Spark-Scala语言实战(15)
在之前的文章中,我们学习了如何在spark中使用键值对中的学习键值对方法中的lookup,cogroup两种方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞,谢谢。
Spark-Scala语言实战(14)-CSDN博客文章浏览阅读1.5k次,点赞33次,收藏25次。今天开始的文章,我会带给大家如何在spark的中使用我们的键值对方法,今天学习键值对方法中的lookup,cogroup两种方法。希望我的文章能帮助到大家,也欢迎大家来我的文章下交流讨论,共同进步。https://blog.csdn.net/qq_49513817/article/details/137441090
今天的文章开始,我会带着大家来做三道任务,运用之前学到的方法,温故知新,举一反三,将知识紧紧掌握,希望你能在我的文章中有所收获。
目录
一、知识回顾
二、任务实现
1.使用Spark完成单词去重
2.使用Spark统计133 136 139开头的总流量
3.完成统计相同字母组成的单词
一、知识回顾
上一篇文章中我们学习了RDD键值对的两种方法,分别是lookup,cogroup。
lookup是我们的查找方法,它用于返回我们指定键所对应的值。

我们创建了两个RDD一个名为p包含了我们的键值对,一个名为pp包含了我们需要查找的键。然后使用 map来实现我们的lookoup方法。
运行代码它就会返回我们需要的键所对应的值,没有就会输出None
然后就是我们 cogroup方法。它是一种常见的组合操作,用于合并两个或多个数据组中具有相同键的数据。
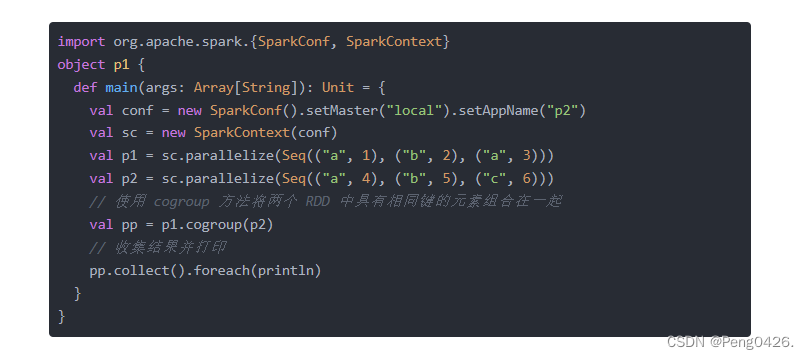
可以看到代码我们通过 cogroup方法将p1,p2组合到一起了,那么收集结果打印出来会是什么样子呢?
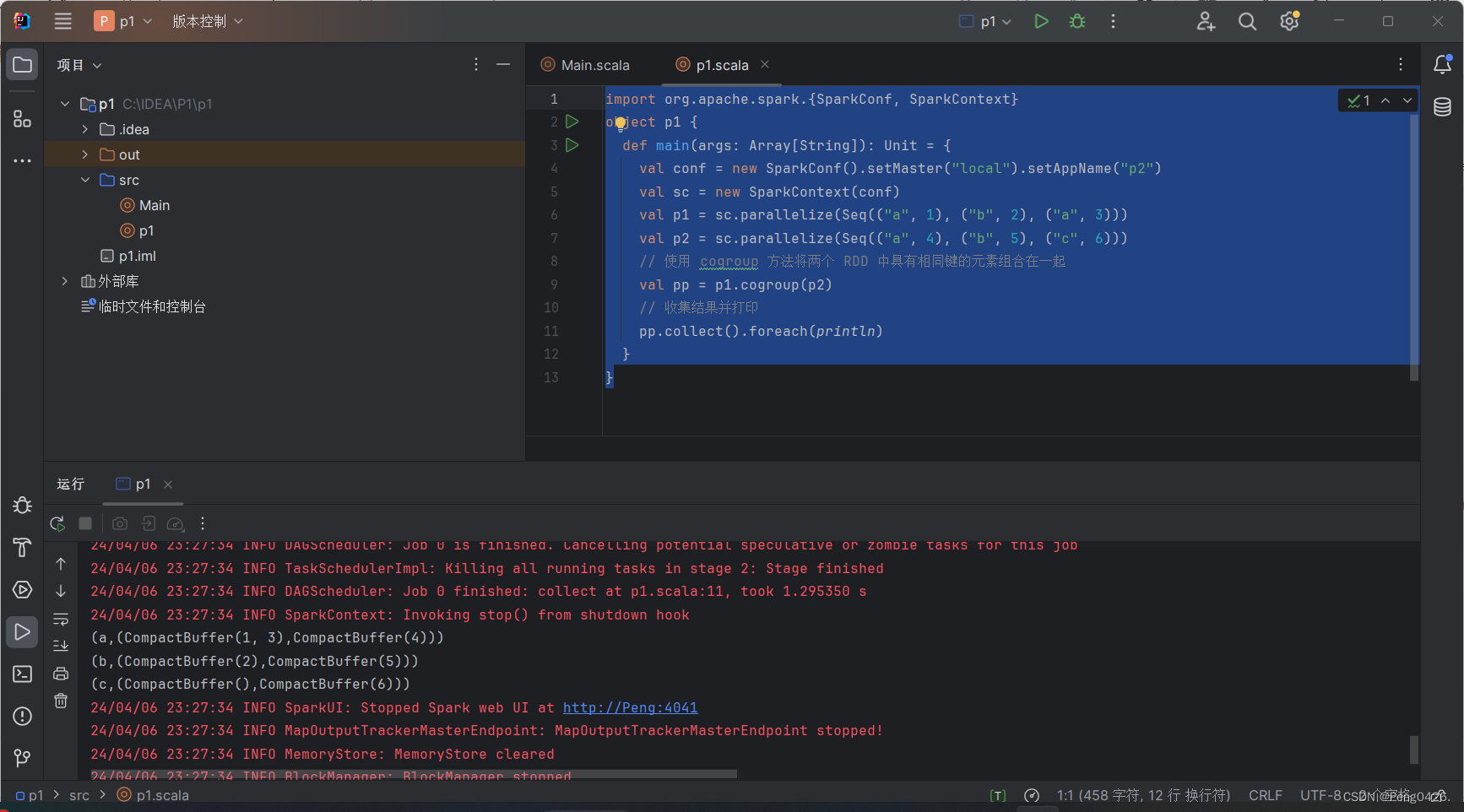
它将我们值通过键全部合并在一起了
复习完毕,现在开始今天的学习吧~
二、任务实现
1.使用Spark完成单词去重
现在我们有一个名为text01的txt文件
