kafka面试常见问题
1、如何判断kafka某个主题消息堆积?
要判断Kafka中某个主题的消息是否堆积,可以通过查看该主题的生产者和消费者的偏移量(offset)差异来实现。Kafka中的每条消息在主题的分区内都有一个唯一的偏移量,生产者每发送一条消息,偏移量就会增加。消费者在消费消息时,会记录其消费到的偏移量。如果生产者的偏移量远大于消费者的偏移量,那么就表明有消息堆积。
一个简单的方法是使用Kafka自带的命令行工具kafka-consumer-groups.sh来查看消费组的状态,包括每个分区的当前偏移量和消费者拉取的最新偏移量,以及两者之间的差异,这个差异就表示了堆积的消息数。
假设你的Kafka集群安装在Linux环境下,可以用以下命令检查特定消费者组的消费情况:
kafka-consumer-groups.sh --bootstrap-server [Kafka服务器地址]:[端口] --describe --group [消费组名称]
请将[Kafka服务器地址]、[端口]和[消费组名称]替换成实际的值。这个命令会列出消费组内所有消费者对应分区的当前偏移量、日志末端的偏移量(即生产者最新的偏移量)和它们之间的差异(即延迟)。如果你看到某个分区的延迟数值很大,那么就意味着该分区有大量消息堆积。
此外,也可以通过编程方式,使用Kafka的客户端API来获取这些信息。以下是一个简单的Java示例,展示了如何使用Kafka客户端API获取特定主题的消费者组延迟:
import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.ConsumerGroupListing;
import org.apache.kafka.clients.admin.ListConsumerGroupsResult;
import org.apache.kafka.common.TopicPartition;import java.util.Collections;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutionException;public class KafkaConsumerGroupInfo {public static void main(String[] args) {Properties props = new Properties();props.put("bootstrap.servers", "[Kafka服务器地址]:[端口]");try (AdminClient adminClient = AdminClient.create(props)) {ListConsumerGroupsResult groups = adminClient.listConsumerGroups();groups.all().get().forEach(group -> {System.out.printf("Consumer Group: %s\n", group.groupId());// 这里可以进一步获取消费者组的详细信息});} catch (InterruptedException | ExecutionException e) {e.printStackTrace();}}
}
这段代码展示了如何连接到Kafka集群并列出所有消费者组,你可以进一步使用describeConsumerGroups和listConsumerGroupOffsets方法来获取消费者组的详细信息和各分区的偏移量信息,从而计算出消息堆积量。
通过这些方法,不仅系统工程师可以轻松判断出是否存在消息堆积的情况,普通用户也能通过命令行工具的结果直观地理解到消费延迟的问题。
2、如何增加消费者组、消费者组与消费者之间的关系是什么?
在Kafka中,消费者组(Consumer Group)是消费消息的一组消费者(Consumer)的集合。消费者组允许你将消息流平行地分发给多个消费者,这样每个消费者只消费部分消息,从而提高了整体的处理速度。每个消费者属于一个特定的消费者组,并且每个消费者组可以有多个消费者。
如何增加消费者组
增加消费者组实际上是在客户端代码中配置新的消费者实例,并为它指定一个新的消费者组ID。当这个新的消费者实例开始运行,它就会自动注册到Kafka集群中作为一个新的消费者组。
以下是增加一个消费者组的简单步骤,假设我们使用Java客户端:
创建一个新的消费者实例。
在消费者配置中指定一个新的group.id,该值即为新消费者组的标识。
指定Kafka集群的连接信息和要消费的主题。
启动消费者实例,它就会作为新消费者组的一部分开始消费消息。
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.util.Collections;
import java.util.Properties;public class NewConsumerGroup {public static void main(String[] args) {Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "[Kafka服务器地址]:[端口]");props.put(ConsumerConfig.GROUP_ID_CONFIG, "new-consumer-group"); // 新消费者组IDprops.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());try (KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {consumer.subscribe(Collections.singletonList("your-topic")); // 订阅主题// 消费者轮询并处理消息的逻辑...}}
}
请将[Kafka服务器地址]、[端口]和"your-topic"替换为实际的值。
消费者组、消费者组与消费者之间的关系
消费者组(Consumer Group):是逻辑上的一个消费者集合,旨在订阅并消费一个或多个Kafka主题的消息。消费者组内的每个消费者负责消费分配给它的分区消息,确保每条消息只被组内的一个消费者消费。
消费者(Consumer):是消费者组的成员,实际上执行消息读取和处理的实体。一个消费者组中可以有一个或多个消费者。
关系:消费者通过属于特定的消费者组来并行消费主题中的消息。Kafka负责平衡每个消费者组内的消息消费,确保每个分区只被组内的一个消费者消费。这种设计使得Kafka可以高效地扩展消息处理能力,通过增加消费者数量来分摊消息处理的负载。
增加消费者组是提高消息消费并行度和容错性的一种方法。同时,通过管理消费者组和消费者的数量和配置,可以优化消息消费的性能和效率。
3、kafka是如何避免重复消费的,重复消费有哪几种情况?
Kafka本身提供了一些机制来帮助避免消息的重复消费,但完全避免重复消费还需要消费者端的适当配置和逻辑处理。理解这一点很重要,因为在分布式系统中,完全避免消息重复是一个具有挑战性的问题,特别是在需要确保消息处理的可靠性和一致性的场景中。
Kafka避免重复消费的机制
偏移量管理:Kafka通过维护消费者偏移量来追踪每个消费者组内的消费者已经读取到哪里。消费者在读取并处理完消息后,会提交它们的偏移量。如果消费者重新启动,它会从上次提交的偏移量开始读取,这有助于防止重复消费。但是,如果在消费消息和提交偏移量之间发生故障,可能会导致消息被重复处理。
幂等生产者:Kafka 0.11版本引入了幂等生产者的概念,它可以确保即使生产者重试发送消息,消息也不会在Kafka中重复。这通过给消息分配一个序列号来实现,Kafka负责检查并防止重复。这有助于减少消费端重复消费的可能性。
事务支持:Kafka提供了跨多个分区和主题的事务支持,允许生产者和消费者在一个事务中写入和读取数据。这意味着要么所有消息都成功处理并确认,要么全部回滚。这有助于避免处理状态不一致导致的重复消费。
重复消费的几种情况
网络问题或消费者故障:在消费者成功处理消息但在提交偏移量之前发生故障(如应用崩溃或网络问题),这可能导致消费者重新启动后再次消费已处理的消息。
偏移量提交失败:消费者可能成功处理了消息,但在尝试提交其偏移量时失败,这会在下次消费时导致消息重复。
不当的重试机制:如果生产者在不确定消息是否成功发送的情况下重试,可能会导致消息在Kafka中重复,进而被消费者重复消费。
消费者组变化:消费者组内的消费者数量变化(例如,增加或减少消费者)会触发再平衡。如果再平衡过程中偏移量管理不当,也可能导致消息的重复消费。
避免这些情况通常需要在应用层面实现一些策略,如确保幂等性处理逻辑(即使多次处理同一消息,也保证最终效果一致),或者使用外部存储来记录处理过的消息ID等。
4、kafka如何保证消息不丢失?
Kafka设计了多个机制来保证消息的可靠性和不丢失,但是,要实现零消息丢失,需要在生产者、消费者和Kafka集群配置上做出相应的调整。以下是Kafka为确保消息不丢失而采取的关键措施:
生产者端
确认(Acknowledgements,简称acks): 生产者在发送消息时可以设置acks参数来指定必须有多少个副本接收到消息,Kafka才确认消息写入成功。
acks=0:生产者不等待来自服务器的任何确认。这个设置将会导致最高的吞吐量,但是一旦生产者在消息发送后遇到问题,消息可能会丢失。
acks=1(默认设置):只要集群的Leader副本接收到消息,生产者就会收到一个成功响应。如果在确认响应之前Leader副本发生故障,消息可能会丢失。
acks=all或acks=-1:只有当所有同步副本都收到消息时,生产者才会收到一个成功的响应。这种设置提供了最高的数据可靠性,但可能会影响吞吐量。
重试机制:生产者发送消息时可能会遇到可恢复的错误(如网络波动),通过配置重试参数可以使生产者在发送失败时重新尝试,减少消息丢失的风险。
Kafka集群
副本机制:Kafka通过在多个服务器上复制数据来保证数据的持久性和容错性。每个主题可以配置副本因子(replication.factor),表示每个分区的数据将被复制到几个副本。增加副本数可以提高数据的可靠性。
最小同步副本(min.insync.replicas):这是一个与acks=all一起使用的配置,它指定了一个分区中必须有多少个副本是同步的,生产者才能认为写入是成功的。这有助于防止数据丢失,但如果同步副本数量低于此值,生产者将无法发送消息。
