深度学习体系结构——CNN, RNN, GAN, Transformers, Encoder-Decoder Architectures算法原理与应用
1. 卷积神经网络
卷积神经网络(CNN)是一种特别适用于处理具有网格结构的数据,如图像和视频的人工神经网络。可以将其视作一个由多层过滤器构成的系统,这些过滤器能够处理图像并从中提取出有助于进行预测的有意义特征。
设想你手头有一张手写数字的照片,你希望计算机能够识别出这个数字。CNN的工作原理是在图像上逐层应用一系列过滤器,每一层都能够提取出从简单到复杂的不同特征。初级过滤器负责识别图像中的基本信息,比如边缘和线条,而更深层次的过滤器则能够识别出更加复杂的图案,比如数字的形状。
CNN的结构主要由三种类型的层组成:卷积层、池化层和全连接层。
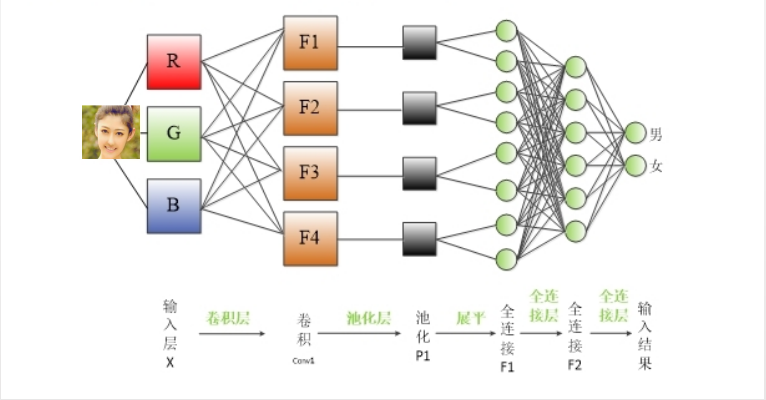
卷积层
卷积层通过将一系列的过滤器(或称为核心)应用到图像上来进行操作。每一个过滤器都会在图像上滑动,与其所覆盖的像素点计算点积,从而生成新的特征图,这些特征图突出显示了图像中的特定模式。通过使用不同的过滤器重复这一过程,可以创建出一系列特征图,它们共同捕捉到了图像的多个方面。
池化层
池化层的作用是对特征图进行下采样,即减少数据的空间尺寸,同时保留那些重要的特征。这样做有助于降低计算的复杂度,并防止模型出现过拟合。最常用的池化技术是最大池化,它会选择一个小区域像素中的最大值作为代表。
全连接层
全连接层的结构类似于传统神经网络中的层。在这一层中,上一层的每个神经元都会与下一层的每个神经元相连接。卷积层和池化层的输出结果会被展平,然后传递到一个或多个全连接层中,网络通过这些层来进行最终的预测,比如识别出图像中的数字。
代表性算法
以下是一些著名的CNN代表算法:
-
LeNet-5:由Yann LeCun等人于1998年提出,是早期卷积神经网络的代表之一,主要应用于手写数字识别。
-
AlexNet:由Alex Krizhevsky、Geoffrey Hinton和Ilya Sutskever于2012年提出,该网络在2012年ImageNet大规模视觉识别挑战赛(ILSVRC)中取得了突破性的成绩,标志着深度学习时代的开始。
-
VGGNet:由Simonyan和Zisserman于2014年提出,该网络通过使用多个较小的卷积核(3x3)堆叠的方式,提高了网络的性能。VGGNet在2014年的ImageNet竞赛中获得了第二名。
-
GoogLeNet (Inception):由Google的研究者于2014年提出,引入了Inception模块,使得网络能够在同一层内并行处理不同尺度的特征图,提高了效率和性能。GoogLeNet在2014年ImageNet竞赛中获得了冠军。
-
ResNet (Residual Network):由Kaiming He等人于2015年提出,通过引入残差学习的概念解决了深层网络训练困难的问题,使得网络能够成功训练上百甚至上千层的深度。ResNet在2015年ImageNet竞赛中取得了冠军。
-
DenseNet (Densely Connected Convolutional Networks):由Huang等人于2017年提出,通过特征重用的方式提高了网络的效率和性能。DenseNet的每个层都与前面的所有层相连,极大地增强了特征的传递。
-
EfficientNet:由Google的研究者于2019年提出,是一种优化的CNN架构,通过系统地缩放网络的宽度、深度和分辨率来提高效率和准确性,同时保持模型大小和计算成本的可控。
2. 递归神经网络(RNN)
递归神经网络(RNNs)它专门设计用来处理具有顺序性的数据,比如时间序列数据、语音信号以及自然语言文本。可以将RNN想象为一条流水线,它逐步处理数据流中的每一个元素,并能够在处理当前元素时“记住”之前元素的信息,从而对下一个元素做出预测。
设想你拥有一个单词序列,你的目标是让计算机能够预测序列中的下一个单词。RNN的工作原理是逐步处理序列中的每个单词,利用前面单词的信息来预测接下来的单词。
RNN的核心机制是递归连接,这种连接方式使得信息能够在不同的时间步骤之间传递。递归连接是神经元内部的一种自我连接,它能够保留前一时间步骤的信息。
RNN的结构主要由以下三个关键部分组成:
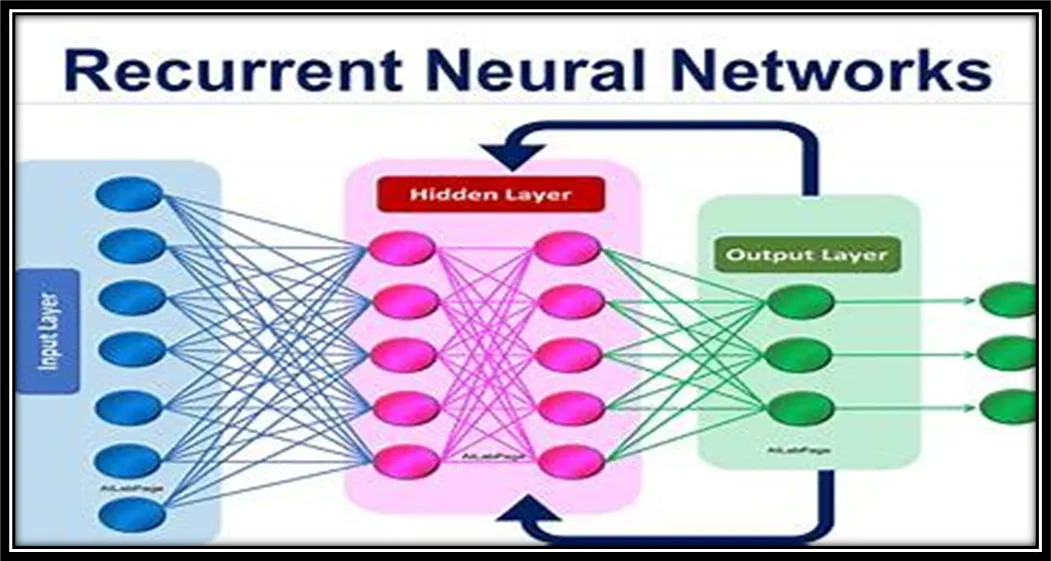
输入层
输入层在每个时间步骤接收新的输入信息,例如序列中的一个单词。
递归层
递归层负责处理输入层传入的信息,并利用递归连接来保留之前时间步骤的信息。递归层由多个神经元组成,每个神经元都通过递归连接与自身相连,并接收当前时间步骤的输入。
输出层
输出层基于递归层处理的信息来生成预测结果。例如,在预测序列中的下一个单词的任务中,输出层将根据前面的单词来预测下一个最可能出现的单词。