它里面的数据如下:
java php hello word
php hi exe java
python hello kitty
php happy abc java
现在,我们需要用到之前所学的知识将它进行去重操作
解题思路:
首先我们肯定要将文件的内容读取出来
val p = sc.textFile("C:\\IDEA\\P1\\p1\\text01.txt")然后就是切分我们文件的内容,将它里面的单词转换成一个数组啊,列表啊或者其他,根据需求转化。
def pp(line: String): Array[String] = {line.split("\\s+")//'\s+中\ 是转义字符。s 是代表空白字符的元字符。+ 表示前面的字符或组(在这里是 \s)可以出现一次或多次。'}这里我们使用了一个\\s+,它的意思注释的很清楚,主要作用还是设置我们的切分。
现在准备工作做完了就可以开始去重了
val ppp= p.flatMap(pp)val pppp = ppp.distinct().collect()pppp.foreach(println)使用我们的distinct()方法进行去重操作,最后收集RDD数据并打印
完整代码:
import org.apache.spark.{SparkConf, SparkContext}object p1 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("ppp")val sc = new SparkContext(conf)val p = sc.textFile("C:\\IDEA\\P1\\p1\\text01.txt")def pp(line: String): Array[String] = {line.split("\\s+")//'\s+中\ 是转义字符。s 是代表空白字符的元字符。+ 表示前面的字符或组(在这里是 \s)可以出现一次或多次。'}val ppp= p.flatMap(pp)val pppp = ppp.distinct().collect()pppp.foreach(println)}
}运行代码:

可以看到成功完成任务需求,读取外部文件并去重。
2.使用Spark统计133 136 139开头的总流量
我们这里有两对数据,分别是手机号和使用的流量
13326293050 81
13626594101 50
13326435696 30
13926265119 40
13326564191 2106
13626544191 1432
13919199499 300
我们需要将它通过手机号前三位区分,然后统计133 136 139开头的总流量
解题思路:
在这里,我想到的方法是创建一个键值对,将手机号和流量进行一个对应
val p = sc.parallelize(Array((13326293050L, 81),(13626594101L, 50),(13326435696L, 30),(13926265119L, 40),(13326564191L, 2106),(13626544191L, 1432),(13919199499L, 300)//int超出存储限制,添加L变为long))然后进行取前手机号三位并且使用groupByKey方法分组的方法
val pp = p.map { case (phone, value) =>val prefix = (phone / 1000000).toString.take(3)(prefix, value)}.groupByKey()//取出前三位并分组最后将我们三个组里的数据进行一个sum求和并打印
val ppp=pp.mapValues(_.sum)//值相加ppp.foreach(println)完整代码:
import org.apache.spark.{SparkConf, SparkContext}object p2 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("ppp")val sc = new SparkContext(conf)val p = sc.parallelize(Array((13326293050L, 81),(13626594101L, 50),(13326435696L, 30),(13926265119L, 40),(13326564191L, 2106),(13626544191L, 1432),(13919199499L, 300)//int超出存储限制,添加L变为long))val pp = p.map { case (phone, value) =>val prefix = (phone / 1000000).toString.take(3)(prefix, value)}.groupByKey()//取出前三位并分组val ppp=pp.mapValues(_.sum)//值相加ppp.foreach(println)}
}运行代码:

完成任务,分组并统计流量
3.完成统计相同字母组成的单词
现在我们有一个名为text02的txt文件
它里面的数据如下:
abc acb java
avaj bac
cba abc
jvaa php hpp
pph python thonpy
现在,我们需要用到之前所学的知识将它统计相同字母组成的单词出现的次数。
解题思路:
首先,肯定还是要读取文件