消费者端
偏移量提交:消费者处理完消息后,会定期提交消费的偏移量。如果消费者允许自动提交偏移量,可能在处理消息后、提交偏移量前遇到问题,从而导致消息重复消费而非丢失。为了避免这种情况,可以采用手动提交偏移量的策略,并在消息成功处理后立即提交偏移量。
幂等性和事务:Kafka 0.11及以上版本支持幂等性和事务性消息,可以在更高层面上防止数据的丢失和重复。
综上所述,Kafka确保消息不丢失的关键在于合理配置生产者的acks参数,合理设置Kafka集群的副本机制,以及在消费者端正确处理偏移量提交。通过这些配置和机制的合理使用,可以大大降低消息丢失的风险。
5、如何保证kafka数据消费的顺序?
Kafka保证在单个分区内的消息是有序的,即消息以其被发送到分区的顺序被存储和消费。因此,保证数据消费的顺序主要涉及到如何设计主题的分区以及如何合理地使用分区。以下是确保Kafka数据消费顺序的关键策略:
- 单分区主题
最简单的策略:如果数据顺序对整个主题都是关键的,可以将该主题配置为只有一个分区。这样,所有的消息都会按照生产者发送的顺序存储,消费者也会按照这个顺序消费消息。
缺点:这种方法限制了主题的吞吐量和可伸缩性,因为所有的消息处理都是串行的。 - 基于键的分区
键值分区:在发送消息时指定一个键(Key),Kafka使用一致性哈希算法将带有相同键的消息发送到相同的分区。这确保了具有相同键的所有消息都会按顺序存储在同一个分区中,并且按顺序被消费。
使用场景:这种方法适用于需要保持特定类别或组消息顺序的场景,如按用户ID或订单ID分组。 - 单消费者模型
单个消费者:如果一个消费者组中只有一个消费者实例,那么它会按照存储顺序消费每个分区内的消息。这保证了在消费者级别消息的顺序性,但这种模式限制了并行处理的能力。
消费者组扩展:通过确保每个分区最多只被一个消费者消费,即使在多消费者的情况下,也可以保持分区内消息的消费顺序。 - 幂等性和事务
幂等性生产者:Kafka的幂等性生产者可以确保即使发生重试,消息也不会被重复发送到分区中,保持了分区内消息的顺序性。
事务性消息:通过使用Kafka的事务性消息,可以在跨分区和跨会话的操作中保持消息的顺序和原子性,避免了复杂场景中的顺序问题。 - 避免消费者重平衡
稳定的消费者组:频繁的消费者组重平衡会影响顺序处理,因为分区可能会在消费者之间重新分配。通过维护稳定的消费者组和避免频繁启动或关闭消费者,可以减少重平衡的发生,保持消息的顺序消费。
总的来说,保证Kafka数据消费的顺序需要在消息生产时、主题分区设计时以及消费者设计时考虑周全。通过以上策略的合理应用,可以在大多数场景下确保消息的有序消费。
6、什么是死信队列?
死信队列(Dead Letter Queue,DLQ)是消息队列管理中的一个重要概念,它用于存储无法成功处理的消息。在消息中间件和分布式系统中,死信队列是用来增强系统的健壮性和可靠性的机制之一。其主要目的是保证系统在面对错误、异常或特定条件下仍能正常运行,同时不丢失任何重要数据。
死信队列的工作原理
消息无法投递:当消息因为各种原因(如目标队列不存在、队列已满)无法被成功投递到目标队列时,这些消息会被发送到死信队列。
消费失败:当消息被消费者接收,但由于业务逻辑错误、系统异常或处理超时等原因不能被成功处理时,这些消息也可以被路由到死信队列。
消息过期:在某些系统中,如果消息在队列中停留的时间超过了其设置的存活时间(TTL,Time-To-Live),这些消息也会被移动到死信队列。
死信队列的用途
错误隔离:将处理失败的消息移动到死信队列可以防止它们干扰正常消息的处理流程,从而提高系统的稳定性。
故障诊断和排错:通过分析死信队列中的消息,开发者可以识别和修复导致消息处理失败的问题,从而提高系统的可靠性。
保证消息不丢失:即使在极端情况下,消息也不会从系统中丢失,开发者可以决定如何处理这些失败的消息,例如,重新处理、手动干预或记录日志。
在Kafka中实现死信队列
虽然Kafka本身没有内置的死信队列概念,但可以通过一些设计模式来实现类似的功能:
单独的死信主题:为无法处理的消息创建一个或多个特定的Kafka主题,作为死信队列。当消费者遇到无法处理的消息时,可以将这些消息生产到这个死信主题。
消息重试与回退逻辑:在消费者处理逻辑中实现消息的重试机制。如果经过多次重试后仍然失败,可以将消息发送到死信主题。
丰富的消息元数据:在发送到死信队列的消息中包含丰富的元数据(如原始主题、错误信息、重试次数),以便于后续的处理和分析。
死信队列是一个重要的模式,用于处理分布式系统中不可避免的消息处理失败情况,确保系统的鲁棒性和消息的可追踪性。
假设我们有一个电商平台的订单处理系统,该系统使用Kafka来处理订单消息。每当用户下单时,订单服务就会向Kafka的orders主题发送一条消息,表示新的订单已经生成。然后,订单处理服务作为消费者从orders主题读取消息来处理订单,比如验证订单信息、扣减库存、生成发货单等。
在这个过程中,可能会出现各种原因导致某些订单无法成功处理。例如,订单信息不完整,导致验证失败;或者所购商品库存不足,无法扣减库存。这时,如果简单地将处理失败的消息丢弃或不断重试,可能会导致用户订单长时间得不到处理,甚至订单数据的丢失,严重影响用户体验和系统的可靠性。
为了解决这个问题,我们可以在Kafka中创建一个名为dead_orders的死信主题。订单处理服务在处理orders主题中的消息时,一旦遇到无法处理的订单,它不会简单地丢弃或无限重试这些消息。相反,它会将这些消息连同处理失败的原因一起发送到dead_orders死信主题。
实际操作流程如下:
订单服务将新订单消息发送到orders主题。
订单处理服务尝试从orders主题消费消息并处理订单。
如果订单处理成功,流程继续,比如发送订单成功确认消息等。
如果处理失败(如验证失败、库存不足等),订单处理服务将失败的订单消息及错误信息发送到dead_orders死信主题。
死信处理服务监控dead_orders主题,对于进入死信队列的消息进行特殊处理,如:
分析失败原因,自动修正可修复的错误并重新提交订单。
对于无法自动修复的问题,通知技术支持团队或相关人员手动介入。
死信队列的优势
隔离处理失败的消息:将问题消息隔离到死信队列中,避免干扰正常的订单处理流程。
确保消息不丢失:即使订单处理失败,订单信息也不会丢失,保证了数据的完整性。
故障排查和修复:通过分析死信队列中的消息,可以快速定位问题原因,及时进行修复和处理,提高系统的稳定性和可靠性。
提高系统的鲁棒性:通过合理处理异常和失败情况,增强了系统对意外情况的适应能力。
通过这个例子,我们可以看到,死信队列不仅帮助电商平台的订单处理系统提高了错误处理能力,也保证了系统的可靠性和用户的体验。
7、什么是ISR、为什么要引入ISR?
7、什么是ISR、为什么要引入ISR?
ChatGPT
ISR(In-Sync Replicas)是Kafka中的一个重要概念,指的是与给定分区的Leader副本保持同步的所有副本(包括Leader副本本身)。这些副本集合中的每个副本都已复制了Leader副本上的所有消息,直到Leader副本的最后一个提交的消息。换句话说,ISR中的副本是那些与Leader副本数据一致(或者说延迟在可接受范围内)的副本。
为什么要引入ISR
Kafka引入ISR的目的主要是为了维持数据的高可靠性和高可用性,同时确保集群的性能。具体来说,ISR机制的引入基于以下几个考虑:
数据一致性:通过只允许与Leader副本同步的副本(即ISR中的副本)参与投票和成为新的Leader,Kafka保证了数据的一致性。这意味着只有那些具有最新数据的副本才有机会成为Leader,从而确保了读写数据的一致性。
高可用性:在分布式系统中,节点可能会因为网络问题、硬件故障或其他原因随时变得不可用。ISR机制允许Kafka在不牺牲数据一致性的前提下,动态地调整可用的副本集合。即使某些副本失败或落后太多,只要有足够的副本在ISR中,Kafka仍能继续处理读写请求。
故障转移:当Leader副本失败时,Kafka会从当前的ISR列表中选择一个新的Leader,这个过程称为Leader选举。由于ISR中的所有副本都有最新的数据,这保证了在Leader故障转移过程中数据的连续性和完整性。
性能考量:Kafka允许配置副本的最小同步数量(min.insync.replicas),这对于生产者而言是一个重要的保证。生产者可以选择等待至少这么多副本确认接收数据后才认为写入成功(通过设置acks参数)。这个机制平衡了数据一致性和写入性能,使得用户可以根据业务需求进行权衡。
总结
综上所述,ISR机制是Kafka保证数据一致性、高可用性和故障转移能力的关键设计。通过只让数据最新的副本参与Leader选举和数据写入确认过程,Kafka能够在分布式环境中有效地管理和维护数据的一致性和可靠性,同时提供灵活的配置以满足不同的业务需求。
8、kafka与zookeeper的关系是什么?
Kafka与ZooKeeper之间的关系是基于Kafka集群管理和协调的需求。直到Kafka 2.8版本之前,Kafka依赖于ZooKeeper来进行集群管理、元数据存储以及协调各种操作。从Kafka 2.8版本开始,引入了KIP-500,它标志着Kafka开始向去除对ZooKeeper依赖的方向迈进,但在此之前,ZooKeeper在Kafka架构中扮演了几个关键角色:
-
集群管理
ZooKeeper用于管理Kafka集群的基本信息,如Broker的注册与管理。当Broker启动时,它会在ZooKeeper中注册自己,并定期向ZooKeeper发送心跳来表明自己是活跃的。如果Broker停止发送心跳,ZooKeeper会将其从活跃Broker列表中移除。 -
分区Leader选举
Kafka的每个分区都有多个副本,其中一个副本被选举为Leader,负责处理读写请求。ZooKeeper负责这个Leader选举过程的协调。当当前的Leader副本因为故障下线时,ZooKeeper会触发新的Leader选举。 -
元数据存储
ZooKeeper存储了Kafka集群的关键元数据信息,包括各个主题的元数据(如分区数和副本位置)、消费者组的偏移量等。这些信息对于Kafka网络客户端和Broker之间的协调操作至关重要。 -
配置管理
ZooKeeper还用于存储和管理Kafka集群的配置信息。这包括全局配置以及每个Broker的特定配置。配置更改时,Kafka可以通过ZooKeeper通知所有Broker更新其配置。
