【数学】主成分分析(PCA)的详细深度推导过程
本文基于Deep Learning (2017, MIT),推导过程补全了所涉及的知识及书中推导过程中跳跃和省略的部分。
blog
1 概述
现代数据集,如网络索引、高分辨率图像、气象学、实验测量等,通常包含高维特征,高纬度的数据可能不清晰、冗余,甚至具有误导性。数据可视化和解释变量之间的关系很困难,而使用这种高维数据训练的神经网络模型往往容易出现过拟合(维度诅咒)。
主成分分析(PCA)是一种简单而强大的无监督机器学习技术,用于数据降维。它旨在从大型变量集中提取一个较小的数据集,同时尽可能保留原始信息和特征(有损压缩)。PCA有助于识别数据集中最显著和有意义的特征,使数据易于可视化。应用场景包括:统计学、去噪和为机器学习算法预处理数据。
- 主成分是什么?
主成分是构建为原始变量的线性组合的新变量。这些新变量是不相关的,并且包含原始数据中大部分的信息。
2 背景数学知识
这些知识对下一节的推导很重要。
- 正交向量和矩阵:
- 如果两个向量垂直,则它们是正交的。即两个向量的点积为零。
- 正交矩阵是一个方阵,其行和列是相互正交的单位向量;每两行和两列的点积为零,每一行和每一列的大小为1。
- 如果 A T = A − 1 A^T=A^{-1} AT=A−1或 A A T = A T A = I AA^T=A^TA=I AAT=ATA=I,则 A A A是正交矩阵。
- 在机器人学中,旋转矩阵通常是一个 3 × 3 3\times3 3×3的正交矩阵,在空间变换中它会旋转向量的方向但保持原始向量的大小。
- 矩阵、向量乘法规则:
- ( A B ) T = B T A T (AB)^T=B^TA^T (AB)T=BTAT,两个矩阵的乘积的转置。
- a ⃗ T b ⃗ = b ⃗ T a ⃗ \vec{a}^T\vec{b}=\vec{b}^T\vec{a} aTb=bTa,两个结果都是标量,标量的转置是相同的。
- ( A + B ) C = A C + B C (A + B)C = AC + BC (A+B)C=AC+BC,乘法是可分配的。
- A B ≠ B A AB \neq{} BA AB=BA,乘法一般不满足交换律。
- A ( B C ) = ( A B ) C A(BC)=(AB)C A(BC)=(AB)C,乘法满足结合律。
- 对称矩阵:
- A = A T A=A^T A=AT, A A A是对称矩阵。
- X T X X^TX XTX是对称矩阵,因为 ( X T X ) T = X T X (X^TX)^T=X^TX (XTX)T=XTX。
- 向量导数规则( B B B是常量矩阵):
- d ( x T B ) / d x = B d(x^TB)/dx=B d(xTB)/dx=B
- d ( x T x ) / d x = 2 x d(x^Tx)/dx=2x d(xTx)/dx=2x
- d ( x T B x ) / d x = 2 B x d(x^TBx)/dx=2Bx d(xTBx)/dx=2Bx
- 矩阵迹规则:
- T r ( A ) = T r ( A T ) Tr(A)=Tr(A^T) Tr(A)=Tr(AT)
- T r ( A B ) = T r ( B A ) Tr(AB)=Tr(BA) Tr(AB)=Tr(BA)
- T r ( A ) = ∑ i λ i Tr(A)=\sum_i{\lambda_i} Tr(A)=∑iλi,其中 λ \lambda λ是 A A A的特征值。
- 迹在循环移位下不变: T r ( A B C D ) = T r ( B C D A ) = T r ( C D A B ) = T r ( D A B C ) Tr(ABCD)=Tr(BCDA)=Tr(CDAB)=Tr(DABC) Tr(ABCD)=Tr(BCDA)=Tr(CDAB)=Tr(DABC)
- 向量和矩阵范数:
- 向量的 L 2 L^2 L2范数,也称为欧几里得范数: ∣ ∣ x ∣ ∣ 2 = ∑ i ∣ x i ∣ 2 ||x||_2=\sqrt{\sum_i|x_i|^2} ∣∣x∣∣2=∑i∣xi∣2。
- 通常使用平方的 L 2 L^2 L2范数来衡量向量的大小,可以计算为 x T x x^Tx xTx。
- Frobenius范数用于衡量矩阵的大小: ∣ ∣ A ∣ ∣ F = ∑ i , j A i , j 2 ||A||_F=\sqrt{\sum_{i,j}A^2_{i,j}} ∣∣A∣∣F=∑i,jAi,j2
- Frobenius范数是所有矩阵元素的绝对平方和的平方根。
- Frobenius范数是矩阵版本的欧几里得范数。
- 特征值分解和特征值:
- 方阵 A A A的特征向量是一个非零向量 v v v,使得 A A A的乘法仅改变 v v v的比例: A v = λ v Av=\lambda v Av=λv。 λ \lambda λ是特征值, v v v是特征向量。
