用Python实现办公自动化(自动化处理PDF文件)
自动化处理 PDF 文件
目录
自动化处理 PDF 文件
谷歌浏览器 Chrome与浏览器驱动ChromeDriver安装
(一)批量下载 PDF 文件
1.使用Selenium模块爬取多页内容
2.使用Selenium模块下载PDF文件
3.使用urllib模块来进行网页的下载和保存
4.使用urllib&Selenium模块判断下载和保存
(二)批量合并 PDF 文件
(三)批量拆分 PDF 文件
(四)批量加密 PDF 文件
(五)批量为 PDF 文件添加水印
1.自定义函数创建水印文件
2.自定义函数添加水印
3.使用循环为每个PDF文件添加水印
Chrome:浏览器
Selenium:是一个用于浏览器自动化测试的工具集,是一个完整的自动化测试框架
WebDriver:是Selenium的一个关键组件,用于控制和操作浏览器
ChromeDriver:是Webdriver的一个实现,专门用于控制和操作Google Chrome浏览器
谷歌浏览器 Chrome与浏览器驱动ChromeDriver安装
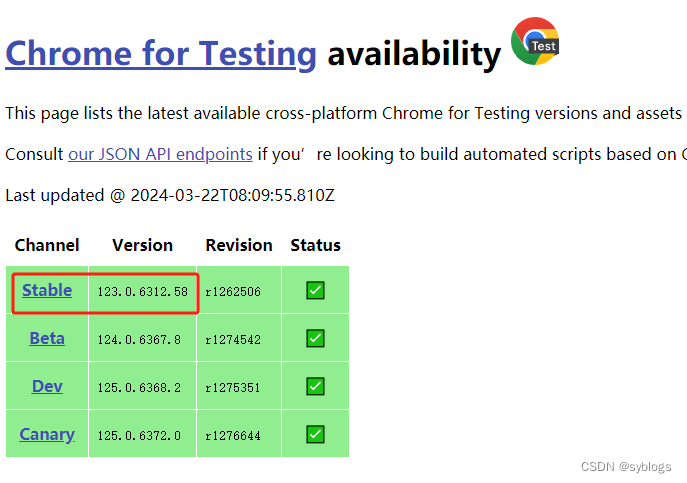
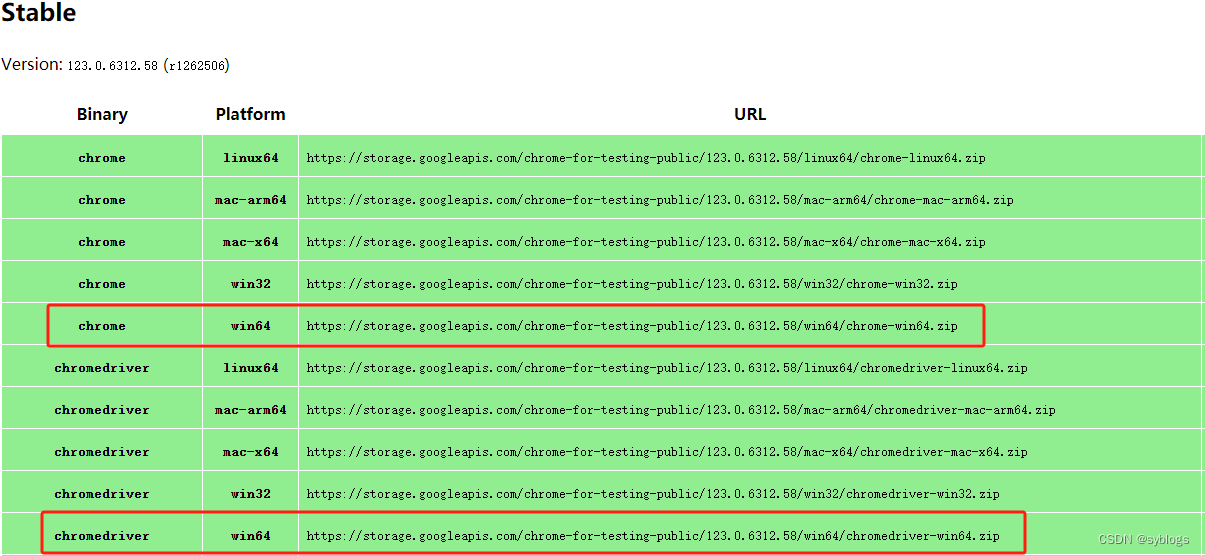
Chrome 73 版本以后, ChromeDriver 和 Chrome 版本是一对一,版本号是一样的。
查看网址:Chrome for Testing availability
“安装路径展示”
(一)批量下载 PDF 文件
1.使用Selenium模块爬取多页内容
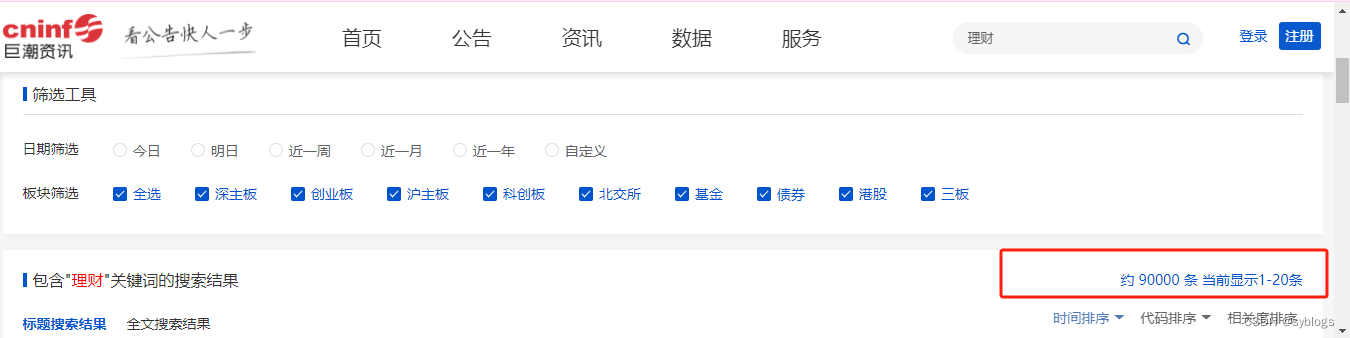
Eg:以下载巨潮资讯网的上市公司公告PDF文件为例。
“获取公告总数”
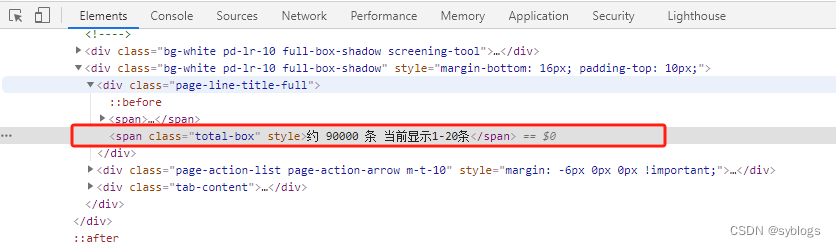
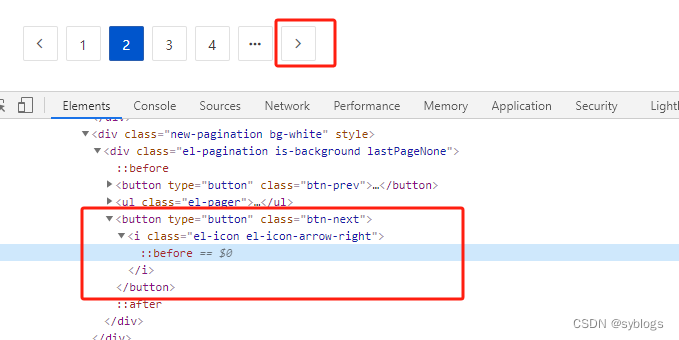
“获取[下一页]单击按钮”
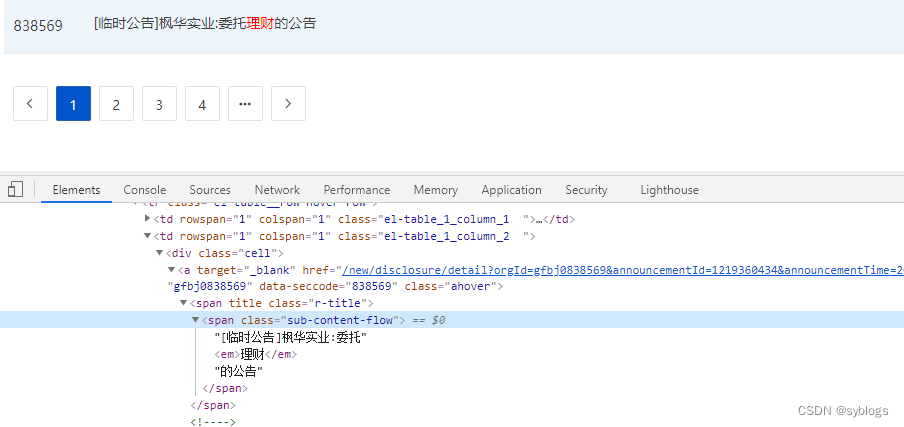
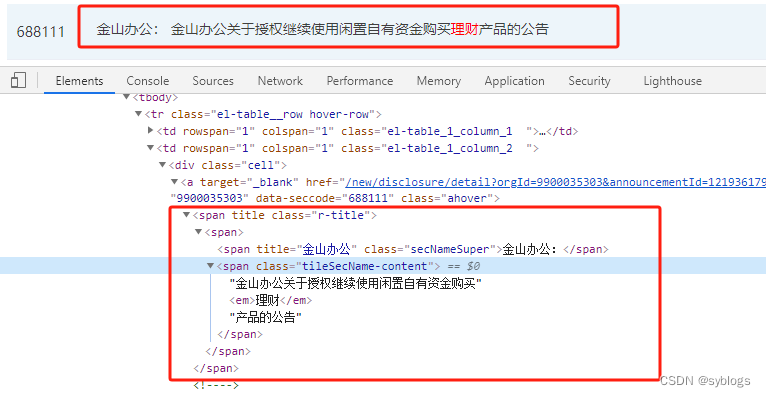
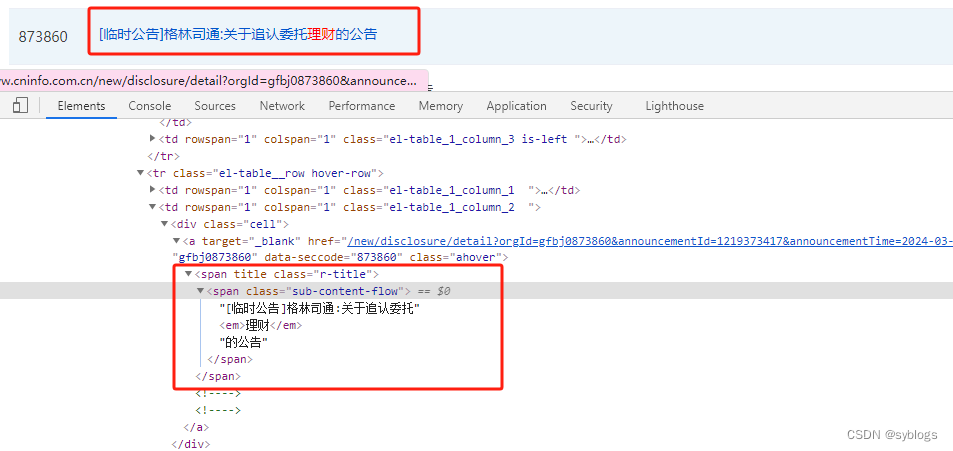
“获取公告标题和网址”
"python程序完整代码"
在Selenium 4之后的版本中,由于引入了新的查找策略,原来的基于
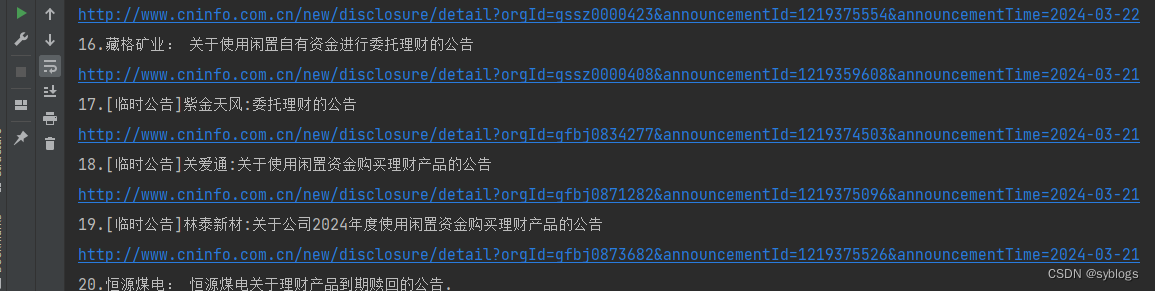
by_*方法的查找方式已经被弃用,需要使用新的方法。“find_element”配合By类来进行元素定位。# 利用Selenium模块模拟鼠标单击"下一页"按钮 from selenium import webdriver from selenium.webdriver.common.by import By import time import re# 1.获取公告总数和单页次数 browser = webdriver.Chrome() url = "http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=理财" browser.get(url) time.sleep(5) data = browser.page_source p_count = '<span class="total-box" style="">约 (.*?) 条' count = re.findall(p_count, data)[0] pages = int(int(count) / 10) # 2.用Selenium模块模拟单击”下一页“按钮 datas = [] datas.append(data) for i in range(1):browser.find_element(By.XPATH,'//*[@id="fulltext-search"]/div[2]/div/div/div[3]/div[3]/div[2]/div/button[2]',).click()time.sleep(3)data = browser.page_sourcedatas.append(data)time.sleep(3) # 3.将列表转换为字符串 alldata = "".join(datas) browser.quit() # 4.通过正则表达式提取公告标题和网址 p_title = '<span title="" class="r-title">(.*?)</a>' p_href = '<a target="_blank" href="(.*?)".*?<span title=' # 5.将提取公告标题和网址的正则表达式应用到汇总了所有页面源代码的字符串变量alldata中 title = re.findall(p_title, alldata) href = re.findall(p_href, alldata) # 6.对爬取到的数据进行清洗工作 for i in range(len(title)):title[i] = re.sub("<.*?>", "", title[i])href[i] = "http://www.cninfo.com.cn" + href[i]href[i] = re.sub("amp;", "", href[i])print(str(i + 1) + "." + title[i])print(href[i])"程序运行结果展示"