代表性算法
-
长短时记忆网络(LSTM):由Hochreiter和Schmidhuber于1997年提出,LSTM通过引入门控机制解决了传统RNN的长期依赖问题。LSTM能够学习长期依赖关系,因此在很多序列处理任务中表现出色。
-
门控循环单元(GRU):由Cho等人于2014年提出,GRU是LSTM的一个变体,它简化了LSTM的门控机制,减少了模型参数,使得GRU在某些任务上比LSTM更快,同时保持了类似的性能。
-
双向RNN(Bi-RNN):双向RNN通过在时间的两个方向上处理序列数据来捕获前后文信息。这种结构能够同时考虑序列中每个元素的前文和后文信息,常用于文本分类和序列标注等任务。
-
序列到序列(Seq2Seq)模型:虽然Seq2Seq模型通常与注意力机制结合使用,但其核心是一个编码器-解码器结构,编码器和解码器通常由RNN或其变体组成。Seq2Seq模型在机器翻译、文本摘要等任务中取得了很好的效果。
-
神经图灵机(Neural Turing Machine, NTM):由Graves等人于2014年提出,NTM是一种结合了外部记忆资源的RNN模型,能够执行更复杂的序列任务,如模拟图灵机的行为。
-
注意力机制(Attention Mechanism):虽然注意力机制本身不是一个独立的RNN模型,但它与RNN结合使用时,能够显著提高处理序列数据的性能。注意力机制允许模型在处理序列时动态地关注序列中的特定部分,这在机器翻译和文本摘要等任务中尤为重要。
-
Transformer:由Vaswani等人于2017年提出,虽然Transformer模型主要基于自注意力机制,但它的解码器部分可以看作是一种特殊的RNN,它通过自注意力机制处理序列数据,而不依赖于传统的递归结构。
3.生成对抗网络(GAN)
生成对抗网络(GANs)是一种深度学习架构,使用两个神经网络,一个生成器和一个鉴别器,来创建新的、逼真的数据。将GANs想象为两个对手艺术家,一个创造假艺术,另一个试图区分真假。
GANs的目标是在各种领域生成高质量、逼真的数据样本,如图像、音频和文本。生成器网络创建新样本,而鉴别器网络评估生成样本的真实性。两个网络同时以对抗的方式进行训练,生成器试图产生更逼真的样本,鉴别器则变得更擅长检测假样本。
GAN的两个主要组成部分是:
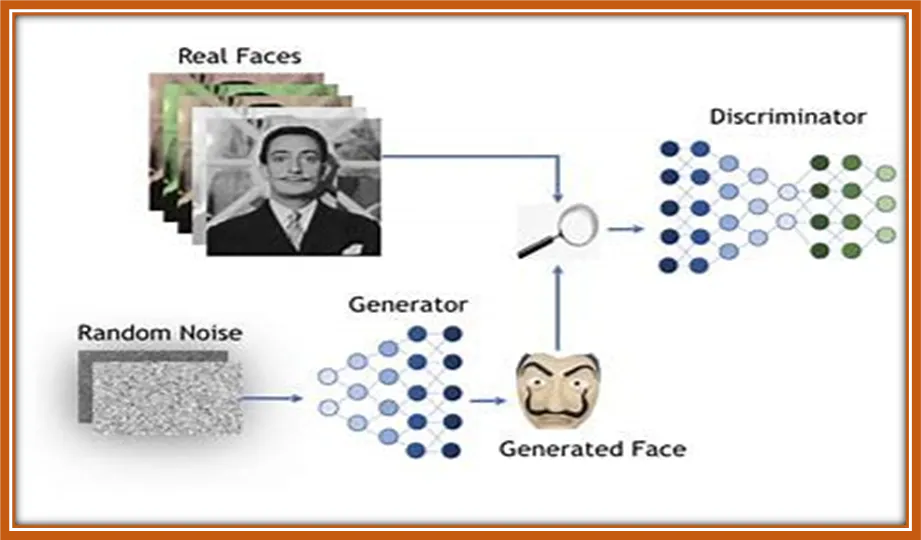
生成器
生成器网络负责创建新样本。它以随机噪声向量作为输入,并生成输出样本,如图像或句子。生成器通过最小化一个衡量生成样本与真实数据之间差异的损失函数来训练,以产生更逼真的样本。
鉴别器
鉴别器网络评估生成样本的真实性。它以样本作为输入,并输出一个概率,指示样本是真实的还是伪造的。鉴别器通过最大化一个衡量真实样本和生成样本概率差异的损失函数来训练,以区分真假样本。
GANs的对抗性质来自于生成器和鉴别器之间的竞争。生成器试图产生更逼真的样本以欺骗鉴别器,而鉴别器则试图提高其区分真假样本的能力。这个过程持续到生成器产生高质量、逼真的数据,这些数据不能轻易与真实数据区分开来。
总结来说,GANs是一种使用两个神经网络,一个生成器和一个鉴别器,来创建新的、逼真的数据的深度学习架构。生成器创建新样本,鉴别器评估它们的真实性。两个网络以对抗的方式进行训练,生成器产生更逼真的样本,鉴别器提高其检测假样本的能力。GANs在各种领域都有应用,如图像和视频生成、音乐合成和文本到图像合成。
代表性算法
-
DCGAN (Deep Convolutional GAN): 由Radford等人于2015年提出,DCGAN是第一个将卷积神经网络(CNN)与GANs结合的算法。它使用卷积层作为生成器和鉴别器的主要组成部分,显著提高了生成图像的质量和稳定性。
-
Pix2Pix: 由Isola等人于2016年提出,Pix2Pix是一种条件GAN,它可以根据输入的标签或图像转换成另一种图像。例如,它可以将黑白照片转换成彩色照片,或者将草图转换成详细的绘画。
-
CycleGAN: 由Zhang等人于2017年提出,CycleGAN是一种无需成对数据的无条件GAN,它可以在没有直接映射的情况下学习两个域之间的转换,例如将夏天的照片转换成冬天的场景。
-
Wasserstein GAN (WGAN): 由Arjovsky等人于2017年提出,WGAN引入了Wasserstein距离作为GANs的优化目标,这有助于改善训练的稳定性,并生成更高质量的样本。
-
Conditional GAN (cGAN): 虽然cGAN并非一个单独的算法,但它是一种重要的概念,指的是在训练过程中引入额外条件信息的GANs。cGAN可以生成特定类别的图像,或者根据给定的文本描述生成图像。
-