- 假设矩阵 A A A有 n n n个线性无关的特征向量 v ( i ) v^{(i)} v(i),我们可以将所有特征向量连接起来形成一个矩阵 V = [ v ( 1 ) , … , v ( n ) ] V=[v^{(1)},\ldots,v^{(n)}] V=[v(1),…,v(n)],并通过连接所有特征值 λ = [ λ 1 , … , λ n ] T \lambda=[\lambda_1,\ldots,\lambda_n]^T λ=[λ1,…,λn]T形成一个向量,那么 A A A的特征分解是 A = V d i a g ( λ ) V − 1 A=Vdiag(\lambda)V^{-1} A=Vdiag(λ)V−1
- 每个实对称矩阵都可以分解为 A = Q Λ Q T A=Q\Lambda Q^T A=QΛQT,其中 Q Q Q是由 A A A的特征向量组成的正交矩阵, Λ \Lambda Λ(读作’lambda’)是一个对角矩阵。
- 拉格朗日乘数法:
- 拉格朗日乘数法是一种在方程约束下寻找函数局部最大值和最小值的策略。
- 一般形式: L ( x , λ ) = f ( x ) + λ ⋅ g ( x ) \mathcal{L}(x,\lambda)=f(x)+\lambda\cdot g(x) L(x,λ)=f(x)+λ⋅g(x), λ \lambda λ称为拉格朗日乘子。
3 详细PCA推导
需求描述
我们有 m m m个点的输入数据,表示为 x ( 1 ) , . . . , x ( m ) {x^{(1)},...,x^{(m)}} x(1),...,x(m)在 R n \mathbb{R}^{n} Rn的实数集中。因此,每个点 x ( i ) x^{(i)} x(i)是一个列向量,具有 n n n维特征。
需要对输入数据进行有损压缩,将这些点编码以表示它们的较低维度版本。换句话说,我们想要找到编码向量 c ( i ) ∈ R l c^{(i)}\in \mathbb{R}^{l} c(i)∈Rl, ( l < n ) (l<n) (l<n)来表示每个输入点 x ( i ) x^{(i)} x(i)。我们的目标是找到产生输入的编码向量的编码函数 f ( x ) = c f(x)=c f(x)=c,以及相应的重构(解码)函数 x ≈ g ( f ( x ) ) x\approx g(f(x)) x≈g(f(x)),根据编码向量 c c c计算原始输入。
解码的 g ( f ( x ) ) g(f(x)) g(f(x))是一组新的点(变量),因此它与原始 x x x是近似的。存储 c ( i ) c^{(i)} c(i)和解码函数比存储 x ( i ) x^{(i)} x(i)更节省空间,因为 c ( i ) c^{(i)} c(i)的维度较低。
解码矩阵
我们选择使用矩阵 D D D作为解码矩阵,将编码向量 c ( i ) c^{(i)} c(i)映射回 R n \mathbb{R}^{n} Rn,因此 g ( c ) = D c g(c)=Dc g(c)=Dc,其中 D ∈ R n × l D\in \mathbb{R}^{n\times l} D∈Rn×l。为了简化编码问题,PCA将 D D D的列约束为彼此正交。
衡量重构的表现
在继续之前,我们需要弄清楚如何生成最优的编码点 c ∗ c^{*} c∗,我们可以测量输入点 x x x与其重构 g ( c ∗ ) g(c^*) g(c∗)之间的距离,使用 L 2 L^2 L2范数(或欧几里得范数): c ∗ = arg min c ∣ ∣ x − g ( c ) ∣ ∣ 2 c^{*}=\arg\min_c||x-g(c)||_2 c∗=argminc∣∣x−g(c)∣∣2。由于 L 2 L^2 L2范数是非负的,并且平方操作是单调递增的,所以我们可以转而使用平方的 L 2 L^2 L2范数:
c ∗ = arg min c ∣ ∣ x − g ( c ) ∣ ∣ 2 2 c^{*}={\arg\min}_c||x-g(c)||_2^2 c∗=argminc∣∣x−g(c)∣∣22 向量的 L 2 L^2 L2范数是其分量的平方和,它等于向量与自身的点积,例如 ∣ ∣ x ∣ ∣ 2 = ∑ ∣ x i ∣ 2 = x T x ||x||_2=\sqrt{\sum|x_i|^2}=\sqrt{x^Tx} ∣∣x∣∣2=∑∣xi∣2=xTx,因此平方的 L 2 L^2 L2范数可以写成以下形式:
∣ ∣ x − g ( c ) ∣ ∣ 2 2 = ( x − g ( c ) ) T ( x − g ( c ) ) ||x-g(c)||_2^2 = (x-g(c))^T(x-g(c)) ∣∣x−g(c)∣∣22=(x−g(c))T(x−g(c)) 由分配率:
= ( x T − g ( c ) T ) ( x − g ( c ) ) = x T x − x T g ( c ) − g ( c ) T x + g ( c ) T g ( c ) =(x^T-g(c)^T)(x-g(c))=x^Tx-x^Tg(c)-g(c)^Tx+g(c)^Tg(c) =(xT−g(c)T)(x−g(c))=xTx−xTg(c)−g(c)Tx+g(c)Tg(c) 由于 x T g ( c ) x^Tg(c) xTg(c)和 g ( c ) T x g(c)^Tx g(c)Tx是标量,标量等于其转置, ( g ( c ) T x ) T = x T g ( c ) (g(c)^Tx)^T=x^Tg(c) (g(c)Tx)T=xTg(c),所以:
= x T x − 2 x T g ( c ) + g ( c ) T g ( c ) =x^Tx-2x^Tg(c)+g(c)^Tg(c) =xTx−2xTg(c)+g(c)Tg(c) 为了找到使上述函数最小化的 c c c,第一项可以省略,因为它不依赖于 c c c,所以:
c ∗ = arg min c − 2 x T g ( c ) + g ( c ) T g ( c ) c^*={\arg\min}_c-2x^Tg(c)+g(c)^Tg(c) c∗=argminc−2xTg(c)+g(c)Tg(c) 然后用 g ( c ) g(c) g(c)的定义 D c Dc Dc进行替换:
= arg min c − 2 x T D c + c T D T D c ={\arg\min}_c-2x^TDc+c^TD^TDc =argminc−2xTDc+cTDTDc 由于 D D D的正交性和单位范数约束:
c ∗ = arg min c − 2 x T D c + c T I l c c^*={\arg\min}_c-2x^TDc+c^TI_lc c∗=argminc−2xTDc+cTIlc = arg min c − 2 x T D c + c T c = {\arg\min}_c-2x^TDc+c^Tc =argminc−2xTDc+cTc
目标函数
现在目标函数是 − 2 x T D c + c T c -2x^TDc+c^Tc −2xTDc+cTc,我们需要找到 c ∗ c^* c∗来最小化目标函数。使用向量微积分,并令其导数等于0:
∇ c ( − 2 x T D c + c T c ) = 0 \nabla_c(-2x^TDc+c^Tc)=0 ∇c(−2xTDc+cTc)=0 根据向量导数规则:
− 2 D T x + 2 c = 0 ⇒ c = D T x -2D^Tx+2c=0 \Rightarrow c=D^Tx −2DTx+2c=0⇒c=DTx
找到编码矩阵 D D D
所以编码器函数是 f ( x ) = D T x f(x)=D^Tx f(x)=DTx。因此我们可以定义 PCA 重构操作为 r ( x ) = g ( f ( x ) ) = D ( D T x ) = D D T x r(x)=g(f(x))=D(D^Tx)=DD^Tx r(x)=g(f(x))=D(DTx)=DDTx。
因此编码矩阵 D D D 也被重构过程使用。我们需要找到最优的 D D D 来最小化重构误差,即输入和重构之间所有维度特征的距离。这里使用 Frobenius 范数(矩阵范数)定义目标函数:
D ∗ = arg min D ∑ i , j ( x j ( i ) − r ( x i ) j ) 2 , D T D = I l D^*={\arg\min}_D\sqrt{\sum_{i,j}(x_j^{(i)}-r(x^{i})_j)^2},\quad D^TD=I_l D∗=argminDi,j∑(xj(i)−r(xi)j)2,DTD=Il 从考虑 l = 1 l=1 l=1 的情况开始(这也是第一个主成分), D D D 是一个单一向量 d d d,并使用平方 L 2 L^2 L2 范数形式:
d ∗ = arg min d ∑ i ∣ ∣ ( x ( i ) − r ( x i ) ) ∣ ∣ 2 2 , ∣ ∣ d ∣ ∣ 2 = 1 d^*={\arg\min}_d{\sum_{i}||(x^{(i)}-r(x^{i}))}||_2^2, ||d||_2=1 d∗=argmindi∑∣∣(x(i)−r(xi))∣∣22,∣∣d∣∣2=1 = arg min d ∑ i ∣ ∣ ( x ( i ) − d d T x ( i ) ) ∣ ∣ 2 2 , ∣ ∣ d ∣ ∣ 2 = 1 = {\arg\min}_d{\sum_{i}||(x^{(i)}-dd^Tx^{(i)})||_2^2}, ||d||_2=1 =argmindi∑∣∣(x(i)−ddTx(i))∣∣22,∣∣d∣∣2=1 d T x ( i ) d^Tx^{(i)} dTx(i) 是一个标量:
= arg min d ∑ i ∣ ∣ ( x ( i ) − d T x ( i ) d ) ∣ ∣ 2 2 , ∣ ∣ d ∣ ∣ 2 = 1 = {\arg\min}_d{\sum_{i}||(x^{(i)}-d^Tx^{(i)}d)}||_2^2, ||d||_2=1 =argmindi∑∣∣(x(i)−dTx(i)d)∣∣22,∣∣d∣∣2=1 标量等于其自身的转置:
d ∗ = arg min d ∑ i ∣ ∣ ( x ( i ) − x ( i ) T d d ) ∣ ∣ 2 2 , ∣ ∣ d ∣ ∣ 2 = 1 d^*= {\arg\min}_d{\sum_{i}||(x^{(i)}-x^{(i)T}dd)}||_2^2, ||d||_2=1 d∗=argmindi∑∣∣(x(i)−x(i)Tdd)∣∣22,∣∣d∣∣2=1
使用矩阵形式表示