2.使用Selenium模块下载PDF文件
在搜索”理财“的结果网址:
http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=理财中,单击任意一个公告标题,打开公告PDF文件的下载页面,网址变更为:
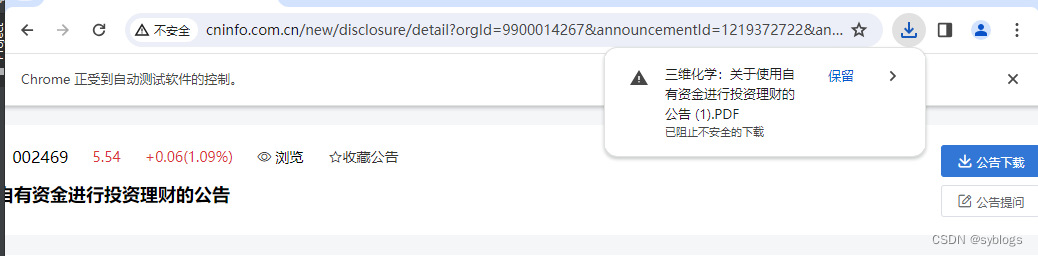
http://www.cninfo.com.cn/new/disclosure/detail?orgId=9900014267&announcementId=1219372722&announcementTime=2024-03-22自动下载页面PDF文件,使用Selenium模块模拟单击页面中的”公告下载“
查看源码,右键获取“公告下载”按钮的XPath内容:
//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button"
文件存在危险,因此 Chrome 已将其拦截"
"python程序完整代码【单公告】"
# 利用Selenium模块模拟鼠标单击"下一页"按钮 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service import time# 设置Chrome驱动本地目录 chromedriver_path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver-win64\\chromedriver.exe" # 创建ChromeOptions对象并设置下载目录 chrome_options = Options() # 启用无头模式,隐藏 Chrome 窗口以在后台执行。 chrome_options.add_argument("--headless") # 禁用 GPU 加速。 chrome_options.add_argument("--disable-gpu") # 这两个参数通常用于 Docker 容器中运行测试。 # chrome_options.add_argument("--no-sandbox") # 运行在没有沙箱的环境中 # chrome_options.add_argument("--disable-dev-shm-usage") # 禁用/dev/shm目录用于临时文件存储 # 隐身模式(无痕模式) chrome_options.add_argument("--incognito") # 设置浏览器的下载参数 chrome_options.add_experimental_option("prefs",{"download.default_directory": r"D:\pppp\第4章\批量下载的PDF文件\公告", # 指定文件下载路径。"download.prompt_for_download": False, # 禁用下载提示对话框(直接开始下载)。"download.directory_upgrade": True, # 启用目录升级,以确保文件下载到指定的文件夹。"download_restrictions": 0, # 禁用下载保护,允许下载所有类型的内容。"safebrowsing_for_trusted_sources_enabled": False, # 禁用针对受信任来源的安全浏览。"safebrowsing.enabled": False, # 禁用安全浏览,允许下载被 Chrome 识别为不安全的文件。}, ) # 说明: Selenium从4.10以后不再支持executeable_path参数了,需要使用service对象参数代替 browser = webdriver.Chrome(service=Service(chromedriver_path), options=chrome_options) browser.get("http://www.cninfo.com.cn/new/disclosure/detail?orgId=9900014267&announcementId=1219372722&announcementTime=2024-03-22" ) try:# 找到下载链接并点击下载文件browser.find_element(By.XPATH, '//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button').click()time.sleep(30)# 退出模拟浏览器。quit 必须要有,否则停留后台,需要在任务管理器中手动关闭browser.quit()print("下载完毕") except:print("没有PDF文件")"python程序完整代码【批量】"
# 利用Selenium模块模拟鼠标单击"下一页"按钮 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service import time import re# 1.