Progressive GAN (ProGAN): 由Karras等人于2017年提出,ProGAN通过逐渐增加生成器和鉴别器的分辨率来生成高分辨率的图像,从而在图像质量上取得了显著进步。
-
StyleGAN: 由Karras等人于2018年提出,StyleGAN引入了一种新颖的架构,通过操纵隐空间中的风格向量来生成高质量的人脸图像。StyleGAN的一个重要特点是其能够通过调整风格向量来控制生成图像的特定属性。
-
BigGAN: 由Sanh等人于2019年提出,BigGAN是一种能够生成高质量、高分辨率图像的GAN,它通过扩大模型规模和使用一种新的正则化技术来提高性能。
4. Transformers
Transformers在自然语言处理(NLP)任务中广泛使用,如翻译、文本分类和问答。它们在2017年由Vaswani等人发表的开创性论文“Attention Is All You Need”中被引入。
将Transformers想象为一个复杂的语言模型,通过将其分解成较小的部分并分析它们之间的关系来处理文本。然后,该模型可以生成连贯流畅的响应来回答广泛的查询。
Transformers由几个重复的模块组成,称为层。每个层包含两个主要组件:
自注意力机制
自注意力机制允许模型分析输入文本不同部分之间的关系。它通过为输入序列中的每个单词分配权重,指示其与当前上下文的相关性。这使得模型能够专注于重要的单词,并降低不那么相关单词的重要性。
前馈神经网络
前馈神经网络是处理自注意力机制输出的多层感知器。它们负责学习输入文本中单词之间的复杂关系。
变换器的关键创新是使用自注意力机制,这使得模型能够有效地处理长文本序列,而无需昂贵的递归或卷积操作。这使得变换器在计算上高效,并适用于广泛的NLP任务。
简单来说,变换器是一种为自然语言处理任务设计的强大的神经网络架构。它们通过自注意力机制将文本分解成较小的部分并分析它们之间的关系。这使得模型能够对各种查询生成连贯流畅的响应。
代表性的Transformers算法
-
BERT (Bidirectional Encoder Representations from Transformers): 由Devlin等人于2018年提出,BERT是第一个在大规模语料库上进行预训练的Transformer模型。它通过双向训练上下文来学习深层次的语言表示,极大地推动了NLP任务的性能,如文本分类、命名实体识别、问答系统等。
-
GPT (Generative Pre-trained Transformer): 由Radford等人于2018年提出,GPT是一个基于Transformer的生成式预训练模型。它通过单向语言模型的方式进行预训练,并在特定任务上进行微调,以生成连贯且有说服力的文本。
-
XLNet: 由Yang等人于2019年提出,XLNet是一种改进的BERT模型,它通过排列语言模型的形式来捕获文本中的双向上下文信息。XLNet在多项NLP任务上取得了当时的最佳性能。
-
RoBERTa (A Robustly Optimized BERT Pretraining Approach): 由Liu等人于2019年提出,RoBERTa是BERT的一个改进版本,通过更大的数据集、更长的训练时间和更细致的超参数调整,实现了更好的性能。
-
T5 (Text-to-Text Transfer Transformer): 由Raffel等人于2019年提出,T5将所有NLP任务统一转换为文本到文本的格式,通过预训练和微调的方式处理各种任务,如文本分类、问答、摘要生成等。
-
ALBERT (A Lite BERT): 由Lan等人于2019年提出,ALBERT是BERT的一个轻量级版本,它通过参数共享和跨层参数预测技术减少了模型的参数数量,从而提高了训练和推理的效率。
-
ELECTRA: 由Raffel等人于2020年提出,ELECTRA采用了一种新颖的预训练方法,通过替换文本中的某些token并让模型预测这些token来学习语言表示,这种方法在多个NLP基准测试中取得了优异的性能。
-
DeBERTa (Decoding-enhanced BERT with Disentangled Attention): 由Zhang等人于2020年提出,DeBERTa通过改进Transformer的自注意力机制和解码器部分,提高了模型对句子结构的理解能力。
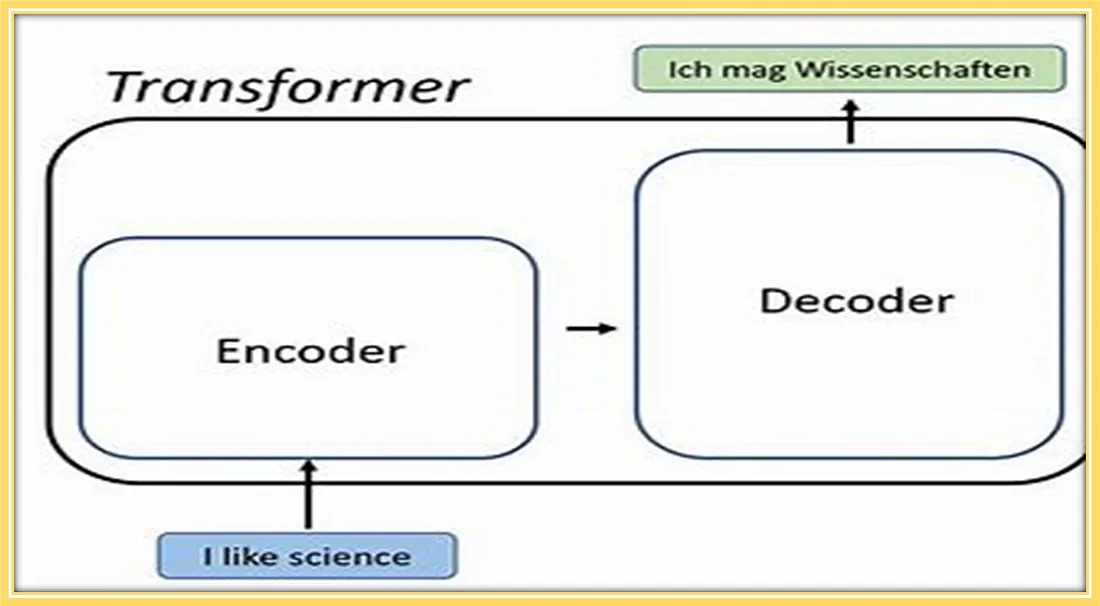
5. 编解码器架构
编解码器架构在自然语言处理(NLP)领域中扮演着至关重要的角色,特别是在处理序列到序列(Seq2Seq)任务时,例如机器翻译、文本摘要、问答系统等。这种架构通过将输入序列(如源语言文本)转换为输出序列(如目标语言文本),实现了高效的信息转换和传递。
编码器的作用与实现
