一文了解Java核心知识——线程池

介绍
什么是线程池?
管理一系列线程的资源池。当有任务要处理时,直接从线程池中获取线程来处理,处理完之后线程并不会立即被销毁,而是等待下一个任务。
为什么要使用线程池?
池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
线程池提供了一种限制和管理资源(包括执行一个任务)的方式。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
创建线程池
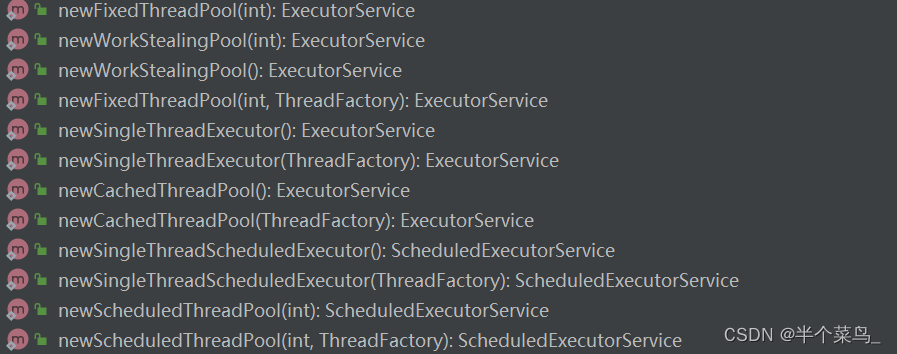
两种方式创建线程池
- 通过ThreadPoolExecutor构造函数来创建(推荐)

