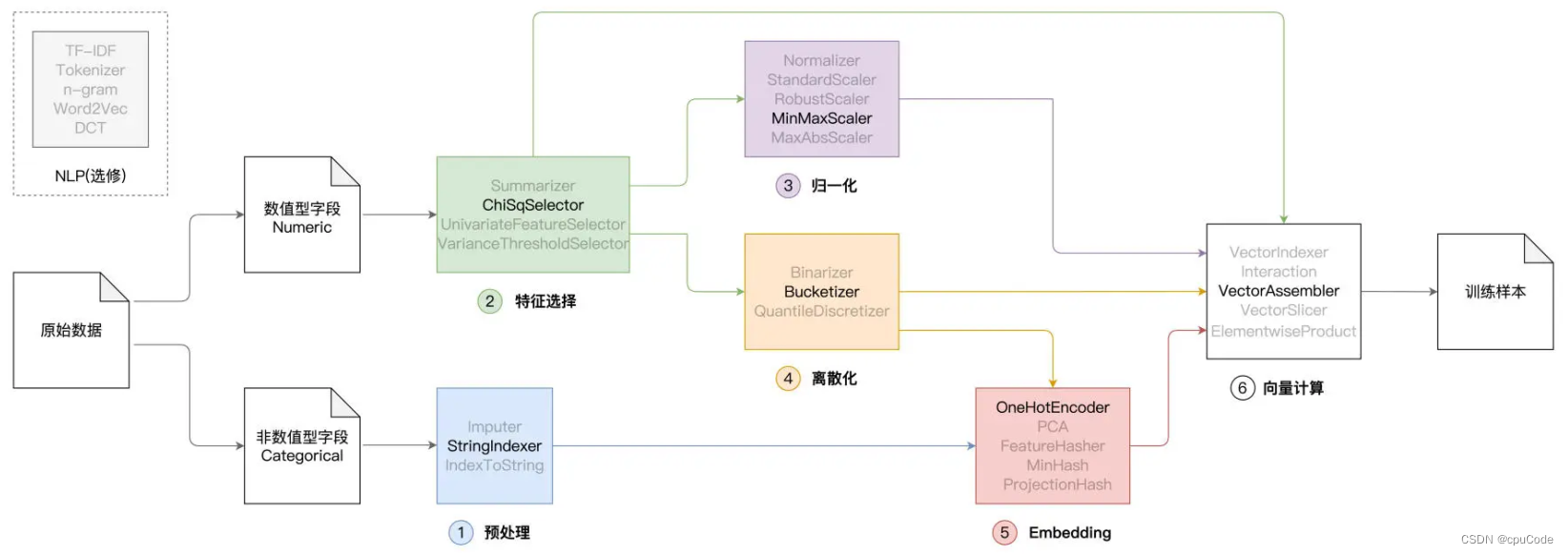
Spark MLlib 特征工程
Spark MLlib 特征工程
- 预处理
- 特征选择
- 归一化
- 离散化
- Embedding
- 向量计算
特征工程制约了模型效果 :
- 决定了模型效果的上限 , 而模型调优只是在不停地逼近上限
- 好的特征工程才能有好的模型
特征处理函数分类 :
- 预处理 : 将模型无法直接消费的数据,转为可消费的数据形式
- 特征选择 : 提取与预测标的关联度更高的特征,精简模型尺寸、提升模型泛化能力
- 归一化 : 去掉不同特征之间量纲的影响,避免因量纲不一致而导致的梯度下降震荡、模型收敛效率低下等问题
- 离散化 : 降低连续数值特征的多样性,让特征与预测标的之间建立更强的关联性
- Embedding : 将特征映射到向量空间,以向量形式刻画特征本身
- 向量计算 : 完成向量的拆分、拼接、运算,从而构建特征向量 (Feature Vectors),进而生成模型可消费的训练样本
预处理
预处理 : 把非数值字段转为数值字段
StringIndexer 作用 : 以数据列为单位,把字段中的字符串转为数值索引
- 如 : 把 GarageType 中的字符串转换为数字
StringIndexer 效果 :

