基于深度学习的人脸表情识别系统(PyQT+代码+训练数据集)
基于深度学习的人脸表情识别系统(PyQT+代码+训练数据集)
- 前言
- 一、数据集
- 1.1 数据集介绍
- 1.2 数据预处理
- 二、模型搭建
- 三、训练与测试
- 3.1 模型训练
- 3.2 模型测试
- 四、PyQt界面实现
前言
本项目是基于mini_Xception深度学习网络模型的人脸表情识别系统,核心采用CNN卷积神经网络搭建,详述了数据集处理、模型构建、训练代码、以及基于PyQt5的应用界面设计。在应用中可以支持图像、视频和实时摄像头进行人脸表情识别。本文附带了完整的应用界面设计、深度学习模型代码和训练数据集的下载链接。
完整资源下载链接:博主在面包多网站上的完整资源下载页
项目演示视频:
【项目分享】基于深度学习的人脸表情识别系统(含PyQt界面)
一、数据集
1.1 数据集介绍
Fer2013人脸表情数据集由35886张人脸表情图片组成,其中,测试图(Training)28708张,公共验证图(PublicTest)和私有验证图(PrivateTest)各3589张,每张图片是由大小固定为48×48的灰度图像组成,共有7种表情,分别对应于数字标签0-6,具体表情对应的标签和中英文如下:0 anger 生气; 1 disgust 厌恶; 2 fear 恐惧; 3 happy 开心; 4 sad 伤心;5 surprised 惊讶; 6 normal 中性。