令 X ∈ R m × n X\in \mathbb{R}^{m\times n} X∈Rm×n 表示所有描述点的向量堆叠,即 { x ( 1 ) T , x ( 2 ) T , … , x ( i ) T , … , x ( m ) T } \{x^{(1)^T}, x^{(2)^T}, \ldots, x^{(i)^T}, \ldots, x^{(m)^T}\} {x(1)T,x(2)T,…,x(i)T,…,x(m)T},使得 X i , : = x ( i ) T X_{i,:}=x^{(i)^T} Xi,:=x(i)T。
X = [ x ( 1 ) T x ( 2 ) T … x ( m ) T ] ⇒ X d = [ x ( 1 ) T d x ( 2 ) T d … x ( m ) T d ] X = \begin{bmatrix} x^{(1)^T}\\ x^{(2)^T}\\ \ldots\\ x^{(m)^T} \end{bmatrix} \Rightarrow Xd = \begin{bmatrix} x^{(1)^T}d\\ x^{(2)^T}d\\ \ldots\\ x^{(m)^T}d \end{bmatrix} X= x(1)Tx(2)T…x(m)T ⇒Xd= x(1)Tdx(2)Td…x(m)Td ⇒ X d d T = [ x ( 1 ) T d d T x ( 2 ) T d d T … x ( m ) T d d T ] \Rightarrow Xdd^T = \begin{bmatrix} x^{(1)^T}dd^T\\ x^{(2)^T}dd^T\\ \ldots\\ x^{(m)^T}dd^T\\ \end{bmatrix} ⇒XddT= x(1)TddTx(2)TddT…x(m)TddT ⇒ X − X d d T = [ x ( 1 ) T − x ( 1 ) T d d T x ( 2 ) T − x ( 2 ) T d d T … x ( m ) T − x ( m ) T d d T ] \Rightarrow X-Xdd^T = \begin{bmatrix} x^{(1)^T}-x^{(1)^T}dd^T\\ x^{(2)^T}-x^{(2)^T}dd^T\\ \ldots\\ x^{(m)^T}-x^{(m)^T}dd^T\\ \end{bmatrix} ⇒X−XddT= x(1)T−x(1)TddTx(2)T−x(2)TddT…x(m)T−x(m)TddT 矩阵中的一行的转置:
( x ( i ) T − x ( i ) T d d T ) T = x ( i ) − d d T x ( i ) (x^{(i)^T}-x^{(i)^T}dd^T)^T=x^{(i)}-dd^Tx^{(i)} (x(i)T−x(i)TddT)T=x(i)−ddTx(i) 由于 d T x ( i ) d^Tx^{(i)} dTx(i) 是标量:
= x ( i ) − d T x ( i ) d = x ( i ) − x ( i ) T d d =x^{(i)}-d^Tx^{(i)}d=x^{(i)}-x^{(i)^T}dd =x(i)−dTx(i)d=x(i)−x(i)Tdd 所以我们知道 X X X 的第 i i i 行的 L 2 L^2 L2 范数与原始形式相同,因此我们可以使用矩阵重写问题,并省略求和符号:
d ∗ = arg min d ∣ ∣ X − X d d T ∣ ∣ F 2 , d T d = 1 d^*={\arg\min}_{d}||X-Xdd^T||_F^2, \quad d^Td=1 d∗=argmind∣∣X−XddT∣∣F2,dTd=1 利用矩阵迹规则简化 Frobenius 范数部分如下:
arg min d ∣ ∣ X − X d d T ∣ ∣ F 2 {\arg\min}_{d}||X-Xdd^T||_F^2 argmind∣∣X−XddT∣∣F2 = arg min d T r ( ( X − X d d T ) T ( X − X d d T ) ) ={\arg\min}_{d}Tr((X-Xdd^T)^T(X-Xdd^T)) =argmindTr((X−XddT)T(X−XddT)) = arg min d − T r ( X T X d d T ) − T r ( d d T X T X ) + T r ( d d T X T X d d T ) ={\arg\min}_{d}-Tr(X^TXdd^T)-Tr(dd^TX^TX)+Tr(dd^TX^TXdd^T) =argmind−Tr(XTXddT)−Tr(ddTXTX)+Tr(ddTXTXddT) = arg min d − 2 T r ( X T X d d T ) + T r ( X T X d d T d d T ) ={\arg\min}_{d}-2Tr(X^TXdd^T)+Tr(X^TXdd^Tdd^T) =argmind−2Tr(XTXddT)+Tr(XTXddTddT) 由于 d T d = 1 d^Td=1 dTd=1:
= arg min d − 2 T r ( X T X d d T ) + T r ( X T X d d T ) ={\arg\min}_{d}-2Tr(X^TXdd^T)+Tr(X^TXdd^T) =argmind−2Tr(XTXddT)+Tr(XTXddT) = arg min d − T r ( X T X d d T ) ={\arg\min}_{d}-Tr(X^TXdd^T) =argmind−Tr(XTXddT) = arg max d T r ( X T X d d T ) ={\arg\max}_{d}Tr(X^TXdd^T) =argmaxdTr(XTXddT) 由于迹是循环置换不变的,将方程重写为:
d ∗ = arg max d T r ( d T X T X d ) , d T d = 1 d^*={\arg\max}_{d}Tr(d^TX^TXd), \quad d^Td=1 d∗=argmaxdTr(dTXTXd),dTd=1 由于 d T X T X d d^TX^TXd dTXTXd 是实数,因此迹符号可以省略:
d ∗ = arg max d d T X T X d , d T d = 1 d^*={\arg\max}_{d}d^TX^TXd,\quad d^Td=1 d∗=argmaxddTXTXd,dTd=1
寻找最优的 d d d
现在的问题是找到最优的 d d d 来最大化 d T X T X d d^TX^TXd dTXTXd,并且有约束条件 d T d = 1 d^Td=1 dTd=1。
使用拉格朗日乘子法来将问题描述为关于 d d d 的形式:
L ( d , λ ) = d T X T X d + λ ( d T d − 1 ) \mathcal{L}(d,\lambda)=d^TX^TXd+\lambda(d^Td-1) L(d,λ)=dTXTXd+λ(dTd−1) 对 d d d 求导数(向量导数规则):
∇ d L ( d , λ ) = 2 X T X d + 2 λ d \nabla_d\mathcal{L}(d,\lambda)=2X^TXd+2\lambda d ∇dL(d,λ)=2XTXd+2λd 令导数等于0, d d d 将是最优的:
2 X T X d + 2 λ d = 0 2X^TXd+2\lambda d=0 2XTXd+2λd=0 X T X d = − λ d X^TXd=-\lambda d XTXd=−λd X T X d = λ ′ d , ( λ ′ = − λ ) X^TXd=\lambda' d,\quad(\lambda'=-\lambda) XTXd=λ′d,(λ′=−λ) 这个方程是典型的矩阵特征值分解形式, d d d 是矩阵 X T X X^TX XTX 的特征向量, λ ′ \lambda' λ′ 是对应的特征值。
利用上述结果,让我们重新审视原方程:
d ∗ = arg max d d T X T X d , d T d = 1 d^*={\arg\max}_{d}d^TX^TXd, \quad d^Td=1 d∗=argmaxddTXTXd,dTd=1 = arg max d d T λ ′ d ={\arg\max}_{d}d^T\lambda' d =argmaxddTλ′d = arg max d λ ′ d T d ={\arg\max}_{d}\lambda'd^T d =argmaxdλ′dTd = arg max d λ ′ ={\arg\max}_{d}\lambda' =argmaxdλ′ 现在问题已经变的非常清楚了, X T X X^TX XTX 的最大特征值会最大化原方程的结果,因此最优的 d d d 是矩阵 X T X X^TX XTX 对应最大特征值的特征向量。
这个推导是针对 l = 1 l=1 l=1 的情况,只包含第一个主成分。当 l > 1 l>1 l>1 时, D = [ d 1 , d 2 , … ] D=[d_1, d_2, \ldots] D=[d1,d2,…],第一个主成分 d 1 d_1 d1 是矩阵 X T X X^TX XTX 对应最大特征值的特征向量,第二个主成分 d 2 d_2 d2 是对应第二大特征值的特征向量,以此类推。
4 总结
我们有一个数据集,包含 m m m 个点,记为 x ( 1 ) , . . . , x ( m ) {x^{(1)},...,x^{(m)}} x(1),...,x(m)。
令 X ∈ R m × n X\in \mathbb{R}^{m\times n} X∈Rm×n 为将所有这些点堆叠而成的矩阵: [ x ( 1 ) T , x ( 2 ) T , … , x ( i ) T , … , x ( m ) T ] [x^{(1)^T}, x^{(2)^T}, \ldots, x^{(i)^T}, \ldots, x^{(m)^T}] [x(1)T,x(2)T,…,x(i)T,…,x(m)T]。
主成分分析(PCA)编码函数表示为 f ( x ) = D T x f(x)=D^Tx f(x)=DTx,重构函数表示为 x ≈ g ( c ) = D c x\approx g(c)=Dc x≈g(c)=Dc,其中 D = [ d 1 , d 2 , … ] D=[d_1, d_2, \ldots] D=[d1,d2,…] 的列是 X T X X^TX XTX 的特征向量,特征向量对应的特征值大小为降序排列。 D T x D^Tx DTx即是降维度之后的数据。
呼~
后续恢复元气后会分析一些PCA的应用案例。