StringIndexer 步骤 :
- 实例化 StringIndexer 对象
- 用 setInputCol 和 setOutputCol 指定输入列和输出列
- 用 fit 和 transform 函数,完成数据转换
读取房屋源数据并创建 DataFrame
import org.apache.spark.sql.DataFrame// 这里的下划线"_"是占位符,代表数据文件的根目录
val rootPath: String = _
val filePath: String = s"${rootPath}/train.csv"val sourceDataDF: DataFrame = spark.read.format("csv").option("header", true)
选出所有的非数值字段,并用 StringIndexer 转换
// 导入StringIndexer
import org.apache.spark.ml.feature.StringIndexer// 所有非数值型字段,即 : StringIndexer所需的“输入列”
val categoricalFields: Array[String] = Array("MSSubClass", "MSZoning", "Street");// 非数值字段对应的目标索引字段,也即StringIndexer所需的“输出列”
val indexFields: Array[String] = categoricalFields.map(_ + "Index").toArray// 将engineeringDF定义为var变量,后续所有的特征工程都作用在这个DataFrame之上
var engineeringDF: DataFrame = sourceDataDF// 核心代码:循环遍历所有非数值字段,依次定义StringIndexer,完成字符串到数值索引的转换
for ((field, indexField) <- categoricalFields.zip(indexFields)) {// 定义StringIndexer,指定输入列名、输出列名val indexer = new StringIndexer().setInputCol(field).setOutputCol(indexField)// 使用StringIndexer对原始数据做转换engineeringDF = indexer.fit(engineeringDF).transform(engineeringDF)// 删除掉原始的非数值字段列engineeringDF = engineeringDF.drop(field)
}
与 GarageType 数据列与数值索引 :
engineeringDF.select("GarageType", "GarageTypeIndex").show(3)/** 结果打印
+----------+---------------+
|GarageType|GarageTypeIndex|
+----------+---------------+
| Attchd| 0.0|
| Detchd| 1.0|
| Attchd| 0.0|
+----------+---------------+
*/
特征选择
特征选择 : 根据一定的标准,对特征字段进行选择
特征选择的标准 :
- 专家的经验初步选出特征集
- 用统计方法计算候选特征与预测标的的关联性
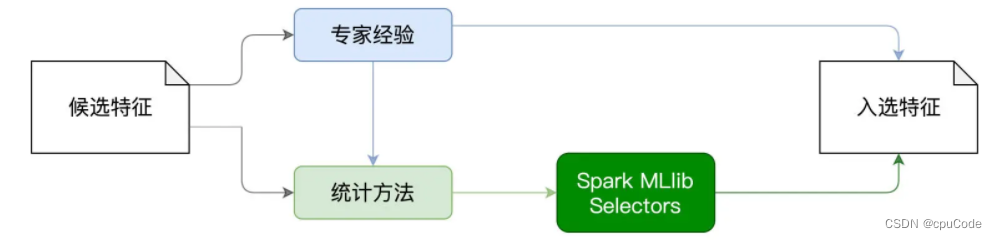
利用 ChiSqSelector 封装的统计方法是卡方检验与卡方分布
ChiSqSelector 选择数值型字段的步骤 :
- 用 VectorAssembler 创建特征向量
- 基于特征向量,用 ChiSqSelector 完成特征选择
VectorAssembler 作用 : 把多个数值列捏合为一个特征向量
- 例子 : 房屋的三个数值列 , 进行捏合成一个新的向量字段
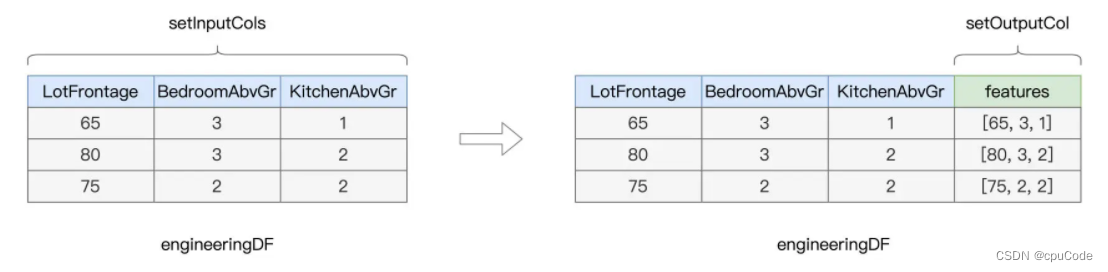
VectorAssembler 用法 :
// 所有数值型字段,共有27个
val numericFields: Array[String] = Array("LotFrontage", "LotArea", "MasVnrArea");// 预测标的字段
val labelFields: Array[String] = Array("SalePrice")import org.apache.spark.sql.types.IntegerType// 将所有数值型字段,转换为整型Int
for (field <- (numericFields ++ labelFields)) {engineeringDF = engineeringDF.withColumn(s"${field}Int",col(field).cast(IntegerType);
} import org.apache.spark.ml.feature.VectorAssembler// 所有类型为Int的数值型字段
val numericFeatures: Array[String] = numericFields.map(_ + "Int").toArray
// 定义并初始化VectorAssembler
val assembler = new VectorAssembler().setInputCols(numericFeatures).setOutputCol("features")// 在DataFrame 应用 VectorAssembler,生成特征向量字段"features"
engineeringDF = assembler.transform(engineeringDF)
基于特征向量进行特征选择
import org.apache.spark.ml.feature.ChiSqSelector
import org.apache.spark.ml.feature.ChiSqSelectorModel// 定义并初始化ChiSqSelector
// 挑选最影响的前 20 个特征
val selector = new ChiSqSelector().setFeaturesCol("features").setLabelCol("SalePriceInt").setNumTopFeatures(20)// 调用fit函数,在DataFrame之上完成卡方检验
val chiSquareModel = selector.fit(engineeringDF)
// 获取ChiSqSelector选取出来的入选特征集合(索引)
val indexs: Array[Int] = chiSquareModel.selectedFeaturesimport scala.collection.mutable.ArrayBufferval selectedFeatures: ArrayBuffer[String] = ArrayBuffer[String]()
// 根据特征索引值,查找数据列的原始字段名
for (index <- indexs) {selectedFeatures += numericFields(index)
}
ChiSqSelector工作流程 :
- ChiSqSelector 记录了 0/1 索引,对应 LotFrontage / BedroomAbvGr