-
通过Executor框架的工具类Executor来创建
-
FixedThreadPool:
- 特点:该线程池维护固定数量的线程,线程数量不会变化。当有新任务提交时,如果有空闲线程,则立即执行;如果所有线程都在忙碌,新任务会暂存在任务队列中,待有线程空闲时再执行。
- 适用场景:适用于需要控制线程数量的情况,例如避免系统资源被过多的线程占用。
-
SingleThreadExecutor:
- 特点:该线程池只包含一个线程,所有任务按顺序在这个线程中执行。如果有多个任务被提交,它们会按照先入先出的顺序被放入任务队列中,等待线程执行。
- 适用场景:适用于需要保证任务按顺序执行的场景,例如需要按照队列中的顺序处理任务。
-
CachedThreadPool:
- 特点:该线程池的线程数量可根据实际情况动态调整。初始时,线程池中不包含任何线程。当有新任务提交时,如果没有可用线程,则会创建新线程处理任务;如果线程在一段时间内闲置,会被销毁以节省资源。
- 适用场景:适用于任务数量和任务执行时间不确定的情况,能够根据需求动态调整线程数量。
-
ScheduledThreadPool:
- 特点:该线程池用于在给定的延迟后运行任务或者定期执行任务。可以设置核心线程数量,根据需要动态创建线程来处理任务。
- 适用场景:适用于需要定期执行任务或者延迟执行任务的场景,例如定时任务调度。
谈谈Executor框架创建线程池有什么不好的地方呢?
-
FixedThreadPool:
- 弊端: 固定大小的线程池使用的是无界的
LinkedBlockingQueue。当任务提交速度快于任务执行速度时,任务队列可能会持续增长,直到消耗完系统的内存资源,导致 OutOfMemoryError。此外,固定大小的线程池的线程数是固定的,可能无法应对任务数量的剧增,导致无法处理新的任务,从而造成任务堆积或请求响应延迟。
- 弊端: 固定大小的线程池使用的是无界的
-
SingleThreadExecutor:
- 弊端: 单线程的线程池使用的也是无界的
LinkedBlockingQueue,因此也存在任务队列持续增长导致内存耗尽的风险。此外,由于只有一个线程,如果该线程发生异常而终止,整个线程池就会无法处理新的任务,造成请求响应延迟或任务堆积。
- 弊端: 单线程的线程池使用的也是无界的
-
CachedThreadPool:
- 弊端: 缓存线程池使用的是同步队列
SynchronousQueue,它不会保存任务,而是会立即将任务交给线程执行。如果任务提交速度快于任务执行速度,会导致线程池不断创建新的线程,直到耗尽系统的内存资源,最终导致 OutOfMemoryError。此外,线程池中的线程数量是不受限制的,当任务数量剧增时,可能会创建大量线程,影响系统的稳定性。
- 弊端: 缓存线程池使用的是同步队列
-
ScheduledThreadPool 和 SingleThreadScheduledExecutor:
- 弊端: 定时任务线程池使用的是无界的延迟阻塞队列
DelayedWorkQueue,同样存在任务队列持续增长导致内存耗尽的风险。当定时任务提交速度快于执行速度时,任务队列可能会不断增长,最终耗尽系统的内存资源,导致 OutOfMemoryError。
- 弊端: 定时任务线程池使用的是无界的延迟阻塞队列
ThreadPoolExecutor的使用以及注意事项
这里是线程池创建的构造方法,下面我们来说说它参数的一些细节
/*** 用给定的初始参数创建一个新的ThreadPoolExecutor。*/
public ThreadPoolExecutor(int corePoolSize, // 线程池的核心线程数量int maximumPoolSize, // 线程池的最大线程数long keepAliveTime, // 当线程数大于核心线程数时,多余的空闲线程存活的最长时间TimeUnit unit, // 时间单位BlockingQueue<Runnable> workQueue, // 任务队列,用来储存等待执行任务的队列ThreadFactory threadFactory, // 线程工厂,用来创建线程,一般默认即可RejectedExecutionHandler handler // 拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务) {// 参数合法性校验if (corePoolSize < 0 ||maximumPoolSize <= 0 ||maximumPoolSize < corePoolSize ||keepAliveTime < 0)throw new IllegalArgumentException();// 参数非空性校验if (workQueue == null || threadFactory == null || handler == null)throw new NullPointerException();// 将参数赋值给对应的成员变量this.corePoolSize = corePoolSize; // 设置核心线程数this.maximumPoolSize = maximumPoolSize; // 设置最大线程数this.workQueue = workQueue; // 设置任务队列this.keepAliveTime = unit.toNanos(keepAliveTime); // 设置空闲线程的存活时间this.threadFactory = threadFactory; // 设置线程工厂this.handler = handler; // 设置拒绝策略
}
ThreadPoolExecutor 3 个最重要的参数:
- corePoolSize: 任务队列未达到队列容量时,最大可以同时运行的线程数量。
- maximumPoolSize: 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
- workQueue: 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
其他参数
- keepAliveTime:当线程数大于核心线程数时,多余的空闲线程存活的最长时间。
- unit: keepAliveTime 参数的时间单位。
- threadFactory:executor 创建新线程的时候会用到。
- handler:饱和策略。
下面举一个例子来说明这几个参数:
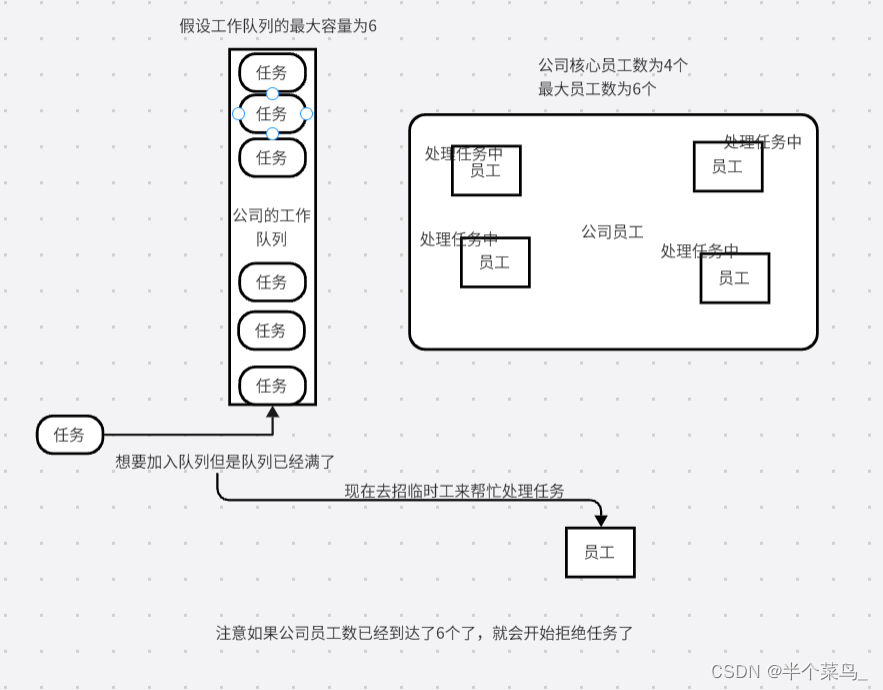
让我们将线程池比喻成一个小公司,并对其中的参数进行解释:
假设我们有一个小公司,公司员工可以处理任务,而线程池中的线程就相当于公司的员工,任务则相当于公司要处理的工作。
-
corePoolSize(核心员工数):这是公司正式员工的数量。无论工作量如何,公司始终保持这么多员工。每个员工可以同时处理一个任务。
-
maximumPoolSize(最大员工数):这是公司允许的最大员工数量,包括核心员工和临时员工。当工作量增加时,公司会招募临时员工来应对高峰时期的工作压力。
-
keepAliveTime(员工空闲时间):如果公司员工超过核心员工数量,那么多余的员工会被视为临时员工。当这些临时员工在一段时间内没有工作可做时,公司会解雇他们。这个时间就是空闲时间,超过这个时间,临时员工就会被解雇。
-
workQueue(工作队列):这是公司的工作任务队列,用来存放还未被处理的任务。如果所有的员工都在忙于处理任务,而新的任务又不断涌入,那么这些任务就会暂时放在队列中,等待员工有空闲的时候再处理。
-
threadFactory(员工招聘渠道):这是公司用来招聘新员工的渠道。线程工厂负责创建新的线程(员工),你可以自定义线程工厂来创建线程。
-
handler(拒绝任务政策):当公司处理不过来任务时,会采取一定的策略来处理。例如,可以采取拒绝策略,直接拒绝接收新任务,或者采取临时雇佣策略,暂时招募更多员工来应对高峰时期的工作压力。
下面是一个demo,在Spring Boot环境下运行
线程池配置类:
package com.pxl.bi.config;import com.pxl.bi.common.ErrorCode;
import com.pxl.bi.exception.BusinessException;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.*;import org.jetbrains.annotations.NotNull;@Configuration
@Slf4j
public class ThreadPoolExecutorConfig {@Beanpublic ThreadPoolExecutor threadPoolExecutor() {// 创建一个线程工厂ThreadFactory threadFactory = new ThreadFactory() {// 初始化线程数为 1private int count = 1;@Override// 每当线程池需要创建新线程时,就会调用newThread方法// @NotNull Runnable r 表示方法参数 r 应该永远不为null,// 如果这个方法被调用的时候传递了一个null参数,就会报错public Thread newThread(@NotNull Runnable r) {// 创建一个新的线程Thread thread = new Thread(r);// 给新线程设置一个名称,名称中包含线程数的当前值thread.setName("线程" + count);// 线程数递增count++;// 返回新创建的线程return thread;}};// 创建一个拒绝执行处理器ThreadPoolExecutor threadPoolExecutor = getThreadPoolExecutor(threadFactory);// 返回创建的线程池return threadPoolExecutor;}@NotNullprivate static ThreadPoolExecutor getThreadPoolExecutor(ThreadFactory threadFactory) {RejectedExecutionHandler rejectionHandler = new RejectedExecutionHandler() {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {// 这里可以根据具体业务需求来处理拒绝执行的任务log.error("线程处理已满,拒绝处理服务");throw new BusinessException(ErrorCode.SYSTEM_BUSY,"系统繁忙");}};// 创建一个新的线程池,线程池核心大小为2,最大线程数为4,// 非核心线程空闲时间为100秒,任务队列为阻塞队列,长度为4,使用自定义的线程工厂创建线程ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 4, 100, TimeUnit.SECONDS,new ArrayBlockingQueue<>(4), threadFactory, rejectionHandler);return threadPoolExecutor;}
}这里是任务添加控制类
package com.pxl.bi.controller;import cn.hutool.json.JSONUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Profile;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ThreadPoolExecutor;/*** 队列测试*/
@Profile({"dev","local"})
@RestController
@Slf4j
@RequestMapping("/queue")
public class QueueController {@Resourceprivate ThreadPoolExecutor threadPoolExecutor;/*** 接收一个名为name的任务,将任务添加到线程池中* @param name*/@GetMapping("/add")public void add(String name){// 使用CompletableFuture运行一个异步任务CompletableFuture.runAsync(() -> {// 打印一条日志信息,包括任务名称和执行线程的名称log.info("任务执行中:" + name + ",执行人:" + Thread.currentThread().getName());try {// 让线程休眠10分钟,模拟长时间运行的任务Thread.sleep(600000);} catch (InterruptedException e) {e.printStackTrace();}// 异步任务在threadPoolExecutor中执行}, threadPoolExecutor);}/*** 获取线程池中的信息* @return*/@GetMapping("/get")public String get(){// 创建一个HashMap存储线程池的状态信息Map<String, Object> map = new HashMap<>();//获取线程池大小int size = threadPoolExecutor.getQueue().size();// 将队列长度放入map中map.put("队列长度", size);// 获取线程池已接收的任务总数long taskCount = threadPoolExecutor.getTaskCount();// 将任务总数放入map中map.put("任务总数", taskCount);// 获取线程池已完成的任务数long completedTaskCount = threadPoolExecutor.getCompletedTaskCount();// 将已完成的任务数放入map中map.put("已完成任务数", completedTaskCount);// 获取线程池中正在执行任务的线程数int activeCount = threadPoolExecutor.getActiveCount();// 将正在工作的线程数放入map中map.put("正在工作的线程数", activeCount);// 将map转换为JSON字符串并返回return JSONUtil.toJsonStr(map);}
}
加入这两个类了,就可以使用Swagger或postman进行测试了。
线程池饱和策略
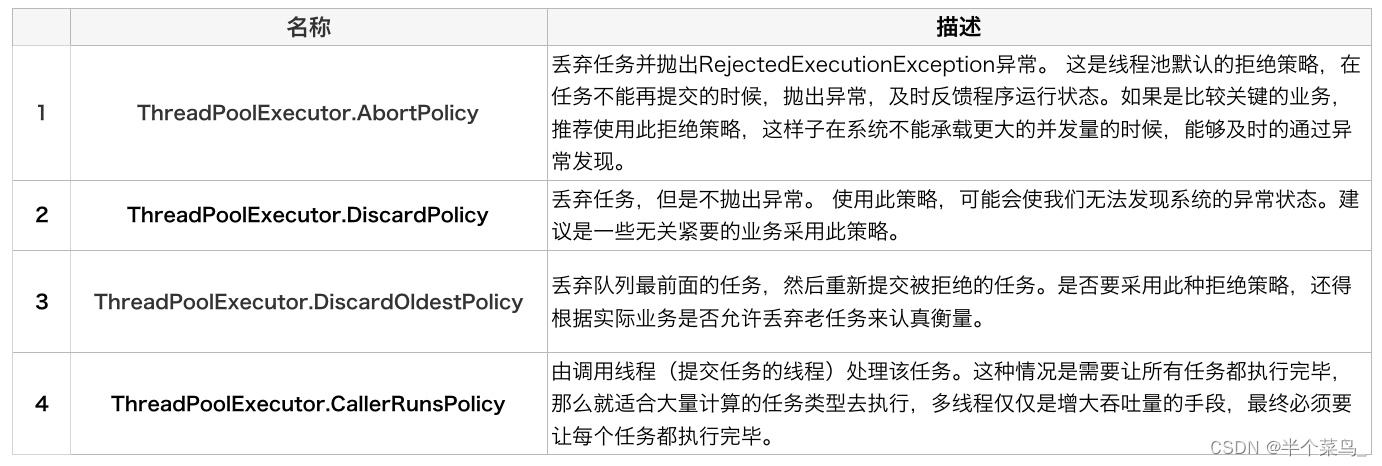
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,ThreadPoolExecutor 定义一些策略:
- ThreadPoolExecutor.AbortPolicy: 抛出 RejectedExecutionException来拒绝新任务的处理。(默认)
- ThreadPoolExecutor.CallerRunsPolicy: 调用执行自己的线程运行任务(如果任务时间过长可能会导致当前服务直接堵死)
- ThreadPoolExecutor.DiscardPolicy: 不处理新任务,直接丢弃掉。
- ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃最早的未处理的任务请求。
线程池中常用的阻塞队列有哪些