相关文章:
【数学】主成分分析(PCA)的详细深度推导过程
本文基于Deep Learning (2017, MIT),推导过程补全了所涉及的知识及书中推导过程中跳跃和省略的部分。 blog 1 概述 现代数据集,如网络索引、高分辨率图像、气象学、实验测量等,通常包含高维特征,高纬度的数据可能不清晰、冗余&am…...

微信跳转页面时发生报错
报错如下图所示: 解决方法:(从下面四种跳转方式中任选一种,哪种能实现效果就用哪个) 带历史回退 wx.navigateTo() //不能跳转到tabbar页面 不带历史回退 wx.redirectTo() //跳转到另一个页面wx.switchTab() //只能…...

8:系统开发基础--8.1:软件工程概述、8.2:软件开发方法 、8.3:软件开发模型、8.4:系统分析
转上一节: http://t.csdnimg.cn/G7lfmhttp://t.csdnimg.cn/G7lfm 课程内容提要: 8:知识点考点详解 8.1:软件工程概述 1.软件的生存周期 2.软件过程改进—CMM Capability Maturity Model能力成熟度模型 3.软件过程改进—CMMI—…...

【简单讲解下Symfony框架】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

[Linux基础]ln硬链接和ln -s软链接的方法参数及区别
区别: 1、ln创建硬链接;ln -s 创建软链接 2、硬链接的两个文件指向同一个inode(inode:存放着文件的目录、权限、block块编号等信息);软链接的目标文件指向源文件,目标文件内存储的是源文件的目…...
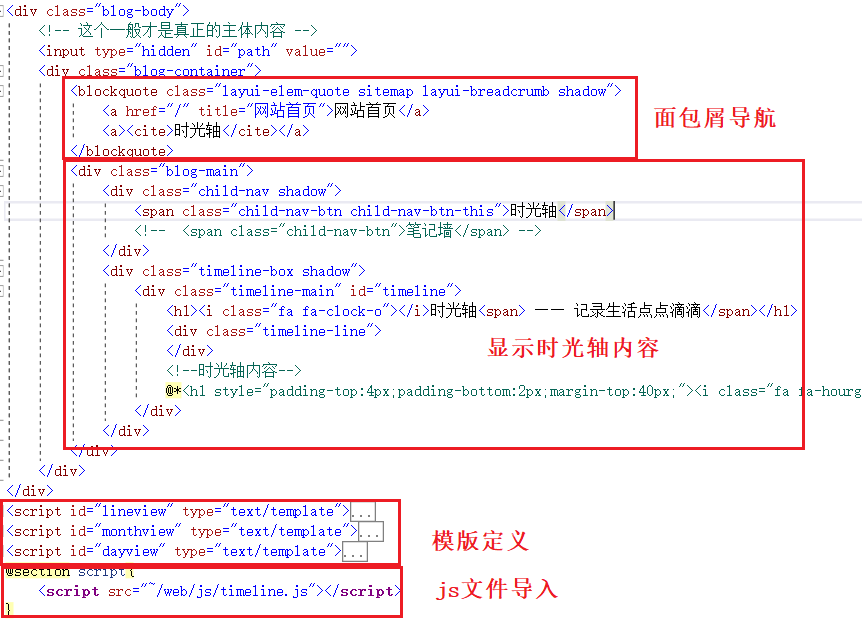
开源博客项目Blog .NET Core源码学习(15:App.Hosting项目结构分析-3)
本文学习并分析App.Hosting项目中前台页面的关于本站页面和点点滴滴页面。 关于本站页面 关于本站页面相对而言布局简单,与后台控制器类的交互也不算复杂。整个页面主要使用了layui中的面包屑导航、选项卡、模版、流加载等样式或模块。 面包屑导航。使用layui…...
