TR4 - Transformer中的多头注意力机制
目录
- 前言
- 自注意力机制
- Self-Attention层的具体机制
- Self-Attention 矩阵计算
- 多头注意力机制
- 例子解析
- 代码实现
- 总结与心得体会
前言
多头注意力机制可以说是Transformer中最主要的模块,没有之一。这次我们来仔细分析一下注意力机制与多头注意力机制。
自注意力机制
在Transformer模型中,输入的文本序列经过输入处理转换为一个向量的序列,然后就会被送到第1层的编码器,第一层的编码器的输出同样是一个向量的序列,再送到下一层编码器。
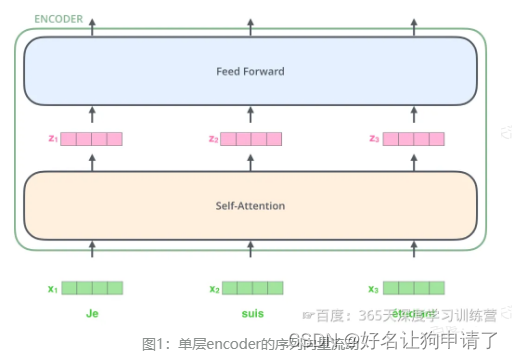
通过上图可以发现,向量在层间流动时,向量的数量和维度都是不变的。单层编码器接收到上一层的输入,然后进入自注意力层计算,然后再输入到前馈神经网络中,最后得到每个位置的新向量。
Self-Attention层的具体机制
例如想要翻译的句子为:“The animal didn’t cross the street because it was too tired”。
句子中的it是一个代词,想要知道它具体代指什么,对模型来说并不容易。通过引用Self-Attention机制,模型就会最终计算出it代指的是animal。同样的,当模型处理句子中其他词时,Self-Attention机制也可以让模型不仅仅关注当前位置的词,还关注句中其它位置相关的词,进而更好地理解当前位置的词。
通过一个简单的例子来解释自注意力机制的计算过程:假设一句话为"Thinking Machines"。
自注意力会计算:Thinking-Thinking、Thinking-Machines、Machines-Thinking、Machines-Machines共2的2次方种组合。
具体的计算过程如下:
- 1 对输入编码器的词向量进行线性变换,得到Query、Key和Value向量。变换的过程是通过词向量分别和3个参数矩阵相乘,参数矩阵可以通过模型训练学习到。

- 2 计算
Attention Score(注意力分数 )。
假如我们现在计算Thinking的Attention Score,需要根据Thinking对应的词向量,对句子中的其他词向量都计算一个分数,这些分数决定了在编码Thinking这个词时,对句子中其它位置的词向量的权重。
Attention Score 是根据Thinking对应的Query向量和其他位置的每个词的Key向量进行点积得到的。Thinking的第一个Attention Score 就是q1和k1的点积,第二个分数是 q 1 q_1 q1和 k 2 k_2 k2的点积。
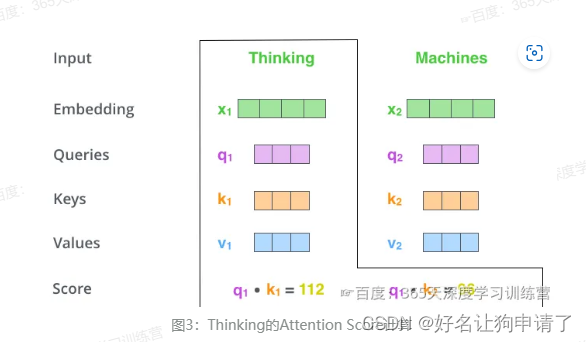
- 3 把得到的每个分数除以 d k \sqrt{d_k} dk。 d k d_k dk是Key向量的维度。这一步的目的是为了在反向传播时,求梯度时更加稳定。
