【动手学深度学习】深入浅出深度学习之RMSProp算法的设计与实现



目录
🌞一、实验目的
🌞二、实验准备
🌞三、实验内容
🌼1. 认识RMSProp算法
🌼2. 在optimizer_compare_naive.py中加入RMSProp
🌼3. 在optimizer_compare_mnist.py中加入RMSProp
🌼4. 问题的解决
🌞四、实验心得
🌞一、实验目的
-
深入学习RMSProp算法的原理和工作机制;
-
根据RMSProp算法的原理,设计并实现一个RMSProp优化器;
-
在optimizer_compare_naive.py中加入RMSProp做比较分析;
-
在optimizer_compare_mnist.py中加入RMSProp做比较分析。
🌞二、实验准备
-
根据GPU安装pytorch版本实现GPU运行实验代码;
-
配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
🌞三、实验内容
资源获取:关注公众号【科创视野】回复 深度学习
🌼1. 认识RMSProp算法
RMSProp(Root Mean Square Propagation)算法是由Geoffrey Hinton在2012年提出的,是对传统的梯度下降算法的改进。它是一种常用的优化算法,用于在深度学习中更新神经网络的参数。
RMSProp算法的基本原理和工作机制如下:
1.基本原理:
RMSProp算法旨在解决传统梯度下降算法中学习率选择的问题。传统梯度下降算法使用固定的学习率,在不同参数上可能导致收敛速度过慢或不收敛。RMSProp通过自适应调整学习率来解决这个问题,对于每个参数使用不同的学习率,根据历史梯度的信息来自动调整。
2.工作机制:
RMSProp使用指数加权平均来计算梯度的平方的移动平均值。对于每个参数的梯度g,计算平方梯度的移动平均值s:
s = β * s + (1 - β) * g^2
其中,β是一个衰减因子,控制历史梯度对当前梯度影响的权重,一般取值范围在0到1之间。然后,更新参数时使用调整后的学习率。对于每个参数的学习率η,计算调整后的学习率:
η' = η / (√(s) + ε)
其中,ε是一个很小的常数,用于避免除以零的情况。最后,使用调整后的学习率更新参数:
参数 = 参数 - η' * 梯度
在每次迭代中,RMSProp算法会根据历史梯度的信息调整学习率,使得对于梯度较大的参数,学习率较小,对于梯度较小的参数,学习率较大,从而更好地适应不同参数的更新需求。
RMSProp算法通过自适应调整学习率,可以提高神经网络的收敛速度和性能。与其他自适应学习率算法(如AdaGrad和Adam)相比,RMSProp在一些情况下可能更稳定和有效。然而,选择合适的学习率和衰减因子对于算法的性能仍然很重要,需要通过实验来确定最佳的超参数设置。
🌼2. 在optimizer_compare_naive.py中加入RMSProp
分析optimizer_compare_naive.py源码如下:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
from common.optimizer import *def f(x, y):return x**2 / 20.0 + y**2def df(x, y):return x / 10.0, 2.0*yinit_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)idx = 1for key in optimizers:optimizer = optimizers[key]x_history = []y_history = []params['x'], params['y'] = init_pos[0], init_pos[1]for i in range(30):x_history.append(params['x'])y_history.append(params['y'])grads['x'], grads['y'] = df(params['x'], params['y'])optimizer.update(params, grads)x = np.arange(-10, 10, 0.01)y = np.arange(-5, 5, 0.01)X, Y = np.meshgrid(x, y) Z = f(X, Y)# for simple contour line mask = Z > 7Z[mask] = 0# plot
fig, axs = plt.subplots(2, 2, figsize=(10, 10), sharey=True, tight_layout=True)
idx = 0for key in optimizers:optimizer = optimizers[key]x_history = []y_history = []params['x'], params['y'] = init_pos[0], init_pos[1]for i in range(30):x_history.append(params['x'])y_history.append(params['y'])grads['x'], grads['y'] = df(params['x'], params['y'])optimizer.update(params, grads)x = np.arange(-10, 10, 0.01)y = np.arange(-5, 5, 0.01)X, Y = np.meshgrid(x, y) Z = f(X, Y)# for simple contour line mask = Z > 7Z[mask] = 0ax = axs[idx//2, idx%2]ax.plot(x_history, y_history, 'o-', color="red")ax.contour(X, Y, Z)ax.set_ylim(-10, 10)ax.set_xlim(-10, 10)ax.plot(0, 0, '+')ax.set_title(key)ax.set_xlabel("x")ax.set_ylabel("y")idx += 1plt.subplots_adjust(hspace=0.5, wspace=0.5)
plt.show()
分析:
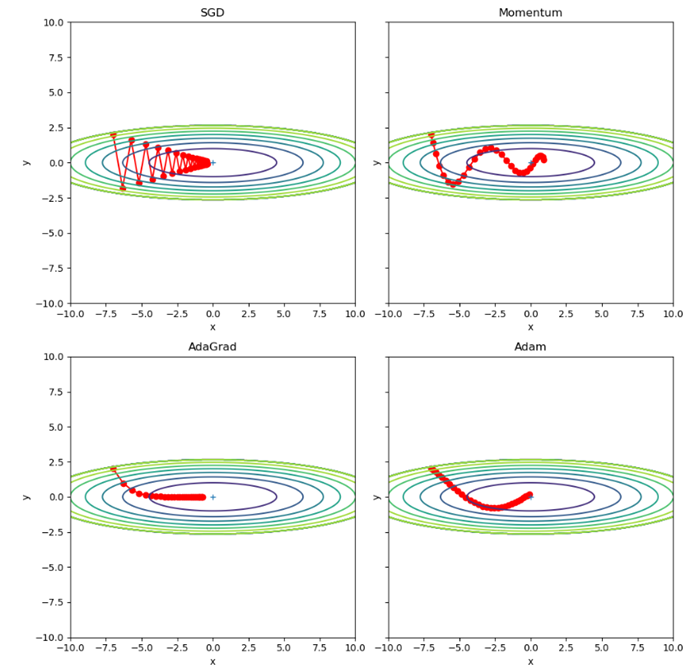
该源码主要是用来展示不同优化器在二维空间中的优化效果。
1.首先是导入必要的库:
- sys、os:用于操作系统相关功能。
- numpy:用于进行数值计算。
- matplotlib.pyplot:用于绘图。
