Linux初学(十二)AWK进阶
一、AWK
1.1 简介
- AWK是Linux中重要的文本处理工具
- Linux三剑客只一
- 处理的对象可以是一个具体的文件,也可以是一个命令的执行结果
- AWK按行读取文件,将每一行视为一条记录
案例一:获取系统中每个用户的uid
方法一:cat /etc/passwd | awk -F ":" '{print $3}'
方法二:awk -F ":" '{print $3}' /etc/passwd
案例二:显示root用户的家目录
方法一:head -n1 /etc/passwd | awk -F ":" '{print %6}'
方法二:grep "^root\>" /etc/passwd | awk -F ":" '{print $6}'
1.2 awk的基本格式
awk [选项] '模式{动作}' 文件
- 选项:
- -F "分隔符" : 用什么字符将这行内容分成一段一段的
- 模式:在处理一行之前先要判断的条件
- 如果条件满足,就处理这行,否则,直接开始读取下一行
- 如果不设置条件,则处理文件中的每一行
- 动作:模式中的条件在满足的情况下,对这行内容执行的操作
awk用来表示每一段的方法
- $1:第一个字段
- $2:第二个字段
- $3:第三个字段
- $NF:表示每行的最后一个字段
- $0:表示一整行
案例
1、获取每行的最后一个字段
awk -F "/" '{print $NF}‘ /etc/passwd’
2、显示系统中的全部用户名awk -F ":" '{print $1}' /etc/passwd
3、显示系统中的前三个用户
awk -F ":" 'NR<=3{print $1}' /etc/passwd
- NR【Number of Record】:awk的内置变量,表示正在读取的是第几条记录
- 当读取第一行内容的时候,NR的值是1;当读取第二行的时候,NR的值是2,依次类推
- 每读取一行内容,NR的值自动加1
1.3 概念
- 记录:文件中的一行就是一条记录
- awk在工作的时候,每次会读取一条记录
- 每读取一条,NR值加1
- 字段:一行被分隔的多个部分,一个部分就是一个字段
- 分隔符:指定用什么来将这个记录分成一段一段的
案例
1、仅显示/etc/passwd中的第三行内容
awk -F ":" 'NR==3 {print $0}' /etc/passwd
2、输出系统中每个用户的姓名以及对应的shell类型awk -F ":" '{print $1,"shell is ",$NF}' /etc/passwd
注意:输出多个字段的情况下,多个字段中间用逗号分隔
1.4 变量
- FS:表示字段分隔符(默认是任何空格)
- NF:表示字段数(当前这个记录中字段的个数)
- NR:表示记录数,在执行过程中对应于当前的行号
- OFS:表示输出域分隔符
- ORS:表示输出记录分隔符(默认值是一个换行符)
- RS:表示记录分隔符(默认是一个换行符)
案例:
1、输出3-5行的用户姓名、和shell类型
方法一:awk -F ":" 'NR>=3&&NR<=5{print $1,$NF}' /etc/passwd
方法二:head -n5 /etc/passwd | tail -n3 | awk -F ":" '{print $1,$NF}'
2、获取ens33的IP地址方法一:ip addr show ens33 | grep "inet\>" | awk -F " " '{print $2}' | awk -F "/" '{print $1}'
方法二:ip addr show ens33 | awk -F " " 'NR==3{print $2}' | awk -F "/" '{print $1}'
方法三:ip addr show ens33 | awk -F "[/ ]+" 'NR==3{print $3}'
3、统计/tmp/a.txt 中每行有多少个单词awk -F " " '{print "第",NR,"行有",NF,"单词"}' /tmp/a.txt
1.5 awk结合正则表达式
1)在awk中进行搜索操作
- 格式:awk -F ":" '/过滤的内容/{print xxx}'
案例:显示tom用户的uid
awk -F ":" '/tom '{print $3}' /etc/passwd
2)awk和^的结合使用
案例:/etc/passwd匹配以root为开头的行,打印整条记录
awk -F ":" '/^root\>/{print $0}' /etc/passwd
3)awk和$的结合使用
案例:/etc/passwd匹配以bash为结尾的行,打印整条记录
awk -F ":" '/bash$/{print $0}' passwd
4)awk和.的结合使用
案例:/etc/passwd匹配以r和t之间有两个字符的行,打印整条记录
