【强化学习实践】Gym+倒立单摆+创建自己的环境
一、Gym
Gym是OpenAI开发的一个强化学习算法测试环境集合包。Gym提供了多种标准的环境,包括经典的游戏(如Atari游戏)、机器人模拟任务以及其他各种类型的问题,供开发者测试和训练强化学习智能体。在Gym环境中,开发者可以轻松定义和切换不同的环境,以便研究和比较不同强化学习算法在不同问题上的表现。
二、倒立单摆
滑动平均数组是一种通过计算数据序列中连续子序列(窗口)的平均值来生成的数组。它通常用于平滑时间序列数据或信号,以减少随机波动和噪声的影响,从而更容易观察和分析数据的长期趋势或周期性模式。
在滑动平均数组的计算过程中,随着窗口在数据序列上滑动,每个窗口内的数据点都会被赋予一个平均值。这个平均值是窗口内所有数据点值的总和除以窗口大小。例如,如果数据序列是
[2, 4, 6, 8, 10, 12, 14, 16],窗口大小为3,那么滑动平均数组的计算过程如下:
- 第一个窗口包含
[2, 4, 6],其平均值为(2 + 4 + 6) / 3 = 4。- 第二个窗口包含
[4, 6, 8],其平均值为(4 + 6 + 8) / 3 = 6。- 第三个窗口包含
[6, 8, 10],其平均值为(6 + 8 + 10) / 3 = 8。- 以此类推,直到覆盖整个数据序列。
最终得到的滑动平均数组将是
[4, 6, 8, 10, 12, 14, 16]。这个新数组展示了原始数据序列的平滑版本,其中每个元素都是相应窗口内数据点的平均值。滑动平均数组的长度通常比原始数据序列短,因为它排除了边界上无法完全填充窗口的部分。此外,滑动平均数组可以帮助识别数据中的模式,例如趋势、周期性和异常值,因此在数据分析和信号处理中非常有用。
Q:滑动平均数组为什么展示了原始数据的平滑趋势呢?
主要是因为它通过计算数据点的局部平均值来减少随机波动和短期噪声的影响。以下是滑动平均数组实现数据平滑的几个关键原因:
局部平均:滑动平均通过对数据序列中连续的子序列(即窗口)求平均值,使得每个数据点的值受到其邻近点的影响。这种局部平均减少了单个异常值或极端波动对整体趋势的影响。
噪声减少:在时间序列数据中,常常包含一些随机的、无关紧要的波动,这些波动可能会掩盖数据的真实趋势。滑动平均通过平滑这些波动,使得重要的趋势和模式更加明显。
趋势增强:滑动平均强化了数据中的长期趋势。由于短期波动被平滑掉,因此长期趋势或周期性模式更容易被观察到。
边缘效应处理:在计算滑动平均时,通常会对数据序列的边缘进行特殊处理,比如通过补零或其他方法来确保窗口在数据的开始和结束位置也能被正确计算。这样可以避免由于边缘数据点不足而导致的计算偏差。
数据可视化:滑动平均数组通常用于数据可视化,它可以帮助我们更清晰地看到数据随时间的变化趋势,尤其是在面对复杂或嘈杂的数据时。
总的来说,滑动平均数组通过对原始数据进行局部平均处理,减少了数据的波动,使得数据的主要趋势和模式更加突出,从而帮助我们更好地理解和分析数据。
# 导入所需的库和模块
import random #生成伪随机数 伪随机数是通过确定性的算法计算得到的,这些算法基于一个或多个初始值(种子)。
import gym
import numpy as np #支持大量的维度数组和矩阵运算
from tqdm import tqdm #用于在命令行中显示进度条,非常适合在循环中使用,以提供用户友好的进度反馈。
import torch #一个开源的机器学习库,基于Torch,用于计算机视觉和自然语言处理等应用。
import torch.nn.functional as F #这是PyTorch中的一个模块,包含了一系列用于构建神经网络的函数,如激活函数、池化函数等。
import torch.nn as nn #这是PyTorch中的一个模块,提供了构建神经网络所需的类和方法,如层、损失函数和优化器。
from torch.optim import Adam #从PyTorch库中的optim模块导入Adam优化器类
# Adam是一种自适应学习率的优化算法,它结合了动量(Momentum)和RMSprop两种优化算法的优点。
# Adam优化器会根据参数的梯度和历史信息,动态调整每个参数的学习率,这使得它在许多深度学习任务中非常有效,尤其是在处理大规模数据集和复杂模型时。
import argparse #这是Python的标准库之一,用于编写用户友好的命令行接口,解析命令行参数和选项。
from collections import deque # 这是Python的标准库之一,提供了一个双端队列数据结构,可以从两端快速添加和删除元素,非常适合实现队列和栈。
import matplotlib.pyplot as plt #这是matplotlib库的一部分,提供了一个类似于MATLAB的绘图系统,用于创建和展示图表。
from matplotlib.animation import FuncAnimation #用于创建动画# 定义经验回放池类
