python自带数据的模型合集
鸢尾花----聚类
Python鸢尾花数据集通常用于分类问题,
这些模型都可以通过Python中的Scikit-learn库进行实现。同时,也可以对这些模型进行参数调优以提高模型的准确性。
Logistic Regression(逻辑回归):
逻辑回归是一种二分类模型,它可以用于预测某种物品是否属于某个类别。例如,可以使用逻辑回归来预测鸢尾花是否为Setosa。
Decision Tree(决策树):
决策树是一种基于树结构的分类模型,它可以用于预测某种物品属于哪个类别。例如,可以使用决策树来预测鸢尾花的品种。
Random Forest(随机森林)
随机森林是一种基于决策树的集成学习模型,它可以用于预测某种物品属于哪个类别。例如,可以使用随机森林来预测鸢尾花的品种。
K-Nearest Neighbors(K近邻):
K近邻是一种基于距离的分类模型,它可以用于预测某种物品属于哪个类别。例如,可以使用K近邻来预测鸢尾花的品种。
Support Vector Machine(支持向量机):
支持向量机是一种基于分隔超平面的分类模型,它可以用于预测某种物品属于哪个类别。例如,可以使用支持向量机来预测鸢尾花的品种。
Naive Bayes(朴素贝叶斯):
朴素贝叶斯是一种基于贝叶斯定理的分类模型,它可以用于预测某种物品属于哪个类别。例如,可以使用朴素贝叶斯来预测品种。
写一个总览的各个模型
首先,需要加载鸢尾花数据集:from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target接着,将数据集拆分为训练集和测试集:from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)然后,我们可以使用以下代码来实现这些模型:Logistic Regression(逻辑回归):from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression()
classifier.fit(X_train, y_train)
accuracy = classifier.score(X_test, y_test)
print("Logistic Regression Accuracy:", accuracy)输出:Logistic Regression Accuracy: 1.0Decision Tree(决策树):from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
accuracy = classifier.score(X_test, y_test)
print("Decision Tree Accuracy:", accuracy)输出:Decision Tree Accuracy: 1.0Random Forest(随机森林):from sklearn.ensemble import RandomForestClassifier
classifier = RandomForestClassifier()
classifier.fit(X_train, y_train)
accuracy = classifier.score(X_test, y_test)
print("Random Forest Accuracy:", accuracy)输出:Random Forest Accuracy: 1.0K-Nearest Neighbors(K近邻):from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier()
classifier.fit(X_train, y_train)
accuracy = classifier.score(X_test, y_test)
print("K-Nearest Neighbors Accuracy:", accuracy)输出:K-Nearest Neighbors Accuracy: 1.0Support Vector Machine(支持向量机):```python
from sklearn.svm import SVC
classifier = SVC()
classifier.fit(X_train, y_train)
accuracy = classifier.score(X_test, y_test)
print("Support Vector Machine Accuracy:", accuracy生成一个python鸢尾花决策树模型,要求进行多次模型拟合并设置种子保留每次结果,进行模型准确率评估并绘制模型准确率的评估图像
# 导入库
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target# 训练模型并计算准确率
accuracies = []
for i in range(10):# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=i)# 训练决策树模型model = DecisionTreeClassifier()model.fit(X_train, y_train)# 预测测试集并计算准确率y_pred = model.predict(X_test)acc = accuracy_score(y_test, y_pred)accuracies.append(acc)print(f"Accuracy {i}: {acc}")# 绘制准确率图像