Kafka去ZooKeeper化(KIP-500)
随着Kafka社区的发展,Kafka项目逐步实施KIP-500,目的是去除对ZooKeeper的依赖,使Kafka成为一个更加独立和自足的系统。KIP-500引入了一个内部的Raft协议实现,称为KRaft模式,来处理之前由ZooKeeper负责的元数据管理和集群协调任务。这个变化旨在简化Kafka的架构,提高其可扩展性和性能,同时减少运维复杂度。
去除对ZooKeeper的依赖是一个重要的里程碑,它标志着Kafka向着更高效、更易管理的方向发展。尽管如此,对于使用较早版本的Kafka集群,ZooKeeper仍然是不可或缺的组件。
9、kafka、activeMQ、RabbitMQ、RocketMQ之间的区别?
Kafka、ActiveMQ、RabbitMQ和RocketMQ是四个流行的消息中间件系统,它们在设计哲学、特性支持和使用场景上各有不同。下面是这些系统之间的一些主要区别:
Kafka
设计目标:Kafka被设计用于处理高吞吐量的数据流,特别适合大数据处理场景。它支持高并发的数据写入和读取,非常适合日志收集、事件流处理等场景。
数据模型:Kafka以时间顺序持久化消息到磁盘的“日志”为基础模型,支持消息的批处理和实时处理。
可扩展性:Kafka通过分区(Partitions)和主题(Topics)来实现高度的可扩展性和并行处理能力。
耐久性和可靠性:通过数据副本机制保证消息的持久性和容错性。
ActiveMQ
设计目标:ActiveMQ是一个多协议、多语言的消息代理,适用于企业应用集成(EAI)和面向服务的架构(SOA)。
数据模型:支持队列(Point-to-Point)和主题(Publish/Subscribe)两种消息模型,适用于不同的消息通信需求。
可扩展性:相对于Kafka,ActiveMQ的可扩展性较弱,但它提供了足够的特性来支持大多数企业级应用。
特性支持:提供广泛的特性支持,包括消息持久化、事务、消息选择器等。
RabbitMQ
设计目标:RabbitMQ是一个轻量级、易于部署的消息代理,专注于提供高可靠性、灵活的路由以及复杂消息队列的模式。
数据模型:基于AMQP(高级消息队列协议)标准,支持多种消息模式,包括发布/订阅、请求/响应和路由等。
可扩展性:通过复杂的交换机(Exchanges)和队列(Queues)绑定机制提供灵活的消息路由能力。
特性支持:支持事务、消息确认、死信队列等高级特性。
RocketMQ
设计目标:RocketMQ是一个分布式、队列模型的消息中间件,旨在提供低延迟、高吞吐量的消息服务。
数据模型:支持丰富的消息模型,包括顺序消息、延时消息和事务消息等。
可扩展性:提供高度的可扩展性和容错能力,支持数万级别的消息并发处理。
特性支持:支持分布式事务、消息回溯等特性,适用于金融、电商等对消息可靠性要求极高的场景。
总结
Kafka:适合大规模的日志处理和实时数据管道。
ActiveMQ:适合企业应用集成和传统的消息代理用途。
RabbitMQ:适合需要复杂路由、灵活消息处理的场景。
RocketMQ:适合对消息可靠性和吞吐量要求极高的分布式系统。
选择哪个消息中间件取决于具体的应用场景、性能需求和系统架构设计。
10、什么是kafka的rebalance机制?
Kafka的Rebalance(再平衡)机制是指在消费者群体(Consumer Group)中动态分配主题分区(Topic Partitions)的过程。当消费者群体的成员或订阅的主题分区发生变化时,Kafka会自动触发再平衡操作,以确保分区的消费者分配尽可能均匀,保持负载平衡。这个机制对于实现高效、可扩展的消息消费至关重要。
触发Rebalance的情况
消费者加入或离开消费者群体:当新的消费者加入消费者群体,或者现有的消费者因网络问题、进程崩溃等原因离开消费者群体时,Kafka将重新分配分区,确保所有活跃的消费者都能参与消息消费。
订阅的主题分区数变化:如果一个被消费者群体订阅的主题增加了分区,Kafka也会触发再平衡,将新分区分配给消费者。
消费者群体的订阅模式变化:如果消费者群体中的消费者改变了其订阅的主题,这同样会导致再平衡。
Rebalance的过程
停止消息消费:一旦再平衡开始,所有受影响的消费者会停止消费消息。
重新分配分区:Kafka的协调者(Coordinator)会根据当前活跃的消费者和可用的分区重新分配分区,确保分配尽可能均匀。
同步状态:消费者将更新其本地状态,包括它们负责的分区集合。
恢复消息消费:一旦分区重新分配完成,消费者会开始消费新分配给它们的分区。
Rebalance的影响
消费延迟:再平衡过程中,消费者不会消费消息,这可能会导致消息处理的短暂延迟。
消息重复:如果消费者在再平衡之前未能提交最后处理的消息的偏移量,那么在再平衡后重新开始消费时,可能会重复处理某些消息。
优化Rebalance
为了减少Rebalance对消息消费的影响,可以采取一些措施,如:
合理配置消费者会话超时和心跳间隔,以避免不必要的再平衡。
在消费者逻辑中优雅地处理偏移量提交,确保再平衡前正确提交消费偏移量。
使用Kafka新版本的增强特性,如静态成员分配(Static Membership)来减少Rebalance的影响。
Kafka的Rebalance机制是其高效处理大规模数据的关键特性之一,通过理解和优化这一机制,可以更好地利用Kafka构建高效、可靠的分布式消息系统。
简述一下kafka副本同步的机制
Kafka副本同步机制是保证数据可靠性和高可用性的核心。在Kafka中,每个主题被分割成多个分区,每个分区可以有一个或多个副本。这些副本分布在不同的Broker上,其中一个副本被指定为Leader,其他的则作为Follower。所有的读写操作都是通过Leader进行的,而Follower负责从Leader同步数据。这种机制旨在通过副本来提高数据的可靠性和可用性。
副本角色
Leader:每个分区有一个Leader副本,负责处理该分区的所有读写请求。Leader管理着该分区的offset。
Follower:跟随Leader,从Leader那里同步数据。Follower不直接服务客户端的读写请求,只负责与Leader的数据同步。
同步过程
写入流程:
当生产者向某个分区发送消息时,消息首先被写入到该分区的Leader副本。
Follower副本周期性地从Leader拉取最新的消息,进行数据同步。
根据配置的acks(确认机制),生产者在写入数据时可以选择等待不同级别的确认。
确认机制(acks):
acks=0:生产者不等待任何确认,最高吞吐量,但数据可丢失。
acks=1:只要Leader写入数据即返回确认,平衡吞吐量和数据可靠性。
acks=all(或-1):要求所有同步的副本(ISR中的副本)都确认接收到数据后才返回确认,最高数据可靠性。
同步模式:
同步复制:Leader等待所有或一部分Follower同步数据后,才认为写入操作成功。
异步复制:Leader写入数据后即可认为操作成功,而不必等待Follower同步数据。
故障转移:
如果Leader副本因故障宕机,Kafka会从当前的ISR(In-Sync Replicas,即与Leader保持同步的副本集合)中选举新的Leader。
故障转移过程中,为了保证数据的一致性,只有处于ISR中的副本才有资格被选举为新的Leader。
最小同步副本数(min.insync.replicas):
这是一个重要的配置参数,用于指定一个消息被认为是成功写入的最小副本数。它可以用来保证高可用性和数据的耐久性。
Kafka通过这种灵活的副本同步机制,既保证了数据的高可靠性,又确保了系统的高吞吐量。用户可以根据具体的业务需求,通过配置来平衡数据的一致性、可用性和性能。
12、简述一下kafka的架构设计
Kafka是一个分布式的流处理平台,它被设计来高效地处理高吞吐量的数据。Kafka的架构设计允许它在提供实时的消息服务的同时,也支持批量处理、存储和分析大规模数据流。以下是Kafka架构的几个关键组成部分:
- Producer(生产者)
生产者是发送消息到Kafka主题的客户端应用程序。生产者可以选择将消息发送到主题的哪个分区,或者让Kafka根据消息的键自动选择分区。 - Consumer(消费者)
消费者从Kafka主题读取消息。消费者可以独立运行或作为消费者组协同运行,以便在消费者之间并行处理数据。 - Broker(服务器)
Kafka集群由一个或多个服务器组成,这些服务器被称为Broker。Broker负责维护发布到它们的消息。每个Broker都可以处理数百万条消息,无需应用程序参与。 - Topic(主题)
主题是消息的类别或者说是消息的归宿。生产者发布消息到主题,消费者从主题读取消息。主题在Kafka内部是分区的,这允许Kafka的水平扩展,每个分区可以独立于其他分区在不同的Broker上。 - Partition(分区)
分区是主题的物理分段,每个分区都是一个有序的、不可变的消息序列。Kafka只保证同一个分区内的消息的顺序,不同分区的消息并不保证全局有序。 - Offset(偏移量)
偏移量是分区中每条消息的唯一标识符。Kafka通过偏移量来保持对消费者读取位置的跟踪。 - ZooKeeper
在Kafka 2.8版本之前,Kafka使用ZooKeeper来管理集群配置、选举Leader以及在消费者之间进行负载平衡。从Kafka 2.8开始,引入KIP-500,逐步去除对ZooKeeper的依赖,转而使用内部的元数据管理系统。 - Replication(副本)
Kafka通过副本机制确保数据的可靠性。每个分区可以有多个副本,分布在不同的Broker上。其中一个副本被指定为Leader,负责处理所有的读写请求,其他副本作为Follower从Leader同步数据。 - ISR(In-Sync Replicas)
ISR是指与Leader副本保持同步的副本集合。如果Follower副本落后于Leader或者发生故障,它会被从ISR中移除。
架构设计的优势
可扩展性:Kafka的分布式架构支持水平扩展,既可以处理高吞吐量的数据也能存储大量数据。
高性能:Kafka支持高速读写操作,尤其是通过批处理和压缩技术优化了性能。
容错性:通过副本和分区机制,Kafka确保了数据在Broker故障时的可用性和持久性。
灵活性:Kafka可以用于日志聚合、实时流处理、事件源等多种场景。
Kafka的这些设计使它成为了处理高速、高容量数据流的理想选择,被广泛应用于日志收集、实时监控、流式处理等多种场景。
相关文章:

kafka面试常见问题
1、如何判断kafka某个主题消息堆积? 要判断Kafka中某个主题的消息是否堆积,可以通过查看该主题的生产者和消费者的偏移量(offset)差异来实现。Kafka中的每条消息在主题的分区内都有一个唯一的偏移量,生产者每发送一条…...

深入解析Hadoop生态核心组件:HDFS、MapReduce和YARN
这里写目录标题 01HDFS02Yarn03Hive04HBase1.特点2.存储 05Spark及Spark Streaming关于作者:推荐理由:作者直播推荐: 一篇讲明白 Hadoop 生态的三大部件 进入大数据阶段就意味着进入NoSQL阶段,更多的是面向…...

【chatGPT】我:在Cadence Genus软件中,出现如下问题:......【1】
我 在Cadence Genus中,出现如下问题:Error:A command argument did not match any of the acceptable command option. [TUI-170] [set_db] :‘/’ is not a legal option for the command. 该如何解决 ChatGPT Cadence Genus的错误消息 “…...
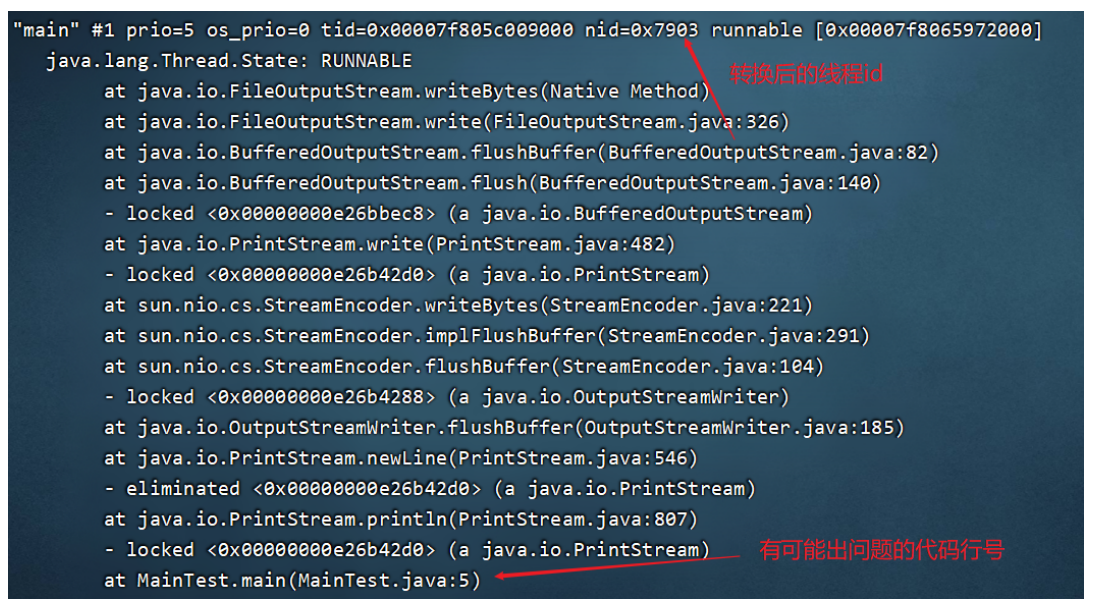
面试题:JVM 调优
一、JVM 参数设置 1. tomcat 的设置 vm 参数 修改 TOMCAT_HOME/bin/catalina.sh 文件,如下图 JAVA_OPTS"-Xms512m -Xmx1024m" 2. springboot 项目 jar 文件启动 通常在linux系统下直接加参数启动springboot项目 nohup java -Xms512m -Xmx1024m -jar…...

