Flink WordCount实践
目录
前提条件
基本准备
批处理API实现WordCount
流处理API实现WordCount
数据源是文件
数据源是socket文本流
打包
提交到集群运行
命令行提交作业
Web UI提交作业
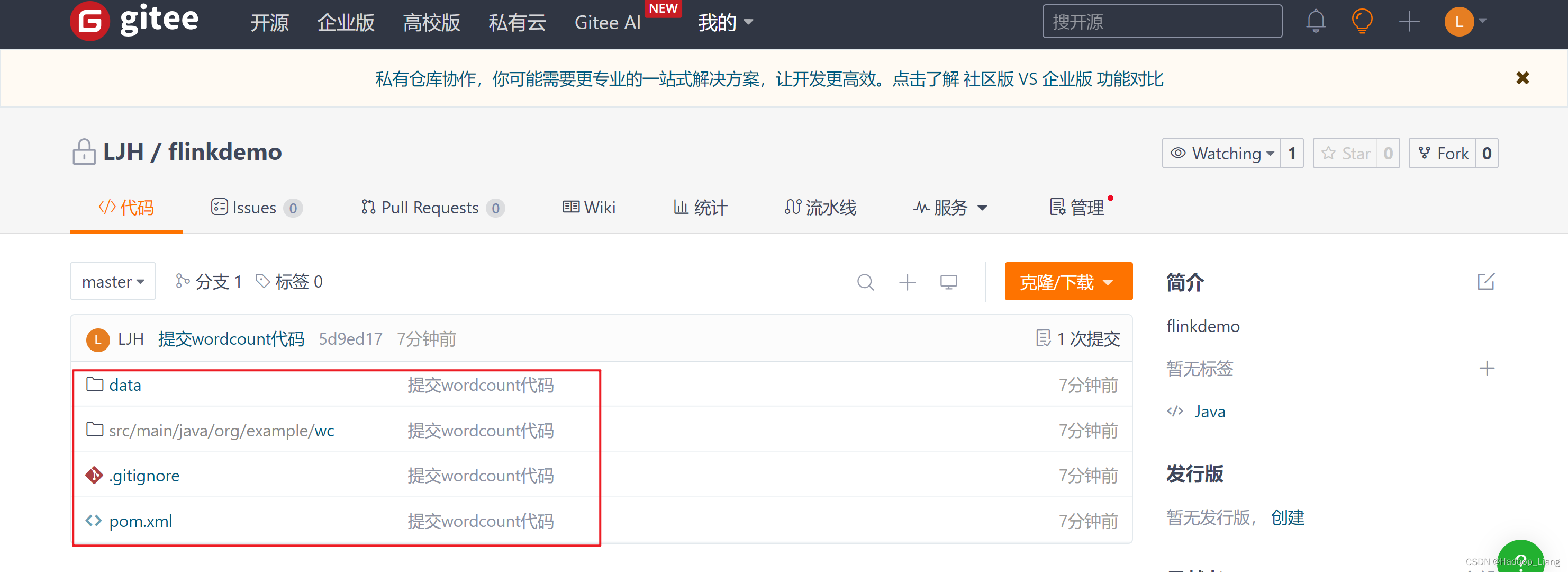
上传代码到gitee
前提条件
Windows安装好jdk8、Maven3、IDEA
Linux安装好Flink集群,可参考:CentOS7安装flink1.17完全分布式
基本准备
创建项目
使用IDEA创建一个新的Maven项目,项目名称,例如:flinkdemo

添加依赖
在项目的pom.xml文件中添加Flink的依赖。
<properties><flink.version>1.17.1</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency></dependencies>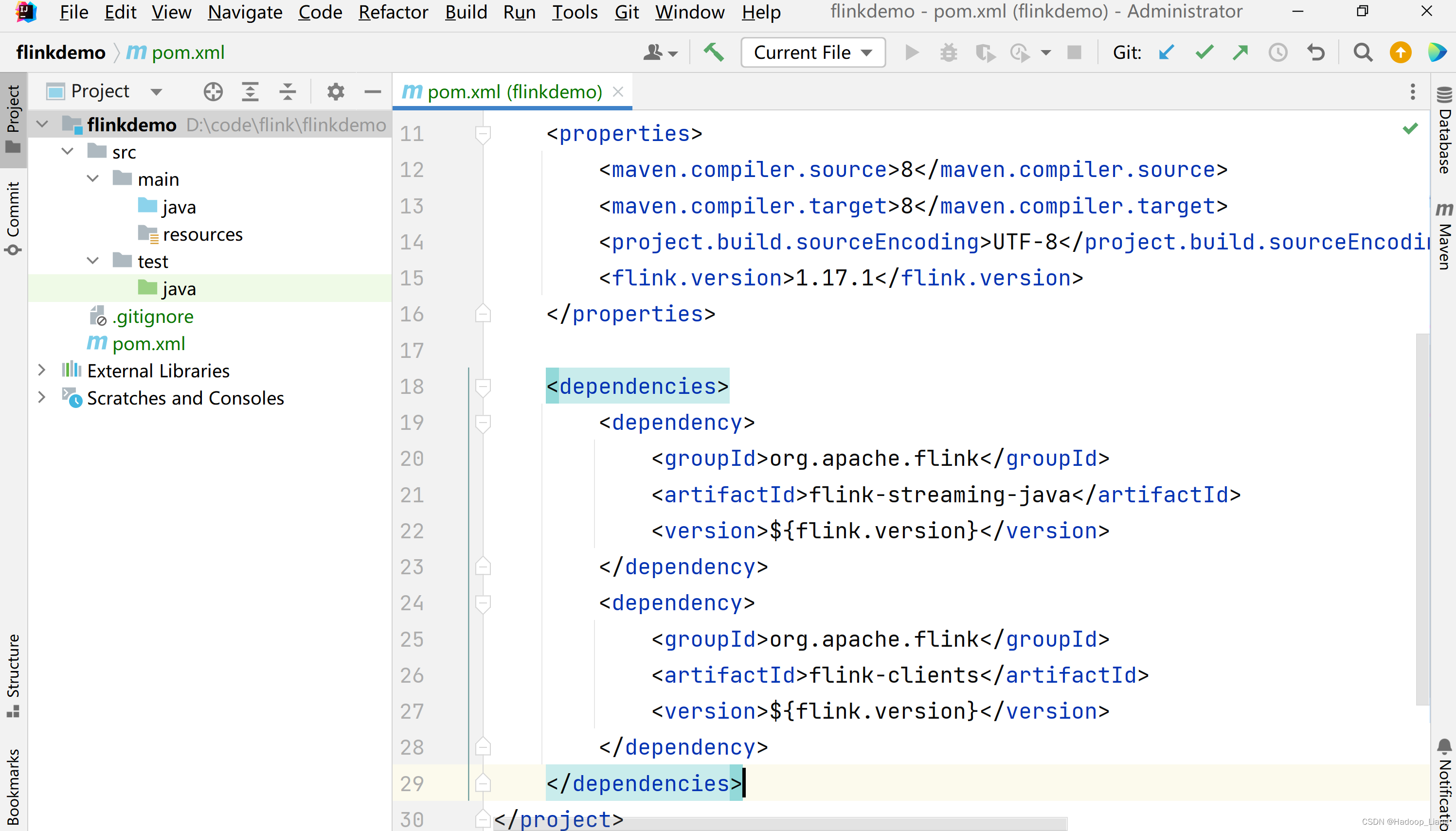
刷新依赖
刷新依赖后,能看到相关依赖如下
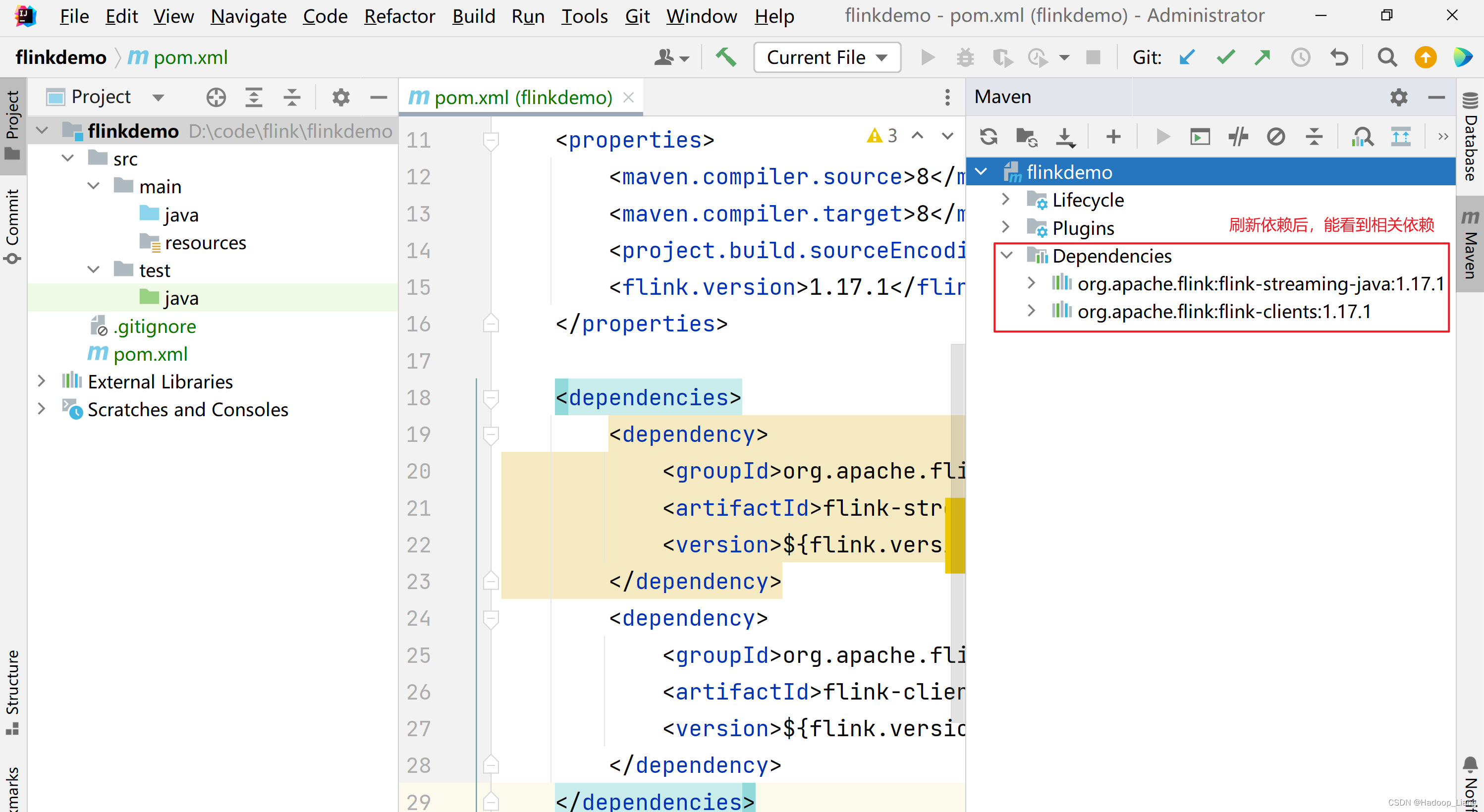
刷新依赖过程需要等待一些时间来下载相关依赖。
如果依赖下载慢,可以设置阿里云仓库镜像:
1.设置maven的settings.xml

在</mirrors>上面一行添加阿里云仓库镜像
<mirror><id>alimaven</id><name>aliyun maven</name><url>http://maven.aliyun.com/nexus/content/groups/public/</url><mirrorOf>central</mirrorOf> </mirror>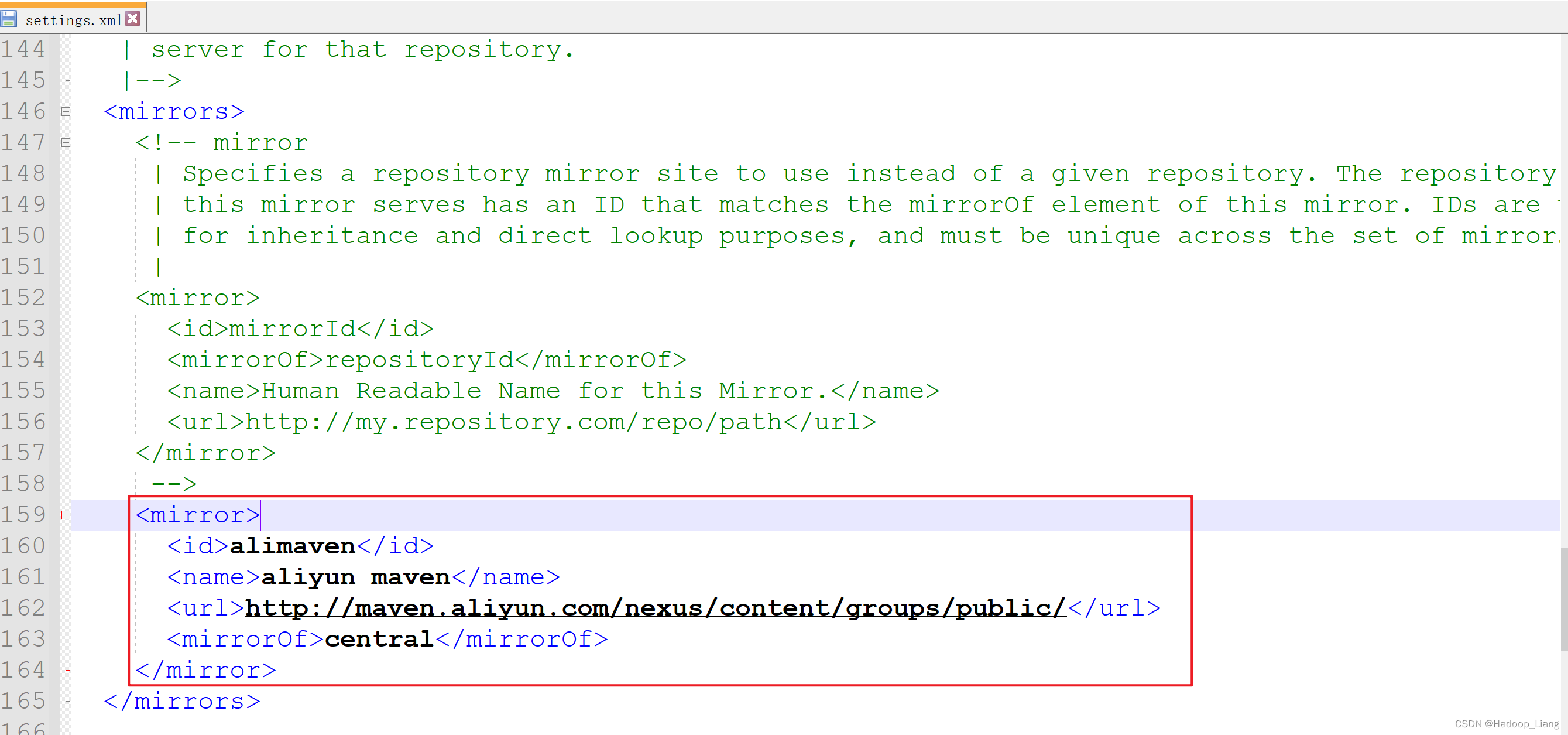
2.IDEA设置maven

