部署HDFS集群(完全分布式模式、hadoop用户控制集群、hadoop-3.3.4+安装包)
目录
前置
一、上传&解压
(一 )上传
(二)解压
二、修改配置文件
(一)配置workers文件
(二)配置hadoop-env.sh文件
(三)配置core-site.xml文件
(四)配置hdfs-site.xml文件
三、分发到hp2、hp3, 并设置环境变量
(一)准备数据目录
(二)配置环境变量
四、创建数据目录,并修改文件权限归属hadoop账户
(一)授权为Hadoop用户
(二)格式化整个文件系统
五、查看HDFS WEBUI
六、常见问题
hadoop-3.3.4.tar.gz提取:
链接:https://pan.baidu.com/s/18ILFiIBei8BqUg31MWEGAQ
提取码:ay17
前置
三台虚拟机硬件配置如下:
| 节点 | CPU | 内存 |
| hp1 | 1核心 | 4GB |
| hp2 | 1核心 | 2GB |
| hp3 | 1核心 | 2GB |
Hadoop HDFS的角色包含:
NameNode:主节点管理者
DataNode:从节点工作者
SecondaryNameNode:主节点辅助
| 节点 | 服务 |
| hp1 | NameNode、DataNode、SecondaryNameNode |
| hp2 | DataNode |
| hp3 | DataNode |
这样的话我们这个集群就是有一个主节点,带领了三个从节点,也就是一个NameNode带领了三个DataNode去工作的一个hdfs集群。此外还有一个SecondaryNameNode的角色也存在。
配置集群之前请确认已经完成前置准备中的服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等部署。(没配好的可以参考前面的博客)
一、上传&解压
(一 )上传
1.上传hadoop安装包到hp1节点中

(二)解压
1.解压缩安装包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server/
![]()
2.构建软链接
先进入/export/server/目录下

构建软链接
ln -s /export/server/hadoop-3.3.4 hadoop

可以去看一下hadoop里面的文件
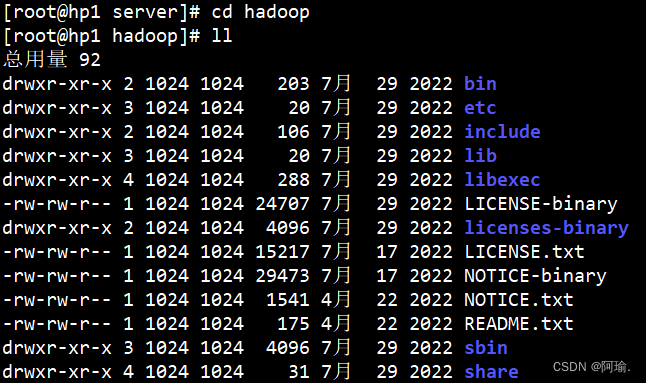
各个文件夹含义如下
bin , 存放Hadoop的各类程序(命令)
etc , 存放Hadoop的配置文件
include , C语言的一些头文件
lib , 存放Linux系统的动态链接库(.so文件)
libexec , 存放配置Hadoop系统的脚本文件(.sh和.cmd)
licenses-binary , 存放许可证文件
sbin , 管理员程序(super bin)
share , 存放二进制源码(java jar包)
二、修改配置文件
配置HDFS集群,我们主要涉及到如下文件的修改:
| workers | 配置从节点(DataNode)有哪些 |
| hadoop-env.sh | 配置Hadoop的相关环境变量 |
| core-site.xml | Hadoop核心配置文件 |
| hdfs-site.xml | HDFS核心配置文件 |
这些文件均存在于 $HADOOP_HOME/etc/hadoop文件夹中
Ps: $HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即 /export/server/hadoop
(一)配置workers文件
1.进入配置文件目录
cd etc/hadoop 完整路径:cd /export/server/hadoop/etc/hadoop/
编辑workers文件

vim workers
把原本的内容删掉,
然后填入以下内容

填入的hp1、hp2、hp3表明集群记录了三个从节点
(二)配置hadoop-env.sh文件
vim hadoop-env.sh
可以在开头或者结尾加入以下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs

JAVA_HOME , 指明JDK环境的位置在哪
HADOOP_HOME , 指明Hadoop安装位置
HADOOP_CONF_DIR , 指明Hadoop配置文件目录位置
conf 是configure,配置 dir是文件夹的缩写
HADOOP_LOG_DIR , 指明Hadoop运行日志目录位置
通过记录这些环境变量,来指明上述运行时的重要信息
(三)配置core-site.xml文件
vim core-site.xml
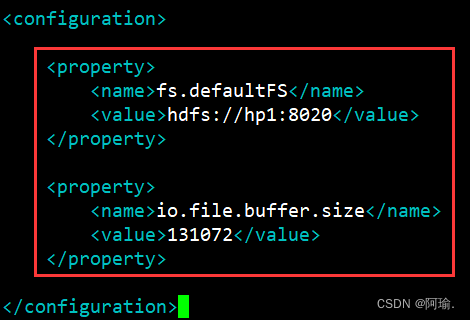
在<configuration></configuration>之间添加如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://hp1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
key: fs.defaultFS
含义:HDFS文件系统的网络通讯路径
值:hdfs://hp1:8020
协议为hdfs://
namenode为hp1
namenode通讯端口为8020
hdfs:hp1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
表明DataNode将和hp1的8020端口通讯,hp1是NameNode所在机器
此配置固定了hp1必须启动NameNode进程
(四)配置hdfs-site.xml文件
在<configuration></configuration>之间添加如下内容
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>hp1,hp2,hp3</value>
</property>
<property>
<name>dfs.blocksieze</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
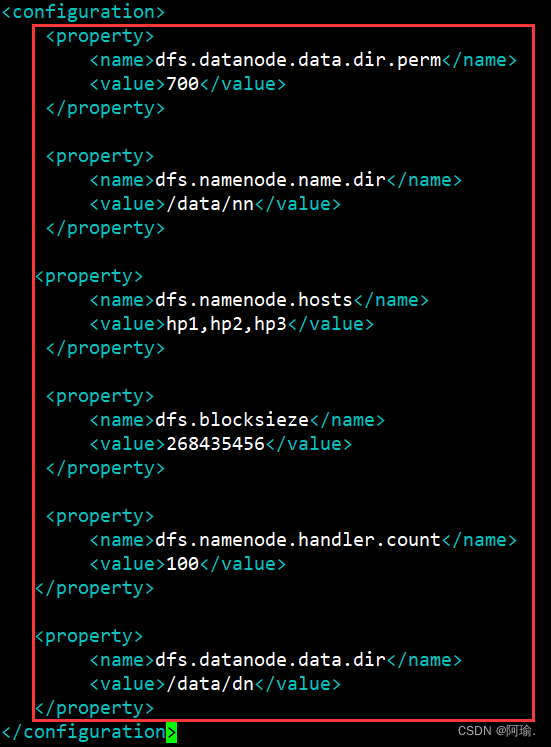
key: dfs.datanode.data.dir.perm
含义:hdfs文件系统,默认创建的文件权限设置
值:700,即rwx------
新建文件默认权限是700
key: dfs.namenode.name.dir
含义:NameNode元数据的存储位置
值:/data/nn,在hp1节点的/data/nn目录下
nn是namenode的缩写
key: dfs.namenode.hosts
含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群)
值:hp1、hp2、hp3,这三台服务器被授权
key: dfs.blocksieze
含义:hdfs默认块大小
值:26843546(256MB)
key: dfs.namenode.handler.count
含义:namenode处理的并发线程数
值:100,以100个并行度处理文件系统的管理任务
key: dfs.datanode.data.dir
含义:从节点DataNode的数据存储目录
值:/data/dn,即数据存放在hp1、hp2、hp3,三台机器的/data/dn内
dn即datanode
三、分发到hp2、hp3, 并设置环境变量
(一)准备数据目录
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
namenode数据存放hp1的/data/nn
datanode数据存放hp1、hp2、hp3的/data/dn
所以应该:
1.在hp1节点:
mkdir -p /data/nn
mkdir /data/dn

在hp2和hp3节点:
mkdir -p /data/dn
![]()
![]()
2.分发Hadoop文件夹
目前,已经基本完成Hadoop的配置操作,可以从hp1将hadoop安装文件夹远程复制到hp2、hp3
分发
scp -r hadoop-3.3.4 root@hp2:/export/server/
scp -r hadoop-3.3.4 root@hp3:/export/server/
![]()
![]()


在hp2为hadoop配置软连接
ln -s /export/server/hadoop-3.3.4 hadoop

在hp3为hadoop配置软连接
ln -s /export/server/hadoop-3.3.4 hadoop

(二)配置环境变量
为了方便我们操作Hadoop,可以将Hadoop的一些脚本、程序配置到PATH中,方便后续使用
在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序,现在来配置以下环境变量
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

内容添加完成之后,source /etc/profile让环境变量生效
在hp2和hp3配置同样的环境变量
四、创建数据目录,并修改文件权限归属hadoop账户
(一)授权为Hadoop用户
Hadoop部署的准备工作基本完成
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务
所以,现在需要对文件权限进行授权
1.以root身份,在hp1、hp2、hp3三台服务器上均执行以下命令
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export