归一化
归一化 (Normalization) 作用 : 把一组数值,统一映射到同一个值域,该值域通常是 [0, 1]
归一化的意义 :
- 当原始数据之间的量纲差异较大时,模型训练时,梯度下降不稳定、抖动较大,模型不容易收敛,从而导致训练效率较差
- 当所有特征数据都被约束到同一个值域时,模型训练的效率就会大幅提升
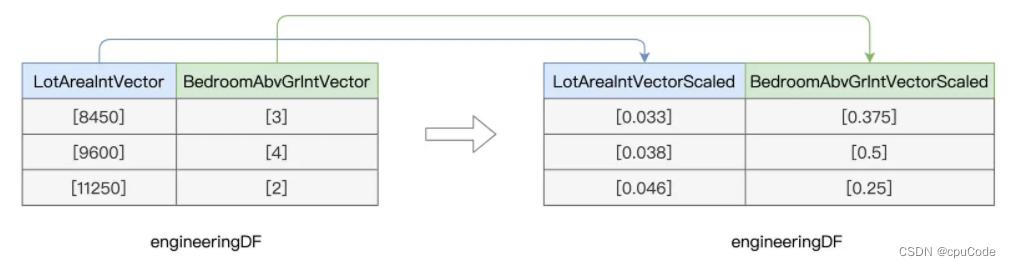
MinMaxScaler 用法 :
- 用 VectorAssembler 创建特征向量
- 基于特征向量,用 MinMaxScaler 完成归一化
// 所有类型为Int的数值型字段
// val numericFeatures: Array[String] = numericFields.map(_ + "Int").toArray// 遍历每一个数值型字段
for (field <- numericFeatures) {// 定义并初始化VectorAssemblerval assembler = new VectorAssembler().setInputCols(Array(field)).setOutputCol(s"${field}Vector")// 调用transform把每个字段由Int转换为Vector类型engineeringData = assembler.transform(engineeringData)
}import org.apache.spark.ml.feature.MinMaxScaler// 锁定所有Vector数据列
val vectorFields: Array[String] = numericFeatures.map(_ + "Vector").toArray
// 归一化后的数据列
val scaledFields: Array[String] = vectorFields.map(_ + "Scaled").toArray// 循环遍历所有Vector数据列
for (vector <- vectorFields) {// 定义并初始化MinMaxScalerval minMaxScaler = new MinMaxScaler().setInputCol(vector).setOutputCol(s"${vector}Scaled")// 使用MinMaxScaler,完成Vector数据列的归一化engineeringData = minMaxScaler.fit(engineeringData).transform(engineeringData)
}
MinMaxScaler 归一化 :
离散化
离散化作用 : 把原本连续的数值打散,降低原始数据的多样性(Cardinality)
- 如 : 居室数量 (BedroomAbvGr),包含从 1 - 8 的连续整数
离散化的意义 : 提升特征数据的区分度与内聚性,实现与预测标的产生更强的关联
BedroomAbvGr离散化 :
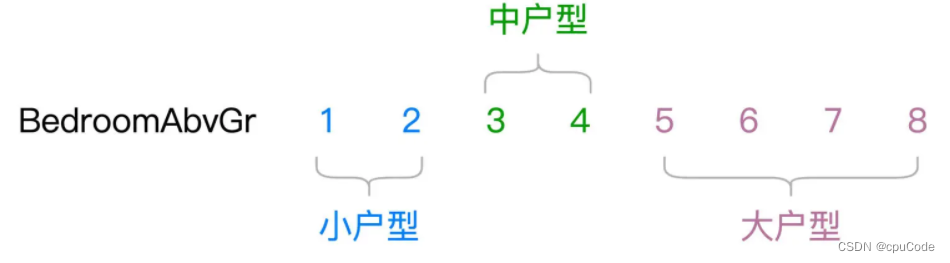
离散化的用法 :
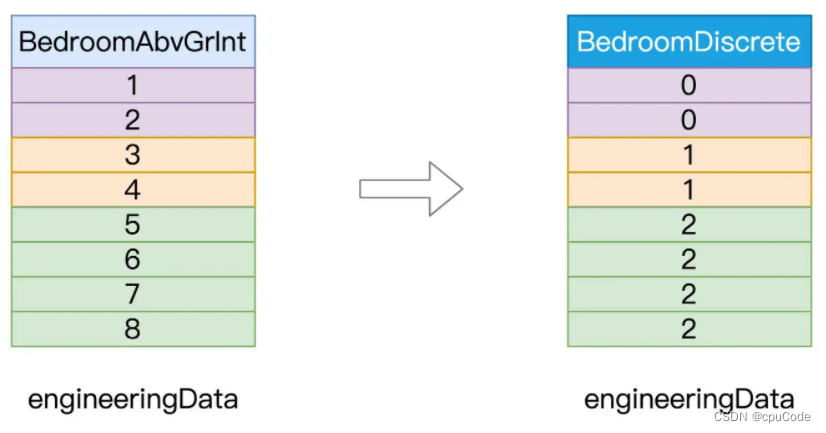
// 原始字段
val fieldBedroom: String = "BedroomAbvGrInt"
// 包含离散化数据的目标字段
val fieldBedroomDiscrete: String = "BedroomDiscrete"// 指定离散区间,分别是[负无穷, 2]、[3, 4]和[5, 正无穷]
val splits: Array[Double] = Array(Double.NegativeInfinity, 3, 5, Double.PositiveInfinity)import org.apache.spark.ml.feature.Bucketizer// 定义并初始化Bucketizer
val bucketizer = new Bucketizer()// 指定原始列.setInputCol(fieldBedroom)// 指定目标列.setOutputCol(fieldBedroomDiscrete)// 指定离散区间.setSplits(splits)// 调用transform完成离散化转换
engineeringData = bucketizer.transform(engineeringData)
离散化前后对比 :
Embedding
Embedding 过程 : 把数据集合映射到向量空间,进而把数据进行向量化的过程
热独编码 (One Hot Encoding) :
- 通过 StringIndexer 把 GarageType 映射成六个数值
- 用热独编码,把每个数值都转为一个向量

