GPT知识库浅析
一、引言
上篇文章《GPT简介及应用》介绍了GPT的应用场景,里面提到GPT bot的基本使用:基于GPT训练好的数据,回答用户的问题。
但在使用过程中,如果用户的问题里面出现最新的术语,就会出现这种提示:
截至我最后更新的时间(2023年4月),"llama_index"这个术语并不是广泛认知或者在特定领域内公认的一个概念,因此我无法直接提供关于"llama_index"的具体信息。这个术语可能是指某个特定项目、工具、指标或者是某个领域内的专有名词。
这时候我们自然会想到,有没有办法将最新的/私有的数据提供给GPT,让GPT基于这些数据来回答问题呢?答案当然是有的,那就是:GPT知识库。
二、简介
GPT 知识库,就像是一个包含了各种武功秘籍的宝库。GPT Bot 像是一位可以通过阅读和理解这些秘籍,来不断提高自己的武功水平的修炼者。
武功大师会将自身的武术经验沉淀升华,编撰成绝世的武功秘籍。
以往武功大师想要把这些武功秘籍传承下去,需要经过层层选拔,挑选出最合适的徒弟,辅以精心指导,日夜打磨,才可能培养出下一代的武功大师。
但现在只需要将武功秘籍给GPT Bot,它就可以快速理解,并且吸收为自身内力,为不同级别的人员提供指导。
这就是GPT知识库+GPT Bot的威力:
GPT Bot 利用 GPT 知识库中的信息,来回答用户的问题,提供帮助和建议,从而更好地满足用户的需求。
三、知识库构建
GPT的核心原理,就是基于大量的数据进行学习,然后根据用户提出的问题,将关联性最高的内容,组装成自然语言作为答案(当然实际的实现要复杂得多)。
GPT知识库的核心逻辑也是差不多:学习用户提供的文档,然后经过算法识别,得到文档内容的关联性。
当用户提供问题时,就可以根据关联性,获取对应的文档内容。然后组装成自然语言,返回给用户。
市面上比较出名的工具有 LangChain、LlamaIndex 等,工具间各有优点,它们的核心功能都是:对大量语言相关的数据进行分析和处理,以提供最佳的搜索结果和答案。
下文均以LlamaIndex为例。
3.1 demo
使用这些工具来构建知识库也相对简单,只需几行代码即可构建成功(前提是有OpenAI的账号)。
from llama_index import VectorStoreIndexindex = VectorStoreIndex.from_documents(documents=documents
)
VectorStoreIndex是LlamaIndex提供的API,只需要将文档documents(如何生成documents在下文中介绍)传入,即可自动解析,根据默认的embedding算法,构建成一个有关联性的索引数据。
然后,将这些索引数据,转换为内置的搜索引擎,即可用自然语言进行问答。
query_engine = index.as_query_engine()
response = query_engine.query("武林第一是谁?")
print(response)
四、文档读取
在构建知识库时,需要将用户文档,转换为LlamaIndex的参数documents,LlamaIndex提供了各式各样的文档读取器 Reader:Llama Hub
4.1 内置文档读取器
LlamaIndex内置了许多文档读取器,可以读取不同格式的文件,如Markdown、PDF、Word、PPT、图片视频等。
from llama_index.core import SimpleDirectoryReaderdocuments = SimpleDirectoryReader("./data").load_data()
4.2 Hive读取器
很多业务数据都存放在大数据仓库Hive中,LlamaIndex也提供了HiveReader快速读取数据:Hive Loader (llamahub.ai)。
但这个读取器,只能读取非安全的Hive,若Hive启用了Kerberos认证则会连接失败。
查看源码,很容易发现这个Reader只是对pyhive的简单封装,没有适配Kerberos认证:
"""Initialize with parameters."""try:from pyhive import hiveexcept ImportError:raise ImportError("`hive` package not found, please run `pip install pyhive`")self.con = hive.Connection(host=host,port=port,username=username,database=database,auth=auth,password=password,)
因此若Hive启用了Kerberos,则需要自定义实现:
from TCLIService.ttypes import TOperationState