s c o r e 11 = q 1 ⋅ k 1 d k score_{11} = \frac{q_1 \cdot k_1}{\sqrt{d_k}} score11=dkq1⋅k1
s c o r e 12 = q 1 ⋅ k 2 d k score_{12} = \frac{q_1 \cdot k_2}{\sqrt{d_k}} score12=dkq1⋅k2
- 4 然后把分数经过一个Softmax函数,通过Softmax将分数归一化,使分数都是正数并且加起来等于1。
s c o r e 11 = s o f t m a x ( s c o r e 11 ) score_{11} = softmax(score_{11}) score11=softmax(score11)
s c o r e 12 = s o f t m a x ( s c o r e 12 ) score_{12} = softmax(score_{12}) score12=softmax(score12)
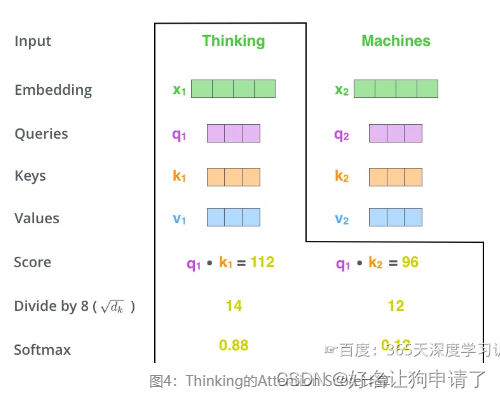
- 5 得到每个词向量的分数后,将分数分别与对应的Value向量相乘。对于分数高的位置,相乘后的值就越大,我们把更多的注意力放到了它们的身上;对于分数低的位置,相乘后的值就越小,这些位置的词可能就相关性不大。
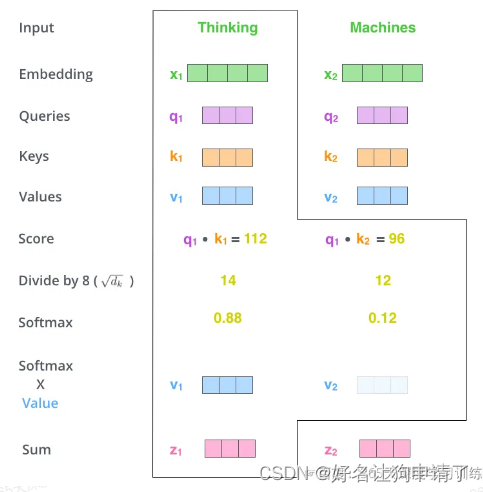
- 6 把第5步得到的Value向量相加,就得到了Self-Attention在当前位置对应的输出
z 1 = v 1 × s c o r e 11 + v 2 × s c o r e 12 z_1 = v_1 \times score_{11} + v_2 \times score_{12} z1=v1×score11+v2×score12
最后整体看一下Self-Attention计算的全过程
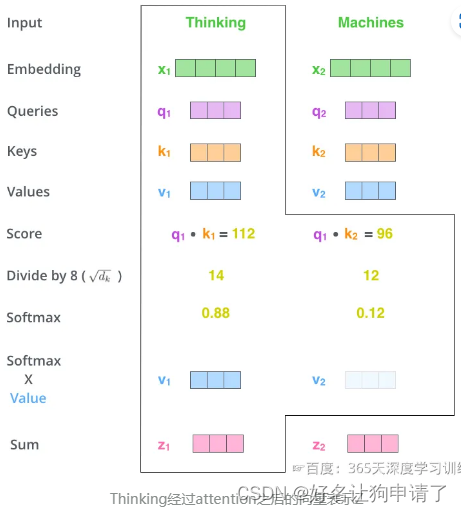
Self-Attention 矩阵计算
具体的实现时,并不会像上面那样阶段分明的分成6个步骤,而是将向量合并到一起,进行矩阵运算。
X 1 X_1 X1: 第一个单词的输入向量
X 2 X_2 X2: 第二个单词的输入向量
X = [ X 1 ; X 2 ] X = [X_1;X_2] X=[X1;X2] 将两个向量合并为矩阵
具体来说分为了两步:
-
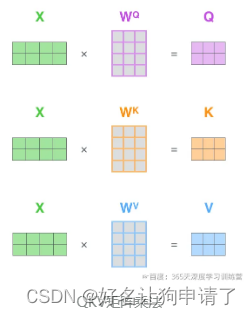
1:计算Query、Key、Value的矩阵。
Q = X W Q Q = XW^Q Q=XWQ:计算Query
K = X W K K = XW^K K=XWK:计算Key
V = X W V V = XW^V V=XWV:计算Value
