论文阅读《Semantic Prompt for Few-Shot Image Recognition》
论文地址:https://arxiv.org/pdf/2303.14123.pdf
论文代码:https://github.com/WentaoChen0813/SemanticPrompt
目录
- 1、存在的问题
- 2、算法简介
- 3、算法细节
- 3.1、预训练阶段
- 3.2、微调阶段
- 3.3、空间交互机制
- 3.4、通道交互机制
- 4、实验
- 4.1、对比实验
- 4.2、组成模块消融
- 4.3、插入层消融
- 4.4、Backbone和分类器消融
- 4.5、投影函数和池化消融
- 4.6、插入图像大小消融
1、存在的问题
目前,针对小样本问题,有一种比较有效的解决方案:
使用其他模态的辅助信息,例如自然语言,来辅助学习新概念。即根据样本的类名提取出文本特征,将文本特征和视觉特征相结合。
该思路存在的问题:文本特征可能包含了新类与已知类之间的语义联系,但缺少与底层视觉表示的交互。因此在只有有限的支持图像的情况下,直接从文本特征中得到类的原型会使学习到的视觉特征受到虚假特征的影响,例如背景杂乱时,难以产生准确的类原型。
例如,给定一个新类别“独轮车”的支持图像,特征提取器可能捕获包含独轮车和其他干扰物(如骑手和瓦片屋顶)的图像特征,而无法识别其他环境中的独轮车。
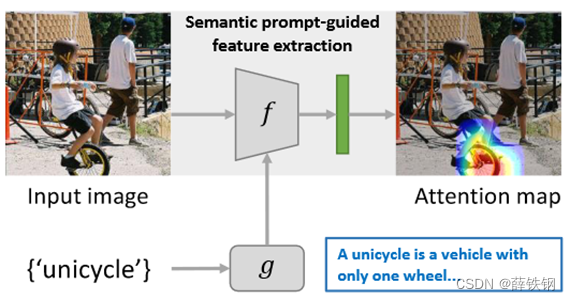
2、算法简介
本文提出了一种新颖的语义提示方法,利用类名的文本信息作为语义提示,自适应地调整特征提取网络,使得图像编码器只关注和语义提示相关的视觉特征,忽略其他干扰信息。
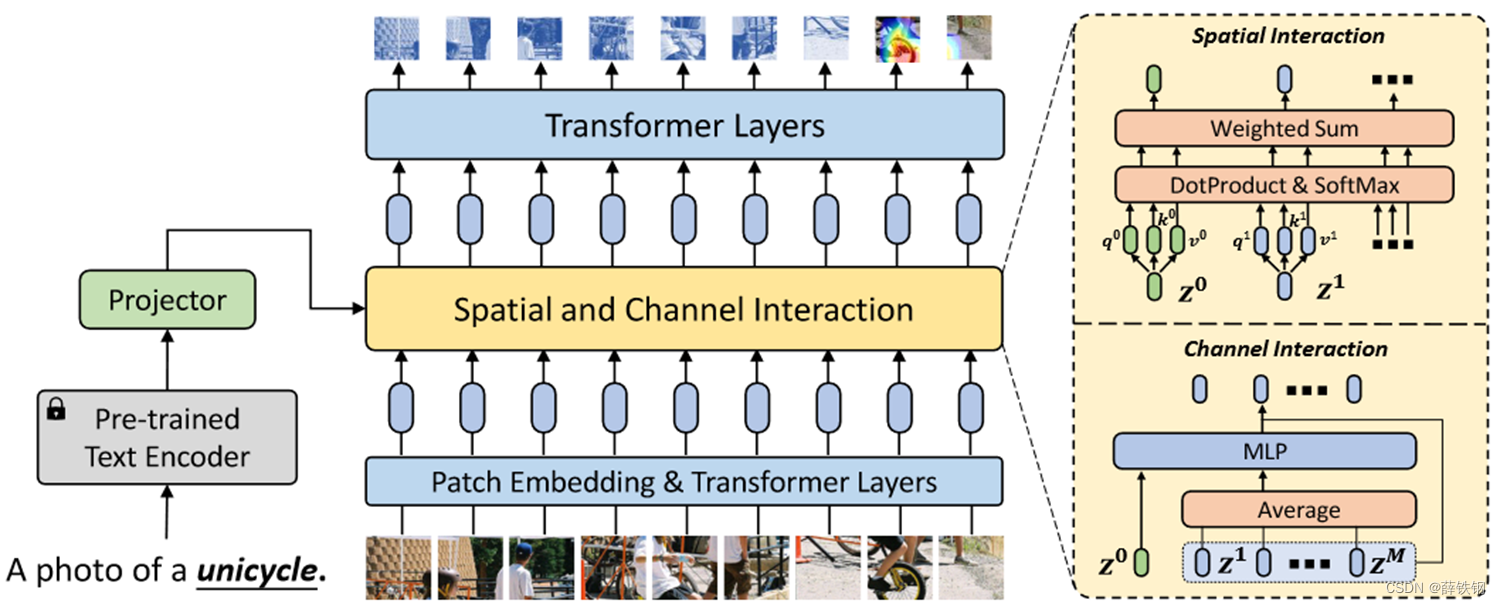
本文主要提出了一个语义提示SP模块和模块中两种互补的信息交互机制:
1、SP模块: 可以插入到特征提取器的任何层中,包含空间和通道交互部分。
2、空间交互机制: 将语义提示特征和图像块特征串联在一起,然后送入Transformer层中,通过自注意力层,语义提示可以和每个图像块特征进行信息交互从而使模型关注类别相关的图像区域。
3、通道交互机制: 首先从所有图像块中提取视觉特征,然后将视觉特征和语义提示特征拼接后送入MLP得到调制向量,最后将调制向量加到每个图像块特征上以实现对视觉特征逐通道的调整。
3、算法细节
网络的训练包括两个阶段:
第一阶段,通过对基数据集中的所有图像进行分类来预训练一个特征提取器 f f f。
第二阶段,采用元训练策略,使用语义提示SP对特征提取器 f f f进行微调。
3.1、预训练阶段
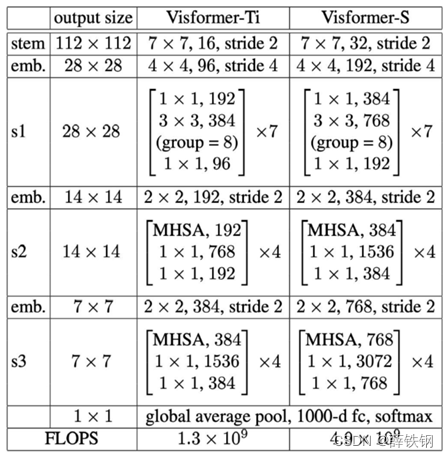
采用Visformer作为特征提取器 f f f,在基类数据集上完成训练。
Visformer是原始ViT的一个变体,用卷积块代替了前7个Transformer层,其网络结构如下图所示:
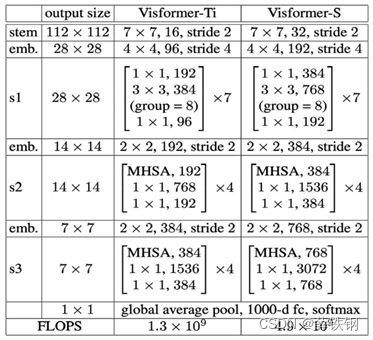