获取公告总数和单页次数 browser = webdriver.Chrome() url = "http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=理财" browser.get(url) time.sleep(5) data = browser.page_source p_count = '<span class="total-box" style="">约 (.*?) 条' count = re.findall(p_count, data)[0] pages = int(int(count) / 10) # 2.用Selenium模块模拟单击”下一页“按钮 datas = [] datas.append(data) for i in range(1):browser.find_element(By.XPATH,'//*[@id="fulltext-search"]/div[2]/div/div/div[3]/div[3]/div[2]/div/button[2]',).click()time.sleep(3)data = browser.page_sourcedatas.append(data)time.sleep(3) # 3.将列表转换为字符串 alldata = "".join(datas) browser.quit() # 4.通过正则表达式提取公告标题和网址 p_title = '<span title="" class="r-title">(.*?)</a>' p_href = '<a target="_blank" href="(.*?)".*?<span title=' # 5.将提取公告标题和网址的正则表达式应用到汇总了所有页面源代码的字符串变量alldata中 title = re.findall(p_title, alldata) href = re.findall(p_href, alldata) # 6.对爬取到的数据进行清洗工作 for i in range(len(title)):title[i] = re.sub("<.*?>", "", title[i])href[i] = "http://www.cninfo.com.cn" + href[i]href[i] = re.sub("amp;", "", href[i])print(str(i + 1) + "." + title[i])print(href[i])# 7.批量下载下载PDF文件 def driver_download():# 设置Chrome驱动本地目录chromedriver_path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver-win64\\chromedriver.exe"# 创建ChromeOptions对象并设置下载目录chrome_options = Options()# 启用无头模式,隐藏 Chrome 窗口以在后台执行。chrome_options.add_argument("--headless")# 禁用 GPU 加速。chrome_options.add_argument("--disable-gpu")# 隐身模式(无痕模式)chrome_options.add_argument("--incognito")# 设置浏览器的下载参数chrome_options.add_experimental_option("prefs",{"download.default_directory": r"D:\pppp\第4章\批量下载的PDF文件\公告", # 指定文件下载路径。"download.prompt_for_download": False, # 禁用下载提示对话框(直接开始下载)。"download.directory_upgrade": True, # 启用目录升级,以确保文件下载到指定的文件夹。"download_restrictions": 0, # 禁用下载保护,允许下载所有类型的内容。"safebrowsing_for_trusted_sources_enabled": False, # 禁用针对受信任来源的安全浏览。"safebrowsing.enabled": False, # 禁用安全浏览,允许下载被 Chrome 识别为不安全的文件。},)# 说明: Selenium从4.10以后不再支持executeable_path参数了,需要使用service对象参数代替browser = webdriver.Chrome(service=Service(chromedriver_path), options=chrome_options)return browserfor i in range(len(href)):browser = driver_download()browser.get(href[i])try:# 找到下载链接并点击下载文件browser.find_element(By.XPATH, '//*[@id="noticeDetail"]/div/div[1]/div[3]/div[1]/button').click()time.sleep(30)# 退出模拟浏览器。quit 必须要有,否则停留后台,需要在任务管理器中手动关闭browser.quit()print("下载完毕")except:print("没有PDF文件")

