[flink 实时流基础] 输出算子(Sink)
学习笔记
Flink作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持。

连接到外部系统
Flink的DataStream API专门提供了向外部写入数据的方法:addSink。与addSource类似,addSink方法对应着一个“Sink”算子,主要就是用来实现与外部系统连接、并将数据提交写入的;Flink程序中所有对外的输出操作,一般都是利用Sink算子完成的。
Flink1.12以前,Sink算子的创建是通过调用DataStream的.addSink()方法实现的。
stream.addSink(new SinkFunction(…));
addSink方法同样需要传入一个参数,实现的是SinkFunction接口。在这个接口中只需要重写一个方法invoke(),用来将指定的值写入到外部系统中。这个方法在每条数据记录到来时都会调用。
Flink1.12开始,同样重构了Sink架构,
stream.sinkTo(…)
当然,Sink多数情况下同样并不需要我们自己实现。之前我们一直在使用的print方法其实就是一种Sink,它表示将数据流写入标准控制台打印输出。Flink官方为我们提供了一部分的框架的Sink连接器。如下图所示,列出了Flink官方目前支持的第三方系统连接器:
https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/connectors/datastream/overview/

我们可以看到,像Kafka之类流式系统,Flink提供了完美对接,source/sink两端都能连接,可读可写;而对于Elasticsearch、JDBC等数据存储系统,则只提供了输出写入的sink连接器。
除Flink官方之外,Apache Bahir框架,也实现了一些其他第三方系统与Flink的连接器。
除此以外,就需要用户自定义实现sink连接器了。
输出到文件
Flink专门提供了一个流式文件系统的连接器:FileSink,为批处理和流处理提供了一个统一的Sink,它可以将分区文件写入Flink支持的文件系统。
FileSink支持行编码(Row-encoded)和批量编码(Bulk-encoded)格式。这两种不同的方式都有各自的构建器(builder),可以直接调用FileSink的静态方法:
- 行编码: FileSink.forRowFormat(basePath,rowEncoder)。
- 批量编码: FileSink.forBulkFormat(basePath,bulkWriterFactory)。
public class SinkFile {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 每个目录中,都有 并行度个数的 文件在写入env.setParallelism(2);// 必须开启checkpoint,否则一直都是 .inprogressenv.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);DataGeneratorSource<String> dataGeneratorSource = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {@Overridepublic String map(Long value) throws Exception {return "Number:" + value;}},Long.MAX_VALUE,RateLimiterStrategy.perSecond(1000),Types.STRING);DataStreamSource<String> dataGen = env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "data-generator");// 输出到文件系统FileSink<String> fieSink = FileSink// 输出行式存储的文件,指定路径、指定编码.<String>forRowFormat(new Path("f:/tmp"), new SimpleStringEncoder<>("UTF-8"))// 输出文件的一些配置: 文件名的前缀、后缀.withOutputFileConfig(OutputFileConfig.builder().withPartPrefix("atguigu-").withPartSuffix(".log").build())// 按照目录分桶:如下,就是每个小时一个目录.withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH", ZoneId.systemDefault()))// 文件滚动策略: 1分钟 或 1m.withRollingPolicy(DefaultRollingPolicy.builder().withRolloverInterval(Duration.ofMinutes(1)).withMaxPartSize(new MemorySize(1024*1024)).build()).build();dataGen.sinkTo(fieSink);env.execute();}
}输出到 Kafka
(1)添加Kafka 连接器依赖
由于我们已经测试过从Kafka数据源读取数据,连接器相关依赖已经引入,这里就不重复介绍了。
(2)启动Kafka集群
(3)编写输出到Kafka的示例代码
public class SinkKafka {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);// 如果是精准一次,必须开启checkpoint(后续章节介绍)env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);SingleOutputStreamOperator<String> sensorDS = env.socketTextStream("hadoop102", 7777);/*** Kafka Sink:* TODO 注意:如果要使用 精准一次 写入Kafka,需要满足以下条件,缺一不可* 1、开启checkpoint(后续介绍)* 2、设置事务前缀* 3、设置事务超时时间: checkpoint间隔 < 事务超时时间 < max的15分钟*/KafkaSink<String> kafkaSink = KafkaSink.<String>builder()// 指定 kafka 的地址和端口.setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")// 指定序列化器:指定Topic名称、具体的序列化.setRecordSerializer(KafkaRecordSerializationSchema.<String>builder().setTopic("ws").setValueSerializationSchema(new SimpleStringSchema()).build())// 写到kafka的一致性级别: 精准一次、至少一次.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)// 如果是精准一次,必须设置 事务的前缀.setTransactionalIdPrefix("atguigu-")// 如果是精准一次,必须设置 事务超时时间: 大于checkpoint间隔,小于 max 15分钟.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10*60*1000+"").build();sensorDS.sinkTo(kafkaSink);env.execute();}
}
自定义序列化器,实现带key的record:
public class SinkKafkaWithKey {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);env.setRestartStrategy(RestartStrategies.noRestart());SingleOutputStreamOperator<String> sensorDS = env.socketTextStream("hadoop102", 7777);/*** 如果要指定写入kafka的key,可以自定义序列化器:* 1、实现 一个接口,重写 序列化 方法* 2、指定key,转成 字节数组* 3、指定value,转成 字节数组* 4、返回一个 ProducerRecord对象,把key、value放进去*/KafkaSink<String> kafkaSink = KafkaSink.<String>builder().setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092").setRecordSerializer(new KafkaRecordSerializationSchema<String>() {@Nullable@Overridepublic ProducerRecord<byte[], byte[]> serialize(String element, KafkaSinkContext context, Long timestamp) {String[] datas = element.split(",");byte[] key = datas[0].getBytes(StandardCharsets.UTF_8);byte[] value = element.getBytes(StandardCharsets.UTF_8);return new ProducerRecord<>("ws", key, value);}}).setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE).setTransactionalIdPrefix("atguigu-").setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "").build();sensorDS.sinkTo(kafkaSink);env.execute();}
}
输出到 mysql
写入数据的MySQL的测试步骤如下。
(1)添加依赖
添加MySQL驱动:
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version>
</dependency>
官方还未提供flink-connector-jdbc的1.17.0的正式依赖,暂时从apache snapshot仓库下载,pom文件中指定仓库路径:
<repositories><repository><id>apache-snapshots</id><name>apache snapshots</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url></repository>
</repositories>
添加依赖:
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>1.17-SNAPSHOT</version>
</dependency>
如果不生效,还需要修改本地maven的配置文件,mirrorOf中添加如下标红内容:
<mirror><id>aliyunmaven</id><mirrorOf>*,!apache-snapshots</mirrorOf><name>阿里云公共仓库</name><url>https://maven.aliyun.com/repository/public</url>
</mirror>
(2)启动MySQL,在test库下建表ws
mysql>
CREATE TABLE ws (
id varchar(100) NOT NULL,
ts bigint(20) DEFAULT NULL,
vc int(11) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
(3)编写输出到MySQL的示例代码
public class SinkMySQL {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<WaterSensor> sensorDS = env
.socketTextStream("hadoop102", 7777)
.map(new WaterSensorMapFunction());/*** TODO 写入mysql* 1、只能用老的sink写法: addsink* 2、JDBCSink的4个参数:* 第一个参数: 执行的sql,一般就是 insert into* 第二个参数: 预编译sql, 对占位符填充值* 第三个参数: 执行选项 ---》 攒批、重试* 第四个参数: 连接选项 ---》 url、用户名、密码*/
SinkFunction<WaterSensor> jdbcSink = JdbcSink.sink("insert into ws values(?,?,?)",new JdbcStatementBuilder<WaterSensor>() {@Overridepublic void accept(PreparedStatement preparedStatement, WaterSensor waterSensor) throws SQLException {//每收到一条WaterSensor,如何去填充占位符preparedStatement.setString(1, waterSensor.getId());preparedStatement.setLong(2, waterSensor.getTs());preparedStatement.setInt(3, waterSensor.getVc());}},JdbcExecutionOptions.builder().withMaxRetries(3) // 重试次数.withBatchSize(100) // 批次的大小:条数.withBatchIntervalMs(3000) // 批次的时间.build(),new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://hadoop102:3306/test?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8").withUsername("root").withPassword("000000").withConnectionCheckTimeoutSeconds(60) // 重试的超时时间.build()
);sensorDS.addSink(jdbcSink);env.execute();
}
}
(4)运行代码,用客户端连接MySQL,查看是否成功写入数据。
自定义 sink
如果我们想将数据存储到我们自己的存储设备中,而Flink并没有提供可以直接使用的连接器,就只能自定义Sink进行输出了。与Source类似,Flink为我们提供了通用的SinkFunction接口和对应的RichSinkDunction抽象类,只要实现它,通过简单地调用DataStream的.addSink()方法就可以自定义写入任何外部存储。
stream.addSink(new MySinkFunction());
在实现SinkFunction的时候,需要重写的一个关键方法invoke(),在这个方法中我们就可以实现将流里的数据发送出去的逻辑。
这种方式比较通用,对于任何外部存储系统都有效;不过自定义Sink想要实现状态一致性并不容易,所以一般只在没有其它选择时使用。实际项目中用到的外部连接器Flink官方基本都已实现,而且在不断地扩充,因此自定义的场景并不常见。
相关文章:
[flink 实时流基础] 输出算子(Sink)
学习笔记 Flink作为数据处理框架,最终还是要把计算处理的结果写入外部存储,为外部应用提供支持。 文章目录 **连接到外部系统****输出到文件**输出到 Kafka输出到 mysql自定义 sink 连接到外部系统 Flink的DataStream API专门提供了向外部写入数据的方…...