第一步,将输入图像 x ∈ R H × W × C x\in\mathbb{R}^{H\times W\times C} x∈RH×W×C划分为 M M M个图像块序列:
X = x p 1 , x p 2 , . . . , x p M , x p i ∈ R P × P × C X=x_p^1,x_p^2,...,x_p^M, \quad x_p^i\in\mathbb{R}^{P\times P\times C} X=xp1,xp2,...,xpM,xpi∈RP×P×C
第二步,将每个图像块映射为一个嵌入向量,并加入位置编码:
Z 0 = [ z 0 1 , z 0 2 , . . . , z 0 M ] , z 0 i ∈ R C z Z_0=[z_0^1,z_0^2,...,z_0^M], \quad z_0^i\in\mathbb{R}^{C_z} Z0=[z01,z02,...,z0M],z0i∈RCz
第三步,patch token被送入到 L L L层的Transformer层进行视觉特征的提取。
每层Transformer都由多头自注意力(MSA)模块、MLP 块、归一化层和残差连接组成。
第四步,最后,在第 L L L层,计算所有嵌入向量的平均值作为提取到的图像特征。
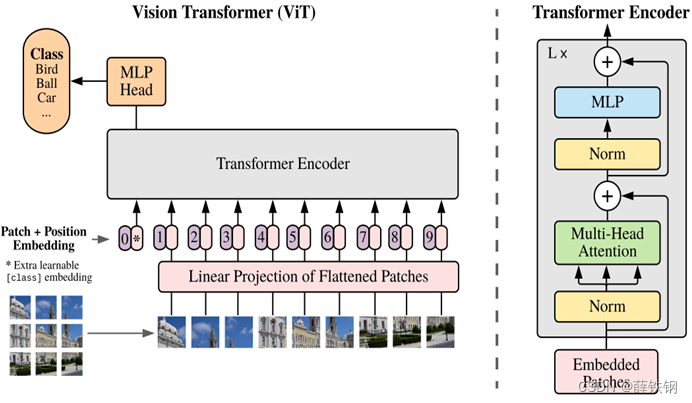
作为参考,同时给出Vision Transformer的网络结构:
3.2、微调阶段
接下来,使用大规模预训练的NLP模型来从类名中提取文本特征。
采用元训练策略对特征提取器进行微调,使模型适应语义提示。
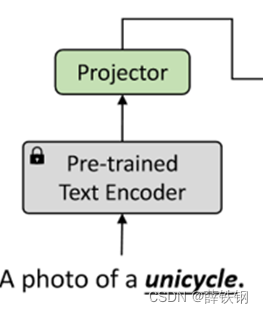
第一步,针对训练集中的支持图像 x s x^s xs,其类名为 y t e x t y^{text} ytext,将类名输入到预先训练好的文本编码器 g ( ⋅ ) g(\cdot) g(⋅)中,提取得到语义特征 g ( y t e x t ) g(y^{text}) g(ytext);
第二步,语义特征被送入训练好的特征提取器中计算图像的特征:
f g ( x s ) = f ( x s ∣ g ( y t e x t ) ) f_g(x^s)=f(x^s|g(y^{text})) fg(xs)=f(xs∣g(ytext))
第三步,在每个类中,将计算得到的支持图像的特征求平均,从而计算出第 i i i个类的原型:
p i = 1 K ∑ j = 1 K f g ( x j s ) p_i = \frac1K \sum_{j=1}^K f_g (x_j^s ) pi=K1∑j=1Kfg(xjs)
第四步,在元训练期间,冻结文本编码器 g ( ⋅ ) g(\cdot) g(⋅),通过交叉熵损失最大化查询样本 与其原型之间的特征相似性来微调其他参数。
3.3、空间交互机制
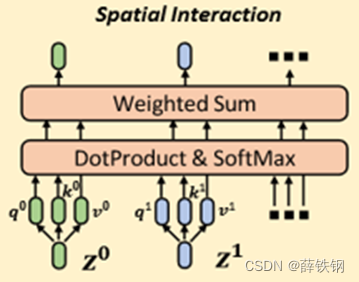
