Scala第十九章节(Actor的相关概述、Actor发送和接收消息以及WordCount案例)
Scala第十九章节
章节目标
- 了解Actor的相关概述
- 掌握Actor发送和接收消息
- 掌握WordCount案例
1. Actor介绍
Scala中的Actor并发编程模型可以用来开发比Java线程效率更高的并发程序。我们学习Scala Actor的目的主要是为后续学习Akka做准备。
1.1 Java并发编程的问题
在Java并发编程中,每个对象都有一个逻辑监视器(monitor),可以用来控制对象的多线程访问。我们添加sychronized关键字来标记,需要进行同步加锁访问。这样,通过加锁的机制来确保同一时间只有一个线程访问共享数据。但这种方式存在资源争夺、以及死锁问题,程序越大问题越麻烦。

线程死锁

1.2 Actor并发编程模型
Actor并发编程模型,是Scala提供给程序员的一种与Java并发编程完全不一样的并发编程模型,是一种基于事件模型的并发机制。Actor并发编程模型是一种不共享数据,依赖消息传递的一种并发编程模式,有效避免资源争夺、死锁等情况。

1.3 Java并发编程对比Actor并发编程
| Java内置线程模型 | Scala Actor模型 |
|---|---|
| "共享数据-锁"模型 (share data and lock) | share nothing |
| 每个object有一个monitor,监视线程对共享数据的访问 | 不共享数据,Actor之间通过Message通讯 |
| 加锁代码使用synchronized标识 | |
| 死锁问题 | |
| 每个线程内部是顺序执行的 | 每个Actor内部是顺序执行的 |
注意:
scala在2.11.x版本中加入了Akka并发编程框架,老版本已经废弃。
Actor的编程模型和Akka很像,我们这里学习Actor的目的是为学习Akka做准备。
2. 创建Actor
我们可以通过类(class)或者单例对象(object), 继承Actor特质的方式, 来创建Actor对象.
2.1 步骤
- 定义class或object继承Actor特质
- 重写act方法
- 调用Actor的start方法执行Actor
注意: 每个Actor是并行执行的, 互不干扰.
2.2 案例一: 通过class实现
需求
- 创建两个Actor,一个Actor打印1-10,另一个Actor打印11-20
- 使用class继承Actor实现.(如果需要在程序中创建多个相同的Actor)
参考代码
import scala.actors.Actor//案例:Actor并发编程入门, 通过class创建Actor
object ClassDemo01 {//需求: 创建两个Actor,一个Actor打印1-10,另一个Actor打印11-20//1. 创建Actor1, 用来打印1~10的数字.class Actor1 extends Actor {override def act(): Unit = for (i <- 1 to 10) println("actor1: " + i)}//2. 创建Actor2, 用来打印11~20的数字.class Actor2 extends Actor {override def act(): Unit = for (i <- 11 to 20) println("actor2: " + i)}def main(args: Array[String]): Unit = {//3. 启动两个Actor.new Actor1().start()new Actor2().start()}
}
2.3 案例二: 通过object实现
需求
- 创建两个Actor,一个Actor打印1-10,另一个Actor打印11-20
- 使用object继承Actor实现.(如果在程序中只创建一个Actor)
参考代码
import scala.actors.Actor//案例:Actor并发编程入门, 通过object创建Actor
object ClassDemo02 {//需求: 创建两个Actor,一个Actor打印1-10,另一个Actor打印11-20//1. 创建Actor1, 用来打印1~10的数字.object Actor1 extends Actor {override def act(): Unit = for (i <- 1 to 10) println("actor1: " + i)}//2. 创建Actor2, 用来打印11~20的数字.object Actor2 extends Actor {override def act(): Unit = for (i <- 11 to 20) println("actor2: " + i)}def main(args: Array[String]): Unit = {//3. 启动两个Actor.Actor1.start()Actor2.start()}
}
2.4 Actor程序运行流程
- 调用start()方法启动Actor
- 自动执行act()方法
- 向Actor发送消息
- act方法执行完成后,程序会调用**exit()**方法结束程序执行.
3. 发送消息/接收消息
我们之前介绍Actor的时候,说过Actor是基于事件(消息)的并发编程模型,那么Actor是如何发送消息和接收消息的呢?
3.1 使用方式
3.1.1 发送消息
我们可以使用三种方式来发送消息:
| ! | 发送异步消息,没有返回值 |
|---|---|
| !? | 发送同步消息,等待返回值 |
| !! | 发送异步消息,返回值是Future[Any] |
例如:要给actor1发送一个异步字符串消息,使用以下代码:
actor1 ! "你好!"
3.1.2 接收消息
Actor中使用receive方法来接收消息,需要给receive方法传入一个偏函数
{case 变量名1:消息类型1 => 业务处理1case 变量名2:消息类型2 => 业务处理2...
}
注意: receive方法只接收一次消息,接收完后继续执行act方法
3.2 案例一: 发送及接收一句话
需求
- 创建两个Actor(ActorSender、ActorReceiver)
- ActorSender发送一个异步字符串消息给ActorReceiver
- ActorReceiver接收到该消息后,打印出来

