【数据库(MySQL)基础】以MySQL为例的数据库基础
文章目录
- 0. 本文用到的emp表,dept表,salgrade表
- 1. MySQL入门
- 2. 简单查询
- 3. 字段计算
- 4. 条件查询
- 4.1 and
- 4.2 null
- 4.3 or
- 4.4 and和or的优先级
- 4.4 in 和 not in
- 4.5 模糊查询
- 5. 排序
- 5.1 简单排序
- 5.2 两个字段排序
- 5.3 综合排序
- 6. 一些常用函数
- 6.1 大小写转换
- 6.2 substr子字符串
- 6.3 concat和rand
- 7. 统计
- 8. 执行循环
- 9. 分组查询
- 9.1 基础分组查询
- 9.2 升级分组查询
- 9.3 having
- 9.4 distinct去重
- 10. 多表查询
- 10.1 笛卡尔积
- 10.2 内连接等值连接
- 10.3 内连接非等值连接
- 10.4 内连接自连接
- 10.5 外连接
- 10.6 三表查询
- 11. 子查询
- 11.1 where
- 11.2 from
- 12. union
- 13. limit
- 14. 表的创建与删除
- 15. 增删改
- 15.1 增insert
- 15.2 改update
- 15.3 删除delete
- 16. 约束
- 16.1 非空约束not null
- 16.2 唯一性约束unique
- 16.3 unique作为表级约束
- 16.4 表约束unique和not null
- 17. 主键自增
- 18. 外键
- 19. 事务开启
0. 本文用到的emp表,dept表,salgrade表
emp表:
empno, ename, dept, mgr表示员工编号,员工姓名,所属部门编号,经理编号
dept表:
deptno, dname表示部门号和部门名
salgrade表:
grade, losal, hisal表示工资等级、该工资等级的最低工资、该工资等级的最高工资
1. MySQL入门
mysql -uroot -proot:进入mysql,-u表用户名,-p表密码
show databases:展示所有数据库
use 数据库名称:打开数据库
show tables:查看所有的数据库表
create 数据库名;:创建数据库,注意一定要有分号
source 表路径:将路径的内容导入到表中(sql文件)
describe 表名或desc 表名:展示表字段名称、类型等信息
select version():查看数据库版本
select database():查看当前使用的数据库
drop database 数据库名:删除数据库
2. 简单查询
select * from 表名:选择表中的所有字段
select 属性名[,属性名,...] from 表名:选择表中的指定字段(属性)
select 属性名 as 别名[,属性名 as 别名...] from 表名:将属性名用别名替代展示在表中。如果别名之间有空格,则:属性名 as '别名1 别名2',用两个引号(单引号、双引号都可以,但双引号在Oracle里边是不行的)引起来,这里的as好像也可以不用
3. 字段计算
select sal*12 (as) 名称 from 表名:其中sal是一个数值类型的字段,这里实际上就是sal*12,由于这一列没有名字,我们可以通过在后面写名称来给这一列加上名字,其中(as)可要可不要
4. 条件查询
4.1 and
select * from 表名 where sal>=10 and sal <= 20,通过where实现,后面写的是字段(属性)的条件,多个条件用and连接,或者用between...and...,如:where sal between 10 and 20
4.2 null
假如有的字段为null,想要查询为null/不为null的行,应写:select * from 表名 where is (not) null
4.3 or
select* from 表名 where job='某职业' or job='另一职业',表示选择job为某职业/另一职业的字段
4.4 and和or的优先级
and的优先级比or的优先级高,解决方案是在or的语句两侧加(),举例子:
想要查询deptno=10/20的,工作为manager的员工信息:
select * from emp where job='manager' and deptno=20 or deptno=10,这个句子会先查出job='manager' and deptno=20的人,再查deptno=10的人。而deptno=10的人中,有的人的job并不是manager,就会导致问题
将and语句和or语句顺序对调,同样会有问题,正确的方法是加括号:
select * from emp where job='manager' and (deptno=20 or deptno=10)
4.4 in 和 not in
select * from 表名 where 属性 (not) in (数值1/带引号的字段1, 数值2/带引号的字段2...)
4.5 模糊查询
select * from 表名 where 属性名 like 'xxxx',其中'xxxx'中,可以使用%表示任意长度的字符串,比如%s%表示包含有s的字符串
注意,如果想要查询带有下划线的,使用like '%_%'会有问题,因为似乎表中存的信息就带有这个_吧,为了避免这个问题,使用转义解决,即like '%\_%'
5. 排序
排序的关键字是order by
5.1 简单排序
select * from 表名 order by 字段名(属性名),将表的内容按照字段名或属性名升序排序(默认为升序排序),这句话等同于select * from 表名 order by 字段名(属性名) asc
若要降序排序,将asc替换成desc
5.2 两个字段排序
select * from 表名 order by 字段1名(属性1名),字段2名(属性2名) asc/desc,通过逗号隔开两个排序,也就是字段1按升序(或降序)排序后,字段1相等的,按照字段2升序(或降序)
select * from 表名 order by 字段1名(属性1名) asc/desc ,字段2名(属性2名) asc/desc
5.3 综合排序
where和order by同时使用:
select * from 表名 where 条件 order by 具体字段
6. 一些常用函数
6.1 大小写转换
lower(内容)可以实现将大写转换为小写,如:select lower(ename) from 表名,其中ename为属性名(字段名)
类似的,upper()是小写转大写
6.2 substr子字符串
substr(属性名,起始字节,截止字节),如:
select substr(ename, 1, 1) from emp,截取的是ename属性的内容,仅展示第一个字符串
从起始字节截取到末尾则需要使用到获取字段长度的length(属性名)函数,如:select substr(ename,2,length(ename)-1) from emp,即截取从第2个字符开始,到长度-1处的字符串
6.3 concat和rand
concat表示的是连接,例如select concat(ename,empno) from emp,则会将ename属性和empno属性的内容进行连接
rand表示的是随机生成随机数,如select rand() from emp,生成的随机数是DOUBLE类型的
7. 统计
max(属性名)表示找到该属性字段下所有内容的最大值
min(属性名)表示找到最小值
sum(属性名)表示统计该属性字段下所有内容的和
count(属性名)表示统计该属性字段下的数量
8. 执行循环
select * from emp where sal >= min(sal)的语句是会出错的,提示错误为:Invalid use of group function
语句的执行顺序为:where, group by, select, order by,统计函数在where中是基于group by的,没有group by会导致统计字段出问题。
9. 分组查询
9.1 基础分组查询
按照职员的job进行分组,来统计薪资:
select job, sum(sal) from emp group by job,表示的是按工作来分组统计总和
在上述语句中加上按部门薪资排序:
select job, sum(sal) from emp group by job order by sum(sal) desc
9.2 升级分组查询
找出每个部门不同岗位的最高薪资,存在两个分组:deptno和job,只需要在group by后使用逗号做区分即可
select dept,job,max(sal) from emp group by deptno,job order by max(sal)
9.3 having
根据deptno汇总每个部门的薪资,并排序,仅统计总薪资>9000的那些部门,若书写语句:
select sum(sal), deptno from emp where sum(sal) > 9000 group by deptno order by deptno
则会报错,原因是:先执行where,才执行group by,而在where语句中就已经出现了sum(sal),所以会报错
