Day:007(1) | Python爬虫:高效数据抓取的编程技术(scrapy框架使用)
Scrapy的介绍
Scrapy 是一个用于抓取网站和提取结构化数据的应用程序框架,可用于各种有用的应用程序,如数据挖掘、信息处理或历史存档。
尽管 Scrapy 最初是为网络抓取而设计的,但它也可用于使用API提取数据或用作通用网络爬虫。
Scrapy的优势
- 可以容易构建大规模的爬虫项目
- 内置re、xpath、css选择器
- 可以自动调整爬行速度
- 开源和免费的网络爬虫框架
- 可以快速导出数据文件: JSON,CSV和XML
- 可以自动方式从网页中提取数据(自己编写规则)
- Scrapy很容易扩展,快速和功能强大
- 这是一个跨平台应用程序框架(在Windows,Linux,Mac OS)
- Scrapy请求调度和异步处理
Scrapy的架构

最简单的单个网页爬取流程是 spiders > scheduler >downloader > spiders > item pipeline
省略了engine环节!
- 引擎(engine)
用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
- 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
- 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应
- 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出
- 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应
安装
pip install scrapy
注意
企业也追求更稳定的不追求最新,而且我们的主要目的是做项目写代码没必要因为环境版本问题出bug浪费太多时间
Scarpy开发第一个爬虫
创建第一个项目
scrapy startproject myfrist(project_name)
文件说明
| 名称 | 作用 |
| scrapy.cfg | 项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中) |
| items.py | 设置数据存储模板,用于结构化数据,如:Django的Model |
| pipelines | 数据处理行为,如:一般结构化的数据持久化 |
| settings.py | 配置文件,如:递归的层数、并发数,延迟下载等 |
| spiders | 爬虫目录,如:创建文件,编写爬虫规则 |
创建第一个爬虫
scrapy genspider 爬虫名 爬虫的地址
注意
一般创建爬虫文件时,以网站域名命名
爬虫包含的内容
- name: 它定义了蜘蛛的唯一名称
- allowed_domains: 它包含了蜘蛛抓取的基本URL;
- start-urls: 蜘蛛开始爬行的URL列表;
- parse(): 这是提取并解析刮下数据的方法;
代码
import scrapyclass DoubanSpider(scrapy.Spider):name = 'douban'allowed_domains = 'douban.com'start_urls = ['https://movie.douban.com/top250/']def parse(self, response):movie_name =
response.xpath("//div[@class='item']//a/span
[1]/text()").extract()movie_core =
response.xpath("//div[@class='star']/span[2]
/text()").extract()yield {'movie_name':movie_name,'movie_core':movie_core}
Scrapy项目的启动介绍
Scrapy启动的方式有多种方式:
- Scrapy命令运行
运行环境
命令行:cmd/powershell/等等
- 运行Python脚本
运行环境
命令行:cmd/powershell/等等
编辑器:VSCode/PyCharm等等
注意
运行程序之前,要确认网站是否允许爬取 robots.txt 文件
Scrapy启动-命令启动
scrapy命令
scrapy框架提供了对项目的命令scrapy ,具体启动项目命令格式如下:
方法1
scrapy crawl 爬虫名
注意
这的爬虫名是爬虫文件中name属性的值
问题
命令无法启动
解决方案
切换到项目目录中,运行即可
方法2
scrapy runspider spider_file.py
注意
- 这是爬虫文件的名字
- 要指定到spider文件夹
Scrapy启动-脚本启动
Scrapy为开发者设置好了启动好的对象。因此,我们通过脚本即可启动Scrapy项目
运行脚本
在项目的目录下,创建脚本,比如项目名为:scrapy01,创建脚本的路径为 scrapy01\scrapy01\脚本.py
脚本
- 使用cmdline
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', '爬虫名字'])
- 使用CrawlerProcess
from scrapy.crawler import CrawlerProcess
from spiders.baidu import BaiduSpiderprocess = CrawlerProcess()
process.crawl(BaiduSpider)
process.start()
- 使用CrawlerRunner
from twisted.internet import reactor
from spiders.baidu import BaiduSpider
from spiders.taobao import TaoBaoSpider