参考代码
//案例: 采用 异步无返回的形式, 发送消息.
object ClassDemo03 {//1. 创建发送消息的Actor, ActorSender, 发送一句话给ActorReceiverobject ActorSender extends Actor {override def act(): Unit = {//发送一句话给ActorReceiverActorReceiver ! "你好啊, 我是ActorSender!"//发送第二句话ActorReceiver ! "你叫什么名字呀? "}}//2. 创建接收消息的Actor, ActorReceiverobject ActorReceiver extends Actor {override def act(): Unit = {//接收发送过来的消息.receive {case x: String => println(x)}}}def main(args: Array[String]): Unit = {//3. 启动两个ActorActorSender.start()ActorReceiver.start()}
}
3.3 案例二: 持续发送和接收消息
如果我们想实现ActorSender一直发送消息, ActorReceiver能够一直接收消息,该怎么实现呢?
答: 我们只需要使用一个while(true)循环,不停地调用receive来接收消息就可以啦。
需求
- 创建两个Actor(ActorSender、ActorReceiver)
- ActorSender持续发送一个异步字符串消息给ActorReceiver
- ActorReceiver持续接收消息,并打印出来
参考代码
//案例:Actor 持续发送和接收消息.
object ClassDemo04 {//1. 创建发送消息的Actor, ActorSender, 发送一句话给ActorReceiverobject ActorSender extends Actor {override def act(): Unit = {while(true) {//发送一句话给ActorReceiverActorReceiver ! "你好啊, 我是ActorSender!"//休眠3秒.TimeUnit.SECONDS.sleep(3) //单位是: 秒}}}//2. 创建接收消息的Actor, ActorReceiverobject ActorReceiver extends Actor {override def act(): Unit = {//接收发送过来的消息, 持续接收.while(true) {receive {case x: String => println(x)}}}}def main(args: Array[String]): Unit = {//3. 启动两个ActorActorSender.start()ActorReceiver.start()}
}
3.4 案例三: 优化持续接收消息
上述代码,是用while循环来不断接收消息的, 这样做可能会遇到如下问题:
- 如果当前Actor没有接收到消息,线程就会处于阻塞状态
- 如果有很多的Actor,就有可能会导致很多线程都是处于阻塞状态
- 每次有新的消息来时,重新创建线程来处理
- 频繁的线程创建、销毁和切换,会影响运行效率
针对上述情况, 我们可以使用loop(), 结合react()来复用线程, 这种方式比while循环 + receive()更高效.
需求
- 创建两个Actor(ActorSender、ActorReceiver)
- ActorSender持续发送一个异步字符串消息给ActorReceiver
- ActorReceiver持续接收消息,并打印出来
注意: 使用loop + react重写上述案例.
参考代码
//案例: 使用loop + react循环接收消息.
object ClassDemo05 {//1. 创建发送消息的Actor, ActorSender, 发送一句话给ActorReceiverobject ActorSender extends Actor {override def act(): Unit = {while(true) {//发送一句话给ActorReceiverActorReceiver ! "你好啊, 我是ActorSender!"//休眠3秒.TimeUnit.SECONDS.sleep(3) //单位是: 秒}}}//2. 创建接收消息的Actor, ActorReceiverobject ActorReceiver extends Actor {override def act(): Unit = {//接收发送过来的消息, 持续接收.loop{react {case x: String => println(x)}}}}def main(args: Array[String]): Unit = {//3. 启动两个ActorActorSender.start()ActorReceiver.start()}
}
3.5 案例四: 发送和接收自定义消息
我们前面发送的消息都是字符串类型,Actor中也支持发送自定义消息,例如:使用样例类封装消息,然后进行发送处理。
3.5.1 示例一: 发送同步有返回消息
需求
- 创建一个MsgActor,并向它发送一个同步消息,该消息包含两个字段(id、message)
- MsgActor回复一个消息,该消息包含两个字段(message、name)
- 打印回复消息
注意:
- 使用
!?来发送同步消息- 在Actor的act方法中,可以使用sender获取发送者的Actor引用
参考代码
//案例: Actor发送和接收自定义消息, 采用 同步有返回的形式
