Hive on Spark 配置
目录
- 1 Hive 引擎简介
- 2 Hive on Spark 配置
- 2.1 在 Hive 所在节点部署 Spark
- 2.2 在hive中创建spark配置文件
- 2.3 向 HDFS上传Spark纯净版 jar 包
- 2.4 修改hive-site.xml文件
- 2.5 Hive on Spark测试
- 2.6 报错
1 Hive 引擎简介
Hive引擎包括:MR(默认)、tez、spark。
Hive on Spark:Hive既作为存储元数据又负责 SQL 的解析优化,语法是 HQL 语法,执行引擎变成了 Spark,Spark 负责采用 RDD 执行。
Spark on Hive:Hive 只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用 RDD 执行。
2 Hive on Spark 配置
注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。

2.1 在 Hive 所在节点部署 Spark
(1)Spark官网下载 jar 包地址:http://spark.apache.org/downloads.html
(2)上传并解压解压spark-3.0.0-bin-hadoop3.2.tgz
[huwei@hadoop101 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
[huwei@hadoop101 software]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
(3)配置 SPARK_HOME 环境变量
[huwei@hadoop101 module]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
使环境变量生效
[huwei@hadoop101 module]$ source /etc/profile.d/my_env.sh
2.2 在hive中创建spark配置文件
[huwei@hadoop101 software]$ cd /opt/module/hive-3.1.2/conf/
[huwei@hadoop101 conf]$ vim spark-defaults.conf
添加如下内容
spark.master=yarn