from llama_index import (Document,
)from pyhive import hive# 注意此处的配置可能根据你的 Hive 配置或集群细节而有所不同
conn = hive.Connection(host=hive_server2_host,port=10000,auth='KERBEROS',kerberos_service_name='hive',database=hive_database
)
cursor = None
try:# 创建游标cursor = conn.cursor()# 执行查询cursor.execute(hive_query_sql)# 以防查询是异步的,等待它完成status = cursor.poll().operationStatewhile status in (TOperationState.INITIALIZED_STATE,TOperationState.RUNNING_STATE):status = cursor.poll().operationState# 获取结果rows = cursor.fetchall()# 处理结果documents = []for row in rows:document = Document(text=row.__str__())documents.append(document)logger.info(document)
finally:# 无论是否遇到异常,始终关闭游标和连接if cursor:cursor.close()conn.close()
这样将用户文档转换为LlamaIndex的文档格式document,即可快速构建成GPT知识库。
五、文档存储
通过以上示例可以看到,GPT知识库只保存在程序的内存中,退出程序就会被丢弃掉,下次再使用就需要重新构建。为了避免重复构建,需要将构建好的索引数据保存下来。
为了存储这些索引数据,业界一般会使用向量数据库。
5.1 向量数据库
向量数据库与常规数据库的不同点,主要在于向量数据库是一种基于向量空间模型的数据库系统,它将数据存储为向量,并利用向量之间的相似度来进行查询和分类。在大模型模型训练中,可以提供更高效的数据存储及查询能力。
各大厂商都提供了自身的向量数据库,如阿里、腾讯、华为等。
以下以腾讯云VectorDB为例。
5.2 上传数据
LlamaIndex集成了腾讯云VectorDB的SDK,二次封装功能接口,简化使用。
Tencent Cloud VectorDB - LlamaIndex
初始化连接:
import tcvectordbvector_store = TencentVectorDB(url="http://10.0.X.X",key="eC4bLRy2va******************************",collection_params=CollectionParams(dimension=1536, drop_exists=True),
)
注意:
drop_exists默认为True,即如果向量集合已存在,会先删除再重建。dimension固定为1536,因为LlamaIndex构建索引数据时,固定维度为1536。若不相同,在上传数据时会出现数据不兼容报错。
上传数据:
storage_context = StorageContext.from_defaults(vector_store=vector_store)index = VectorStoreIndex.from_documents(documents,storage_context=storage_context
)
这样,即可将构建好的索引数据,同步保存到腾讯云VectorDB。
5.3 复用数据
GPT查询腾讯云VectorDB,初始化连接时需要将drop_exists参数设置为False,并且去掉documents即可。
import tcvectordbvector_store = TencentVectorDB(url="http://10.0.X.X",key="eC4bLRy2va******************************",collection_params=CollectionParams(dimension=1536, drop_exists=False),
)storage_context = StorageContext.from_defaults(vector_store=vector_store)index = VectorStoreIndex.from_documents(storage_context=storage_context
)
到这里,GPT知识库基本构建成功。
接下来就是让GPT去查询索引数据,组装成自然语言,返回给用户。
待续。
相关文章:

GPT知识库浅析
一、引言 上篇文章《GPT简介及应用》介绍了GPT的应用场景,里面提到GPT bot的基本使用:基于GPT训练好的数据,回答用户的问题。 但在使用过程中,如果用户的问题里面出现最新的术语,就会出现这种提示: 截至我…...

SpringMVC--SpringMVC的视图
目录 1. 总述 2. ThymeleafView视图 3. 转发视图 4. 重定向视图 5. 视图控制器view-controller 1. 总述 在SpringMVC框架中,视图(View)是一个非常重要的概念,它负责将模型数据(Model)展示给用户。简单…...
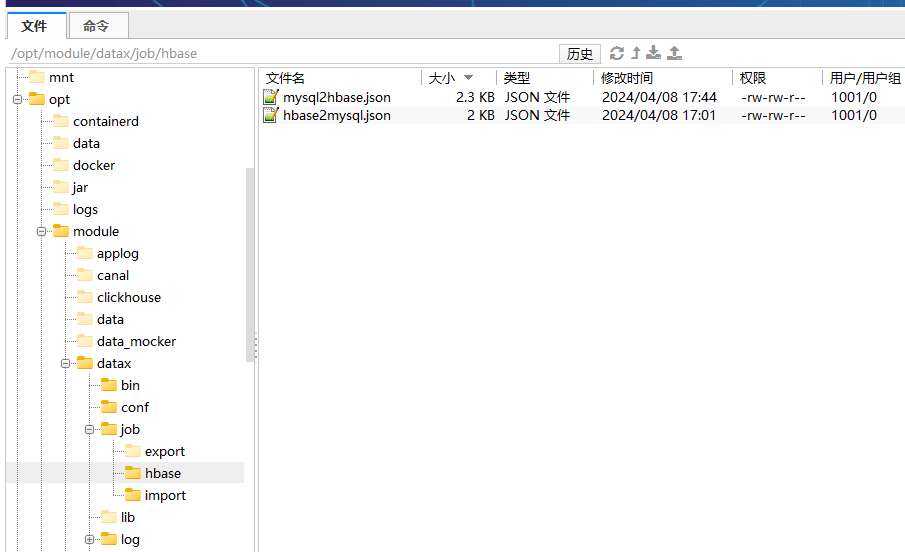
Datax,hbase与mysql数据相互同步
参考文章:datax mysql 和hbase的 相互导入 目录 0、软件版本说明 1、hbase数据同步至mysql 1.1、hbase数据 1.2、mysql数据 1.3、json脚本(hbase2mysql.json) 1.4、同步成功日志 2、mysql数据同步至hbase 1.1、hbase数据 1.2、mysql…...

ubuntu spdlog 封装成c++类使用
安装及编译方法:ubuntu spdlog 日志安装及使用_spdlog_logger_info-CSDN博客 h文件: #ifndef LOGGING_H #define LOGGING_H#include <iostream> #include <cstring> #include <sstream> #include <string> #include <memor…...

【C语言】——字符串函数的使用与模拟实现(上)
【C语言】——字符串函数 前言一、 s t r l e n strlen strlen 函数1.1、函数功能1.2、函数的使用1.3、函数的模拟实现(1)计数法(2)递归法(3)指针 - 指针 二、 s t r c p y strcpy strcpy 函数2.1、函数功能…...

数据库(1)
目录 1.什么是事务?事务的基本特性ACID? 2.数据库中并发一致性问题? 3.数据的隔离等级? 4.ACID靠什么保证的呢? 5.SQL优化的实践经验? 1.什么是事务?事务的基本特性ACID? 事务指…...

VirtualBox - 与 Win10 虚拟机 与 宿主机 共享文件
原文链接 https://www.cnblogs.com/xy14/p/10427353.html 1. 概述 需要在 宿主机 和 虚拟机 之间交换文件复制粘贴 貌似不太好使 2. 问题 设置了共享文件夹之后, 找不到目录 3. 环境 宿主机 OS Win10开启了 网络发现 略虚拟机 OS Win10开启了 网络发现 略Virtualbox 6 4…...

深入浅出 useEffect:React 函数组件中的副作用处理详解
useEffect 是 React 中的一个钩子函数,用于处理函数组件中的副作用操作,如发送网络请求、订阅消息、手动修改 DOM 等。下面是 useEffect 的用法总结: 基本用法 import React, { useState, useEffect } from react;function Example() {cons…...