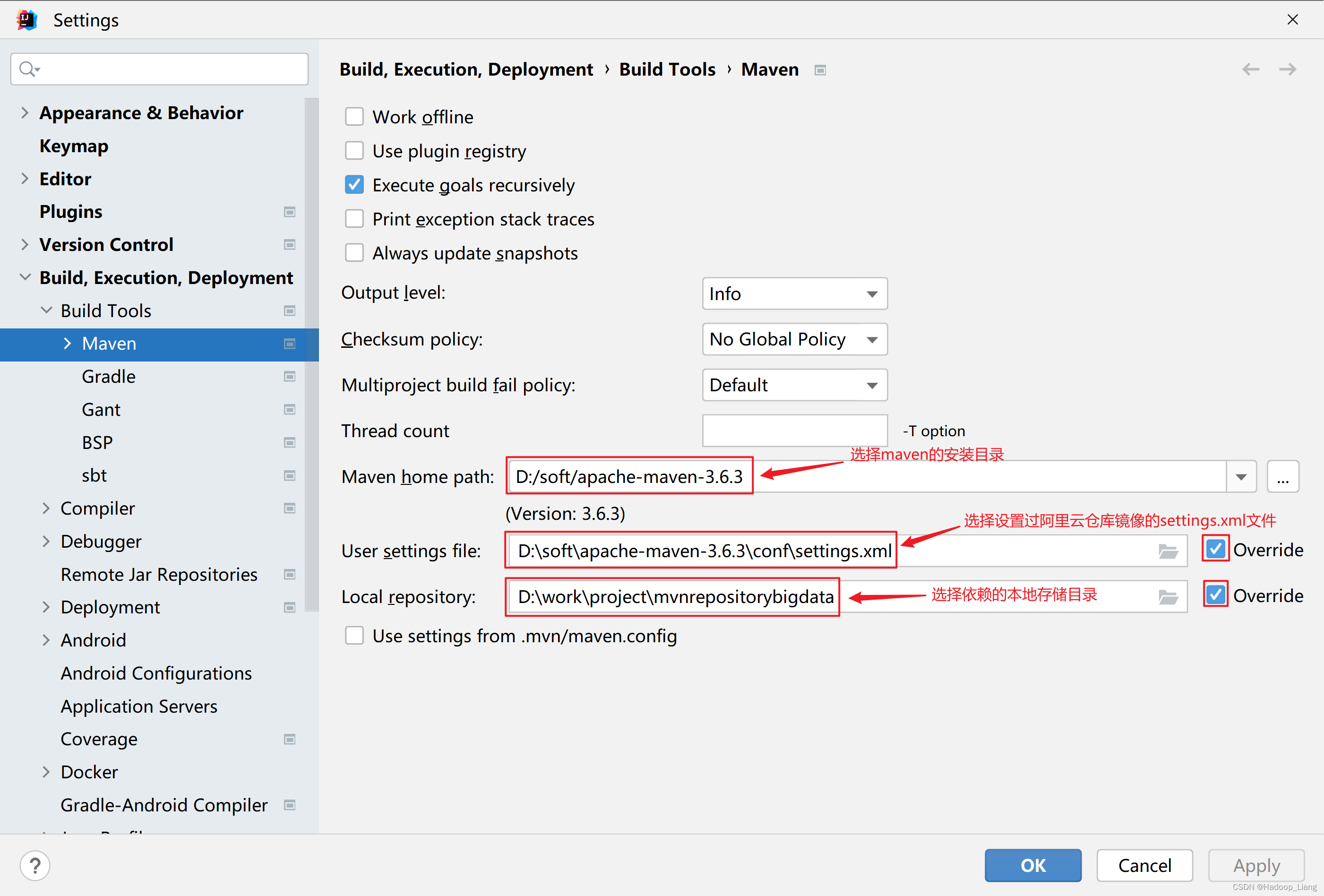
数据准备
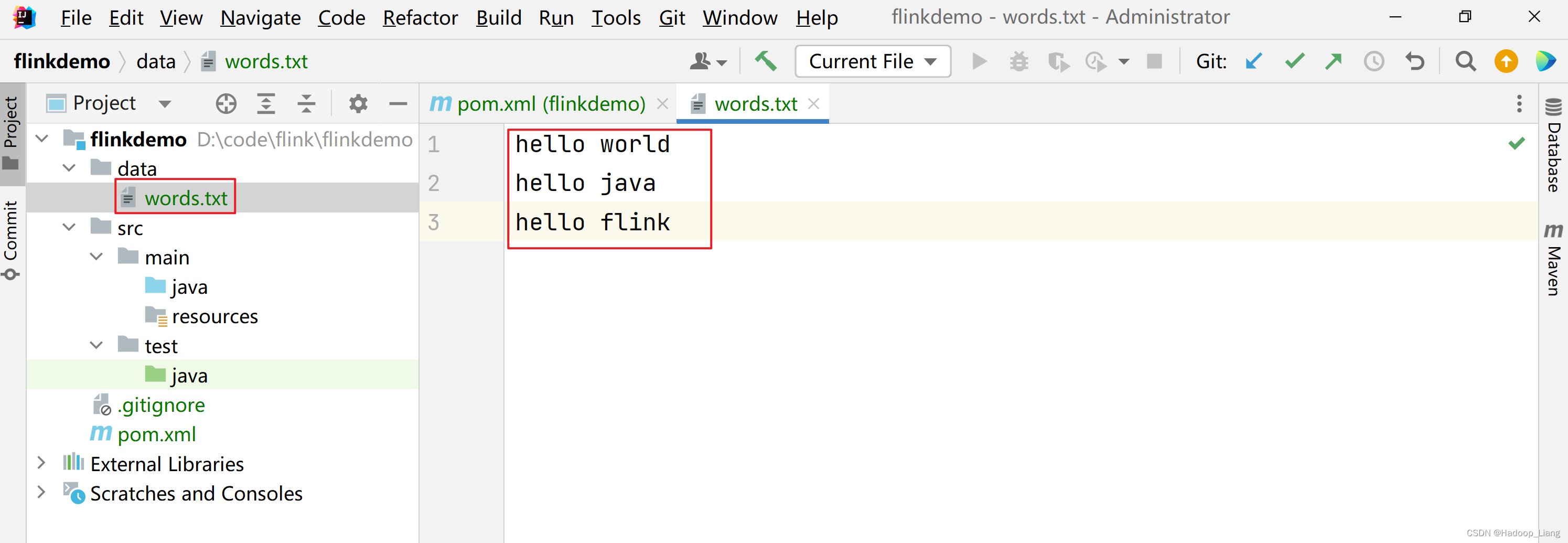
在工程的根目录下,新建一个data文件夹
并在data文件夹下创建文本文件words.txt
内容如下
hello world hello java hello flink
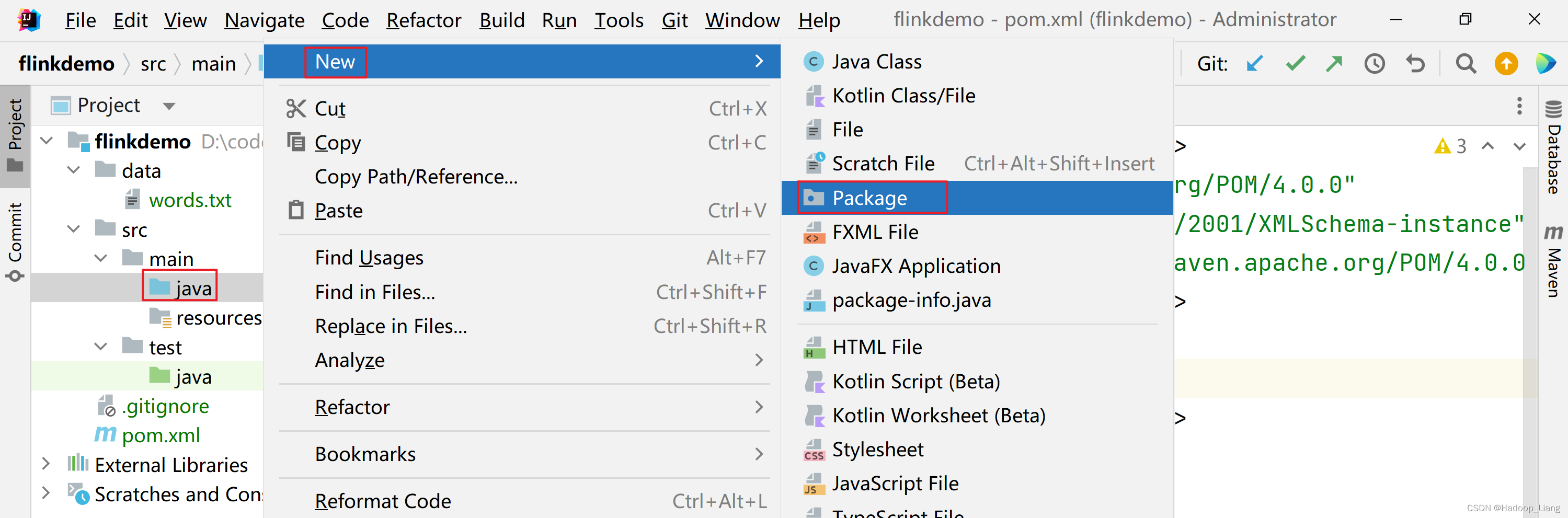
新建包
右键src/main下的java,新建Package
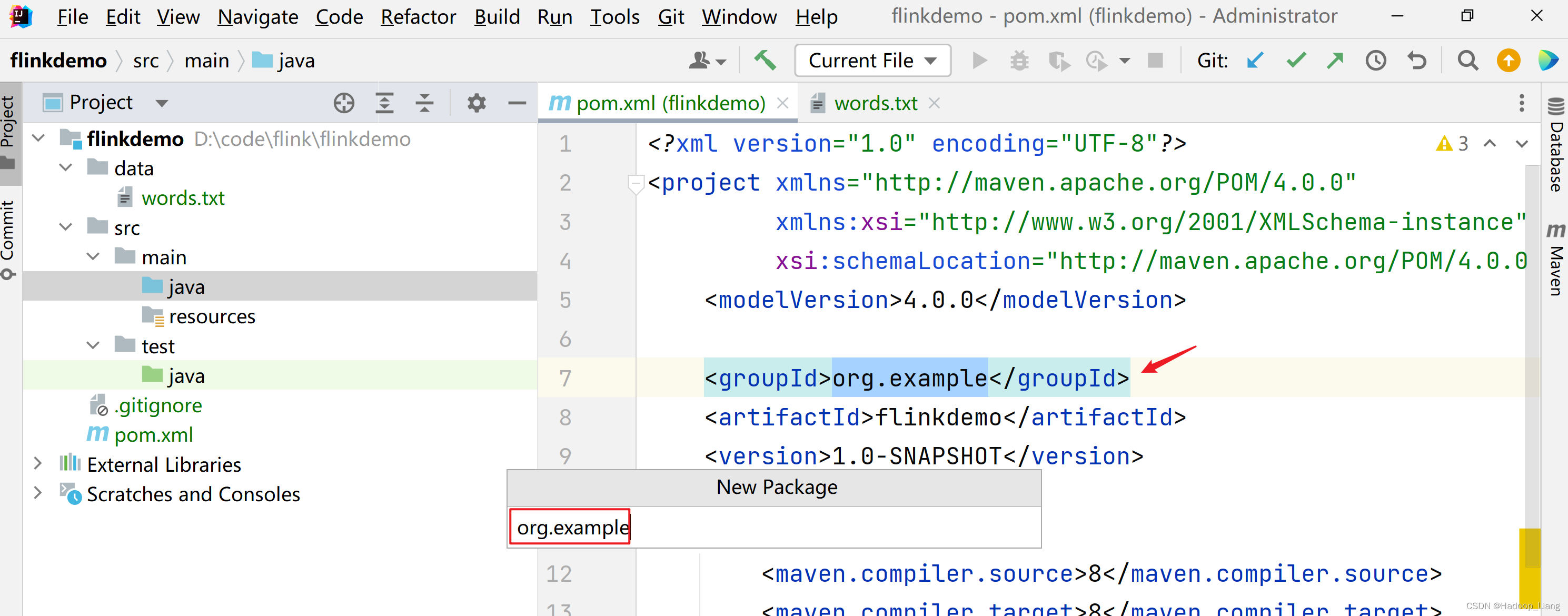
填写包名org.example,包名与groupId的内容一致。
批处理API实现WordCount
在org.exmaple下新建wc包及BatchWordCount类
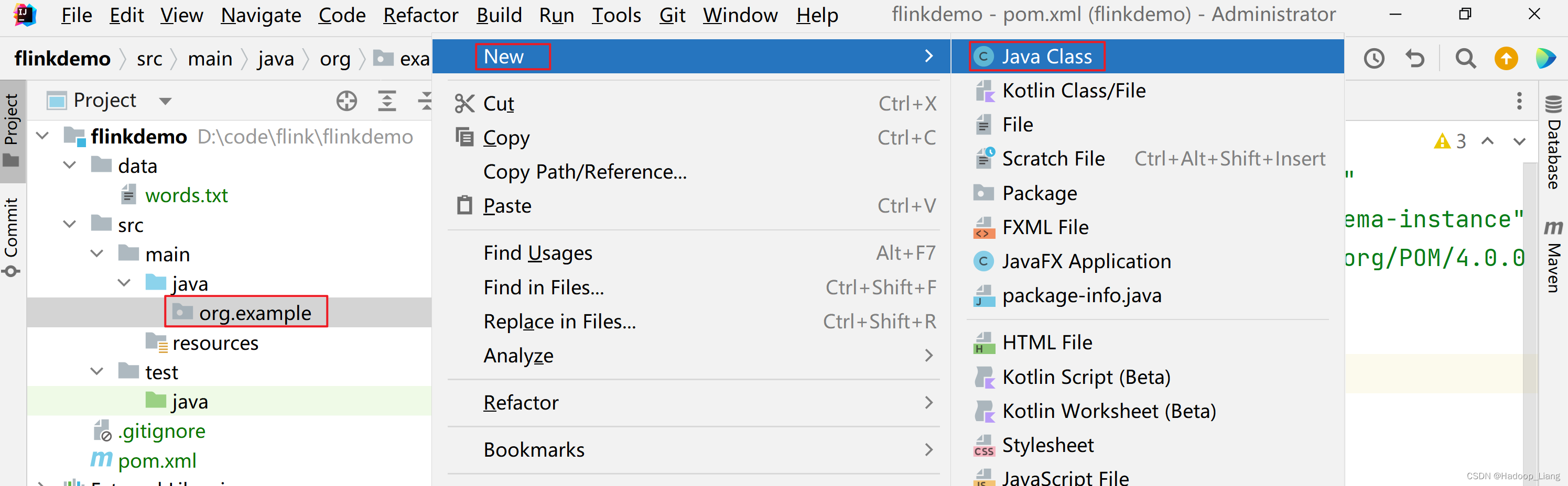
填写wc.BatchWordCount
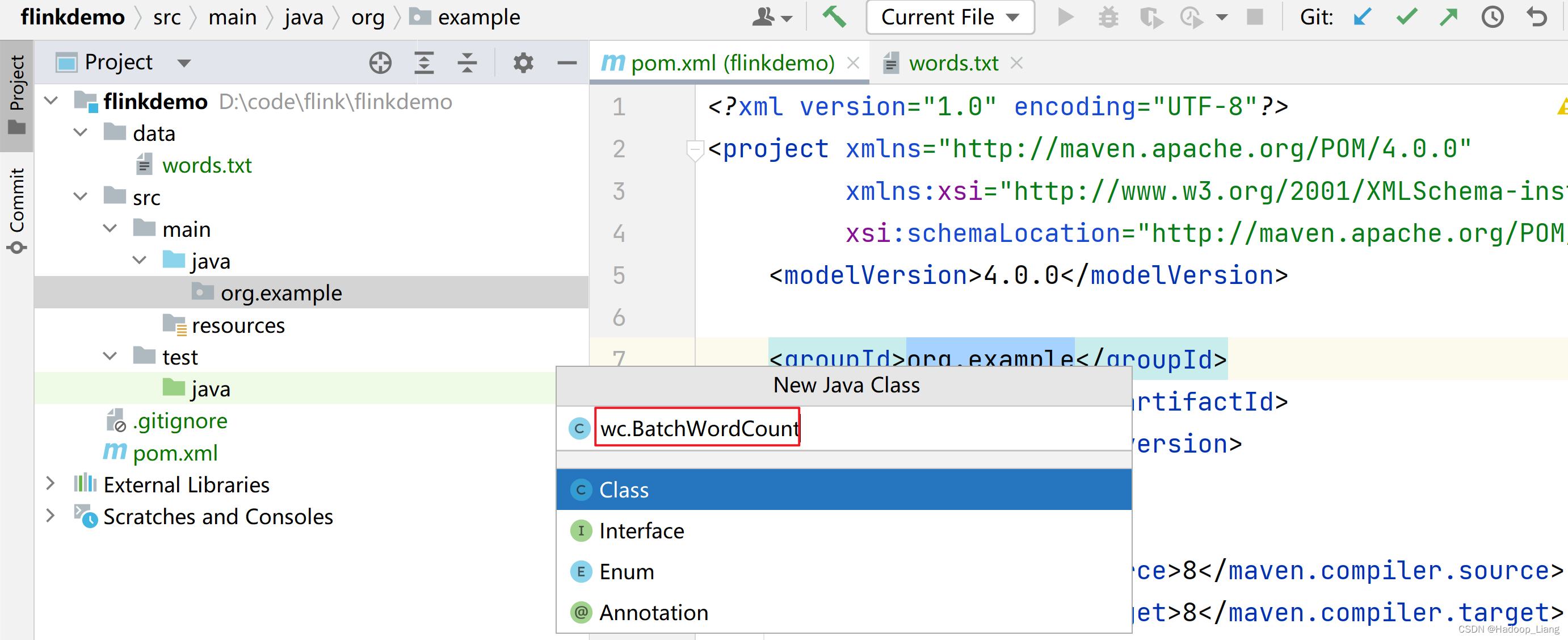
效果如下
BatchWordCount.java代码如下:
package org.example.wc;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;public class BatchWordCount {public static void main(String[] args) throws Exception {// 1. 创建执行环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 2. 从文件读取数据 按行读取DataSource<String> lineDS = env.readTextFile("data/words.txt");// 3. 转换数据格式FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = lineDS.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word,1L));}}});// 4. 按照 word 进行分组UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);// 5. 分组内聚合统计AggregateOperator<Tuple2<String, Long>> sum = wordAndOneUG.sum(1);// 6. 打印结果sum.print();}
}
运行程序,查看结果
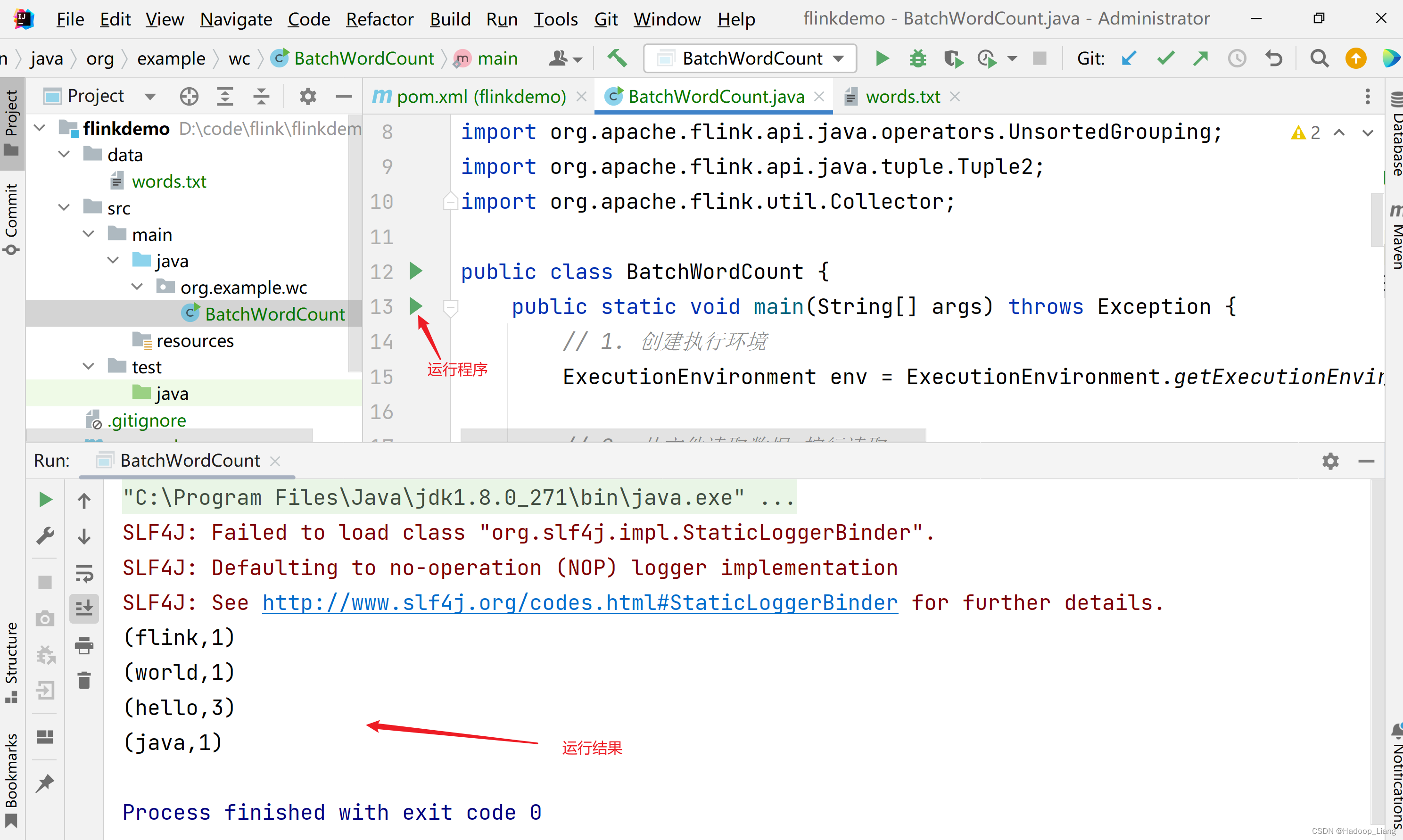
注意,以上代码的实现方式是基于DataSet API的,是批处理API。而Flink本身是流批统一的处理架构,批量的数据集本质上也是流,没有必要用两套不同的API来实现。从Flink 1.12开始,官方推荐直接使用DataStream API,在提交任务时通过将执行模式设为BATCH来进行批处理:
$ flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
流处理API实现WordCount
数据源是文件
在org.example.wc包下新建Java类StreamWordCount,代码如下:
package org.example.wc;import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class StreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 读取文件DataStreamSource<String> lineStream = env.readTextFile("input/words.txt");// 3. 转换、分组、求和,得到统计结果SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap(new FlatMapFunction<String, Tuple2<String, Long>>() {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Long>> out) throws Exception {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}}).keyBy(data -> data.f0).sum(1);// 4. 打印sum.print();// 5. 执行env.execute();}
}
运行结果
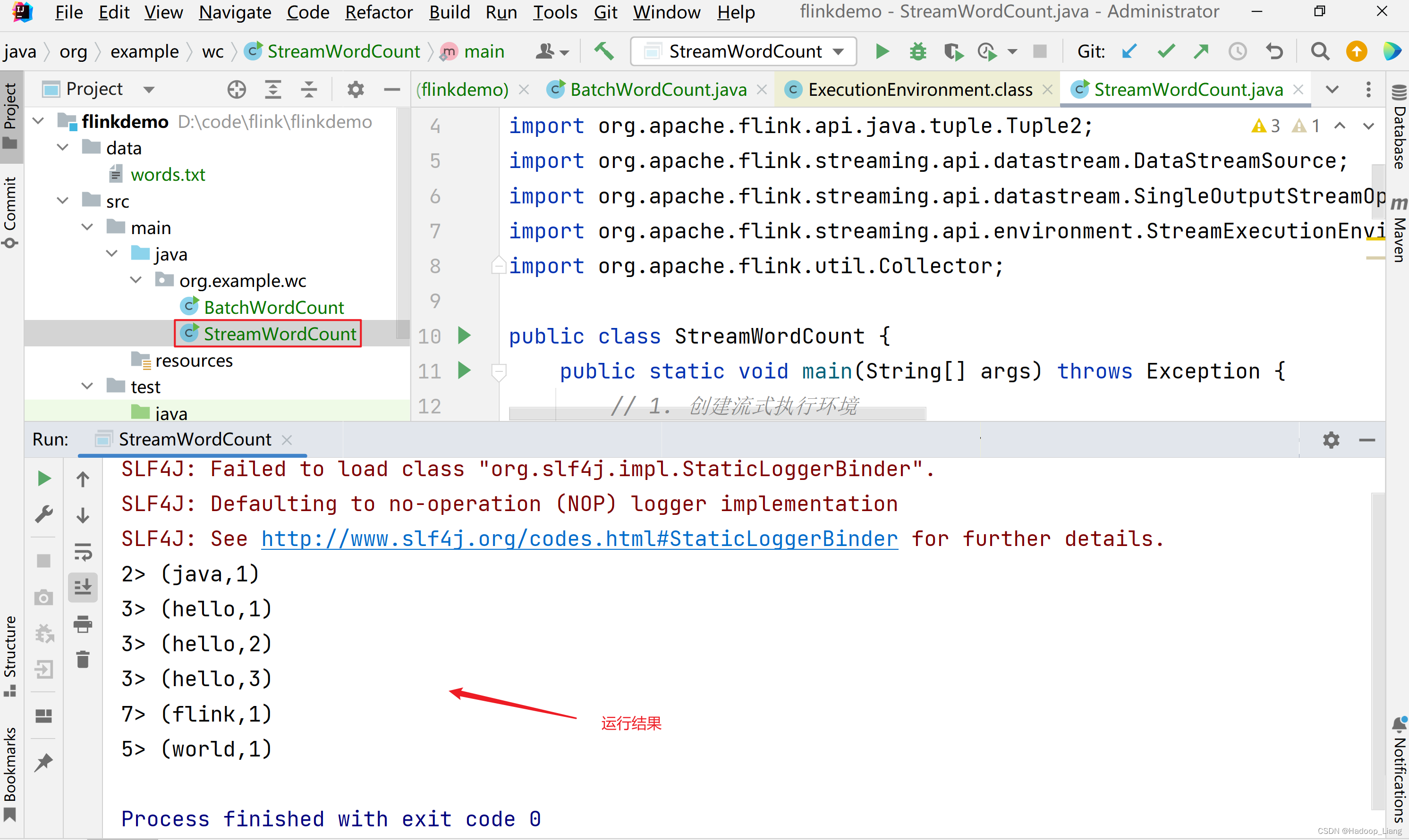
与批处理程序BatchWordCount的区别:
-
创建执行环境的不同,流处理程序使用的是StreamExecutionEnvironment。
-
转换处理之后,得到的数据对象类型不同。
-
分组操作调用的是keyBy方法,可以传入一个匿名函数作为键选择器(KeySelector),指定当前分组的key是什么。
-
代码末尾需要调用env的execute方法,开始执行任务。
数据源是socket文本流
流处理的输入数据通常是流数据,将StreamWordCount代码中读取文件数据的readTextFile方法,替换成读取socket文本流的方法socketTextStream。
在org.example.wc包下新建Java类SocketStreamWordCount,代码如下:
package org.example.wc;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class SocketStreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建流式执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 读取文本流:node2表示发送端主机名(根据实际情况修改)、7777表示端口号DataStreamSource<String> lineStream = env.socketTextStream("node2", 7777);// 3. 转换、分组、求和,得到统计结果SingleOutputStreamOperator<Tuple2<String, Long>> sum = lineStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG)).keyBy(data -> data.f0).sum(1);// 4. 打印sum.print();// 5. 执行env.execute();}
}进入node2终端,如果没有nc命令,需要先安装nc命令,安装nc命令如下:
[hadoop@node2 ~]$ sudo yum install nc -y
开启nc监听
[hadoop@node2 ~]$ nc -lk 7777
IDEA中,运行SocketStreamWordCount程序。
往7777端口发送数据,例如发送hello world