把索引字段转为向量字段 :
import org.apache.spark.ml.feature.OneHotEncoder// 非数值字段对应的目标索引字段,也即StringIndexer所需的“输出列”
// val indexFields: Array[String] = categoricalFields.map(_ + "Index").toArray// 热独编码的目标字段,也即OneHotEncoder所需的“输出列”
val oheFields: Array[String] = categoricalFields.map(_ + "OHE").toArray// 循环遍历所有索引字段,对其进行热独编码
for ((indexField, oheField) <- indexFields.zip(oheFields)) {val oheEncoder = new OneHotEncoder().setInputCol(indexField).setOutputCol(oheField)engineeringData= oheEncoder.transform(engineeringData)
}
向量计算
向量计算作用 : 构建训练样本中的特征向量 (FeatureVectors)
构建特征向量 :
import org.apache.spark.ml.feature.VectorAssembler/**
入选的数值特征:selectedFeatures
归一化的数值特征:scaledFields
离散化的数值特征:fieldBedroomDiscrete
热独编码的非数值特征:oheFields
*/
val assembler = new VectorAssembler().setInputCols(selectedFeatures ++ scaledFields ++ fieldBedroomDiscrete ++ oheFields).setOutputCol("features")engineeringData = assembler.transform(engineeringData)
定义出线性回归模型 :
// 定义线性回归模型
val lr = new LinearRegression().setFeaturesCol("features").setLabelCol("SalePriceInt").setMaxIter(100)// 训练模型
val lrModel = lr.fit(engineeringData)
// 获取训练状态
val trainingSummary = lrModel.summary// 获取训练集之上的预测误差
println(s"Root Mean Squared Error (RMSE) on train data: ${trainingSummary.root}");
相关文章:
Spark MLlib 特征工程
Spark MLlib 特征工程预处理特征选择归一化离散化Embedding向量计算特征工程制约了模型效果 : 决定了模型效果的上限 , 而模型调优只是在不停地逼近上限好的特征工程才能有好的模型 特征处理函数分类 : 预处理 : 将模型无法直接消费的数据,转为可消费的数据形式特…...