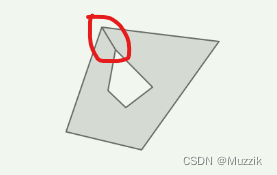
【muzzik 分享】3D模型平面切割
# 前言 一年一度的征稿到了,倒腾点存货,3D平面切割通常用于一些解压游戏里,例如水果忍者,切菜这些,今天我就给大家讲讲怎么实现3D切割以及其原理,帮助大家更理解3D中的 Mesh(网格),以及UV贴图和…...

SCI一区 | Matlab实现OOA-TCN-BiGRU-Attention鱼鹰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测
SCI一区 | Matlab实现OOA-TCN-BiGRU-Attention鱼鹰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测 目录 SCI一区 | Matlab实现OOA-TCN-BiGRU-Attention鱼鹰算法优化时间卷积双向门控循环单元融合注意力机制多变量时间序列预测预测效果基本介绍模型描述程序…...

nodejs安装常用命令
安装 Node.js 后,你可以在命令行中使用以下常用命令: node:启动 Node.js 的交互式解释器,可以直接在命令行中执行 JavaScript 代码。 npm install <package-name>:安装一个 Node.js 模块,<packag…...

使用 Prometheus 在 KubeSphere 上监控 KubeEdge 边缘节点(Jetson) CPU、GPU 状态
作者:朱亚光,之江实验室工程师,云原生/开源爱好者。 KubeSphere 边缘节点的可观测性 在边缘计算场景下,KubeSphere 基于 KubeEdge 实现应用与工作负载在云端与边缘节点的统一分发与管理,解决在海量边、端设备上完成应…...
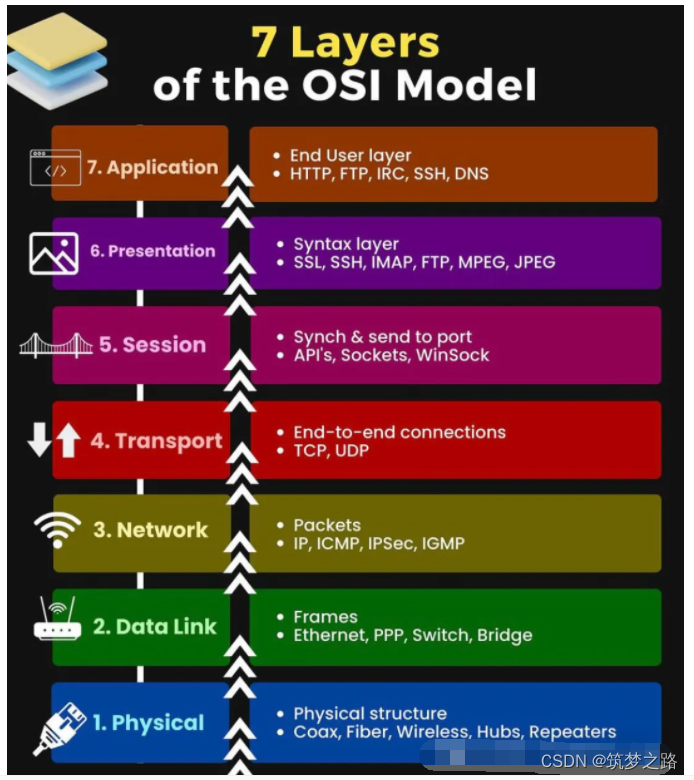
OSI七层网络模型 —— 筑梦之路
在信息技术领域,OSI七层模型是一个经典的网络通信框架,它将网络通信分为七个层次,每一层都有其独特的功能和作用。为了帮助记忆这七个层次,有一个巧妙的方法:将每个层次的英文单词首字母组合起来,形成了一句…...