1.2 数据预处理
数据给的是一个csv文件,其中的表情数据并没有直接给图片,而是给了像素值。我们需要在整理的时候顺便转换成图片就好,这里我们使用getpic.py。
# getpic.py 生成图像数据
import codecs
import cv2
from tqdm import tqdm
import numpy as np
f = codecs.open('fer2013.csv','r','utf8').readlines()[1:]
labelfile = codecs.open('label.txt','w','utf8')
index = 0
for line in tqdm(f):flist = line.split(',')label = flist[0]img = flist[1].split(' ')img = [int(i) for i in img]img = np.array(img)img = img.reshape((48,48))cv2.imwrite('ferpic/'+str(index)+'.png',img)labelfile.write(str(index)+'\t'+label+'\n')index += 1
将像素值归一化到[0, 1]的范围内有助于训练模型时梯度更加稳定,从而更容易收敛到较好的解。归一化可以避免某些像素值过大或过小导致的梯度爆炸或梯度消失问题。使用utils.py对图像进行预处理,以便在神经网络中使用。根据参数v2的不同取值,可以选择不同的预处理方式。
# utils.py
def preprocess_input(x, v2=True):x = x.astype('float32')x = x / 255.0if v2:x = x - 0.5x = x * 2.0return x
这个预处理方法主要包含两个步骤:归一化和零均值化。归一化:通过将像素值除以255.0,将输入的图像数据归一化到[0, 1]的范围内。这一步可以确保所有的像素值都在相似的数值范围内,有利于模型训练的稳定性。零均值化:如果参数v2为True,那么将对图像进行零均值化。零均值化的过程包括两个操作:将像素值减去0.5,这样可以将像素值平移至以0.5为中心,即像素值的均值为0.5。这一步使得图像数据的中心点在零点附近,有利于模型的收敛速度。将像素值乘以2.0,将像素值缩放到[-1, 1]的范围内。这一步可以确保图像数据的值域适合一些需要对称分布输入数据的模型,同时提高了模型对输入数据的鲁棒性。
最后使用dataset.py文件将处理好的数据集封装成data.hdf5文件方面后面训练模型使用。
# dataset.py
import codecs
import cv2
import numpy as np
from maketwo import Detecttwo
from tqdm import tqdm
datapath = '/unsullied/sharefs/lh/isilon-home/fer2013/ferpic/'
label = '/unsullied/sharefs/lh/isilon-home/fer2013/label.txt'
label = codecs.open(label,'r','utf8').readlines()
label = [i.split('\t') for i in label]
label = [ [i[0] ,int(i[1]) ] for i in label]
#print(label[0:5])
X = []
Y = []
for i in tqdm(label):picname = datapath+i[0]+'.png'img = cv2.imread(picname,0)img = np.expand_dims(img,axis=2)#224*224*1img = cv2.resize(img, (48,48), interpolation=cv2.INTER_LINEAR)#cv2.imwrite('1.png',img)img = np.expand_dims(img,axis=2)#224*224*1X.append(img)y = [0,0,0,0,0,0,0]y[i[1]]=1y = np.array(y)Y.append(y)
X = np.array(X)
Y = np.array(Y)
print(X.shape,Y.shape)
print(X[0],Y[0:5])import h5py
f = h5py.File("Data.hdf5",'w')
f.create_dataset('X',data=X)
f.create_dataset('Y',data=Y)
f.close()
#np.save('X.npy',X)
#np.save('Y.npy',Y)
二、模型搭建
我们使用的是基于CNN实现的网络模型mini_XCEPTION。Xception网络模型是由Google提出的,它在Inception v3的基础上进行了进一步的优化。主要是采用深度可分离的卷积(depthwise separable convolution)来替换原来Inception v3中的卷积操作。XCEPTION的网络结构在ImageNet数据集(Inception v3的设计解决目标)上略优于Inception v3,并且在包含3.5亿个图像甚至更大的图像分类数据集上明显优于Inception v3,而两个结构保持了相同数目的参数,性能增益来自于更加有效地使用模型参数,详细可参考论文:Real-time Convolutional Neural Networks for Emotion and Gender Classification–O Arriaga。网络结构图,如下图所示:
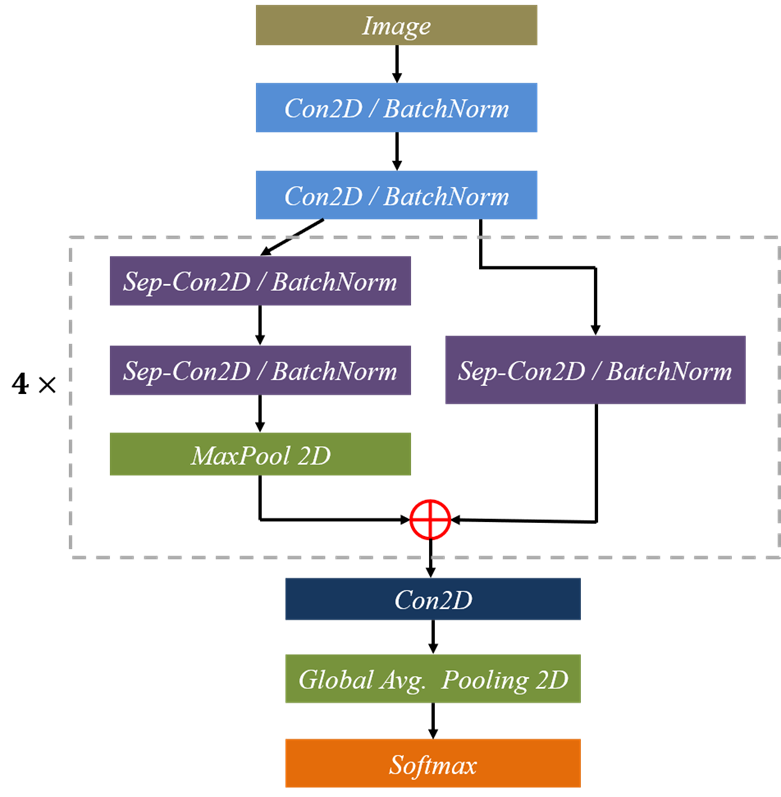
基于CNN的模型实现代码如下:
# 模型实现代码
def mini_XCEPTION(input_shape, num_classes, l2_regularization=0.01):regularization = l2(l2_regularization)# baseimg_input = Input(input_shape)x = Conv2D(8, (3, 3), strides=(1, 1), kernel_regularizer=regularization,use_bias=False)(img_input)x = BatchNormalization()(x)x = Activation('relu')(x)x = Conv2D(8, (3, 3), strides=(1, 1), kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)# module 1residual = Conv2D(16, (1, 1), strides=(2, 2),padding='same', use_bias=False)(x)residual = BatchNormalization()(residual)x = SeparableConv2D(16, (3, 3), padding='same',kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(16, (3, 3), padding='same',kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)x = layers.add([x, residual])# module 2residual = Conv2D(32, (1, 1), strides=(2, 2),padding='same', use_bias=False)(x)residual = BatchNormalization()(residual)x = SeparableConv2D(32, (3, 3), padding='same',kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(32, (3, 3), padding='same',kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)x = layers.add([x, residual])# module 3residual = Conv2D(64, (1, 1), strides=(2, 2),padding='same', use_bias=False)(x)residual = BatchNormalization()(residual)x = SeparableConv2D(64, (3, 3), padding='same',kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(64, (3, 3), padding='same',kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)x = layers.add([x, residual])# module 4residual = Conv2D(128, (1, 1), strides=(2, 2),padding='same', use_bias=False)(x)residual = BatchNormalization()(residual)x = SeparableConv2D(128, (3, 3), padding='same',kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = SeparableConv2D(128, (3, 3), padding='same',kernel_regularizer=regularization,use_bias=False)(x)x = BatchNormalization()(x)x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)x = layers.add([x, residual])x = Conv2D(num_classes, (3, 3),#kernel_regularizer=regularization,padding='same')(x)x = GlobalAveragePooling2D()(x)output = Activation('softmax',name='predictions')(x)model = Model(img_input, output)return model
三、训练与测试
3.1 模型训练
使用Keras库和自定义的mini_XCEPTION模型进行情绪识别的训练。首先,设置了一些关键的训练参数,如批量大小、训练周期、输入数据的维度、验证集的比例、类别数目等参数。
# parameters
batch_size = 32
num_epochs = 800
input_shape = (48, 48, 1)
validation_split = 0.1
num_classes = 7
patience = 50
base_path = 'trained_models/float_models/'
接着,通过ImageDataGenerator类创建了一个数据生成器,用于在训练过程中对图像进行数据增强,包括旋转、平移、缩放和翻转等操作。
# data generator
data_generator = ImageDataGenerator(featurewise_center=False,featurewise_std_normalization=False,rotation_range=10,width_shift_range=0.1,height_shift_range=0.1,zoom_range=.1,horizontal_flip=True)
然后,定义了mini_XCEPTION模型,并使用Adam优化器和分类交叉熵损失函数进行编译。
# model parameters/compilation
model = mini_XCEPTION(input_shape, num_classes)
model.compile(optimizer='adam', loss='categorical_crossentropy',metrics=['accuracy'])
model.summary()
随后,为训练过程设置了回调函数,包括CSVLogger用于记录日志、EarlyStopping用于提前终止训练、ReduceLROnPlateau用于在验证损失不再下降时减少学习率,以及ModelCheckpoint用于保存最佳模型。在加载数据集后,使用train_test_split函数将数据分为训练集和测试集,并开始训练模型。训练过程中,通过flow方法从数据生成器中获取数据,并在每个epoch后进行验证,直至达到指定的训练周期或满足提前终止的条件。最终,模型的性能通过准确率等指标进行评估,并保存最佳模型以供后续使用。
for dataset_name in datasets:print('Training dataset:', dataset_name)# callbackslog_file_path = base_path + dataset_name + '_emotion_training.log'csv_logger = CSVLogger(log_file_path, append=False)early_stop = EarlyStopping('val_loss', patience=patience)reduce_lr = ReduceLROnPlateau('val_loss', factor=0.1,patience=int(patience/4), verbose=1)trained_models_path = base_path + dataset_name + '_mini_XCEPTION'model_names = trained_models_path + '.{epoch:02d}-{accuracy:.2f}.hdf5'model_checkpoint = ModelCheckpoint(model_names, 'val_loss', verbose=1,save_best_only=True)callbacks = [model_checkpoint, csv_logger, early_stop, reduce_lr]# loading datasetf = h5py.File('Data.hdf5','r')X = f['X'][()]X = preprocess_input(X)Y = f['Y'][()]f.close()#X = np.load('X.npy')#Y = np.load('Y.npy')train_X,test_X,train_Y,test_Y = train_test_split(X,Y,test_size=validation_split,random_state=0)model.fit_generator(data_generator.flow(train_X, train_Y,batch_size),steps_per_epoch=len(train_X) / batch_size,epochs=num_epochs, verbose=1, callbacks=callbacks,validation_data=(test_X,test_Y))
使用train.py文件进行训练,训练好的模型文件会被保存下如下目录中

