SQL Serve---查询
概要
1、order by子句
—默认asc(升序)、desc(降序)
2、distinct关键字
3、group by子句
4、聚合函数
—max()、min()、sum()、avg()、count()
5、having子句
6、compute子句
英文关键字
order by 排序
asc 升序
desc 降序
distinct 去除重复值
group by 分组
max() 最大值
min() 最小值
sum() 求和
avg() 平均值
count() 记录数量
with rollup 汇总
having 分组条件
compute 统计
order by
order by [字段1[asc/desc]],[字段2[asc/desc]],…
注意: asc 升序(默认值) desc 降序
例
--按出生日期先后显示tb_student表。
select * from tb_student order by birthday
--按年龄由大到小显示tb_student表中学号,姓名和年龄。
select sno as 学号, sn as 姓名,
year(getdate()) - year(birthday) as 年龄
from tb_student
order by 年龄 desc
可用列别名排序,但是不能用列别名筛选
NULL(空值)默认为最小值
group by
group by子句指导SQL Server将一些行(这些行在子句中指定的一列或多列中具有相同的值)组合到一行中,也就是分组。
注意:查询输入中包括的列, “必须” 在group by子句中出现。
使用GROUP BY的一些规定:
distinct关键字
distinct关键字,紧跟在select语句之后的distinct指导SQL Server消除结果集中的重复行,指导SQL Server仅返回唯一的行
聚合函数
group by子句通常与“聚合函数”一起使用。聚合函数针对一组值进行计算,并返回一个值。group by查询中使用的最常见的聚合函数有:
Select count(*) from tb_student
where dept=‘软件学院’
group by子句中使用having
having子句限制由group by子句返回的行,其方式与where子句限制select子句返回的行相同。where和having子句可以同时包括在一个select语句中,也就是说,在进行分组操作之前应用where子句,在分组操作之后应用having子句。
having 列名 操作符 值
然后将 HAVING 子句应用于由分组生成的结果集中的行。只有符合 HAVING 子句条件的组才出现在查询输出中。只能将 HAVING 子句应用于也出现在 GROUP BY 子句或聚合函数中的
compute子句
compute子句:统计结果,出现在查询结果最后
这个地方一定要改,要不查不到表
实验
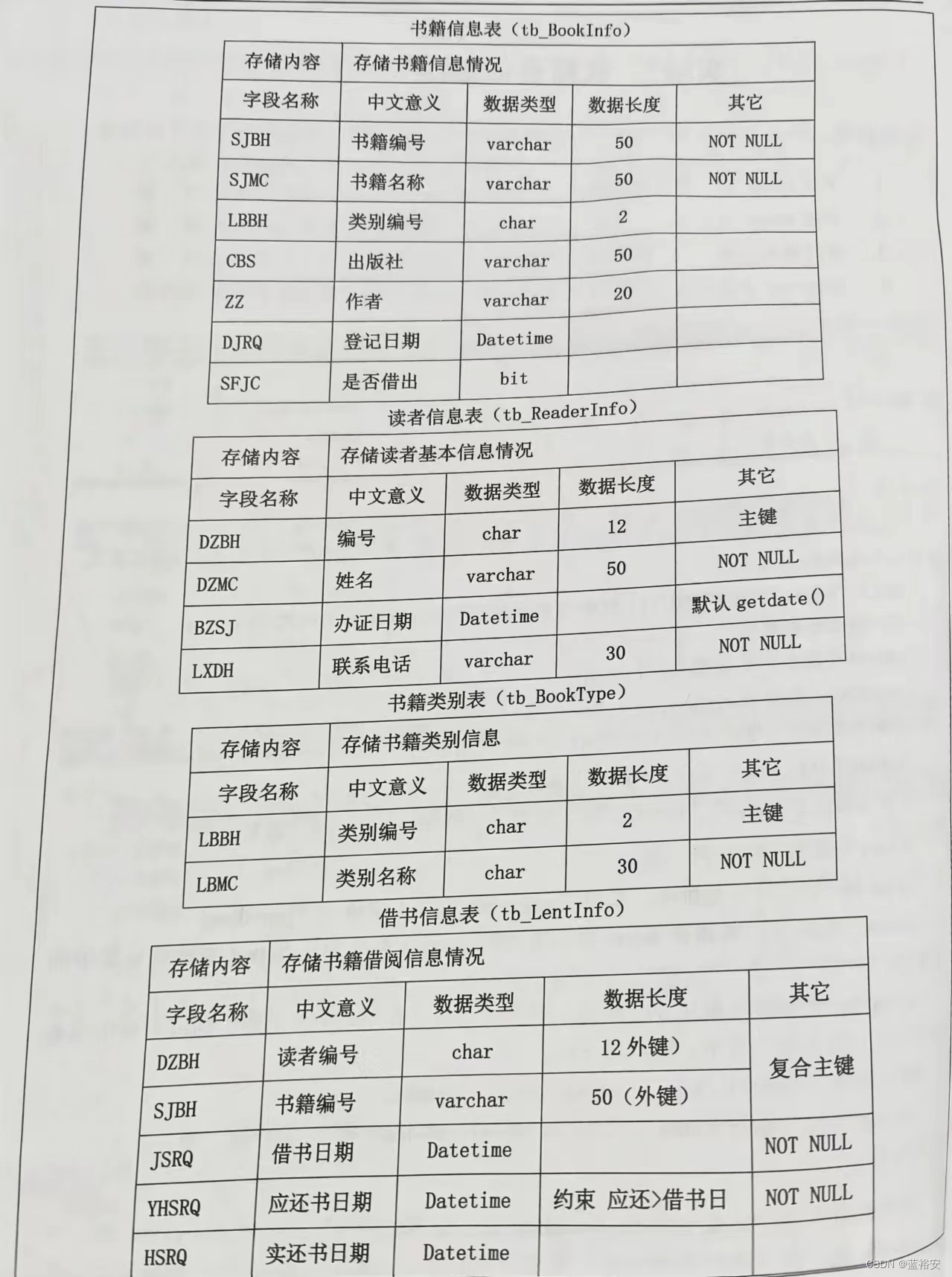
--查询tb_BookInfo(书籍信息表)中的所有的书籍的书籍编号、书籍名称、是否借出字段的信息
--查询tb_ReaderInto(读者信息表)中所有读者的信息
--使用别名定义的三种方法查询每个读者的编号、姓名和联系电话
--(4)查询 tb_BookInfo(书籍信息表)中前5条记录的书籍编号、书籍名称。
--(5)查询tb_BookInfo(书籍信息表)表中已借出的书籍信息。
--(6)查询tb_BookInfo(书籍信息表)中 2017年4月份登记的图书名称和登记日期,
--(7)查询tb_BookInfo(书籍信息表)中人民邮电出版社书籍的信息。
--(8)查询tb_BookInfo(书籍信息表)中2017年4月1日前登记的书籍信息。