class ReplayBuffer:# 初始化方法,设置缓冲区的最大容量def __init__(self, capacity):self.buffer = deque(maxlen=capacity)# 添加经验到回放池的方法def add(self, state, action, reward, next_state, done):# 这个方法的作用是将一条新的经验和数据添加到经验回放池中。# state(当前状态)、action(采取的动作)、reward(获得的奖励)、next_state(下一个状态)和done(是否结束的标志),self.buffer.append((state, action, reward, next_state, done))# 从回放池中采样指定数量的经验的方法# batch_size表示希望从回放池抽取的经验数量def sample(self, batch_size):# 随机抽取不重复的batch_size个经验,放到trans这个元组内transitions = random.sample(self.buffer, batch_size)state, action, reward, next_state, done = zip(*transitions)# 这行代码使用zip函数和解包操作*将transitions列表中的每个经验元组拆分成单独的序列。# zip函数将相同位置的元素从不同的序列或可迭代对象中聚集在一起,形成一个元组的迭代器。return np.array(state), action, reward, np.array(next_state), done# 返回一个包含五个元素的元组,其中包含了转换后的数据。# np.array(state)和np.array(next_state)将状态和下一个状态的列表转换为NumPy数组,NumPy数组在进行科学计算和深度学习操作时更加高效。# 而action和done是直接从经验元组中提取的列表。# 这些数据将被用于后续的神经网络训练,其中状态和下一个状态作为输入,动作作为输出,奖励用于评估动作的好坏,done标志用于确定是否需要更新Q值。# 返回回放池中经验数量的方法def __len__(self):return len(self.buffer)# 定义滑动平均函数
# 滑动平均是一种常用的数据平滑技术,可以减少短期波动的影响,更清晰地展示数据的长期趋势。
def moving_average(a, window_size):cumulative_sum = np.cumsum(np.insert(a, 0, 0)) # 数组a的开头插入0,为了处理窗口开始的数据middle = (cumulative_sum[window_size:] - cumulative_sum[:-window_size]) / window_size# middle 是中间窗口的平均值r = np.arange(1, window_size - 1, 2)#奇数索引,步长是2 r这个数组将用于计算窗口开始和结束部分的累积和的权重。begin = np.cumsum(a[:window_size - 1])[::2] / r # 偶数索引# 分别求奇数和偶数索引的累积和是为了处理滑动窗口边缘的情况。end = (np.cumsum(a[:-window_size:-1])[::2] / r)[::-1]return np.concatenate((begin, middle, end))# 定义参数配置函数
def define_args():# define_args 函数使得用户可以通过命令行灵活地设置 DQN 算法的参数,而不需要修改代码本身。parser = argparse.ArgumentParser(description='DQN parametes settings')# 设置命令行参数parser.add_argument('--batch_size', type=int, default=64, help='batch size') # 样本批次大小parser.add_argument('--lr', type=float, default=2e-3, help='Learning rate for the net.') # 学习率,控制权重更新的步长parser.add_argument('--num_episodes', type=int, default=500, help='the num of train epochs') # 训练周期数parser.add_argument('--seed', type=int, default=0, help='Random seed.') # 随机种子用于确保实验的可重复性# 通过设置相同的随机种子,可以在不同的运行中获得相同的随机数序列。parser.add_argument('--gamma', type=float, default=0.98, help='the discount rate') # 折扣因子,权衡即时奖励和未来奖励# 较高的折扣因子意味着未来奖励被赋予更大的权重,而较低的折扣因子则更注重即时奖励。parser.add_argument('--epsilon', type=float, default=0.01, help='the epsilon rate') # greed策略的ε# 较小的ε值意味着智能体更倾向于利用,而较大的ε值则鼓励探索(随机。parser.add_argument('--target_update', type=int, default=10, help='the frequency of the target net') # 目标网络更新频率# 目标网络更新频率决定了多久更新一次用于计算目标Q值的网络。