plt.plot(range(10), accuracies, 'o-')
plt.xlabel('Iteration')
plt.ylabel('Accuracy')
plt.title('Model Accuracy')
plt.show()
这个模型使用了sklearn库中的LinearRegression类,通过train_test_split将数据集分为训练集和测试集,
并使用fit()方法拟合训练集数据。最后使用predict()方法预测测试集,输出模型评价结果,包括系数、截距和R²得分。
系数、截距和R²得分是线性回归模型的评价指标。
系数指的是线性回归模型中每个特征对目标变量的影响程度,即斜率。在上述示例中,输出的model.coef_即为各特征的系数。
截距指的是线性回归模型中的常数项,与特征无关。在上述示例中,输出的model.intercept_即为截距。
R²得分是模型预测结果与实际结果的拟合程度,其取值范围为0到1。
R²得分越接近1,表示模型的预测结果越接近实际结果。
在上述示例中,输出的model.score(X_test, y_test)即为R²得分。
波士顿房价–回归
# 导入所需库
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
data_url = "http://lib.stat.cmu.edu/datasets/boston" #1.2版本boston被从sklearn移除
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
X = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
y = raw_df.values[1::2, 2]# 切分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# 建立线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)# 预测测试集
y_pred = model.predict(X_test)# 输出模型评价结果
print('Model Coefficients:', model.coef_)
print('Model Intercept:', model.intercept_)
print('Model Score:', model.score(X_test, y_test))知识点
train_test_split 中参数含义
train_test_split()是sklearn库中用于将数据集分为训练集和测试集的函数,在机器学习中经常使用。它的参数含义如下:
arrays:表示需要划分的数据集,可以是数组、列表或稀疏矩阵等。
test_size:表示测试集的大小,可以是浮点数(表示测试集占总数据集的比例)或整数(表示测试集的样本数量)。默认值为0.25。
train_size:表示训练集的大小,可以是浮点数(表示训练集占总数据集的比例)或整数(表示训练集的样本数量)。默认值为None,即train_size=1-test_size。
random_state:表示随机种子,用于控制随机数生成器的种子。如果使用相同的随机种子,则每次生成的随机数序列都相同。
shuffle:表示是否在划分之前对数据集进行随机排序。默认值为True,即对数据集进行随机排序。
stratify:表示是否根据标签的分布情况对数据集进行分层抽样,以保证训练集和测试集的标签分布相似。默认值为None,即不进行分层抽样。
train_test_split()函数的返回值是一个元组,包含四个变量,分别是训练集数据、测试集数据、训练集标签、测试集标签。
评价模型准确率有哪些方法
评价模型准确率是机器学习中非常重要的一步,以下是常见的几种评价模型准确率的方法:
精确度(Accuracy):精确度是模型对所有样本进行分类的正确率。即正确分类的样本数除以总样本数。在样本分布均匀的情况下,精确度可以作为一个良好的评价指标,但在不平衡的情况下,精确度可能会给出误导性的结果。
召回率(Recall):召回率是指模型能够正确识别出正样本的能力。即在所有正样本中,模型正确分类的样本数除以总正样本数。召回率是在样本不平衡的情况下,更好的评价指标。
F1值(F1 Score):F1值综合了精确度和召回率的评价指标,是一个综合考虑模型准确率和召回率的评价指标。F1值越大,说明模型的预测结果越好。F1值等于2精确度召回率 / (精确度 + 召回率)。
ROC曲线:ROC曲线是根据不同的阈值绘制的分类器的性能曲线。ROC曲线的横轴是假阳性率(False Positive Rate),纵轴是真阳性率(True Positive Rate)。ROC曲线越接近左上角,说明分类器性能越好。
AUC值:AUC(Area Under Curve)是ROC曲线下的面积。AUC值越大,说明模型性能越好。
在实际应用中,根据不同的需求和数据集特征,选择不同的评价指标来评价模型的准确率。
相关文章:

python自带数据的模型合集
鸢尾花----聚类 Python鸢尾花数据集通常用于分类问题, 这些模型都可以通过Python中的Scikit-learn库进行实现。同时,也可以对这些模型进行参数调优以提高模型的准确性。 Logistic Regression(逻辑回归): 逻辑回归是一…...

女生学习大数据怎么样~有前景么
当前大数据发展前景非常不错,且大数据领域对于人才类型的需求比较多元化,女生学习大数据也会有比较多的工作机会。大数据是一个交叉学科涉及到的知识量比较大学习有一定的难度,女生则有女生的优势,只要认真学习了都是可以做大数据…...
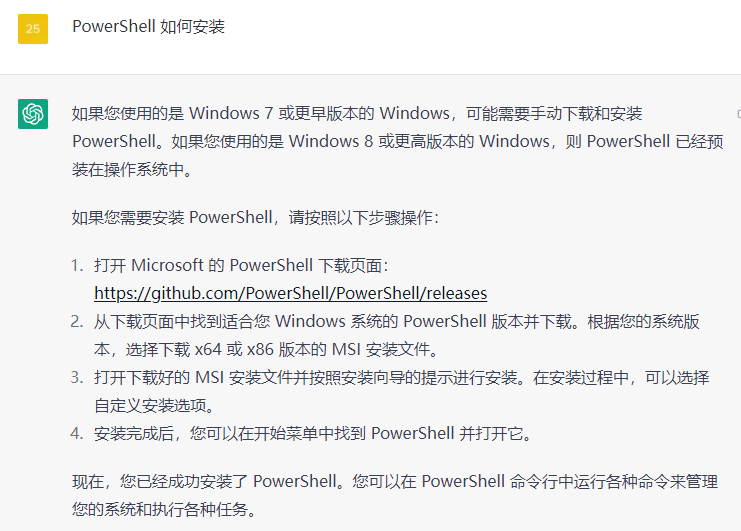
统计代码量
一 windows 在 Windows 系统上,您可以使用 PowerShell 命令行工具来统计项目的代码量。下面是使用 PowerShell 统计项目代码量的步骤: 打开 PowerShell 终端:按下 Win X 键,选择「Windows PowerShell(管理员…...

uniapp在线升级关联云空间
升级中心 uni-upgrade-center - App: https://ext.dcloud.net.cn/plugin?id4542 App升级中心 uni-upgrade-center文档: https://uniapp.dcloud.net.cn/uniCloud/upgrade-center.html#uni-upgrade-center-app 升级中心 uni-upgrade-center - Admin&#…...
学习streamlit-2
首先视频快速预览下今天的学习内容: Streamlit Shorts: How to make a button今天继续学习streamlit,首先激活之前建立的虚拟环境: ❯ conda activate streamlit-env (streamlit-env) ~ via 🐍 v3.9.16 via …...

Vscode中Vue文件保存格式化、 ElementUI、Font Awesome俩大插件使用
Vscode中Vue文件老一片红色出现格式错误??如何运行别人的项目(没有node_modules文件)??选用组件与图标?? 解决问题一 前提有:Prettier ESLint插件、ESLint插件 1.打开s…...

汽车标定知识整理(三):CCP报文可选命令介绍
目录 一、可选命令 CRO命令报文的可选命令表: 二、可选命令帧格式介绍 1、GET_SEED——获取被请求资源的种子(0x12) 2、UNLOCK——解锁保护(0x13) 3、SET_S_STATUS——设置Session状态(0x0C࿰…...
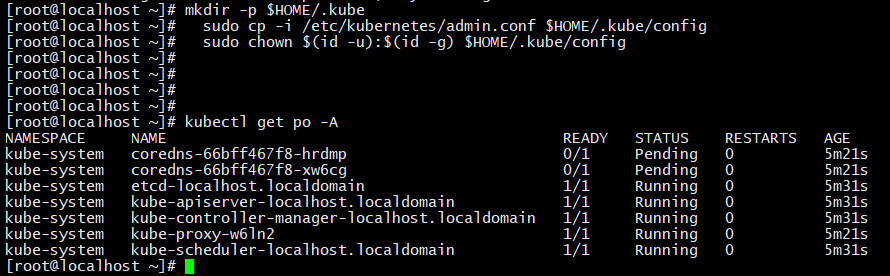
kubeadm安装K8S(集群)
前言市面上很多k8s的安装工具,作为产品的设计者和推广者,K8S组织也知道自己的产品部署起来十分的困难,于是把开源爱好者写的工具kubeadmn收编为正规军,纳入到了自己的麾下。为什么我们要用kubeadmn来部署?因为kubeadm不…...
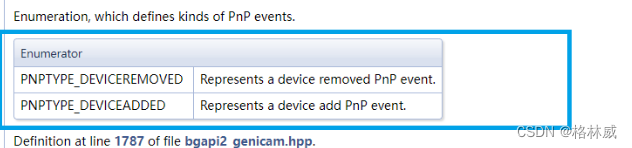
Baumer工业相机堡盟相机如何使用PnPEventHandler实现相机掉线自动重连(C++新)
项目场景: Baumer工业相机堡盟相机传统开发包BGAPI SDK进行工业视觉软件整合时,常常需要将SDK中一些功能整合到图像处理软件中,方便项目的推进使用; 在项目的图像处理任务中,可能会因为一些硬件比如线缆网卡的原因导…...