val p = sc.textFile("C:\\IDEA\\P1\\p1\\text02.txt")然后对单词中的字母排序
def sortLetters(word: String): String = {word.toLowerCase().replaceAll("\\s+", "").sorted}最后,分割单词,进行排序与reduceByKey方法统计
val pp = p.flatMap(_.split("\\s+")) // 分割每行文本为单词.map(word => (sortLetters(word), 1)) // 对单词中的字母进行排序,并映射到计数1.reduceByKey(_ + _) // 统计相同字母组成的单词数量收集数据并打印
pp.collect().foreach(println)完整代码:
import org.apache.spark.{SparkConf, SparkContext}object p3 {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local").setAppName("ppp")val sc = new SparkContext(conf)val p = sc.textFile("C:\\IDEA\\P1\\p1\\text02.txt")// 用于对单词中的字母进行排序def sortLetters(word: String): String = {word.toLowerCase().replaceAll("\\s+", "").sorted}// 对每一行文本进行处理,统计具有相同字母组成的单词数量val pp = p.flatMap(_.split("\\s+")) // 分割每行文本为单词.map(word => (sortLetters(word), 1)) // 对单词中的字母进行排序,并映射到计数1.reduceByKey(_ + _) // 统计相同字母组成的单词数量pp.collect().foreach(println)}
}运行代码:
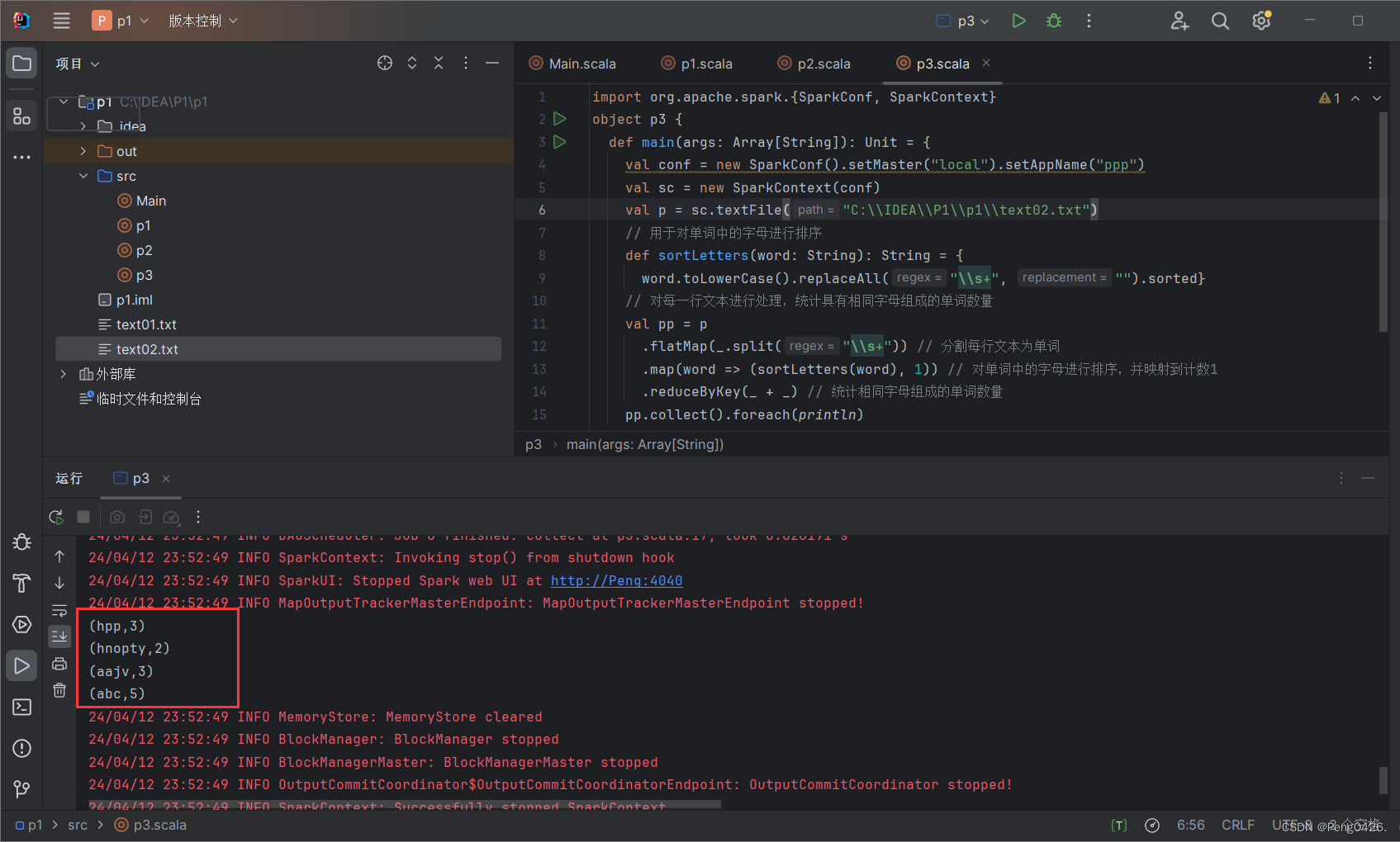 完成任务,统计相同字母组成的单词次数
完成任务,统计相同字母组成的单词次数
最后,代码的可变性很多,不同的写法不同的方法有时候也能完成相同的任务。我的解题思路可以当作一种参考,期待大家能用自己不同的方式完成任务。
相关文章:
Spark-Scala语言实战(15)
在之前的文章中,我们学习了如何在spark中使用键值对中的学习键值对方法中的lookup,cogroup两种方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章写的不错,请留下你宝贵的点赞&#…...
【SpringBoot XSS存储漏洞 拦截器】Java纯后端对于前台输入值的拦截校验实现 一个类加一个注解结束
先看效果: 1.js注入拦截: 2.sql注入拦截 生效只需要两步: 1.创建Filter类,粘贴如下代码: package cn.你的包命.filter; import java.io.BufferedReader; import java.io.ByteArrayInputStream; import java.io.IO…...