所以需要使用到having,having和where的性质类似,但必须与group by同时出现
select sum(sal), deptno from emp group by deptno having sum(sal)>9000 order by deptno
9.4 distinct去重
select distinct job from emp,表示去除job中的重复值,去重复的值,每个出现的值值保留一次
select distinct job, deptno from emp,表示对于job和deptno的组合,有很多不同的组合,去重复的组合
10. 多表查询
10.1 笛卡尔积
select ename, dname from emp,dept从emp表和dept表中查询ename和dname数据,这时候会出现的问题是,一个人会对应多个部门,所以会有问题。
此时就需要使用笛卡尔积,对于emp中每个职工对应的部门号,在dept中根据部门号查具体的部门名。
select ename, dname from emp, dept where emp.deptno=dept.deptno,通过where使得两个表的某个字段相等
10.2 内连接等值连接
select ename, dname from emp (inner) join dept on emp.deptno=dept.deptno,通过join...on...进行内连接等值连接
10.3 内连接非等值连接
emp表内有员工工资sale,工资等级(salgrade)内有(等级,最低值,最高值),想根据员工工资判断他们的所属等级,查询语句为:
select ename, grade from emp join salgrade on emp.sal between salgrade.losal and salgrade.hisal
通过between...and...获得员工的工资
10.4 内连接自连接
emp表内有empno和mgr(员工对应经理的empno),想通过表的自连接来查询每个员工对应的经理姓名,则:
select a.ename, b.ename from emp a join emp b on a.mgr = b.empno
10.5 外连接
10.4也可以通过外连接实现:
select a.ename as '员工名', b.ename as '领导名' from emp a (right) join emp b on a.mgr=b.empno,join前的()中可以填right/left,right以右边表为主,left以左边表为主。
这时候以右边的表为主,有一位员工没有更大的领导,其mgr为NULL,相当于NULL=b.empno,把每一个员工的查询都显示出来了,显示为空?有一点没想明白
所以这里的语句应该写left join以左边为主
10.6 三表查询
就是通过一些值什么的多表连接,连接emp,dept,salgrade三张表,查出员工名、员工部门名、员工工资等级
select e.ename, d.dname, s.sgrade from emp e join dept d on e.deptno=d.deptno join salgrade s on e.sal between s.losal and s.hisal
11. 子查询
11.1 where
想要选出所有工资比 工资最少的人 多的人的信息
这可能需要两条语句实现:
select min(sal) from emp -> 查出min(sal)是800
select ename, sal from emp where sal > 800实现目标
合并成一条语句就需要通过子查询实现:
select ename, sal from emp where sal > (select min(sal) from emp)
11.2 from
查询每个岗位平均工资的所属等级:
select t.job, t.avgsal, s.grade from (select job, avg(sal) as avgsal from emp group by job) t join salgrade s on t.avgsal between s.losal and s.hisal order by s.grade
12. union
select ename from emp where empno=7369
union
select ename from emp where empno=7499
union类似于求并集,会过滤掉相同记录
故select * from emp union select * from emp等价于select * from emp
而union all不会过滤相同记录
对于select * from emp union all select * from emp,得到的结果是将两个表查询的结果合并到一张表里,两个子查询的结果是一样的,但会将查询出来的两个表的内容放到一个表里边
MySQL中UNION语句用法详解与示例
13. limit
做一个限制,限制数据条数等,例如:select * from emp limit 8就得到表中的8条数据
或者select * from emp limit 0,5,0是起始位置,5是条数(长度),得到的是1-5名,如果limit 2,3就是3到5名
14. 表的创建与删除
表的创建如下:
create 表名(属性1 类型1,属性2 类型2,...
);
类型包括:字符串varchar(长度)、int(长度)、char(长度)等,类型还可以通过default 值来给默认值,如defalt 'm'
删除为:drop table 表名
加上if判断:drop table if exist 表名,表存在则删除,表不存在不删除,这样就不会因为表不在而出错
15. 增删改
15.1 增insert
插入语句为:
insert into 表名(属性1,属性2,...) values(值1,值2...)
注意:有多少个属性就要有多少个值
insert into 表名 values(值1,值2),不写属性的时候,默认值依次对应了表中的所有属性
15.2 改update
更改属性的语句为:
update 表名 set 字段名1=值1,字段名2=值2,...
也可以使用where指定更新的条件。值得注意的是这里不需要添加括号(和insert区别开来,不要弄混)
15.3 删除delete
删除语句为:
delete from 表名 where 条件
如果不写条件,则默认删除表中的所有语句
16. 约束
约束在建表时写明
16.1 非空约束not null
表示该字段属性不能为空,插入时为空则会报错
create 表名(属性1 类型1 not null,...
);
16.2 唯一性约束unique
表示该属性字段不能与现有的其他值重复,值在该字段下是唯一的
create 表名(属性1 类型1 unique,...
);
16.3 unique作为表级约束
create 表名(属性1 类型1,属性2 类型2,...unique (属性1, 属性2)
);
表示要求(属性1,属性2)的值不可以重复
16.4 表约束unique和not null
create 表名(属性1 类型1 not null unique,属性2 类型2,...
);
实际上unique和not null属性就代表的是主键,所以也可以直接用primary key指定
create 表名(属性1 类型1 not null unique,属性2 类型2,...primary key(属性1)
);
17. 主键自增
auto_increment表自增:
create 表名(属性1 类型1 primary key auto_increment,属性2 类型2,...
);
18. 外键
举个例子,假如有学生表和班级表,每个学生属于一个班级,但是如果这个班级在班级表中没有出现的话,就是不合理的,为此需要设置外键来约束学生的班级来源于班级表
假设有班级表:含有属性classno班级编号,name班级名
假设有学生表:含有属性name学生名,sno学生号,age年龄,班级编号classno,则建表时候通过foreign key来做外键:
create 表名{属性1 类型1 ,属性2 类型2,...foreign key(学生表的班级编号classno) references 班级表名(classno)
19. 事务开启
事务开启:start transaction
事务开启之后就不会自动提交,如果执行过程中报错,则回滚事务,把数据恢复到事务开始之前的状态。
相关文章:
基础】以MySQL为例的数据库基础)
【数据库(MySQL)基础】以MySQL为例的数据库基础
文章目录 0. 本文用到的emp表,dept表,salgrade表1. MySQL入门2. 简单查询3. 字段计算4. 条件查询4.1 and4.2 null4.3 or4.4 and和or的优先级4.4 in 和 not in4.5 模糊查询 5. 排序5.1 简单排序5.2 两个字段排序5.3 综合排序 6. 一些常用函数6.1 大小写转换6.2 substr子字符串6.…...
权限修饰符,代码块,抽象类,接口.Java
1,权限修饰符 权限修饰符:用来控制一个成员能够被访问的范围可以修饰成员变量,方法,构造方法,内部类 👻👗👑权限修饰符的分类 🧣四种作用范围由小到大(private<空着…...