3.2 模型测试
使用image_demo.py对图像进行测试,具体的代码实现如下:
(1)初始化加载两个检测模型
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)emotion_model_path = 'trained_models/float_models/fer2013_mini_XCEPTION.33-0.65.hdf5'
emotion_labels = {0:'angry',1:'disgust',2:'fear',3:'happy',4:'sad',5:'surprise',6:'neutral'}
detection_model_path = 'trained_models/facemodel/haarcascade_frontalface_default.xml'emotion_classifier = load_model(emotion_model_path, compile=False)
face_detection = cv2.CascadeClassifier(detection_model_path)
emotion_target_size = emotion_classifier.input_shape[1:3]
(2)使用opencv检测人脸
gray_image = np.expand_dims(imggray,axis=2)#224*224*1faces = face_detection.detectMultiScale(imggray, 1.3, 5)res = []if len(faces)==0:print('No face')return None
(3)调用Xception网络对框选出的人脸进行表情检测
for face_coordinates in faces:x1,y1,width,height = face_coordinatesx1,y1,x2,y2 = x1,y1,x1+width,y1+heightgray_face = gray_image[y1:y2, x1:x2]try:gray_face = cv2.resize(gray_face, (emotion_target_size))except:continuegray_face = preprocess_input(gray_face, True)gray_face = np.expand_dims(gray_face, 0)gray_face = np.expand_dims(gray_face, -1)emotion_prediction = emotion_classifier.predict(gray_face)#emotion_probability = np.max(emotion_prediction)emotion_label_arg = np.argmax(emotion_prediction)res.append([emotion_label_arg,x1,y1,x2,y2])
(4)在图像上绘制检测况以及相关信息
def save_predict(imgurl,targeturl='images/predicted_test_image.png'):imggray = cv2.imread(imgurl,0)imgcolor = cv2.imread(imgurl,1)ress = general_predict(imggray,imgcolor)if ress==None:print('No face and no image saved')for res in ress:label = emotion_labels[res[0]]lx,ly,rx,ry = res[1],res[2],res[3],res[4]cv2.rectangle(imgcolor,(lx,ly),(rx,ry),(0,0,255),2)cv2.putText(imgcolor,label,(lx,ly),cv2.FONT_HERSHEY_SIMPLEX,2,(0,0,255),2,cv2.LINE_AA) # cv2.imwrite('images/res_1.png', imgcolor)cv2.imwrite('res.png', imgcolor)
识别前后的效果图