case语句
Oracle从入门到总裁:https://blog.csdn.net/weixin_67859959/article/details/135209645 CASE 语句的执行方式与 IF...THEN...ELSIF 语句的执行方式类似,但是它是通过一个表达式的值来决定执行哪个分支 CASE 选择器表达式 WHEN 条件 1 THEN 语句序列 …...

全国加油站分布数据/停车场分布/公园分布/景区分布/保护区分布/poi感兴趣点
加油站是指为汽车和其它机动车辆服务的、零售汽油和机油的补充站,一般为添加燃料油、润滑油等。由于加油站所销售的石油商品具有易燃爆、易挥发、易渗漏、易集聚静电荷的特性,故加油站以“安全”为第一准则。在加油站内严禁烟火,严禁从事可能…...

单片机简介(一)
51单片机 一台能够运行的计算机需要CPU做运算和控制,RAM做数据存储,ROM做程序存储,还有输入/输出设备(串行口、并行输出口等),这些被分为若干块芯片,安装在主板(印刷线路板…...

Naiveui将message挂载到axios拦截器
最近在做项目,需要将后端的请求结果打印出来 但是想着,要是这样一个一个手动引入naiveui的msg,那不得累死 于是灵机一动,想着既然所有接口要通过拦截器,为什么不将msg写在拦截器呢 一、定义一个消息挂载文件 // The…...
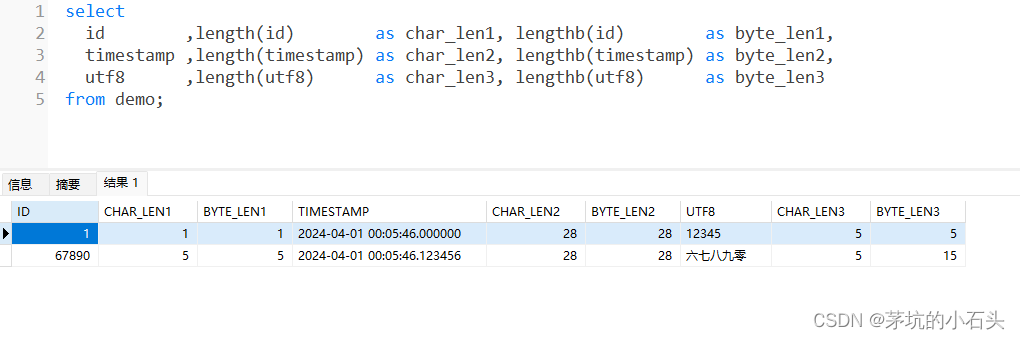
MySQL、Oracle查看字节和字符长度个数的函数
目录 0. 总结1. MySQL1.1. 造数据1.2. 查看字符/字节个数 2. Oracle2.1. 造数据2.2. 查看字符/字节个数 0. 总结 databasecharbyteMySQLchar_length()length()Oraclelength()lengthB() 1. MySQL 1.1. 造数据 sql drop table if exists demo; create table demo (id …...
第五篇:3.4 用户归因和受众(User attribution and audience) - IAB/MRC及《增强现实广告效果测量指南1.0》
翻译计划 第一篇概述—IAB与MRC及《增强现实广告效果测量指南》之目录、适用范围及术语第二篇广告效果测量定义和其他矩阵之- 3.1 广告印象(AD Impression)第三篇广告效果测量定义和其他矩阵之- 3.2 可见性 (Viewability)第四篇广…...

ES6: class类
类 class 面相对象class关键字创建类关于类的继承 面相对象 一切皆对象。 举例: 操作浏览器要使用window对象;操作网页要使用document对象;操作控制台要使用console对象; ES6中增加了类的概念,其实ES5中已经可以实现类…...