-
LinkedBlockingQueue(无界队列):
- 应用于FixedThreadPool和SingleThreadExecutor。
- 无界队列意味着队列可以无限增长,不会出现任务被拒绝的情况。在FixedThreadPool和SingleThreadExecutor中,无界队列的作用是用来存储等待执行的任务,而且这两种线程池都有固定的核心线程数,因此任务队列永远不会被放满。
-
SynchronousQueue(同步队列):
- 应用于CachedThreadPool。
- SynchronousQueue 是一个没有容量的队列,它不存储元素,而是直接将任务交给线程执行。在CachedThreadPool中,每当有任务提交时,如果有空闲线程则立即使用,如果没有则会新建一个线程来处理任务。这种设计使得CachedThreadPool的线程数可以根据需求动态地增加,但同时也会增加系统资源的消耗,可能导致OutOfMemoryError。
-
DelayedWorkQueue(延迟阻塞队列):
- 应用于ScheduledThreadPool和SingleThreadScheduledExecutor。
- DelayedWorkQueue 用于存储延迟执行的任务,并根据任务的延迟时间对任务进行排序。它的内部采用堆的数据结构,保证每次出队的任务都是当前队列中执行时间最靠前的。这种队列的特性使得ScheduledThreadPool和SingleThreadScheduledExecutor能够按照预定的时间执行任务,而且队列不会阻塞,可以动态地扩容,最多只能创建核心线程数的线程。
线程池执行流程