awk -F ":" '/r..t/{print $0}' /etc/passwd
5)awk和.*的结合使用
案例:/etc/passwd匹配以r和t之间有任意字符的行,打印整条记录
awk -F ":" '/r.*t/{print $0}' /etc/passwd
6)指定多个分隔符
- 指定单个分割符:-F "xxx"
- 指定多个分隔符:-F [xxx],分隔符中如果有空格和其他符号同时作为分隔符,那么[ ]中空格必须在最后
- 指定多个连续的符号作为分隔符,可以用+
awk -F "[/-]+" '{print $1}' 1.txt
1.6 awk练习
1)在passwd文件中,找用户名是以a为开头的行
awk -F ":" '$1~/^a/{print $0}' /etc/passwd
2)倒数第二列$(NF-1)这一列查找匹配以tom结尾的行
awk -F ":" '$(NF-1)~/tom$/{print NR,$0}' /etc/passwd
3)$3这一列查找匹配以a或b或s开头的行
方法一:awk -F ":" '$3~/^(a|b|s)/{print $0}' /etc/passwd
方法二:awk -F ":" '$3~/^[abs]/{print $0}' /etc/passwd
4)取ens33网卡ip地址
方法一:纯grep方法
ip addr show ens33 | grep -oP '(?<=inet\s)\d+(\.\d+){3}'
方法二:grep结合awk
ip addr show ens33 | grep "inet\>" | awk -F " " '{print $2}' | awk -F "/" '{print $1}'
方法三:纯awk
ip addr show ens33 | awk -F "[/ ]+" 'NR==3{print $3}'ip addr show ens33 | awk -F "[/ ]+" '/inet\>/{print $3}'
ip addr show ens33 | awk -F "[/ ]+" '$NF~/ens33$/{print $3}'
5)找出/etc/passwd的第六个字段(以:为分隔符)以/sbin开头的行
awk -F ":" '$6~/^\/sbin/{print $0}' /etc/passwd
6)找出/etc/passwd的第六个字段(以:为分隔符)不是以/sbin开头的行
awk -F ":" '$6!~/^\/sbin/{print $0}' /etc/passwd
1.7 awk的表达式
| 序号 | 符号 | 含义 | 举例 |
| 1 | < | 小于【处理数字】 | NR<7 |
| 2 | > | 大于【处理数字】 | NR>5 |
| 3 | == | 等于【处理数字】 | NR==3 |
| 4 | != | 不等【处理数字】 | NR!=6 |
| 5 | >= | 大于等于【处理数字】 | NR>=3 |
| 6 | <= | 小于等于【处理数字】 | NR<=4 |
| 7 | ~ | 用于进行正则表达式匹配【处理字符串】 | $3~/^abc/ |
| 8 | !~ | 用于进行正则表达式不匹配【处理字符串】 | $3!~/^abc/ |
1.8 awk模块
awk的模块包含两个
BEGIN:
END:
BEGIN模块
- 用于定义一个动作,用{ }表示要执行的动作
- 这个动作要在读取文件之前执行
- 这里的动作大多要用于定义变量,包括内置变量,自定义变量
END模块
- 用于定义一个动作,用{ }表示要执行的动作
- 这个动作是awk将文件中的内容读取完成之后,而且处理完成以后,END模块才会执行
- 这里的动作通常用于输出一个结果
格式:
- awk 'BEGIN{}END{}' fileName
- 工作过程
- step 1:执行BEGIN中的操作,通常是定义变量:内置变量、自定义变量
- step 2:BEGIN中的操作执行完成以后,读取一行fileName文件中的内容,然后执行一次中间的动作;然后重复读取fileName中的每行内容,并重复执行中间的动作
- step 3:fileName中的内容全部读取完成后,执行END中的操作,通常是用于输出
案例:
1、输出每个用户的用户名、id、shell
方法一:awk -F ":" '{print $1,$3,$NF}' /etc/passwd
方法二:awk 'BEGIN{FS=":"}{print $1,$3,$NF}' /etc/passwd
2、统计 /etc/passwd 中有多少行awk 'BEGIN{num=0}{num+=1}END{print num}' /etc/passwd
3、统计a.txt中有多少个单词方法一:awk 'BEGIN{sum=0}{sum+=NF}END{print sum}' a.txt
