InstructGPT方法简读
InstructGPT方法简读
引言
仅仅通过增大模型规模和数据规模来训练更大的模型并不能使得大模型更好地理解用户意图。由于数据的噪声极大,并且现在的大多数大型语言模型均为基于深度学习的“黑箱模型”,几乎不具有可解释性和可控性,因此,大模型很可能会输出虚构的、有害的,或者对用户无用的结果。换句话说,大模型并没有与用户对齐(aligned)。本文提出了一种通过微调人类反馈来调整语言模型和用户在广泛任务中的意图的方法。从一组标注员编写的 prompt 和通过 OpenAI API 提交的 prompt 开始,本文收集了人类标注的所需模型行为的数据集,使用该数据集通过有监督学习来微调 GPT-3。然后,由标注员对模型输出的回答质量进行排序,得到一个问答质量排序数据集。使用该数据集来训练一个评分模型,为回答质量进行打分。最后结合评分模型,使用强化学习来进一步微调第一步有监督微调过的模型。得到的模型称为InstructGPT。
从 GPT 到 InstructGPT/ChatGPT:对齐(align),不仅仅是简单的语言模型(LM),而能够进行对话。
优化目标:3H:Helpful、Honest、Harmless。三点优化目标要求模型输出人类想要的信息,分别是有用、诚实和无害。
方法
如图 1 所示,由 GPT 到 InstructGPT 的训练共有三个步骤,分别是第一阶段有监督微调、第二阶段奖励模型训练、第三阶段根据 PPO 近端算法进行强化学习训练。接下来将分别从三个阶段的数据集、模型和训练目标出发,介绍 InstructGPT 的完整训练过程。
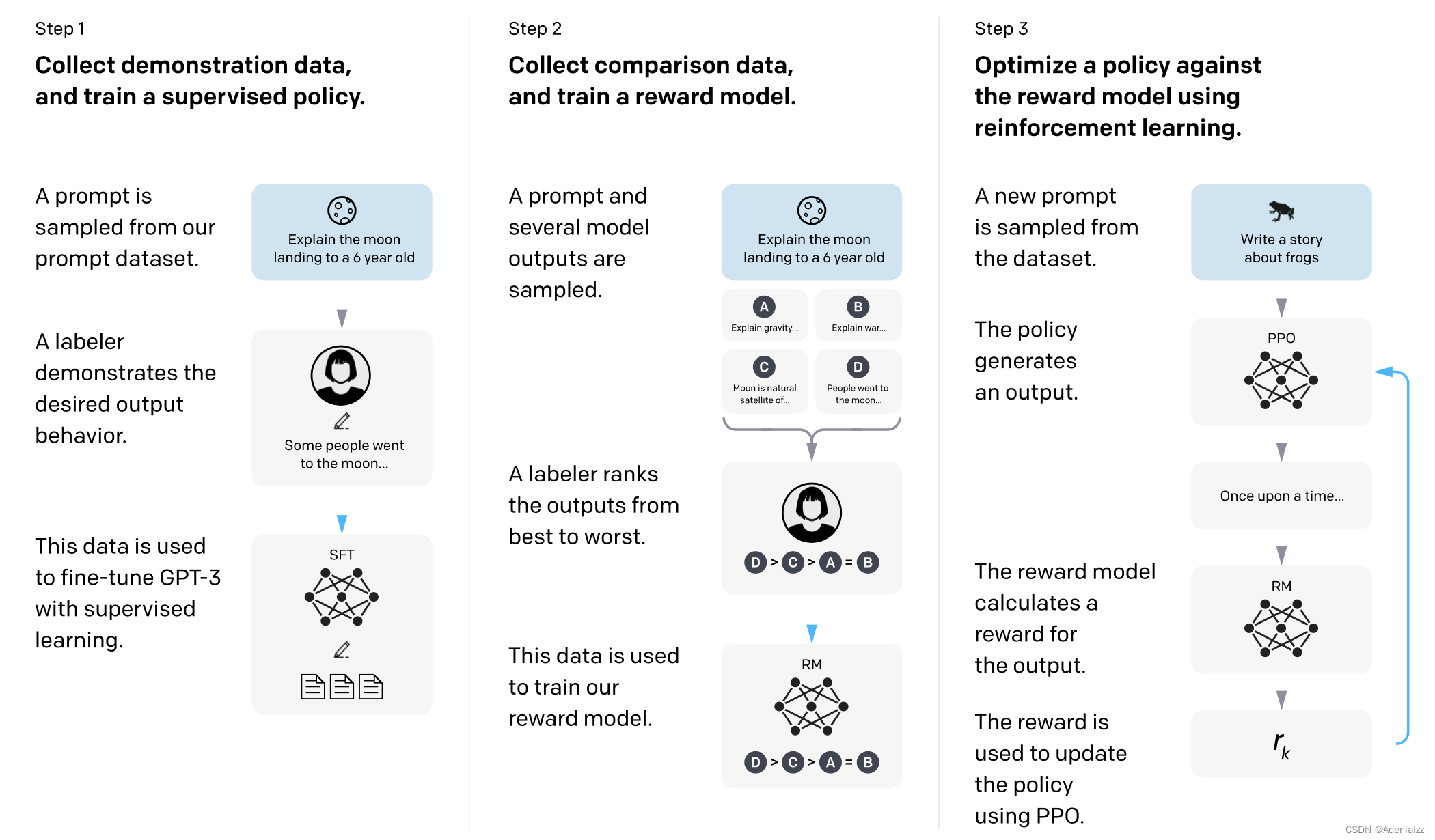
数据集
数据集的收集过程如下。首先使用初步模型,发布内测版接口给用户使用,收集问题(prompt)。根据这些问题构建数据集:
- 请标注工直接写问题的答案,用于微调训练 SFT 模型,~13k;
- 将问题输入 LM,生成多个答案,请标注工对这些答案的质量进行排序,用于训练 RM 模型,~33k;
- 不需要标注工,RM 模型对 LM 进行强化学习训练,~31k;
模型与训练目标
SFT(Supervised Fine-Tuned)
16ep,虽然 ep1 就过拟合了,但是由于是用于后续的训练步骤,而非最终模型,因此不怕过拟合。
RM(Reward Model)
在 SFT 模型的基础上进行微调,输出层改为 FC,最后输出一个标量值,表示问答质量得分(reward)。
该模型的训练数据是标注工标注的回答质量排序,而非具体的标量得分,损失函数为成对排序损失(pairwise ranking loss):
loss(θ)=−1(K2)E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]\text{loss}(\theta)=-\frac{1}{\begin{pmatrix}K\\2\end{pmatrix}}E_{(x,y_w,y_l)\sim D}[\log(\sigma(r_\theta(x,y_w)-r_\theta(x,y_l)))] loss(θ)=−(K2)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]