(二)格式化整个文件系统
前期准备全部完成,现在对整个文件系统执行初始化
1.确保以hadoop用户执行
先切换用户
su - hadoop

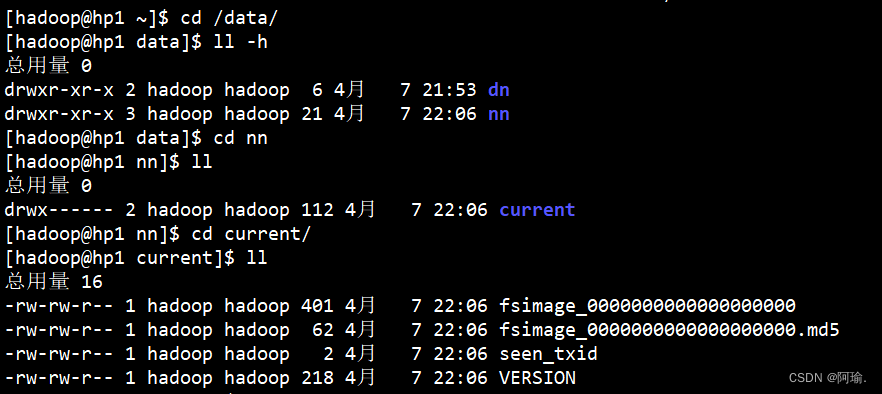
格式化namenode
hadoop namenode -format
![]()
可以cd进去看到里面多了一些文件
current里面都是namenode的源数据
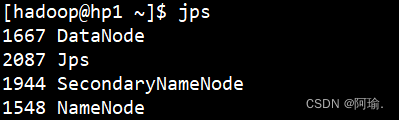
2.一键启动hdfs集群
start-dfs.sh

第一次启动的时候会有个警告说logs这个文件不存在,不用管它。这是运行的日志文件夹。
(第一次忘记截图了,所以从别的地方找的图,由于连接工具不一样,所以图形界面有差异)
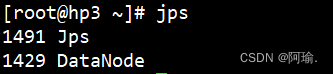
Jps可以查看当前运行的进程

一键关闭hdfs集群
stop-dfs.sh
如果遇到命令未找到的错误,表面环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
五、查看HDFS WEBUI
http://hp1:9870 ,即可查看到hdfs文件系统的管理网页。

hdfs在运行的时候,会给我们提供一个管理平台网站页面,它是namenode所在服务器。
9870是namenode所在服务器的端口
往下翻,有汇总信息
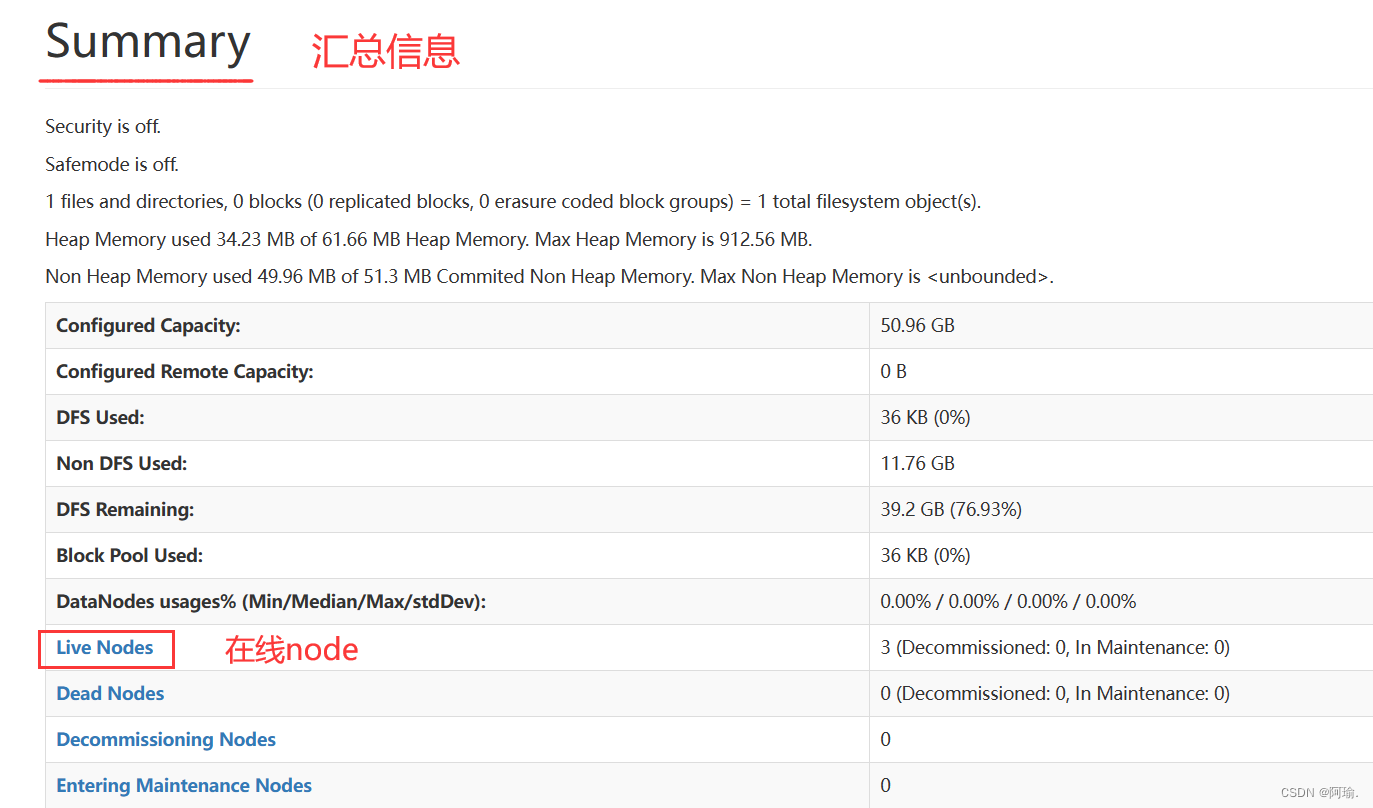
在线node就是我们naemnode下面的小弟,
点进去可以看到整个hdfs文件系统的一些基本信息