方法二:cat 1.txt | tr ' ' '\n' >2.txt
awk '{num+=1}END{print num}' 2.txttr ' ' '\n' 作用每个空格字符替换为换行符
4、统计系统中有多少用户的shell类型是/bin/bashawk 'BEGIN{FS=":"; sum=0}$NF~/\/bin\/bash$/{sum+=1}END{print sum}' /etc/passwd
5、输出前三个用户的用户名、id、shell
awk 'BEGIN{FS=":"}NR<=3{print $1,$3,$NF}' /etc/passwd
注意:通常每种都有默认值
- FS默认值就是空格
- OFS默认值就是空格
- ORS默认是换行符
- RS默认是换行符
案例:
1、在读取文件前输出一个提示信息
awk 'BEGIN{print "start to awk process..."}{print $0}' /etc/passwd
2、在读取文件前和后分别输出一个提示信息
awk 'BEGIN{print "start to awk process..."}{print $0}END{print "over....."}' /etc/passwd
3、统计文件中的空白行的行数方法一:grep "^$" a.txt | wc -l
方法二:awk 'BEGIN{num=0}/^$/{num+=1}END{print num}' a.txt
方法三:awk '/^$/{num+=1}END{print num}' a.txt
4、统计文件中以#开头的行的行数awk 'BEGIN{num=0}/^#/{num+=1}END{print num}' a.txt
awk '/^#/{num+=1}END{print num}' a.txt
5、统计系统中uid大于大于499的用户个数awk 'BEGIN{num=0}$3>499{num+=1}END{print num}' /etc/passwd
6、计算1~100的累加和
seq 100 | awk 'BEGIN{sum=0}{sum+=$0}END{print sum}'
7、将用户信息格式中的密码占位符和描述信息去除掉awk 'BEGIN{FS=":";OFS=":"}{print $1,$3,$4,$6,$7}' /etc/passwd
1.9 awk 数组
变量:一个变量只能存储一个值
- name=tom
- age=20
数组:一组相同数据类型的集合
- userList = ['tom','jerry','bajie','wukong']
- 三个概念
- 数组名
- 数组的索引
- 数组的索引对应的值
定义数组:
- 数组名[索引]=值
案例:
- 数组名:userList
定义数组元素和值:
- userList[1]=tom
- userList[2]=jerry
- userList[3=bok
- userList[4]=bajie
- userInfo["name"]="tom"
- userInfo["age"]=33
- userInfo["addr"]="hebei"
获取数组中的值
- userList[2]
- userInfo["name"]
数组的索引
- 数字、数字索引的变号是从0开始
- 字母
- 字符串
案例
[root@ansible tmp]# awk
'BEGIN{stu[0]="tom";stu[1]="jerry";stu[2]="jack";print stu[1]}'
jerry[root@ansible tmp]# awk
'BEGIN{stu[0]="tom";stu[1]="jerry";stu[2]="jack";print stu[2]}'
jack[root@ansible tmp]# awk
'BEGIN{stu["name"]="tom";stu["age"]="20";stu["tel"]="1308888123";print stu["age"]}'
20[root@ansible tmp]# awk
'BEGIN{stu["name"]="tom";stu["age"]="20";stu["tel"]="1301111";print stu["tel"]}'
13011111.10 数组的循环遍历
- 格式:for(变量 in 数组名)
- 变量中存储的是数组的索引
[root@test ~]# awk
'BEGIN{userList[0]="tom";userList[1]="jerry";userList[2]="jack"}
END{for(var in userList) print "第",var1+1,"个用户是",userList[var]}' mypwd
第 1 个用户是 tom
第 2 个用户是 jerry
第 3 个用户是 jack[root@test ~]# awk