编码器的主要职责是理解输入序列的内容,并将其压缩成一个紧凑的上下文向量。这个向量也被称为上下文嵌入,它捕捉了输入序列的关键信息,包括语法结构、语义含义和语境信息。编码器可以采用不同的神经网络结构,如循环神经网络(RNN)、长短期记忆网络(LSTM)、门控循环单元(GRU)或者更先进的Transformer结构。
在编码过程中,编码器逐步读取输入序列中的每个元素(如单词或字符),并更新其内部状态以反映对输入序列的理解。最终,编码器将输入序列的信息整合到上下文向量中,为解码器提供必要的信息。
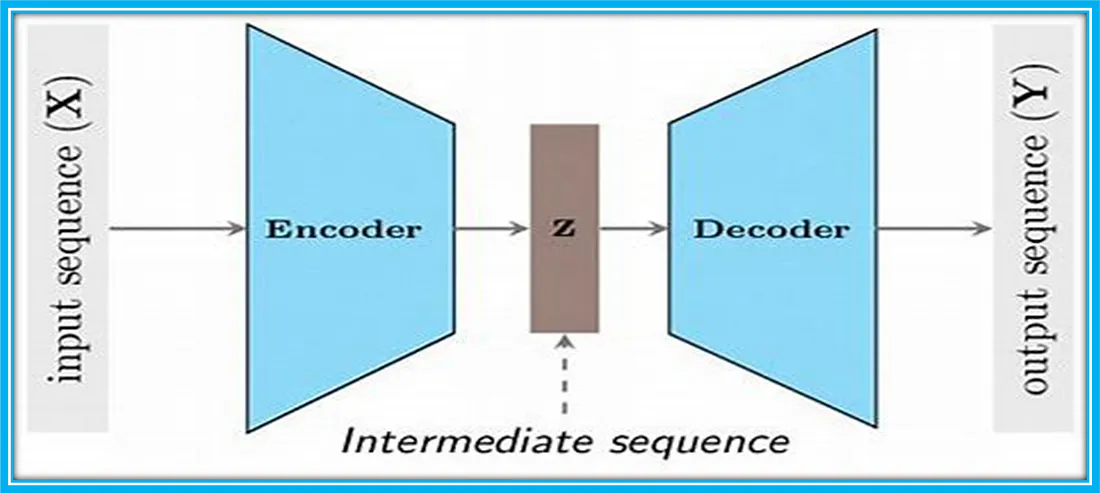
解码器的作用与实现
解码器的任务是将编码器生成的上下文向量转换为输出序列。它通常从一个空的序列开始,逐步生成目标语言的文本,一次生成一个元素(如一个单词)。解码器在生成每个新元素时,都会考虑到已经生成的序列部分和上下文向量中的信息。
解码器的内部结构通常与编码器相似,可以是RNN、LSTM、GRU或者Transformer。它利用已生成的序列和上下文向量来预测下一个最可能的元素,然后将这个新元素添加到输出序列中,并继续这个过程,直到生成完整的目标序列。
在训练阶段,解码器接收真实的目标序列作为输入,并学习如何基于编码器的输出和已生成的序列部分来预测下一个元素。在推理阶段,解码器则基于编码器的输出和已生成的序列来递归地生成整个输出序列。
训练与推理过程
在训练期间,编解码器架构通过大量的平行语料库进行训练,这些语料库包含源语言文本和对应的目标语言翻译。通过这种方式,模型学习如何将源语言文本映射到目标语言文本。
在推理阶段,模型接收新的源语言文本作为输入,并生成相应的目标语言文本。这个过程通常涉及到一个搜索策略,如贪婪搜索、束搜索(beam search)等,以在可能的输出序列中找到最佳的翻译。
编解码器架构通过编码器和解码器的协同工作,实现了从源语言到目标语言的有效转换。编码器负责理解输入序列并生成上下文向量,而解码器则基于这个向量生成目标序列。这种架构已经成为NLP领域中处理序列到序列问题的核心方法,并在多种语言处理任务中取得了显著的成果。随着深度学习技术的不断进步,编解码器架构将继续在NLP领域发挥重要作用。
编解码器架构代表算法:
-
序列到序列(Seq2Seq)模型:
- 这是最早的编解码器架构之一,由Sutskever等人在2014年提出。它使用一个RNN作为编码器来处理输入序列,并使用另一个RNN作为解码器来生成输出序列。这个模型引入了注意力机制的概念,以便解码器能够关注输入序列中的相关部分。
-
注意力机制(Attention Mechanism):
- 由Bahdanau等人在2014年提出,注意力机制允许解码器在生成每个新词时,能够“注意”到输入序列中的特定部分。这显著提高了机器翻译的质量,尤其是在处理长句子时。
-
神经机器翻译(NMT)系统:
- 随着深度学习的发展,基于Transformer的NMT系统成为了主流。这些系统通常包含一个编码器和一个解码器,两者都是基于自注意力机制的多层网络。
-
Google的Transformer模型:
- 由Vaswani等人在2017年提出,这个模型完全基于自注意力机制,没有使用传统的RNN或CNN结构。它在多项NLP任务中取得了新的最佳性能。
-
BERT(Bidirectional Encoder Representations from Transformers):
- 由Devlin等人在2018年提出,BERT使用了Transformer的编码器部分作为预训练模型,通过双向训练来学习文本的深层表示。BERT在多个NLP任务上取得了显著的性能提升。
-
GPT(Generative Pre-trained Transformer):
- 由Radford等人在2018年提出,GPT是一个基于Transformer的生成式预训练模型,它通过大量的文本数据进行预训练,并能够在特定任务上进行微调。
-
XLNet:
- 由Yang等人在2019年提出,XLNet是BERT的一个改进版本,它通过排列语言模型的形式来捕获文本中的双向上下文信息,并在多项NLP任务上取得了优异的性能。
-
T5(Text-to-Text Transfer Transformer):
- 由Raffel等人在2019年提出,T5将所有NLP任务统一转换为文本到文本的格式,通过预训练和微调的方式处理各种任务,如文本分类、问答、摘要生成等。
相关文章:
深度学习体系结构——CNN, RNN, GAN, Transformers, Encoder-Decoder Architectures算法原理与应用
1. 卷积神经网络 卷积神经网络(CNN)是一种特别适用于处理具有网格结构的数据,如图像和视频的人工神经网络。可以将其视作一个由多层过滤器构成的系统,这些过滤器能够处理图像并从中提取出有助于进行预测的有意义特征。 设想你手…...