其中 rθ(x,y)r_\theta(x,y)rθ(x,y) 是参数为 θ\thetaθ 的 RM 模型对于问答对 (x,y)(x,y)(x,y) 的评分,yw,yly_w,y_lyw,yl 是一对回答,其中 ywy_wyw 的质量相对更好,DDD 是标注员标注的问答质量排序数据集。该损失函数的优化目标就是 RM 需要对较好的回答给出更高的评分。
强化学习训练最终的 LM 模型
该阶段强化学习的目标函数为
objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain[log(πϕRL(x))]\text{objective}(\phi)=E_{(x,y)\sim D_{\pi_\phi^{RL}}}[r_\theta(x,y)-\beta\log (\pi_\phi^{RL}(y|x)/\pi^{SFT}(y|x))]+\gamma E_{x\sim D_\text{pretrain}}[\log(\pi_\phi^{RL}(x))] objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain[log(πϕRL(x))]
其中 πϕRL\pi_\phi^{RL}πϕRL 是要学习的 RL 策略(即最终的 InstructGPT 模型),πSFT\pi^{SFT}πSFT 是经过第一步有监督训练之后的模型,DpretrainD_\text{pretrain}Dpretrain 是预训练时的数据分布。式中二三两项分别是 KL 惩罚项和语言建模预训练正则项,分别用来约束模型参数不要与 πSFT\pi^{SFT}πSFT 差距太大,重新使用预训练阶段的语言建模作为优化目标,保证模型的通用 NLP 能力。β\betaβ 和 γ\gammaγ 分别是控制这两项的权重参数。
LM 模型对给定问题生成答案。目标函数共有三项,分别是
- 最大化 RM 评分值
- KL 散度正则项,使得模型与 SFT 模型的输出接近
- LM 预训练(原 GPT 训练) 正则项
Ref
-
Training language models to follow instructions with human feedback
-
InstructGPT 论文精读【论文精读·48】
-
ChatGPT/InstructGPT详解
-
关于Instruct GPT复现的一些细节与想法
相关文章:
InstructGPT方法简读
InstructGPT方法简读 引言 仅仅通过增大模型规模和数据规模来训练更大的模型并不能使得大模型更好地理解用户意图。由于数据的噪声极大,并且现在的大多数大型语言模型均为基于深度学习的“黑箱模型”,几乎不具有可解释性和可控性,因此&…...