'BEGIN{info["name"]="tom";info["age"]="25";info["addr"]="beijing"}
END(for var in info) print var,"is",info[var]}' mypwd
age is 25
addr is beijing
name is tom[root@test ~]# awk
'BEGIN{info["www.baidu.com"]=5;info["ftp.baidu.com"]=11;info["mail.baidu.com"]=
9;info[cdn.baidu.com"]=23}END(for(var in info) print var,"is",info[var]}' mypwd
ftp.baidu.com is 11
cdn.baidu.com is 23
www.baidu.com is 5
mail.baidu.com is 9[root@ansible ~]# awk -F "/+" '{list[$2]++}END{for(site in list)print site,
list[site]}' web.log
ftp.baidu.com 6
www.baidu.com 5
mail.baidu.com 3方法一:
[root@ansible ~]# awk -F "/+" '{list[$2]++}END{for(site in list)print
site,list[site]}' web.log | sort -n -k2 -r
ftp.baidu.com 6
www.baidu.com 5
mail.baidu.com 3方法二:
[root@ensible ~]# awk -F "/+" '{print $2}' web.log | sort | uniq -c | sort -k1 -n
3 mail.baidu.com
5 www.baidu.com
6 ftp.baidu.com[root@test log]# awk -F "(from|port)" /Accepted password/{ip[$2]+=1}END{
for(var in ip)print var,ip[var]}' log1.txt | sort -t " " -k2 -r -n
192.168.31.100 36
192.168.1.123 24
192.168.1.5 2
192.168.1.100 2
192.168.1.8 1awk '{day[$1,$2]++}END{for(var in day)print var,day[var]}' log1.txtawk -F "[: ]+" '$2==13(date[$3]++}END{for(var in date)print var,date[var]}' log1.txtawk -F "[: ]+" '$2==13&&$3>=12&&$3<=14{sum+=1}END{print sum}' log1.txtawk -F "[: ]+" '/Accepted password/&&$2==13&&$3>=12&&$3<=14{sum++}END{print sum}' log1.txtawk -F "[: ]+" '$0~/Accepted password/&&$2==13&&$3>=12&&$3<=14{ip[$3]++}END{for
(var in ip)print var,ip[var]}' log1.txt
192.168.1.123 2
192.168.1.100 5
192.168.1.8 3sort命令
- 作用:排序
- 选项
- -n:基于数字进行排序
- -r:逆序排序
- -k#:根据那个字段进行排序
相关文章:
AWK进阶)
Linux初学(十二)AWK进阶
一、AWK 1.1 简介 AWK是Linux中重要的文本处理工具Linux三剑客只一处理的对象可以是一个具体的文件,也可以是一个命令的执行结果AWK按行读取文件,将每一行视为一条记录 案例一:获取系统中每个用户的uid 方法一:cat /etc/passwd |…...

文字识别 Optical Character Recognition,OCR CTC STN
文字识别 Optical Character Recognition,OCR 自然场景文本检测识别技术综述 将图片上的文字内容,智能识别成为可编辑的文本。 场景文字识别(Scene Text Recognition,STR) OCR(Optical Character Recognition, 光学字符识别)传统上指对输入扫描文档图像进行分析处理,识…...
四、MySQL读写分离之MyCAT
一、读写分离概述 1、什么是读写分离: 读写分离:就是将读写操作分发到不同的服务器,读操作分发到对应的服务器 (slave),写操作分发到对应的服务器(master) ① M-S (主从) 架构下&…...