- collections.OrderedDict:有序字典,用于存储优化器。
2.定义函数f(x, y)和df(x, y):
- f(x, y):定义了一个简单的二维函数,即 f(x, y) = x^2 / 20 + y^2。
- df(x, y):计算函数f(x, y)在(x, y)点处的偏导数,即 (∂f/∂x, ∂f/∂y) = (x/10, 2y)。
3.初始化参数和梯度:
- init_pos:初始位置,为(-7.0, 2.0)。
- params:存储优化器中使用的参数,包括x和y。
- grads:存储梯度,包括x和y的偏导数。
4.定义优化器:
- 使用collections.OrderedDict()创建了一个有序字典optimizers,用于存储不同的优化器。
- 分别添加了"SGD"、"Momentum"、"AdaGrad"和"Adam"四种优化器,并给定了不同的学习率。
5.迭代优化器并绘制图形:
- 使用for循环遍历optimizers中的每个优化器。
- 初始化空列表x_history和y_history,用于存储参数更新的历史轨迹。
- 在每个优化器下进行30次迭代:
- 将当前参数位置params['x']和params['y']添加到x_history和y_history中。
- 计算当前位置的梯度grads['x']和grads['y']。
- 调用优化器的update方法,更新参数params。
- 生成x和y的取值范围,用于绘制等高线图。
- 绘制当前优化器的参数更新轨迹、等高线图和起点位置。
- 设置标题、坐标轴等信息。
6.显示图形:
- 使用plt.show()显示绘制的图形。
以上代码展示了四种不同的优化器在二维空间中的优化过程。通过迭代更新参数,每个优化器根据自己的更新策略不断优化目标函数,并绘制出参数更新轨迹和等高线图,以便比较不同优化器的效果。
源码运行结果为:
这里其实我们很容易可以发现在头文件处导入了from common.optimizer import *,而这个库是书籍提供的因此我们打开后查看其目录层级如下图:
由于使用了其中的optimizer因此查看其内容如下:
# coding: utf-8
import numpy as npclass SGD:"""随机梯度下降法(Stochastic Gradient Descent)"""def __init__(self, lr=0.01):self.lr = lrdef update(self, params, grads):for key in params.keys():params[key] -= self.lr * grads[key] class Momentum:"""Momentum SGD"""def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = {}for key, val in params.items(): self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] = self.momentum*self.v[key] - self.lr*grads[key] params[key] += self.v[key]class Nesterov:"""Nesterov's Accelerated Gradient (http://arxiv.org/abs/1212.0901)"""def __init__(self, lr=0.01, momentum=0.9):self.lr = lrself.momentum = momentumself.v = Nonedef update(self, params, grads):if self.v is None:self.v = {}for key, val in params.items():self.v[key] = np.zeros_like(val)for key in params.keys():self.v[key] *= self.momentumself.v[key] -= self.lr * grads[key]params[key] += self.momentum * self.momentum * self.v[key]params[key] -= (1 + self.momentum) * self.lr * grads[key]class AdaGrad:"""AdaGrad"""def __init__(self, lr=0.01):self.lr = lrself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] += grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)class RMSprop:"""RMSprop"""def __init__(self, lr=0.01, decay_rate = 0.99):self.lr = lrself.decay_rate = decay_rateself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] *= self.decay_rateself.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:"""Adam (http://arxiv.org/abs/1412.6980v8)"""def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):self.lr = lrself.beta1 = beta1self.beta2 = beta2self.iter = 0self.m = Noneself.v = Nonedef update(self, params, grads):if self.m is None:self.m, self.v = {}, {}for key, val in params.items():self.m[key] = np.zeros_like(val)self.v[key] = np.zeros_like(val)self.iter += 1lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter) for key in params.keys():#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)
Common分析:
1.这里定义了几种优化算法,包括随机梯度下降法(SGD)、动量法(Momentum)、Nesterov加速梯度法(Nesterov)、AdaGrad、RMSprop和Adam。这些优化算法用于在机器学习和深度学习中更新模型参数以最小化损失函数。
2.SGD(随机梯度下降法):每次迭代时,通过乘以学习率(lr)和梯度值更新参数。即 params[key] -= lr * grads[key]。
3.Momentum(动量法):引入动量(momentum)的概念,通过累积之前的速度来决定当前的更新方向。在每次迭代中,更新速度和参数值。速度(self.v)初始化为零,然后根据当前梯度和动量参数更新速度和参数。更新速度的公式为 self.v[key] = self.momentumself.v[key] - self.lrgrads[key],更新参数的公式为 params[key] += self.v[key]。
4.Nesterov's Accelerated Gradient(Nesterov加速梯度法):与Momentum类似,但在更新参数之前使用了动量的“预期”位置。在每次迭代中,先根据当前速度和动量参数更新速度和参数的“预期”位置,然后再根据当前梯度更新速度和参数的值。更新速度的公式为 self.v[key] *= self.momentum,self.v[key] -= self.lr * grads[key],更新参数的公式为 params[key] += self.momentum * self.momentum * self.v[key],params[key] -= (1 + self.momentum) * self.lr * grads[key]。
5.AdaGrad:针对不同参数的梯度值进行归一化处理,对于每个参数,根据梯度平方的累积和和学习率更新参数。归一化的方式是除以历史梯度平方的平方根加上一个很小的数(1e-7)以避免除以零。更新参数的公式为 params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7),其中 self.h[key] 为历史梯度平方的累积和。
6.RMSprop:与AdaGrad类似,但不是累积所有历史梯度平方的和,而是通过指数加权平均的方式计算历史梯度平方的累积和。在每次迭代中,更新参数的方式与AdaGrad相同,只是累积和的计算方式不同。更新参数的公式为 params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7),其中 self.h[key] *= self.decay_rate,self.h[key] += (1 - self.decay_rate继续解释Adam算法:
7.Adam:结合了动量法和RMSprop的优点。它使用两个动量参数(beta1和beta2)和一个迭代计数器(iter)来更新参数。初始化时,将动量(m)和二阶矩估计(v)初始化为零。在每次迭代中,更新动量和二阶矩估计的值,然后根据当前的学习率计算修正后的学习率。最后,根据修正后的学习率和二阶矩估计来更新参数。更新动量和二阶矩估计的公式为:
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
修正后的学习率(lr_t)计算公式为:
lr_t = self.lr * np.sqrt(1.0 - self.beta2self.iter) / (1.0 - self.beta1self.iter)
最终,根据修正后的学习率和二阶矩估计来更新参数的公式为:
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
根据上述的common分析,为了添加RMSProp优化器,还需进行以下步骤:
1. 导入RMSProp优化器类:
- 在代码开头导入RMSProp类, from common.optimizer import RMSProp
2.在优化器字典中添加RMSProp优化器:
- 在optimizers字典中添加RMSProp优化器,类似于其他优化器的添加方式,指定合适的学习率:
optimizers["RMSProp"] = RMSProp(lr=0.1, decay_rate=0.99)3.在循环中使用RMSProp优化器更新参数:
- 在循环迭代的部分,根据当前优化器选择RMSProp进行参数更新。
- 在每次迭代时,调用RMSProp优化器的update方法更新参数。
for i in range(30):x_history.append(params['x'])y_history.append(params['y'])grads['x'], grads['y'] = df(params['x'], params['y'])optimizer.update(params, grads)4. 最后,运行代码并观察RMSProp优化器的效果。
- 当运行代码时,RMSProp优化器将被迭代,并在绘图中显示其参数更新轨迹。
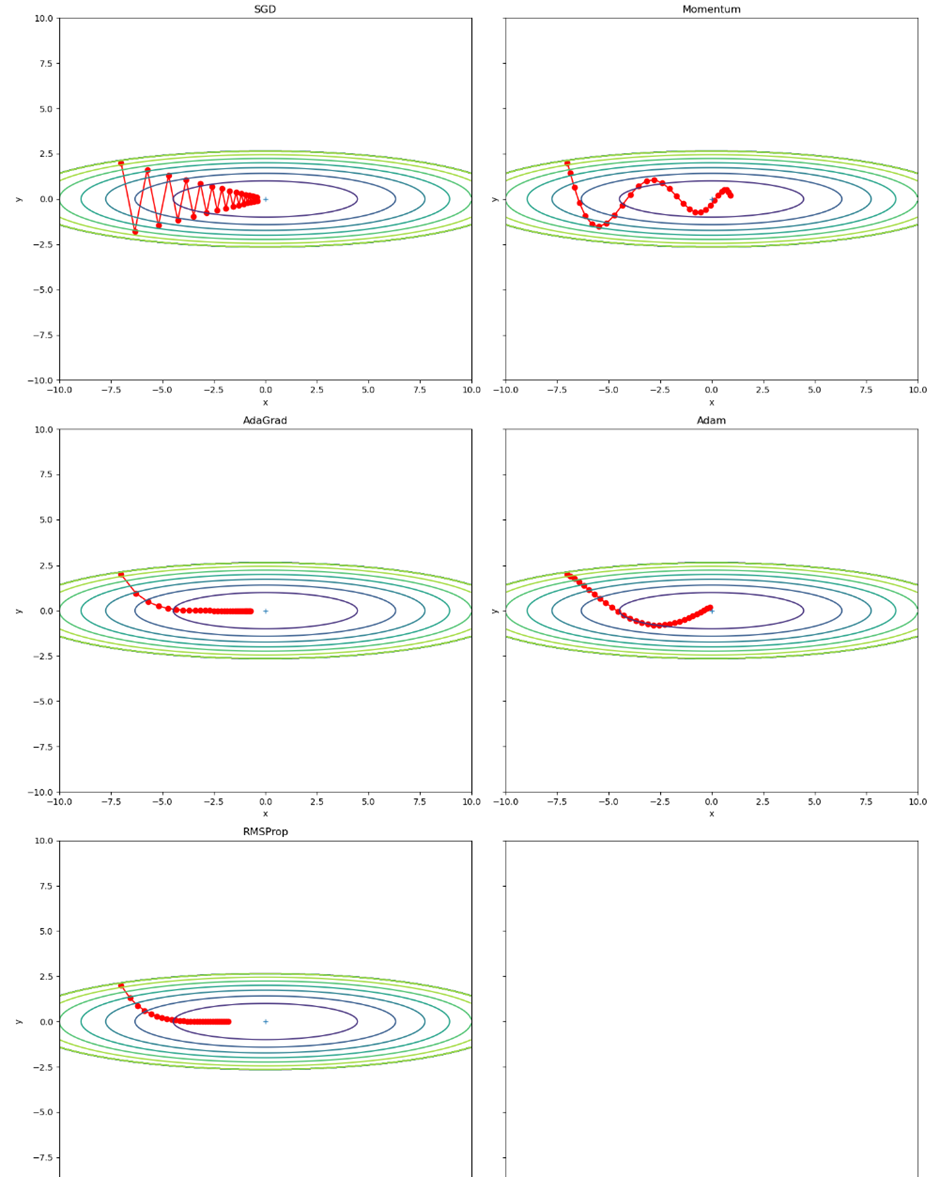
添加RMSProp后代码为:
# coding: utf-8
import sys, os
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
from common.optimizer import *def f(x, y):return x**2 / 20.0 + y**2def df(x, y):return x / 10.0, 2.0*yinit_pos = (-7.0, 2.0)
params = {}
params['x'], params['y'] = init_pos[0], init_pos[1]
grads = {}
grads['x'], grads['y'] = 0, 0optimizers = OrderedDict()
optimizers["SGD"] = SGD(lr=0.95)
optimizers["Momentum"] = Momentum(lr=0.1)
optimizers["AdaGrad"] = AdaGrad(lr=1.5)
optimizers["Adam"] = Adam(lr=0.3)