js 数字的常用方法梳理
toFixed:保留几位小数。toFixed(保留小数位)。注意:不做任何的四舍五入。 Math集合: random:获取一个0-1之间的随机数。注意,包含0,不包含1。 round:四舍五入取整数,最后返回一个整数值。 ceil:向上取整。 floor:…...

STM32H743VIT6使用STM32CubeMX通过I2S驱动WM8978(5)
接前一篇文章:STM32H743VIT6使用STM32CubeMX通过I2S驱动WM8978(4) 本文参考以下文章及视频: STM32CbueIDE Audio播放音频 WM8978 I2S_stm32 cube配置i2s录音和播放-CSDN博客 STM32第二十二课(I2S,HAL&am…...
4.10)
Objective-C学习笔记(block,协议)4.10
1.block:是一个数据类型,存储一段代码,代码可以有参数有返回值。 2.声明block: 返回值类型 (^block变量名称)(参数列表); int (^myblock) (int num1,int num2); 代码段格式:^返回值类型(参数列表){ 代码段 }; int (^m…...

AD7982BRMZRL7 二进制 500kSPS 模数转换芯片 ADI
AD7982BRMZRL7是一款由Analog Devices(亚德诺)公司生产的18位逐次逼近型模数转换器(ADC)。它主要用于将模拟信号转换为数字信号,适用于数据采集系统、嵌入式系统、工业控制和医疗设备等领域。 AD7982BRMZRL7的主要功能…...
采集某新闻网资讯网站保存PDF
网址:融资总额近3亿美元、药明康德押注,这家抗衰老明星公司有何过人之处-36氪 想要抓取文章内容,但是找不到啊,可能是文字格式的问题,也可能文章内容进行了加密。 在元素中查看,window.initialState返回的就…...