【微信小程序】canvas开发笔记
【微信小程序】canvasToTempFilePath:fail fail canvas is empty 看说明书 最好是先看一下官方文档点此前往 如果是canvas 2d 写canvas: this.canvas,,如果是旧版写canvasId: ***, 解决问题 修改对应的代码,如下所示,然后再试试运行&#x…...

TripoSR: Fast 3D Object Reconstruction from a Single Image 论文阅读
1 Abstract TripoSR的核心是一个基于变换器的架构,专为单图像3D重建设计。它接受单张RGB图像作为输入,并输出图像中物体的3D表示。TripoSR的核心包括:图像编码器、图像到三平面解码器和基于三平面的神经辐射场(NeRF)。…...

u盘为什么一插上电脑就蓝屏,u盘一插电脑就蓝屏
u盘之前还好好的,可以传输文件,使用正常,但是最近使用时却出现问题了。只要将u盘一插入电脑,电脑就显示蓝屏。u盘为什么一插上电脑就蓝屏呢?一般,导致的原因有以下几种。一,主板的SATA或IDE控制器驱动损坏…...

【Redis】redis面试相关积累
Redis到底是多线程还是单线程? Redis 在设计上是单线程的,这意味着 Redis 服务器在任何给定时刻只能执行一个命令。然而,这并不意味着 Redis 无法利用多核 CPU,因为 Redis 使用了一些技术来提高性能和并发性,例如非阻…...
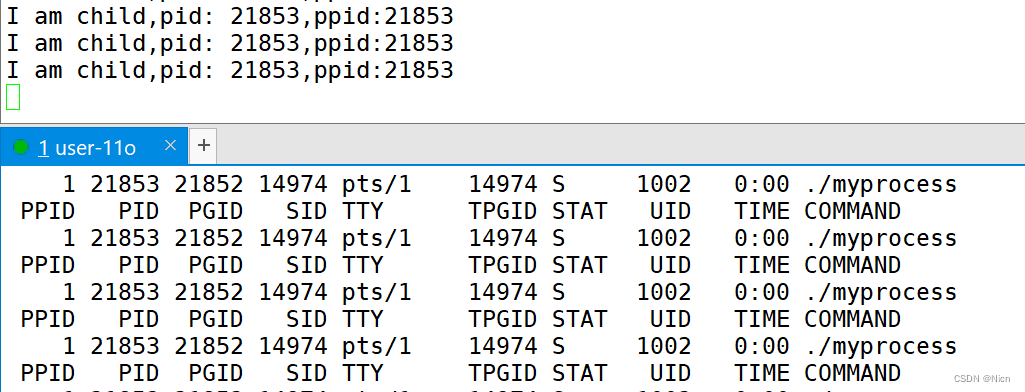
【Linux】进程的状态(运行、阻塞、挂起)详解,揭开孤儿进程和僵尸进程的面纱,一篇文章万字讲透!!!!进程的学习②