3.使用urllib模块来进行网页的下载和保存
案例:网址:
沅陵县国民经济和社会发展第十四个五年规划和二〇三五年远景目标纲要 - 沅陵县人民政府
“Python程序完整代码”
import os.pathfrom selenium import webdriver from selenium.webdriver.common.by import By from urllib.request import urlretrieve from selenium.webdriver.chrome.service import Service import time# 设置Chrome驱动本地目录 chromedriver_path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver-win64\\chromedriver.exe" # 说明: Selenium从4.10以后不再支持executeable_path参数了,需要使用service对象参数代替 browser = webdriver.Chrome(service=Service(chromedriver_path)) url = "http://www.yuanling.gov.cn/yuanling/c132955/202112/ac08a665e96644ad8e6e31215f518c77.shtml" browser.get(url) time.sleep(2) # XPath选择所有图片 img_elements = browser.find_elements(By.XPATH, "/html/body/div[2]/div[2]/div[2]/div/img" ) # 循环遍历图片元素并下载图片 for img in img_elements:src = img.get_attribute("src")print(src.title())# src为要下载文件的URL地址;filename参数用于指定下载后文件的保存路径和文件名。urlretrieve(src, filename=os.path.join("D:\\pppp\\test\\", src.split("/")[-1])) # 关闭WebDriver browser.quit()"查看下载图片"
4.使用urllib&Selenium模块判断下载和保存
如果图片是Base64编码的,则会进行解码后保存;否则,会直接根据图片的源地址进行保存。
“Python程序完整代码”
import os.pathfrom selenium import webdriver from selenium.webdriver.common.by import By from urllib.request import urlretrieve from selenium.webdriver.chrome.options import Options from selenium.webdriver.chrome.service import Service import time# 设置Chrome驱动本地目录 chromedriver_path = "C:\\Program Files\\Google\\Chrome\\Application\\chromedriver-win64\\chromedriver.exe" # 创建ChromeOptions对象并设置下载目录 chrome_options = Options() # 启用无头模式,隐藏 Chrome 窗口以在后台执行。 chrome_options.add_argument("--headless") # 禁用 GPU 加速。 chrome_options.add_argument("--disable-gpu") # 隐身模式(无痕模式) chrome_options.add_argument("--incognito") # 设置浏览器的下载参数 chrome_options.add_experimental_option("prefs",{"download.default_directory": r"D:\pppp\test2", # 指定文件下载路径。"download.prompt_for_download": False, # 禁用下载提示对话框(直接开始下载)。"download.directory_upgrade": True, # 启用目录升级,以确保文件下载到指定的文件夹。"download_restrictions": 0, # 禁用下载保护,允许下载所有类型的内容。"safebrowsing_for_trusted_sources_enabled": False, # 禁用针对受信任来源的安全浏览。"safebrowsing.enabled": False, # 禁用安全浏览,允许下载被 Chrome 识别为不安全的文件。}, ) # 说明: Selenium从4.10以后不再支持executeable_path参数了,需要使用service对象参数代替 browser = webdriver.Chrome(service=Service(chromedriver_path), options=chrome_options) url = "http://www.yuanling.gov.cn/yuanling/c132955/202112/ac08a665e96644ad8e6e31215f518c77.shtml" browser.get(url) time.sleep(2) # XPath选择所有图片 img_elements = browser.find_elements(By.XPATH, "/html/body/div[2]/div[2]/div[2]/div/img" ) # 循环遍历图片元素并下载图片 counter = 1 for img in img_elements:try:# 获取图片的源地址src = img.get_attribute("src")# 如果图片是Base64编码的,则需要解码并保存if src.startswith("data:image"):import base64data = src.split(",")[1]with open(f"image_{counter}.png", "wb") as file:file.write(base64.b64decode(data))else:# 直接通过源地址保存图片import urllib.requesturllib.request.urlretrieve(src, filename=os.path.join("D:\\pppp\\test2\\", f"image_{counter}.png"))counter += 1except Exception as e:print(f"Error saving image: {e}")# 关闭浏览器 browser.quit()“下载保存结果展示”
(二)批量合并 PDF 文件
“合并前PDF文件”
“Python完整程序代码”
# 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path# 使用Python第三方模块PyPDF2来操控PDF文件.PdfReader类用于读取PDF文件,PdfMerger类用于合并PDF文件 from PyPDF2 import PdfReader, PdfMerger# 1.设置相关文件夹路径 src_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\") des_file = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\合并后的公告文件.PDF") if not des_file.parent.exists():des_file.parent.mkdir(parents=True) file_list = list(src_folder.glob("*.PDF")) # 2.逐个读取PDF文件并进行合并 merger = PdfMerger() outputPages = 0 for pdf in file_list:inputfile = PdfReader(str(pdf))merger.append(inputfile)pageCount = len(inputfile.pages)print(f"{pdf.name} 页数:{pageCount}")outputPages += pageCount # 3.将合并后的PDF文件写入指定的路径中 merger.write(str(des_file)) # 4.关闭PdfFileMerger对象,释放占用的系统资源 merger.close() print(f"\n合并后的总页数:{outputPages}")“合并后的PDF文件”