定期更新目标网络有助于稳定学习过程。parser.add_argument('--buffer_size', type=int, default=10000, help='the size of the buffer')parser.add_argument('--minimal_size', type=int, default=500, help='the minimal size of the learning') # 最小学习尺寸# 最小学习尺寸指定了经验回放池中必须存储的最小经验数量,只有达到这个数量后,智能体才能开始从经验中学习。parser.add_argument('--display_frequency', type=int, default=100, help='The frequency of displaying the cartpole image during training') # 显示频率# 显示频率决定了在训练过程中多久显示一次环境的图像。这有助于观察智能体的行为和学习进度。parser.add_argument('--env_name', type=str, default="CartPole-v0", help='the name of the environment') # 环境名称# 环境名称指定了智能体将要交互的环境。在这个例子中,使用的是OpenAI Gym提供的CartPole环境。# 解析命令行参数args = parser.parse_args()return args# 定义Q网络的神经网络结构
class Qnet(nn.Module): # 实现深度Q网络(DQN)算法中的 Q 函数。# 初始化方法,设置网络层def __init__(self, state_dim, hidden_dim, action_dim):# state_dim:状态空间的维度,即每个状态向量的元素数量。# hidden_dim:隐藏层的大小,即隐藏层中的神经元数量。# action_dim:动作空间的维度,即可供智能体选择的动作数量。super(Qnet, self).__init__()# 这行代码调用了父类nn.Module的构造函数,这是初始化继承自nn.Module的类的必要步骤。# 这样做可以确保Qnet类正确地继承了所有必要的属性和方法。self.layer = nn.Sequential(# 使用nn.Sequential容器创建了一个顺序模型,它将按顺序包含两个全连接层(nn.Linear)和一个激活函数(nn.ReLU)。nn.Linear(state_dim, hidden_dim),# 第一个全连接层。nn.Linear(state_dim, hidden_dim) 创建了一个线性层,它将状态向量(s)映射到隐藏层。# state_dim 是输入特征的数量,hidden_dim 是输出特征的数量(即隐藏层的大小)。nn.ReLU(),# 激活函数:nn.ReLU()是一个非线性激活函数,用于增加网络的表达能力。# ReLU函数计算方式为max(0, x),它将所有负值置为0,而保持正值不变。# 这种非线性变换有助于网络学习复杂的模式。nn.Linear(hidden_dim, action_dim)# 第二个全连接层:# 第二个 nn.Linear 层将隐藏层的输出映射到动作空间。# 这个层的输入特征数量是 hidden_dim,输出特征数量是 action_dim。每个输出对应于一个可能的动作的Q值。)# 前向传播方法def forward(self, s):s = self.layer(s)return s# 经过网络处理后的输出数据。# 在 DQN 算法中,这个输出通常是一个 Q 值向量,表示在给定状态下采取每个可能动作的预期效用。# 定义DQN算法的主要类
class DQN:# 初始化方法,设置算法的参数和网络def __init__(self, args):self.args = args #将传入的参数 args 保存为类的成员变量,以便在类的其他方法中使用。self.hidden_dim = 128 # 隐藏层大小self.batch_size = args.batch_size # 从 args 中获取批次大小,并保存为类的成员变量。self.lr = args.lrself.gamma = args.gammaself.epsilon = args.epsilonself.target_update = args.target_updateself.display_frequency = args.display_frequencyself.num_episodes = args.num_episodesself.minimal_size = args.minimal_sizeself.count = 0 # 计数器,记录训练步数self.env = gym.make(args.env_name)# 创建一个 OpenAI Gym 环境实例,并保存为类的成员变量。self.env.seed(args.seed) #为环境设置随机种子,以确保实验的可重复性。torch.manual_seed(args.seed) #为 PyTorch 设置随机种子,以确保实验的可重复性。