目录 1.进程排队 时间片 时间片的分配 结构体内存对齐 偏移量补充 对齐规则 为什么会有对齐 2.操作系统学科层面对进程状态的理解 2.1进程的状态理解 ①我们说所谓的状态就是一个整型变量,是task_struct中的一个整型变量 ②.状态决定了接下来的动作 2.2运行状态 2.…...
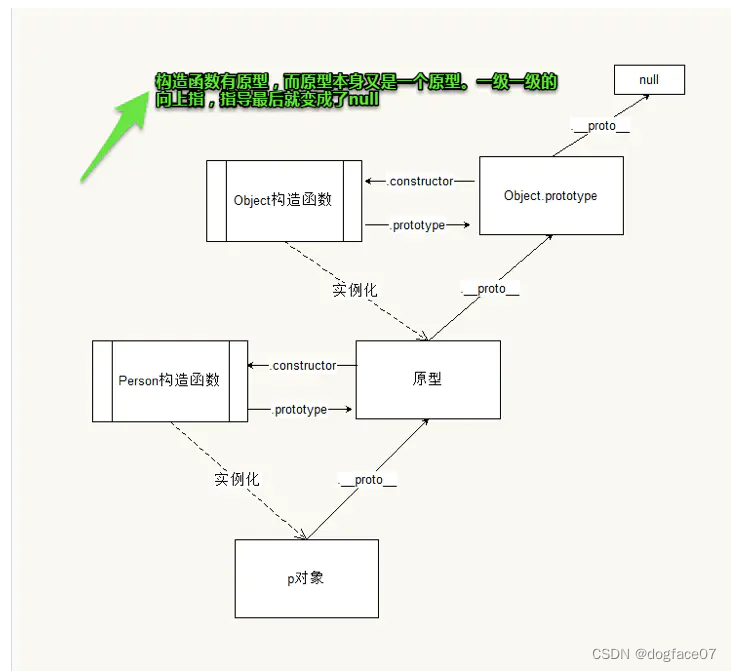
前端js基础知识(八股文大全)
一、js的数据类型 值类型(基本类型):数字(Number)、字符串(String)、布尔(Boolean)、对空(Null)、未定义(Undefined)、Symbol,大数值类型(BigInt) 引用数据类型:对象(Object)、数组…...
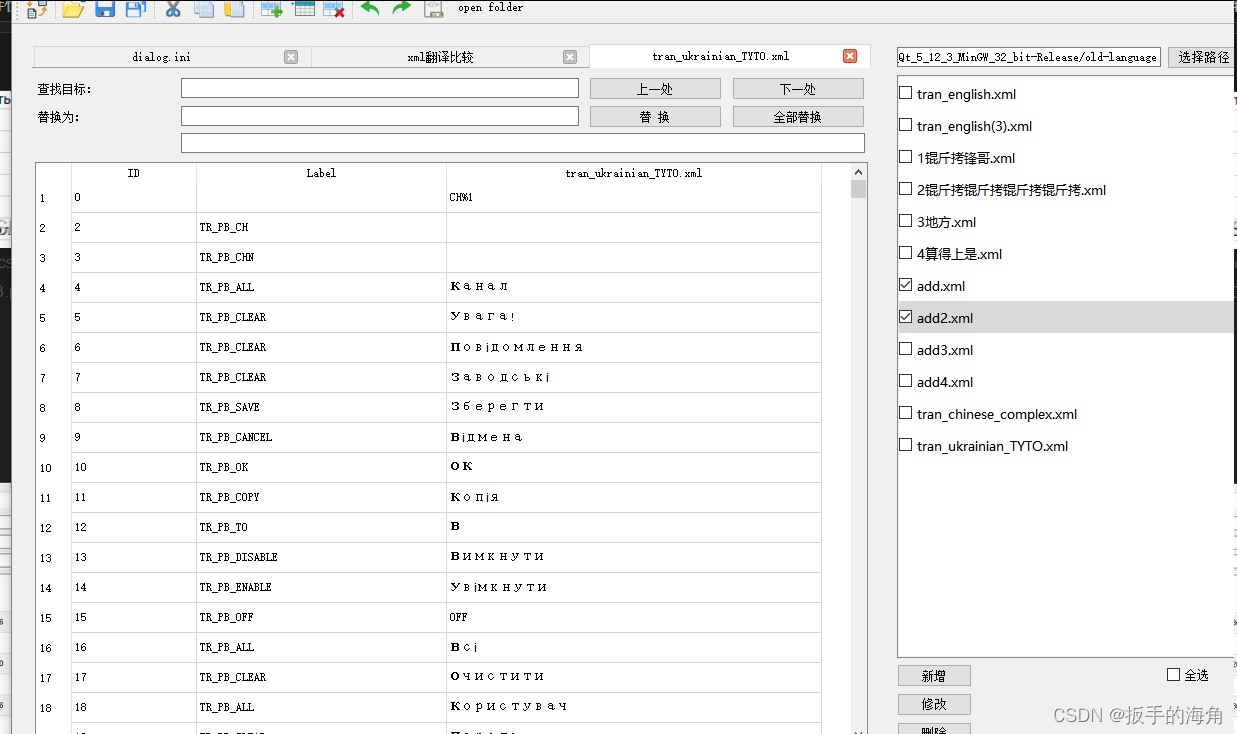
316_C++_xml文件解析成map,可以放到表格上 + xml、xlsx文件互相解析
xml文件例如: <?xml version"1.0" encoding"UTF-8" standalone"yes"?> <TrTable> <tr id"0" label"TR_PB_CH" text"CH%2"/> <tr id"4" label"TR_PB_CHN"…...
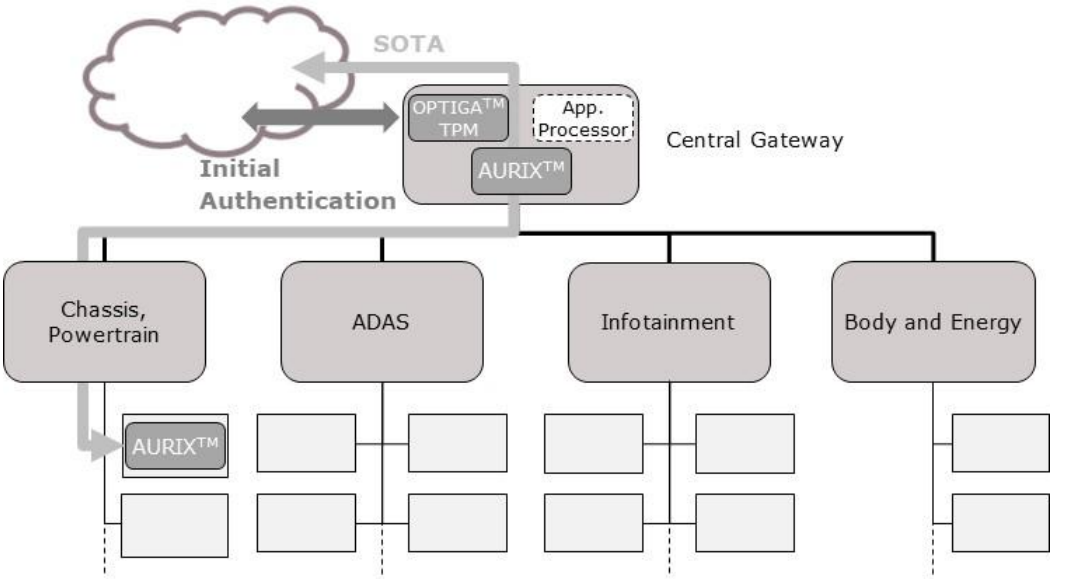
未来汽车硬件安全的需求(2)
目录 4.汽车安全控制器 4.1 TPM2.0 4.2 安全控制器的硬件保护措施 5. EVITA HSM和安全控制器结合 6.小结 4.汽车安全控制器 汽车安全控制器是用于汽车工业安全关键应用的微控制器。 他们的保护水平远远高于EVITA HSM。今天的典型应用是移动通信,V2X、SOTA、…...