第一步,给定第 l l l层的语义特征 g ( y t e x t ) g(y^{text}) g(ytext)和图像块嵌入序列 Z l − 1 = [ z l − 1 1 , z l − 1 2 , . . . , z l − 1 M ] ∈ R M × C z Z_{l-1}=[z_{l-1}^1,z_{l-1}^2,...,z_{l-1}^M]\in\mathbb{R}^{M\times C_z} Zl−1=[zl−11,zl−12,...,zl−1M]∈RM×Cz,
使用投影函数调整语义特征的维度和图像块嵌入的维度一致 z 0 = h s ( g ( y t e x t ) ) ∈ R C z z^0=h_s\left(g(y^{text})\right)\in\mathbb{R}^{C_z} z0=hs(g(ytext))∈RCz
使用投影后的语义特征与图像块嵌入序列拼接 Z ^ l − 1 = [ z 0 , z l − 1 1 , . . . , z l − 1 M ] \hat{Z}_{l-1}=[z^0,z_{l-1}^1,...,z_{l-1}^M] Z^l−1=[z0,zl−11,...,zl−1M]
第二步,将扩展后的序列输入到Transformer层,其中包含多头自注意力模块MSA;
第三步,MSA将每个图像块嵌入映射为3个向量:
[ q , k , v ] = Z ^ l − 1 W q k v , q , k , v ∈ R N h × ( M + 1 ) × C h [q,k,v]=\hat{Z}_{l-1}W_{qkv},\quad q,k,v\in\mathbb{R}^{N_h\times(M+1)\times C_h} [q,k,v]=Z^l−1Wqkv,q,k,v∈RNh×(M+1)×Ch
第四步,取q和k之间的内积并沿空间维度执行softmax计算注意力权重A,注意力 权重用于选择和聚合来自不同位置的信息:
A = s o f t m a x ( q k T / C h 1 4 ) , A ∈ R N h × ( M + 1 ) × ( M + 1 ) A=softmax(qk^T/C_h^{\frac14}),\quad A\in\mathbb{R}^{N_h\times(M+1)\times(M+1)} A=softmax(qkT/Ch41),A∈RNh×(M+1)×(M+1)
第五步,通过连接所有头输出的注意力权重并通过线性投影得到最终输出:
M S A ( Z l − 1 ^ ) = ( A v ) W o u t MSA(\hat{Z_{l-1}})=(Av)W_{out} MSA(Zl−1^)=(Av)Wout
3.4、通道交互机制
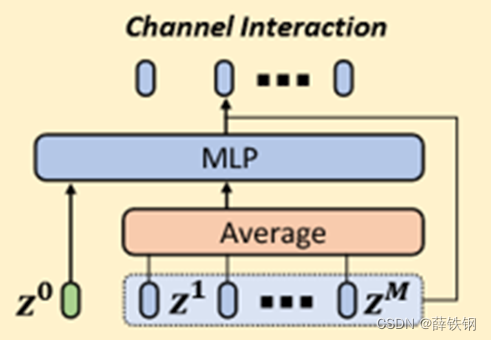