对于视频流的识别处理,则使用Video_demo.py调用摄像头对人脸表情进行实时检测,其文件程序逻辑与图像的相同,只不过是调用摄像头取其中的每一帧做检测。
# Video_demo.py的主要实现
# starting video streaming
cv2.namedWindow('window_frame')
video_capture = cv2.VideoCapture(0)
while True:bgr_image = video_capture.read()[1]gray_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2GRAY)rgb_image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)faces = face_detection.detectMultiScale(gray_image, 1.3, 5)for face_coordinates in faces:x1,y1,width,height = face_coordinatesx1,y1,x2,y2 = x1,y1,x1+width,y1+height#x1, x2, y1, y2 = apply_offsets(face_coordinates, emotion_offsets)gray_face = gray_image[y1:y2, x1:x2]try:gray_face = cv2.resize(gray_face, (emotion_target_size))except:continuegray_face = preprocess_input(gray_face, True)gray_face = np.expand_dims(gray_face, 0)gray_face = np.expand_dims(gray_face, -1)emotion_prediction = emotion_classifier.predict(gray_face)#emotion_probability = np.max(emotion_prediction)emotion_label_arg = np.argmax(emotion_prediction)emotion_text = emotion_labels[emotion_label_arg]emotion_window.append(emotion_text)if len(emotion_window) > frame_window:emotion_window.pop(0)try:emotion_text = mode(emotion_window)except:continuecolor = (0,0,255)cv2.rectangle(rgb_image,(x1,y1),(x2,y2),(0,0,255),2)cv2.putText(rgb_image,emotion_text,(x1,y1),cv2.FONT_HERSHEY_SIMPLEX,2,(0,0,255),2,cv2.LINE_AA)bgr_image = cv2.cvtColor(rgb_image, cv2.COLOR_RGB2BGR)cv2.imshow('window_frame', bgr_image)if cv2.waitKey(1) & 0xFF == ord('q'):break
四、PyQt界面实现
当整个项目构建完成后,使用PyQt5编写可视化界面,可以支持图像、视频和实时摄像头进行人脸表情识别。
整个界面文件框架如下:
1)connect.py: 主运行文件,连接各个子界面
# connect.py
class jiemian2(QtWidgets.QMainWindow,Ui_MainWindow2):def __init__(self):super(jiemian2,self).__init__()self.setupUi(self) #加载相机识别模块 camera.pyself.file.clicked.connect(self.back) #返回主界面功能按钮 连接下面的back函数def back(self):self.hide() #隐藏此窗口self.log = loginWindow()self.log.show() #显示登录窗口#必须加上selfclass jiemian3(QtWidgets.QMainWindow,Ui_MainWindow3):def __init__(self):super(jiemian3,self).__init__()self.setupUi(self) #加载视频文件识别模块 file.pyself.file.clicked.connect(self.back) #返回主界面功能按钮 连接下面的back函数def back(self):self.hide() #隐藏此窗口self.log = loginWindow()self.log.show() #显示登录窗口class jiemian4(QtWidgets.QMainWindow,Ui_MainWindow4):def __init__(self):super(jiemian4,self).__init__()self.setupUi(self)self.file.clicked.connect(self.back) #返回主界面功能按钮 连接下面的back函数def back(self):self.hide() #隐藏此窗口self.log = loginWindow()self.log.show() #显示登录窗口#主界面
class loginWindow(QtWidgets.QMainWindow,Ui_MainWindow):def __init__(self):super(loginWindow,self).__init__()self.setupUi(self)self.pushButton.clicked.connect(self.camera) #相机检测按钮 连接下面的camera_detect功能函数self.pushButton_2.clicked.connect(self.file_detect) #视频文件检测按钮 连接下面的file_detect函数self.pushButton_3.clicked.connect(self.photo_detect)# def camera_detect(self):# self.hide() #隐藏本界面# self.jiemian2 = jiemian2(model=self.model,model_gender=self.model_gender) #加载相机识别界面## self.jiemian2.show()#显示相机识别界面def file_detect(self):self.hide()self.jiemian3 = jiemian3() #加载视频文件识别界面self.jiemian3.show()def camera(self):self.hide()self.jiemian2 = jiemian2() #加载视频文件识别界面self.jiemian2.show()def photo_detect(self):self.hide()self.jiemian4 = jiemian4() #加载视频文件识别界面self.jiemian4.show()
2)main.py: 连接各个功能模块