如何给线程池命名
两种方式实现:
-
利用 guava 的 ThreadFactoryBuilder
-
自己实现 ThreadFactory。
guava 的 ThreadFactoryBuilder
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;public class Main {public static void main(String[] args) {// 创建一个 ThreadFactoryBuilderThreadFactoryBuilder threadFactoryBuilder = new ThreadFactoryBuilder();// 设置线程名称格式threadFactoryBuilder.setNameFormat("my-pool-%d");// 创建 ThreadFactoryThreadFactory threadFactory = threadFactoryBuilder.build();// 使用自定义的 ThreadFactory 创建线程池ExecutorService executorService = Executors.newFixedThreadPool(5, threadFactory);// 提交一些任务到线程池中for (int i = 0; i < 10; i++) {executorService.submit(() -> {System.out.println(Thread.currentThread().getName() + " is executing task");});}// 关闭线程池executorService.shutdown();}
}
自己实现ThreadFactory实现命名
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;public class NamedThreadFactoryExample {public static void main(String[] args) {// 创建一个带有自定义命名的线程池ExecutorService executorService = Executors.newFixedThreadPool(5, new NamedThreadFactory("MyThreadPool"));// 提交一些任务到线程池中for (int i = 0; i < 10; i++) {executorService.submit(() -> {System.out.println(Thread.currentThread().getName() + " is executing task");});}// 关闭线程池executorService.shutdown();}
}// 自定义的线程工厂类
class NamedThreadFactory implements ThreadFactory {private final String namePrefix;public NamedThreadFactory(String namePrefix) {this.namePrefix = namePrefix;}@Overridepublic Thread newThread(Runnable r) {// 创建一个新线程,并设置名称Thread t = new Thread(r, namePrefix + "-Thread");return t;}
}
扩展
如何设置线程池大小问题
主要其实还是看具体的业务场景来看,有些时候实际处理能力或需求只有那么多,如果线程太多会导致性能上的浪费。
有一个简单并且适用面比较广的公式:
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1。(用来计算之类的操作)
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。(一般这种使用在文件传输、通信、数据库访问等方面)
如何动态修改线程池的参数
-
使用可调整的线程池实现:
- Java 并发包中提供了
ThreadPoolExecutor类的相关实现,例如ScheduledThreadPoolExecutor和ThreadPoolExecutor。它们允许你动态地修改线程池的参数,如核心线程数、最大线程数、任务队列大小等。你可以通过提供新的参数值来调用相应的 setter 方法来实现动态修改。
- Java 并发包中提供了
-
使用自定义的动态调整方法:
- 你可以编写自定义的方法来动态地调整线程池的参数。例如,你可以编写一个方法,定期检查系统的负载情况,根据负载情况动态地调整线程池的参数。这种方法需要一定的编程技巧和经验,但可以根据具体需求来实现更灵活和智能的调整。
-
使用监控工具:
- 你可以使用监控工具来监视线程池的运行状态和性能指标,如活动线程数、任务队列长度、任务完成率等。根据监控数据的分析,你可以手动或自动地调整线程池的参数。常用的监控工具包括 JConsole、VisualVM、Prometheus 等。
-
使用外部配置文件:
- 你可以将线程池的参数配置到外部配置文件中,如 properties 文件、XML 文件等。然后,在程序运行时动态地加载和解析配置文件,根据配置文件中的参数值来调整线程池的参数。这种方法适用于需要频繁修改参数但又不希望修改源代码的情况。
-
使用管理平台:
- 如果你的应用程序部署在容器或云平台上,通常会提供管理平台或控制台,你可以通过管理平台来动态地调整线程池的参数。例如,在容器管理平台中,你可以通过修改容器的环境变量或配置文件来修改线程池的参数。
下面是两个可以实现动态线程池的开源程序:
- Hippo4jopen in new window:异步线程池框架,支持线程池动态变更&监控&报警,无需修改代码轻松引入。支持多种使用模式,轻松引入,致力于提高系统运行保障能力。
- Dynamic TPopen in new window:轻量级动态线程池,内置监控告警功能,集成三方中间件线程池管理,基于主流配置中心。
相关文章:
一文了解Java核心知识——线程池
介绍 什么是线程池? 管理一系列线程的资源池。当有任务要处理时,直接从线程池中获取线程来处理,处理完之后线程并不会立即被销毁,而是等待下一个任务。 为什么要使用线程池? 池化技术的思想主要是为了减少每次获取资…...