第一步,给定第 l l l层的语义特征 g ( y t e x t ) g(y^{text}) g(ytext)和图像块嵌入序列 Z l − 1 = [ z l − 1 1 , z l − 1 2 , . . . , z l − 1 M ] ∈ R M × C z Z_{l-1}=[z_{l-1}^1,z_{l-1}^2,...,z_{l-1}^M]\in\mathbb{R}^{M\times C_z} Zl−1=[zl−11,zl−12,...,zl−1M]∈RM×Cz,
计算所有的图像块嵌入的平均值,得到一个全局视觉上下文向量:
z l − 1 c = 1 M ∑ i = 1 M z l − 1 i z_{l-1}^c=\frac1M\sum_{i=1}^Mz_{l-1}^i zl−1c=M1∑i=1Mzl−1i
第二步,使用投影函数调整语义特征的维度和图像块嵌入的维度一致 z 0 = h c ( g ( y t e x t ) ) ∈ R C z z^0=h_c(g(y_{text}))\in\mathbb{R}^{C_z} z0=hc(g(ytext))∈RCz
第三步,使用投影后的语义特征与全局视觉上下文向量拼接 [ z 0 ; z l − 1 c ] [z^0;z_{l-1}^c] [z0;zl−1c]
第四步,将拼接后的向量送入两层的MLP得到调制向量:
β l − 1 = σ ( W 2 σ ( W 1 [ z 0 ; z l − 1 c ] + b 1 ) + b 2 ) \beta_{l-1}=\sigma(W_2\sigma(W_1[z^0;z_{l-1}^c]+b_1)+b_2) βl−1=σ(W2σ(W1[z0;zl−1c]+b1)+b2)
第五步,将调制向量添加到所有的图像块嵌入中:
Z ~ l − 1 = [ z l − 1 i + β l − 1 , ] i = 1 , 2 , . . . , M \tilde{Z}_{l-1}=[z_{l-1}^i+\beta_{l-1},]\quad i=1,2,...,M Z~l−1=[zl−1i+βl−1,]i=1,2,...,M
这样就可以在每个通道上调整视觉特征了。
4、实验
4.1、对比实验
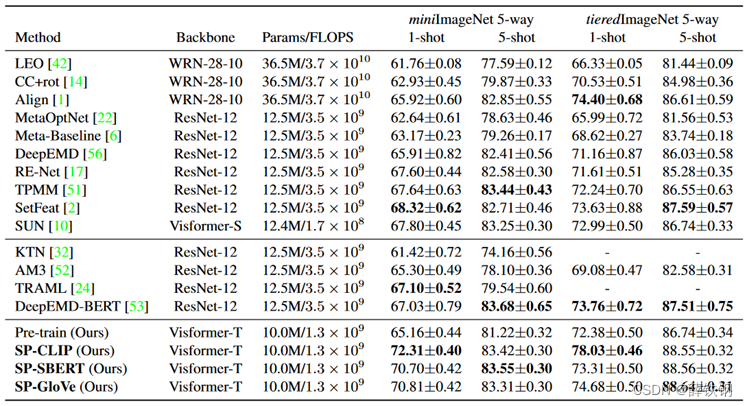
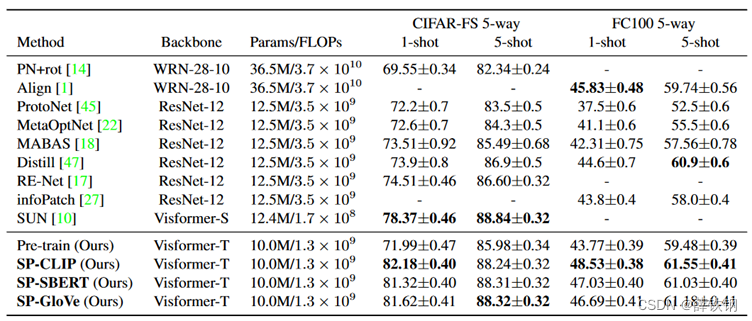
在四个数据集上进行了对比实验,报告准确率
第一部分的信息不使用语义信息,中间的方法利用来自类名的提示信息或描述类语义信息
带有CLIP的SP比SBERT和GloVe在1-shot上取得了更好的效果,这可能是因为CLIP的多模态预训练导致语义嵌入与视觉概念更好的对齐。
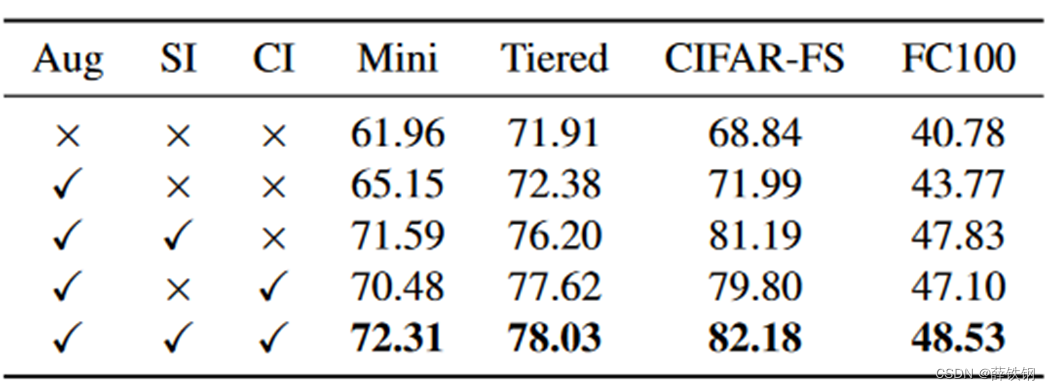
4.2、组成模块消融
Aug:数据增强
SI:空间交互机制
CI:通道交互机制
4.3、插入层消融
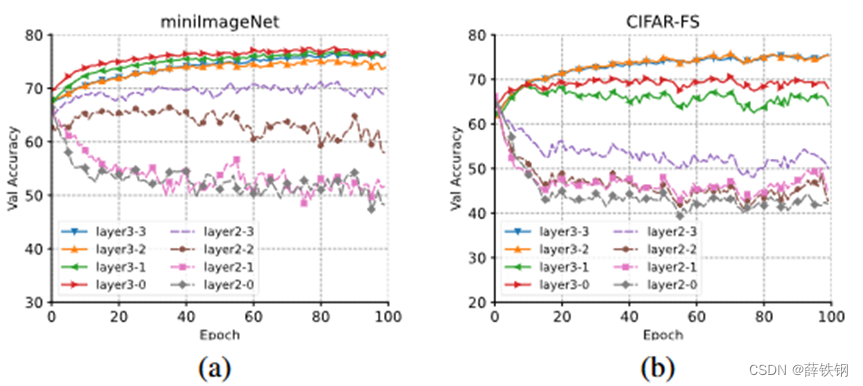
特征提取器有三个阶段,每个阶段含有多个Transformer层。理论上语义提示可以在任意层插入,实验研究了二、三阶段不同层插入语义提示的实验结果。