CSS设置文本
目录 概述: text-aling: text-decoration: text-transform: text-indent: line-height: letter-spacing: word-spacing: text-shadow: vertical-align: white-space: direction: 概述: 在CSS中我们可以设置文本的属性,就像Word文…...

【svg】—— java提取svg中的颜色
需要针对svg元素进行解析,并提取其中的颜色,首先需要知道svg中的颜色。针对svg中颜色的格式大致可以一般有纯色和渐变两种形式。对于渐变有分为:线性渐变和放射性渐变针对svg中的颜色支持16进制的格式,又可以支持RGB的格式&#x…...

论文分享 | FAST'23 阿里云提出的针对SMR优化的存储引擎SMRSTORE
今天分享的一篇最近阅读的论文是FAST23的SMRstore: A Storage Engine for Cloud Object Storage on HM-SMR Drives。 https://www.usenix.org/conference/fast23/presentation/zhou 这篇文章是由阿里巴巴公司完成的,在这篇文章中,团队针对SMR的特性提出了…...

题目:建造房屋 (蓝桥OJ3362)
问题描述: 代码: #include<bits/stdc.h> using namespace std; int n, m, k, ans, mod 1e9 7; long long dp[55][2605]; /*dp[i][j]:第i个街道上建j个房屋的总方案数枚举所有的转移,累加到dp[n][k]即总方案数 */ int main() {cin >> n &…...

智能合约平台开发指南
随着区块链技术的普及,智能合约平台已经成为了这个领域的一个重要趋势。智能合约可以自动化执行合同条款,大大减少了执行和监督合同条款所需的成本和时间。那么,如何开发一个智能合约平台呢?以下是一些关键步骤。 一、选择合适的区…...
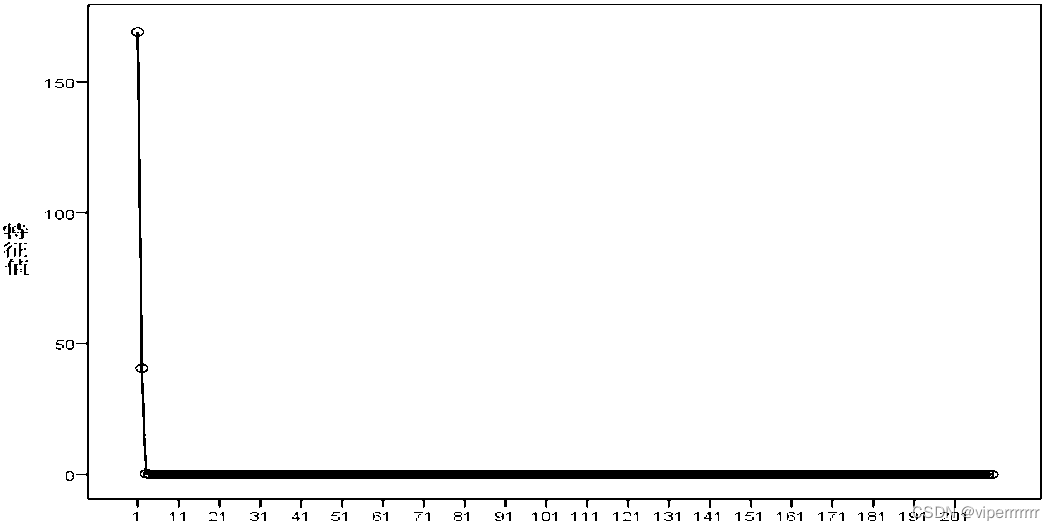
数学建模-最优包衣厚度终点判别法(主成分分析)
💞💞 前言 hello hello~ ,这里是viperrrrrrr~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 💥个人主页ÿ…...