spark.eventLog.enabled=true
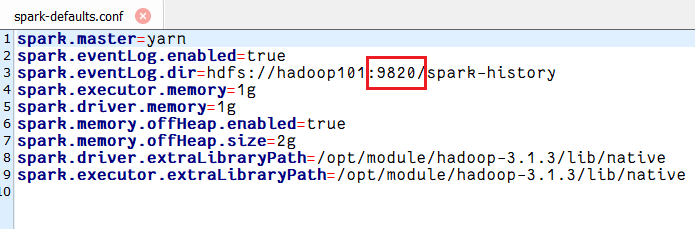
spark.eventLog.dir=hdfs://hadoop101:9820/spark-history
spark.executor.memory=1g
spark.driver.memory=1g
spark.memory.offHeap.enabled=true
spark.memory.offHeap.size=2g
spark.driver.extraLibraryPath=/opt/module/hadoop-3.1.3/lib/native
spark.executor.extraLibraryPath=/opt/module/hadoop-3.1.3/lib/native
在HDFS创建如下路径,用于存储历史日志
[huwei@hadoop101 conf]$ hadoop fs -mkdir /spark-history
2.3 向 HDFS上传Spark纯净版 jar 包
由于Spark3.0.0非纯净版默认支持的是 hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
(1)上传并解压spark-3.0.0-bin-without-hadoop.tgz
[huwei@hadoop101 conf]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz -C /opt/module/
(2)上传Spark纯净版jar包到HDFS
[huwei@hadoop101 conf]$ hadoop fs -mkdir /spark-jars
[huwei@hadoop101 conf]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
2.4 修改hive-site.xml文件
[huwei@hadoop101 conf]$ vim /opt/module/hive-3.1.2/conf/hive-site.xml
添加如下内容
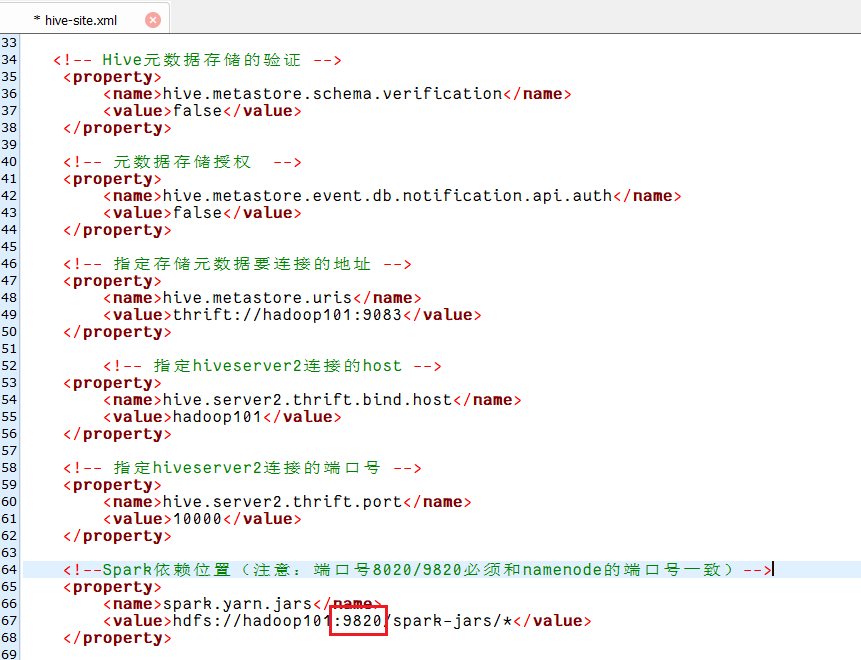
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property><name>spark.yarn.jars</name><value>hdfs://hadoop101:9820/spark-jars/*</value>