SpringCloud-5_模块集群化
避免一台Server挂掉,影响整个服务,搭建server集群创建e-commerce-eureka-server-9002微服务模块【作为注册中心】创建步骤参考e-commerce-eureka-server-9001修改pom.xml,加入依赖同9001创建resources/application.yml9002的ymlserver: # 修改端口号por…...
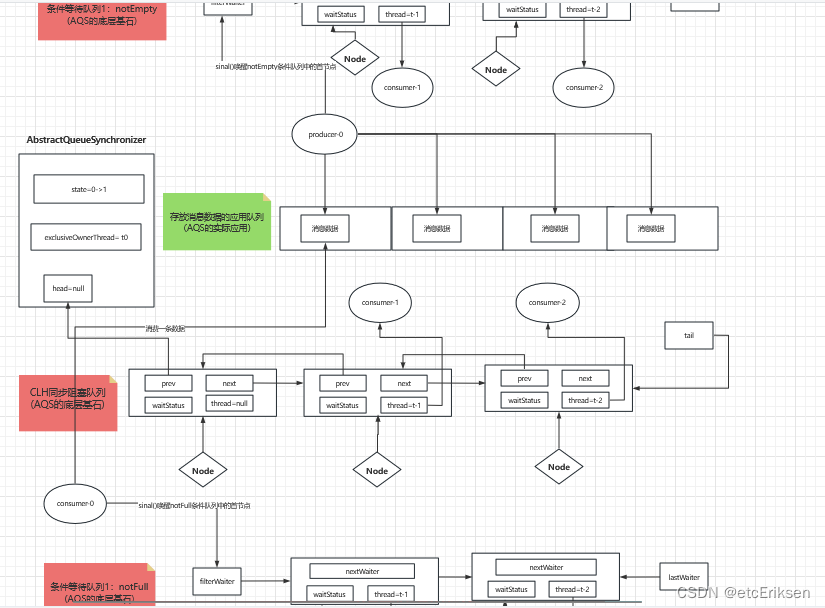
AQS底层源码深度剖析-BlockingQueue
目录 AQS底层源码深度剖析-BlockingQueue BlockingQueue定义 队列类型 队列数据结构 ArrayBlockingQueue LinkedBlockingQueue DelayQueue BlockingQueue API 添加元素 检索(取出)元素 BlockingQueue应用队列总览图 AQS底层源码深度剖析-BlockingQueue【重点中的重…...

Kotlin协程:Flow的异常处理
示例代码如下:launch(Dispatchers.Main) {// 第一部分flow {emit(1)throw NullPointerException("e")}.catch {Log.d("liduo", "onCreate1: $it")}.collect {Log.d("liudo", "onCreate2: $it")}// 第二部分flow …...