Mysql内存表及使用场景(12/16)
内存表(Memory引擎) InnoDB引擎使用B树作为主键索引,数据按照索引顺序存储,称为索引组织表(Index Organized Table)。 Memory引擎的数据和索引分开存储,数据以数组形式存放,主键索…...
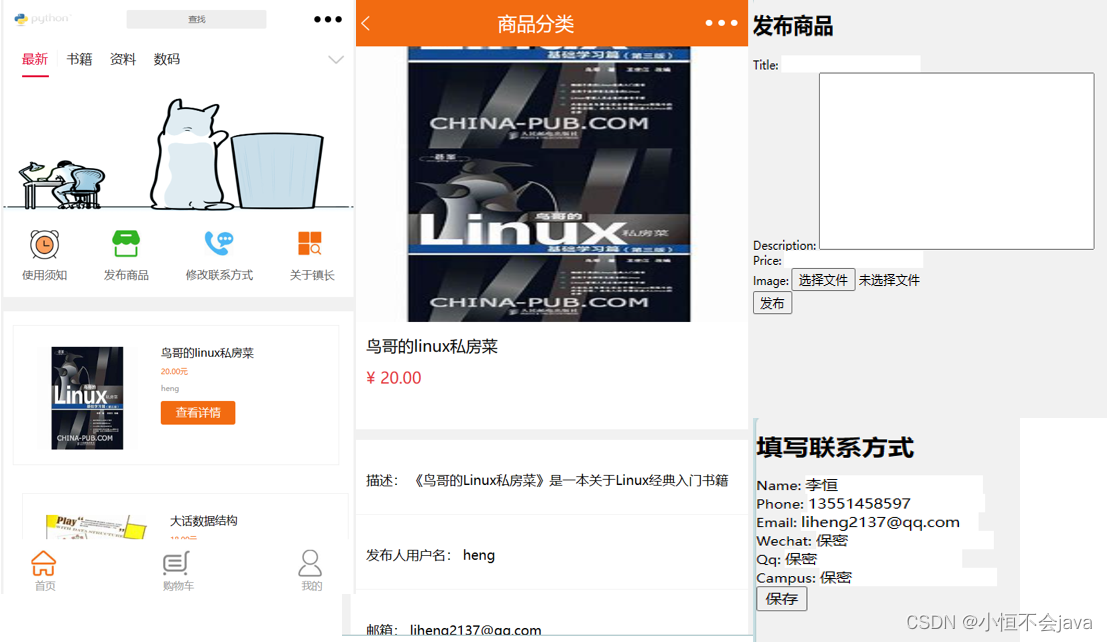
Django交易商场
Hello,我是小恒不会java 最近学习django,写了一个demo,学到了不少东西。 我在GitHub上开源了,提示‘自行查看代码,维护,运行’。 最近有事,先发布代码了,我就随缘维护更新吧 介绍: 定…...

华为校园公开课走入上海交大,鸿蒙成为专业核心课程
4月12日,华为校园公开课在中国上海交通大学成功举办,吸引了来自计算机等相关专业的150余名学生参加。据了解,由吴帆、陈贵海、过敏意、吴晨涛、刘生钟等教授在中国上海交通大学面向计算机系本科生开设的《操作系统》课程,是该系学…...