--(9)查询名为《数据库原理与应用》的书籍的基本信息。
--(10)查询tb_BookType(书籍类别表)中书籍类别为文学类的书籍信息
--(11)查询在2017-3-1到2017年4-1之间借出的书籍编号、读者编号。
--(12)查询人民邮电大学出版社、上海交通大学出版社的书籍信息。
--(13)查询不是清华大学出版社、大连理工大学出版社出版的书籍信息。
--(14)查询出版社是清华大学出版社并已借出的图书信息。
--(15)查询tb_ReaderInfo(读者信息表)表中姓“田”的读者。
--(16)在tbReaderInfo(读者信息表)中找到所有姓名中姓李并且带飞字的读者
--(17)查询tb_BookInfo(书籍信息表),按书籍名称升序显示书籍编号,书籍名称,是否借出字段。
--(18)查询书籍信息表,按书籍名称降序排序,书名相同按登记日期先后顺序排列
--(19)返回tb_BookInfo(书籍信息表)中的出版社信息(distinct)
--(20)按读者姓名降序显示tb_ReaderInfo(读者信息表)中的信息
--(21)查询tbBookInfo(书籍信息表),按书籍类别(LBBH)统计各类书籍的数量
--(22)统计 tb BookInfo(书籍信息表)中的书籍数量。
--(23)按书籍名称统计各种书籍的数量,并按书籍名称升序排序。
--(24)按出版社统计各个出版社的书籍数量,并显示数量超过100本的出版社名称
--(25)统计人民邮电出版社书籍的数量
--(26)统计2017年4月份借出书籍的数量,并按数量降序排列
--查询tb_BookInfo(书籍信息表)中的所有的书籍
--的书籍编号、书籍名称、是否借出字段的信息
SELECT SJBH,SJMC,SFJC
FROM tb_BookInfo
--查询tb_ReaderInto(读者信息表)中所有读者的信息
SELECT *
FROM tb_ReaderInfo
--使用别名定义的三种方法查询每个读者的编号、姓名和联系电话
SELECT DZBH '编号', DZMC'姓名', LXDH'联系电话'
FROM tb_ReaderInfo;
SELECT DZBH AS'编号', DZMC AS'姓名', LXDH AS'联系电话'
FROM tb_ReaderInfo;
SELECT '编号'=DZBH, '姓名'=DZMC , '联系电话'=LXDH
FROM tb_ReaderInfo;
--(4)查询 tb_BookInfo(书籍信息表)中前5条记录的书籍编号、书籍名称。
SELECT TOP 5 SJBH,SJMC
FROM tb_BookInfo
--(5)查询tb_BookInfo(书籍信息表)表中已借出的书籍信息。
SELECT SFJC=1
FROM tb_BookInfo
--(6)查询tb_BookInfo(书籍信息表)中 2017年4月份登记的图书名称和登记日期,
SELECT SJMC,DJRQ
FROM tb_BookInfo
--(7)查询tb_BookInfo(书籍信息表)中人民邮电出版社书籍的信息。
SELECT *
FROM tb_BookInfo
WHERE CBS='人民邮电出版社'
--(8)查询tb_BookInfo(书籍信息表)中2017年4月1日前登记的书籍信息。
SELECT *
FROM tb_BookInfo
WHERE DJRQ<'2017-4-1'
--(9)查询名为《数据库原理与应用》的书籍的基本信息。
SELECT *
FROM tb_BookInfo
WHERE SJMC='数据库原理与应用'
--(10)查询tb_BookType(书籍类别表)中书籍类别为文学类的书籍信息
SELECT *
FROM tb_BookType