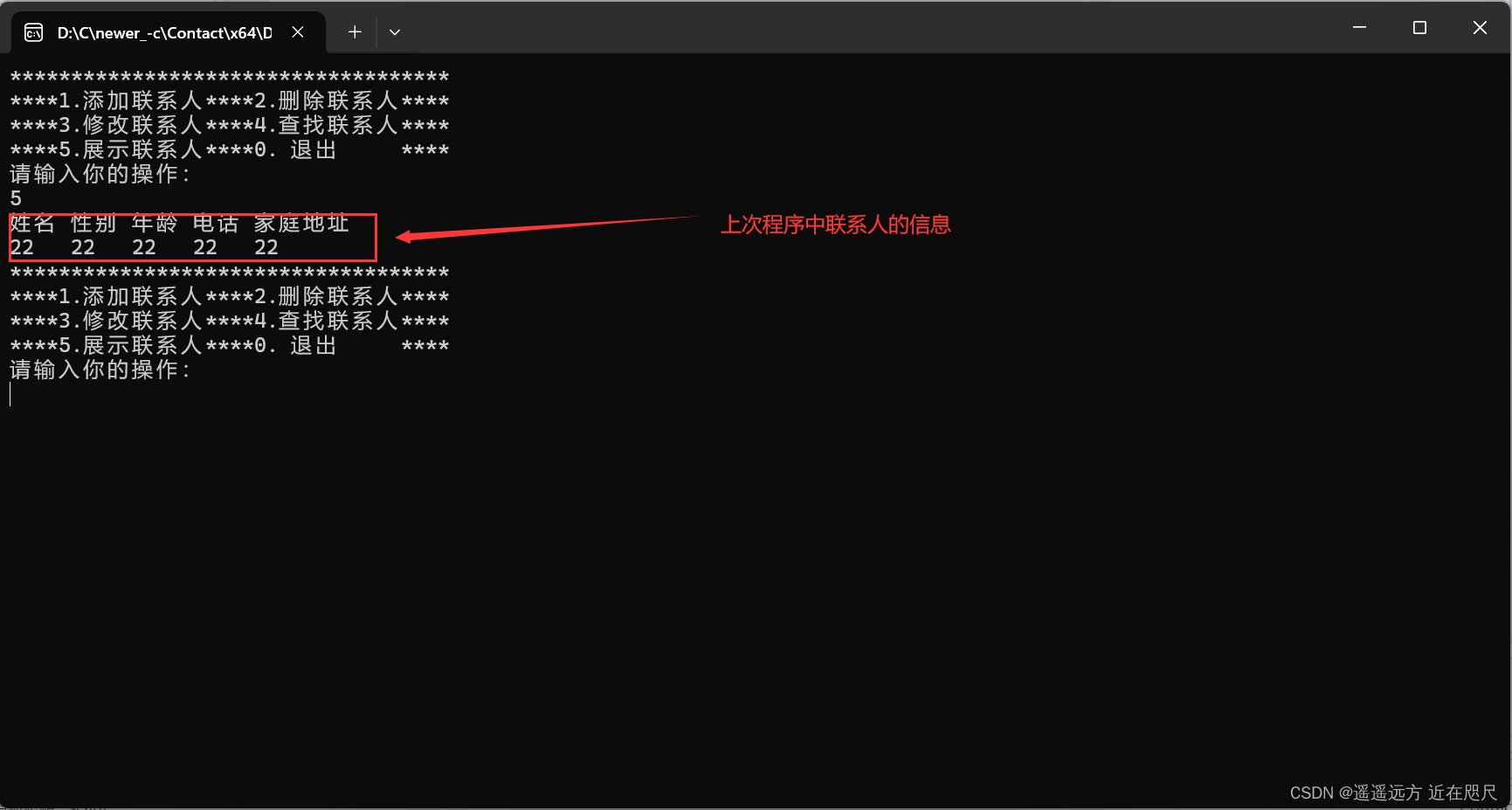
通讯录项目实现
引言:通过顺序表的逻辑实现通讯录。这里就不讲关于顺序表的函数了。如果有不明白的可以看我写的顺序表的博客。 目录 顺序表与通讯录的比较 各源文件文件大榄 Contact.c中通讯录相关函数的定义 初始化和销毁通讯录 添加联系人: 删除联系人…...