【会员单位】泰州玉安环境工程有限公司
中华环保联合会理事单位 水环境治理专业委员会副主任委员单位 我会为会员单位提供服务: 1、企业宣传与技术项目对接; 2、企业标准、行业标准制定; 3、院士专家指导与人才培训 4、国际与国内会议交流 5、专精特新、小巨人等申报认证 6…...
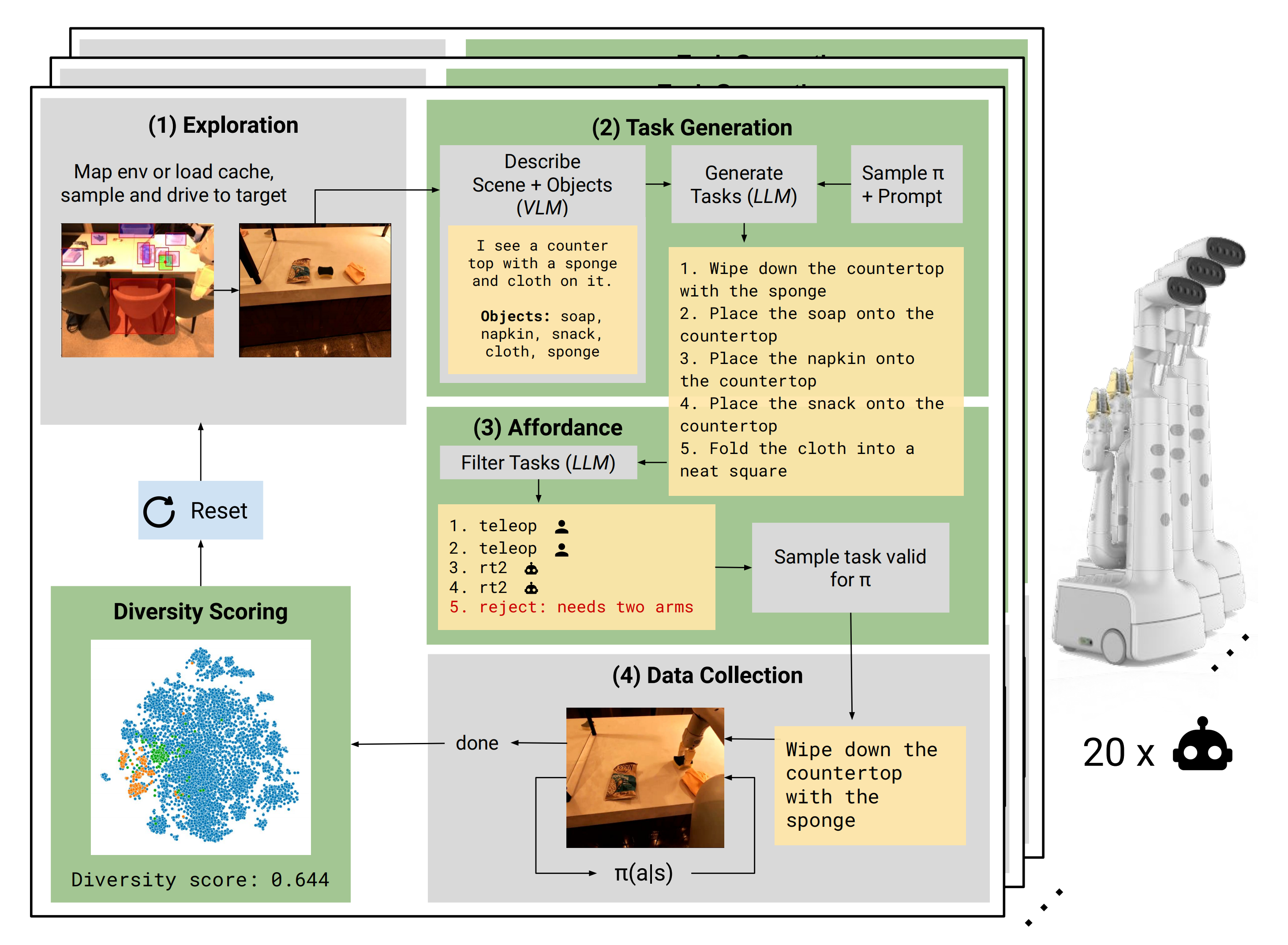
Google视觉机器人超级汇总:从RT、RT-2到AutoRT/SARA-RT/RT-Trajectory、RT-H
前言 随着对视觉语言机器人研究的深入,发现Google的工作很值得深挖,比如RT-2 想到很多工作都是站在Google的肩上做产品和应用,Google真是科技进步的核心推动力,做了大量大模型的基础设施,服(推荐重点关注下Googl…...