WHERE LBMC='文学'
--(11)查询在2017-3-1到2017年4-1之间借出的书籍编号、读者编号。
SELECT SJBH,DZBH
FROM tb_BookInfo,tb_ReaderInfo
WHERE DJRQ BETWEEN '2017-3-1' AND' 2017-4-1'
--(12)查询人民邮电大学出版社、上海交通大学出版社的书籍信息。
SELECT *
FROM tb_BookInfo
WHERE CBS='人民邮电大学出版社'OR CBS='上海交通大学出版社'
--(13)查询不是清华大学出版社、大连理工大学出版社出版的书籍信息。
SELECT *
FROM tb_BookInfo
WHERE NOT CBS='清华大学出版社'OR CBS='大连理工大学出版社'
--(14)查询出版社是清华大学出版社并已借出的图书信息。
SELECT *
FROM tb_BookInfo
WHERE CBS='清华大学出版社' AND SFJC=1
--(15)查询tb_ReaderInfo(读者信息表)表中姓“田”的读者。
SELECT DZMC
FROM tb_ReaderInfo
WHERE DZMC LIKE '田%'
--(16)在tbReaderInfo(读者信息表)中找到所有姓名中姓李并且带飞字的读者
SELECT DZMC
FROM tb_ReaderInfo
WHERE DZMC LIKE '李%飞%'
--(17)查询tb_BookInfo(书籍信息表),按书籍名称升序显示书籍编号,书籍名称,是否借出字段。
SELECT SJBH,SJMC,SFJC
FROM tb_BookInfo
ORDER BY SJMC ASC;
--(18)查询书籍信息表,按书籍名称降序排序,书名相同按登记日期先后顺序排列
SELECT *
FROM tb_BookInfo
ORDER BY SJMC DESC,DJRQ ASC
--(19)返回tb_BookInfo(书籍信息表)中的出版社信息(distinct)
SELECT DISTINCT CBS
FROM tb_BookInfo;
--(20)按读者姓名降序显示tb_ReaderInfo(读者信息表)中的信息
SELECT *
FROM tb_ReaderInfo
ORDER BY DZMC DESC
--(21)查询tbBookInfo(书籍信息表),按书籍类别(LBBH)统计各类书籍的数量
SELECT LBBH '书籍类别',count(SFJC) '书籍的数量'
FROM tb_BookInfo
GROUP BY LBBH
ORDER BY LBBH
--(22)统计 tb BookInfo(书籍信息表)中的书籍数量。
SELECT count(SJBH) AS '书籍总数'
FROM tb_BookInfo
--(23)按书籍名称统计各种书籍的数量,并按书籍名称升序排序。
SELECT SJMC,count(SJMC) AS '数量'
FROM tb_BookInfo
GROUP BY SJMC
ORDER BY SJMC asc
--(24)按出版社统计各个出版社的书籍数量,并显示数量超过100本的出版社名称
SELECT CBS,COUNT(SJBH) '数量'
FROM tb_BookInfo
GROUP BY CBS HAVING COUNT(CBS) > 100
--(25)统计人民邮电出版社书籍的数量
SELECT CBS, COUNT (SJBH) '数量'
FROM tb_BookInfo
WHERE CBS='人民邮电出版社'
--分组,把数量放到一个组里面
GROUP BY CBS
--(26)统计2017年4月份借出书籍的数量,并按数量降序排列