xss相关知识点与绕过思路总结
前言 对xss的绕过进行了系统的学习与实践后,重新审视一下xss,对他的绕过进行一个总结。 (当然我也是个小白,这些也是我当时瞎鸡儿乱搞绕过了几个xss自己做的小总结) 可能有点丑陋,献丑了。 好博客推荐 …...

深入解析语言模型:原理、实战与评估
引言 随着人工智能的飞速发展,语言模型作为自然语言处理(NLP)的核心技术之一,日益受到业界的广泛关注。本文旨在深入探讨语言模型的原理、实战应用以及评估方法,帮助读者更好地理解和应用这一技术。 一、语言模型原理…...

Elasticsearch 的索引优化常规项
优化常规项 https://blog.csdn.net/bairo007/article/details/132019575 1、按实际情况适当调整主分片的数量 如果主分片数量太少,会导致每个分片中的数据量过大,而且无法利用集群中所有节点的计算资源。如果主分片数量太多,会导致索引过度…...
)
【JavaParser笔记01】JavaParser解析Java源代码中的类信息(javadoc注释、类名称)
这篇文章,主要介绍如何使用JavaParser解析Java源代码中的类信息(javadoc注释、类名称)。 目录 一、JavaParser依赖库 1.1、引入依赖 1.2、获取类注释信息...
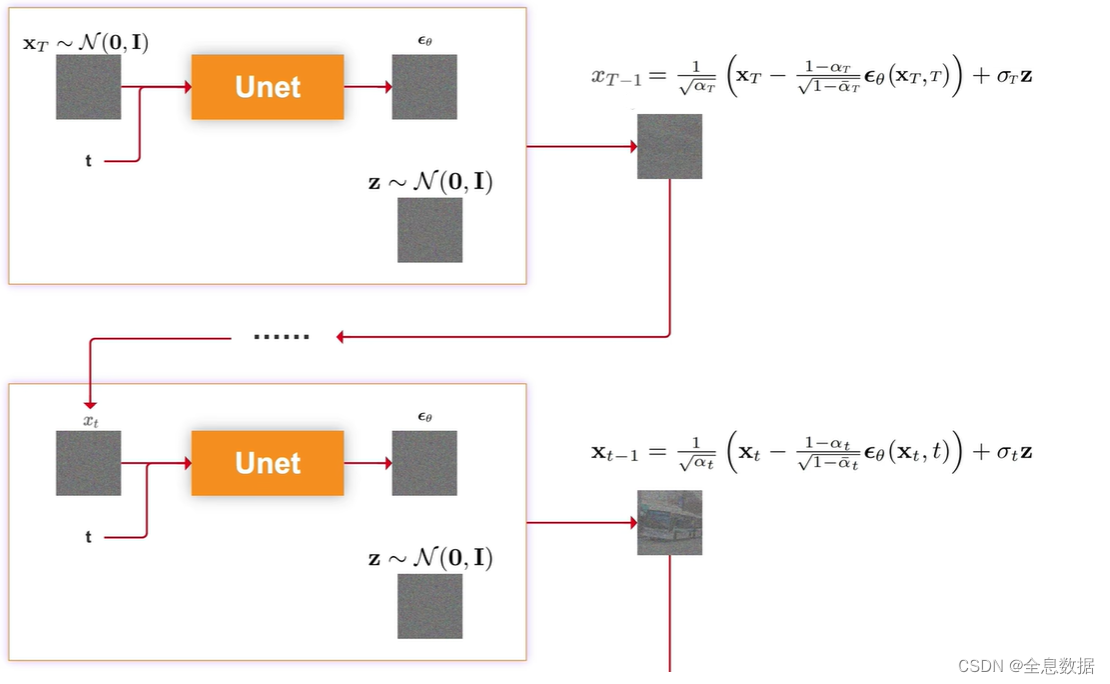
Stable Diffusion扩散模型【详解】小白也能看懂!!
文章目录 1、Diffusion的整体过程2、加噪过程2.1 加噪的具体细节2.2 加噪过程的公式推导 3、去噪过程3.1 图像概率分布 4、损失函数5、 伪代码过程 此文涉及公式推导,需要参考这篇文章: Stable Diffusion扩散模型推导公式的基础知识 1、Diffusion的整体…...