object ClassDemo06 {//1. 定义两个样例类Message(表示发送数据), ReplyMessage(表示返回数据.)case class Message(id: Int, message: String) //自定义的发送消息 样例类case class ReplyMessage(message: String, name: String) //自定义的接收消息 样例类//2. 创建一个MsgActor,用来接收MainActor发送过来的消息, 并向它回复一条消息.object MsgActor extends Actor {override def act(): Unit = {//2.1 接收 主Actor(MainActor) 发送过来的消息.loop {react {//结合偏函数使用case Message(id, message) => println(s"我是MsgActor, 我收到的消息是: ${id}, ${message}")//2.2 给MainActor回复一条消息.//sender: 获取消息发送方的Actor对象sender ! ReplyMessage("我很不好, 熏死了!...", "车磊")}}}}def main(args: Array[String]): Unit = {//3. 开启MsgActorMsgActor.start()//4. 通过MainActor, 给MsgActor发送一个 Message对象.//采用 !? 同步有返回.val reply:Any = MsgActor !? Message(1, "你好啊, 我是MainActor, 我在给你发消息!")//resutl表示最终接收到的 返回消息.val result = reply.asInstanceOf[ReplyMessage]//5. 输出结果.println(result)}
}
3.5.2 示例二: 发送异步无返回消息
需求
创建一个MsgActor,并向它发送一个异步无返回消息,该消息包含两个字段(id, message)
注意: 使用
!发送异步无返回消息
参考代码
//案例: Actor发送和接收自定义消息, 采用 异步 无返回的形式
object ClassDemo07 {//1. 定义一个样例类Message(表示发送数据)case class Message(id: Int, message: String) //自定义的发送消息 样例类//2. 创建一个MsgActor,用来接收MainActor发送过来的消息, 并打印.object MsgActor extends Actor {override def act(): Unit = {//2.1 接收 主Actor(MainActor) 发送过来的消息.loop {react {//结合偏函数使用case Message(id, message) => println(s"我是MsgActor, 我收到的消息是: ${id}, ${message}")}}}}def main(args: Array[String]): Unit = {//3. 开启MsgActorMsgActor.start()//4. 通过MainActor, 给MsgActor发送一个 Message对象.//采用 ! 异步无返回MsgActor ! Message(1, "我是采用 异步无返回 的形式发送消息!")}
}
3.5.3 示例三: 发送异步有返回消息
需求
- 创建一个MsgActor,并向它发送一个异步有返回消息,该消息包含两个字段(id、message)
- MsgActor回复一个消息,该消息包含两个字段(message、name)
- 打印回复消息
注意:
- 使用
!!发送异步有返回消息- 发送后,返回类型为Future[Any]的对象
- Future表示异步返回数据的封装,虽获取到Future的返回值,但不一定有值,可能在将来某一时刻才会返回消息
- Future的isSet()可检查是否已经收到返回消息,apply()方法可获取返回数据
图解
参考代码
//案例: Actor发送和接收自定义消息, 采用 异步有返回的形式
object ClassDemo08 {//1. 定义两个样例类Message(表示发送数据), ReplyMessage(表示返回数据.)case class Message(id: Int, message: String) //自定义的发送消息 样例类case class ReplyMessage(message: String, name: String) //自定义的接收消息 样例类//2. 创建一个MsgActor,用来接收MainActor发送过来的消息, 并向它回复一条消息.object MsgActor extends Actor {override def act(): Unit = {//2.1 接收 主Actor(MainActor) 发送过来的消息.loop {react {//结合偏函数使用case Message(id, message) => println(s"我是MsgActor, 我收到的消息是: ${id}, ${message}")//2.2 给MainActor回复一条消息.//sender: 获取消息发送方的Actor对象sender ! ReplyMessage("我很不好, 熏死了!...", "糖糖")}}}}def main(args: Array[String]): Unit = {//3. 开启MsgActorMsgActor.start()//4. 通过MainActor, 给MsgActor发送一个 Message对象.//采用 !! 异步有返回.val future: Future[Any] = MsgActor !! Message(1, "你好啊, 我是MainActor, 我在给你发消息!")//5. 因为future中不一定会立马有数据, 所以我们要校验.//Future的isSet()可检查是否已经收到返回消息,apply()方法可获取返回数据//!future.isSet表示: 没有接收到具体的返回消息, 就一直死循环.while(!future.isSet){}//通过Future的apply()方法来获取返回的数据.val result = future.apply().asInstanceOf[ReplyMessage]//5. 输出结果.println(result)}
}
4. 案例: WordCount
4.1 需求
接下来,我们要使用Actor并发编程模型实现多文件的单词统计。
案例介绍
给定几个文本文件(文本文件都是以空格分隔的),使用Actor并发编程来统计单词的数量.
思路分析