注意!!一定要hadoop用户去操作集群,以root执行的话所有权就会回归root,后续以hadoop用户启动会出错(没有权限)!
关闭集群后再关闭虚拟机,就可以进行快照的拍摄
每一台都需要进行快照的拍摄
六、常见问题
Permission denied(权限被拒绝)
hadoop安装文件夹或/data文件夹,未授权给hadoop用户,则无权限操作,所有的Permission denied提示,都是权限导致的。
出现command not found
没有配置好环境变量导致的
启动后仅hp1有进程出现
hp2、hp3没反应
检查workers文件有没有正确配置
start-dfs.sh脚本会:
在当前机器启动SecondaryNameNode , 并根据core-site.xml的记录启动NameNode
根据workers文件的记录,启动各个机器的datanode
相关文章:
部署HDFS集群(完全分布式模式、hadoop用户控制集群、hadoop-3.3.4+安装包)
目录 前置 一、上传&解压 (一 )上传 (二)解压 二、修改配置文件 (一)配置workers文件 (二)配置hadoop-env.sh文件 (三)配置core-site.xml文件 &…...

TCP协议简单总结
TCP:传输控制协议 特点:面向连接、可靠通信 TCP的最终目的:要保证在不可靠的信道上实现可靠的传输 TCP主要有三个步骤实现可靠传输:三次握手建立连接,传输数据进行确认,四次挥手断开连接 三次握手建立可靠…...

【Qt 实现录音】
Qt 实现录音源代码: #include <QAudioInput> #include <QAudioDeviceInfo> #include <QAudioRecorder> #include <QFile> #include...

python:算法竞赛入门之一
计算 斐波那契数列(Fibonacci sequence),不受长整型位数限制。 编写 fibonacci.py 如下 # -*- coding: utf-8 -*- """ 计算 斐波那契数列(Fibonacci sequence)""" import sys from …...
【大数据与云计算】虚拟机安装Linux
前言:使用Linux系统对大数据学习必不可少,本文主要介绍虚拟机安装linux的流程 文章目录 一、 下载VMware二、下载Linux三、安装Linux 一、 下载VMware 官网链接 下载VMware-player,一直下一步安装即可。 二、下载Linux 点击链接直接下载&…...

从零开始编写一个cmake构建脚本
简介 本文档介绍cmake构建脚本编写,包含的一些主要元素和命名规范。 cmake构建脚本编写步骤 cmake构建工具版本要明确 # 命令名字要小写,这条语句要求构建工具至少需要版本为3.12或以上 cmake_minimum_required (VERSION 3.12)工程名及库的版本号明确…...
pringboot2集成swagger2出现guava的FluentIterable方法不存在
错误信息 Description: An attempt was made to call a method that does not exist. The attempt was made from the following location: springfox.documentation.spring.web.scanners.ApiListingScanner.scan(ApiListingScanner.java:117) The following method did not ex…...

进程线程的关系
举个例子 滑稽老师吃100只鸡 如何加快滑稽老师吃鸡的效率?? 有一个方案,搞两个房间,两个滑稽老师 一个滑稽吃50只鸡,速度一定会大幅度增加 多进程的方案 创建新的进程 就需要申请更多的资源(房间和…...