from scrapy.crawler import CrawlerRunner
from scrapy.utils.log import configure_loggingconfigure_logging() # 开启日志出输出
runner = CrawlerRunner()
runner.crawl(BaiduSpider)
runner.crawl(TaoBaoSpider)
d = runner.join()
d.addBoth(lambda _: reactor.stop())
reactor.run()
运行
命令行运行
python 脚本.py
VSCode运行
右键脚本编辑区空白处==> run python file in terminal(运行python文件在命令行)

VSCode调试运行
打开脚本文件 ==> 选择调试运行

Scrapy输出日志-了解
启动Scrapy时,默认会输出日志,内容如下(做为参考):
2030-07-13 16:45:19 [scrapy.utils.log] INFO:Scrapy 2.6.1 started (bot: scrapy02)
2030-07-13 16:45:19 [scrapy.utils.log] INFO:Versions: lxml 4.8.0.0, libxml2 2.9.12,
cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0,Twisted 22.4.0, Python 3.10.2
(tags/v3.10.2:a58ebcc, Jan 17 2022,14:12:15) [MSC v.1929 64 bit (AMD64)],pyOpenSSL 22.0.0 (OpenSSL 3.0.4 21 Jun2022), cryptography 37.0.3, PlatformWindows-10-10.0.22000-SP0
2030-07-13 16:45:19 [scrapy.crawler] INFO:
Overridden settings:
{'BOT_NAME': 'scrapy02',
'NEWSPIDER_MODULE': 'scrapy02.spiders',
'SPIDER_MODULES': ['scrapy02.spiders']}2030-07-13 16:45:19 [scrapy.utils.log]DEBUG: Using reactor:
twisted.internet.selectreactor.SelectReactor
2030-07-13 16:45:19
[scrapy.extensions.telnet] INFO: Telnet
Password: a7b76850d59e14d0
2030-07-13 16:45:20 [scrapy.middleware]
INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2030-07-13 16:45:20 [scrapy.middleware]
INFO: Enabled downloader middlewares:
2030-07-13 16:45:19
[scrapy.extensions.telnet] INFO: Telnet
Password: a7b76850d59e14d0
2030-07-13 16:45:20 [scrapy.middleware]
INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2030-07-13 16:45:20 [scrapy.middleware]
INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.Http
AuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeo
ut.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheader
s.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.Use
rAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMi
ddleware',
'scrapy.downloadermiddlewares.redirect.Meta
RefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompressi
on.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.Redi
rectMiddleware',
'scrapy.downloadermiddlewares.cookies.Cooki
esMiddleware',
'scrapy.downloadermiddlewares.httpproxy.Htt
pProxyMiddleware',
'scrapy.downloadermiddlewares.stats.Downloa
derStats']
2030-07-13 16:45:20 [scrapy.middleware]
INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErr
orMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMi
ddleware',
'scrapy.spidermiddlewares.referer.RefererMi
ddleware',
'scrapy.spidermiddlewares.urllength.UrlLeng
thMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddle
ware']
2030-07-13 16:45:20 [scrapy.middleware]
INFO: Enabled item pipelines:
[]
2030-07-13 16:45:20 [scrapy.core.engine]
INFO: Spider opened
2030-07-13 16:45:20
[scrapy.extensions.logstats] INFO: Crawled 0
pages (at 0 pages/min), scraped 0 items (at
0 items/min)
2030-07-13 16:45:20
[scrapy.extensions.telnet] INFO: Telnet
console listening on 127.0.0.1:6023
2030-07-13 16:45:24 [filelock] DEBUG:
Attempting to acquire lock 1733280163264 on
D:\python_env\spider2_env\lib\sitepackages\tldextract\.suffix_cache/publicsuff
ix.orgtlds\de84b5ca2167d4c83e38fb162f2e8738.tldext
ract.json.lock
2030-07-13 16:45:24 [filelock] DEBUG: Lock
1733280163264 acquired on
D:\python_env\spider2_env\lib\sitepackages\tldextract\.suffix_cache/publicsuff
ix.orgtlds\de84b5ca2167d4c83e38fb162f2e8738.tldext
ract.json.lock
2030-07-13 16:45:24 [filelock] DEBUG:
Attempting to release lock 1733280163264 on
D:\python_env\spider2_env\lib\sitepackages\tldextract\.suffix_cache/publicsuff
ix.orgtlds\de84b5ca2167d4c83e38fb162f2e8738.tldext
ract.json.lock
2030-07-13 16:45:24 [filelock] DEBUG: Lock
1733280163264 released on
D:\python_env\spider2_env\lib\sitepackages\tldextract\.suffix_cache/publicsuff
ix.orgtlds\de84b5ca2167d4c83e38fb162f2e8738.tldext
ract.json.lock
2030-07-13 16:45:24 [scrapy.core.engine]
DEBUG: Crawled (200) <GET
http://www.baidu.com/> (referer: None)
1111111111111111111111111111111111111111111111
2030-07-13 16:45:24 [scrapy.core.engine]
INFO: Closing spider (finished)
2030-07-13 16:45:24 [scrapy.statscollectors]
INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 213,
'downloader/request_count': 1,'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 1476,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 4.716963,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2030, 7,
13, 8, 45, 24, 923094),
'httpcompression/response_bytes': 2381,
'httpcompression/response_count': 1,
'log_count/DEBUG': 6,
'log_count/INFO': 10,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2030, 7,
13, 8, 45, 20, 206131)}
2030-07-13 16:45:24 [scrapy.core.engine]
INFO: Spider closed (finished)
- 启动爬虫
- 使用的模块与版本
- 加载配置文件
- 打开下载中间件
- 打开中间件
- 打开管道
- 爬虫开启
- 打印统计
相关文章:
Day:007(1) | Python爬虫:高效数据抓取的编程技术(scrapy框架使用)
Scrapy的介绍 Scrapy 是一个用于抓取网站和提取结构化数据的应用程序框架,可用于各种有用的应用程序,如数据挖掘、信息处理或历史存档。 尽管 Scrapy 最初是为网络抓取而设计的,但它也可用于使用API提取数据或用作通用网络爬虫。 Scrapy的优势…...
)
Echarts使用dataTool写可自定义横坐标的盒须图(箱线图)
在vue2中的完整盒须图组件代码 可自适应浏览器窗体变化,可自定义横坐标,无需写箱线图数据处理逻辑。dataTool是echarts自带的,无需额外安装,只要引入。 <template><span><div ref"BoxPlotChart" id&qu…...
