MySQL实战之事务到底是隔离的还是不隔离的
1.前言
我们在MySQL实战之事务隔离:为什么你改了我还看不见讲过事务隔离级别的时候提到过,如果是可重复读隔离级别,事务T启动的时候会创建一个视图read-view,之后事务T执行期间,即使有其他事务修改了数据,事务T看到的仍然跟在启动时看到一样。也就是说,一个在可重复读隔离级别下执行的事务,好像与世无争,不受外界影响。
但是我们在MySQL实战之行锁功过:怎么减少行锁对性能的影响?分享行锁的时候又提到,一个事务要更新一行,如果刚好有另外一个事务拥有这一行的行锁,它又不能这么超然了,会被锁住,进入等待状态。问题是,既然进入了等待状态,那么等这个事务自己获取到行锁要更新数据的时候,它读到的值又是什么呢?
我们来看一个例子,
mysql> CREATE TABLE `t` (`id` int(11) NOT NULL,`k` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, k) values(1,1),(2,2);

这里,我们需要注意的是事务的启动时机
begin/start transaction命令并不是一个事务的起点,在执行到他们之后第一个操作InnoDB表的语句,事务才真正启动。如果你想要马上启动一个事务,可以使用start transaction with consistent snapshot这个命令。
- 第一种启动方式,一致性视图是在执行第一个快照读语句时创建的;
- 第二种启动方式,一致性视图是在执行start transaction with consistent snapshot时创建的。
在这个例子中,事务C没有显示的使用begin/commit,表示这个update语句本身就是一个事务,语句完成的时候会自动提交。事务B在更新了行之后查询;事务A在一个只读事务中查询,并且时间顺序是在事务B的查询之后。
这时,如果我告诉你事务B查到的k值是3,而事务A查到的k值是1,你是不是感觉是有点晕呢?
所以,本篇文章,主要就是说明白这个问题,希望借由把这个疑惑解开的过程,能够帮助你对InnoDB的事务和锁有更进一步的理解。
在MySQL中,有两个视图的概念:
- 一个是view。它是一个用于查询语句定义的虚拟表,在调用的时候执行查询语句并生成结果。创建视图的语法是create view…,而他的查询和表一样。
- 另一个是InnoDB在实现MVCC时用到的一致性读视图,即consistent read view,用于支持RC(read committed 读已提交)和RR(Repeatable Read 可重复读)隔离级别的实现。
他没有物理结构,作用是事务执行期间用来定义”我能看到什么数据“。
在MySQL实战之事务隔离:为什么你改了我还看不见中,我们讲过了MVCC的实现逻辑。今天为了说明查询和更新的区别,我们换一个方式来说明,把read view拆开。你可以结合这两篇的说明来更深一步的理解MVCC。
2. 快照在MVCC里是怎么工作的
在可重复读隔离级别下,事务在启动的时候就拍了个快照。注意,这个快照是基于整库的。
这是,你会说这看上去不太现实啊,如果一个库有100G,那么我启动事务,MySQL就要拷贝100G的数据出来,这个过程的多慢呀。可是,我平时的事务执行起来很快呀。
实际上,我们并不需要拷贝100G的数据。我们先来看看这个快照读是怎么实现的。
InnoDB里面每个事务有一个唯一的事务ID,叫做transaction id。它是事务开始的时候向InnoDB的事务系统申请的,是按照申请顺序严格递增的。
而每行数据也都是有多个版本的。每次事务更新数据的时候,都会生成一个新的数据版本,并且把transaction id赋值给这个数据版本的事务ID,即为row trx_id…同时,旧的数据版本要保留,并且在新的数据版本中,能够有信息可以直接拿到它。
也就是说,数据库中的一行记录,其实可能有多个版本,每个版本由自己的row trx_id.
如下图所示,就是一个记录被多个事务连续更新后的状态。
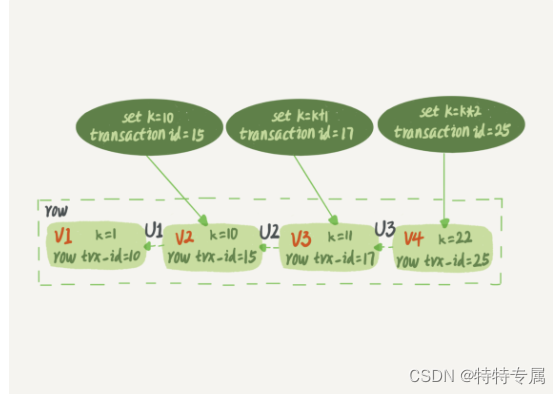
图中虚线框里是同一行数据的4个版本,当前最新版本是V4,k的值是22,它是被transaction id为25的事务更新的,因此它的row trx_id也是25.
你可能会问,前面的文章不是说,语句更新会生成undo log(回滚日志)吗?那么,undo log在哪呢?
实际上,上图中,三个虚线箭头,就是undo log;而V1、V2、V3并不是物理上真实存在的,而是每次需要的时候根据当前版本和undo log计算出来的。比如:需要V2的时候,就是通过V4依次执行U3、U2算出来。
明白了多版本和row trx_id的概念后,我们再来想一下,InnoDB是怎么定义那个100G的快照的。
按照可重复读的定义,一个事务启动的时候,能够看到所有已经提交的事务结果但是之后,这个事务执行期间,其他事务的更新对它不可见。
因此,一个事务只需要在启动的时候声明说,以我启动的时刻为准,如果一个数据版本是在我启动之前生成的,就认;如果是我启动以后生成的,我就不认,我必须要找到它的上一个版本。
当然,如果上一个版本也不可见,那就继续往前找。还有,如果这个事务自己更新的数据,还是要认的。
在实际上,InnoDB为每个事务构造了一个数组,用来保存这个事务启动瞬间,当前正在活跃的所有事务ID,活跃指的是,启动了但未提交。
数组里面事务ID的最小值为低水位,当前系统里面已经创建过的事务ID的最大值+1记为高水位。
这个视图数组和高水位,就组成当前事务的一致性视图。
而数据版本的可见性规则,就是基于数据row trx_id和这个一致性视图的对比结果得到的。
这个视图数组所有的rox trx_id分成了以下几种情况