一些 VLP 下游任务的相关探索
目录 一、Image-Text Retrieval (ITR , 图像文本检索) 任务目的: 数据集格式 训练流程 evaluation流程 实际使用推测猜想 二、Visual Question Answering (VQA , 视觉问答) 任务目的 数据集格式 训练流程 demo以及评估流…...
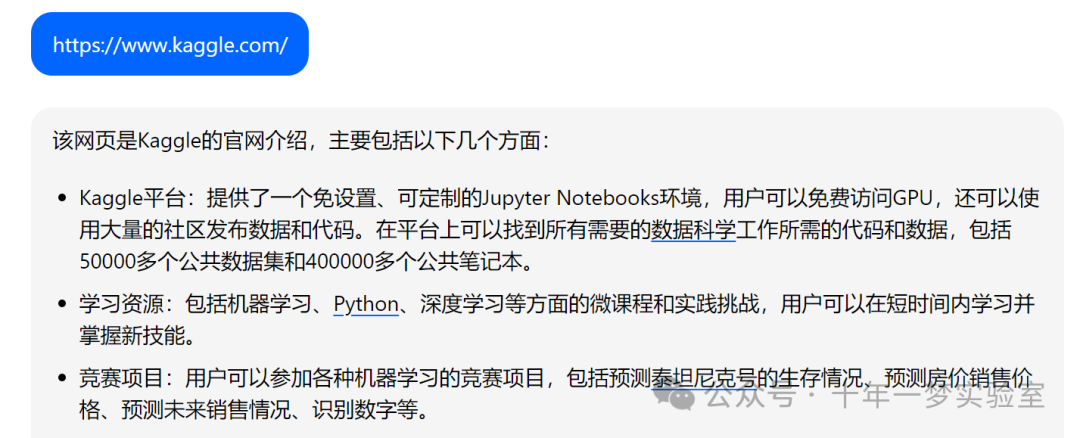
【opencv】示例-pca.cpp PCA图像重建演示
// 加载必要的头文件 #include <iostream> // 用于标准输入输出流 #include <fstream> // 用于文件的输入输出 #include <sstream> // 用于字符串的输入输出流操作#include <opencv2/core.hpp> // OpenCV核心功能的头文件 #include "o…...

C语言中的编译和链接
系列文章目录 文章目录 编辑 系列文章目录 文章目录 前言 一、 翻译环境和运行环境 二、 翻译环境 2.1 编译 2.1.1 预处理 2.1.2 编译 2.1.2.1 词法分析 : 2.1.2.2 语法分析 2.1.2.3 语义分析 2.1.3 汇编 2.2 链接 三、运行环境 前言 在我们平常的写代码时,我们很…...
如何将三方库集成到hap包中——通过IDE集成cmak构建方式的C/C++三方库
简介 cmake构建方式是开源三方库的主流构建方式。DevEco Studio目前以支持cmake的构建方式。本文将通过在IDE上适配cJSON三方库为例讲来解如何在IDE上集成cmake构建方式得三方库。 创建工程 在开发进行三方库适配以及napi接口开发前,我们需要创建一个三方库对应的…...
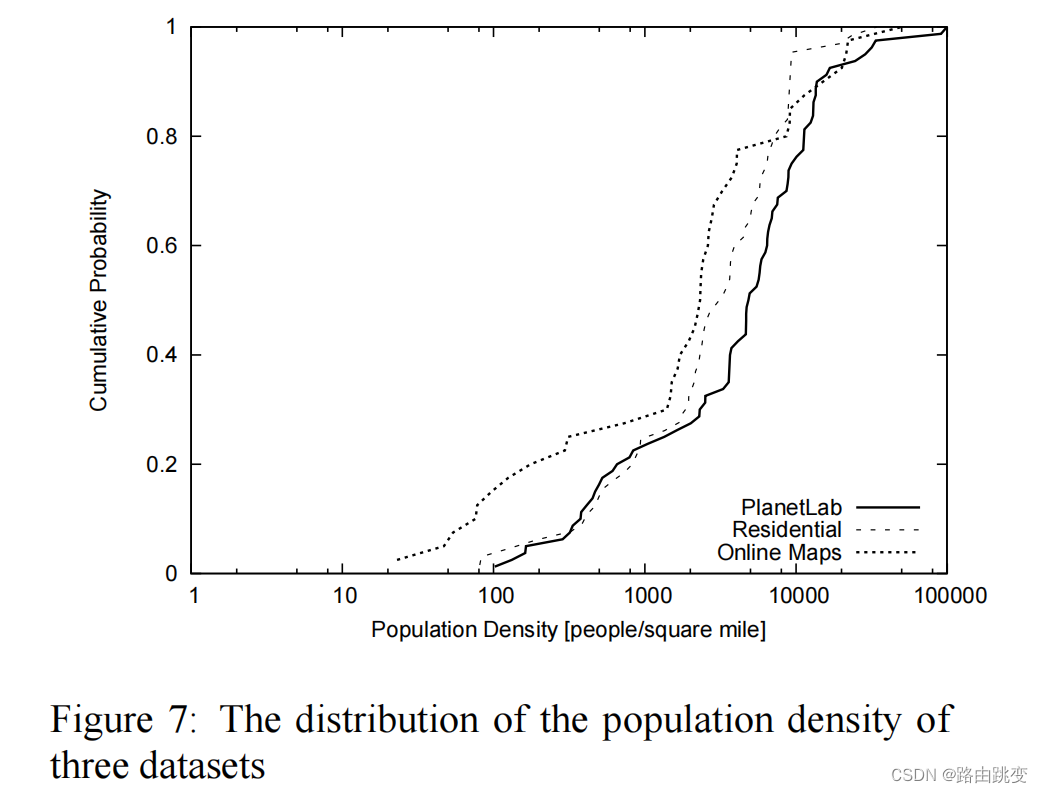
Towards Street-Level Client-Independent IP Geolocation(2011年)(第二部分)
被引次数:306 Wang Y, Burgener D, Flores M, et al. Towards {Street-Level}{Client-Independent}{IP} Geolocation[C]//8th USENIX Symposium on Networked Systems Design and Implementation (NSDI 11). 2011. 接着Towards Street-Level Client-Independent IP Geolocati…...