控制台输出
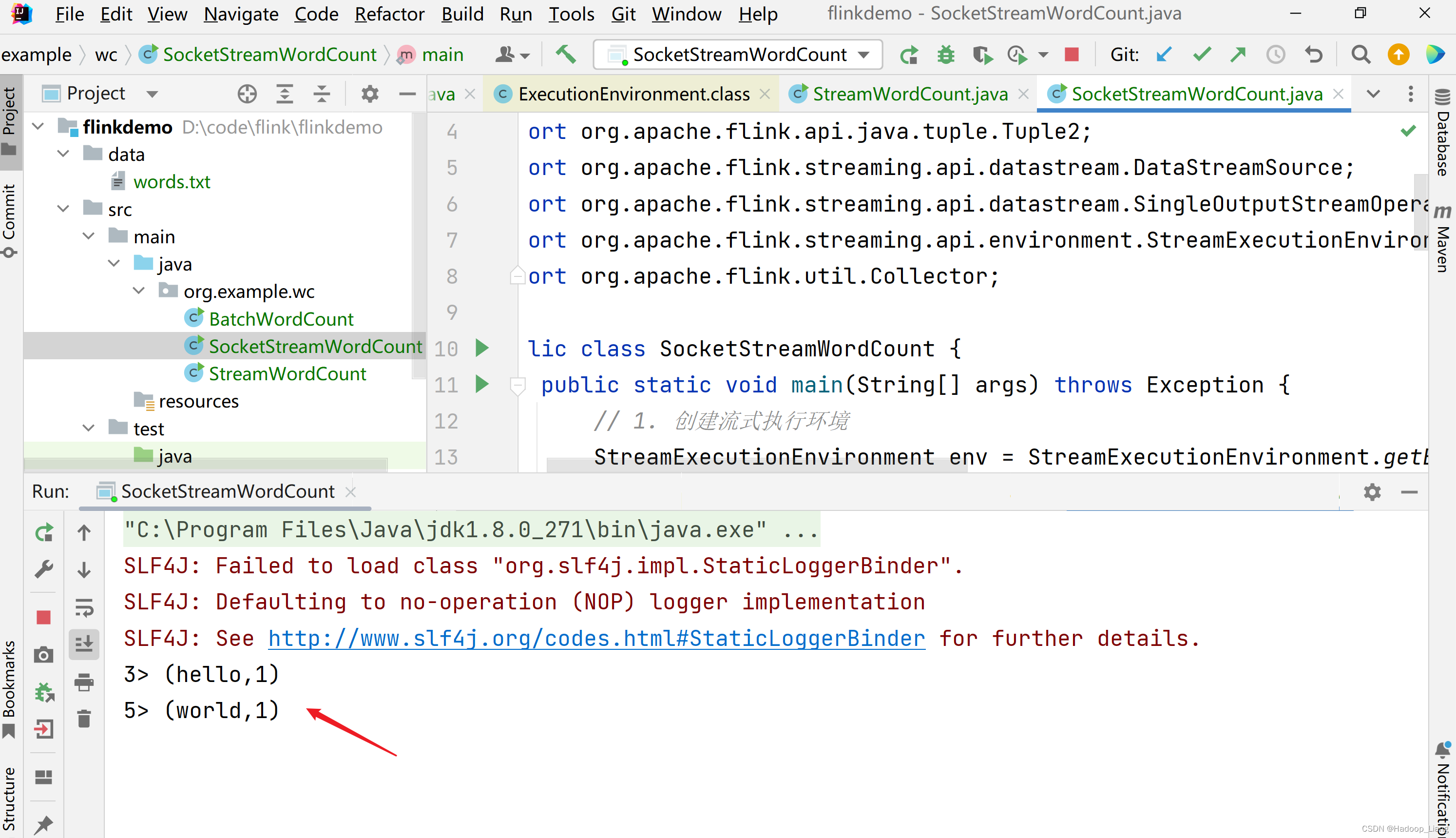
继续往7777端口发送数据,例如发送hello flink

控制台输出
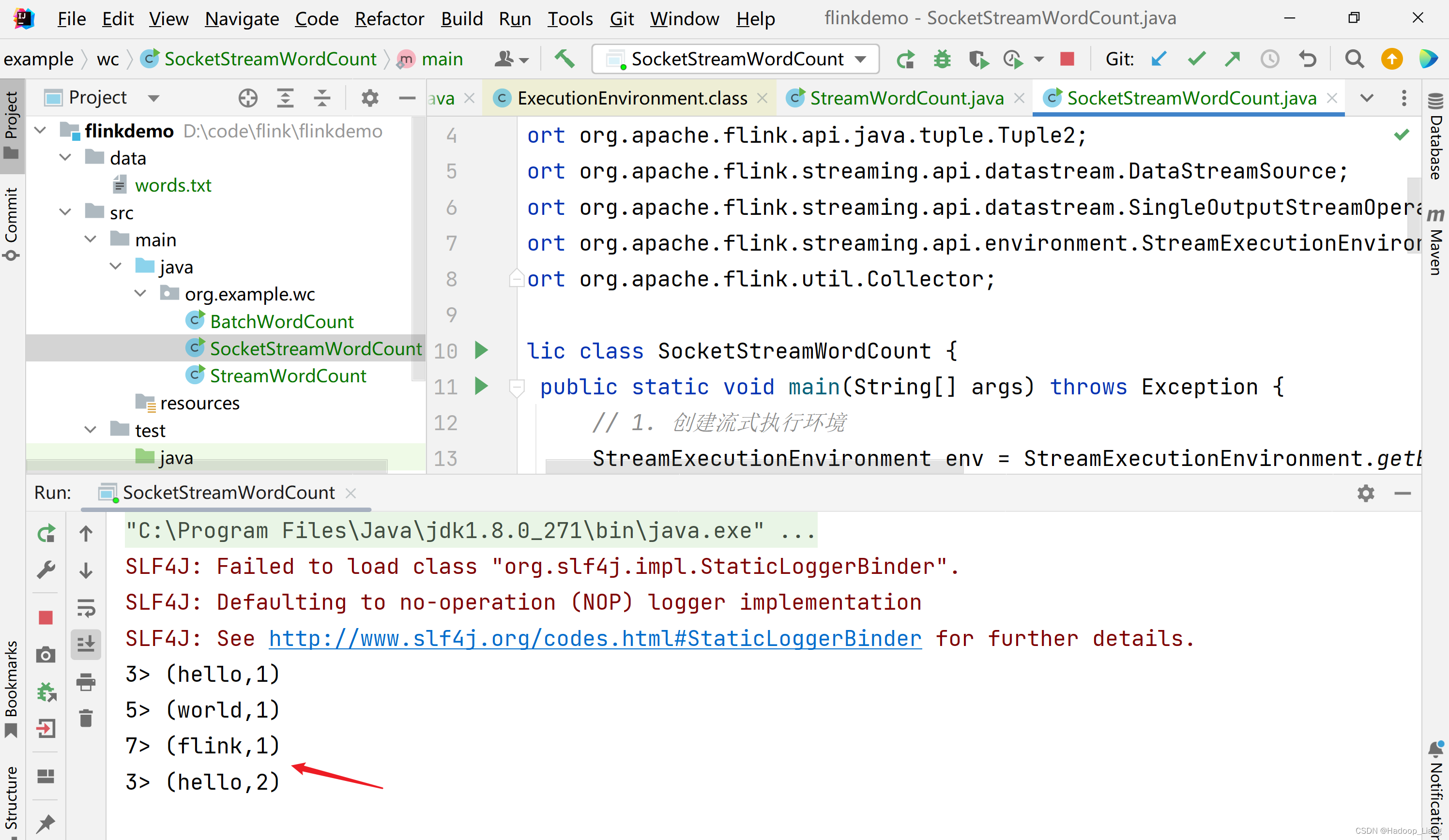
停止SocketStreamWordCount程序。
按Ctrl+c停止nc命令。
打包
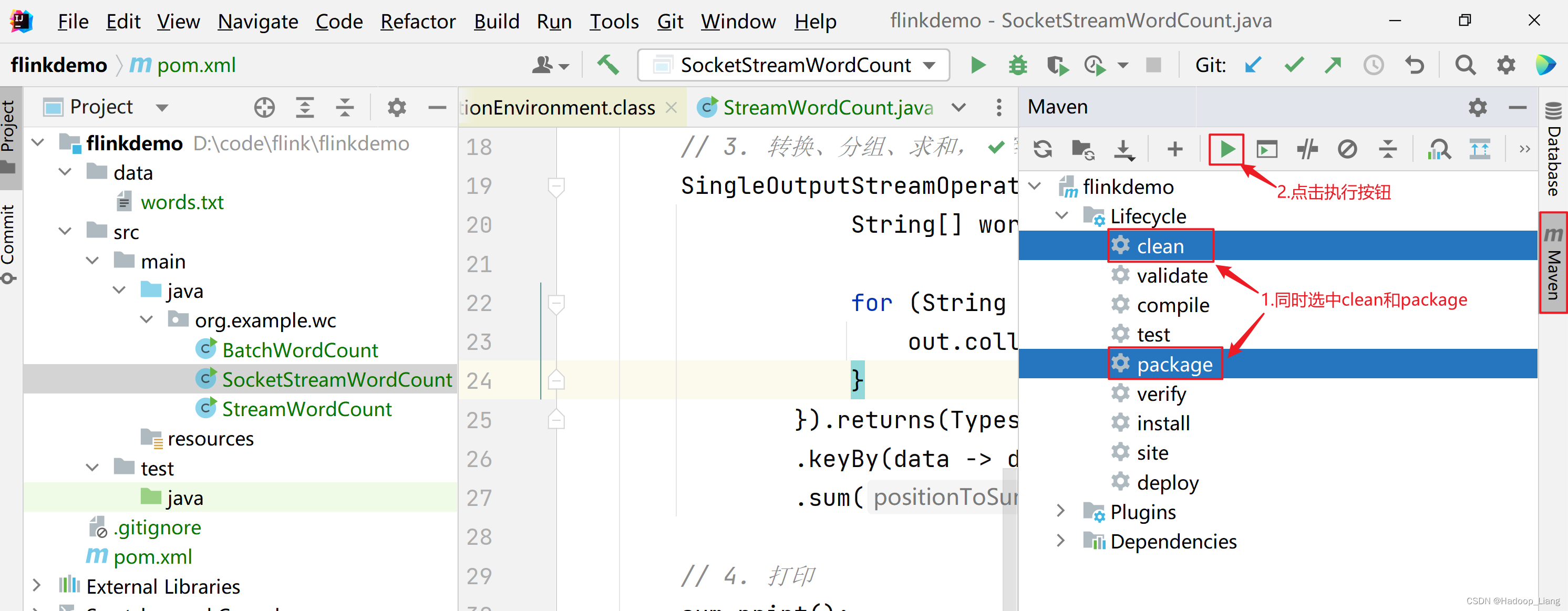
这里的打包是将写好的程序打成jar包。
点击IDEA右侧的Maven,按住Ctrl键同时选中clean和package(第一次打包可以只选中package),点击执行打包。
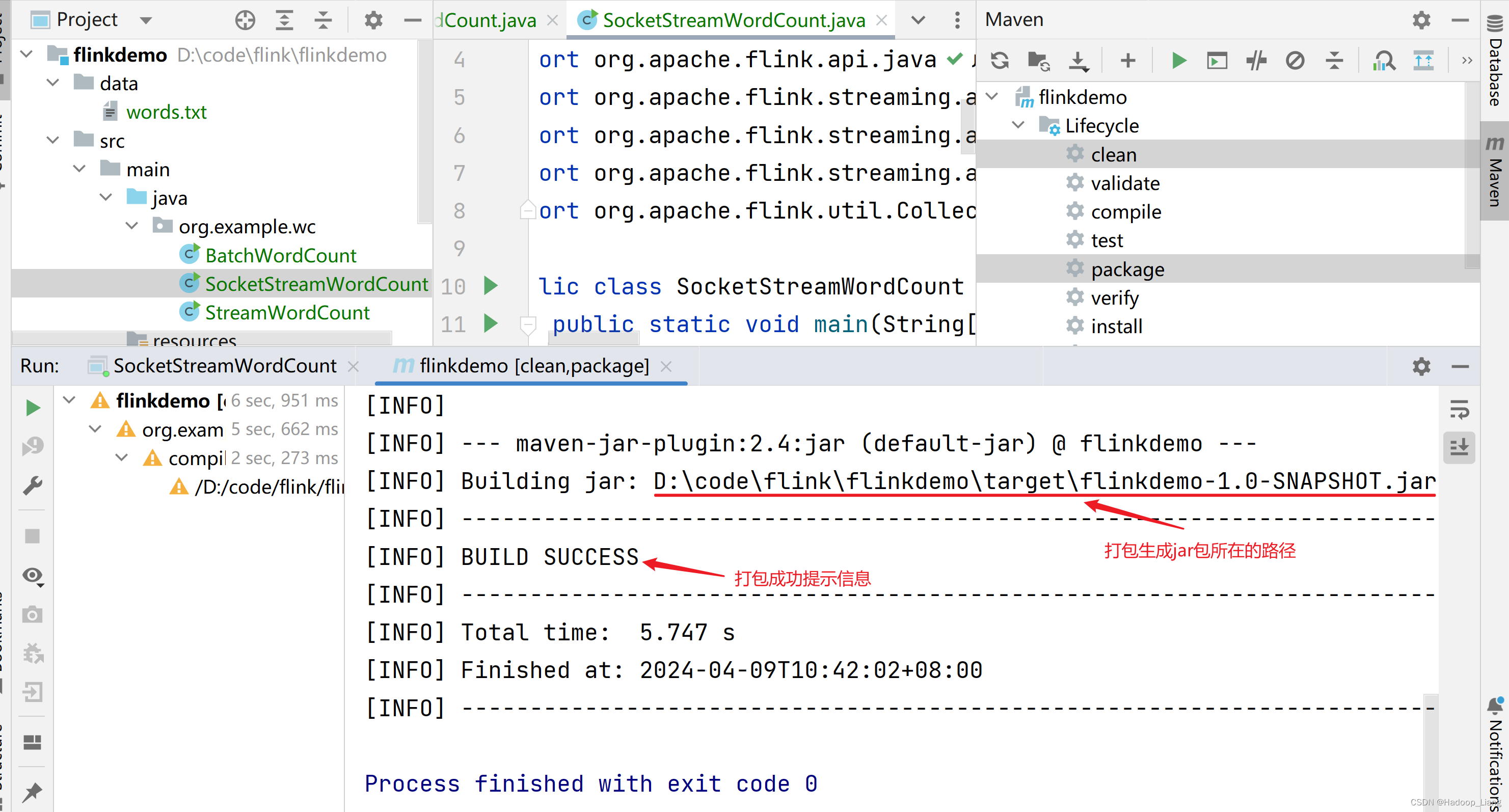
打包成功后,看到如下输出信息,生成的jar包在项目的target目录下
提交到集群运行
把jar包提交到flink集群运行有两种方式:
1.通过命令行提交作业
2.通过Web UI提交作业
命令行提交作业
将jar包上传Linux
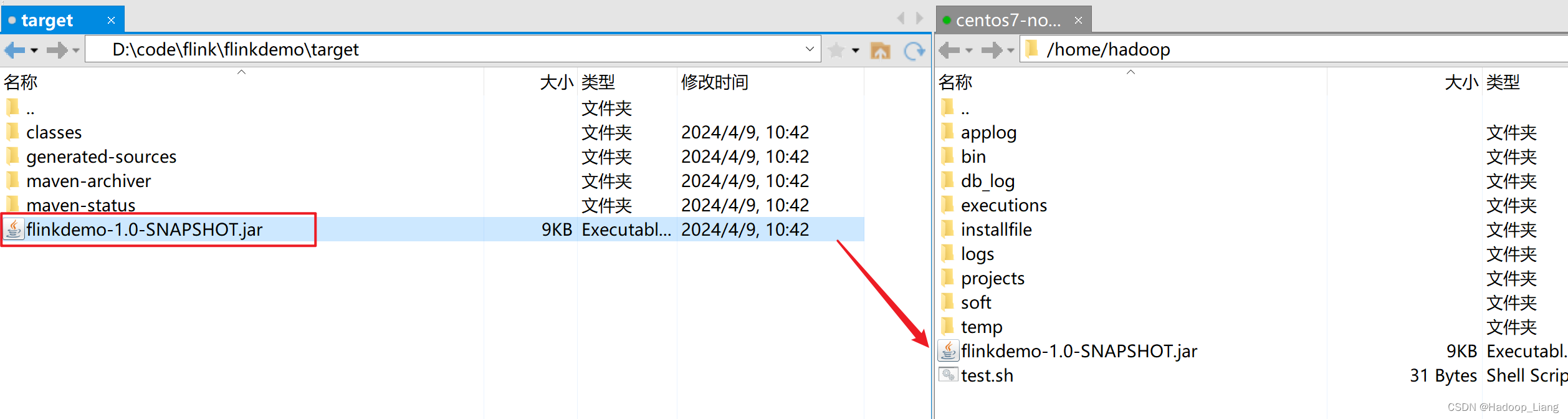
启动flink集群
[hadoop@node2 ~]$ start-cluster.sh Starting cluster. Starting standalonesession daemon on host node2. Starting taskexecutor daemon on host node2. Starting taskexecutor daemon on host node3. Starting taskexecutor daemon on host node4.
开启nc监听
[hadoop@node2 ~]$ nc -lk 7777
命令提交作业
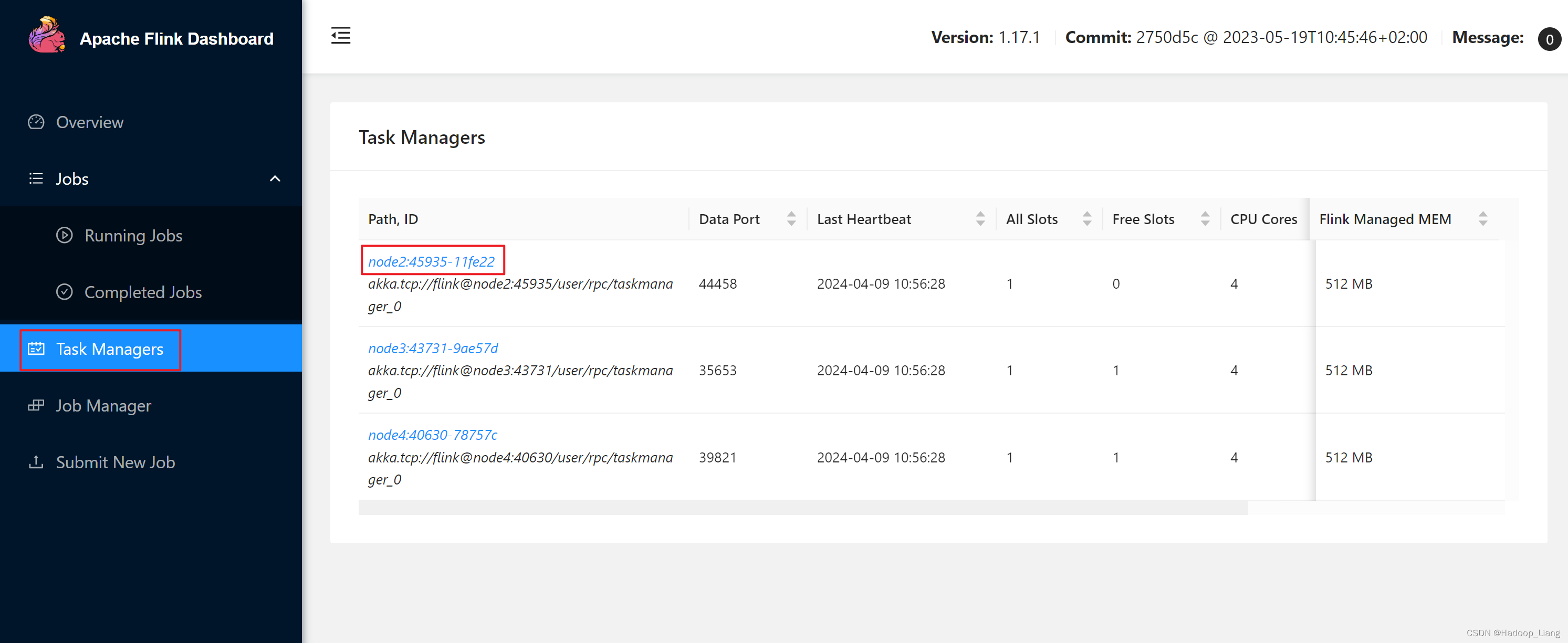
开启另一个node2终端,使用flink run命令提交作业到flink集群
[hadoop@node2 ~]$ flink run -m node2:8081 -c org.example.wc.SocketStreamWordCount flinkdemo-1.0-SNAPSHOT.jar