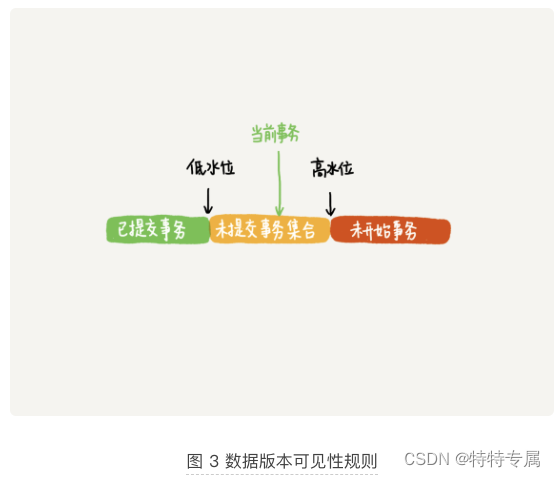
这样,对于当前事务的启动瞬间来说,一个数据版本的rox trx_id,有以下几种可能
- 如果落在绿色部分,表示这个版本是已经提交的事务或者当前事务自己生成的,这个数据是可见的。
- 如果落在红色部分,表示这个版本是由将来启动的事务生成的,是肯定不可见的;
- 如果落在黄色部分,那就包括两种情况
a. 若rox trx_id在数组中,表示这个版本是由还没有提交的事务生成的,不可见
b. 若rox trx_id不在数组中,表示这个版本是已经提交了的事务生成的,可见
比如,对于图2中的数据来说,如果有一个事务,它的低水位是18,那么当访问这一行数据时,就会从V4通过U3计算出V3,所以在它看来,这一行的只是11.
你看,有了这个声明后,系统里面随后发生的更新,是不是就跟这个事务看到的内容无关了呢?因为之后的更新,生成的版本一定属于上面2或者3(a)的情况,而对它来说,这些新的数据版本是不存在的,所以这个事务的快照,就是静态的了。
所以你现在知道了,InnoDB利用了所有数据都有多个版本的特性,实现了秒级创建快照的能力。
接下来,我们继续看一下图1中的三个事务,分析下事务A的语句返回的结果,为什么是k=1.
这里我们不妨做一个假设:
- 事务A开始前,系统里面只有一个活跃事务ID是99;
- 事务A、B、C的版本号分别是100、101、102,且当前系统只有这四个事务
- 三个事务开始前,(1,1)这一行数据的rox trx_id是90
这样,事务A的视图数组就是[99, 100],事务B的视图数组是[99,100,101],事务C的视图数组是[99,100,101,102]。
为了简化分析,我先把其他的干扰语句去掉,只画出跟事务A查询逻辑相关的操作:
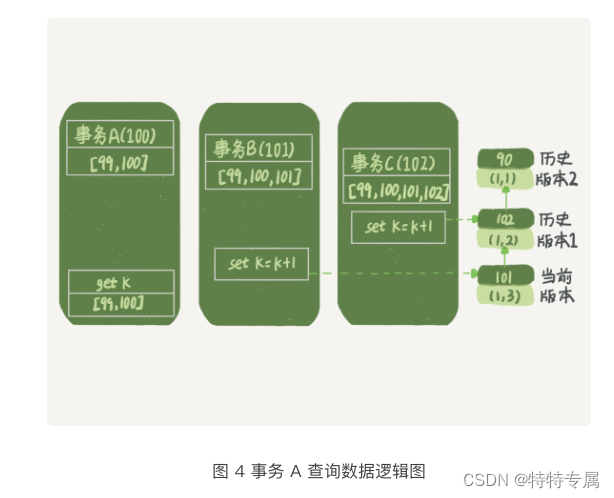
从图中可以看到,第一个有效更新的是事务C,把数据从(1,1)改成了(1,2)。这时候,这个数据的最新版本rox trx_id是102,而90这个版本已经成为历史版本。
第二个有效更新是事务B,把数据从(1,2)改成了(1,3)。这时候,这个数据的最新版本rox trx_id是101,而102又成为了历史版本。
你可能注意到了,在事务A查询的时候,其实事务B还没有提交,但是它生成的(1,3)这个版本已经变成当前版本了。但这个版本对事务A必须是不可见的,否则就变成了脏读了。
好,现在事务A来读取数据了,它的视图是[99,100]。当然了,读数据都是从当前版本读起的。所以,事务A查询语句读数据的流程是这样的:
- 找到(1,3)的时候,判断出rox trx_id=101,比高水位打,处于红色区域,不可见;
- 接着,找到上一个历史版本,一看rox trx_id=102,比高水位打,处于红色区域,不可见
- 再往前找,终于找到了(1,1),他的rox trx_id=90,比低水位小,处于绿色区域,可见
这样执行下来,虽然期间这一行数据被修改过,但是事务A不论在什么时候查询,看到这行数据的结果都是一致的,所以我们称之为一致性读。
这个判断规则是从代码逻辑直接转译过来的,但是正如你所见,用于人肉分析可见性很麻烦。
所以,我来给你翻译一下。一个数据版本,对于一个事务视图来说,除了自己的更新总是可见外,有三种情况:
- 版本未提交,不可见
- 版本已提交,但是在视图创建后提交的,不可见
- 版本已提交,而且是在视图创建前提交的,可见
现在我们用这个规则来判断图4中的查询结果,事务A的查询语句的视图数组是在事务A启动的时候生成的,这时候:
- (1,3)还没有提交,属于情况1,不可见
- (1,2)虽然已经提交,但是在事务A视图创建后,属于情况2,可见
- (1,1)虽然已经提交,但是是在事务A视图创建前,属于情况3,可见
你看,去掉数字对比后,只用时间的先后顺序来判断,分析起来是不是轻松多了,所以,后面我们就用这个规则来分析。
3.更新逻辑
细心的同学可能有疑问了:事务B的update语句,如果按照一致性读,好像结果不对哦?
你看图5 中,事务B的视图数组是先生成的,之后事务C才提交的,不是应该看不见(1,2)吗,怎么能算出(1,3)来?
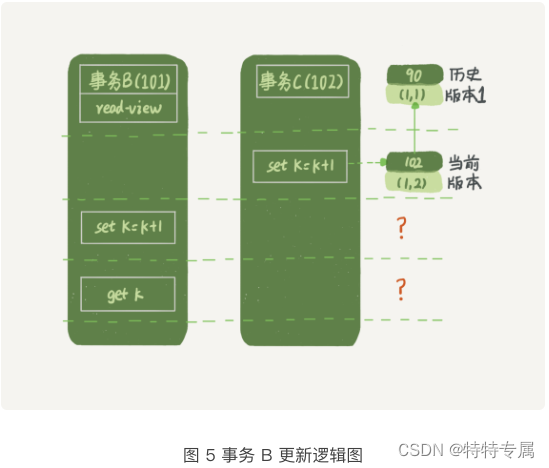
是的,如果事务B在更新之前查询一次数据,这个查询返回的k确实是1.
但是,当它要去更新数据的时候,就不能在历史版本上更新了,否则事务C的更新就丢失了。因此,事务B此时的set k=k+1是在(1,2)的基础上进行的操作。
所以,这里就用了这样一条规则:更新数据都是先读后写的,而这个读,只能读当前值,成为当前读。
因此,在更新的时候,当前读拿到的数据是(1,2),更新后生成了新版本数据(1,3),这个新版本的rox trx_id是101.
所以,在执行事务B查询语句的时候,一看自己的版本号是101,最新数据的版本号也是101,是自己的更新,可以直接使用,所以查询得到的k值是3.
这里我们提到了一个概念,叫做当前读。其实,处理update语句外,select语句如果加锁,也是当前读。
所以,如果把事务A的查询语句select * from t where id = 1修改一下,加上lock in share mode或for update,也都可以读到版本号是101的数据,返回k=3.下面这两个select,就是分别加了读锁(S锁,共享锁)和写锁(X锁,排他锁).
mysql> select k from t where id=1 lock in share mode;
mysql> select k from t where id=1 for update;
再往前一步,假设事务C不是马上提交的,而是变成下面的事务C‘,会怎么样呢?