软件测试过程和测试生命周期
众所周知,软件生命周期包括,需求阶段、设计阶段、设计构建阶段、测试周期阶段、最后测试、实施阶段、最后运维和维护验收。每个阶段都需要在软件开发的生命周期中从前一阶段交付。需求转化为设计,设计转化为开发和开发成测试,经过…...
python-study-day1
ps:前言 可做毕设,html,web,app,小程序,bug修改,可加急 作者自述 作为一名前端开发工程师,这个大环境不好的情况下,我试过我前端接单子但是没有后端,…...

【Apache2】彻底删除 Apache2 服务器
要彻底删除 Apache2 服务器,需要卸载 Apache2 软件包并删除其配置文件和数据文件。在 Ubuntu 上,可以按照以下步骤来完成: 停止 Apache2 服务: sudo systemctl stop apache2卸载 Apache2 软件包: sudo apt-get purge a…...

C#:成绩等级转换
任务描述 本关任务:给出一百分制成绩,要求输出成绩等级‘A’、‘B’、‘C’、‘D’、‘E’。 90分以上为A 80-89分为B 70-79分为C 60-69分为D 60分以下为E,如果输入数据不在0~100范围内,请输出一行:“Score is error!”…...
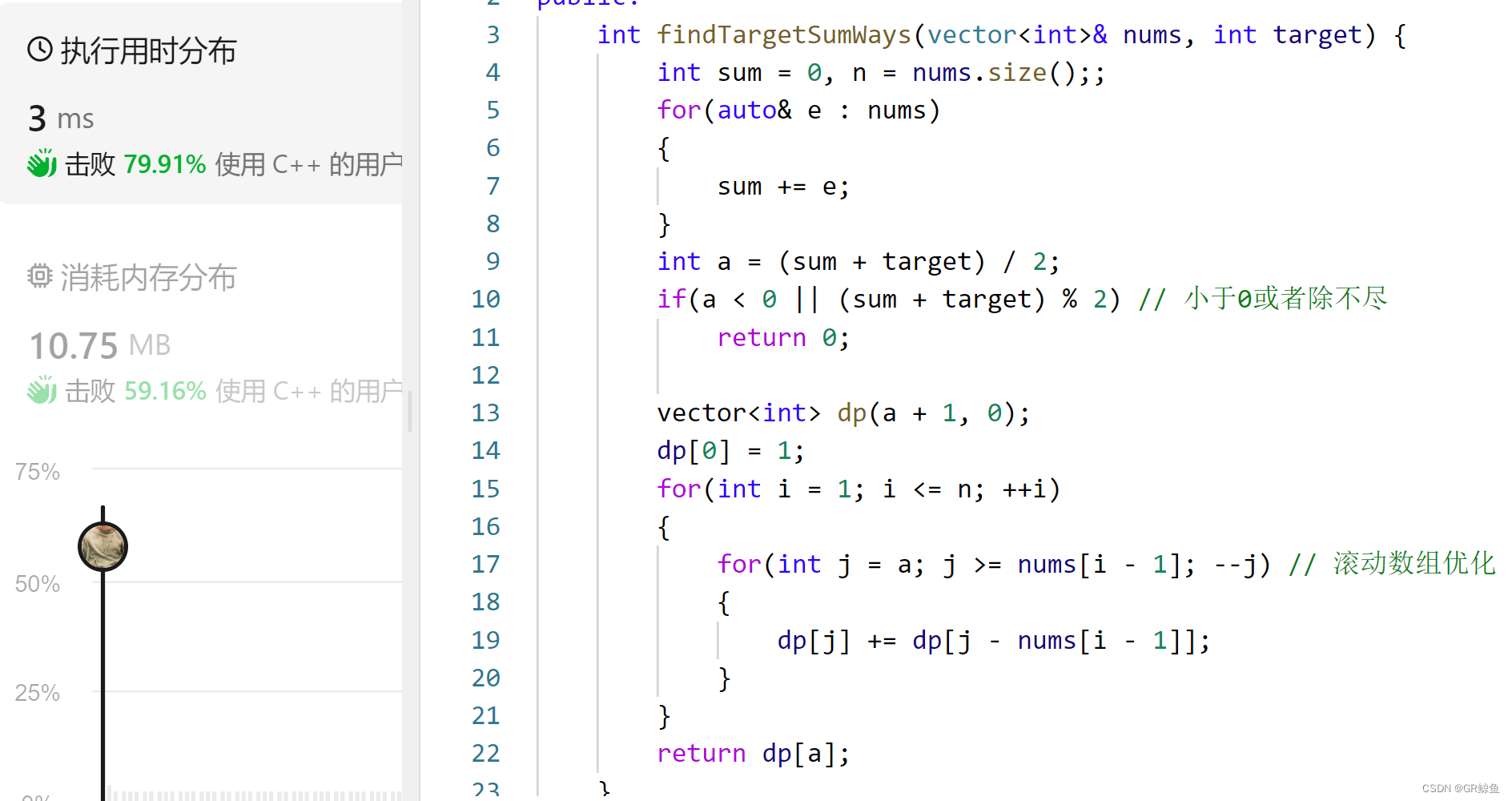
每日OJ题_01背包③_力扣494. 目标和(dp+滚动数组优化)
目录 力扣494. 目标和 问题解析 解析代码 滚动数组优化代码 力扣494. 目标和 494. 目标和 难度 中等 给你一个非负整数数组 nums 和一个整数 target 。 向数组中的每个整数前添加 或 - ,然后串联起所有整数,可以构造一个 表达式 : …...