把所有的词向量放到一个矩阵X中,然后分别和3个权重矩阵 W Q W^Q WQ、 W K W^K WK、 W V W^V WV相乘,得到 Q Q Q、 K K K、 V V V矩阵。矩阵X中的每一行,表示句子中的每一个词的词向量。 Q Q Q、 K K K、 V V V矩阵中的每一行表示Query向量、Key向量、Value向量,向量的维度是 d k d_k dk。
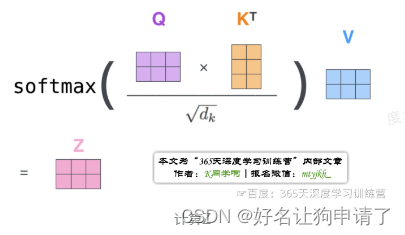
-
2:矩阵计算把上面第2步到第6步压缩为一步,直接得到Self-Attention的输出
Z = s o f t m a x ( Q K T d k ) × V Z = softmax(\frac {QK^T} {\sqrt{d_k}}) \times V Z=softmax(dkQKT)×V
多头注意力机制
Transformer的论文中,通过增加多头注意力机制(一组注意力称为一个Attention Head),进一步完善了Self-Attention。这种机制从如下两个方面增强了Attention层的能力:
-
扩展了模型关注不同位置的能力
在上面的例子中,第一个位置的输出 z 1 z_1 z1包含了句子中其他每个位置的很小一部分信息。但 z 1 z_1 z1仅仅是单个向量,所以可能仅由第1个位置的信息主导了。而当我们翻译句子:
The animal didn't cross the street because it was too tired时,我们不仅希望模型关注到it本身,还希望模型关注到The和animal,甚至关注到tired。 -
多头注意力机制赋予了Attention层多个“子表示空间”
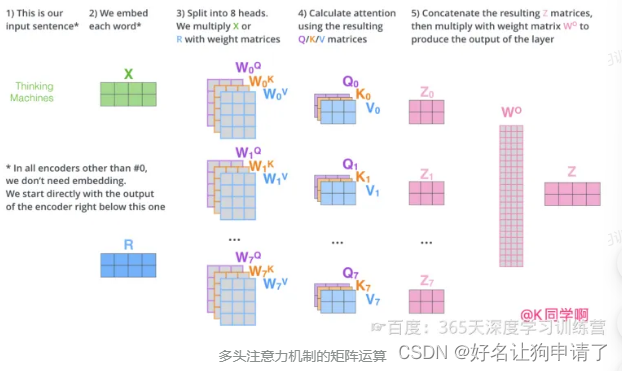
多头注意力机制会有多组 W Q W^Q WQ、 W K W^K WK、 W V W^V WV的权重矩阵,因此可以将 X X X变换到更多种子空间中进行表示 。
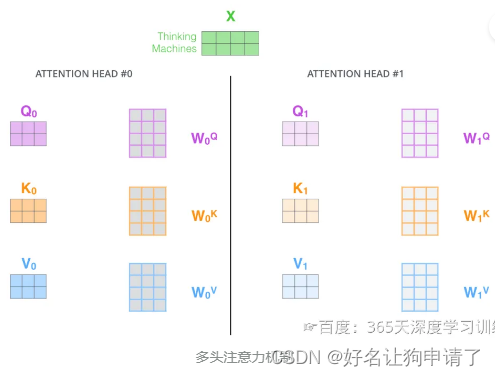
每组注意力设定单独的 W Q W^Q WQ、 W K W^K WK、 W V W^V WV参数矩阵。将输入 X X X与它们相乘,得到多组 Q Q Q、 K K K、 V V V矩阵。接下来把每组的 Q Q Q、 K K K、 V V V计算得到各自的 Z Z Z。
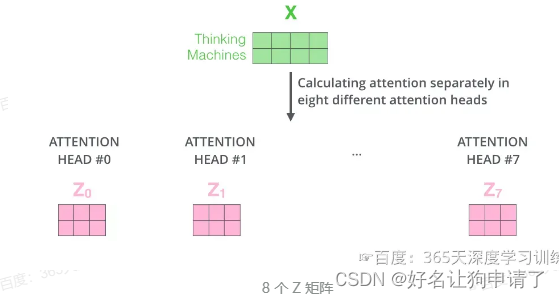
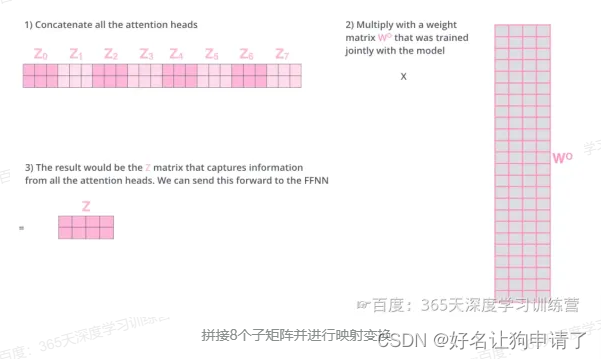
由于前馈神经网络层接收的是1个矩阵(其中每行的向量表示一个词),而不是8个矩阵,所以要直接把8个子矩阵拼接得到一个大矩阵,然后和另一个权重矩阵 W O W^O WO相乘做一次变换,映射到前馈神经网络层所需要的维度。
把多头注意力放到一张图中:
例子解析
再来看一下上面提到的it的例子,不同的Attention Heads对应的it attention了哪些内容。
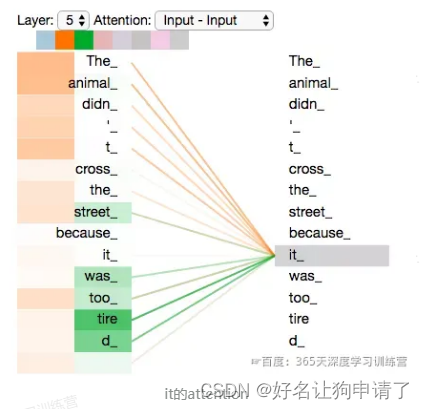