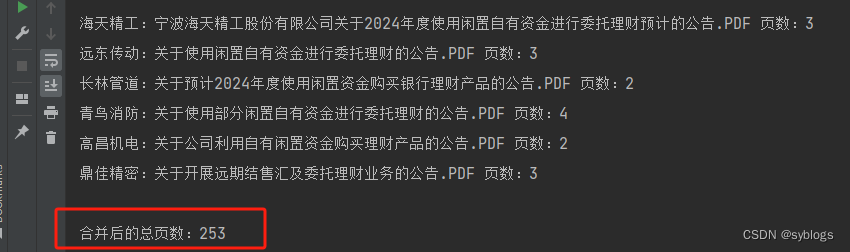

(三)批量拆分 PDF 文件
“Python程序完整代码”
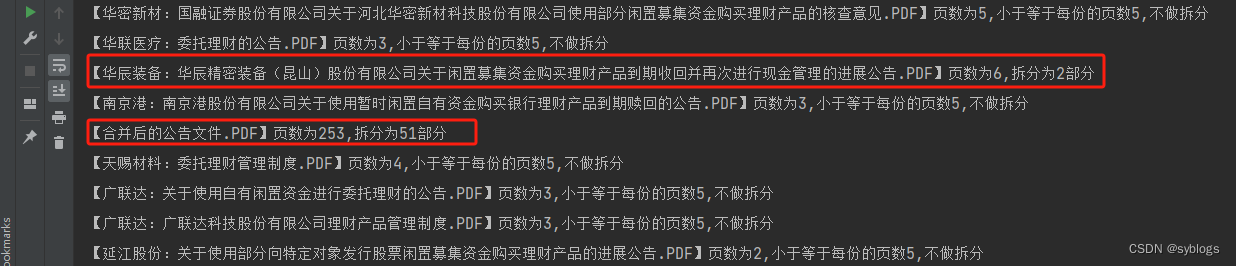
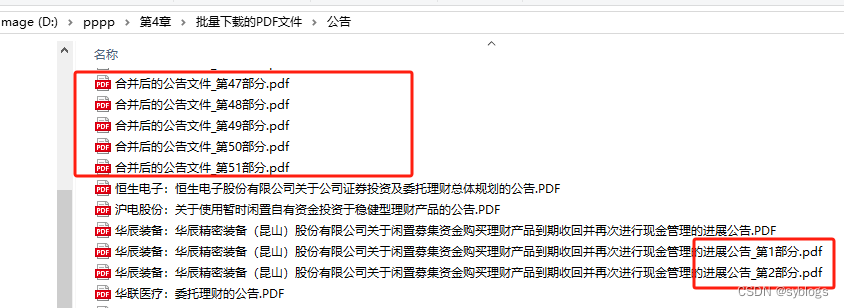
# 采用按照固定页数进行拆分的方式 # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path# 使用Python第三方模块PyPDF2来操控PDF文件.PdfReader类用于读取PDF文件,PdfWriter类用于输出PDF文件 from PyPDF2 import PdfReader, PdfWriter# 1.0 设置相关文件夹路径 src_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\") file_list = list(src_folder.glob("*.PDF")) # 2.0 逐个读取PDF文件并获取页数,计算拆分后的份数,每份的页数设置为5 step = 5 for pdf in file_list:inputfile = PdfReader(str(pdf))pages = len(inputfile.pages)if pages <= step:print(f"【{pdf.name}】页数为{pages},小于等于每份的页数{step},不做拆分")continueparts = pages // step + 1# 3.0 根据份数进行循环,计算每一份的开始页码和结束页码for pt in range(parts):start = step * ptif pt != (parts - 1):end = start + step - 1else:end = pages - 1# 4.0 拆分PDF文件,调用路径对象的stem属性获取文件的主名outputfile = PdfWriter()for pn in range(start, end + 1):outputfile.add_page(inputfile.pages[pn])pt_name = f"{pdf.stem}_第{pt+1}部分.pdf"pt_file = src_folder / pt_namewith open(pt_file, "wb") as f_out:outputfile.write(f_out)# 5.0 输出拆分完毕的信息print(f"【{pdf.name}】页数为{pages},拆分为{parts}部分")“批量拆分后的信息”
(四)批量加密 PDF 文件
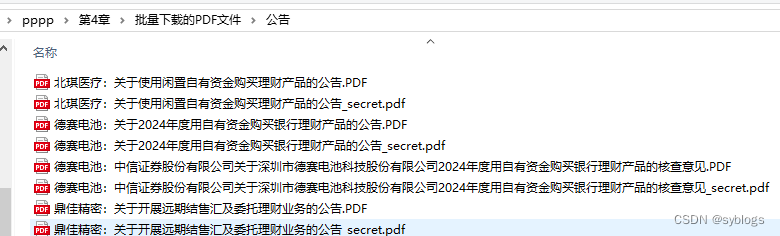
为PDF文件设置打开密码来防止泄密。
“Python完整代码”
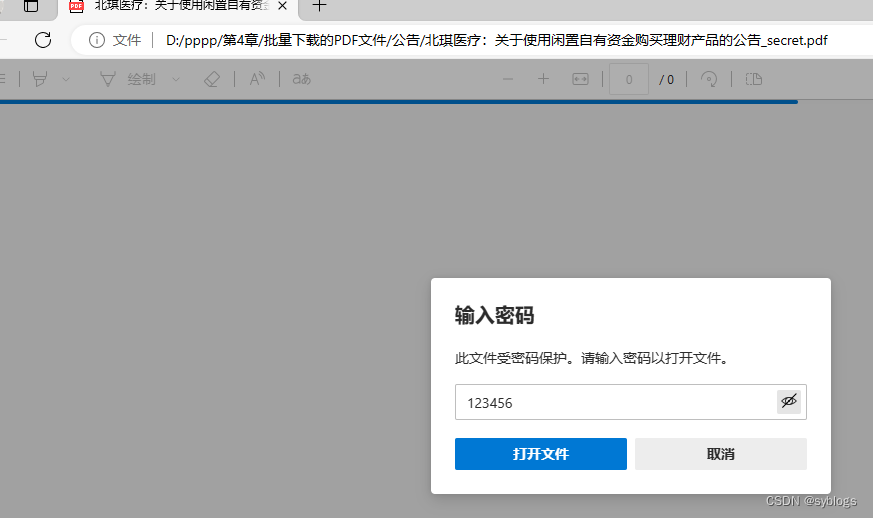
""" 为PDF文件设置打开密码来防止泄密 """ # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path# 使用Python第三方模块PyPDF2来操控PDF文件.PdfReader类用于读取PDF文件,PdfWriter类用于输出PDF文件 from PyPDF2 import PdfReader, PdfWriter# 1.0 设置相关文件夹路径 src_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\") file_list = list(src_folder.glob("*.PDF")) # 2.0 逐个读取PDF文件 for pdf in file_list:inputfile = PdfReader(str(pdf))outputfile = PdfWriter()pageCount = len(inputfile.pages)for page in range(pageCount):outputfile.add_page(inputfile.pages[page])# 3.0 将PDF文件的打开密码设置为“123456”outputfile.encrypt("123456")# 4.0 设置加密后的PDF文件名des_name = f"{pdf.stem}_secret.pdf"des_file = src_folder / des_namewith open(des_file, "wb") as f_out:outputfile.write(f_out)“查看加密文件”
(五)批量为 PDF 文件添加水印
为了防止PDF文件内容被他人随意盗用,可以为PDF文件添加水印。
1.自定义函数创建水印文件
要批量添加水印,需准备一个PDF格式的水印文件。
“Python程序代码”
""" 为PDF文件添加水印,防止他人随意盗用 """ # 导入pathlib模块中的Path()函数,用于完成路径相关操作 from pathlib import Path# 使用Python第三方模块PyPDF2来操控PDF文件.PdfReader类用于读取PDF文件,PdfWriter类用于输出PDF文件 from PyPDF2 import PdfReader, PdfWriter# 使用Python第三方模块reportlab来制作水印文件 from reportlab.lib.units import cm from reportlab.pdfgen import canvas import reportlab.pdfbase.ttfontsdef create_watermark(content):"""自定义函数:创建水印文件,并对水印文字的字体,字号等格式进行设置"""# 设置水印文件的文件名file_name = "水印.PDF"# 设置水印文件的页面大小,默认大小是21cm×29.7cma = canvas.Canvas(file_name, pagesize=(30 * cm, 30 * cm))# 设置页面的坐标原点,默认(0,0)左下角a.translate(5 * cm, 0 * cm)# 注册水印文字要使用的字体,注意:如果水印文字为中文,需使用显示中文的字体,否则水印文字会显示为乱码reportlab.pdfbase.pdfmetrics.registerFont(reportlab.pdfbase.ttfonts.TTFont("阿里巴巴普惠体", "D:\\pppp\\第4章\\Alibaba-PuHuiTi-Regular.ttf"))# 设置水印文字的字体a.setFont("阿里巴巴普惠体", 25)# 设置水印文字的旋转角度a.rotate(30)# 设置水印文字的填充颜色a.setFillColorRGB(0, 0, 0)# 设置水印文字的透明度a.setFillAlpha(0.2)# 在页面绘制6行6列的水印文字for i in range(0, 30, 5):for j in range(0, 30, 5):# drawString()的前两个参数为文字的坐标,第三个参数为文字的内容a.drawString(i * cm, j * cm, content)a.save()return file_name
2.自定义函数添加水印
为每一页PDF都添加水印。
“Python程序代码”
def add_watermark(pdf_file_in, pdf_file_mark, pdf_file_out):"""自定义函数:为每一页PDF文件添加水印"""outputfile = PdfWriter()inputfile = PdfReader(pdf_file_in)pageCont = len(inputfile.pages)markfile = PdfReader(pdf_file_mark)# 读取PDF文件的每一页,与水印文件融合后添加到PdfWriter对象中for i in range(pageCont):page = inputfile.pages[i]page.merge_page(markfile.pages[0])outputfile.add_page(page)with open(pdf_file_out, "wb") as f_out:outputfile.write(f_out)
3.使用循环为每个PDF文件添加水印
“Python程序代码”
# 1.0 设置相关文件夹路径 src_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告\\") des_folder = Path("D:\\pppp\\第4章\\批量下载的PDF文件\\公告添加水印后\\") if not des_folder.exists():des_folder.mkdir(parents=True) file_list = list(src_folder.glob("*.PDF")) # 2.0依次为每个PDF文件添加水印 for pdf in file_list:pdf_file_in = str(pdf)# 设置水印的文本内容pdf_file_mark = create_watermark("巨潮资讯网")pdf_file_out = str(des_folder / pdf.name)add_watermark(pdf_file_in, pdf_file_mark, pdf_file_out)“水印文件查看”
相关文章:

用Python实现办公自动化(自动化处理PDF文件)
自动化处理 PDF 文件 目录 自动化处理 PDF 文件 谷歌浏览器 Chrome与浏览器驱动ChromeDriver安装 (一)批量下载 PDF 文件 1.使用Selenium模块爬取多页内容 2.使用Selenium模块下载PDF文件 3.使用urllib模块来进行网页的下载和保存 4.使用urllib…...
银河麒麟操作系统Kylin Linux 离线安装Nginx1.21.5
一、查看操作系统版本号 nkvers ############## Kylin Linux Version ################# Release: Kylin Linux Advanced Server release V10 (Lance)Kernel: 4.19.90-52.15.v2207.ky10.x86_64Build: Kylin Linux Advanced Server release V10 (SP3) /(Lance)-x86_64-Build20/…...

ApiFox 使用教程
ApiFox 使用教程 目录概述需求: 设计思路实现思路分析1.基本使用教程(Apifox 使用 Postman)Apifox 下使用 mockapifox 下 swaggerApifox 下使用 Jmeter 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show…...
github拉取的项目添加至自己的仓库
想把GitHub的开源项目拉到本地进行二开,研究了一下上传到gitee的步骤: 步骤 gitee新建仓库,仓库名与本地文件夹的名称一致,建好后gitee的页面也会有显示git命令 打开项目目录,右键打开git bash(或者在gi…...
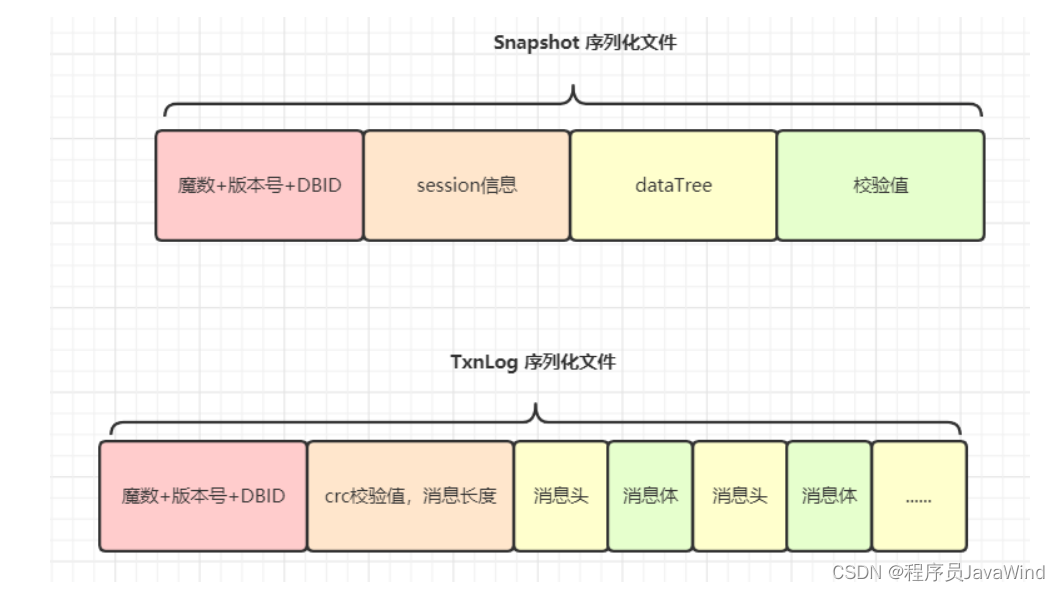
ZooKeeper 的持久化机制
持久化的定义: 数据,存到磁盘或者文件当中。机器重启后,数据不会丢失。内存 -> 磁盘的映射,和序列化有些像。 ZooKeeper 的持久化: SnapShot 快照,记录内存中的全量数据TxnLog 增量事务日志ÿ…...