PS从入门到精通视频各类教程整理全集,包含素材、作业等(8)
PS从入门到精通视频各类教程整理全集,包含素材、作业等 最新PS以及插件合集,可在我以往文章中找到 由于阿里云盘有分享次受限制和文件大小限制,今天先分享到这里,后续持续更新 B站-PS异闻录:萌新系统入门课课程视频 …...
VSCode安装及Python、Jupyter插件安装使用
VSCode 介绍 Visual Studio Code(简称VSCode)是一个由微软开发的免费、开源的代码编辑器。VSCode是一个轻量级但是非常强大的代码编辑器,它支持多种编程语言(如C,C#,Java,Python,PHP࿰…...
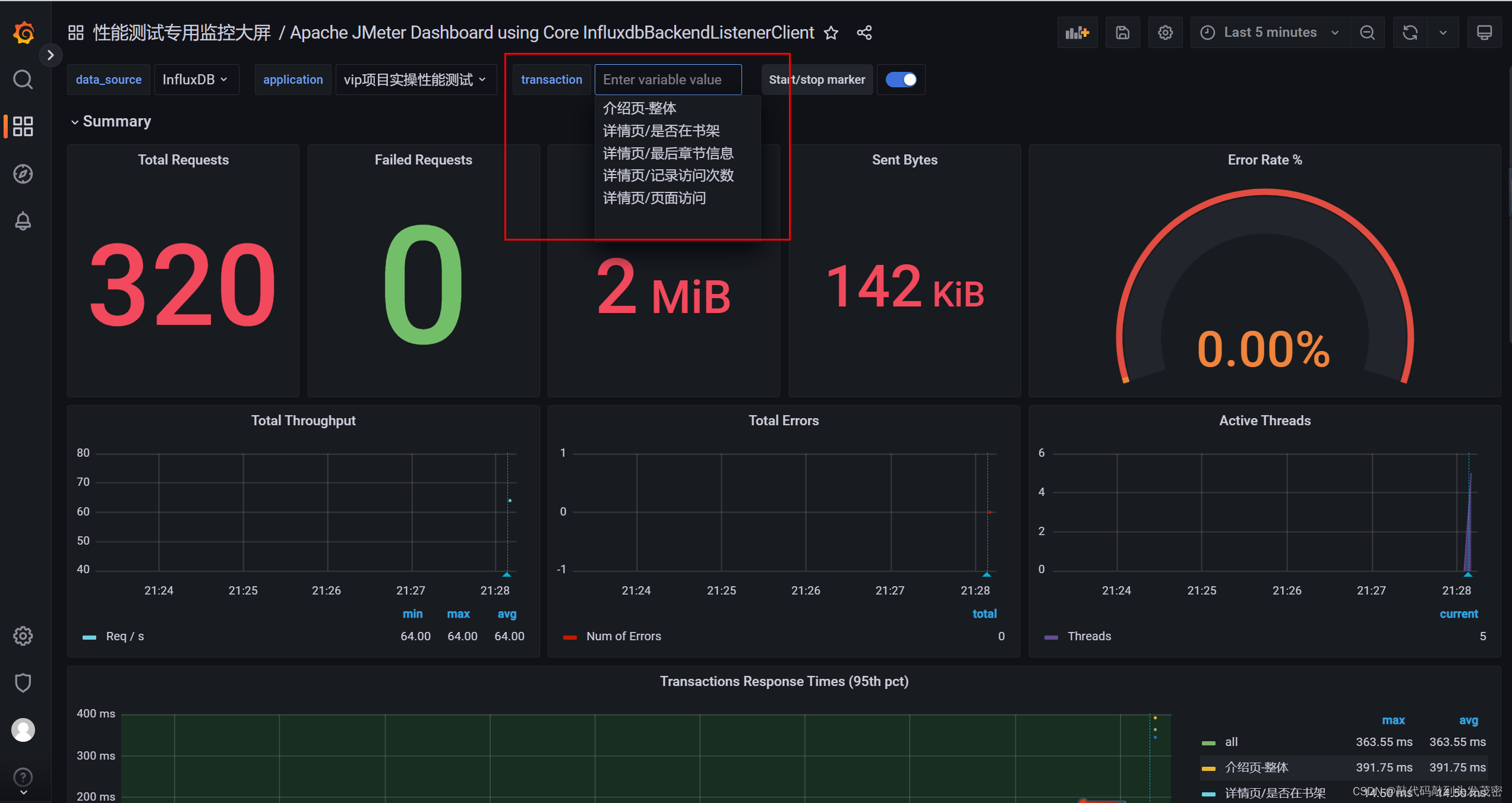
JMeter+Grafana+influxdb 配置出现transaction无数据情况解决办法
JMeterGrafanainfluxdb 配置出现transaction无数据情况解决办法 一、问题描述二、解决方法 一、问题描述 如下图所示出现application有数据但是transaction无数据情况 二、解决方法 需要做如下设置 打开变量设置如下图打开两个选项 然后再进行后端监听器的设置 如下图所…...