事务C’的不同是,更新后并没有马上提交,在它提交前,事务B的更新语句先发起了。前面说过了,虽然事务C’还没提交,但是(1,2)这个版本已经生成了,并且是当前的最新版本。那么,事务B的更新语句会怎么处理呢?
这时候,我们在上一篇文章中提到的“两阶段锁协议”就要上场了。事务C’没提交,也就是说(1,2)这个版本上的写锁还没释放。而事务B是当前读,必须要读取最新版本,而且必须要加锁,因此就被锁住了,必须等到事务C‘释放这个锁,才能继续它的当前读
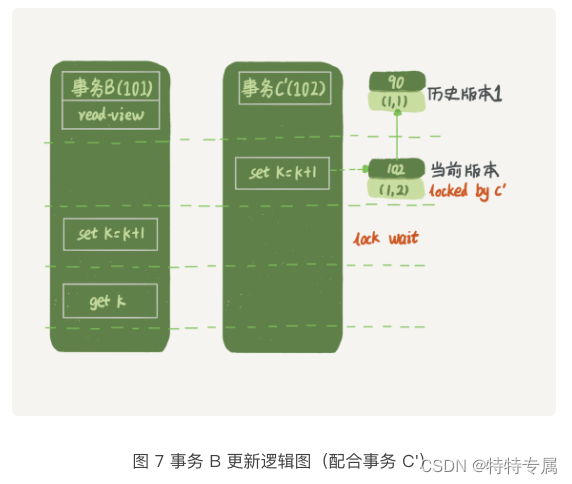
到这里,我们把一致性读、当前读、和行锁就串起来了。
现在,我们在回到文章的开头的问题:事务的可重复读的能力是怎么实现的?
可重复读的核心就是一致性读;而事务更新数据的时候,只能用当前读。如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待。
而读提交的逻辑和可重复读的逻辑类似,他们最主要的区别是:
- 在可重复读的隔离级别下,只需要在事务开始的时候创建一致性视图,之后事务里的其他查询都公用这个一致性视图
- 在读提交隔离级别下,每个语句执行前都会重新算出一个新的视图
那么,我们再看一下,在读提交隔离级别下,事务A和事务B的查询语句查到的k,分别是多少呢?
这里需要说明一下,start transaction with consistent snapshot;的意思是从这个语句开始,创建一个持续整个事务的一致性快照。所以在读提交隔离级别下,这个用法就没意义了,等效于 start transaction。
下面是读提交的状态图,可以看到这两个查询的创建视图数组的时机发生了变化,就是图中的read view框
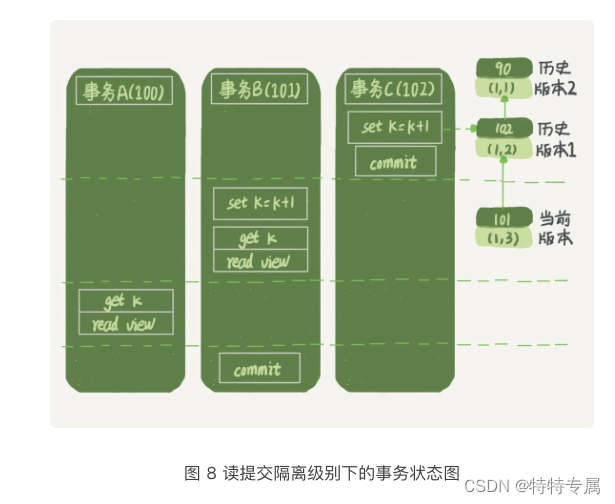
这时,事务A的查询语句的视图数组是在执行这个语句的时候创建的,时序上(1,2)、(1,3)的生成时间都在创建这个视图数组的时刻之前,但是,在这个时刻:
- (1,3)还没有提交,属于情况1,不可见
- (1,2)已经提交,属于情况3,可见。
所以,这时候事务A查询语句返回的是k=2;事务B查询结果是k=3;
4.小结
InnoDB的行数据有多个版本,每个数据版本由自己的row trx_id,每个事务或者语句有自己的一致性视图。普通查询语句是一致性读,一致性读会根据row trx_id和一致性视图确定数据版本的可见性。
- 对于可重复读,查询只承认在事务启动前就已经提交完成的数据
- 对于读提交,查询只承认在语句启动前就已经提交完成的数据
而当前读,总是读取已经提交完成的最新版本。
你也可以想一下,为什么表结构不支持“可重复读”?这是因为表结构没有对应的行数据,也没有 row trx_id,因此只能遵循当前读的逻辑。
当然,MySQL 8.0 已经可以把表结构放在 InnoDB 字典里了,也许以后会支持表结构的可重复读。
相关文章:
MySQL实战之事务到底是隔离的还是不隔离的
1.前言 我们在MySQL实战之事务隔离:为什么你改了我还看不见讲过事务隔离级别的时候提到过,如果是可重复读隔离级别,事务T启动的时候会创建一个视图read-view,之后事务T执行期间,即使有其他事务修改了数据,事务T看到的…...
Elasticsearch:理解 Master,Elections,Quorum 及 脑裂
集群中的每个节点都可以分配多个角色:master、data、ingest、ml(机器学习)等。 我们在当前讨论中感兴趣的角色之一是 master 角色。 在 Elasticsearch 的配置中,我们可以配置一个节点为 master 节点。master 角色的分配表明该节点…...
【致敬女神】HTMLReport应用之Unittest+Python+Selenium+HTMLReport项目自动化测试实战
HTMLReport应用之UnittestPythonSeleniumHTMLReport项目自动化测试实战1 测试框架结构2 技术栈3 实现思路3.1 使用HtmlTestRunner3.2 使用HTMLReport4 TestRunner参数说明4.1 源码4.2 参数说明5 框架代码5.1 common/reportOut.py5.2 common/sendMain.py5.3 report5.3.1 xxx.htm…...