03攻防世界-unserialize3
根据题目可以看出,这是个反序列化的题目 打开网址观察题目可以看到这里是php的代码,那么也就是php的反序列化 本题需要利用反序列化字符串来进行解题,根据源码提示我们需要构造code。 序列化的意思是:是将变量转换为可保存或传输…...

蓝桥杯备考随手记: 常见的二维数组问题
在Java中,二维数组是一种可以存储多个元素的数据结构。它由多个一维数组组成,这些一维数组可以看作是行和列的组合,形成了一个矩阵。 1. 二维数组旋转问题 二维数组的旋转是指将数组中的元素按照一定规则进行旋转。通常有两种常见的旋转方式…...

Java | Leetcode Java题解之第28题找出字符串中第一个匹配项的下标
题目: 题解: class Solution {public int strStr(String haystack, String needle) {int n haystack.length(), m needle.length();if (m 0) {return 0;}int[] pi new int[m];for (int i 1, j 0; i < m; i) {while (j > 0 && needl…...
【数据结构与算法】:二叉树经典OJ
目录 1. 二叉树的前序遍历 (中,后序类似)2. 二叉树的最大深度3. 平衡二叉树4. 二叉树遍历 1. 二叉树的前序遍历 (中,后序类似) 这道题的意思是对二叉树进行前序遍历,把每个结点的值都存入一个数组中,并且返回这个数组。 思路&…...

uniapp——长按识别二维码
说明 转变思路,长按图片,进入预览图片,这时候再长按就可以了。 <view class"codeMain"><view class"codeWhite" longpress"handleLongPress(i.image(qrcode))"><image :src"i.image(qrc…...
云服务器环境web环境搭建之JDK、redis、mysql
一、Linux安装jdk,手动配置环境 链接: https://pan.baidu.com/s/1LRgRC5ih7B9fkc588uEQ1whttps://pan.baidu.com/s/1LRgRC5ih7B9fkc588uEQ1w 提取码: 0413 tar -xvf 压缩包名 修改配置文件/etc/profile 二、安装redis环境 方案一: Linux下安装配置r…...