VS2022+QT5.9 提示找不到qtmain.lib
从VS2013QT的项目切换到VS2022QT5.9,安装好mscv2017版本的QT5.9,项目工程选择QT project settings中的Qt Installation为mscv2017版本的QT5.9,编译好提示找不到qtmain.lib 解决思路: 提示找到xxxx.lib,第一库目录不对…...
HTTP和HTTPS谁传输数据更安全?
1.HTTP HTTP在传输数据时,通常都是明文传输,也就是传输的数据没有进行加密。在这种情况下,如果传输的是一些敏感数据,比如某银行卡密码,就很容易被别人截获到,这就对我们的个人利益产生了威胁。 HTTP传输数…...
图论)
竞赛常考的知识点大总结(七)图论
最短路 最短路问题(Shortest Path Problem)是图论中的一个经典问题,它要求在给定的图中找到两个顶点之间的最短路径。最短路问题可以是单源最短路问题(从一个顶点到其他所有顶点的最短路径)或所有对最短路问题&#x…...
NOSQL - Redis的简介、安装、配置和简单操作
目录 一. 知识了解 1. 关系型数据库与非关系型数据库 1.1 关系型数据库 1.2 非关系型数据库 1.3 区别 1.4 非关系型数据库产生背景 1.5 NOSQL 与 SQL的数据记录对比 2. 缓存相关知识 2.1 缓存概念 2.2 系统缓存 2.3 缓存保存位置及分层结构 二 . redis 相关知识 1.…...

书生·浦语大模型开源体系(二)笔记
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...
docker-compse安装es(包括IK分词器扩展)、kibana、libreoffice
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。你可以用kibana搜索、查看存放在Elasticsearch中的数据。 Kibana与Elasticsearch的交互方式是各种不同的图表、表格、地图等,直观的展示数据,从而达到高级的数据…...
Electron 读取本地配置 增加缩放功能(ctrl+scroll)
最近,一个之前做的electron桌面应用,需要增加两个功能;第一是读取本地的配置文件,然后记载配置文件中的ip地址;第二就是增加缩放功能; 第一,配置本地文件 首先需要在vue工程根目录中࿰…...
docker中配置交互式的JupyterLab环境的问题
【报错1】 Could not determine jupyter lab build status without nodejs 【解决措施】安装nodejs(利用conda进行安装/从官网下载进行安装) 1、conda安装 conda install -c anaconda nodejs 安装后出现其他报错:Please install nodejs 5 and npm bef…...

SQLAlchemy 来查询并统计 MySQL 中 JSON 字段的一个值
在使用 SQLAlchemy 来查询并统计 MySQL 中 JSON 字段的一个值时,你可以结合 SQLAlchemy 的 func 模块来实现 SQL 函数的调用,比如 JSON_EXTRACT,并使用 group_by 和 count 方法来进行分组统计。下面是如何在 SQLAlchemy 中实现这一点的基本步…...
)
HTTPS ECDHE 握手解析(计算机网络)
使用了 ECDHE,在 TLS 第四次握手前,客户端就已经发送了加密的 HTTP 数据,而对于 RSA 握手过程,必须要完成 TLS 四次握手,才能传输应用数据。 所以,ECDHE 相比 RSA 握手过程省去了一个消息往返的时间&#…...
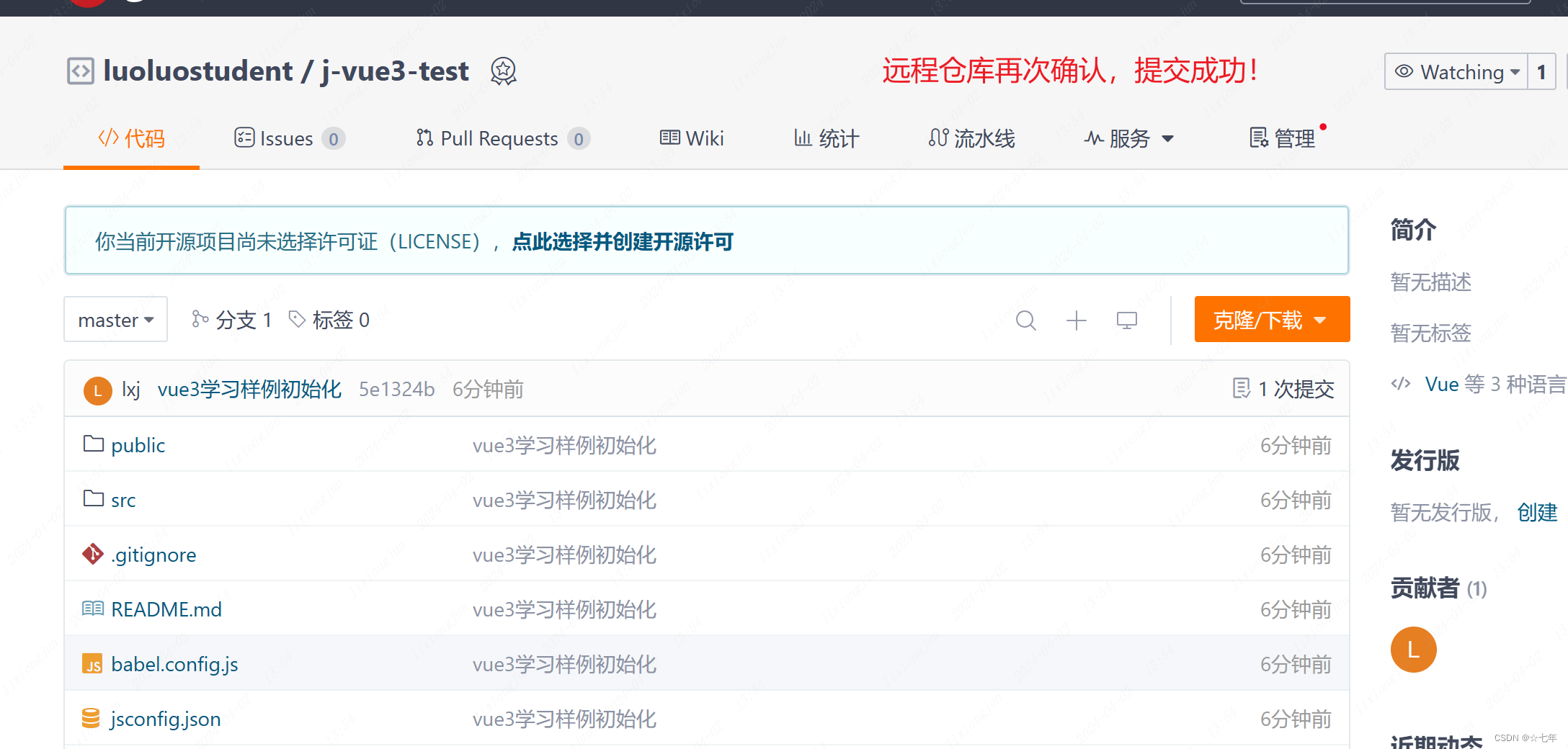
在git上先新建仓库-把本地文件提交远程
一.在git新建远程项目库 1.选择新建仓库 以下以gitee为例 2.输入仓库名称,点击创建 这个可以选择仓库私有化还公开权限 3.获取仓库clone链接 这里选择https模式就行,就不需要配置对电脑进行sshkey配置了。只是需要每次提交输入账号密码 二、远…...