实现思路
- MainActor获取要进行单词统计的文件
- 根据文件数量创建对应的WordCountActor
- 将文件名封装为消息发送给WordCountActor
- WordCountActor接收消息,并统计单个文件的单词计数
- 将单词计数结果发送给MainActor
- MainActor等待所有的WordCountActor都已经成功返回消息,然后进行结果合并
4.2 步骤一: 获取文件列表
实现思路
-
在当前项目下的data文件夹下有: 1.txt, 2.txt两个文本文件, 具体存储内容如下:
1.txt文本文件存储内容如下:
hadoop sqoop hadoop hadoop hadoop flume hadoop hadoop hadoop spark2.txt文本文件存储内容如下:
flink hadoop hive hadoop sqoop hadoop hadoop hadoop hadoop spark -
获取上述两个文本文件的路径, 并将结果打印到控制台上.
参考代码
object MainActor {def main(args: Array[String]): Unit = {//1. 获取所有要统计的文件的路径.//1.1 定义变量dir, 记录保存所有文件的: 文件夹路径. ./data/var dir = "./data/"//1.2 获取该文件夹下, 所有的文件名.var fileNameList = new File(dir).list().toList //List("1.txt", "2.txt")//1.3 对获取到的文件名进行封装, 获取其全路径. ./data/1.txt ./data/2.txtvar fileDirList = fileNameList.map(dir + _)//println(fileDirList)}
}
4.3 步骤二: 创建WordCountActor
实现思路
- 根据文件数量创建对应个数的WordCountActor对象.
- 为了方便后续发送消息给Actor,将每个Actor与文件名关联在一起
实现步骤
- 创建WordCountActor
- 将文件列表转换为WordCountActor
- 为了后续方便发送消息给Actor,将Actor列表和文件列表拉链到一起
- 打印测试
参考代码
-
WordCountActor.scala文件中的代码
//2.1 先创建WordCountActor类, 用来获取WordCountActor对象. //创建WordCountActor类, 每一个WordCountActor对象, 统计一个文件. class WordCountActor extends Actor {override def act(): Unit = { } } -
MainActor.scala文件中的代码
object MainActor {def main(args: Array[String]): Unit = {//1. 获取所有要统计的文件的路径.//1.1 定义变量dir, 记录保存所有文件的: 文件夹路径. ./data/var dir = "./data/"//1.2 获取该文件夹下, 所有的文件名.var fileNameList = new File(dir).list().toList //List("1.txt", "2.txt")//1.3 对获取到的文件名进行封装, 获取其全路径. ./data/1.txt ./data/2.txtvar fileDirList = fileNameList.map(dir + _)//println(fileDirList)//2. 根据文件数量, 创建对应的WordCountActor对象.//2.1 先创建WordCountActor类, 用来获取WordCountActor对象.//2.2 根据文件数量, 创建对应的WordCountActor对象.val wordCountList = fileNameList.map(_ => new WordCountActor) //根据两个txt文件, 创建了两个wordCount对象.//println(wordCountList)//2.3 将WordCountActor和文件全路径关联起来val actorWithFile = wordCountList.zip(fileDirList) //WordCountActor -> ./data/1.txt , WordCountActor -> ./data/2.txtprintln(actorWithFile)} }
4.4 步骤三: 启动Actor/发送/接收任务消息
实现思路
启动所有WordCountActor对象,并发送单词统计任务消息给每个WordCountActor对象.
注意: 此处应
发送异步有返回消息
实现步骤
- 创建一个WordCountTask样例类消息,封装要进行单词计数的文件名
- 启动所有WordCountActor,并发送异步有返回消息
- 获取到所有的WordCountActor中返回的消息(封装到一个Future列表中)
- 在WordCountActor中接收并打印消息
参考代码
-
MessagePackage.scala文件中的代码
/*** 表示: MainActor 给每一个WordCountActor发送任务的 格式.* @param fileName 具体的要统计的 文件路径.*/ case class WordCountTask(fileName:String) -
MainActor.scala文件中的代码
object MainActor {def main(args: Array[String]): Unit = {//1. 获取所有要统计的文件的路径.//1.1 定义变量dir, 记录保存所有文件的: 文件夹路径. ./data/var dir = "./data/"//1.2 获取该文件夹下, 所有的文件名.var fileNameList = new File(dir).list().toList //List("1.txt", "2.txt")//1.3 对获取到的文件名进行封装, 获取其全路径. ./data/1.txt ./data/2.txtvar fileDirList = fileNameList.map(dir + _)//println(fileDirList)//2. 根据文件数量, 创建对应的WordCountActor对象.//2.1 先创建WordCountActor类, 用来获取WordCountActor对象.//2.2 根据文件数量, 创建对应的WordCountActor对象.val wordCountList = fileNameList.map(_ => new WordCountActor) //根据两个txt文件, 创建了两个wordCount对象.//println(wordCountList)//2.3 将WordCountActor和文件全路径关联起来val actorWithFile = wordCountList.zip(fileDirList) //WordCountActor -> ./data/1.txt , WordCountActor -> ./data/2.txtprintln(actorWithFile)//3. 启动WordCountActor, 并给每一个WordCountActor发送任务./*Map(spark -> 1, hadoop -> 7, sqoop -> 1, flume -> 1)Map(sqoop -> 1, flink -> 1, hadoop -> 6, spark -> 1, hive -> 1)*/val futureList: List[Future[Any]] = actorWithFile.map { //futureList: 记录的是所有WordCountActor统计的结果.keyVal => //keyVal的格式: WordCountActor -> ./data/1.txt//3.1 获取具体的要启动的WordCountActor对象.val actor = keyVal._1 //actor: WordCountActor//3.2 启动具体的WordCountActor.actor.start()//3.3 给每个WordCountActor发送具体的任务(文件路径) 异步有返回.val future: Future[Any] = actor !! WordCountTask(keyVal._2)future //记录的是某一个WordCountActor返回的统计结果.}} } -
WordCountActor.scala文件中的代码
//2.1 先创建WordCountActor类, 用来获取WordCountActor对象. //创建WordCountActor类, 每一个WordCountActor对象, 统计一个文件. class WordCountActor extends Actor {override def act(): Unit = { loop {react {//3.4 接收具体的任务case WordCountTask(fileName) =>//3.5 打印具体的任务println(s"接收到的具体任务是: ${fileName}")}}} }
4.5 步骤四: 统计文件单词计数
实现思路
读取文件文本,并统计出来单词的数量。例如:
(hadoop, 3), (spark, 1)...
实现步骤
- 读取文件内容,并转换为列表
- 按照空格切割文本,并转换为一个一个的单词
- 为了方便进行计数,将单词转换为元组
- 按照单词进行分组,然后再进行聚合统计
- 打印聚合统计结果
参考代码
-
WordCountActor.scala文件中的代码