-m指定提交到的JobManager,-c指定程序入口类。
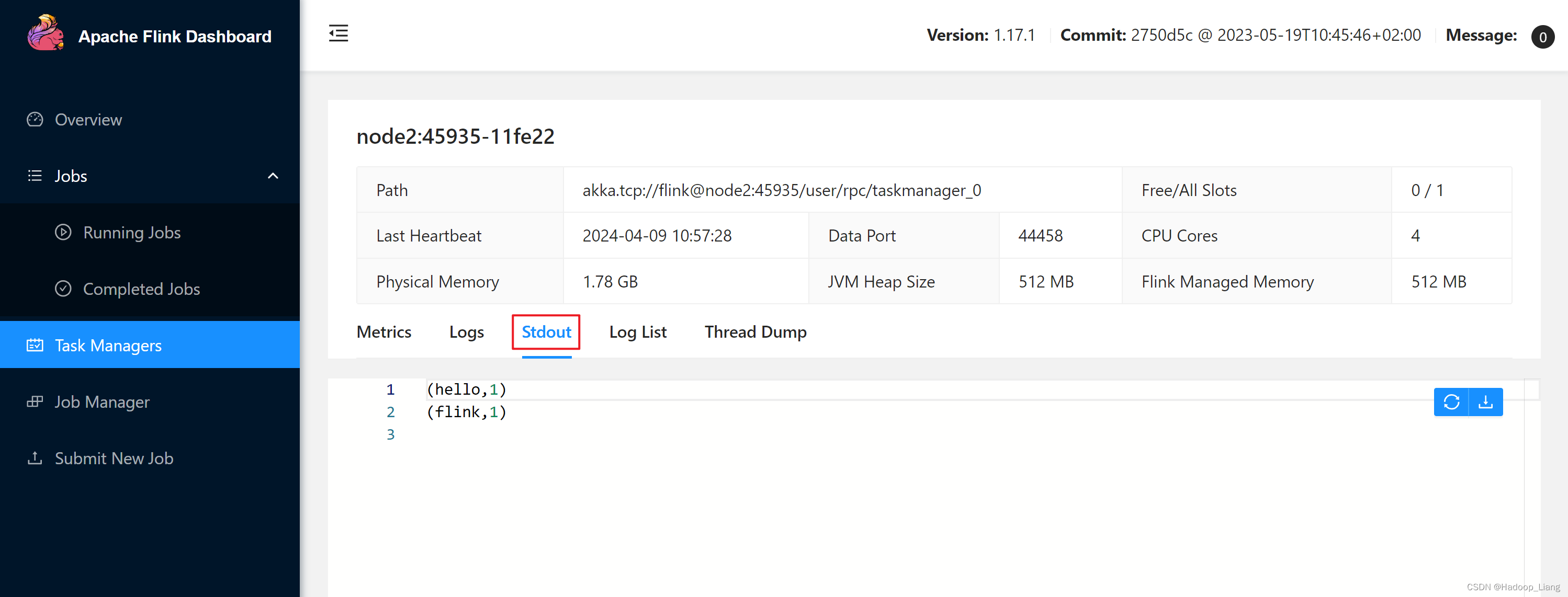
发送测试数据
在nc监听终端,往7777端口发送数据

查看结果
Web UI查看结果
浏览器访问
node2:8081
看到正在运行的作业如下
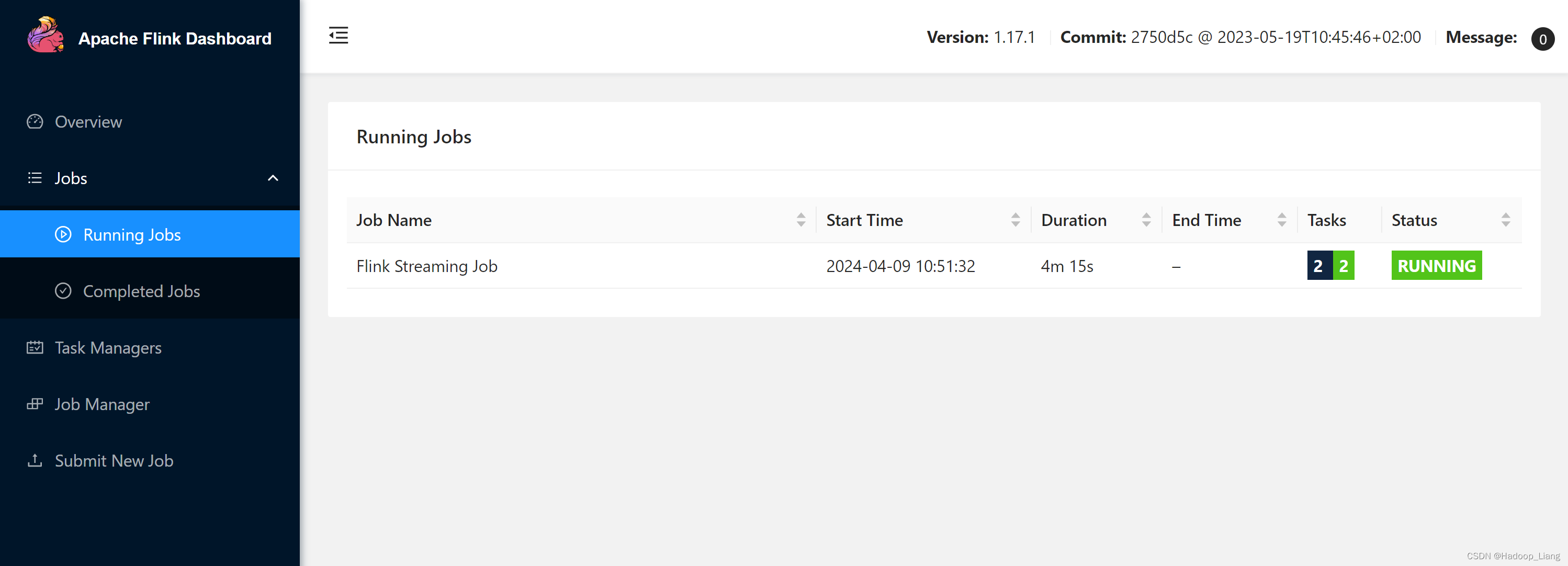
查看结果
继续发送测试数据
在nc终端继续发送数据

Web UI刷新结果
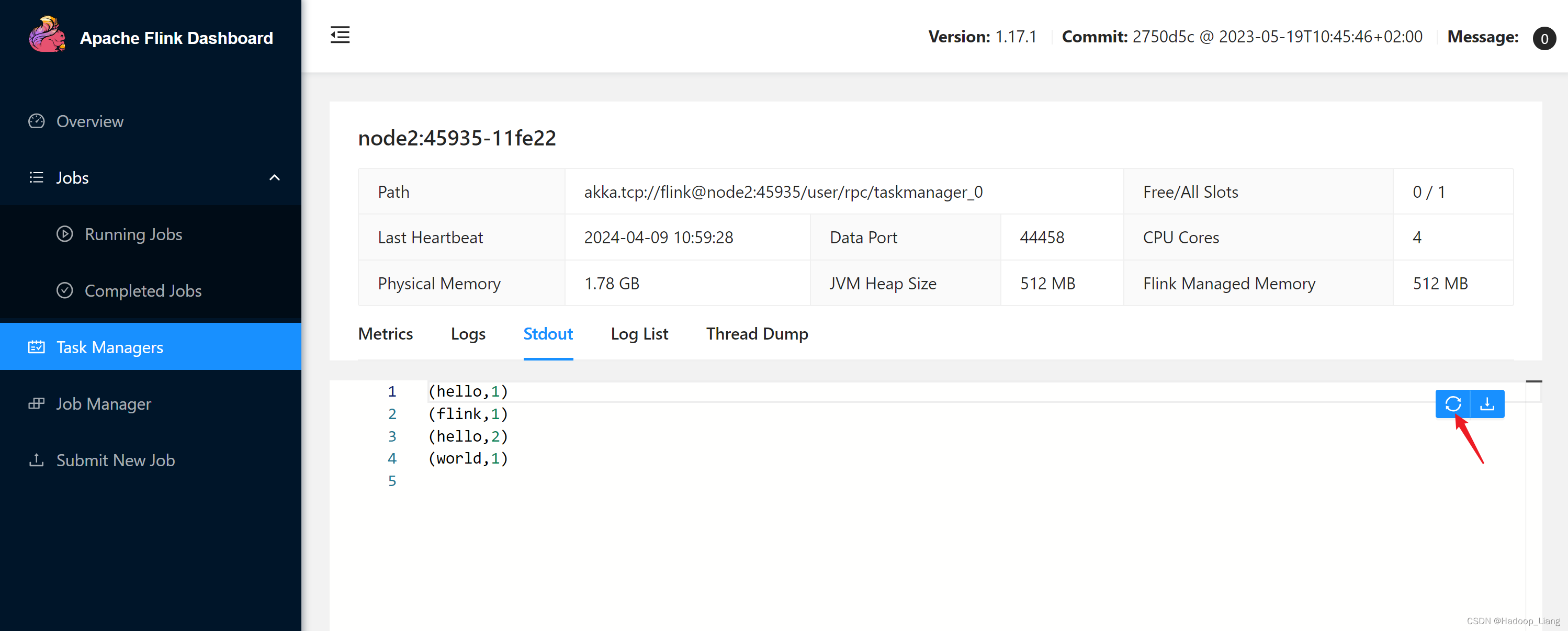
命令行查看结果
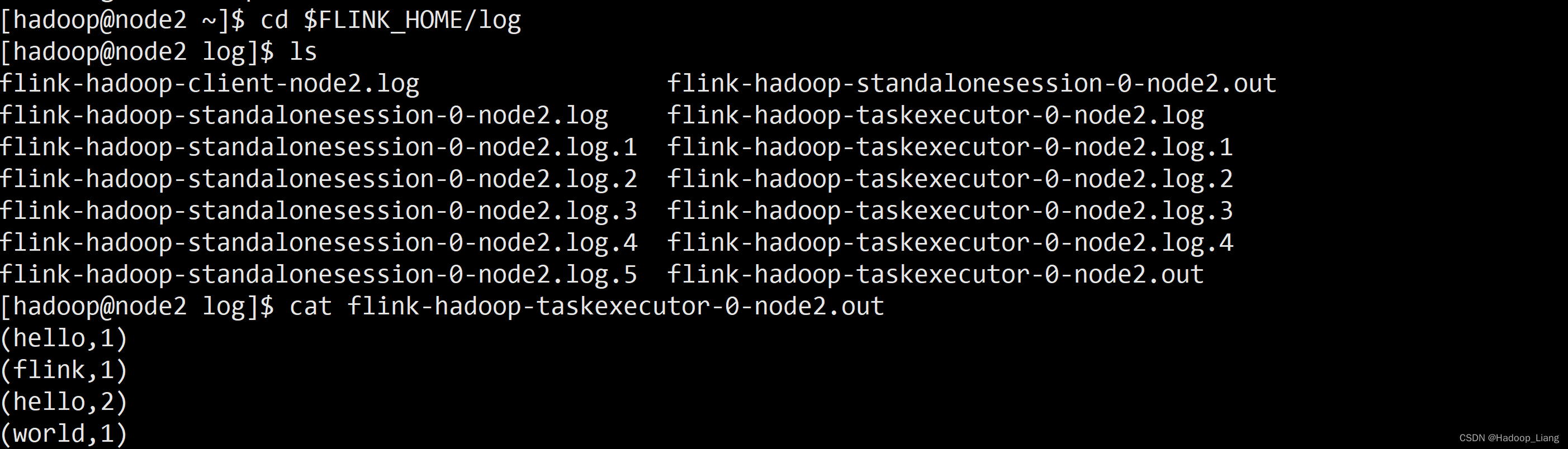
打开新的node2终端,查看结果
[hadoop@node2 ~]$ cd $FLINK_HOME/log [hadoop@node2 log]$ ls flink-hadoop-client-node2.log flink-hadoop-standalonesession-0-node2.out flink-hadoop-standalonesession-0-node2.log flink-hadoop-taskexecutor-0-node2.log flink-hadoop-standalonesession-0-node2.log.1 flink-hadoop-taskexecutor-0-node2.log.1 flink-hadoop-standalonesession-0-node2.log.2 flink-hadoop-taskexecutor-0-node2.log.2 flink-hadoop-standalonesession-0-node2.log.3 flink-hadoop-taskexecutor-0-node2.log.3 flink-hadoop-standalonesession-0-node2.log.4 flink-hadoop-taskexecutor-0-node2.log.4 flink-hadoop-standalonesession-0-node2.log.5 flink-hadoop-taskexecutor-0-node2.out [hadoop@node2 log]$ cat flink-hadoop-taskexecutor-0-node2.out (hello,1) (flink,1) (hello,2) (world,1)
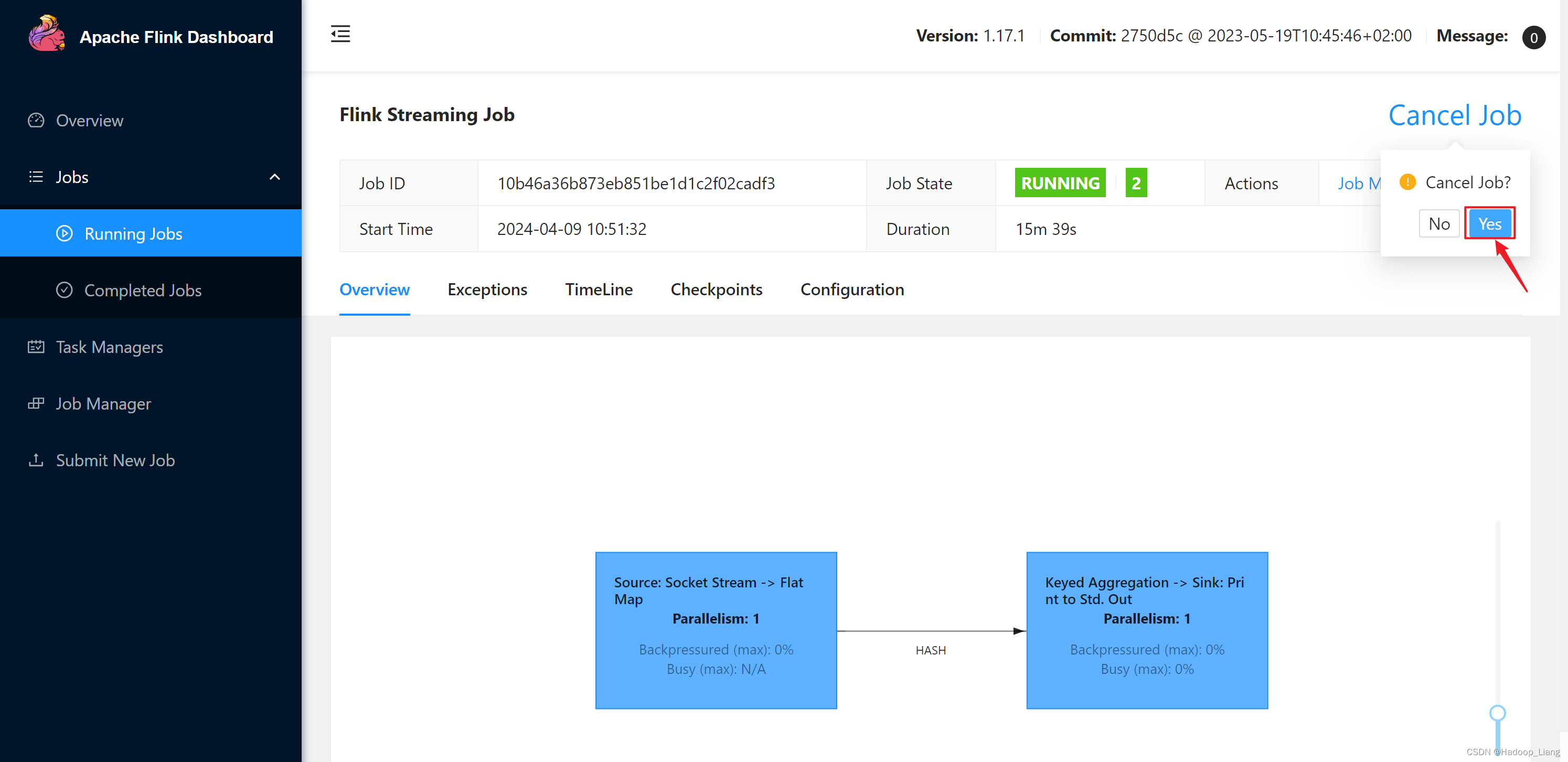
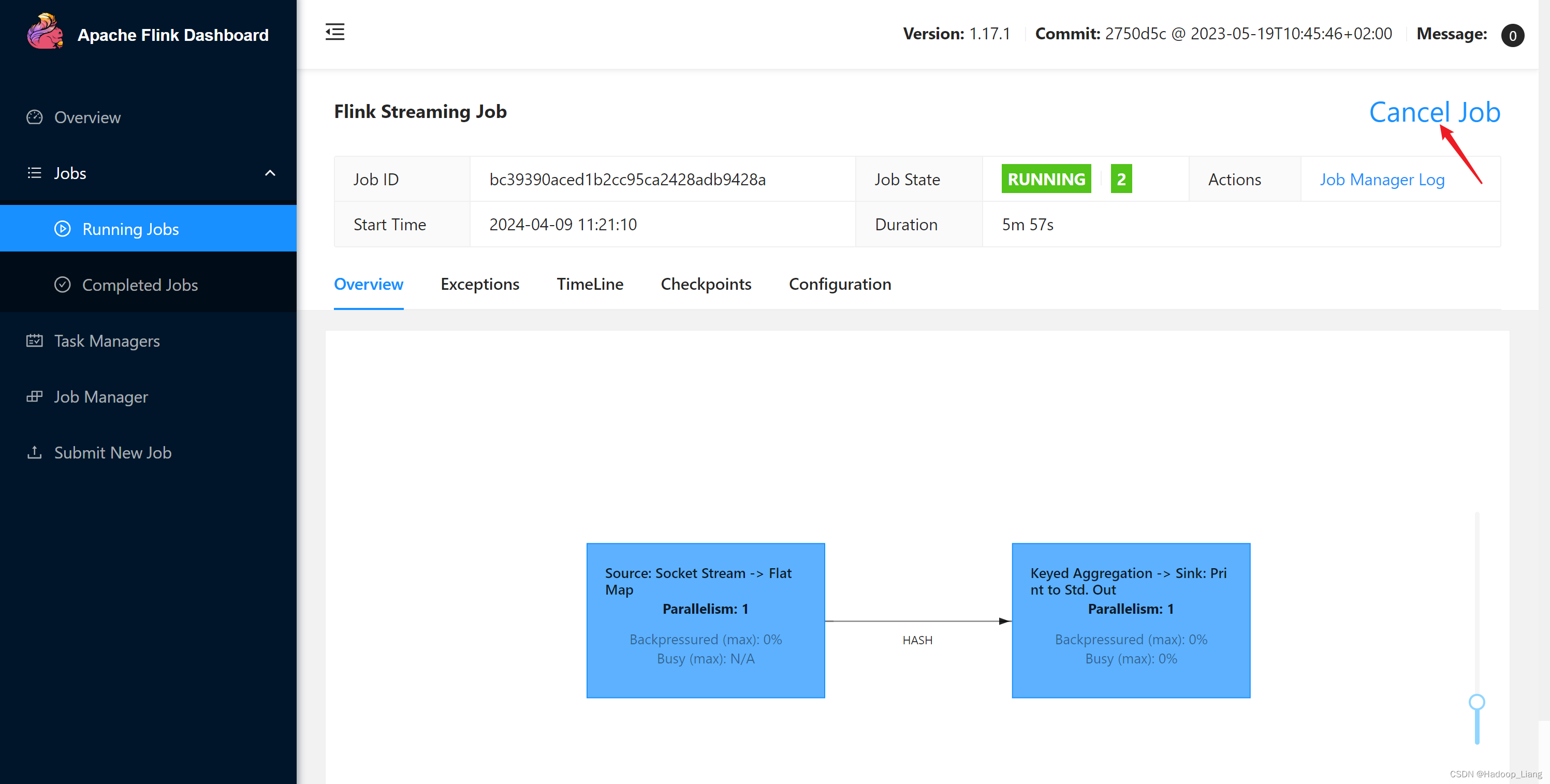
取消flink作业
点击Cancel Job取消作业
停止nc监听
按Ctrl+c停止nc命令
Web UI提交作业
开启nc监听
开启nc监听发送数据
[hadoop@node2 ~]$ nc -lk 7777
Web UI提交作业
浏览器访问
node2:8081
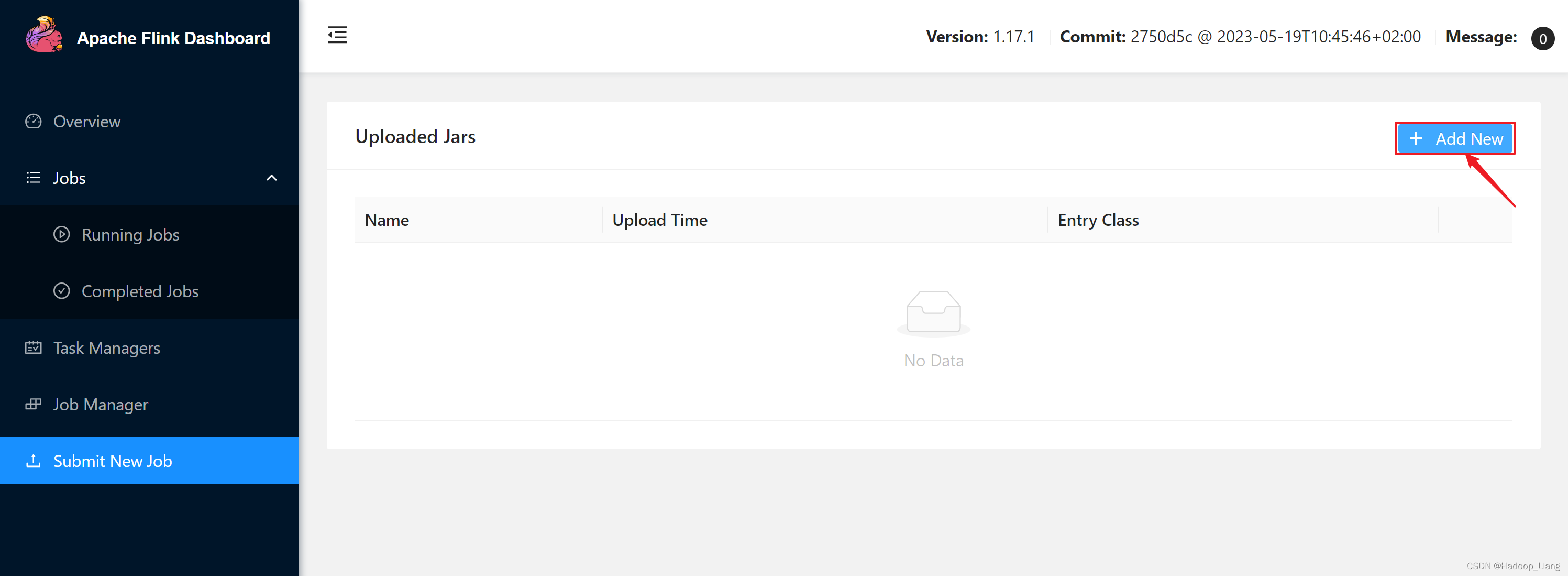
点击Submit New Job
点击Add New
选择flink作业jar包所在路径

