RAGFlow:基于OCR和文档解析的下一代 RAG 引擎
一、引言
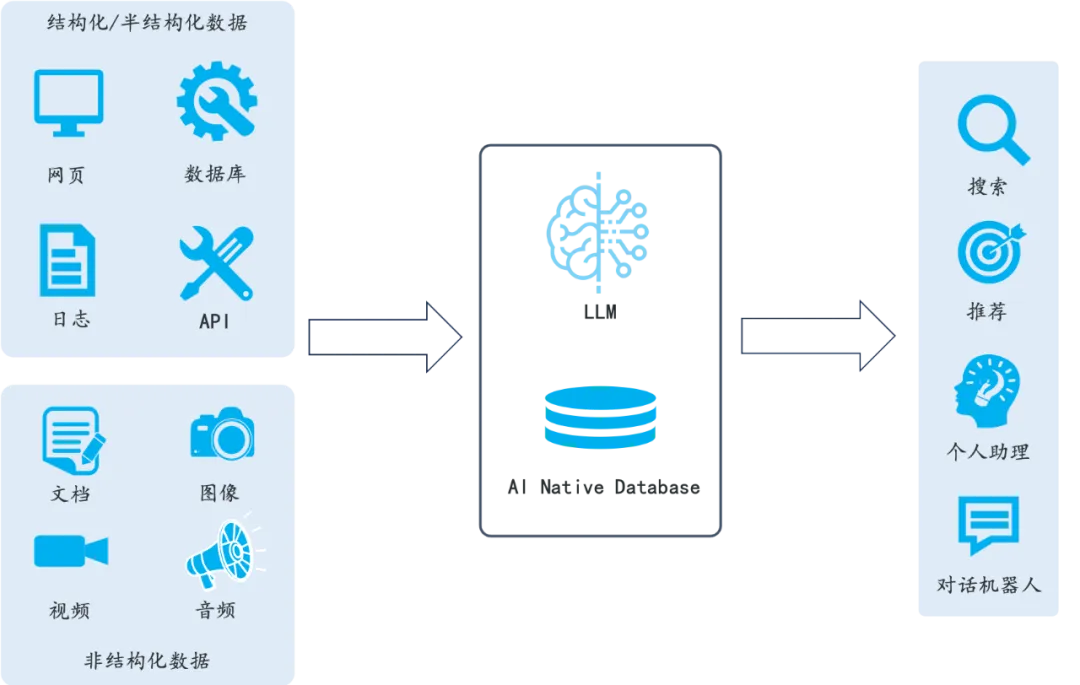
在人工智能的浪潮中,检索增强生成(Retrieval-Augmented Generation,简称RAG)技术以其独特的优势成为了研究和应用的热点。RAG技术通过结合大型语言模型(LLMs)的强大生成能力和高效的信息检索系统,为用户提供了一种全新的交互体验。然而,随着技术的深入应用,一系列挑战也逐渐浮现。
首先,现有的RAG系统在处理海量数据时面临着效率和准确性的双重压力。尽管LLMs能够生成流畅的文本,但在面对复杂、非结构化的数据时,它们往往难以准确把握和召回关键信息。此外,RAG系统在数据管理和理解方面也存在局限,这导致了所谓的“垃圾输入,垃圾输出”(GIGOut)问题,即如果输入数据质量不高,那么生成的答案也很难达到预期的准确性。
正是在这种背景下,RAGFlow 应运而生。作为一款端到端的RAG解决方案,RAGFlow 旨在通过深度文档理解技术,解决现有RAG技术在数据处理和生成答案方面的挑战。它不仅能够处理多种格式的文档,还能够智能地识别文档中的结构和内容,从而确保数据的高质量输入。RAGFlow 的设计哲学是“高质量输入,高质量输出”,它通过提供可解释性和可控性的生成结果,让用户能够信任并依赖于系统提供的答案。
2024年4月1日,RAGFlow宣布正式开源,这一消息在技术界引起了轰动。开源当天,RAGFlow 在 GitHub 上迅速获得了数千的关注,不到一周时间,已吸收2900颗星,这不仅体现了社区对 RAGFlow 的高度认可,也显示出大家对这一新技术的热情。
随着 RAGFlow 的开源,它不仅为技术社区带来了新的活力,也为解决RAG技术面临的困难提供了新的思路和工具。RAGFlow的出现,标志着我们在构建更加智能、高效和可靠的RAG系统的道路上迈出了坚实的一步。
二、RAGFlow 的核心功能
-
深度文档理解:"Quality in, quality out",RAGFlow 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。真正在无限上下文(token)的场景下快速完成大海捞针测试。对于用户上传的文档,它需要自动识别文档的布局,包括标题、段落、换行等,还包含难度很大的图片和表格。对于表格来说,不仅仅要识别出文档中存在表格,还会针对表格的布局做进一步识别,包括内部每一个单元格,多行文字是否需要合并成一个单元格等。并且表格的内容还会结合表头信息处理,确保以合适的形式送到数据库,从而完成 RAG 针对这些细节数字的“大海捞针”。
-
可控可解释的文本切片:RAGFlow 提供多种文本模板,用户可以根据需求选择合适的模板,确保结果的可控性和可解释性。因此 RAGFlow 在处理文档时,给了不少的选择:Q&A,Resume,Paper,Manual,Table,Book,Law,通用... 。当然,这些分类还在不断继续扩展中,处理过程还有待完善。后续还会抽象出更多共通的东西,使各种定制化的处理更加容易。
-
