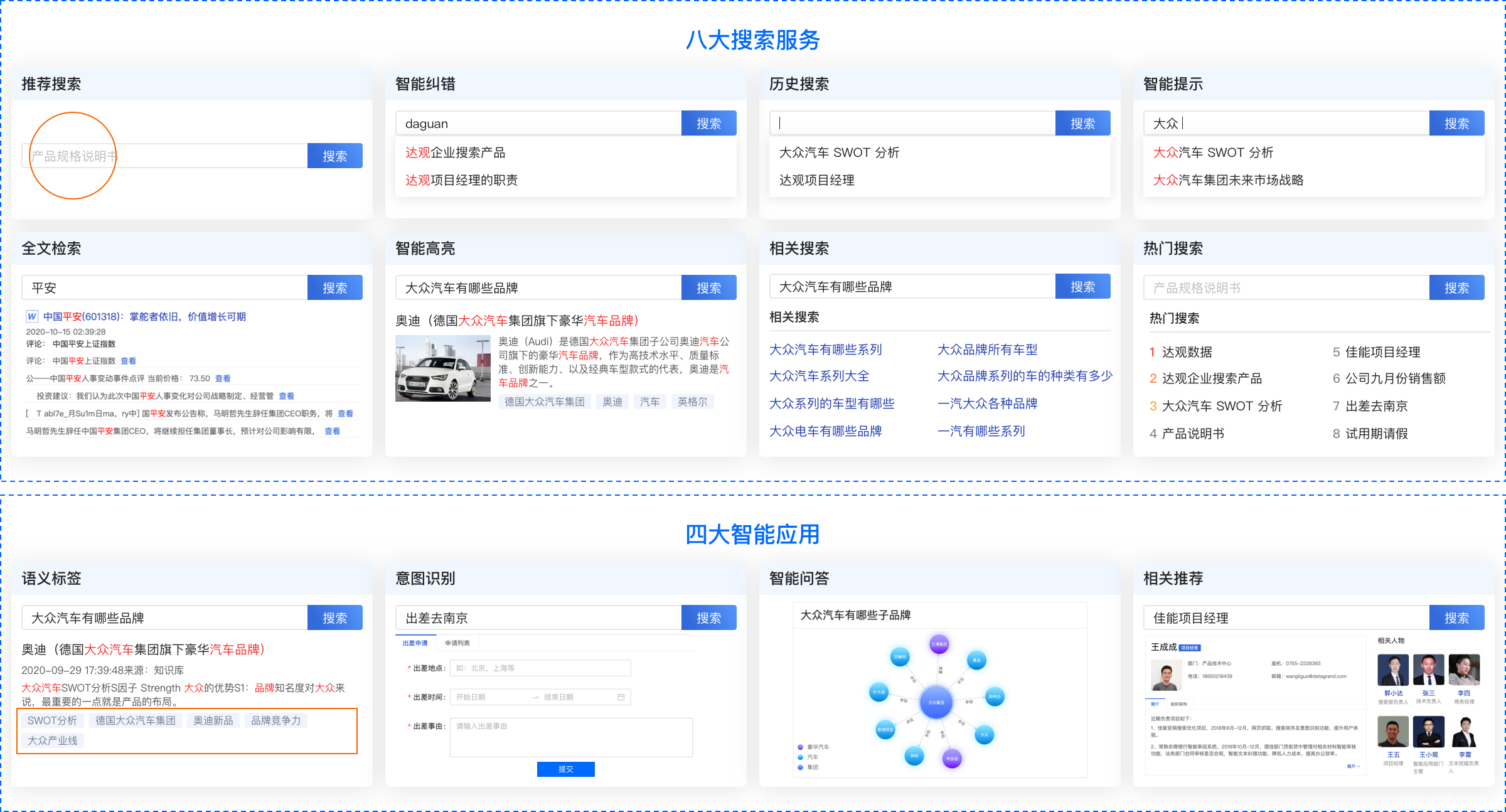
思通数科:利用开源AI能力引擎平台打造企业智能搜索系统
在信息爆炸的时代,如何高效地管理和检索海量数据已成为企业和个人面临的一大挑战。思通数科 StoneDT 多模态AI能力引擎平台,以其强大的自然语言处理(NLP)、OCR识别、图像识别和文本抽取技术,为用户带来了前所未有的智能…...