Redis 过期删除策略
Redis 过期删除策略 Redis 过期删除策略主要包括两种:惰性删除(Lazy Expiration)和定期删除(Periodic Expiration)。这两种策略通常会配合使用,以在内存使用效率、CPU 资源消耗以及过期键清理的及时性之间…...

MySQL 锁合集与事务隔离级别
概览 在数据库管理中,锁是用来控制多个事务对同一数据的并发访问的机制。InnoDB作为MySQL的默认事务型存储引擎,提供了多种类型的锁来保障事务的隔离性并减少冲突,从而维护数据库的完整性和一致性。以下是InnoDB提供的主要锁类型:…...

题解 -- 第六届蓝桥杯大赛软件赛决赛C/C++ 大学 C 组
https://www.lanqiao.cn/paper/ 1 . 分机号 模拟就行 : inline void solve(){int n 0 ;for(int a1;a<9;a){for(int b0;b<9;b){for(int c0;c<9;c){if(a>b && b>c){n ;}}}}cout << n << endl ; } 2 . 五星填数 直接调用全排列的库函数…...

Lua脚本的使用
一、使用lua脚本扣减单个商品的库存 SpringBootTest class LuaTests {AutowiredStringRedisTemplate stringRedisTemplate;Testvoid test3() {for (int i 1; i < 5; i) {stringRedisTemplate.opsForValue().set("product."i,String.valueOf(i));}}Testvoid test…...

Puter云原生架构:从单体应用到微服务的转型之路
Puter云原生架构:从单体应用到微服务的转型之路 【免费下载链接】puter Puter 是一个先进、开源的互联网操作系统,旨在功能丰富、异常快速且高度可扩展,它可以用于构建远程桌面环境或作为云存储服务、远程服务器、Web托管平台等的接口。 项…...

【工业级CAN FD安全协议白皮书】:基于AUTOSAR SecOC v4.4.0的轻量级C实现,内存占用<4.2KB,认证延迟≤12μs
第一章:工业级CAN FD安全通信协议总体架构与设计目标工业级CAN FD安全通信协议面向高可靠性、强实时性与抗干扰能力要求严苛的智能制造、轨道交通及新能源车控系统场景,其总体架构以分层解耦为核心思想,融合物理层增强、链路层安全扩展、传输…...

如何用Roo Code的语音功能提升编程效率:完整指南
如何用Roo Code的语音功能提升编程效率:完整指南 【免费下载链接】Roo-Code Roo Code (prev. Roo Cline) is a VS Code plugin that enhances coding with AI-powered automation, multi-model support, and experimental features 项目地址: https://gitcode.com…...
 从零到一:三种固件烧录实战全解析)
手搓STM32H743开源飞控系列教程---(七) 从零到一:三种固件烧录实战全解析
1. 三种烧录方式的核心差异与适用场景 刚焊接完STM32H743飞控板的开发者,第一个要面对的问题就是如何把固件烧录到芯片里。我见过太多新手在这个环节卡住,要么是烧录工具连不上,要么是选错了烧录方式导致功能异常。其实STM32H743支持三种主流…...

基于Autoware与ROS的相机-激光雷达联合标定实战指南
1. 为什么需要相机-激光雷达联合标定 在自动驾驶和机器人领域,相机和激光雷达是最常用的两种传感器。相机能提供丰富的纹理和颜色信息,但对距离感知较弱;激光雷达能精确测量物体距离,却缺乏颜色和纹理细节。要让它们优势互补&…...

多模态Agent持续学习新思路,解决工具使用和编排两大难题!
本文介绍了XSkill,一种用于多模态Agent的持续学习方法。XSkill通过将“过往经历”沉淀为Skills(技能)和Experiences(经验)两类可复用知识,并形成闭环,有效解决了当前多模态Agent在真实开放环境中…...

YOLOv8车辆跟踪避坑指南:BoT-SORT和ByteTrack算法选择与优化技巧
YOLOv8车辆跟踪避坑指南:BoT-SORT和ByteTrack算法选择与优化技巧 在智能交通和自动驾驶领域,车辆跟踪技术的精准度和实时性直接影响着整个系统的可靠性。YOLOv8作为当前最先进的目标检测框架之一,配合不同的跟踪算法可以展现出截然不同的性能…...

OpenEuler环境下的Apache服务器优化配置与性能调优实战
1. OpenEuler与Apache服务器基础环境搭建 在OpenEuler操作系统上部署Apache服务器是构建Web服务的第一步。OpenEuler作为一款面向企业级应用的开源Linux发行版,其稳定性与安全性使其成为服务器部署的理想选择。这里我会分享从系统准备到Apache基础安装的全流程实战经…...

M1 Mac实战:从零反编译微信小程序源码
1. 环境准备:M1 Mac的特别注意事项 在M1/M2芯片的Mac上反编译微信小程序,首先要解决架构差异带来的环境适配问题。与Intel Mac不同,Apple Silicon设备需要特别注意Node.js的版本选择和系统权限配置。我实测发现,直接使用Homebrew安…...

LaTeX科技论文写作:深度学习实验结果可视化技巧
LaTeX科技论文写作:深度学习实验结果可视化技巧 论文图表的质量直接影响审稿人对研究成果的第一印象,好的可视化能让复杂数据一目了然。 1. 为什么LaTeX是深度学习论文的首选 写深度学习论文最头疼的就是处理那些复杂的实验结果。模型性能对比、损失曲线…...