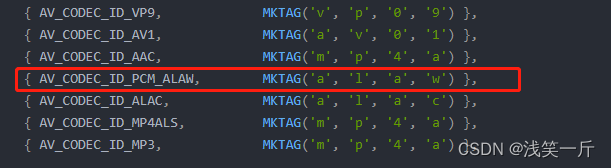
qt下ffmpeg录制mp4经验分享,支持音视频(h264、h265,AAC,G711 aLaw, G711muLaw)
前言 MP4,是最常见的国际通用格式,在常见的播放软件中都可以使用和播放,磁盘空间占地小,画质一般清晰,它本身是支持h264、AAC的编码格式,对于其他编码的话,需要进行额外处理。本文提供了ffmpeg录…...

C#读取Excel解析入门-1仅围绕三个主要的为阵地,进行重点解析,就是最理性的应对上法所在
业务中也是同样的功能点实现。只是多扩展了很多代码,构成了项目的其他部分,枝干所在。但是有用的枝干,仅仅不超过三个主要的!所以您仅仅围绕三个主要的为阵地,进行重点解析,就是最理性的应对上法所在了 str…...
)
一起Talk Android吧(第五百一十八回:在Android中使用MQTT通信五)
文章目录 知识回顾问题描述解决过程经验分享各位看官们大家好,这一回中咱们说的例子是" 在Android中使用MQTT通信五",本章回内容与前后章节内容无关联。闲话休提,言归正转,让我们一起Talk Android吧! 知识回顾 我们在前面章回中介绍了如何使用MQTT通信,包含它…...
100种思维模型之混沌与秩序思维模型-027
人类崇尚秩序与连续性,我们习惯于我们的日常世界,它以线性方式运作,没有不连续或突跳。 为此,我们学会了期望各种过程以连续方式运行,我们的内心为了让我们更有安全感,把很多事物的结果归于秩序,…...
Java开发 - Redis初体验
前言 es我们已经在前文中有所了解,和es有相似功能的是Redis,他们都不是纯粹的数据库。两者使用场景也是存在一定的差异的,本文目的并不重点说明他们之间的差异,但会简要说明,重点还是在对Redis的了解和学习上。学完本…...

Python - 使用 pymysql 操作 MySQL 详解
目录创建连接 pymsql.connect() 方法的可传参数连接对象 conn pymsql.connect() 方法游标对象 cursor() 方法使用示例创建数据库表插入数据操作数据查询操作数据更新操作数据删除操作SQL中使用变量封装使用简单使用: import pymysqldb pymysql.connect(host,user…...
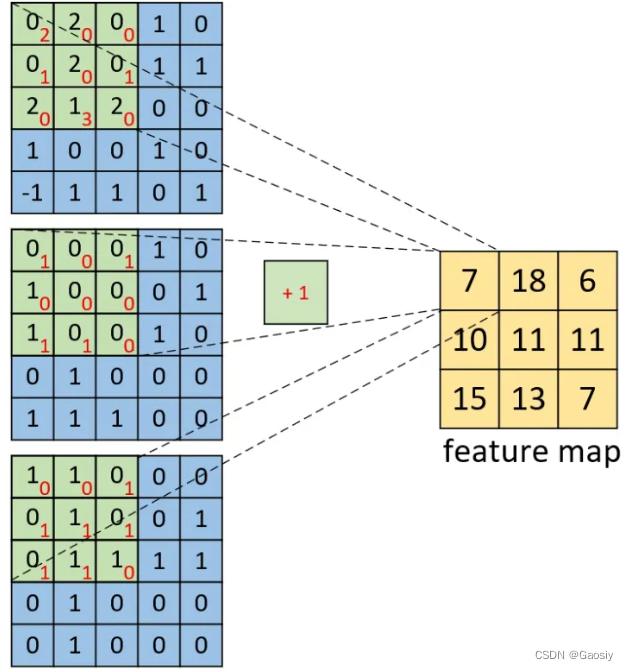
机器学习-卷积神经网络CNN中的单通道和多通道图片差异
背景 最近在使用CNN的场景中,既有单通道的图片输入需求,也有多通道的图片输入需求,因此又整理回顾了一下单通道或者多通道卷积的差别,这里记录一下探索过程。 结论 直接给出结论,单通道图片和多通道图片在经历了第一…...