点击jar包名称
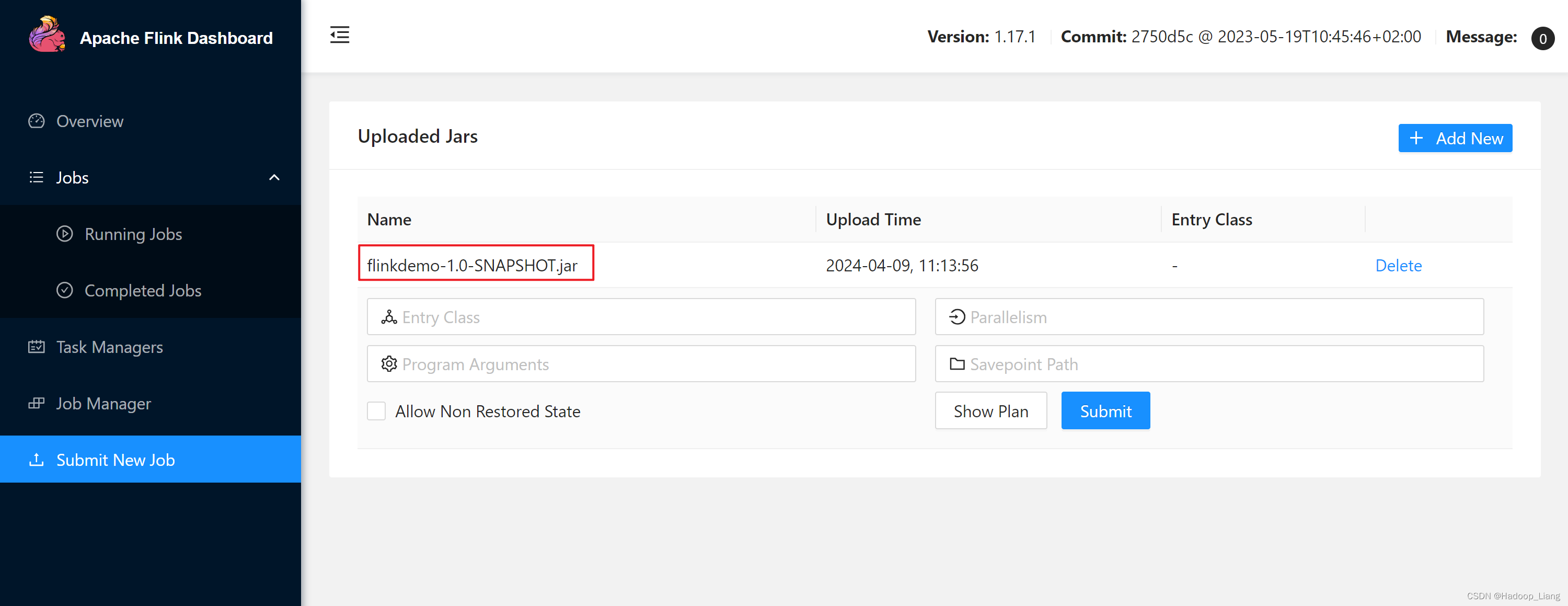
填写相关内容,点击Submit提交作业
Entry Class填写运行的主类,例如:org.example.wc.SocketStreamWordCount
Parallesim填写作业的并行度,例如:1
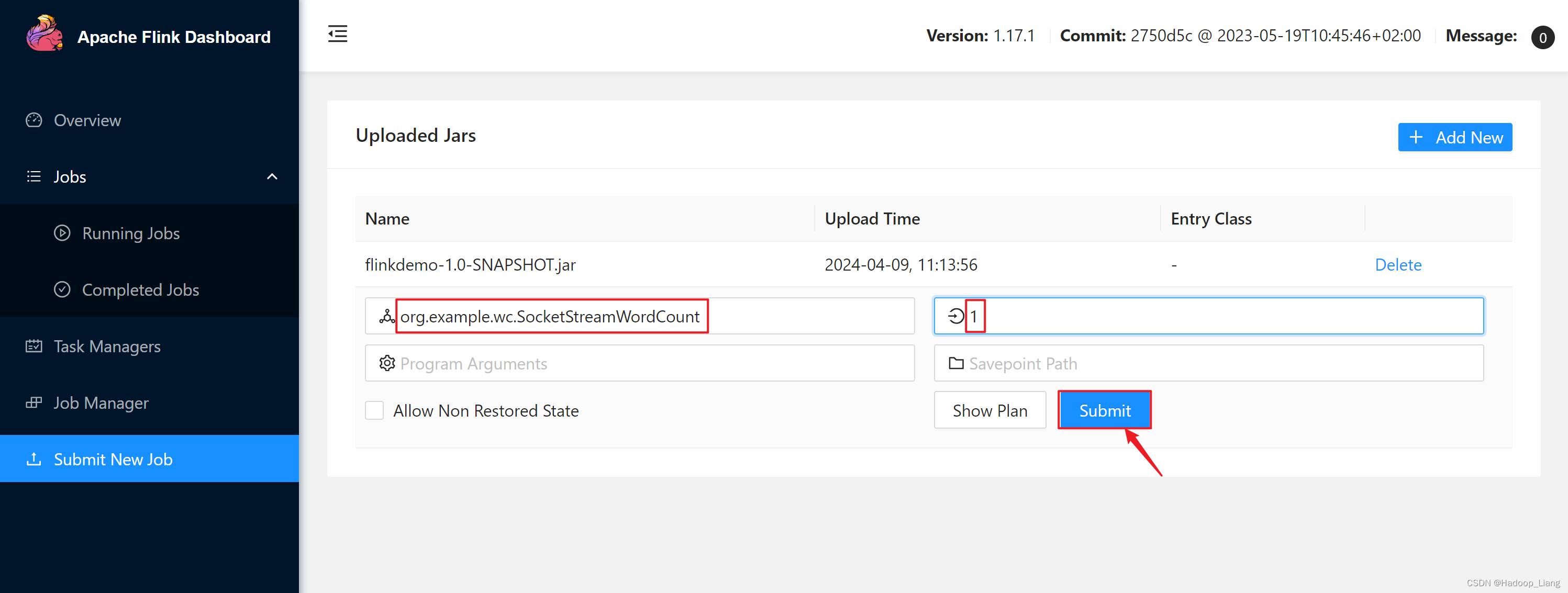
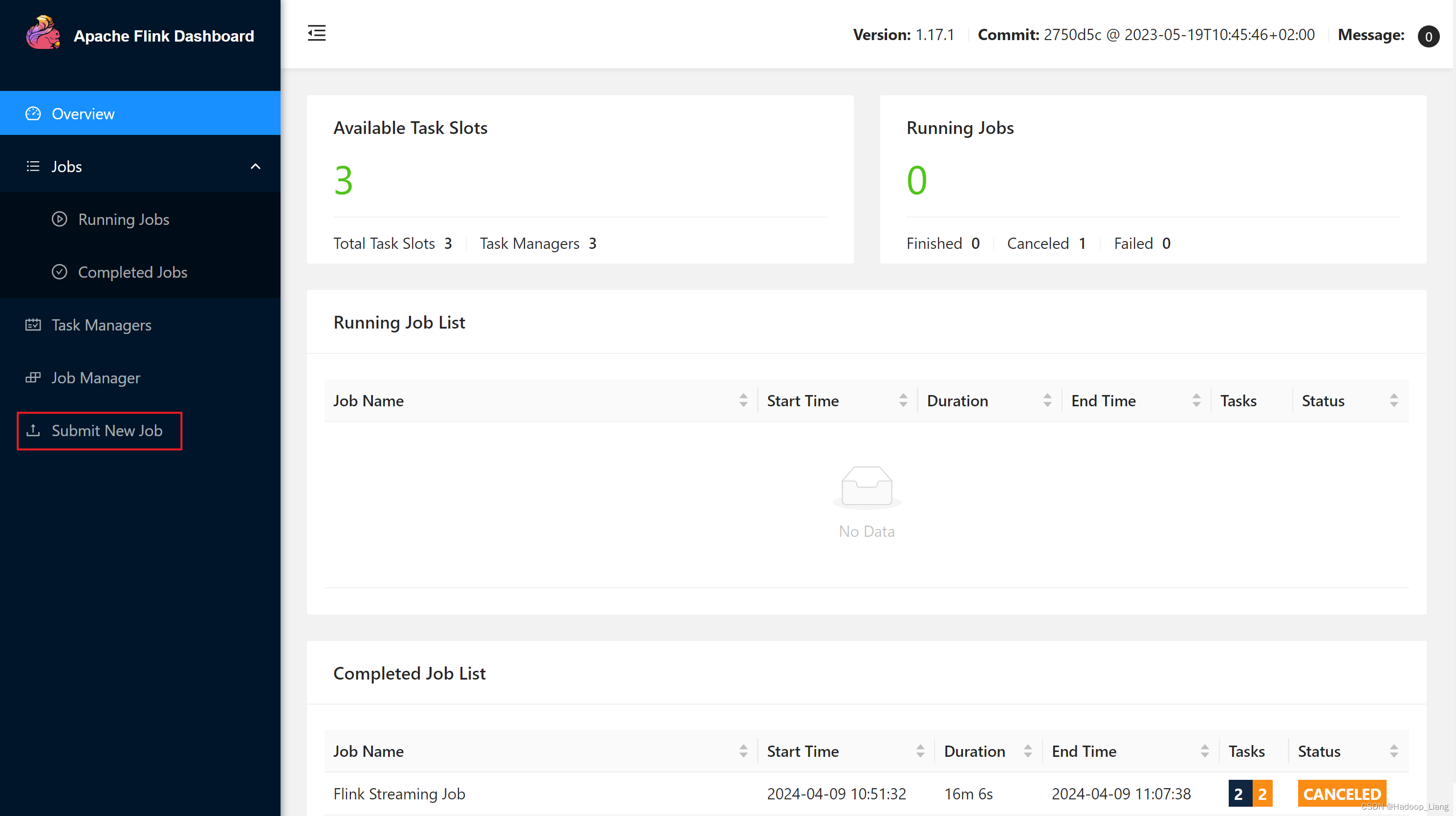
提交后,在Running Jobs里看到运行的作业
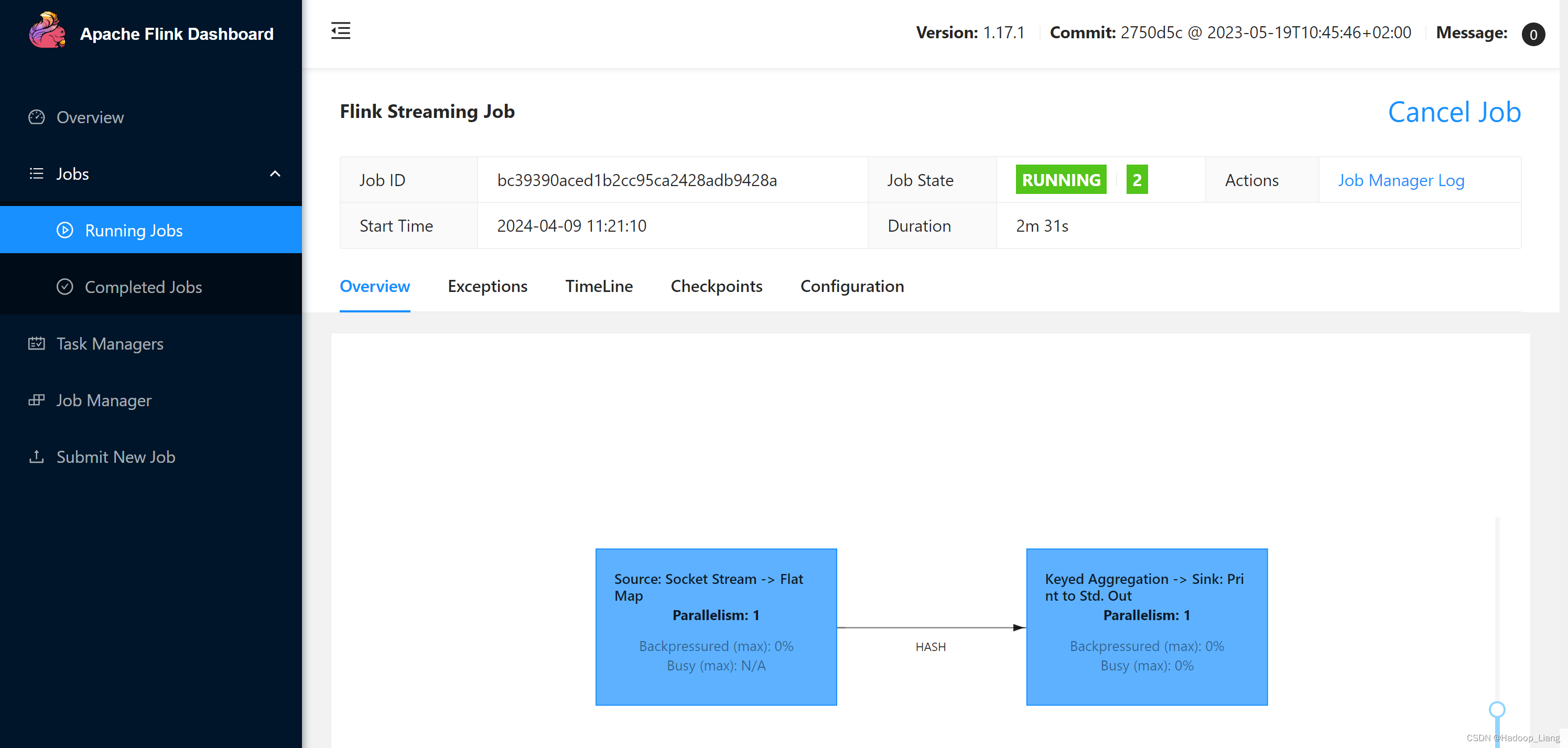
发送测试数据
往7777端口发送数据