[中级]软考_软件设计_计算机组成与体系结构_08_输入输出技术
输入输出技术 前言控制方式考点往年真题 前言 输入输出技术就是IO技术 控制方式 程序控制(查询)方式:分为无条件传送和程序查询方式两种。 方法简单,硬件开销小,但I/O能力不高,严重影响CPU的利用率。 程序中断方式࿱…...

2024-04-04 问AI: 在深度学习中,微调是什么?
文心一言 在深度学习中,微调(Fine-tuning)是一种训练策略,特别针对预训练模型进行。预训练模型通常是在大规模无标注数据上通过自监督学习得到的,它们已经具备了对一般自然语言结构或视觉特征的良好理解能力。微调则是…...

db2数据仓库集群的搭建
db2数据仓库集群的搭建 DB2 集群的搭建通常涉及到多个环节,包括网络配置、DB2 软件安装、集群配置和数据库创建等。以下是搭建DB2集群的基本步骤,并不是实际的命令和配置,因为每个环境的具体配置可能会有所不同。 1、网络配置:确…...
 5.1 u-boot的启动流程分析(ARMv8-a))
Linux ARM平台开发系列讲解(u-boot篇) 5.1 u-boot的启动流程分析(ARMv8-a)
1. 概述 对于嵌入式来说,bootload对于开发人员来说并不陌生,但是在不同芯片架构中,bootload程序所做的一些操作是有所不同的,比如常见的STM32 Cotex-M和RK3568 之间的启动流程所做的操作是有所不同的。本小节就来概述一下U-boot的启动流程: 注意:本章节中的源码我大多数…...
)
ST表(数据结构中的问题)
RMQ问题 RMQ问题指对于数值,每次给一个区间[l,r],要求返回区间区间的最大值或最小值 也就是说,RMQ就是求区间最值的问题 对于RMQ问题,容易想到一种O(n)的方法,就是用i直接遍历[l,r]区间&…...

一、OpenCV(C#版本)环境搭建
一、Visual Studio 创建新项目 二、选择Windows窗体应用(.NET Framework) 直接搜索模板:Windows窗体应用(.NET Framework) 记得是C#哈,别整成VB(Visual Basic)了 PS:若搜索搜不到,直接点击安装多个工具和…...

ubuntu远程服务部署,Docker,蓝牙无线局域网,SSH,VNC,xfce4,NextTerminal,宝塔,NPS/NPC,gost,openwrt
SSH服务 apt update apt upgrade -y apt install -y openssh-server/etc/ssh/sshd_config PermitRootLogin yesDocker curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun apt install -y docker-compose宝塔 wget -O install.sh https://download.bt.cn…...

kettle安装与部署使用教程
kettle 官网下载与部署使用 文章目录 kettle 官网下载与部署使用1. 前言:2. 访问官方网站:3. Download Pentaho3.1 官网首页**滑动到最底**,寻找下载链接:3.2 跳转到下载界面后,选择 Pentaho Community Edition (CE)3.…...

【C语言】编译和链接
1. 翻译环境和运行环境 在ANSI C的任何⼀种实现中,存在两个不同的环境。 第1种是翻译环境,在这个环境中源代码被转换为可执⾏的机器指令(⼆进制指令)。 第2种是执⾏环境,它⽤于实际执⾏代码。 2. 编译环境 那翻译环境…...

Python学习: 错误和异常
Python 语法错误 解析错误(Parsing Error)通常指的是程序无法正确地解析(识别、分析)所给定的代码,通常是由于代码中存在语法错误或者其他无法理解的结构导致的。这可能是由于缺少括号、缩进错误、未关闭的引号或其他括号等问题造成的。 语法错误(Syntax Error)是指程序…...

WebGIS 之 vue3+vite+ceisum
1.项目搭建node版本在16以上 1.1创建项目 npm create vite 项目名 1.2选择框架 vuejavaScript 1.3进入项目安装依赖 cd 项目名 npm install 1.4安装cesium依赖 pnpm i cesium vite-plugin-cesium 1.5修改vite.config.js文件 import { defineConfig } from vite import vue fr…...

## CSDN创作活动:AI技术创业有哪些机会?
AI技术创业有哪些机会? 人工智能(AI)技术作为当今科技创新的前沿领域,为创业者提供了广阔的机会和挑战。随着AI技术的快速发展和应用领域的不断拓展,未来AI技术方面会有哪些创业机会呢? 方向一࿱…...