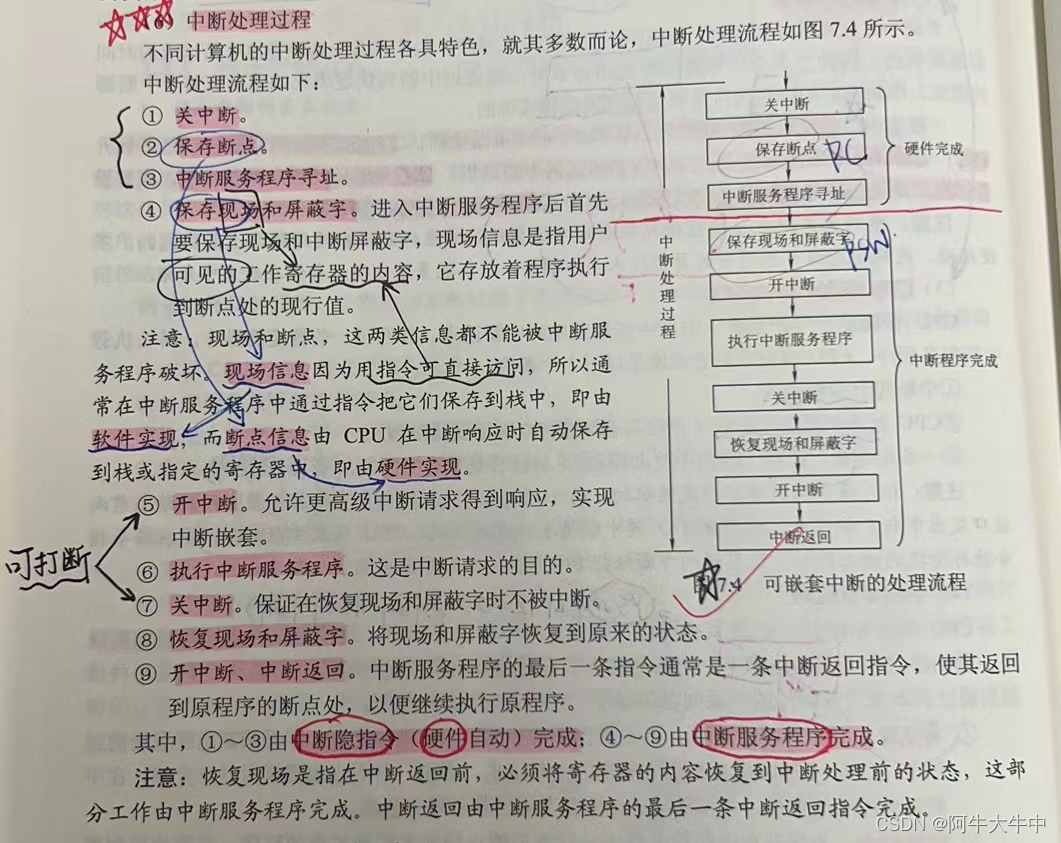
考研复试——计算机组成原理
文章目录计算机组成原理1. 计算机系统由哪两部分组成?计算机系统性能取决于什么?2. 冯诺依曼机的主要特点?3. 主存储器由什么组成,各部分有什么作用?4. 什么是存储单元、存储字、存储字长、存储体?5. 计算机…...

硬件设计 之摄像头分类(IR摄像头、mono摄像头、RGB摄像头、RGB-D摄像头、鱼眼摄像头)
总结一下在机器人上常用的几种摄像头,最近在组装机器人时,傻傻分不清摄像头的种类。由于本人知识有限,以下资料都是在网上搜索而来,按照摄像头的分类整理一下,供大家参考: 1.IR摄像头: IRinfr…...
)
PTA:C课程设计(2)
山东大学(威海)2022级大一下C习题集(2)2-5-1 字符定位函数(程序填空题)2-5-2 判断回文(程序填空题)2-6-1 数字金字塔(函数)2-6-2 使用函数求最大公约数(函数)2-6-3 使用函数求余弦函…...