optimizers["RMSProp"] = RMSprop(lr=0.1, decay_rate=0.99) # 添加RMSProp优化器idx = 1for key in optimizers:optimizer = optimizers[key]x_history = []y_history = []params['x'], params['y'] = init_pos[0], init_pos[1]for i in range(30):x_history.append(params['x'])y_history.append(params['y'])grads['x'], grads['y'] = df(params['x'], params['y'])optimizer.update(params, grads)x = np.arange(-10, 10, 0.01)y = np.arange(-5, 5, 0.01)X, Y = np.meshgrid(x, y) Z = f(X, Y)# for simple contour line mask = Z > 7Z[mask] = 0# plot
fig, axs = plt.subplots(3, 2, figsize=(15, 20), sharey=True, tight_layout=True)
idx = 1for key in optimizers:optimizer = optimizers[key]x_history = []y_history = []params['x'], params['y'] = init_pos[0], init_pos[1]for i in range(30):x_history.append(params['x'])y_history.append(params['y'])grads['x'], grads['y'] = df(params['x'], params['y'])optimizer.update(params, grads)x = np.arange(-10, 10, 0.01)y = np.arange(-5, 5, 0.01)X, Y = np.meshgrid(x, y) Z = f(X, Y)# for simple contour line mask = Z > 7Z[mask] = 0ax = axs[(idx - 1) // 2, (idx - 1) % 2]ax.plot(x_history, y_history, 'o-', color="red")ax.contour(X, Y, Z)ax.set_ylim(-10, 10)ax.set_xlim(-10, 10)ax.plot(0, 0, '+')ax.set_title(key)ax.set_xlabel("x")ax.set_ylabel("y")idx += 1plt.show()运行结果为:
🌼3. 在optimizer_compare_mnist.py中加入RMSProp
分析optimizer_compare_mnist.py源码如下:
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import *# 0:读入MNIST数据==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000# 1:进行实验的设置==========
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
#optimizers['RMSprop'] = RMSprop()networks = {}
train_loss = {}
for key in optimizers.keys():networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],output_size=10)train_loss[key] = [] # 2:开始训练==========
for i in range(max_iterations):batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]for key in optimizers.keys():grads = networks[key].gradient(x_batch, t_batch)optimizers[key].update(networks[key].params, grads)loss = networks[key].loss(x_batch, t_batch)train_loss[key].append(loss)if i % 100 == 0:print( "===========" + "iteration:" + str(i) + "===========")for key in optimizers.keys():loss = networks[key].loss(x_batch, t_batch)print(key + ":" + str(loss))# 3.绘制图形==========
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D"}
x = np.arange(max_iterations)
for key in optimizers.keys():plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()
源码分析:
1.数据准备
- 通过调用load_mnist函数加载了MNIST数据集,将训练数据集和测试数据集分别赋值给(x_train, t_train)和(x_test, t_test)变量。
- train_size记录了训练数据集的样本数量,batch_size定义了每个小批量训练的样本数量,max_iterations定义了训练的迭代次数。
2.实验设置
- 定义字典optimizers包含了不同的优化算法对象,包括SGD、Momentum、AdaGrad和Adam。
- 定义空的字典networks用于存储不同优化算法下的神经网络模型。
- 定义空的字典train_loss用于存储不同优化算法下的训练损失。
3.开始训练
- 使用一个循环迭代max_iterations次进行训练。
- 在每次迭代中,通过随机选择索引生成一个小批量的训练数据,并根据选择的优化算法计算梯度并更新模型参数。
- 计算当前模型在训练数据上的损失,并将其存储到train_loss字典中。
- 每隔100次迭代,打印出各个优化算法的损失。
4.绘制图形
- 使用smooth_curve函数平滑训练损失曲线。
- 使用不同的标记符号和颜色,将各个优化算法的训练损失曲线绘制在同一张图上。
- 添加坐标轴标签和图例,并显示图形。
- 过比较不同优化算法在训练过程中的损失变化情况,可以对比它们的性能和收敛速度,进而选择最合适的优化算法来训练神经网络模型。
运行结果如下:

图4-4
前文的common的RMSprop定义如下:
class RMSprop:"""RMSprop"""def __init__(self, lr=0.01, decay_rate=0.99):self.lr = lrself.decay_rate = decay_rateself.h = Nonedef update(self, params, grads):if self.h is None:self.h = {}for key, val in params.items():self.h[key] = np.zeros_like(val)for key in params.keys():self.h[key] *= self.decay_rateself.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
为了添加RMSProp优化器,还需进行以下步骤:
1. 取消注释optimizers['RMSprop'] = RMSprop()这一行,以导入RMSprop优化器。
2.在实验设置部分(步骤1)的循环中,为RMSprop优化器添加一个网络和训练损失的条目。修改以下代码段:
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
#optimizers['RMSprop'] = RMSprop()networks = {}
train_loss = {}
for key in optimizers.keys():networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],output_size=10)train_loss[key] = []
将其修改为:
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
optimizers['RMSprop'] = RMSprop()networks = {}
train_loss = {}
for key in optimizers.keys():networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],output_size=10)train_loss[key] = []
3.在训练部分(步骤2)的循环中,更新RMSprop优化器的参数。修改以下代码段:
for i in range(max_iterations):batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]for key in optimizers.keys():grads = networks[key].gradient(x_batch, t_batch)optimizers[key].update(networks[key].params, grads)loss = networks[key].loss(x_batch, t_batch)train_loss[key].append(loss)if i % 100 == 0:print( "===========" + "iteration:" + str(i) + "===========")for key in optimizers.keys():loss = networks[key].loss(x_batch, t_batch)print(key + ":" + str(loss))结果以上详细分析,最终加入的RMSprop的代码为:
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.util import smooth_curve
from common.multi_layer_net import MultiLayerNet
from common.optimizer import *# 0:读入MNIST数据==========
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)train_size = x_train.shape[0]
batch_size = 128
max_iterations = 2000# 1:进行实验的设置==========
optimizers = {}
optimizers['SGD'] = SGD()
optimizers['Momentum'] = Momentum()
optimizers['AdaGrad'] = AdaGrad()
optimizers['Adam'] = Adam()
optimizers['RMSprop'] = RMSprop() # 添加RMSProp优化器networks = {}
train_loss = {}
for key in optimizers.keys():networks[key] = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100],output_size=10)train_loss[key] = [] # 2:开始训练==========
for i in range(max_iterations):batch_mask = np.random.choice(train_size, batch_size)x_batch = x_train[batch_mask]t_batch = t_train[batch_mask]for key in optimizers.keys():grads = networks[key].gradient(x_batch, t_batch)if key == 'RMSprop': # 添加RMSProp更新部分optimizer = optimizers[key]optimizer.lr = 0.01 # 可根据需要设置学习率optimizer.decay_rate = 0.99 # 可根据需要设置衰减率optimizer.update(networks[key].params, grads)else:optimizers[key].update(networks[key].params, grads)loss = networks[key].loss(x_batch, t_batch)train_loss[key].append(loss)if i % 100 == 0:print("===========" + "iteration:" + str(i) + "===========")for key in optimizers.keys():loss = networks[key].loss(x_batch, t_batch)print(key + ":" + str(loss))# 3.绘制图形==========
markers = {"SGD": "o", "Momentum": "x", "AdaGrad": "s", "Adam": "D", "RMSprop": "v"}
x = np.arange(max_iterations)
for key in optimizers.keys():plt.plot(x, smooth_curve(train_loss[key]), marker=markers[key], markevery=100, label=key)
plt.xlabel("iterations")
plt.ylabel("loss")
plt.ylim(0, 1)
plt.legend()
plt.show()
运行结果:

图4-5
🌼4. 问题的解决
1. 如果我们设置γ = 1,实验会发生什么?为什么?
解:如果将RMSprop算法中的decay_rate参数γ设置为1,即self.decay_rate = 1。在RMSprop算法中,decay_rate参数用于控制历史梯度平方和的衰减率。在每次更新参数时,历史梯度平方和会乘以decay_rate,表示旧的历史梯度平方和的贡献在更新中保持不变。当decay_rate等于1时,历史梯度平方和不会被衰减,它将保持不变。这意味着在每次参数更新中,历史梯度平方和的值不会改变,对梯度的调整没有任何影响。
结果是RMSprop算法将变得与普通的梯度下降算法(如SGD)类似,因为历史梯度平方和的衰减不再发挥作用。实验中的网络更新将类似于SGD,不会发生自适应调整学习率的效果。从而导致算法的性能下降,训练过程中的更新步长可能过大,且收敛速度可能变慢。

图4-6 设置γ = 1的RMSprop两次结果(右图不显示)
2. 旋转优化问题以最小化f(x) = 0.1*(x1 + x2)**2 + 2(x1 − x2)**2。收敛会发生什么?
解:在使用优化算法进行收敛时,不同的优化算法可能表现出不同的收敛行为:
SGD:由于旋转对称性,SGD可能会在搜索空间中震荡并缓慢收敛到最优点。它的收敛速度较慢。
Momentum:具有积累梯度的特性,可以在梯度方向上加速收敛。由于旋转对称性,Momentum算法可能会更快地收敛到最优点。
AdaGrad:通过自适应地调整学习率来处理不同特征的梯度变化。然而,在旋转优化问题中,由于旋转对称性,AdaGrad可能会导致学习率过早地衰减,从而导致收敛速度较慢。
Adam:结合了Momentum和AdaGrad的优点,具有较好的收敛性能。由于旋转对称性,Adam算法可能会更快地收敛到最优点。
RMSProp:自适应学习率的优化算法,通过调整学习率的大小来适应不同特征的梯度变化。在旋转优化问题中,由于函数 f(x) 具有旋转对称性,不同方向上的梯度变化可能会不同。RMSProp算法的自适应学习率机制可以在不同方向上调整学习率的大小,从而有助于更快地收敛到最优点。
3. 随着优化的进展,需要调整γ吗?RMSProp算法对此有多敏感?
解:通常情况下,较小的默认值(例如0.9或0.99)已经可以在许多问题上产生良好的效果,因此通常不需要频繁地调整γ的值。
RMSProp算法在大多数情况下对γ的选择相对不太敏感。
🌞四、实验心得
通过此次实验,我深入学习了RMSProp算法的原理和工作机制,并成功实现了一个RMSProp优化器。RMSProp算法通过自适应地调整学习率和使用梯度平方的指数加权移动平均缓存,可以在训练过程中加速收敛并提高性能。
在实验中,我将RMSProp算法应用于神经网络的训练过程。首先,选择了适当的神经网络模型和训练数据集,然后使用自己实现的RMSProp优化器进行参数更新。通过观察训练过程中的损失函数值和准确率等指标,从而比较使用RMSProp算法和传统梯度下降算法在训练过程中的性能和收敛速度。
在收集实验结果和进行分析时,我记录了训练过程中的损失函数值和准确率,并绘制了曲线图。通过对比使用RMSProp算法和传统梯度下降算法的实验结果,我发现RMSProp算法在加速收敛和提高性能方面表现出色。相较于传统梯度下降算法,使用RMSProp算法的自适应学习率调整和梯度平方的指数加权移动平均缓存机制使得它能够在训练过程中自动调整学习率,并更有效地利用梯度信息,从而加速了模型的收敛速度和提高了性能。并且能够更快地收敛到较低的损失函数值。

相关文章:
【动手学深度学习】深入浅出深度学习之RMSProp算法的设计与实现
目录 🌞一、实验目的 🌞二、实验准备 🌞三、实验内容 🌼1. 认识RMSProp算法 🌼2. 在optimizer_compare_naive.py中加入RMSProp 🌼3. 在optimizer_compare_mnist.py中加入RMSProp 🌼4. 问…...

大转盘抽奖小程序源码
源码介绍 大转盘抽奖小程序源码,测试依旧可用,无BUG,跑马灯旋转效果,非常酷炫。 小程序核心代码参考 //index.js //获取应用实例 var app getApp() Page({data: {circleList: [],//圆点数组awardList: [],//奖品数组colorCirc…...
)
数据结构(无图版)
数据结构与算法(无图版,C语言实现) 1、绪论 1.1、数据结构的研究内容 一般应用步骤:分析问题,提取操作对象,分析操作对象之间的关系,建立数学模型。 1.2、基本概念和术语 数据:…...

软件测试中的顶级测试覆盖率技术
根据 CISQ 报告,劣质软件每年给美国公司造成约2.08 万亿美元的损失。虽然软件工具是企业和行业领域的必需品,但它们也容易出现严重错误和性能问题。人类手动测试不再足以检测和消除软件错误。 因此,产品或软件开发公司必须转向自动化测试&am…...