插入高层时模型的表现较好,插入低层时模型的表现下降。这是因为语义提示向量特定于类,更高层的网络层提取的特征特定于类,而在低层提取的特征会在类间共享。
语义提示插入三阶段的整体表现较好,语义提示默认插入位置为layer3-2(三阶段的第二层)。
4.4、Backbone和分类器消融
简单地用Visformer替换ResNet-12并不能获得显著的提升。
而在本文的网络结构中,即当使用语义提示明显可以提高性能。

NN:余弦距离最近原型分类器。LR:线性逻辑回归分类器。
对于1-shot,NN分类器表现与LR分类器相当,而对于5-shot,LR从更多的训练样本中获益,性能比NN提高了0.53%。
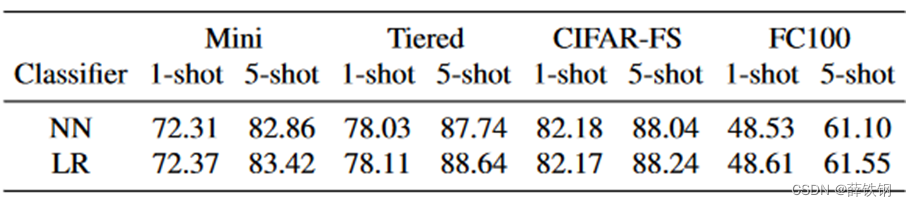
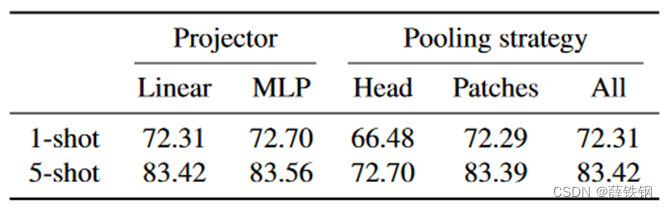
4.5、投影函数和池化消融
线性投影函数和MLP投影函数相比,MLP投影函数略占优势。
相比之下,池化策略对性能的影响要大得多。当采用“Head”策略时,1-shot和5-shot的学习精度都很差。这表明提示向量位置处的输出容易对语义特征过度拟合,忽略图像块中丰富的视觉特征
Head: 选择语义提示向量位置处的输出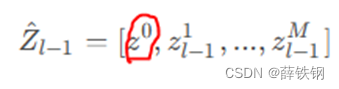
Patch: 对所有图像块的特征取平均
All: 对所有特征向量取平均
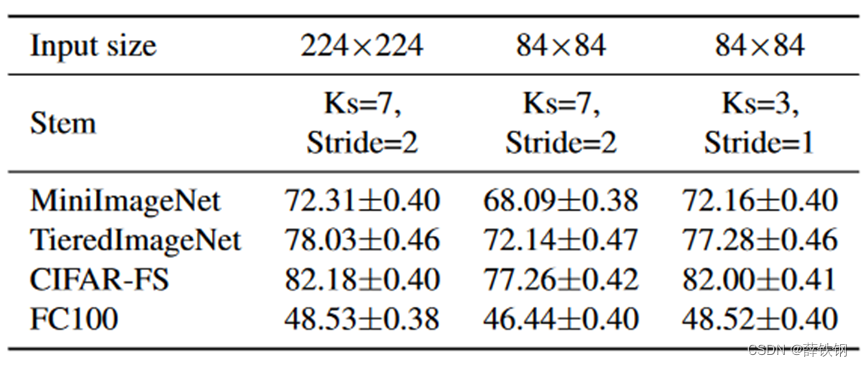
4.6、插入图像大小消融
保持卷积核大小和步长不变的情况下,缩小图像会导致精度下降,这是因为此时卷积核和步长太大不能捕获详细的视觉特征,应该相应地减少卷积核和步长,这样精度会提高。
相关文章:
论文阅读《Semantic Prompt for Few-Shot Image Recognition》
论文地址:https://arxiv.org/pdf/2303.14123.pdf 论文代码:https://github.com/WentaoChen0813/SemanticPrompt 目录 1、存在的问题2、算法简介3、算法细节3.1、预训练阶段3.2、微调阶段3.3、空间交互机制3.4、通道交互机制 4、实验4.1、对比实验4.2、组…...
docker)
Linux初学(十七)docker
一、docker 1.1 简介 容器技术 容器其实就是虚拟机,每个容器可以运行不同的系统【系统以Linux为主的】 为什么要使用docker? docker容器之间互相隔离,可以提高安全性通过使用docker可以做靶场 1.2 安装配置docker 方法一:yum安装…...
Python---Numpy线性代数
1.数组和矩阵操作: 创建数组和矩阵:np.array, np.matrix 基本的数组操作:形状修改、大小调整、转置等 import numpy as np# 创建一个 2x3 的数组 A np.array([[1, 2, 3], [4, 5, 6]]) print("数组 A:\n", A)# 将数组 A 转换为矩阵…...