CentOS7 完全卸载 php
在 CentOS 7 使用 yum install 简单安装 php 后,发现 php 版本 5.4 ,太低了! 然后,使用 yum remove 简单卸载后,发现 php 还在,不干净! 只好 rpm 慢慢卸载 rpm -qa |grep php php-gd-5.4.16-4…...

关于OCS认证里必须知晓的内容
【关于OCS认证里必须知晓的内容】美国非营利组织Textile Exchange推出的有机认证标准——有机含量标准(The Organic Content Standard),简称OCS。该标准通过跟踪有机原材料的种植从而监管整个有机产业链。OCS将应用于各种有机种植原料的验证,而不只限于有…...

创业做电商难不难?新人做电商怎么才能挣钱?
这几年经济不景气,创业做电商的人越来越多,但是,对于多数人来说,一开始做电商,都是试错成本,没有系统学习或者是跟着半吊子二把刀学的,结果赔钱就算了,新人创业做电商到底难不难&…...
【项目设计】高并发内存池(七)[性能测试和提升]
🎇C学习历程:入门 博客主页:一起去看日落吗持续分享博主的C学习历程博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记&…...

PHP:Laravel cast array json数据存数据库时unicode 编码问题和update更新不触发数据转换
目录问题描述问题解决方式一:自定义属性方式二:继承覆写方式三:trait复用方式四:定义Cast子类update不生效参考文章问题描述 Model示例 class UserModel extends Model {protected $table tb_user;protected $casts [alias …...
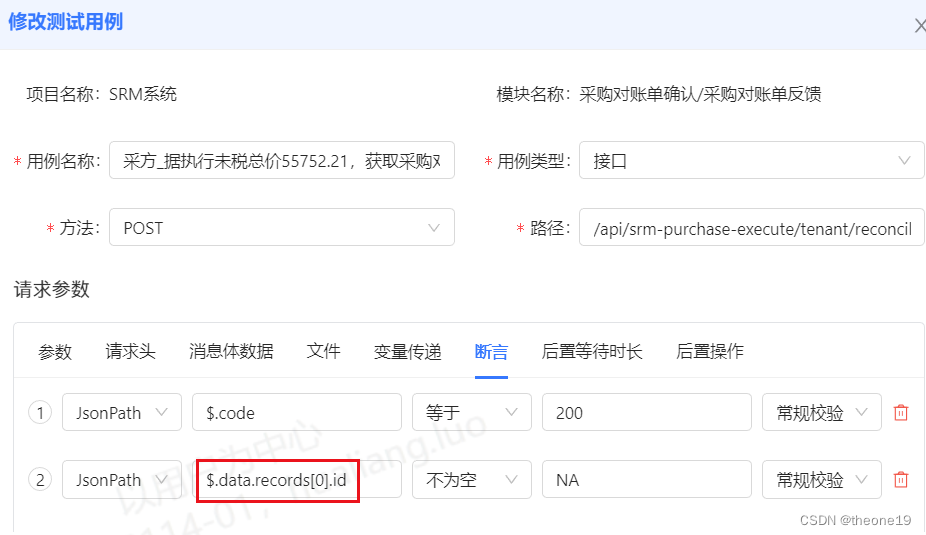
自动化测试总结--断言
采购对账测试业务流程中,其中一个测试步骤总是失败,原因是用例中参数写错及断言不明确 一、问题现象: 采购对账主流程中,其中一个步骤失败了,会导致这个套件一直失败 图(1)测试报告视图中&…...