self.replay_buffer = ReplayBuffer(args.buffer_size) #创建一个经验回放池实例,并保存为类的成员变量。self.state_dim = self.env.observation_space.shape[0] #获取环境观测空间的维度,并保存为类的成员变量。self.action_dim = self.env.action_space.n # 获取环境动作空间的大小,并保存为类的成员变量。self.q_net = Qnet(self.state_dim, self.hidden_dim, self.action_dim) # 创建一个 Q 网络实例,并保存为类的成员变量。self.target_q_net = Qnet(self.state_dim, self.hidden_dim, self.action_dim) # 创建一个目标 Q 网络实例,并保存为类的成员变量。self.optimizer = Adam(self.q_net.parameters(), lr=self.lr)# 创建一个 Adam 优化器实例,并将其与 Q 网络的参数关联。self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#根据是否有可用的 CUDA 设备,设置网络和优化器运行的设备。# 选择动作的方法,实现epsilon-greedy策略def select_action(self, state):#定义了一个方法,用于根据当前状态选择动作。if np.random.random() < self.epsilon:# 如果随机数小于 epsilon 值,执行探索动作。action = np.random.randint(self.action_dim)else:state = torch.tensor([state], dtype=torch.float32).to(self.device)# 将当前状态转换为PyTorch张量,并移动到指定的设备。action = self.q_net(state).argmax().item()return action# 更新网络权重的方法 使用采样的数据更新 Q 网络。def update(self, transition):#transition,这个参数是一个包含一批经验的元组或列表,其中包括状态、动作、奖励、下一个状态和完成标志。states, actions, rewards, next_states, dones = transition # 解包操作将 transition 中的数据分别赋值states = torch.tensor(states, dtype=torch.float32).to(self.device)actions = torch.tensor(actions, dtype=torch.long).to(self.device)rewards = torch.tensor(rewards, dtype=torch.float32).to(self.device)next_states = torch.tensor(next_states, dtype=torch.float32).to(self.device)dones = torch.tensor(dones, dtype=torch.float32).to(self.device)q_values = self.q_net(states).gather(1, actions.unsqueeze(1)).squeeze(1)# 通过 Q 网络对当前状态 states 进行前向传播,计算每个状态的所有可能动作的 Q 值。# 然后使用 gather 方法根据 actions 选择对应的 Q 值。actions.unsqueeze(1) 是为了增加动作张量的维度,使其可以被 gather 方法正确处理。# squeeze(1) 是为了移除结果张量中不必要的单一维度。max_next_q_values = self.target_q_net(next_states).max(1)[0].detach()# 使用目标 Q 网络对下一个状态 next_states 进行前向传播,并找到每个状态的最大 Q 值。max(1) 是沿着指定维度(这里是维度 1)寻找最大值的操作。# [0] 是获取最大值的索引,detach() 是为了在计算梯度时不计算这部分的梯度,因为目标 Q 值不应该直接影响 Q 网络的更新。q_targets = rewards + self.gamma * max_next_q_values * (1 - dones)# 根据奖励 rewards、折扣因子 self.gamma 和下一个状态的最大 Q 值 max_next_q_values 计算目标 Q 值 q_targets。# 如果 dones 为真(表示回合结束),则不计算未来奖励的折现值。loss = F.mse_loss(q_values, q_targets)# 使用均方误差损失函数 F.mse_loss 计算预测的 Q 值 q_values 和目标 Q 值 q_targets 之间的损失。self.optimizer.zero_grad()# 清除优化器中的梯度信息,这是在执行反向传播和参数更新之前的一个必要步骤。