SELECT JSRQ '借书日期',SJBH'借书编号',COUNT(*)AS '数量'
FROM tb_LentInfo
WHERE JSRQ BETWEEN '2017-04-01'AND '2017-04-30'
GROUP BY SJBH,JSRQ
ORDER BY '数量' DESC相关文章:
SQL Serve---查询
概要 1、order by子句 —默认asc(升序)、desc(降序) 2、distinct关键字 3、group by子句 4、聚合函数 —max()、min()、sum()、avg()、count() 5、having子句 6、compute子句 英文关键字 order by 排序 asc…...

RabbitMQ3.13.x之十一_RabbitMQ中修改用户密码及角色tags
RabbitMQ3.13.x之十一_RabbitMQ中修改用户密码及角色tgs 文章目录 RabbitMQ3.13.x之十一_RabbitMQ中修改用户密码及角色tgs1. 修改用户的密码1. 修改密码语法2. 修改案例 2.修改角色tags1. 修改标签(tags)语法2. 修改案例 可以使用 RabbitMQ 的命令行工具 rabbitmqctl 来修改用…...
Taro打包生成不同目录
使用taro init创建taro项目时,taro默认打包目录是: /config/index.js outputRoot:dist默认的目录,编译不同平台代码时就会覆盖掉,为了达到多端同步调试的目的,这时需要修改默认生成目录了,通过查看官方文…...

2024-04-08 NO.5 Quest3 手势追踪进行 UI 交互
文章目录 1 玩家配置2 物体配置3 添加视觉效果4 添加文字5 其他操作5.1 双面渲染5.2 替换图片 在开始操作前,我们导入先前配置好的预制体 MyOVRCameraRig,相关介绍在 《2024-04-03 NO.4 Quest3 手势追踪抓取物体-CSDN博客》 文章中。 1 玩家配置 &a…...
PaddleDetection 项目使用说明
PaddleDetection 项目使用说明 PaddleDetection 项目使用说明数据集处理相关模块环境搭建 PaddleDetection 项目使用说明 https://github.com/PaddlePaddle/PaddleDetection/blob/release/2.7/configs/ppyoloe/README_cn.md 自己项目: https://download.csdn.net/d…...
1352 - 1358 题)
leetcode解题思路分析(一百五十五)1352 - 1358 题
最后 K 个数的乘积 请你实现一个「数字乘积类」ProductOfNumbers,要求支持下述两种方法: add(int num) 将数字 num 添加到当前数字列表的最后面。 getProduct(int k) 返回当前数字列表中,最后 k 个数字的乘积。 你可以假设当前列表中始终 至少…...

如何将普通maven项目转为maven-web项目
文件-项目结构(File-->Project Structure ) 模块-->learn(moudle-->learn) 选中需要添加web的moudle,点击加号,我得是learn,单击选中后进行下如图操作: 编辑路径 结果如下…...
LeetCode 226. 翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1: 输入:root [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1] 示例 2: 输入:root [2,1,3] 输出:[2,3,1] 示例…...