class WordCountActor extends Actor {override def act(): Unit = {//采用loop + react 方式接收数据.loop {react {//3.4 接收具体的任务case WordCountTask(fileName) =>//3.5 打印具体的任务println(s"接收到的具体任务是: ${fileName}")//4. 统计接收到的文件中的每个单词的数量.//4.1 获取指定文件中的所有的文件. List("hadoop sqoop hadoop","hadoop hadoop flume")val lineList = Source.fromFile(fileName).getLines().toList//4.2 将上述获取到的数据, 转换成一个一个的字符串. //List("hadoop", "sqoop", "hadoop","hadoop", "hadoop", "flume")val strList = lineList.flatMap(_.split(" "))//4.3 给每一个字符串后边都加上次数, 默认为1. //List("hadoop"->1, "sqoop"->1, "hadoop"->1, "hadoop"->1, "flume"->1)val wordAndCount = strList.map(_ -> 1)//4.4 按照 字符串内容分组. //"hadoop" -> List("hadoop"->1, "hadoop"->1), "sqoop" -> List("sqoop"->1)val groupMap = wordAndCount.groupBy(_._1)//4.5 对分组后的内容进行统计, 统计每个单词的总次数. "hadoop" -> 2, "sqoop" -> 1val wordCountMap = groupMap.map(keyVal => keyVal._1 -> keyVal._2.map(_._2).sum)//4.6 打印统计后的结果. println(wordCountMap)}}} }
4.6 步骤五: 返回结果给MainActor
实现思路
- 将单词计数的结果封装为一个样例类消息,并发送给MainActor
- MainActor等待所有WordCountActor均已返回后,获取到每个WordCountActor单词计算后的结果
实现步骤
- 定义一个样例类封装单词计数结果
- 将单词计数结果发送给MainActor
- MainActor中检测所有WordCountActor是否均已返回,如果均已返回,则获取并转换结果
- 打印结果
参考代码
-
MessagePackage.scala文件中的代码
/*** 表示: MainActor 给每一个WordCountActor发送任务的 格式.* @param fileName 具体的要统计的 文件路径.*/ case class WordCountTask(fileName:String)/*** 每个WordCountActor统计完的返回结果的: 格式* @param wordCountMap 具体的返回结果, 例如: Map("hadoop"->6, "sqoop"->1)*/ case class WordCountResult(wordCountMap:Map[String, Int]) -
WordCountActor.scala文件中的代码
class WordCountActor extends Actor {override def act(): Unit = {//采用loop + react 方式接收数据.loop {react {//3.4 接收具体的任务case WordCountTask(fileName) =>//3.5 打印具体的任务println(s"接收到的具体任务是: ${fileName}")//4. 统计接收到的文件中的每个单词的数量.//4.1 获取指定文件中的所有的文件. List("hadoop sqoop hadoop","hadoop hadoop flume")val lineList = Source.fromFile(fileName).getLines().toList//4.2 将上述获取到的数据, 转换成一个一个的字符串. List("hadoop", "sqoop", "hadoop","hadoop", "hadoop", "flume")val strList = lineList.flatMap(_.split(" "))//4.3 给每一个字符串后边都加上次数, 默认为1. List("hadoop"->1, "sqoop"->1, "hadoop"->1,"hadoop"->1, "hadoop"->1, "flume"->1)val wordAndCount = strList.map(_ -> 1)//4.4 按照 字符串内容分组. "hadoop" -> List("hadoop"->1, "hadoop"->1), "sqoop" -> List("sqoop"->1)val groupMap = wordAndCount.groupBy(_._1)//4.5 对分组后的内容进行统计, 统计每个单词的总次数. "hadoop" -> 2, "sqoop" -> 1val wordCountMap = groupMap.map(keyVal => keyVal._1 -> keyVal._2.map(_._2).sum)//4.6 把统计后的结果返回给: MainActor.sender ! WordCountResult(wordCountMap)}}} }
4.7 步骤六: 结果合并
实现思路
对接收到的所有单词计数进行合并。
参考代码
-
MainActor.scala文件中的代码
object MainActor {def main(args: Array[String]): Unit = {//1. 获取所有要统计的文件的路径.//1.1 定义变量dir, 记录保存所有文件的: 文件夹路径. ./data/var dir = "./data/"//1.2 获取该文件夹下, 所有的文件名.var fileNameList = new File(dir).list().toList //List("1.txt", "2.txt")//1.3 对获取到的文件名进行封装, 获取其全路径. ./data/1.txt ./data/2.txtvar fileDirList = fileNameList.map(dir + _)//println(fileDirList)//2. 根据文件数量, 创建对应的WordCountActor对象.//2.1 先创建WordCountActor类, 用来获取WordCountActor对象.//2.2 根据文件数量, 创建对应的WordCountActor对象.val wordCountList = fileNameList.map(_ => new WordCountActor) //根据两个txt文件, 创建了两个wordCount对象.//println(wordCountList)//2.3 将WordCountActor和文件全路径关联起来val actorWithFile = wordCountList.zip(fileDirList) //WordCountActor -> ./data/1.txt , WordCountActor -> ./data/2.txtprintln(actorWithFile)//3. 启动WordCountActor, 并给每一个WordCountActor发送任务./*Map(spark -> 1, hadoop -> 7, sqoop -> 1, flume -> 1)Map(sqoop -> 1, flink -> 1, hadoop -> 6, spark -> 1, hive -> 1)*/val futureList: List[Future[Any]] = actorWithFile.map { //futureList: 记录的是所有WordCountActor统计的结果.keyVal => //keyVal的格式: WordCountActor -> ./data/1.txt//3.1 获取具体的要启动的WordCountActor对象.val actor = keyVal._1 //actor: WordCountActor//3.2 启动具体的WordCountActor.actor.start()//3.3 给每个WordCountActor发送具体的任务(文件路径) 异步有返回.val future: Future[Any] = actor !! WordCountTask(keyVal._2)future //记录的是某一个WordCountActor返回的统计结果.}//5. MainActor对接收到的数据进行合并.//5.1 判断所有的future都有返回值后, 再往下执行.// 过滤没有返回值的future 不为0说明还有future没有收到值while(futureList.filter(!_.isSet).size != 0) {} //futureList: future1, future2//5.2 从每一个future中获取数据.//wordCountMap: List(Map(spark -> 1, hadoop -> 7, sqoop -> 1, flume -> 1), Map(sqoop -> 1, flink -> 1, hadoop -> 6, spark -> 1, hive -> 1))val wordCountMap = futureList.map(_.apply().asInstanceOf[WordCountResult].wordCountMap)//5.3 对获取的数据进行flatten, groupBy, map, 然后统计.val result = wordCountMap.flatten.groupBy(_._1).map(keyVal => keyVal._1 -> keyVal._2.map(_._2).sum)//5.4 打印结果println(result)} }
相关文章:
Scala第十九章节(Actor的相关概述、Actor发送和接收消息以及WordCount案例)
Scala第十九章节 章节目标 了解Actor的相关概述掌握Actor发送和接收消息掌握WordCount案例 1. Actor介绍 Scala中的Actor并发编程模型可以用来开发比Java线程效率更高的并发程序。我们学习Scala Actor的目的主要是为后续学习Akka做准备。 1.1 Java并发编程的问题 在Java并…...