降低幻觉:RAGFlow 是一个完整的 RAG 系统,而目前开源的 RAG,大都忽视了 RAG 本身的最大优势之一:可以让 LLM 以可控的方式回答问题,或者换种说法:有理有据、消除幻觉。我们都知道,随着模型能力的不同,LLM 多少都会有概率会出现幻觉,在这种情况下, 一款 RAG 产品应该随时随地给用户以参考,让用户随时查看 LLM 是基于哪些原文来生成答案的,这需要同时生成原文的引用链接,并允许用户的鼠标 hover 上去即可调出原文的内容,甚至包含图表。如果还不能确定,再点一下便能定位到原文。RAGFlow 的文本切片过程可视化,支持手动调整,答案提供关键引用的快照并支持追根溯源,从而降低幻觉的风险。
-
兼容各类异构数据源:RAGFlow 支持 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据, 网页等。对于无序文本数据,RAGFlow 可以自动提取其中的关键信息并转化为结构化表示;而对于结构化数据,它则能灵活切入,挖掘内在的语义联系。最终将这两种不同来源的数据统一进行索引和检索,为用户提供一站式的数据处理和问答体验。
-
自动化 RAG 工作流:RAGFlow 支持全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统;大语言模型 LLM 以及向量模型均支持配置,用户可以根据实际需求自主选择。;基于多路召回、融合重排序,能够权衡上下文语义和关键词匹配两个维度,实现高效的相关性计算;提供易用的 API,可以轻松集成到各类企业系统,无论是对个人用户还是企业开发者,都极大方便了二次开发和系统集成工作。
三、技术架构
3.1、RAGFlow 系统架构
RAGFlow 系统是一个高效、智能的信息处理平台,它通过一系列精心设计的组件,实现了对复杂查询的快速响应和精准处理。这个系统的核心组件包括:
-
文档解析器:这是 RAGFlow 系统的“大脑”,负责将各种格式的文档进行解析,从中提取出文本、图像和表格等关键内容。无论是PDF、Word文档还是Excel表格,文档解析器都能够准确捕捉信息,为后续的处理打下基础。
-
查询分析器:这个组件是 RAGFlow 系统的“神经系统”,它对用户的查询进行深入分析,识别并提取出查询中的关键信息。通过这种分析,系统能够更准确地理解用户的需求,为检索工作提供精确的指导。
-
检索:这是 RAGFlow 系统的“搜索引擎”,它使用查询分析器提供的关键信息,从海量文档中快速检索出与之相关的信息。检索组件的强大能力保证了用户能够及时获得所需的数据。
-
重排:这个组件是 RAGFlow 系统的“过滤器”,它对检索到的信息进行排序和过滤,确保最终呈现给用户的信息是最相关、最有价值的。通过这种方式,系统能够去除冗余和不相关的数据,提高信息的准确性和可用性。
-
LLM:作为 RAGFlow 系统的“语言生成器”,LLM(大型语言模型)负责将排序后的信息整合并生成最终的答案或输出。LLM的强大生成能力不仅能够确保答案的准确性,还能够使答案表达得更加自然和流畅。
这些组件共同构成了RAGFlow系统的强大架构,使得它能够高效地处理用户的查询,快速地从文档中检索信息,并生成准确、有用的答案。这个系统不仅提高了信息处理的效率,也极大地提升了用户的使用体验。