Redis热点Key问题分析与解决
目录 一、问题现象描述 二、什么是热点Key 三、热点Key的危害 3.1 Redis节点负载过高 3.2 Redis集群负载不均 3.3 Redis集群性能下降 3.4 数据不一致 3.5 缓存击穿 四、热点Key产生的原因分析 4.1 热点数据 4.2 业务高峰期 4.3 代码逻辑问题 五、如何检测热点Key …...

深度学习armv8/armv9 cache的原理
快速链接: 【精选】ARMv8/ARMv9架构入门到精通-[目录] 👈👈👈 1、为什么要用cache? ARM 架构刚开始开发时,处理器的时钟速度和内存的访问速度大致相似。今天的处理器内核要复杂得多,并且时钟频率可以快几个数量级。然…...
Python基础之pandas:文件读取与数据处理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一、文件读取1.以pd.read_csv()为例:2.数据查看 二、数据离散化、排序1.pd.cut()离散化,以按范围加标签为例2. pd.qcut()实现离散化3.排序4.…...
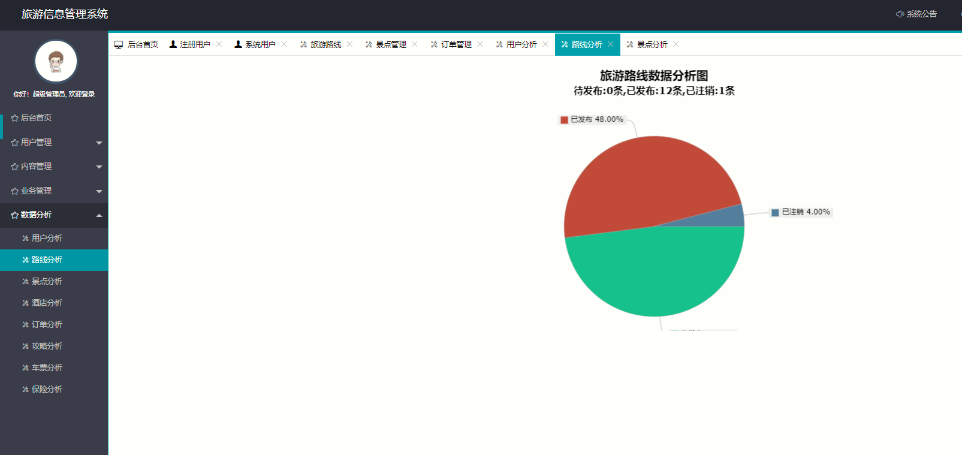
基于Springboot旅游网站管理系统设计和实现
基于Springboot旅游网站管理系统设计和实现 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言 文末获取源码联系…...