图中绿色和橙色线条分别表示2组不同的Attention Heads。可以看到,当我们编码单词it时,其中一个Attention Head(橙色)最关注的是the animal,另外一个绿色Attention Head关注的是tired。因此在某种意义上,it在模型中的表示,融合了animal和tire的部分表达。
代码实现
class MultiHeadAttention(nn.Module):def __init__(self, hid_dim, n_heads, dropout):super().__init__()self.hid_dim = hid_dimself.n_heads = n_heads# hid_dim必须整除assert hid_dim % n_heads == 0# 定义wqself.w_q = nn.Linear(hid_dim, hid_dim)# 定义wkself.w_k = nn.Linear(hid_dim, hid_dim)# 定义wvself.w_v = nn.Linear(hid_dim, hid_dim)self.fc = nn.Linear(hid_dim, hid_dim)self.do = nn.Dropout(dropout)self.scale = torch.sqrt(torch.FloatTensor([hid_dim//n_heads]))def forward(self, query, key, value, mask=None):# Q与KV在句子长度这一个维度上数值可以不一样bsz = query.shape[0]Q = self.w_q(query)K = self.w_k(key)V = self.w_v(value)# 将QKV拆成多组,方案是将向量直接拆开了# (64, 12, 300) -> (64, 12, 6, 50) -> (64, 6, 12, 50)# (64, 10, 300) -> (64, 10, 6, 50) -> (64, 6, 10, 50)# (64, 10, 300) -> (64, 10, 6, 50) -> (64, 6, 10, 50)Q = Q.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)K = K.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)V = V.view(bsz, -1, self.n_heads, self.hid_dim//self.n_heads).permute(0, 2, 1, 3)# 第1步,Q x K / scale# (64, 6, 12, 50) x (64, 6, 50, 10) -> (64, 6, 12, 10)attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale# 需要mask掉的地方,attention设置的很小很小if