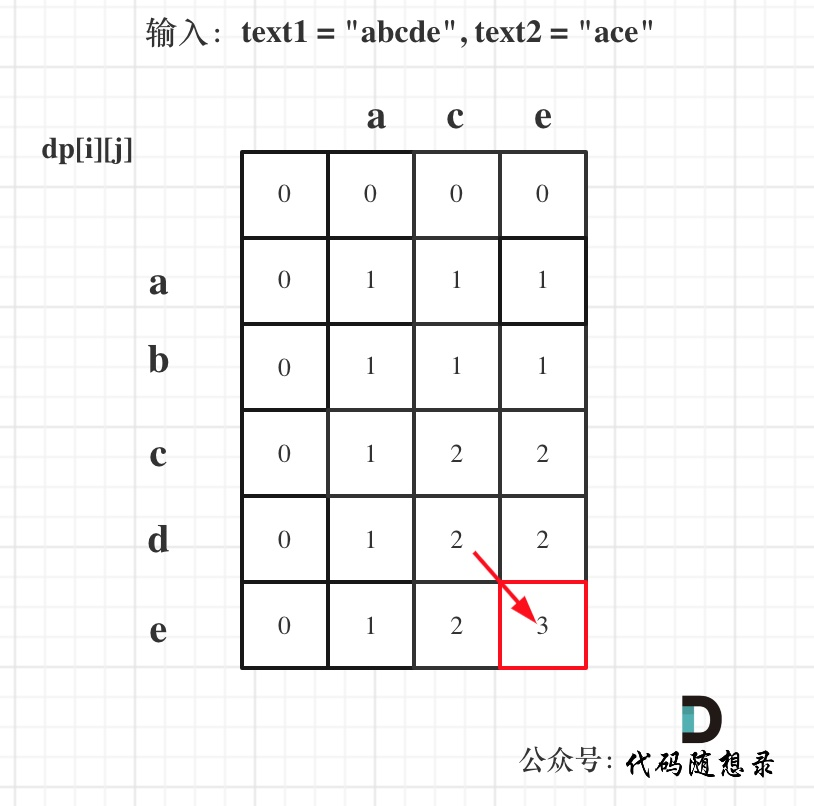
LeetCode-1143. 最长公共子序列【字符串 动态规划】
LeetCode-1143. 最长公共子序列【字符串 动态规划】 题目描述:解题思路一:动规五部曲解题思路二:1维DP解题思路三:0 题目描述: 给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。…...
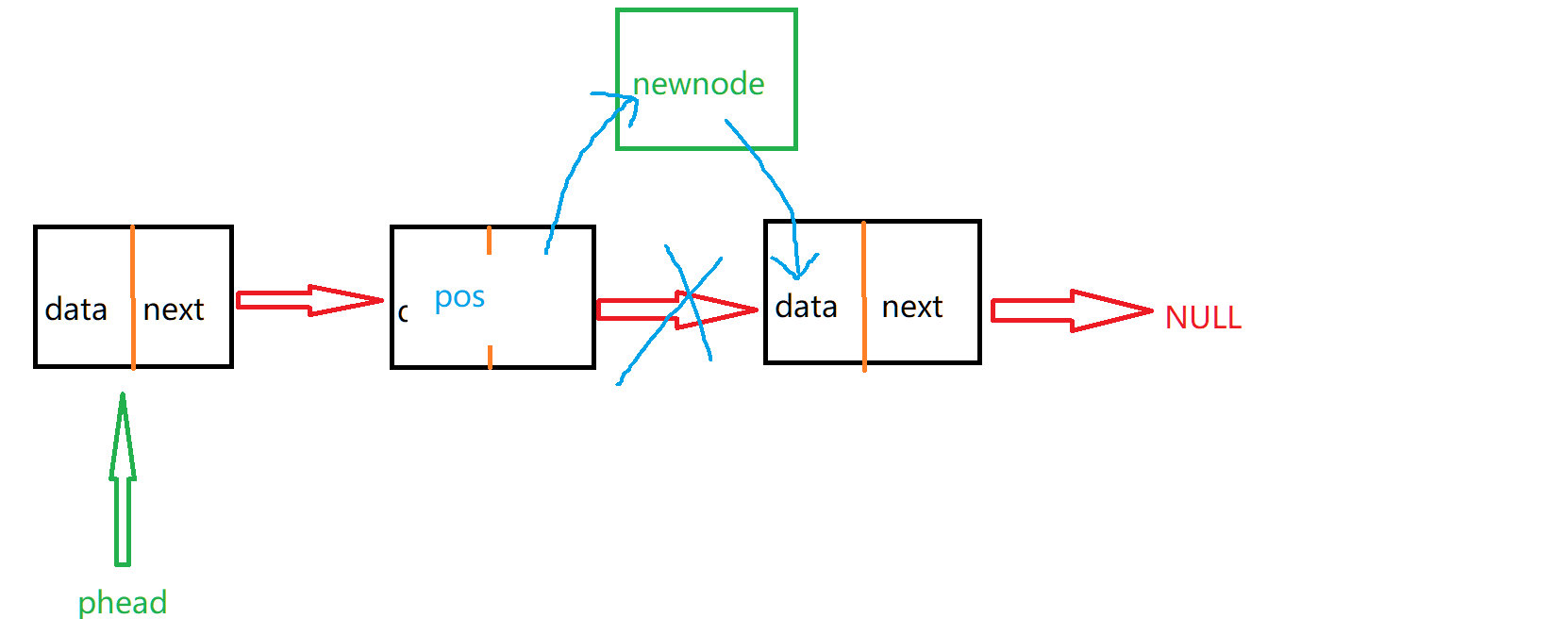
从0开始创建单链表
前言 这次我来为大家讲解链表,首先我们来理解一下什么是单链表,我们可以将单链表想象成火车 每一节车厢装着货物和连接下一个车厢的链子,单链表也是如此,它是将一个又一个的数据封装到节点上,节点里不仅包含着数据&…...