《QT实用小工具·十九》回车跳转到不同的编辑框
1、概述 源码放在文章末尾 该项目实现通过回车键让光标从一个编辑框跳转到另一个编辑框,下面是demo演示: 项目部分代码如下: #ifndef WIDGET_H #define WIDGET_H#include <QWidget>namespace Ui { class Widget; }class Widget : p…...
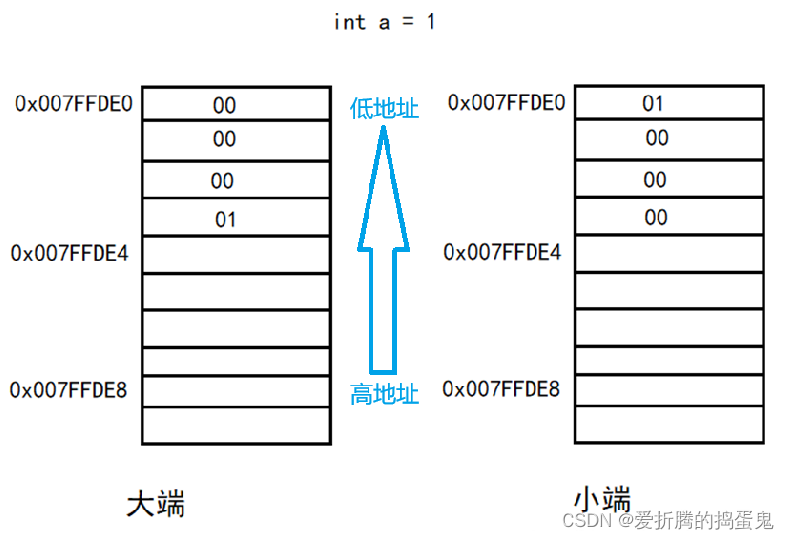
基本的数据类型在16位、32位和64位机上所占的字节大小
1、目前常用的机器都是32位和64位的,但是有时候会考虑16位机。总结一下在三种位数下常用的数据类型所占的字节大小。 数据类型16位(byte)32位(byte)64位(byte)取值范围char111-128 ~ 127unsigned char1110 ~ 255short int / short222-32768~32767unsigned short222…...

关注招聘 关注招聘 关注招聘
🔥关注招聘 🔥关注招聘 🔥关注招聘 🔥开源产品: 1.农业物联网平台开源版 2.充电桩系统开源版 3.GPU池化软件(AI人工智能训练平台/推理平台) 开源版 产品销售: 1.农业物联网平台企业版 2.充电桩系统企业…...

Django框架设计原理
相信大多数的Web开发者对于MVC(Model、View、Controller)设计模式都不陌生,该设计模式已经成为Web框架中一种事实上的标准了,Django框架自然也是一个遵循MVC设计模式的框架。不过从严格意义上讲,Django框架采用了一种更…...
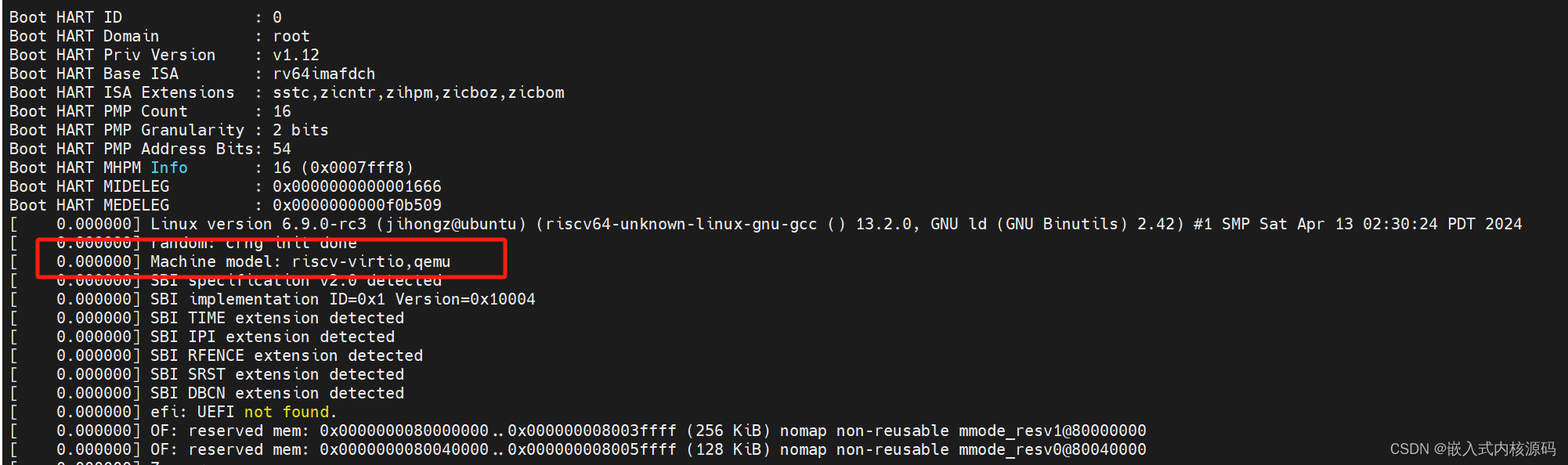
Linux ARM平台开发系列讲解(QEMU篇) 1.2 新添加一个Linux kernel设备树
1. 概述 上一章节我们利用QEMU成功启动了Linux kernel,但是细心的小伙伴就会发现,我们用默认的defconfig是没有找到设备树源文件的,但是又发现kernel启动时候它使用了设备树riscv-virtio,qemu,这是因为qemu用了一个默认的设备树文件,该章节呢我们就把这个默认的设备树文件…...