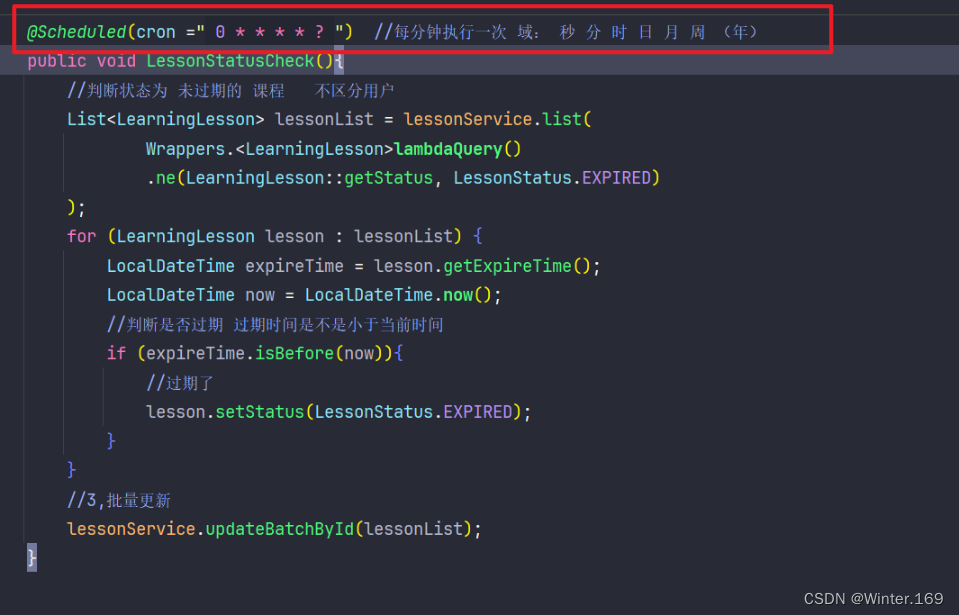
SpringBoot编写一个SpringTask定时任务的方法
1,在启动类上添加注解 EnableScheduling//开启定时任务调度 2, 任务(方法)上也要添加注解: Scheduled(cron " 0 * * * * ? ") //每分钟执行一次 域: 秒 分 时 日 月 周 (年&#…...
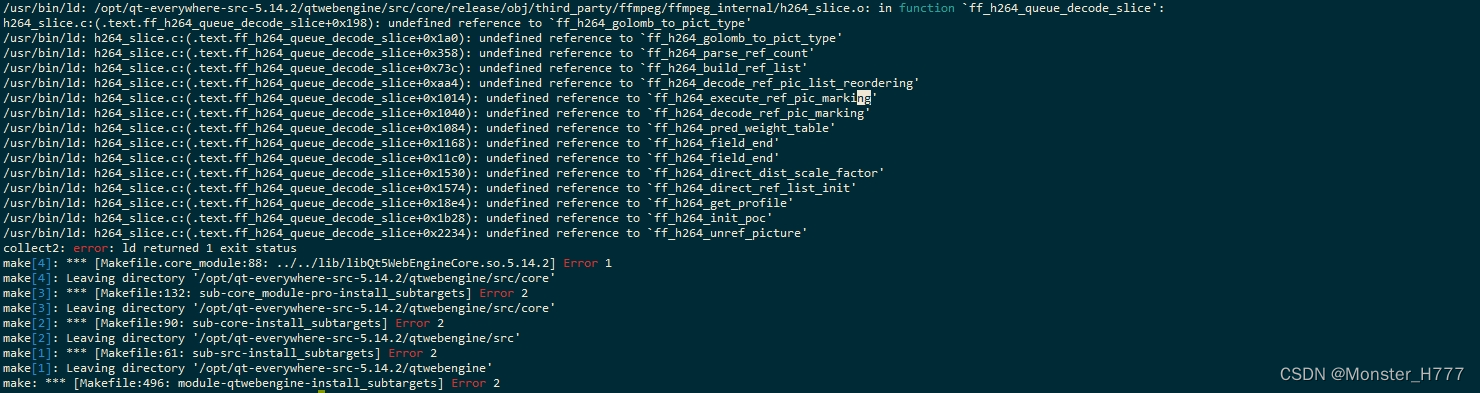
【Qt编译】ARM环境 Qt5.14.2-QtWebEngine库编译 (完整版)
ARM 编译Qt5.14.2源码 1.下载源码 下载Qt5.14.2源代码(可根据自己的需求下载不同版本) 下载网站:https://download.qt.io/new_archive/qt/5.14/5.14.2/single/ 2.相关依赖(如果需要的话) 先参考官方文档的需求进行安装: 官方…...