STC89C52学习笔记(十)
STC89C52学习笔记(十) 综述:本文介绍了DS18B20和单总线协议,以及讲述了如何使用DS18B20测量温度。 一、单总线协议 1.只有一根通讯线:DQ (常见的运用单总线的两种设备:DS18B20和DHT11&#…...
初识二叉树和二叉树的基本操作
目录 一、树 1.什么是树 2. 与树相关的概念 二、二叉树 1.什么是二叉树 2.二叉树特点 3.满二叉树与完全二叉树 4.二叉树性质 相关题目: 5.二叉树的存储 6.二叉树的遍历和基本操作 二叉树的遍历 二叉树的基本操作 一、树 1.什么是树 子树是不相交的;…...

如何开辟动态二维数组(C语言)
1. 开辟动态二维数组 C语言标准库中并没有可以直接开辟动态二维数组的函数,但我们可以通过动态一维数组来模拟动态二维数组。 二维数组其实可以看作是一个存着"DataType []"类型数据的一维数组,也就是存放着一维数组地址的一维数组。 所以&…...
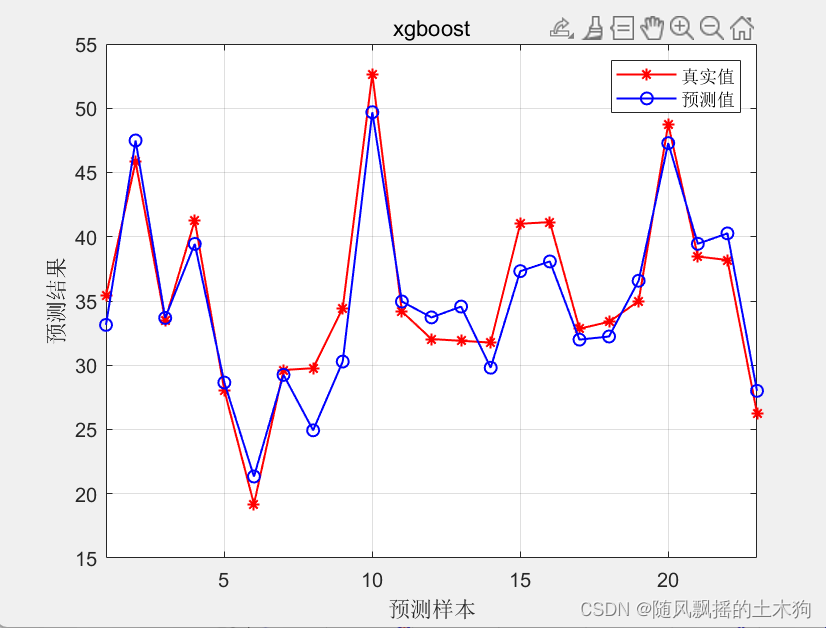
【MATLAB第104期】基于MATLAB的xgboost的敏感性分析/特征值排序计算(针对多输入单输出回归预测模型)
【MATLAB第104期】基于MATLAB的xgboost的敏感性分析/特征值排序计算(针对多输入单输出回归预测模型) 因matlab的xgboost训练模型不含敏感性分析算法,本文通过使用single算法,即单特征因素对输出影响进行分析,得出不同…...