loss.backward()# 执行损失函数的反向传播,计算 Q 网络参数的梯度。self.optimizer.step()#根据计算出的梯度更新 Q 网络的参数。这一步是优化过程的核心,它使用之前定义的优化算法(如 Adam)来调整网络权重。# 根据经验回放池更新策略的方法# 在经验回放池中的样本数量达到一定的最小大小时,从池中采样一批样本,并使用这些样本来更新Q网络的策略。def update_policy(self):if len(self.replay_buffer) > self.minimal_size:#self.minimal_size 是一个预先设定的阈值。transitions = self.replay_buffer.sample(self.batch_size)# 这行代码调用经验回放池的 sample 方法来随机采样 self.batch_size 个样本。self.update(transitions)# 这行代码调用 DQN 类的 update 方法,并将采样出的经验 transitions 作为参数传递给它。# update 方法将使用这些经验来计算损失,并通过反向传播和优化器来更新 Q 网络的参数。# 运行训练的方法def run(self):return_list = [] # 初始化一个空列表 return_list,用于存储每个训练回合的累积回报。for episode in tqdm(range(self.num_episodes), desc='Training'):# 使用 tqdm 库创建一个进度条,并通过它遍历指定数量的训练回合 self.num_episodes。# desc='Training' 参数设置进度条的描述为 "Training"。episode_return = 0 # 为当前回合初始化累积回报 episode_return。state = self.env.reset() # 调用环境的 reset 方法来重置环境,获取初始状态。done = False # 初始化一个标志 done,用于判断训练回合是否结束。while not done: # 当回合未结束时,执行循环。action = self.select_action(state) # 调用 select_action 方法根据当前状态选择一个动作。next_state, reward, done, _ = self.env.step(action) # 执行选择的动作,获取下一个状态、奖励、回合结束标志和一些额外信息(这里用 _ 忽略)。self.replay_buffer.add(state, action, reward, next_state, done)# 将当前回合的经验(状态、动作、奖励、下一个状态和结束标志)添加到经验回放池。episode_return += reward # 更新当前回合的累积回报。state = next_state # 更新当前状态为下一个状态。if self.count % self.display_frequency == 0 and len(self.replay_buffer) > self.minimal_size:# 如果当前训练步数 self.count 是显示频率 self.display_frequency 的倍数,并且经验回放池中的样本数量超过最小大小 self.minimal_size,则执行下面的代码块。screen = self.env.render(mode='rgb_array') # 获取当前环境的屏幕图像。plt.imshow(screen)# 使用 matplotlib 库显示屏幕图像。plt.axis('off') # 关闭坐标轴。plt.title(f'Episode: {episode}, Step: {self.count}, Return: {episode_return}')# 设置图像的标题,显示当前回合、步数和累积回报。plt.pause(0.001)# 暂停一小段时间,以便观察图像。self.count += 1 #增加训练步数。if done: # 如果回合结束,跳出循环。breakreturn_list.append(episode_return) # 将当前回合的累积回报添加到 return_list 列表中。self.update_policy() # 调用 update_policy 方法更新 Q 网络的策略。self.plot_reward(return_list) #调用 plot_reward 方法绘制累积回报随训练回合变化的曲线。# 绘制奖励曲线的方法 它用于绘制训练过程中累积奖励的曲线以及平滑后的累积奖励曲线。def plot_reward(self, reward_list): # 这行代码定义了一个名为 plot_reward 的方法,它接受一个参数 reward_list,这个参数是一个包含每个训练回合累积奖励的列表。episodes_list = list(range(1, len(reward_list) + 1))# 创建一个列表 episodes_list,它包含从 1 到 reward_list 长度加 1 的整数序列。这个列表用于 X 轴的值,表示每个训练回合的索引。plt.plot(episodes_list, reward_list)# 使用 matplotlib.pyplot 库的 plot 函数绘制一个线图,X 轴是 episodes_list(训练回合索引),Y 轴是 reward_list(每个回合的累积奖励)。