蓝桥杯杯赛之深度优先搜索优化《1.分成互质组》 《 2.小猫爬山》【dfs】【深度搜索剪枝优化】【搜索顺序】
文章目录 思想例题1. 分成互质组题目链接题目描述【解法一】【解法二】 2. 小猫爬山题目链接题目描述输入样例:输出样例:【思路】【WA代码】【AC代码】 思想 本质为两种搜索顺序: 枚举当前元素可以放入哪一组枚举每一组可以放入哪些元素 操…...

软件设计原则:依赖倒置
定义 依赖倒置原则(Dependency Inversion Principle, DIP)是面向对象设计原则之一,其核心是高层模块(如业务逻辑)不应当依赖于低层模块(如具体的数据访问或设备控制实现),而是双方都…...
03-自媒体文章发布
自媒体文章发布 1)自媒体前后端搭建 1.1)后台搭建 ①:资料中找到heima-leadnews-wemedia.zip解压 拷贝到heima-leadnews-service工程下,并指定子模块 执行leadnews-wemedia.sql脚本 添加对应的nacos配置 spring:datasource:driver-class-name: com…...

Oracle中实现一次插入多条数据
一、需求描述 在我们实际的业务场景中,由于单条插入的效率很低(每次都需要数据库资源连接关闭的开销),故需要实现一次性插入多条数据,用以提升数据插入的效率; 如下图是常见的单条插入数据: 二…...
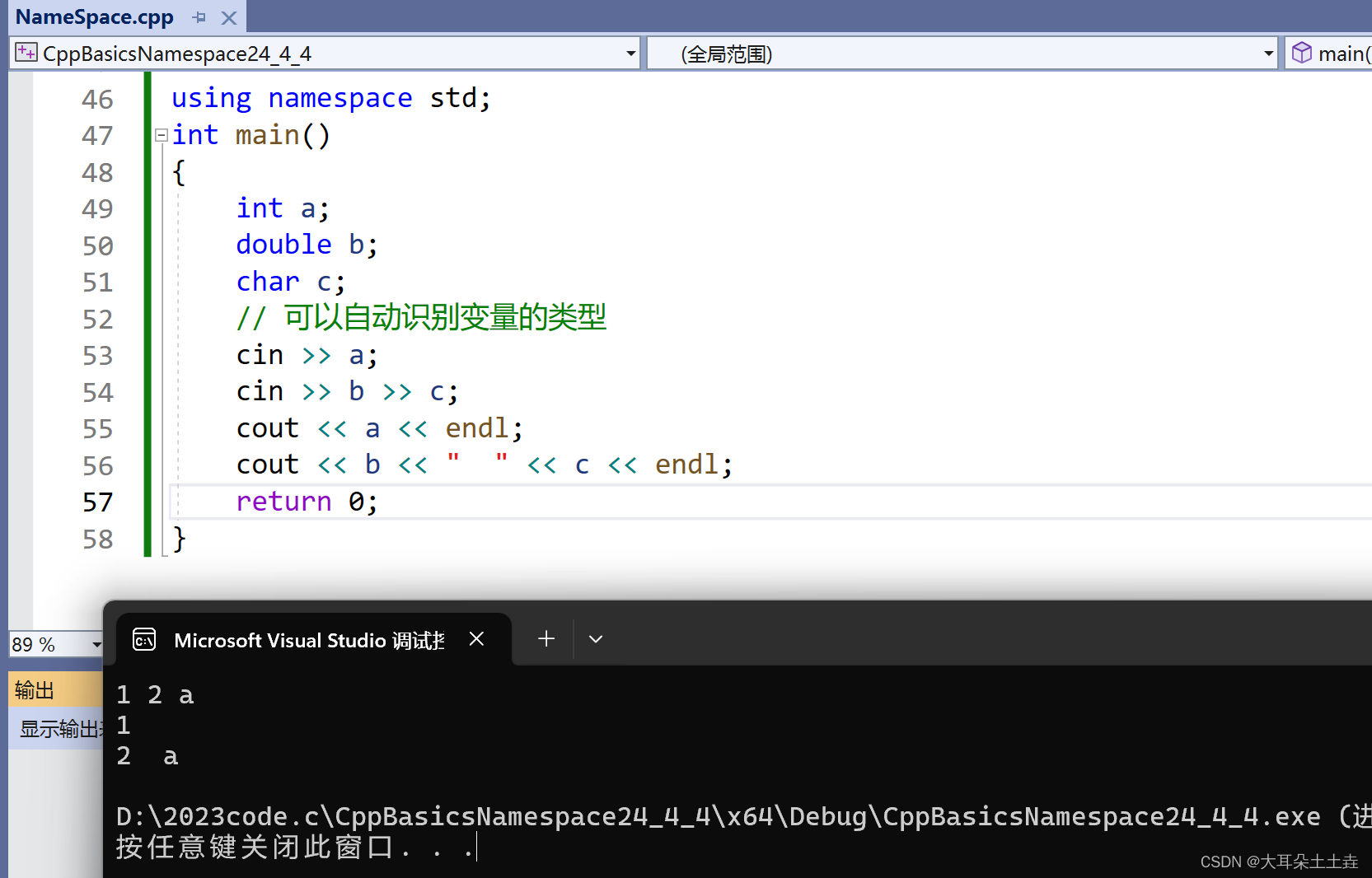
【C++入门】关键字、命名空间以及输入输出
💞💞 前言 hello hello~ ,这里是大耳朵土土垚~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 💥个人主页&#x…...