Nginx配置其实很简单
Nginx配置其实很简单 不管作为前端还是后端,我们工作中或多或少得接触反向代理,比如代理静态页面或者文件、代理接口解决跨域、配置https、配置缓存和负载等等。而这些需求的实现,我们肯定能接触到Nginx,即使我们使用Caddy等等其它代理方式,但也肯定知道Nginx的存在。如果…...
)
Redis中的serverCron函数(一)
serverCron函数 Redis服务器中的serverCron函数默认每隔100毫秒执行一次,这个函数负责管理服务器的资源,并保持服务器自身的良好运转。 更新服务器时间缓存 Redis服务器中有不少功能需要获取系统的当前时间,而每次获取系统的当前时间都需要…...
)
python保存中间变量(学习笔记)
python保存中间变量 原因: 最近在部署dust3r算法,虽然在本地部署了,也能测试出一定的结果,但是发现无法跑很多图片,为了能够测试多张图片跑出来的模型,于是就在打算在autodl上部署算法,但是由…...

CTF wed安全(攻防世界)练习题
一、Training-WWW-Robots 进入网站如图: 翻译:在这个小小的挑战训练中,你将学习Robots exclusion standard。网络爬虫使用robots.txt文件来检查它们是否被允许抓取和索引您的网站或只是其中的一部分。 有时这些文件会暴露目录结构,…...

计算机网络链路层
数据链路 链路是从一个节点到相邻节点之间的物理线路(有线或无线) 数据链路是指把实现协议的软件和硬件加到对应链路上。帧是点对点信道的数据链路层的协议数据单元。 点对点信道 通信的主要步骤: 节点a的数据链路层将网络层交下来的包添…...

VUE3——reactive对比ref
从定义数据角度对比: 。ref用来定义:基本类型数据 。reactive用来定义:对象(或数组)类型数据。 。备注:ref也可以用来定义对象(或数组)类型数据,它内部会自动通过 reactive 转为代理对象。 从原理角度对比: 。ref通过 object.defineProperty()的 get 与set 来实现响应式(数据劫…...

广场舞团系统的设计与实现|Springboot+ Mysql+Java+ B/S结构(可运行源码+数据库+设计文档)
本项目包含可运行源码数据库LW,文末可获取本项目的所有资料。 推荐阅读100套最新项目持续更新中..... 2024年计算机毕业论文(设计)学生选题参考合集推荐收藏(包含Springboot、jsp、ssmvue等技术项目合集) 目录 1. 系…...
经典永不过时 Wordpress模板主题
经得住时间考验的模板,才是经典模板,带得来客户的网站,才叫NB网站。 https://www.jianzhanpress.com/?p2484...
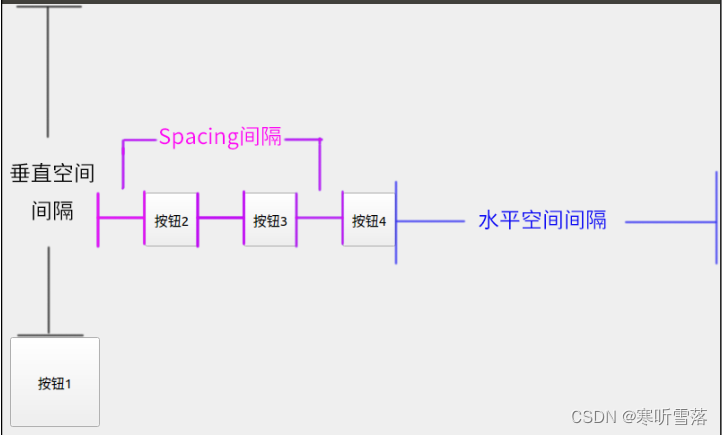
QT布局管理和空间提升为和空间间隔
QHBoxLayout:按照水平方向从左到右布局; QVBoxLayout:按照竖直方向从上到下布局; QGridLayout:在一个网格中进行布局,类似于HTML的table; 基本布局管理类包括:QBoxLayout、QGridL…...
Yolo 自制数据集dect训练改进
上一文请看 Yolo自制detect训练-CSDN博客 简介 如下图: 首先看一下每个图的含义 loss loss分为cls_loss, box_loss, obj_loss三部分。 cls_loss用于监督类别分类,计算锚框与对应的标定分类是否正确。 box_loss用于监督检测框的回归,预测框…...