深度解析C语言——预处理详解
对C语言有一定了解的同学,相信对预处理一定不会陌生。今天我们就来聊一聊一些预处理的相关知识。预处理是在编译之前对源文件进行简单加工的过程,主要是处理以#开头的命令,例如#include <stdio.h>、#define等。预处理是C语言的一个重要…...
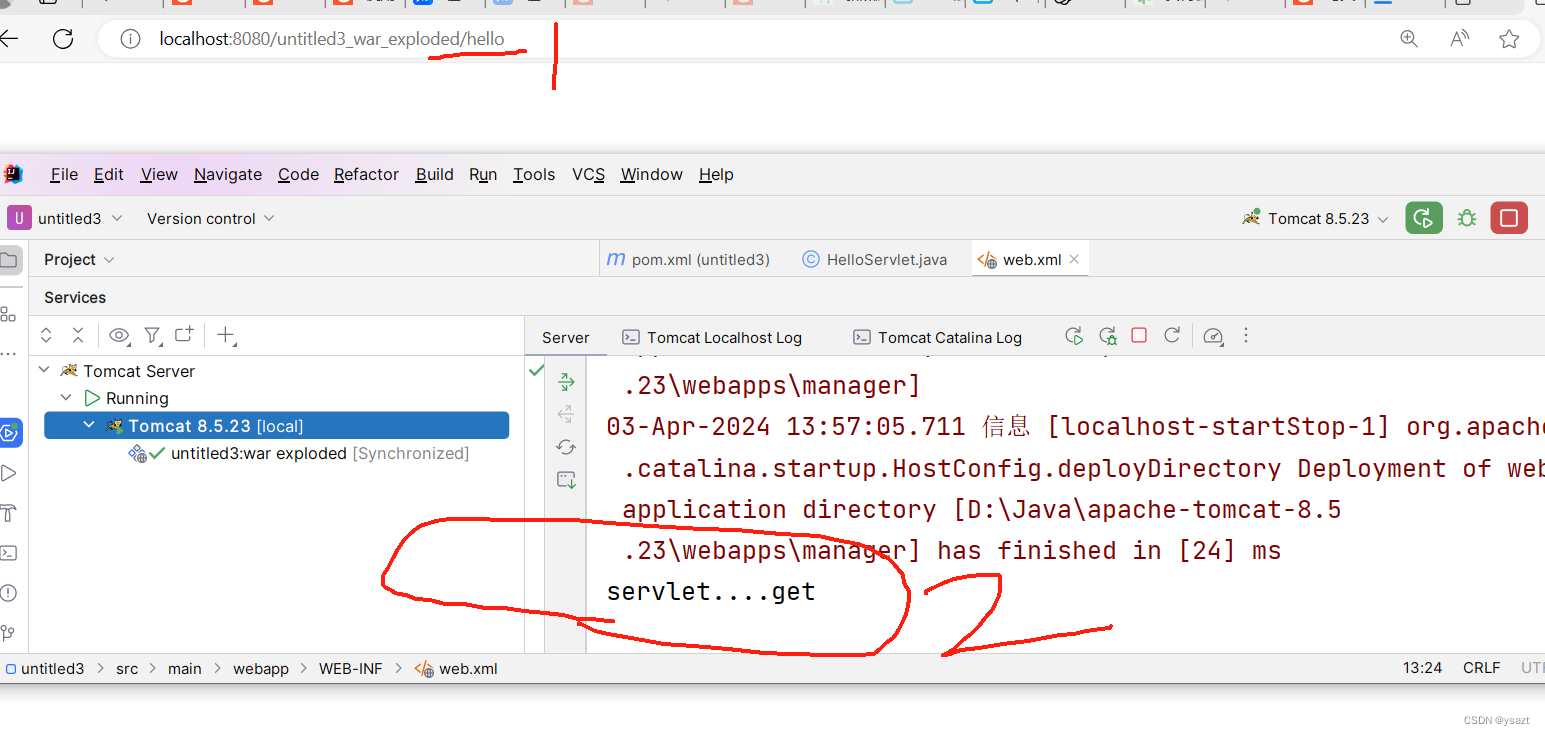
idea2023.2.1 java项目-web项目创建-servlet类得创建
如何创建Java项目 1.1 方式1: 1.2 方式: 1.3 方式 如何创建web项目 方式 ----- 推荐 如何创建servlet类 复制6 中得代码 给servlet 配置一个路径 启动tomcat 成功了...