RAG 系统的架构是一个精密而高效的工作流程,它通过一系列精心设计的组件,确保了用户查询的准确处理和高质量答案的生成。这个系统的工作流程可以概括为以下几个步骤:
-
首先,当用户输入一个查询时,查询分析器便开始工作。它对用户的查询进行深入分析,从中提取出关键信息,这些信息是后续检索工作的基础。
-
接下来,检索模块根据查询分析器提供的关键信息,在大量的文档资源中寻找与之相关的数据。这一步骤是在整个系统中非常关键的一环,因为它直接决定了后续答案的相关性和准确性。
-
然后,重排模块对检索到的信息进行进一步的排序和过滤。这一步骤确保了最终呈现给用户的信息是经过优化的,去除了不相关或冗余的内容,使得答案更加精确和有价值。
-
最后,LLM(大型语言模型)根据重排模块提供的信息,生成最终的答案或输出。LLM的强大生成能力使得答案不仅准确,而且表达流畅自然,就像一个知识丰富的助手在回答用户的问题一样。
通过这样的工作流程,RAG系统架构能够高效地处理用户的查询,从文档中提取有价值的信息,并生成准确、有用的答案。这种系统不仅提高了信息检索的效率,也极大地提升了用户体验。
3.2、DeepDoc:深度文档理解的基石
DeepDoc 是 RAGFlow 的核心组件,它利用视觉信息和解析技术,对文档进行深度理解,提取文本、表格和图像等信息。DeepDoc 的功能模块包括:
-
OCR 技术:支持多种语言和字体,并能够处理复杂的文档布局和图像质量。
-
布局识别(布局分析识别)技术:RAGFlow 使用 Yolov8 进行 OCR/布局识别/TSR(表格结构识别),识别文档的布局结构,例如标题、段落、表格、图像等。
-
表格结构识别 (TSR):识别表格的结构,例如行列、表头、单元格合并等,并将其转换为自然语言句子。
-
文档解析:支持解析 PDF、DOCX、EXCEL 和 PPT 等多种文档格式,并提取文本块、表格和图像等信息。
-
简历解析:将简历中的非结构化文本解析为结构化数据,例如姓名、联系方式、工作经历、教育背景等。
3.3、LLM 和嵌入模型在 RAGFlow 中的作用
在 RAGFlow 中,LLM(Large Language Models,大型语言模型)和嵌入模型(Embedding Models)扮演着至关重要的角色,它们共同协作以实现高效的信息检索和生成任务。
LLM是RAGFlow中的核心组件之一,负责理解和生成自然语言。在RAGFlow中,LLM的主要作用包括:
-
理解用户查询: LLM能够理解用户的自然语言查询,并将其转化为可执行的指令或问题。
-
生成回答: 基于用户查询和检索到的信息,LLM能够生成流畅、连贯且相关性强的回答。
-
提供可控性: LLM可以根据用户的指示生成特定风格或格式的回答,确保生成内容的可控性和准确性。
-
跨语言能力: 对于多语言环境下的RAG任务,LLM需要具备跨语言理解和生成的能力,以便在不同语言之间进行有效的信息检索和转换。
嵌入模型在RAGFlow中主要用于将文本数据转换为向量表示,这对于信息检索和相似性比较至关重要。嵌入模型的主要作用包括:
-
文本向量化: 嵌入模型将文本(如文档、段落、句子等)转换为数值向量,这些向量能够表示文本的语义信息。
-
相似性比较: 通过计算向量之间的相似度,嵌入模型可以帮助 RAGFlow 快速找到与用户查询最相关的信息。
-
数据检索: 嵌入模型使得RAGFlow能够在大规模数据集中高效地执行检索任务,尤其是在处理非结构化数据时,如文档和图片。
-
多模态能力: 对于包含图表、图片等非文本元素的文档,嵌入模型可以辅助提取和理解这些元素的语义信息,增强RAGFlow的多模态处理能力。
在 RAGFlow 中,LLM 和嵌入模型的结合使用,使得系统不仅能够理解复杂的自然语言查询,还能够在海量数据中快速准确地检索到相关信息,并生成高质量的回答。这种协同工作机制大大提高了RAGFlow在知识库问答、企业数据集成和多模态信息处理等场景下的应用潜力和效率。
3.4、文本分块过程中的可视化和人工干预
RAGFlow在处理文档时,特别强调了智能文档处理的可视化和可解释性。这意味着用户不仅可以获得由系统处理后的结果,还能够清晰地看到文档是如何被分块和解析的。这样的设计使得用户可以对AI的处理结果进行核查和必要的干预,确保最终输出的准确性和可靠性。
在文本分块过程中,RAGFlow首先会对用户上传的文档进行结构识别,这包括但不限于标题、段落、换行等。对于更为复杂的元素,如图片和表格,RAGFlow也会进行详细的布局识别和结构分析。例如,在处理表格时,系统不仅会识别出表格的存在,还会进一步识别表格内部的每一个单元格,以及多行文字是否需要合并成一个单元格等。这些信息都会被合理地处理并结合表头信息,以确保数据的正确性和完整性。