# plt.xlabel('Episodes')# 设置 X 轴的标签为 "Episodes"。# plt.ylabel('Returns') # 设置 Y 轴的标签为 "Returns",这里的 "Returns" 指的是每个训练回合的累积奖励。# plt.title('DQN on {}'.format(self.args.env_name)) # 设置图表的标题,格式为 "DQN on [环境名称]",其中 [环境名称] 被 self.args.env_name 的值所替换。## plt.show()mv_return = moving_average(reward_list, 9)# 调用 moving_average 函数计算 reward_list 的滑动平均值,窗口大小为 9。这个平滑后的累积奖励列表被存储在变量 mv_return 中。plt.plot(episodes_list, mv_return) # 再次使用 plot 函数绘制一个线图,这次 Y 轴是平滑后的累积奖励 mv_return。plt.xlabel('Episodes')plt.ylabel('Returns')plt.title('DQN on {}'.format(self.args.env_name))plt.show()# 主函数,运行DQN算法
if __name__ == '__main__':args = define_args()# 调用 define_args 函数,该函数使用 argparse 库来定义和解析命令行参数。解析后的参数被存储在变量 args 中。model = DQN(args) # 使用解析得到的参数 args 创建 DQN 类的一个实例,并将其存储在变量 model 中。model.run()# 调用 model 实例的 run 方法来启动训练过程。这个方法将执行整个深度Q网络算法的训练,包括与环境的交互、收集经验、更新网络参数等。
三、利用gym创建自己的环境
1. 对自己环境进行注册
D:\anaconda\Lib\site-packages\gym\envs
在该路径中的__init__.py 中添加
# 注册环境
gym.register(id='UWANEnv-v0', # 环境IDentry_point='gym.envs.myenv:UWANEnv', # 入口点,路径timestep_limit=500, # 可选,环境的最大步数reward_threshold=200.0 # 可选,奖励阈值
)
2. 放入库中
D:\anaconda\Lib\site-packages\gym\envs 路径下新建一个文件夹 myenv
D:\anaconda\Lib\site-packages\gym\envs\myenv 其中myenv包括两个文件
相关文章:
【强化学习实践】Gym+倒立单摆+创建自己的环境
一、Gym Gym是OpenAI开发的一个强化学习算法测试环境集合包。Gym提供了多种标准的环境,包括经典的游戏(如Atari游戏)、机器人模拟任务以及其他各种类型的问题,供开发者测试和训练强化学习智能体。在Gym环境中,开发者可…...
实习记录小程序|基于SSM的实习记录小程序设计与实现(源码+数据库+文档)
知识管理 目录 基于SSM的习记录小程序设计与实现 一、前言 二、系统设计 三、系统功能设计 1、小程序端: 2、后台 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕…...
Netty NioEventLoop详解
文章目录 前言类图主要功能NioEventLoop如何实现事件循环NioEventLoop如何处理多路复用Netty如何管理Channel和Selector管理Channel管理Selector注意事项 前言 Netty通过事件循环机制(EventLoop)处理IO事件和异步任务,简单来说,就是通过一个死循环&…...

互联网大厂常见面试题目
1. CPU 的内存结构分为哪几层,分别是用于放什么数据的,如果一个函数里面有全局变量,局部变量和静态变量数据是如何存放的 2.C多态的实现原理是什么,父类是如何找到子类的虚函数实现的 3.操作系统中的虚拟内存实现机制是什么&…...

TechTool Pro for Mac v19.0.3中文激活版 硬件监测和系统维护工具
TechTool Pro for Mac是一款专为Mac用户设计的强大系统维护和故障排除工具。它凭借全面的功能、高效的性能以及友好的操作界面,赢得了广大用户的信赖和好评。 软件下载:TechTool Pro for Mac v19.0.3中文激活版 作为一款专业的磁盘和系统维护工具&#x…...

Linux-docker安装数据库redis
1.拉取redis镜像 docker pull redis # 下载最新的redis版本 docker pull redis:版本号 # 下载指定的redis版本ps:我这是已经下载最新版本的redis 2.查看redis镜像 docker images3.创建挂在路径并授权 mkdir -p /usr/local/redis/data mkdir -p /usr/local…...