</property><!--Hive执行引擎-->
<property><name>hive.execution.engine</name><value>spark</value>
</property><!--Hive和Spark连接超时时间-->
<property><name>hive.spark.client.connect.timeout</name><value>10000ms</value>
</property>
2.5 Hive on Spark测试
(1)启动 spark
[huwei@hadoop101 ~]$ cd /opt/module/
[huwei@hadoop101 module]$ cd spark
[huwei@hadoop101 spark]$ sbin/start-all.sh(2)启动hive客户端
[huwei@hadoop101 conf]$ hive
(3)创建一张测试表
hive (default)> create table student(id int, name string);
(4)通过insert测试效果
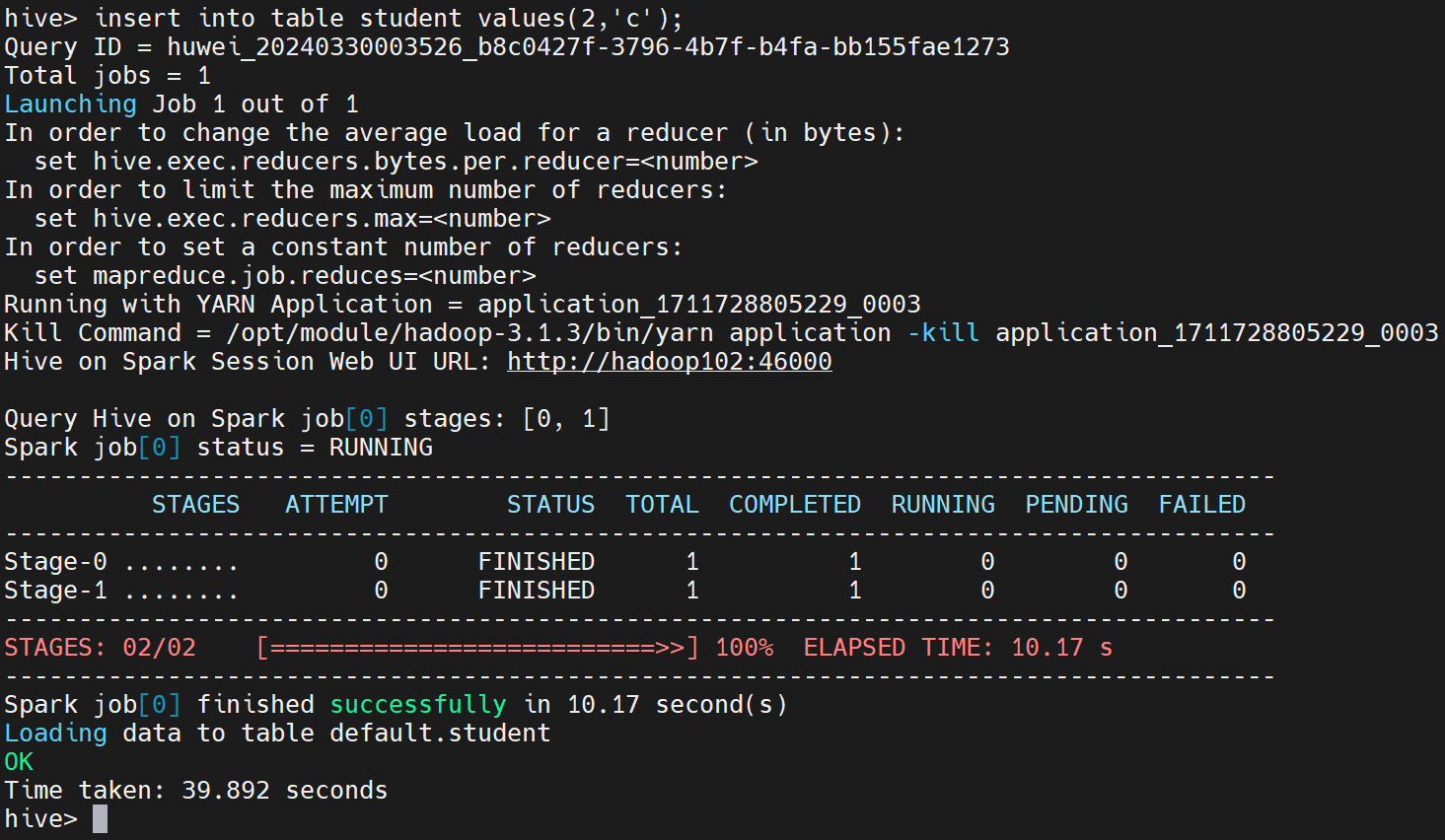
hive (default)> insert into table student values(1,'abc');
若结果如下,则说明配置成功
2.6 报错
在最后插入数据测试Hive on Spark的时候总是报错,也不是版本问题,也不是内存问题,困扰了一天了,最后发现跟着教程走的namenode端口号写成了8020,而我使用的是hadoop3版本,在安装hadoop时,将namenode端口号设的是9820
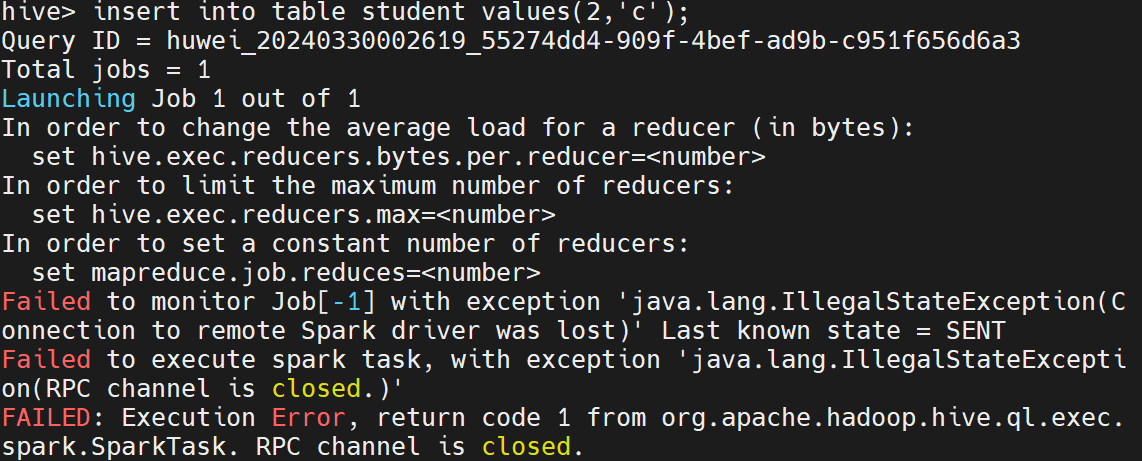
后来,我将以下两个配置文件namenode的端口号改成9820,最终才解决。
相关文章:
Hive on Spark 配置
目录 1 Hive 引擎简介2 Hive on Spark 配置2.1 在 Hive 所在节点部署 Spark2.2 在hive中创建spark配置文件2.3 向 HDFS上传Spark纯净版 jar 包2.4 修改hive-site.xml文件2.5 Hive on Spark测试2.6 报错 1 Hive 引擎简介 Hive引擎包括:MR(默认)…...