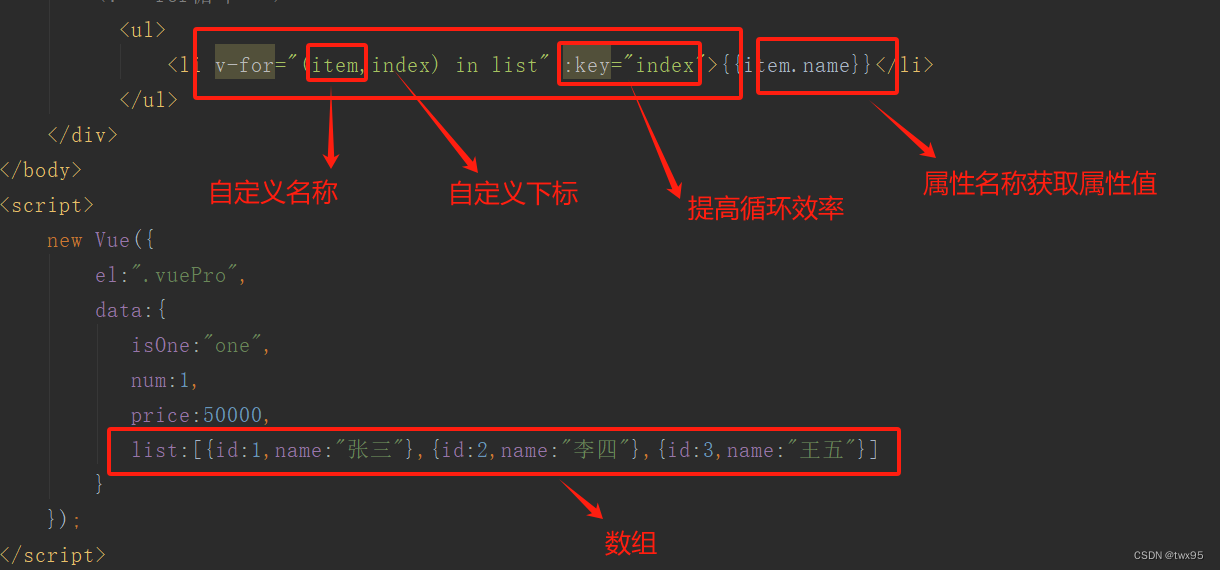
vue简单使用二(循环)
目录 属性绑定 if判断: for循环: 属性绑定 代码的形式来说明 三元表达式的写法: if判断: for循环: 完整代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"…...

JavaScript入门--变量
JavaScript入门--变量 一、JS变量二、变量命名三、常量四、局部变量 一、JS变量 定义变量a, b, c,并输出到控制台。 var a 1; var b 13.14; var c hello Js;console.log(a, b, c) //console.log()语句用于输出结果到控制台,类似python的print语句…...
给自己的机器人部件安装单目摄像头并实现gazebo仿真功能
手术执行器添加摄像头 手术执行器文件夹surgical_new内容展示如何添加单目摄像头下载现成的机器人环境文件启动仿真环境 手术执行器文件夹surgical_new内容展示 进入src文件夹下选择进入vision_obliquity文件夹 选择launch 有两个可用gazebo中rviz展示的launch文件࿰…...