LisJson解析配置表
每日一句:南来北往,不辜负生活,不迷失方向 [{ "ID": 0, "Name": "SmallPeople", "InitHealth": 100, "CostGold": 0, "MoveSpeed": 1…...
)
剑指offer10.斐波那契数列(动态规划)
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N))。斐波那契数列的定义如下: F(0) 0, F(1) 1 F(N) F(N - 1) F(N - 2), 其中 N > 1. 斐波那契数列由 0 和 1 开始&#x…...

HarmonyOS实战开发-WebSocket的使用。
介绍 本示例展示了WebSocket的使用,包括客户端与服务端的连接和断开以及客户端数据的接收和发送。 WebSocket连接:使用WebSocket建立服务器与客户端的双向连接,需要先通过createWebSocket方法创建WebSocket对象,然后通过connect…...
【前缀合】Leetcode 连续数组
题目解析 525. 连续数组 寻找一个子数组,这个子数组中包含相同数目的0和1,但是这个子数组需要最长的 算法讲解 只需在[0,i]寻找一段区间使得这一段区间的和也等于sum即可 细节问题:1. 这里的哈希表的value存的是下标,因为需要找…...

一些优雅的算法(c++)
求最大公约数:辗转相除法 int gcd(int a,int b){return b0?a:gcd(b,a%b); }求最小公倍数:两整数之积除以最大公约数 int lcm(int a, int b){return a*b / gcd(a, b); }十进制转n进制: char get(int x){if(x<9){return x0;}else{return…...
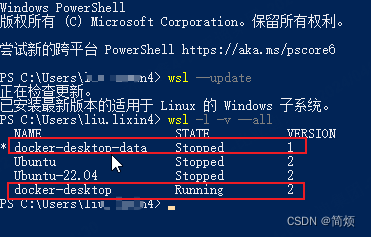
Docker Desktop修改镜像存储路径 Docker Desktop Start ... 卡死
1、CMD执行wsl -l -v --all 2、Clean / Purge data 3、导出wsl子系统镜像: wsl --export docker-desktop D:\docker\wsl\distro\docker-desktop.tar wsl --export docker-desktop-data D:\docker\wsl\data\docker-desktop-data.tar4、删除现有的wsl子系统: wsl -…...

小型企业网络安全指南
许多小型企业刚刚起步,没有大公司所拥有的相同资源来保护其数据。他们不仅可能没有资金来支持多样化的安全计划,而且也可能没有人力或时间。 网络犯罪分子知道小型企业缺乏这些资源,并利用这些资源来谋取利益。遭受网络攻击后,小…...
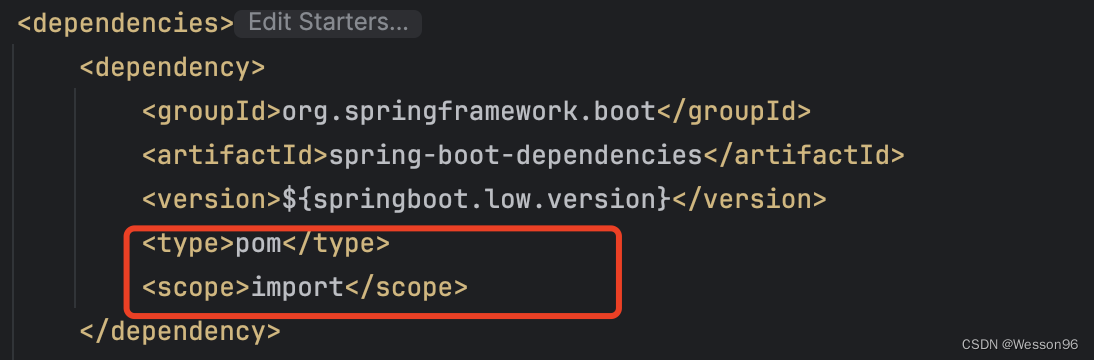
springboot相关报错解决
Caused by: java.lang.ClassNotFoundException: 目录 Caused by: java.lang.ClassNotFoundException: org.springframework.context.event.GenericApplicationListener spring-boot-dependencies:jar:2.1.9.RELEASE was not found org.springframework.context.event.Generi…...