react+ echarts 轮播饼图
react echarts 轮播饼图 图片示例 代码 import * as echarts from echarts; import { useEffect } from react; import styles from ./styles.scss;const Student (props) > {const { dataList, title } props;// 过滤数据const visionList [{ value: 1048, name: Se…...
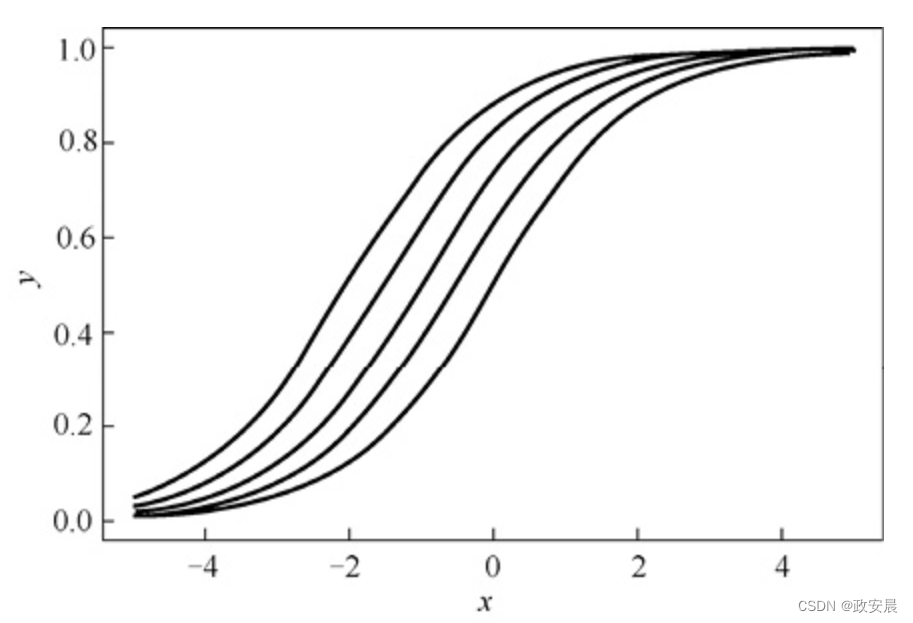
政安晨:【深度学习神经网络基础】(三)—— 激活函数
目录 线性激活函数 阶跃激活函数 S型激活函数 双曲正切激活函数 修正线性单元 Softmax激活函数 偏置扮演什么角色? 政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: 政安晨的机器学习笔记 希望政安晨的博客能够对您有所裨…...
使用tomcat里的API - servlet 写动态网页
一、创建一个新的Maven空项目 首次创建maven项目的时候,会自动从maven网站上下载一些依赖组件(这个过程需要保证网络稳定,否则后续打包一些操作会出现一些问题) ps:校园网可能会屏蔽一些网站,可能会导致maven的依赖…...
从0到1搭建文档库——sphinx + git + read the docs
sphinx git read the docs 目录 一、sphinx 1 sphinx的安装 2 本地构建文件框架 1)创建基本框架(生成index.rst ;conf.py) conf.py默认内容 index.rst默认内容 2)生成页面(Windows系统下…...

EasyExcel 校验后导入
引入pom <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.3.3</version></dependency>触发校验类 import com.baomidou.mybatisplus.extension.api.R; import lombok.experimental…...

【星计划★C语言】c语言初相识:探索编程之路
🌈个人主页:聆风吟_ 🔥系列专栏:星计划★C语言、Linux实践室 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. ⛳️第一个c语言程序二. ⛳️数据类型2.1 🔔数据单位2.2 &…...

搜维尔科技:借助 ARVR 的力量缩小现代制造业的技能差距
借助ARVR的力量缩小现代制造业的技能差距 搜维尔科技:Senseglove案例-扩展机器人技术及其VR应用...
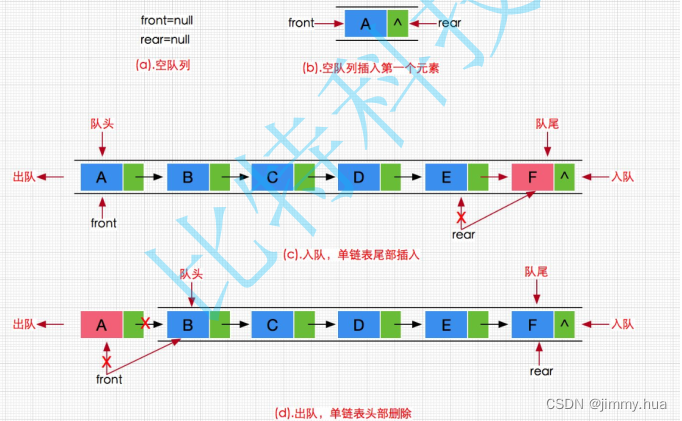
数据结构之栈和队列
1.前言 大家好久不见,这段时间由于忙去了。就没有即使维护我的博客,先给大家赔个不是。 我们还是规矩不乱,先赞后看~ 今天讲的内容是数据结构中非常重要的一个部分:栈和队列。它在今后的学习中也会再次出现(c&#…...