JAVA的16 个实用代码优化小技巧
一、类成员与方法的可见性最小化 举例:如果是一个private的方法,想删除就删除。 如果一个public的service方法,或者一个public的成员变量,删除一下,不得思考很多。 二、使用位移操作替代乘除法 计算机是使用二进制…...

并发编程的三大挑战之原子性及其解决方案
目录 一、原子性问题 1、带来原子性问题的原因 2、如何解决线程切换带来的原子问题 2.1、使用synchronized关键字来保证 2.2、使用CAS来保证原子性 2.3、使用lock锁来保证 一、原子性问题 1、带来原子性问题的原因 线程切换是带来原子的根本原因,java的并发程…...
)
QML动画(其他的动画)
PauseAnimation (暂停动画) 为动画提供暂停 Rectangle{id:rect1width: 100;height: 100;x:100;y:100color: "lightBlue"SequentialAnimation{running: trueColorAnimation {target: rect1;property: "color";…...
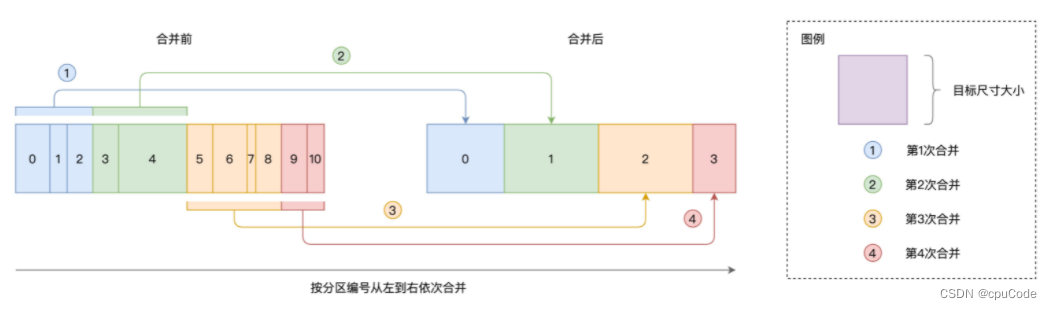
Spark 配置项
Spark 配置项硬件资源类CPU内存堆外内User Memory/Spark 可用内存Execution/Storage Memory磁盘ShuffleSpark SQLJoin 策略调整自动分区合并自动倾斜处理配置项分为 3 类: 硬件资源类 : 与 CPU、内存、磁盘有关的配置项Shuffle 类 : Shuffle 计算过程的配置项Spark SQL : Spar…...