第1章 计算机网络体系结构
王道学习 【考纲内容】 (一)计算机网络概述 计算机网络的概念、组成与功能;计算机网络的分类; 计算机网络的性能指标 (二)计算机网络体系结构与参考模型 计算机网络分层结…...
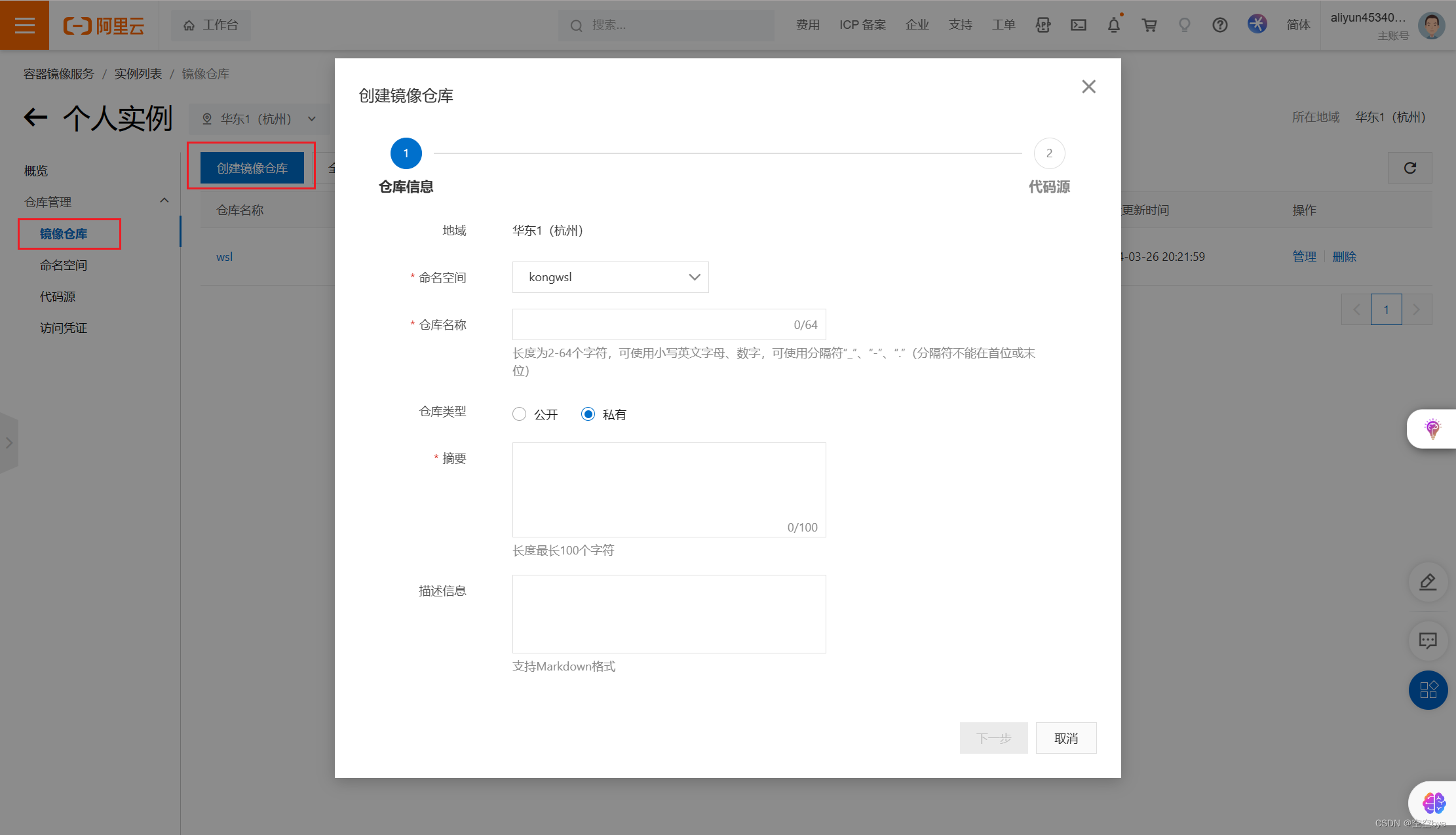
Docker之自定义镜像上传至阿里云
一、Alpine介绍 Alpine Linux是一个轻量级的Linux发行版,专注于安全、简单和高效。它采用了一个小巧的内核和基于musl libc的C库,使得它具有出色的性能和资源利用率。 Alpine Linux的主要特点包括: 小巧轻量:Alpine Linux的安装…...
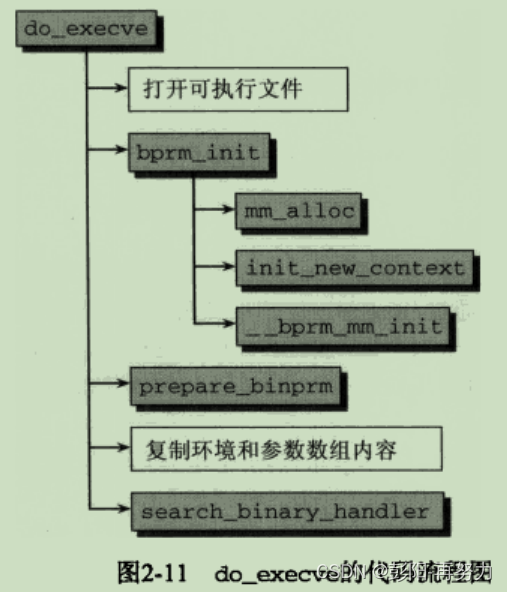
《深入Linux内核架构》第2章 进程管理和调度 (2)
目录 2.4 进程管理相关的系统调用 2.4.1 进程复制 2.4.2 内核线程 2.4.3 启动新程序 2.4.4 退出进程 本专栏文章将有70篇左右,欢迎关注,订阅后续文章。 2.4 进程管理相关的系统调用 2.4.1 进程复制 1. _do_fork函数 fork vfork clone都最终调用_…...
PostgreSQL的psql命令)
(四)PostgreSQL的psql命令
PostgreSQL的psql命令 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777psql 是 PostgreSQL 数据库的命令行界面…...