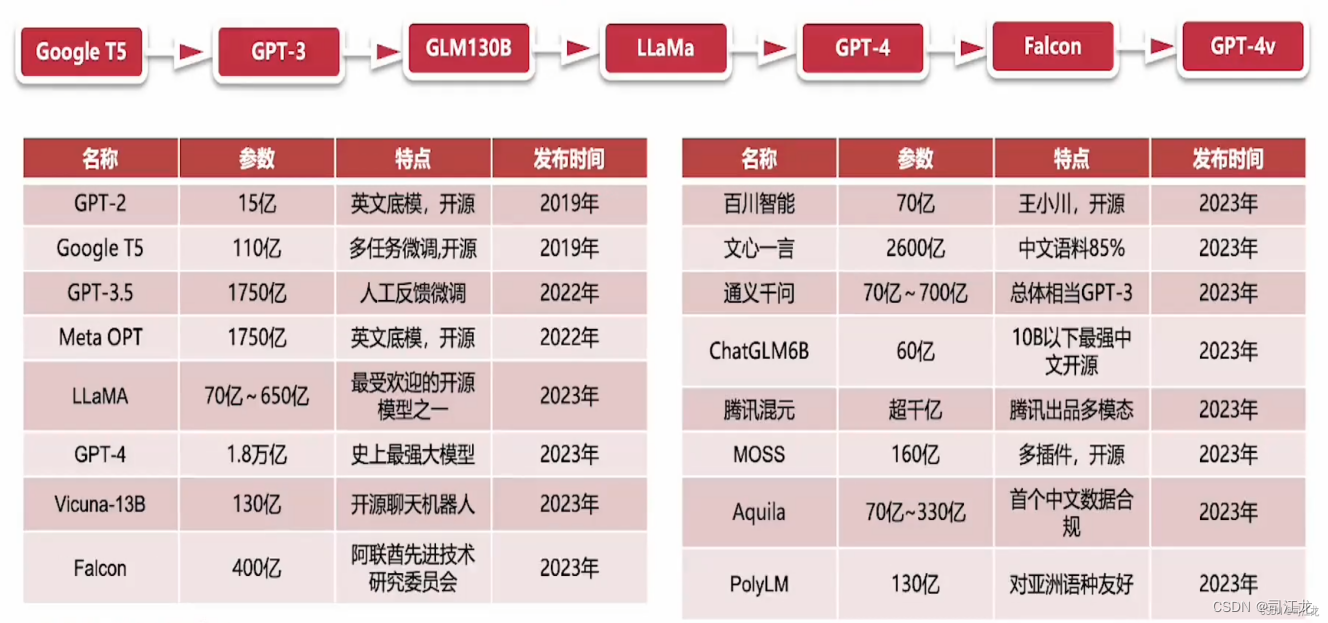
用AI的视角看世界
前言 2024年将是Ai人工智能在各个行业垂直领域发展的元年。 随着2022年11月openai 的大语言模型chatgpt3.5的诞生,已经预示着互联网时代,移动互联网时代即将迎来新的变革,也预示着web3.0和元宇宙更近了一步。 回顾历史,互联网的…...

MATLAB 自定义实现点云法向量和曲率计算(详细解读)(64)
MATLAB 自定义实现点云法向量和曲率计算(详细解读)(64) 一、算法介绍二、算法步骤三、算法实现1.代码 (完整,注释清晰,可直接用)2.结果一、算法介绍 首先说明: ------这里代码手动实现,不调用matlab提供的法向量计算接口,更有助于大家了解法向量和曲率的计算方法,…...
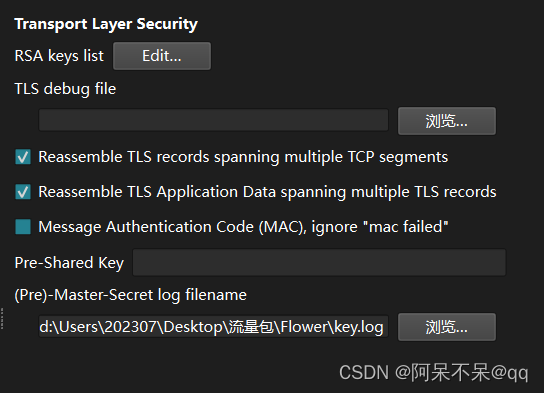
拯救鲨鱼!Helping wireshark!wireshark未响应解决方法
前言 做题的的时候 在用wireshark解密tls秘钥的时候 我的小鲨鱼突然未响应了 然后我多次尝试无果 并且殃及池鱼 我电脑上所有的流量包都打不开了?!!! 于是乎 尝试删了重下 还是未响应 开始怀疑电脑 重启电脑两次 还是打…...