ROS 基本
ROS创建自己的功能包 ROS中工作空间(workspace)是一个存放工程开发相关文件的文件夹,其中有四个文件夹。 src:代码空间(Source Space)build:编译空间(Build Space)devel:开发空间(Development Space)install:安装空间(Install Space) OK接下来创作工作空间&#…...

Pygame基础9-射击
简介 玩家用鼠标控制飞机(白色方块)移动,按下鼠标后,玩家所在位置出现子弹,子弹匀速向右飞行。 代码 没有什么新的东西,使用两个精灵类表示玩家和子弹。 有一个细节需要注意,当子弹飞出屏幕…...

Ps:颜色查找
颜色查找 Color Lookup命令通过应用预设的 LUT 来改变图像的色彩和调性,从而为摄影师和设计师提供了一种快速实现复杂色彩调整的方法,广泛应用于颜色分级、视觉风格的统一和创意色彩效果的制作。 Ps菜单:图像/调整/颜色查找 Adjustments/Colo…...
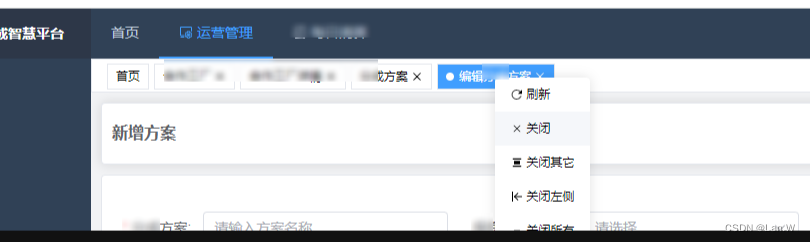
vue3+vite 模板vue3-element-admin框架如何关闭当前页面跳转 tabs
使用模版: 有来开源组织 / vue3-element-admin 需要关闭的.vue 页面增加以下方法 //setup 里import {LocationQuery, useRoute, useRouter} from "vue-router"; const router useRouter(); function close() {console.log(|--router.currentRoute.value, router.cur…...
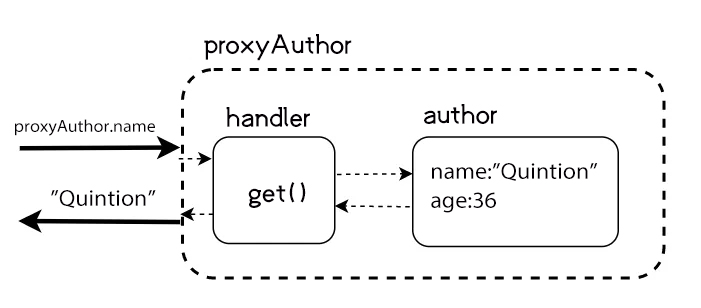
JavaScript 对象管家 Proxy
JavaScript 在 ES6 中,引入了一个新的对象类型 Proxy,它可以用来代理另一个对象,并可以在代理过程中拦截、覆盖和定制对象的操作。Proxy 对象封装另一个对象并充当中间人,其提供了一个捕捉器函数,可以在代理对象上拦截…...

Qt + Vs联合开发
Qt + Vs联合开发 文章目录 Qt + Vs联合开发环境说明VS+Qt安装注意事项QtCreator msvc编译器配置Visual Studio 2019 + Qt 5.12.10Visual Studio 2015 + Qt5.12.10VsQt环境配置安装插件 Qt Visual Studio Tools插件配置Qt创建项目Vs创建Qt项目VsQt工程转换Vs工程转Qt工程Qt工程转…...

开源知识库平台Raneto--使用Docker部署Raneto
文章目录 一、Raneto介绍1.1 Raneto简介1.2 知识库介绍 二、阿里云环境2.1 环境规划2.2 部署介绍 三、环境检查3.1 检查Docker服务状态3.2 检查Docker版本3.3 检查docker compose 版本 四、下载Raneto镜像五、部署Raneto知识库平台5.1 创建挂载目录5.2 编辑config.js文件5.3 编…...