vlan间单臂路由
【项目实践4】 --vlan间单臂路由 一、实验背景 实验的目的是在一个有限的网络环境中实现VLAN间的通信。网络环境包括两个交换机和一个路由器,交换机之间通过Trunk链路相连,路由器则连接到这两个交换机的Trunk端口上。 二、案例分析 在网络工程中&#…...

day4 linux上部署第一个nest项目(java转ts全栈/3R教室)
背景:上一篇吧nest-vben-admin项目,再开发环境上跑通了,并且build出来了dist文件,接下来再部署到linux试试吧 dist文件夹是干嘛的? 一个pnpn install 直接生成了两个dist文件夹,前端admin项目一个…...
学会这几点,是搭建产品知识库的关键
现如今,企业都特别看重产品知识库,因为有了它,企业就能更好地管理产品信息,提升客户服务水平,还能帮企业做决策。但是,搭建一个好用、高效的产品知识库,也难倒了不少人。下面,我们一…...

MySql 常用的聚合函数总结
MySQL 中的聚合函数用于对一组数据进行计算,并返回单个值作为结果。以下是常用的 MySQL 聚合函数的总结及其功能描述: 1. COUNT() 功能:用于计算指定列或表中的行数。 语法: COUNT(*) COUNT(expression) 示例: SELECT …...

Charles for Mac 强大的网络调试工具
Charles for Mac是一款功能强大的网络调试工具,可以帮助开发人员和测试人员更轻松地进行网络通信测试和调试。以下是一些Charles for Mac的主要特点: 软件下载:Charles for Mac 4.6.6注册激活版 流量截获:Charles可以截获和分析通…...
【数据结构】优先级队列——堆
🧧🧧🧧🧧🧧个人主页🎈🎈🎈🎈🎈 🧧🧧🧧🧧🧧数据结构专栏🎈🎈🎈&…...

【力扣】45.跳跃游戏Ⅱ
45.跳跃游戏Ⅱ 给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。 每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i j] 处: 0 < j < nums[i]i j < n 返回到达 n…...

新手也能懂的SSRF漏洞实战:用iwebsec靶场复现文件读取与内网探测
从零开始掌握SSRF漏洞:iwebsec靶场实战指南1. 认识SSRF漏洞的本质想象一下,你正在一家高档餐厅点餐,服务员承诺可以帮你从任何地方获取食材——包括隔壁竞争对手的厨房。SSRF(Server-Side Request Forgery)漏洞就像这个…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

配置OpenClaw Agent使用Taotoken作为后端模型提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 配置OpenClaw Agent使用Taotoken作为后端模型提供商 基础教程类,指导希望使用OpenClaw等Agent工具的开发者,…...

别被忽悠了!2026亲测靠谱的AI论文网站|避坑精选版
2026 年学术写作工具已高度分化,千笔AI与ThouPen为全流程首选,豆包、DeepSeek 为专项强手;避坑关键:拒绝假文献、严控 AIGC 率、优先国内适配、免费试用先行。 一、TOP3 全流程首选(亲测不踩雷) 1. 千笔AI&…...

Unity iOS构建报错SDK version is 0的根因与精准修复
1. 这个报错不是Unity在“发脾气”,而是工程配置在“装死”刚接手一个老项目,打开Unity编辑器,点Build Settings准备打包iOS,结果弹出一行红字:“SDK version is 0, cannot build”。我第一反应是——这什么鬼…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...

AWS DevOps Agent 完全指南
AWS DevOps Agent 是 AWS 推出的前沿 AI 运维代理,自主调查和解决事件、持续预防故障、提升系统可靠性。本文档覆盖从原理到实战的全生命周期管理。 一、定位与价值 一句话定义 AWS DevOps Agent = AI 驱动的 SRE 队友,724 自主调查告警、定位根因、生成修复方案、预防未来…...

5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南
5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专为Windows设计的鼠…...

如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍
如何高效使用HiveWE:魔兽争霸III地图制作的完整秘籍 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为魔兽争霸III原版编辑器加载缓慢、操作卡顿而烦恼吗?HiveWE作为一款专注于速…...

Armv9-A架构解析:SVE/SME与安全增强技术
1. Armv9-A架构演进与核心特性全景Armv9-A架构代表了Arm公司面向未来十年计算需求的设计哲学,其核心在于三个维度的突破:性能、安全与专用计算。作为长期从事Arm架构开发的工程师,我见证了从Armv7到Armv9的技术跃迁。与固定宽度向量指令的NEO…...