Windows 命令行基础
1. 引言:为什么要使用命令行在 DOS 时代,人们只能依靠输入命令同计算机互交。而现在,微软的 Windows 操作系统已得到了广泛使用,我们处理日常事务也大多使用基于图形用户界面(GUI,Graphics User Interface&…...

面试官: 谈下音视频同步原理,音频和视频能绝对同步吗?
作者:波哥 心理分析:音视频同步本身比较难,一般使用ijkplayer 第三方做音视频同步。不排除有视频直播 视频通话需要用音视频同步,可以从三种 音频为准 视频为准 自定义时钟为准三种方式实现音视频同步 求职者:如果被问到 放正心态…...

CFS三层靶机安装与配置
CFS三层靶机安装与配置 环境下载 百度网盘 提取码:Chen 环境安装 下载完成后,有三个文件夹,每个文件夹对应一个靶机 进入三个文件夹,双击打开后缀为.ovf的文件,按提示安装虚拟机 环境配置 网段划分 target1&#…...

爬虫入门教程-Spider
Spider 爬虫是定义如何抓取某个网站(或一组网站)的类,包括如何执行抓取(即关注链接)以及如何从其网页中提取结构化数据(即抓取项目)。换句话说,Spider是您定义用于为特定网站&#x…...

Python|蓝桥杯进阶第二卷——贪心
欢迎交流学习~~ 专栏: 蓝桥杯Python组刷题日寄 蓝桥杯进阶系列: 🏆 Python | 蓝桥杯进阶第一卷——字符串 🔎 Python | 蓝桥杯进阶第二卷——贪心 💝 Python | 蓝桥杯进阶第三卷——动态规划(待续…...

Chrome开发使用技巧总结
Chrome一个程序员开发神器,但是好多猿子们不会或者没有正确使用。今天教大家如何利用它快速高效的开发调试工作。代码格式化有很多css/js的代码都会被 minify 掉,你可以点击代码窗口左下角的那个 { } 标签,chrome会帮你给格式化掉。强制DOM状…...