传输线的物理基础(三):传输线的瞬时阻抗
每个信号都有一个上升时间 RT,通常是从 10% 到 90% 的电压电平测量的。当信号沿传输线向下移动时,前沿在传输线上展开并具有空间范围。如果我们可以冻结时间并观察电压分布向外移动时的大小,我们会发现类似下图的东西。传输线上上升时间的长度…...

第六章:多线程
第六章:多线程 6.1:程序、进程、线程基本概念 程序 程序program是为了完成特定任务、用某种语言编写的一组指令的集合。即指一段静态的代码,静态对象。 进程 进程process是程序的一次执行过程,或是正在运行的一个程序。是一个…...
铁路与公路
蓝桥杯集训每日一题acwing4074 某国家有 n 个城市(编号 1∼n)和 m 条双向铁路。 每条铁路连接两个不同的城市,没有两条铁路连接同一对城市。 除了铁路以外,该国家还有公路。 对于每对不同的城市 x,y,当且仅当它们之…...

GitHub Copilot 全新升级,工作效率提升 55%
2021年 6 月,GitHub 和 OpenAI 推出了 GitHub Copilot 预览版,可根据命名或者正在编辑的代码上下文为开发者提供代码建议,被称为“你的 AI 结对程序员”。 近日,GitHub 宣布,经过去年 12 月以来的短暂测试后ÿ…...

【IoT】《天道》中音响案例的SWOT分析
在20世纪80年代初,SWOT最初是由美国知名管理学教授海因茨韦里克提出的。 之后这个工具就经常被用于企业的战略分析、竞争对手分析等场景。 在每年例行的公司产品规划过程中,我个人也经常使用这个工具。 由于涉及一些公司商业上的信息,下面会用…...
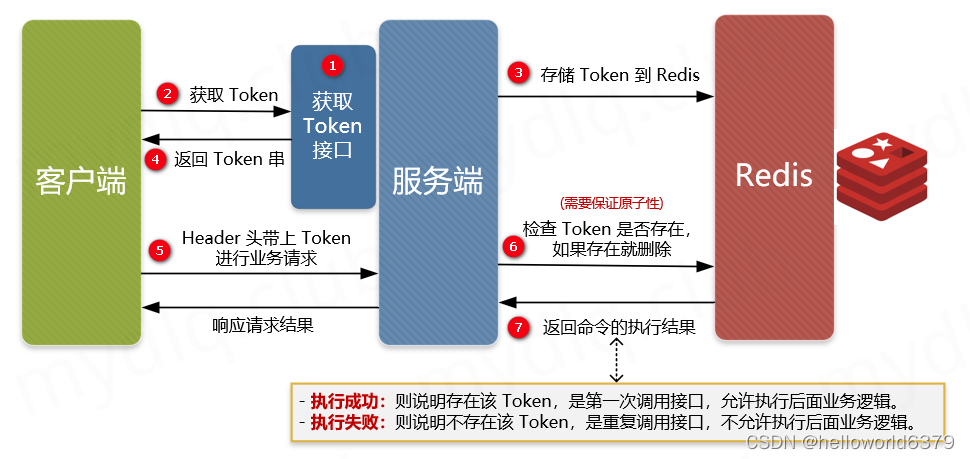
如何实现接口幂等性
1 什么是幂等 幂等操作的特点是一次或者任意多次执行所产生的影响均与一次执行的影响相同,不会因为多次的请求而产生不一样的结果。换句话说,就是我使用相同的请求参数,去请求同一个接口,不管请求多少次获取到的响应数据应该是一…...