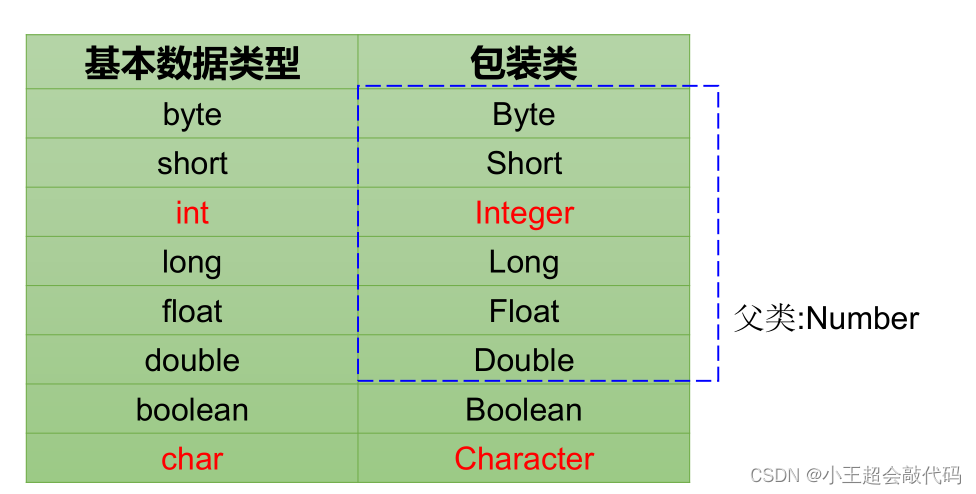
第四章:面向对象编程
第四章:面向对象编程 4.1:面向过程与面向对象 面向过程(POP)与面向对象(OOP) 二者都是一种思想,面向对象是相对于面向过程而言的。面向过程,强调的是功能行为,以函数为最小单位,考虑怎么做。面向对象&…...

Linux 安装npm yarn pnpm 命令
下载安装包 node 下载地址解压压缩包 tar -Jxf node-v19.7.0-linux-x64.tar.xz -C /root/app echo "export PATH$PATH:/app/node-v16.9.0-linux-x64" >> /etc/profile source /etc/profile ln -sf /app/node-v16.9.0-linux-x64/bin/npm /usr/local/bin/ ln -…...
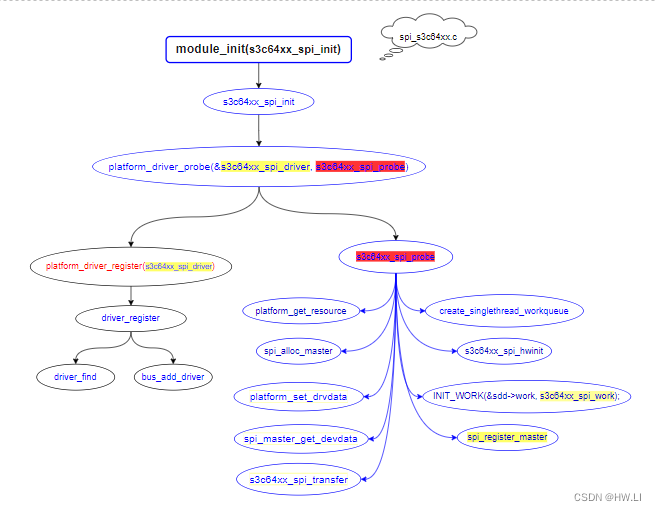
linux SPI驱动代码追踪
一、Linux SPI 框架概述 linux系统下的spi驱动程序从逻辑上可以分为3个部分: SPI Core:SPI Core 是 Linux 内核用来维护和管理 spi 的核心部分,SPI Core 提供操作接口,允许一个 spi master,spi driver 和 spi device 在 SPI Cor…...

Ls-dyna材料的相关学习笔记
Elastic Linear elastic materials -Isotropic:各向同性材料 -orthotropic 正交各向异性的 -anistropic 各向异性的...