:Aspose.Cells中的Excel操作)
【ArcGIS Pro二次开发】(85):Aspose.Cells中的Excel操作
Aspose.Cells是一款功能强大的Excel文档处理和转换控件,开发人员和客户电脑无需安装Microsoft Excel也能在应用程序中实现类似Excel的强大数据管理功能。 1、获取工作薄Workbook string excelFile "C:\Users\Administrator\Desktop\FE.xlsx"; Workbook …...
基于java+springboot+vue实现的兴顺物流管理系统(文末源码+Lw)23-287
摘 要 传统信息的管理大部分依赖于管理人员的手工登记与管理,然而,随着近些年信息技术的迅猛发展,让许多比较老套的信息管理模式进行了更新迭代,货运信息因为其管理内容繁杂,管理数量繁多导致手工进行处理不能满足广…...
pytorch view、expand、transpose、permute、reshape、repeat、repeat_interleave
非contiguous操作 There are a few operations on Tensors in PyTorch that do not change the contents of a tensor, but change the way the data is organized. These operations include: narrow(), view(), expand() and transpose() permute() This is where the con…...
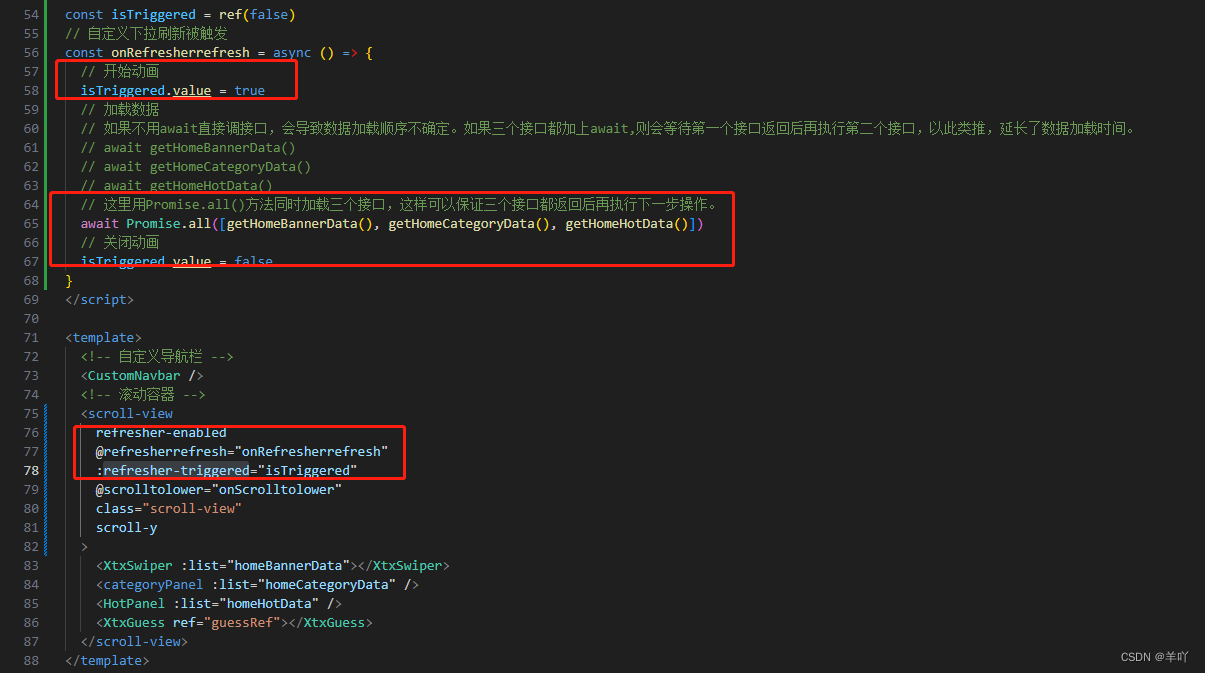
uni-app实现下拉刷新
业务逻辑如下: 1.在滚动容器中加入refresher-enabled属性,表示为开启下拉刷新 2.监听事件,添加refresherrefresh事件 3.在事件监听函数中加载数据 4.关闭动画,添加refresher-triggered属性,在数据请求前开启刷新动画…...