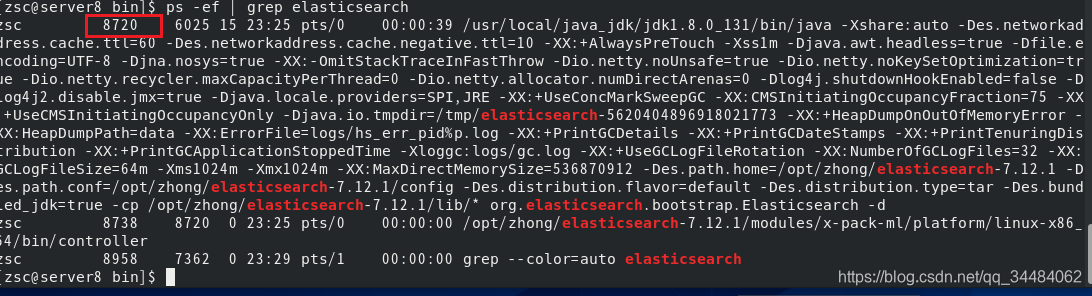
centos安装使用elasticsearch
1.首先可以在 Elasticsearch 官网 Download Elasticsearch | Elastic 下载安装包 2. 在指定的位置(我的是/opt/zhong/)解压安装包 tar -zxvf elasticsearch-7.12.1-linux-x86_64.tar.gz 3.启动es-这种方式启动会将日志全部打印在当前页面,一旦使用 ctrlc退出就会导…...
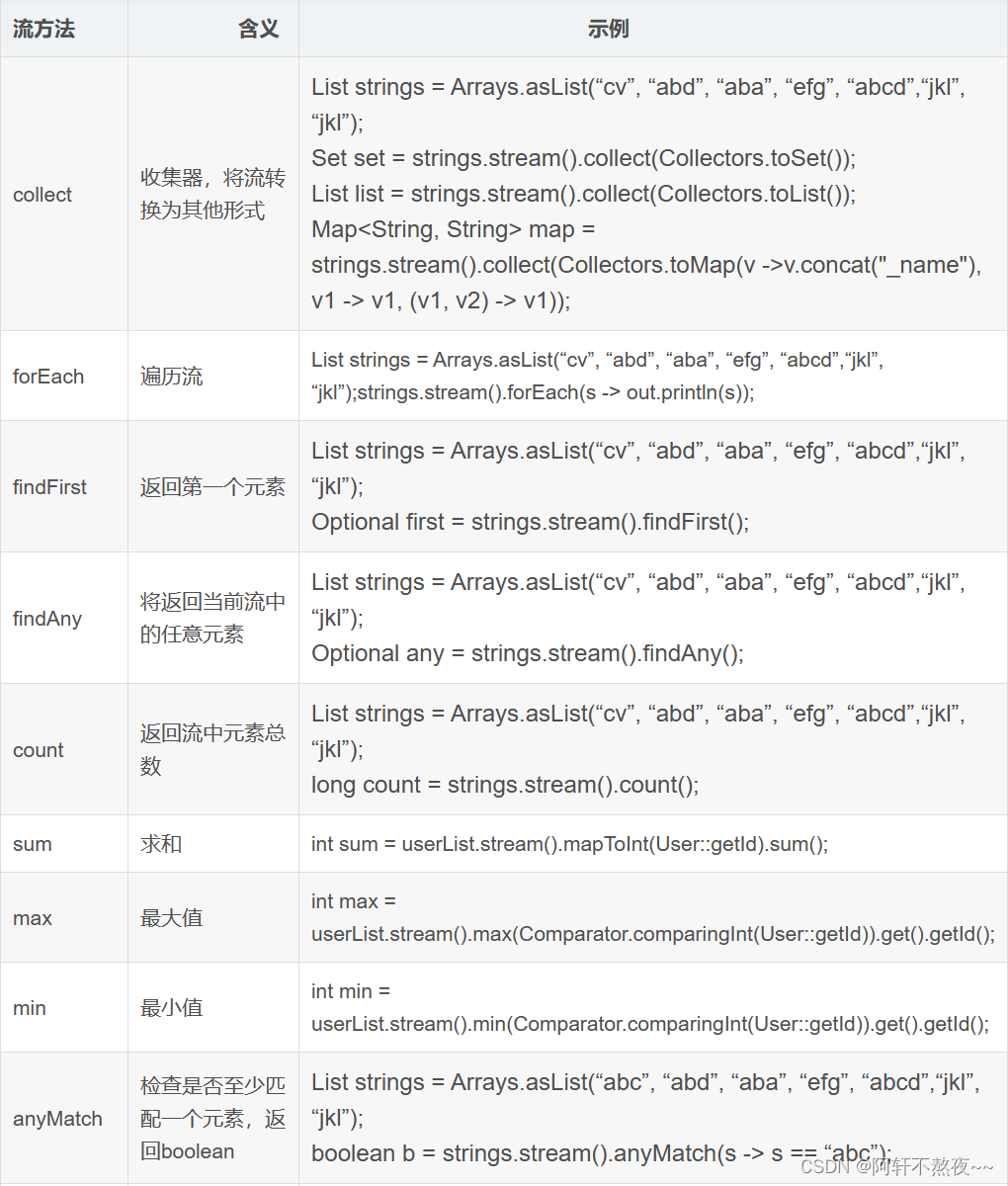
4.7学习总结
java学习 一.Stream流 (一.)概念: Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。Stream流是对集合(Collection)对象功能的增强&…...