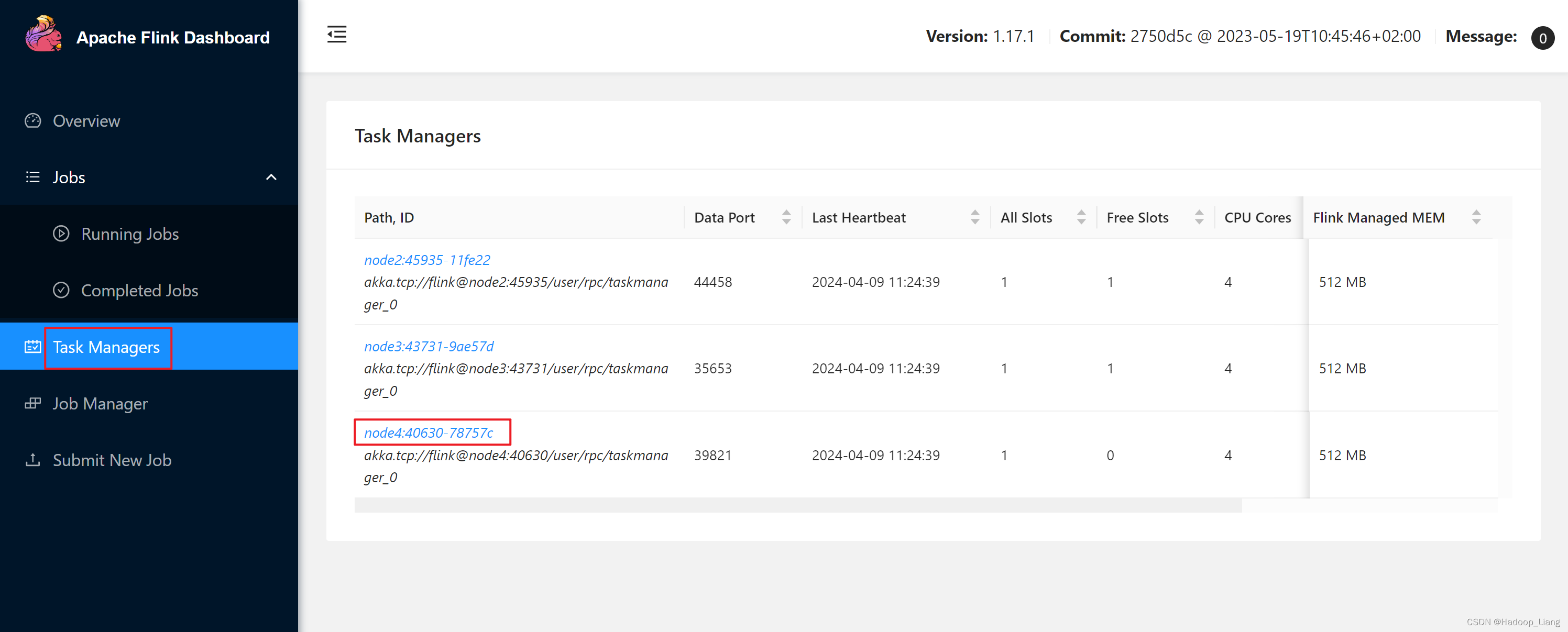
查看结果
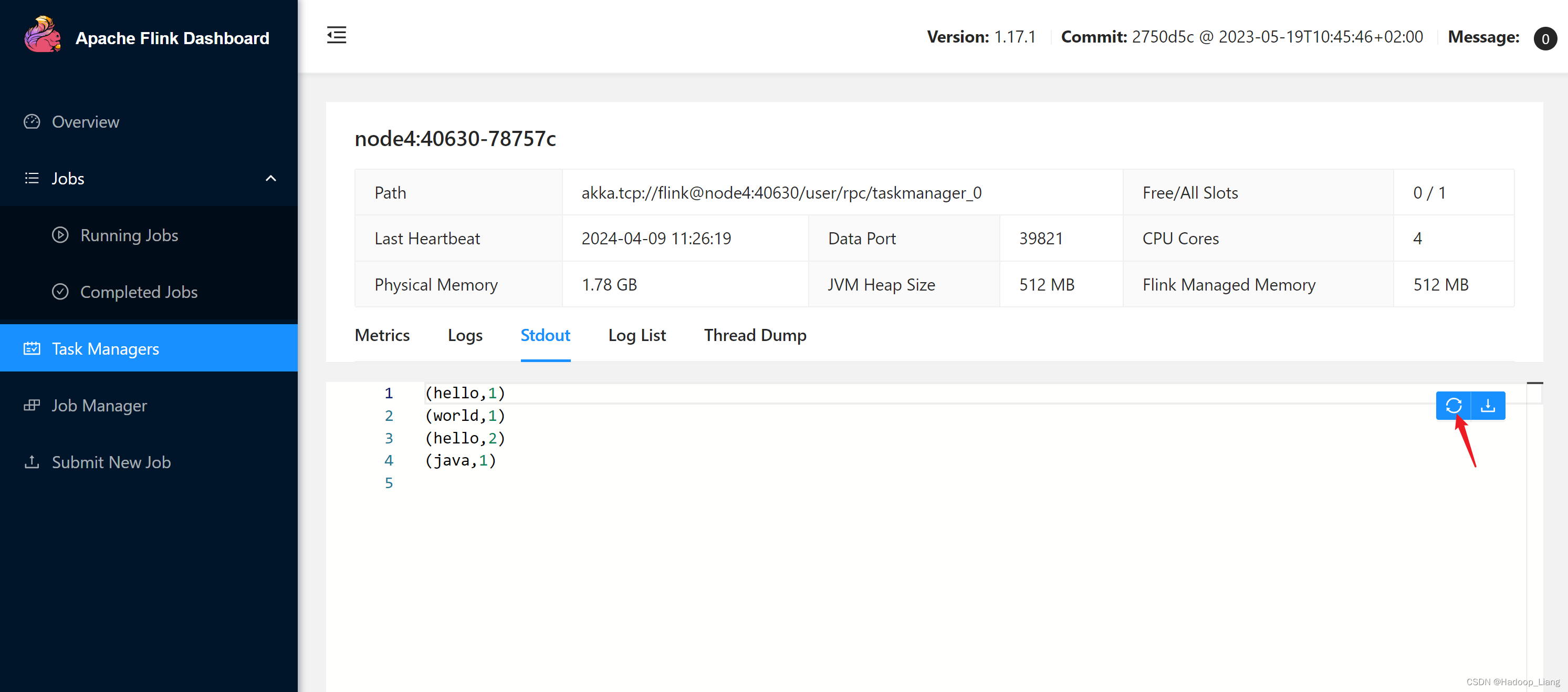
继续发送测试数据

刷新结果
取消作业
停止nc监听
按住Ctrl+c停止nc命令
关闭flink集群
[hadoop@node2 ~]$ stop-cluster.sh Stopping taskexecutor daemon (pid: 2283) on host node2. Stopping taskexecutor daemon (pid: 1827) on host node3. Stopping taskexecutor daemon (pid: 1829) on host node4. Stopping standalonesession daemon (pid: 1929) on host node2.
上传代码到gitee
登录gitee
https://gitee.com/
注意:如果还没有gitee账号,需要先注册;如果之前没有设置过SSH公钥,需要先设置SSH公钥。
创建仓库