vscode使用技巧
常用快捷键 代码格式 Windows系统。格式化代码的快捷键是“ShiftAltF” Mac系统。格式化代码的快捷键是“ShiftOptionF” Ubuntu系统。格式化代码的快捷键是“CtrlShiftI”配置缩进 点击左上角的“文件”菜单,然后选择“首选项”>“设置”,或者使用…...
JSP
概念:Java Server Pages,Java服务端页面 一种动态的网页技术,其中既可以定义HTML、JS、CSS等静态内容,还可以定义Java代码的动态内容 JSP HTML Java 快速入门 注:Tomcat中已经有了JSP的jar包,因此我们…...
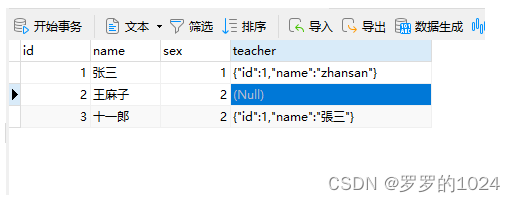
Mybatis--TypeHandler使用手册
TypeHandler使用手册 场景:想保存user时 teacher自动转String ,不想每次保存都要手动去转String;从DB查询出来时,也要自动帮我们转换成Java对象 Teacher Data public class User {private Integer id;private String name;priva…...
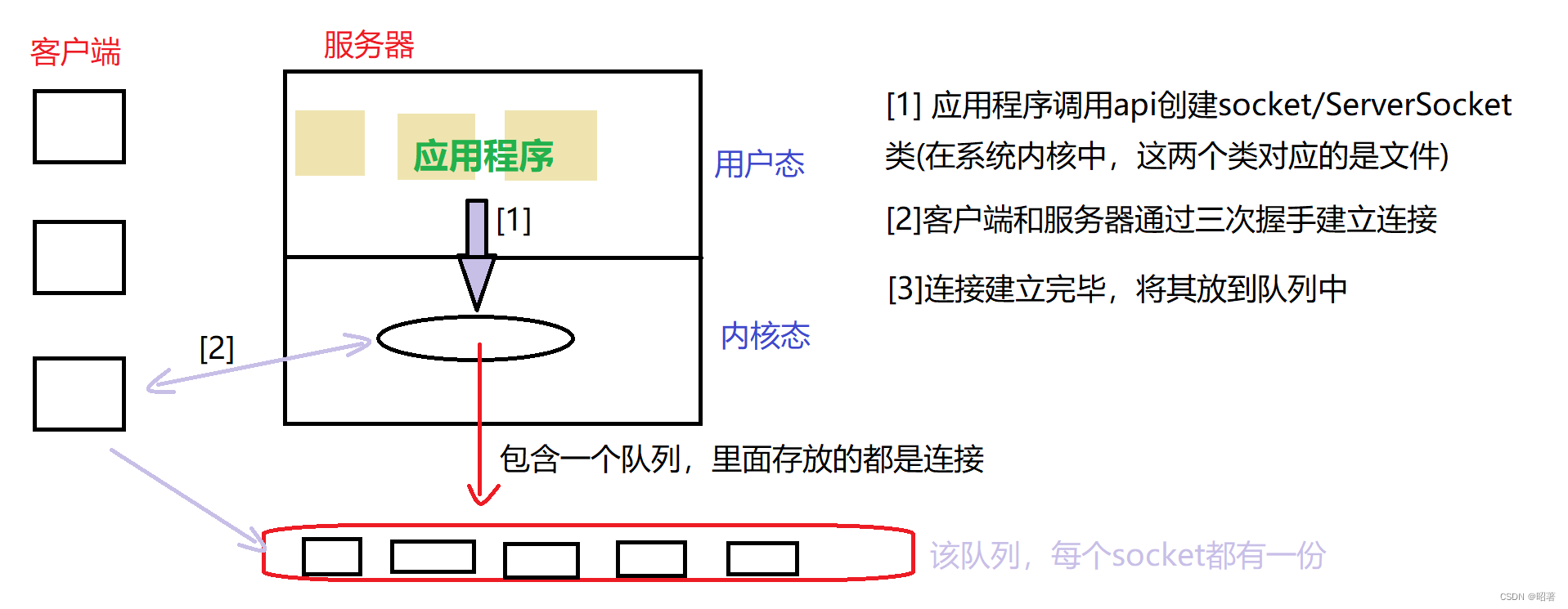
网络编程(TCP、UDP)
文章目录 一、概念1.1 什么是网络编程1.2 网络编程中的基本知识 二、Socket套接字2.1 概念及分类2.2 TCP VS UDP2.3 通信模型2.4 接口方法UDP数据报套接字编程TCP流套接字编程 三、代码示例3.1 注意点3.2 回显服务器基于UDP基于TCP 一、概念 首先介绍了什么是网络编程ÿ…...

Python快速入门系列-7(Python Web开发与框架介绍)
第七章:Python Web开发与框架介绍 7.1 Flask与Django简介7.1.1 Flask框架Flask的特点Flask的安装一个简单的Flask应用示例7.1.2 Django框架Django的特点Django的安装一个简单的Django应用示例7.2 前后端交互与数据传输7.2.1 前后端交互7.2.2 数据传输格式7.2.3 示例:使用Flas…...

最长对称子串
对给定的字符串,本题要求你输出最长对称子串的长度。例如,给定Is PAT&TAP symmetric?,最长对称子串为s PAT&TAP s,于是你应该输出11。 输入格式: 输入在一行中给出长度不超过1000的非空字符串。 输出格式&…...
【大模型】大模型 CPU 推理之 llama.cpp
【大模型】大模型 CPU 推理之 llama.cpp llama.cpp安装llama.cppMemory/Disk RequirementsQuantization测试推理下载模型测试 参考 llama.cpp 描述 The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide var…...
异地组网怎么管理?
在当今信息化时代,随着企业的业务扩张和员工的分布,异地组网已经成为越来越多企业的需求。异地组网管理相对来说是一项复杂而繁琐的任务。本文将介绍一种名为【天联】的管理解决方案,帮助企业更好地管理异地组网。 【天联】组网的优势 【天联…...
Kafka参数介绍
官网参数介绍:Apache KafkaApache Kafka: A Distributed Streaming Platform.https://kafka.apache.org/documentation/#configuration...
如何利用待办事项清单提高工作效率?
你是否经常因为繁重的工作量而感到不堪重负?你是否在努力赶工期或经常忘记重要的电子邮件?你并不是特例。如何利用待办事项清单提高工作效率?这里有一个简单的方法可以帮你理清混乱并更高效地完成任务—待办事项清单。 这种类型的清单可以帮…...