vue3+element plus图片预览点击按钮直接显示图片的预览形式
1 需求 直接上需求: 我想要直接点击下面这个“预览”按钮,然后呈现出预览图片的形式 ok,需求知道了,下面让我们来看看如何实现吧 ~ 2 实现 template部分 <el-buttontype"primary"size"small"click&qu…...
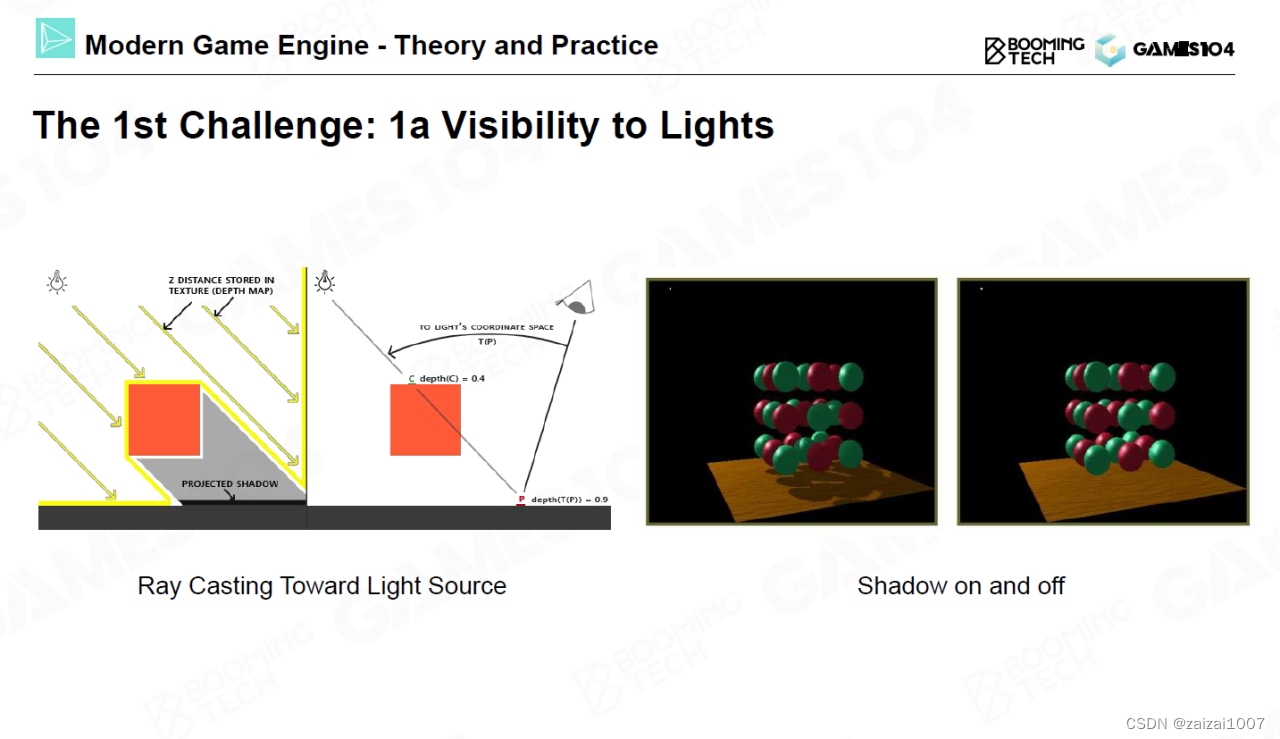
GAMS104 现代游戏引擎 2
渲染的难点可以分为一下三部分:如何计算入射光线、如何考虑材质以及如何实现全局光照。 渲染的难点之一在于阴影,或者说是光的可见性。如何做出合适的阴影效果远比想象中要难得多,在实践中往往需要通过大量的技巧才能实现符合人认知的阴影效…...
)
别再为小物体分割发愁了!手把手教你用PyTorch复现DeepLab V3的ASPP模块(附完整代码)
从零实现DeepLab V3的ASPP模块:解决小物体分割的实战指南 当你面对医学影像中的微小病灶或街景图片中的交通标志时,是否遇到过传统分割模型对细节捕捉不足的困扰?DeepLab V3的ASPP模块正是为解决这类多尺度分割问题而生。本文将带你深入模块实…...