OSPF动态路由实验(思科)
华为设备参考: 一,技术简介 OSPF(Open Shortest Path First)是一种内部网关协议,主要用于在单一自治系统内决策路由。它是一种基于链路状态的路由协议,通过链路状态路由算法来实现动态路由选择。 OSPF的…...

MyBatis 等类似的 XML 映射文件中,当传入的参数为空字符串时,<if> 标签可能会导致 SQL 语句中的条件判断出现意外结果。
问题 传入的参数为空字符串,但还是根据参数查询了。 原因 在 XML 中使用 标签进行条件判断时,需要明确理解其行为。在 MyBatis 等类似的 XML 映射文件中, 标签通常用于动态拼接 SQL 语句的条件部分。当传入的参数 riskLevel 为空字符串时…...
git的安装
git的安装 在CentOS系统上安装git时,我们可以选择yum安装或者源码编译安装两种方式。Yum的安装方式的好处是比较简单,直接输入”yum install git”命令即可。但是Yum的安装的话,不好控制安装git的版本。如果我们想选择安装git的版本…...

蓝桥杯嵌入式模板(cubemxkeil5)
LED 引脚PC8~PC15,默认高电平(灭)。 此外还要配置PD2为输出引脚(控制LED锁存) ,默认低电平(锁住)!!! #include "led.h"void led_disp…...
ELFK (Filebeat+ELK)日志分析系统
一. 相关介绍 Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进或是直接发给 Elasticsearch 存储,性能上相…...
)
HttpClient、OKhttp、RestTemplate接口调用对比( Java HTTP 客户端)
文章目录 HttpClient、OKhttp、RestTemplate接口调用对比HttpClientOkHttprestTemplate HttpClient、OKhttp、RestTemplate接口调用对比 HttpClient、OkHttp 和 RestTemplate 是三种常用的 Java HTTP 客户端库,它们都可以用于发送 HTTP 请求和接收 HTTP 响应&#…...

[旅游] 景区排队上厕所
人有三急,急中最急是上个厕所要排队,而且人还不少!这样就需要做一个提前量的预测,万一提前量的预测,搞得不当,非得憋出膀光炎,或者尿裤子。尤其是女厕所太少!另外一点是儿童根本就没…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

Android15默认授权浮窗权限
我们经常有那种需求,客户需要定制的apk集成在ROM中,并且默认授予其【显示在其他应用的上层】权限,也就是我们常说的浮窗权限,那么我们就可以通过以下方法在wms、ams等系统服务的systemReady()方法中调用即可实现预置应用默认授权浮…...

UR 协作机器人「三剑客」:精密轻量担当(UR7e)、全能协作主力(UR12e)、重型任务专家(UR15)
UR协作机器人正以其卓越性能在现代制造业自动化中扮演重要角色。UR7e、UR12e和UR15通过创新技术和精准设计满足了不同行业的多样化需求。其中,UR15以其速度、精度及人工智能准备能力成为自动化领域的重要突破。UR7e和UR12e则在负载规格和市场定位上不断优化…...
)
OpenLayers 分屏对比(地图联动)
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图分屏对比在WebGIS开发中是很常见的功能,和卷帘图层不一样的是,分屏对比是在各个地图中添加相同或者不同的图层进行对比查看。…...

全志A40i android7.1 调试信息打印串口由uart0改为uart3
一,概述 1. 目的 将调试信息打印串口由uart0改为uart3。 2. 版本信息 Uboot版本:2014.07; Kernel版本:Linux-3.10; 二,Uboot 1. sys_config.fex改动 使能uart3(TX:PH00 RX:PH01),并让boo…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...