RAGFlow的可视化功能允许用户查看文档解析的具体结果。用户可以看到文档被分割成了多少块,各种图表是如何处理的。如果系统识别的结果与用户的预期有所出入,用户可以进行适当的干预。这种干预可能包括调整分块的方式、合并或分割某些部分,以及修改表格的识别结果等。RAGFlow提供了直观的用户界面,使得用户可以轻松地进行这些操作。
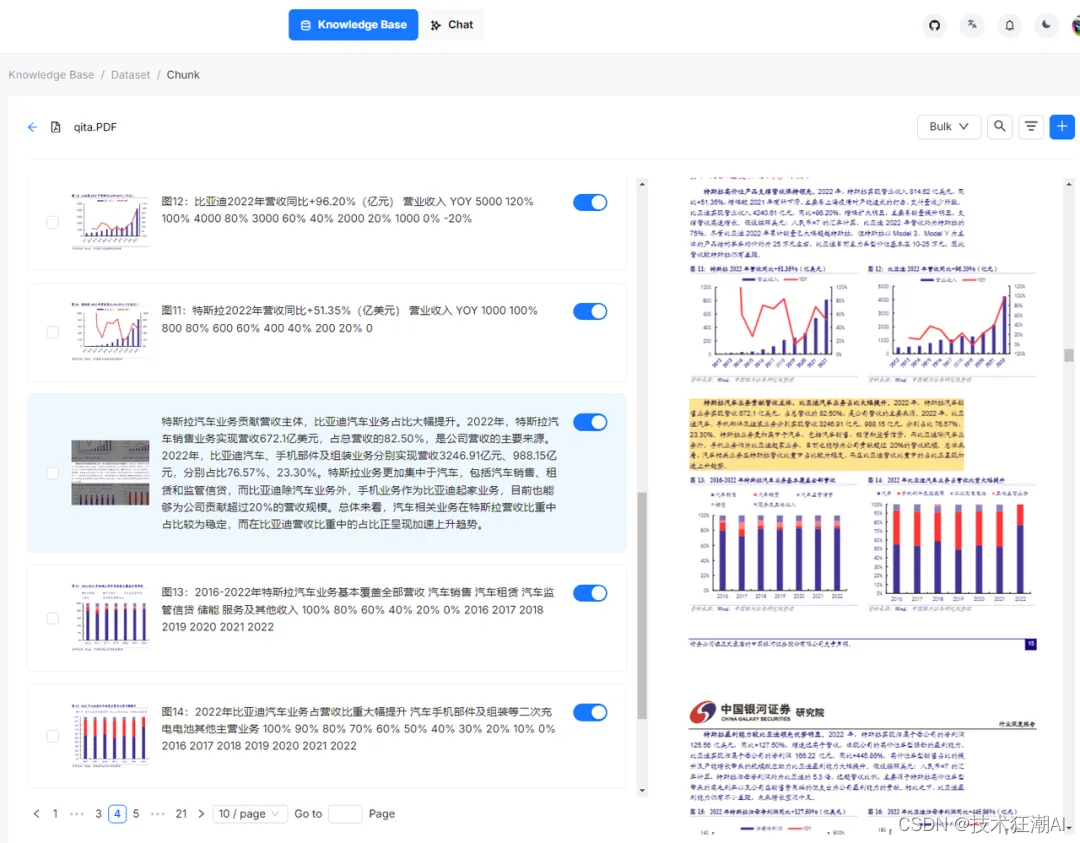
此外,RAGFlow还提供了一种机制,允许用户通过点击来定位到原文,对比处理结果和原文的差异。这种对比功能不仅可以帮助用户确认AI的处理是否准确,还可以让用户对处理过程有更多的了解和控制。这种可视化和可解释性的设计,大大提高了用户对AI处理结果的信任度,同时也使得RAGFlow成为一个更加强大和灵活的工具。
四、设置和运行 RAGFlow
RAGFlow 是一个基于深度文档理解的开源 RAG(检索增强生成)引擎,旨在为企业提供一个简化的 RAG 工作流程。以下是设置和运行 RAGFlow 的详细指南:
4.1、系统要求
在开始安装 RAGFlow 之前,请确保您的系统满足以下基本要求:
-
CPU 核心数:至少 2 核
-
内存大小:至少 8 GB
4.2、安装 Docker
RAGFlow 需要 Docker 来运行。如果您的本地计算机(Windows、Mac 或 Linux)尚未安装 Docker,请访问 Docker 官网进行安装。
4.3、启动 RAGFlow 服务器
-
调整系统设置:确保
vm.max_map_count的值大于或等于 262144。您可以通过运行以下命令来检查和设置该值:
# 要检查 vm.max_map_count 的值: sysctl vm.max_map_count# 如果不是,请将 vm.max_map_count 重置为至少 262144 的值。 sudo sysctl -w vm.max_map_count=262144为了使更改永久生效,请在
/etc/sysctl.conf文件中添加或更新vm.max_map_count=262144。
1、克隆 RAGFlow 存储库:
git clone https://github.com/infiniflow/ragflow.git2、克隆 RAGFlow 存储库:
git clone https://github.com/infiniflow/ragflow.git3、构建 Docker 镜像并启动服务器:
cd ragflow/docker
docker compose up -d核心映像大小约为 9 GB,加载可能需要一些时间。
4、检查服务器状态:
docker logs -f ragflow-server如果系统成功启动,您将看到确认消息。
____ ______ __/ __ \ ____ _ ____ _ / ____// /____ _ __/ /_/ // __ `// __ `// /_ / // __ \| | /| / // _, _// /_/ // /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_| \__,_/ \__, //_/ /_/ \____/ |__/|__//____/* Running on all addresses (0.0.0.0)* Running on http://127.0.0.1:9380* Running on http://172.22.0.5:9380INFO:werkzeug:Press CTRL+C to quit4.4、配置选项
-
选择 LLM 工厂:在
service_conf.yaml文件中的user_default_llm部分选择所需的 LLM 工厂。 -
API 密钥设置:使用相应的 API 密钥更新
service_conf.yaml文件中的API_KEY字段。更多信息请参阅/docs/llm_api_key_setup.md。 -
要更新默认 HTTP 服务端口 (80),请转到 docker-compose.yml 并将
80:80更改为<YOUR_SERVING_PORT>:80。
所有系统配置的更新需要重新启动系统才能生效:
docker-compose up -d
4.5、访问 RAGFlow 界面
一旦服务器启动并运行,您可以通过浏览器访问 RAGFlow 界面。在默认配置下,您可以省略默认 HTTP 服务端口 80。只需在浏览器中输入 RAGFlow 服务器的 IP 地址即可。
通过上述步骤,您可以成功设置和运行 RAGFlow。确保遵循所有配置指南,并在启动服务器后检查其状态以确认一切正常。通过选择适当的 LLM 工厂和设置 API 密钥,您可以确保 RAGFlow 与您的业务需求无缝集成。最后,通过简单的浏览器操作,您就可以开始使用 RAGFlow 强大的文档理解和问答功能了。