设计模式之责任链讲解
责任链模式适用于需要将请求和处理解耦的场景,同时又需要动态地组织处理逻辑的场景。 通过使用责任链模式,可以实现请求的动态处理、灵活的扩展和简化的代码编写,提高系统的可维护性和可扩展性。 一、责任链入门 以下这是GPT生成的责任链代…...

K8s: 将一个节点移出集群和相关注意事项
前置步骤 在Kubernetes集群中,要移出一个节点,你需要执行以下步骤: 1 )将节点标记为不可调度 首先,你需要将目标节点标记为不可调度,以确保Kubernetes不会在该节点上调度新的Pod这可以通过执行以下命令实…...
Python学习笔记24 - 学生信息管理系统
1. 需求分析 2. 系统设计 3. 系统开发必备 4. 主函数设计 5. 学生信息维护模块设计 a. 录入学生信息 b. 删除学生信息 c. 修改学生信息 d. 查询学生信息 e. 统计学生总人数 f. 显示所有学生信息 g. 排序模块设计 6. 项目打包...

【物联网应用案例】某制造企业电锅炉检测项目
供暖行业在我国的经济发展中占据着重要的地位,然而,长期以来,该行业存在着自动化水平低、管理效率不高等问题,制约了其持续发展。为了解决这些问题,吉林某电锅炉生产厂家进行了一项创新性的尝试。 该厂家通过集成物联…...
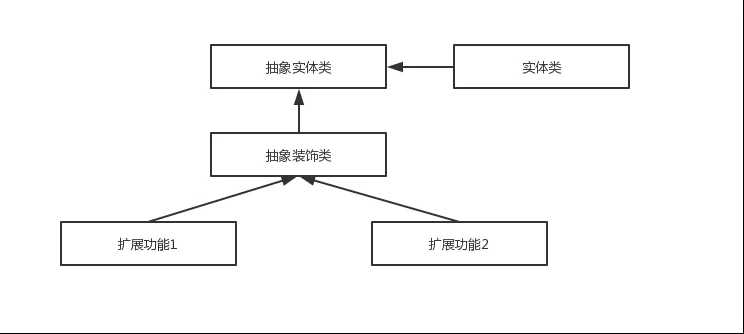
设计模式实践
结合设计模式概念和在java/spring/spring boot中的实战,说明下列设计模式。 一、工厂模式 这里只讲简单工厂模式,详细的可以参考Java工厂模式(随笔)-CSDN博客。工厂类会根据不同的参数或条件来决定创建哪种对象,这样…...
嵌入式学习52-ARM1
知识零散: 1.flash: nor flash 可被寻地址 …...
Java(MySQL基础)
数据库相关概念 MySOL数据库 关系型数据库(RDBMS) 概念: 建立在关系模型基础上,由多张相互连接的二维表组成的数据库。特点: 使用表存储数据,格式统一,便于维护使用SQL语言操作,标准统一,使用方便 SQL SOL通用语法…...

预约系统的使用
预约系统的使用 目录概述需求: 设计思路实现思路分析1.用户年规则 在 预约系统中的使用流程 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a better result,wa…...
酷开科技OTT大屏营销:开启新时代的营销革命
随着互联网技术的不断发展和普及,大屏已经成为越来越多家庭选择的娱乐方式。在这个背景下,酷开科技凭借其强大的技术实力和敏锐的市场洞察力,成功地将大屏转化为一种新的营销渠道,为品牌和企业带来了前所未有的商业机会。 酷开科技…...

网络安全(防火墙,IDS,IPS概述)
问题一:什么是防火墙,IDS,IPS? 防火墙是对IP:port的访问进行限制,对访问端口进行制定的策略去允许开放的访问,将不放开的端口进行拒绝访问,从而达到充当防DDOS的设备。主要是拒绝网络流量,阻断所有不希望出现的流程,禁止数据流量流通,达到安全防护的作用。如将一些恶…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...