Acrobat Pro DC 2023 for Mac PDF编辑管理软件
Acrobat Pro DC 2023 for Mac是一款功能强大的PDF编辑和管理软件,旨在帮助用户轻松处理PDF文件。它提供了丰富的工具和功能,使用户可以创建、编辑、转换和注释PDF文件,以及填写和签署PDF表单。 软件下载:Acrobat Pro DC 2023 for …...
可视化和Pillow解释性视觉推理及材料粒子凝聚)
Python大型数据集(GPU)可视化和Pillow解释性视觉推理及材料粒子凝聚
🎯要点 Python图像处理Pillow库:🎯打开图像、保存图像、保存期间的压缩方式、读取方法、创建缩略图、创建图像查看器。🎯获取 RGB 值,从图像中获取颜色,更改像素颜色,转换为黑…...
1、快速上手Docker:入门指南
文章目录 Linux中安装docker防火墙端口配置web项目需要的环境安装yarn安装nodejs安装脚手架并准备项目 构建镜像启动镜像查看日志管理镜像推送镜像 发布项目准备服务器环境部署项目: PS:扩展一点小知识 这篇文章只是docker入门的第一个Docker项目&#x…...
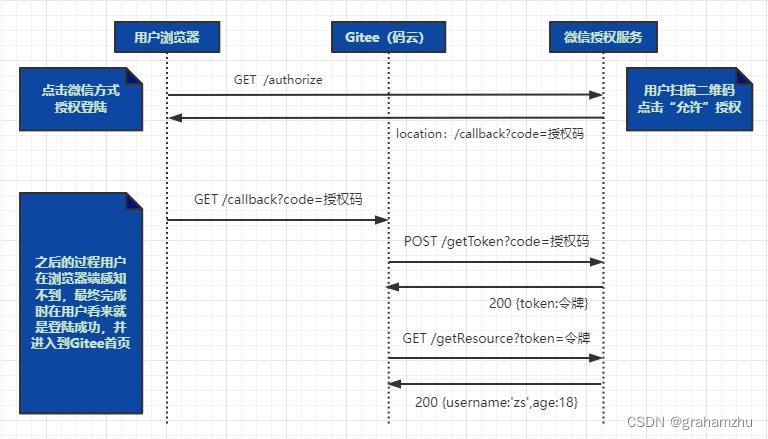
通用开发技能系列:Authentication、OAuth、JWT 认证策略
云原生学习路线导航页(持续更新中) 本文是 通用开发技能系列 文章,主要对编程通用技能 Authentication、OAuth、JWT 认证策略 进行学习 1.Basic Authentication认证 每个请求都需要将 用户名密码 进行base64编码后,放在请求头的A…...