掌握Vue3模板语法,助你轻松实现高效Web开发
Vue3作为前端开发中的一种主流框架,为我们提供了多种灵活的方式来处理模板语法。除了基础的模板语法,Vue3还提供了一些高级的语法,可以让我们更好地处理组件、响应式数据和UI逻辑等。在这篇博客中,我们将介绍Vue3中的一些高级模板…...
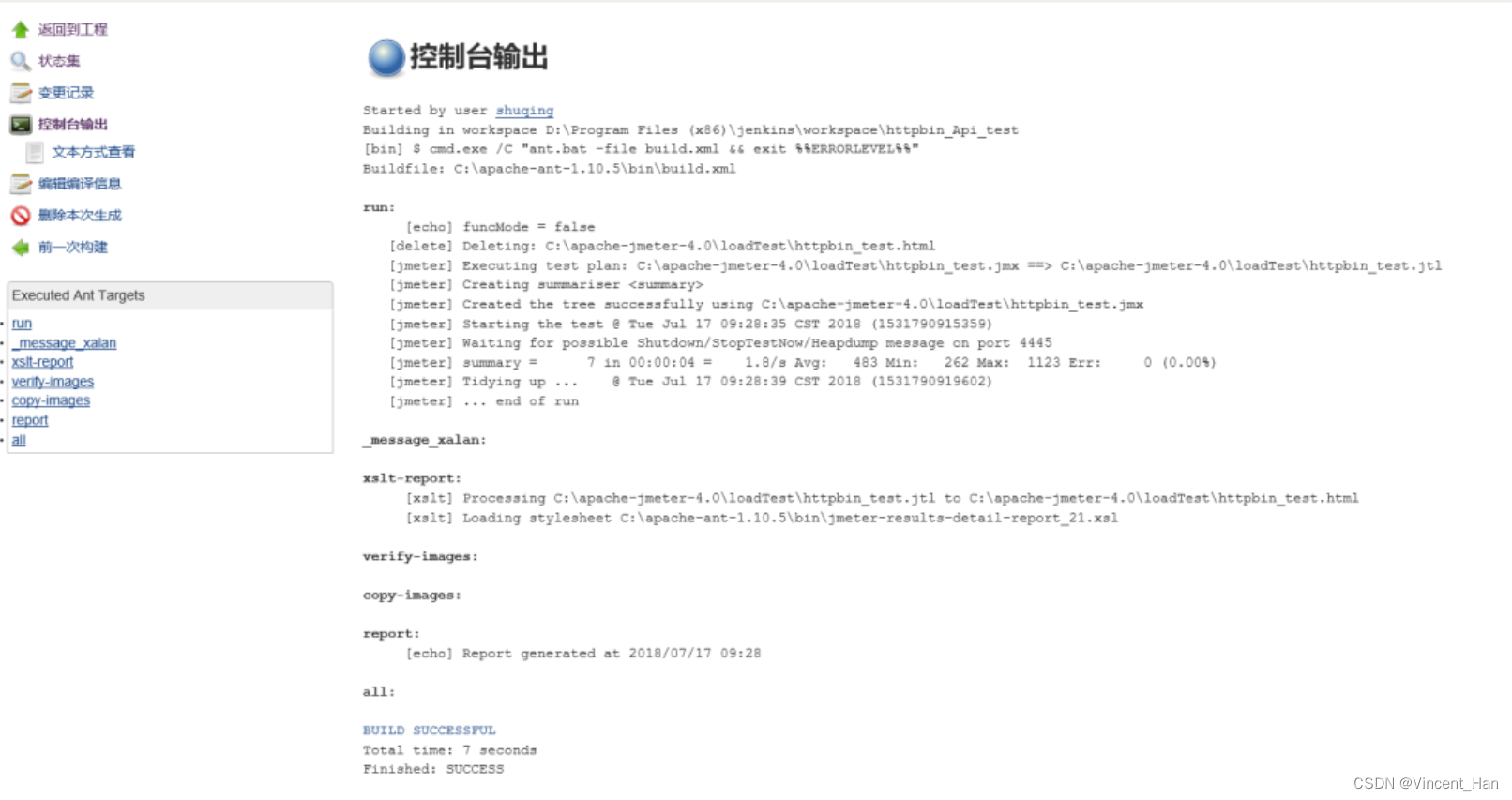
Jmeter+Ant+Jenkins接口自动化测试平台搭建
平台简介一个完整的接口自动化测试平台需要支持接口的自动执行,自动生成测试报告,以及持续集成。Jmeter支持接口的测试,Ant支持自动构建,而Jenkins支持持续集成,所以三者组合在一起可以构成一个功能完善的接口自动化测…...
)
ncnn部署(CMakelists.txt)
1. NCNN 环境安装 参考博客: 基于ncnn的yolov5模型部署 1. 1 protobuf编译 打开VS2013/VS2019的X64命令行(注意不是cmd),我这里以V32013环境进行编译 > cd <protobuf-root-dir> > mkdir build-vs2013 > cd build-vs2013 > cmake -G"NMake Makefil…...
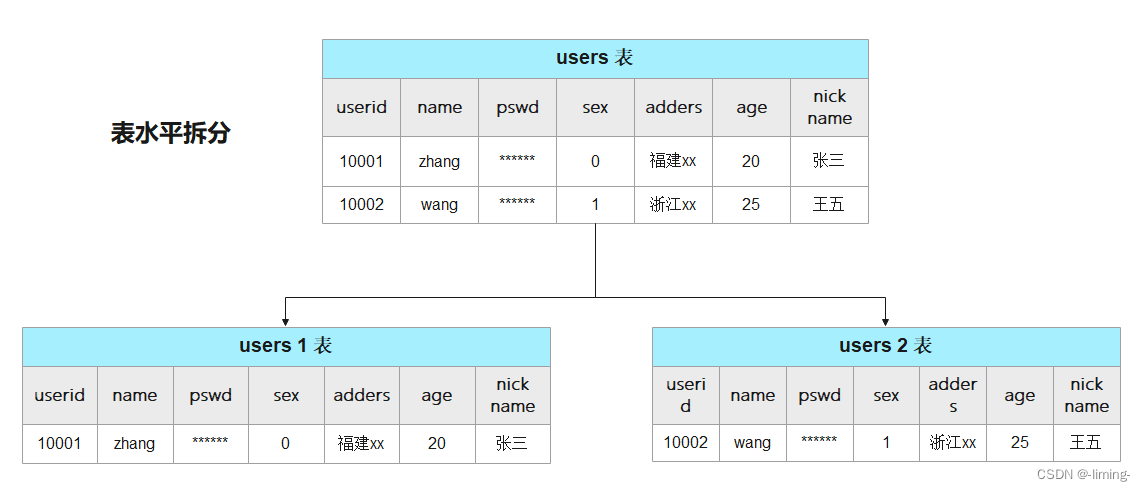
SQL分库分表
什么是分库分表? 分库分表是两种操作,一种是分库,一种是分表。 分库分表又分为垂直拆分和水平拆分两种。 (1)分库:将原来存放在单个数据库中的数据,拆分到多个数据库中存放。 (2&…...