html+javascript,用date完成,距离某一天还有多少天
图片展示: html代码 如下: <style>* {margin: 0;padding: 0;}.time-item {width: 500px;height: 45px;margin: 0 auto;}.time-item strong {background: orange;color: #fff;line-height: 100px;font-size: 40px;font-family: Arial;padding: 0 10px;margin-right: 10px…...
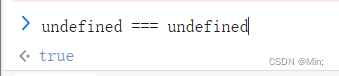
跟bug较劲的第n天,undefined === undefined
前情提要 场景复现 看到这张图片,有的同学也许不知道这个冷知识,分享一下,是因为我在开发过程中踩到的坑,花了三小时排查出问题的原因在这,你们说值不值。。。 我分享下我是怎么碰到的这个问题,下面看代码…...

数据结构_基于链表的通讯录
顺序表的源代码需要略作修改,如下 将数据类型改为通讯录的结构体。注释掉打印,查找的函数。 SList.h #define _CRT_SECURE_NO_WARNINGS 1#include<stdio.h> #include<stdlib.h> #include<assert.h> #include"Contact.h"ty…...

jenkins+gitlab配置
汉化 1、安装Localization: Chinese (Simplified)插件 (此处我已安装) (安装完成后重启jenkins服务即可实现汉化) 新增用户权限配置 1、安装插件 Role-based Authorization Strategy 2、全局安全配置 3、配置角色权限 4、新建…...
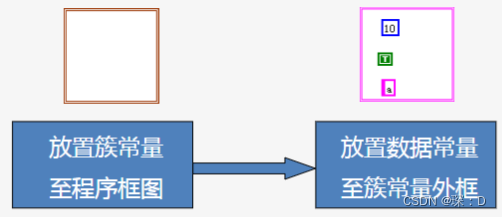
【Labview】虚拟仪器技术
一、背景知识 1.1 虚拟仪器的定义、组成和应用 虚拟仪器的特点 虚拟仪器的突出特征为“硬件功能软件化”,虚拟仪器是在计算机上显示仪器面板,将硬件电路完成信号调理和处理功能由计算机程序完成。 虚拟仪器的组成 硬件软件 硬件是基础,负责将…...

IvorySQL 3.2原理解析|与Oracle 12c XML函数兼容性的实现机制
[发行日期:2024年4月11日] IvorySQL 3.2基于PostgreSQL 16.2,引入了多种Oracle XML函数的全面兼容性功能,同时修复了多个问题,更多信息请参考文档网站。 >>>新版本体验链接: https://docs.ivorysql.org/cn…...
SpringBoot + Dobbo + nacos
SpringBoot Dobbo nacos 一、nacos https://nacos.io/zh-cn/docs/quick-start.html 1、下载安装包 https://github.com/alibaba/nacos/releases/下载后在主目录下,创建一个logs的文件夹:用来存日志 2、启动nacos 在bin目录下打开cmd运行启动命令&a…...
)
学习笔记-微服务基础(黑马程序员)
框架 spring cloudspring cloud alibaba Eureka eureka-server 注册中心 eureka-client 客户端每30s发送心跳服务 服务消费者服务提供者 server 依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-star…...