【Leetcode】【240404】1614. Maximum Nesting Depth of the Parentheses
BGM(?):圣堂之门-阿沁《梵谷的左耳》 Description A string is a valid parentheses string (denoted VPS) if it meets one of the following: It is an empty string “”, or a single character not equal to “(” or “)…...

联通iccid 19转20 使用luhn 算法的计算公式
联通iccid 19转20 使用luhn 算法的计算公式 第一次对接iccid 才知道 使用的是luhn 算法 19转20位 文章来源于 文章来源 当时也是一脸懵逼 的状态,然后各种chatgpt 寻找,怎么找都发现不对,最后看到这片java的文章实验是正确的,因…...

I.MX6ULL的MAC网络外设设备树实现说明一
一. 简介 IMX6ULL芯片内部集成了两个 10/100M 的网络 MAC 外设,所以,ALPHA开发板上的有线网络的硬件方案是: SOC内部集成网络MAC外设 PHY网络芯片方案。 本文来说明一下MAC网络外设的设备节点信息的实现。 因此, I.MX6ULL 网络…...
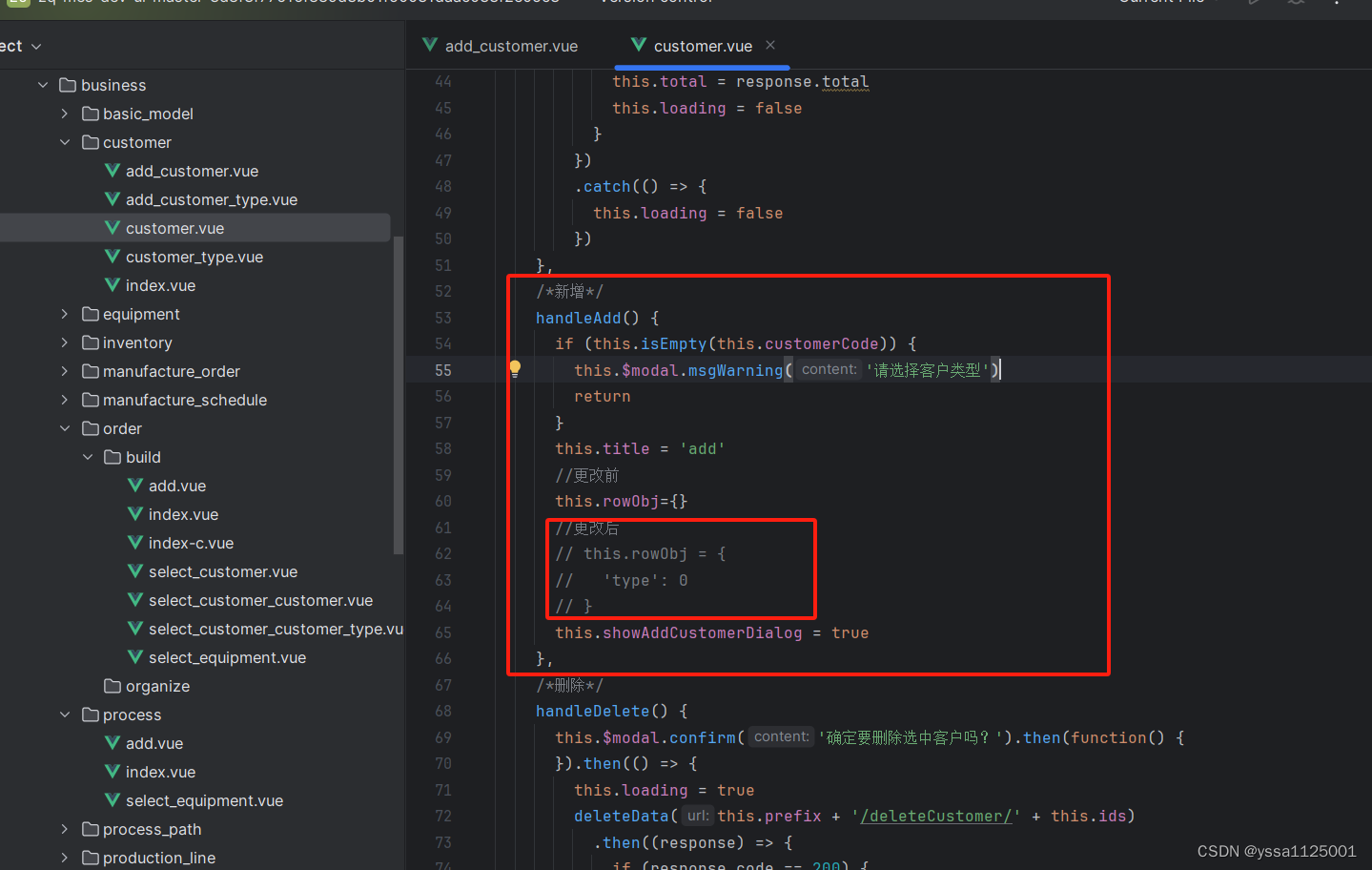
vue弹出的添加信息组件中 el-radio 单选框无法点击问题
情景描述:在弹出的添加信息的组件中的form中有一个单选框,单选框无法进行点击切换 原因如下: 单选框要求有个默认值,因为添加和更新操作复用同一个组件,所以我在初始化时对相关进行了判定,如果为空则赋初始值 结果这样虽然实现了初始值的展示,但是就是如此造成了单选框的无法切…...