鸿蒙原OS开发实例:【ArkTS类库单次I/O任务开发】
Promise和async/await提供异步并发能力,适用于单次I/O任务的场景开发,本文以使用异步进行单次文件写入为例来提供指导。 实现单次I/O任务逻辑。 import fs from ohos.file.fs; import common from ohos.app.ability.common;async function write(data:…...
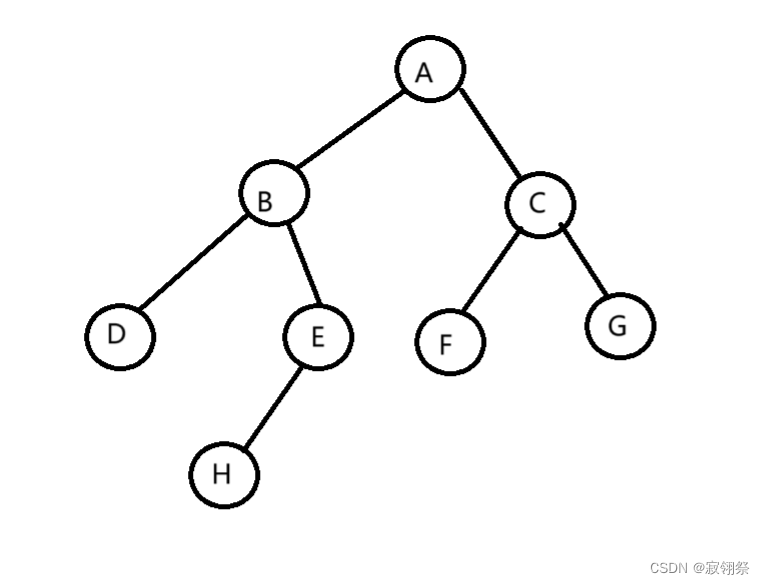
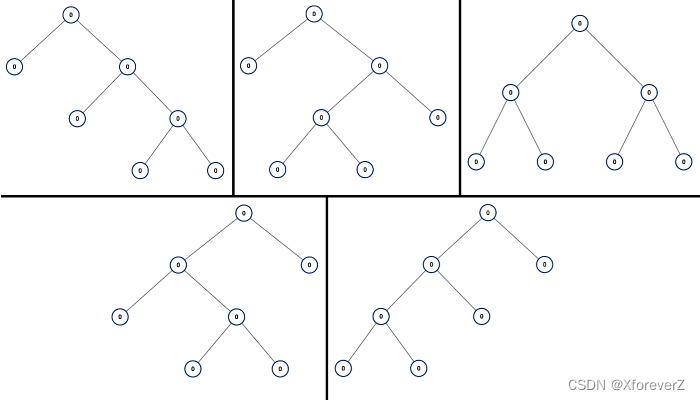
C语言:二叉树的构建
目录 一、二叉树的存储 1.1 顺序存储 1.2 链式存储 二、二叉树的顺序结构及实现 2.1堆的概念及结构 2.2堆的构建 2.3堆的插入 2.4堆顶的删除 2.5堆的完整代码 三、二叉树的链式结构及实现 3.1链式二叉树的构建 3.2链式二叉树的遍历 3.2.1前序遍历 …...

软件测试工程师面试汇总功能测试篇
Q:一、进行测试用例设计的时候用到的方法有哪些? A:最常使用的测试用例设计方法包括等价类划分法、边界值分析方法、场景法、错误推测法。其中,最容易 发现错误的是边界值法,使用最多的是场景法。以注册为例:首先从需求确定用户名…...

javaAPI1
API application pragramming interface 应用程序编程接口 除java.lang包以外,其他包中的类在使用时需要导入 建包 package com.abc.javabean; 导包格式,import 包名.类名 API使用技巧 1,先看关键字 2,看参数列表 3,看返回值类型 String 封装字符串和处理字符串的类…...

案例研究|DataEase实现物业数据可视化管理与决策支持
河北隆泰物业服务有限责任公司(以下简称为“隆泰物业”)创建于2002年,总部设在河北省高碑店市,具有国家一级物业管理企业资质,通过了质量体系、环境管理体系、职业健康安全管理体系等认证。自2016年至今,隆…...
Android Studio Iguana | 2023.2.1 补丁 1
Android Studio Iguana | 2023.2.1 Canary 3 已修复的问题Android Gradle 插件 问题 295205663 将 AGP 从 8.0.2 更新到 8.1.0 后,任务“:app:mergeReleaseClasses”执行失败 问题 298008231 [Gradle 8.4][升级] 由于使用 kotlin gradle 插件中已废弃的功能&#…...