3)实时检测: camera.py

4)图像检测photo.py

5)视频检测file.py

相关文章:
基于深度学习的人脸表情识别系统(PyQT+代码+训练数据集)
基于深度学习的人脸表情识别系统(PyQT代码训练数据集) 前言一、数据集1.1 数据集介绍1.2 数据预处理 二、模型搭建三、训练与测试3.1 模型训练3.2 模型测试 四、PyQt界面实现 前言 本项目是基于mini_Xception深度学习网络模型的人脸表情识别系统&#x…...

Qt 中的项目文件解析和命名规范
🐌博主主页:🐌倔强的大蜗牛🐌 📚专栏分类:QT❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、Qt项目文件解析 1、.pro 文件解析 2、widget.h 文件解析 3、main.cpp 文件解析 4、widget.cpp…...

【chatGPT】我:在Cadence Genus软件中,出现如下问题:......【4】
我 在Cadence Genus中,tcl代码为:foreach clk $clk_list{ set clkName [lindex $clk_list 0] set targetFreq [lindex $clk_list 1] set uncSynth [lindex $clk_list 4] set clkPeriod [lindex “%.3f” [expr 1 / $targetFreq]] … } 以上代码出现如下…...
在JAVA中的应用)
单例模式(Singleton Pattern)在JAVA中的应用
在软件开发中,设计模式是解决特定问题的一种模板或者指南。它们是在多年的软件开发实践中总结出的有效方法。JAVA设计模式广泛应用于各种编程场景中,以提高代码的可读性、可维护性和扩展性。本文将介绍单例模式,这是一种常用的创建型设计模式…...

手把手教你创建新的OpenHarmony 三方库
创建新的三方库 创建 OpenHarmony 三方库,建议使用 Deveco Studio,并添加 ohpm 工具的环境变量到 PATH 环境变量。 创建方法 1:IDE 界面创建 在现有应用工程中,新创建 Module,选择"Static Library"模板&a…...

从零开始,如何成功进入IT行业?
0基础如何进入IT行业? 简介:对于没有任何相关背景知识的人来说,如何才能成功进入IT行业?是否有一些特定的方法或技巧可以帮助他们实现这一目标? 在当今数字化时代,IT行业无疑是一个充满活力和机遇的领域。…...
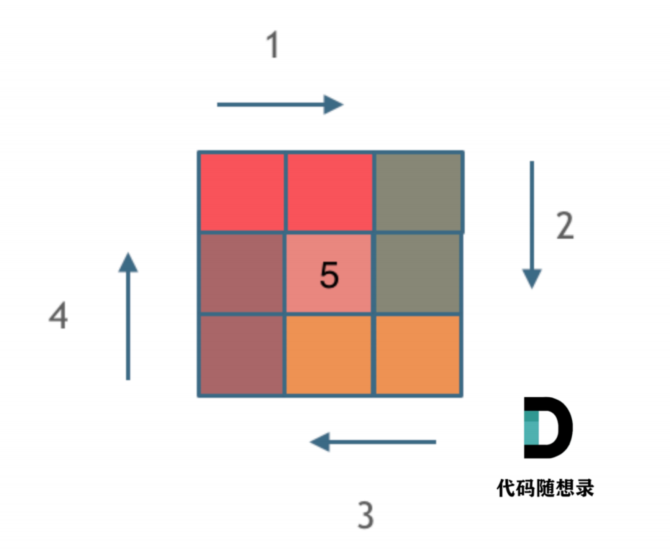
【数组】5螺旋矩阵
这里写自定义目录标题 一、题目二、解题精髓-循环不变量三、代码 一、题目 给定⼀个正整数 n,⽣成⼀个包含 1 到 n^2 所有元素,且元素按顺时针顺序螺旋排列的正⽅形矩阵。 示例: 输⼊: 3 输出: [ [ 1, 2, 3 ], [ 8, 9, 4 ], [ 7, 6, 5 ] ] 二、解题精髓…...