五、RAGFlow 未来规划
RAGFlow 作为一款先进的检索增强生成引擎,其未来发展规划主要围绕以下几个核心方向:
-
增强多语言支持能力:
-
RAGFlow 将致力于提升其对不同语言的支持能力,使其能够更好地服务于全球化的市场。这意味着 RAGFlow 将开发和集成更多语言的文档结构识别模型,从而能够准确理解和处理各种语言的非结构化数据。这不仅包括常见的英语、中文等,还将扩展到其他语种,以满足不同地区用户的需求。
-
提升本地大型语言模型(LLM)的性能:
-
为了提高 RAGFlow 在处理非结构化数据时的准确性和效率,未来将对本地的大型语言模型进行优化和升级。这可能包括改进模型的训练数据、调整模型结构以及采用新的算法和技术,以提高模型的理解和生成能力。通过这些改进,RAGFlow 将能够更准确地理解和生成复杂的语言内容,为用户提供更加丰富和精准的信息。
-
扩展网络爬虫功能:
-
RAGFlow 计划扩展其网络爬虫的功能,以便能够从更广泛的来源获取数据。这包括接入企业的各类数据源,如 MySQL 的 binlog、数据湖的 ETL 以及外部的爬虫等。通过这些数据源的集成,RAGFlow 将能够更全面地收集和分析信息,为用户提供更全面的知识库和更准确的检索结果。
-
适应更多复杂场景:
-
RAGFlow 的设计目标之一是让其能够适应更多的复杂场景,尤其是企业级(B 端)的应用场景。为此,RAGFlow 将开发更多的定制化模板和处理流程,以满足不同行业和岗位对文档处理和信息检索的特殊需求。这可能涉及到对特定行业术语的理解、对复杂文档结构的处理等。
-
提供更灵活的企业级数据接入:
-
RAGFlow 将推出面向企业级数据接入的低代码平台,使得企业能够更容易地将内部数据和文档整合到 RAGFlow 系统中。这将极大地提高企业使用 RAGFlow 的便利性和效率,同时也为企业提供了更多的灵活性和自主性。
-
高级内容生成:
-
除了问答对话之外,RAGFlow 还将提供高级内容生成的功能,如长文生成等。这将使得 RAGFlow 不仅能够回答用户的问题,还能够创作文章、报告等内容,为用户提供更加全面的服务。
通过这些未来规划,RAGFlow 旨在成为一个更加强大、灵活且易于使用的系统,能够满足不同用户在各种场景下的需求,特别是在企业级应用中发挥重要作用,可以期待一下。
六、总结
在对 RAGFlow 的探索中,我们可以清晰地看到其在RAG(Retrieval-Augmented Generation)领域中的重要地位和显著优势。RAGFlow作为一款下一代开源RAG引擎,不仅在问答对话方面表现出色,还具备高级内容生成的能力,例如长文生成等。这使得RAGFlow能够为用户提供更为全面和深入的服务,满足不同场景下的需求,尤其在企业级应用中发挥着重要作用。
RAGFlow 的核心功能和技术架构,包括其系统架构、DeepDoc深度文档理解模块、LLM和嵌入模型的应用,以及文本分块过程中的可视化和人工干预等,共同构成了一个强大、灵活且易于使用的系统。这些特点不仅提升了用户体验,也为开发者提供了更多的创新空间。
开源项目如 RAGFlow 在推动技术创新方面扮演着至关重要的角色。它们促进了知识的共享和技术的民主化,为全球开发者社区提供了一个共同成长和协作的平台。通过开源,RAGFlow鼓励更多的开发者参与到项目中来,共同解决问题,分享最佳实践,从而加速了创新的步伐。
最终,RAGFlow 的成功不仅体现在其技术成就上,更在于其对整个RAG领域乃至人工智能技术发展的贡献。它不仅推动了相关技术的创新和应用,也为未来的技术进步和产业发展奠定了坚实的基础。随着RAGFlow的不断发展和完善,我们有理由相信,它将继续在推动人工智能技术进步和促进社会数字化转型方面发挥重要作用。
七、参考文献
[1]. DeepDoc: https://huggingface.co/InfiniFlow/deepdoc
[2]. RAGFlow GitHub: https://github.com/infiniflow/ragflow
[3]. RAGFlow Demo: https://demo.ragflow.io/
[4]. Infinity : https://github.com/infiniflow/infinity
[5]. RAGFlow YC News: https://news.ycombinator.com/item?id=39896923
[6]. DTrOCR: Decoder-only Transformer for Optical Character Recognition: https://arxiv.org/pdf/2308.15996v1.pdf
相关文章:
RAGFlow:基于OCR和文档解析的下一代 RAG 引擎
一、引言 在人工智能的浪潮中,检索增强生成(Retrieval-Augmented Generation,简称RAG)技术以其独特的优势成为了研究和应用的热点。RAG技术通过结合大型语言模型(LLMs)的强大生成能力和高效的信息检索系统…...