vue ts 应用梳理
文章目录 前言一、页面传值1.1 [props](https://cn.vuejs.org/guide/components/props.html)1.2 [emit](https://cn.vuejs.org/guide/components/events.html)1.3 [store](https://pinia.vuejs.org/zh/getting-started.html) 二、实时计算2.1 [watch](https://cn.vuejs.org/gui…...
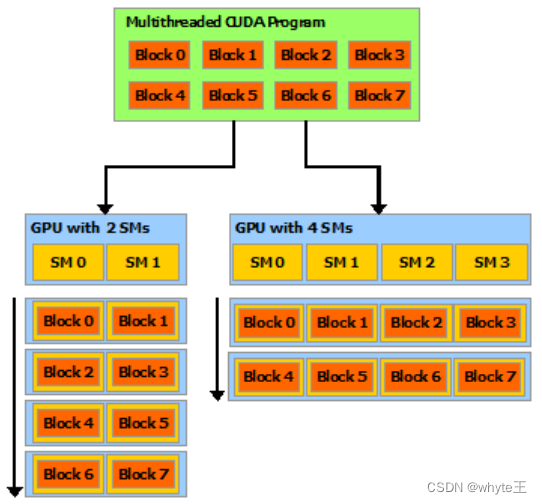
CUDA12.4文档-全文翻译
本博客参考官方文档进行介绍,全网仅此一家进行中文翻译,走过路过不要错过。 官方网址:https://docs.nvidia.com/cuda/cuda-c-programming-guide/ 本文档分成多个博客进行介绍,在本人专栏中含有所有内容: https://blog.csdn.net/qq_33345365/category_12610860.html CU…...
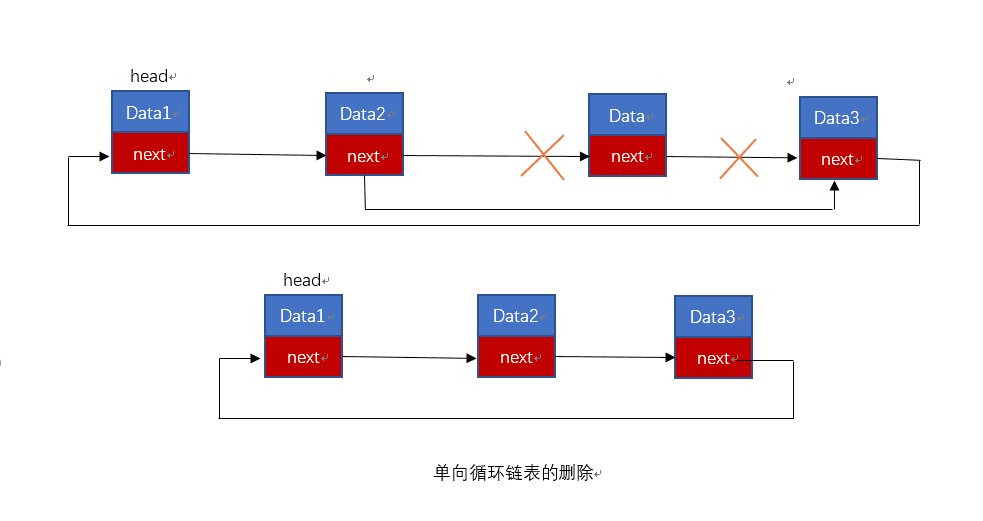
【C 数据结构】循环链表
文章目录 【 1. 基本原理 】【 2. 循环链表的创建 】2.1 循环链表结点设计2.2 循环单链表初始化 【 3. 循环链表的 插入 】【 4. 循环单链表的 删除操作 】【 5. 循环单链表的遍历 】【 6. 实例 - 循环链表的 增删查改 】【 7. 双向循环链表 】 【 1. 基本原理 】 对于单链表以…...

Python列表
使用场景:列表是用来存储多组数据的 列表是可变类型 列表支持切片 1.基本规则 1.列表使用[]来表示 2.初始化列表:list [] 3.列表可以一次性存储多个数据:[数据1,数据2,数据3,…] 4.列表中的每一项&#…...