Ollama教程——入门:开启本地大型语言模型开发之旅
Ollama教程——入门:开启本地大型语言模型开发之旅 引言安装ollamamacOSWindows预览版LinuxDocker ollama的库和工具ollama-pythonollama-js 快速开始运行模型访问模型库 自定义模型从GGUF导入模型自定义提示 CLI参考创建模型拉取模型删除模型复制模型多行输入多模态…...
基于PHP的新闻管理系统(用户发布版)
有需要请加文章底部Q哦 可远程调试 基于PHP的新闻管理系统(用户发布版) 一 介绍 此新闻管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。本新闻管理系统采用用户发布新闻,管理员审核后展示模式。 技术栈&am…...
基础篇3 浅试Python爬虫爬取视频,m3u8标准的切片视频
浅试Python爬取视频 1.页面分析 使用虾米视频在线解析使用方式:https://jx.xmflv.cc/?url目标网站视频链接例如某艺的视频 原视频链接 解析结果: 1.1 F12查看页面结构 我们发现页面内容中什么都没有,video标签中的src路径也不是视频的数据。 1.2 …...
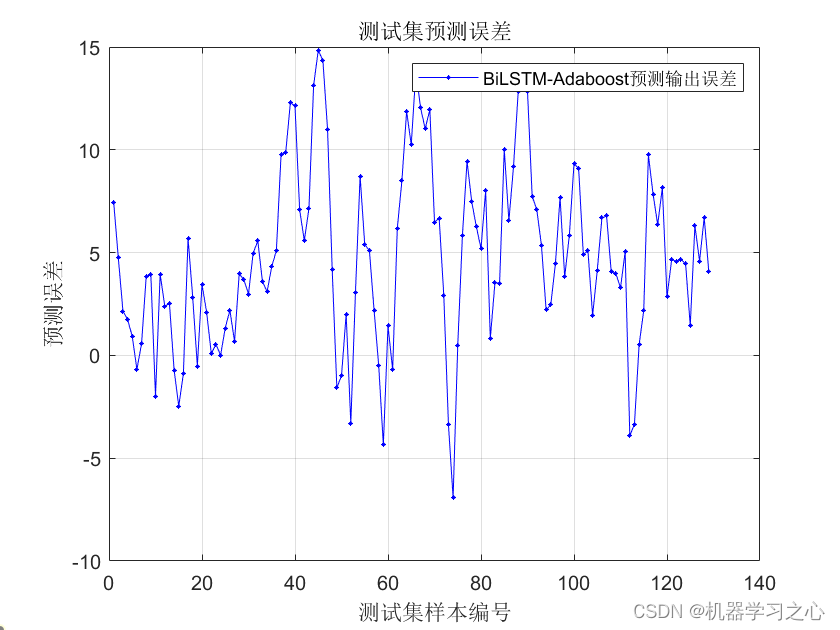
Adaboost集成学习 | Matlab实现基于BiLSTM-Adaboost双向长短期记忆神经网络结合Adaboost集成学习时间序列预测(股票价格预测)
目录 效果一览基本介绍模型设计程序设计参考资料效果一览 基本介绍 Matlab实现基于BiLSTM-Adaboost双向长短期记忆神经网络结合Adaboost集成学习时间序列预测(股票价格预测) 模型设计 股票价格预测是一个具有挑战性的时间序列预测问题,可以使用深度学习模型如双向长短期记忆…...

MySQL两表联查之分组成绩第几问题
MySQL 数据库操作实践:两表联查之分组成绩第几问题 在本篇博客中,我将展示MySQL 从创建表、到插入数据,并进行一些复杂的查询操作。 1. 建立表格 首先,我们创建两个表:department(部门)和 em…...

每日一题(leetcode2952):添加硬币最小数量 初识贪心算法
这道题如果整体去思考,情况会比较复杂。因此我们考虑使用贪心算法。 1 我们可以假定一个X,认为[1,X-1]区间的金额都可以取到,不断去扩张X直到大于target。(这里为什么要用[1,X-1]而不是[1,X],总的来说是方便,潜在思想…...