)
Arrays方法(copyOfRange,fill)
Arrays方法 1、Arrays.copyOfRange Arrays.copyOfRange的使用方法 功能: 将数组拷贝至另外一个数组 参数: original:第一个参数为要拷贝的数组对象 from:第二个参数为拷贝的开始位置(包含) to:…...
)
AcWing - 蓝桥杯集训每日一题(DAY 1——DAY 5)
文章目录一、AcWing 3956. 截断数组(中等)1. 实现思路2. 实现代码二、AcWing 3729. 改变数组元素(中等)1. 实现思路2. 实现代码三、AcWing 1460. 我在哪?(简单)1. 实现思路2. 实现代码四、AcWin…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

人机融合智能 | “人智交互”跨学科新领域
本文系统地提出基于“以人为中心AI(HCAI)”理念的人-人工智能交互(人智交互)这一跨学科新领域及框架,定义人智交互领域的理念、基本理论和关键问题、方法、开发流程和参与团队等,阐述提出人智交互新领域的意义。然后,提出人智交互研究的三种新范式取向以及它们的意义。最后,总结…...
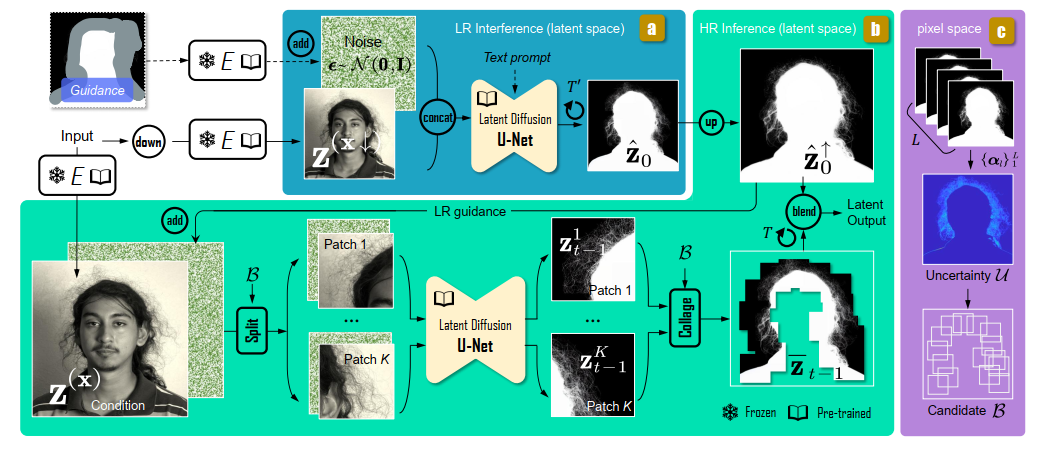
论文阅读:Matting by Generation
今天介绍一篇关于 matting 抠图的文章,抠图也算是计算机视觉里面非常经典的一个任务了。从早期的经典算法到如今的深度学习算法,已经有很多的工作和这个任务相关。这两年 diffusion 模型很火,大家又开始用 diffusion 模型做各种 CV 任务了&am…...

【java面试】微服务篇
【java面试】微服务篇 一、总体框架二、Springcloud(一)Springcloud五大组件(二)服务注册和发现1、Eureka2、Nacos (三)负载均衡1、Ribbon负载均衡流程2、Ribbon负载均衡策略3、自定义负载均衡策略4、总结 …...

Redis——Cluster配置
目录 分片 一、分片的本质与核心价值 二、分片实现方案对比 三、分片算法详解 1. 范围分片(顺序分片) 2. 哈希分片 3. 虚拟槽分片(Redis Cluster 方案) 四、Redis Cluster 分片实践要点 五、经典问题解析 C…...

TI德州仪器TPS3103K33DBVR低功耗电压监控器IC电源管理芯片详细解析
1. 基本介绍 TPS3103K33DBVR 是 德州仪器(Texas Instruments, TI) 推出的一款 低功耗电压监控器(Supervisor IC),属于 电源管理芯片(PMIC) 类别,主要用于 系统复位和电压监测。 2. …...