相恨见晚的office办公神器(不坑盒子/打工人Excel插件2023年最新版)
不坑盒子 这是一个非常好用的插件工具,专门应用在Word文档和wps,支持Office 2010以上的版本,操作也简单且实用。 不坑盒子下载及使用说明 一键排版功能 像是下面的自动排版功能,可以在配置里面先设定好需要的格式,…...
matlab基础到实战(1)
目录概述sin函数例子四则运算实数复数逻辑运算复数运算模幅角共轭向量二维向量定义序列生成向量向量索引方式加减乘除向量间运算加减乘法除法概述 MATLAB是美国MathWorks公司出品的商业数学软件,用于数据分析、无线通信、深度学习、图像处理与计算机视觉、信号处理…...

谷歌发布编写分布式应用的框架Service Weaver
一个新的框架,在本地以模块化单体的形式运行,一旦部署,则为分布式微服务架构 转载请注明来源:https://janrs.com/2023/03/%e8%b0%b7%e6%ad%8c%e5%8f%91%e5%b8%83%e7%bc%96%e5%86%99%e5%88%86%e5%b8%83%e5%bc%8f%e5%ba%94%e7%94%a8…...
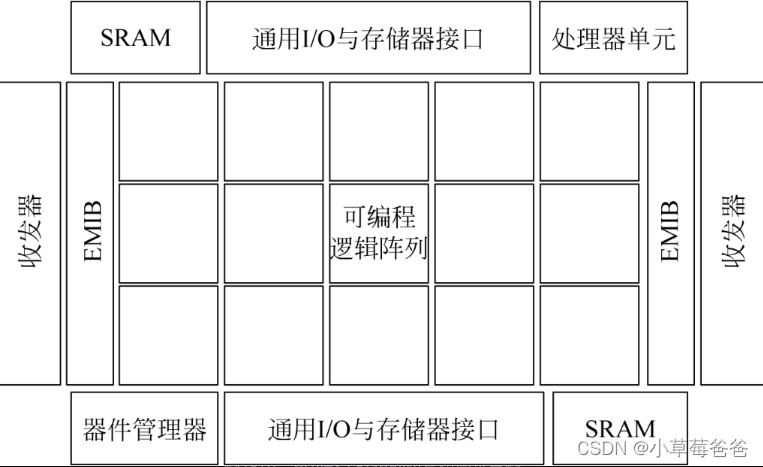
详解FPGA:人工智能时代的驱动引擎观后感
详解FPGA:人工智能时代的驱动引擎观后感 本书大目录 第一章 延续摩尔定律 第二章 拥抱大数据的洪流 第三章 FPGA在人工智能时代的独特优势 第四章 更简单也更复杂——FPGA开发的新方法 第五章 站在巨人肩上——FPGA发展新趋势 文章目录详解FPGA:人工智能…...