mask is not None:attention = attention.masked_fill(mask == 0, -1e10)# 第2步,做softmax 再dropout得到attentionattention = self.do(torch.softmax(attention, dim=-1))# 第3步,attention结果与k相乘,得到多头注意力的结果# (64, 6, 12, 10) x (64, 6, 10, 50) -> (64, 6, 12, 50)x = torch.matmul(attention, V)# 把结果转回去# (64, 6, 12, 50) -> (64, 12, 6, 50)x = x.permute(0, 2, 1, 3).contiguous()# 把结果合并# (64, 12, 6, 50) -> (64, 12, 300)x = x.view(bsz, -1, self.n_heads * (self.hid_dim // self.n_heads))x = self.fc(x)return x
测试一下是否能输出
query = torch.rand(64, 12, 300)
key = torch.rand(64, 10, 300)
value = torch.rand(64, 10, 300)
attention = MultiHeadAttention(hid_dim=300, n_heads=6, dropout=0.1)
output = attention(query, key, value)
print(output.shape)
总结与心得体会
通过对多头注意力机制的学习,有一个让我印象深刻的地方就是,它的多头注意力机制不是像其它模块设计思路一样,对同一个输入做了多组运算,而是将输入切分成不同的部分,每部分分别做了多组运算。由于自然语言处理中,一个单词的词向量往往是很长的,所以这种方式比CV的那种堆叠的方式能减少很多计算量,并且在效果方面不会损失太多。
个人感觉:词向量的不同分组之间的关系有点像计算机视觉中,彩色图像的多个通道,多头注意力机制有点像后面的通道注意力的计算。
相关文章:
TR4 - Transformer中的多头注意力机制
目录 前言自注意力机制Self-Attention层的具体机制Self-Attention 矩阵计算 多头注意力机制例子解析 代码实现总结与心得体会 前言 多头注意力机制可以说是Transformer中最主要的模块,没有之一。这次我们来仔细分析一下注意力机制与多头注意力机制。 自注意力机制…...

three.js跟着教程实现VR效果(四)
参照教程:https://juejin.cn/post/6973865268426571784(作者:大帅老猿) 1.WebGD3D引擎 用three.js (1)使用立方体6面图 camera放到 立方体的中间 like “回” 让贴图向内翻转 (2)使…...