初识MySQL(中篇)
使用语言 MySQL 使用工具 Navicat Premium 16 代码能力快速提升小方法,看完代码自己敲一遍,十分有用 目录 1.SQL语言 1.1 SQL语言组成部分 2.MySQL数据类型 2.1 数值类型 2.2 字符串类型 2.3 日期类型 3.创建数据表 3.1 创建数据表方法1 …...
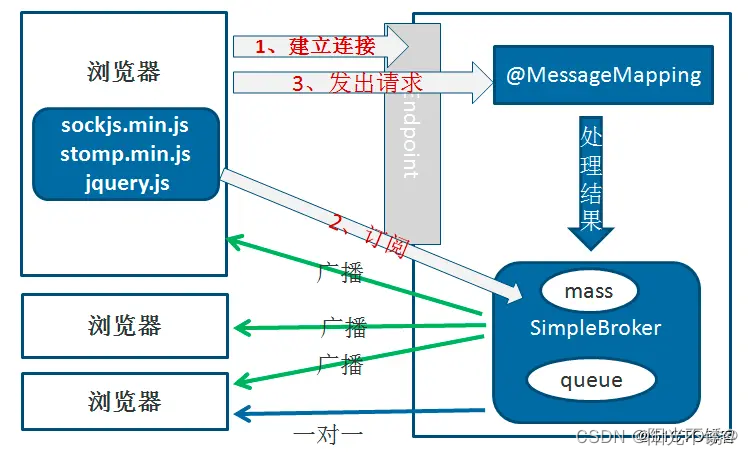
前端订阅后端推送WebSocket定时任务
0.需求 后端定时向前端看板推送数据,每10秒或者30秒推送一次。 1.前言知识 HTTP协议是一个应用层协议,它的特点是无状态、无连接和单向的。在HTTP协议中,客户端发起请求,服务器则对请求进行响应。这种请求-响应的模式意味着服务器…...

提高机器人系统稳定性:引入阻尼作为共振后的相位超前
在机器人关节中,引入阻尼作为共振后的相位超前,确实是一种提高系统稳定性的有效策略。机器人关节的振动和共振是影响其性能稳定性的关键因素,特别是在进行高速、高精度操作时。阻尼的引入能够显著减少这些不利因素,提升机器人的整…...

深度学习理论基础(三)封装数据集及手写数字识别
目录 前期准备一、制作数据集1. excel表格数据2. 代码 二、手写数字识别1. 下载数据集2. 搭建模型3. 训练网络4. 测试网络5. 保存训练模型6. 导入已经训练好的模型文件7. 完整代码 前期准备 必须使用 3 个 PyTorch 内置的实用工具(utils): ⚫…...
vue3+eachrts饼图轮流切换显示高亮数据
<template><div class"charts-box"><div class"charts-instance" ref"chartRef"></div>// 自定义legend 样式<div class"charts-note"><span v-for"(items, index) in data.dataList" cla…...
UTONMOS:AI+Web3+元宇宙数字化“三位一体”将触发经济新爆点
人工智能、元宇宙、Web3,被称为数字化的“三位一体”,如何看待这三大技术所扮演的角色? 3月24日,2024全球开发者先锋大会“数字化的三位一体——人工智能、元宇宙、Web3.0”论坛在上海漕河泾开发区举行,首次提出&…...

开始焦虑了
大家好,我是洋子,25届的暑期实习自从3月份开始招聘有一段时间了,最近接到了几个25届同学的咨询,其中一个学妹印象比较深刻,她的情况如下 个人情况 学历是双非本,计算机专业,学习方向是Java&…...
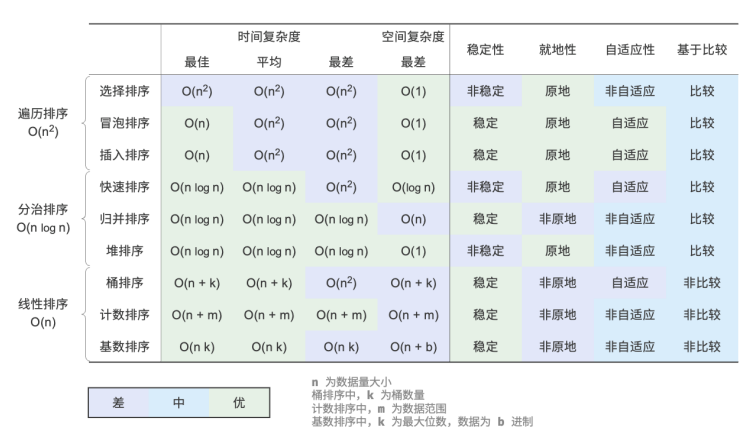
数据结构和算法:十大排序
排序算法 排序算法用于对一组数据按照特定顺序进行排列。排序算法有着广泛的应用,因为有序数据通常能够被更高效地查找、分析和处理。 排序算法中的数据类型可以是整数、浮点数、字符或字符串等。排序的判断规则可根据需求设定,如数字大小、字符 ASCII…...
LLaMA-Factory微调(sft)ChatGLM3-6B保姆教程
LLaMA-Factory微调(sft)ChatGLM3-6B保姆教程 准备 1、下载 下载LLaMA-Factory下载ChatGLM3-6B下载ChatGLM3windows下载CUDA ToolKit 12.1 (本人是在windows进行训练的,显卡GTX 1660 Ti) CUDA安装完毕后,…...