关于rabbitmq的prefetch机制
消息预取机制(Prefetch Mechanism)是RabbitMQ中用于控制消息传递给消费者的一种机制。它定义了在一个信道上,消费者允许的最大未确认的消息数量。一旦未确认的消息数量达到了设置的预取值,RabbitMQ就会停止向该消费者发送更多消息…...

机器学习介绍
机器学习是人工智能(AI)的一个分支,它使计算机系统能够从数据中学习并改进它们的性能。机器学习的核心在于开发算法,这些算法可以从大量数据中识别模式和特征,并用这些信息来做出预测或决策,而无需进行明确…...
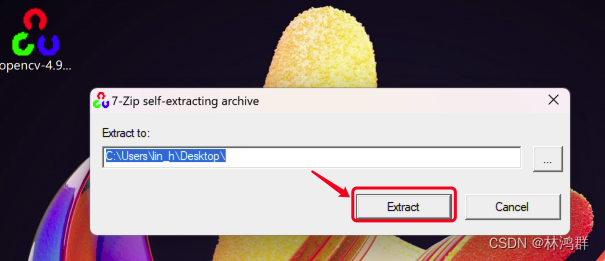
OpenCV4.9开发之Window开发环境搭建
1.打开OpenCV所在github地址 2.点击opencv仓库,进入仓库详情,点击右下方的OpenCV 4.9.0进入下载页面 3.点击opencv-4.9.0-windows.exe下载 开始下载中... 下载完成 下载完成后,双击运行解压,默认解压路径,修改为c:/...

DDD 中的实体和值对象有什么区别?
在DDD中,实体 Entity 和值对象 Value Object 是两个基本的概念,它们之间有一些重要的区别。 唯一性:实体是唯一的,每个实体都有一个唯一的标识符,即使它的属性在一段时间内发生了变化,它仍然是这个实体。与…...

算法-最值问题
#include<iostream> using namespace std; int main() {int a[7];//上午上课时间int b[7];//下午上课时间int c[7];//一天总上课时间for (int i 0; i < 7; i) {cin >> a[i] >> b[i];c[i] a[i] b[i];}int max c[0];//max记录最长时间int index -1;//索…...

Go 性能压测工具之wrk介绍与使用
在项目正式上线之前,我们通常需要通过压测来评估当前系统能够支撑的请求量、排查可能存在的隐藏bug;压力测试(压测)是确保系统在高负载情况下仍能稳定运行的重要步骤。通过模拟高并发场景,可以评估系统的性能瓶颈、可靠…...
)
数学思想论(有目录)
数学思想是数学发展过程中的重要指导原则,它涉及对数学概念、方法和理论的理解和认识,以及如何利用这些工具来解决实际问题。数学思想的形成和演进是随着数学的发展而逐渐深化的,它体现了人类对数学本质和应用的不断探索和思考。 一些主要的数学思想包括: 函数与方程思想…...
C++的并发世界(五)——线程状态切换
0.线程状态 初始化:该线程正在被创建; 就绪:该线程在列表中就绪,等待CPU调度; 运行:该线程正在运行; 阻塞:该线程被阻塞挂机,Blocked状态包括:pendÿ…...
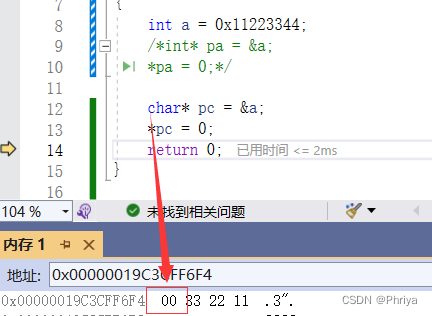
C语言——指针
地址是由物理的电线上产生的,能够标识唯一一个内存单元。在C语言中,地址也叫做指针。 在32位机器中,有32根地址线。地址是由32个0/1组成的二进制序列,也就是用4个字节来存储地址。 在64位机器中,有64根地址线。地址是…...