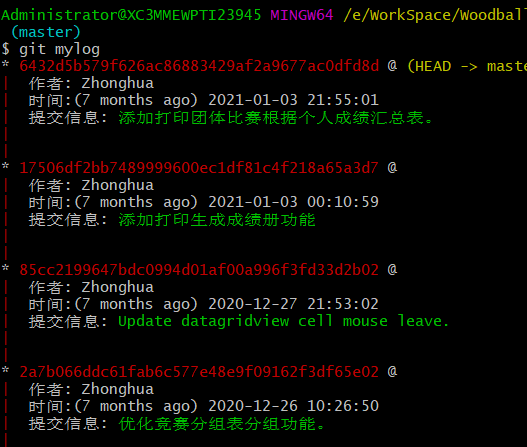
自定义gitlog格式
git log命令非常强大而好用,在复杂系统的版本管理中扮演着重要的角色,但默认的git log命令显示出的东西实在太丑,不好好打扮一下根本没法见人,打扮好了用alias命令拍个照片,就正式出道了! 在使用git查看lo…...

Redission--分布式锁
Redission的锁的好处 Redission分布式锁的底层是setnx和lua脚本(保证原子性) 1.是可重入锁。 2.Redisson 锁支持自动续期功能,这可以帮助我们合理控制分布式锁的有效时长,当业务逻辑执行时间超出了锁的过期时间,锁会自动续期,避免…...

非关系型数据库(缓存数据库)redis的集群
目录 一.群集模式——Cluster 1.原理 2.作用 3.特点 4.工作机制 哈希槽 哈希槽的分配 哈希槽可按照集群主机数平均分配(默认分配) 根据主机的性能以及功能自定义分配 redis集群的分片 分片 如何找到给定key的分片 优势 二. 搭建Redis群集…...
)
MySQL:表的约束(上)
文章目录 空属性默认值列描述zerofill主键 本篇总结的是MySQL中关于表的约束部分的内容 空属性 在进行表的创建时,会有两个值,null和not null,而数据库默认的字段基本都是空,但是在实际的开发过程中要保证字段不能为空ÿ…...
树莓派5使用体验
原文地址:树莓派5使用体验 - Pleasure的博客 下面是正文内容: 前言 好久没有关于教程方面的博文了,由于最近打算入门嵌入式系统,所以就去购入了树莓派5开发板 树莓派5是2023年10月23日正式发售的,过去的时间不算太远吧…...

代码随想录算法训练营第42天| 背包问题、416. 分割等和子集
01 背包 题目描述:有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次,求解将哪些物品装入背包里物品价值总和最大。 二维dp数组01背包: 确定dp数组以及下标的含义 …...

Node.js安装及环境配置指南
Node.js安装及环境配置指南 一、Node.js的安装 安装Node.js之前,首先需要确保你的电脑已经安装了合适的编译器和开发环境。Node.js是一个开源的、跨平台的JavaScript运行环境,它使得JavaScript可以在服务器端运行。 下载Node.js安装包 访问Node.js的…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

【Go语言基础【13】】函数、闭包、方法
文章目录 零、概述一、函数基础1、函数基础概念2、参数传递机制3、返回值特性3.1. 多返回值3.2. 命名返回值3.3. 错误处理 二、函数类型与高阶函数1. 函数类型定义2. 高阶函数(函数作为参数、返回值) 三、匿名函数与闭包1. 匿名函数(Lambda函…...

MySQL 主从同步异常处理
阅读原文:https://www.xiaozaoshu.top/articles/mysql-m-s-update-pk MySQL 做双主,遇到的这个错误: Could not execute Update_rows event on table ... Error_code: 1032是 MySQL 主从复制时的经典错误之一,通常表示ÿ…...
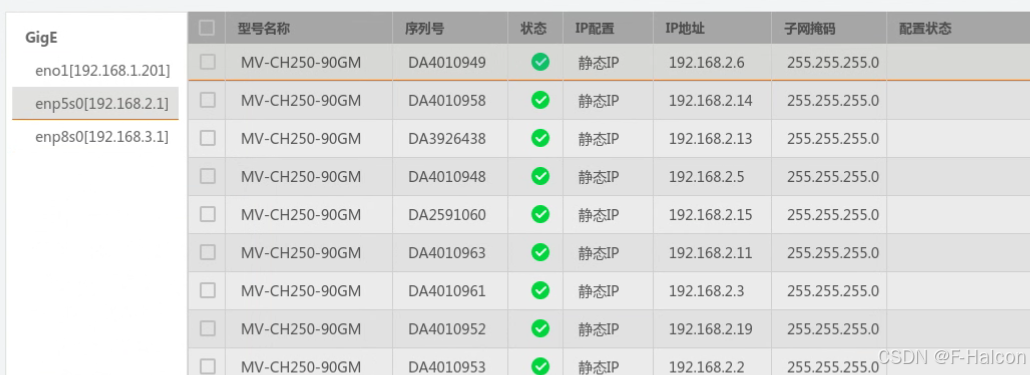
Ubuntu系统多网卡多相机IP设置方法
目录 1、硬件情况 2、如何设置网卡和相机IP 2.1 万兆网卡连接交换机,交换机再连相机 2.1.1 网卡设置 2.1.2 相机设置 2.3 万兆网卡直连相机 1、硬件情况 2个网卡n个相机 电脑系统信息,系统版本:Ubuntu22.04.5 LTS;内核版本…...