谈谈系列之金融直播展业畅想
近些年直播异常火热,对于各大中小型基金证券公司,也纷纷引入直播作为新型展业渠道。在这其中有一部分直接采用第三方云平台,也有少部分选择自建直播平台。当然自建直播平台也不是纯自研,大抵都是外购第三方厂商整体解决方案&#…...
【C 数据结构】双向链表
文章目录 【 1. 基本原理 】【 2. 双向链表的 创建 】实例 - 输出双向链表 【 3. 双向链表 添加节点 】【 4. 双向链表 删除节点 】【 5. 双向链表查找节点 】【 7. 双向链表更改节点 】【 8. 实例 - 双向链表的 增删查改 】 【 1. 基本原理 】 表中各节点中都只包含一个指针&…...
Leetcode刷题之消失的数字(C语言版)
Leetcode刷题之消失的数字(C语言版) 一、题目描述二、题目解析 一、题目描述 数组nums包含从0到n的所有整数,但其中缺了一个。请编写代码找出那个缺失的整数。你有办法在O(n)时间内完成吗? 注意:本题相对书上原题稍作…...
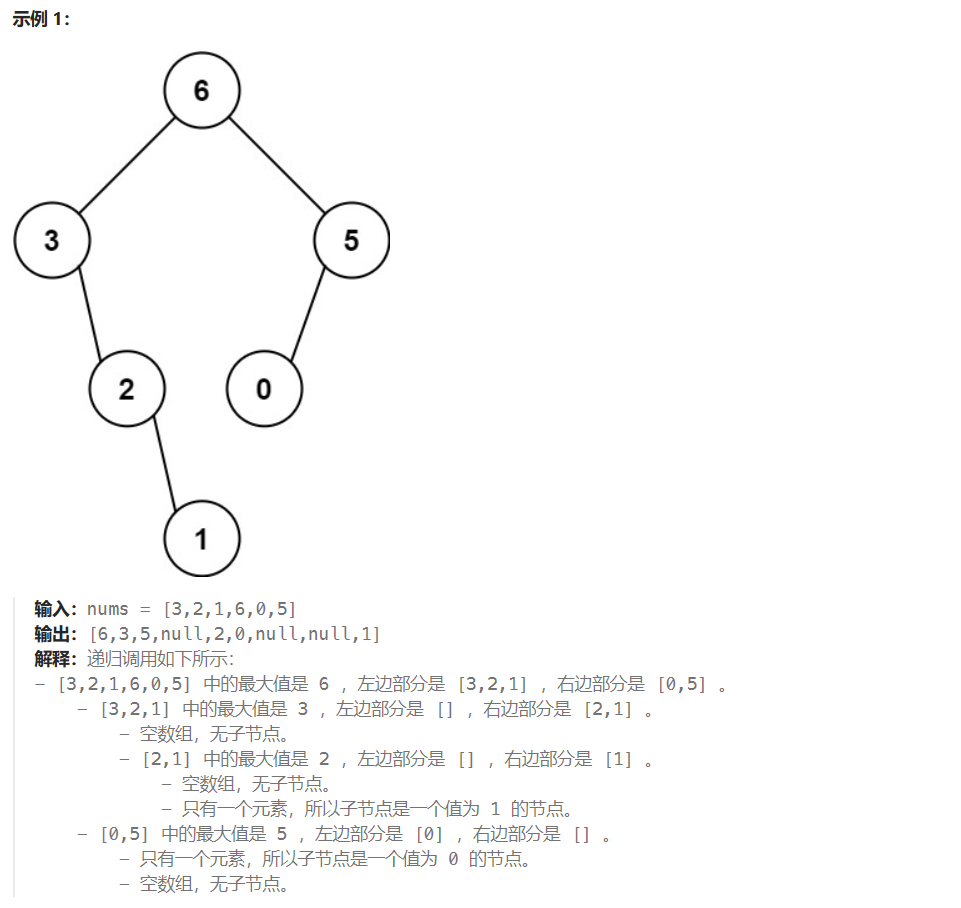
LeetCode654:最大二叉树
题目描述 给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值。 递归地在最大值 左边 的 子数组前缀上 构建左子树。 递归地在最大值 右边 的 子数组后缀上 构建右子树。 返回 nums 构建的 …...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...