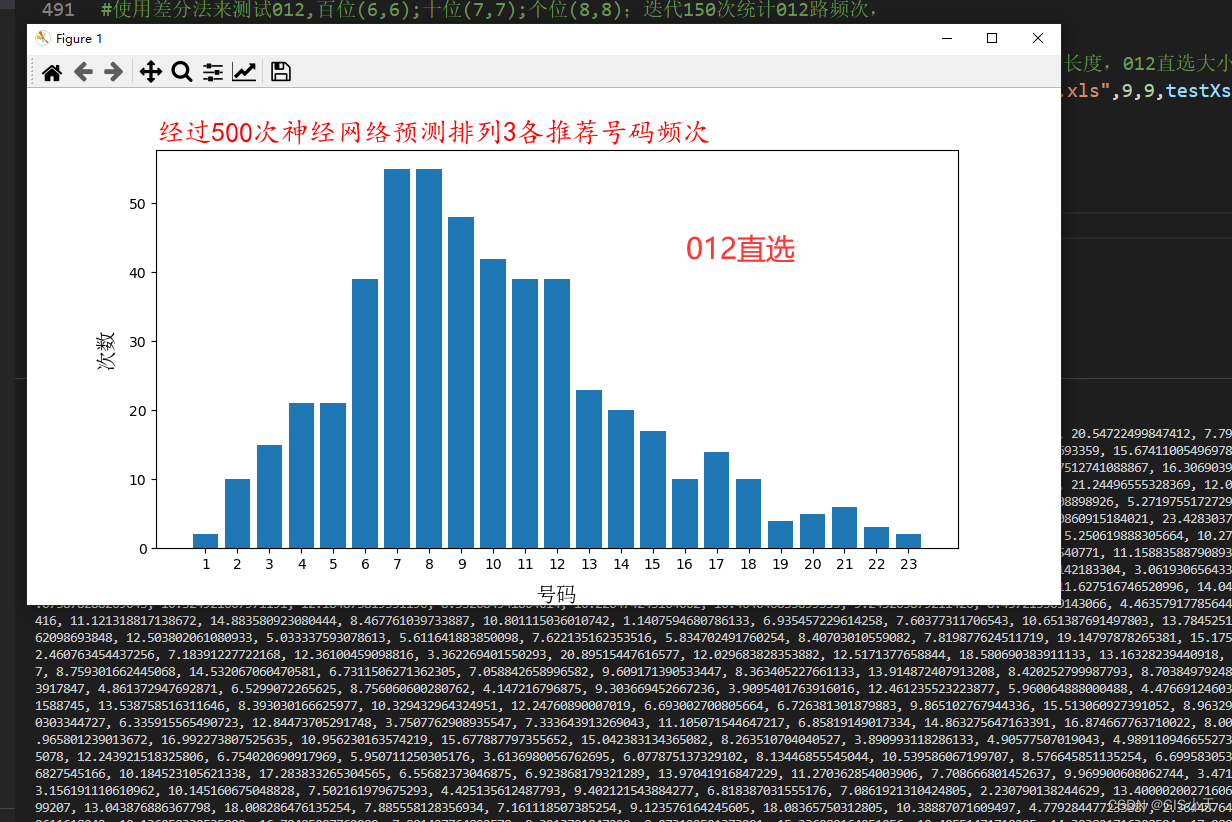
AI预测体彩排3第1弹【2024年4月12日预测--第1套算法开始计算第1次测试】
前面经过多个模型几十次对福彩3D的预测,积累了一定的经验,摸索了一些稳定的规律,有很多彩友让我也出一下排列3的预测结果,我认为目前时机已成熟,且由于福彩3D和体彩排列3的玩法完全一样,我认为3D的规律和模…...

spring 中的控制反转
在Spring框架中,控制反转(IoC,Inversion of Control)是指将对象的创建和管理交给了容器,而不是在应用程序代码中直接创建对象。在传统的编程模式中,应用程序代码通常负责创建对象并管理它们的生命周期&…...

GO并发总是更快吗?
许多开发人员的一个误解是,并发解决方案总是比串行更快,大错特错。解决方案的整体性能取决于许多因素,例如,结构的效率(并发)、可以并行处理的部分以及计算单元的竞争程度。 1. GO调度 线程是操作系统可以执行的最小单元。如果一个进程想要同时执行多个动作,它可以启动…...