大数据分析案例-基于逻辑回归算法构建微博评论情感分类模型
🤵♂️ 个人主页:@艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+ 喜欢大数据分析项目的小伙伴,希望可以多多支持该系列的其他文章 大数据分析案例合集…...
)
0105深度优先搜索算法非递归2种实现对比-无向图-数据结构和算法(Java)
1 两种非递归实现 在前面我们解决无向图的单点通性和单点路径问题时,都用到了深度优先搜索算法。深度优先搜索算法可以用递归和非递归两种方式。这里讨论非递归实现。 无向图结构使用邻接表实现。 第一种非递归方法(推荐),代码如…...
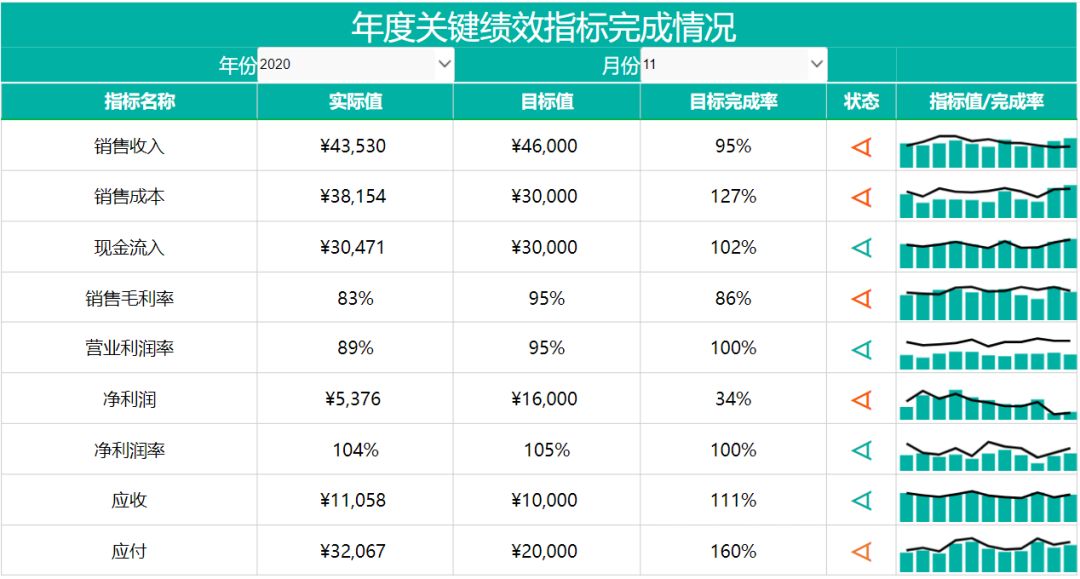
传统手工数据采集耗时耗力?Smartbi数据填报实现数据收集分析自动化
企业在日常经营管理过程中,往往需要收集很多内外部的信息,清洗整理后再进行存储、分析、呈现、决策支持等各种作业,如何高效收集结构化数据是企业管理者经常要面对的问题。传统手工的数据采集方式不仅耗费了大量人力时间成本,还容…...