python 中 from import, __name__, __all__, __init__.py 作用,python的模块和导入包
from import 即类似于其他语言一样,是为了将别人写好的 .py 文件引入,并用于自己使用 例如我在一个.py 文件中写了很多用于计数学计算的方法,当别人想要调用我写好的这一套方法时 就需要先 from 我写的文件或其他人写好的文件(py…...

Composer安装与配置详解
目录 第一章:Composer简介 1.1 什么是Composer? 1.2 Composer与传统的依赖管理工具的区别 1.3 Composer的发展历程 1.4 本章小结 第二章:Composer安装 2.1 全局安装与项目内安装 2.1.1 全局安装 安装步骤 2.1.2 项目内安装 安装步骤 2.2 不同操作系统下的安装方…...

A5 STM32_HAL库函数 之 CAN通用驱动程序所有函数的介绍及使用
A5 STM32_HAL库函数 之 CAN通用驱动程序所有函数的介绍及使用 1 CAN通用驱动程序所有函数预览1.1 HAL_CAN_Init1.2 HAL_CAN_ConfigFilter1.3 HAL_CAN_DeInit1.4 HAL_CAN_MspInit1.5 HAL_CAN_MspDeInit1.6 HAL_CAN_Transmit1.7 HAL_CAN_Transmit_IT1.8 HAL_CAN_Receive1.9 HAL_C…...

python如何判断图片为黑白还是彩色
基本原理 灰度图分两种情况: 单通道的图片 RGB 三通道的图片,但是每个通道的值相等 对于单通道的图片只需要判断图片的通道值是否为1 对于RGB模式的图片,情况稍稍复杂些。理论上只需判断RGB三个通道的值是否相等,但是现实中灰度…...
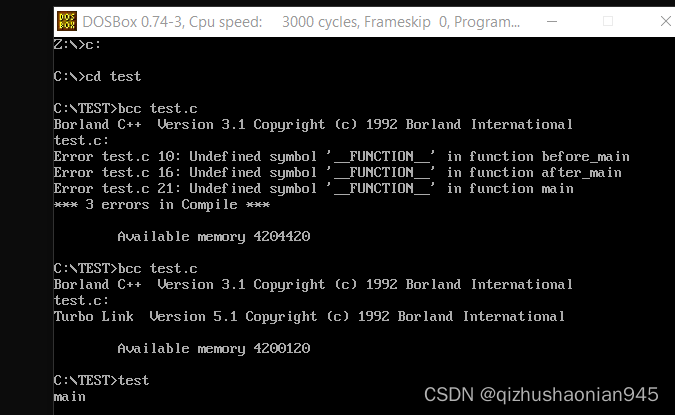
C语言进阶课程学习记录-main函数与命令行参数
C语言进阶课程学习记录-main函数与命令行参数 main函数验证以下4中定义是否正确实验-main的返回值cmd窗口 实验-main的输入参数cmd窗口 在main函数执其执行的函数实验-程序执行的第一个函数gcc编译器cmd窗口bcc编译器 小结 本文学习自狄泰软件学院 唐佐林老师的 C语言进阶课程&…...

Utilize webcam to capture photo with camera
1. Official Guide& my github Official course my github 2. Overcome Webcam js Error in Chrome: Could not access webcam link 直接把代码拷贝到本机的下述目录下 To ignore Chrome’s secure origin policy, follow these steps. Navigate to chrome://flags/#un…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

12.找到字符串中所有字母异位词
🧠 题目解析 题目描述: 给定两个字符串 s 和 p,找出 s 中所有 p 的字母异位词的起始索引。 返回的答案以数组形式表示。 字母异位词定义: 若两个字符串包含的字符种类和出现次数完全相同,顺序无所谓,则互为…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

Go语言多线程问题
打印零与奇偶数(leetcode 1116) 方法1:使用互斥锁和条件变量 package mainimport ("fmt""sync" )type ZeroEvenOdd struct {n intzeroMutex sync.MutexevenMutex sync.MutexoddMutex sync.Mutexcurrent int…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...