Rest/Restful接口
Rest Rest的全称是Representational State Transfer 。Rest是一种架构风格。Rest有很多原则和限制: 客户端-服务端架构模式无状态可缓存统一接口分层系统按需缓存 Rest对我们开发人员来说基本上就是资源,我们一般通过URI表示我们请求的一个资源。例如:…...
【vue init】三.项目引入axios、申明全局变量、设置跨域
教程目录 一:《【vue init】使用vue init搭建vue项目》 二:《【vue init】项目使用vue-router,引入ant-design-vue的UI框架,引入less》 三:《【vue init】项目引入axios、申明全局变量、设置跨域》 根据前文《【vue init】项目使…...

搭建nextcloud私有云盘
要搭建Nextcloud,需要在服务器上安装和配置Nginx、PHP和SQLite3。下面是一些基本步骤: 安装Nginx 可以使用包管理器进行安装。例如,在Ubuntu上可以运行以下命令: sudo apt update sudo apt install nginx配置Nginxwget -P /home/u…...

OpenClaw二手数据抓取:Qwen3-32B监控多个平台价格变动
OpenClaw二手数据抓取:Qwen3-32B监控多个平台价格变动 1. 为什么需要自动化价格监控 作为一个经常在二手平台淘货的玩家,我发现自己总是错过最佳购买时机。要么是刚买完就降价,要么是犹豫太久被其他人抢走。手动刷新比价不仅效率低下&#…...

BepInEx插件框架:新手问题全解析与实战解决方案
BepInEx插件框架:新手问题全解析与实战解决方案 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx 一、游戏启动异常:四步定位与修复方案 问题定位 当BepInE…...

OpenClaw排错大全:Qwen3-32B模型接入常见报错与修复
OpenClaw排错大全:Qwen3-32B模型接入常见报错与修复 1. 为什么需要这份排错指南 上周我在本地部署OpenClaw对接Qwen3-32B模型时,连续遭遇了三次不同层级的报错。从最初的Connection refused到后来的Invalid API Key,再到Model not found&am…...

如何修正GOM Inspect中的关键词格式问题
关键词格式问题与解决◇ 问题描述在使用GOM Inspect软件时,你可能会遇到关键词格式不符合预期的情况。例如,“日期”这个关键词可能并非你期望的日期格式,从而影响了关键词的正常使用。那么,为什么会出现格式不符的关键词呢&#…...

终极指南:如何使用LeRobot构建现实世界机器人机器学习系统
终极指南:如何使用LeRobot构建现实世界机器人机器学习系统 【免费下载链接】lerobot 🤗 LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot LeRobot是一…...

ILRepack:.NET程序集整合的现代解决方案
ILRepack:.NET程序集整合的现代解决方案 【免费下载链接】il-repack Open-source alternative to ILMerge 项目地址: https://gitcode.com/gh_mirrors/il/il-repack 在.NET应用开发过程中,随着项目规模扩大,程序集数量往往会不断增加。…...

30分钟入门:OpenClaw+GLM-4.7-Flash自动化办公初体验
30分钟入门:OpenClawGLM-4.7-Flash自动化办公初体验 1. 为什么选择这个组合? 上周处理月度报表时,我对着上百封邮件和十几个Excel文件发呆——这些重复性工作消耗了太多精力。直到发现OpenClaw这个能操控本地电脑的AI框架,配合o…...

跨平台开发:Flutter集成DDColor实现移动端着色APP
跨平台开发:Flutter集成DDColor实现移动端着色APP 1. 引言 你有没有遇到过这样的情况?翻看老照片时,那些黑白影像虽然珍贵,却总觉得缺少了些许生机。或者作为开发者,你想为用户提供一个简单易用的图片着色功能&#…...

造相-Z-Image-Turbo 亚洲美女LoRA 基础教程:Ubuntu20.04环境下的快速部署指南
造相-Z-Image-Turbo 亚洲美女LoRA 基础教程:Ubuntu20.04环境下的快速部署指南 你是不是也对那些能生成惊艳亚洲风格人像的AI绘画模型感到好奇?想自己动手部署一个,却看着复杂的命令行和依赖库感到头疼?别担心,今天我就…...

unrpa工具全方位使用指南:从入门到精通
unrpa工具全方位使用指南:从入门到精通 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 一、认知:揭开unrpa的神秘面纱 工具定位与核心价值 unrpa是一款专…...