手搓二分查找
第一种: 该种方法是若a[mid]目标数,则让r一直等于mid,让l往右移动,一直移动到rl,这时候跳出循环,在循环外判断 但是不能写成让lmid,让r往左移动,比如a[2]key,这时&#x…...

pycharm调试(步过(Step Over)、单步执行(Step Into)、步入(Step Into)、步出(Step Out))
pycharm调试 pycharm调试 pycharm调试为什么要学会调试?1. 步过 (Step Over)2. 单步执行 (Step Into)3. 步入(Step Into)4. 步出(Step Out) 为什么要学会调试? 调试可以帮助初学者更深入地理解编程基础&am…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...
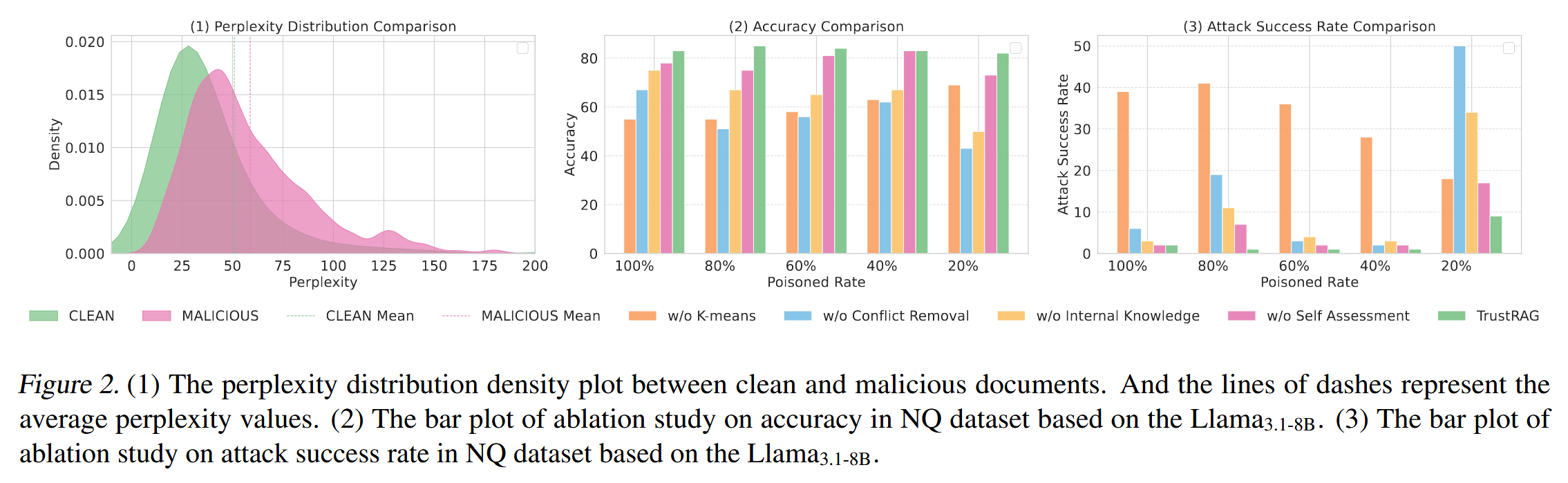
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...

【题解-洛谷】P10480 可达性统计
题目:P10480 可达性统计 题目描述 给定一张 N N N 个点 M M M 条边的有向无环图,分别统计从每个点出发能够到达的点的数量。 输入格式 第一行两个整数 N , M N,M N,M,接下来 M M M 行每行两个整数 x , y x,y x,y,表示从 …...

STL 2迭代器
文章目录 1.迭代器2.输入迭代器3.输出迭代器1.插入迭代器 4.前向迭代器5.双向迭代器6.随机访问迭代器7.不同容器返回的迭代器类型1.输入 / 输出迭代器2.前向迭代器3.双向迭代器4.随机访问迭代器5.特殊迭代器适配器6.为什么 unordered_set 只提供前向迭代器? 1.迭代器…...