《Spring源码深度分析》第5章 Bean的加载
目录标题前言一、Bean加载入口与源码分析1、Bean加载的入口2、Bean加载源码二、FactoryBean的使用三、缓存中获取单例bean(待补充)前言 经过前面的分析,我们终于结束了对XML 配置文件的解析,接下来将会面临更大的挑战,就是对 bean 加载的探索…...
)
华为OD机试真题Java实现【求最大数字】真题+解题思路+代码(20222023)
求最大数字 题目 给定一个由纯数字组成以字符串表示的数值,现要求字符串中的每个数字最多只能出现2次,超过的需要进行删除;删除某个重复的数字后,其它数字相对位置保持不变。 如34533,数字3重复超过2次,需要删除其中一个3,删除第一个3后获得最大数值4533 请返回经过删…...
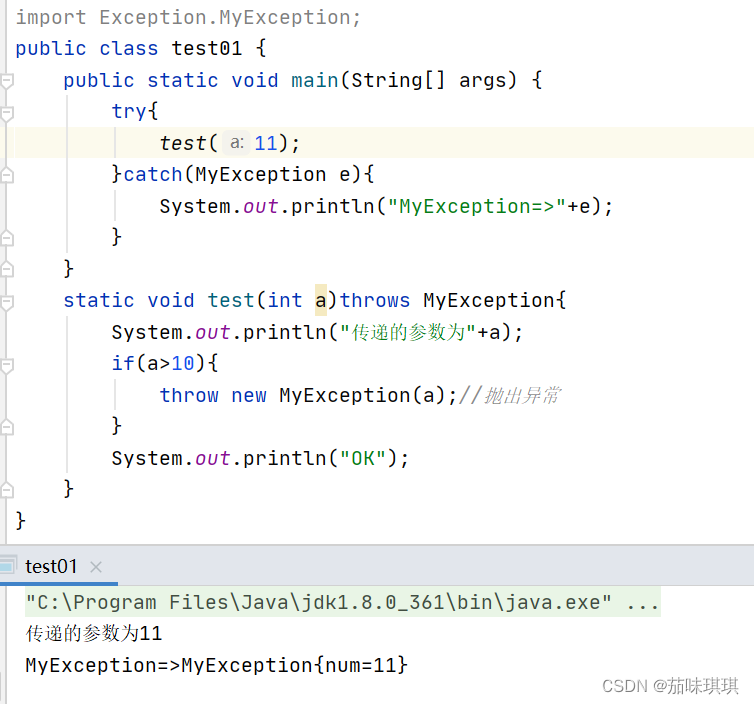
Java——异常机制
前言 随着对java的不断深入学习,在对语法以及编程思想有了一定的了解之后,在编程的过程中有可能会因为用户的输入不正确或者逻辑错误而出现异常或者错误,因此如何去捕捉与避免不应该出现的异常或者错误就变得十分重要。本文就介绍了java的异…...
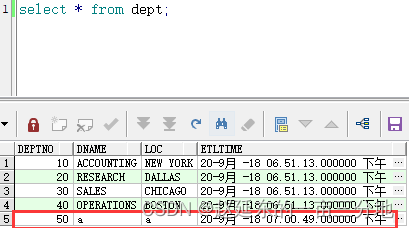
【大数据实时数据同步】超级详细的生产环境OGG(GoldenGate)12.2实时异构同步Oracle数据部署方案(下)
系列文章目录 【大数据实时数据同步】超级详细的生产环境OGG(GoldenGate)12.2实时异构同步Oracle数据部署方案(上) 【大数据实时数据同步】超级详细的生产环境OGG(GoldenGate)12.2实时异构同步Oracle数据部署方案(中) 【大数据实时数据同步】超级详细的生产环境OGG(GoldenGate…...

ESP32设备驱动-土壤湿度传感器驱动
土壤湿度传感器驱动 1、土壤湿度传感器介绍 土壤湿度传感器由两个探头组成,用于测量水的体积含量。 两个探头让电流通过土壤,然后得到电阻值来测量水分值。 当有更多的水时,土壤会传导更多的电,这意味着电阻会更小。 因此,水分含量会更高。 干燥的土壤导电性差,所以当…...
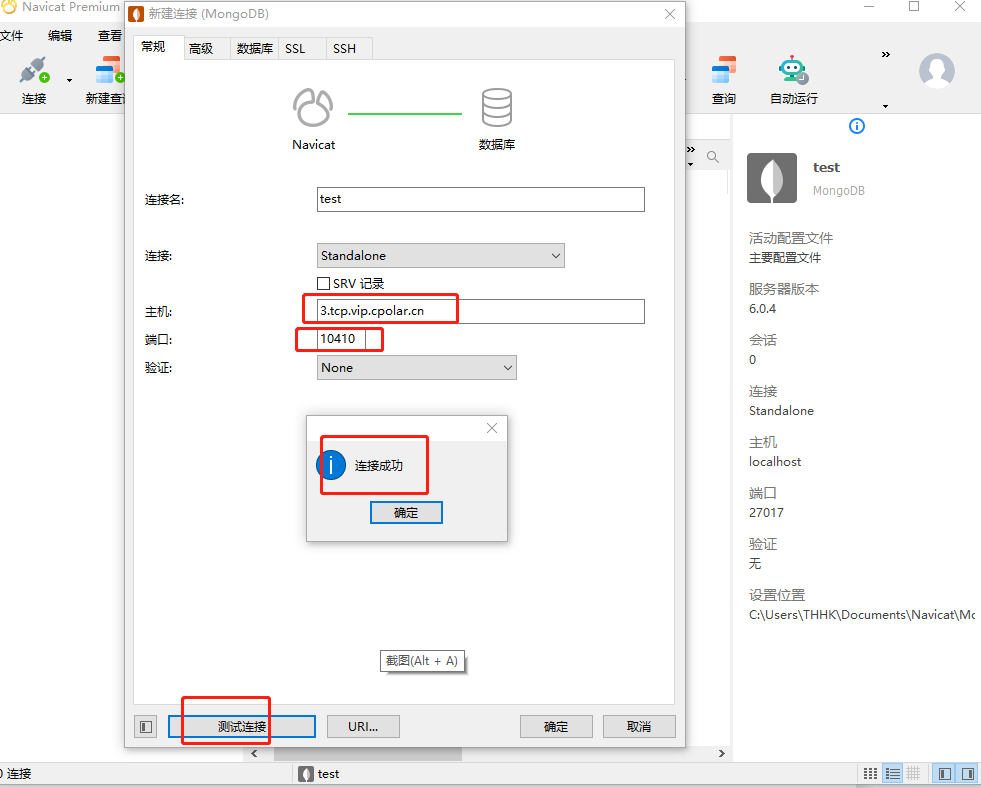
公网远程连接MongoDB数据库【内网穿透】
文章目录1. 安装数据库2. 内网穿透2.1 创建隧道映射2.2 测试随机公网地址远程连接3. 配置固定TCP端口地址3.1 保留一个固定的公网TCP端口地址3.2 配置固定公网TCP端口地址3.3 测试固定地址公网远程访问MongoDB是一个基于分布式文件存储的数据库。由C语言编写。旨在为WEB应用提供…...