Web安全-浏览器安全策略及跨站脚本攻击与请求伪造漏洞原理
Web安全-浏览器安全策略及跨站脚本攻击与请求伪造漏洞原理 Web服务组件分层概念 静态层 :web前端框架:Bootstrap,jQuery,HTML5框架等,主要存在跨站脚本攻击脚本层:web应用,web开发框架,web服务…...
)
蓝桥杯B组C++省赛——飞机降落(DFS)
题目连接:https://www.lanqiao.cn/problems/3511/learning/ 思路:由于数据范围很小,所有选择用DFS枚举所有飞机的所有的降落顺序,看哪个顺序可以让所有飞机顺利降落,有的话就算成功方案,输出了“YES”。 …...

Java 中的 Map集合
文章目录 添加和修改元素获取元素检查元素删除元素获取所有键 / 值 / 键值对大小 在 Java 中,Map 接口是 Java 集合框架的一部分,它存储键值对(key-value pairs)。Map 接口有许多常用的方法,用于添加、删除、获取元素&…...
基于springboot大学生兼职平台管理系统(完整源码+数据库)
一、项目简介 本项目是一套基于springboot大学生兼职平台管理系统 包含:项目源码、数据库脚本等,该项目附带全部源码可作为毕设使用。 项目都经过严格调试,eclipse或者idea 确保可以运行! 该系统功能完善、界面美观、操作简单、功…...
C#学生信息管理系统
一、引言 学生信息管理系统是现代学校管理的重要组成部分,它能够有效地管理学生的基本信息、课程信息、成绩信息等,提高学校管理的效率和质量。本文将介绍如何使用SQL Server数据库和C#语言在.NET平台上开发一个学生信息管理系统的课程设计项目。 二、项…...

关于初次学习的c语言心得
我是一名大一下的学生,双非二本,因为一些原因休学了两年,现在正在努力学习c语言目标成为公司里面所谓的精通编程,学习c语言的过程每天坚持三小时以上,希望能进入像京东,华为等公司,我也想挣钱买…...

WarcraftHelper完全指南:从显示异常到性能飞跃的5个关键突破
WarcraftHelper完全指南:从显示异常到性能飞跃的5个关键突破 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 诊断宽屏适配问题 在34英寸2…...

3MF格式与Blender插件实战解决方案:从设计障碍到3D打印全流程优化
3MF格式与Blender插件实战解决方案:从设计障碍到3D打印全流程优化 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat 一、问题:当3D打印遭遇"数…...

qt模块学习记录
qt模块学习记录一、Qt Core其他模块都用到的核心非图形类二、Qt GUI 设计 GUI 界面的基础类,包括 OpenGL三、功能模块Qt Network 使网络编程更简单和轻便的类Qt SQL 使用 SQL 用于数据库操作的类Qt Multimedia 音频、视频、摄像头和广播功能的类四、老式界面Qt Widg…...

Qwen3.5-2B模型环境搭建保姆级教程:从Anaconda安装到模型调用
Qwen3.5-2B模型环境搭建保姆级教程:从Anaconda安装到模型调用 1. 开篇:为什么选择这个教程? 如果你刚接触AI大模型,可能会被各种环境配置问题搞得头大。别担心,这篇教程就是为你准备的。我们将从最基础的Anaconda安装…...

Wan2.2-I2V-A14B多场景应用:文旅宣传/电商主图/社交媒体动态生成
Wan2.2-I2V-A14B多场景应用:文旅宣传/电商主图/社交媒体动态生成 1. 开箱即用的视频创作利器 想象一下,你只需要输入一段文字描述,就能自动生成一段高清视频。这就是Wan2.2-I2V-A14B文生视频模型带来的革命性体验。无论你是文旅行业的宣传人…...

MCP23017按键矩阵驱动库:嵌入式I²C GPIO扩展与中断控制
1. 项目概述MentorBitMatrizPulsadores 是一款专为 MentorBit 兼容硬件平台设计的嵌入式驱动库,核心目标是简化基于 MCP23017 IC GPIO 扩展器的按键矩阵(Keypad Matrix)控制与状态读取。该库并非从零实现底层 IC 通信协议,而是构建…...
核心特性与工业实践解析)
实时操作系统(RTOS)核心特性与工业实践解析
1. 实时操作系统核心特性解析实时操作系统(RTOS)的核心设计理念在于"确定性响应",这与我们日常使用的通用操作系统有着本质区别。我曾参与过工业控制系统的开发,深刻体会到RTOS在关键任务场景下的不可替代性。以数控机床…...

音频驱动现代适配技术解密:老旧Mac设备的音质重生实战指南
音频驱动现代适配技术解密:老旧Mac设备的音质重生实战指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 当你的2012年MacBook Pro升级到macOS S…...

IP离线库每周更新一次够用吗?企业风控建议多久更新?
在风控体系中,IP数据的时效性直接决定了拦截效果。当攻击者使用秒拨IP或住宅代理发起攻击时,IP地址的轮换速度可以达到分钟级。如果依赖的IP库更新周期过长,就等于在防御上留下了数天的空窗期。 周更不够用。秒拨IP平均存活3-5分钟ÿ…...