Sora视频生成模型:开启视频创作新纪元
随着人工智能技术的飞速发展,视频生成领域也迎来了前所未有的变革。Sora视频生成模型作为这一领域的佼佼者,凭借其卓越的性能和创新的应用场景,受到了广泛的关注与好评。本文将对Sora视频生成模型进行详细介绍,带您领略其魅力所在…...
OpenAI现已普遍提供带有视觉应用程序接口的GPT-4 Turbo
OpenAI宣布,其功能强大的GPT-4 Turbo with Vision模型现已通过公司的API全面推出,为企业和开发人员将高级语言和视觉功能集成到其应用程序中开辟了新的机会。 PS:使用Wildcard享受不受网络限制的API调用,详情查看教程 继去年 9 月…...

Swift中的元组属性
在Swift中,元组属性指的是一个元组作为结构体、类或枚举的属性。可以将一个元组作为属性来存储和访问多个值。 例如,考虑以下的Person类: class Person {var name: Stringvar age: Intvar address: (String, Int)init(name: String, age: I…...

【go从入门到精通】作用域,包详解
作者简介: 高科,先后在 IBM PlatformComputing从事网格计算,淘米网,网易从事游戏服务器开发,拥有丰富的C,go等语言开发经验,mysql,mongo,redis等数据库,设计模…...
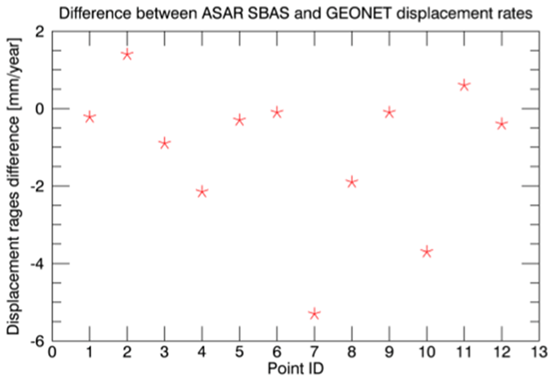
利用SARscape对日本填海造陆和天然气开采进行地表形变监测
日本千叶市,是日本南部重要的工业港市。位于西部的浦安市是一个典型的"填海造田"城市,东南部的东金区有一片天然气开采区域,本文利用SARscape,用干涉叠加的方法,即PS和SBAS,对这两个区域进行地表…...