计算机组成原理:从零搭建数据通路——累加器实验全解析
1. 累加器实验入门指南 第一次接触累加器实验时,我和大多数初学者一样感到困惑:为什么需要这个看似简单的寄存器?它到底在计算机中扮演什么角色?直到亲手完成这个实验,才真正理解了它的精妙之处。累加器(Ac…...

深入解析差错控制技术:从奇偶校验到循环冗余校验的实战应用
1. 为什么我们需要差错控制技术? 想象一下你正在给朋友发送一条重要消息:"明天下午3点会议室见"。如果传输过程中某个比特位出错,消息变成"明天下午8点会议室见",后果可能很严重。这就是差错控制技术存在的意…...
)
告别依赖烦恼:在Kylin V10桌面版一键部署Qt 5.12.3开发环境(附离线包制作方法)
告别依赖烦恼:在Kylin V10桌面版一键部署Qt 5.12.3开发环境(附离线包制作方法) 在团队协作开发中,开发环境的标准化部署一直是个令人头疼的问题。特别是当项目需要迁移到国产化平台时,如何快速、高效地为整个团队搭建统…...

GLM-OCR在AIGC内容创作流水线中的应用:从图片素材到文案生成
GLM-OCR在AIGC内容创作流水线中的应用:从图片素材到文案生成 1. 引言 你有没有遇到过这样的情况:看到一张设计精美的海报,或者一份产品介绍图,觉得里面的文案写得特别好,想借鉴一下,但只能一个字一个字地…...

PaddleOCR与Python3.8.5在Windows环境下的快速安装与实战调试指南
1. 环境准备:Python与PaddleOCR的完美组合 如果你正在寻找一个简单高效的OCR解决方案,PaddleOCR绝对值得一试。作为百度开源的OCR工具库,它支持多种语言的文本检测和识别,而且对中文场景特别友好。我最近在Windows 10上使用Python…...
)
Qt5实战:手把手教你用QPainter绘制一个工业级仪表盘(附完整源码)
Qt5实战:工业级仪表盘开发全流程解析与性能优化 在工业控制、汽车电子和能源监测领域,仪表盘作为关键的人机交互界面,其视觉效果和性能直接影响用户体验。本文将带您从零开始构建一个专业级仪表盘控件,不仅涵盖基础的QPainter绘图…...

【谷歌TPU全栈技术解析】第五章 集群部署与性能工程
5. 集群部署与性能工程 5.1 TPU Pod超级计算机架构 TPU Pod架构历经多代演进,从v4到v7形成了独特的可扩展超算体系。TPU v4 Pod配置4096颗芯片,采用液冷系统支持8.5MW功率负载,通过光路交换(OCS)技术构建3D Torus拓扑互联网络。该架构允许单Pod内部实现亚微秒级延迟的Al…...

STM8 CAN总线Bootloader设计与实现
1. STM8单片机CAN总线Bootloader设计与实现在工业现场、车载电子及长期部署的嵌入式设备中,产品完成量产封装后,物理访问调试接口(如SWIM、JTAG、SWD)往往不可行。当用户端出现功能缺陷或需迭代新特性时,必须依赖远程固…...

学习周报三十七
文章目录摘要abstract一、mclip的论文-Multilingual CLIP via Cross-lingual Transfer-23.二、实践总结摘要 围绕多语言图文检索模型mCLIP论文展开学习,论文提出了一种多语言视觉-语言预训练模型。核心创新在于通过三角形跨模态知识蒸馏(TriKDÿ…...

高性能字体处理架构设计:FontTools 4.62.2版本深度解析与最佳实践
高性能字体处理架构设计:FontTools 4.62.2版本深度解析与最佳实践 【免费下载链接】fonttools A library to manipulate font files from Python. 项目地址: https://gitcode.com/gh_mirrors/fo/fonttools FontTools是一个用于操作字体文件的强大Python库&am…...