状态模式:管理对象状态转换的动态策略
在软件开发中,状态模式是一种行为型设计模式,它允许一个对象在其内部状态改变时改变它的行为。这种模式把与特定状态相关的行为局部化,并且将不同状态的行为分散到对应的状态类中,使得状态和行为可以独立变化。本文将详细介绍状态…...

【论文阅读】MCTformer: 弱监督语义分割的多类令牌转换器
【论文阅读】MCTformer: 弱监督语义分割的多类令牌转换器 文章目录 【论文阅读】MCTformer: 弱监督语义分割的多类令牌转换器一、介绍二、联系工作三、方法四、实验结果 Multi-class Token Transformer for Weakly Supervised Semantic Segmentation 本文提出了一种新的基于变换…...

FMix: Enhancing Mixed Sample Data Augmentation 论文阅读
1 Abstract 近年来,混合样本数据增强(Mixed Sample Data Augmentation,MSDA)受到了越来越多的关注,出现了许多成功的变体,例如MixUp和CutMix。通过研究VAE在原始数据和增强数据上学习到的函数之间的互信息…...

2024蓝桥A组A题
艺术与篮球(蓝桥) 问题描述格式输入格式输出评测用例规模与约定解析参考程序难度等级 问题描述 格式输入 无 格式输出 一个整数 评测用例规模与约定 无 解析 模拟就好从20000101-20240413每一天计算笔画数是否大于50然后天数; 记得判断平…...

Linux journalctl命令详解
文章目录 1.介紹2.概念设置system time基本的日志查阅方法按时过滤日志(by Time)显示本次启动以来的日志(Current Boot)按Past Boots按时间窗口按感兴趣的消息筛选按unit按进程、用户、Group ID按组件路径显示内核消息按消息优先级…...
恢复MySQL!是我的条件反射,PXB开源的力量...
📢📢📢📣📣📣 哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA及大数据工作经验 一位上进心十足的【大数据领域博主】!😜&am…...

Storm详细配置
一、认识Storm Apache Storm是个实时数据处理的“大能”,它可以实时接收、处理并转发大量数据流,就像一个高速运转的物流中心,确保数据及时、准确地到达目的地。我们要做的,就是把这个物流中心搭建起来,并且根据我们的…...

linux redis部署教程
单节点部署: 单节点部署 Redis 非常简单,只需要在一台服务器上安装 Redis 服务即可。以下是在 Linux 环境下的单节点部署步骤: 安装 Redis:打开终端,并执行以下命令来更新软件包列表并安装 Redis 服务器:…...
:如何解决餐厅等座的并发难题)
【Java】隐式锁(synchronized):如何解决餐厅等座的并发难题
当你走进一家熙熙攘攘的餐厅,准备享受一顿美味的晚餐时,你是否曾想过,这里正上演着一场场微观的线程战争?在这个场景中,每一张桌子都代表着珍贵的共享资源,而每一位顾客(线程)都在争…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

嵌入式学习笔记DAY33(网络编程——TCP)
一、网络架构 C/S (client/server 客户端/服务器):由客户端和服务器端两个部分组成。客户端通常是用户使用的应用程序,负责提供用户界面和交互逻辑 ,接收用户输入,向服务器发送请求,并展示服务…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...