每日Bug汇总--Day05
Bug汇总—Day05 一、项目运行报错 二、项目运行Bug 1、**问题描述:**前端将从后台查询的数据作为参数进行get请求,参数为空 原因分析: 这种写法可能只支全局的参数调用方法的传参响应 代码实现 if (this.jishiName) {this.$http({url…...

docker、ctr、crictl命令对比
命令dockerctr(containerd)crictl(kubernetes)查看运行的容器docker psctr task ls/ctr container lscrictl ps查看镜像docker imagesctr image lscrictl images查看容器日志docker logs无crictl logs查看容器数据信息docker insp…...

单电源运放差分放大电路实战:3.3V供电下的精确计算与仿真验证
单电源运放差分放大电路实战:3.3V供电下的精确计算与仿真验证 在嵌入式系统开发中,信号调理电路的设计往往面临低功耗与高精度的双重挑战。单电源运放差分放大电路因其结构简单、成本低廉,成为3.3V供电环境下小信号放大的首选方案。本文将深入…...

StructBERT情感分类实操案例:10分钟搭建客服情绪识别工具
StructBERT情感分类实操案例:10分钟搭建客服情绪识别工具 1. 引言:为什么需要客服情绪识别? 你有没有遇到过这样的情况:客服团队每天处理大量客户咨询,却很难快速识别哪些客户真的不满意,哪些只是普通询问…...

开箱即用!Ollama+EmbeddingGemma-300m搭建本地RAG系统基础
开箱即用!OllamaEmbeddingGemma-300m搭建本地RAG系统基础 1. 为什么选择EmbeddingGemma-300m 在构建本地检索增强生成(RAG)系统时,文本嵌入模型的选择至关重要。传统方案往往面临两个痛点:要么模型体积庞大需要GPU支持,要么轻量…...

Tao-8k代码解释与教学:针对C语言基础知识的智能辅导
Tao-8k代码解释与教学:针对C语言基础知识的智能辅导 最近在辅导几个朋友学习C语言,发现一个挺普遍的问题:很多初学者卡在指针、内存管理这些概念上,看教材觉得懂了,一写代码就懵。传统的学习方式要么是看书࿰…...

Stable Yogi Leather-Dress-Collection保姆级教程:LoRA目录扫描失败、加载卡顿等5类报错解决
Stable Yogi Leather-Dress-Collection保姆级教程:LoRA目录扫描失败、加载卡顿等5类报错解决 1. 工具简介 Stable Yogi Leather-Dress-Collection是一款基于Stable Diffusion v1.5(SD 1.5)和Anything V5动漫底座模型开发的2.5D皮衣穿搭生成…...
)
LeetCode(15/100)
数组中除当前数外所有数乘积。不许用除法,时间复杂度O(N),左右指针求前缀乘积和后缀乘积,还能u空间。 class Solution {public int[] productExceptSelf(int[] nums) {int len nums.length;// L 和 R 分别表示左右两侧的乘积列表int[] L ne…...

从“冷肿瘤”到“热肿瘤”:CAF亚型如何影响免疫治疗疗效?给临床医生的解读
解码CAF亚型:如何通过肿瘤微环境优化免疫治疗策略 在肿瘤免疫治疗的时代,我们常常困惑于为什么某些患者对PD-1/PD-L1抑制剂反应良好,而另一些则完全无响应。越来越多的证据表明,肿瘤微环境(TME)中的癌症相关成纤维细胞(CAF)亚型可…...

Mujoco入门指南:从安装到基础控制
1. Mujoco简介与安装准备 Mujoco(Multi-Joint dynamics with Contact)是一款专注于机器人动力学仿真的物理引擎。我第一次接触Mujoco时就被它的轻量化震惊了——Windows安装包只有5.7MB,相比其他动辄上GB的仿真软件简直是轻量级选手。它特别适…...
)
RStudio Server配置避坑指南:解决常见安装与启动问题(含conda环境配置)
RStudio Server配置避坑指南:解决常见安装与启动问题(含conda环境配置) 在数据科学和统计分析领域,RStudio Server作为一款强大的集成开发环境,为团队协作和远程工作提供了极大便利。然而,当我们将RStudio …...

Everything Claude Code 爆火背后:我们正在用“团队”而非“个体”构建 AI 编程助手
最近 24 小时,GitHub 上一个叫 Everything Claude Code 的项目新增了 5707 颗星,总星数突破 13 万。如果你只把它看作“Claude Code 的配置增强包”,那可能错过了更重要的信号——这波热度背后,是一场从“工具竞争”向“工程体系竞…...