前端使用minio传输文件
minio官方文档 minio-js可以支持ts。 安装完可能会出现 Can‘t import the named export ‘xxx‘ from non EcmaScript module (only default export is available)可以尝试降低minio的版本 npm install minio7.0.18 --save代码: 初始化 const Minio require(…...

[大模型] BlueLM-7B-Chat WebDemo 部署
BlueLM-7B-Chat WebDemo 部署 模型介绍 BlueLM-7B 是由 vivo AI 全球研究院自主研发的大规模预训练语言模型,参数规模为 70 亿。BlueLM-7B 在 C-Eval 和 CMMLU 上均取得领先结果,对比同尺寸开源模型中具有较强的竞争力(截止11月1号)。本次发布共包含 7…...

一文了解ERC404协议
一、ERC404基础讲解 1、什么是ERC404协议 ERC404协议是一种实验性的、混合的ERC20/ERC721实现的,具有原生流动性和碎片化的协议。即该协议可让NFT像代币一样进行拆分交易。是一个图币的互换协议。具有原生流动性和碎片化的协议。 这意味着通过 ERC404 协议…...

iOS cocoapods pod FrozenError and RuntimeError
0x00 报错日志 /Library/Ruby/Gems/2.6.0/gems/cocoapods-1.12.0/lib/cocoapods/user_interface/error_report.rb:34:in force_encoding: cant modify frozen String (FrozenError)from /Library/Ruby/Gems/2.6.0/gems/cocoapods-1.12.0/lib/cocoapods/user_interface/error_r…...
)
Python-docx实战:如何用run对象精细控制Word文档样式(附完整代码示例)
Python-docx实战:用run对象精细控制Word文档样式的专业指南 在自动化办公和批量文档生成领域,Python-docx库已经成为处理Word文档的事实标准工具。对于需要生成合同、报告、发票等标准化文档的开发者而言,仅仅创建基础文本远远不够——精确控…...

突破限制:跨设备使用三星笔记的开源技术方案
突破限制:跨设备使用三星笔记的开源技术方案 【免费下载链接】galaxybook_mask This script will allow you to mimic your windows pc as a Galaxy Book laptop, this is usually used to bypass Samsung Notes 项目地址: https://gitcode.com/gh_mirrors/ga/gal…...

5分钟搞定OpenClaw+百川2-13B:星图平台镜像一键部署指南
5分钟搞定OpenClaw百川2-13B:星图平台镜像一键部署指南 1. 为什么选择云端沙盒体验OpenClaw 上周我在本地尝试部署OpenClaw时,经历了长达3小时的依赖冲突和配置报错。当最终看到"openclaw gateway started"的提示时,我的开发环境…...

让 Claude Code 帮你“看家“:Hooks 与 /loop 入门
让 Claude Code 帮你"看家":Hooks 与 /loop 入门 上周我把一个重构任务扔给 Claude,出门开了两小时会。回来发现它把 .env.production 改了。 那一刻我才意识到,单纯会用 Claude Code 还不够,你还得学会怎么管住它。折…...

基于云平台的智能客服系统实战:架构设计与性能优化指南
最近在负责一个面向多租户的智能客服项目,从零到一踩了不少坑。传统单体架构的客服系统,一到业务高峰期就卡顿、超时,扩容更是噩梦。经过一番折腾,我们最终基于云平台构建了一套相对稳定、可扩展的解决方案。今天就把整个架构设计…...

从零构建 eNSP 小型校园网络毕业设计:架构解析与避坑指南
最近在帮学弟学妹们看网络相关的毕业设计,发现很多同学在用华为 eNSP 搭建小型校园网络时,思路容易混乱。要么是拓扑图画得一团麻,分不清层次;要么是配置完 VLAN 后,不同网段的电脑死活 ping 不通;还有的干…...

解锁Intel RealSense三维点云生成:3大突破点与实战秘籍
解锁Intel RealSense三维点云生成:3大突破点与实战秘籍 【免费下载链接】librealsense Intel RealSense™ SDK 项目地址: https://gitcode.com/GitHub_Trending/li/librealsense 在工业检测、机器人导航和增强现实等领域,三维数据获取一直是技术落…...

从八股到实战!3月25日Python高并发面试,TaskGroup+JIT双杀通关
面试官推了推眼镜,盯着你的简历:“说说Python高并发吧,asyncio用过吗?” 你心里冷笑一声。这要是搁三年前,你肯定开始背诵:"asyncio是Python的异步IO库,使用事件循环机制,通过a…...

如何用AnythingLLM构建企业级知识库:从零到一的完整指南
如何用AnythingLLM构建企业级知识库:从零到一的完整指南 【免费下载链接】anything-llm 这是一个全栈应用程序,可以将任何文档、资源(如网址链接、音频、视频)或内容片段转换为上下文,以便任何大语言模型(L…...
)
用MATLAB玩转三维可视化:手把手教你绘制动态曲面图(含peaks函数详解)
MATLAB三维可视化实战:从静态曲面到动态交互的全方位指南 科研工作者常面临海量数据的可视化挑战,而MATLAB提供的三维图形工具链能将这些抽象数字转化为直观的空间形态。本文将带您深入探索三维可视化的核心技巧,从基础绘图到高级交互&#x…...