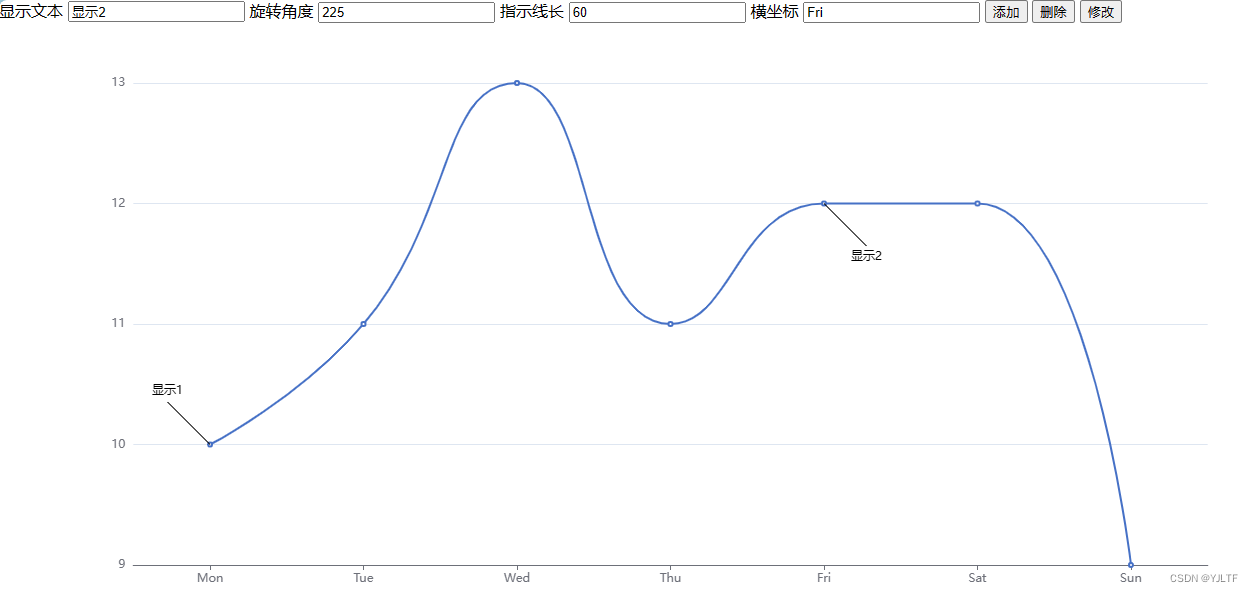
echarts折线图自定义打点标记小工具
由于没研究明白echarts怎么用label和lableLine实现自定义打点标记,索性用markPoint把长方形压扁成线模拟了一番自定义打点标记,记录下来备用。(markLine同理也能实现) 实现代码如下: <!DOCTYPE html> <html…...

【图论】Leetcode 200. 岛屿数量【中等】
岛屿数量 给你一个由 ‘1’(陆地)和 ‘0’(水)组成的的二维网格,请你计算网格中岛屿的数量。 岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。 此外,你可以…...

酒店大厅装水离子雾化壁炉前和装后对比
在酒店大厅装水离子雾化壁炉之前和之后,大厅的氛围和体验会有显著的对比: 装水离子雾化壁炉之前: 传统感:在壁炉安装之前,大厅可能会有传统的装饰或者简单的暖气设备,缺乏现代化的元素。这种传统感可能会…...
城市内涝与海绵城市规划设计中的水文水动力模拟
原文链接:城市内涝与海绵城市规划设计中的水文水动力模拟https://mp.weixin.qq.com/s?__bizMzUzNTczMDMxMg&mid2247601198&idx5&sn35b9e5e3961ea2f190f9742236a7217f&chksmfa820dc9cdf584df97633f64d19bdc3e5f7d1a5a85000c8f040e1953c51b9b39c87b5…...

C++项目实战与经验分享
在编程世界中,C++ 是一种功能强大且灵活的编程语言,广泛应用于系统级编程、游戏开发、嵌入式系统以及高性能计算等领域。本文将分享一个基于C++的图像处理系统项目实战经验,并深入探讨在开发过程中遇到的问题及解决方案。 一、项目概述 本次项目实战的目标是开发一个基于C…...