正则表达式|*+?
在理解编程语言和编译技术的上下文中,了解正则表达式(regular expressions)和正则集(regular sets)的概念是非常重要的。这些概念主要用于描述一组字符串的模式,广泛应用于词法分析中识别各类标记ÿ…...
前端开发攻略---根据音频节奏实时绘制不断变化的波形图。深入剖析如何通过代码实现音频数据的可视化。
1、演示 2、代码分析 逐行解析 JavaScript 代码块: const audioEle document.querySelector(audio) const cvs document.querySelector(canvas) const ctx cvs.getContext(2d)这几行代码首先获取了 <audio> 和 <canvas> 元素的引用,并使用…...

【计算机毕业设计】基于Java+SSM的实战开发项目150套(附源码+演示视频+LW)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 🧡今天给大家分享150的Java毕业设计,基于ssm框架,这些项目都经过精心挑选,涵盖了不同的实战主题和用例,可做毕业设计和课程…...

STM32H7的MPU学习和应用示例
STM32H7的MPU学习记录 什么是MPU?MPU的三种内存类型内存映射MPU保护区域以及优先级 MPU的寄存器XN位AP位TEX、C、B、S位SRD 位SIZE 位CTRL 寄存器的各个位 示例总结 什么是MPU? MPU(Memory Protection Unit,内存保护单元…...
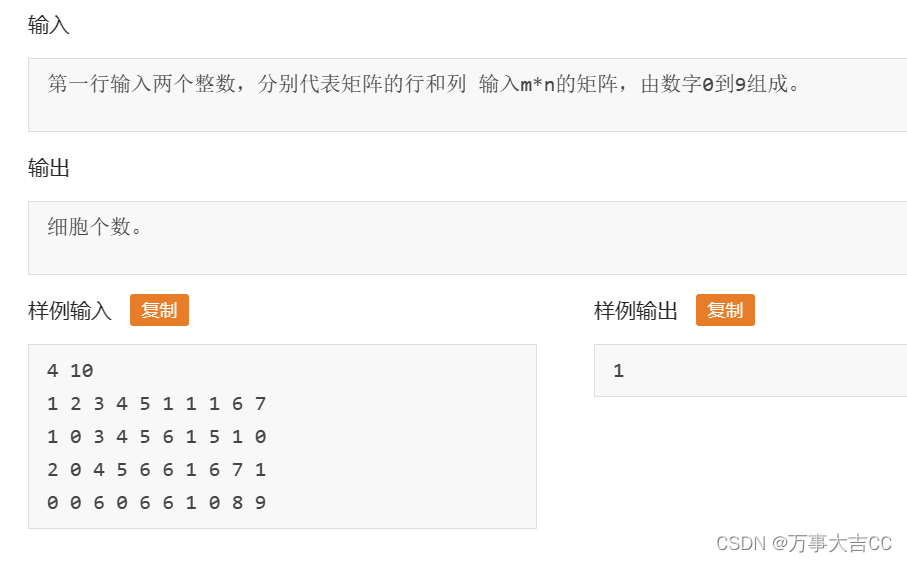
964: 数细胞
样例: 解法: 1.遍历矩阵 2.判断矩阵[i][j],若是未标记细胞则遍历相邻所有未标记细胞并标记,且计数 实现:遍历相邻所有未标记细胞 以DFS实现: function dfs(当前状态) {if (终止条件) {}vis[标记当前状…...

流程图步骤条
1.结构 <ul class"stepUl"> <li class"stepLi" v-for"(item, index) in stepList" :key"index"> <div class"top"> <p :class"{active: currentState > item.key}">{{ item.value }}…...

GPT知识库浅析
一、引言 上篇文章《GPT简介及应用》介绍了GPT的应用场景,里面提到GPT bot的基本使用:基于GPT训练好的数据,回答用户的问题。 但在使用过程中,如果用户的问题里面出现最新的术语,就会出现这种提示: 截至我…...