C语言程序与设计——工程项目开发
之前我们已经了解了C语言的基础知识部分,掌握这些之后,基本就可以开发一些小程序了。在开发时,就会出现合作的情况,C语言是如何协作开发的呢,将在这一篇文章进行演示。 工程项目开发 在开发过程中,你接到…...

破解土地-生态耦合难题,从数据处理到SCI论文:AI辅助下PLUS-InVEST模型土地利用格局模拟与生态系统服务
做土地利用、生态系统服务、国土空间规划的同学,是不是经常遇到这些问题:PLUS 模型装不上、跑不通、参数看不懂InVEST 产水 / 土壤保持 / 碳储量 / 生境质量数据总是报错ArcGIS 栅格处理、投影转换、重分类一头雾水多情景模拟不会设计,结果不…...

BetterGI:原神智能辅助系统 重新定义游戏体验
BetterGI:原神智能辅助系统 重新定义游戏体验 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条龙 | 全连音游 - UI Automa…...

大模型应用开发第三天
时间过得真快,一晃眼已经到2026年了。遥想2023年,ChatGPT横空出世的时候,大家还在讨论“AI会不会取代人类工作”。如今三年过去,打工人早已接受现实:该加班还是加班,AI只是让PPT做得更快了而已。但变化也是…...
终极指南:如何用BallonTranslator快速完成漫画翻译?
终极指南:如何用BallonTranslator快速完成漫画翻译? 【免费下载链接】BallonsTranslator 深度学习辅助漫画翻译工具, 支持一键机翻和简单的图像/文本编辑 | Yet another computer-aided comic/manga translation tool powered by deeplearning 项目地址…...

思源宋体完整使用指南:如何免费获得专业级中文字体解决方案
思源宋体完整使用指南:如何免费获得专业级中文字体解决方案 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还记得上次为商业项目挑选字体时的头疼经历吗?看着那…...

Intv_ai_mk11在人工智能教育中的应用:个性化学习伙伴
Intv_ai_mk11在人工智能教育中的应用:个性化学习伙伴 1. 教育领域的新助手 最近几年,人工智能在教育领域的应用越来越广泛。作为一款专门为教育场景设计的AI助手,Intv_ai_mk11正在改变传统学习方式。它不仅能解答学生问题,还能根…...

像素剧本圣殿从零开始:Windows/Linux双平台Qwen2.5镜像部署步骤详解
像素剧本圣殿从零开始:Windows/Linux双平台Qwen2.5镜像部署步骤详解 1. 项目介绍与核心价值 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct模型深度优化的专业剧本创作工具。这个项目将先进的大语言模型能力与独特的8-…...

3个实用技巧让你彻底告别浏览器自动化测试的版本兼容性烦恼
3个实用技巧让你彻底告别浏览器自动化测试的版本兼容性烦恼 【免费下载链接】chrome-for-testing 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-for-testing 还在为Chrome浏览器和ChromeDriver版本不匹配而头疼吗?Chrome for Testing项目正是为了解…...

Mi-Create:让小米穿戴设备拥有专属表盘的3步可视化设计法
Mi-Create:让小米穿戴设备拥有专属表盘的3步可视化设计法 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 你是否厌倦了小米手表上那些千篇一律的官…...
颠覆式效率工具:BaiduPanFilesTransfers重构百度网盘批量管理流程
颠覆式效率工具:BaiduPanFilesTransfers重构百度网盘批量管理流程 【免费下载链接】BaiduPanFilesTransfers 百度网盘批量转存、分享和检测工具 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduPanFilesTransfers 在数字化办公与资源管理场景中ÿ…...