Qwen3-4B-Instruct-2507响应质量低?提示词工程优化指南
Qwen3-4B-Instruct-2507响应质量低?提示词工程优化指南 1. 理解Qwen3-4B-Instruct-2507的核心能力 Qwen3-4B-Instruct-2507是阿里云推出的最新版本语言模型,相比之前的版本有了显著提升。这个模型专门设计用于指令跟随任务,不再需要复杂的思…...
)
《自指黑洞与自指宇宙学的对话》及内部研讨纪要(2024版)
《自指黑洞与自指宇宙学的对话》及内部研讨纪要(报送创始人方见华裁定) 一、核心理论对标与统一方程 1. 双理论维度对照 维度 自指宇宙学(方见华) 自指黑洞理论(世毫九实验室) 统一对应 核心方程 …...

sdut-软件测试-软件测试概述1
1. 单选题 某网上购物软件,与京东、淘宝等现有主流系统操作流程一致,符合最终用户的使用习惯和操作模式,主要目的是为了改善 ISO/IEC 9126 质量模型中的( C )质量特性。 A. 功能性B. 可靠性C. 易用性D. 可维护性E.…...
)
避开这些坑!单片机驱动电路设计中最容易犯的3个错误(附正确接法示意图)
避开这些坑!单片机驱动电路设计中最容易犯的3个错误(附正确接法示意图) 在单片机驱动电路设计中,即使是经验丰富的工程师也难免会踩到一些"坑"。这些错误轻则导致电路性能下降,重则可能烧毁元器件࿰…...

三菱PLC恒定张力收卷机控制程序解析
三菱plc恒定张力收卷机控制程序 结构化编程,逻辑清晰 包含三菱触摸屏程序,电路接线图,bom,程序有注释,值得学习和借鉴。 最近在做一个三菱PLC恒定张力收卷机的项目,感觉收获挺多的。整个项目从程序设计到硬…...

HY-Motion 1.0行业实践:医疗康复中个性化训练动作处方生成
HY-Motion 1.0行业实践:医疗康复中个性化训练动作处方生成 1. 引言:智能康复训练的新机遇 在医疗康复领域,个性化训练方案一直是个难题。传统康复训练依赖治疗师的经验判断,难以精准匹配每位患者的实际需求和恢复进度。现在&…...
✅)
计算机毕业设计:Python动漫数据可视化分析系统 Flask框架 可视化 爬虫 大数据 机器学习 番剧推荐(建议收藏)✅
博主介绍:✌全网粉丝50W,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,…...

避开中文用户名陷阱:Proteus安装报错There is a problem...的3种修复方案
避开中文用户名陷阱:Proteus安装报错的深度解决方案 当你在Windows系统上安装Proteus时遇到"There is a problem with this Windows Installer package"错误,这通常与系统环境中的中文用户名有关。这个看似简单的报错背后,隐藏着Wi…...

深入解析BLE GATT:从属性表到数据交互实战
1. BLE GATT协议基础入门 第一次接触BLE开发时,我被GATT这个术语搞得一头雾水。直到实际调试一个智能手环项目,才真正理解GATT就像快递公司的物流系统——它规定了数据该怎么打包、贴标签、以及如何安全送达。GATT全称Generic Attribute Profile…...