Day17_学点JavaEE_转发、重定向、Get、POST、乱码问题总结
1 转发 转发:一般查询了数据之后,转发到一个jsp页面进行展示 req.setAttribute("list", list); req.getRequestDispatcher("student_list.jsp").forward(req, resp);2 重定向 重定向:一般添加、删除、修改之后重定向到…...
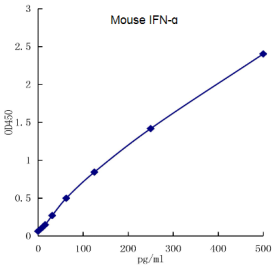
Mouse IFN-α ELISA kit (Quick Test)
干扰素α(IFN-α)是一类由免疫细胞分泌的内源性调节因子,也被称为白细胞干扰素,主要参与响应病毒感染的先天性免疫。 基于结构特征、受体、细胞来源和生物活性的不同,干扰素可被分为Ⅰ、Ⅱ、Ⅲ三种类型,其中…...
AMD Tensile 简介与示例
按照知其然,再知其所以然的认知次序进行 1,下载代码 git clone --recursive https://github.com/ROCm/Tensile.git 2,安装 Tensile cd Tensile mkdir build cd build ../Tensile/bin/Tensile ../Tensile/Configs/rocblas_dgemm_nn_asm_full…...
Rust语言
文章目录 Rust语言一,Rust语言是什么二,Rust语言能做什么?Rust语言的设计使其适用于许多不同的领域,包括但不限于以下几个方面:1. 传统命令行程序:2. Web 应用:3. 网络服务器:4. 嵌入…...

排序算法之冒泡排序
目录 一、简介二、代码实现三、应用场景 一、简介 算法平均时间复杂度最好时间复杂度最坏时间复杂度空间复杂度排序方式稳定性冒泡排序O(n^2 )O(n)O(n^2)O(1)In-place稳定 稳定:如果A原本在B前面,而AB,排序之后A仍然在B的前面; 不…...

js打印页面源码 ,打印选取的容器里的内容,打印指定内容
js打印页面源码 ,打印选取的容器里的内容,打印指定内容 效果 代码 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge&…...

算法练习第五十天|123.买卖股票的最佳时机III、188.买卖股票的最佳时机IV
123. 买卖股票的最佳时机 III 188. 买卖股票的最佳时机 IV 123.买卖股票的最佳时机III class Solution {public int maxProfit(int[] prices) {//dp[i][j] 第i天买卖股票获得的最大利润/**j0不操作j1第一次持有j2第一次不持有j3第二次持有j4第二次不持有dp[i][0] dp[i-1][0]d…...

细胞世界:4.细胞分化(划区域)与细胞衰老(设施磨损)
(1)细胞凋亡 1. 概念:细胞凋亡可以比作城市的规划者主动拆除某些建筑来更新城市或防止危险建筑对市民的潜在伤害。这是一个有序的过程,由城市(细胞内部)的特定规划(基因)所决定。 2. 特征:细…...
c语言:操作符
操作符 一.算术操作符: + - * % / 1.除了%操作符之外,其他的几个操作符可以作用与整数和浮点数,如:5%2.0//error. 2.对于操作符,如果两个操作数都为整数,执行整数除法而只要有浮点数执行的就是浮点数除法。 3.%操作符的两个操作数必须为整数。 二.移位操作符:<&…...

谷歌seo自然搜索排名怎么提升快?
要想在谷歌上排名快速上升,关键在于运用GPC爬虫池跟高低搭配的外链组合 首先你要做的,就是让谷歌的蜘蛛频繁来你的网站,网站需要被谷歌蜘蛛频繁抓取和索引,那这时候GPC爬虫池就能派上用场了,GPC爬虫池能够帮你大幅度提…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...