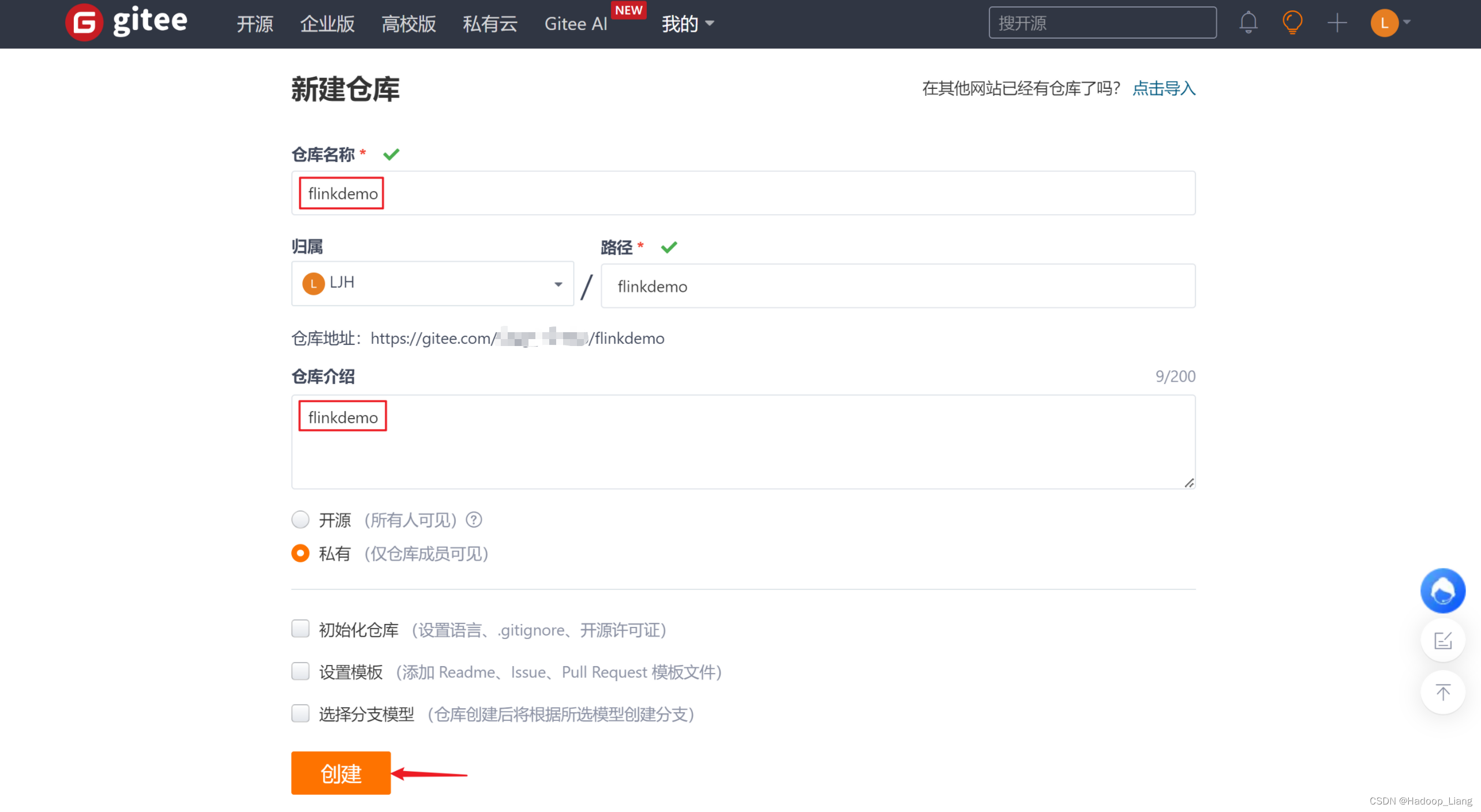
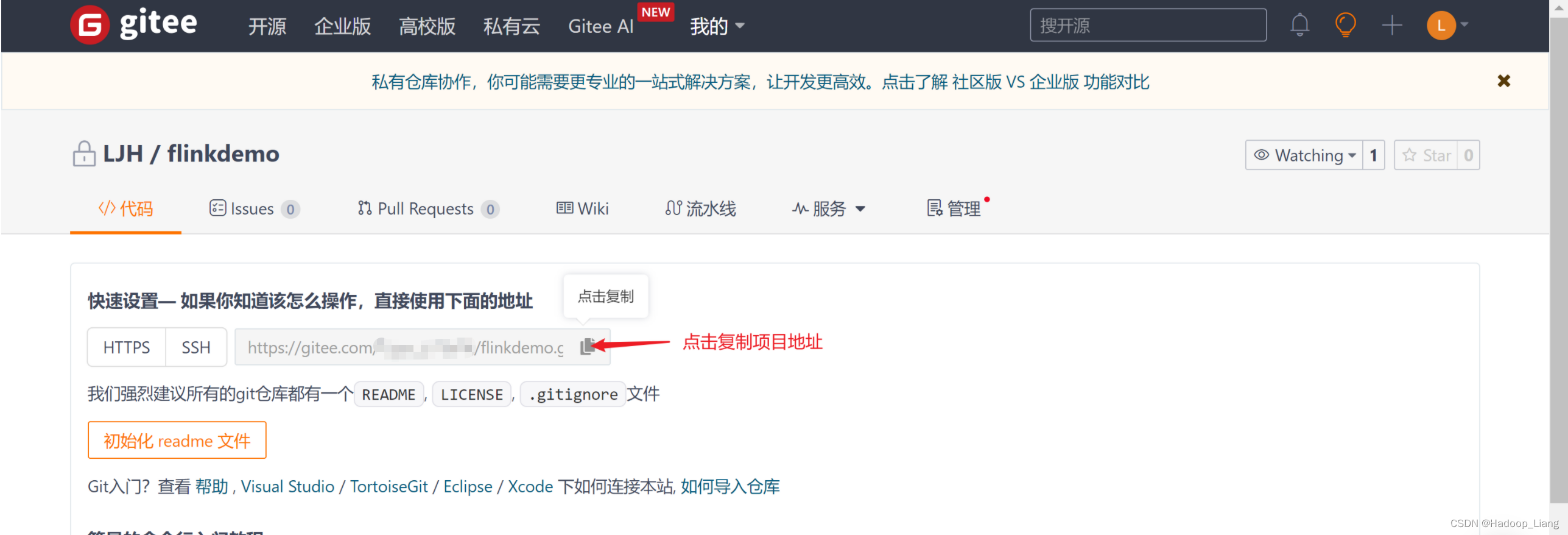
提交代码
使用IDEA提交代码
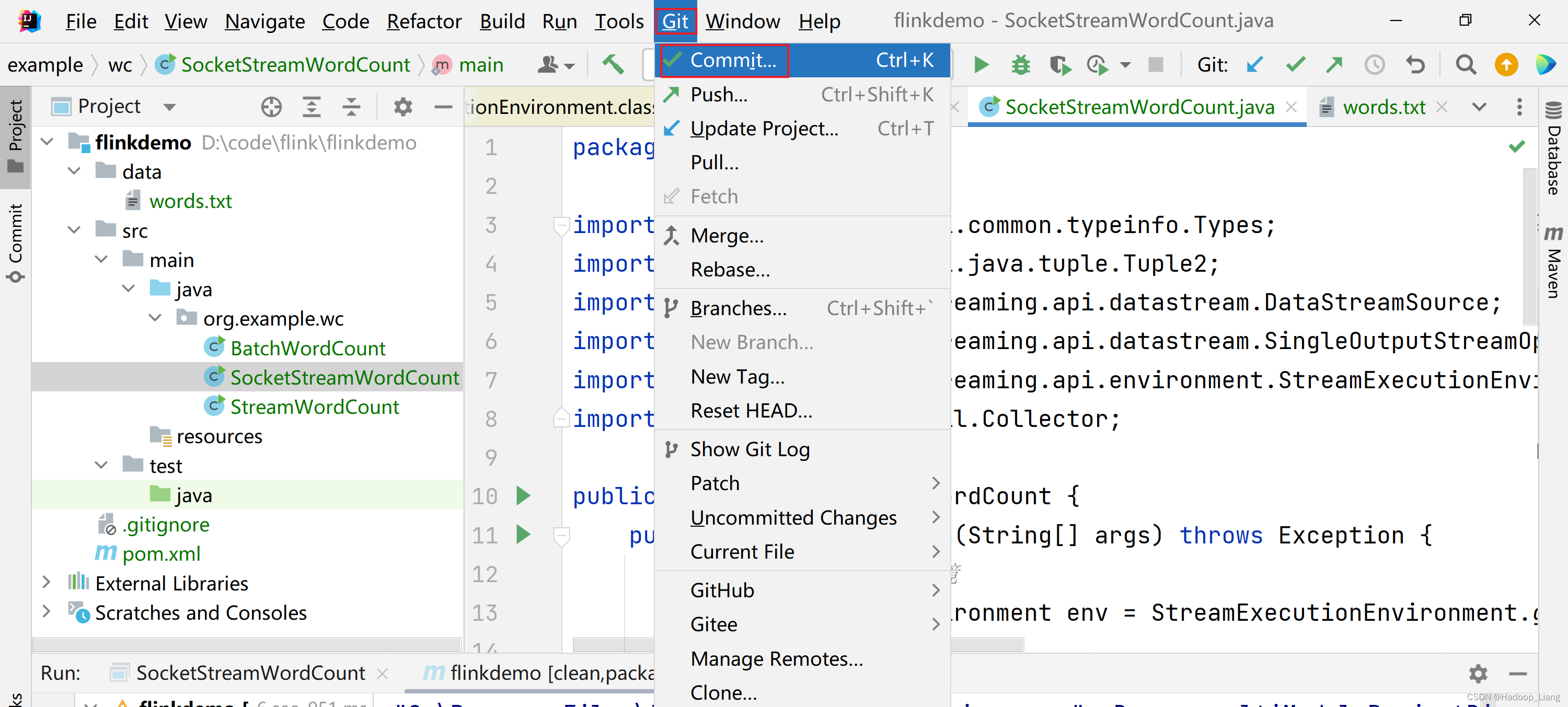
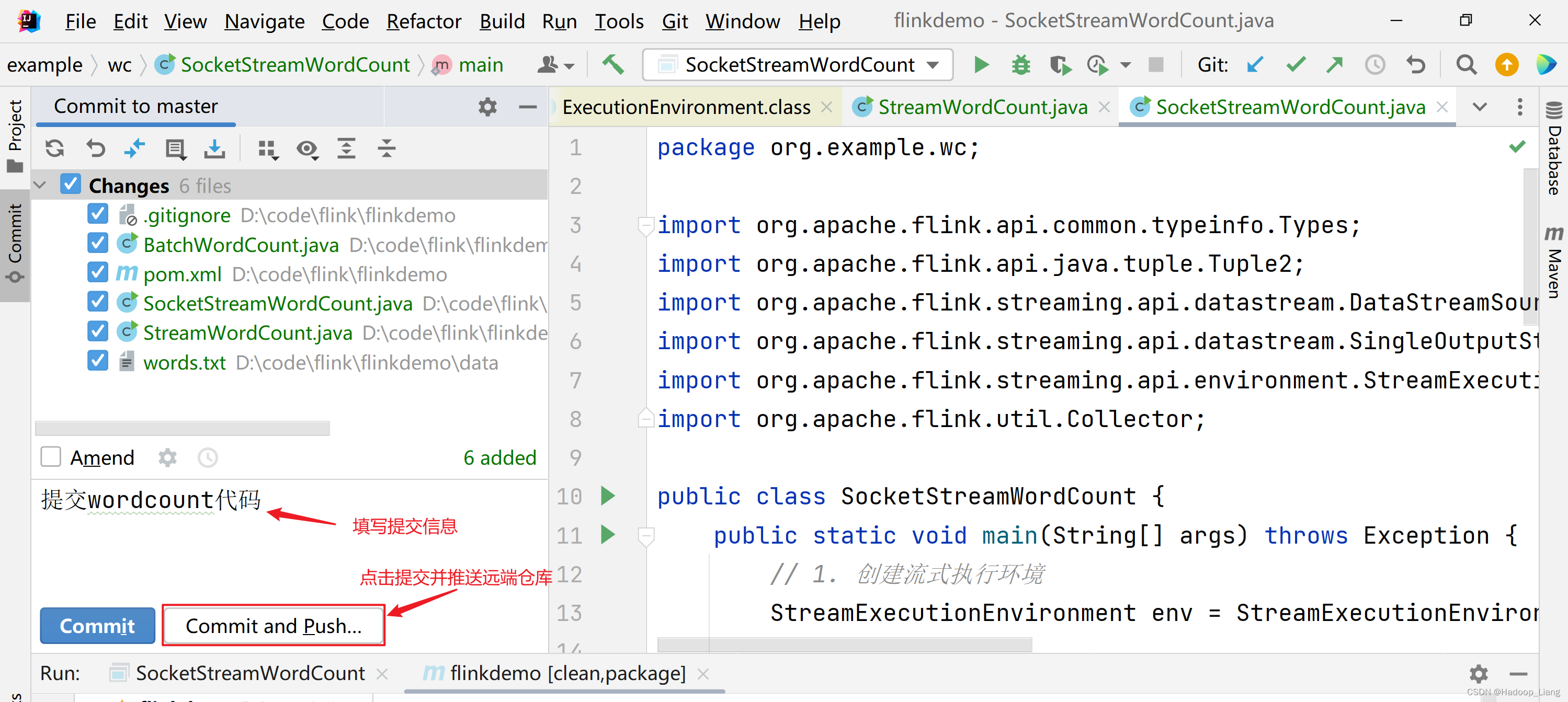
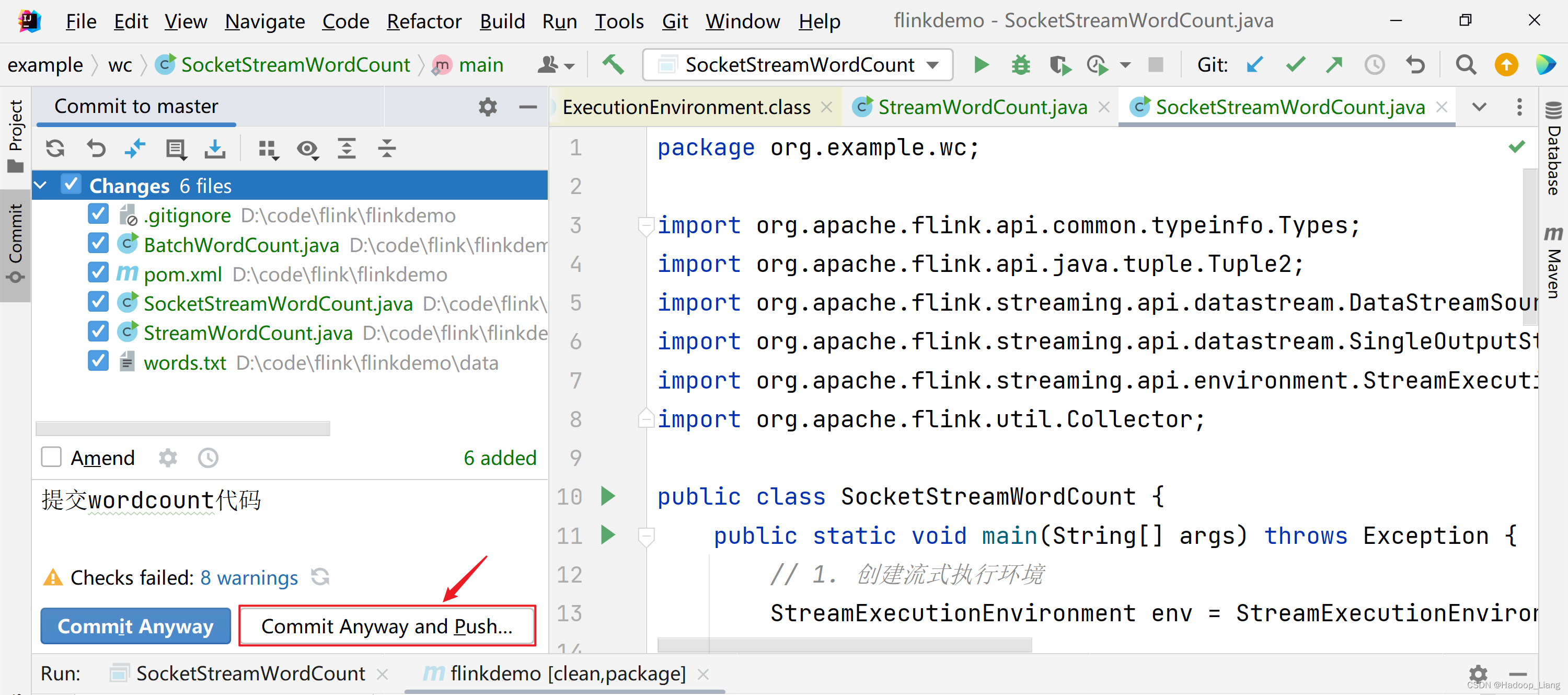
提示有警告,忽略警告,继续提交
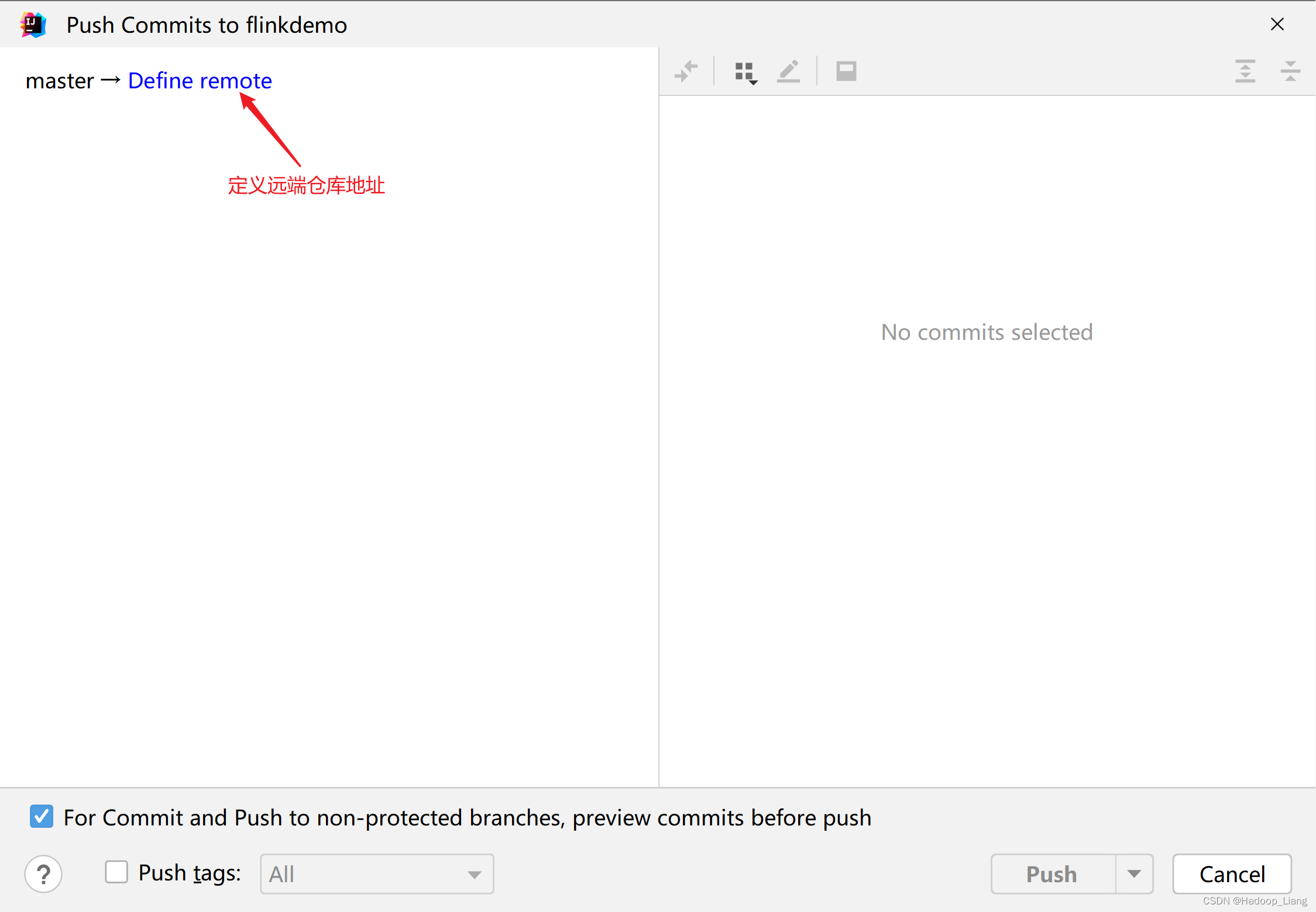
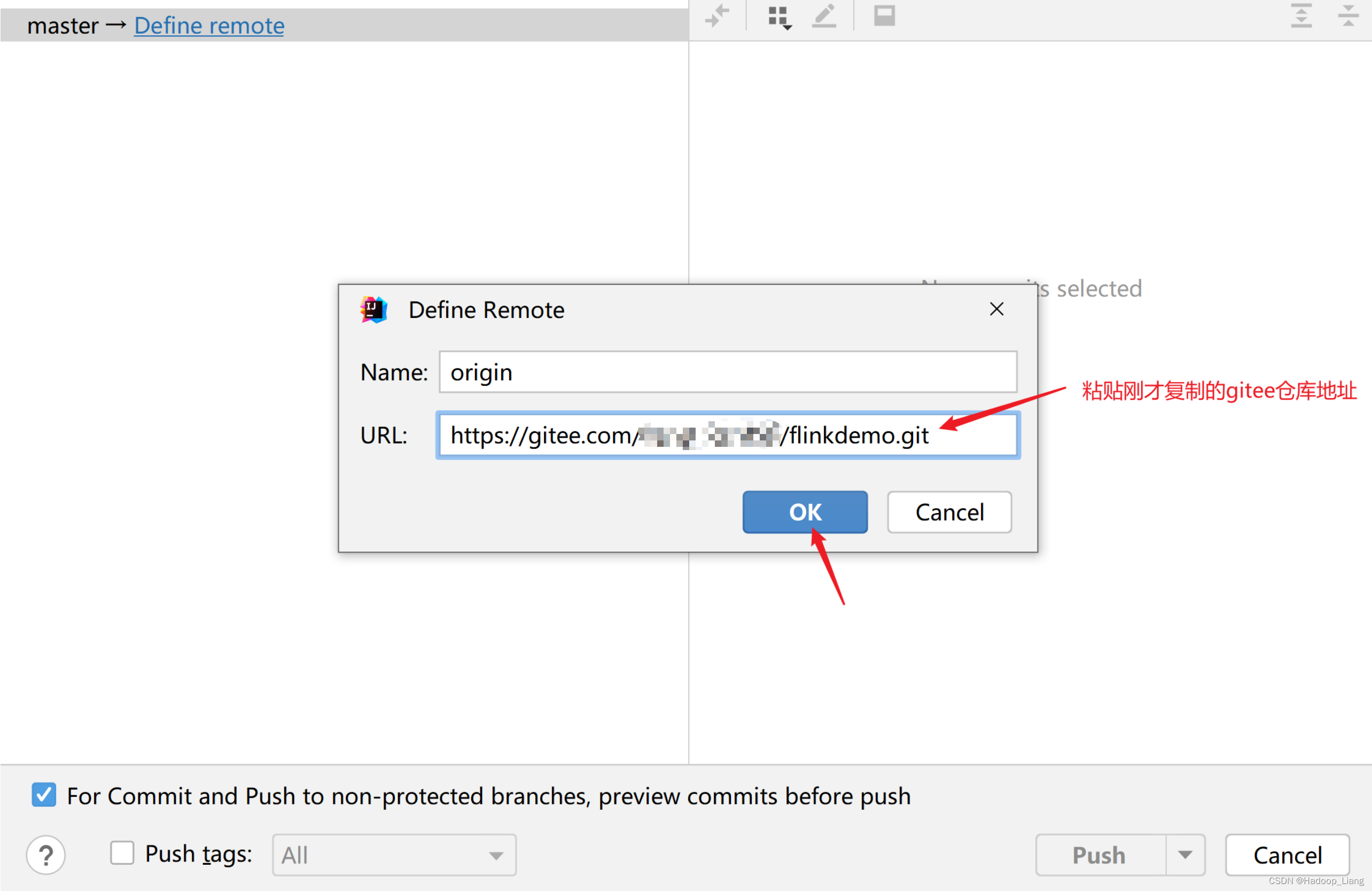
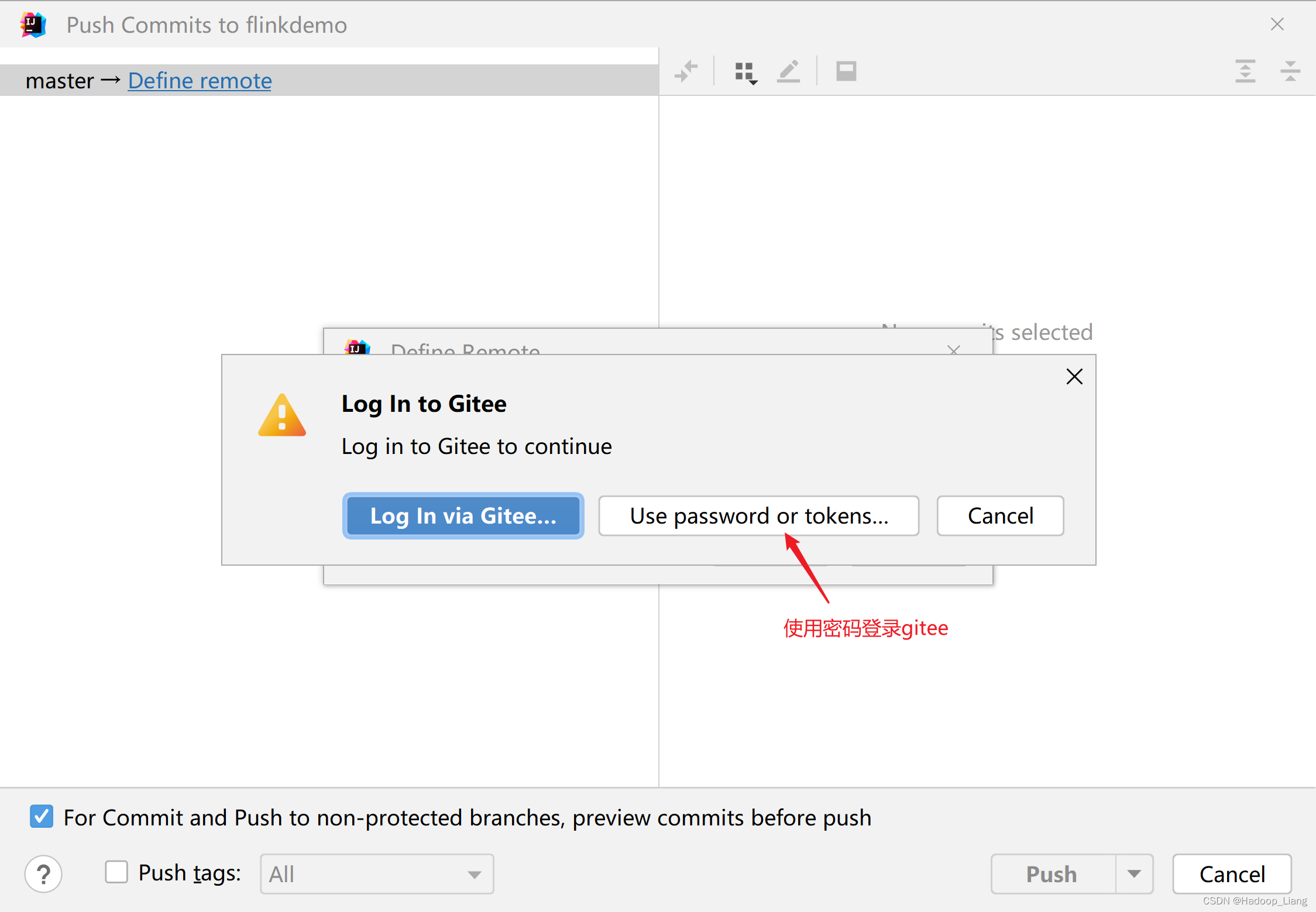
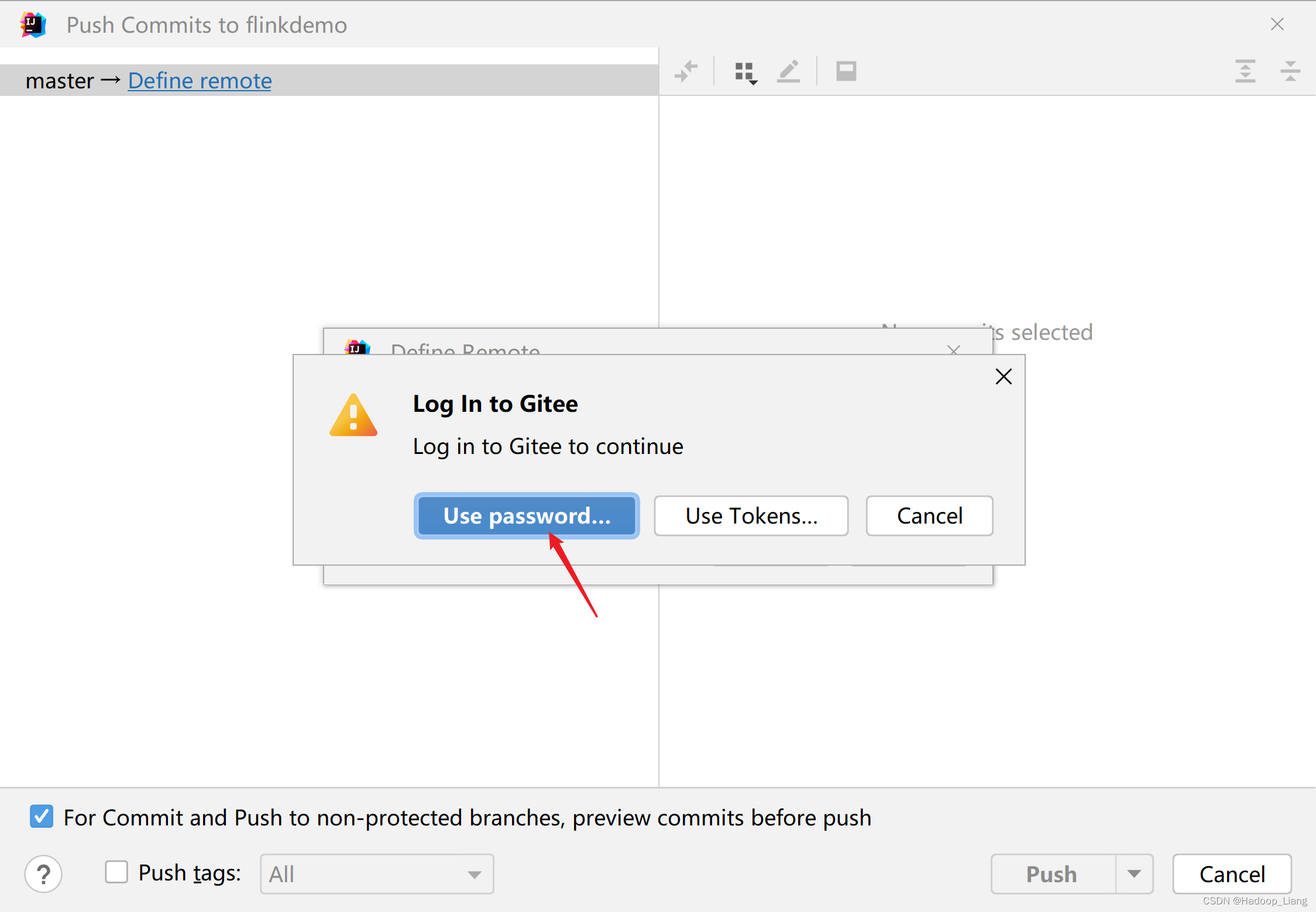
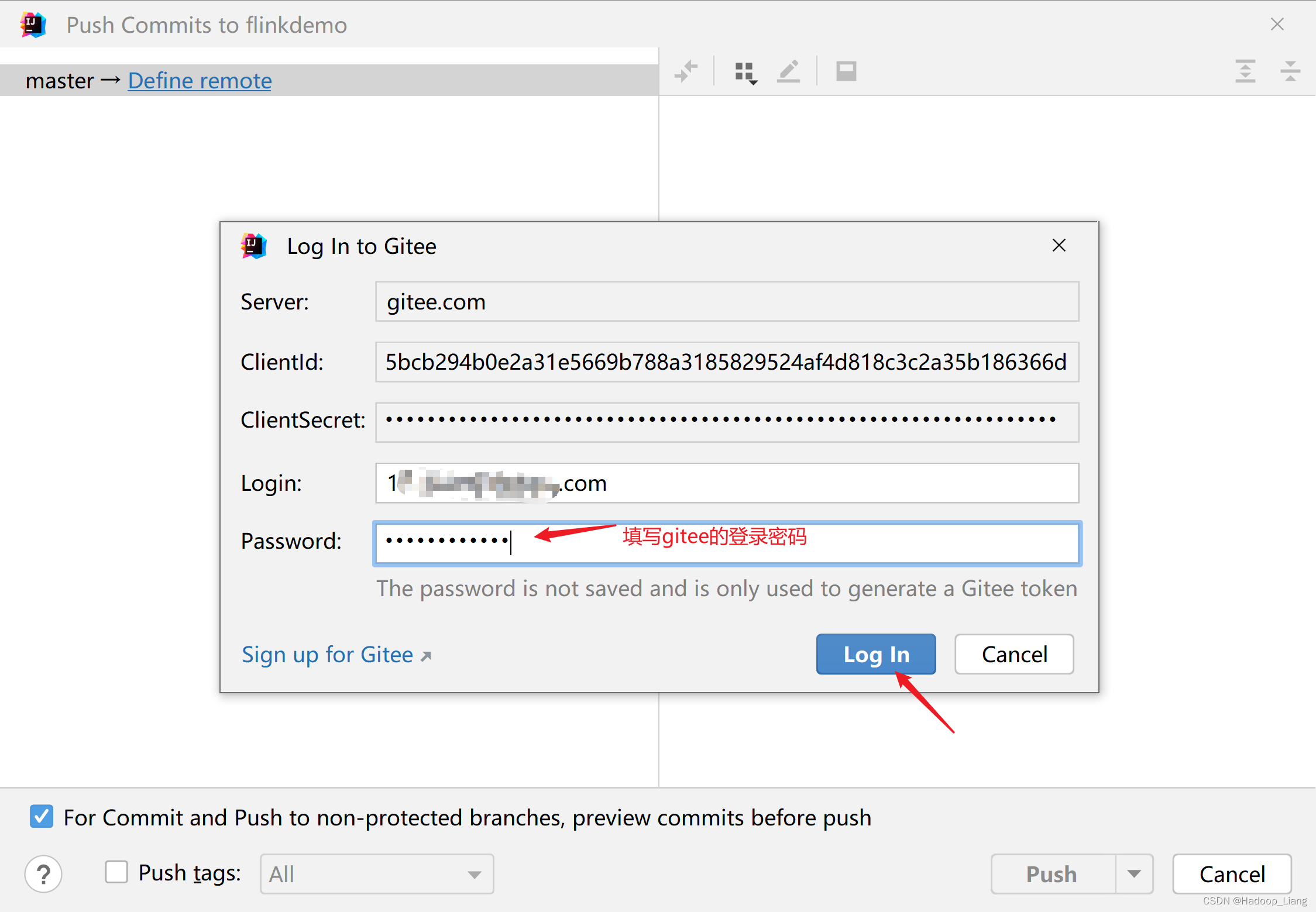
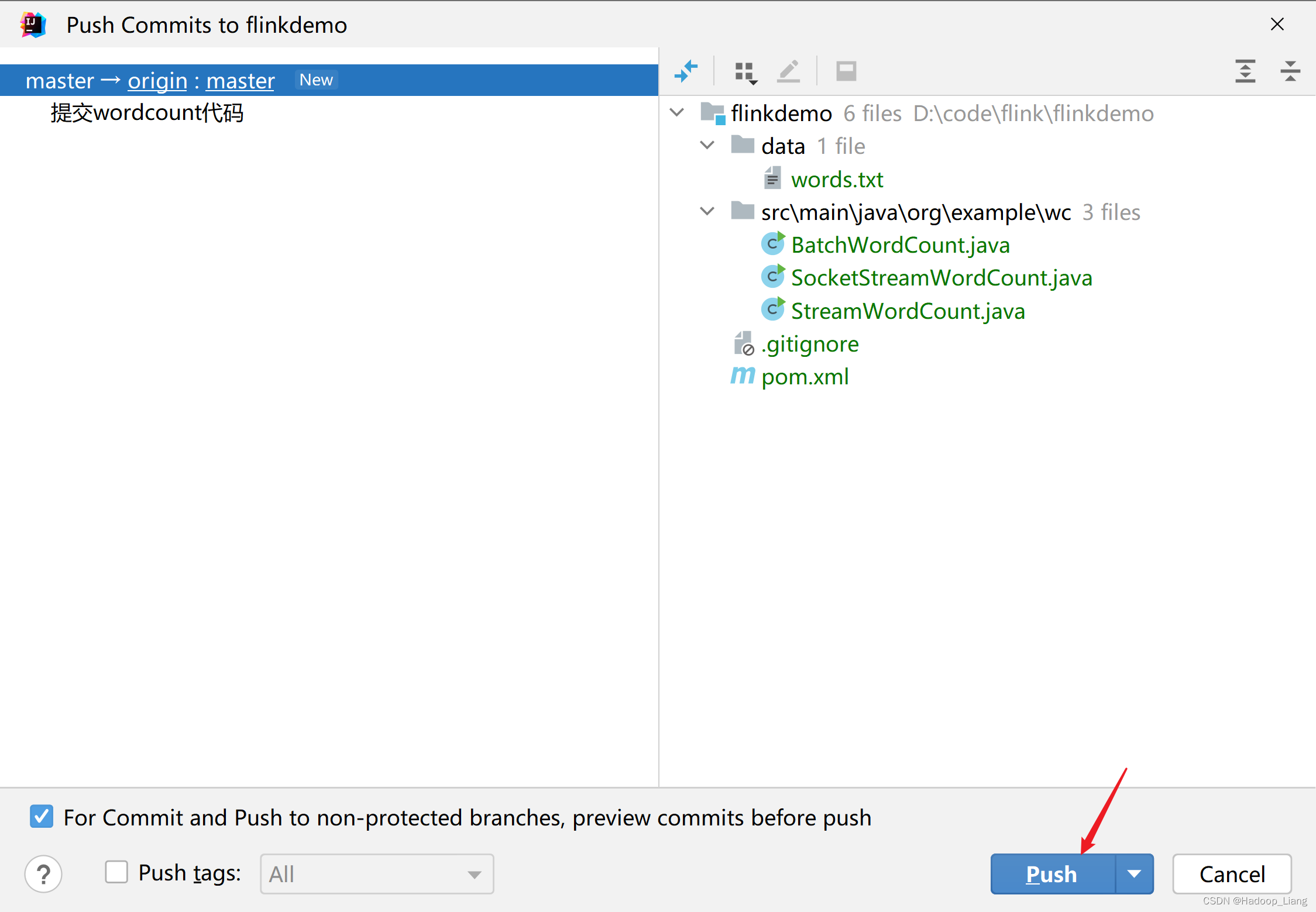
提交成功后,IDEA显示如下