力扣经典150题第二题:移除元素
移除元素问题详解与解决方法 1. 介绍 移除元素问题是 LeetCode 经典题目之一,要求原地修改输入数组,移除所有数值等于给定值的元素,并返回新数组的长度。 问题描述 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等…...

55555555555555
欢迎关注博主 Mindtechnist 或加入【Linux C/C/Python社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和…...
:图像形态学处理(上))
用Skimage学习数字图像处理(018):图像形态学处理(上)
本节开始讨论图像形态学处理,这是上篇,将介绍与二值形态学相关的内容,重点介绍两种基本的二值形态学操作:腐蚀和膨胀,以及三种复合二值形态学操作:开、闭和击中击不中变换。 目录 9.1 基础 9.2 基本操作…...

MySQL中 in 和 exists 区别
在MySQL中,IN和EXISTS都是用于在子查询中测试条件的操作符,但它们在处理和效率上有一些重要的区别。MySQL中的in语句是把外表和内表作hash连接,⽽exists语句是对外表作loop循环,每次loop循环再对内表进⾏查询。⼤家⼀直认为exists…...

Java基础 - 代码练习
第一题:集合的运用(幸存者) public class demo1 {public static void main(String[] args) {ArrayList<Integer> array new ArrayList<>(); //一百个囚犯存放在array集合中Random r new Random();for (int i 0; i < 100; …...
【Redis】redis集群模式
概述 Redis集群,即Redis Cluster,是Redis 3.0开始引入的分布式存储方案。实际使用中集群一般由多个节点(Node)组成,Redis的数据分布在这些节点中。集群中的节点分为主节点和从节点:只有主节点负责读写请求和集群信息的维护&#…...

中科院拒绝支付版面费的期刊名单!
中科院拒绝支付版面费的期刊名单来了,都是质量不错的期刊,总共34本。若没有足够预算的,注意避雷!√ 分布学科:医学23本生物学8本综合性期刊3本√ 分区和IF:中科院1-2区占比82.4%,IF>5分占比79.4%√ TOP期…...

【AI面试】Agent、Skills、Function calling、MCP 的区别与联系
参考文档: Skills、MCP、Agent、Function calling 的本质区别,一张图讲清楚 Function calling,告别 AI “抽风”第一步 Skills 是什么?AI 真的开始“使用工具”了吗? 什么是 MCP,有什么用? 新鲜词太多,学习成本蹭蹭上涨:Agent、Skills、MCP、Function calling(也常被…...

为什么复位时PC指针指向的复位向量地址与flash中查看的不一样
观察到的 0x080000D8 是复位向量地址的最低字节(为什么说是最低字节往后面看),而不是栈顶地址,这里的关键是区分两个不同的地址: 1. 栈顶地址(MSP):存储在 0x08000000,值为 0x200011D8。 2. 复位…...

爬虫对抗:ZLibrary反爬机制实战分析技术文章大纲
爬虫对抗:ZLibrary反爬机制实战分析技术文章大纲爬虫与反爬虫概述爬虫技术的基本原理与应用场景反爬虫机制的必要性与常见手段ZLibrary作为典型案例的背景介绍ZLibrary的反爬机制分析IP限制与封禁策略请求频率检测与验证码挑战动态页面渲染与JavaScript加密用户行为…...

QGraphicView + QGraphicItem
1,rectitem->rect——item的矩形框。原点点左上角为00点 rectitem_>setTransforOriginPoint()——设置参考原点2,rectitem.pos()——item在scene中的位置3,scence的原点为左上角为00点4,QGraphicsView->setAlignment(Qt::AlignLef |…...

联合循环——33 油罐,水罐,凝汽器和地下管道阴极保护
一、阴极保护一般有两种方式: 在电厂、化工装置及管道系统的阴极保护(Cathodic Protection)技术中,常用的两种方法为: 牺牲阳极法(Sacrificial Anode Cathodic Protection)外加电源法࿰…...

探索Swaptube分形渲染:Mandelbrot与Julia集的视觉艺术
探索Swaptube分形渲染:Mandelbrot与Julia集的视觉艺术 【免费下载链接】swaptube youtube video renderer 项目地址: https://gitcode.com/gh_mirrors/sw/swaptube Swaptube是一个功能强大的YouTube视频渲染项目,专注于分形艺术的视觉呈现。它通过…...

5个开源语义模型部署推荐:BAAI/bge-m3免配置镜像一键启动
5个开源语义模型部署推荐:BAAI/bge-m3免配置镜像一键启动 1. 项目简介 BAAI/bge-m3语义相似度分析引擎是一个基于先进多语言嵌入模型的智能文本分析工具。这个镜像封装了北京智源人工智能研究院开发的bge-m3模型,是目前开源领域最强大的语义理解模型之…...

卡证检测矫正模型在复杂网络环境下的自适应传输优化
卡证检测矫正模型在复杂网络环境下的自适应传输优化 1. 引言 想象一下这个场景:你正在银行网点办理业务,柜员用手机或平板对你的身份证进行拍照识别。网络信号时好时坏,图片上传缓慢,识别结果迟迟出不来,后面排队的人…...

三相无刷电机控制进阶:从六步换向到FOC的实战解析
1. 三相无刷电机控制技术概述 第一次接触三相无刷电机时,很多人都会被它复杂的控制方式吓到。但如果你拆开一个普通电脑风扇,就会发现里面藏着的就是这种神奇的小东西。与传统的直流有刷电机相比,无刷电机通过电子换向取代了机械电刷…...