iOS17 隐私协议适配详解
1. 背景 网上搜了很多文章,总算有点头绪了。其实隐私清单最后做出来就是一个plist文件。找了几个常用三方已经配好的看了看,比着做就好了。 WWDC23 中关于隐私部分的更新(WWDC23 隐私更新官网),其中提到了第三方 SDK 的…...
LeetCode 每日一题 Day 116-122
2580. 统计将重叠区间合并成组的方案数 给你一个二维整数数组 ranges ,其中 ranges[i] [starti, endi] 表示 starti 到 endi 之间(包括二者)的所有整数都包含在第 i 个区间中。 你需要将 ranges 分成 两个 组(可以为空…...

linux离线安装jenkins及使用教程
本教程采用jenkins.war的方式离线安装部署,在线下载的方式会遇到诸多问题,不宜采用 基本环境: 1.jdk环境,Jenkins是java语言开发的,因需要jdk环境。 2.git/svn客户端,因一般代码是放在git/svn服务器上的&a…...
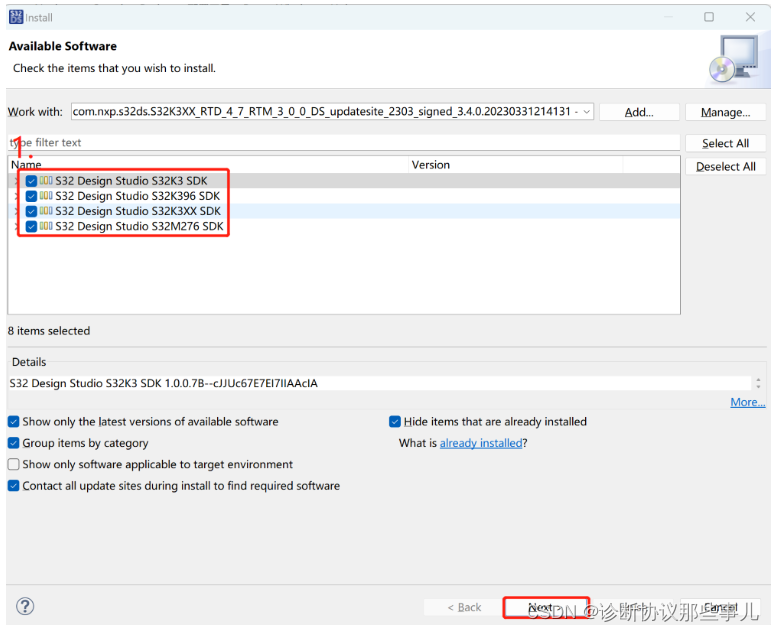
NXP-S32DS软件安装
文章目录 一、安装包获取二、S32DS安装三、芯片插件安装 一、安装包获取 登录NXP官网,进入软件目录https://www.nxp.com/ 下载S32DS软件和RTD驱动库,并安装S32DS软件。 单击“S32DS.3.5_b220726_win32.x86_64.exe”下载该软件 点击“License Keys”&…...
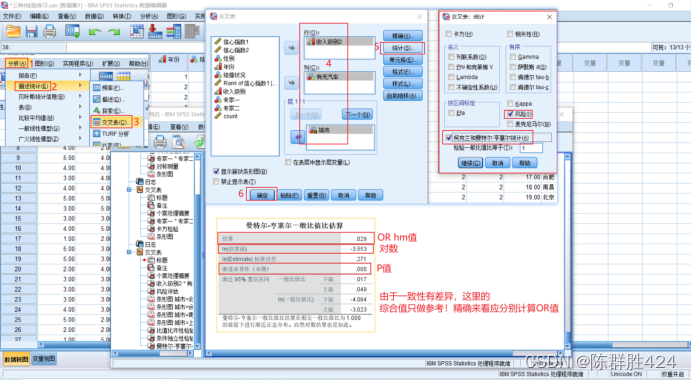
26版SPSS操作教程(初级第十五章)
前言 #由于导师最近布置了学习SPSS这款软件的任务,因此想来平台和大家一起交流下学习经验,这期推送内容接上一次第十四章的学习笔记,希望能得到一些指正和帮助~ 粉丝及官方意见说明 #针对官方爸爸的意见说的推送缺乏操作过程的数据案例文件…...
docker部署实用的运维开发手册
下载镜像 docker pull registry.cn-beijing.aliyuncs.com/wuxingge123/reference:latestdocker-compose部署 vim docker-compose.yml version: 3 services:reference:container_name: referenceimage: registry.cn-beijing.aliyuncs.com/wuxingge123/reference:latestports:…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...