“Python爬虫实战:高效获取网上公开美图“
如何通过Python创建一个简单的网络爬虫,以爬取网上的公开图片。网络爬虫是一种自动化工具,能够浏览互联网、下载内容并进行处理。请注意,爬取内容时应遵守相关网站的使用条款,尊重版权和隐私权。 ### 网络爬虫简介 网络爬虫&…...
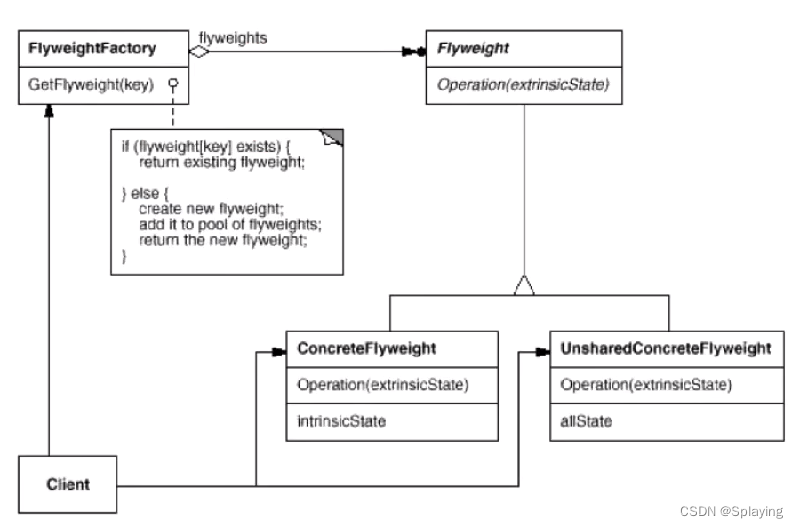
C++设计模式:享元模式(十一)
1、定义与动机 概述:享元模式和单例模式一样,都是为了解决程序的性能问题。面向对象很好地解决了"抽象"的问题,但是必不可免得要付出一定的代价。对于通常情况来讲,面向对象的成本大豆可以忽略不计。但是某些情况&#…...
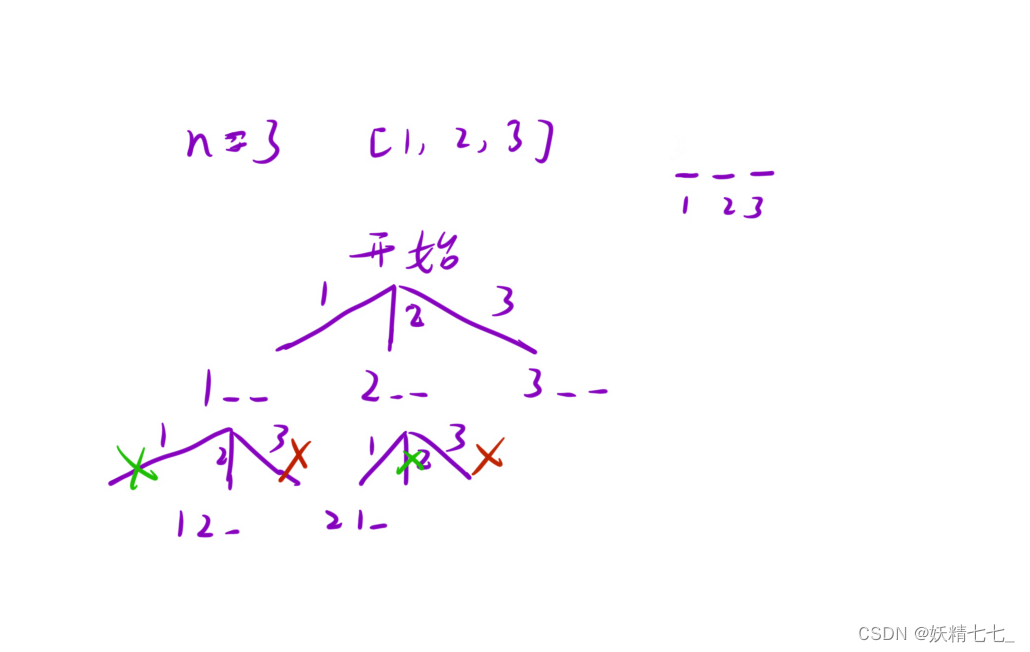
【三十六】【算法分析与设计】综合练习(3),39. 组合总和,784. 字母大小写全排列,526. 优美的排列
目录 39. 组合总和 对每一个位置进行枚举 枚举每一个数出现的次数 784. 字母大小写全排列 526. 优美的排列 结尾 39. 组合总和 给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不…...
——架构简介)
ARM Cordio WSF(一)——架构简介
1. 关于WSF WSF(wireless Software Foundation API),是一个RTOS抽象层。Wireless Software Foundation software service and porting layer,提供实时操作系统所需的基础服务,可基于不同平台进行实现,移植…...
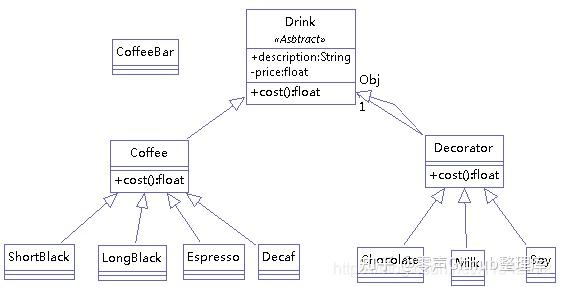
设计模式总结-装饰者模式
模式动机 一般有两种方式可以实现给一个类或对象增加行为: 继承机制,使用继承机制是给现有类添加功能的一种有效途径,通过继承一个现有类可以使得子类在拥有自身方法的同时还拥有父类的方法。但是这种方法是静态的,用户不能控制增…...

Stunnel网络加密服务
简介: Stunnel是一个用于创建SSL加密隧道的工具,针对本身无法进行TLS或SSL通信的客户端及服务器,Stunnel 可提供安全的加密连接。可以用于保护服务器之间的通信。您可以在每台服务器上安装Stunnel,并将其配置为在公网上加密传输数…...
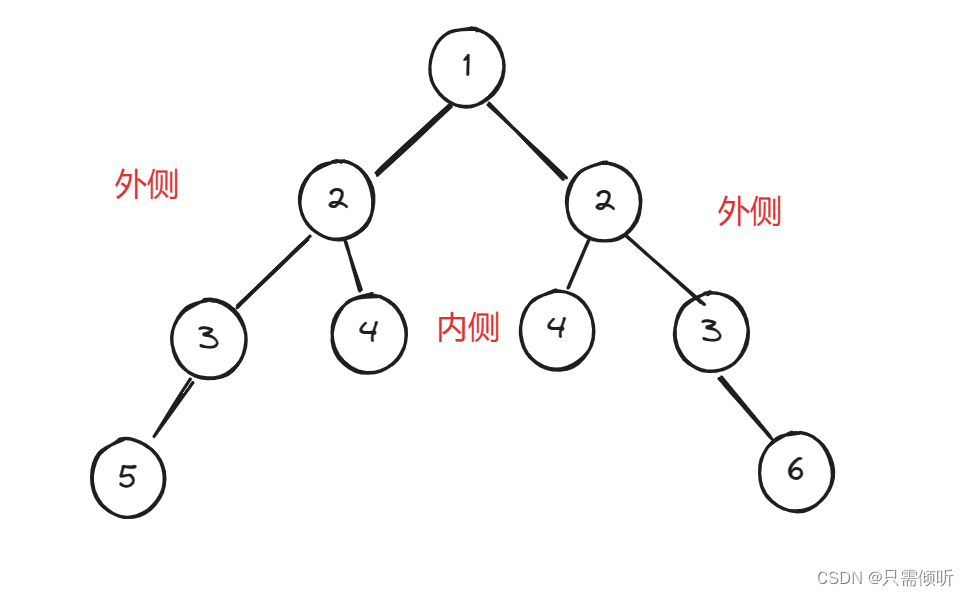
算法练习第16天|101. 对称二叉树
101. 对称二叉树 力扣链接https://leetcode.cn/problems/symmetric-tree/description/ 题目描述: 给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true示例 2&#x…...
YOLOV8实战教程——最新安装(截至24.4)
前言:YOLOV8更新比较快,最近用的时候发现有些地方已经跟之前不一样,甚至安装都会出现差异,所以做一个最新版的 yolov8 安装教程 一、Github 或者 GitCode 搜索 ultralytics 下载源码包,下载后解压到你需要安装的位置…...