SpringMVC--SpringMVC的视图
目录 1. 总述 2. ThymeleafView视图 3. 转发视图 4. 重定向视图 5. 视图控制器view-controller 1. 总述 在SpringMVC框架中,视图(View)是一个非常重要的概念,它负责将模型数据(Model)展示给用户。简单…...
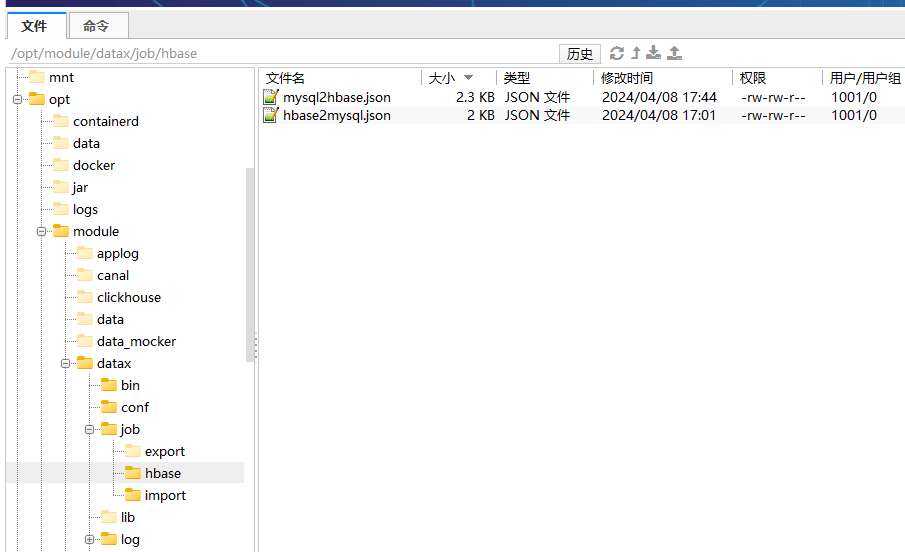
Datax,hbase与mysql数据相互同步
参考文章:datax mysql 和hbase的 相互导入 目录 0、软件版本说明 1、hbase数据同步至mysql 1.1、hbase数据 1.2、mysql数据 1.3、json脚本(hbase2mysql.json) 1.4、同步成功日志 2、mysql数据同步至hbase 1.1、hbase数据 1.2、mysql…...

ubuntu spdlog 封装成c++类使用
安装及编译方法:ubuntu spdlog 日志安装及使用_spdlog_logger_info-CSDN博客 h文件: #ifndef LOGGING_H #define LOGGING_H#include <iostream> #include <cstring> #include <sstream> #include <string> #include <memor…...

【C语言】——字符串函数的使用与模拟实现(上)
【C语言】——字符串函数 前言一、 s t r l e n strlen strlen 函数1.1、函数功能1.2、函数的使用1.3、函数的模拟实现(1)计数法(2)递归法(3)指针 - 指针 二、 s t r c p y strcpy strcpy 函数2.1、函数功能…...

数据库(1)
目录 1.什么是事务?事务的基本特性ACID? 2.数据库中并发一致性问题? 3.数据的隔离等级? 4.ACID靠什么保证的呢? 5.SQL优化的实践经验? 1.什么是事务?事务的基本特性ACID? 事务指…...

VirtualBox - 与 Win10 虚拟机 与 宿主机 共享文件
原文链接 https://www.cnblogs.com/xy14/p/10427353.html 1. 概述 需要在 宿主机 和 虚拟机 之间交换文件复制粘贴 貌似不太好使 2. 问题 设置了共享文件夹之后, 找不到目录 3. 环境 宿主机 OS Win10开启了 网络发现 略虚拟机 OS Win10开启了 网络发现 略Virtualbox 6 4…...

深入浅出 useEffect:React 函数组件中的副作用处理详解
useEffect 是 React 中的一个钩子函数,用于处理函数组件中的副作用操作,如发送网络请求、订阅消息、手动修改 DOM 等。下面是 useEffect 的用法总结: 基本用法 import React, { useState, useEffect } from react;function Example() {cons…...

《QT实用小工具·十九》回车跳转到不同的编辑框
1、概述 源码放在文章末尾 该项目实现通过回车键让光标从一个编辑框跳转到另一个编辑框,下面是demo演示: 项目部分代码如下: #ifndef WIDGET_H #define WIDGET_H#include <QWidget>namespace Ui { class Widget; }class Widget : p…...
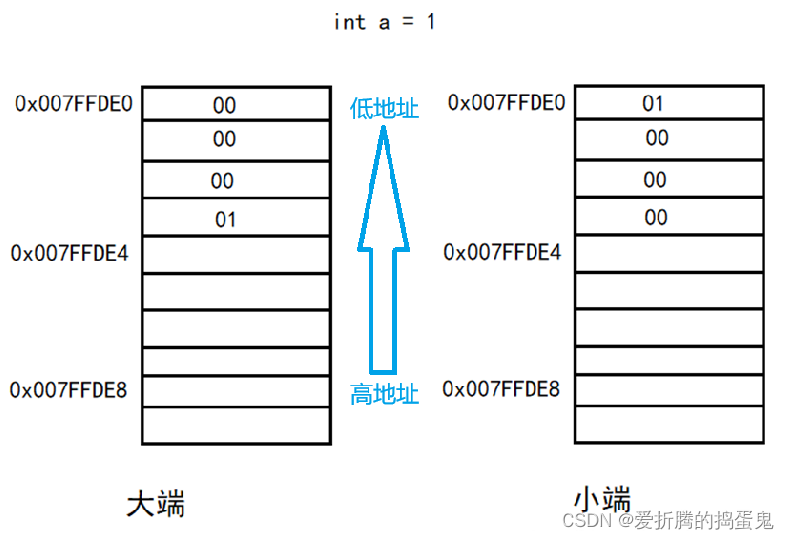
基本的数据类型在16位、32位和64位机上所占的字节大小
1、目前常用的机器都是32位和64位的,但是有时候会考虑16位机。总结一下在三种位数下常用的数据类型所占的字节大小。 数据类型16位(byte)32位(byte)64位(byte)取值范围char111-128 ~ 127unsigned char1110 ~ 255short int / short222-32768~32767unsigned short222…...