19c补丁后oracle属主变化,导致不能识别磁盘组
补丁后服务器重启,数据库再次无法启动 ORA01017: invalid username/password; logon denied Oracle 19c 在打上 19.23 或以上补丁版本后,存在与用户组权限相关的问题。具体表现为,Oracle 实例的运行用户(oracle)和集…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...
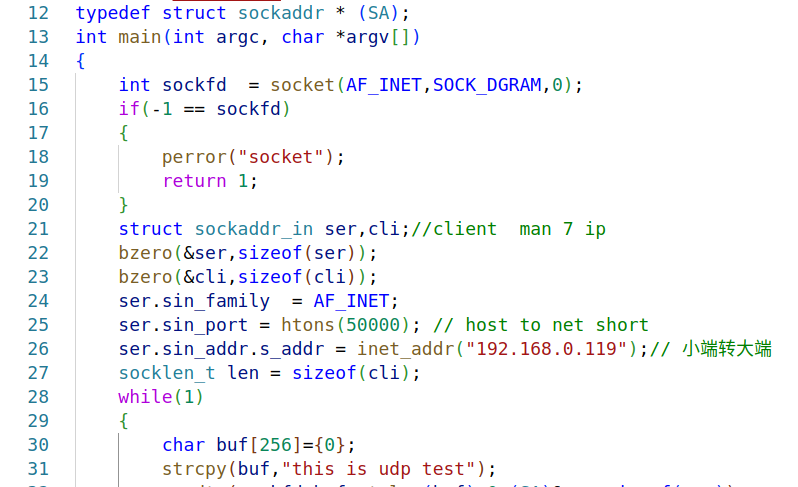
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...

Android写一个捕获全局异常的工具类
项目开发和实际运行过程中难免会遇到异常发生,系统提供了一个可以捕获全局异常的工具Uncaughtexceptionhandler,它是Thread的子类(就是package java.lang;里线程的Thread)。本文将利用它将设备信息、报错信息以及错误的发生时间都…...
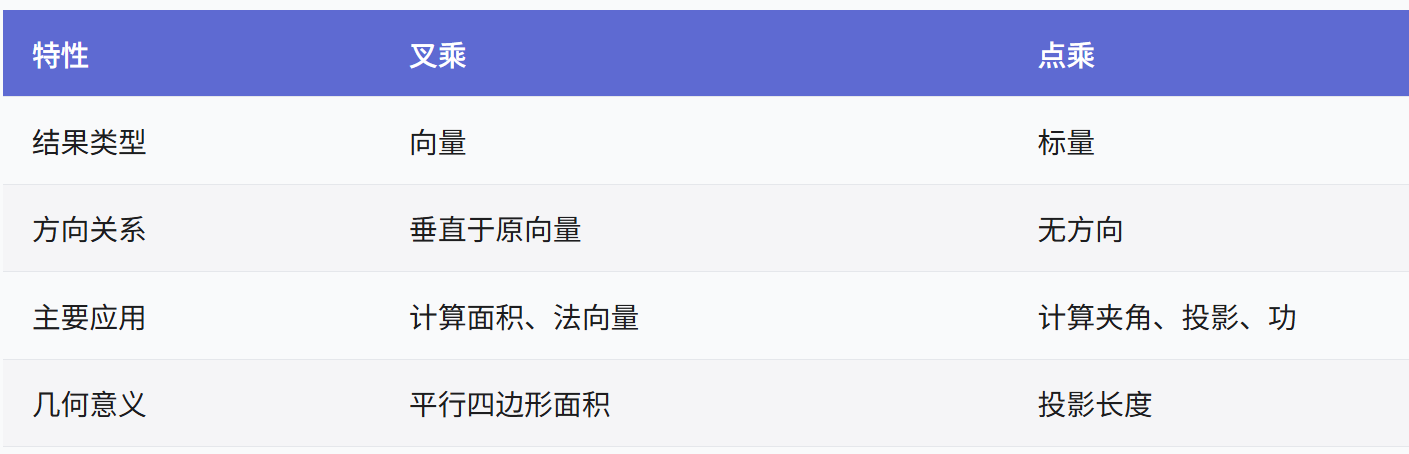
向量几何的二元性:叉乘模长与内积投影的深层联系
在数学与物理的空间世界中,向量运算构成了理解几何结构的基石。叉乘(外积)与点积(内积)作为向量代数的两大支柱,表面上呈现出截然不同的几何意义与代数形式,却在深层次上揭示了向量间相互作用的…...