你真的会在阳光下拍照片么?
你好,我是小麥。 上节课我们讲了如何通过影子判断光的质量,也就是光的软硬,这节课我们来接着说一说光的方向和环境光的实际运用。 虽然在现实生活里,我们可能没有从软硬的角度观察过光线,但我相信你在拍照片的时候一…...
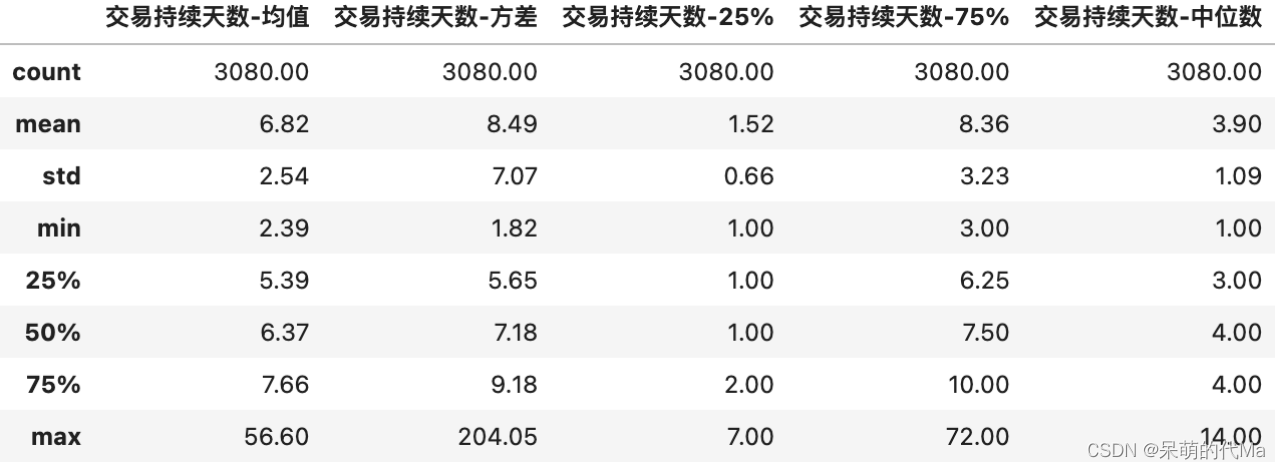
量化择时——均线策略及改进方法(第1部分—因子测算)
文章目录道氏理论个股股价走势阶段板块、行业股价走势均线策略交易逻辑均线策略效果测算改进一:设置策略信号偏移量改进二:生成止盈止损信号道氏理论 使用盘面数据,根据计算出的一条或多条均线,判断入场与离场的时机,…...

封装几个有用的 Vue3 组合式API
本文将介绍如何使用Vue3来封装一些比较有用的组合API,主要包括背景、实现思路以及一些思考。 就我自己的感觉而言,Hook与Composition API概念是很类似的,事实上在React大部分可用的Hook都可以使用Vue3再实现一遍。 为了拼写方便,下文内容均使用Hook代替Composition API。相…...
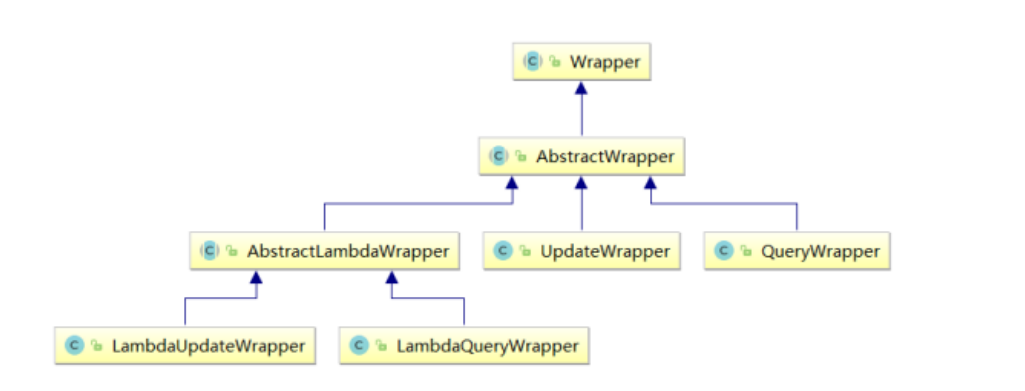
MyBatisPlus中的条件构造器Wrapper
引言为什么要了解Wrapper?Wrapper解决的了什么问题?一、Wrapper:条件构造抽象类,用来解决单表操作出现的一些复杂问题,例如排序,和模糊查询等等结构图文字解释AbstractWrapper : 用于查询条件封装ÿ…...

类和对象及其构造方法
类和对象 现实世界的事物由什么组成? 属性 行为 类也可以包含属性和行为,所以使用类描述现实世界事物是非常合适的类和对象的关系是什么? 类是程序中的“设计图纸” 对象是基于图纸生产的具体实体什么是面向对象编程? 面向对象编…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...