关注招聘 关注招聘 关注招聘
🔥关注招聘 🔥关注招聘 🔥关注招聘 🔥开源产品: 1.农业物联网平台开源版 2.充电桩系统开源版 3.GPU池化软件(AI人工智能训练平台/推理平台) 开源版 产品销售: 1.农业物联网平台企业版 2.充电桩系统企业…...

Django框架设计原理
相信大多数的Web开发者对于MVC(Model、View、Controller)设计模式都不陌生,该设计模式已经成为Web框架中一种事实上的标准了,Django框架自然也是一个遵循MVC设计模式的框架。不过从严格意义上讲,Django框架采用了一种更…...
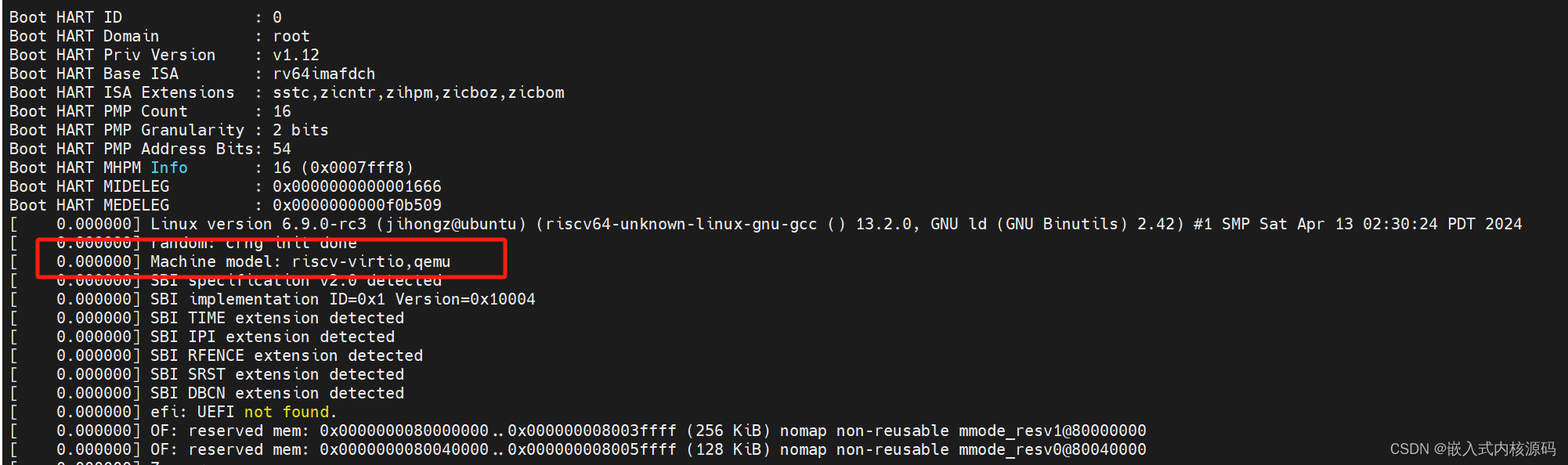
Linux ARM平台开发系列讲解(QEMU篇) 1.2 新添加一个Linux kernel设备树
1. 概述 上一章节我们利用QEMU成功启动了Linux kernel,但是细心的小伙伴就会发现,我们用默认的defconfig是没有找到设备树源文件的,但是又发现kernel启动时候它使用了设备树riscv-virtio,qemu,这是因为qemu用了一个默认的设备树文件,该章节呢我们就把这个默认的设备树文件…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...
` 方法)
深入浅出:JavaScript 中的 `window.crypto.getRandomValues()` 方法
深入浅出:JavaScript 中的 window.crypto.getRandomValues() 方法 在现代 Web 开发中,随机数的生成看似简单,却隐藏着许多玄机。无论是生成密码、加密密钥,还是创建安全令牌,随机数的质量直接关系到系统的安全性。Jav…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

JUC笔记(上)-复习 涉及死锁 volatile synchronized CAS 原子操作
一、上下文切换 即使单核CPU也可以进行多线程执行代码,CPU会给每个线程分配CPU时间片来实现这个机制。时间片非常短,所以CPU会不断地切换线程执行,从而让我们感觉多个线程是同时执行的。时间片一般是十几毫秒(ms)。通过时间片分配算法执行。…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...