老马失前蹄,竟然在数据库外键上翻车了,重温外键级联
一、什么是setuptools? setuptools 是一个用于创建、分发和安装 Python 包的核心库。 它可以帮助你: 定义 Python 包的元数据(如名称、版本、作者等)。 声明包的依赖项,确保你的包能够正确运行。 构建源代码分发包&…...

DSP题目:FFT算法的Matlab实现及其应用研究
DSP 题目:FFT算法的Matlab实现及应用研究最近帮室友调毕设的信号处理部分,他拿了个麦克风录的杂音,想把背景的50Hz工频噪音去掉,上来就问我“为啥我fft出来的峰不对”——害,这问题我刚学DSP的时候也踩过无数坑&#x…...

论文AIGC全红99%怎么救?2026实测Gemini去痕术:3组指令集联合3大工具,稳稳拉回10%安全线
视角重构,打破“平铺直叙”的机械感 AI生成的最大特征是“正确但平庸的上帝视角”。要ai降ai,第一步不是改词,而是强行植入一个具有批判性的“人类观察者”视角,迫使模型重组叙事逻辑。 核心原理:通过引入“辩证法”…...
)
避坑指南:Maya LiveLink插件安装常见报错解决方案(附FBX传输优化技巧)
Maya LiveLink插件避坑实战:从安装报错到FBX传输优化的全流程指南 每次打开Maya准备大干一场时,那个熟悉的.mll加载失败弹窗就像个不速之客——特别是当你需要在截止日期前完成虚幻引擎的动画对接时。作为连接Maya与虚幻引擎的神经中枢,LiveL…...

新手福音:用快马平台生成wsl安装ubuntu图文教程,轻松入门linux开发
最近在学Linux开发,发现Windows Subsystem for Linux(WSL)真是个神器,特别是搭配Ubuntu使用,既保留了Windows的便利性,又能体验原汁原味的Linux环境。不过刚开始安装配置时踩了不少坑,后来用Ins…...

保姆级教程:在OpenEuler 22.03 LTS-SP4上,用cephadm搞定Ceph Pacific集群部署
在OpenEuler 22.03 LTS-SP4上部署Ceph Pacific集群的完整指南 OpenEuler作为国产操作系统的代表,凭借其高性能和安全性,正逐渐成为企业级应用的首选。而Ceph作为开源的分布式存储解决方案,以其高可靠性和可扩展性赢得了广泛认可。本文将详细介…...

突破限制的完整方案:开源工具免费解锁Cursor Pro功能实战指南
突破限制的完整方案:开源工具免费解锁Cursor Pro功能实战指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...

LangGraph多智能体框架:构建持久化AI智能体的终极指南 [特殊字符]
LangGraph多智能体框架:构建持久化AI智能体的终极指南 🚀 【免费下载链接】langgraph Build resilient language agents as graphs. 项目地址: https://gitcode.com/GitHub_Trending/la/langgraph 在当今快速发展的AI领域,多智能体框架…...

新手福音:在快马平台开启你的云端代码编程第一课
作为一名刚接触编程的新手,我最近发现了一个特别适合入门的学习方式——云端代码编程。以前总觉得学编程要先装一堆软件、配置环境,光是这些准备工作就能劝退不少人。但在InsCode(快马)平台上,这些烦恼都不存在了。 零门槛的编程初体验 打开平…...

【论文速递】BubbleRAG:为“黑盒”知识图谱打造高召回、高精度的证据检索引擎
黑盒知识图谱检索中的三个挑战:语义实例化不确定性、结构路径不确定性、证据比较不确定性 01 研究背景 在复杂问答(如多跳推理、专家识别)任务中,基于知识图谱(KG)的检索增强生成(RAG&#x…...