刷新浏览器查看gitee界面,看到代码已上传成功
完成!enjoy it!
相关文章:
Flink WordCount实践
目录 前提条件 基本准备 批处理API实现WordCount 流处理API实现WordCount 数据源是文件 数据源是socket文本流 打包 提交到集群运行 命令行提交作业 Web UI提交作业 上传代码到gitee 前提条件 Windows安装好jdk8、Maven3、IDEA Linux安装好Flink集群,可…...
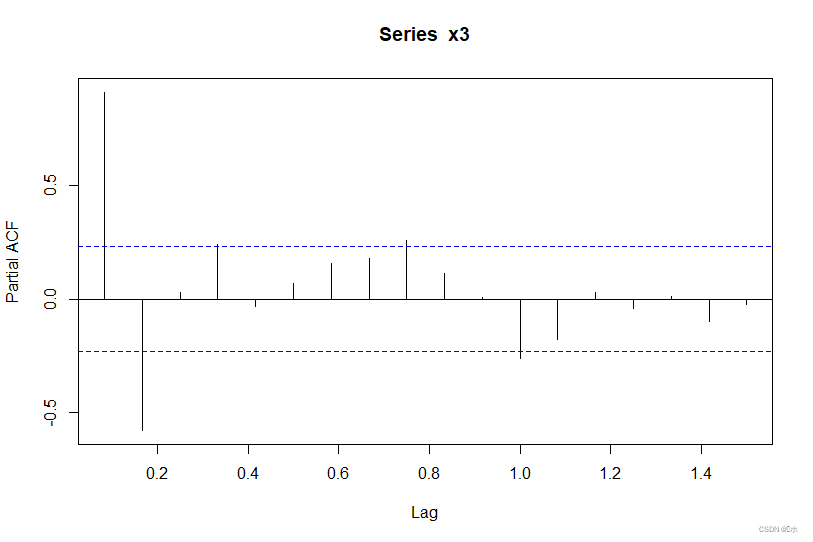
时间序列分析 # 平稳性检验和ARMA模型的识别与定阶 #R语言
掌握单位根检验的原理并能解读结果;掌握利用序列的自相关图和偏自相关图识别模型并进行初步定阶。 原始数据在文末!!! 练习1、根据某1971年9月-1993年6月澳大利亚季度常住人口变动(单位:千人)的…...

算法-日期问题
算法-日期问题 1.判断是否闰年 int is_leap(int y) {if((y%4000)||(y%40&&y%100!0)){return 1;}return 0; }2.每个月的天数 const int months[]{0,31,28,31,30,31,30,31,31,30,31,30,31};3.计算当前年当前月的天数 int get_month_days(int year,int month) {int re…...
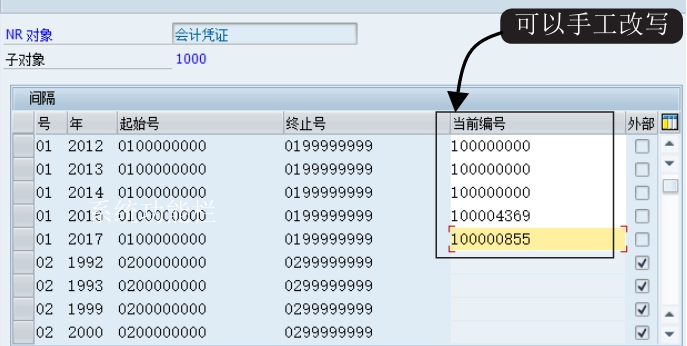
《由浅入深学习SAP财务》:第2章 总账模块 - 2.6 定期处理 - 2.6.5 年末操作:维护新财政年度会计凭证编号范围
2.6.5 年末操作:维护新财政年度会计凭证编号范围 财务系统的维护者要在每年年末预先设置好下一年度的会计凭证编号范围(number range),以便下一年度会计凭证能够顺利生成。这一操作一定要在下一年度1月1日以前预先完成。 …...

2024年第十七届“认证杯”数学中国数学建模网络挑战赛A题思路
A题 保暖纤维的保暖能力 冬装最重要的作用是保暖,也就是阻挡温暖的人体与寒冷环境之间的热量传递。人们在不同款式的棉衣中会填充保暖材料,从古已有之的棉花,羽绒到近年来各种各样的人造纤维。不同的保暖纤维具有不同的保暖性能,比如人们以往的经验表明,高品质的羽绒具有…...
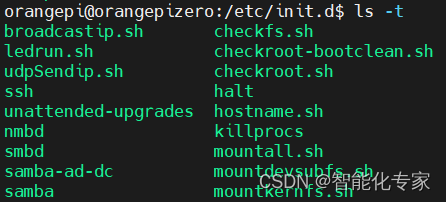
Linux 添加启动服务--Service
1,服务配置service文件 Service 服务的实际作用是开启后自动启动服务,运行一些不须要登录的程序,任务。 实例1、上电自动连接WIFI热点 1.1 新建.service文件 /etc/systemd/system/wificonnect.service [Unit] DescriptionService [wifico…...
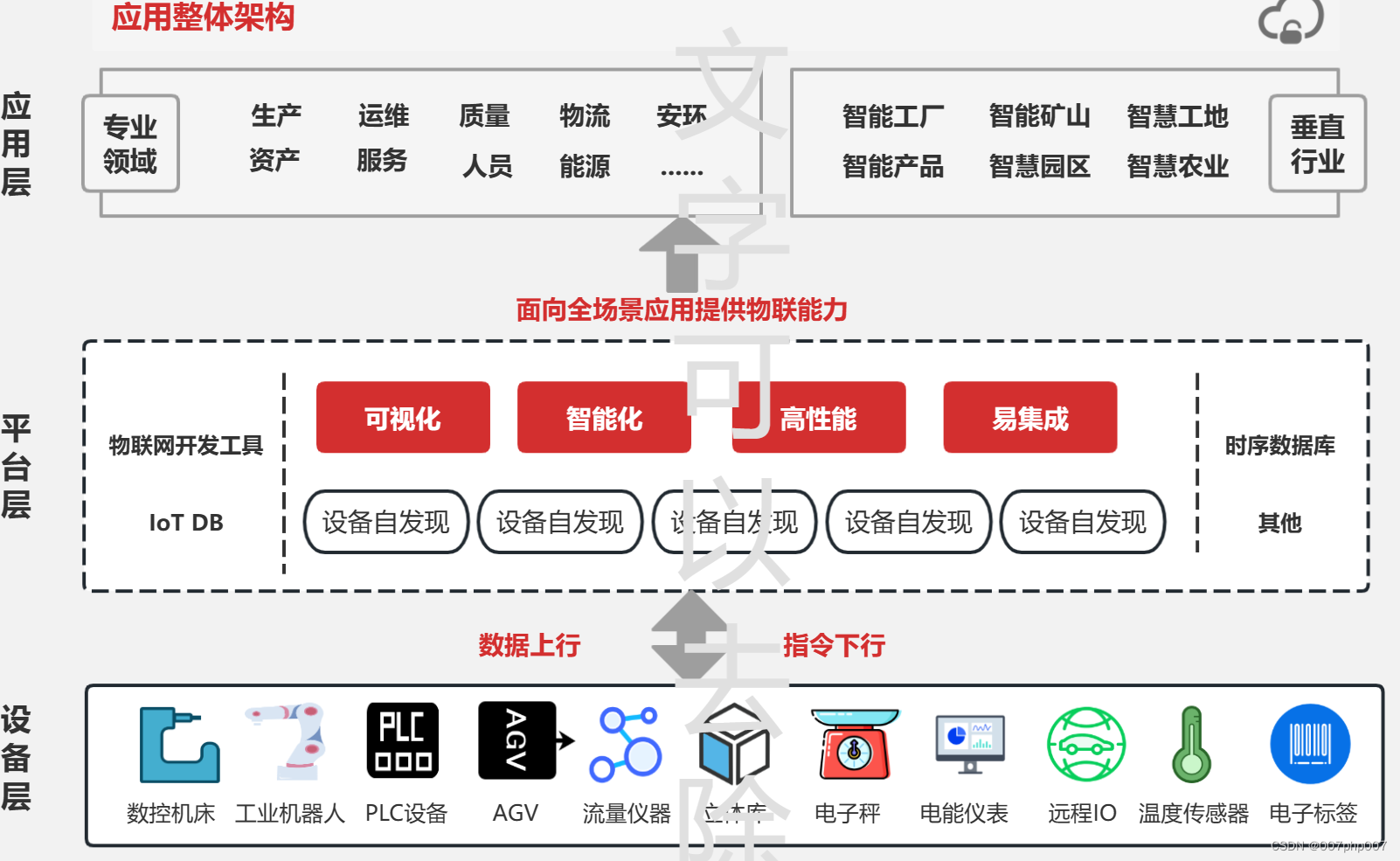
构建智能连接的未来:物联网平台系统架构解析
随着科技的不断进步和互联网的普及,物联网(Internet of Things, IoT)已成为连接世界的新方式。物联网平台作为实现物联网应用的核心基础设施,其系统架构的设计和实施至关重要。本文将深入探讨物联网平台系统架构的关键要素和最佳实…...

element-ui的年份范围选择器,选择的年份需等于或小于当前年份,选择的年份范围必须在三年之内
写在前面 日期限制处理(禁用),下面我以我这边的需求为例, 选择的年份需等于或小于当前年份 选择的年份范围必须在三年之内 1.限制起始日期小于截止日期 1)根据用户选中的开始日期,置灰不可选的日期范围&…...

2024年蓝桥杯40天打卡总结
2024蓝桥杯40天打卡总结 真题题解其它预估考点重点复习考点时间复杂度前缀和二分的两个模板字符串相关 String和StringBuilderArrayList HashSet HashMap相关蓝桥杯Java常用算法大数类BigInteger的存储与运算日期相关考点及函数质数最小公倍数和最大公约数排序库的使用栈Math类…...

STL函数对象
1,函数对象 1.1 函数对象概念 概念: 重载函数调用操作符的类,其对象常称为函数对象函数对象使用重载的()时,行为类似函数调用,也称为仿函数 本质: 函数对象(仿函数&…...

DedeCMS 未授权远程命令执行漏洞分析
dedecms介绍 DedeCMS是国内专业的PHP网站内容管理系统-织梦内容管理系统,采用XML名字空间风格核心模板:模板全部使用文件形式保存,对用户设计模板、网站升级转移均提供很大的便利,健壮的模板标签为站长DIY自己的网站提供了强有力…...

学习 Rust 的第二天:Cargo包管理器的使用
今天,我们来探讨一下 Cargo,这个强大而方便的 Rust 构建系统和包管理器。 Cargo 是一个稳健而高效的 Rust 构建系统和包管理器,旨在帮助管理项目依赖关系,并确保在不同环境下进行一致的构建。 使用 cargo 创建新程序:…...

【爬虫+数据清洗+可视化分析】Python文本分析《狂飙》电视剧的哔哩哔哩评论
一、背景介绍 把《狂飙》换成其他影视剧,套用代码即可得分析结论! 2023《狂飙》热播剧引发全民追剧,不仅全员演技在线,且符合主旋律,创下多个收视记录! 基于此热门事件,我用python抓取了B站上千…...

使用vite从头搭建一个vue3项目(二)创建目录文件夹以及添加vue-router
目录 一、创建 vue3 项目 vite-vue3-project-js二、创建项目目录三、创建Home、About组件以及 vue-router 配置路由四、修改完成后页面 一、创建 vue3 项目 vite-vue3-project-js 使用 vite 创建一个极简 vue3 项目请参考此文章:使用Vite创建一个vue3项目 下面是我…...
)
循环控制语句的实际应用(3)
3194:【例32.3】 数位积 时间限制: 1000 ms 内存限制: 65536 KB 提交数: 5116 通过数: 1971 【题目描述】 給出一个非负整数n,请求出n中各个数位上的数字之积。 【输入】 一开始有一个整数 T(1≤T≤100),表示共有几组测试数据。接下来有T个…...

突破像素限制,尽显照片细腻之美——Topaz Gigapixel AI for Mac/Win
在这个数字化的时代,我们都热爱用照片记录生活中的美好瞬间。然而,有时候我们会发现,由于各种原因,照片的像素可能无法满足我们的需求。这时候,Topaz Gigapixel AI for Mac/Win 这款强大的照片放大工具应运而生。 Top…...

CSS特效---HTML+CSS实现3D旋转卡片
1、演示 2、一切尽在代码中 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-width, initial-scale1.0" /><title>Document</title&…...

Rust跨平台编译
❝ 如果你感觉自己被困住了,焦虑并充满消极情绪,生命出现了停滞,那么治疗方法很简单:「做点什么」。 ❞ 大家好,我是「柒八九」。一个「专注于前端开发技术/Rust及AI应用知识分享」的Coder 前言 之前我们不是写了一篇R…...

php其他反序列化知识学习
简单总结一下最近学习的,php其他的一些反序列化知识 phar soap session 其他 __wakeup绕过gc绕过异常非公有属性,类名大小写不敏感正则匹配,十六进制绕过关键字检测原生类的利用 phar 基础知识 在 之前学习的反序列化利用中࿰…...
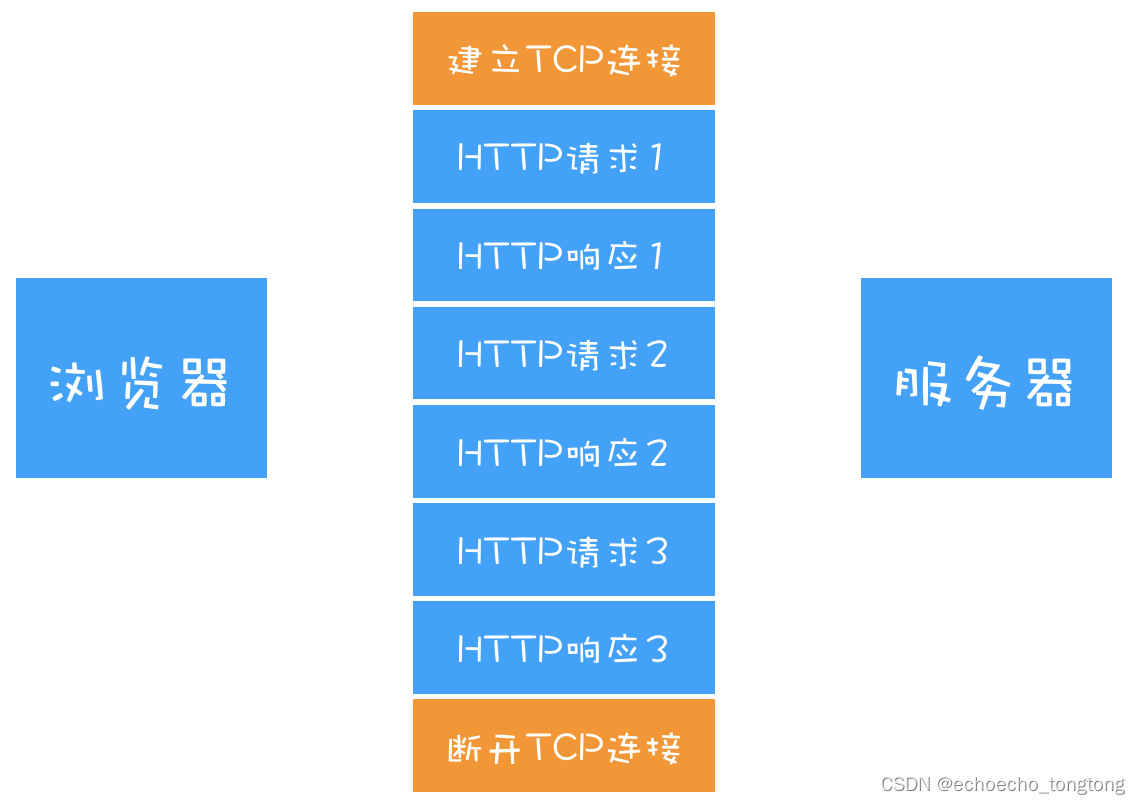
浏览器工作原理与实践--HTTP/1:HTTP性能优化
谈及浏览器中的网络,就避不开HTTP。我们知道HTTP是浏览器中最重要且使用最多的协议,是浏览器和服务器之间的通信语言,也是互联网的基石。而随着浏览器的发展,HTTP为了能适应新的形式也在持续进化,我认为学习HTTP的最佳…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...