蓝桥杯刷题day13——玩游戏【算法赛】
一、问题描述 小 A 和小 B 两个人在海边找到了 n 个石子,准备开始进行一些游戏,具体规则如下:小 B 首先将 n 个石子分成若干堆,接下来从小 A 开始小 A 和小 B 轮流取石子,每次可以任选一堆石子取走任意个,…...

Three.js——scene场景、几何体位置旋转缩放、正射投影相机、透视投影相机
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

springboot集成rabbitmq
一 添加pom <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId> </dependency>二,配置yml spring:rabbitmq:host: 192.168.56.200port: 5672username: adminpasswor…...

腾讯云轻量4核8G12M应用服务器性能测评和优惠价格表
腾讯云4核8G服务器价格:轻量4核8G12M优惠价格646元15个月、CVM S5服务器4核8G配置1437元买1年送3个月。腾讯云4核8G服务器支持多少人同时在线?支持30个并发数,可容纳日均1万IP人数访问。腾讯云百科txybk.com整理4核8G服务器支持多少人同时在线…...

判断点在多边形内的算法
在计算几何中,判定点是否在多边形内,是个非常有趣的问题。通常有两种方法: 一、Crossing Number(交叉数) 它计算从点P开始的射线穿过多边形边界的次数。当“交叉数”是偶数时,点在外面;当它是奇数时&…...

最近在折腾语音端点检测的时候发现个有意思的方法——频带方差检测。这玩意儿特别适合对付环境噪声,原理简单粗暴但有效。今天咱们就手撕代码看看它怎么玩转语音段定位
基于matlab的频带方差端点检测,噪声频谱中,各频带之间变化很平缓,语音各频带之间变化较激烈。 据此特征,语音和噪声就极易区分。 计算短时频带方差,实质就是计算某一帧信号的各频带能量之间的方差。 这种以短时频带方差…...

RobotFramework自定义关键字开发指南:用Python扩展你的测试库
RobotFramework自定义关键字开发实战:Python扩展与分层设计 1. 为什么需要自定义关键字? 在自动化测试领域,RobotFramework以其关键字驱动的特性广受欢迎。但当你深入使用后会发现,标准库和第三方库提供的关键字往往无法完全满足…...
)
手把手教你用V4L2框架开发USB摄像头驱动(附UVC协议解析)
深入解析V4L2框架下的USB摄像头驱动开发与UVC协议实战 在嵌入式Linux开发领域,视频采集设备的驱动开发一直是工程师们需要掌握的核心技能之一。随着物联网和边缘计算的快速发展,USB摄像头在各种智能设备中的应用越来越广泛,从工业检测到智能家…...

终极Google Drive下载解决方案:专业级gdrivedl实战指南
终极Google Drive下载解决方案:专业级gdrivedl实战指南 【免费下载链接】gdrivedl Google Drive Download Python Script 项目地址: https://gitcode.com/gh_mirrors/gd/gdrivedl Google Drive文件下载是许多开发者和技术爱好者面临的常见挑战,特…...
识别)
Ostrakon-VL扫描终端效果:不同材质价签(纸质/塑料/金属)识别
Ostrakon-VL扫描终端效果:不同材质价签(纸质/塑料/金属)识别 1. 像素特工:Ostrakon-VL扫描终端介绍 这是一个基于Ostrakon-VL-8B多模态大模型开发的Web交互终端,专门针对零售与餐饮场景优化。与传统工业级UI不同&…...

【完整源码+数据集+部署教程】光纤缺陷检测系统源码分享[一条龙教学YOLOV8标注好的数据集一键训练_70+全套改进创新点发刊_Web前端展示]
一、背景意义 随着光纤通信技术的迅猛发展,光纤作为信息传输的主要媒介,其质量的优劣直接影响到通信系统的性能和稳定性。光纤在生产、运输和安装过程中,可能会出现各种缺陷,如划痕、气泡、折弯等,这些缺陷不仅会导致信…...

极验三代验证码全流程解析:从注册请求到ajax.php验证
1. 极验三代验证码技术架构解析 极验三代验证码作为当前主流的交互式安全验证方案,其技术架构设计体现了多重防御思想。整个验证流程采用分阶段验证机制,每个环节都设置了独立的安全校验点。从技术实现角度看,系统由前端SDK、验证逻辑引擎和风…...

30分钟搞定OpenClaw:Qwen3-4B镜像云端体验与技能测试
30分钟搞定OpenClaw:Qwen3-4B镜像云端体验与技能测试 1. 为什么选择云端体验OpenClaw 上周我在本地尝试部署OpenClaw时,被各种环境依赖和配置问题折磨得够呛。正当我准备放弃时,偶然发现星图平台提供了预置OpenClaw和Qwen3-4B模型的完整镜像…...

Qwen3.5-9B实战落地:政务公文校对+政策条款关联性分析案例
Qwen3.5-9B实战落地:政务公文校对政策条款关联性分析案例 1. 项目背景与模型介绍 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,在政务场景中展现出强大的应用潜力。这个模型特别适合处理结构化文本分析任务,能够理解复杂的政策语言和公文…...

OFA-VE开源多模态分析系统:GPU算力优化部署实操手册
OFA-VE开源多模态分析系统:GPU算力优化部署实操手册 1. 系统概述与核心价值 OFA-VE是一个基于阿里巴巴达摩院OFA大模型构建的多模态推理平台,专门用于分析图像内容与文本描述之间的逻辑关系。这个系统不仅能看懂图片内容,还能理解文字描述&…...