[Errno 2] No such file or directory: ‘g++‘
报错解释: 这个错误表明系统试图访问名为g++的文件或目录,但没有找到。g++是GNU编译器集合(GNU Compiler Collection)中的C++编译器。如果系统中没有安装g++或者g++不在环境变量的路径中,就会出现这个错误。 解决方法: 确认g++是否已安装: 在Linux上,可以尝试运行g+…...
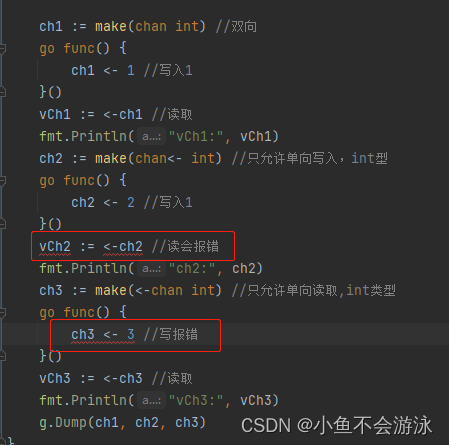
go的通信Channel
一、channel是什么 1.一种通信机制 channel是goroutine与goroutine之间数据通信的一种通信机制。一般都是2个g及以上一起工作。 channel与关键字range和select紧密相关。 二、channel的结构 go源码:GitHub - golang/go: The Go programming language src/runt…...
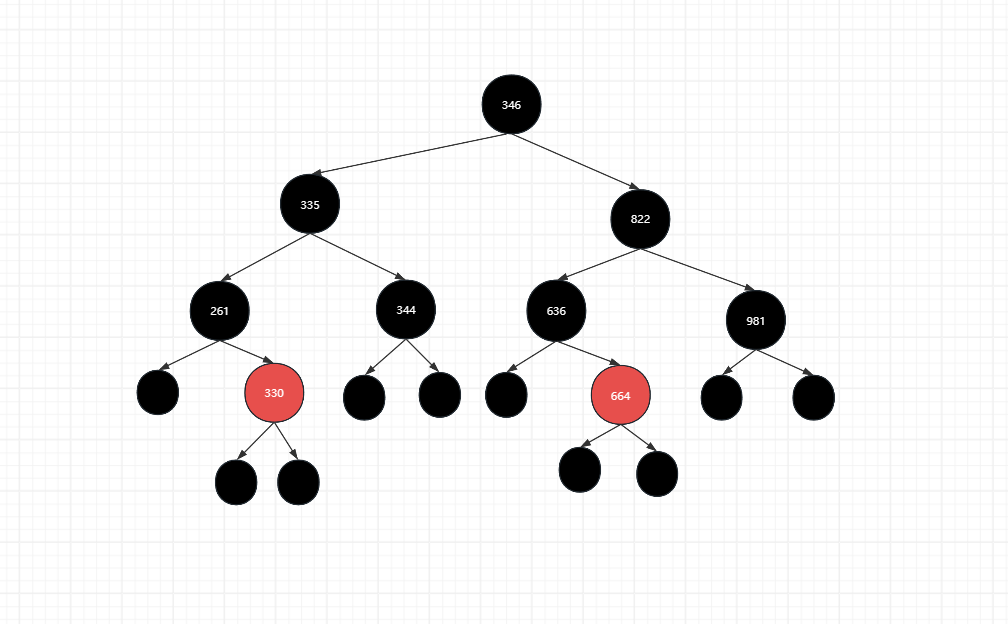
手写红黑树【数据结构】
手写红黑树【数据结构】 前言版权推荐手写红黑树一、理论知识红黑树的特征增加删除 二、手写代码初始-树结点初始-红黑树初始-遍历初始-判断红黑树是否有效查找增加-1.父为黑,直接插入增加-2. 父叔为红,颜色调换增加-3. 父红叔黑,颜色调换&am…...
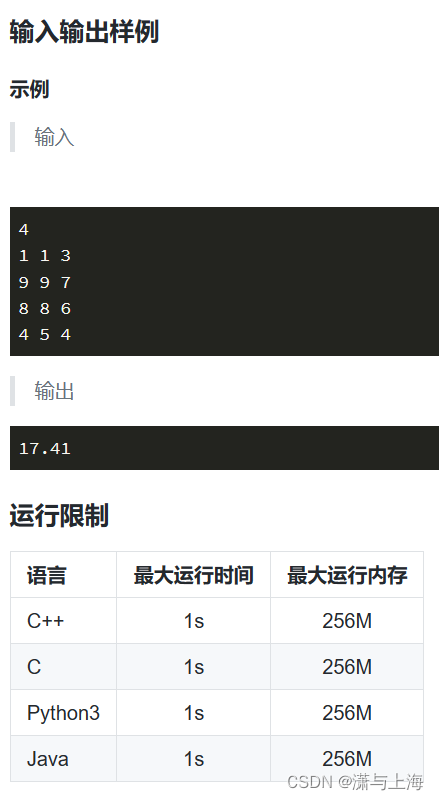
[蓝桥杯练习]通电
kruskal做法(加边) #include <bits/stdc.h> using namespace std; int x[10005],y[10005],z[10005];//存储i点的x与y坐标 int bcj[10005];//并查集 struct Edge{//边 int v1,v2; double w; }edge[2000005]; int cmp(Edge a, Edge b){return a.w < b.w;} int find(i…...

安全算法 - 摘要算法
摘要算法是一种将任意长度的数据转换为固定长度字节串的算法。它具有以下特点和应用。 首先,摘要算法能够生成一个唯一且固定长度的摘要值,用于验证数据的完整性和一致性。无论输入数据有多长,生成的摘要值始终是固定长度的,且即…...

操作系统:动静态库
目录 1.动静态库 1.1.如何制作一个库 1.2.静态库的使用和管理 1.3.安装和使用库 1.4.动态库 1.4.1.动态库的实现 1.4.2.动态库与静态库的区别 1.4.3.共享动态库给系统的方法 2.动态链接 2.1.操作系统层面的动态链接 1.动静态库 静态库(.a)&…...

车载电子电器架构 —— 局部网络管理汇总
车载电子电器架构 —— 局部网络管理汇总 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

1688商品列表API与其他数据源的对接思路
将1688商品列表API与其他数据源对接时,需结合业务场景设计数据流转链路,重点关注数据格式兼容性、接口调用频率控制及数据一致性维护。以下是具体对接思路及关键技术点: 一、核心对接场景与目标 商品数据同步 场景:将1688商品信息…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...